
Analytical Redundancy for Variable Cycle Engine Based on Variable-Weights-Biases Neural Network


Abstract
1. Introduction
2. Method
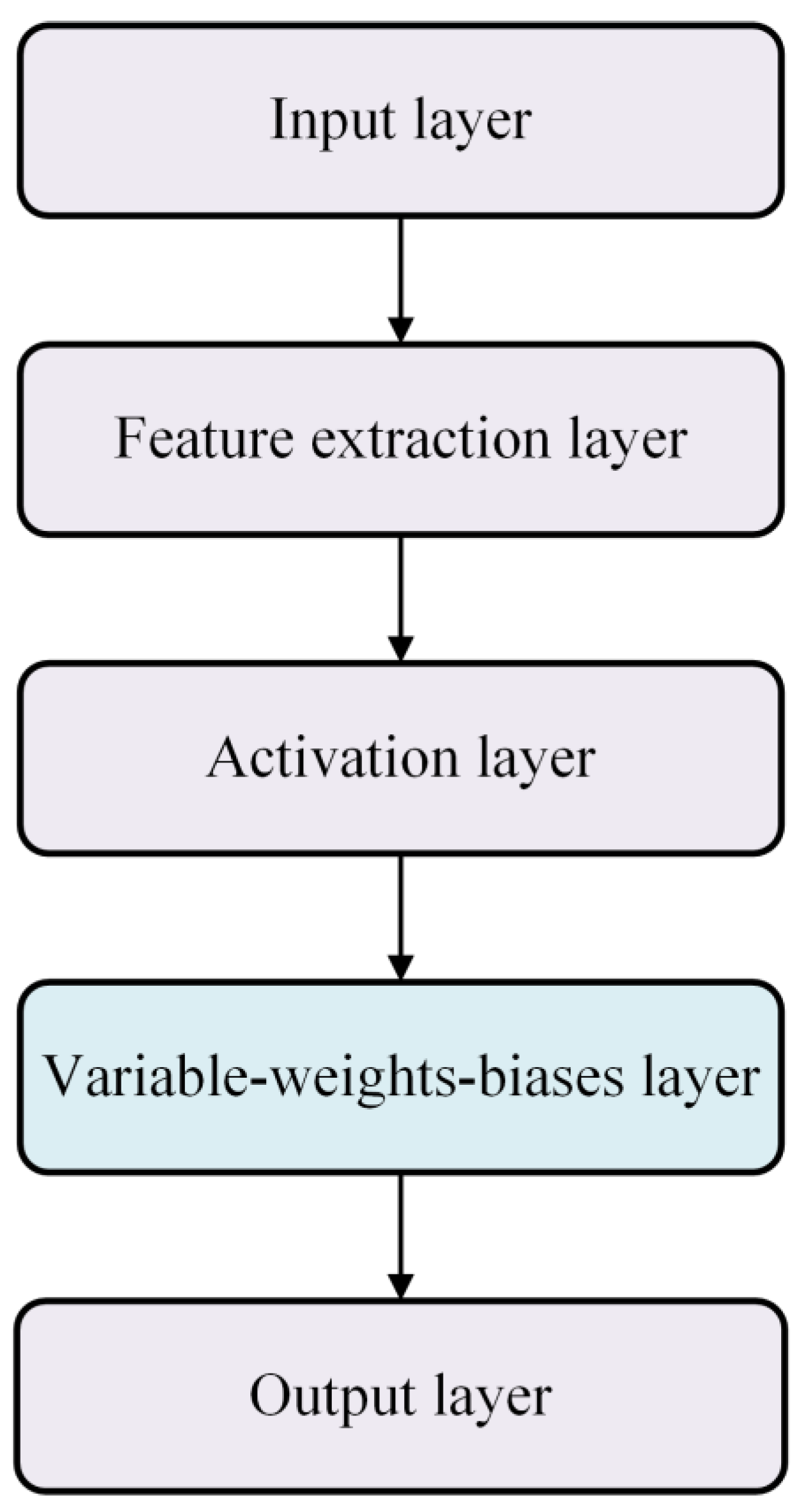
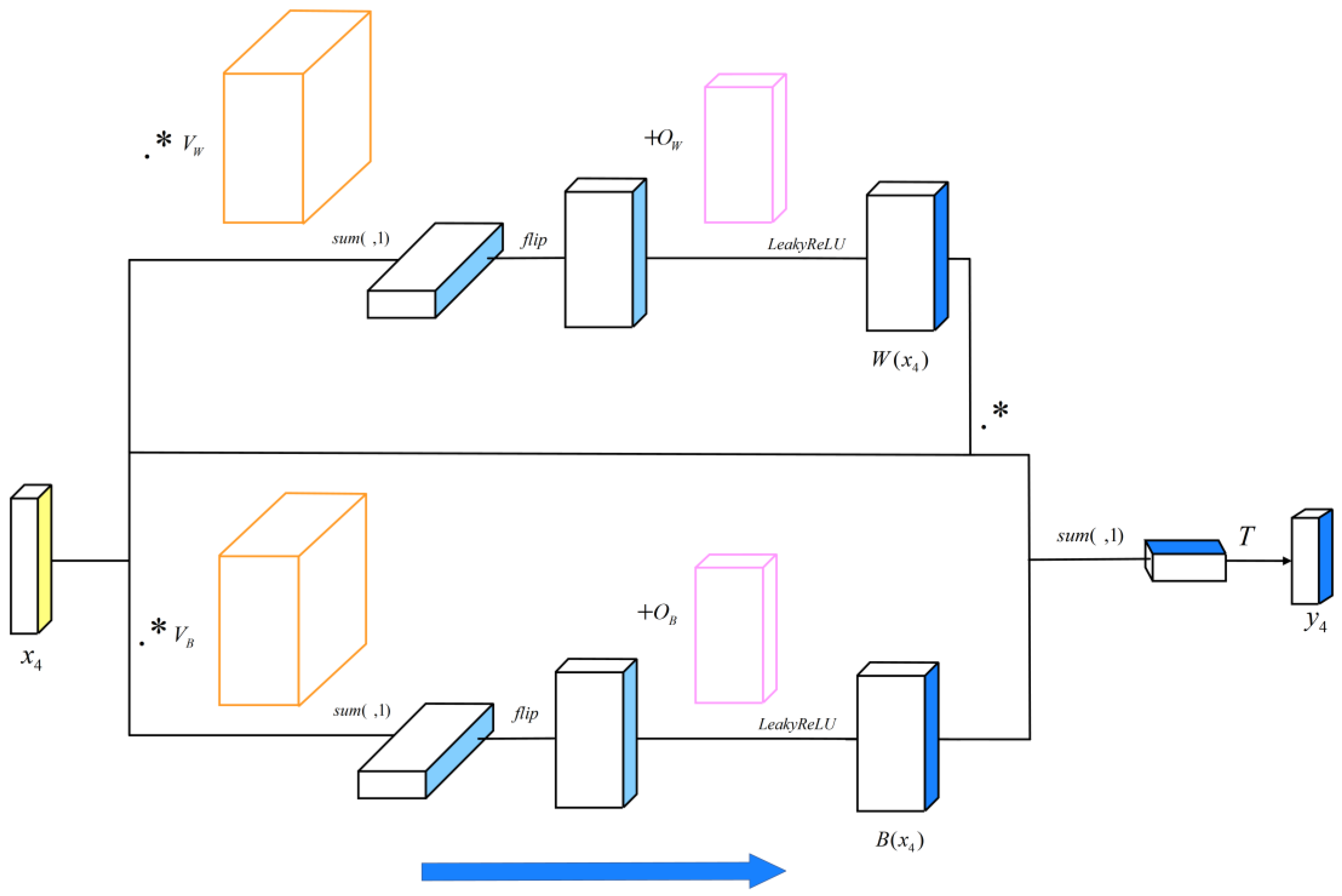
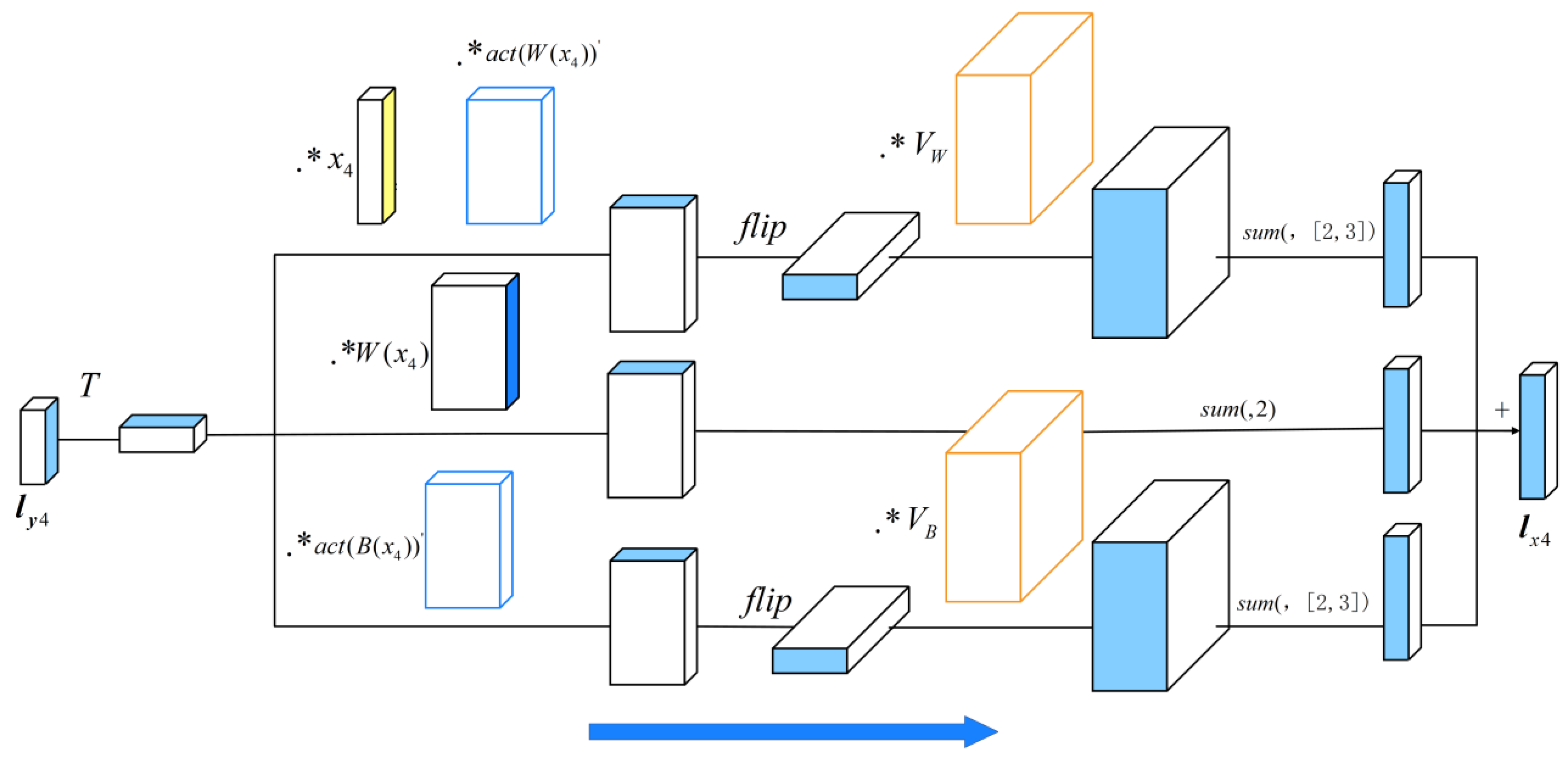
2.1. Core Principle of VWB Net
2.2. The Structure of VWB Net
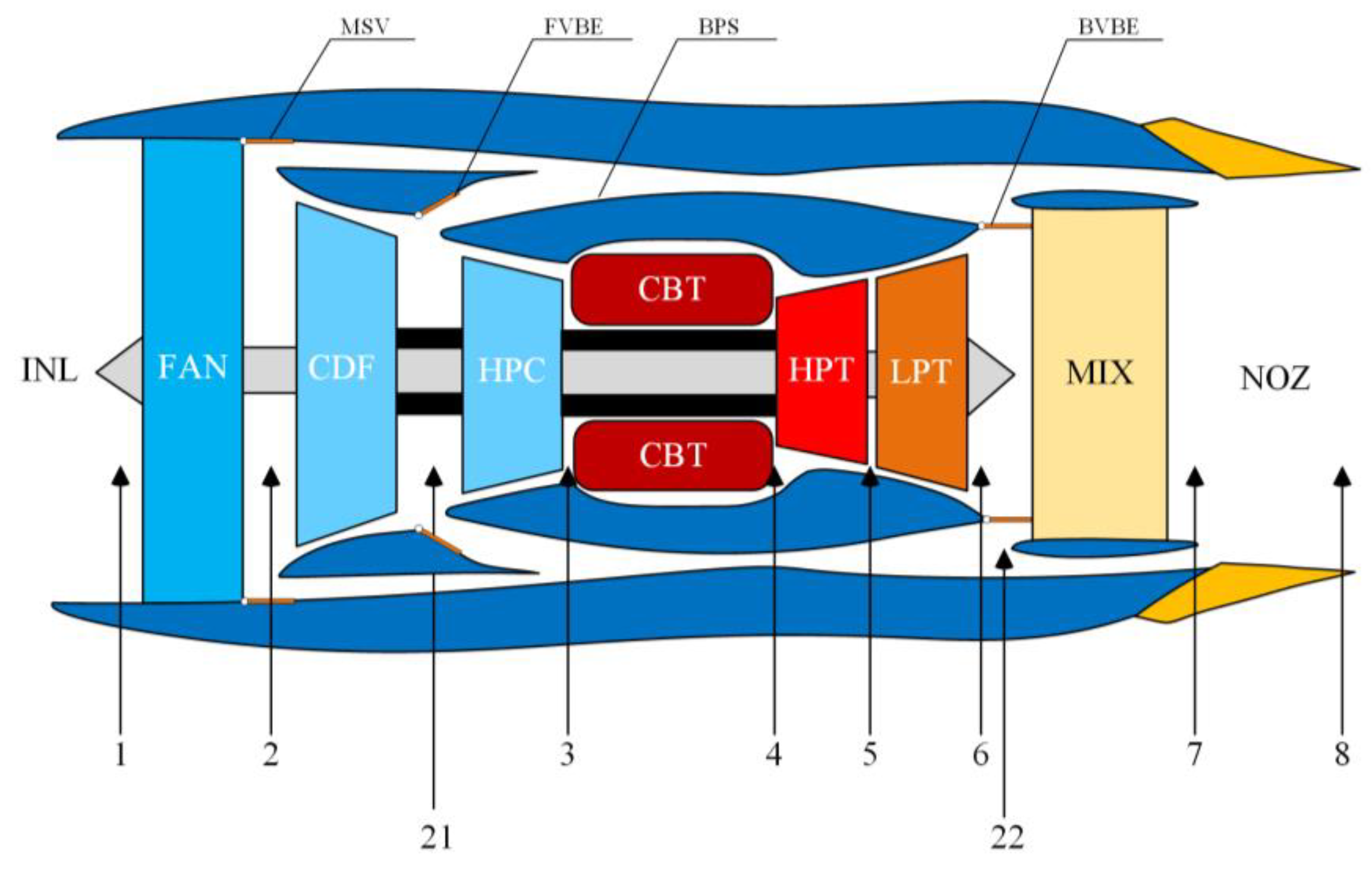
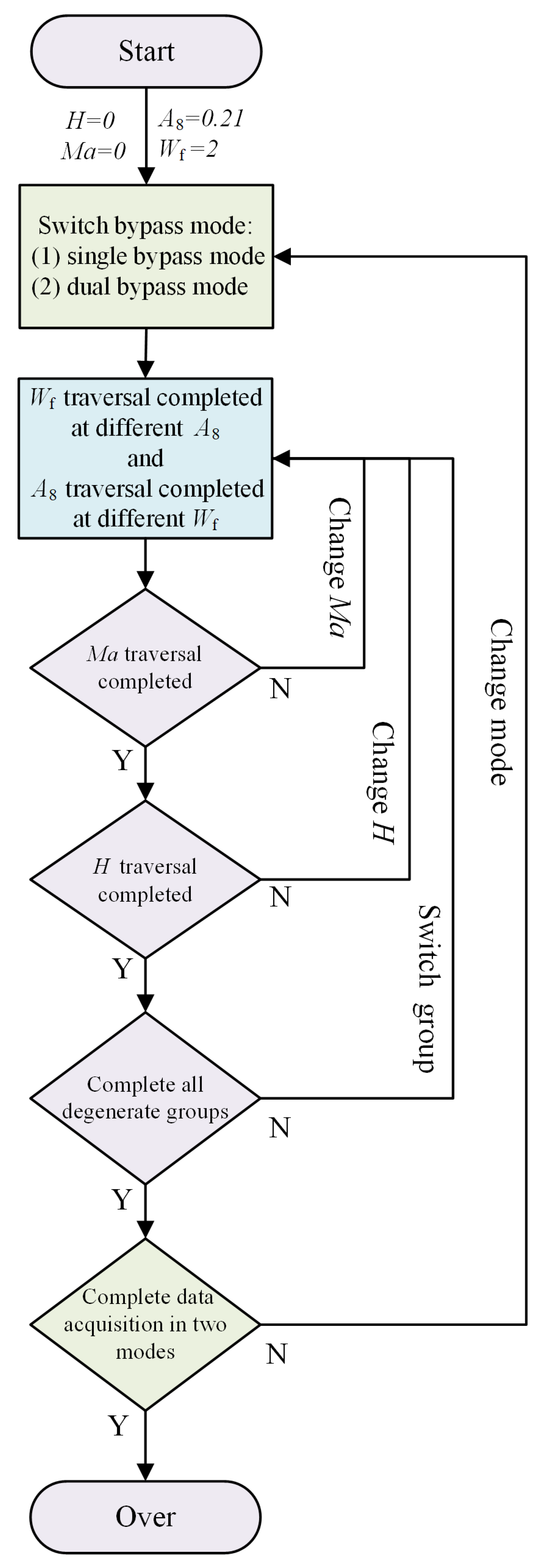
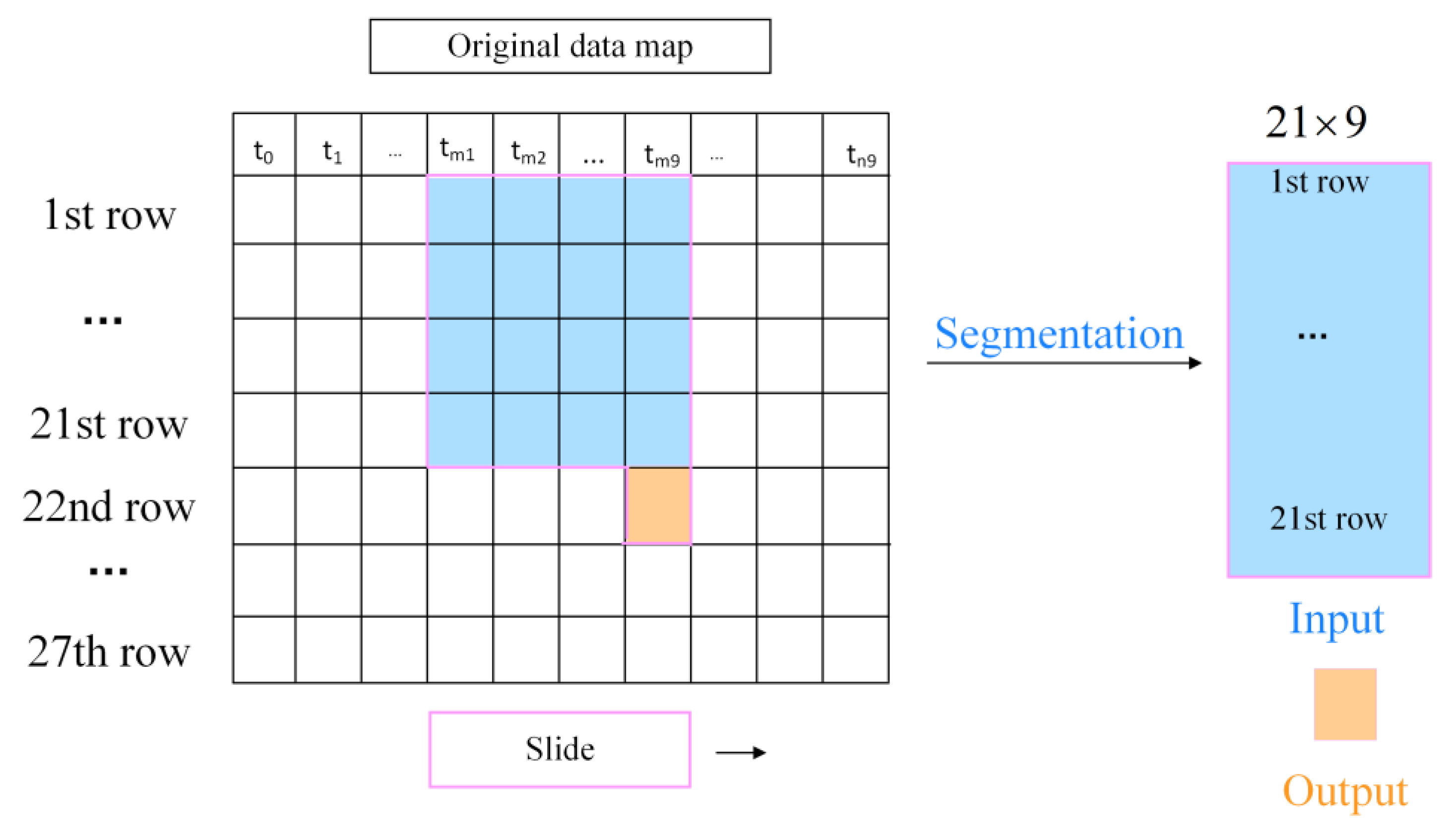
2.3. Data Acquisition of Experiment Object
3. Experiment, Results, and Discussion
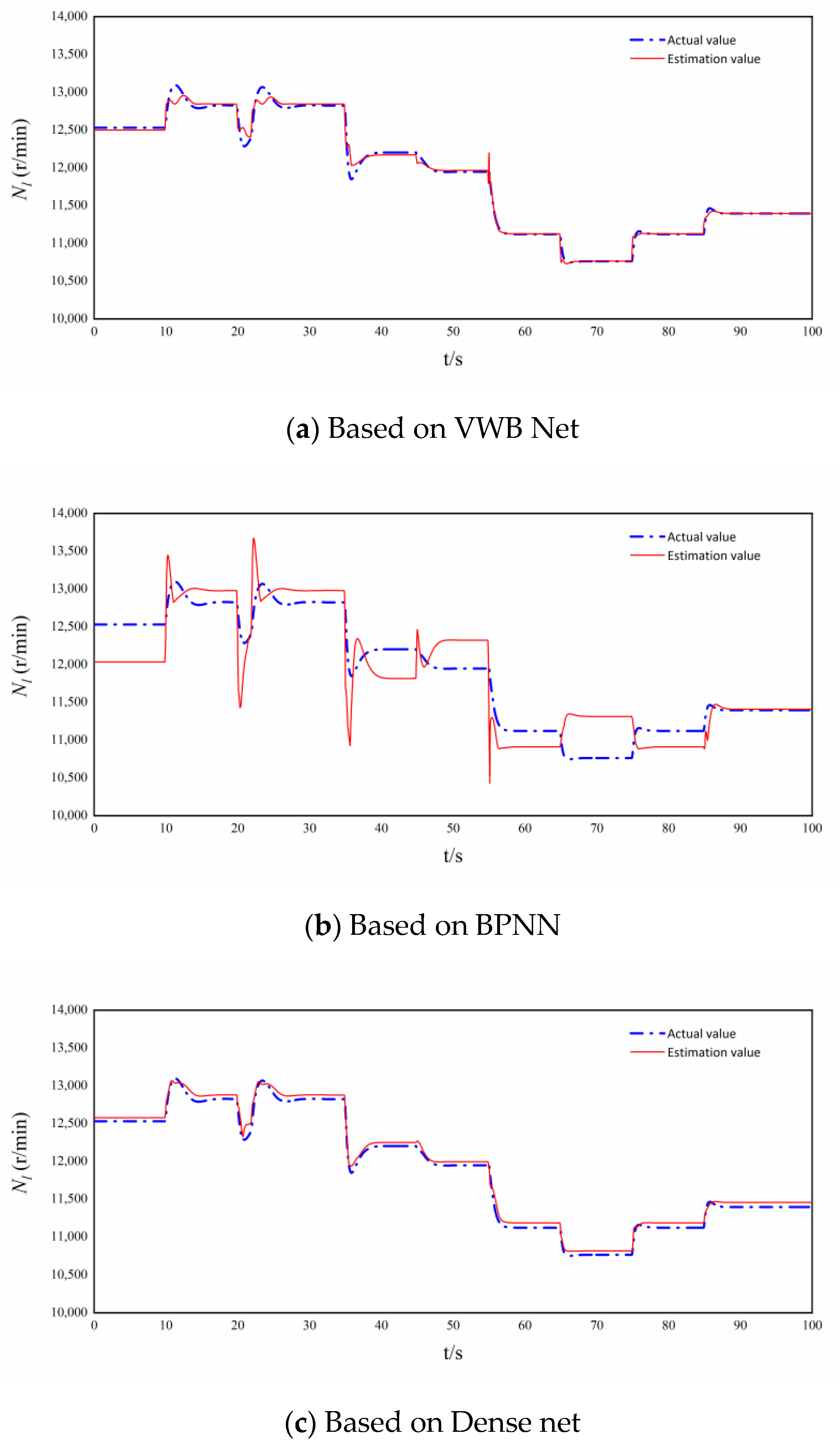
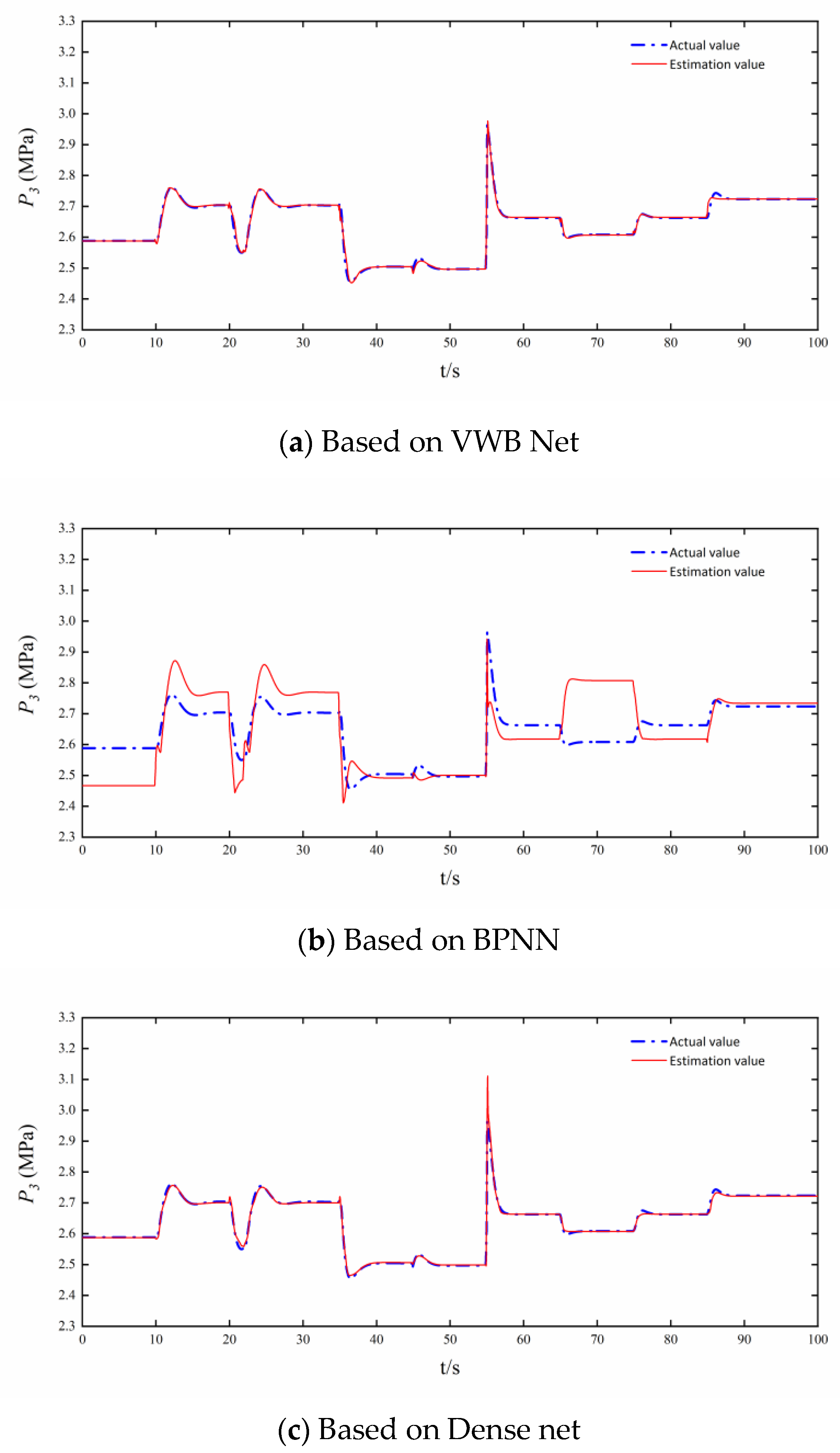
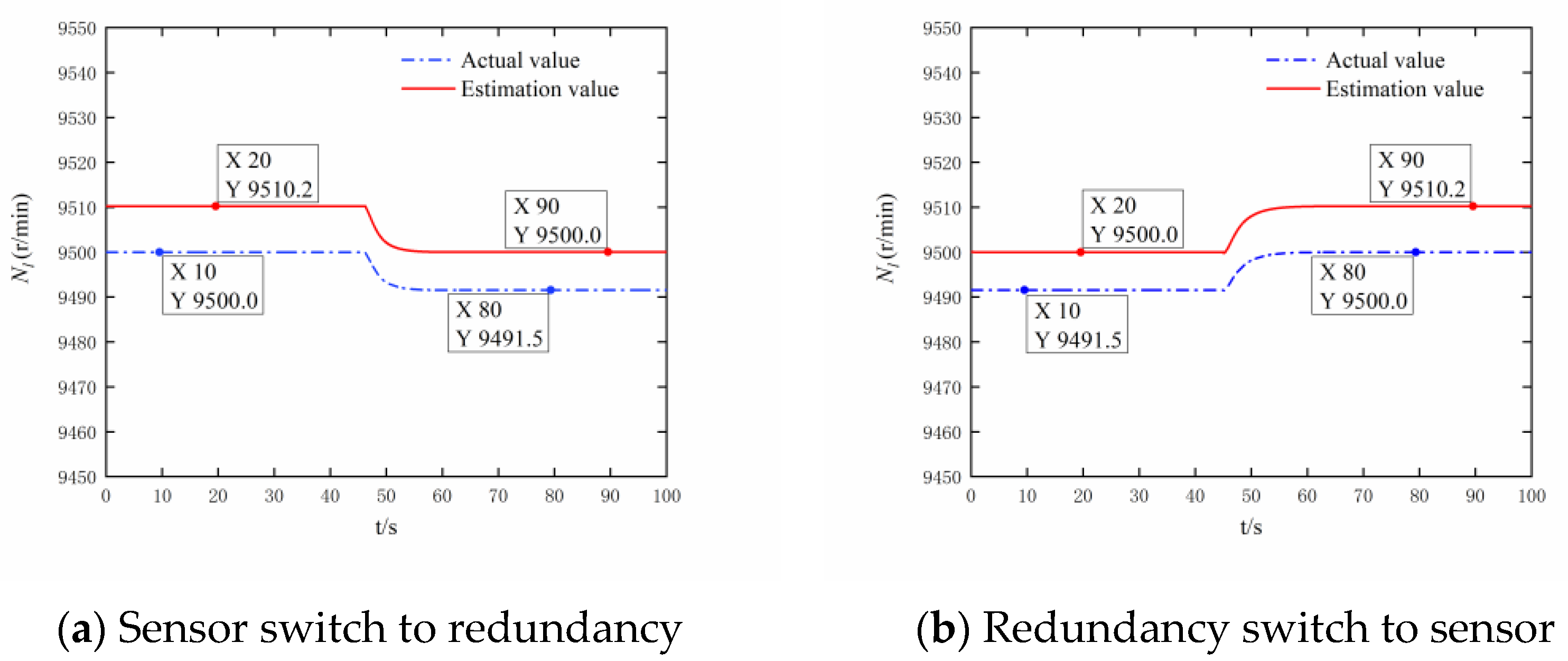
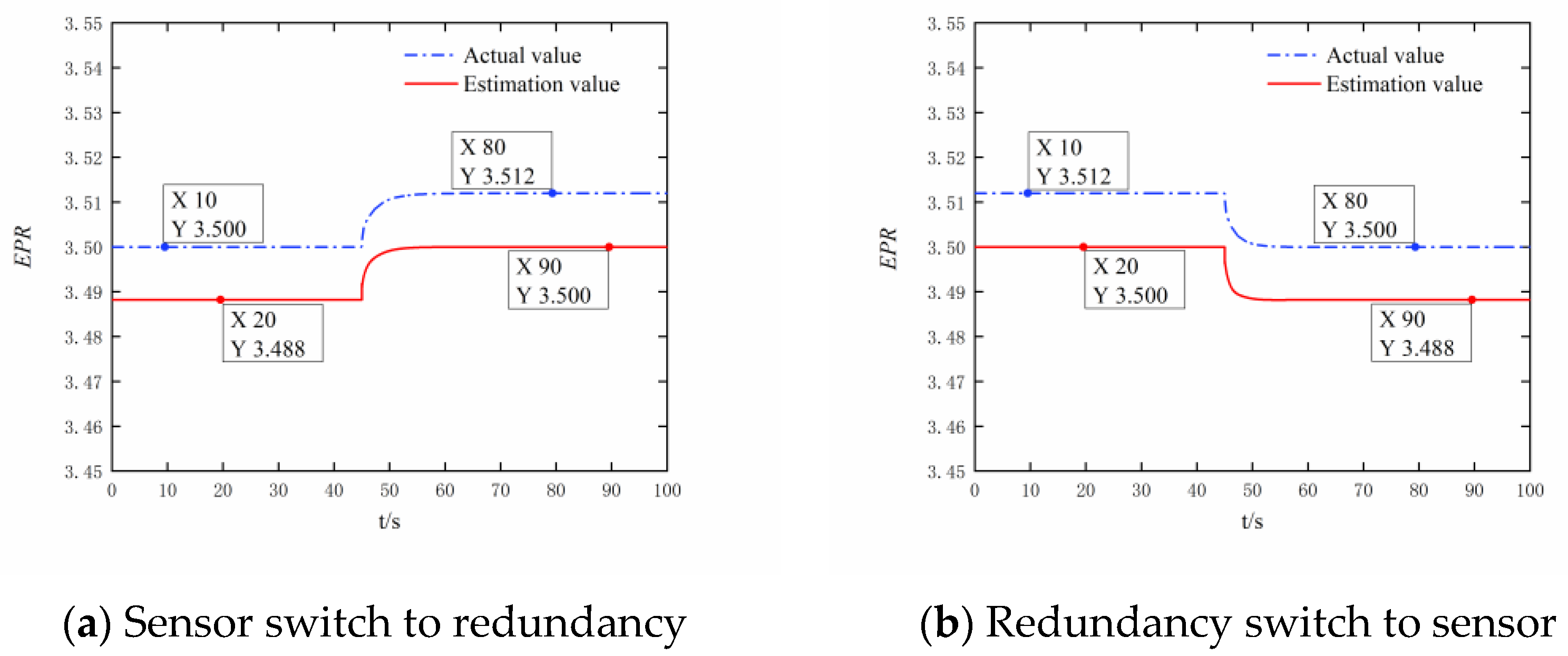
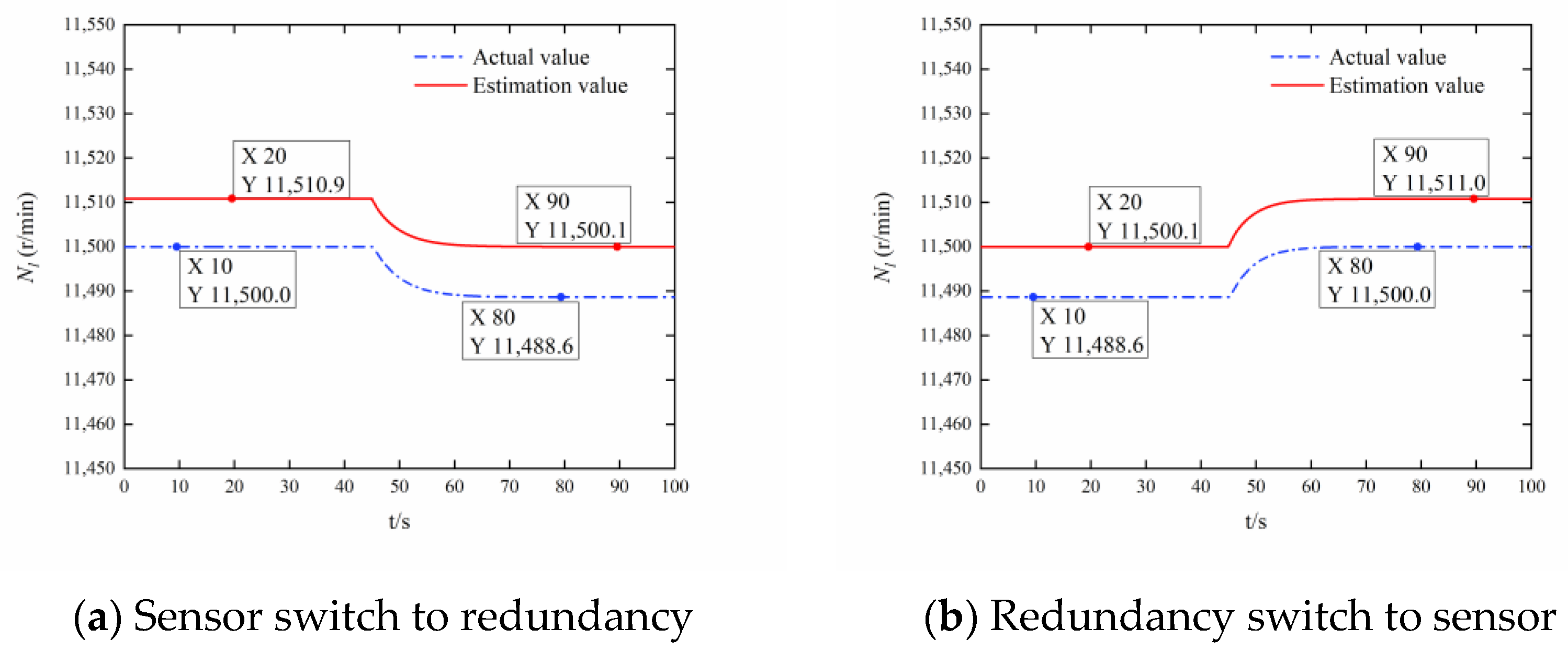
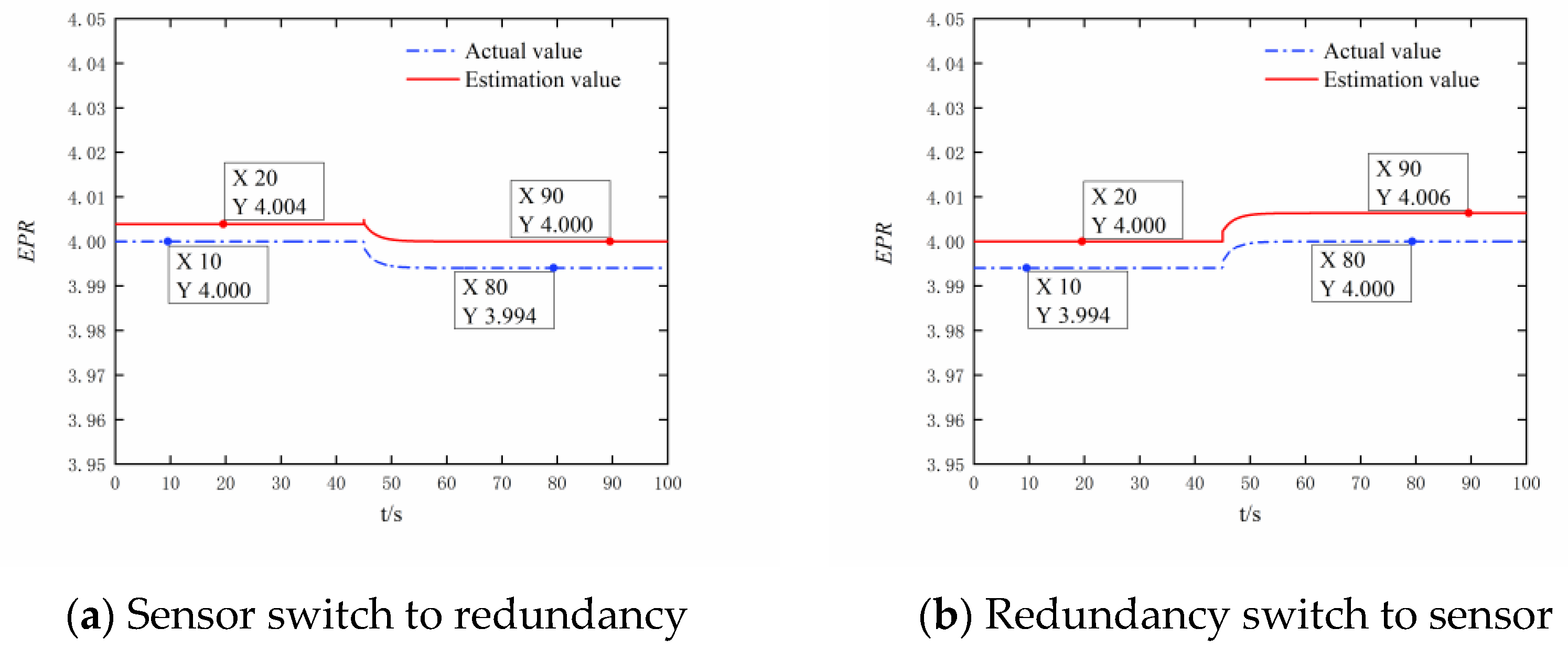
3.1. Digital Simulation Experiment
- (1)
- Single bypass mode simulation validation
- (2)
- Dual bypass mode simulation verification
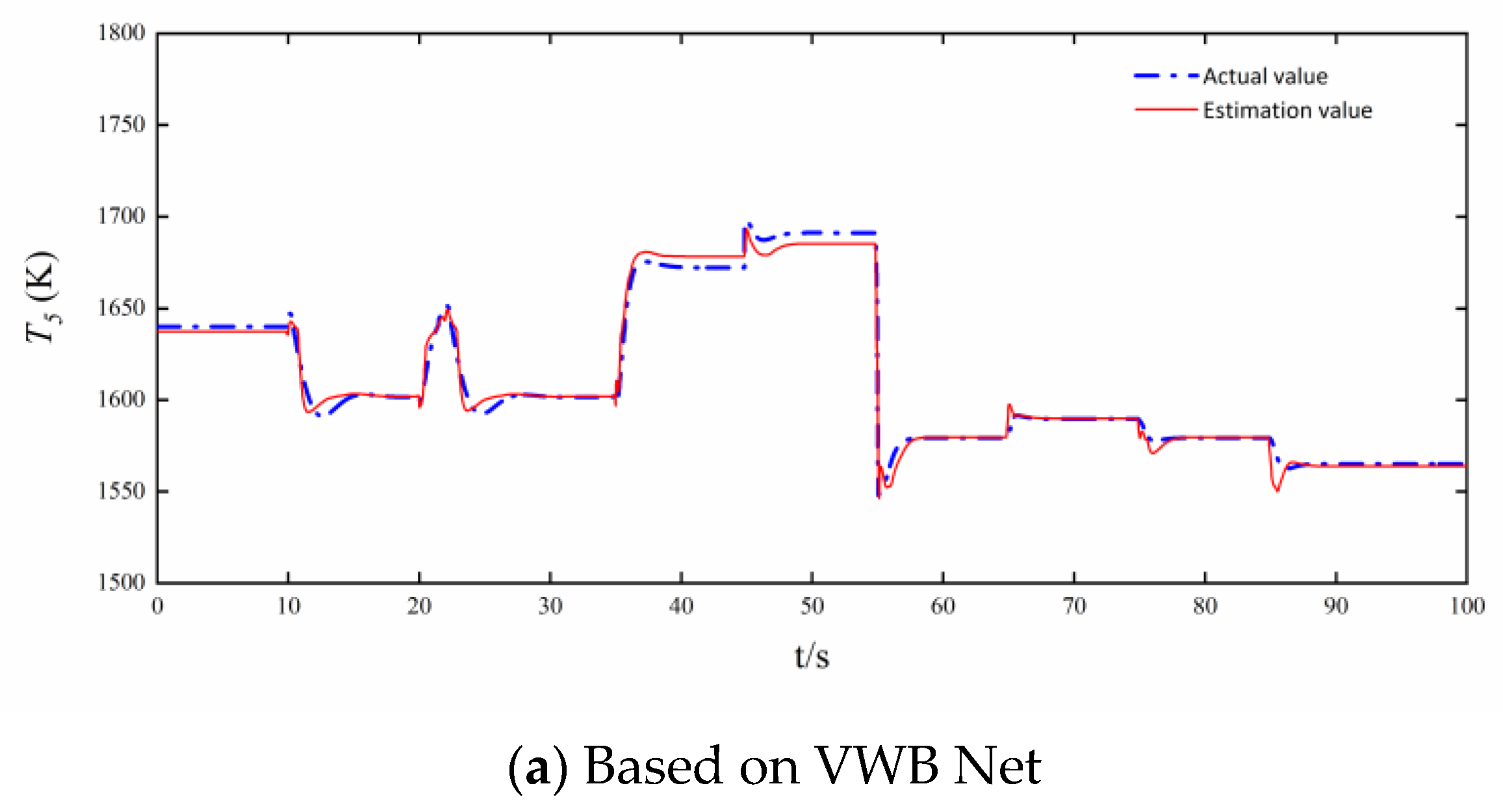
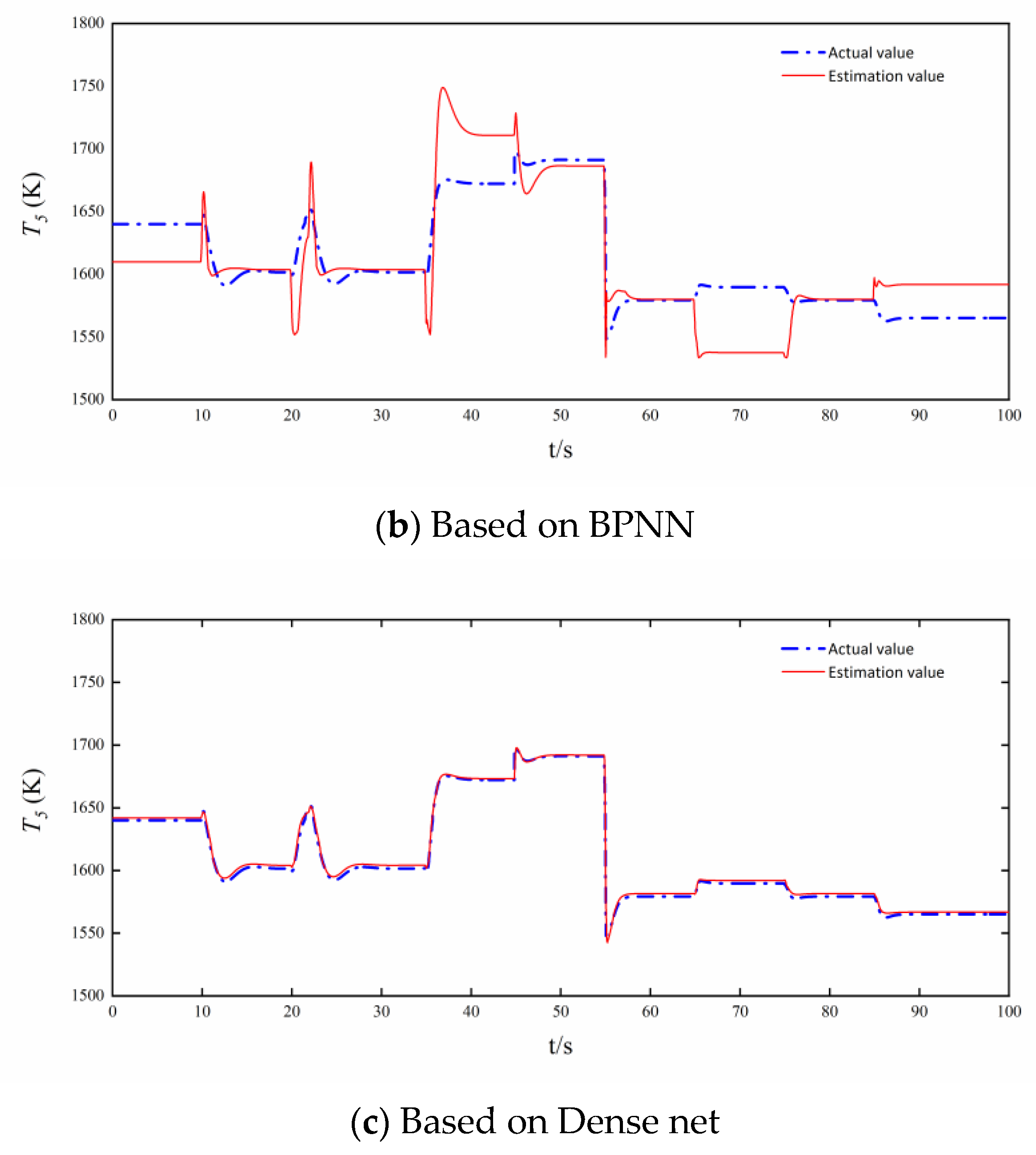
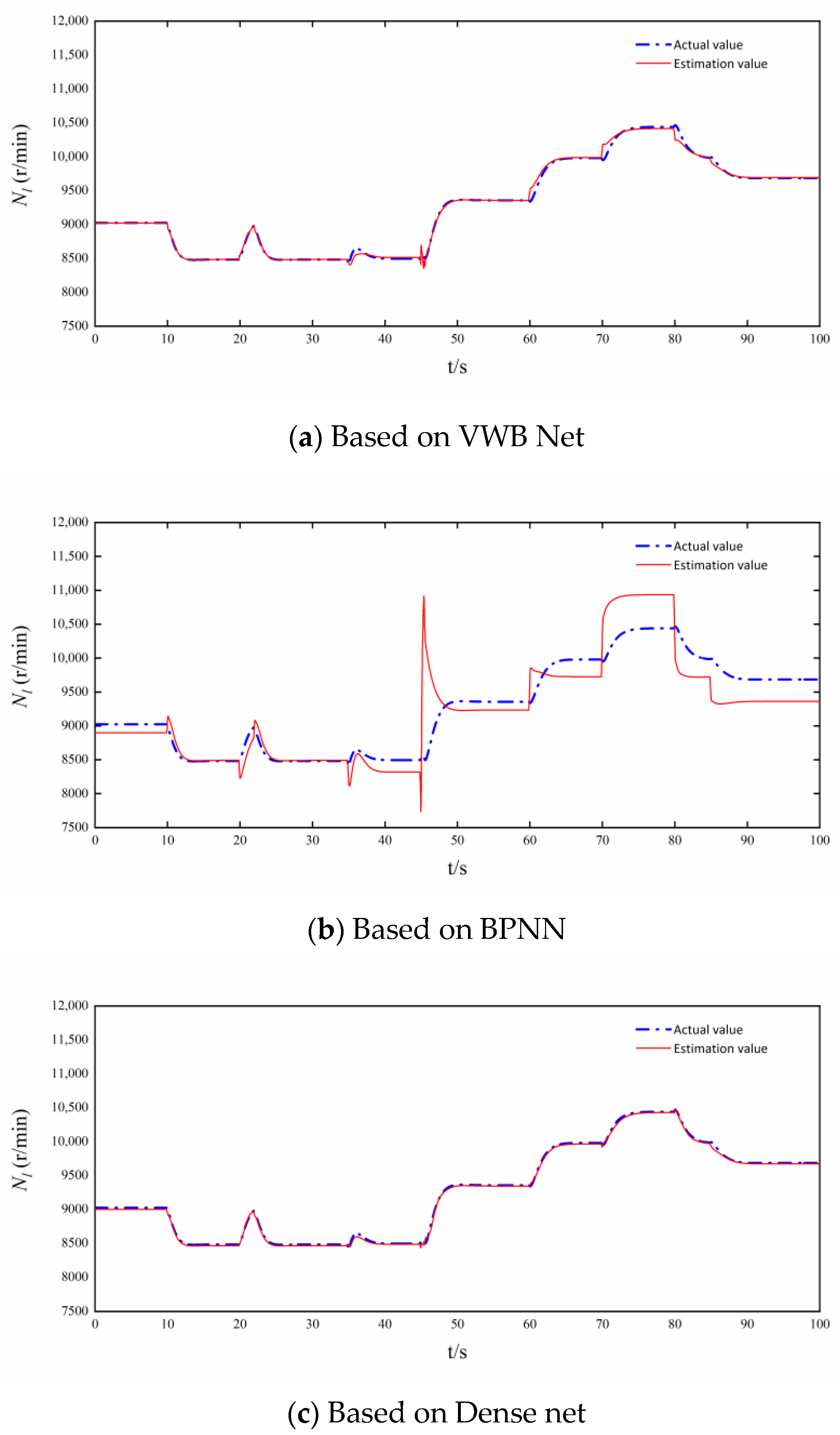
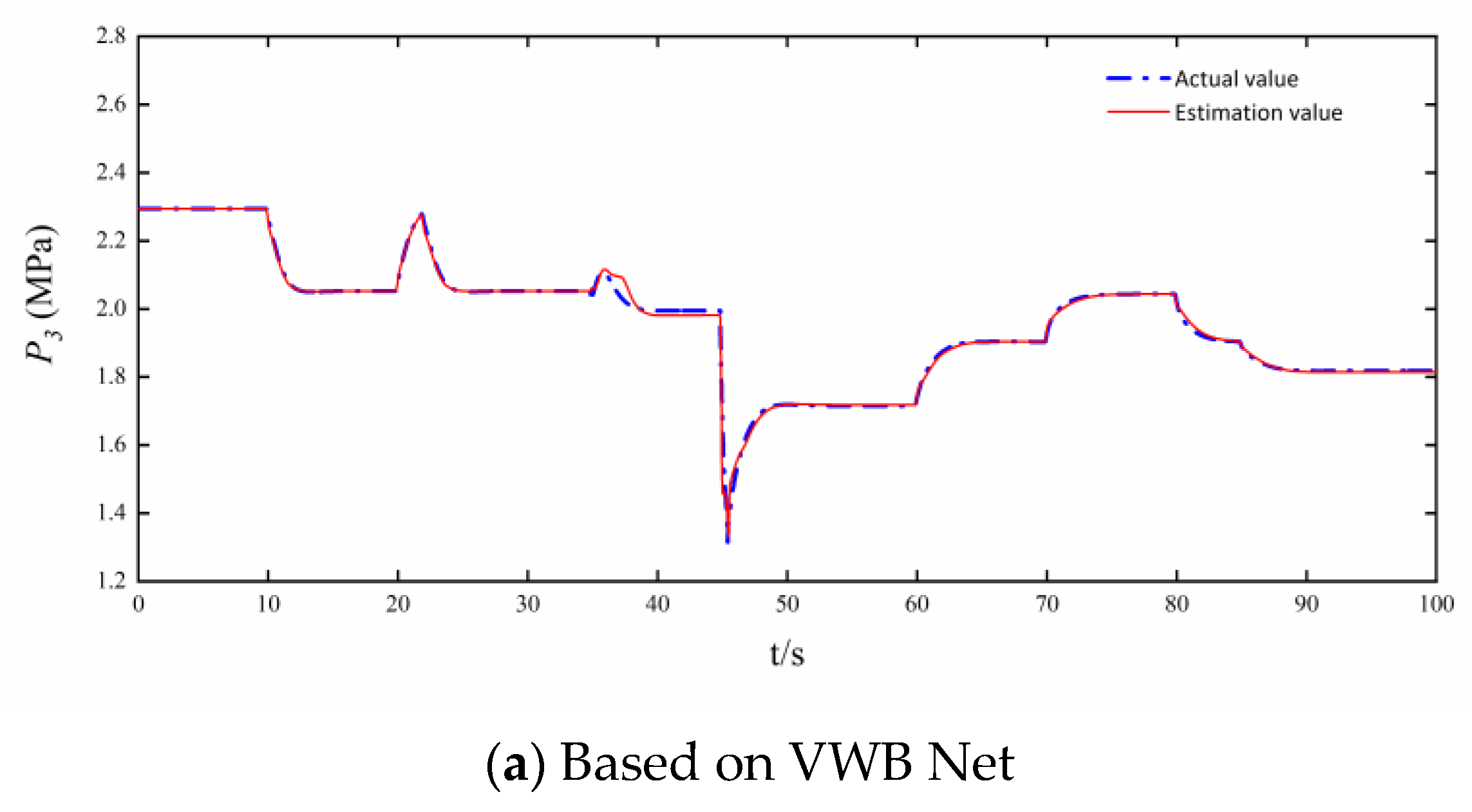
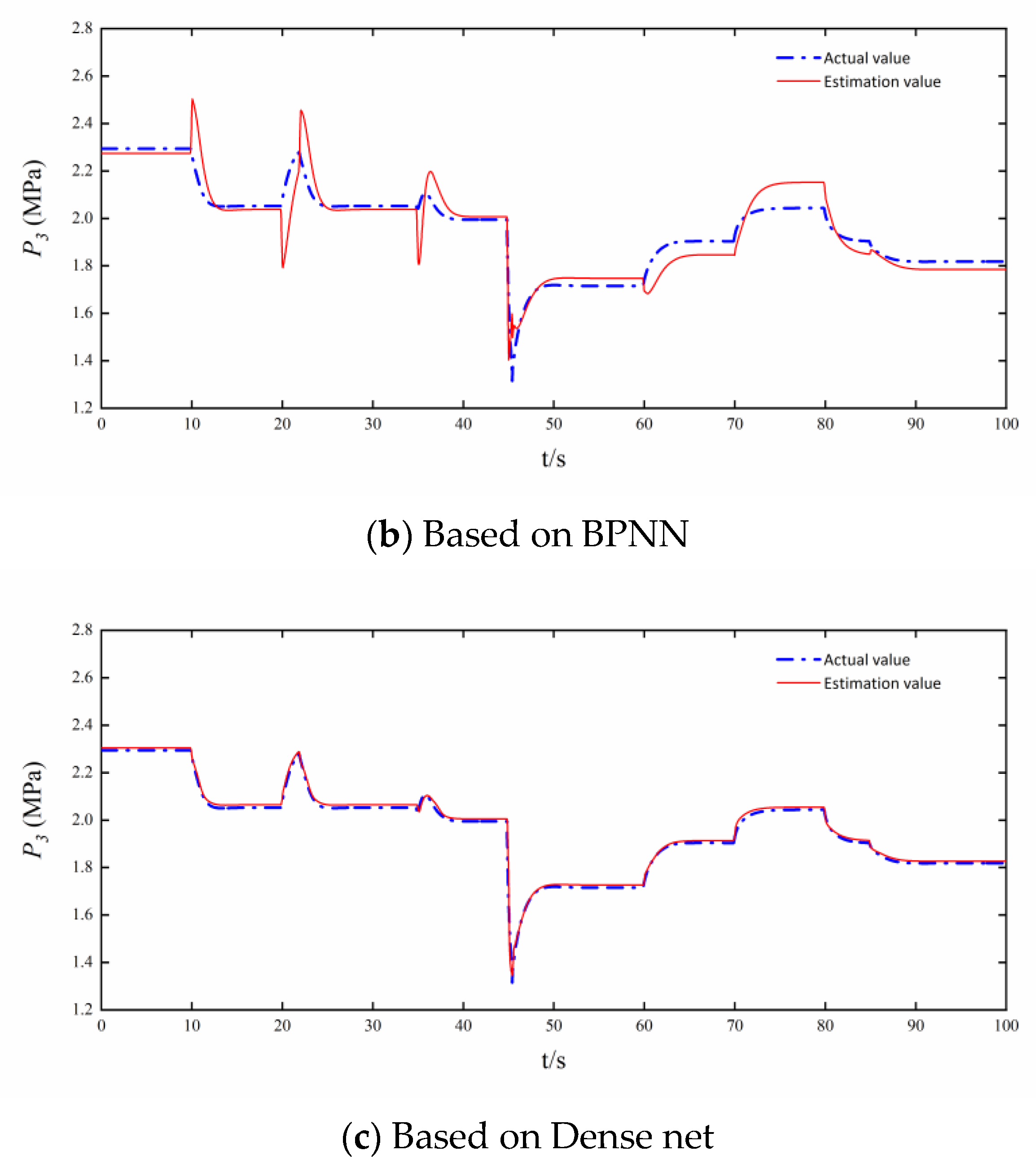
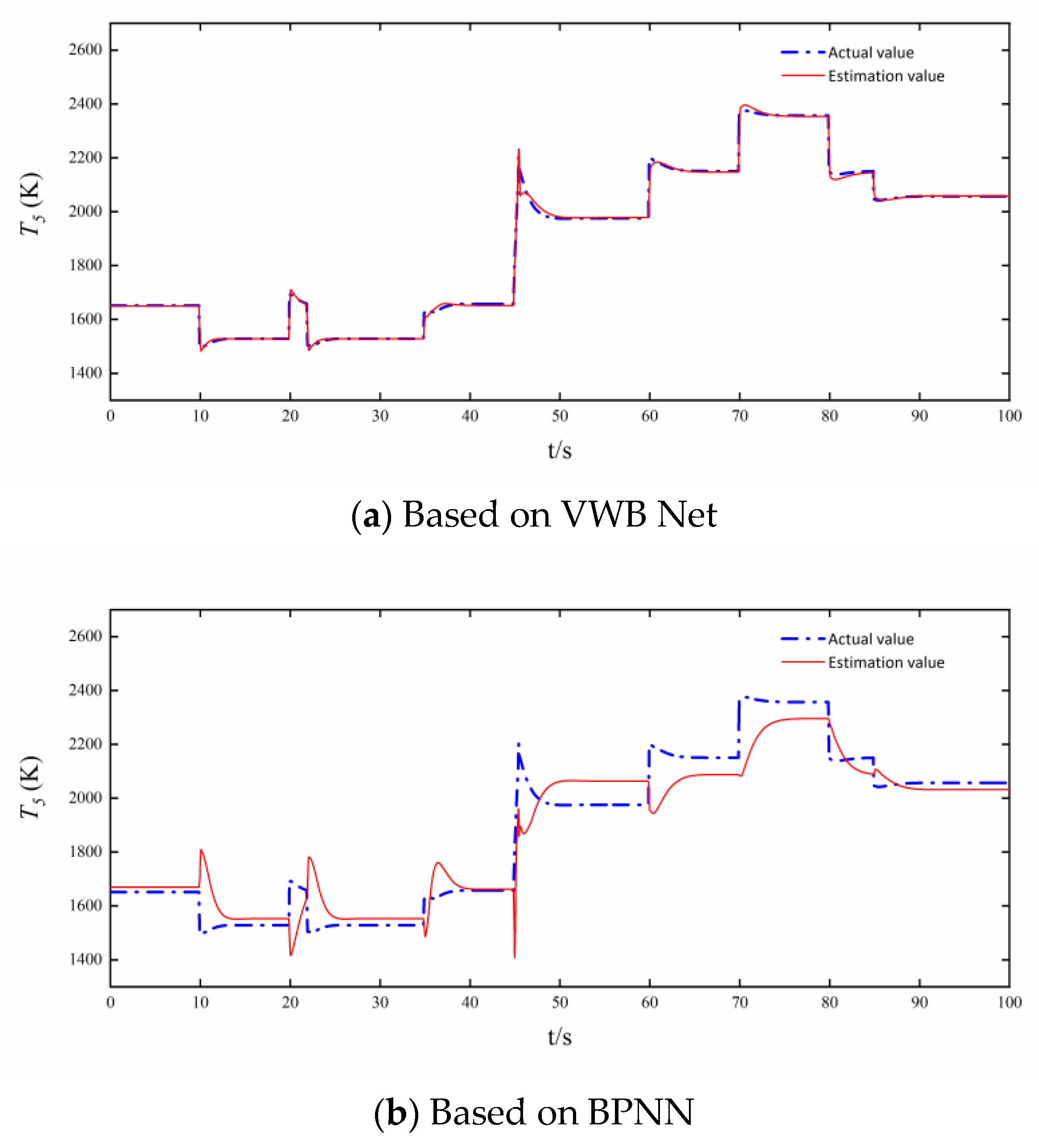
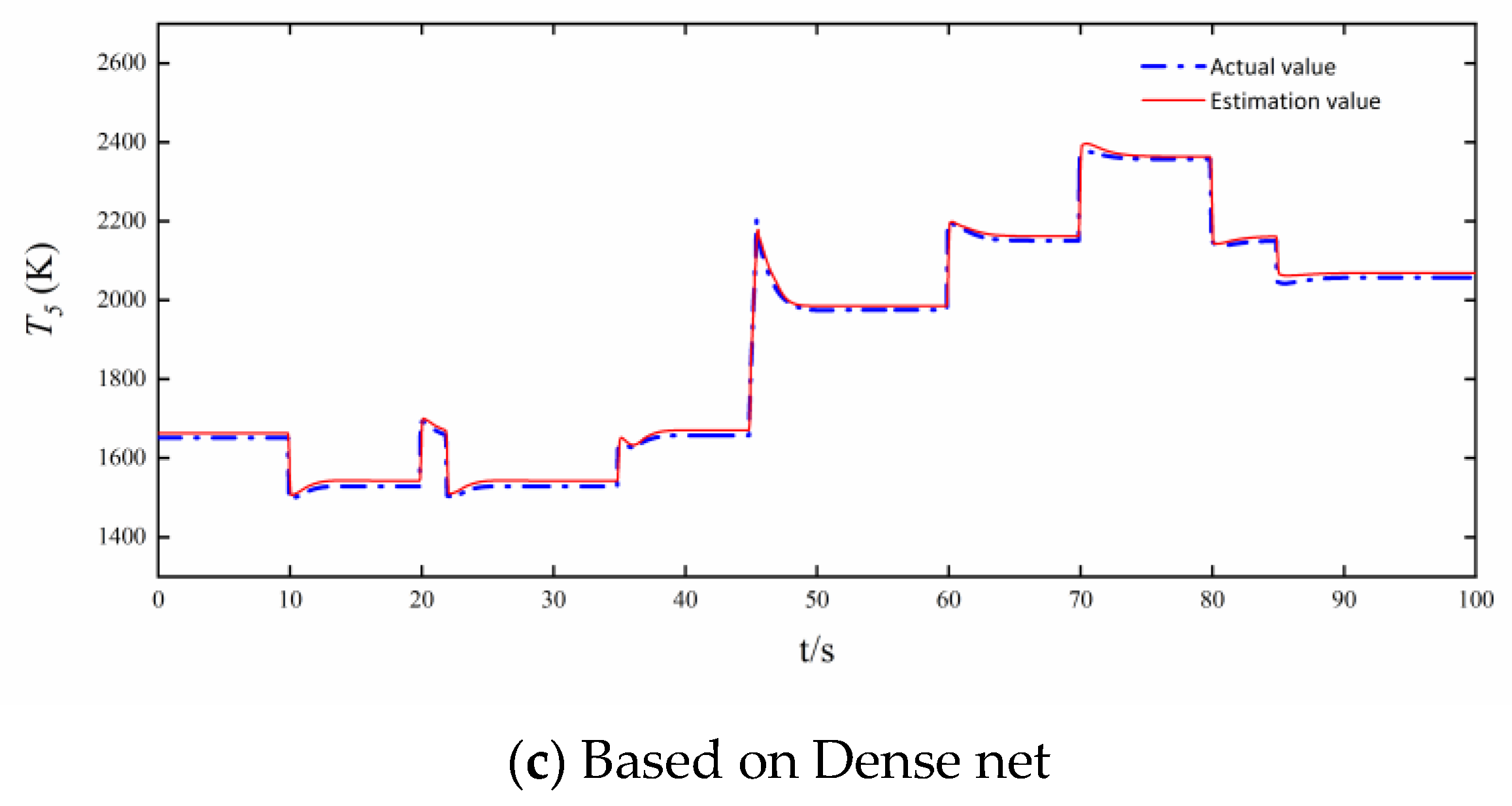
3.2. Comparison of Estimation Accuracy and Real-Time Performance
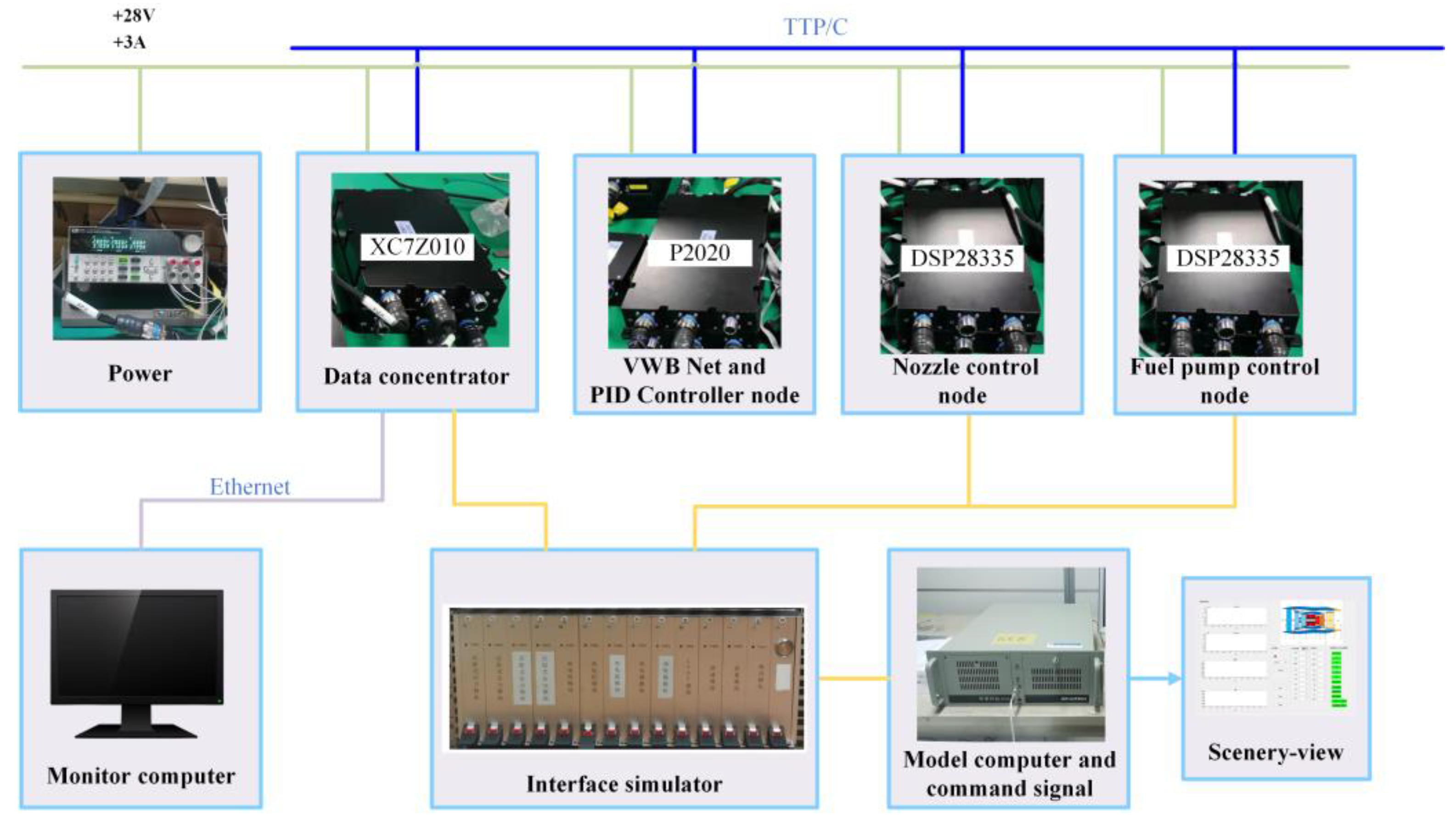
3.3. Framework of Hardware in Loop Simulation Experiment
3.4. Hardware in the Loop Simulation Experiment
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.J.; Huang, J.Q.; Pan, M.X.; Zhou, W.X. Variable-Geometry Rotating Components Modeling Based on Reference Characteristic Curves for the Variable Cycle Engine. Aerospace 2023, 10, 196. [Google Scholar] [CrossRef]
- Wang, Y.J.; Huang, J.Q.; Pan, M.X.; Zhou, W.X. Game-Theory-Based Mode Switch Control Schedule Design for Variable Cycle Engine. Aerospace 2023, 10, 112. [Google Scholar] [CrossRef]
- Lv, C.K.; Chang, J.T.; Bao, W.; Yu, D.R. Recent research progress on airbreathing aero-engine control algorithm. Propuls. Power Res. 2022, 11, 1–57. [Google Scholar] [CrossRef]
- Li, L.; Shi, W. A fault tolerant model for multi-sensor measurement. Chin. J. Aeronaut. 2015, 28, 874–882. [Google Scholar] [CrossRef]
- Cristaldi, L.; Ferrero, A.; Macchi, M.; Mehrafshan, A.; Arpaia, P. Virtual sensors: A tool to improve reliability. In Proceedings of the 2020 IEEE International Workshop on Metrology for Industry 4.0 & IoT, Rome, Italy, 3–5 June 2020; pp. 142–145. [Google Scholar]
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques—Part I: Fault diagnosis with model-based and signal-based approaches. IEEE Trans. Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef]
- Liu, S.C.; Lyu, P.; Lai, J.Z.; Yuan, C.; Wang, B.Q. A fault-tolerant attitude estimation method for quadrotors based on analytical redundancy. Aerosp. Sci. Technol. 2019, 93, 105290. [Google Scholar] [CrossRef]
- Boomadevi, P.; Paulson, V.; Samlal, S.; Varatharajan, M.; Sekar, M.; Alsehli, M.; Elfasakhany, A.; Tola, S. Impact of microalgae biofuel on microgas turbine aviation engine: A combustion and emission study. Fuel 2021, 302, 121155. [Google Scholar] [CrossRef]
- Zhang, L.; Lin, J.; Liu, B.; Zhang, Z.; Yan, X.; Wei, M. A review on deep learning applications in prognostics and health management. IEEE Access 2019, 7, 162415–162438. [Google Scholar] [CrossRef]
- Pang, S.W.; Li, Q.H.; Feng, H.L. A hybrid onboard adaptive model for aero-engine parameter prediction. Aerosp. Sci. Technol. 2020, 105, 105951. [Google Scholar] [CrossRef]
- Csank, J.; Connolly, J.W. Enhanced engine performance during emergency operation using a model-based engine control architecture. In Proceedings of the 51st AIAA/SAE/ASEE Joint Propulsion Conference, Orlando, FL, USA, 27–29 July 2015; p. 3991. [Google Scholar]
- Zhao, Y.P.; Li, Z.Q.; Hu, Q.K. A size-transferring radial basis function network for aero-engine thrust estimation. Eng. Appl. Artif. Intell. 2020, 87, 103253. [Google Scholar] [CrossRef]
- Volponi, A.J. Gas Turbine Engine Health Management Past, Present and Future Trends. In Proceedings of the ASME Turbo Expo: Turbine Technical Conference and Exposition, San Antonio, TX, USA, 3–7 June 2013. [Google Scholar]
- Simon, D.; Simon, D.L. Constrained Kalman filtering via density function truncation for turbofan engine health estimation. Int. J. Syst. Sci. 2010, 41, 159–171. [Google Scholar] [CrossRef]
- Liu, Y.; Frederick, D.K.; DeCastro, J.A.; Litt, J.S.; Chan, W.W. User’s Guide for the Commercial Modular Aero-Propulsion System Simulation (c-Mapss): Version 2. 2012. Available online: https://ntrs.nasa.gov/citations/20120003211 (accessed on 11 April 2023).
- Lu, F.; Ju, H.F.; Huang, J.Q. An improved extended Kalman filter with inequality constraints for gas turbine engine health monitoring. Aerosp. Sci. Technol. 2016, 58, 36–47. [Google Scholar] [CrossRef]
- Li, B.; Zhao, Y.P.; Chen, Y.B. Learning transfer feature representations for gas path fault diagnosis across gas turbine fleet. Eng. Appl. Artif. Intell. 2022, 111, 104733. [Google Scholar] [CrossRef]
- Yongping, Z.; Jianguo, S. Fast online approximation for hard support vector regression and its application to analytical redundancy for aeroengines. Chin. J. Aeronaut. 2010, 23, 145–152. [Google Scholar] [CrossRef]
- Li, Y.; Xu, M.; Wei, Y.; Huang, W. A new rolling bearing fault diagnosis method based on multiscale permutation entropy and improved support vector machine based binary tree. Measurement 2016, 77, 80–94. [Google Scholar] [CrossRef]
- Rodil, S.S.; Fuente, M.J. Fault tolerance in the framework of support vector machines based model predictive control. Eng. Appl. Artif. Intell. 2010, 23, 1127–1139. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, Y.; Zhang, T. Analytical redundancy design for aeroengine sensor fault diagnostics based on SROS-ELM. Math. Probl. Eng. 2016, 2016, 8153282. [Google Scholar] [CrossRef]
- Li, Y.; Li, D.; Sun, X.; Yi, X. Safety Boundary Extraction Using FCM and Prediction Using ELM for Aero-engine Performance Parameters. In Proceedings of the 2019 International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Beijing, China, 15–17 August 2019; pp. 18–23. [Google Scholar]
- Zhang, K.; Lin, B.; Chen, J.; Wu, X.; Lu, C.; Zheng, D.; Tian, L. Aero-Engine Surge Fault Diagnosis Using Deep Neural Network. Comput. Syst. Sci. Eng. 2022, 42, 351–360. [Google Scholar] [CrossRef]
- Du, X.; Chen, J.J.; Zhang, H.B.; Wang, J.Q. Fault Detection of Aero-Engine Sensor Based on Inception-CNN. Aerospace 2022, 9, 236. [Google Scholar] [CrossRef]
- Liu, Y.; Meenakshi, V.; Karthikeyan, L.; Maroušek, J.; Krishnamoorthy, N.R.; Sekar, M.; Nasif, O.; Alharbi, S.A.; Wu, Y.; Xia, C. Machine learning based predictive modelling of micro gas turbine engine fuelled with microalgae blends on using LSTM networks: An experimental approach. Fuel 2022, 322, 124183. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Qiu, X.J.; Chang, X.D.; Chen, J.; Fan, B.Q. Research on the Analytical Redundancy Method for the Control System of Variable Cycle Engine. Sustainability 2022, 14, 5905. [Google Scholar] [CrossRef]
- Zhang, Z.H.; Huang, X.H.; Zhang, T.H. Analytical Redundancy of Variable Cycle Engine Based on Proper Net considering Multiple Input Variables and the Whole Engine’s Degradation. Int. J. Aerosp. Eng. 2021, 2021, 9959264. [Google Scholar] [CrossRef]
- Aygun, H.; Turan, O. Exergetic sustainability off-design analysis of variable-cycle aero-engine in various bypass modes. Energy 2020, 195, 117008. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Row | Symbol | Explanation | Unit | Range |
|---|---|---|---|---|
| 1 | Flight height | km | 0–12 | |
| 2 | Flight Mach number | 0–2 | ||
| 3 | Fuel consumption | kg/s | 2–2.8 | |
| 4 | Nozzle area | m2 | 0.21–0.25 | |
| 5 | The opening of MSV | [0, 100] | ||
| 6 | Opening of forward variable bypass ejector | [0, 100] | ||
| 7 | Opening of backward variable bypass ejector | [0, 100] | ||
| 8 | Fan inlet total temperature | K | ||
| 9 | Fan inlet total pressure | Pa | ||
| 10 | Core driven fan inlet total temperature | K | ||
| 11 | Core driven fan inlet total pressure | Pa | ||
| 12 | High-pressure compressor inlet total temperature | K | ||
| 13 | High-pressure compressor inlet total pressure | Pa | ||
| 14 | Bypass outlet total temperature | K | ||
| 15 | Bypass outlet total pressure | Pa | ||
| 16 | Mixer outlet total temperature | K | ||
| 17 | Mixer outlet total pressure | Pa | ||
| 18 | Nozzle outlet total temperature | K | ||
| 19 | Nozzle outlet total pressure | Pa | ||
| 20 | High-pressure turbine outlet total pressure | Pa | ||
| 21 | Low-pressure turbine outlet total temperature | K | ||
| 22 | Low-pressure rotor speed | r/min | ||
| 23 | High-pressure rotor speed | r/min | ||
| 24 | High-pressure compressor outlet total pressure | Pa | ||
| 25 | High-pressure turbine outlet total temperature | K | ||
| 26 | Low-pressure turbine outlet total pressure | Pa | ||
| 27 | Engine pressure ratio |
| Net | |||
|---|---|---|---|
| VWB Net | 65,772 | 5 | 1 |
| BPNN | 97,664 | 5 | 2 |
| Dense net | 18,154,753 | 709 | 165 |
| Net | |||
|---|---|---|---|
| VWB Net | 0.19 | 0.25 | 0.27 |
| BPNN | 2.65 | 2.37 | 3.34 |
| Dense net | 0.20 | 0.34 | 0.39 |
| Net | ||||||
|---|---|---|---|---|---|---|
| VWB Net | 99.81 | 99.75 | 99.73 | 151.75 | 151.66 | 151.63 |
| BPNN | 48.68 | 48.82 | 48.33 | 99.68 | 99.97 | 98.97 |
| Dense net | 0.60 | 0.60 | 0.60 | 0.55 | 0.55 | 0.55 |
| Environment | |||
|---|---|---|---|
| H = 0 km Ma = 0 | (%) | 0.09 | 0.34 |
| (%) | 0.09 | 0.34 | |
| (%) | 0.11 | 0.34 | |
| H = 11 km Ma = 1.2 | (%) | 0.10 | 0.15 |
| (%) | 0.10 | 0.15 | |
| (%) | 0.09 | 0.15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ran, P.; Huang, X.; Zhang, Z.; Hao, X. Analytical Redundancy for Variable Cycle Engine Based on Variable-Weights-Biases Neural Network. Aerospace 2023, 10, 419. https://doi.org/10.3390/aerospace10050419
Ran P, Huang X, Zhang Z, Hao X. Analytical Redundancy for Variable Cycle Engine Based on Variable-Weights-Biases Neural Network. Aerospace. 2023; 10(5):419. https://doi.org/10.3390/aerospace10050419
Chicago/Turabian StyleRan, Pengyu, Xianghua Huang, Zihao Zhang, and Xuanzhang Hao. 2023. "Analytical Redundancy for Variable Cycle Engine Based on Variable-Weights-Biases Neural Network" Aerospace 10, no. 5: 419. https://doi.org/10.3390/aerospace10050419
APA StyleRan, P., Huang, X., Zhang, Z., & Hao, X. (2023). Analytical Redundancy for Variable Cycle Engine Based on Variable-Weights-Biases Neural Network. Aerospace, 10(5), 419. https://doi.org/10.3390/aerospace10050419