Application of Machine Learning to Attribution and Prediction of Seasonal Precipitation and Temperature Trends in Canberra, Australia

Abstract
1. Introduction
2. Materials and Methods
2.1. Data
2.2. Statistical Analysis
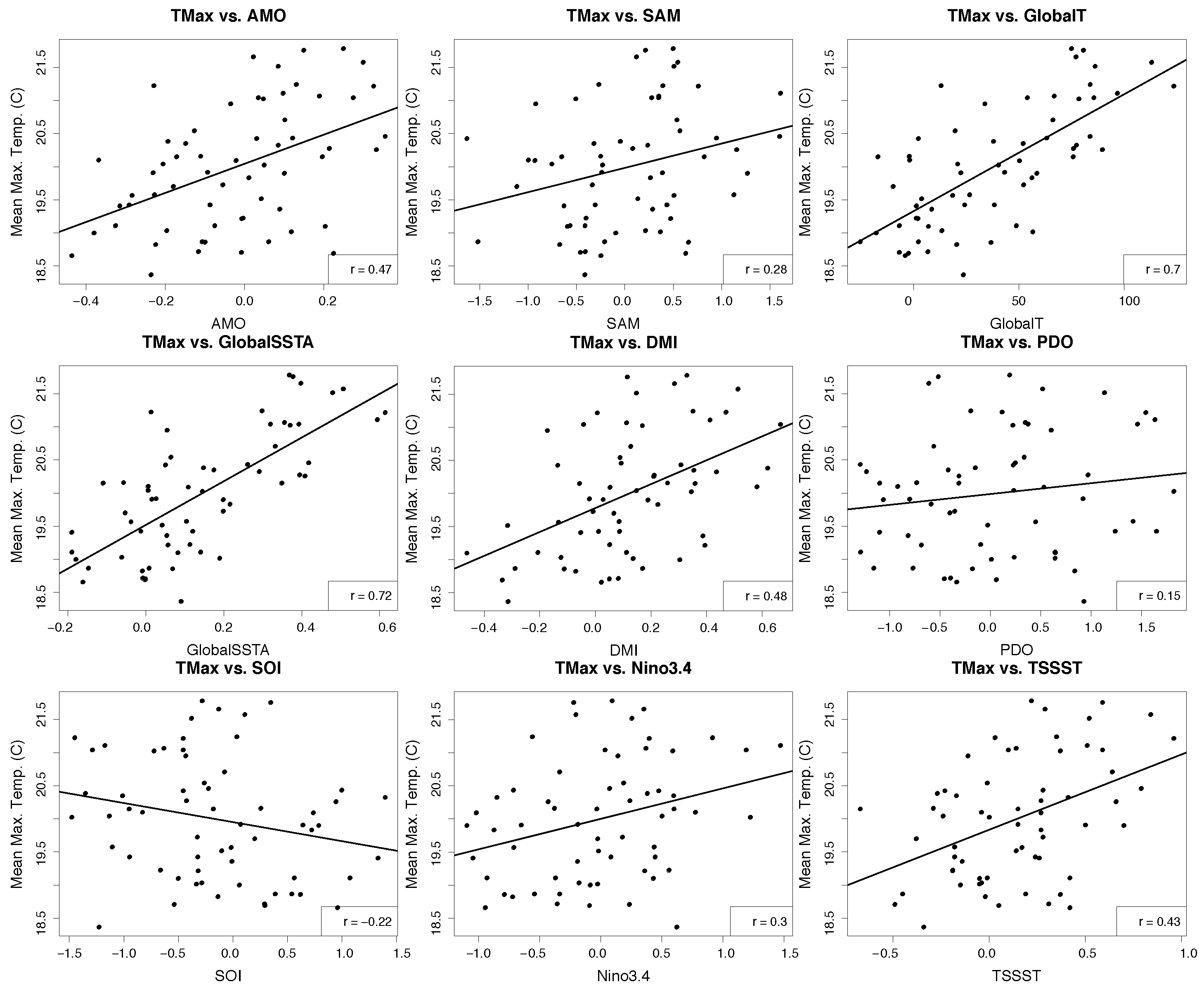
2.3. Attribute Selection
2.4. Training and Prediction
3. Results
3.1. Evolution of Precipitation
3.2. Evolution of Temperature
3.3. Wavelet Analysis of Precipitation
3.4. Wavelet Analysis of Temperature
3.5. Training and Prediction of Precipitation
3.6. Training and Prediction of TMax
4. Discussion
4.1. Drought Vulnerability
4.2. Attribution and Prediction
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Data Availability
References
- Bureau of Meteorology. The “Federation Drought”, 1895–1902. 2009. Available online: https://webarchive.nla.gov.au/awa/20090330051442/http://pandora.nla.gov.au/pan/96122/20090317-1643/www.bom.gov.au/lam/climate/levelthree/c20thc/drought1.html (accessed on 4 June 2020).
- The World War II Droughts 1937–1945. Available online: https://webarchive.nla.gov.au/awa/20090330051442/http://pandora.nla.gov.au/pan/96122/20090317-1643/www.bom.gov.au/lam/climate/levelthree/c20thc/drought3.html (accessed on 4 June 2020).
- Chiew, F.H.S.; Potter, N.J.; Vaze, J.; Petheram, C.; Zhang, L.; Teng, J.; Post, D.A. Observed hydrologic non-stationarity in far south-eastern Australia: Implications for modelling and prediction. Stoch. Environ. Res. Risk Assess. 2014, 28, 3–15. [Google Scholar] [CrossRef]
- Richman, M.B.; Leslie, L.M. Uniqueness and Causes of the California Drought. Procedia Comput. Sci. 2015, 61, 428–435. [Google Scholar] [CrossRef]
- Richman, M.B.; Leslie, L.M. The 2015–2017 Cape Town Drought: Attribution and Prediction Using Machine Learning. Procedia Comput. Sci. 2018, 140, 248–257. [Google Scholar] [CrossRef]
- Niang, I.; Ruppel, O.C.; Abdrabo, M.A.; Essel, A.; Lennard, C.; Padgham, J.; Urquhart, P. 2014: Africa. In Climate Change 2014: Impacts, Adaptation, and Vulnerability. Part B: Regional Aspects. Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Technical Report; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2014; pp. 1199–1265. [Google Scholar]
- Diffenbaugh, N.S.; Swain, D.L.; Touma, D. Anthropogenic warming has increased drought risk in California. Proc. Natl. Acad. Sci. USA 2015, 112, 3931–3936. [Google Scholar] [CrossRef] [PubMed]
- Narisma, G.T.; Pitman, A.J. The Impact of 200 Years of Land Cover Change on the Australian Near-Surface Climate. J. Hydrometeorol. 2003, 4, 424–436. [Google Scholar] [CrossRef]
- De Fraiture, C.; Wichelns, D. Satisfying future water demands for agriculture. Agr. Water Manag. 2010, 97, 502–511. [Google Scholar] [CrossRef]
- Wilhite, D.A.; Sivakumar, M.V.K.; Pulwarty, R. Managing drought risk in a changing climate: The role of national drought policy. Weather Clim. Extrem. 2014, 3, 4–13. [Google Scholar] [CrossRef]
- Icon Water. Water for Generations. 2019. Available online: https://www.iconwater.com.au/Water-education/Water-and-sewerage-system/Water-for-Generations.aspx (accessed on 26 February 2019).
- Australian Bureau of Statistics. Australian Demographic Statistics; Technical Report; Cat. No. 3101.0; Australian Bureau of Statistics: Canberra, Australia, 2018; p. 60.
- Timbal, B.; Fawcett, R. A Historical Perspective on Southeastern Australian Rainfall since 1865 Using the Instrumental Record. J. Clim. 2013, 26, 1112–1129. [Google Scholar] [CrossRef]
- Timbal, B.; Drosdowsky, W. The relationship between the decline of Southeastern Australian rainfall and the strengthening of the subtropical ridge. Int. J. Climatol. 2013, 33, 1021–1034. [Google Scholar] [CrossRef]
- Post, D.A.; Timbal, B.; Chiew, F.H.S.; Hendon, H.H.; Nguyen, H.; Moran, R. Decrease in southeastern Australian water availability linked to ongoing Hadley cell expansion. Earth’s Future 2014, 2, 231–238. [Google Scholar] [CrossRef]
- Burgess, K. Canberra’s emergency water pipeline makes short-lived debut. Canberra Times. 2018. Article 6000370. Available online: https://www.canberratimes.com.au/story/6000370/canberras-emergency-water-pipeline-makes-short-lived-debut/#gsc.tab=0 (accessed on 27 February 2019).
- Holland, J.E.; Luck, G.W.; Finlayson, C.M. Threats to food production and water quality in the Murray-Darling Basin of Australia. Ecosyst. Serv. 2015, 12, 55–70. [Google Scholar] [CrossRef]
- Deo, R.C.; Şahin, M. Application of the Artificial Neural Network model for prediction of monthly Standardized Precipitation and Evapotranspiration Index using hydrometeorological parameters and climate indices in eastern Australia. Atmos. Res. 2015, 161, 65–81. [Google Scholar] [CrossRef]
- Bagirov, A.M.; Mahmood, A.; Barton, A. Prediction of monthly rainfall in Victoria, Australia: Clusterwise linear regression approach. Atmos. Res. 2017, 188, 20–29. [Google Scholar] [CrossRef]
- Choudhury, D.; Mehrotra, R.; Sharma, A.; Gupta, A.; Sivakumar, B. Effectiveness of CMIP5 Decadal Experiments for Interannual Rainfall Prediction Over Australia. Water Resour. Res. 2019, 55, 7400–7418. [Google Scholar] [CrossRef]
- Richman, M.B.; Leslie, L.M. Machine Learning for Attribution of Heat and Drought in Southwestern Australia. Procedia Comput. Sci. 2019, 168, 3–10. [Google Scholar] [CrossRef]
- Buishand, T. Some methods for testing the homogeneity of rainfall records. J. Hydrol. 1982, 58, 11–27. [Google Scholar] [CrossRef]
- Buishand, T. Tests for detecting a shift in the mean of hydrological time series. J. Hydrol. 1984, 73, 51–69. [Google Scholar] [CrossRef]
- Hubert, P.; Carbonnel, J.; Chaouche, A. Segmentation des séries hydrométéorologiques—application à des séries de précipitations et de débits de l’Afrique de l’ouest. J. Hydrol. 1989, 110, 349–367. [Google Scholar] [CrossRef]
- Torrence, C.; Compo, G.P. A Practical Guide to Wavelet Analysis. Bull. Am. Meteorol. Soc. 1998, 79, 61–78. [Google Scholar] [CrossRef]
- Lau, K.M.; Weng, H. Climate Signal Detection Using Wavelet Transform: How to Make a Time Series Sing. Bull. Am. Meteorol. Soc. 1995, 76, 2391–2402. [Google Scholar] [CrossRef]
- Henley, B.; Gergis, J.; Karoly, D.; Power, S.; Kennedy, J.; Folland, C. A tripole index for the interdecadal Pacific oscillation. Clim. Dyn. 2015, 45, 3077–3090. [Google Scholar] [CrossRef]
- Richman, M.B.; Leslie, L.M.; Trafalis, T.B.; Mansouri, H. Data Selection Using Support Vector Regression. Adv. Atmos. Sci. 2015, 32, 277–286. [Google Scholar] [CrossRef]
- Risbey, J.S.; Pook, M.J.; McIntosh, P.C.; Wheeler, M.C.; Hendon, H.H. On the Remote Drivers of Rainfall Variability in Australia. Mon. Weather Rev. 2009, 137, 3233–3253. [Google Scholar] [CrossRef]
- Cai, W.; van Rensch, P.; Cowan, T.; Hendon, H.H. Teleconnection Pathways of ENSO and the IOD and the Mechanisms for Impacts on Australian Rainfall. J. Clim. 2011, 24, 3910–3923. [Google Scholar] [CrossRef]
- Ramsay, H.A.; Richman, M.B.; Leslie, L.M. Seasonal Tropical Cyclone Predictions Using Optimized Combinations of ENSO Regions: Application to the Coral Sea Basin. J. Clim. 2014, 27, 8527–8542. [Google Scholar] [CrossRef]
- Prasad, R.; Deo, R.C.; Li, Y.; Maraseni, T. Input selection and performance optimization of ANN-based streamflow forecasts in the drought-prone Murray Darling Basin region using IIS and MODWT algorithm. Atmos. Res. 2017, 197, 42–63. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T. Computer Age Statistical Inference; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Maldonado, S.; Weber, R. A wrapper method for feature selection using Support Vector Machines. Inf. Sci. 2009, 179, 2208–2217. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Chang, C.-C.; Lin, C.-J. A Practical Guide to Support Vector Classification; Technical Report; National Taiwan University: Taipei, Taiwan, 2003; p. 16. [Google Scholar]
- Kirono, D.; Chiew, F.; Kent, D. Identification of best predictors for forecasting seasonal rainfall and runoff in Australia. Hydrol. Process. 2010, 24, 1237–1247. [Google Scholar] [CrossRef]
- Cai, W.; Cowan, T. Dynamics of late autumn rainfall reduction over southeastern Australia. Geophys. Res. Lett. 2008, 35, L09708. [Google Scholar] [CrossRef]
- Cai, W.; Cowan, T.; Briggs, P.; Raupach, M. Rising temperature depletes soil moisture and exacerbates severe drought conditions across southeast Australia. Geophys. Res. Lett. 2009, 36. [Google Scholar] [CrossRef]
- Chiew, F.; Piechota, T.; Dracup, J.; McMahon, T. El Nino/Southern Oscillation and Australian rainfall, streamflow and drought: Links and potential for forecasting. J. Hydrol. 1998, 204, 138–149. [Google Scholar] [CrossRef]
- Power, S.; Casey, T.; Folland, C.; Colman, A.; Mehta, V. Inter-decadal modulation of the impact of ENSO on Australia. Clim. Dyn. 1999, 15, 319–324. [Google Scholar] [CrossRef]
- Kiem, A.; Franks, S. Multi-decadal variability of drought risk, eastern Australia. Hydrol. Process. 2004, 18, 2039–2050. [Google Scholar] [CrossRef]
- Wilks, D.S. Statistical Methods in the Atmospheric Sciences; Academic Press: Oxford, UK, 2011; Volume 100. [Google Scholar]
- McBride, J.L.; Nicholls, N. Seasonal Relationships between Australian Rainfall and the Southern Oscillation. Mon. Weather Rev. 1983, 111, 1998–2004. [Google Scholar] [CrossRef]
- Kiem, A.S.; Johnson, F.; Westra, S.; van Dijk, A.; Evans, J.P.; O’Donnell, A.; Rouillard, A.; Barr, C.; Tyler, J.; Thyer, M.; et al. Natural hazards in Australia: Droughts. Clim. Chang. 2016, 139, 37–54. [Google Scholar] [CrossRef]
- Hendon, H.H.; Thompson, D.W.J.; Wheeler, M.C. Australian Rainfall and Surface Temperature Variations Associated with the Southern Hemisphere Annular Mode. J. Clim. 2007, 20, 2452–2467. [Google Scholar] [CrossRef]
- Ummenhofer, C.C.; England, M.H.; McIntosh, P.C.; Meyers, G.A.; Pook, M.J.; Risbey, J.S.; Gupta, A.S.; Taschetto, A.S. What causes southeast Australia’s worst droughts? Geophys. Res. Lett. 2009, 36. [Google Scholar] [CrossRef]
- Ummenhofer, C.; Gupta, A.; Briggs, P.; England, M.; McIntosh, P.; Meyers, G.; Pook, M.; Raupach, M.; Risbey, J. Indian and Pacific Ocean Influences on Southeast Australian Drought and Soil Moisture. J. Clim. 2011, 24, 1313–1336. [Google Scholar] [CrossRef]
- Choudhury, D.; Gupta, A.; Sharma, A.; Taschetto, A.; Mehrotra, R.; Sivakumar, B. Impacts of the tropical trans-basin variability on Australian rainfall. Clim. Dyn. 2017, 49, 1617–1629. [Google Scholar] [CrossRef]
- Johnson, Z.; Chikamoto, Y.; Luo, J.J.; Mochizuki, T. Ocean Impacts on Australian Interannual to Decadal Precipitation Variability. Climate 2018, 6, 61. [Google Scholar] [CrossRef]
- Hall, M.A. Correlation-based Feature Selection for Machine Learning. Ph.D. Thesis, University of Waikato, Hamilton, New Zealand, 1999. [Google Scholar]
- Abbot, J.; Marohasy, J. Skilful rainfall forecasts from artificial neural networks with long duration series and single-month optimization. Atmos. Res. 2017, 197, 289–299. [Google Scholar] [CrossRef]
- Hartigan, J. Seasonal Precipitation and Temperature Data in Canberra, Australia. Zenodo. 2020. Available online: https://zenodo.org/record/3797615#.XuBM9XERXIU (accessed on 6 May 2020).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | LR | SVR (RBF) | SVR (Poly) | Attribute | LR | SVR (RBF) | SVR (Poly) |
|---|---|---|---|---|---|---|---|
| AMO | 10 | 80 | 40 | DMI*TSSST | 10 | 70 | 50 |
| DMI | 100 | 60 | 50 | GlobalSSTA*GlobalT | 0 | 80 | 40 |
| GlobalSSTA | 0 | 60 | 50 | GlobalSSTA*Nino3.4 | 0 | 60 | 60 |
| GlobalT | 0 | 70 | 70 | GlobalSSTA*PDO | 20 | 50 | 50 |
| Nino3.4 | 30 | 50 | 60 | GlobalSSTA*SAM | 10 | 70 | 50 |
| PDO | 10 | 60 | 60 | GlobalSSTA*SOI | 10 | 40 | 60 |
| SAM | 100 | 60 | 70 | GlobalSSTA*TSSST | 0 | 70 | 60 |
| SOI | 60 | 50 | 50 | GlobalT*Nino3.4 | 30 | 50 | 50 |
| TSSST | 0 | 70 | 60 | GlobalT*PDO | 40 | 50 | 70 |
| AMO*DMI | 40 | 60 | 30 | GlobalT*SAM | 20 | 70 | 70 |
| AMO*GlobalSSTA | 0 | 90 | 70 | GlobalT*SOI | 10 | 50 | 50 |
| AMO*GlobalT | 0 | 90 | 60 | GlobalT*TSSST | 0 | 70 | 50 |
| AMO*Nino3.4 | 20 | 60 | 40 | Nino3.4*PDO | 0 | 60 | 70 |
| AMO*PDO | 20 | 70 | 20 | Nino3.4*SAM | 20 | 80 | 60 |
| AMO*SAM | 70 | 70 | 30 | Nino3.4*SOI | 0 | 50 | 60 |
| AMO*SOI | 0 | 70 | 50 | Nino3.4*TSSST | 30 | 50 | 50 |
| AMO*TSSST | 0 | 70 | 50 | PDO*SAM | 10 | 80 | 40 |
| DMI*GlobalSSTA | 0 | 30 | 70 | PDO*SOI | 10 | 60 | 50 |
| DMI*GlobalT | 0 | 30 | 40 | PDO*TSSST | 10 | 70 | 60 |
| DMI*Nino3.4 | 0 | 50 | 40 | SAM*SOI | 0 | 80 | 40 |
| DMI*PDO | 20 | 50 | 50 | SAM*TSSST | 60 | 80 | 60 |
| DMI*SAM | 40 | 70 | 30 | SOI*TSSST | 90 | 60 | 50 |
| DMI*SOI | 0 | 70 | 30 |
| Attribute | LR | SVR (RBF) | SVR (Poly) | Attribute | LR | SVR (RBF) | SVR (Poly) |
|---|---|---|---|---|---|---|---|
| AMO | 10 | 50 | 80 | DMI*TSSST | 0 | 60 | 70 |
| DMI | 100 | 70 | 70 | GlobalSSTA*GlobalT | 10 | 60 | 60 |
| GlobalSSTA | 100 | 40 | 70 | GlobalSSTA*Nino3.4 | 0 | 70 | 60 |
| GlobalT | 70 | 40 | 70 | GlobalSSTA*PDO | 0 | 80 | 60 |
| Nino3.4 | 60 | 50 | 60 | GlobalSSTA*SAM | 0 | 60 | 80 |
| PDO | 10 | 60 | 70 | GlobalSSTA*SOI | 0 | 60 | 60 |
| SAM | 100 | 70 | 70 | GlobalSSTA*TSSST | 90 | 60 | 70 |
| SOI | 10 | 60 | 60 | GlobalT*Nino3.4 | 0 | 40 | 60 |
| TSSST | 0 | 30 | 80 | GlobalT*PDO | 90 | 80 | 70 |
| AMO*DMI | 0 | 60 | 70 | GlobalT*SAM | 0 | 60 | 90 |
| AMO*GlobalSSTA | 30 | 70 | 70 | GlobalT*SOI | 0 | 60 | 60 |
| AMO*GlobalT | 10 | 80 | 60 | GlobalT*TSSST | 0 | 60 | 70 |
| AMO*Nino3.4 | 0 | 60 | 60 | Nino3.4*PDO | 0 | 60 | 70 |
| AMO*PDO | 20 | 80 | 60 | Nino3.4*SAM | 0 | 80 | 90 |
| AMO*SAM | 90 | 50 | 90 | Nino3.4*SOI | 0 | 60 | 60 |
| AMO*SOI | 0 | 70 | 70 | Nino3.4*TSSST | 0 | 70 | 60 |
| AMO*TSSST | 0 | 50 | 50 | PDO*SAM | 0 | 100 | 50 |
| DMI*GlobalSSTA | 0 | 50 | 50 | PDO*SOI | 10 | 50 | 70 |
| DMI*GlobalT | 0 | 50 | 70 | PDO*TSSST | 0 | 70 | 70 |
| DMI*Nino3.4 | 0 | 80 | 40 | SAM*SOI | 0 | 90 | 90 |
| DMI*PDO | 10 | 50 | 60 | SAM*TSSST | 0 | 60 | 90 |
| DMI*SAM | 10 | 70 | 50 | SOI*TSSST | 0 | 60 | 70 |
| DMI*SOI | 70 | 70 | 60 |
| Years | Precipitation | TMax | TMin |
|---|---|---|---|
| Annual | |||
| 1939–1958 vs. 1999–2018 | 0.7610 | 0.0000 | 0.0022 |
| 1979–1998 vs. 1999–2018 | 0.8620 | 0.0000 | 0.5210 |
| Autumn | |||
| 1939–1958 vs. 1999–2018 | 0.0262 | 0.0000 | 0.5730 |
| 1979–1998 vs. 1999–2018 | 0.0840 | 0.0094 | 0.2350 |
| Winter | |||
| 1939–1958 vs. 1999–2018 | 0.8790 | 0.0000 | 0.5760 |
| 1979–1998 vs. 1999–2018 | 0.3680 | 0.0000 | 0.8050 |
| Spring | |||
| 1939–1958 vs. 1999–2018 | 0.2160 | 0.0000 | 0.0002 |
| 1979–1998 vs. 1999–2018 | 0.6120 | 0.0002 | 0.3030 |
| Summer | |||
| 1939–1958 vs. 1999–2018 | 0.0466 | 0.0004 | 0.0000 |
| 1979–1998 vs. 1999–2018 | 0.0978 | 0.0150 | 0.0372 |
| Model | Precip. LR | Precip. SVR (RBF) | Precip. SVR (Poly) | TMax LR | TMax SVR (RBF) | TMax SVR (Poly) |
|---|---|---|---|---|---|---|
| RMSE (mm/C) | 131.5 | 126.0 | 127.502 | 0.871 | 1.113 | 0.783 |
| Skill | 0.246 | 0.308 | 0.291 | 0.594 | 0.337 | 0.673 |
| Correlation | 0.516 | 0.738 | 0.568 | 0.415 | 0.708 | 0.531 |
| R | 0.266 | 0.544 | 0.322 | 0.173 | 0.502 | 0.282 |
| Error Mean (mm/C) | −21.1 | −22.6 | 0.2 | 0.435 | −1.026 | −0.595 |
| Error SD (mm/C) | 135.5 | 129.4 | 133.2 | 0.788 | 0.452 | 0.531 |
| Error Skewness | −0.181 | −0.115 | 0.133 | −0.395 | 0.387 | 0.032 |
| Error Kurtosis | −1.191 | −0.813 | −0.639 | −1.453 | −1.068 | −1.577 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hartigan, J.; MacNamara, S.; Leslie, L.M. Application of Machine Learning to Attribution and Prediction of Seasonal Precipitation and Temperature Trends in Canberra, Australia. Climate 2020, 8, 76. https://doi.org/10.3390/cli8060076
Hartigan J, MacNamara S, Leslie LM. Application of Machine Learning to Attribution and Prediction of Seasonal Precipitation and Temperature Trends in Canberra, Australia. Climate. 2020; 8(6):76. https://doi.org/10.3390/cli8060076
Chicago/Turabian StyleHartigan, Joshua, Shev MacNamara, and Lance M. Leslie. 2020. "Application of Machine Learning to Attribution and Prediction of Seasonal Precipitation and Temperature Trends in Canberra, Australia" Climate 8, no. 6: 76. https://doi.org/10.3390/cli8060076
APA StyleHartigan, J., MacNamara, S., & Leslie, L. M. (2020). Application of Machine Learning to Attribution and Prediction of Seasonal Precipitation and Temperature Trends in Canberra, Australia. Climate, 8(6), 76. https://doi.org/10.3390/cli8060076