2. Analysis of Existing Review Works
Let us make a review of the works devoted to the areas of software security, in the interest of which the analysis of meta-information in programs is required—header fields, sequences of instructions and their entropy, and other information. At the same time, we will take both the ELF format (mainly used in the Internet of Things and similar devices based on Linux OS) and the PE format (mainly used in Desktop computers based on Windows OS) as program types. In addition, although the aspect of consideration will be the applicability of methods for identifying the MC Architecture, nevertheless, we will evaluate the elaboration in related areas. Otherwise, due to the low elaboration of the field, the review will consist of only a few articles directly related to this problem, although other relevant studies reflecting certain aspects of this topic will also be considered. When searching for articles, the IEEE Xplore, Scopus, MDPI, ResearchGate, and Google Scholar databases were used. The following keywords (and their variations) were taken as queries: identification of processor architecture, detection of processor architecture, detection of code architecture, detection of code processor, binary code identification, binary code processor, binary architecture detection, instruction processor detection, instruction set architecture detection, instruction set architecture classification, architecture binary analysis, ELF architecture, and portable executable.
The work [
20] can be considered quite close to the current research. Thus, the authors of the article are engaged in the analysis of the binary code to determine the following meta-information: code and data areas, byte order and MC architecture. As a way to determine the MC Architecture, a byte histogram is used, supplemented by the number of data pairs 0x0001 and 0x0100, which takes into account the order of bytes. At the same time, information entropy [
21] is used to highlight areas in the program that contain MC and data. Thus, since the MC consists of a byte representation of sequentially executed instructions of completely different purposes (for example, arithmetic operations with numbers, jumps to addresses, function calls, etc.) [
22], then the entropy of such a section will have high values. In contrast, the data section will have lower entropy values, since it contains more meaningful and ordered values (for example, text strings from the character set of the same alphabet, tables of numbers from the same range, just the same byte sequences, etc.) [
23]. The following machine learning algorithms are used to classify architectures: Neural Network, AdaBoost, Random Forest, K-nearest neighbors (kNN), Tree, Support Vector Machine (SVM), Naive Bayes and Logistic Regression. The Binwalk software tool that implements the author’s Method has been developed. The authors experimented with binaries from a Debian 7.0 build for the following architectures: amd64, i386, armhf, armel, mips, mipsel, and powerpc. The results of the experiment show almost 100% correctness of determining the program architecture for all machine learning algorithms. If there are less than 80% of files for Identification, the correctness of some (and then all) algorithms starts to decrease. This solution is a development of the works of other authors [
24].
The work [
25] is devoted to the search for a binary code that is similar in functionality, but executed either on different processor architectures, or on the same architecture, but with different compiler settings. The relevance of this task is also indicated when malicious code is detected. The essence of the proposed solution lies in the sequence of steps: code disassembly, creation of a control flow graph, analysis of blocks and transitions in the graph, definition of subroutine arguments, definition of switch statements, and emulation of subroutine execution. The results of such an analysis make it possible to create appropriate patterns of the program’s functioning, according to which semantic signatures are calculated. MinHash [
26] is used to compare the digital signatures of the MC in advance known and investigated (for proximity) subroutines. Architectural invariance is achieved by using a platform-independent representation of information about subroutines. An implementation of a software prototype called CACompare is proposed. The efficiency of the prototype is rated as high. Machine learning is not used in the solution.
In [
27], a problem close to [
25] is solved. The same shortcomings are indicated—a strong dependence on processor architectures and a decrease in efficiency with different compiler switches. One of the main differences between this work, and [
25] is the use of subroutines that implement kNN instead of MinHash for comparison.
The work [
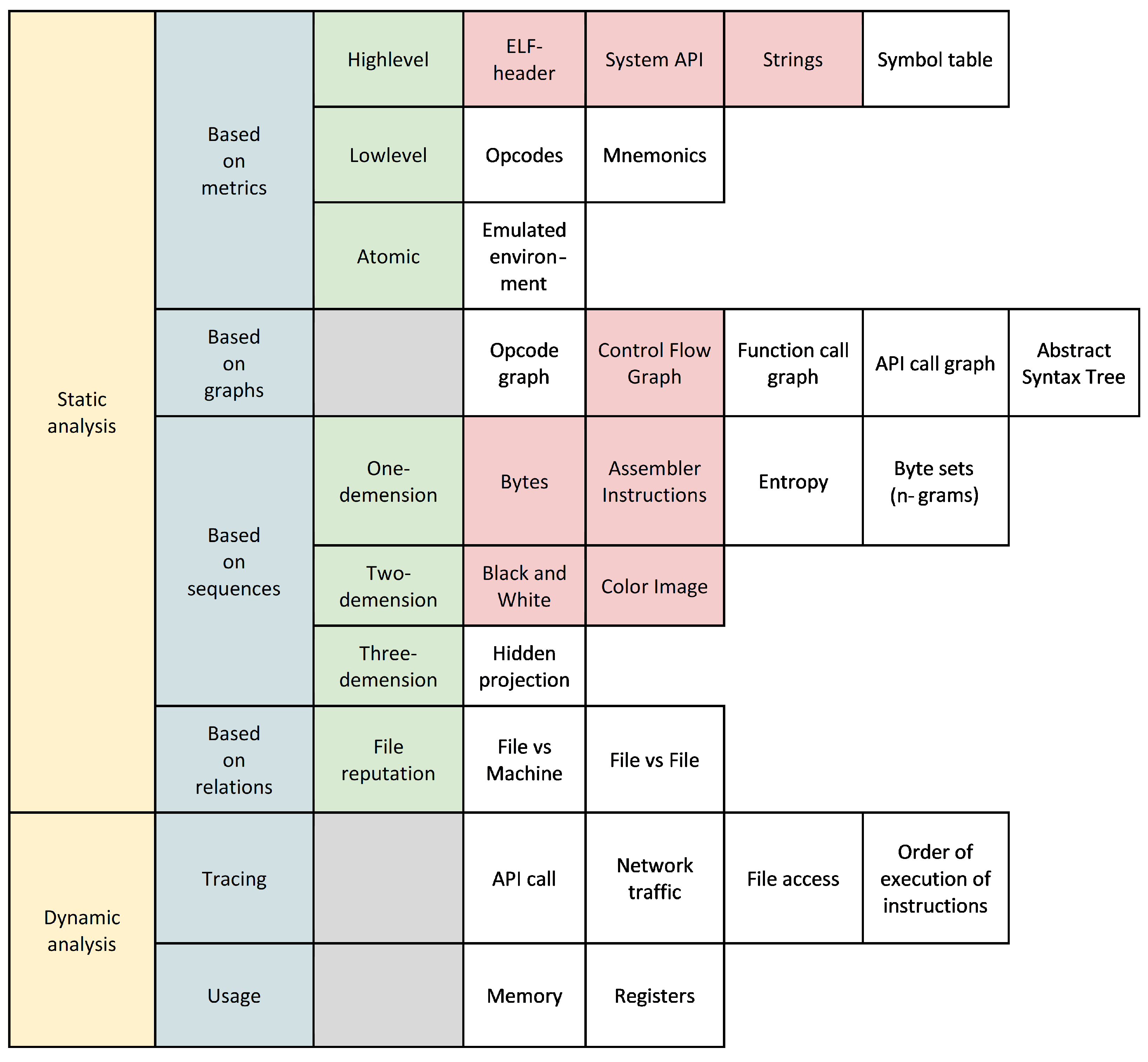
28] is devoted to an overview of possible ways to search for malicious software in binary images of the Internet of Things (IoT). It is indicated that the typical format of binary programs is ELF, and a large number of architectures used (x86, ARM, MIPS, SPARC, AARCH64, PowerPC, Renesas SH, Motorola 68020) is one of the problems for effective malware detection in the code. The specific architecture of the IoT binary image can be obtained from the ELF header. However, the work aims to develop methods that are independent of a specific architecture and use certain features of the MC. Based on the work, the following taxonomy of features (underlying the corresponding search methods) can be distinguished in a hierarchical form; the CAF label indicates Cross-Architectural Features—i.e., those that can be applied to any programs, regardless of their Architecture, which is especially important in the aspect of solving the problem of the current research:
Static analysis:
- −
Based on metrics:
- *
Highlevel:
- ·
ELF-header (CAF);
- ·
System API (CAF);
- ·
Strings (CAF);
- ·
Symbol table;
- *
Lowlevel:
- ·
Opcodes;
- ·
Mnemonics;
- *
Atomic (in the original—Machine level):
- ·
Emulated environment (in the original—Static emulation);
- −
Based on graphs:
- *
(no subgroup)
- ·
Opcode graph;
- ·
Control Flow Graph (CAF);
- ·
Function call graph;
- ·
API call graph;
- ·
Abstract Syntax Tree;
- −
Based on sequences:
- *
One-demension:
- ·
Bytes (CAF);
- ·
Assembler Instructions (CAF);
- ·
Entropy;
- ·
Byte sets (n-grams);
- *
Two-demension:
- ·
Black and White (CAF);
- ·
Color Image (CAF);
- *
Three-demension:
- ·
Hidden projection;
- −
Based on relations:
- *
File reputation:
- ·
File vs. Machine;
- ·
File vs. File;
Dynamic analysis:
- −
Tracing:
- *
(no subgroup)
- ·
API call;
- ·
Network traffic;
- ·
File access;
- ·
Order of execution of instructions;
- −
Usage:
- *
(no subgroup)
- ·
Memory;
- ·
Registers.
Note that, for static atomic analysis based on metrics, the taxonomy indicated Static emulation, for which it is possible to use dynamic analysis of MC (for example, using QEMU [
29]). However, from the point of view of the features used, it is more correct to give the name of the taxonomy element as Emulated environment. In addition, in this work, static low-level analysis based on metrics using opcodes was marked as CAF, which is not correct because the metrics depend on the architecture of the instruction set.
The given taxonomy can be presented in a more visual form using the diagram in
Figure 1.
Thus, of all the features, the following eight belong to cross-architectural (i.e., those that have the CAF label):
ELF header describing properties of the program executed on one of the possible Architectures;
System API, which defines the mechanism of interaction with the operating system, regardless of the MC Architecture;
Lines containing text in some formalized language (natural, artificial) not related to specific MC instructions;
Control flow graph that describes the middle and high-level logic of the program execution, and not the low-level instructions of the MC;
Bytes and Assembly instructions that are converted into a one-dimensional sequence, thereby losing the semantic features of the Architecture instructions;
Black and white and color image, which only display the MC byte sequences in a visual form.
In most binary code analysis methods that use various features, machine learning is used.
A fairly brief article [
30] presents a Web service for checking malware by dynamic analysis. To do this, based on the ELF header, the architecture of the binary code processor is determined (one of the ARM, MIPS, X86, X86-64, PPC, SPARC, SH4 and m68k), and the program is launched. During operation, the IoT environment is emulated. Then, the logs of system calls and network traffic are collected. Applying kNN to logs allows you to classify a user ELF program as safe or malicious.
The work [
31] is devoted to the problem of reverse engineering of the executable code. The binary code ELF files for Linux and Java byte code (JBC) are considered, and the structure of their headers is given. The purpose of the proposed method is to determine the compiler of the program’s executable code. Meta-information about files was taken as features to determine the compiler type, for example: for Java—release level, constant pool entries number, method info structures number, etc.; for ELF—entry point address, section header table offset, program headers number, etc. For classification, the General Regression Neural Network machine learning model is used.
The work [
32] is devoted to finding errors in a binary code. At the same time, the shortcomings of the existing search methods are emphasized—the requirement of the source code, work with a specific instruction architecture, and the use of dynamic analysis. Therefore, cross-architecture signature search is used in the work. To do this, the instruction code is translated into an intermediate representation that is not related to the execution architecture. Then, code signatures are built, which are compared with templates corresponding to errors. A prototype has been developed that implements the method and supports x86, ARM, and MIPS architectures.
Ref. [
33] belongs to the field of reverse engineering and is devoted to detecting areas of obfuscated code. To do this, the binary code is translated into an intermediate representation—using the Binary Analysis Platform Framework. Then, this representation is processed for protection against analysis (i.e., obfuscation) using the rules of an expert system. The solution has the form of a REDIR debugging software module (abbr. from the Rule Engine Detection by Intermediate Representation), which, unlike similar solutions, works with a static code form.
Ref. [
34] is devoted to the identification of subroutines in code that has been ported from one processor architecture to another. Thus, if the source code remains 99% unchanged, then the binary code for different architectures will change significantly. To solve the identification problem, semantic signatures are used, which mean a set of conditional transitions and calls in the MC. If two different programs consist of a conditional branch, in each branch of which there is the same API function call, then the semantic signatures of the programs will be the same (or at least close). Thus, since this signature defines some execution logic like “make compare + call API function”, it can be considered platform independent. The Jaccard index is used to determine the similarity of signatures.
Ref. [
35] relates to the field of auditing information systems and is aimed at identifying ELF programs. For this, a metric classification is used. The detection method consists of three successive steps. First, 118 features are extracted from ELF files, which are the frequencies of occurrence of assembler commands (add, mov, jmp, etc.). Secondly, the Minkowski metric [
29] is calculated for the identified file and samples from the database. Thirdly, it evaluates how close the tested file is to each sample from the database. For file comparison, the following three methods are applied and evaluated: center of mass, k-NN, and STOLP (selection of reference objects for the metric classifier).
Ref. [
36] is devoted to ensuring the security of software IoT devices. The importance of the cross-platform solution is emphasized, and ELF is justified as the most relevant program format. The essence of the malware detection method is to consider ELF files as a sequence of bytes from the address of the entry point to the program. Then, classical classification based on machine learning is applied using Levenshtein distance [
37] and p-spectrum [
38]. For testing, firmware images of IoT devices of the following seven architectures were selected: ARM, MIPS, x86, x86, PowerPC, SPARC, Renesas. kNN and SVM were chosen as classifiers. The obtained malware detection accuracy is 99.9%.
Ref. [
39] describes one of the methods for identifying malicious PE files. To do this, information such as code size, section order, etc. is extracted from the executable file. This information is fed to the input of a binary machine learning classifier. The result of the classifier’s work is the fact that the program is safe or malicious. The following are selected as machine learning models: Naive Bayes, Decision Tree, Random Forests, Logistic, Regression and Artificial Neural Networks. The best obtained malware detection accuracy is 97%.
Ref. [
40] belongs to the field of forensics. The paper proposes an extended procedure for forensic analysis of executable files in PE format. The procedure for their research consists of five stages implemented by the corresponding modules: identifying string constants and program functions, services in the operating system, statistical data about the program, and generating a final report with detailed information. The authors include the following statistics about the PE file: general information, binary form (in HEX format), lines read, and network/registry/file activity.
Ref. [
41] is devoted to a full-fledged framework aimed at analyzing PE files in order to detect malware. For this, 60 basic and 10 derived features were identified from the program. Then, the features were subjected to data mining and static analysis using the following techniques: building frequencies and distributions of features, their ratios and ranges, obtaining the corresponding derived indicators for normal and malicious programs, building detection rules based on the divergence of indicators, introducing levels for the divergence of metrics. The frequency of occurrence, ranges and ratio of features were determined for both normal and malicious programs. As a result, 34 indicators were obtained that have significant differences for safe and malicious programs. Based on this, the corresponding rules were built. Some of the most significant indicators were as follows: the size of the last section, the physical properties of the file (for example, code architecture), the number of sections, etc. The total number of rules was 32, and the accuracy of determination was 95%.
Ref. [
42] is devoted to the detection of malware by comparing the fuzzy hash of the file under investigation with the same hashes in the database of virus instances. As hashes in the study, Ssdeep (a contextual piecewise hash separately for the entire file and its resources), Imphash (a hash by import sections) and PeHash (a hash of the characteristics of a PE header and its sections) were selected. Experiments have shown high efficiency in detecting malware using fuzzy hashes.
Ref. [
43] is devoted to the detection of PE files containing packaged code that can potentially be malicious. For this, machine learning based on SVM is used. The following features were used: the starting address, unknown fields in the optional header, the number of sections with certain characteristics (accessibility for reading, writing, executing, etc.), the number of imported functions, and the entropy of sections. The authors see the continuation of the study in the refinement of the mechanism for detecting packaged PE programs using malicious code detection methods.
Ref. [
44] is devoted to the detection of malicious programs. Insufficient effectiveness of the use of signature methods is indicated, since the code of viruses can change. As a solution, it is proposed to use a histogram of operation codes. An implemented solution is described that takes a PE program as input and compares its histogram with others from the virus database. To assess the similarity of histograms, the Minkowski distance is used.
Ref. [
45] is devoted to the detection of malicious PE programs using machine learning. To do this, 28 features are extracted from the PE file, divided into the following groups: file metadata (number of sections, compilation time, number of characters, etc.), file packing (Shannon entropy, presence of raw data and certain string occurrences in section names), imported files and imported functions (of certain types). To identify malware, a binary classifier of one of the following algorithms was used: kNN, decision tree, SVM, and random forest. The method and classifiers were evaluated for four types of malware: backdoor, virus, trojan, and worm. The random forest algorithm showed the best results.
In [
46], it is proposed to take into account the structural features of PE files to identify embedded malware. Thus, if the malicious code was built into the original one, then part of the program will have anomalous homogeneity. The PEAT toolkit (abbr. from Portable Executable Analysis Toolkit) is described, which performs simple static checks (for example, the address of the entry point or instructions for determining the address of the virus in memory), visualizes information about the program (for example, code areas, lines, etc.)., etc.) and automates statistical analysis (for example, instruction frequency, opcode entropy, etc.).
Ref. [
47] uses a PE file header to detect ransomware, represented as a sequence of 1024 bytes. For classification, artificial neural networks of the following types are used: Long Short Term Memory and multilayer. The method was tested on safe and malicious programs of five families Cerber, Locky, Torrent, Tesla and Wannacry. The results show high performance with little gain for the first family.
Let us give a brief analysis of the above works based on the following characteristics for each article (
Table 1):
Ref.—reference to the article;
Title—title of the article;
Year—article publication year;
Format—the format of the program to be emphasized (ELF/PE/JBC/Any);
Mechanism (Mech.) the main mechanism used to solve the problem:
- −
ML—classical ML models and methods that use MC features (for example, classification of ELF programs into normal and malicious ones based on the analysis of system call logs and network traffic [
30]);
- −
Signature (Sign.)—definition of a digital signature from MC elements (for example, a sequence of conditional jumps and function calls [
34]);
- −
Metric (Metr.)—calculation of various derivative complex indicators by MC (for example, the Minkowski metric for the histogram of command opcodes [
44]);
- −
Hash—applying hash functions to the MC area or its indicators (for example, comparing fuzzy hashes of the program under investigation with hashes from the malware database [
42]);
- −
Rules—application of strict detection rules (for example, creating rules for detecting malware by comparing their indicators with the maximum allowable [
41]);
- −
Statistic (Stat.)—collection and analysis of statistical information about the MC (for example, identification of an embedded malicious code by the statistical anomaly of its instruction appearance [
46]);
Proposal (Prop.) application target (Information Detection (ID), Malware Detection (MD), Packing Detection (PD), Duplicate Detection (DD), Obfuscation Detection (OD), File Detection (FD)).
Based on the analysis of the studies, the following preliminary conclusions can be drawn. First, according to the publication date, they were all published between 2000 and 2021. At the same time, articles with an emphasis on the ELF format have later dates. This is most likely due to the increasing popularity of IoT, for which this format can be considered “native”. Secondly, there is no advantage over the analysis of ELF or PE programs (10 papers belong to ELF, 9—to PE, 1—without specifying the format). Thirdly, although the mechanism most often used in decisions is ML (9 works), nevertheless, others are used separately or in combination with it (in descending order of frequency): Statistic—6 works, Signature—5 works, Metrics—3 works, Hash and Rules—2 works each. Ref. [
28] is an overview and includes all mechanisms. At the same time, slightly more than half of the ML mechanisms (5 out of 9) are used in conjunction with others. In addition, fourthly, the main target application is malware detection (11 works), followed by the collection of meta-information about the program (4 works) and the search for information duplicated in programs (3 works). In addition, one work is presented on the definition of the same packed and obfuscated data, as well as one work on the identification of programs. Thus, the current task of research on the identification of the MC Architecture, although not the most frequently covered, is nevertheless in second place in terms of relevance.
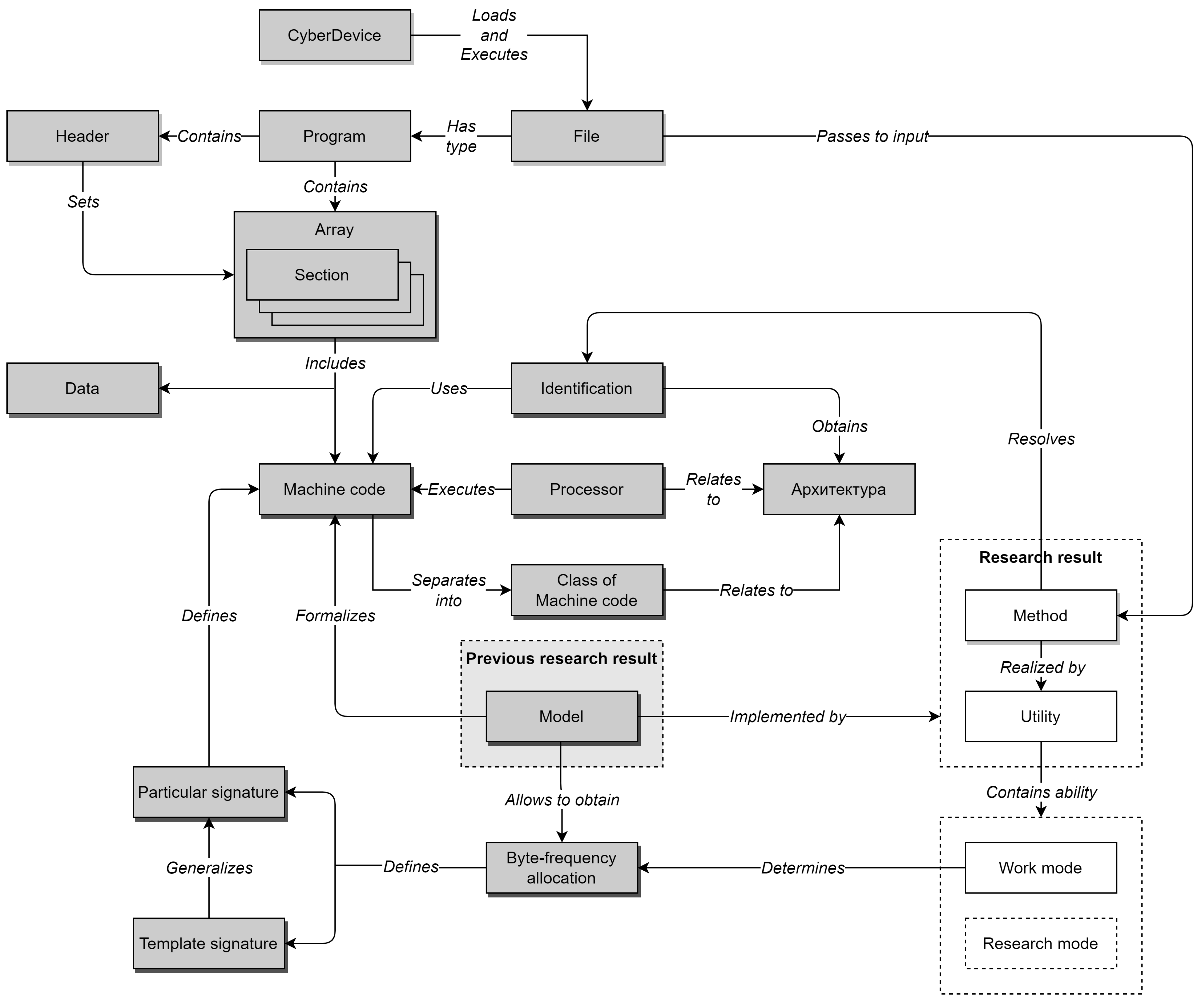
4. Identification Method
The idea of the Identification Method is to select the MC for a set of Architectures and form their template Signatures. These signatures can be compared with the file signature of a single program, which will determine the Architecture of its microcontroller. At the same time, not only the identity of the signatures is important, but also some proximity (i.e., identification with some high probability). The MC model that underlies the Method (and the Utility) was obtained, formalized and studied by the authors in the previous study [
17]. The possibility of such an approach to Identification was justified there by verifying the hypothesis of Identification (hereinafter—the Hypothesis).
4.1. Method Prerequisites
For a more understandable presentation of the Method, we briefly describe the MC Model and the Hypothesis introduced in the previous author’s investigations [
17].
The MC Model is designed to represent the MC as a sequence of bytes, suitable for the subsequent calculation of its Signature. At the same time, the MC Model is applicable for Identification (i.e., it is not “destroyed”) even with partial loss or modification of parts of the partially changed program, i.e., has the property of “stability” to input disturbances. This property means that, even if an incomplete or partially changed MC is provided to the Model input, then the simulation result (i.e., the resulting sequence of bytes at the Model output), if it changes, is insignificant. As a result, the signature calculated later will also remain practically unchanged.
The set of bytes is obtained from the sections of code allocated in each program. In case of “destruction” of information about sections, the entire contents of the file can be taken as bytes (which, accordingly, will lead to a decrease in the adequacy of the Model).
In a formal form, the Program signature can be written as a fixed array (or a buffer of a given length, an analogue of a vector) of the frequencies of the values of its bytes from
elements (see Equation (
1)):
where
is a set of bytes in the file,
is the definition of an array of values (in the form “Name[Dimension]”, where
is the semantic name of the dimension,
is the size of the array or the number of all arrays in the array), and
is the frequency meetings of each byte (normalized by the maximum number of workers).
The frequency of occurrences of each byte is calculated as in Equation (
2):
In statements, the definition of a Class has the notation as at the Equation (
3):
where
is the procedure for precise determination of the MC Class, which provides obtaining (→) from its Signature Model using the set of all MC bytes (
);
N is the number of program sections with MC;
is the number of bytes in the i-th section;
is j-th byte in the i-th section.
The hypothesis is that any microcontroller running on the same architecture has similarities. This feature is just used for identification.
The text entry looks like this:
“A set of native code files used on a single processor architecture has its own unique signature frequency, different from the others.”
The analytical notation of the Hypothesis has the form as at the Equation (
4):
where
is the Signature of MC Models of one Class (
);
is the procedure for constructing the MC Signature from the consideration of the
models of the same Class;
F is the number of Models of this Class; while the Signature of one Class (
) is significantly different (
) from the Signature of another Class (
).
4.2. Formalized Notation
Using the ontological terms and records introduced above, the Identification Method can be represented in the analytical form as in Equation (
5):
where
is the f-th file whose MC belongs to the k-th Class (
);
is the MC file model, calculated as a set of bytes of all sections (number
N) from the MC file;
is the number of bytes in the i-th section;
is j-th byte in the i-th section for the f-file, the MC of which belongs to the k-th Class;
is a collection of Signatures consisting of pairs of MC Signatures (
) and their corresponding Classes (
);
C is the number of all Classes (and, accordingly, Signatures);
is the procedure for building a Signature for a MC of a certain Class from a set of MC Models in the corresponding files;
F is the number of files from the MC of the k-th Class;
is the procedure for determining the probability (
) of assigning the MC in the file being tested (
), using its Model, to each of the
C Classes;
is the desired Class of the file being tested (i.e., its MC), determined by the highest probability (obtained using the
procedure) of being assigned to each of the Classes. Thus, in the beginning, a set of template Signatures is built using a set of files from the MC of each Class. Then, the Signature of the file under test is determined. After that, the Class is determined, the MC Signature of which is closest to the Signature of the person being tested.
4.3. Approaches to Creation
To synthesize the Identification Method, it is necessary to solve the methodological problem of choosing the actual mechanism for such creation. There are various mechanisms, the most obvious of which are as follows:
Expansion/specialization, when a particular method is developed/contracted to solve a larger/smaller problem;
Merging, when methods close to the task are taken, the most necessary parts of which are then combined;
Heuristic, based on the intuition (“brilliant guess”) of the researcher;
Empirical, based on observed data.
Based on the specifics of the problem being solved, the most appropriate mechanism would be to combine the specialization mechanism (since both the task of processing binary files and the problem of class definition have proven approaches to solving) and the empirical mechanism (due to the presence of many files with MC, the Signature of which is almost impossible to calculate manually).
Following this approach, the Method can be built on the basis of artificial intelligence models and methods, in particular, machine learning models and methods, namely classification. According to the latter, the Identification Method can be the training of its internal model by precedents in the form of a pair: “average byte-frequency distribution of MC files” vs. “their belonging to a certain type of Architecture”, which is identical to the “Signature → Class” comparison. Having collected a sufficient “mass” of training data in this way, the machine learning model will be used to map the MC of new files (or rather, their Signatures) to one of the already trained MC Classes. Naturally, a separate task is to obtain a training sample—a set of byte distributions of the MC and its Architecture in sufficient quantity (which will give template Signatures) that should also be taken into account in the Method.
Using the analytical representation of the Identification Method proposed above and the chosen creation mechanism, we will perform an algorithmic synthesis of the Method in the form of a sequence of steps. This view will allow us to create an Identification Utility. As data for training, we will take the Gentoo OS assembly for various Architectures, which was previously used to obtain template MC Signatures when proving the Hypothesis. Despite the fact that executable files of this OS can only be in the ELF format, in the interests of greater generality of algorithms and applicability of the Utility, we will support the second common program format—PE, which is used mainly in Microsoft Windows. It is also necessary to take into account that, in addition to the section with MC, the file contains other sections with data that do not contain processor instructions.
Since Identification should not only answer the question of whether the MC of the tested file belongs to a known Architecture, but also indicate this Architecture, then from the point of view of machine learning, it is necessary to solve the problem of multiclass classification. Since the process is executed only once, it is advisable to execute it with saving the results of the work as templates (i.e., Signatures, which is why they are called templates). To take into account the above features of the Method, it is advisable to single out three phases of this process with the possibility of their separate execution (which will be especially justified when collecting MC Signatures for a large number of files). Thus, in Phase 1, you need to unpack the files from the MC for various Architectures, taken from the images of the Gentoo distribution kit, into temporary directories. At Phase 2, you need to build template Signatures and save them in separate files (used below as some invariants). At Phase 3, it is required to carry out the Identification itself by first training the internal model for multiclass classification, and then testing the input files on it (i.e., finding the probabilities of classifying the MC as Processor Architectures).
It is advisable to be able to identify both full-fledged executable files (in the form of headers with a set of sections) and “raw” MC (that is, sequences of instructions to be executed by the processor without additional meta-information). The division of training and testing into two phases does not make practical sense, since the training time for a set of Signatures takes an extremely short time—Signatures consist of 256 bytes (in terms of machine learning—features), and the total number of processor Architectures is unlikely to exceed 100 (in terms of machine learning—training samples or precedents).
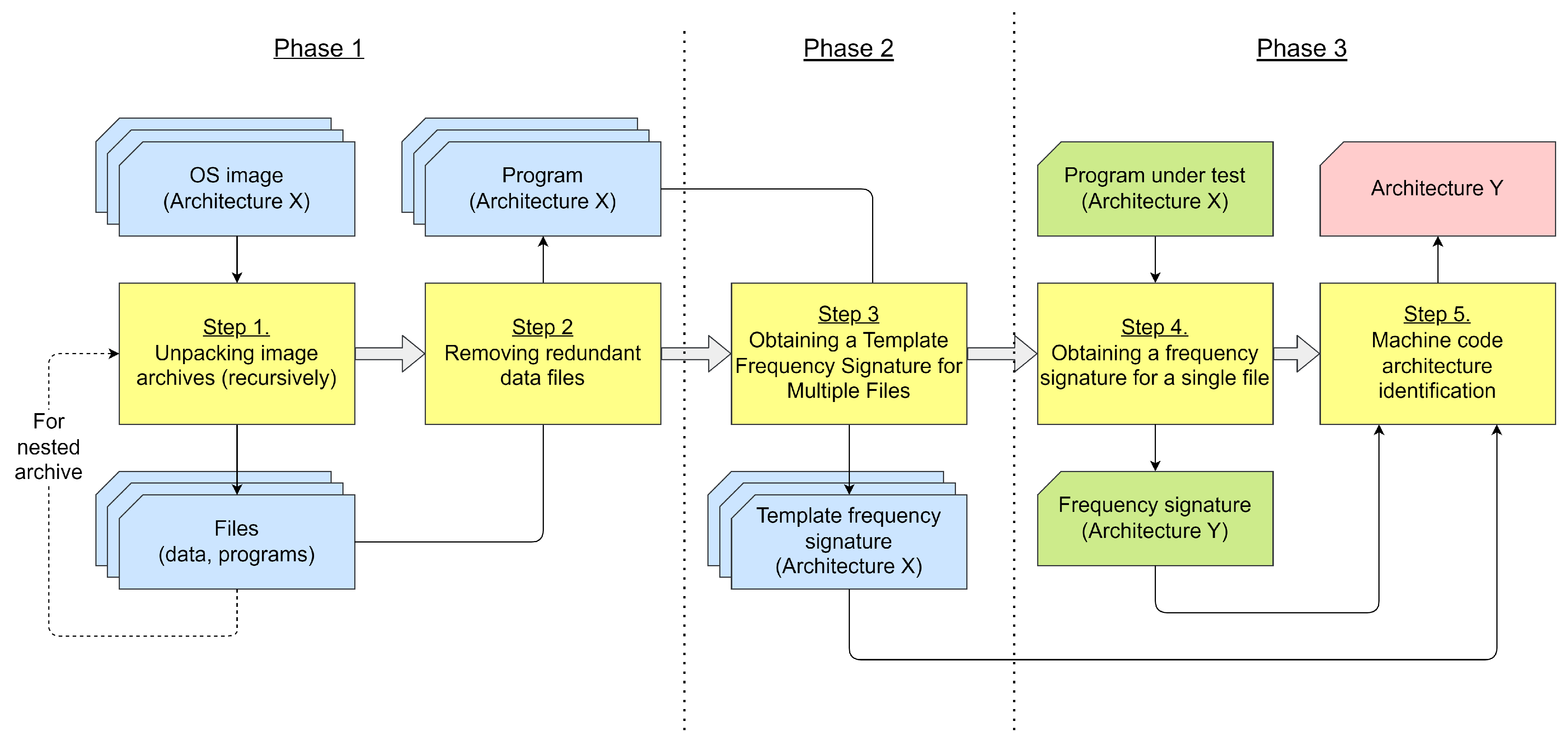
4.4. General Scheme
The scheme of operation of this method consists of five consecutive steps-blocks (grouped into three phases). The scheme is shown in
Figure 3.
4.5. Basic Steps
The scheme consists of the following successive steps.
Step 1 (“Unpacking image archives (recursively)”) takes as input a set of OS images (in the form of an archive) for certain processor architectures and returns a set of unpacked files at the output, which may include files with other data (scripts, images, information storages, etc.); since the unpacked files themselves can be archives, the algorithm of this step must be performed recursively.
Step 2 (“Removing redundant data files”) aims to optimize the Identification process for speed of execution; at the step, in the sets of unpacked files, those files that are not programs with MC of this Architecture are deleted; this allows you to increase the speed of their future processing, both in the next steps and in the future with additional studies; otherwise, the decrease in speed will occur due to the fact that, in order to determine both the program itself and the Architecture of its MC, it is necessary to read the beginning of the file, check the magic number at the beginning of the header structure (file signature; for example, “0x7f 0x45 0x4c 0x46” for ELF and “ 0x4D 0x5A” for PE) and the field with the Architecture.
Step 3 (“Obtaining a template frequency signature for a set of files”) takes as input the sets of programs with MC from unpacked and “cleaned” OS images and calculates the corresponding set of template Signatures for each Architecture; template in this case means generalization or averaging for any MC of a given Architecture.
Step 4 (“Obtaining a frequency signature for one file”) takes as input a program under test with an MC of an unknown (desired) Architecture and calculates the Signature for this particular program.
Step 5 (“MC Architecture Identification”) accepts as input the previously received template Signatures, as well as the Signature of the program under test; in the course of work at the step, these Signatures are compared in order to determine whether the MC Architecture of the tested program belongs to one of the given Architectures.
4.6. Method Requirements
In the interests of the synthesis of the Method, it is necessary to note the structural features of the Gentoo distribution. The Gentoo OS distribution builds have the extension “.xz” or “.bx2” and are compressed containers from a single file. The latter is an uncompressed “.tar” archive containing a complete directory and file structure. Some of these files may also be compressed archives. Archives can be unpacked using the external utility 7-Zip, which supports all standard formats. Based on the above features, the following efficiency requirements can be put forward for the implementation of the Method:
In terms of performance, correct files with MC (i.e., without destruction and intended for one processor Architecture) must be uniquely identified;
In terms of efficiency, a high speed of work should be ensured, since otherwise the Method will not be applicable to large information systems (which is a very real situation);
In terms of resource efficiency, the costs of both program resources and experts should be minimal.
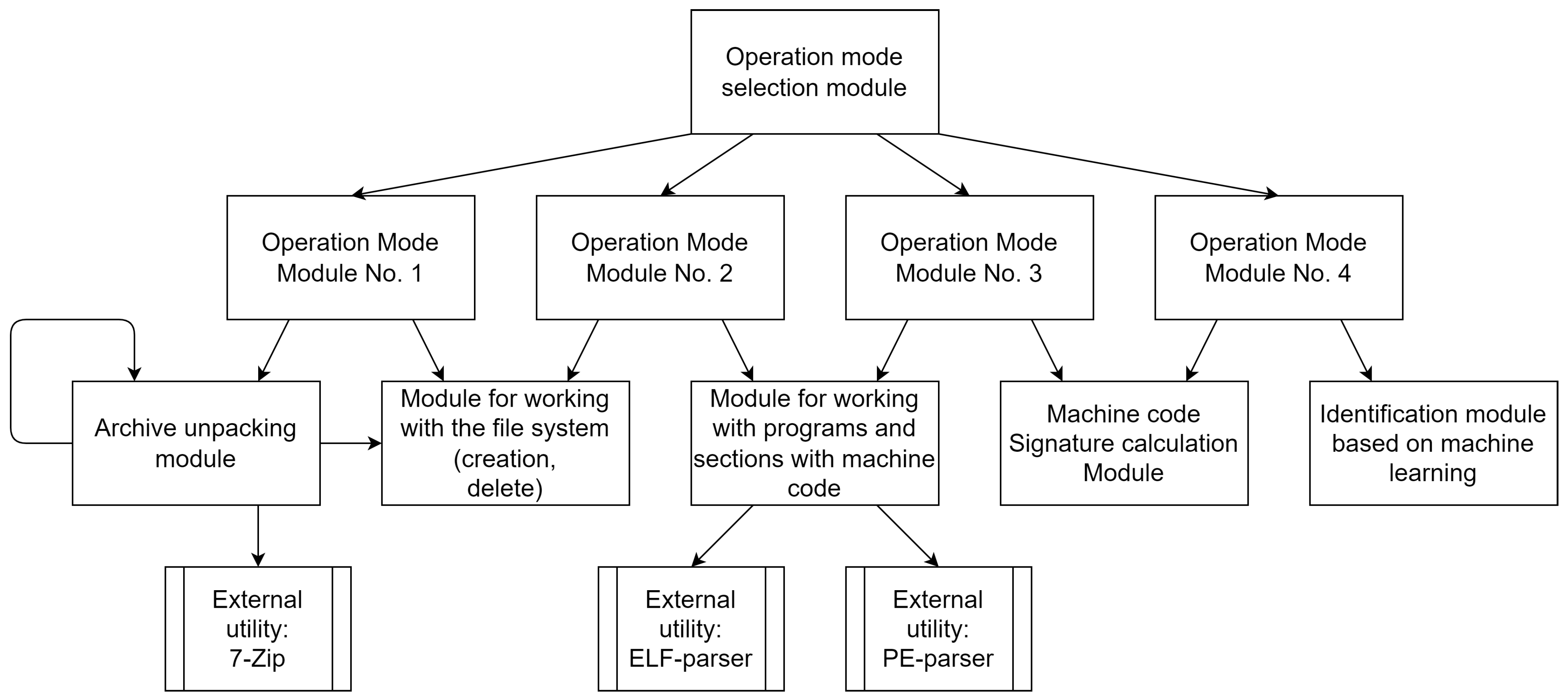
The method should have not only practical application, but also be used for research purposes in the future. To do this, the following two modes of operation were identified (and subsequently implemented):
Since the implementation of the Method (in the form of a Utility) in the operating mode should be able to repeatedly launch different steps with the necessary set of settings, then, after the prefix “O”, each such sub-mode (hereinafter simply—the mode) was designated by the corresponding number: O1, O2 and O3—for Steps 1, 2 and 3; O4—to combine Steps 4 and 5.
Let us describe further each of the four modes.
4.7. O1 Mode. Unpacking Archives
This mode is preparatory and is intended for unpacking a tree of archives with files into a separate directory for further processing. The Mode implements Step 1 in the Method. The mode parameters are the path to the archive and the directory for unpacking. If nested archives are found, they will also be unpacked, i.e., file extraction algorithms are executed recursively. Archive formats (including compressed ones) such as 7z [
49], Bzip [
50] and Tar [
51] are supported, which allows the unpacker to be used for a large number of images of various software products (not only for Gentoo, as in this study).
The principle of operation of the this mode is presented using pseudocode in the form of Algorithms 1–3.
| Algorithm 1: Operating principle of the O1 mode—UnpackMode() |
 |
| Algorithm 2: Operating principle of the O1 mode—UnpackFile() |
 |
| Algorithm 3: Operating principle of the O1 mode—UnpackDirRec() |
 |
It can be seen from the pseudocode that the operation of the mode consists of executing three procedures.
The procedure is the entry point to the mode. It contains the path to the archive and the path to unpack its files. This procedure starts unpacking all nested archives, starting from the top one. In addition, at the beginning, the directory is prepared for storing the files to be unpacked by checking its existence and cleaning or creating a new one—using the procedure in the program class.
The procedure is an auxiliary procedure designed to unpack a single archive using the full path to it and the output directory. As an unpacking utility, you can use any external unpacker with suitable functionality, for example 7-zip, using the procedure in the program class.
The procedure is the main one for the mode. The procedure takes a directory path as a parameter and consists of two parts. First (Part 1), all files are bypassed (including those located in nested directories) and, if an archive is found using the function, it is unpacked into a new directory, the path to which is generated uniquely using the function. In addition, secondly (Part 2), the procedure repeats its work for each directory created in this way.
4.8. O2 Mode. Removing Extra Files
This mode is an optimization (in terms of speed), deleting all unpacked files that are unnecessary for work. The Mode implements Step 2 in the Method. Junk files include all those that are not considered programs (i.e., do not have an ELF or PE format header). The mode parameter is the path to the directory with the files in which you need to remove the extra ones.
The principle of operation of this mode is presented using pseudocode in the form of Algorithm 4.
| Algorithm 4: Operating principle of the O2 mode—RemoveExtra() |
 |
It can be seen from the pseudo-code that the mode procedure iteratively goes through all nested directories and files, checks whether the latter correspond to programs in ELF and PE format using the and functions, and if they do not match, removes them using the procedure in the program class. As a result, after executing this mode, only programs should remain in the unpacked directory, i.e., files from MC of a certain Architecture.
4.9. O3 Mode: Calculation of Template Signatures
This mode is one of the main ones, since it processes the MC contained in programs and builds template Signatures by their bytes. The Mode implements Step 3 in the Method. The mode parameters are the path to the directory with programs and the path to the file for saving the MC Architecture Signature, which is located in these programs. In addition, to avoid getting into the MC Signature bytes of other Architectures, programs with which can be located in this directory, it is necessary to pass the numeric identifier of the required Architecture as parameters (separately for ELF and PE, since the values may differ). The list of values of these identifiers will be given below.
The principle of operation of this mode is presented using pseudocode in the form of Algorithm 5.
From the pseudocode, one can see that the main procedure consists of three parts.
First (Part 1), all programs in the given directory are iteratively traversed and, according to their types (by checking the function for the ELF format and the function for the PE format), the bytes of the MC of their sections are read.
Secondly (Part 2), the MC Signature is calculated by the bytes read by counting the occurrence of each and entering the counter into the
array (the size of the array is identical to the maximum byte value—
).
| Algorithm 5: Operating principle of the O3 mode—SignatureMode() |
 |
In addition, thirdly (Part 3), the Signature is normalized according to the maximum value of the counters of all bytes. To do this, first, the maximum value is obtained—using the function of the array program class, and then each array value is divided by the maximum—using the function of the array program class. As a result, all values in the array storing the Signature will not exceed 1, which will allow working with the received Signatures for Architectures on the same scale.
4.10. O4 Mode. File Identification
This mode is the second of the two main ones (after the O1 Mode), since it actually performs the Identification of the Architectures of the tested files using the template Signatures obtained earlier. Mode implements Step 4 and 5 in Method. The mode parameters are the path to the directory with the files being tested, as well as the enumeration of N elements—Architectures for Identification and the corresponding paths to files with their Signatures. As a result of the work, a list will be returned with the assignment of each of the tested files to one of the given Architectures. Based on the prerequisites described earlier, Identification is based on machine learning in terms of classification.
The principle of operation of this mode is presented using the pseudocode in the form of Algorithm 6.
| Algorithm 6: Operating principle of the O4 mode—TestMode |
 |
From the pseudocode, you can see that the main procedure consists of four parts.
First (Part 1), there is a loading from files of template Signatures calculated earlier on large sets of MCs of the same Architecture. For this, the function is used, which returns the Signature structure (for example, as an array of 255 elements).
Second (Part 2), a classification model for machine learning is built by using a training set as a list of pairs of Architecture names and their Signatures. For this, the program class in the namespace is used. In this class, there is a special procedure for this—.
Thirdly (Part 3), the files under test are read from the given directory and their own Signatures are built, obtaining a test sample. For building, the function is used, which is similar to the O3 mode, but only for one file.
In addition, fourthly (Part 4), the direct Identification of the tested files using machine learning is carried out—based on the training and test samples. For this, the function from the program class is used. The result of the Identification (in the form of a list of predicted Architectures) is returned from the mode—for example, by displaying it.
6. Experiments
To fully verify the Identification Method, it is necessary to conduct a series of experiments. At the same time, such a check can be not only theoretical, but also practical, since the Method has an implementation in the form of the corresponding Utility. Experimenting with different operation modes the Utility on test files using template Signatures are described below.
6.1. Initial Data
In the current experiments (as in the previous investigation by the authors [
17]), the Gentoo OS of the Stage 3 build was used for the Top-16 Architectures: Alpha, X32, Amd64, Arm64, Hppa, I486, I686, Ia64, Mips, Mips64, Ppc, Ppc64, RiscV64, S390, S390x, Sparc64. A brief breakdown of the Architectures (including their number with a “#” prefix, name, description, and the numeric identifier of the Architecture to check in the ELF header for Mode O3) is given in
Table 2.
Each Architecture in
Table 2 corresponds to a Class, which must be identified by MC.
6.2. O1 Mode. Unpacking Archives
Run the Utility in O1 Mode, passing as arguments the Gentoo image file for the Alpha Architecture—along the pathD:\stage3-alpha-20200215T160133Z.tar.bz2, also specifying the unpacking directory -D:\Alpha\. To do this, run the following command:
> MCArchIdent.exe UnpackMode D:\stage3-alpha-20200215T160133Z.tar.bz2
D:\Alpha\
As a result of execution, the following log will be displayed:
(01.01.2022 01:01:01) [Unpack Archive]
stage3-alpha-20200215T160133Z.tar.bz2:\-> D:\Alpha\
(01.01.2022 01:01:01) Unpack Bzip:
’D:\stage3-alpha-20200215T160133Z.tar.bz2’ -> D:\Alpha\
(01.01.2022 01:01:01) Unpack Tar:
’D:\Alpha\stage3-alpha-20200215T160133Z.tar’ -> D:\Alpha\!__stage3-alpha-
20200215T160133Z.tar\
(01.01.2022 01:01:01) Unpack Tar:
’D:\Alpha\!__stage3-alpha-20200215T160133Z.tar\usr\lib\python2.7\test\
testtar.tar’ -> D:\Alpha\!__stage3-alpha-20200215T160133Z.tar\usr\lib\
python2.7\test\!__testtar.tar\
(01.01.2022 01:01:01) Unpack Tar:
’D:\Alpha\!__stage3-alpha-20200215T160133Z.tar\usr\lib\python2.7\test\
PaxHeaders.138508\testtar.tar’ -> D:\Alpha\!__stage3-alpha-20200215T160133Z.
tar\usr\lib\python2.7\test\PaxHeaders.138508\!__testtar.tar\
(01.01.2022 01:01:01) Unpack Tar:
’D:\Alpha\!__stage3-alpha-20200215T160133Z.tar\usr\lib\python3.6\test\
testtar.tar’ -> D:\Alpha\!__stage3-alpha-20200215T160133Z.tar\usr\lib\
python3.6\test\!__testtar.tar\…
6.3. O2 Mode. Removing Extra Files
Let us run the Utility in PO Mode, passing as arguments the directory with the unpacked files of the Gentoo OS image for the Alpha Architecture—along the pathD:\Alpha\. To do this, run the following command:
> MCArchIdent.exe RemoveMode D:\Alpha\
As a result of execution, the following log will be displayed:
01.01.2021 01:01:01) [Remove extra files (not ELF, PE)] D:\Alpha\
Thus, all files that are not programs in ELF and PE format will be removed from the unpacked Gentoo OS image for Alpha Architecture.
6.4. O3 Mode. Template Signature Calculation
Run the Utility in O3 Mode, passing as arguments the directory with the unpacked files of the Gentoo OS image for the Alpha Architecture (after removing all of them, except for ELF and PE programs)—along the path
D:\Alpha\, passing the file for writing the Signature—
, after which the numeric Identifier of the required Architecture for the ELF and PE format from
Table 2 is 0x9026 and 0x0 (the last number means the mode of skipping MC programs of this format when building a template Signature). To do this, run the following command:
> MCArchIdent.exe SignatureMode D:\Alpha\Alpha.sig 0x9026 0x0
As a result of execution, the following log will be displayed:
(01.01.2021 01:01:01) [Collect signature] D:\Alpha\-> Alpha.sig
Thus, for MC programs of ELF format with Architecture ID 0x9026 (i.e., for Alpha), a template Signature will be built from the D:\Alpha\directory, which will then be saved in the Alpha.sig file.
6.5. O4 Mode. File Identification
Run the Utility in O4 Mode, passing as arguments the directory with the files being tested—D:\Test\ and a sequence of pairs of Architecture names and files of their template Signatures (separated by “=” symbol):
> MCArchIdent.exe TestMode D:\Test\Alpha=Alpha.sig X32=X32.sig …
S390x=S390x.sig Sparc64=Sparc64.sig
The bash program from the Gentoo OS for different Architectures was taken as the test files. The size of the program is approximately 1 MB, which can be considered sufficient to test the functionality of the Method and the Utility. The files to be tested have a name in the format “Test_ARCH”, where ARCH are the names of the corresponding Architecture.
As a result of execution, the following log will be displayed, consisting of two parts (for simplicity, only part of it is given, the rest of the lines are replaced by the symbols “⋯”):
(First part of the log)
(01.01.2021 01:01:01) [Test files] D:\Test\
(01.01.2021 01:01:01) D:\Test\test_Alpha -> Alpha (0.31)
(01.01.2021 01:01:01) D:\Test\test_X32 -> X32 (0.27)
…
(01.01.2021 01:01:01) D:\Test\test_S390x -> S390x (0.32)
(01.01.2021 01:01:01) D:\Test\test_Sparc64 -> Sparc64 (0.29)
(Second part of the log)
(01.01.2021 01:01:01) Alpha X32 Amd64 Arm64 Hppa2 I486 I686 Ia64
Mips32r2 Mips64r2_multilib Ppc Ppc64 RiscV64 S390 S390x Sparc64
(01.01.2021 01:01:01) D:\Test\test_Alpha -> 0.31 0.04 0.04 0.04 0.04
0.04 0.04 0.06 0.05 0.06 0.05 0.06 0.04 0.04 0.04 0.04
(01.01.2021 01:01:01) D:\Test\test_X32 -> 0.07 0.27 0.04 0.04 0.04 0.05
0.04 0.05 0.04 0.05 0.05 0.05 0.05 0.05 0.07 0.06
…
(01.01.2021 01:01:01) D:\Test\test_S390x -> 0.04 0.04 0.04 0.04 0.04
0.04 0.04 0.04 0.04 0.04 0.04 0.04 0.04 0.05 0.32 0.10
(01.01.2021 01:01:01) D:\Test\test_Sparc64 -> 0.05 0.04 0.04 0.04 0.04
0.04 0.04 0.06 0.05 0.06 0.05 0.06 0.04 0.04 0.04 0.29
It can be seen from the log that the MC Architecture of all files in the D:\Test\ directory will be identified, about which the corresponding information is displayed.
The first part of the log contains the name of the file and the most likely Architecture for it (the probability is indicated in brackets, taking into account the fact that there is a small probability of classifying MC as other Architectures, and the total probability for all Architectures is ). Thus, for example, part of the string
D:\Test\test_Alpha -> Alpha (0.31) says that the MC file in the program corresponds to the Alpha Architecture with a probability of 0.31, while the average probability for all Architectures is: .
In the second part of the log, in string notation, there is a table of probabilities for assigning each of the files in the directory to each of the Architectures (in which a space is used to separate the columns).
The results obtained in an assembled and readable form are presented in
Table 3. For convenience, instead of Architectures, their numbers are indicated (see
Table 2). Each value in a cell of the table means the probability of classifying the tested programs, which have an Architecture according to the first column, to one of the known Architectures (i.e., those whose Signatures have been calculated) according to the first row. Thus, in case of inoperability (to be more precise, if it is unable to determine the correct MC Architectures), the Utility will issue an equiprobable distribution of Identifications and all cells will take the value
.
6.6. Results Analysis
Let us analyze the obtained Identification probabilities (see
Table 3).
As you can clearly see, the values with the maximum probability are located exactly diagonally, which indicates the correct Identification of the Architectures of the tested files. Let us find the minimum ratio of the maximum probability to the nearest one. This situation corresponds to row #9, in which the diagonal value is , and the second highest probability is located in column #16 and is equal to . Thus, the maximum value to the nearest one is , i.e., the minimum gain of a correctly defined Architecture exceeds the nearest alternative by more than times, which can be considered a fairly large “gap”. In addition, one can note an interesting fact that half of the probabilities (after the diagonal ones) tend to assign programs to Architecture #16 (Sparc64), since half of the cells in column #16 have a yellow background. This effect can be attributed to the peculiarities of the distribution of byte coding of MC instructions of this Architecture.
Note that the generation of data for
Table 3 was not specified in the description of mode O4. Thus, the second part of the log is used more for debugging purposes and contains additional information for the first part. However, this is precisely what makes it possible to more accurately judge the work of Identification.
The results of the basic testing of the sequential launch of the modes, as a result of which the correct Identification of the MC of all tested programs for all declared Architectures, were obtained. These results allow us to assert that all the steps of the Method and the Utility are working.
8. Conclusions
The study is a continuation of the previous scientific work of the authors, dedicated to confirming the hypothesis of identifying the MC Architecture by its unique digital “portrait”—a template Signature.
The work synthesizes the Identification Method and specifies the requirements for it. To check and evaluate the performance of the Method, a Utility has been developed that allows for both obtaining template Signatures and identifying the MC of input files. Then, an experiment was carried out with the File Identification Utility for the Top-16 Architectures. The success of the experiment confirms the efficiency of the Method and the Utility.
The advantage of the study is the methodological correctness and completeness of this stage. Thus, the stage of synthesis of the Method (as well as the implementation of the Utility) of identification and its basic testing comes after the stage of analyzing the features of the MC and creating the MC model. After this stage, there will be a stage of a full-fledged experiment to assess the boundaries of the applicability of the solutions obtained.
The advantages of the proposed solution lie in the complete automation of the entire identification process—from collecting data for building identification models, to the identification process itself and evaluating its effectiveness.
The differences between the Method and the Utility from the closest analogues are based on a strict theoretical base—the MC model and the analytical record of the identification process. In addition, the Method contains a number of modes that can be used for additional research. The solution supports the analysis of both popular formats—ELF and PE—and also works with a large set of Top-16 Architectures.
All phases of the study have a high degree of detail, which allows them to be directly applied in practice and modified for other tasks of this kind.
Further development of the work, as mentioned earlier, should be a comprehensive assessment of the limits of applicability of the Method and Utility for various conditions—the absence of program headers, the small size of the MC, the destruction of the MC, and the presence of the MC from two different Architectures. These results have already been obtained and will be described in the next article.
In addition, despite the fact that the applied SVM machine learning classifier showed good results in identification, it will be useful to compare it with other classifiers (artificial neural networks, decision trees, etc.).





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}