Optimized Location-Allocation of Earthquake Relief Centers Using PSO and ACO, Complemented by GIS, Clustering, and TOPSIS




Abstract
1. Introduction
2. Previous Work
2.1. Optimized Location-Allocation of Relief Centers
2.2. Meta-Heuristic Algorithms
- Although PSO is essentially used for problems with continuous search space, some researchers proposed discrete versions of PSO for discrete location/allocation problems [50,51,52,53]. Therefore, comparison of the adequacy of a discrete PSO with ACO, for the location-allocation of relief center, was raised as the research question of the present study.
- As mentioned earlier, these two algorithms are frequently used for location-allocation problems. However, they are rarely compared when used for such issues. In addition, the results obtained for one application cannot be simply generalized to other applications [54]. As shown in the reviewed literature, no comparison has been made regarding these two algorithms for the location-allocation of relief centers. Therefore, in the present research, these two algorithms are used and compared for the considered new application.
3. Theoretical Background
3.1. Swarm Intelligence Algorithm
3.1.1. PSO Algorithm
- For each particle, making an x position vector and a v velocity vector randomly.
- Assessing the goodness of all particles using an optimization function.
- Updating the best position found by each particle and the best position found so far by the group.
- Updating the velocity and position of each particle using Equations (1) and (2).
- Repeating stages 2 to 4 until reaching the stop condition.
3.1.2. ACO Algorithm
| Algorithm 1 ACO meta-heuristic [68] |
| Set parameters, initialize pheromone trails |
| while termination conditions not met do |
| ConstructAntSolutions |
| ApplyLocalSearch [optional] |
| UpdatePheromones |
| end while |
- Initialize the parameters (pheromone, etc.);
- Insert the origin city for each ant in its forbidden list, in order to prevent it from going back that city;
- Calculate the probability of selecting the next city, at each city, for any ant;
- Adjust the population of cities for the selection of each ant to the forbidden list of the ant;
- Add the selected city of each ant to its forbidden list;
- Determine the best path;
- Update pheromones based on the path quality;
- Evaporate the pheromone;
- Go to step 3 (if the stop condition is not met).
3.2. TOPSIS
- Establishing a decision matrix
- Calculating the normalized decision matrix
- Calculating the weighted normalized decision matrix
- Determining the positive and negative ideal solutions
- Calculating the distances through Euclidean norm
- Calculating the relative closeness to the ideal solution
- Ranking the alternative
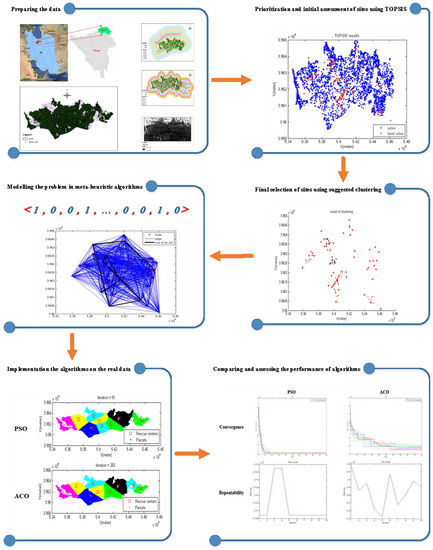
4. Data and Methodology
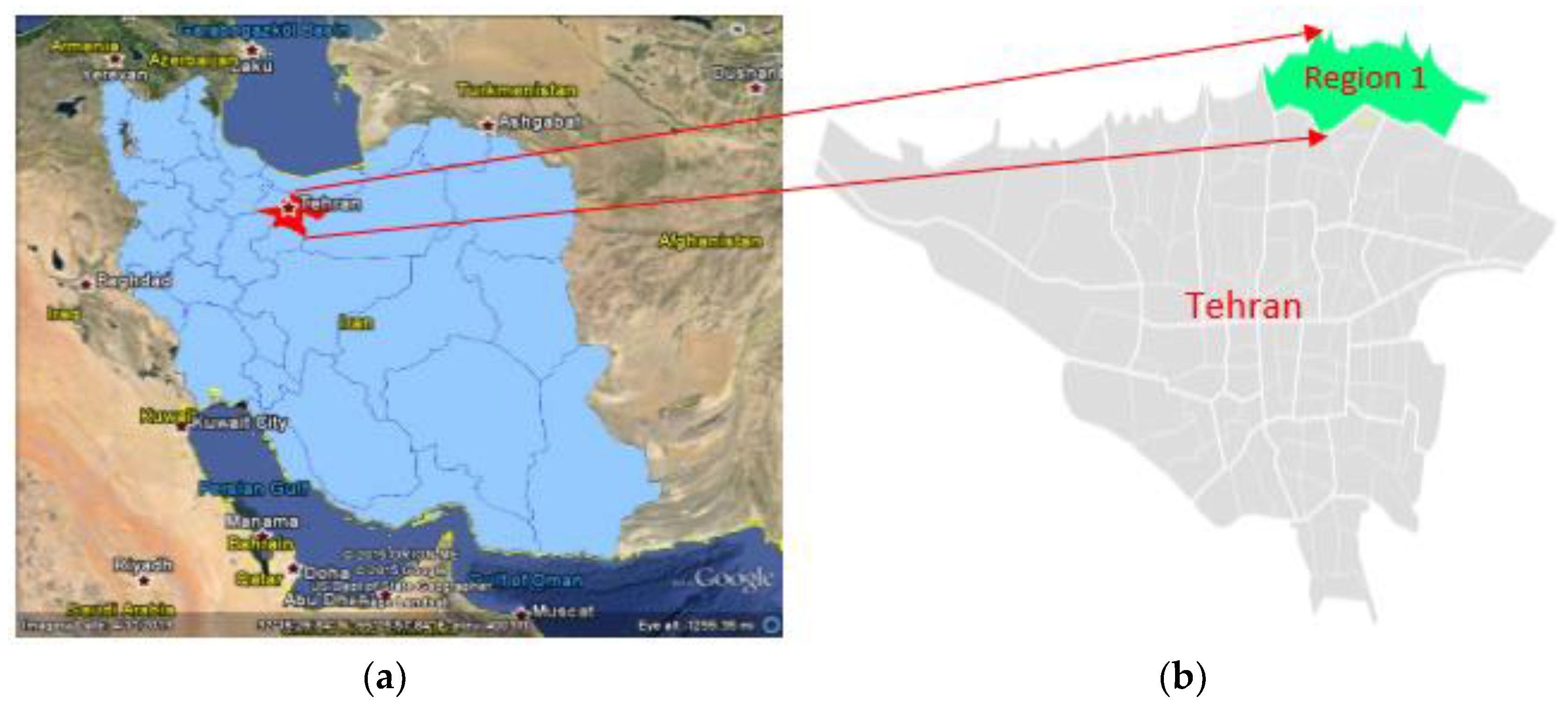
4.1. Application Site
4.2. Data Collection
4.3. Data Preparation
4.4. Important Parameters in Relief Centers Allocation
- present land use of the relief centers
- area of the relief centers
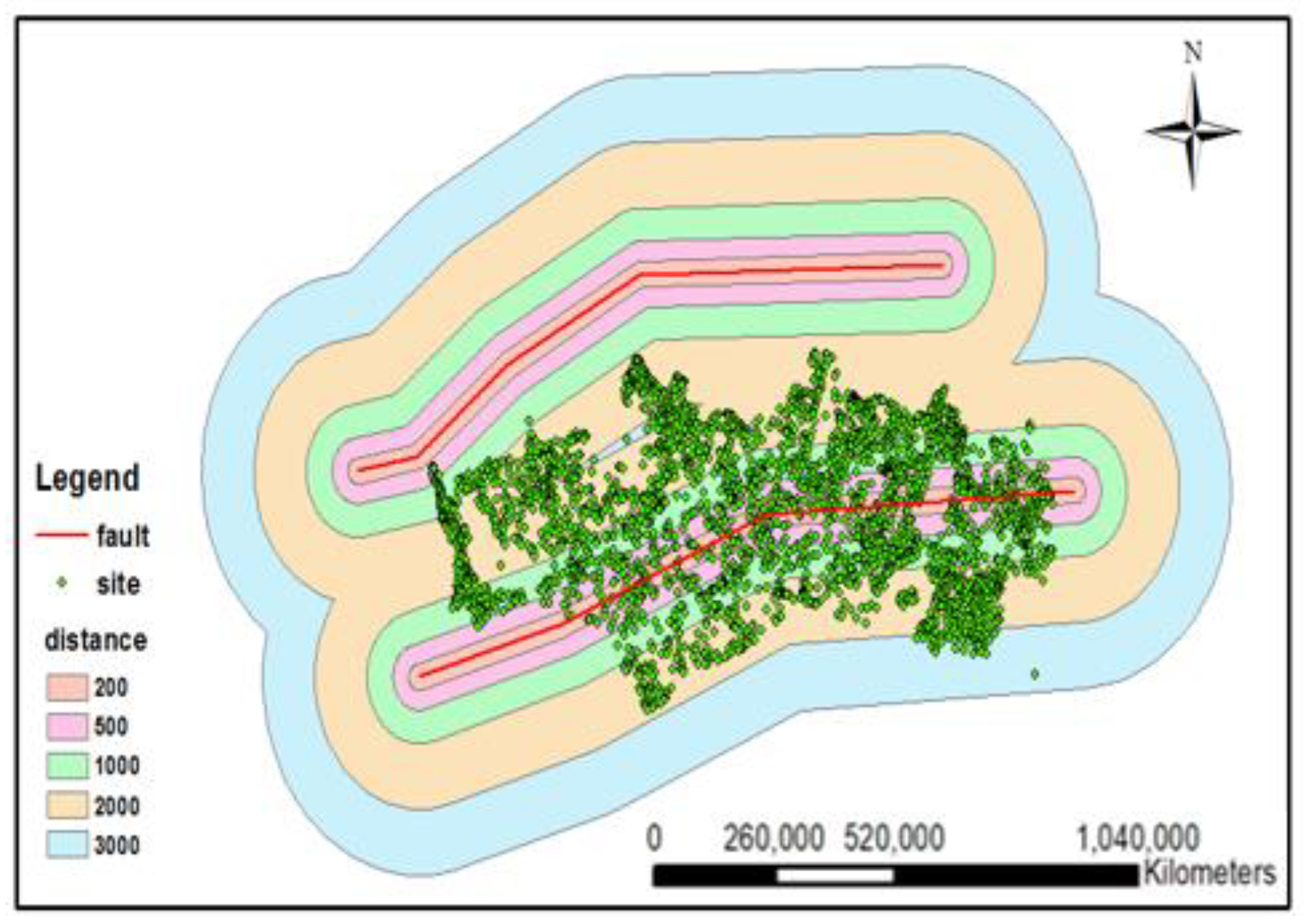
- distance of the relief center from the fault lines
- population
- slope of the relief center
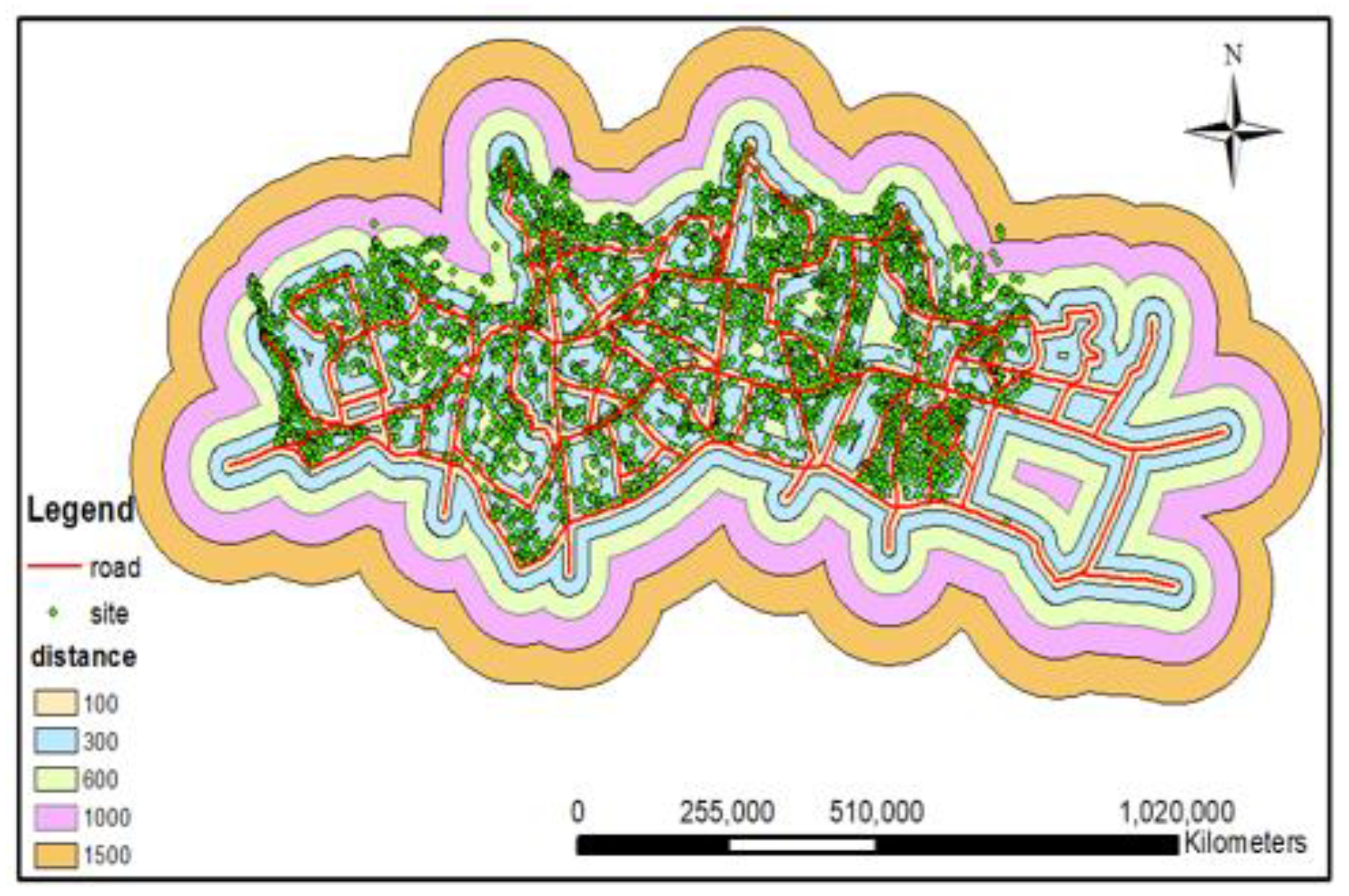
- distance of the relief centers from the routes
- distance of the relief centers from each other
- distance of the parcels from the relief centers
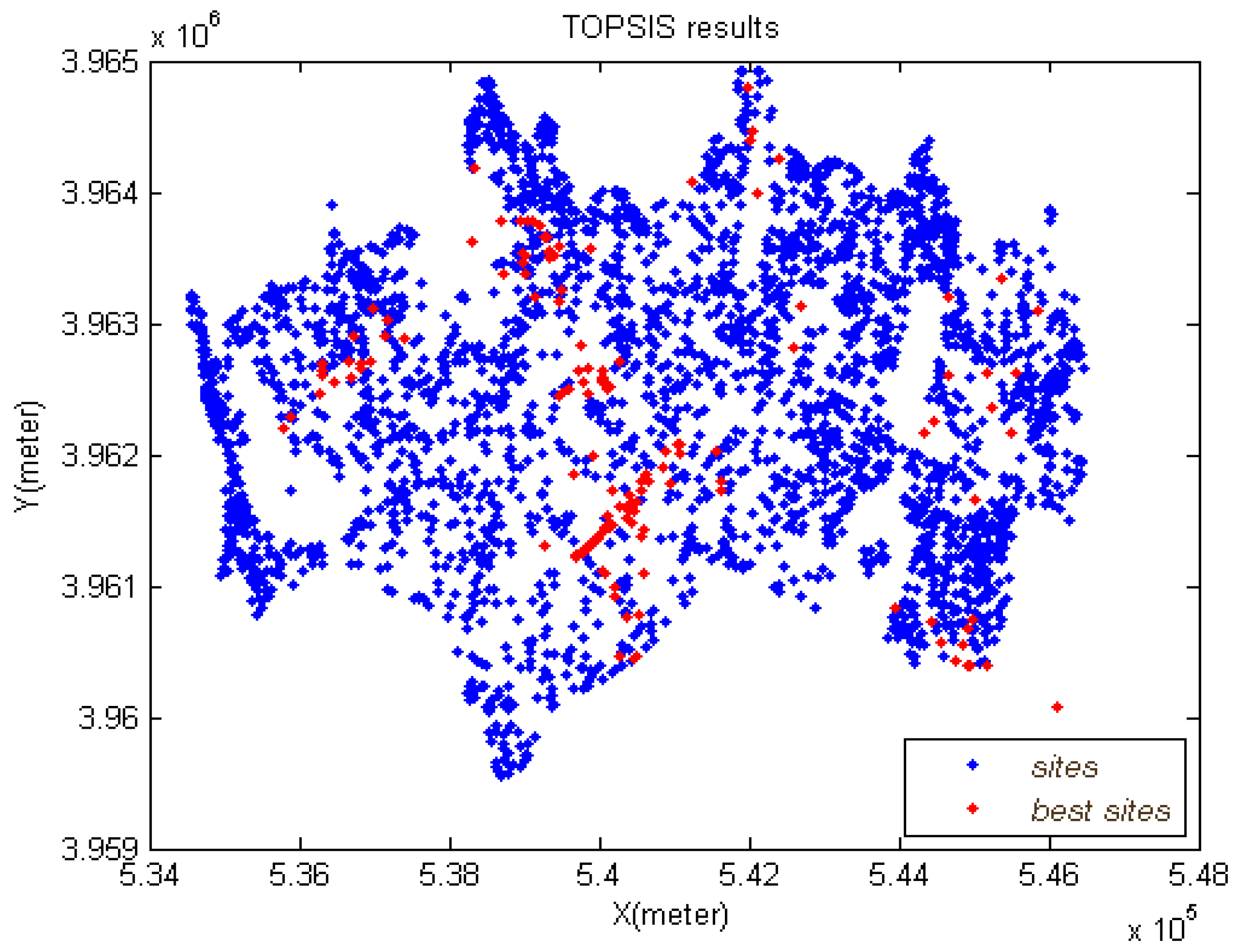
4.5. TOPSIS Implementation
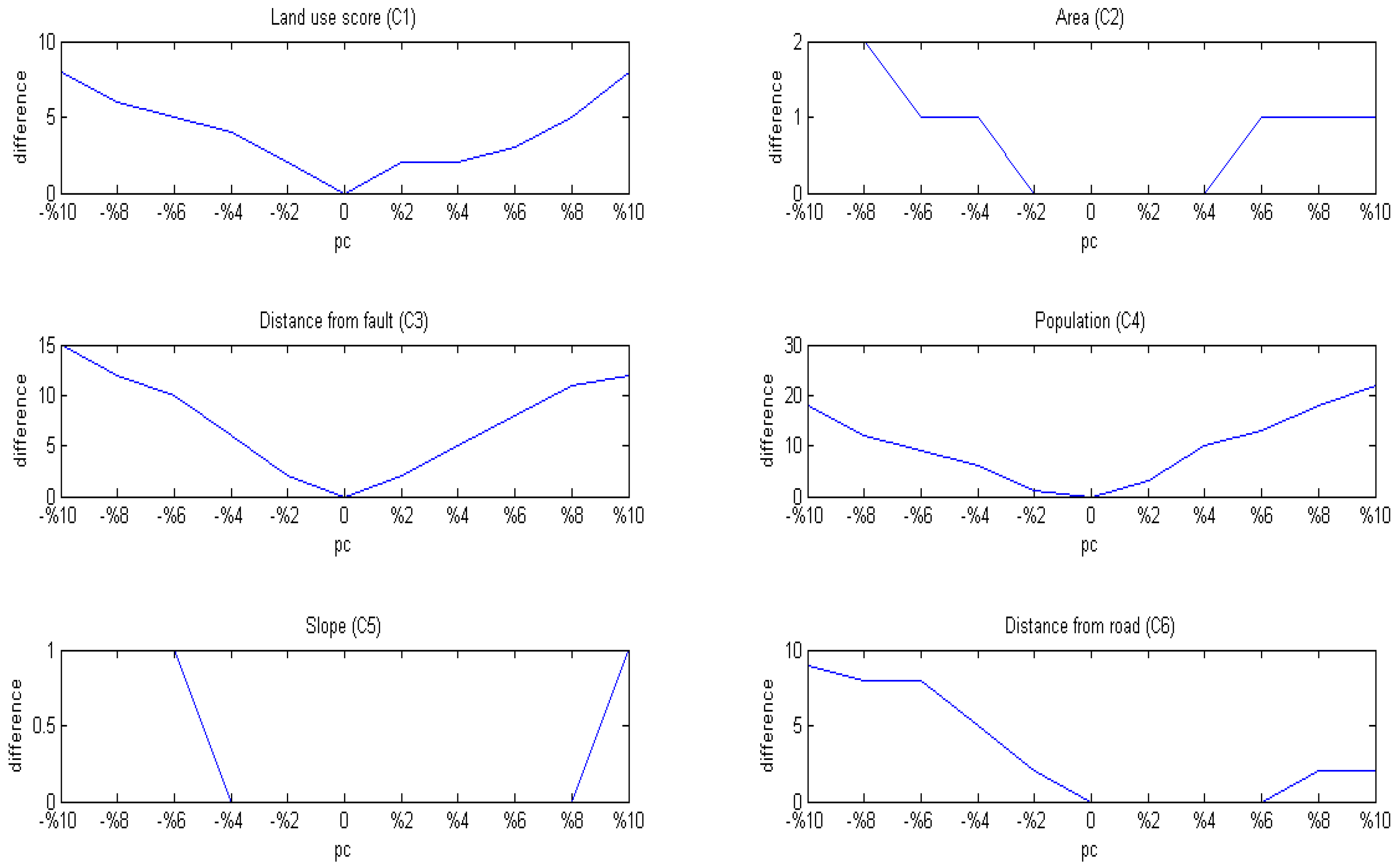
4.6. Sensitivity Analyses
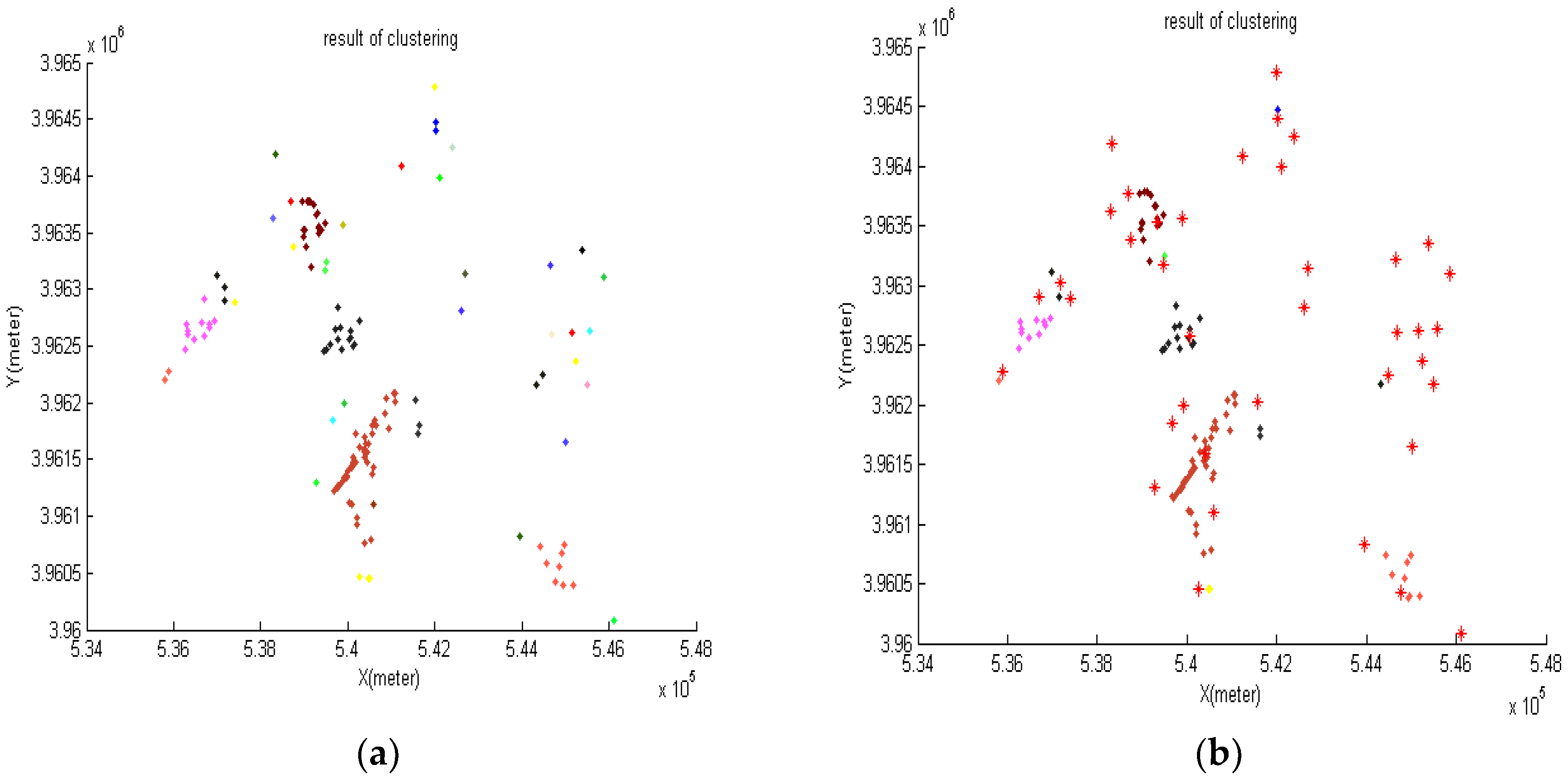
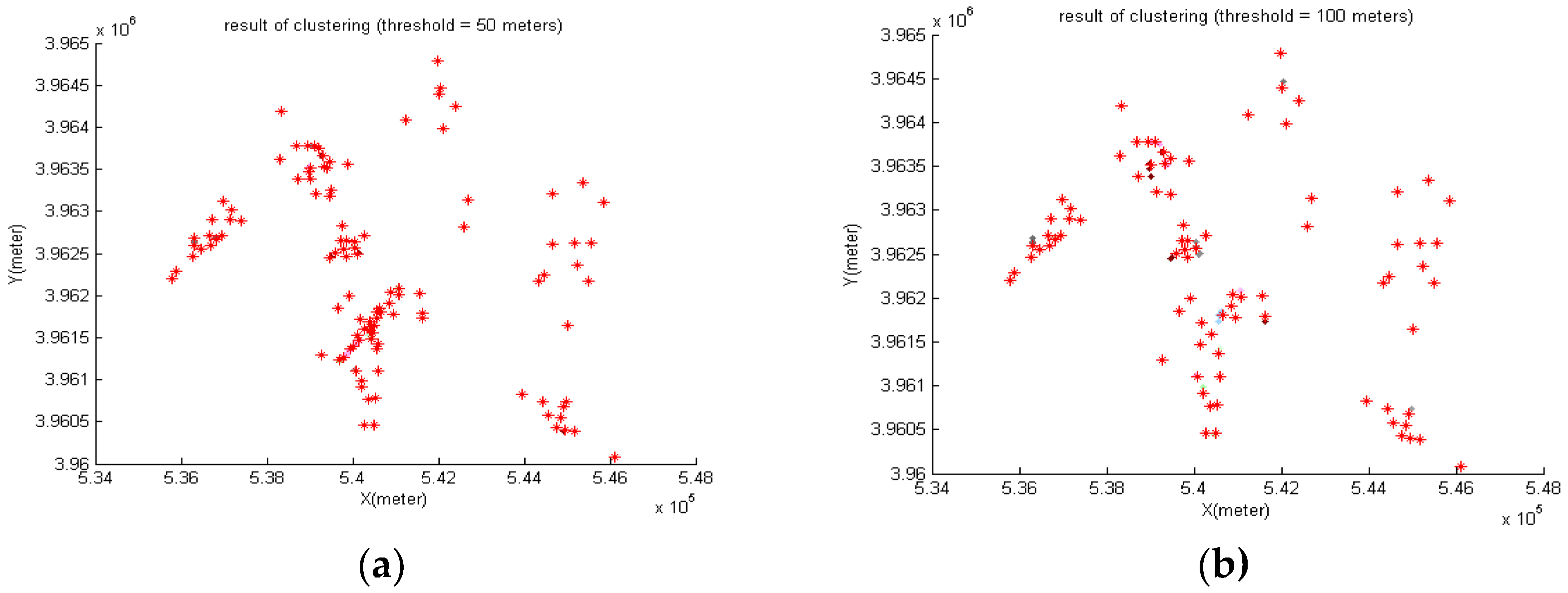
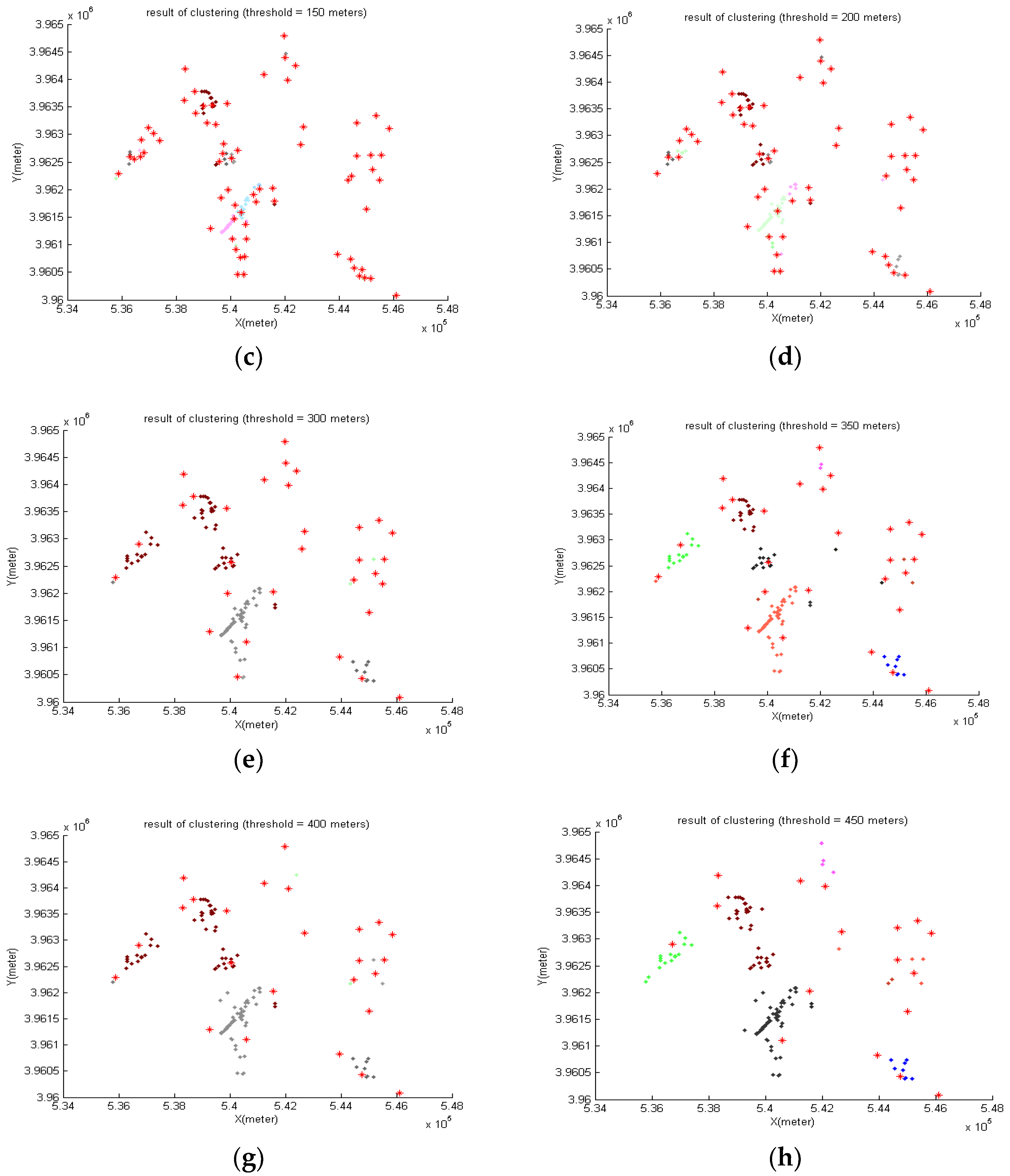
4.7. Reducing the Density of Sites by Clustering
- Proximity threshold (limit) is determined.
- Every site is placed in a cluster.
- The distances between all sites are calculated, and if two sites are closer than the threshold, their clusters are merged.
- Clusters having a common site are merged.
- In each cluster, the site having higher TOPSIS rank is kept and the rest are removed.
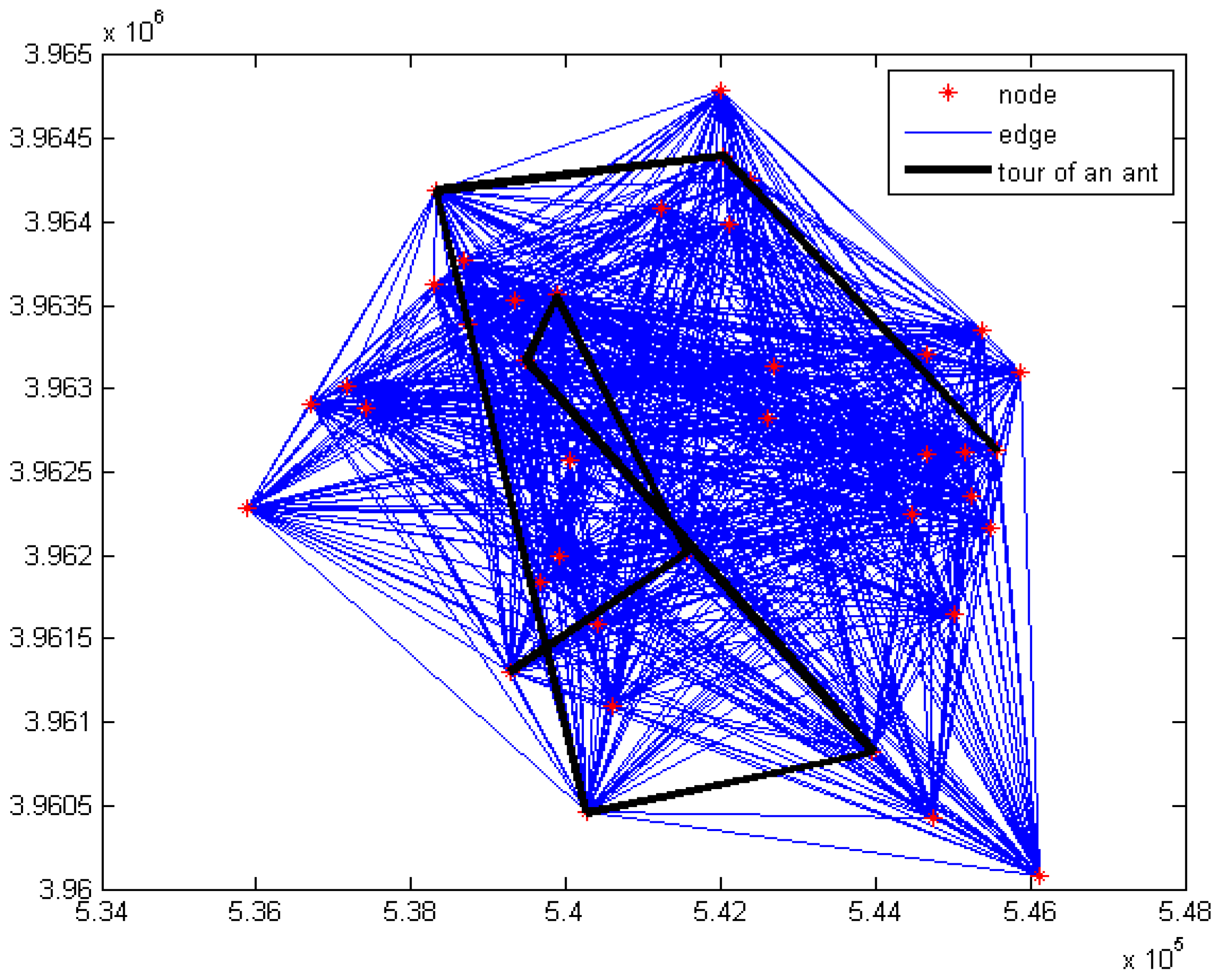
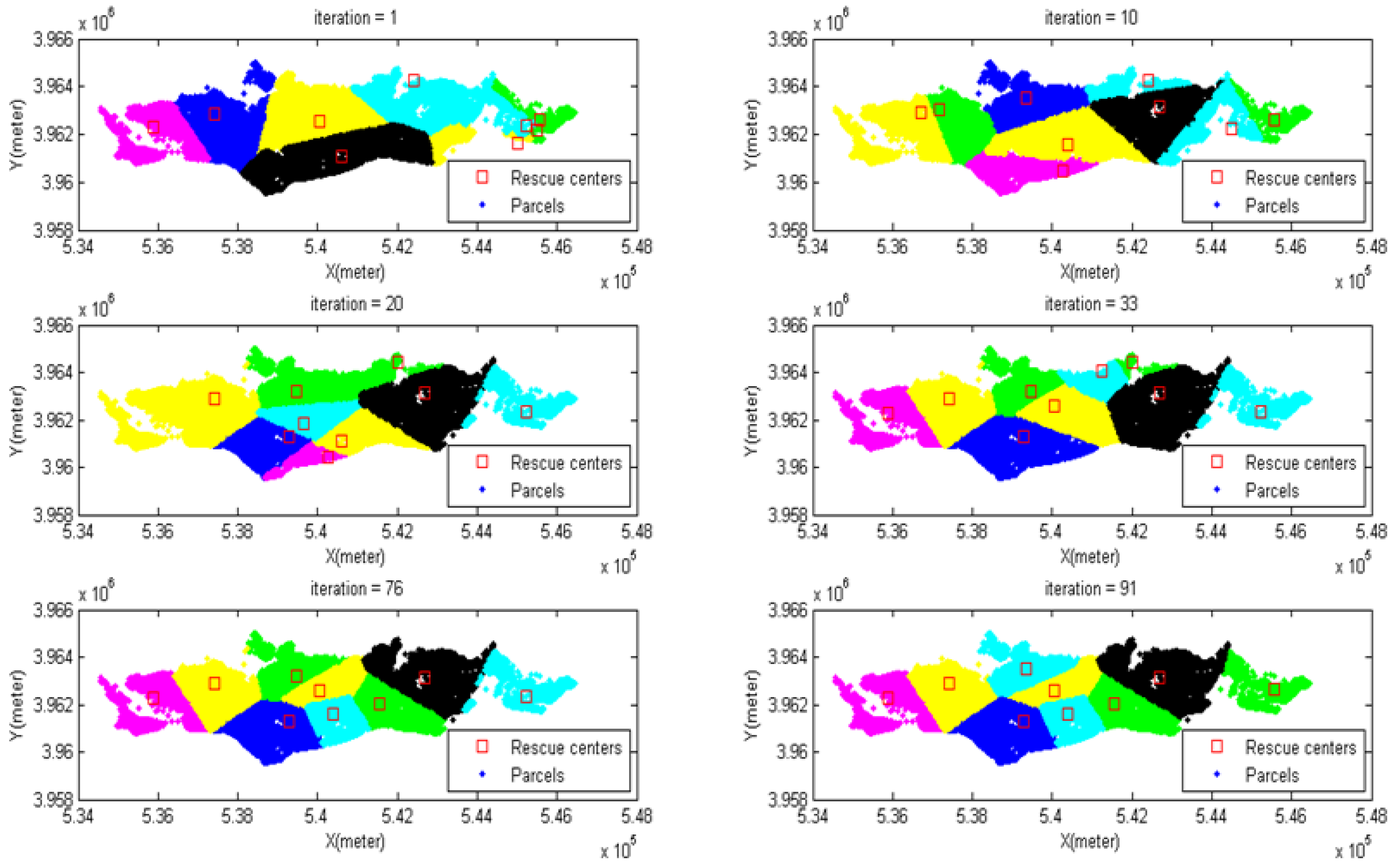
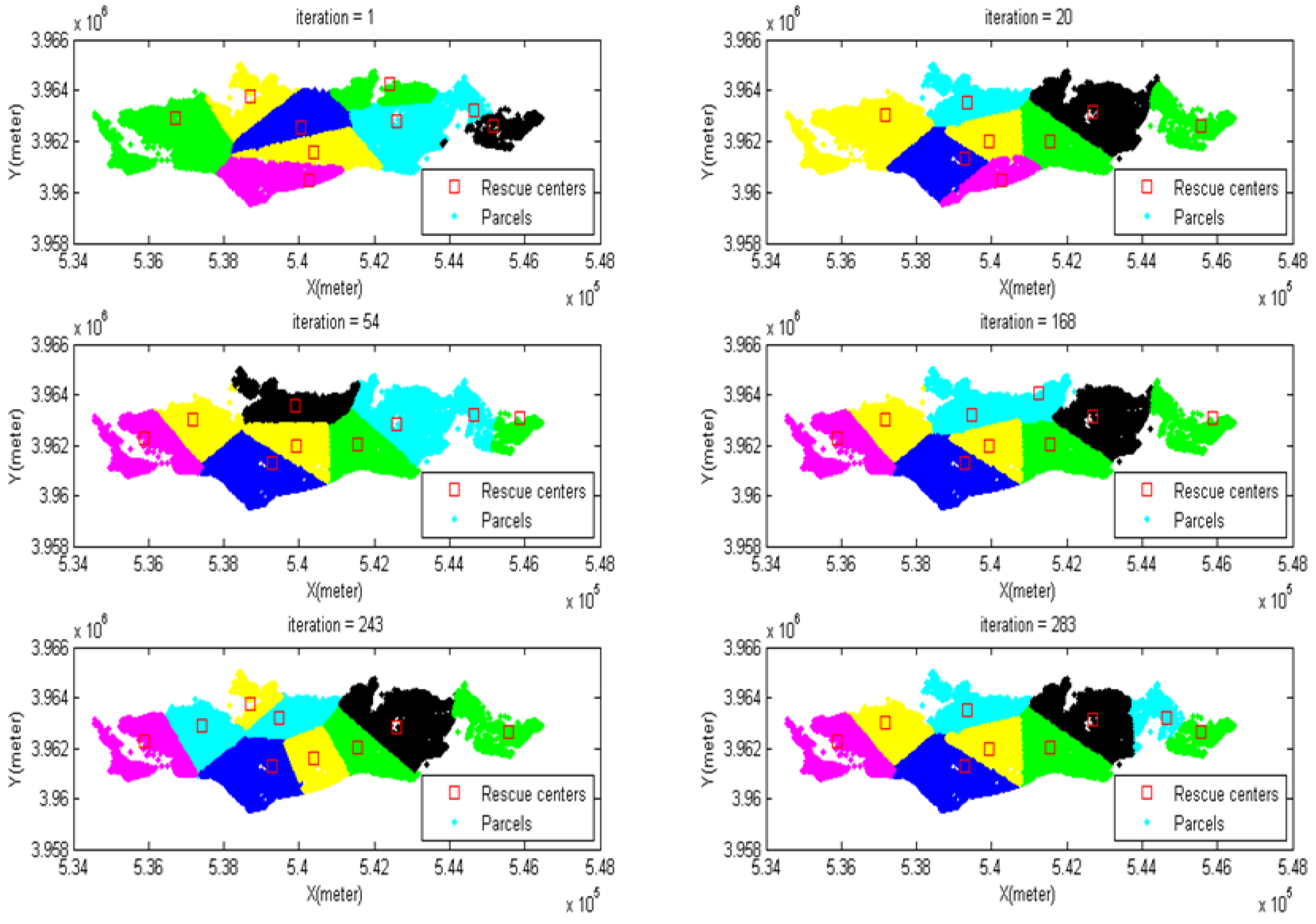
4.8. Modeling the Meta-Heuristic Algorithms
4.8.1. Modeling PSO
4.8.2. Modeling ACO
5. The Result of Algorithm Implementation
5.1. Results Comparison
5.1.1. Comparing Fitness Function Values
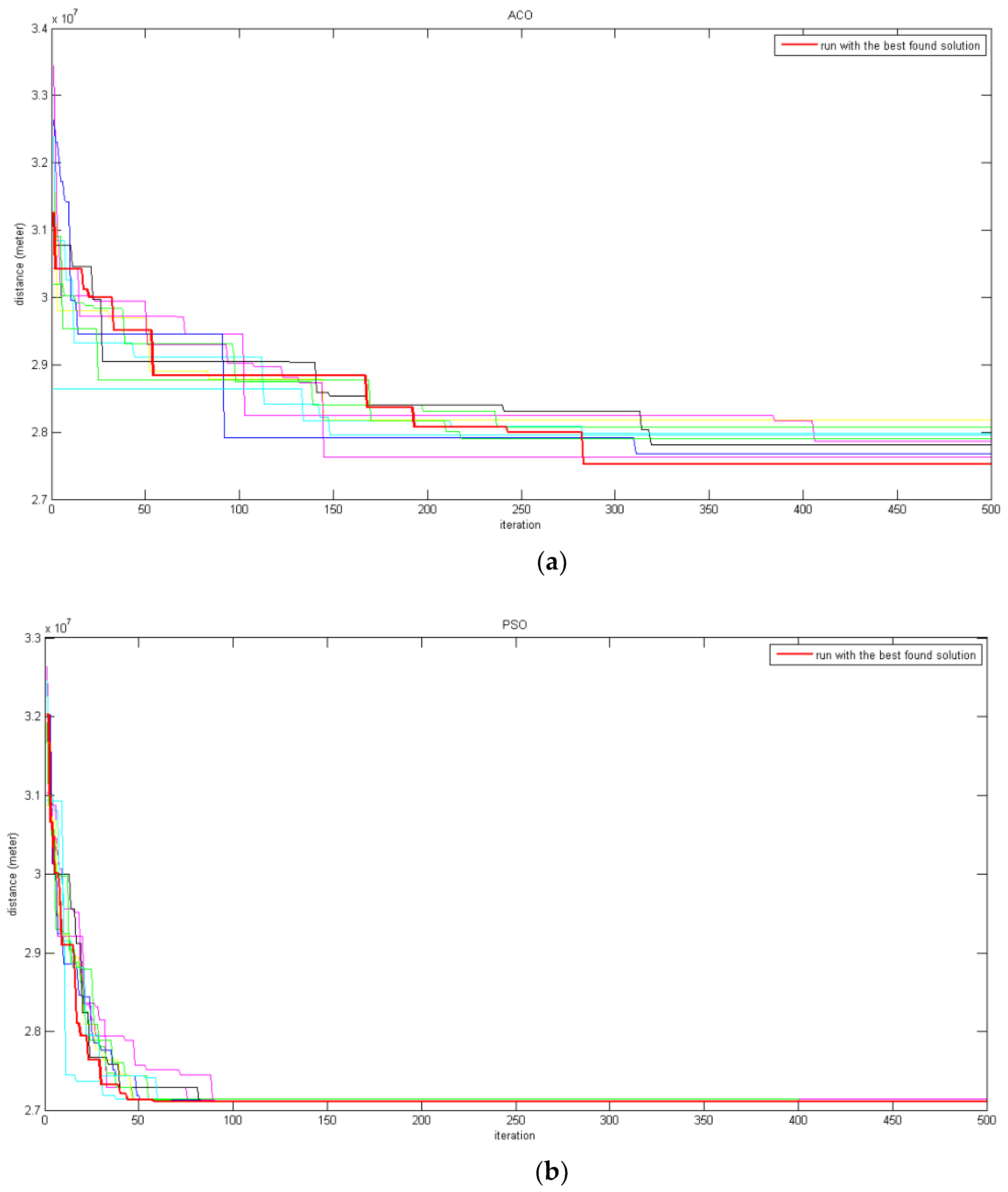
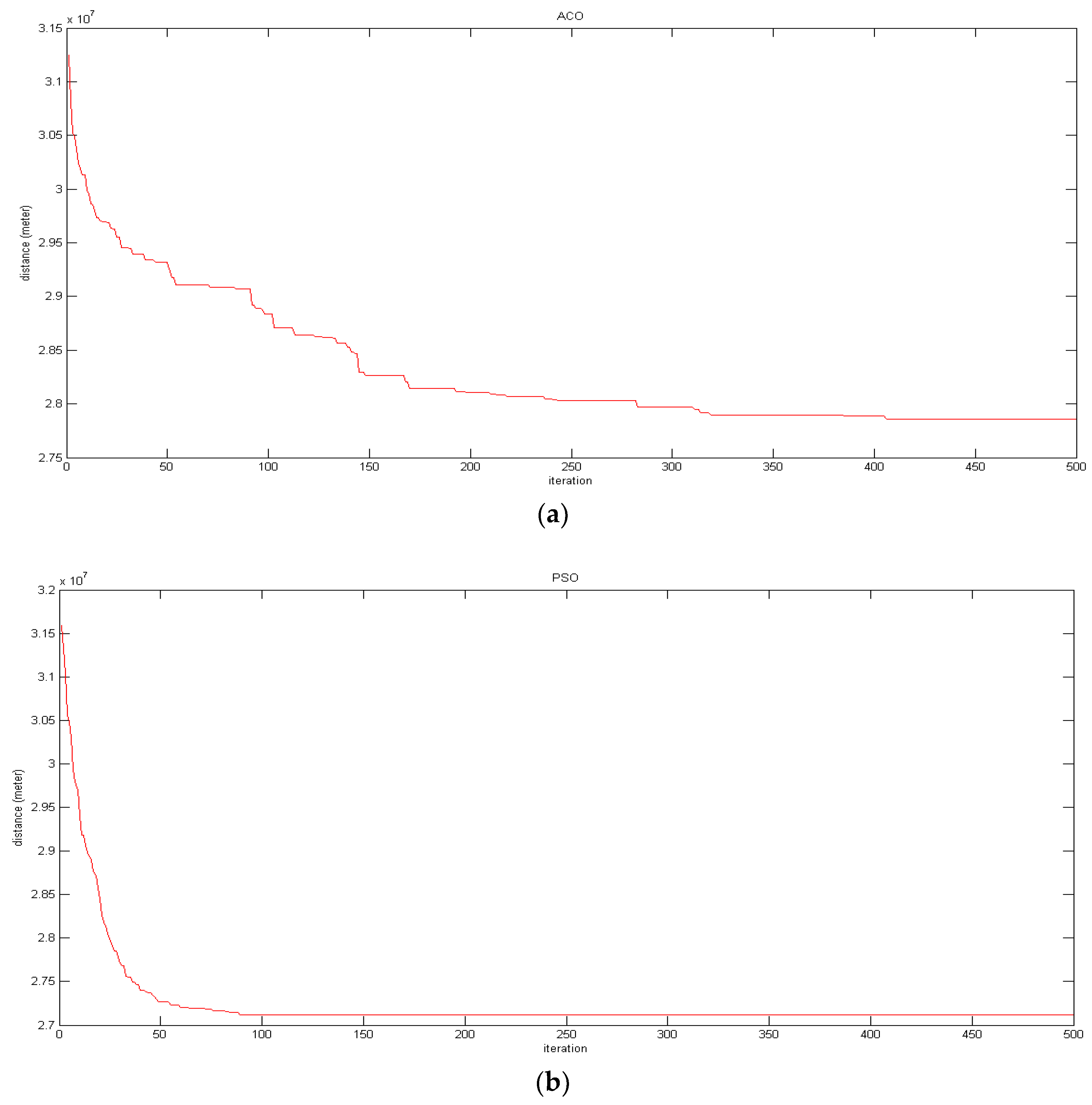
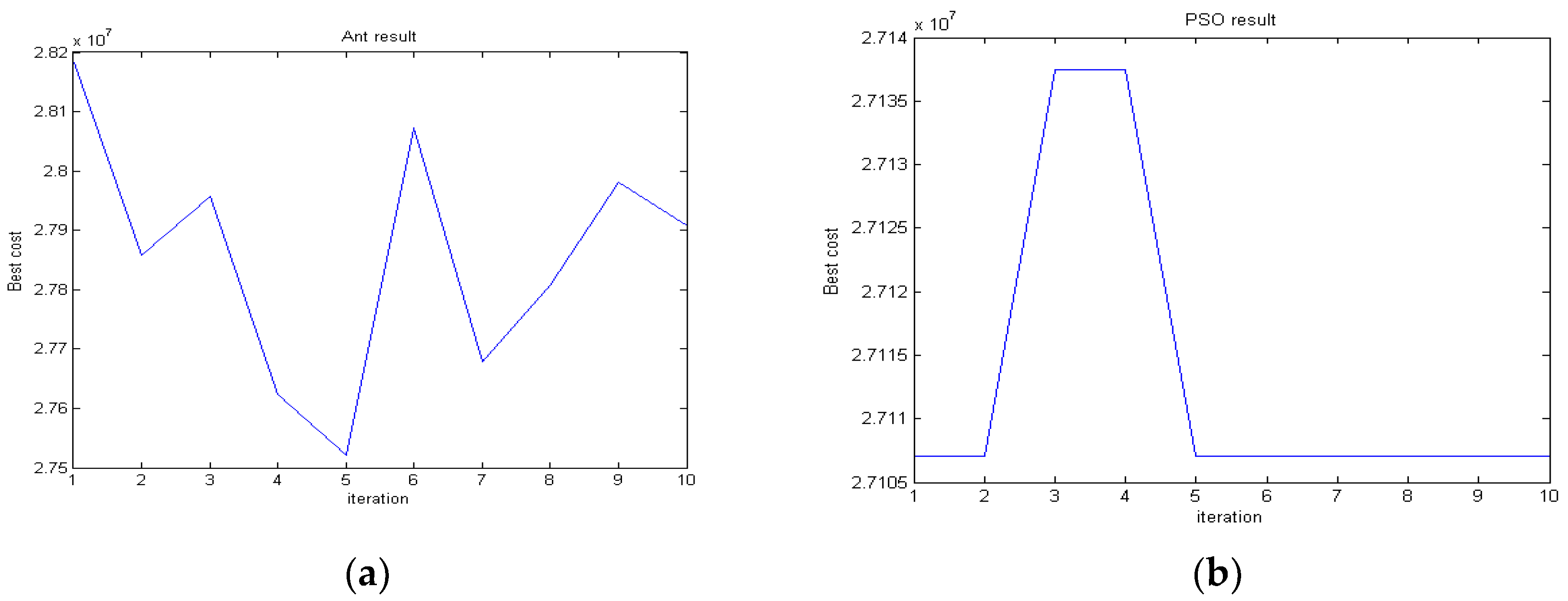
5.1.2. Comparing the Convergence Rate of the Algorithms
- The convergence of the PSO is much smoother than that of ACO in all runs. This shows that, in this study, PSO is stronger than ACO in dealing with local optimums.
- The convergence rate is faster in the earlier iterations of both algorithms.
- In general, the convergence rate of PSO is higher (better) than that of ACO. In other words, in all executions including the best ones (presented by red color), PSO convergences to lower values of the objective function much faster than ACO. In addition, the best values found by PSO in iteration 90 are not found by ACO, even in iteration 500.
- In all iterations of the algorithms, the diagrams of PSO are more similar than those of ACO. In other words, the convergence rates of PSO for different executions are more similar than the convergence rates of ACO. Additionally, in the final iterations, any execution of ACO converges to a different value. This means that, apparently PSO is more robust and repeatable than ACO. To examine this further, a repeatability test is carried out and presented in the next section of the article.
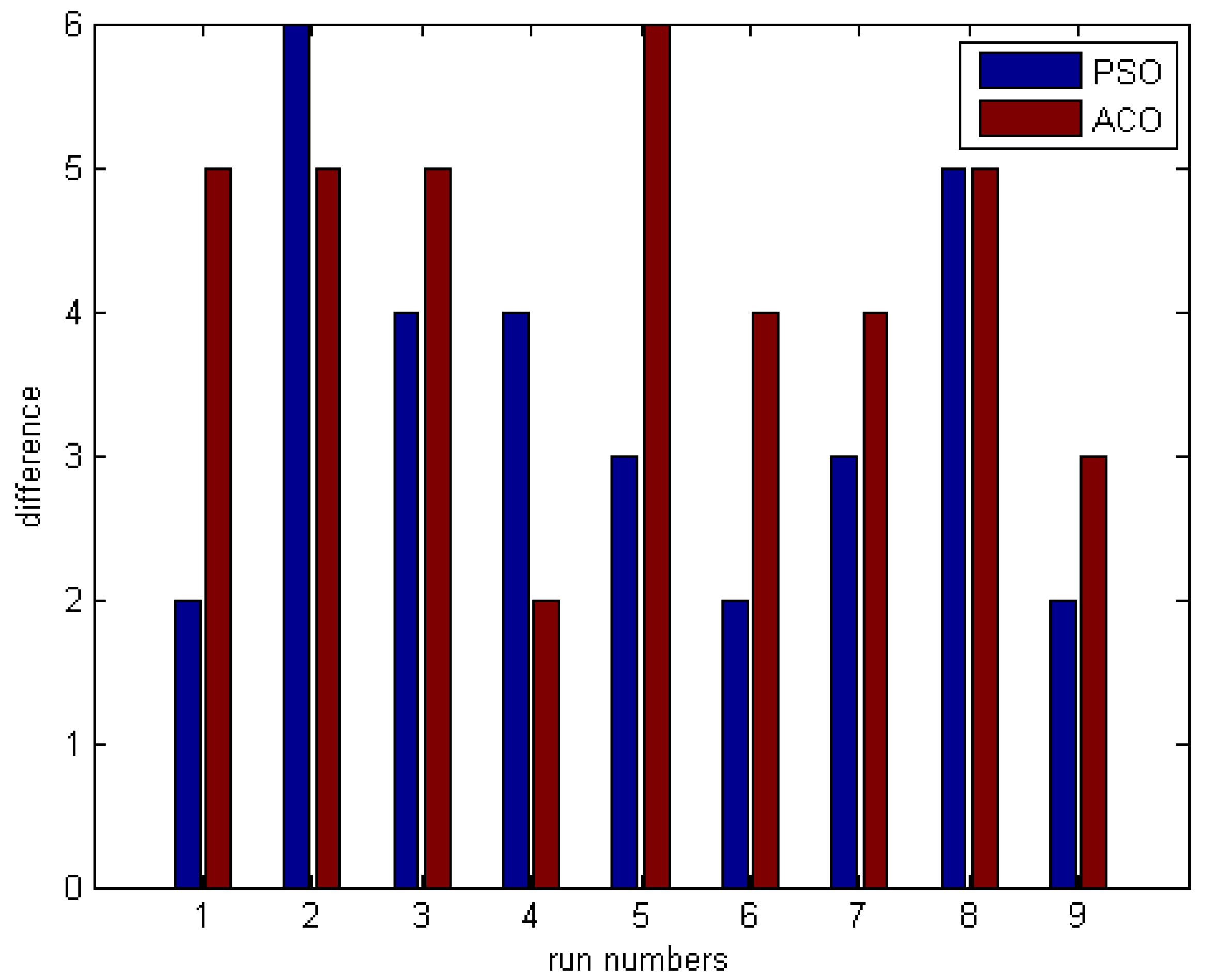
5.1.3. Comparing Algorithm Constancy
5.1.4. Complexity of Run Time
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hualou, L. Disaster prevention and management: A Geographical Perspective. Dis. Adv. 2011, 4, 3–5. [Google Scholar]
- Saeedy, S.; Shamsipour, A.A.; Fallah, S.; Saeedy, S. Evaluation of Relief and Rescue Operations in Historic Regions (Case of Study: Fahadan District in Yazd City, Iran). Available online: https://www.researchgate.net/profile/Aliakbar_Shamsipour/publication/260136058_Evaluation_of_Relief_and_Rescue_Operations_in_Historic_Regions_Case_of_Study_Fahadan_District_in_Yazd_City_Iran/links/00b4952fb804d64012000000/Evaluation-of-Relief-and-Rescue-Operations-in-Historic-Regions-Case-of-Study-Fahadan-District-in-Yazd-City-Iran.pdf (accessed on 30 May 2018).
- Soltani, A.; Ardalan, A.; Boloorani, A.D.; Haghdoost, A.; Hosseinzadeh-Attar, M.J. Site selection criteria for sheltering after earthquakes: A systematic review. PLoS Curr. 2014. [Google Scholar] [CrossRef] [PubMed]
- Bramante, J.F.; Raju, D.K. Predicting the distribution of informal camps established by the displaced after a catastrophic disaster, Port-au-Prince, Haiti. Appl. Geogr. 2013, 40, 30–39. [Google Scholar] [CrossRef]
- Aras, N.; Orbay, M.; Altinel, I. Efficient heuristics for the rectilinear distance capacitated multi-facility Weber problem. J. Oper. Res. Soc. 2008, 59, 64–79. [Google Scholar] [CrossRef]
- Arnaout, J.-P. Ant colony optimization algorithm for the Euclidean location-allocation problem with unknown number of facilities. J. Intell. Manuf. 2013, 24, 45–54. [Google Scholar] [CrossRef]
- Ghosh, A.; Rushton, G. Spatial Analysis and Location-Allocation Models; Van Nostrand Reinhold Company: New York, NY, USA, 1987. [Google Scholar]
- Saeidian, B.; Mesgari, M.S.; Ghodousi, M. Evaluation and comparison of genetic algorithm and bees algorithm for location–allocation of earthquake relief centers. Int. J. Dis. Risk Reduct. 2016, 15, 94–107. [Google Scholar] [CrossRef]
- Beraldi, P.; Bruni, M.E. A probabilistic model applied to emergency service vehicle location. Eur. J. Oper. Res. 2009, 196, 323–331. [Google Scholar] [CrossRef]
- Tzeng, G.-H.; Cheng, H.-J.; Huang, T.D. Multi-objective optimal planning for designing relief delivery systems. Transp. Res. Part E 2007, 43, 673–686. [Google Scholar] [CrossRef]
- Balcik, B.; Beamon, B.M. Facility location in humanitarian relief. Int. J. Logist. 2008, 11, 101–121. [Google Scholar] [CrossRef]
- Hooshangi, N.; Alesheikh, A.A. Agent-based task allocation under uncertainties in disaster environments: An approach to interval uncertainty. Int. J. Dis. Risk Reduct. 2017, 24, 160–171. [Google Scholar] [CrossRef]
- Mingang, Z.; Zeng, M.; Xiaoyan, W. Research on location-routing problem of relief system based on emergency logistics. In Proceedings of the 16th International Conference on Industrial Engineering and Engineering Management, Beijing, China, 21–23 October 2009. [Google Scholar]
- Memon, I.; Mangi, F.A.; Jamro, D.A. Collision avoidance of intelligent service robot for industrial security system. IJCSI Int. J. Comput. Sci. Issues 2013, 10, 397–401. [Google Scholar]
- Saeidian, B.; Mesgari, M.S.; Ghodousi, M. Optimum allocation of water to the cultivation farms using Genetic Algorithm. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 631–638. [Google Scholar] [CrossRef]
- Yi, W.; Kumar, A. Ant colony optimization for disaster relief operations. Transp. Res. Part E 2007, 43, 660–672. [Google Scholar] [CrossRef]
- Sheu, J.-B. An emergency logistics distribution approach for quick response to urgent relief demand in disasters. Transp. Res. Part E 2007, 43, 687–709. [Google Scholar] [CrossRef]
- Ohlemüller, M. Tabu search for large location-allocation problems. J. Oper. Res. Soc. 1997, 48, 745–750. [Google Scholar] [CrossRef]
- Brimberg, J.; Hansen, P.; Mladenović, N.; Taillard, E.D. Improvements and comparison of heuristics for solving the uncapacitated multisource Weber problem. Oper. Res. 2000, 48, 444–460. [Google Scholar] [CrossRef]
- Zheng, Y.-J.; Chen, S.-Y.; Ling, H.-F. Evolutionary optimization for disaster relief operations: A survey. Appl. Soft Comput. 2015, 27, 553–566. [Google Scholar] [CrossRef]
- Li, X.; Zhao, Z.; Zhu, X.; Wyatt, T. Covering models and optimization techniques for emergency response facility location and planning: A review. Math. Methods Oper. Res. 2011, 74, 281–310. [Google Scholar] [CrossRef]
- Mirjalili, S. Dragonfly algorithm: A new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems. Neural Comput. Appl. 2016, 27, 1053–1073. [Google Scholar] [CrossRef]
- Askarzadeh, A. A novel metaheuristic method for solving constrained engineering optimization problems: Crow search algorithm. Comput. Struct. 2016, 169, 1–12. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Salimi, H. Stochastic fractal search: A powerful metaheuristic algorithm. Knowl. Based Syst. 2015, 75, 1–18. [Google Scholar] [CrossRef]
- Shbib, R.; Zhou, S.; Al-Mosawi, M. Optimal route selection method with ant colony optimization (ACO) for Cognitive network in disaster information network. Available online: https://www.researchgate.net/publication/229088815_Optimal_Route_Selection_Method_with_Ant_Colony_Optimization_ACO_for_Cognitive_Network_in_Disaster_Information_Network (accessed on 30 May 2018).
- Tian, J.; Ma, W.-Z.; Wang, Y.-L.; Wang, K.-L. Emergency supplies distributing and vehicle routes programming based on particle swarm optimization. Syst. Eng. Theory Pract. 2011, 5, 898–906. [Google Scholar]
- Yunxiao, Q.L.J.H.L.; Jiayi, H. Mix K-Means Clustering with Ant Colony Optimization Used in City Emergency Rescue Decision-Making; China Public Security: Beijing, China, 2011.
- Zade, A.-V.; Tugnayat, R.-M. Ant Colony Optimization (ACO) in disaster information network. Int. J. Innov. Eng. Res. Technol. 2014, 1, 1–5. [Google Scholar]
- Zheng, Y.-J.; Ling, H.-F.; Xue, J.-Y.; Chen, S.-Y. Population classification in fire evacuation: A multiobjective particle swarm optimization approach. IEEE Trans. Evol. Comput. 2014, 18, 70–81. [Google Scholar] [CrossRef]
- Hu, F.; Xu, W.; Li, X. A modified particle swarm optimization algorithm for optimal allocation of earthquake emergency shelters. Int. J. Geogr. Inf. Sci. 2012, 26, 1643–1666. [Google Scholar] [CrossRef]
- Chaharsooghi, S.K.; Kermani, A.H.M. An effective ant colony optimization algorithm (ACO) for multi-objective resource allocation problem (MORAP). Appl. Math. Comput. 2008, 200, 167–177. [Google Scholar] [CrossRef]
- Garg, H.; Sharma, S. Multi-objective reliability-redundancy allocation problem using particle swarm optimization. Comput. Ind. Eng. 2013, 64, 247–255. [Google Scholar] [CrossRef]
- Gong, Y.-J.; Zhang, J.; Chung, H.S.-H.; Chen, W.-N.; Zhan, Z.-H.; Li, Y.; Shi, Y.-H. An efficient resource allocation scheme using particle swarm optimization. IEEE Trans. Evol. Comput. 2012, 16, 801–816. [Google Scholar] [CrossRef]
- Liang, Y.-C.; Smith, A.E. An ant colony optimization algorithm for the redundancy allocation problem (RAP). IEEE Trans. Reliab. 2004, 53, 417–423. [Google Scholar] [CrossRef]
- Saravanan, M.; Slochanal, S.M.R.; Venkatesh, P.; Abraham, P.S. Application of PSO technique for optimal location of FACTS devices considering system loadability and cost of installation. In Proceedings of the International Power Engineering Conference, Singapore, 29 November–2 December 2005. [Google Scholar]
- Vilovic, I.; Burum, N.; Sipus, Z. Ant colony approach in optimization of base station position. In Proceedings of the 3rd European Conference on Antennas and Propagation, Berlin, Germany, 23–27 March 2009. [Google Scholar]
- Wang, K.-J.; Lee, C.-H. A revised ant algorithm for solving location–allocation problem with risky demand in a multi-echelon supply chain network. Appl. Soft Comput. 2015, 32, 311–321. [Google Scholar] [CrossRef]
- Yin, P.-Y.; Wang, J.-Y. Ant colony optimization for the nonlinear resource allocation problem. Appl. Math. Comput. 2006, 174, 1438–1453. [Google Scholar] [CrossRef]
- Yin, P.-Y.; Wang, J.-Y. A particle swarm optimization approach to the nonlinear resource allocation problem. Appl. Math. Comput. 2006, 183, 232–242. [Google Scholar] [CrossRef]
- Aghababa, M.P.; Amrollahi, M.H.; Borjkhani, M. Application of GA, PSO, and ACO algorithms to path planning of autonomous underwater vehicles. J. Marine Sci. Appl. 2012, 11, 378–386. [Google Scholar] [CrossRef]
- Elbeltagi, E.; Hegazy, T.; Grierson, D. Comparison among five evolutionary-based optimization algorithms. Adv. Eng. Inf. 2005, 19, 43–53. [Google Scholar] [CrossRef]
- Hasan, M.K.; Ismail, A.F.; Islam, S.; Hashim, W.; Ahmed, M.M.; Memon, I. A novel HGBBDSA-CTI approach for subcarrier allocation in heterogeneous network. Telecommun. Syst. 2018. [Google Scholar] [CrossRef]
- Marinakis, Y.; Marinaki, M.; Doumpos, M.; Zopounidis, C. Ant colony and particle swarm optimization for financial classification problems. Expert Syst. Appl. 2009, 36, 10604–10611. [Google Scholar] [CrossRef]
- Moussouni, F.; Brisset, S.; Brochet, P. Comparison of two multi-agent algorithms: ACO and PSO for the optimization of a brushless DC wheel motor. In Intelligent Computer Techniques in Applied Electromagnetics; Springer: Berlin, Germany, 2008. [Google Scholar]
- Selvi, V.; Umarani, D.R. Comparative analysis of ant colony and particle swarm optimization techniques. Int. J. Comput. Appl. 2010, 5. [Google Scholar] [CrossRef]
- Shakerian, R.; Kamali, S.H.; Hedayati, M.; Alipour, M. Comparative study of ant colony optimization and particle swarm optimization for grid scheduling. J. Math. Comput. Sci. 2011, 2, 469–474. [Google Scholar]
- Vilovic, I.; Burum, N.; Sipus, Z.; Nad, R. PSO and ACO algorithms applied to location optimization of the WLAN base station. In Proceedings of the 19th International Conference on Applied Electromagnetics and Communications, Dubrovnik, Croatia, 24–26 September 2007. [Google Scholar]
- Adrian, A.M.; Utamima, A.; Wang, K.-J. A comparative study of GA, PSO and ACO for solving construction site layout optimization. KSCE J. Civ. Eng. 2015, 19, 520–527. [Google Scholar] [CrossRef]
- Bailey, A.; Ornbuki-Berrnan, B.; Asobiela, S. Discrete pso for the uncapacitated single allocation hub location problem. In Proceedings of the IEEE Symposium on Computational Intelligence in Production and Logistics Systems (CIPLS), Singapore, 16–19 April 2013. [Google Scholar]
- Guner, A.R.; Sevkli, M. A discrete particle swarm optimization algorithm for uncapacitated facility location problem. J. Artif. Evol. Appl. 2008, 10. [Google Scholar] [CrossRef]
- Noory, H.; Liaghat, A.; Parsinejad, M.; Bozorg-Haddad, O. Optimizing irrigation water allocation and multicrop planning using discrete PSO algorithm. J. Irrig. Drain. Eng. 2011, 138, 437–444. [Google Scholar] [CrossRef]
- Yu, X. Facility allocation based on hybrid discrete PSO under emergency. Inf. Technol. J. 2013, 12. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Beni, G.; Wang, J. Swarm Intelligence in Cellular Robotic Systems, in Robots and Biological Systems: Towards a New Bionics? Springer: Berlin, Germany, 1993. [Google Scholar]
- Dorigo, M. Optimization, Learning and Natural Algorithms; Politecnico di Milano: Milan, Italy, 1992. [Google Scholar]
- Eberhart, R.C.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the 6th International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995. [Google Scholar]
- Kennedy, J.; Eberhart, R.C. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995. [Google Scholar]
- Pham, D.T.; Ghanbarzadeh, A.; Koc, E.; Otri, S.; Rahim, S.; Zaidi, M. The Bees Algorithm; Manufacturing Engineering Centre, Cardiff University: Cardiff, UK, 2005. [Google Scholar]
- Engelbrecht, A.P. Fundamentals of Computational Swarm Intelligence; Wile: Chichester, UK, 2005. [Google Scholar]
- Heppner, F.; Grenander, U. A stochastic nonlinear model for coordinated bird flocks. Available online: https://www.researchgate.net/profile/Frank_Heppner/publication/278411001_A_Stochastic_Non-Linear_Model_for_Bird_Flocking/links/5580a02908aea3d7096e4c8a.pdf (accessed on 30 May 2018).
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Samsami, R. Comparison between Genetic Algorithm (GA), Particle Swarm Optimization (PSO) and Ant Colony Optimization (ACO) Techniques for NO Emission Forecasting in Iran. World Appl. Sci. J. 2013, 28, 1996–2002. [Google Scholar]
- Eberhart, R.C.; Shi, Y. Comparing inertia weights and constriction factors in particle swarm optimization. In Proceedings of the Congress on Evolutionary Computation. CEC00 (Cat. No.00TH8512), La Jolla, CA, USA, 16–19 July 2000. [Google Scholar]
- Eberhart, R.C.; Shi, Y. Tracking and optimizing dynamic systems with particle swarms. In Proceedings of the Congress on Evolutionary Computation (IEEE Cat. No.01TH8546), Seoul, Korea, 27–30 May 2001. [Google Scholar]
- Dorigo, M.; Blum, C. Ant colony optimization theory: A survey. Theor. Comput. Sci. 2005, 344, 243–278. [Google Scholar] [CrossRef]
- Dorigo, M.; Gambardella, L.M. Ant colonies for the travelling salesman problem. BioSystems 1997, 43, 73–81. [Google Scholar] [CrossRef]
- Dorigo, M.; Socha, K. An introduction to ant colony optimization. In Handbook of Approximation Algorithms and Metaheuristics; IRIDIA (Institut de Recherches Interdisciplinaires et de Developpements en Intelligence Artificielle): Bruxelles, Belgium, 2006. [Google Scholar]
- Opricovic, S.; Tzeng, G.-H. Compromise solution by MCDM methods: A comparative analysis of VIKOR and TOPSIS. Eur. J. Oper. Res. 2004, 156, 445–455. [Google Scholar] [CrossRef]
- Sarvar, H.; Amini, J.; Laleh-Poor, M. Assessment of risk caused by earthquake in region 1 of Tehran using the combination of RADIUS, TOPSIS and AHP models. J. Civ. Eng. Urban 2011, 1, 39–48. [Google Scholar]
- Wikipedia. District 1 of Tehran municipality. 2017. Available online: https://fa.wikipedia.org/wiki/%D9%85%D9%86%D8%B7%D9%82%D9%87_%DB%B1_%D8%B4%D9%87%D8%B1%D8%AF%D8%A7%D8%B1%DB%8C_%D8%AA%D9%87%D8%B1%D8%A7%D9%86 (accessed on 30 May 2018).
- Arain, Q.A.; Aslam Uqaili, M.; Deng, Z.; Memon, I.; Jiao, J.; Shaikh, M.A.; Zubedi, A.; Ashraf, A.; Arain, U.A. Clustering based energy efficient and communication protocol for multiple mix-zones over road networks. Wirel. Pers. Commun. 2017, 95, 411–428. [Google Scholar] [CrossRef]
- Gustav, Y.H.; et al. Velocity similarity anonymization for continuous query location based services. In Proceedings of the International Conference on Computational Problem-Solving (ICCP), Jiuzhai, China, 26–28 October 2013. [Google Scholar]
- Malczewski, J. GIS and Multicriteria Decision Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Zardari, N.H.; Ahmed, K.; Shirazi, S.M.; Yusop, Z.B. Literature Review, in Weighting Methods and Their Effects on Multi-Criteria Decision Making Model Outcomes in Water Resources Management; Springer: Berlin, Germany, 2015. [Google Scholar]
- Chen, Y.; Yu, J.; Khan, S. Spatial sensitivity analysis of multi-criteria weights in GIS-based land suitability evaluation. Environ. Model. Softw. 2010, 25, 1582–1591. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R.C. A discrete binary version of the particle swarm algorithm. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997. [Google Scholar]
- Dorigo, M.; Maniezzo, V.; Colorni, A. Ant system: Optimization by a colony of cooperating agents. IEEE Trans. Syst. Man Cybern. Part B 1996, 26, 29–41. [Google Scholar] [CrossRef] [PubMed]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wi | 0.25 | 0.15 | 0.2 | 0.2 | 0.05 | 0.15 |
| Criteria | Land Use Score (C1) | Area (C2) | Distance from Fault (C3) | Population (C4) | Slope (C5) | Istance from Road (C6) |
| Altern. | ||||||
| 1 | 3 | 2495.900 | 1302.500 | 2799 | 6.086 | 73.463 |
| 2 | 3 | 31.700 | 1289.880 | 3279 | 10.133 | 265.751 |
| 3 | 3 | 207.400 | 1301.798 | 2799 | 6.086 | 49.904 |
| … | … | … | … | … | … | …. |
| 3065 | 5 | 3991.800 | 1034.640 | 9439 | 10.948 | 58.597 |
| Rank | Altern. | CL |
|---|---|---|
| 1 | 209 | 0.92239 |
| 2 | 20 | 0.66403 |
| 3 | 1522 | 0.22652 |
| 4 | 2547 | 0.22043 |
| 5 | 842 | 0.20619 |
| 6 | 77 | 0.18900 |
| 7 | 283 | 0.18603 |
| … | … | |
| 3059 | 934 | 0.06885 |
| 3060 | 773 | 0.06737 |
| 3061 | 939 | 0.06434 |
| 3062 | 387 | 0.05200 |
| 3063 | 447 | 0.05143 |
| 3064 | 395 | 0.05142 |
| 3065 | 405 | 0.05141 |
| PSO | ACO | ||
|---|---|---|---|
| Parameter | Value | Parameter | Value |
| number of Particle | 30 | number of Ant | 30 |
| w | 1 | α | 1 |
| C1 | 2 | β | 0.5 |
| C2 | 2 | Q | 10,000 |
| initial velocity | 0 | evaporate rate (ρ) | 0.1 |
| min & max velocity | ±4 | ||
| Φ1 & Φ2 | Rand (0,1) | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saeidian, B.; Mesgari, M.S.; Pradhan, B.; Ghodousi, M. Optimized Location-Allocation of Earthquake Relief Centers Using PSO and ACO, Complemented by GIS, Clustering, and TOPSIS. ISPRS Int. J. Geo-Inf. 2018, 7, 292. https://doi.org/10.3390/ijgi7080292
Saeidian B, Mesgari MS, Pradhan B, Ghodousi M. Optimized Location-Allocation of Earthquake Relief Centers Using PSO and ACO, Complemented by GIS, Clustering, and TOPSIS. ISPRS International Journal of Geo-Information. 2018; 7(8):292. https://doi.org/10.3390/ijgi7080292
Chicago/Turabian StyleSaeidian, Bahram, Mohammad Saadi Mesgari, Biswajeet Pradhan, and Mostafa Ghodousi. 2018. "Optimized Location-Allocation of Earthquake Relief Centers Using PSO and ACO, Complemented by GIS, Clustering, and TOPSIS" ISPRS International Journal of Geo-Information 7, no. 8: 292. https://doi.org/10.3390/ijgi7080292
APA StyleSaeidian, B., Mesgari, M. S., Pradhan, B., & Ghodousi, M. (2018). Optimized Location-Allocation of Earthquake Relief Centers Using PSO and ACO, Complemented by GIS, Clustering, and TOPSIS. ISPRS International Journal of Geo-Information, 7(8), 292. https://doi.org/10.3390/ijgi7080292