Deep Belief Networks Based Toponym Recognition for Chinese Text




Abstract
1. Introduction
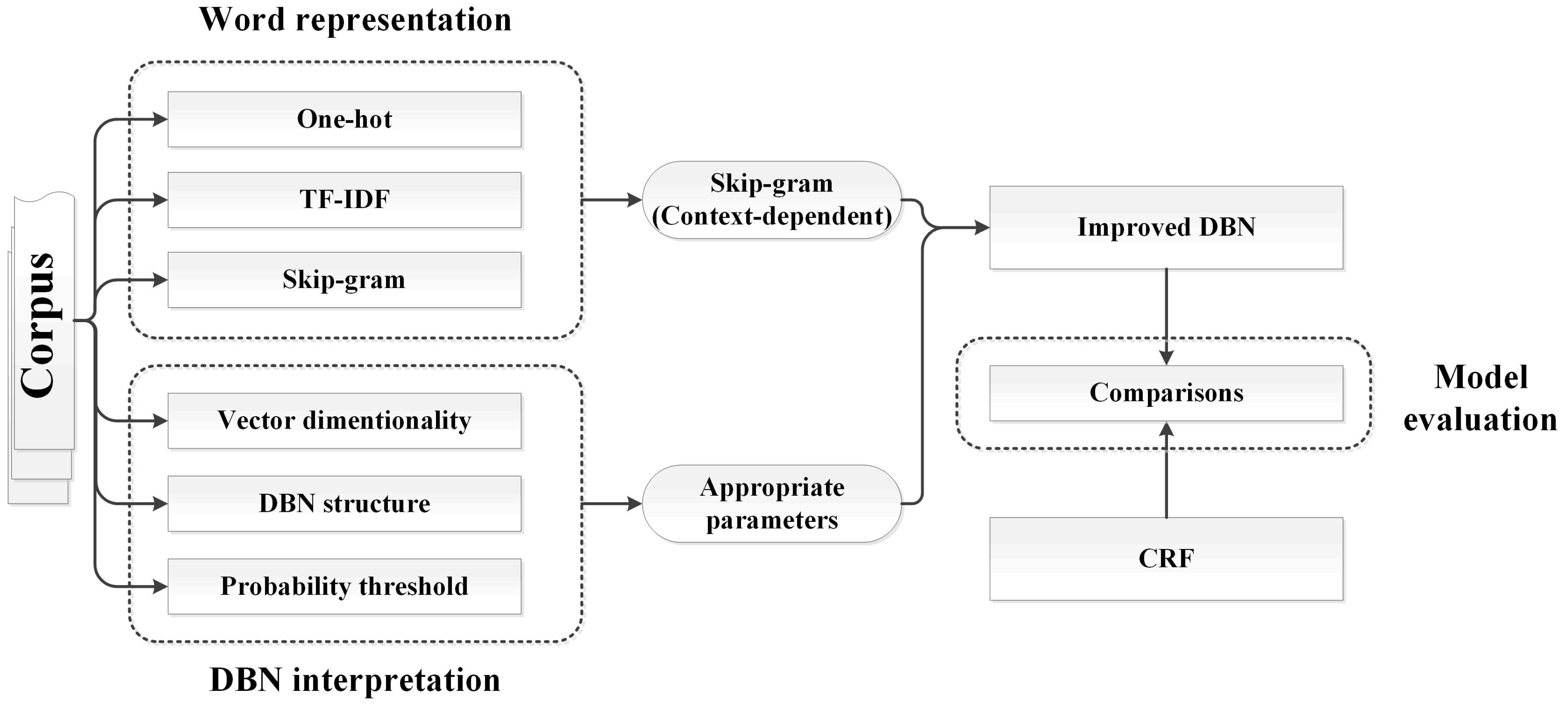
2. Basic Idea
2.1. Linguistic Features and Word Representation Models
2.2. Toponym Recognition Models
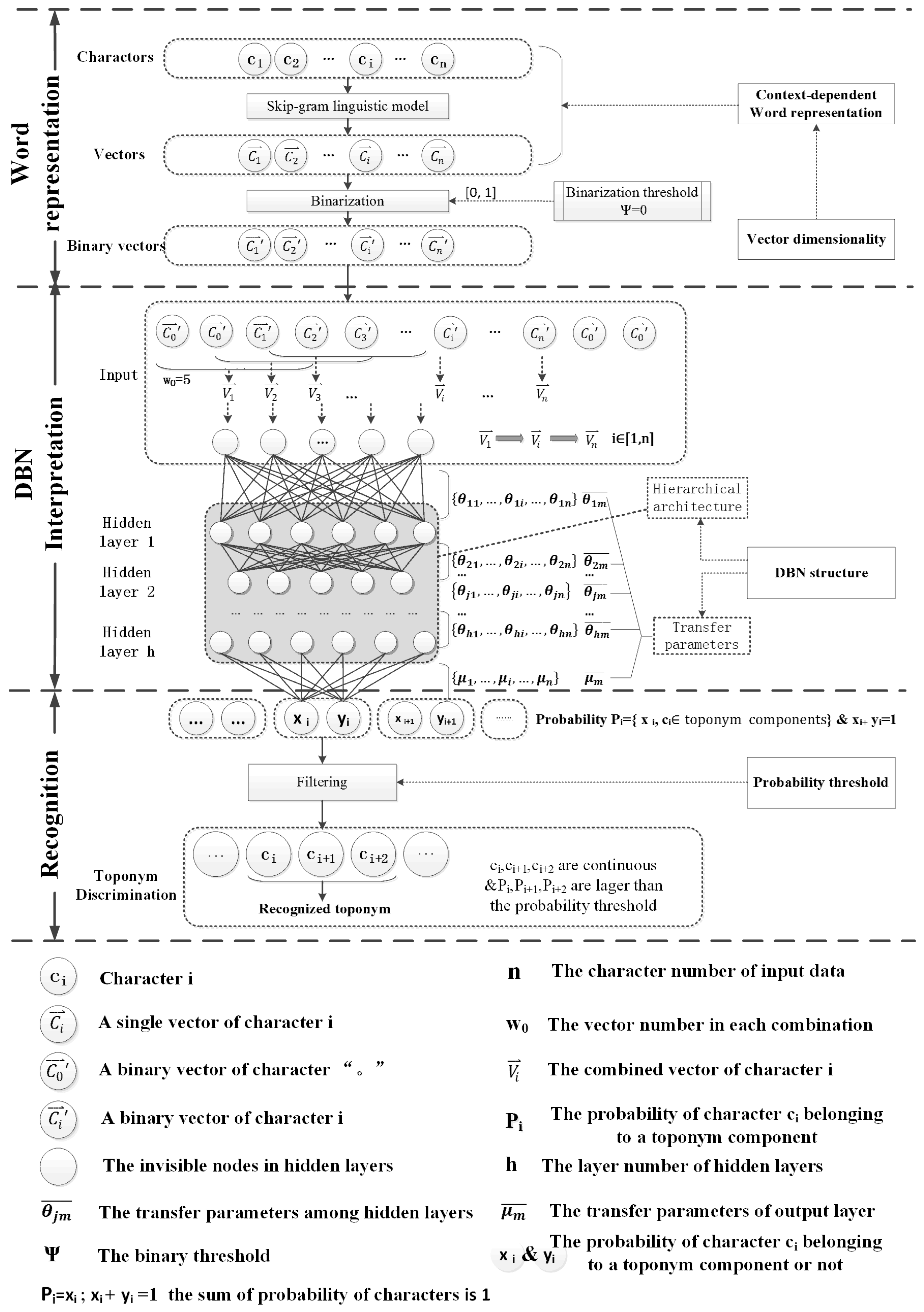
3. Methodology
3.1. Context-Dependent Word Representation
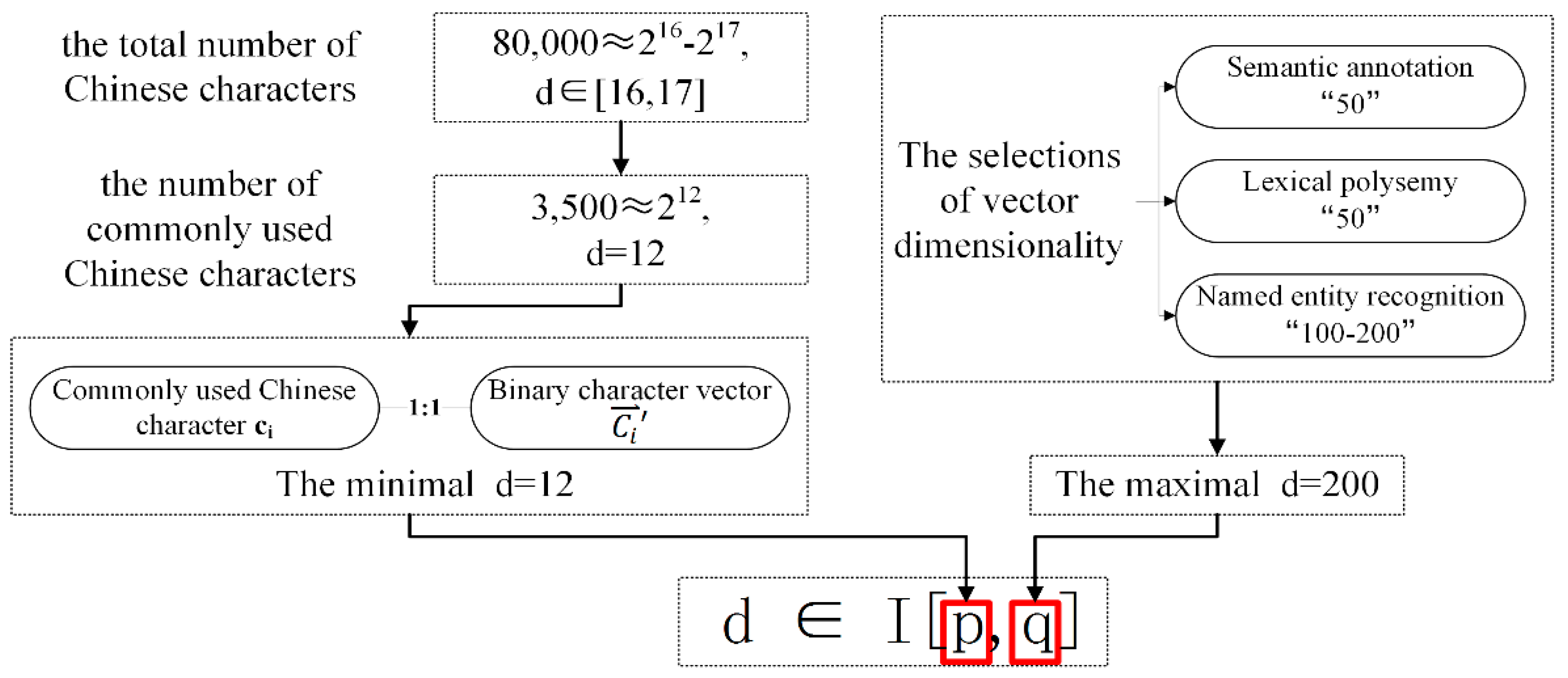
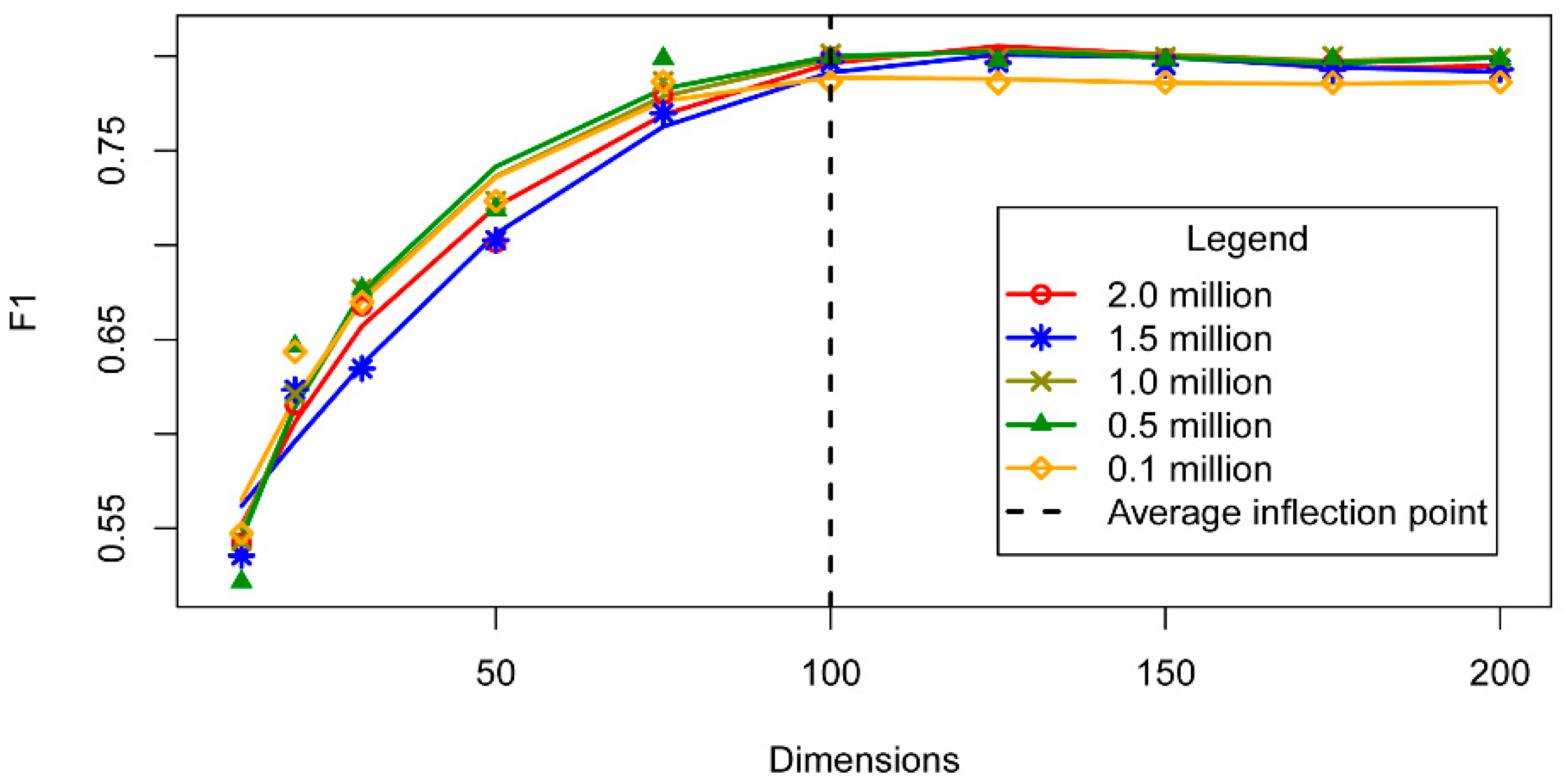
3.2. Vector Dimensionality
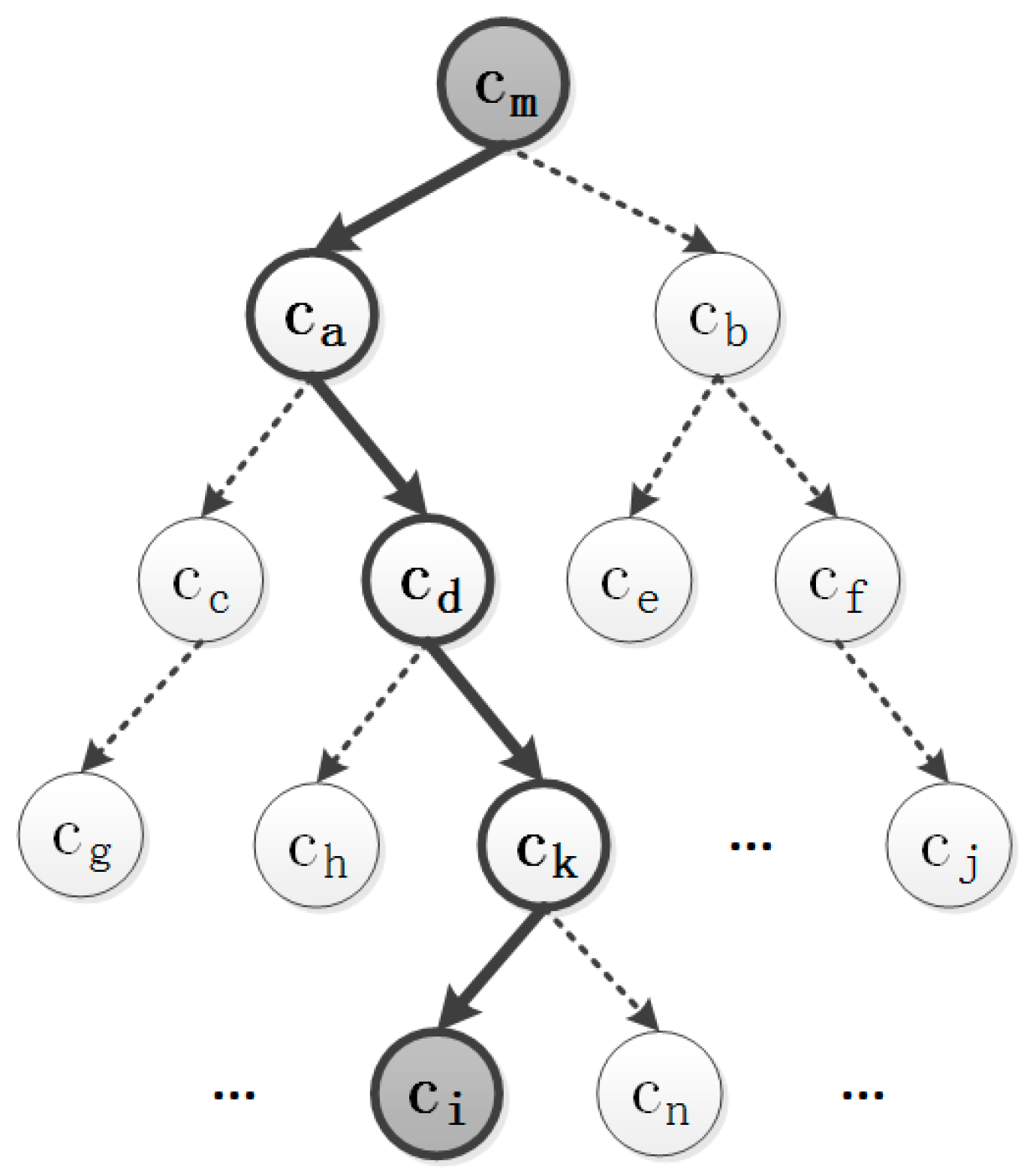
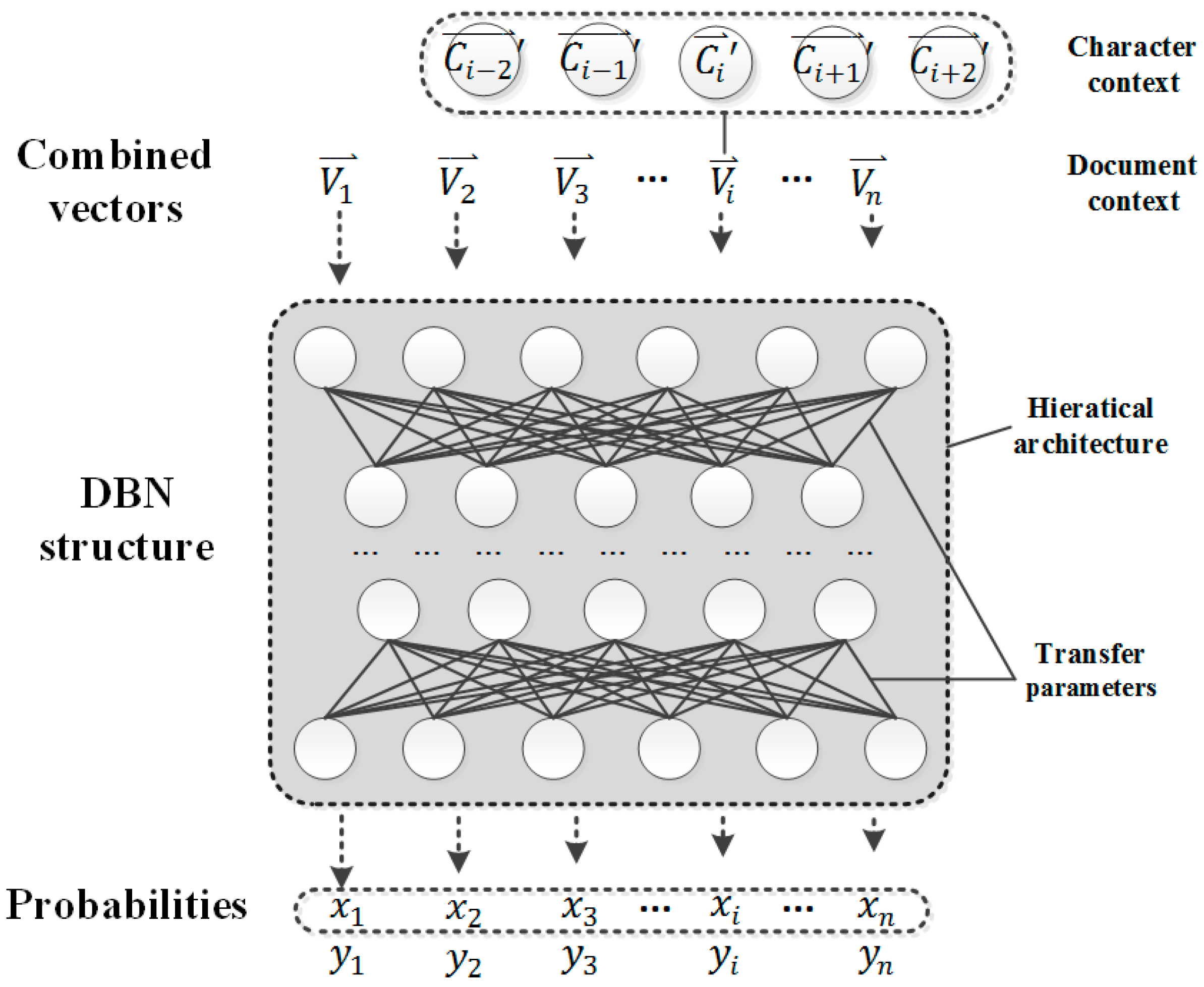
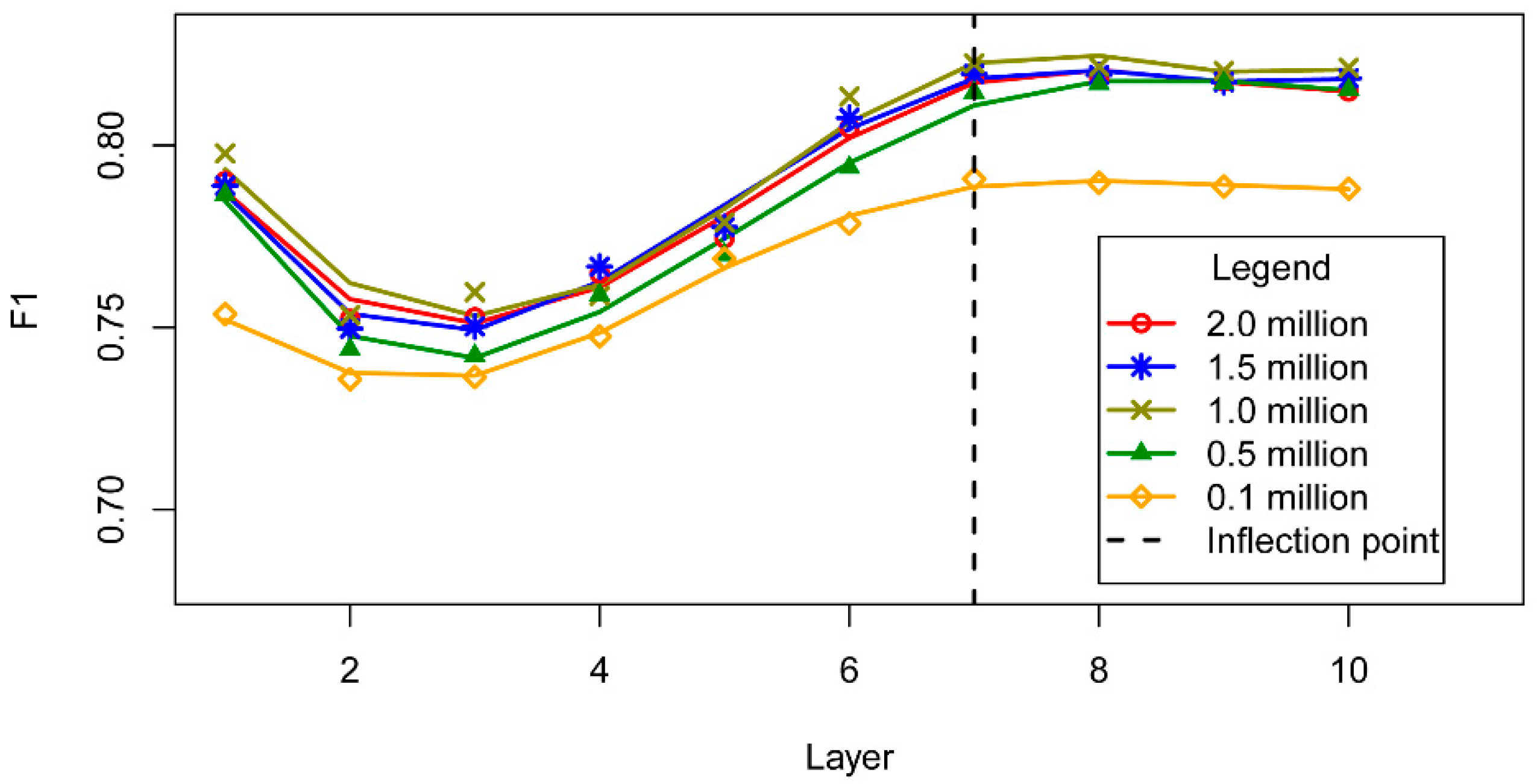
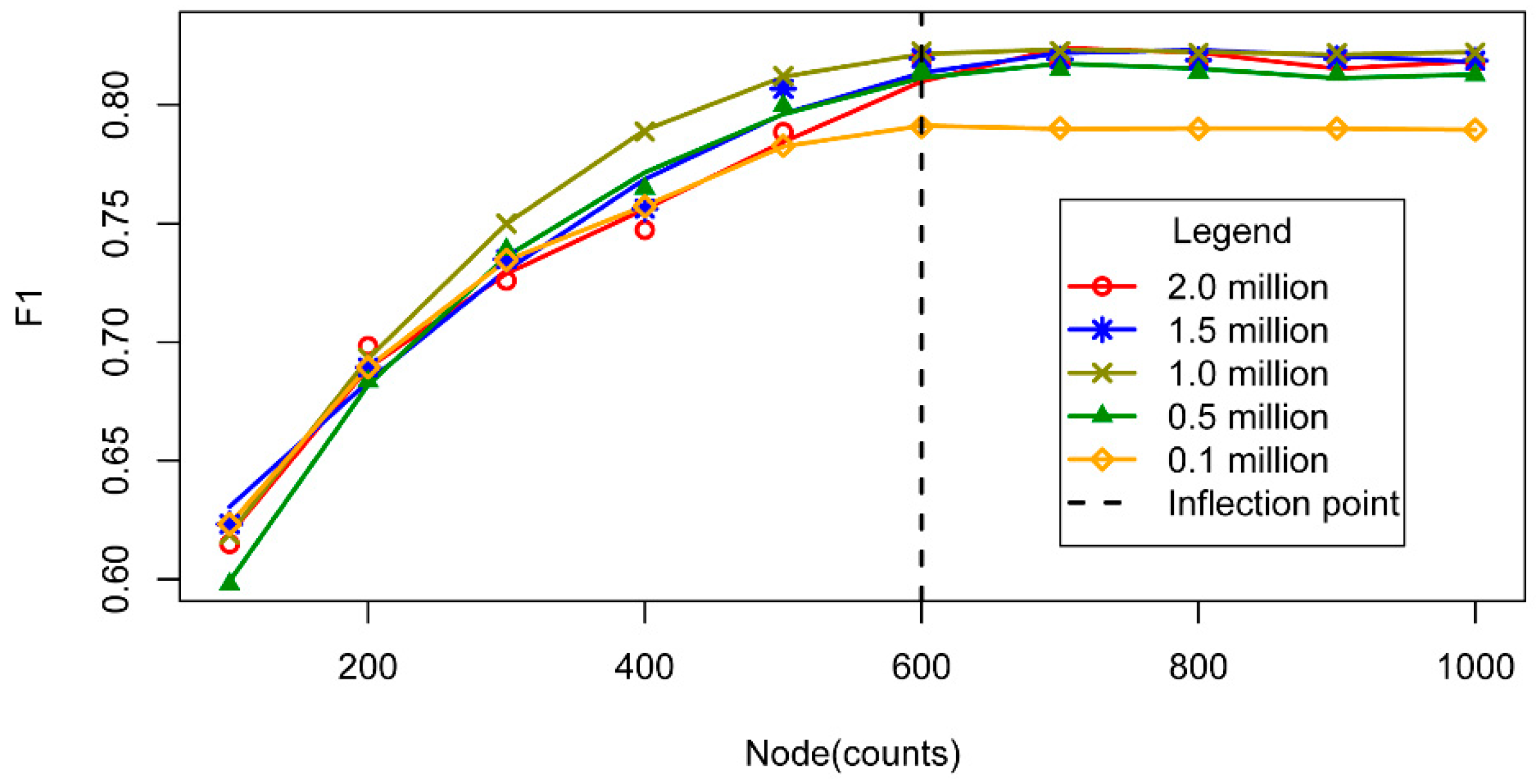
3.3. DBN Structure
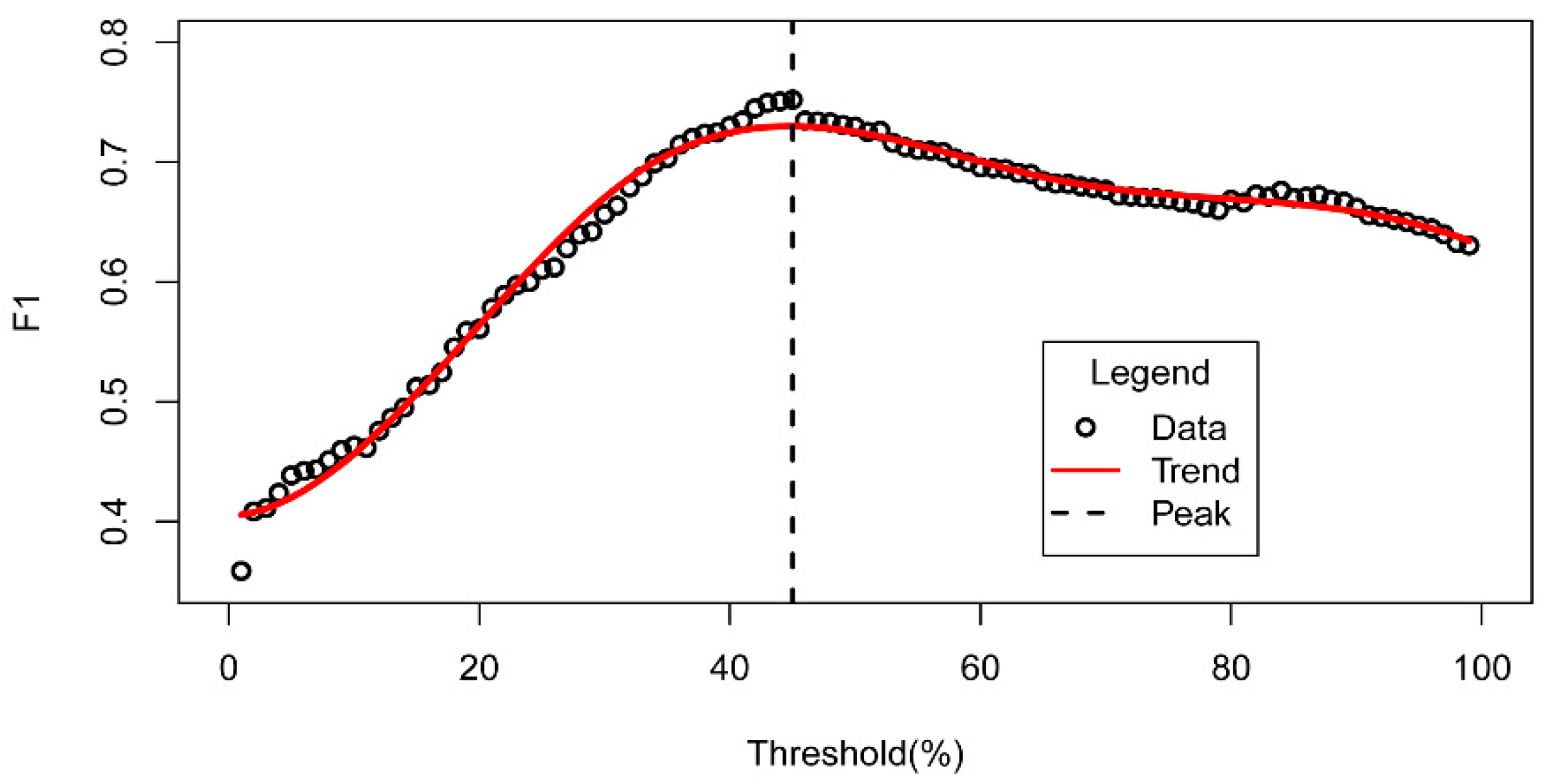
3.4. Probability Threshold
- : the set of characters in the text;
- : character i in the text;
- : toponym i;
- : the probability that character i belongs to a toponym component.
4. Experiments
4.1. Framework
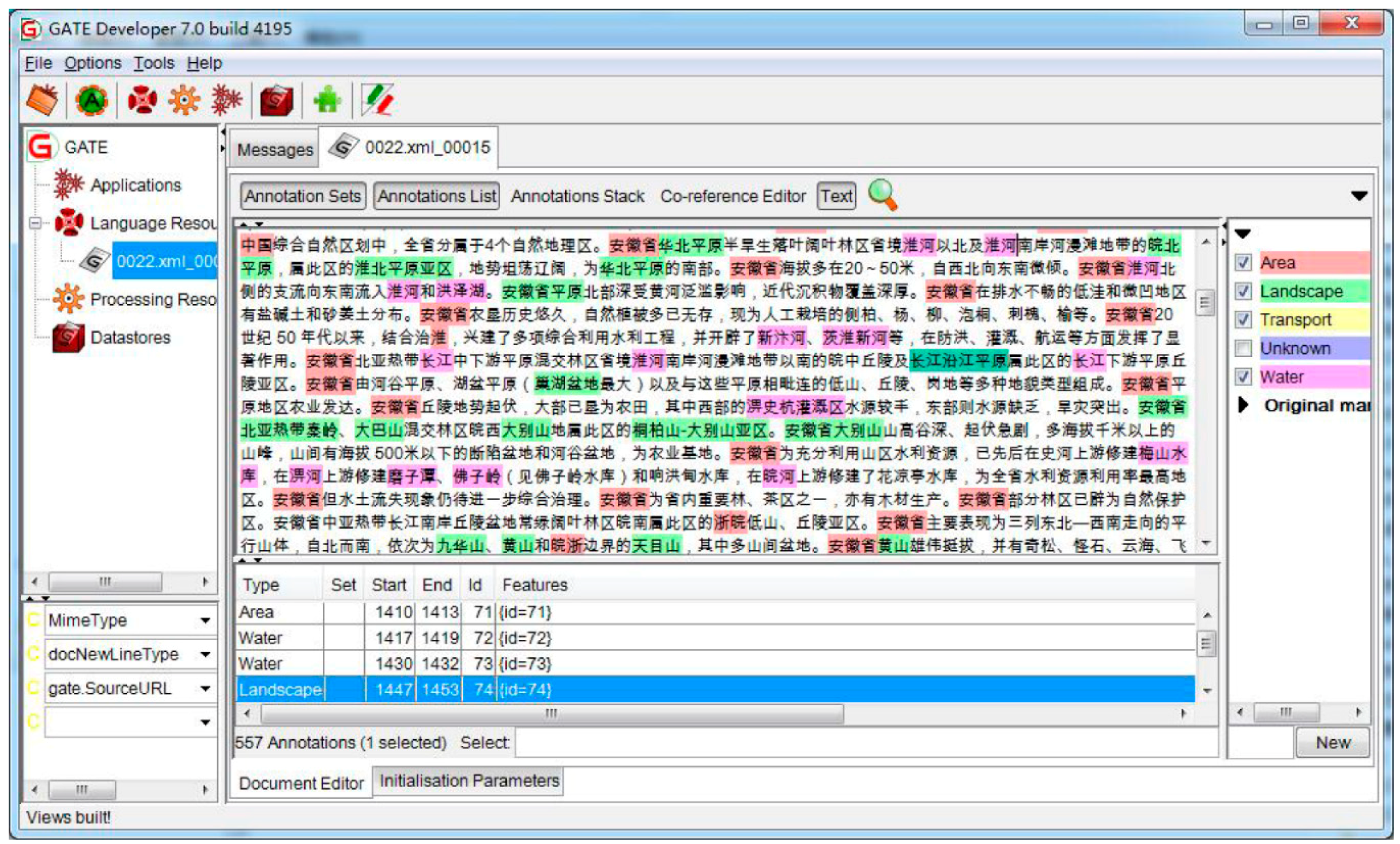
4.2. Datasets
4.3. Evaluation Measures
4.4. Implementation Details
5. Results
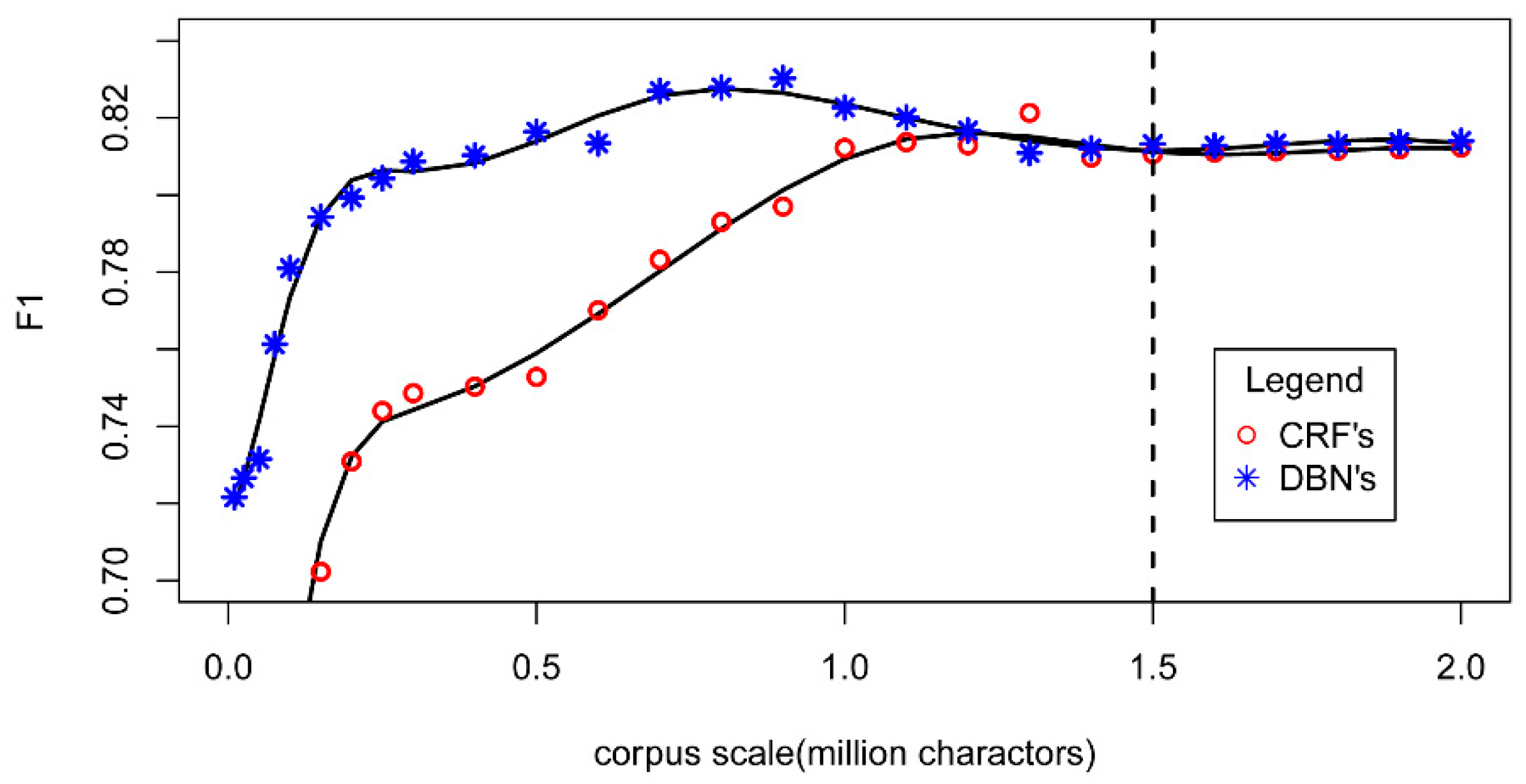
5.1. Word Representation Model
5.2. Effects of the Hyper-Parameters on the DBN Interpretation
5.3. Comparison with a CRF Model
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Leidner, J.L. Toponym resolution in text: Annotation, evaluation and applications of spatial grounding. ACM SIGIR Forum 2007, 41, 124–126. [Google Scholar] [CrossRef]
- Jones, C.B.; Purves, R.S. Geographical information retrieval. Int. J. Geogr. Inf. Sci. 2008, 22, 219–228. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Yu, K.; Lei, J.; Chen, Y.Q.; Wei, X. Deep Learning: Yesterday, Today, and Tomorrow. J. Comput. Res. Dev. 2013, 20, 1349. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. Comput. Sci. 2015, arXiv:1508.01991. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the HLT-NAACL, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Chen, Y.; Ouyang, Y.; Li, W.J.; Zheng, D.Q.; Zhao, T.J. Using deep belief nets for Chinese named entity categorization. In Proceedings of the 2010 Named Entities Workshop, Uppsala, Sweden, 16 July 2010; pp. 102–109. [Google Scholar]
- Jiang, M.Y.; Liang, Y.C.; Feng, X.Y.; Fan, X.J.; Pei, Z.L.; Xue, Y.; Guan, R.C. Text classification based on deep belief network and softmax regression. Neural Comput. Appl. 2016, 29, 61–70. [Google Scholar] [CrossRef]
- Liu, T. A Novel Text Classification Approach Based on Deep Belief Network. In Proceedings of the International Conference on Neural Information Processing, Sydney, Australia, 22–25 November 2010; pp. 314–321. [Google Scholar]
- Song, J.; Qin, S.J.; Zhang, P.Z. Chinese text categorization based on deep belief networks. In Proceedings of the 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), Okayama, Japan, 26–29 June 2016; pp. 1–5. [Google Scholar]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar]
- Melo, F.; Martins, B. Automated Geocoding of Textual Documents: A Survey of Current Approaches. Trans. Gis 2017, 21, 1–35. [Google Scholar] [CrossRef]
- Moschitti, A.; Basili, R. Complex linguistic features for text classification: A comprehensive study. In Proceedings of the European Conference on Information Retrieval, Sunderland, UK, 5–7 April 2004; pp. 181–196. [Google Scholar]
- Hong, S.; Chen, J.J. Research on the Chinese Topontm recognition method with two-layer CRF and rules combination. Comput. Appl. Softw. 2014, 11, 175–177. [Google Scholar]
- Névéol, A.; Grouin, C.; Tannier, X.; Hamon, T.; Kelly, L.; Goeuriot, L.; Zweigenbaum, P. CLEF eHealth Evaluation Lab 2015 Task 1b: Clinical Named Entity Recognition. Available online: http://ceur-ws.org/Vol-1391/inv-pap5-CR.pdf (accessed on 20 April 2018).
- Bikel, D.M.; Miller, S.; Schwartz, R.; Weischedel, R. Nymble: A high-performance learning name-finder. In Proceedings of the Proceedings of the Fifth Conference on Applied Natural Language Processing, Washington, DC, USA, 31 March–3 April 1997; pp. 194–201. [Google Scholar]
- Bick, E. A Named Entity Recognizer for Danish. In Proceedings of the Fourth International Conference on Language Resources and Evaluation, Lisbon, Portugal, 26–28 May 2004; pp. 305–308. [Google Scholar]
- Chen, W.L.; Zhang, Y.J.; Isahara, H. Chinese named entity recognition with conditional random fields. In Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing, Sydney, Australia, 22–23 July 2006; pp. 118–121. [Google Scholar]
- Appelt, D.E.; Hobbs, J.R.; Bear, J.; Israel, D.; Tyson, M. FASTUS: A finite-state processor for information extraction from real-world text. IJCAI 1993, 93, 1172–1178. [Google Scholar]
- Sarawagi, S.; Cohen, W.W. Semi-markov conditional random fields for information extraction. NIPS 2004, 17, 1185–1192. [Google Scholar]
- Gao, J.F.; Li, M.; Wu, A.D.; Huang, C.N. Chinese word segmentation and named entity recognition: A pragmatic approach. Comput. Linguist. 2005, 31, 531–574. [Google Scholar] [CrossRef]
- Turian, J.; Ratinov, L.; Bengio, Y. Word representations: A simple and general method for semi-supervised learning. In Proceedings of the Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 384–394. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Bengio, S.; Pereira, F.; Singer, Y.; Strelow, D. Group Sparse Coding. Adv. Neural Inf. Process. Syst. 2009, 22, 82–89. [Google Scholar]
- Morin, F.; Bengio, Y. Hierarchical probabilistic neural network language model. In Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics, Barbados, 6–8 January 2005; pp. 246–252. [Google Scholar]
- Mnih, A.; Hinton, G.E. A scalable hierarchical distributed language model. In Proceedings of the 21st International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–10 December 2008; pp. 1081–1088. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. Comput. Sci. 2013, arXiv:1301.3781. [Google Scholar]
- Curran, J.R.; Clark, S. Language independent NER using a maximum entropy tagger. In Proceedings of the Seventh Conference on Natural language learning at HLT-NAACL, Edmonton, AB, Canada, 27 May–1 June 2003; pp. 164–167. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Mccallum, A.; Li, W. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In Proceedings of the Seventh Conference on Natural language learning at HLT-NAACL, Edmonton, AB, Canada, 27 May–1 June 2003; pp. 188–191. [Google Scholar]
- Zhang, C.J. Interpretation of Event Spatio-temporal and Attribute Information in Chinese Text. Acta Geod. Cartogr. Sin. 2015, 44, 590. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Yan, Y.; Yin, X.C.; Li, S.J.; Yang, M.Y.; Hao, H.W. Learning document semantic representation with hybrid deep belief network. Comput. Intell. Neurosci. 2015, 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Bordes, A.; Chopra, S.; Weston, J. Question answering with subgraph embeddings. arXiv, 2014; arXiv:1406.3676. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 3104–3112. [Google Scholar]
- Hinton, G.E. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Hinton, G.E.; Sejnowski, T.J. Learning and Relearning in Boltzmann Machines; MIT Press: Cambridge, MA, USA, 1986; pp. 45–76. [Google Scholar]
- Mateescu, A. On Context-Sensitive Grammars; Springer: Berlin/Heidelberg, Germany, 2004; pp. 139–161. [Google Scholar]
- Rong, X. word2vec Parameter Learning Explained. Comput. Sci. 2014, arXiv:1411.2738. [Google Scholar]
- Goldberg, Y.; Levy, O. word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. Comput. Sci. 2014, arXiv:1402.3722. [Google Scholar]
- Huang, E.H.; Socher, R.; Manning, C.D.; Ng, A.Y. Improving word representations via global context and multiple word prototypes. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju, Korea, 8–14 July 2012; pp. 873–882. [Google Scholar]
- Pan, G.Y.; Chai, W.; Qiao, J.F. Calculation for depth of deep belief network. Control. Decis. 2015, 30, 256–260. [Google Scholar]
- Le Roux, N.; Bengio, Y. Representational power of restricted Boltzmann machines and deep belief networks. Neural Comput. 2008, 20, 1631–1649. [Google Scholar] [CrossRef] [PubMed]
- Tariyal, S.; Majumdar, A.; Singh, R.; Vatsa, M. Greedy Deep Dictionary Learning. arXiv, 2016; arXiv:1602.00203. [Google Scholar]
- Thiele, J.; Diehl, P.; Cook, M. A wake-sleep algorithm for recurrent, spiking neural networks. arXiv, 2017; arXiv:1703.06290. [Google Scholar]
- Hinton, G.E.; Dayan, P.; Frey, B.; Neal, R.M. The wake-sleep algorithm for self-organizing neural networks. Science 1995, 268, 1158–1161. [Google Scholar] [CrossRef] [PubMed]
- Leveling, J.; Hartrumpf, S. On metonymy recognition for geographic information retrieval. Int. J. Geogr. Inf. Sci. 2008, 22, 289–299. [Google Scholar] [CrossRef]
- Stokes, N.; Li, Y.; Moffat, A.; Rong, J. An empirical study of the effects of NLP components on Geographic IR performance. Int. J. Geogr. Inf. Sci. 2008, 22, 247–264. [Google Scholar] [CrossRef]
- Zong, C.Q. Statistical Natural Language Processing; Tsinghua University Publisher: Beijing, China, 2008. [Google Scholar]
- Zhang, X.Y.; Zhu, S.N.; Zhang, C.J. Annotation of Geographical Named Entitiesin Chinese Text. Acta Geod. Cartogr. Sin. 2012, 41, 115–120. [Google Scholar]
- CLDC. Chinese Toponym Annotation Corpus. Available online: http://www.chineseldc.org/resource_list.php?begin=60&count=20 (accessed on 20 April 2018).
- Hamish, C.; Yorick, W.; Robert, J.G. GATE: A General Architecture for Text Engineering. Comput. Hum. 2002, 36, 223–254. [Google Scholar]
- Yeh, A. More accurate tests for the statistical significance of result differences. In Proceedings of the 18th Conference on Computational Linguistics, Saarbrücken, Germany, 31 July–4 August 2012; pp. 947–953. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Main Type | Number of Toponyms | Number of Character in Each Toponym | Toponym Number | Proportion (%) |
|---|---|---|---|---|
| area | 56954 | 1 | 5476 | 4.36 |
| 2 | 37482 | 29.84 | ||
| water | 25377 | 3 | 31842 | 25.35 |
| 4 | 12373 | 9.85 | ||
| 5 | 12536 | 9.98 | ||
| landscape | 20518 | 6 | 8503 | 6.77 |
| 7 | 6241 | 4.97 | ||
| transport | 17004 | 8 | 6645 | 5.29 |
| 9+ | 4384 | 3.49 |
| Group | Word Representation Model | DBN Structure | Training Dataset | Testing Dataset | Precision (P) | Recall (R) | F1 Value |
|---|---|---|---|---|---|---|---|
| 1 | One-Hot | Chen’s DBN | ECCG | ECCG | 0.7758 | 0.5921 | 0.6716 |
| 2 | TF-IDF | Chen’s DBN | ECCG | ECCG | 0.7476 | 0.7249 | 0.7360 |
| 3 | Skip-Gram | Chen’s DBN | ECCG | ECCG | 0.8056 | 0.6843 | 0.7400 |
| 4 | One-Hot | Our DBN (See Section 5.2) | ECCG | ECCG | 0.7124 | 0.7131 | 0.7127 |
| 5 | TF-IDF | Our DBN (See Section 5.2) | ECCG | ECCG | 0.7594 | 0.7621 | 0.7607 |
| 6 | Skip-Gram | Our DBN (See Section 5.2) | ECCG | ECCG | 0.8146 | 0.7749 | 0.7943 |
| Group | Approach | Training Dataset | Testing Dataset | Precision (P) | Recall (R) | F1 Value |
|---|---|---|---|---|---|---|
| 1 | Chen’s | ACE 2004 | ACE 2004 | 0.7758 | 0.5921 | 0.6716 |
| Proposed | ACE 2004 | ACE 2004 | 0.8534 | 0.8211 | 0.8369 | |
| 2 | Chen’s | ECCG | ECCG | 0.7476 | 0.7249 | 0.7361 |
| Proposed | ECCG | ECCG | 0.8146 | 0.7749 | 0.7943 | |
| 3 | Chen’s | ECCG | ACE 2004 | 0.8124 | 0.7432 | 0.7763 |
| Proposed | ECCG | ACE 2004 | 0.8811 | 0.8457 | 0.8630 |
| Approach | Corpus | Number of Annotated Toponyms | Number of Recognized Toponyms | Number of Different Recognitions | Proportion (%) |
|---|---|---|---|---|---|
| Chen’s | ECCG | 123921 | 92643 | 2131 | 2.30 |
| Proposed | ECCG | 123921 | 100946 | 2131 | 2.11 |
| Feature ID | Types | Feature Description |
|---|---|---|
| 1 | Character feature | Ci−2, Ci−1, Ci, Ci+1, Ci−2 |
| 2 | Character feature | Ci−2Ci−1, Ci−1Ci, CiCi+1, Ci+1Ci+2 |
| 3 | Context feature | The frequency of Ci in the paragraph |
| 4 | Syntax feature | The part-of-speech of Ci |
| 5 | Dictionary feature | Y or N (whether Ci belongs to the commonly used trigger words) |
| 6 | Dictionary feature | Y or N (whether Ci belongs to the commonly used characters in toponyms) |
| Model | Precision (P) | Recall (R) | F1 Value |
|---|---|---|---|
| DBN | 0.8146 | 0.7749 | 0.7943 |
| CRF | 0.8198 | 0.7634 | 0.7906 |
| Combined | 0.7901 | 0.9375 | 0.8575 |
| ID | Main type of Recognition Errors | CRF | DBN | Relevant Linguistic Features | Corresponding Linguistic Feature in the CRF Model (Details in Table 5) |
|---|---|---|---|---|---|
| 1 | abbreviation descriptions | × | √ | Part of speech, commonly used characters, syntax (neighborhood characters) | Feature 4 Feature 6 Feature 1 & Feature 2 |
| 2 | long toponym descriptions | × | √ | Part of speech, Toponym boundary characters (adjacent character combination) | Feature 4 Feature 2 |
| 3 | continuous toponyms | √ | × | Part of speech | Feature 4 |
| 4 | trigger character descriptions | √ | × | Trigger characters | Feature 5 |
| Type | Description | Number of Recognized Toponyms | Proportion (%) |
|---|---|---|---|
| Same recognitions | Both correct | 13065 | 69.69 |
| Both incorrect | 1172 | 6.25 | |
| Different recognitions | Correct in DBN | 2207 | 11.77 |
| Correct in CRF | 2304 | 12.29 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Zhang, X.; Ye, P.; Du, M. Deep Belief Networks Based Toponym Recognition for Chinese Text. ISPRS Int. J. Geo-Inf. 2018, 7, 217. https://doi.org/10.3390/ijgi7060217
Wang S, Zhang X, Ye P, Du M. Deep Belief Networks Based Toponym Recognition for Chinese Text. ISPRS International Journal of Geo-Information. 2018; 7(6):217. https://doi.org/10.3390/ijgi7060217
Chicago/Turabian StyleWang, Shu, Xueying Zhang, Peng Ye, and Mi Du. 2018. "Deep Belief Networks Based Toponym Recognition for Chinese Text" ISPRS International Journal of Geo-Information 7, no. 6: 217. https://doi.org/10.3390/ijgi7060217
APA StyleWang, S., Zhang, X., Ye, P., & Du, M. (2018). Deep Belief Networks Based Toponym Recognition for Chinese Text. ISPRS International Journal of Geo-Information, 7(6), 217. https://doi.org/10.3390/ijgi7060217