A Graph Database Model for Knowledge Extracted from Place Descriptions



Abstract
1. Introduction
- The identification of eight types of information that are either embedded in place descriptions or in external context and have not been captured by the original place graph model.
- An extended place graph model that represents such information and enables future tracing as well as querying.
- The implementation of the extended place graph into a graph database management system, which allows operations including querying, visualizing, and mapping.
- The demonstration of how the extended model overcomes limitations of the original place graph in georeferencing, reasoning, and querying tasks based on three experiments.
2. Related Work
2.1. Place as a Cognitive Concept
2.2. Place Models from an Information System Perspective
2.3. Modelling Place Descriptions
3. Extending the Place Graph Model
3.1. Information not Captured in the Original Place Graph Model
3.1.1. Place Semantics and Characteristics
3.1.2. Places and Relationships from Discourse and Their Sequential Order of Appearance
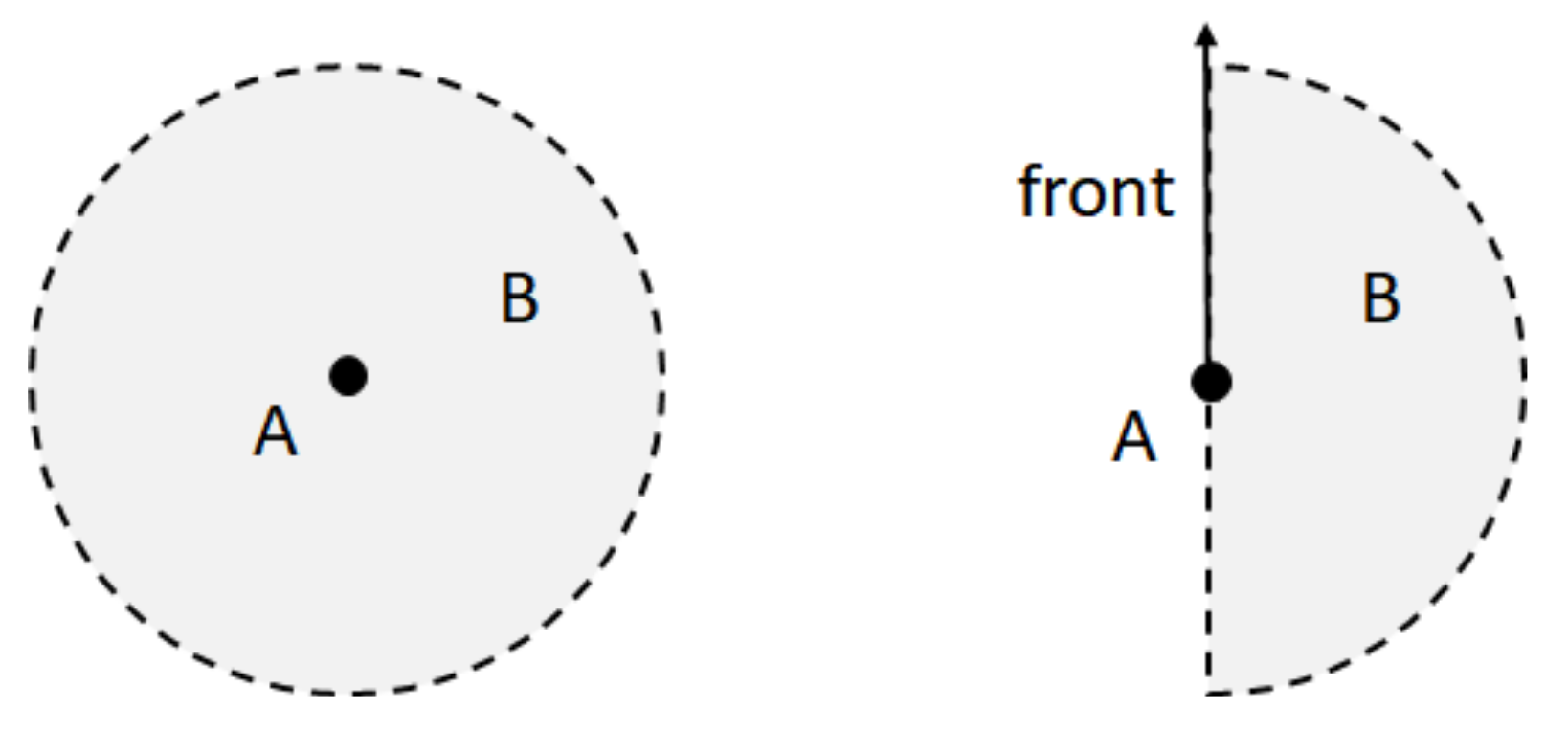
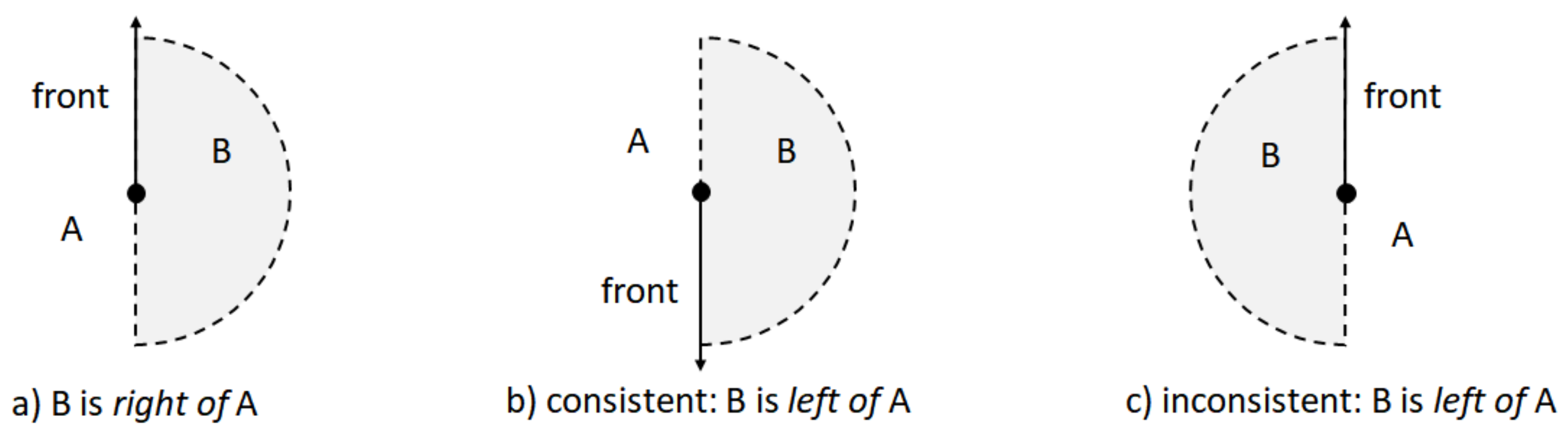
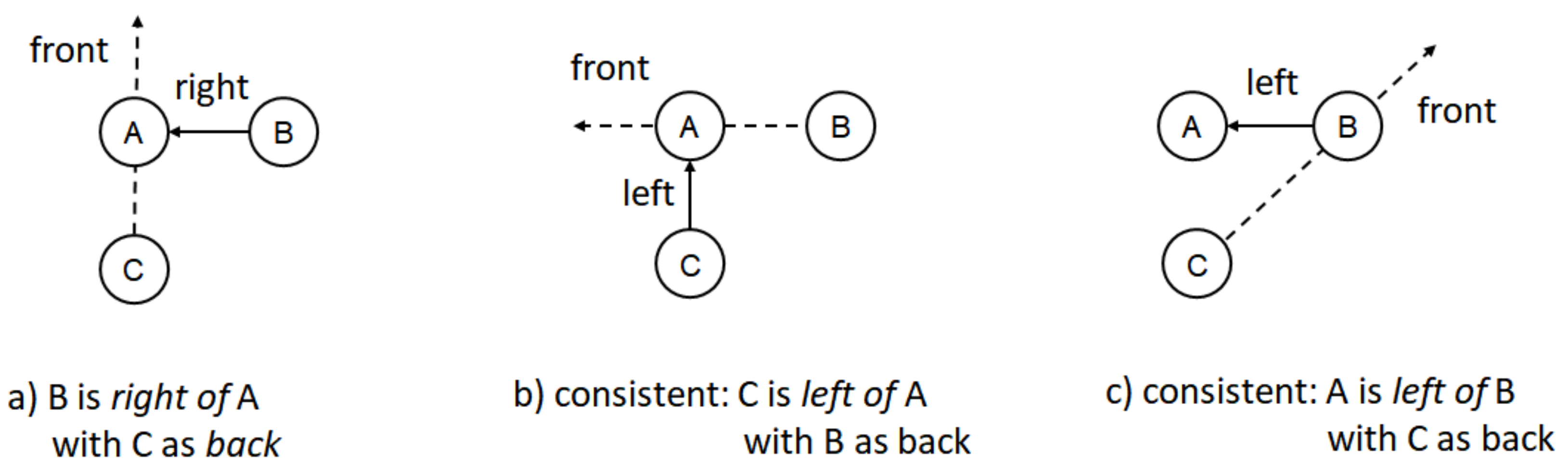
3.1.3. Reference Frame and Direction
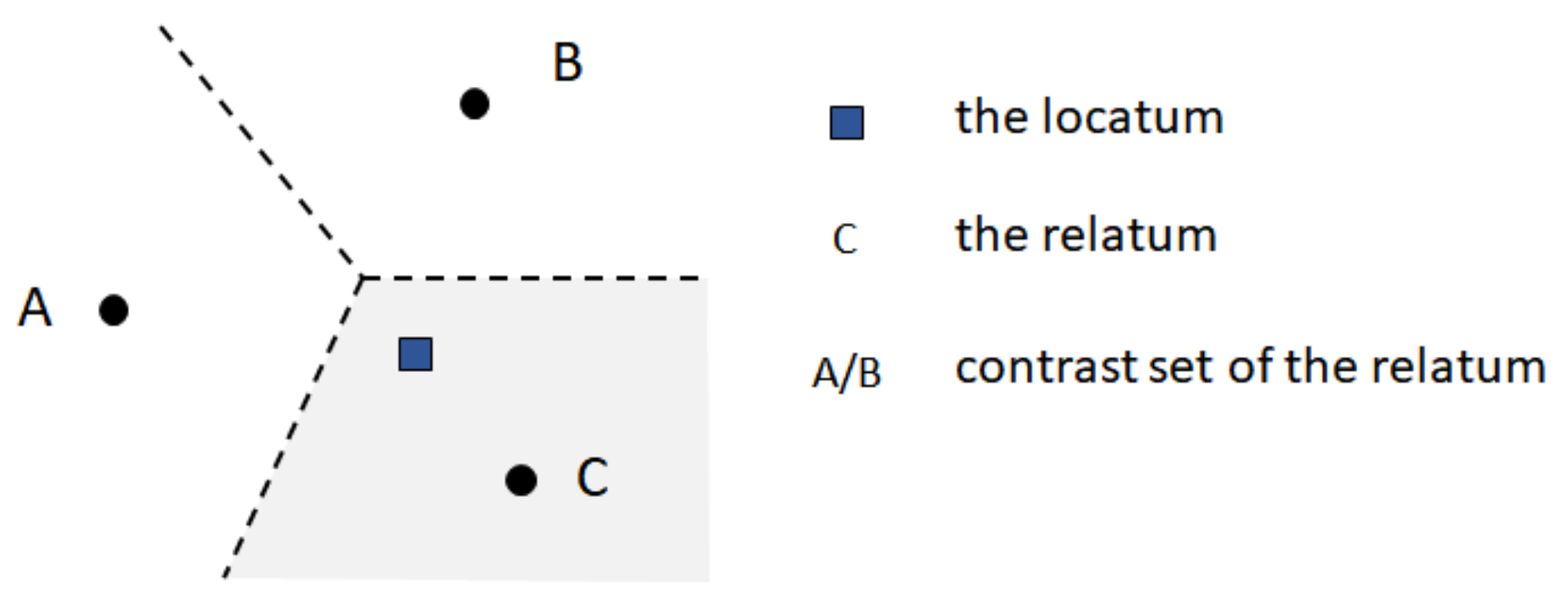
3.1.4. Non-Binary Relationships
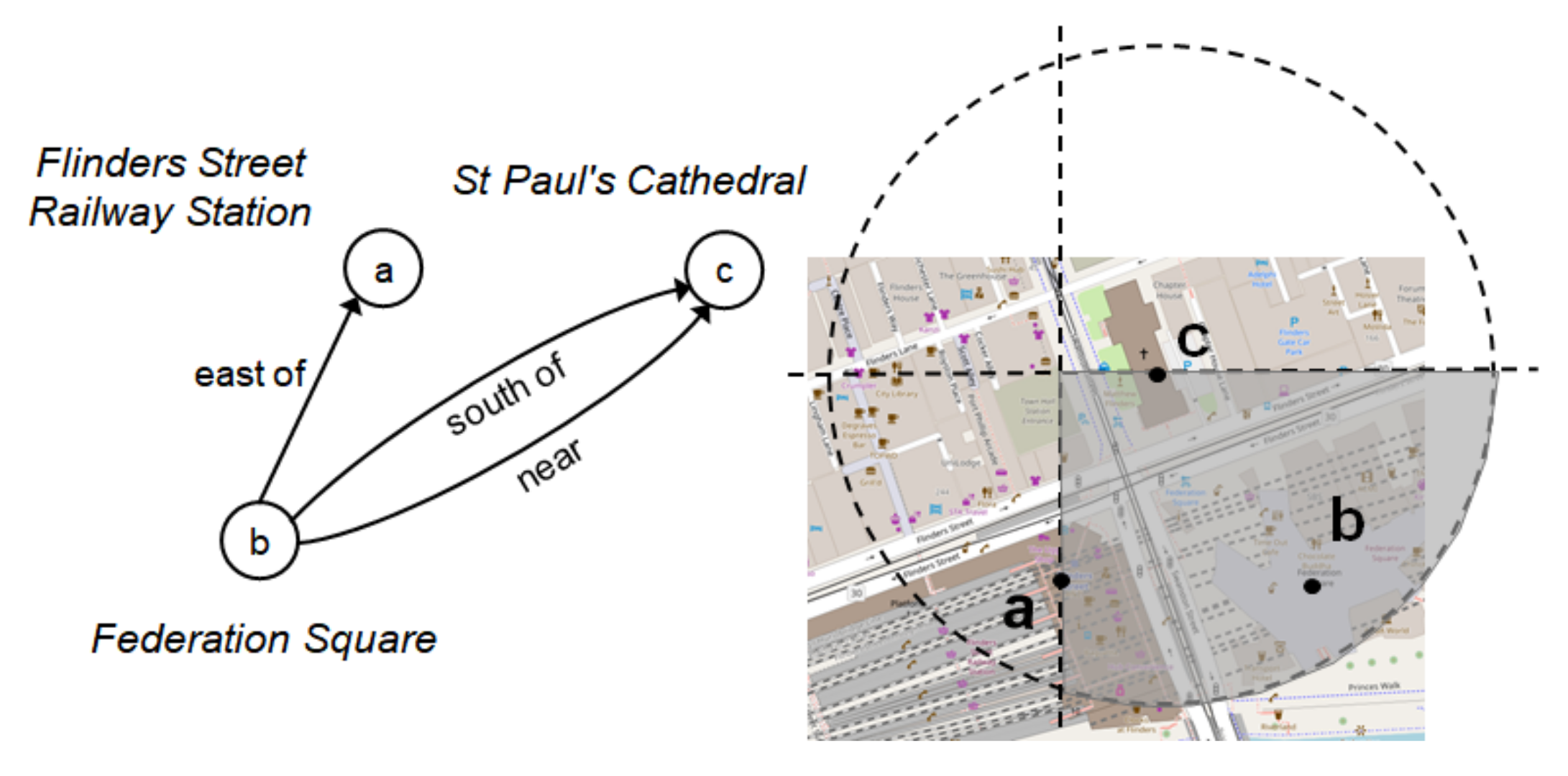
3.1.5. Number of Occurrences of Place References and Spatial Relationships
3.1.6. Conceptualization of Places
3.1.7. Route and Accessibility
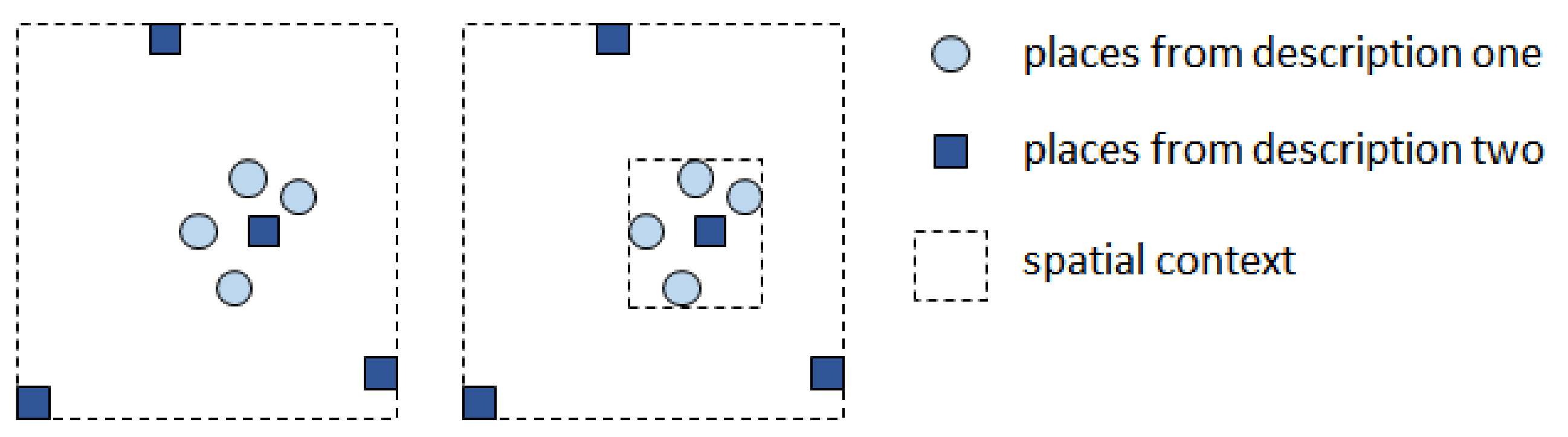
3.1.8. Description Context and Source Context
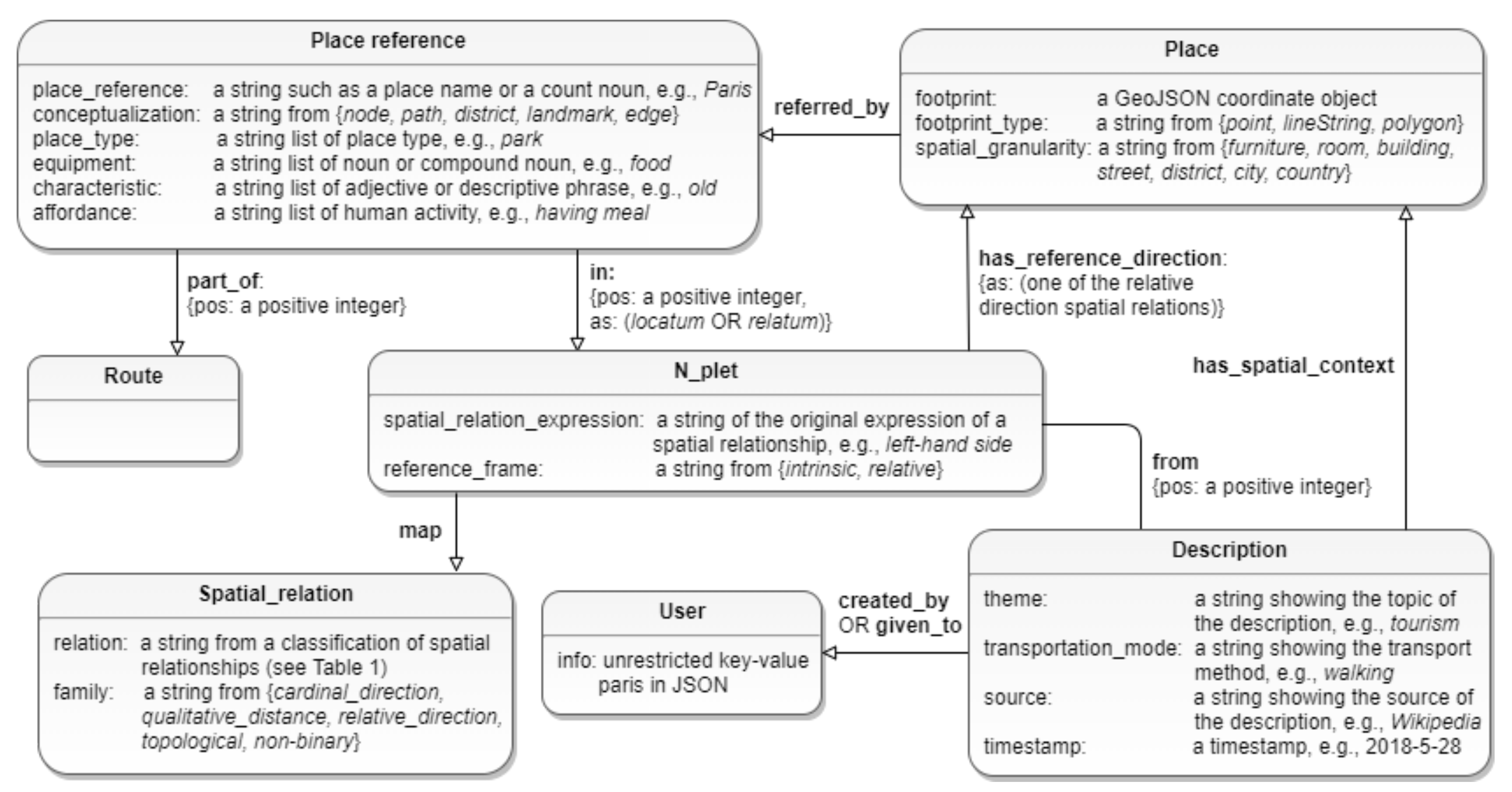
3.2. The Extended Place Graph Database Model
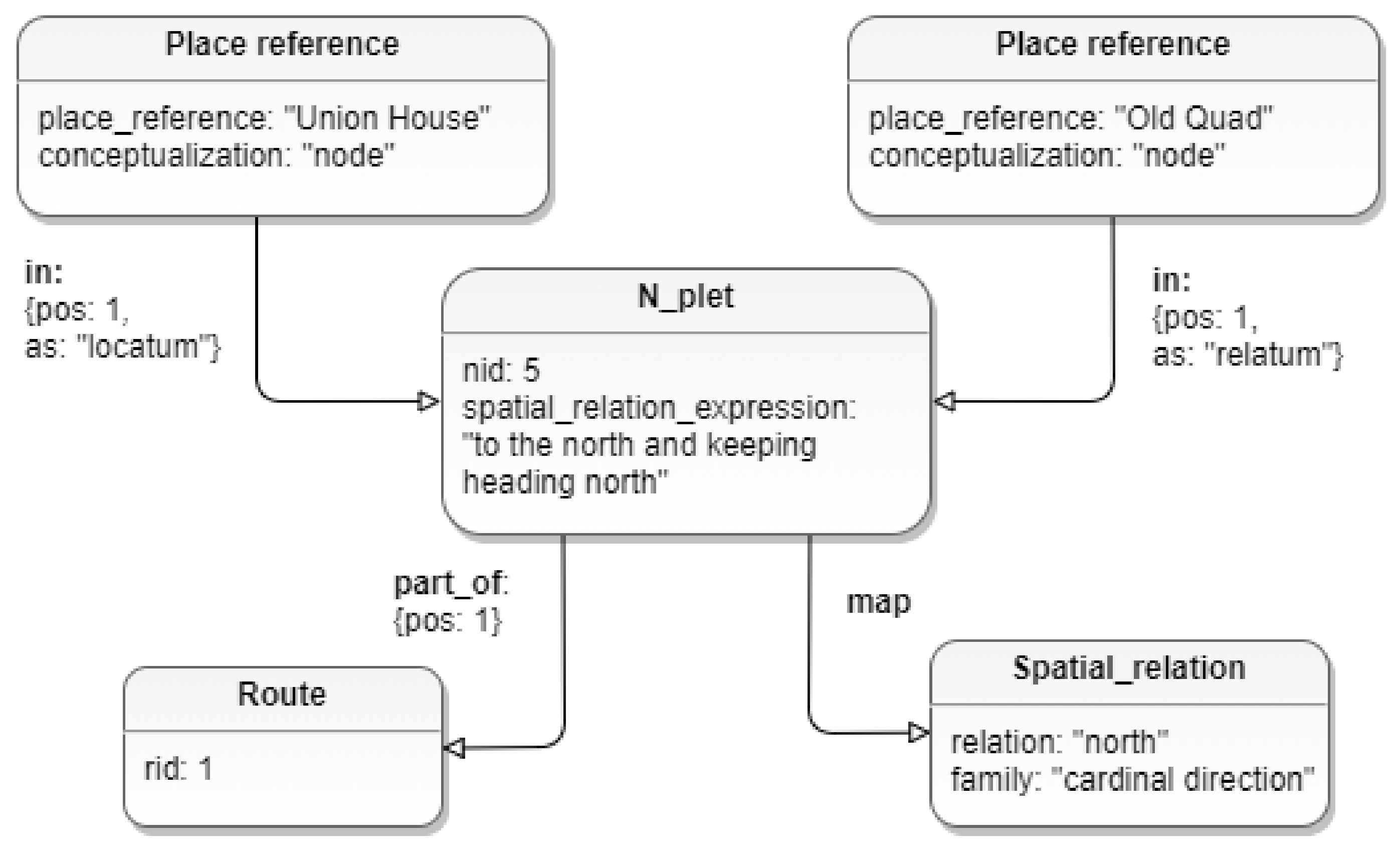
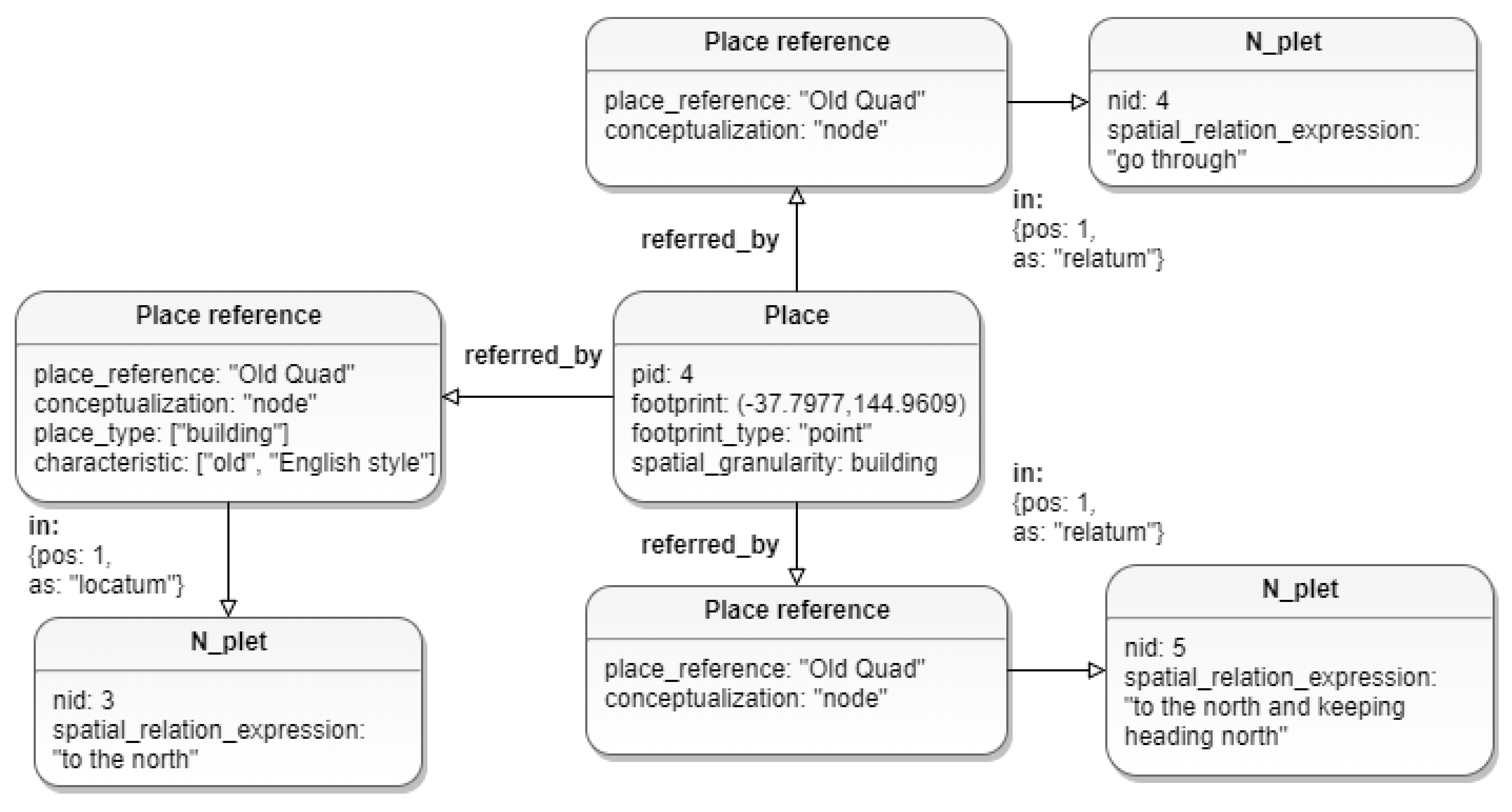
3.2.1. Place Reference Node
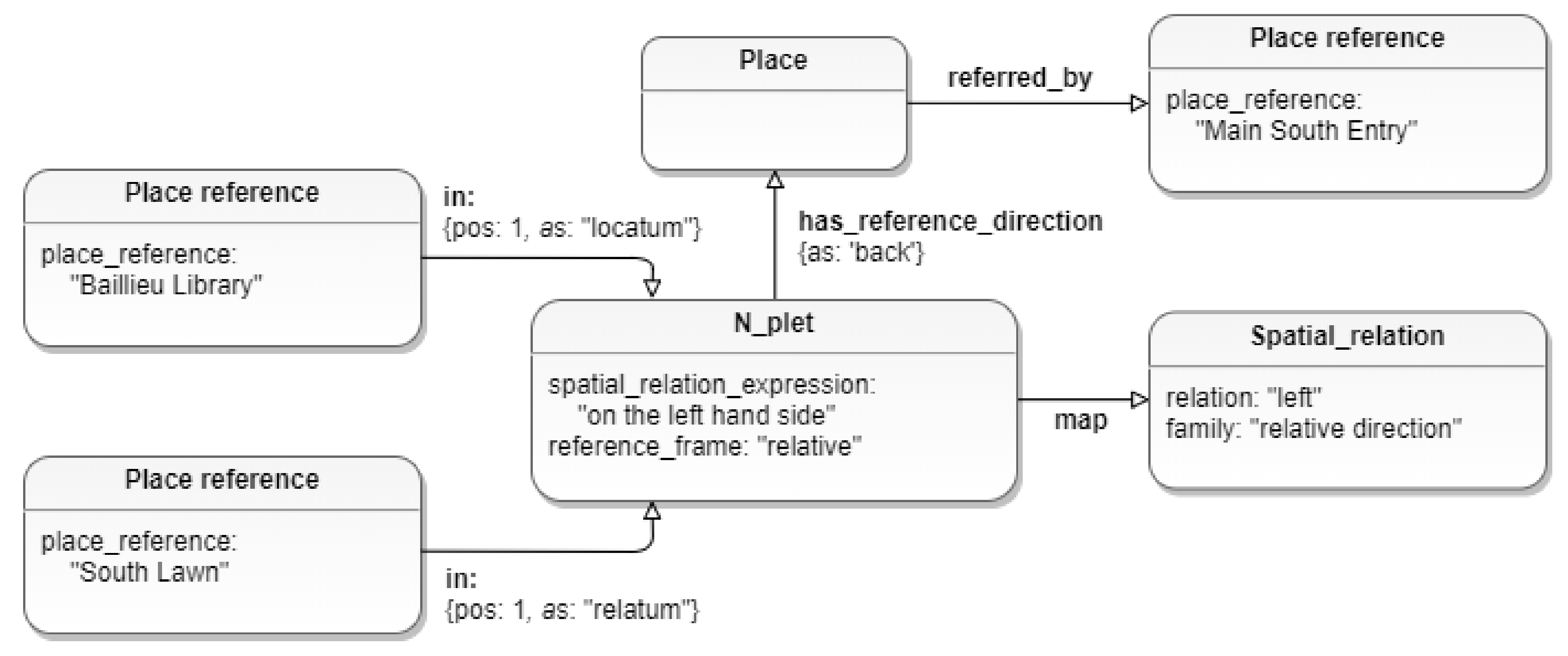
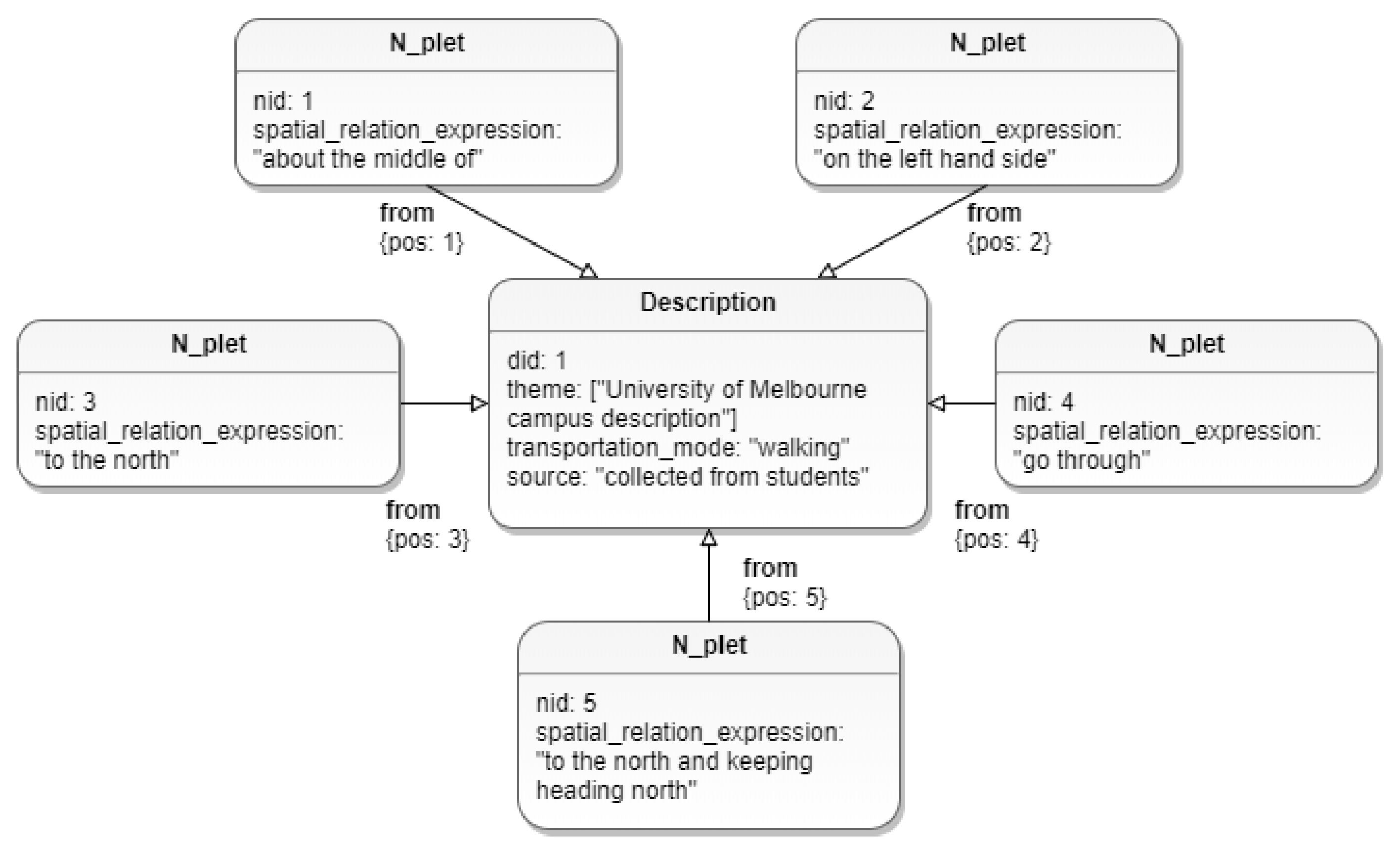
3.2.2. N-Plet Node
“… coming from the Main South Entry, the Baillieu Library will be on the left hand side of the South Lawn …”
3.2.3. Place Node
3.2.4. Route Node
3.2.5. Spatial Relation Node
3.2.6. Description Node
3.2.7. User Node
3.3. Summary
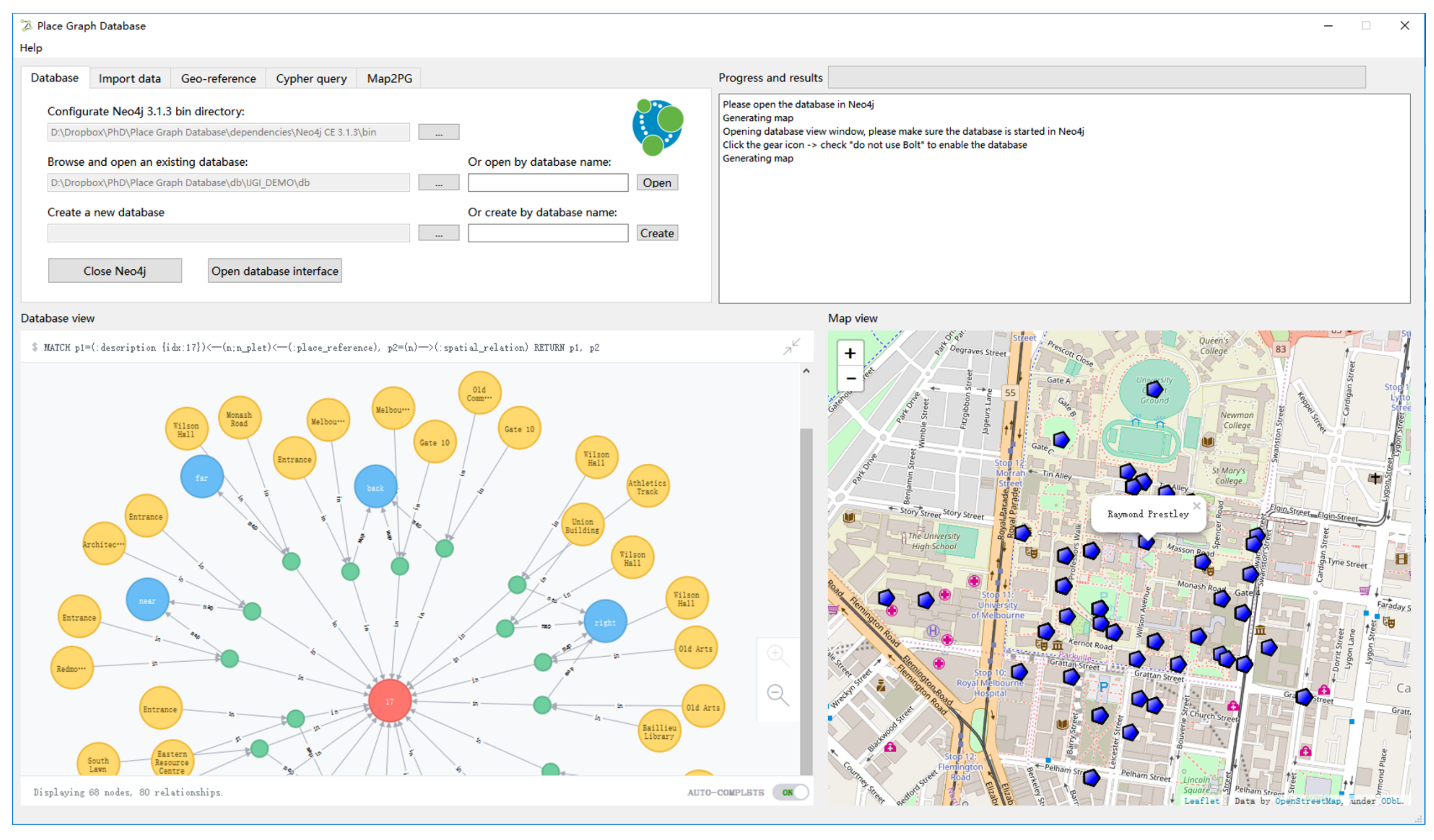
4. Implementation and Experiments
4.1. Data Overview and Construction of the Test Place Graph Database
“… If you go into the Old Quad, you will reach a square courtyard and at the back of the courtyard. You can either turn left to go to the Arts Faculty Building, or turn right into the John Medley Building and Wilson Hall. Raymond Priestly Building is the open aired ground area which is in front of Wilson Hall that is adjacent to it. Towards North, which is when you turn left when exiting the Old Quad, you will see Union House where there are shops selling foods. If you continue walk along the road on the right side where you’re facing Union House, you can see the Beaurepaire and Swimming Pool. There will also be a sport tracks and university oval behind it …”
{"descriptions": [
…
{"did": 1,
"nplets":
[{"nid": 2,
"locatum␣reference": "Baillieu Library",
"spatial␣relation␣expression": "on the left hand side",
"relatum␣reference": "South Lawn",
"reference␣frame": "relative",
"reference␣direction": ["Main South Entry", "back"],
"relation␣map": ["left"],
…},
{…}, …]
},
{…}, …
]}
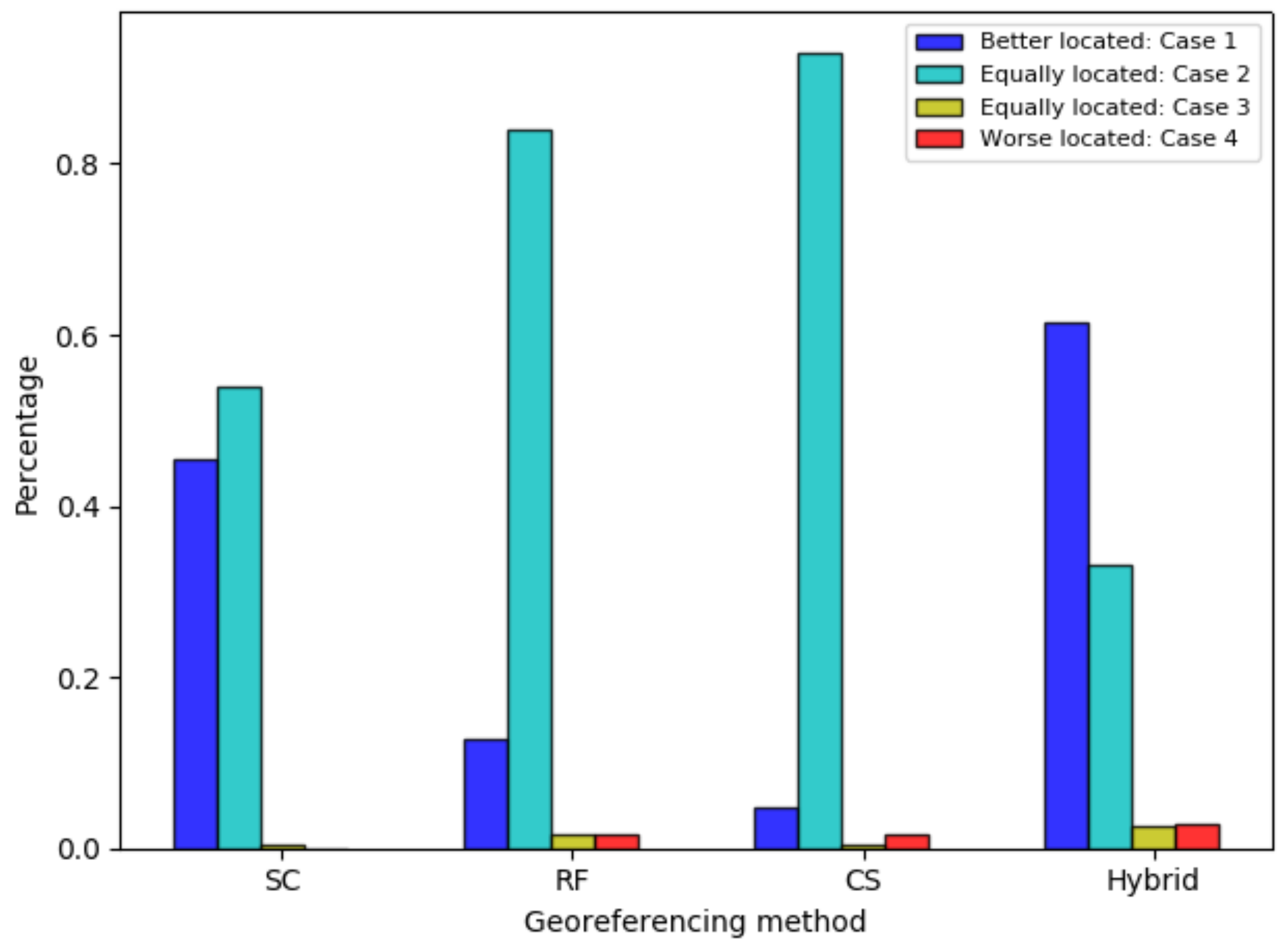
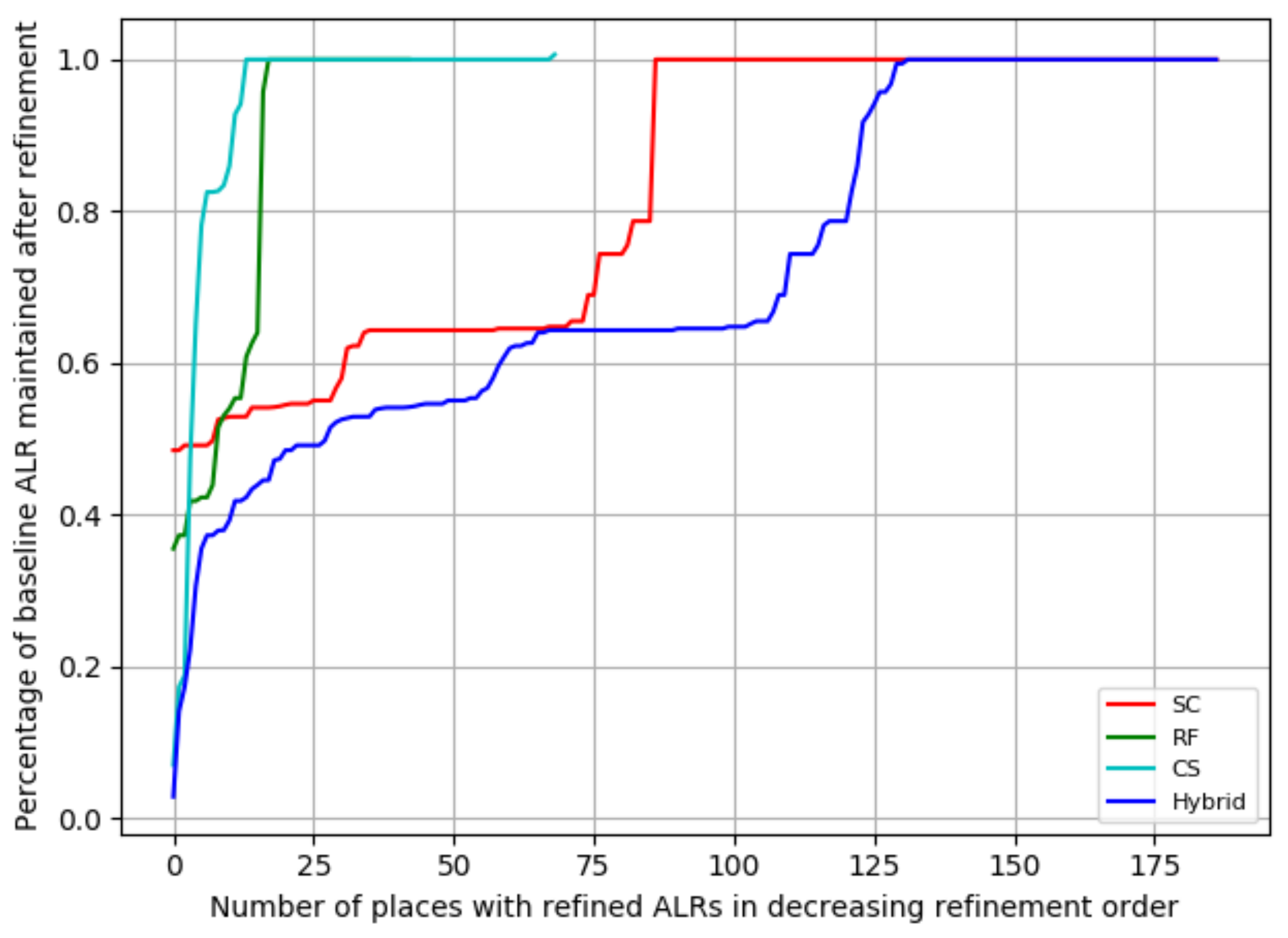
4.2. Experiment I: Locating Places Without Gazetteered References
4.3. Experiment II: Relational Consistency Reasoning Using Reference Direction Information
| Algorithm 1 Consistency reasoning of directional relationships. |
| Input: Output:
|
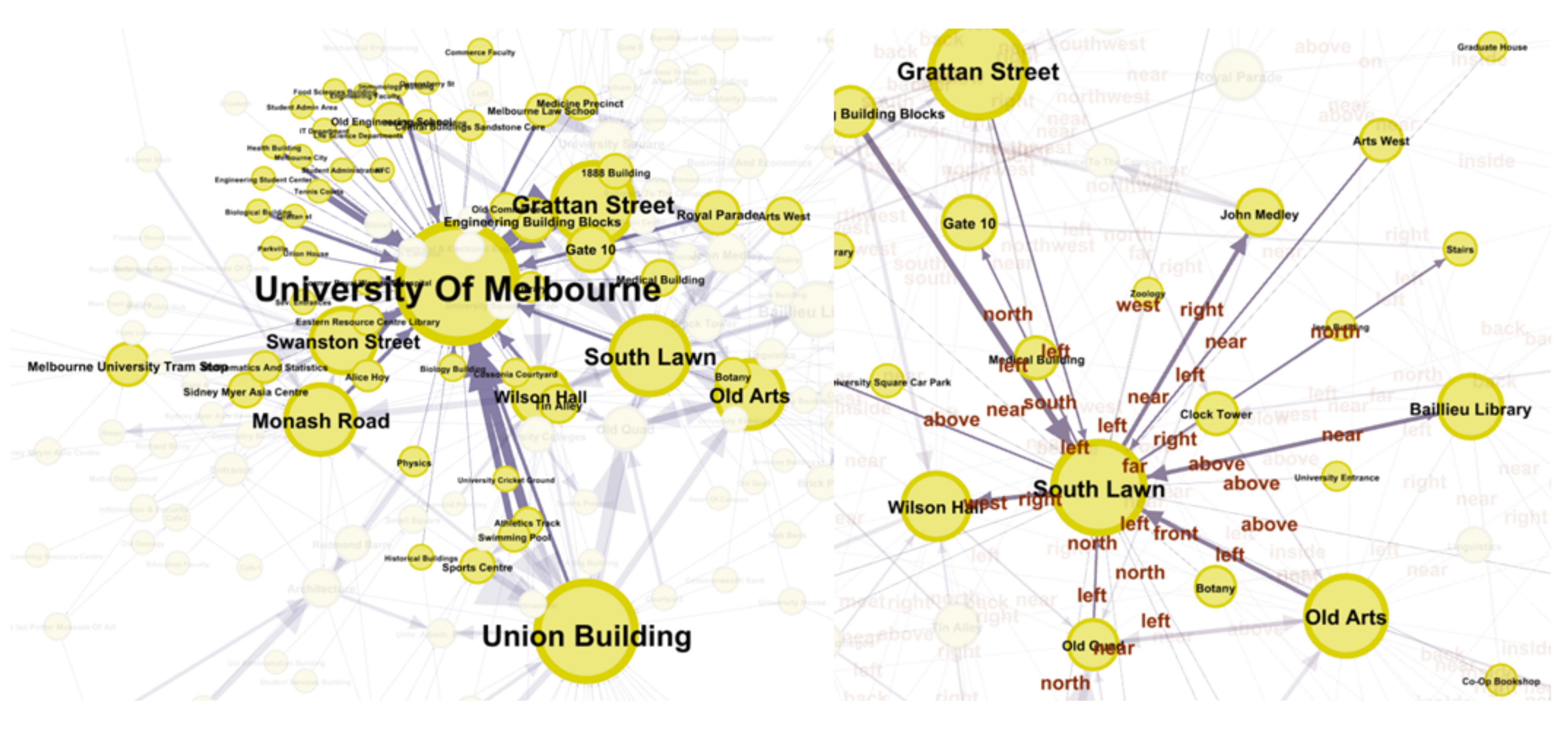
4.4. Experiment III: Spatial Knowledge Querying
- Find the most frequently referred to relatum (landmarks).
- Find places that are most frequently linked to a specific place by spatial relations (place relevance by co-occurrence).
- Find the most frequent paths of length three, consisting of only directional relationships, i.e., place A-relation a->place B-relation b->place C (prominent routes)
MATCH (p:place)-->(:place_reference)-[r {as: ’relatum’}]->(:n_plet),
RETURN p, count(r) AS c
ORDER BY c DESC
MATCH (p:place)-[*2]->(n:n_plet)<--({place_reference: ’Alice Hoy’})<--(:place)
RETURN p, count(n) AS c
ORDER BY c DESC
MATCH path=(p1:place)-[*2]->(n1:n_plet)<-[*2]-(p2:place)-[*2]->(n2:n_plet)<-[*2]-(p3:place), (n1)-->(r1:spatial_relation), (n2)-->(r2:spatial_relation), (n1)-->(:description)<--(n2) WHERE r1.family in [’cardinal_direction’, ’relative_direction’] and r2.family in [’cardinal_direction’, ’relative_direction’] RETURN p1, r1, p2, r2, p3, count(path) AS c ORDER BY c DESC
5. Results and Discussion
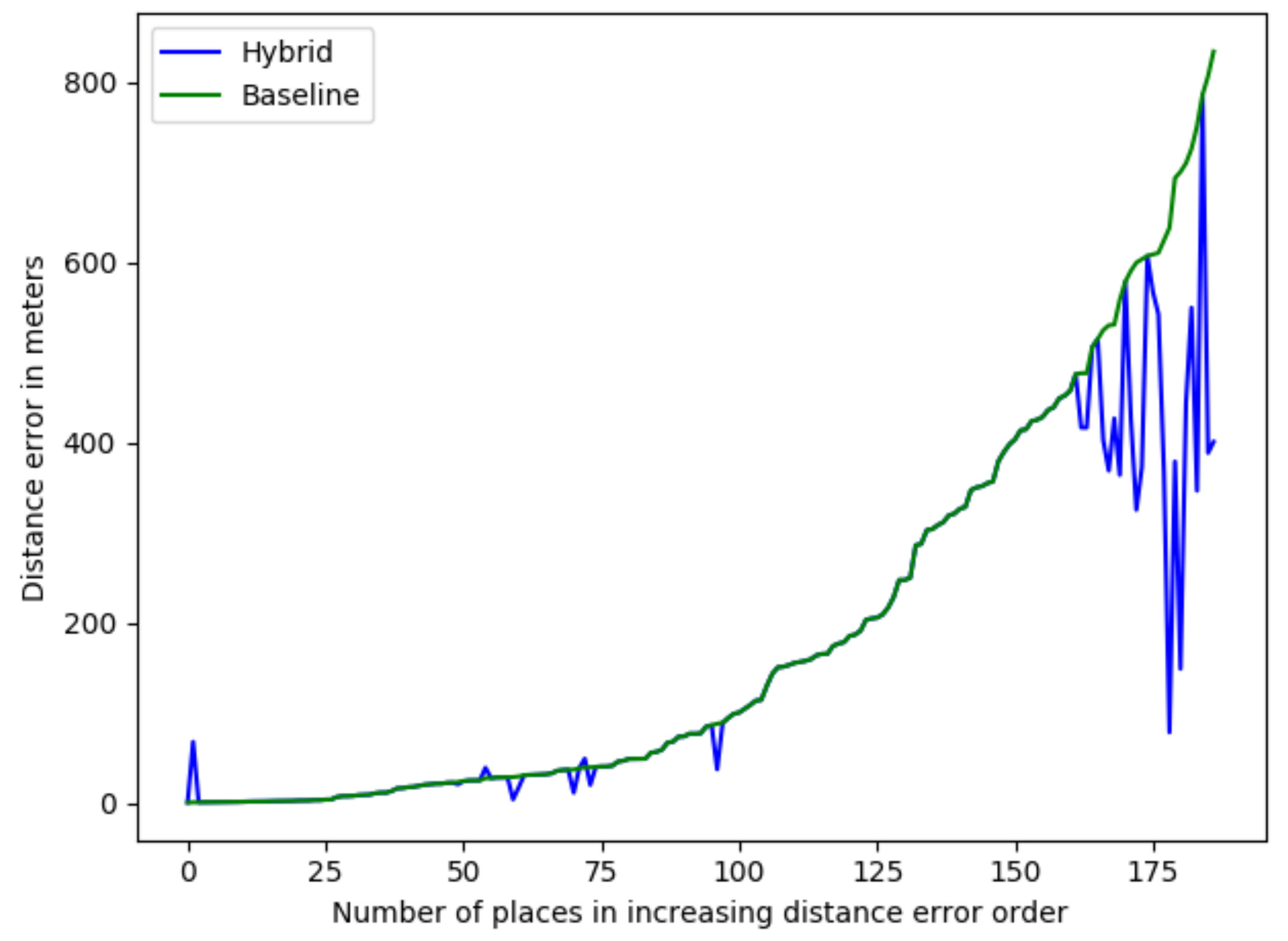
- The size of the ALR is reduced compared to the one from the baseline, but both ALRs capture the ground-truth location of the place (Case 1).
- There is no change in the ALR’s size (Case 2).
- The ground-truth location is not captured in the either ALR (Case 3).
- The ground-truth location is captured by the ALR of the baseline method, but not in the reduced-size ALR (Case 4).
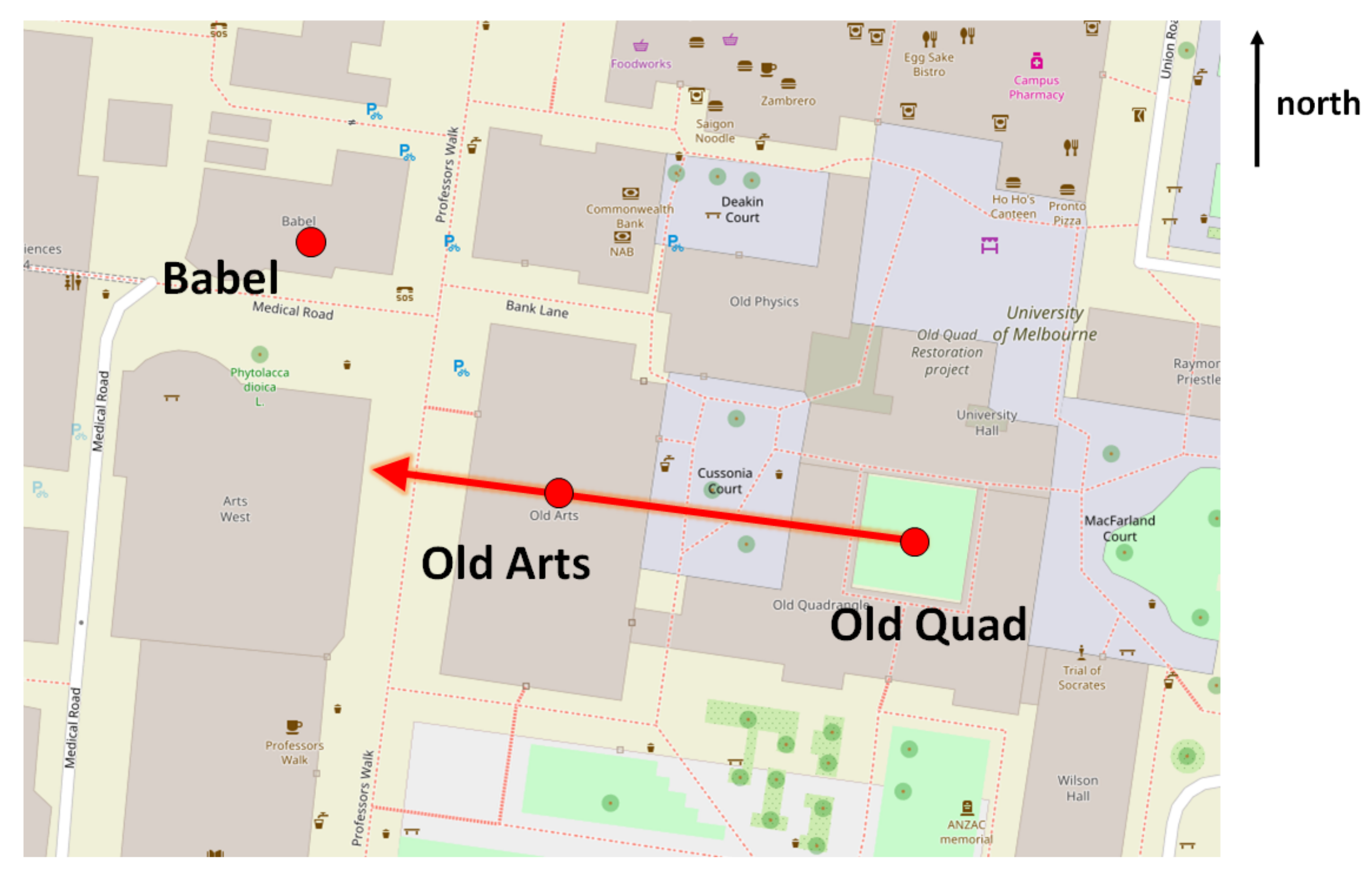
“… You’re now in the Old Quad … Pass through the Old Arts building and immediately look to your left—the tall building is the Babel building that, somewhat ironically, houses the languages and linguistics departments …”
“… From the Old Quad, you can go through the Old Arts building, and then turn right and walk until you come to a building called the Babel building (a 1970s yellow brick monolith) …”
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
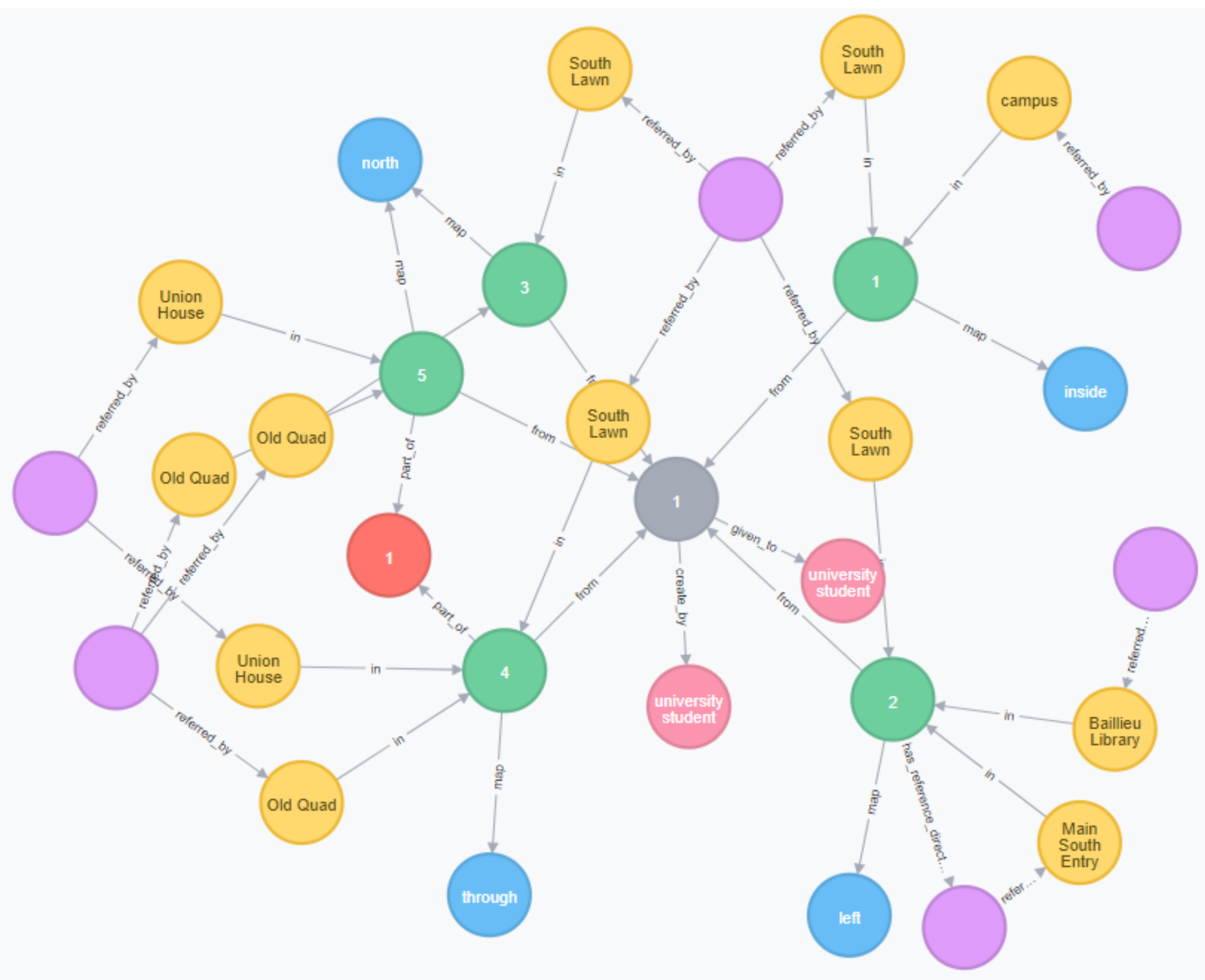
Appendix A. Graph Construction Example
“South Lawn is the major reference point which is situated in about the middle of the campus. Coming from the Main South Entry, the Baillieu Library will be on the left hand side of the South Lawn. To the north of this you have the Old Quad (really old English style building). If you want food and are currently on South Lawn go through the Old Quad to the north and keeping heading north until you get to a Union House.”
{"descriptions": [
{"did": 1,
"theme": ["University of Melbourne campus description"],
"transportation␣mode": "walking",
"source": "collected from students",
"descriptor":
{"uid": 1,
"identity": "university student"},
"recipient":
{"uid": 2,
"identity": "university student"},
"n␣plets":
[{"nid": 1,
"locatum␣reference": "South Lawn",
"locatum␣characteristic": "the major reference point",
"locatum␣conceptualization": "node",
"spatial␣relation␣expression": "about the middle of",
"relatum␣reference": "campus",
"relatum␣conceptualization": "district",
"relation␣map": ["inside"]},
{"nid": 2,
"locatum␣reference": "Baillieu Library",
"locatum␣conceptualization": "node",
"spatial␣relation␣expression": "on the left hand side",
"relatum␣reference": "South Lawn",
"relatum␣conceptualization": "node",
"reference␣frame": "relative",
"reference␣direction": ["Main South Entry", "back"],
"relation␣map": ["left"]},
{"nid": 3,
"locatum␣reference": "Old Quad",
"locatum␣type": "building",
"locatum␣characteristic": ["old", "English style"],
"locatum␣conceptualization": "node",
"spatial␣relation␣expression": "to the north",
"relatum␣reference": "South Lawn",
"relatum␣conceptualization": "node",
"relation␣map": ["north"]},
{"nid": 4,
"route_id": 1,
"locatum␣reference": "Union House",
"locatum␣equipment": "food",
"locatum␣conceptualization": "node",
"spatial␣relation␣expression": "go through",
"relatum␣reference": ["Old Quad", "South Lawn"],
"relatum␣conceptualization": ["node", "node"],
"relation␣map": ["through"]},
{"nid": 5,
"route_id": 1,
"locatum␣reference": "Union House",
"locatum␣conceptualization": "node",
"spatial␣relation␣expression": "to the north and keeping heading north",
"relatum␣reference": "Old Quad",
"relatum␣conceptualization": "node",
"relation␣map": ["north"]}]
}
]}





References
- Vasardani, M.; Timpf, S.; Winter, S.; Tomko, M. From descriptions to depictions: A conceptual framework. In Spatial Information Theory; Lecture Notes in Computer Science; Tenbrink, T., Stell, J.G., Galton, A., Wood, Z., Eds.; Springer: Berlin, Germany, 2013; Volume 8116, pp. 299–319. [Google Scholar]
- Elwood, S.; Goodchild, M.F.; Sui, D. Prospects for VGI research and the emerging fourth paradigm. In Crowdsourcing Geographic Knowledge; Springer: Berlin, Germany, 2013; pp. 361–375. [Google Scholar]
- Lieberman, M.D.; Samet, H.; Sankaranarayanan, J.; Sperling, J. STEWARD: Architecture of a spatio-textual search engine. In Proceedings of the 15th Annual ACM International Symposium on Advances in Geographic Information Systems, Seattle, Washington, 7–9 November 2007; Samet, H., Shahabi, C., Schneider, M., Eds.; ACM: New York, NY, USA, 2007; pp. 186–193. [Google Scholar]
- Moncla, L.; Renteria-Agualimpia, W.; Nogueras-Iso, J.; Gaio, M. Geocoding for texts with fine-grain toponyms: an experiment on a geoparsed hiking descriptions corpus. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; Huang, Y., Schneider, M., Gertz, M., Krumm, J., Sankaranarayanan, J., Eds.; ACM: New York, NY, USA, 2014; pp. 183–192. [Google Scholar]
- DeLozier, G.; Baldridge, J.; London, L. Gazetteer-Independent Toponym Resolution Using Geographic Word Profiles. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2382–2388. [Google Scholar]
- Kordjamshidi, P.; Van Otterlo, M.; Moens, M.F. Spatial role labelling: Towards extraction of spatial relations from natural language. ACM Trans. Speech Lang. Process. 2011, 8, 4. [Google Scholar] [CrossRef]
- Khan, A.; Vasardani, M.; Winter, S. Extracting Spatial Information From Place Descriptions. In Proceedings of the ACM SIGSPATIAL Workshop on Computational Models of Place 2013, Orlando, FL, USA, 5–8 November 2013; Scheider, S., Adams, B., Janowicz, K., Vasardani, M., Winter, S., Eds.; ACM: New York, NY, USA, 2013; pp. 62–69. [Google Scholar]
- Liu, F.; Vasardani, M.; Baldwin, T. Automatic Identification of Locative Expressions from Social Media Text: A Comparative Analysis. In Proceedings of the 4th International Workshop on Location and the Web, Shanghai, China, 3 November 2014; Ahlers, D., Wilde, E., Martins, B., Eds.; ACM: New York, NY, USA, 2014; pp. 9–16. [Google Scholar]
- Bateman, J.A.; Hois, J.; Ross, R.; Tenbrink, T. A linguistic ontology of space for natural language processing. Artif. Intell. 2010, 174, 1027–1071. [Google Scholar] [CrossRef]
- Mani, I.; Doran, C.; Harris, D.; Hitzeman, J.; Quimby, R.; Richer, J.; Wellner, B.; Mardis, S.; Clancy, S. SpatialML: Annotation scheme, resources, and evaluation. Lang. Resour. Eval. 2010, 44, 263–280. [Google Scholar] [CrossRef]
- Kim, J.; Vasardani, M.; Winter, S. Similarity matching for integrating spatial information extracted from place descriptions. Int. J. Geogr. Inf. Sci. 2016, 1, 1–25. [Google Scholar] [CrossRef]
- Kim, J.; Vasardani, M.; Winter, S. Landmark Extraction from Web-Harvested Place Descriptions. KI-Künstliche Intelligenz 2016, 2, 151–159. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Goodchild, M.F. Formalizing place in geographical information systems. In Communities, Neighborhoods, and Health: Expanding the Boundaries of Place; Burton, L.M., Kemp, S.P., Leung, M.C., Matthews, S.A., Takeuchi, D.T., Eds.; Springer: New York, NY, USA, 2011; pp. 21–35. [Google Scholar]
- Winter, S.; Baldwin, T.; Renz, J.; Tomko, M.; Kuhn, W. Place knowledge as a trans-disciplinary research challenge for Geographic Information Science. In Proceedings of the UCGIS Symposium, Scottsdale, AZ, USA, 24–26 May 2016. [Google Scholar]
- Egenhofer, M.J.; Mark, D.M. Naive geography. In Proceedings of the International Conference on Spatial Information Theory, Semmering, Austria, 21–23 September 1995; Springer: Berlin/Heidelberg, Germany, 1995; pp. 1–15. [Google Scholar]
- Goodchild, M.F. Formalizing place in geographic information systems. In Communities, Neighborhoods, and Health; Springer: New York, NY, USA, 2011; pp. 21–33. [Google Scholar]
- Relph, E. Place and Placelessness; Pion: London, UK, 1976. [Google Scholar]
- Winter, S.; Bennett, R.; Truelove, M.; Rajabifard, A.; Duckham, M.; Kealy, A.; Leach, J. Spatially enabling ‘Place’ information. In Spatially Enabling Society: Research, Emerging Trends, and Critical Assessment; Rajabifard, A., Ed.; GSDI Association: Melbourne, Australia, 2010. [Google Scholar]
- Bennett, B.; Agarwal, P. Semantic Categories Underlying the Meaning of ‘Place’. In Lecture Notes in Computer Science, Proceedings of the Conference on Spatial Information Theory, Melbourne, Australia, 19–23 September 2007; Winter, S., Duckham, M., Kulik, L., Kuipers, B., Eds.; Springer: Berlin, Germany, 2007; Volume 4736, pp. 78–95. [Google Scholar]
- Winter, S.; Freksa, C. Approaching the notion of place by contrast. J. Spat. Inf. Sci. 2012, 5, 31–50. [Google Scholar] [CrossRef]
- Tuan, Y.F. Space and Place: The Perspective of Experience; University of Minnesota Press: Minneapolis, MN, USA, 1977. [Google Scholar]
- Cresswell, T. Place: An Introduction; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Agarwal, P. Operationalising Sense of Place’as a Cognitive Operator for Semantics in Place-Based Ontologies. In Proceedings of the Conference on Spatial Information Theory, Ellicottville, NY, USA, 14–18 September 2005; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3693, pp. 96–114. [Google Scholar]
- Curry, M.R. The Work in the World: Geographical Practice and the Written Word; University of Minnesota Press: Minneapolis, MN, USA, 1996. [Google Scholar]
- Agnew, J. Space and place. Handb. Geogr. Knowl. 2011, 2011, 316–331. [Google Scholar]
- Vasardani, M.; Winter, S.; Richter, K.F. Locating place names from place descriptions. Int. J. Geogr. Inf. Sci. 2013, 27, 2509–2532. [Google Scholar] [CrossRef]
- Adams, B.; McKenzie, G. Inferring thematic places from spatially referenced natural language descriptions. In Crowdsourcing Geographic Knowledge; Springer: Berlin, Germany, 2013; pp. 201–221. [Google Scholar]
- Hill, L.L. Core elements of digital gazetteers: Placenames, categories, and footprints. In Research and Advanced Technology for Digital Libraries; Lecture Notes in Computer Science; Borbinha, J.L., Baker, T., Eds.; Springer: Berlin, Germany, 2000; Volume 1923, pp. 280–290. [Google Scholar]
- Goodchild, M.F.; Hill, L.L. Introduction to digital gazetteer research. Int. J. Geogr. Inf. Sci. 2008, 22, 1039–1044. [Google Scholar] [CrossRef]
- Silva, M.J.; Martins, B.; Chaves, M.; Afonso, A.P.; Cardoso, N. Adding geographic scopes to web resources. Comput. Environ. Urban Syst. 2006, 30, 378–399. [Google Scholar] [CrossRef]
- Purves, R.S.; Clough, P.; Jones, C.B.; Arampatzis, A.; Bucher, B.; Finch, D.; Fu, G.; Joho, H.; Syed, A.K.; Vaid, S.; et al. The design and implementation of SPIRIT: A spatially aware search engine for information retrieval on the Internet. Int. J. Geogr. Inf. Sci. 2007, 21, 717–745. [Google Scholar] [CrossRef]
- Jones, C.B.; Purves, R.S. Geographical information retrieval. Int. J. Geogr. Inf. Sci. 2008, 22, 219–228. [Google Scholar] [CrossRef]
- Cohn, A.G.; Gotts, N.M. The ‘egg-yolk’representation of regions with indeterminate boundaries. In Geographic Objects with Indeterminate Boundaries; Taylor & Francis: London, UK, 1996; Volume 2, pp. 171–187. [Google Scholar]
- Fisher, P. Boolean and fuzzy regions. In Geographic Objects with Indeterminate Boundaries; Taylor & Francis: London, UK, 1996; Volume 2. [Google Scholar]
- Bittner, T.; Stell, J.G. Rough sets in approximate spatial reasoning. In Proceedings of the International Conference on Rough Sets and Current Trends in Computing, Banff, AB, Canada, 16–19 October 2000; Springer: Berlin, Germany, 2000; pp. 445–453. [Google Scholar]
- Clementini, E.; Di Felice, P. An algebraic model for spatial objects with indeterminate boundaries. In Geographic Objects with Indeterminate Boundaries; Taylor & Francis: London, UK, 1996; Volume 2, pp. 155–169. [Google Scholar]
- Kulik, L. A geometric theory of vague boundaries based on supervaluation. In Proceedings of the International Conference on Spatial Information Theory, Morro Bay, CA, USA, 19–23 September 2001; Springer: Berlin, Germany, 2001; pp. 44–59. [Google Scholar]
- Wieczorek, J.; Guo, Q.; Hijmans, R. The point-radius method for georeferencing locality descriptions and calculating associated uncertainty. Int. J. Geogr. Inf. Sci. 2004, 18, 745–767. [Google Scholar] [CrossRef]
- Guo, Q.; Liu, Y.; Wieczorek, J. Georeferencing locality descriptions and computing associated uncertainty using a probabilistic approach. Int. J. Geogr. Inf. Sci. 2008, 22, 1067–1090. [Google Scholar] [CrossRef]
- Liu, Y.; Guo, Q.H.; Wieczorek, J.; Goodchild, M.F. Positioning localities based on spatial assertions. Int. J. Geogr. Inf. Sci. 2009, 23, 1471–1501. [Google Scholar] [CrossRef]
- Montello, D.R.; Goodchild, M.F.; Gottsegen, J.; Fohl, P. Where’s down town?: Behavioral methods for determining referents of vague spatial queries. Spat. Cognit. Comput. 2003, 3, 185–204. [Google Scholar]
- Jones, C.B.; Purves, R.S.; Clough, P.D.; Joho, H. Modelling vague places with knowledge from the Web. Int. J. Geogr. Inf. Sci. 2008, 22, 1045–1065. [Google Scholar] [CrossRef]
- Grothe, C.; Schaab, J. Automated footprint generation from geotags with kernel density estimation and support vector machines. Spat. Cognit. Comput. 2009, 9, 195–211. [Google Scholar] [CrossRef]
- Hollenstein, L.; Purves, R. Exploring place through user-generated content: Using Flickr tags to describe city cores. J. Spat. Inf. Sci. 2010, 2010, 21–48. [Google Scholar]
- Gao, S.; Janowicz, K.; Montello, D.R.; Hu, Y.; Yang, J.A.; McKenzie, G.; Ju, Y.; Gong, L.; Adams, B.; Yan, B. A data-synthesis-driven method for detecting and extracting vague cognitive regions. Int. J. Geogr. Inf. Sci. 2017, 31, 1245–1271. [Google Scholar] [CrossRef]
- Speriosu, M.; Brown, T.; Moon, T.; Baldridge, J.; Erk, K. Connecting language and geography with region-topic models. In Proceedings of the Workshop on Computational Models of Spatial Language Interpretation (COSLI), Portland, OR, USA, 15 August 2010. [Google Scholar]
- Adams, B.; Janowicz, K. Thematic signatures for cleansing and enriching place-related linked data. Int. J. Geogr. Inf. Sci. 2015, 29, 556–579. [Google Scholar] [CrossRef]
- Twigger-Ross, C.L.; Uzzell, D.L. Place and identity processes. J. Environ. Psychol. 1996, 16, 205–220. [Google Scholar] [CrossRef]
- Vasardani, M.; Stirling, L.F.; Winter, S. The preposition at from a spatial language, cognition, and information systems perspective. Sema. Pragmat. 2017, 10. [Google Scholar] [CrossRef]
- Jordan, T.; Raubal, M.; Gartrell, B.; Egenhofer, M. An affordance-based model of place in GIS. In Proceedings of the 8th International Symposium on Spatial Data Handling, Vancouver, BC, Canada, 11–15 July 1998; Volume 98, pp. 98–109. [Google Scholar]
- Kuhn, W. Ontologies in support of activities in geographical space. Int. J. Geogr. Inf. Sci. 2001, 15, 613–631. [Google Scholar] [CrossRef]
- Scheider, S.; Kuhn, W. Affordance-based categorization of road network data using a grounded theory of channel networks. Int. J. Geogr. Inf. Sci. 2010, 24, 1249–1267. [Google Scholar] [CrossRef]
- Janowicz, K.; Keßler, C. The role of ontology in improving gazetteer interaction. Int. J. Geogr. Inf. Sci. 2008, 22, 1129–1157. [Google Scholar] [CrossRef]
- Jarvella, R.J.; Klein, W. Speech, Place, and Action: Studies of Deixis and Related Topics; John Wiley & Sons: Hoboken, NJ, USA, 1982. [Google Scholar]
- Couclelis, H.; Golledge, R.G.; Gale, N.; Tobler, W. Exploring the anchor-point hypothesis of spatial cognition. J. Environ. Psychol. 1987, 7, 99–122. [Google Scholar] [CrossRef]
- Richter, D.; Winter, S.; Richter, K.F.; Stirling, L. Granularity of locations referred to by place descriptions. Comput. Environ. Urban Syst. 2013, 41, 88–99. [Google Scholar] [CrossRef]
- Pustejovsky, J. Iso-space: Annotating static and dynamic spatial information. In Handbook of Linguistic Annotation; Springer: Berlin, Germany, 2017; pp. 989–1024. [Google Scholar]
- Coyne, B.; Sproat, R.; Hirschberg, J. Spatial relations in text-to-scene conversion. In Proceedings of the Computational Models of Spatial Language Interpretation, Workshop at Spatial Cognition, Portland, OR, USA, 15–19 August 2010. [Google Scholar]
- Kordjamshidi, P.; Frasconi, P.; Van Otterlo, M.; Moens, M.F.; De Raedt, L. Relational learning for spatial relation extraction from natural language. In Proceedings of the International Conference on Inductive Logic Programming, Windsor, UK, 31 July–3 August 2011; Springer: Berlin, Germany, 2011; pp. 204–220. [Google Scholar]
- Langacker, R.W. Foundations of Cognitive Grammar: Theoretical Prerequisites; Stanford University Press: Redwood City, CA, USA, 1987; Volume 1. [Google Scholar]
- Lakoff, G. Women, fire, and Dangerous Things; University of Chicago Press: Chicago, IL, USA, 2008. [Google Scholar]
- Talmy, L. How language structures space. In Spatial Orientation; Springer: Berlin, Germany, 1983; pp. 225–282. [Google Scholar]
- Levinson, S.C. Frames of reference and Molyneux’s question: Crosslinguistic evidence. Lang. Space 1996, 109, 169. [Google Scholar]
- Vandeloise, C. Spatial pRepositions: A Case Study from French; University of Chicago Press: Chicago, IL, USA, 1991. [Google Scholar]
- Chen, H.; Vasardani, M.; Winter, S. Georeferencing places from collective human descriptions using place graphs. J. Spat. Inf. Sci. 2018. Available online: http://www.josis.org/index.php/josis/article/viewFile/417/214 (accessed on 15 June 2018).
- Kim, J.; Vasardani, M.; Winter, S. From descriptions to depictions: A dynamic sketch map drawing strategy. Spat. Cognit. Comput. 2016, 16, 29–53. [Google Scholar] [CrossRef]
- Wolter, D.; Yousaf, M. Context and Vagueness in Automated Interpretation of Place Description: A Computational Model. In Proceedings of the International Conference on Spatial Information Theory, L’Aquila, Italy, 4–8 September 2017; Springer: Berlin, Germany, 2017; pp. 137–142. [Google Scholar]
- Scheider, S.; Janowicz, K. Place reference systems. Appl. Ontol. 2014, 9, 97–127. [Google Scholar]
- Alazzawi, A.N.; Abdelmoty, A.I.; Jones, C.B. What can I do there? Towards the automatic discovery of place-related services and activities. Int. J. Geogr. Inf. Sci. 2012, 26, 345–364. [Google Scholar] [CrossRef]
- Janowicz, K. Sim-DL: Towards a Semantic Similarity Measurement Theory for the Description Logic ALCNR\mathcal ALCNR in Geographic Information Retrieval. In Proceedings of the on the Move to Meaningful Internet Systems 2006: OTM 2006 Workshops, Montpellier, France, 29 October–3 November 2006; Springer: Berlin, Germany, 2006; pp. 1681–1692. [Google Scholar]
- Hobel, H.; Fogliaroni, P. Extracting semantics of places from user generated content. In Proceedings of the 19th AGILE International Conference on Geographic Information Science, Atlanta, GA, USA, 25–29 July 2016. [Google Scholar]
- Tenbrink, T. Reference frames of space and time in language. J. Pragmat. 2011, 43, 704–722. [Google Scholar] [CrossRef]
- Wallgrün, J.O.; Frommberger, L.; Wolter, D.; Dylla, F.; Freksa, C. Qualitative spatial representation and reasoning in the SparQ-toolbox. In Proceedings of the International Conference on Spatial Cognition, Bremen, Germany, 24–28 September 2006; Springer: Berlin, Germany, 2006; Volume 4387, pp. 39–58. [Google Scholar]
- Cohn, A.G.; Renz, J. Qualitative spatial representation and reasoning. Found. Artif. Intell. 2008, 3, 551–596. [Google Scholar]
- Lynch, K. The Image of the City; MIT Press: Cambridge, MA, USA, 1960; Volume 11. [Google Scholar]
- Tomko, M.; Winter, S. Describing the Functional Spatial Structure of Urban Environments. Comput. Environ. Urban Syst. 2013, 41, 177–187. [Google Scholar] [CrossRef]
- Moncla, L.; Gaio, M.; Nogueras-Iso, J.; Mustière, S. Reconstruction of itineraries from annotated text with an informed spanning tree algorithm. Int. J. Geogr. Inf. Sci. 2016, 30, 1137–1160. [Google Scholar] [CrossRef]
- Yao, X.; Thill, J.C. How Far Is Too Far?—A Statistical Approach to Context-contingent Proximity Modeling. Trans. GIS 2005, 9, 157–178. [Google Scholar] [CrossRef]
- Richter, D.; Winter, S.; Richter, K.F.; Stirling, L. How people describe their place: Identifying predominant types of place descriptions. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Crowdsourced and Volunteered Geographic Information, Redondo Beach, CA, USA, 6 November 2012; pp. 30–37. [Google Scholar]
- Kuhn, W. Core concepts of spatial information for transdisciplinary research. Int. J. Geogr. Inf. Sci. 2012, 26, 2267–2276. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spatial Relation Family | Spatial Relation Type |
|---|---|
| Cardinal direction | north, south, east, west, northeast, southeast, northwest, southwest |
| Qualitative distance | near |
| Relative direction | front, back, left, right, left front, right front, left back, right back |
| Topological | inside, covered by, overlap, meet, disjoint, cover, contain, equal |
| Rank | Most Frequent Relata | Places Most Frequently Co-Occurring with Alice Hoy | Most Frequent Length-3 Paths |
|---|---|---|---|
| 1 | University Of Melbourne | Monash Road | <Old Arts, right, Baillieu Library, left, South Lawn> |
| 2 | Union Building | Entrance | <Baillieu Library, left, South Lawn, front, John Medley> |
| 3 | Grattan Street | University of Melbourne | <Royal Parade, left, Baillieu Library, left, South Lawn> |
| 4 | South Lawn | Wilson Hall | <Medical Building, left, Baillieu Library, left, South Lawn> |
| 5 | Swanston Street | Peter Hall Building | <Baillieu Library, left, South Lawn, left, Wilson Hall> |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Vasardani, M.; Winter, S.; Tomko, M. A Graph Database Model for Knowledge Extracted from Place Descriptions. ISPRS Int. J. Geo-Inf. 2018, 7, 221. https://doi.org/10.3390/ijgi7060221
Chen H, Vasardani M, Winter S, Tomko M. A Graph Database Model for Knowledge Extracted from Place Descriptions. ISPRS International Journal of Geo-Information. 2018; 7(6):221. https://doi.org/10.3390/ijgi7060221
Chicago/Turabian StyleChen, Hao, Maria Vasardani, Stephan Winter, and Martin Tomko. 2018. "A Graph Database Model for Knowledge Extracted from Place Descriptions" ISPRS International Journal of Geo-Information 7, no. 6: 221. https://doi.org/10.3390/ijgi7060221
APA StyleChen, H., Vasardani, M., Winter, S., & Tomko, M. (2018). A Graph Database Model for Knowledge Extracted from Place Descriptions. ISPRS International Journal of Geo-Information, 7(6), 221. https://doi.org/10.3390/ijgi7060221