Multi-Temporal Sentinel-1 and -2 Data Fusion for Optical Image Simulation



Abstract
1. Introduction
2. Approaches
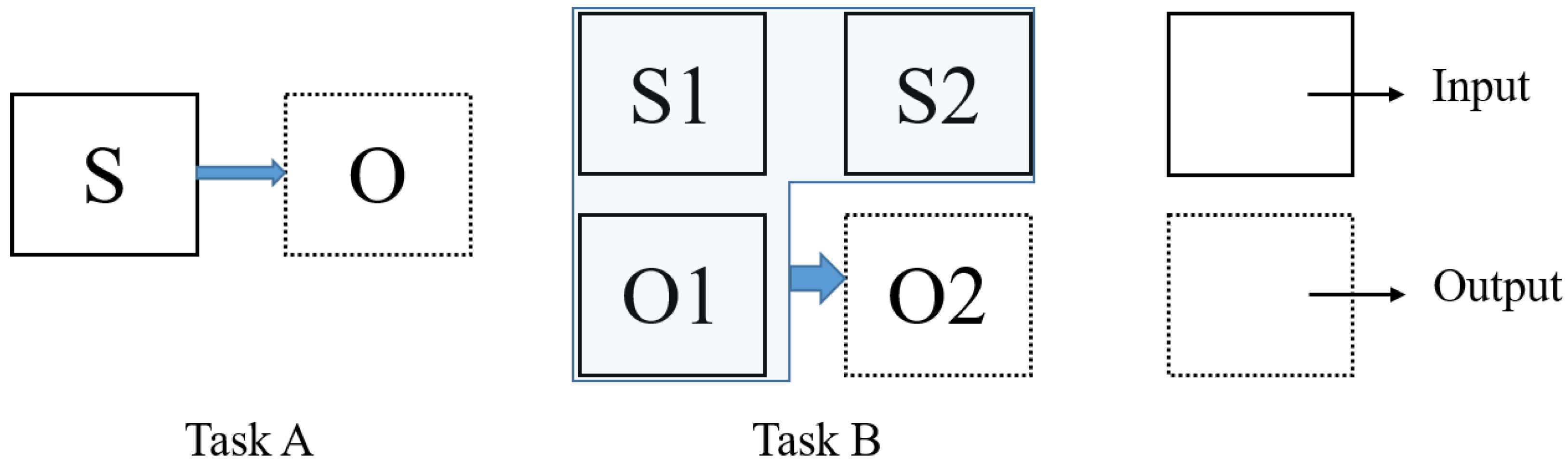
2.1. Problem Formulation
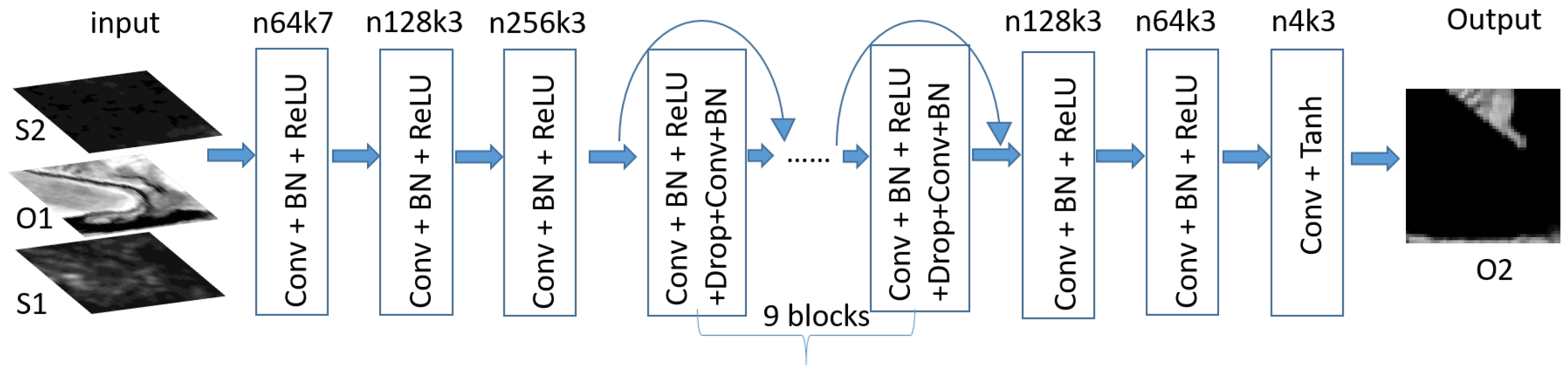
2.2. Architecture of CNN Network
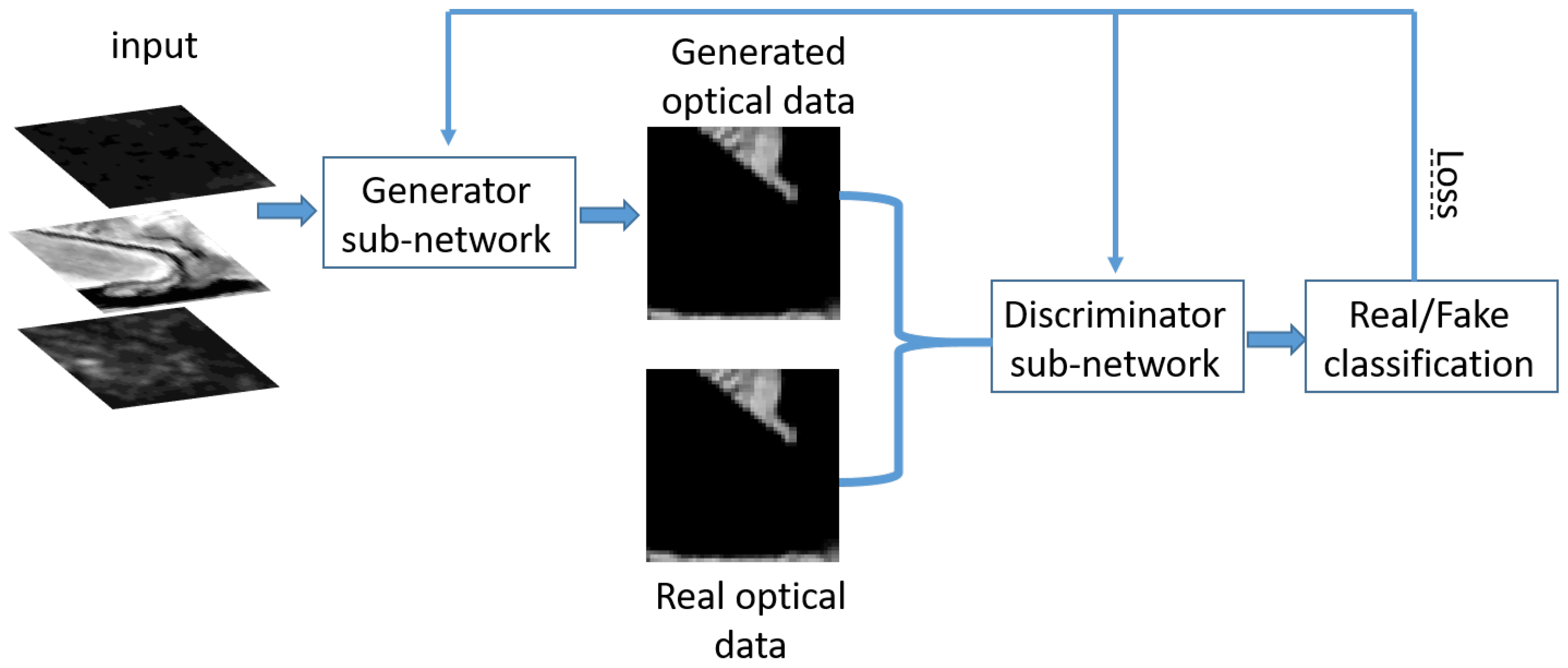
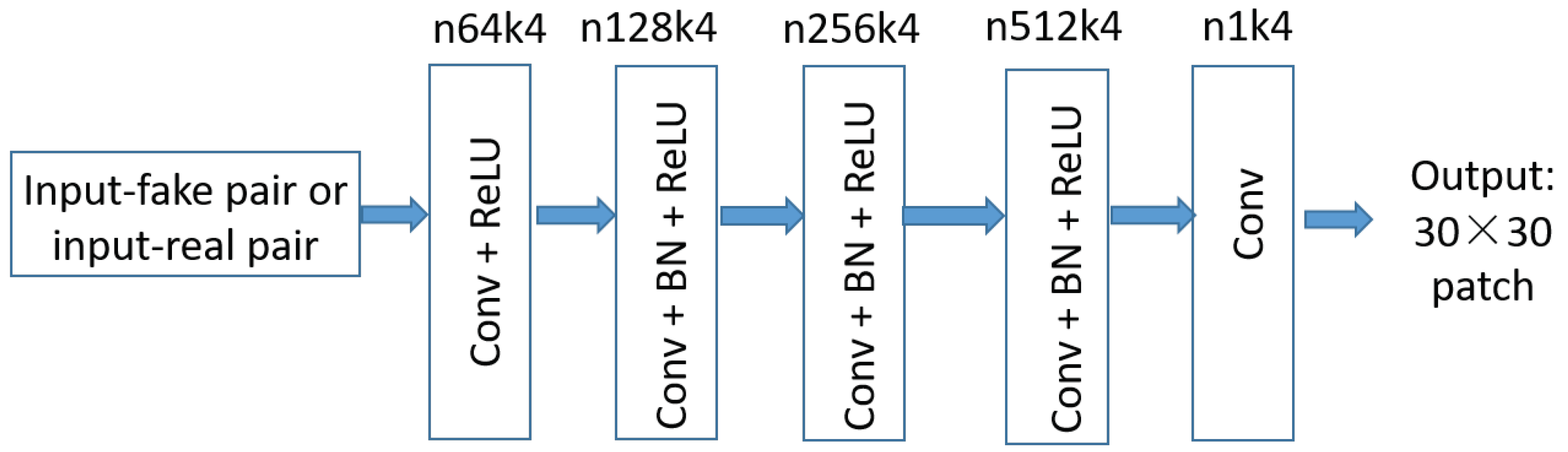
2.3. cGAN
2.4. Implementation Issues
3. Dataset Description and Experimental Setting
3.1. Dataset
3.2. Training and Test Setup
3.3. Evaluation Index
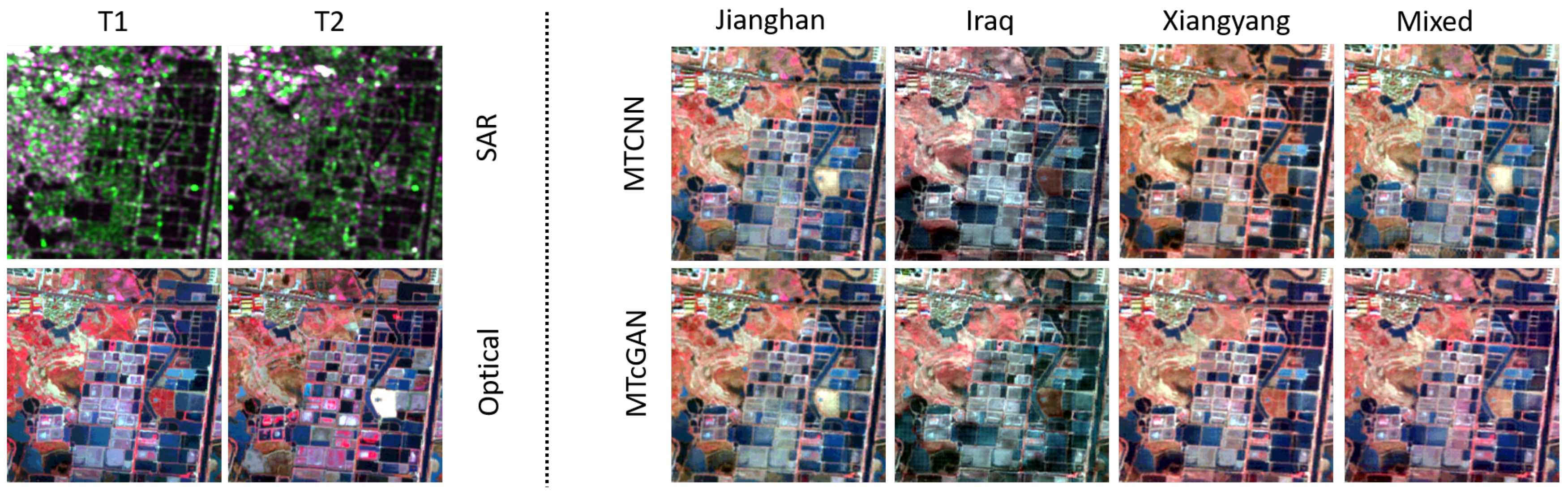
4. Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | convolutional neural network |
| cGAN | conditional generative adversarial network |
| ResNets | residual networks |
| MTCNN | multi-temporal CNN |
| MTcGAN | multi-temporal cGAN |
References
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Hagolle, O.; Huc, M.; Pascual, D.V.; Dedieu, G. A multi-temporal method for cloud detection, applied to FORMOSAT-2, VENuS, LANDSAT and SENTINEL-2 images. Remote Sens. Environ. 2010, 114, 1747–1755. [Google Scholar] [CrossRef]
- Cheng, Q.; Shen, H.; Zhang, L.; Yuan, Q.; Zeng, C. Cloud removal for remotely sensed images by similar pixel replacement guided with a spatio-temporal MRF model. ISPRS J. Photogramm. Remote Sens. 2014, 92, 54–68. [Google Scholar] [CrossRef]
- Torres, R.; Snoeij, P.; Geudtner, D.; Bibby, D.; Davidson, M.; Attema, E.; Potin, P.; Rommen, B.; Floury, N.; Brown, M.; et al. GMES Sentinel-1 mission. Remote Sens. Environ. 2012, 120, 9–24. [Google Scholar] [CrossRef]
- Verdoliva, L.; Gaetano, R.; Ruello, G.; Poggi, G. Optical-Driven Nonlocal SAR Despeckling. IEEE Geosci. Remote Sens. Lett. 2015, 12, 314–318. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-To-Image Translation With Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Merkle, N.; Auer, S.; Mller, R.; Reinartz, P. Exploring the Potential of Conditional Adversarial Networks for Optical and SAR Image Matching. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, PP, 1–10. [Google Scholar] [CrossRef]
- Wang, P.; Patel, V.M. Generating high quality visible images from SAR images using CNNs. In Proceedings of the Radar Conference (RadarConf18), Oklahoma City, OK, USA, 23–27 April 2018; pp. 570–575. [Google Scholar]
- Merkle, N.; Fischer, P.; Auer, S.; Müller, R. On the possibility of conditional adversarial networks for multi-sensor image matching. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 2633–2636. [Google Scholar]
- Schmitt, M.; Hughes, L.H.; Zhu, X.X. The SEN1-2 Dataset for Deep Learning in SAR-Optical Data Fusion. arXiv, 2018; arXiv:1807.01569. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; ACM: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Yan, L.; Zhu, R.; Liu, Y.; Mo, N. TrAdaBoost Based on Improved Particle Swarm Optimization for Cross-Domain Scene Classification With Limited Samples. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 99, 1–17. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Ma, J. Learning Source-Invariant Deep Hashing Convolutional Neural Networks for Cross-Source Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2018, 99, 1–16. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv, 2015; arXiv:1511.06434. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Computer Vision ECCV; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; ACM: New York, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Ghamisi, P.; Yokoya, N. IMG2DSM: Height Simulation from Single Imagery Using Conditional Generative Adversarial Nets. IEEE Trans. Geosci. Remote Sens. Lett. 2018, PP, 1–5. [Google Scholar] [CrossRef]
- Zuhlke, M.; Fomferra, N.; Brockmann, C.; Peters, M.; Veci, L.; Malik, J.; Regner, P. SNAP (Sentinel Application Platform) and the ESA Sentinel 3 Toolbox. In Proceedings of the Sentinel-3 for Science Workshop, Venice, Italy, 2–5 June 2015; Volume 734, p. 21. [Google Scholar]
- He, W.; Zhang, H.; Zhang, L.; Shen, H. Total-Variation-Regularized Low-Rank Matrix Factorization for Hyperspectral Image Restoration. IEEE Trans. Geosci. Remote Sens. 2016, 54, 178–188. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Y-M-D | S1 | O1 | S2 | O2 |
|---|---|---|---|---|
| Iraq | 12 November 2017 | 10 November 2017 | 6 December 2017 | 10 December 2017 |
| Jianghan | 14 November 2017 | 12 November 2017 | 20 December 2017 | 19 December 2017 |
| Xiangyang | 14 November 2017 | 12 November 2017 | 20 December 2017 | 19 December 2017 |
| Iraq | Jianghan | Xiangyang | |
|---|---|---|---|
| Train | 561 | 1188 | 754 |
| Test | 99 | 165 | None |
| Index | [10] | CNN | cGAN | MTCNN | MTcGAN | O1 |
|---|---|---|---|---|---|---|
| PSNR (dB) | 26.50 | 26.60 | 26.79 | 30.61 | 32.32 | 29.77 |
| SSIM | 0.6419 | 0.6477 | 0.6519 | 0.9028 | 0.9110 | 0.8528 |
| MSA | 0.6545 | 0.6769 | 0.6581 | 0.3796 | 0.3146 | 0.5529 |
| Training Time (s) | 4252 | 3747 | 4025 | 3506 | 3892 | None |
| Method | Index | Jianghan | Iraq | Xiangyang | Mixed | O1 |
|---|---|---|---|---|---|---|
| PSNR | 35.08 | 29.44 | 34.30 | 34.38 | 34.01 | |
| MTCNN | SSIM | 0.9508 | 0.8585 | 0.9412 | 0.9479 | 0.9401 |
| MSA | 0.4684 | 0.8400 | 0.5138 | 0.4774 | 0.5319 | |
| PSNR | 35.25 | 31.09 | 34.44 | 34.83 | 34.01 | |
| MTcGAN | SSIM | 0.9509 | 0.8850 | 0.9413 | 0.9463 | 0.9401 |
| MSA | 0.4629 | 0.6137 | 0.5070 | 0.4649 | 0.5319 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, W.; Yokoya, N. Multi-Temporal Sentinel-1 and -2 Data Fusion for Optical Image Simulation. ISPRS Int. J. Geo-Inf. 2018, 7, 389. https://doi.org/10.3390/ijgi7100389
He W, Yokoya N. Multi-Temporal Sentinel-1 and -2 Data Fusion for Optical Image Simulation. ISPRS International Journal of Geo-Information. 2018; 7(10):389. https://doi.org/10.3390/ijgi7100389
Chicago/Turabian StyleHe, Wei, and Naoto Yokoya. 2018. "Multi-Temporal Sentinel-1 and -2 Data Fusion for Optical Image Simulation" ISPRS International Journal of Geo-Information 7, no. 10: 389. https://doi.org/10.3390/ijgi7100389
APA StyleHe, W., & Yokoya, N. (2018). Multi-Temporal Sentinel-1 and -2 Data Fusion for Optical Image Simulation. ISPRS International Journal of Geo-Information, 7(10), 389. https://doi.org/10.3390/ijgi7100389