1. Introduction
Destination Choice modeling using multinomial logit models allows for more sophisticated models than the aggregate approaches that have persisted in the field since the 1950s [
1]. Despite the opportunities for more advanced representations of destination utility, models still rely mainly on socio-economic indicators such as the population and employment of the destination zone. However, a traveler’s destination choice is not necessarily made based on how many people live and work there. An example demonstrates where such traditional metrics fall short; national parks have no population and little employment but are large attractors of leisure trips. Ski areas are another example of this effect.
Although it is desirable to better represent the zonal utility, destination choice modeling is often characterized by a large set of alternatives [
2]. As such, the acquisition of detailed data for each alternative is not a feasible proposition during the development of many transport models. Simma et al. [
3] explored such variables in detail for long distance leisure travel in Switzerland, reporting that the data collection work was indeed particularly onerous. This paper presents an alternative approach, using aggregated data from the location based social network (LBSN) Foursquare to represent destination attractiveness in the utility function of a multinomial logit model.
Big data, such as those collected by Foursquare or Twitter, are a “topic du jour” in transport modeling. Rashidi et al. [
4] presented the first comprehensive literature review exploring the opportunities and challenges inherit to working with such data, with a special focus on travel demand modeling. They examined the recent applications of social media data to both aggregate and disaggregate models, activity behavior, traffic behavior, incidents and natural disasters. Most previous works use geotagged messages, called “tweets”, from the social media platform Twitter in their analysis. In particular, they emphasize the opportunity to use websites, such as Yelp or Foursquare, to identify trip purposes from the venue classifications of visited places.
Foursquare provides a platform for users to “check-in” to a point of interest (POI), known as a “venue” and provide tips, ratings and reviews. With 50 million monthly active users and over 7.8 billion check-ins to date [
5], Foursquare is the largest LBSN. This enormous amount of data can be used in a multitude of ways to explore mobility patterns. In recent relevant research using Foursquare, Lindqvist et al. [
6] looked at how and why people use location sharing services such as Foursquare and discussed how users manage their privacy when using such services. Cheng et al. [
7] collected 22 million check-ins across 220,000 users to quantitatively assess human mobility patterns. A total of 53% of their check-ins came from Foursquare, highlighting the dominance of Foursquare in the LBSN space. More recently, data-driven approaches to transport modeling and analysis have been developed using Foursquare data. S.A. et al. [
8] combined cell phone and Foursquare data to calculate origin–destination (OD) demand matrices. They found that the results generally matched the observed OD travel, though some differences in trip volumes and patterns were evident. Noulas et al. [
9] used Foursquare data in a gravity model based on Stouffer’s theory of intervening opportunities [
10]. Using a probabalistic modeling approach, Hasan and Ukkusuri [
11] extracted the true transition and activity distributions from incomplete trajectory information using Foursquare check-ins in New York City. Their approach reconstructs timing and location sequences from selective user reporting of check-ins. It has wide applications to other sources of geolocated data, which are affected by similar issues of missing information.
Comprehensive travel surveys such as the Transport Survey of Residents of Canada (TSRC) often have a sample size of around only 50,000 records per year. In contrast, big data sources can record the movements of millions of individuals at unprecedented spatial and temporal accuracy [
12]. It is important to note that the high temporal and spatial resolution of geolocated big data comes with its own trade-offs. Often social demographic attributes are not available, making it extremely difficult to correctly weigh the sample. Furthermore, publicly available data for research can be limited or highly aggregated and the collection and sampling methodologies are normally not available for validation [
13].
Clearly, there is a need to discover ways of combining both “traditional” (travel surveys and census data) and “new” (big) data sources to harness the best attributes of both. In the field of transport modeling, Chaniotakis et al. [
14] empirically investigated the potential for social media to augment travel survey data in Thessaloniki, Greece. They performed both temporal and spatial analyses, comparing the level of activity in destination zones between a traditional travel survey and three social media, namely, Foursquare, Facebook and Twitter. Their findings conclude that while social media cannot be used to directly extract demand models, it can be used as an additional source to enrich conventional methods.
This paper presents a long distance destination choice model for Ontario, Canada, incorporating data from both Foursquare and traditional data sources.
Section 2 describes a zoning system for the destination choice model and a methodology to enrich it with Foursquare data.
Section 3 defines the model variables and design.
Section 4 presents the results of the model estimation results and a scenario analysis.
Section 5 provides a discussion of the results, including limitations and areas for future work.
Section 6 concludes the paper.
2. Methodology and Data
2.1. Applying the Travel Survey of Residents of Canada
The TSRC is a monthly, cross-sectional survey collected by Statistics Canada measuring the volume, characteristics and economic impact of domestic travel. In this paper, the TSRC provides the ‘traditional’ data source for the estimation and calibration of the destination choice model. Trip origins, destinations and stopovers are available in the microdata at three resolutions (from lowest to highest): province or territory, census division, and census metropolitan agglomeration (CMA).
The TSRC trip files provide trip records for all of Canada. However, as a model for Ontario, trips were removed that do not concern Ontario, namely
After filtering, 69,328 individual trip records remained from the TSRC dataset for model estimation (see
Table 1).
2.2. Defining a Zone System for Ontario Based on the TSRC Data
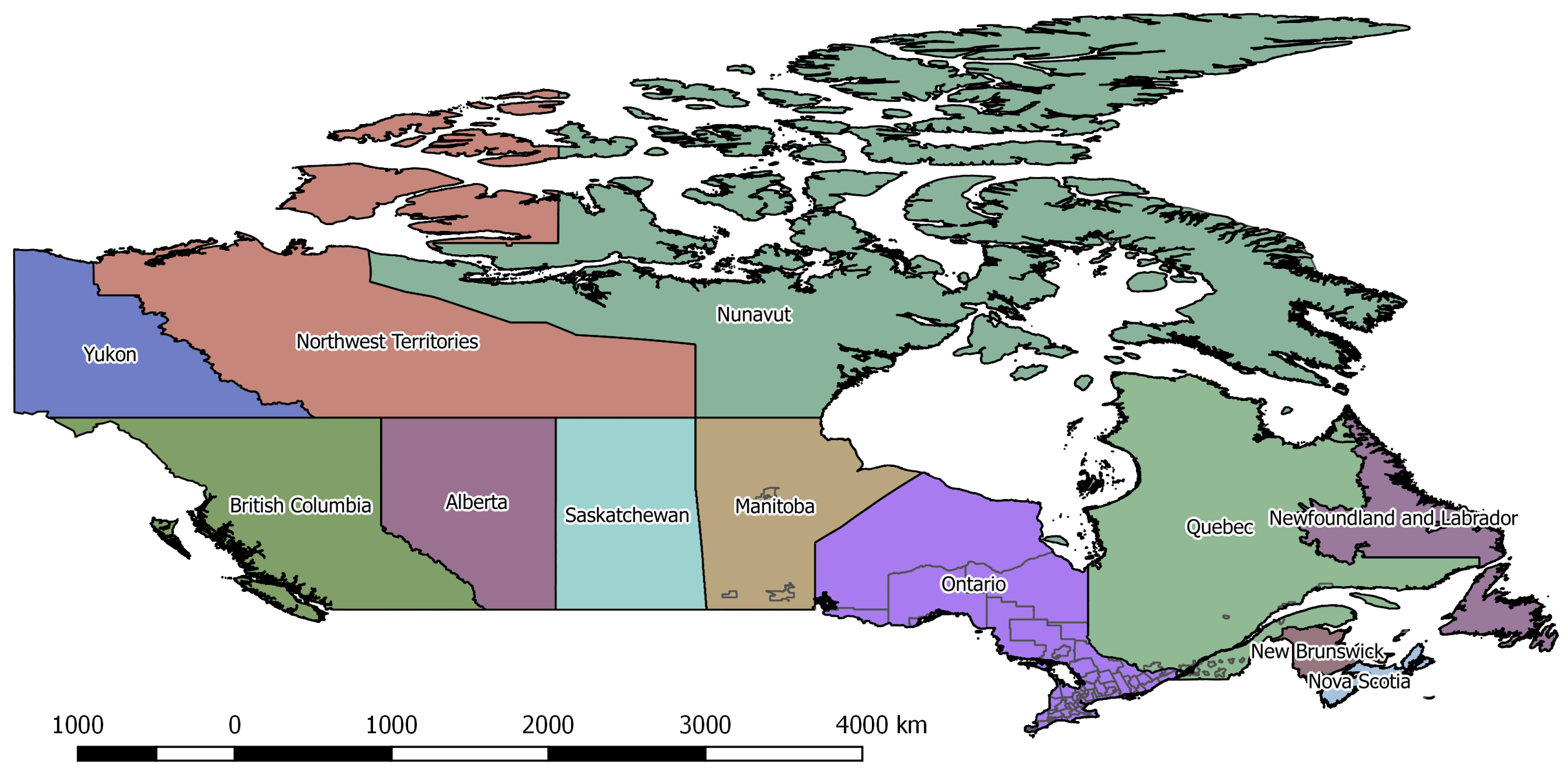
A domestic zone system was already provided by the project partner, consisting of 6,495 Traffic analysis zones (TAZs) for Ontario and 48 representing the rest of Canada. Sociodemographic data was provided for each TAZ. However, in the TSRC, the trip origins and destinations were only defined at broader spatial resolutions, namely, province, census division and CMA. Hence, a new internal zone system for Ontario was defined for this destination choice model, based on the TSRC.
The external TAZs were defined by the project partner from the TSRC Census Divisions and selected CMAs of interest to the model and could be transferred directly to the new zone system. The internal TAZs were not aligned to the TSRC resolution, as they were allocated using a gradual raster-based zone approach, developed by Moeckel and Donnelly [
15]. The 6495 generated TAZs varied in size from 0.879 km
to 3600 km
, with smaller cells defined for more populous areas and larger cells for regional areas.
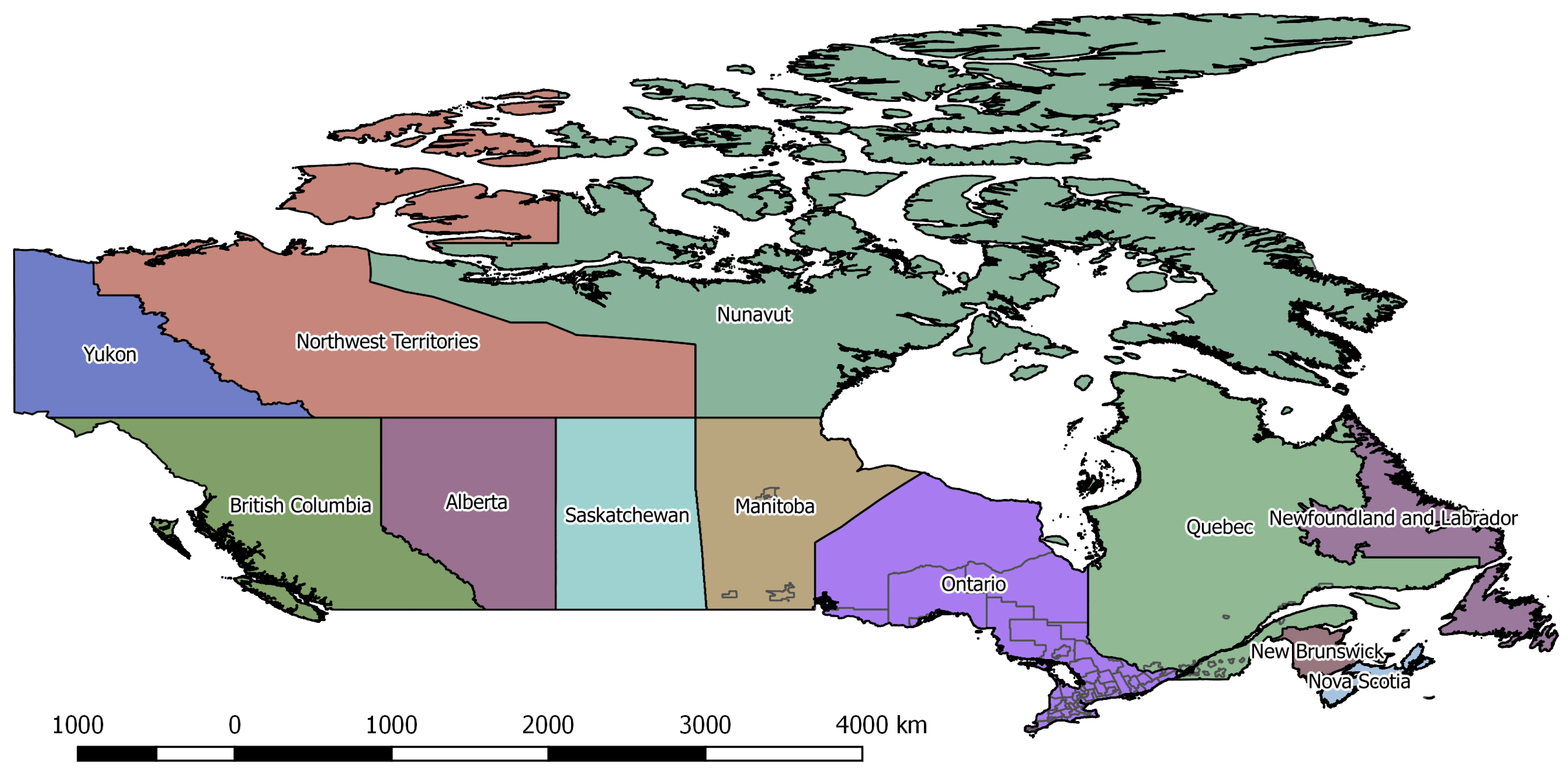
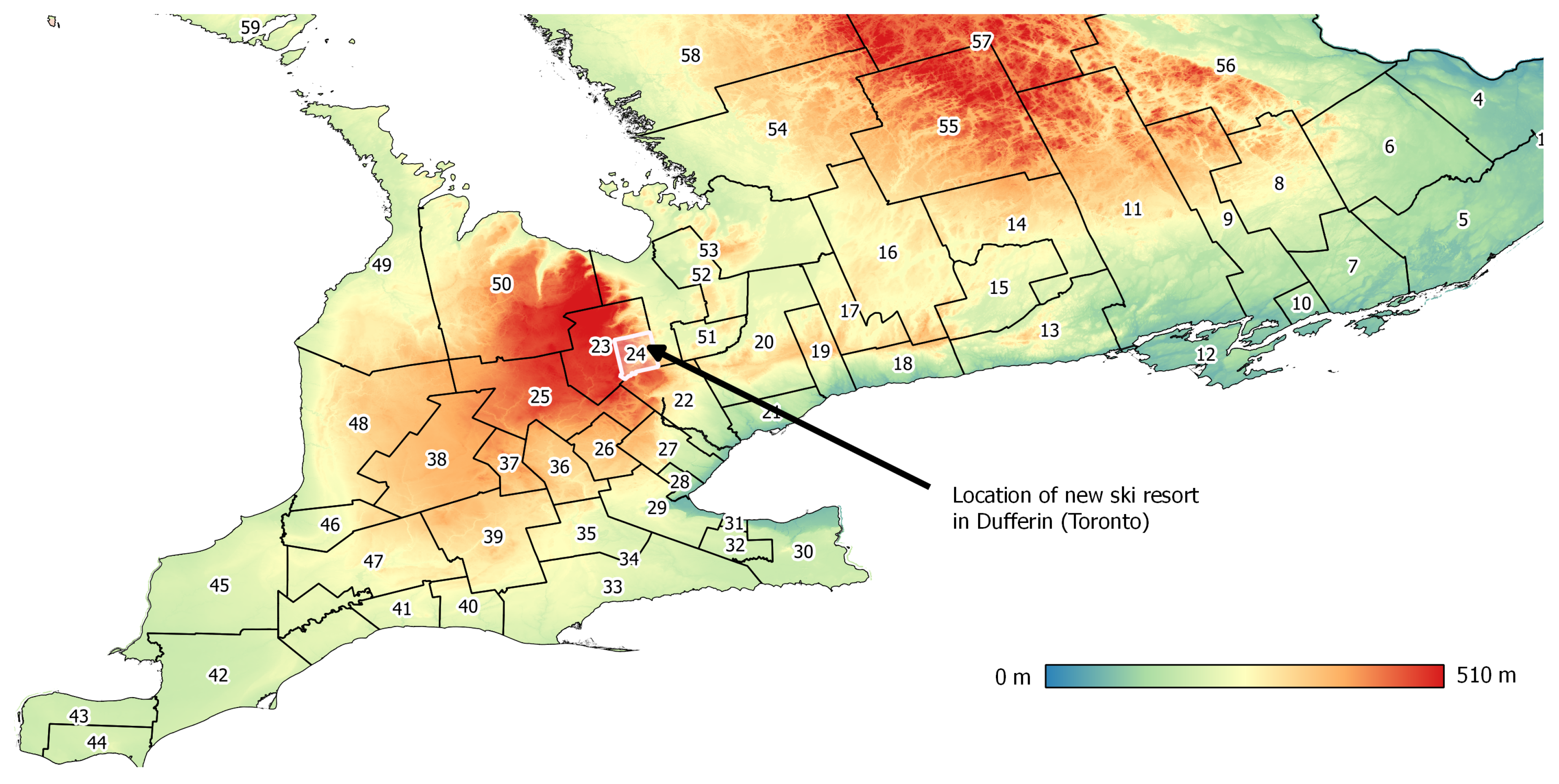
Since CMAs often overlap multiple census divisions, zones were defined by the union of the census division and CMA geometries. The resulting zone system had 69 internal zones for Ontario, the maximum number of destination choices discernible in the TSRC data. Using this approach, the distinction between urban and rural areas was encoded into the zone system. Interestingly, 51.5% of trips in the filtered TSRC survey originated from a CMA and 48.3% had a CMA destination. Both urban and regional areas contribute to long distance travel, with CMAs more likely to be origins than destinations. The final zone system used is presented in
Figure 1.
The travel time, population and employment data was provided at the TAZ level by the project partner for the development of a larger statewide transport model. Each TAZ was assigned to the respective TSRC zone and the socioeconomic variables, namely, population and employment, summed for each zone. To aggregate the auto travel times between all TAZs to the zonal level, the travel time between each child origin–destination pair was weighted by the multiplied populations of the origin and destination.
where
is the travel time between zones
i;
j,
k, and
l are TAZs belonging to zone
j; and
is the population in zone
i.
This approach provides the benefits of considering the range of travel times that may exist between OD pairs. This was particularly important as in some of the larger regional zones, where the population centers are not centrally located. Travel times were available from a provincial transport model. Alternatively, travel times could be collected from Google Maps API (
https://developers.google.com/maps/) or other online routing tools such as Graphhopper (
https://github.com/graphhopper).
2.3. Foursquare
Foursquare collects a wealth of data on where and when users check-in. Data was collected using the Foursquare public venue API (
https://developer.Foursquare.com/overview/venues.html). The API returns a list of venues in JSON format. Each venue record provides the following relevant information.
There are some limitations to the API. Each request is restricted to roughly 1 square degree of longitude and latitude in search area and only the top 50 venues for that search are returned, based on venue popularity. A limit of 5000 requests per hour is also enforced. Foursquare does not publish how the rank of returned venues is determined and the API does not return check-in counts by date. Hence, it could only be used to generate a total metric of activity for each venue, up to the time of the search. For the forecasting of trips to individual venues, this would present a significant obstacle. As such, the Foursquare metrics were only used for identifying the intensity of activity not reflected by socioeconomic variables.
The method to collect the venue data from the Foursquare API was as follows.
A search grid of one degree raster cells was generated for the entire study area.
A selection of potentially important venue categories was curated using the activities specified in the TSRC as a reference.
To exclude Foursquare subcategories such as ‘States & Municipalities’, each category was mapped to at most five main Foursquare venue categories.
The Foursquare API was queried for each cell and category, returning the top 50 venues, adhering to the rate limit of 5000 requests per hour.
The resulting individual venues were stored in a PostGIS database and the number of check-ins for each category and zone were calculated (see
Table 2).
Duplicate venues were removed.
In total, 34,041 unique venues and 7,981,458 check-ins were collected for the different categories.
4. Model Estimation and Results
This section discusses the estimation results of the destination choice models, shown in
Table 4. The dataset was split into three categories, representing the three travel purposes: leisure, visit and business. In the first model iteration, model A, only the TSRC data was used to generate parameters.
The NRMSE considers the sample size of the estimation data by dividing the RMSE by the standard division of the observed values, to allow for the comparison of the model performance across trip purposes, despite their varying sample sizes. In terms of both the and normalized root mean square error (NRMSE), the results of this first model were good, particularly when compared to the singly-constrained gravity model estimated on the same dataset. However, the performance of the leisure sub-model was the weakest.
Furthermore, all parameters were highly significant and had the expected signs. The parameter signs and magnitude vary strongly across trip purposes. Business was the only purpose for which urban destinations were more likely to attract urban trips. On the other hand, leisure travelers were more likely to head for destinations outside the city. For visitation, there was a weak positive effect towards urban areas.
There was a strong negative effect of urban intra-zonal connections for all trip purposes, whereas for intra-zonal rural travel the effect was positive. This was as expected as urban areas are often too small to support long distance trips (those over 40 km). In rural zones, which are larger, the power law of travel distance means that long distance trips crossing into other zones are less likely [
18]. The large negative coefficient for leisure intra-metro travel, combined with the other two origin–destination interaction parameters for leisure travel, suggest a strong preference for leaving urban areas for leisure. This is supported by the TSRC data, where the key leisure travel reasons include outdoor activities such as skiing, visiting national parks and camping.
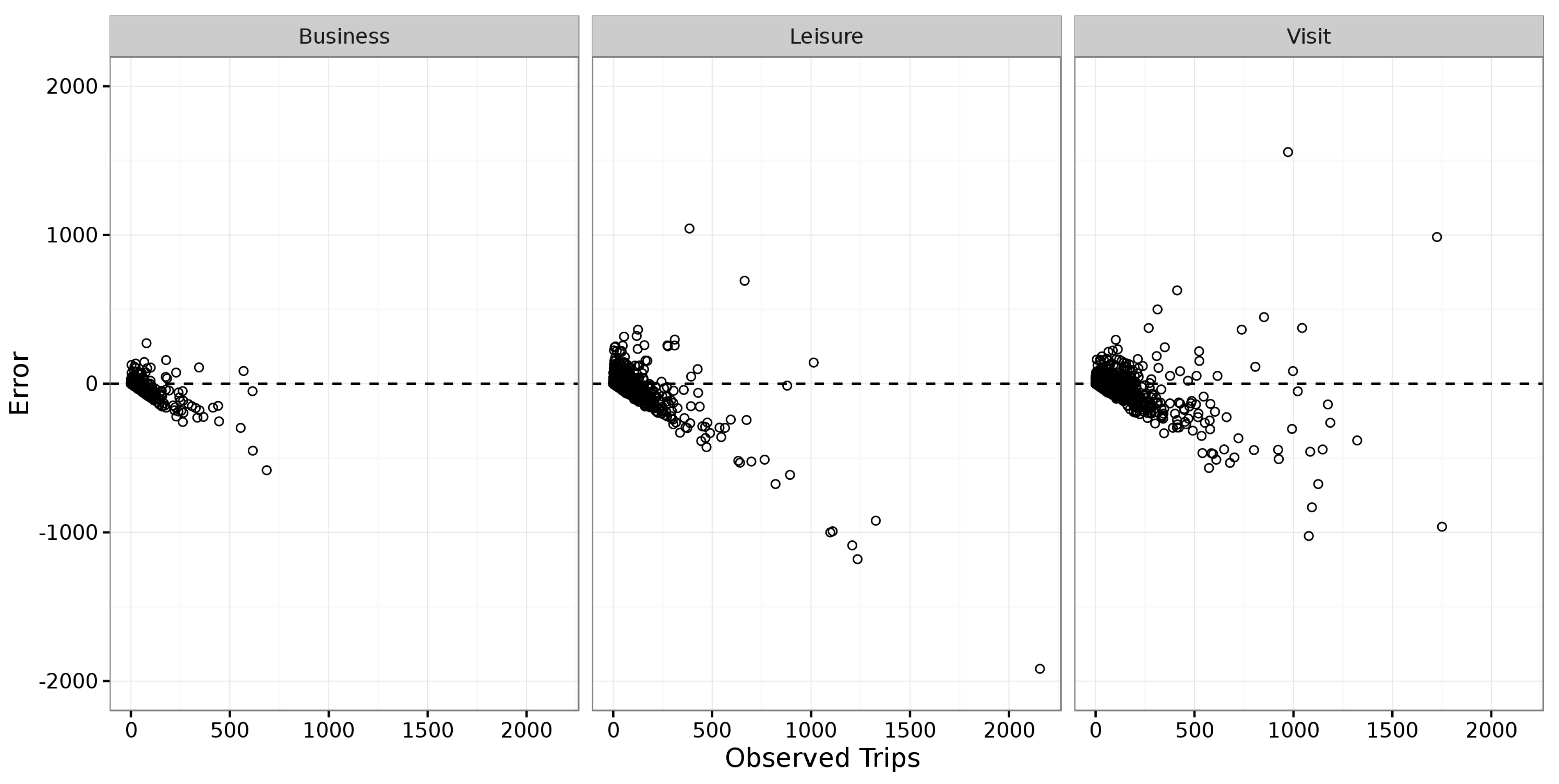
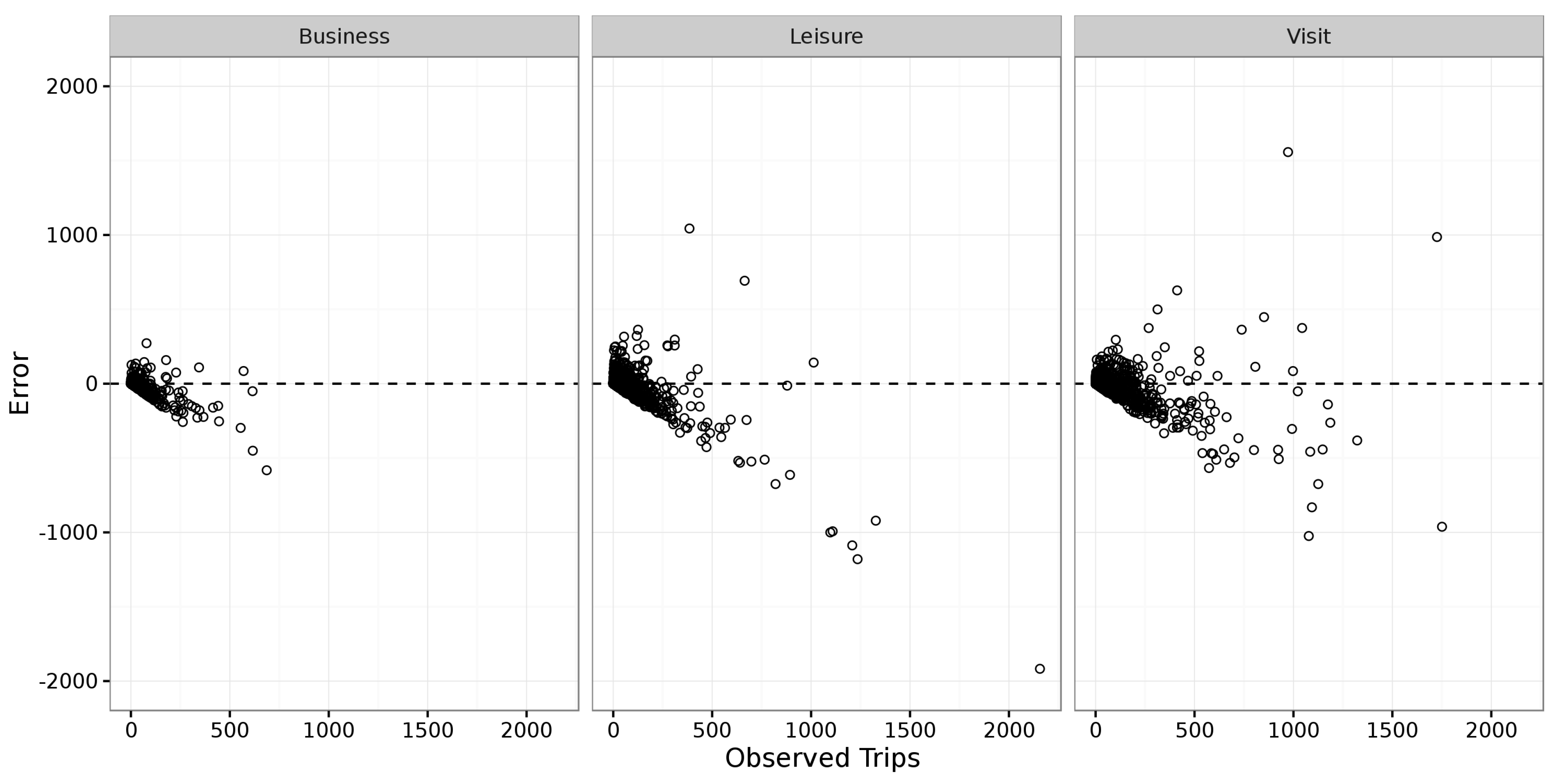
On closer inspection, the residuals graph in
Figure 2 indicate that model A underestimated OD pairs with large numbers of trips and greatly overestimated some other smaller OD pairs. These sources of error fall into two categories:
In model B, certain categories based on Foursquare check-ins were found to be significant for particular trip purposes, i.e., the outdoor category for leisure trips and the medical category for visit trips. It is logical that the presence of hotels and sightseeing venues would be particularly important for leisure travel, and this was appropriately reflected in the coefficients in the model. The number of hotel check-ins was a significant variable across all trip purposes for long distance travel. Additionally, business conferences are often located in areas of significance to tourism as a way of promoting an event, supporting the large coefficient for sightseeing in the business category. The presence of medical facilities was found to be influential on the attractiveness of visit trip destinations. In model A, leisure trips to the zone containing Niagara Falls were underestimated by 85%. In model B, the Niagara variable controlled for this using the sightseeing category for leisure travel to the Niagara zone. Two variables, outdoors and skiing were found to be significant only for leisure travel in the season in which the respective activity is normally performed.
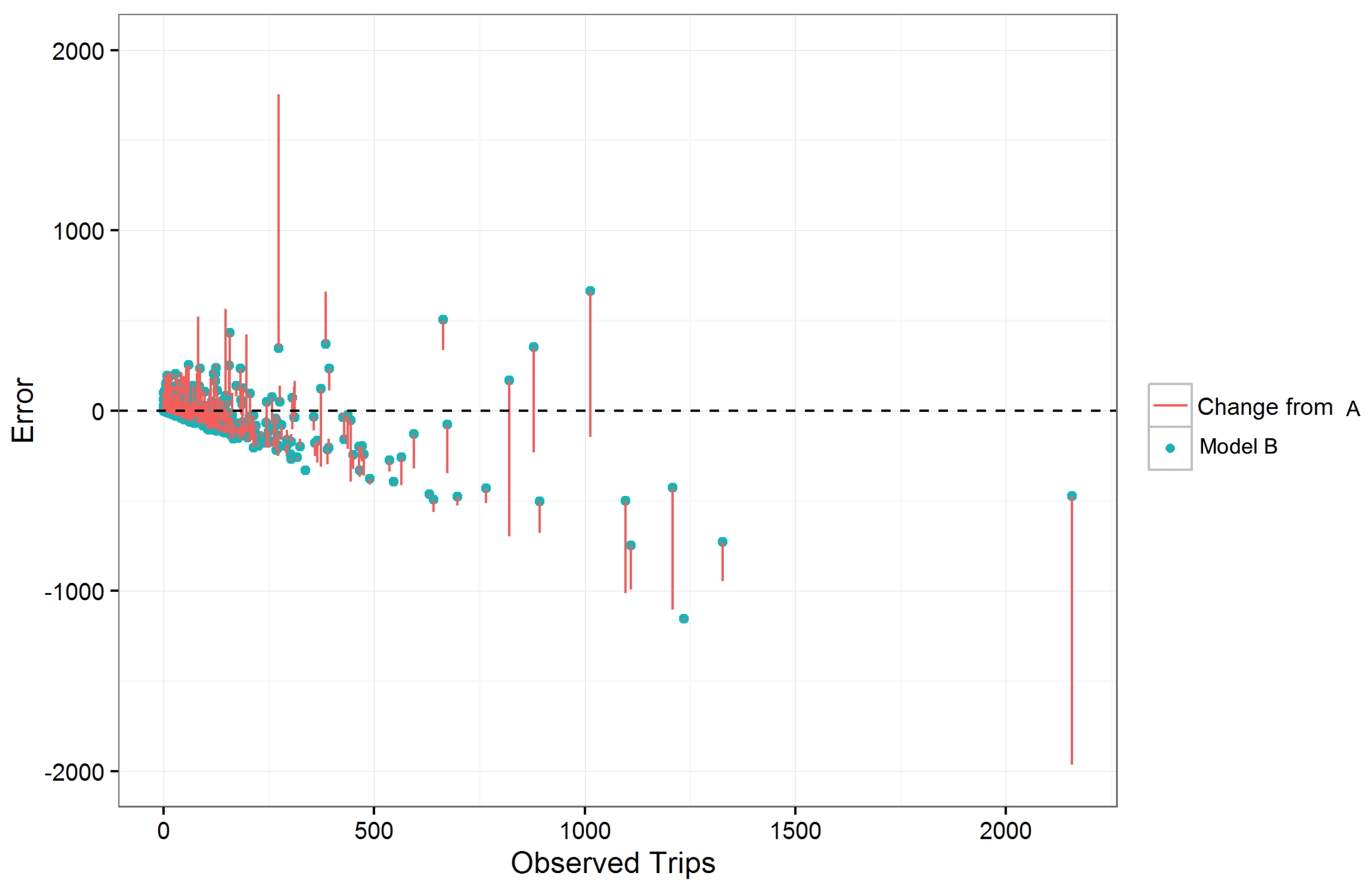
Overall, model B performed better across all trip purposes than model A, demonstrating the benefit of including the Foursquare based parameters. Particularly noticeable was the large improvement across all metrics for leisure travel.
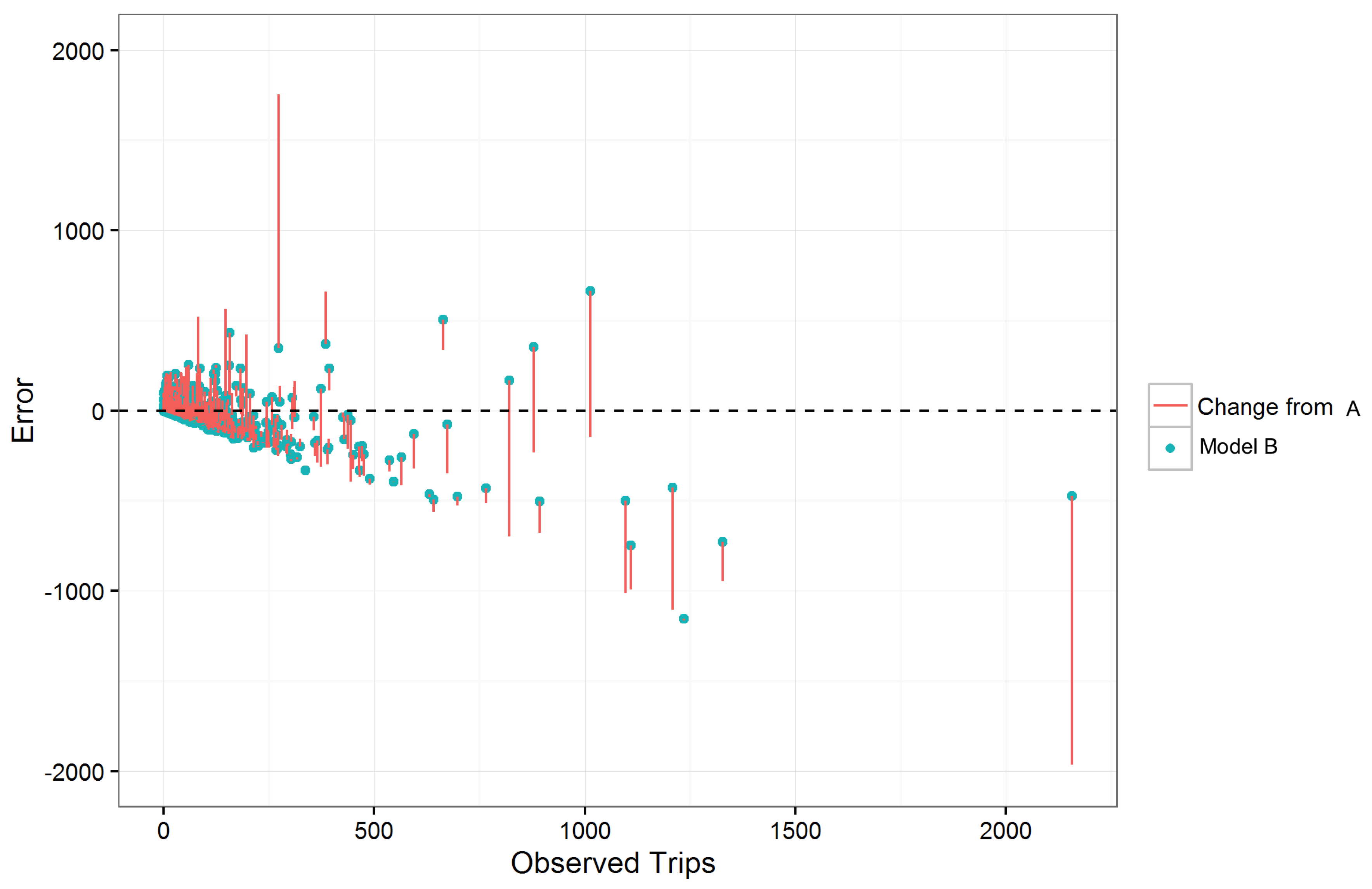
Figure 3 shows the impact of the Foursquare variables for leisure travel. While it is hard to visualize the impacts for smaller OD pairs, the graph illustrates how the errors for major OD pairs were reduced.
In both figures, there is a clear trend from the overestimation of trip counts for small OD pairs, to an underestimation as the number of observed trips increases. There are two reasons for the apparent trend. Firstly, there were 7819 OD pairs over the three trip purposes, with the majority having both very small trip counts and very small errors; 92% of the OD pairs had expected trip count of less than 100 and 99% of the residual error data points in
Figure 3 are also less than 100. This significant skew means that the outliers, namely those that visualize a trend, constituted a very small portion of the dataset. Secondly, the trip count of an OD pair has a lower bound of zero but no upper bound. This lower bound is responsible for the linear lower limits observable in the residual graphs,
Figure 2 and
Figure 3. Fortunately, the trip counts were improved for both large and small OD by adding Foursquare data, as indicated by the vertical lines in
Figure 3.
Scenario Analysis—Case Study of a New Ski Resort
This section presents a hypothetical application of the destination choice model. For any large scale land-use planning or development, it is important to model the impacts that such development would have on the transport network. As an example of this, a hypothetical scenario of the development of a large new ski resort was conducted. Ski resorts not only provide infrastructure for skiing and other snow-based activities but require the development of multiple new hotels, employee housing, and retail infrastructure. In the winter months, ski resorts place significant demands on the transport network that must be taken account when considering such a development.
In the hypothetical scenario, a new resort is proposed for the highlands area north of Toronto in Dufferin (Toronto CMA) (see
Figure 4). Its development is expected to bring similar numbers of visitors as other large resorts in Ontario. Three average sized hotels will also be built at the base of the resort to accommodate guests. In the summer, the resort will attract visitors by providing mountain biking facilities and hiking. Additional housing for 400 new residents are required to support 300 jobs. This scenario does not consider other policy and development considerations, such as site location and transport access. The impact of the new development was estimated by adjusting the hotels, skiing and outdoor variables for the zone in which the development will take place. The Foursquare POI database developed in
Section 2.3 was used to estimate adjustments for each of the categories. Taking all venues in Ontario, the average number of check-ins per venue for each search category was calculated. The following adjustments were made for the respective zones and their values are displayed in
Table 5.
Skiing: The average number of check-ins for ski areas
Hotel: Twice the average number of check-ins for hotels
Outdoor: The average number of check-ins per outdoor venue
The trips from the TSRC data used for estimation were used as input to the scenario, with
copies of each record added to the trip table, where
w is the trip weight of the record. The weighted TSRC data represents the trip count over four years. For simplicity, the weights were scaled to give the approximate number of daily trips. Twenty iterations of the scenario were performed using a calibrated version of model B to account for the stochastic nature of destination choice. The calibration process was documented in [
17].
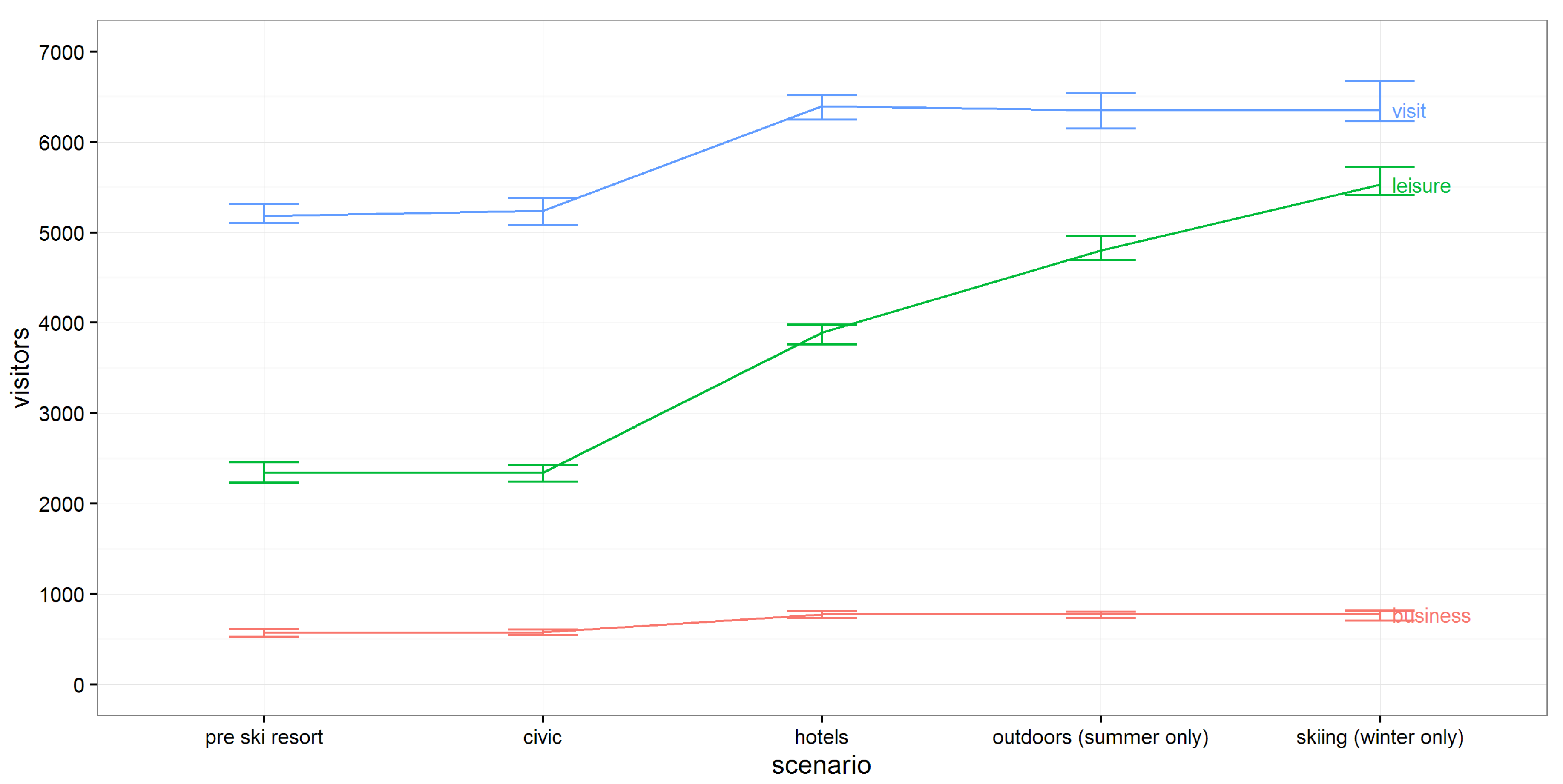
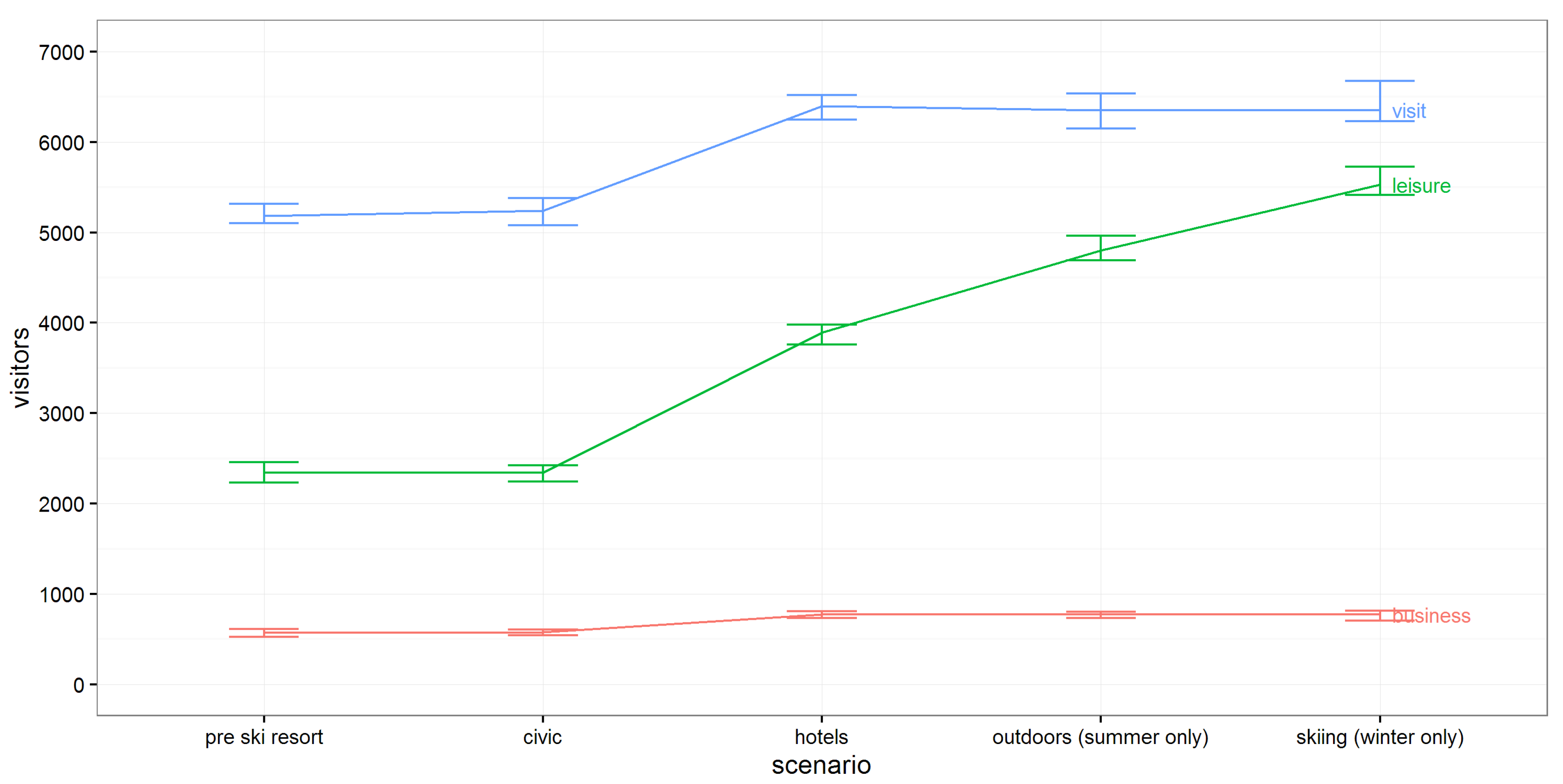
Figure 5 shows the increase in incoming trips to Dufferin due to the new ski resort. The cumulative impact of each input is presented from left to right, with the rightmost column being the total impact of the combined parameters. The results show that the parameters behave reasonably. In particular the attractive effect for leisure travel is clearly visible. Without the Foursquare based parameters, the number of leisure trips would in fact decrease with the addition of a new ski resort, due to the negative coefficient of the
variable in model A for leisure travel. This is a good example of why better representations of destination attractiveness are important, particularly for leisure travel.
5. Discussion
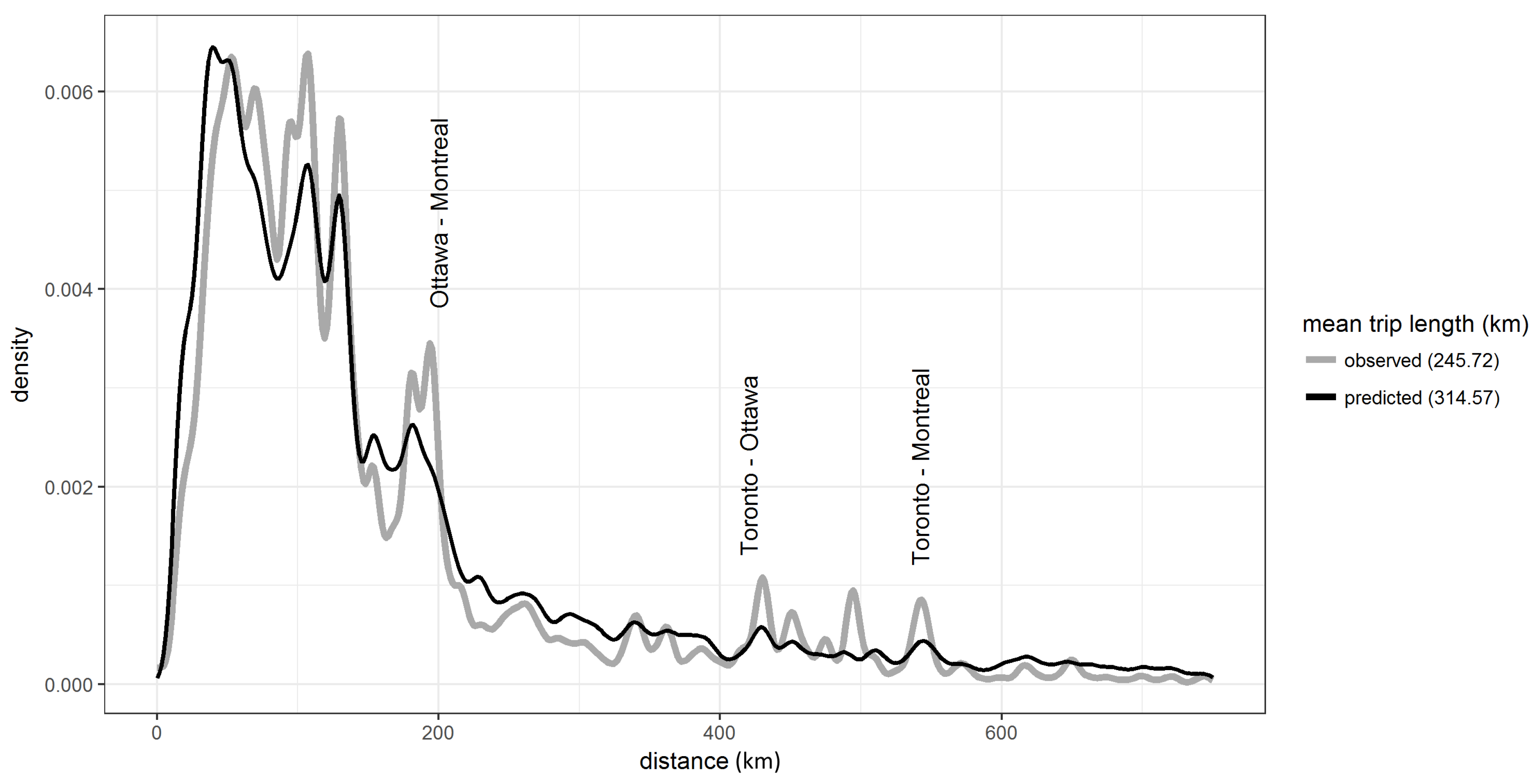
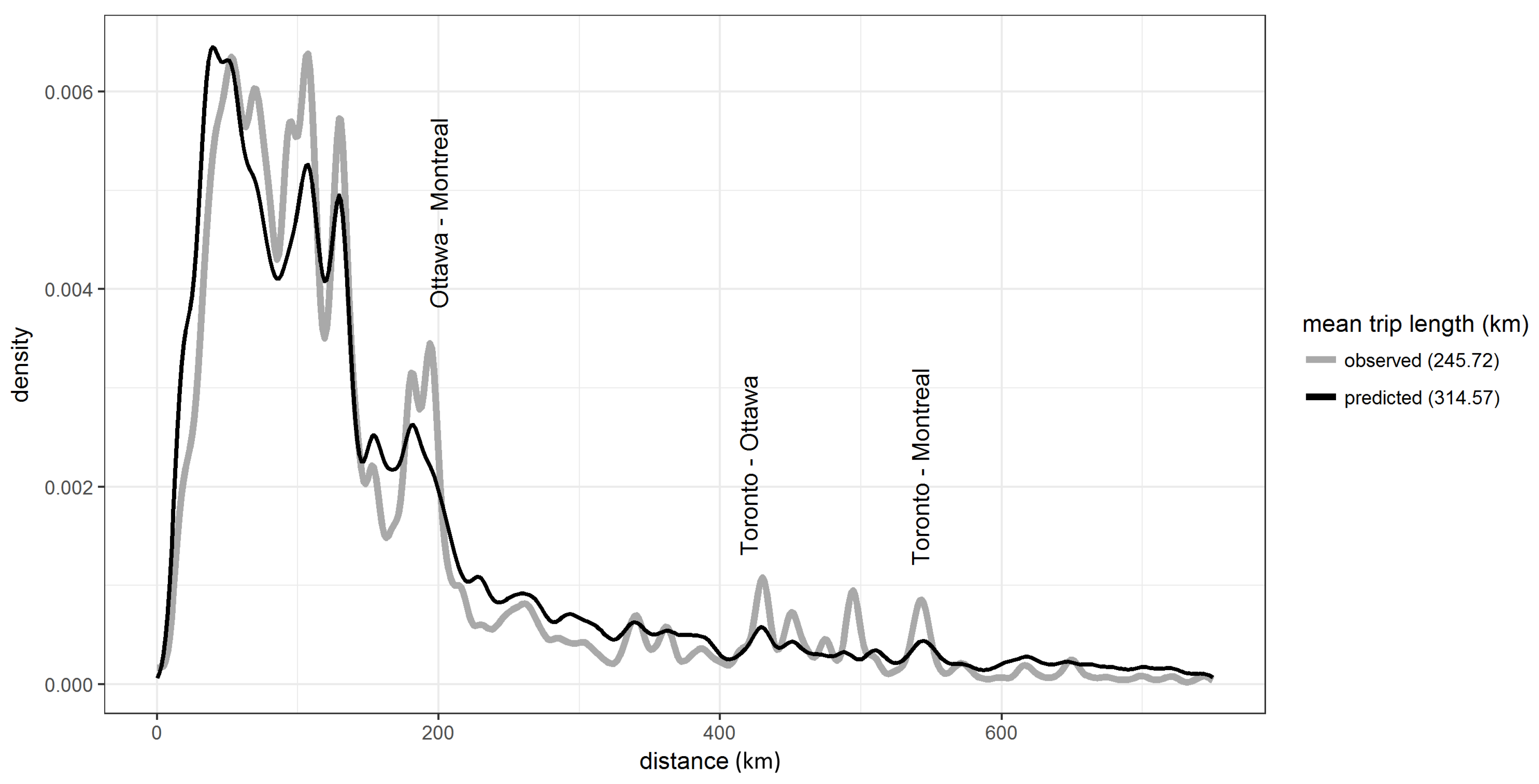
A closer inspection of the OD matrix generated by model B on the estimated data indicated the model still overestimated the number of intra-zonal trips within Toronto and underestimated the inter-zonal trips between large population centers, such as Toronto, Ottawa and Montreal.
Figure 6 identifies the connections where the model falls short. The connections between the triangle of major cities, Toronto, Montreal and Ottawa are underestimated. The car journey from Toronto to Ottawa takes over four hours, while flying takes only 55 minutes. For this paper, only a skim matrix for car travel was available. The incorporation of travel times for all modes and the inclusion of feedback from the mode choice model, when available, would improve the estimation of these connections.
While there has been a ‘virtual explosion of data availability’ [
19], Horni and Axhausen [
20] note that the collection of big data such as GPS and GSM data “is generally associated with privacy, cost and technical issues”. These challenges go against the ideal of general models that are flexible and transferable [
21]. Nonetheless, big data undoubtedly has a role to play in the future of transport modeling. Erath [
22] suggests further research into probabilistic models based on big data and the blending of big data with data from travel diaries.
Venue data for each zone acted as database of the points of interest (POI) at a particular destination. POI data is available from many sources, such as Open Street Maps. However, LBSNs such as Foursquare take this POI database one step further, by measuring the popularity of each POI. In the case of Foursquare, check-ins measure the intensity of activity at each POI. A measure of importance is clearly beneficial in the model presented above, as not all POIs are equal; hotels are of different sizes and some national parks are more visited than others. Of course, the importance of each POI can be measured based on attributes such as the number of hotel beds or recorded visitors per year. However, the data collection required is prohibitive for most large scale models. LBSNs provides easily accessible data on the importance of individual POIs and, in turn, destination utility.
A mention must be made of the issue of model endogeneity. In reality, an increase in visits to a destination would most probably cause an increase in the number of check-ins. This leads to an endogeneity problem between the independent and dependent variables. One solution to avoid the endogeneity problem would be to use lagged variables, where the Foursquare check-ins are tallied from a period occurring before the TSRC data. Unfortunately, the public Foursquare API, at this time, does not allow the analyst to specify a time window. Hence, in this particular model, the endogeneity problem had to be accepted. Nonetheless, the work presented in this paper demonstrated the potential of such services to enhance our transportation models beyond the limitations of travel diaries and socioeconomic datasets.
Limitations and Future Work
One of the benefits of models based on socioeconomic variables is the ability to run the model for future years and model the impacts of demographic change. Forecasting the Foursquare check-in counts for different categories presents challenges to the modeler. Not only is it hard to predict how the popularity of certain venues will grow or decline in future years, but the quantity of check-ins depends on the uptake of the Foursquare platform and the potential emergence of competing platforms. Further study of the demographics of Foursquare users would help to define the statistical limitations of LBSN-based models. In future work utilizing more detailed Foursquare data, check-ins could be filtered for those performed only by residents of Canada or grouped by season to further improve the modeling of different trip purposes.
In study on why people use Foursquare, Lindqvist et al. [
6] found that ‘participants expressed reluctance to check-in at home, work, and other places that one might expect them to be at’. This suggests that there are limits to how effectively Foursquare can model travel behavior. A potential alternative would be to take Foursquare or a similar LBSN as a POI database and use GPS traces to identify or impute the intensity of activity at these locations, thereby avoiding the selective reporting behavior evident in Foursquare usage.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}