
Generation Method for Shaded Relief Based on Conditional Generative Adversarial Nets


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
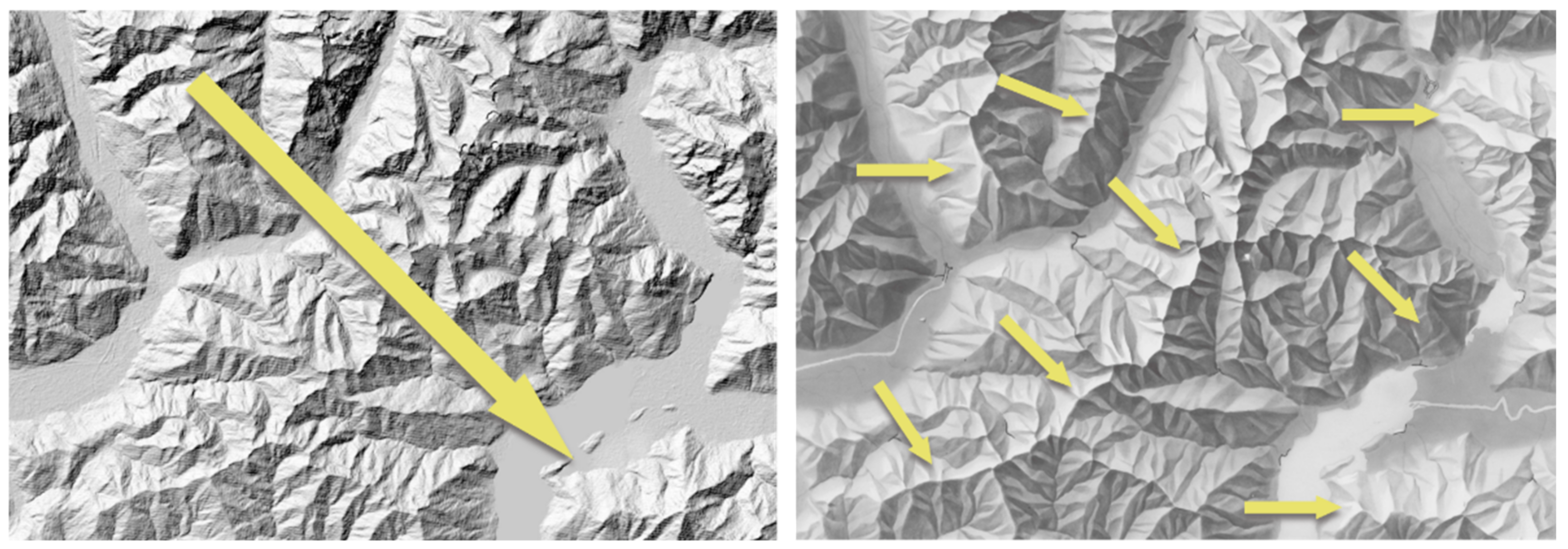
:1. Introduction
2. Related Work
3. Materials and Methods
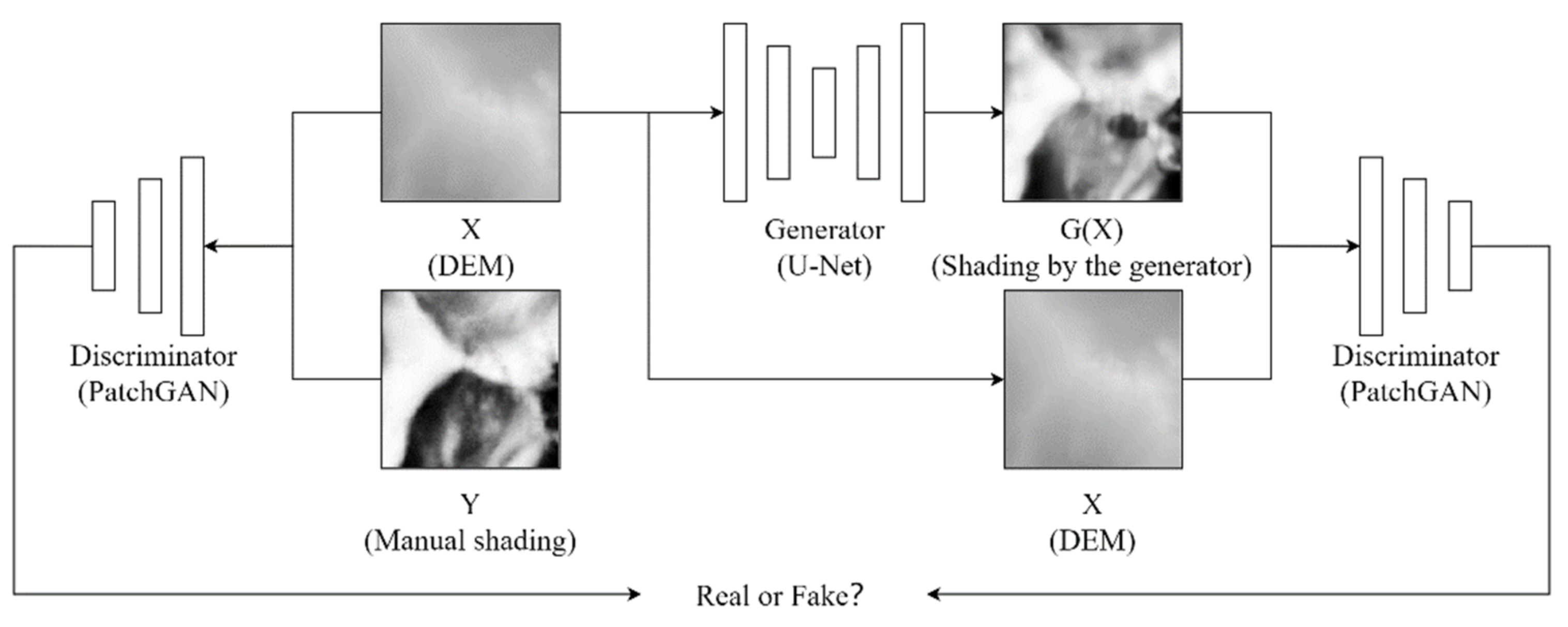
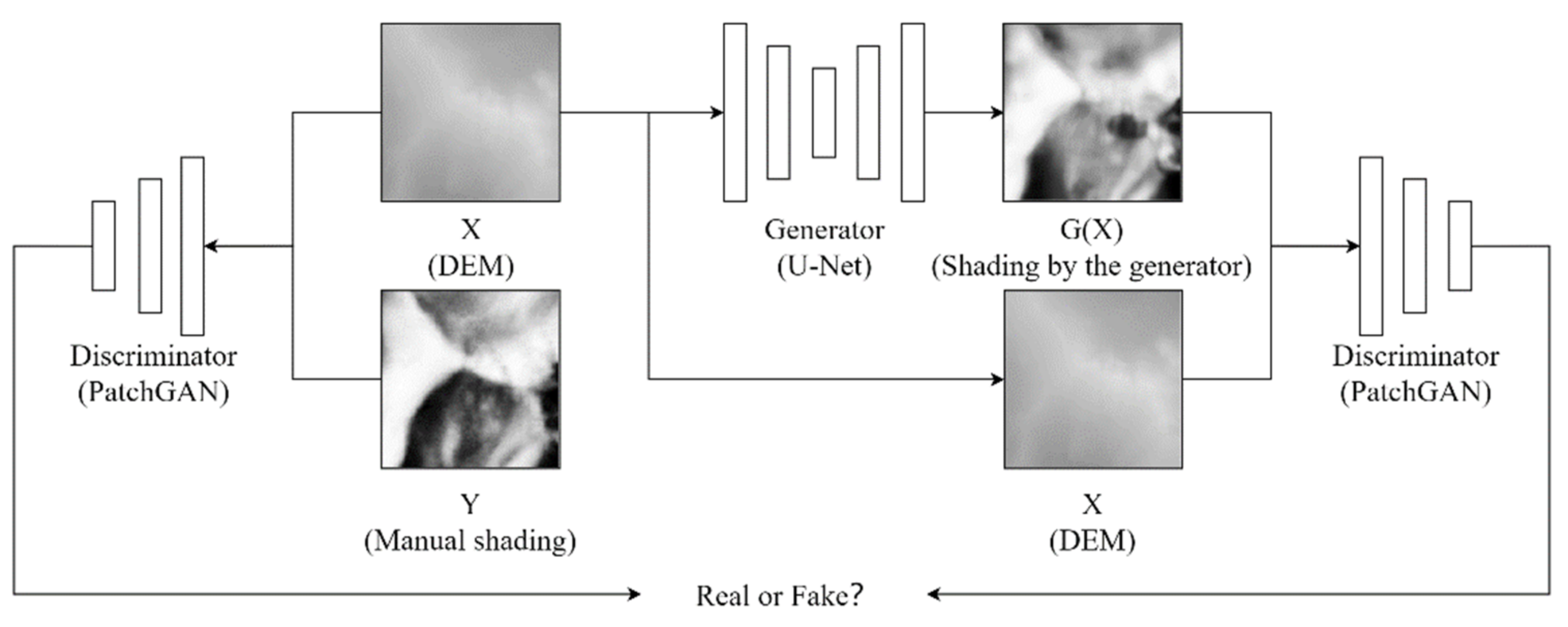
3.1. Network Architecture
3.2. Data and Pre-Processing
3.3. Network Training and Output
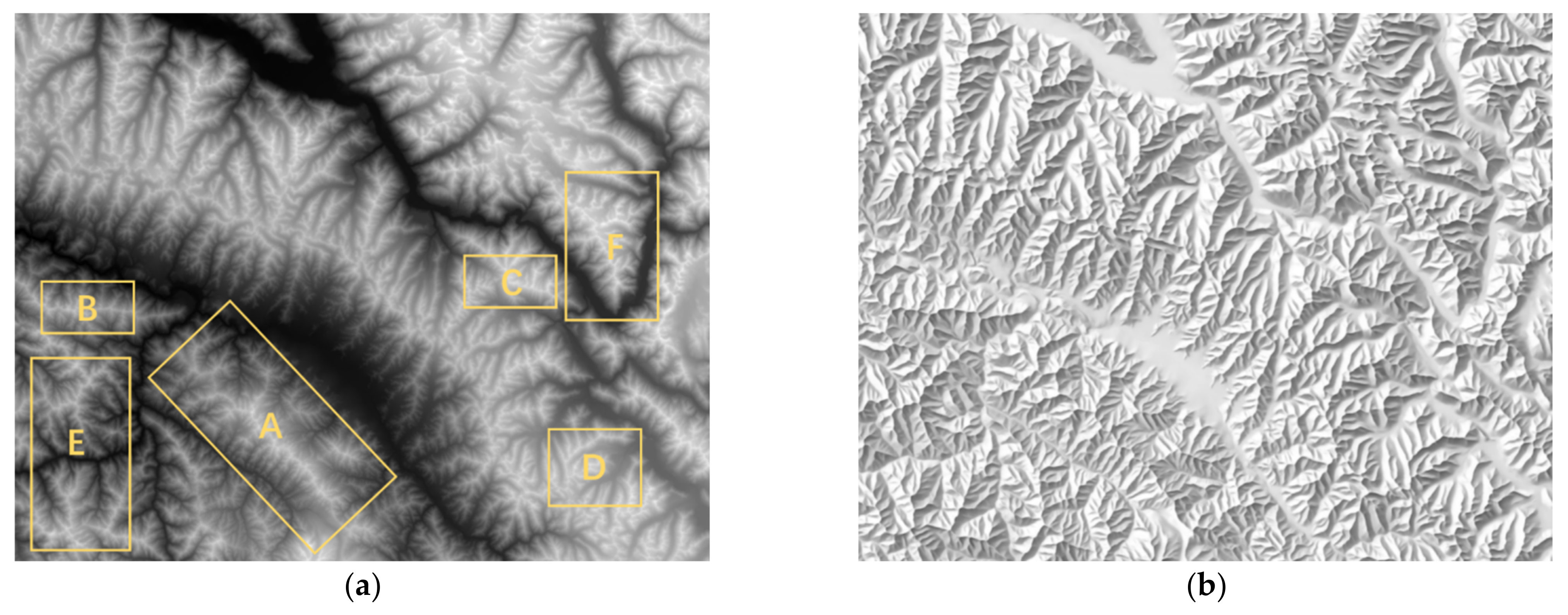
4. Results and Discussion
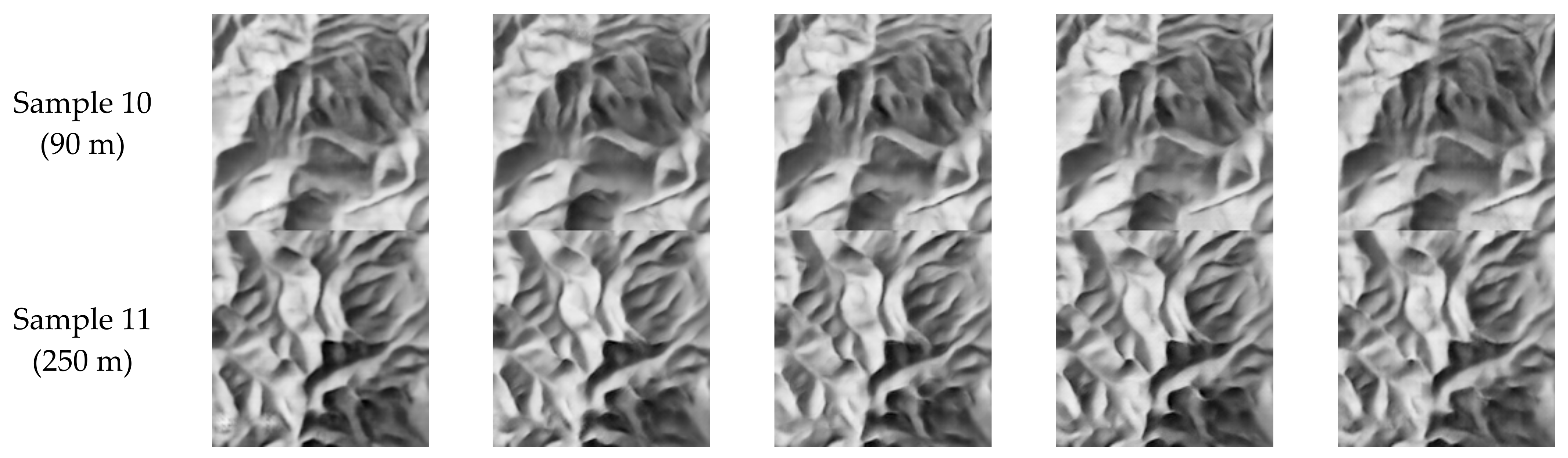
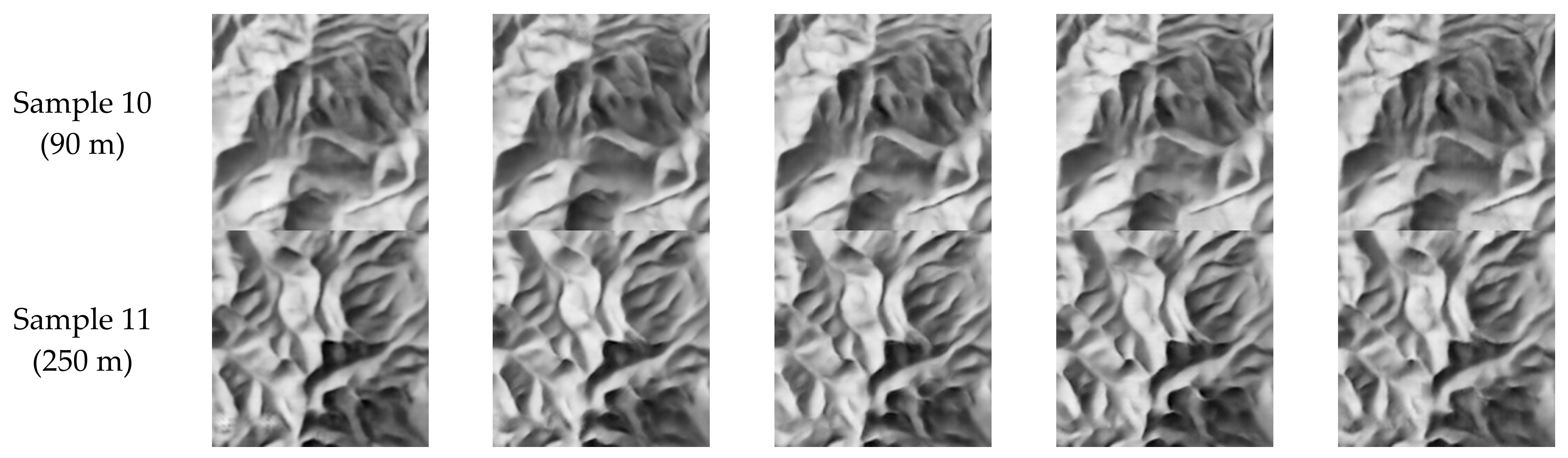
4.1. Determination of Hyperparameters
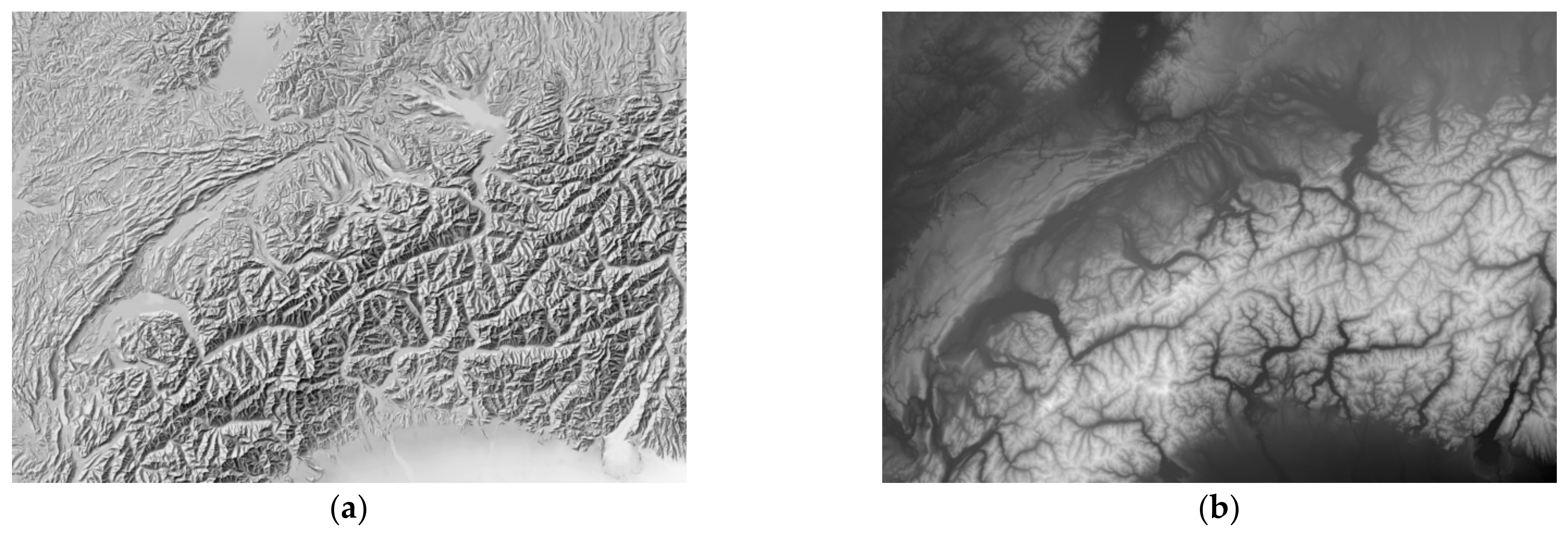
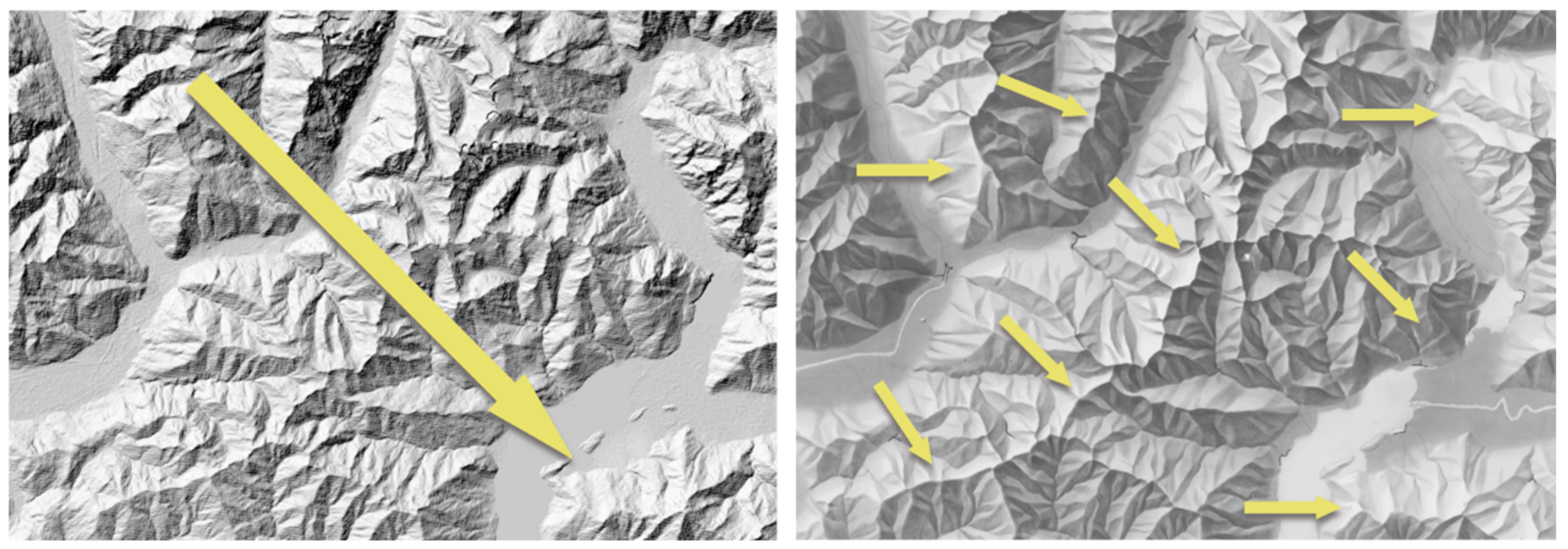
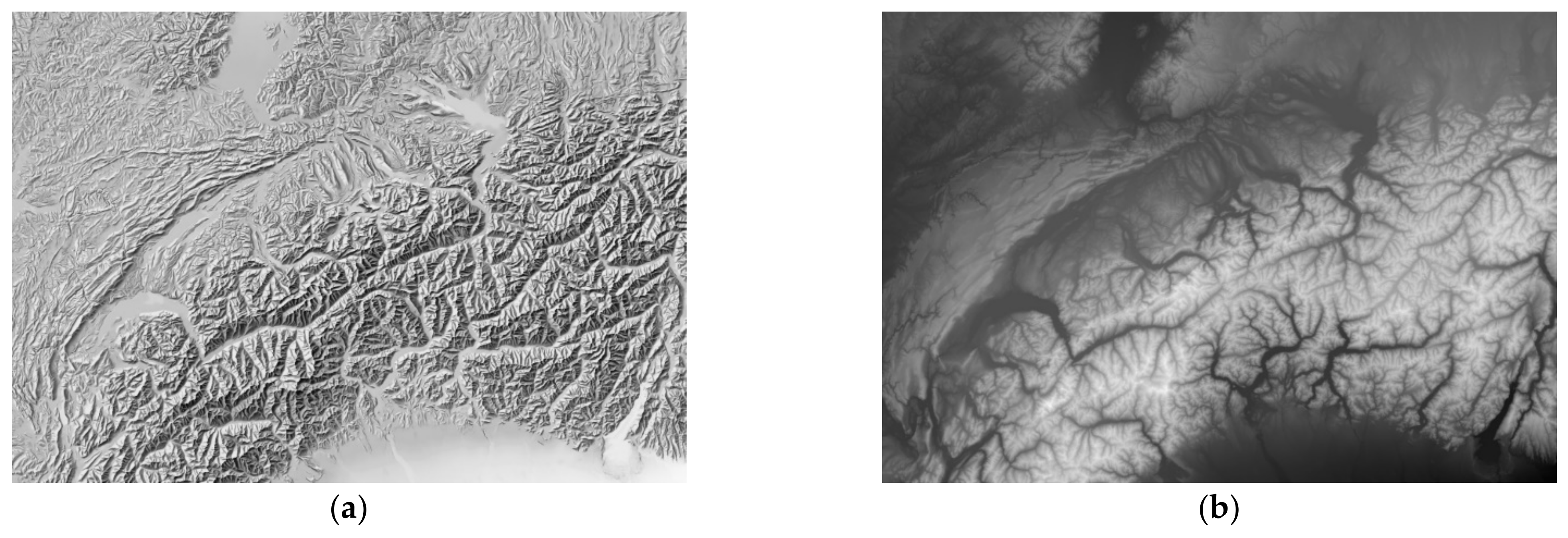
4.2. Comparison with Analytical Shading
4.3. Comparison with Manual Shading
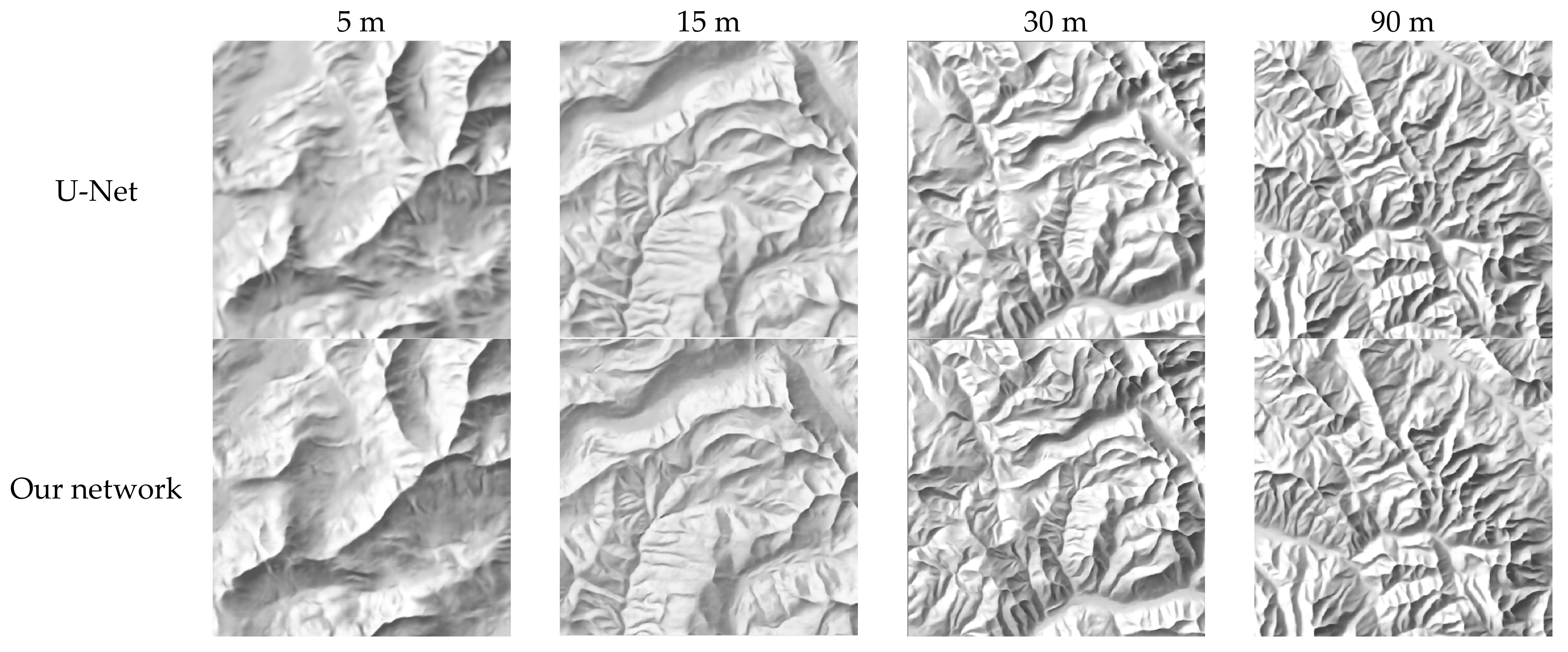
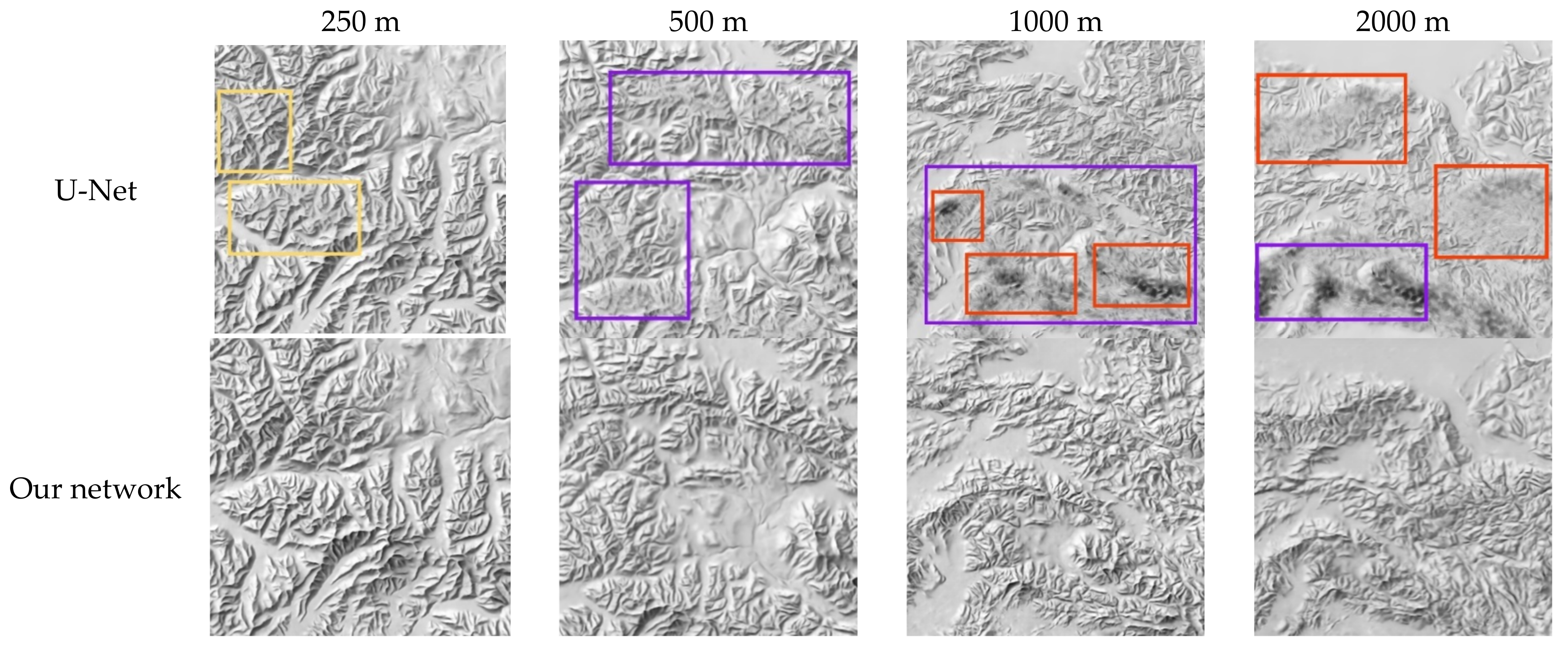
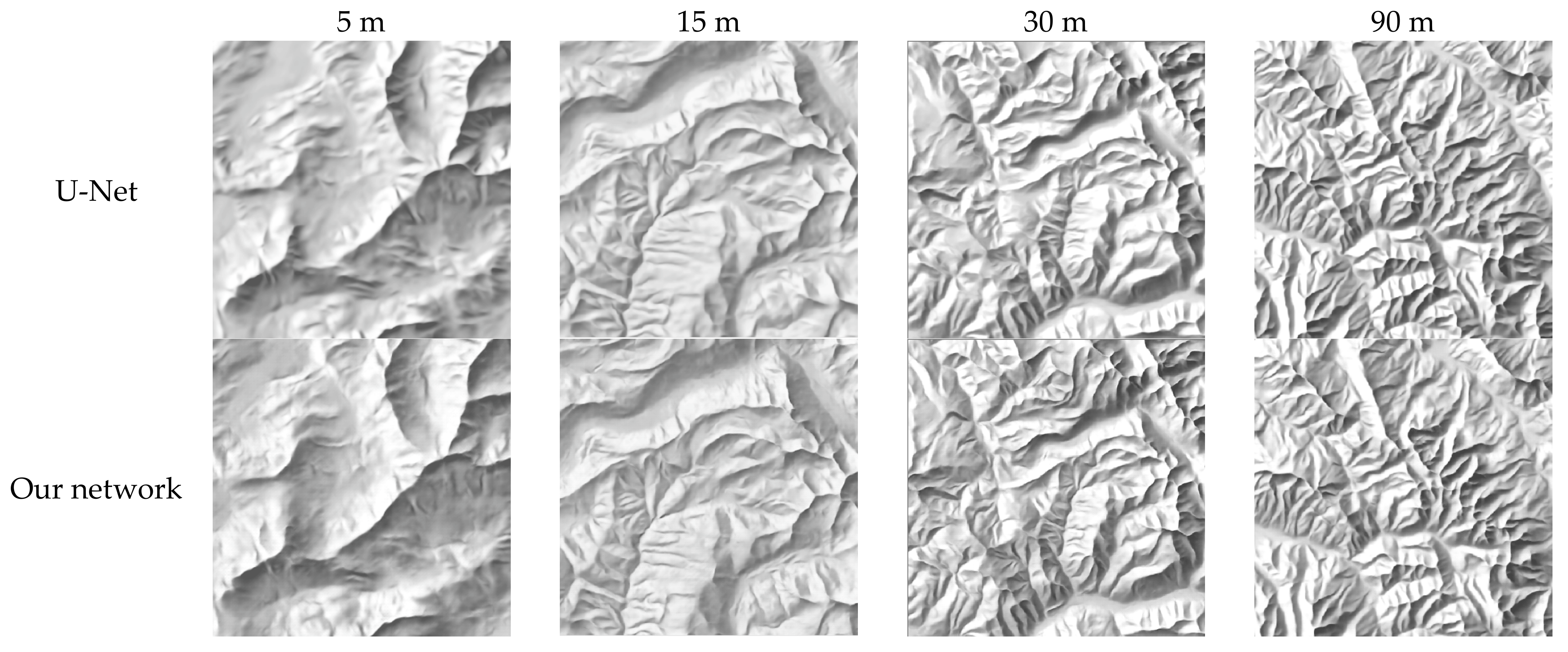
4.4. Comparison with Other Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, J.; Sun, Q.; Wang, G.; Jiang, N.; Lyu, X. Principle and Method of Cartography, 2nd ed.; Science Press: Beijing, China, 2014. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE Publications: Columbus, OH, USA, 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE Publications: Boston, MA, USA, 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; SenGupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Dong, Y.; Tang, G. Research on Terrain Simplification Using Terrain Significance Information Index From Digital Elevation Models. Geomat. Inf. Sci. Wuhan Univ. 2013, 38, 353–357. [Google Scholar] [CrossRef]
- Ai, T.; Li, J. A DEM Generalization by Minor Valley Branch Detection and Grid Filling. ISPRS J. Photogramm. Remote Sens. 2010, 65, 198–207. [Google Scholar] [CrossRef]
- Li, J.; Li, D. A DEM Generalization by Catchment Area Combination. Geomat. Inf. Sci. Wuhan Univ. 2015, 40, 1095–1099. [Google Scholar] [CrossRef]
- Geisthövel, R.; Hurni, L. Automated Swiss-Style Relief Shading and Rock Hachuring. Cartogr. J. 2018, 55, 341–361. [Google Scholar] [CrossRef]
- Jenny, B. Terrain Generalization With Line Integral Convolution. Cartogr. Geogr. Inf. Sci. 2021, 48, 78–92. [Google Scholar] [CrossRef]
- He, Z.; Guo, Q.; Zhao, M.; Liu, J.; Zhang, J.; Li, X.; Liang, Z. Research on DEM Automatic Generalisation in Complex Geomorphic Areas Based on Wavelet Analysis. Geogr. Geo-Inf. Sci. 2019, 4, 57–63. [Google Scholar]
- Lindsay, J.B.; Francioni, A.; Cockburn, J.M.H. LiDAR DEM Smoothing and the Preservation of Drainage Features. Remote Sens. 2019, 11, 1926. [Google Scholar] [CrossRef] [Green Version]
- Raposo, P. Variable DEM Generalization Using Local Entropy for Terrain Representation Through Scale. Int. J. Cartogr. 2020, 6, 99–120. [Google Scholar] [CrossRef]
- Yu, W.; Zhang, Y.; Ai, T.; Chen, Z. An Integrated Method for DEM Simplification With Terrain Structural Features and Smooth Morphology Preserved. Int. J. Geogr. Inf. Sci. 2021, 35, 273–295. [Google Scholar] [CrossRef]
- Imhof, E. Cartographic Relief Presentation; ESRI Press: Redlands, CA, USA, 2007. [Google Scholar]
- Jenny, B. An Interactive Approach to Analytical Relief Shading. Cartographica 2001, 38, 67–75. [Google Scholar] [CrossRef]
- Marston, B.E.; Jenny, B. Improving the Representation of Major Landforms in Analytical Relief Shading. Int. J. Geogr. Inf. Sci. 2015, 29, 1144–1165. [Google Scholar] [CrossRef]
- Veronesi, F.; Hurni, L. A GIS Tool to Increase the Visual Quality of Relief Shading by Automatically Changing the Light Direction. Comput. Geosci. 2015, 74, 121–127. [Google Scholar] [CrossRef]
- Veronesi, F.; Hurni, L. Changing the Light Azimuth in Shaded Relief Representation by Clustering Aspect. Cartogr. J. 2014, 51, 291–300. [Google Scholar] [CrossRef]
- Kennelly, P.J.; Stewart, A.J. General Sky Models for Illuminating Terrains. Int. J. Geogr. Inf. Sci. 2014, 28, 383–406. [Google Scholar] [CrossRef]
- Florinsky, I.V.; Filippov, S.V. Three-Dimensional Terrain Modeling with Multiple-Source Illumination. Trans. GIS 2019, 23, 937–959. [Google Scholar] [CrossRef]
- Kennelly, P.J. Terrain Maps Displaying Hill-Shading with Curvature. Geomorphology 2008, 102, 567–577. [Google Scholar] [CrossRef]
- Podobnikar, T. Multidirectional Visibility Index for Analytical Shading Enhancement. Cartogr. J. 2012, 49, 195–207. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Patterson, T. Designing the Equal Earth Physical Map. Available online: https://youtu.be/UYQ6vhxc9Dw (accessed on 8 April 2022).
- Jenny, B.; Heitzler, M.; Singh, D.; Farmakis-Serebryakova, M.; Liu, J.C.; Hurni, L. Cartographic Relief Shading with Neural Networks. IEEE Trans. Vis. Comput. Graph. 2021, 27, 1225–1235. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Publications: Honolulu, HI, USA, 2017; pp. 5967–5976. [Google Scholar] [CrossRef] [Green Version]
- Heitzler, M.; Hurni, L. Cartographic Reconstruction of Building Footprints from Historical Maps: A Study on the Swiss Siegfried Map. Trans. GIS 2020, 24, 442–461.32. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE Publications: Santiago, Chile, 2015; pp. 1026–1034. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Sky Models. Available online: http://watkins.cs.queensu.ca/~jstewart/skyModels.zip (accessed on 8 April 2022).
- Shaded Relief Archive. Available online: http://www.shadedreliefarchive.com (accessed on 8 April 2022).
- Kennelly, P.J.; Patterson, T.; Jenny, B.; Huffman, D.P.; Marston, B.E.; Bell, S.; Tait, A.M. Elevation Models for Reproducible Evaluation of Terrain Representation. Cartogr. Geogr. Inf. Sci. 2021, 48, 63–77. [Google Scholar] [CrossRef]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Yin, G.; Ma, J.; Wen, B.; Zhou, Z. Generation Method for Shaded Relief Based on Conditional Generative Adversarial Nets. ISPRS Int. J. Geo-Inf. 2022, 11, 374. https://doi.org/10.3390/ijgi11070374
Li S, Yin G, Ma J, Wen B, Zhou Z. Generation Method for Shaded Relief Based on Conditional Generative Adversarial Nets. ISPRS International Journal of Geo-Information. 2022; 11(7):374. https://doi.org/10.3390/ijgi11070374
Chicago/Turabian StyleLi, Shaomei, Guangzhi Yin, Jingzhen Ma, Bowei Wen, and Zhao Zhou. 2022. "Generation Method for Shaded Relief Based on Conditional Generative Adversarial Nets" ISPRS International Journal of Geo-Information 11, no. 7: 374. https://doi.org/10.3390/ijgi11070374
APA StyleLi, S., Yin, G., Ma, J., Wen, B., & Zhou, Z. (2022). Generation Method for Shaded Relief Based on Conditional Generative Adversarial Nets. ISPRS International Journal of Geo-Information, 11(7), 374. https://doi.org/10.3390/ijgi11070374