
Improvement of Oracle Bone Inscription Recognition Accuracy: A Deep Learning Perspective



Abstract
:1. Introduction
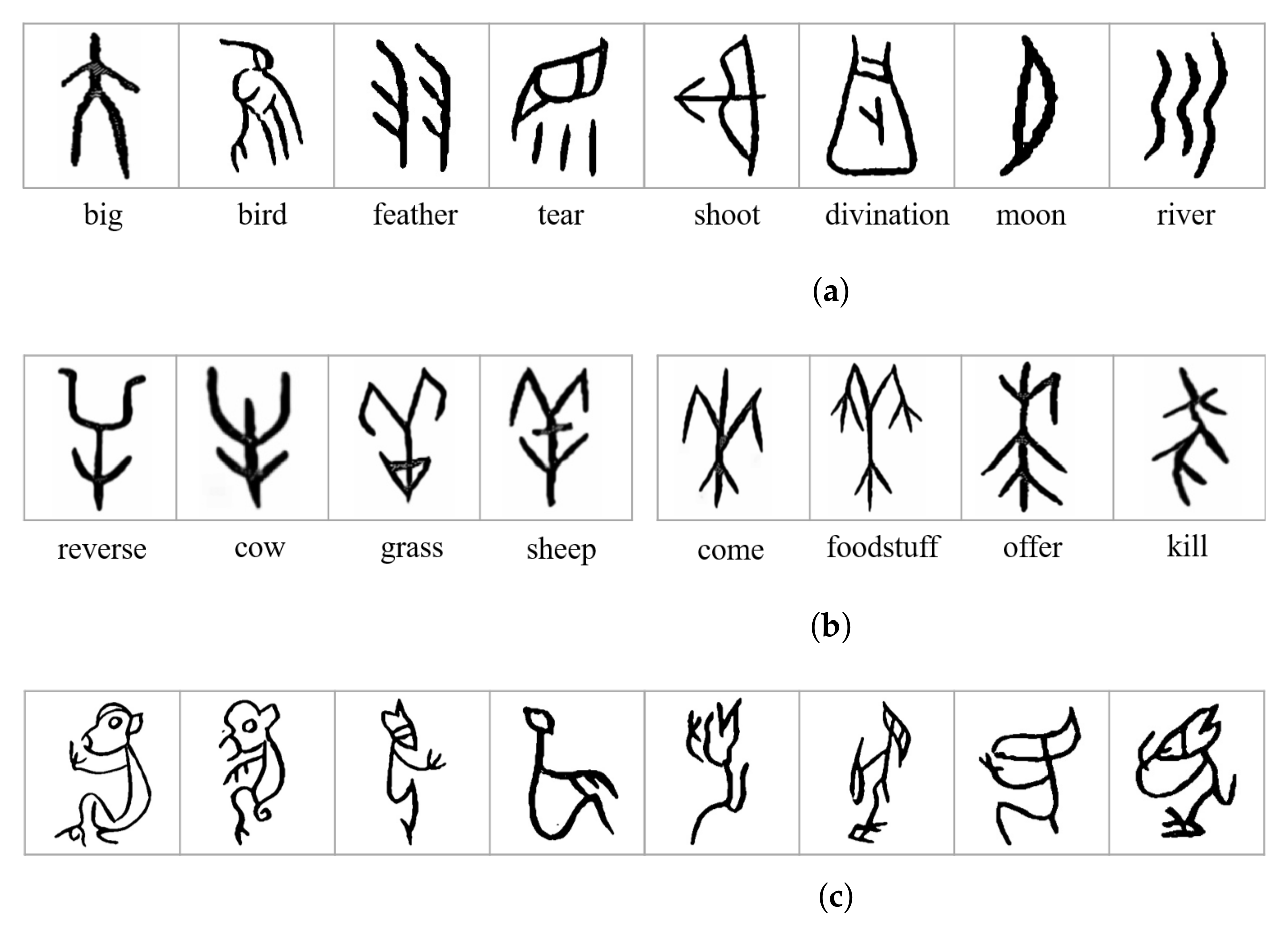
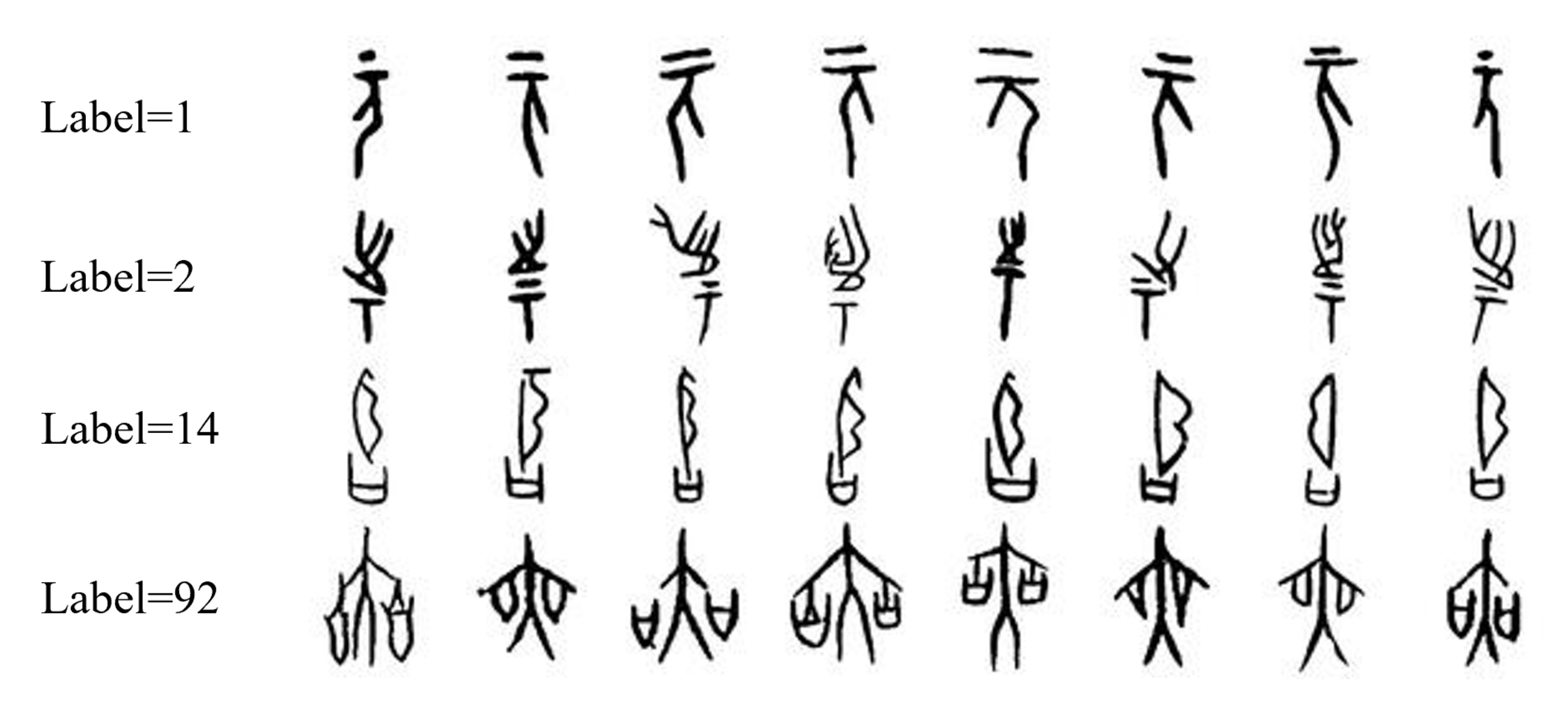
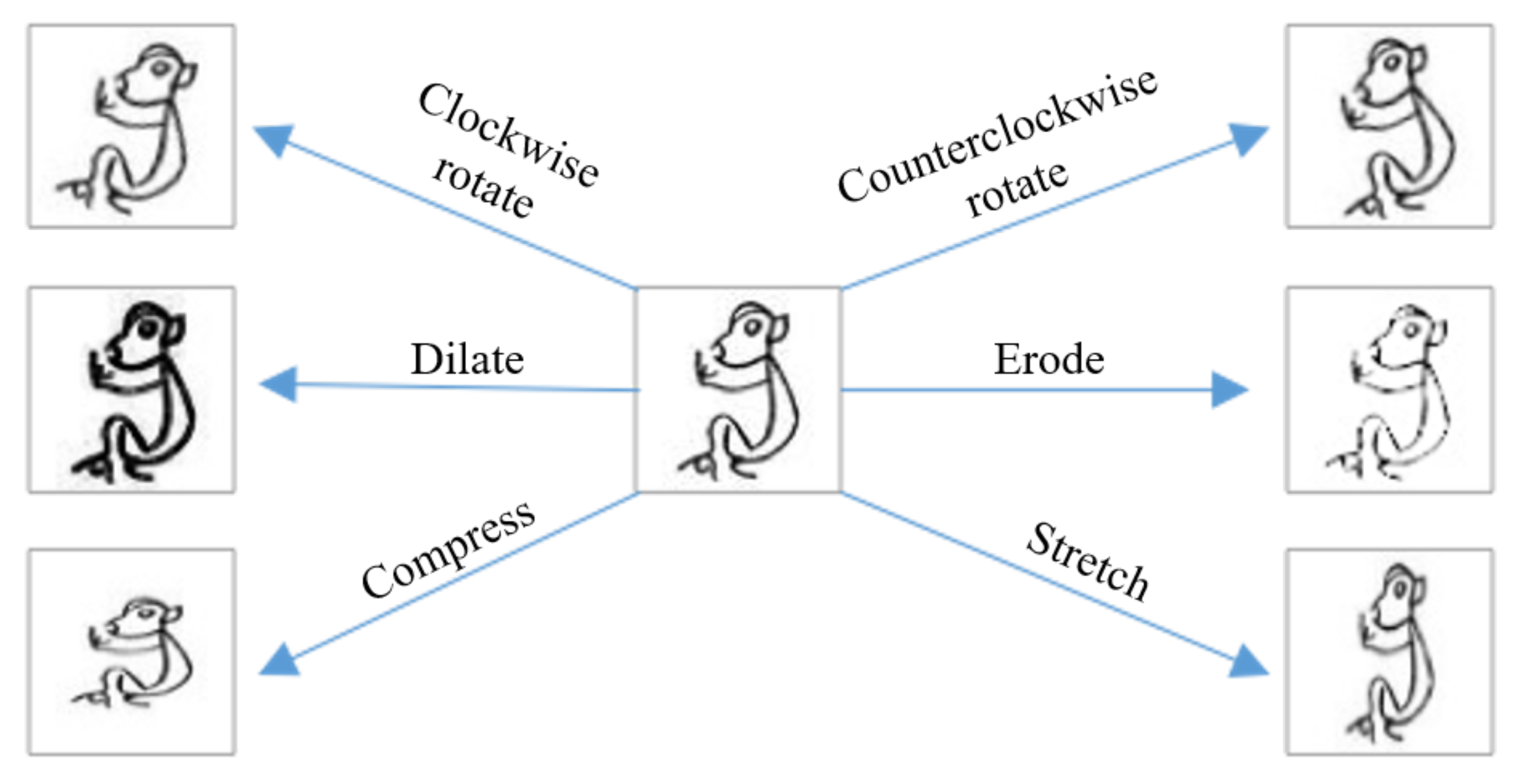
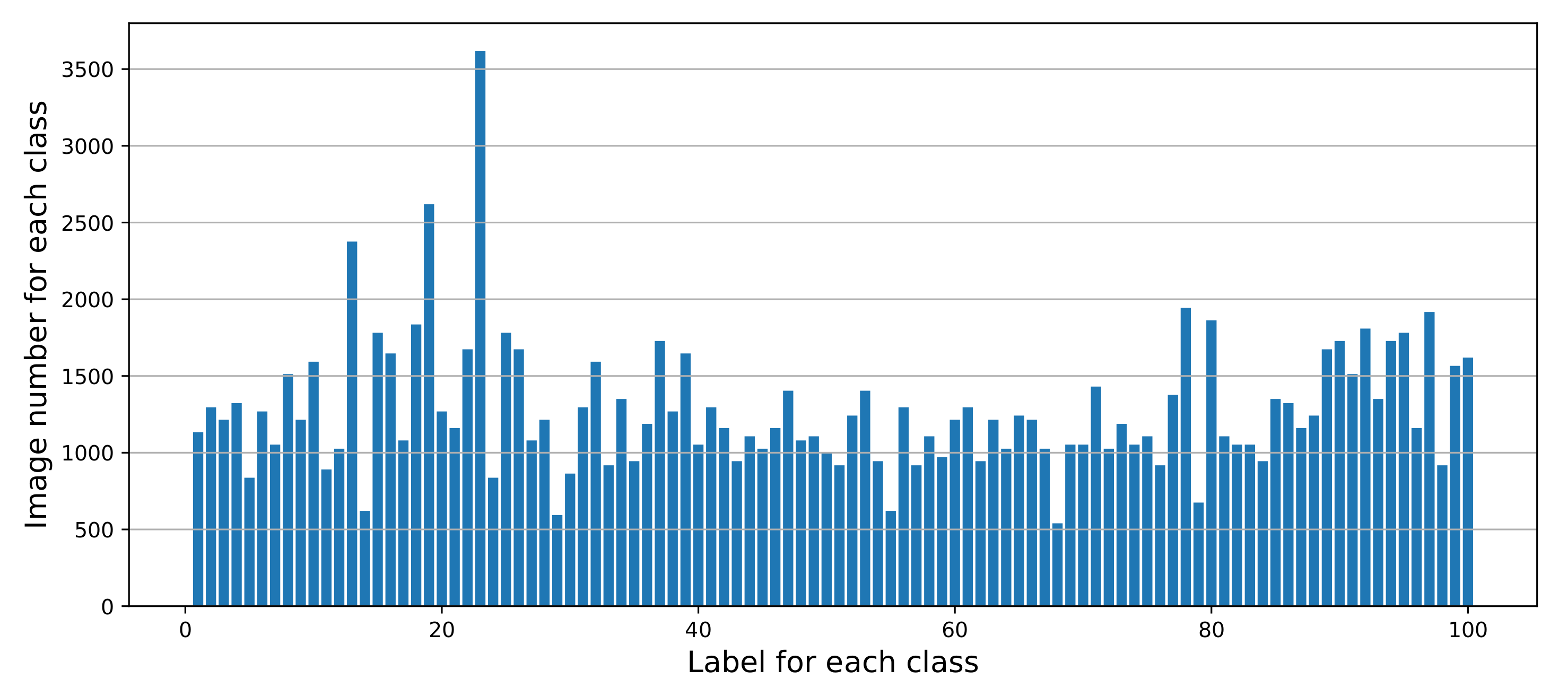
- We created a dataset named OBI-100 with 100 classes characters of OBI, covering various types of characters, such as animals, plants, humanity, society, etc., with a total of 4748 samples. Each sample in the dataset was selected carefully from two definitive dictionaries [16,17]. In view of the diversity of ancient OBI writing styles, we also used rotation, resizing, dilation, erosion, and other transformations to augment the dataset to over 128,000 images. The original dataset can be found at https://github.com/ShammyFu/OBI-100.git (accessed on 10 December 2021).
- Based on the convolutional neural frameworks of LeNet, AlexNet, and VGGNet, we produced new models by adjusting network parameters and modify network layers. These new models were trained and tested with various optimization strategies. From hundreds of different model attempts, ten CNN models with the best performance were selected to identify the 100-class OBI dataset.
- The proposed models achieved great recognition results on the OBI dataset, with the highest accuracy rate of 99.5%, which is better than the three classic network models and better than other methods in the literature.
2. Materials and Methods
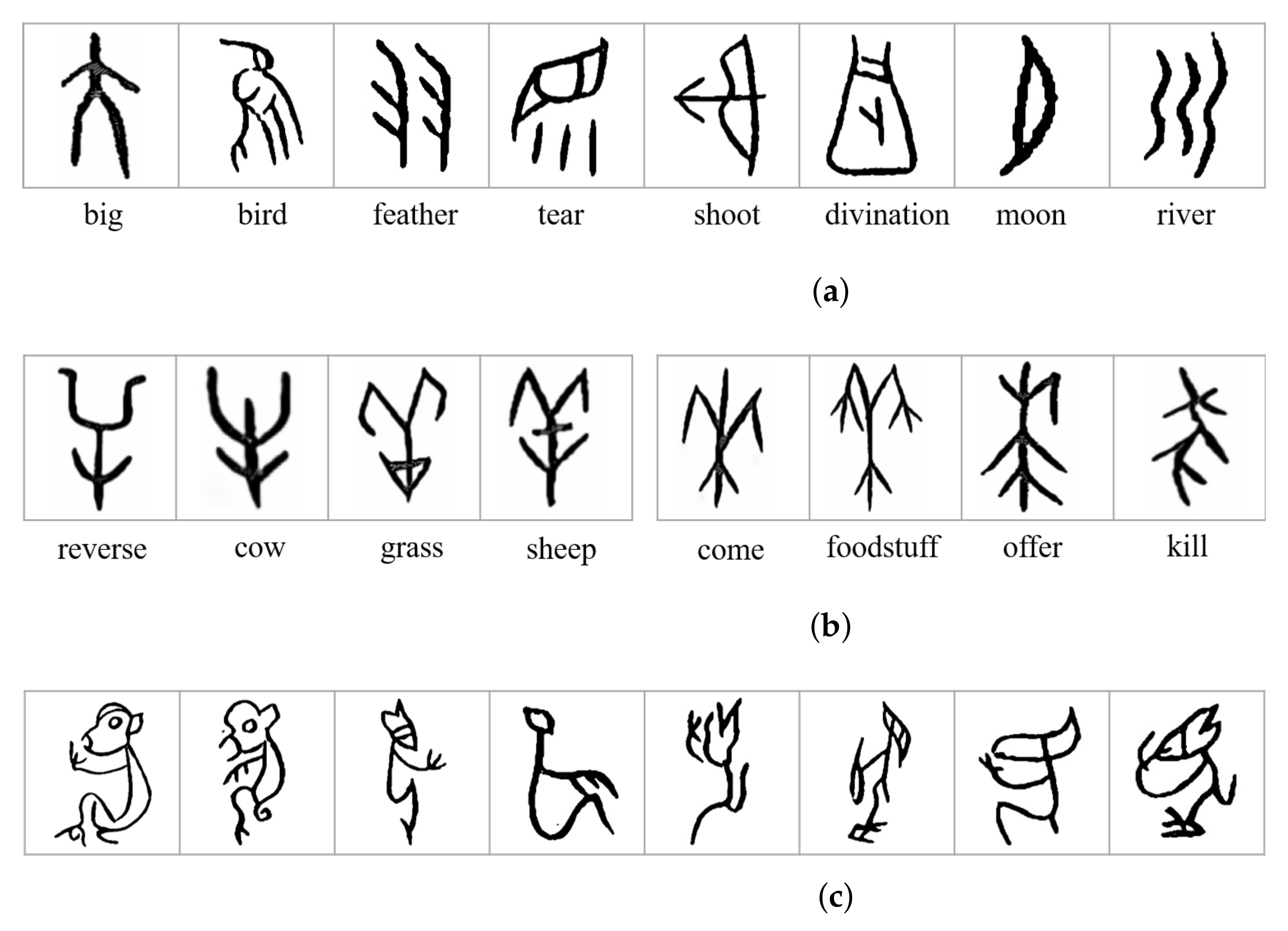
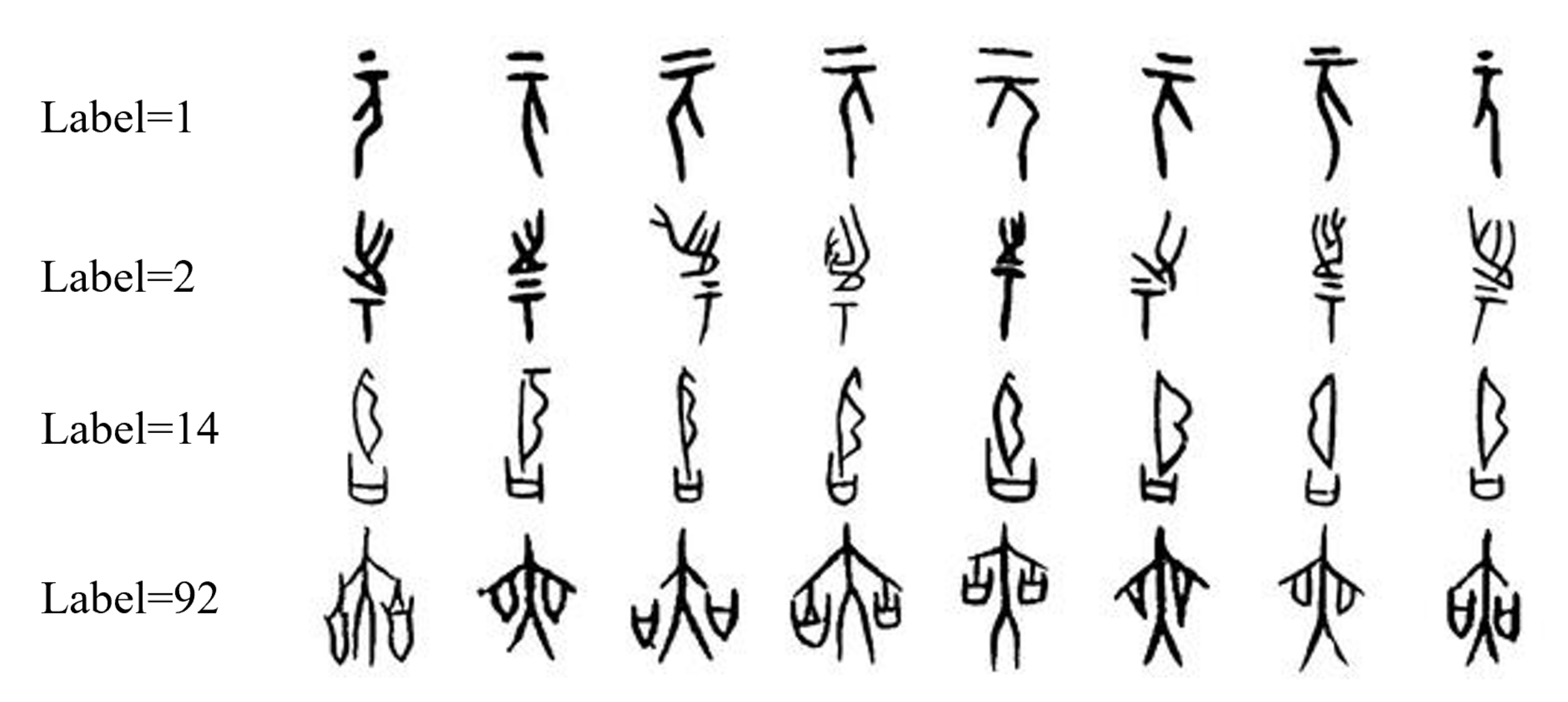
2.1. Dataset Preparation
2.1.1. Sample Acquisition
2.1.2. Dataset Preprocessing
- Denoising: since the OBI samples are from scanned e-books, Gaussian noise was introduced in the images. We first chose the non-local method (NLM) [18] to denoise. For a pixel in an image, this method finds similar regions of that pixel in terms of image blocks, and then averages the pixel values in these regions, and replaces the original value of this pixel with the average value [19], which can effectively eliminate Gaussian noise.
- Binarization: since the OBI images used for recognition require only black and white pixel values, we converted the denoised samples into grayscale ones and then binarized them.
- Size normalization: to keep the size of all images consistent without destroying the useful information areas of them, we rescaled the size of the image to . For the original non-square images, we filled the blank edge area with white pixels first and then scaled them to the required size.
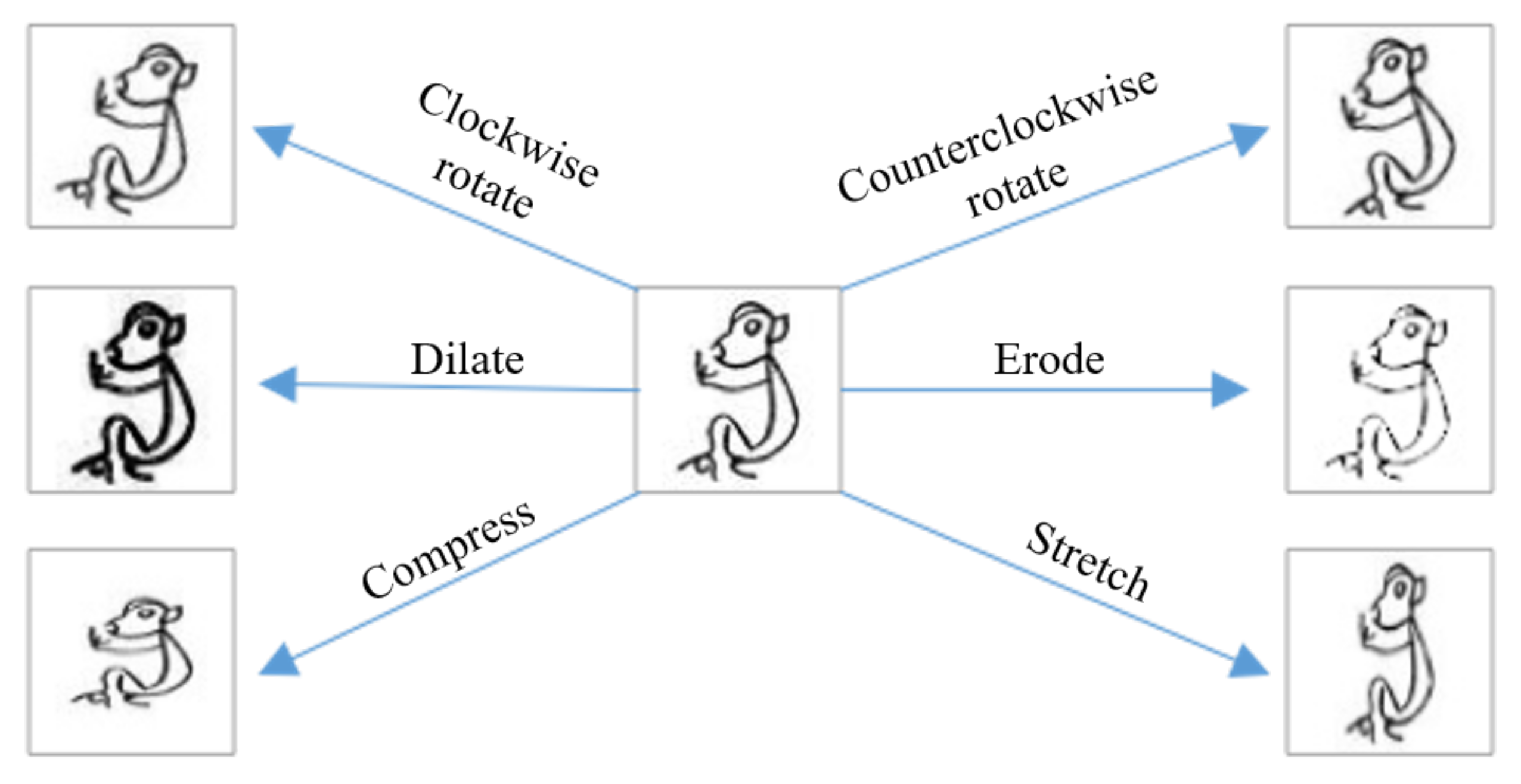
2.1.3. Data Augmentation
- Rotation: generate new images by rotating the original images clockwise or counterclockwise. The rotation angle is randomly selected from 0 to 15 degrees.
- Compress/stretch: adjust the shape of the characters on images by stretching or compressing, using a stretching ratio of 1 to 1.5, and a compression ratio of 0.67 to 1. The deformed images are rescaled to .
- Dilation/erosion: dilate or erode the lines of characters of OBI [20] to produce new samples. Due to the small image size, direct corrosion will cause the loss of many features. We first enlarged the image, then implemented the corrosion operation, and finally resized the image size to to obtain the best corrosion effect.
- Composite transformation: in addition to the six individual transformations described above, we also apply twenty combinations of transformations to the samples. That is, the image is transformed several times by choosing two or more of the above methods to generate the corresponding new samples.
2.2. Models Preparation
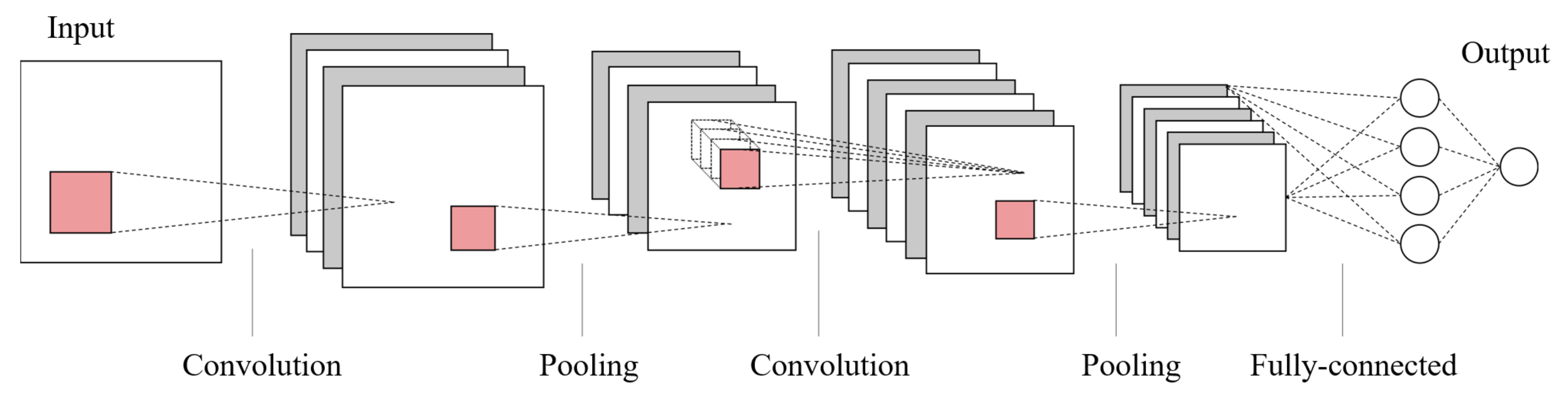
2.2.1. Background of CNN
2.2.2. The Improved LeNet Models
2.2.3. The Improved AlexNet Models
2.2.4. The Improved VGGNet Models
2.3. Methods
2.3.1. Dataset Division
2.3.2. Parameter Setting
2.3.3. Optimization Methods
- Batch normalization [31]: batch normalization normalizes the input of each small batch to one layer, which has the effect of stabilizing the learning process and can significantly reduce the training time required for training deep networks. In our experiment, when using this optimization method, the batch normalization layer is added before each activation function to make the distribution of the data return to the normalized distribution, so that the input value of the activation function falls in the region where the activation function is more sensitive to the input.
- Dropout [32]: by randomly removing the nodes of the network during the training process, a single model can simulate a large number of different architectures, which is called the dropout method. It provides a very low computational cost and very effective regularization approach to alleviate overfitting of deep neural networks and improve the generalization performance. When this method is used in our experiments, we add a dropout layer to each fully connected layer, which reduces the interdependence between the neuron nodes in the network by deactivating some neurons with a certain probability value (making the output of the neurons zero). In our experiment, we train models by jointly adjusting the probability value of the dropout layer and the batch size value. First, we try to set the probability value of dropout layers to the value in (0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1). Second, through multiple experiments, we select the best combination of dropout and batch size values.
- Shuffle: to eliminate the potential impact of the order in which the training data are fed into the network and further increase the randomness of the training data samples, we introduce the shuffle method into the model evaluation experiments. Specifically, when this method is applied, we shuffle all training samples in each new training epoch, and then input each shuffled data batch into the network.
3. Results
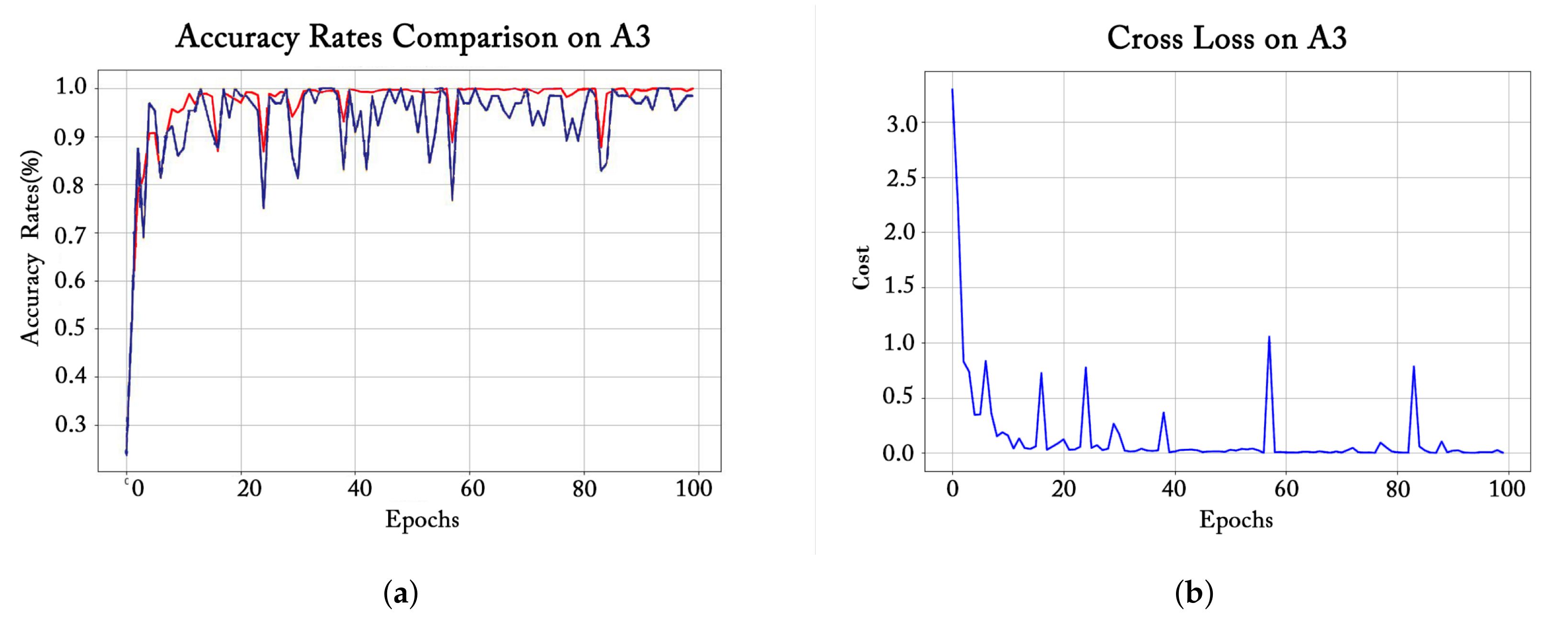
- We visualized the changes in the training loss value, the accuracy rates on the training set and the validation set of different models during the training process as the number of training epochs increases. In addition, by comparing the training accuracy and validation accuracy, we can infer the overall learning effect of the models corresponding to each epoch. These are discussed in Section 3.1.
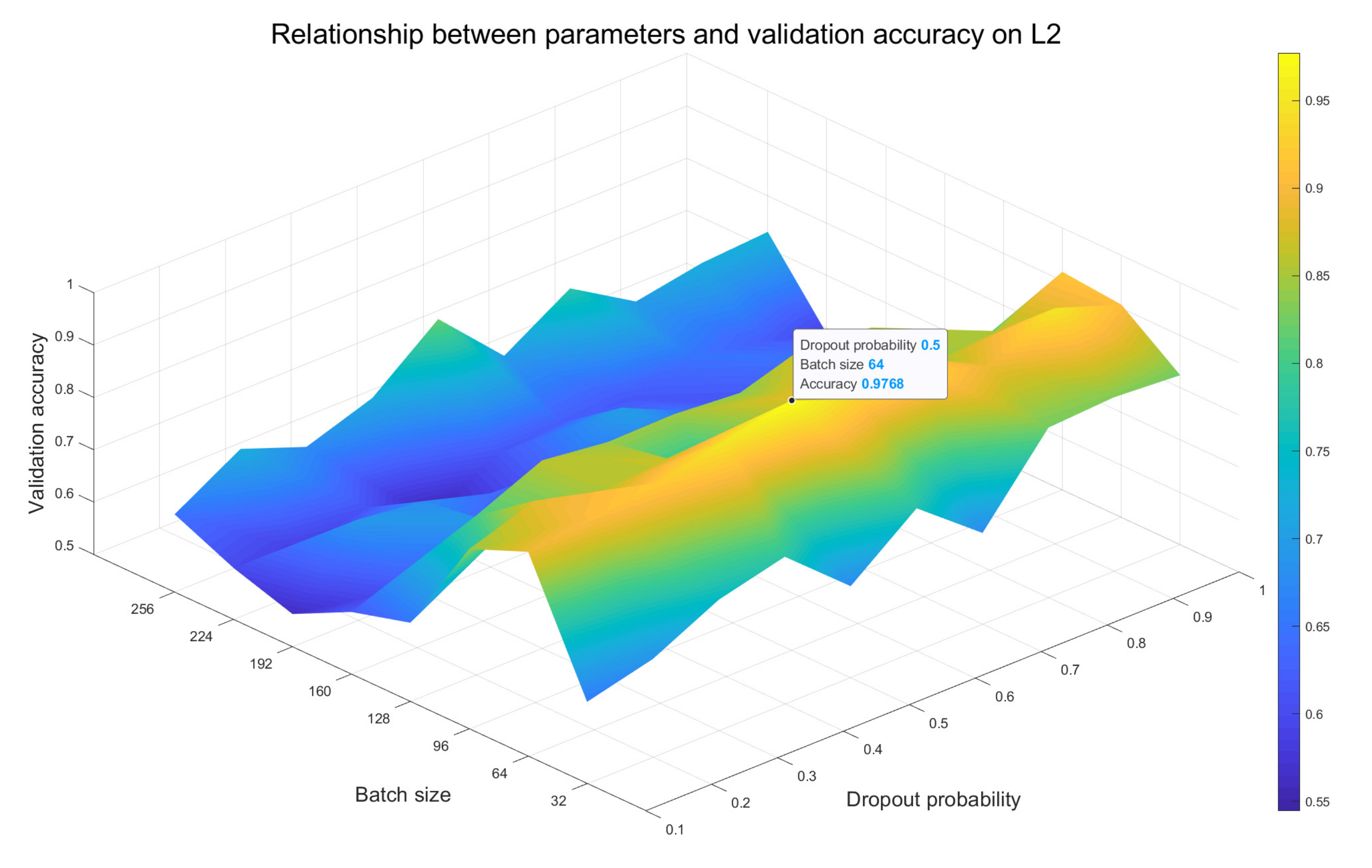
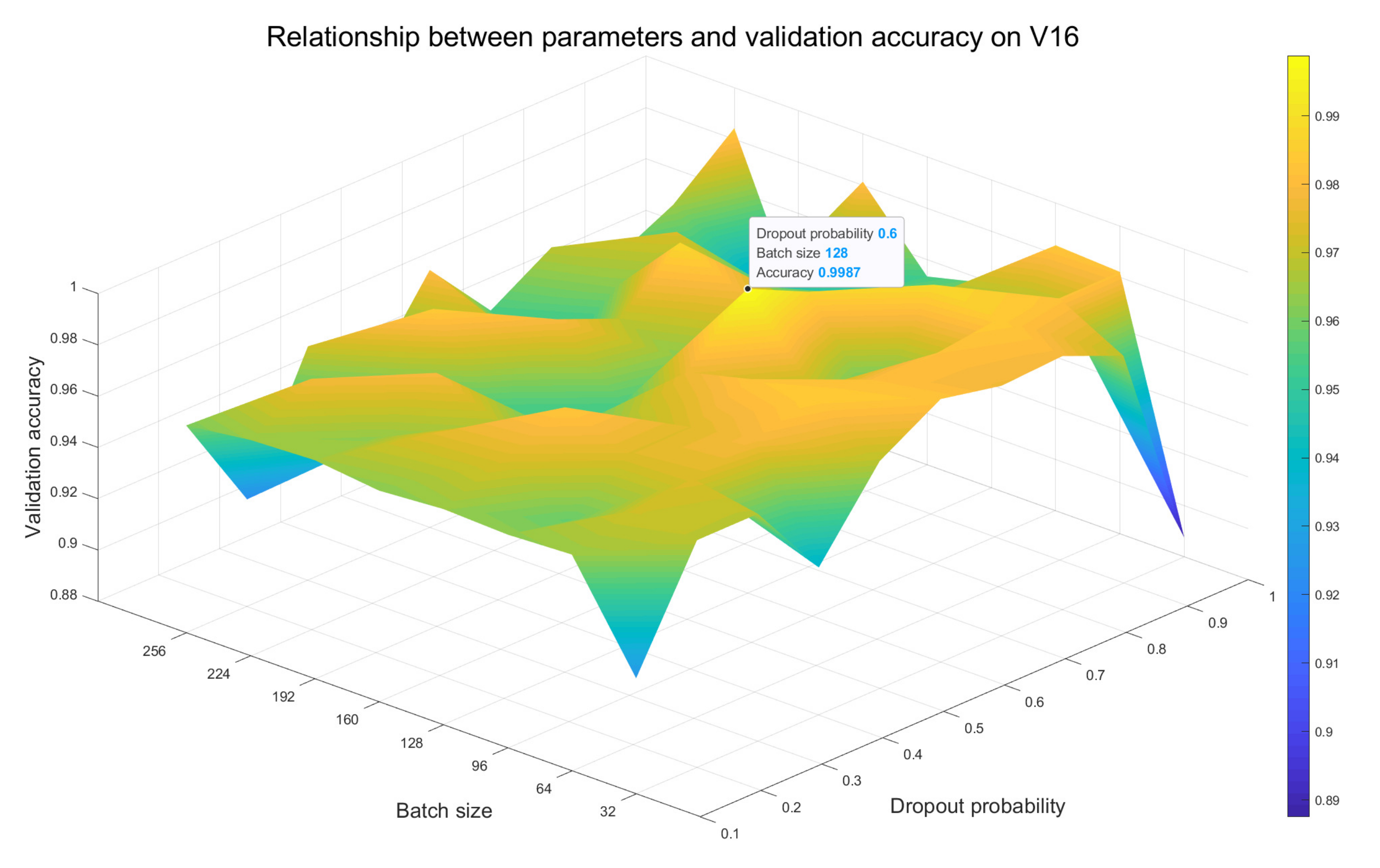
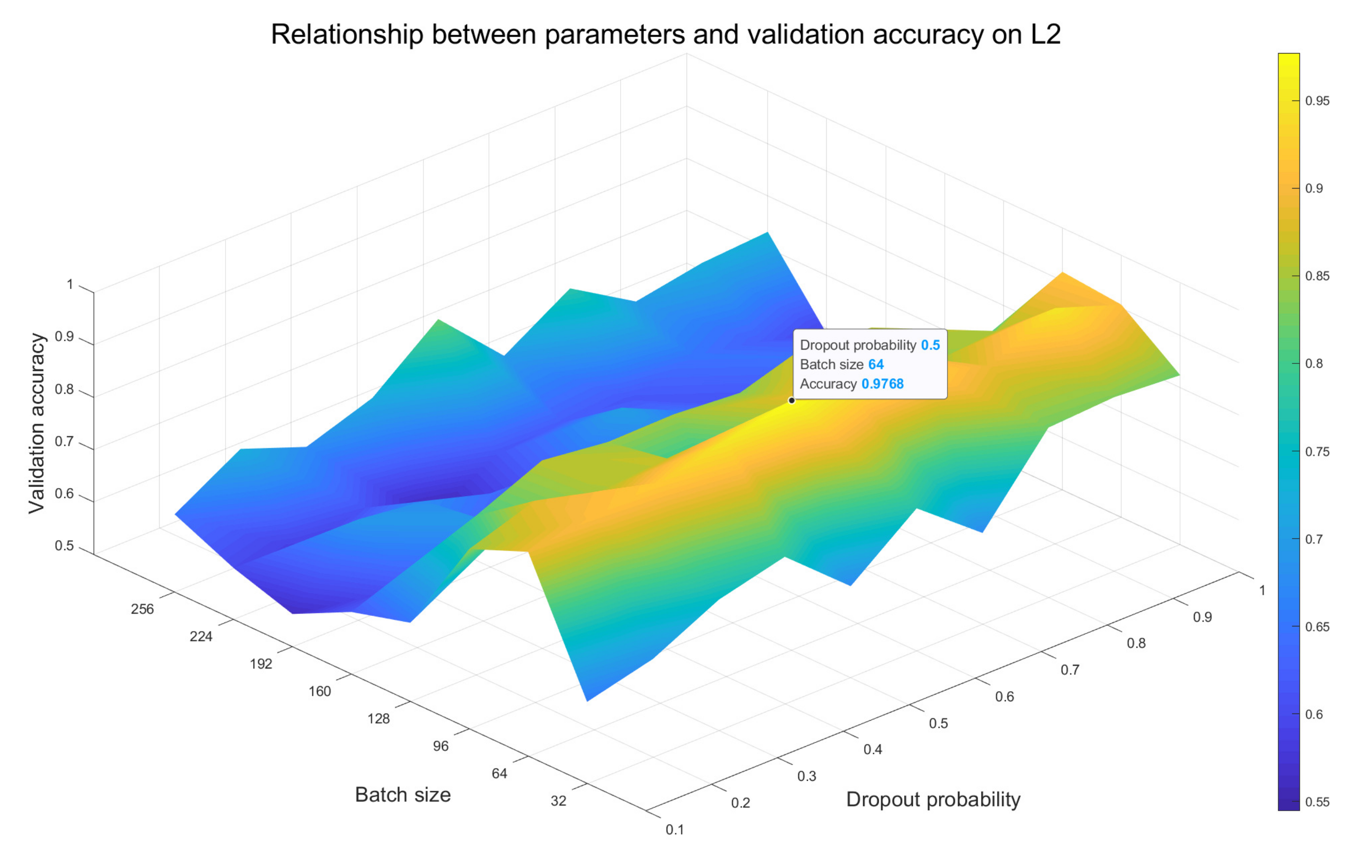
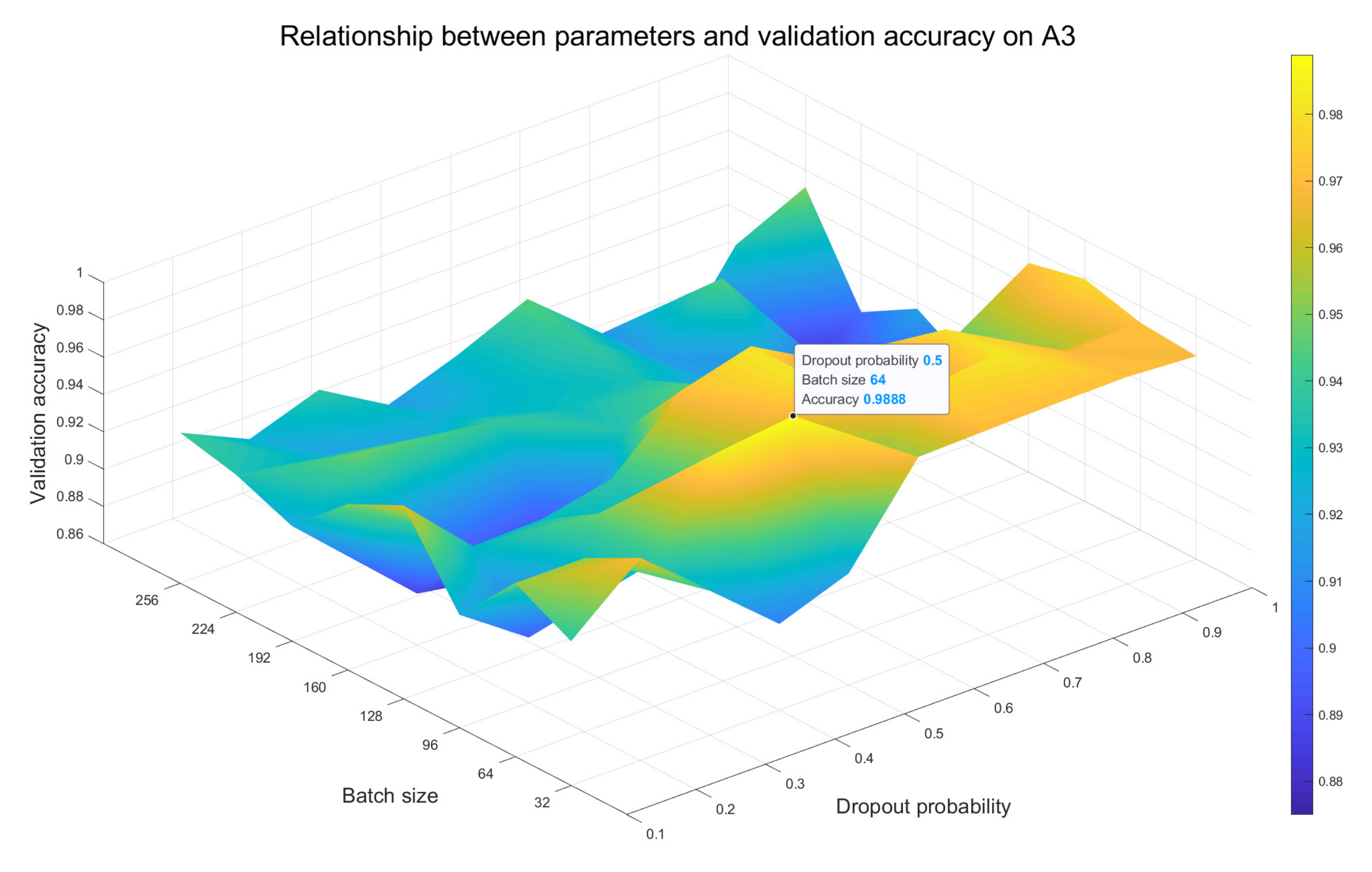
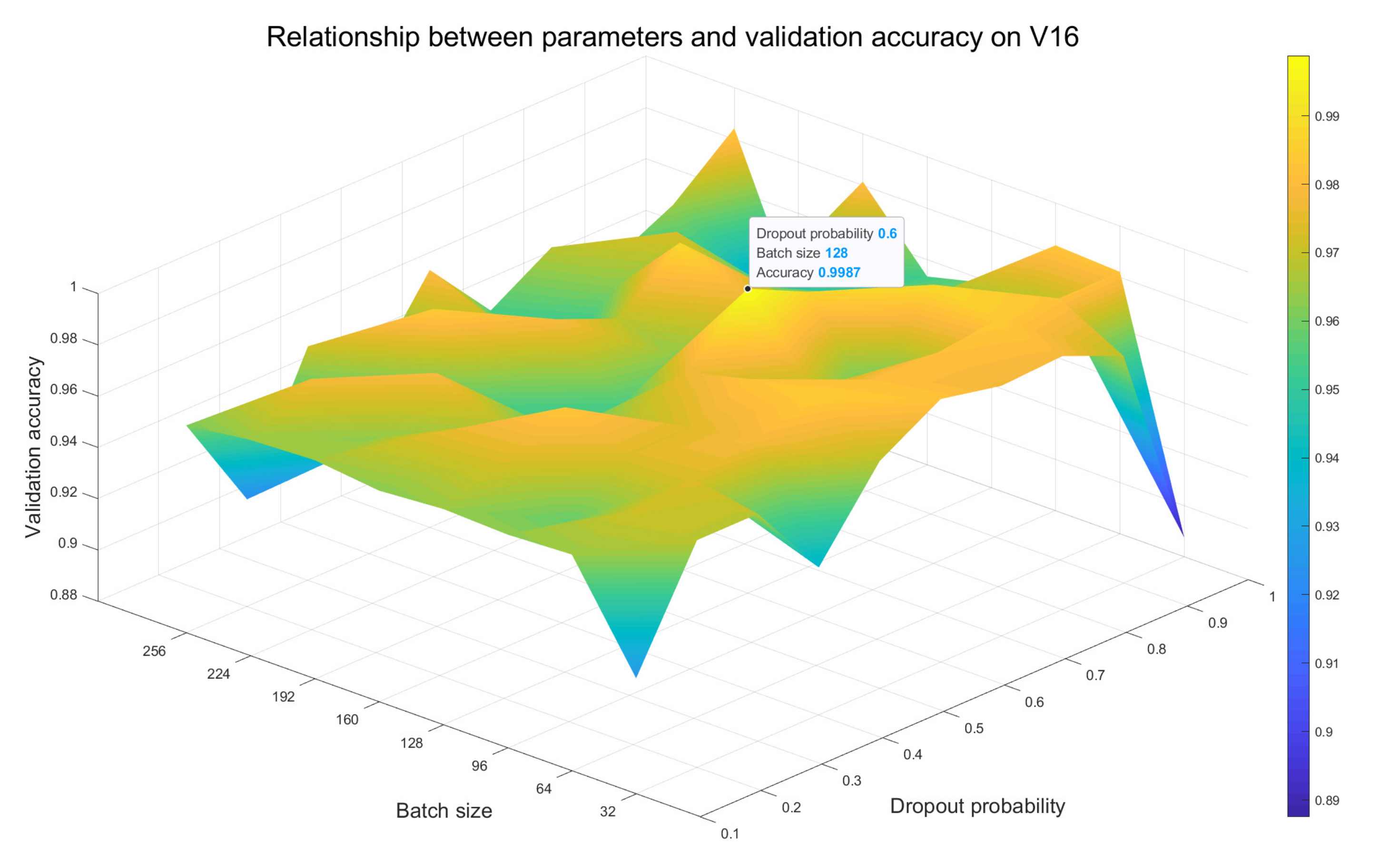
- For different models, we test the impact of multiple combinations of batch size value and dropout probability value on recognition accuracy of the validation set. By comparison, the optimal combination of these two parameters is selected as the setting strategy for the final performance experiment of the corresponding model. The results are mainly analyzed in Section 3.2.
- From the three aspects of data augmentation, model structure adjustment, and optimization implementation, we evaluate the effects of various improvement methods on model learning and OBI recognition. Results and discussions are presented in Section 3.3.
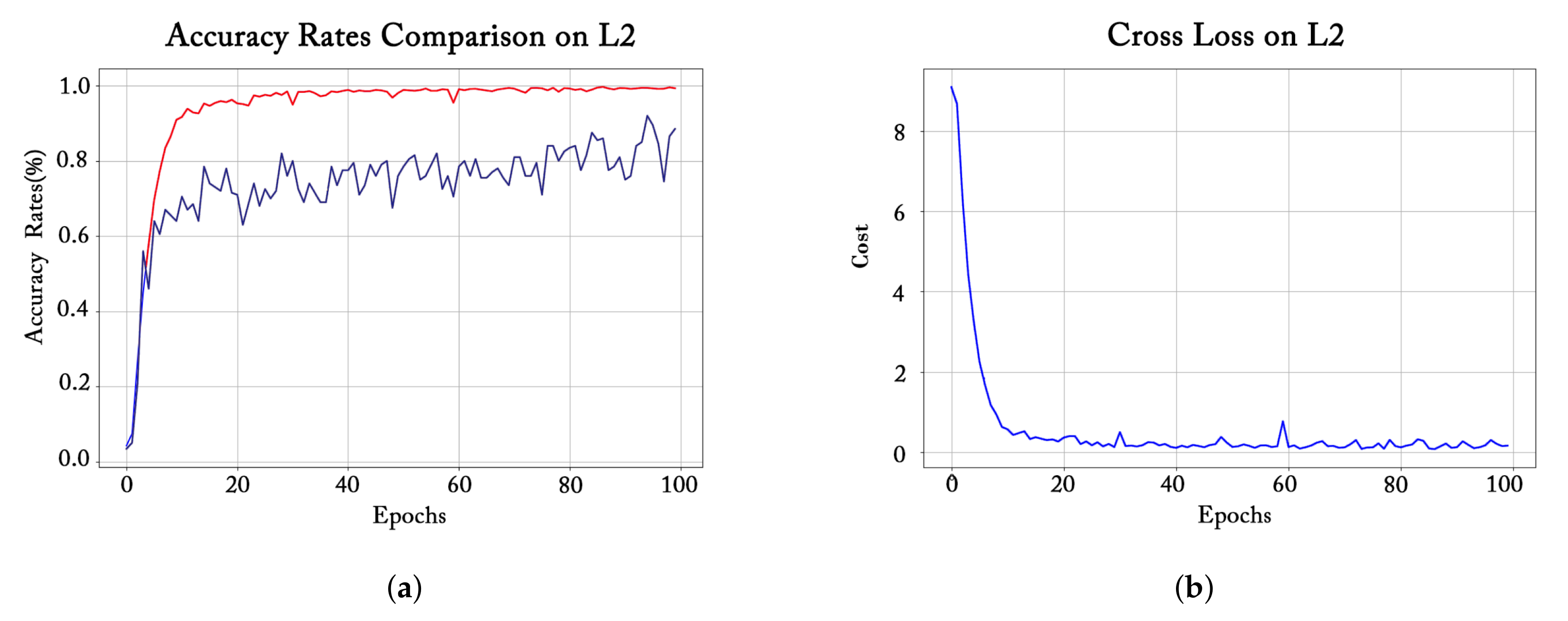
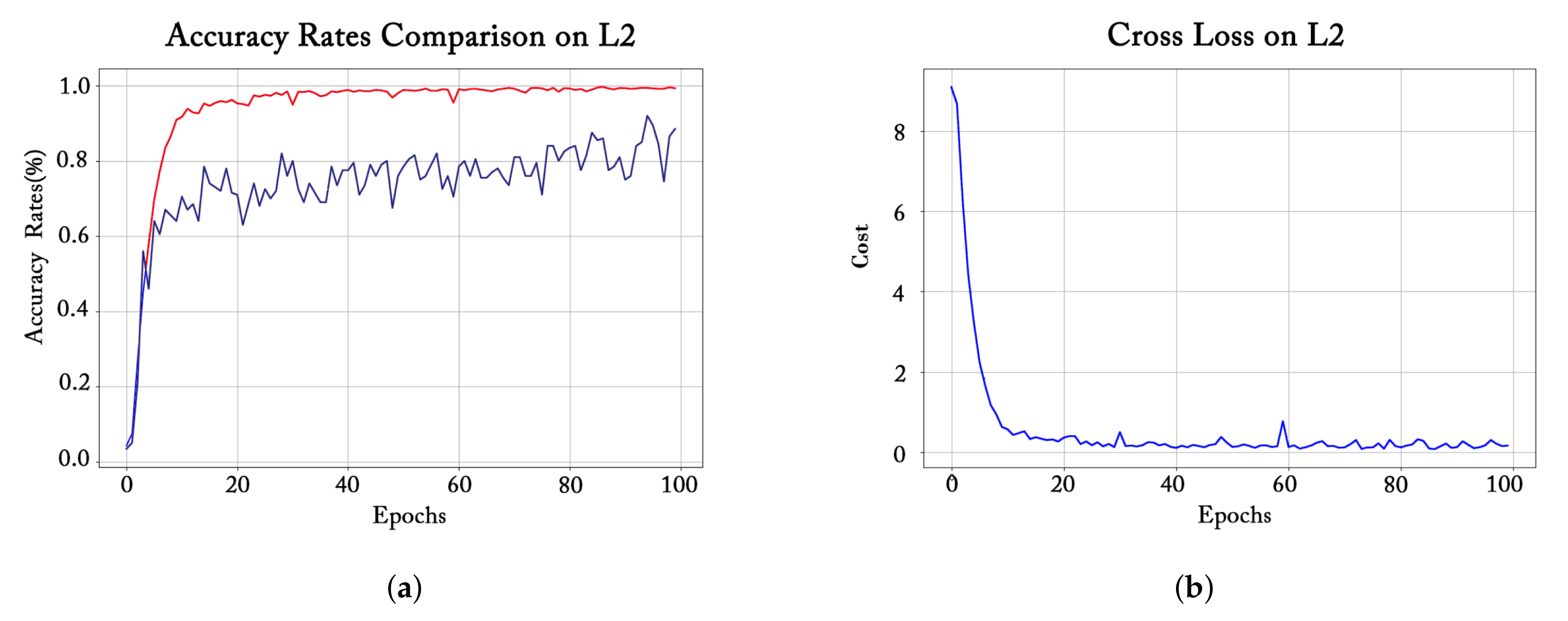
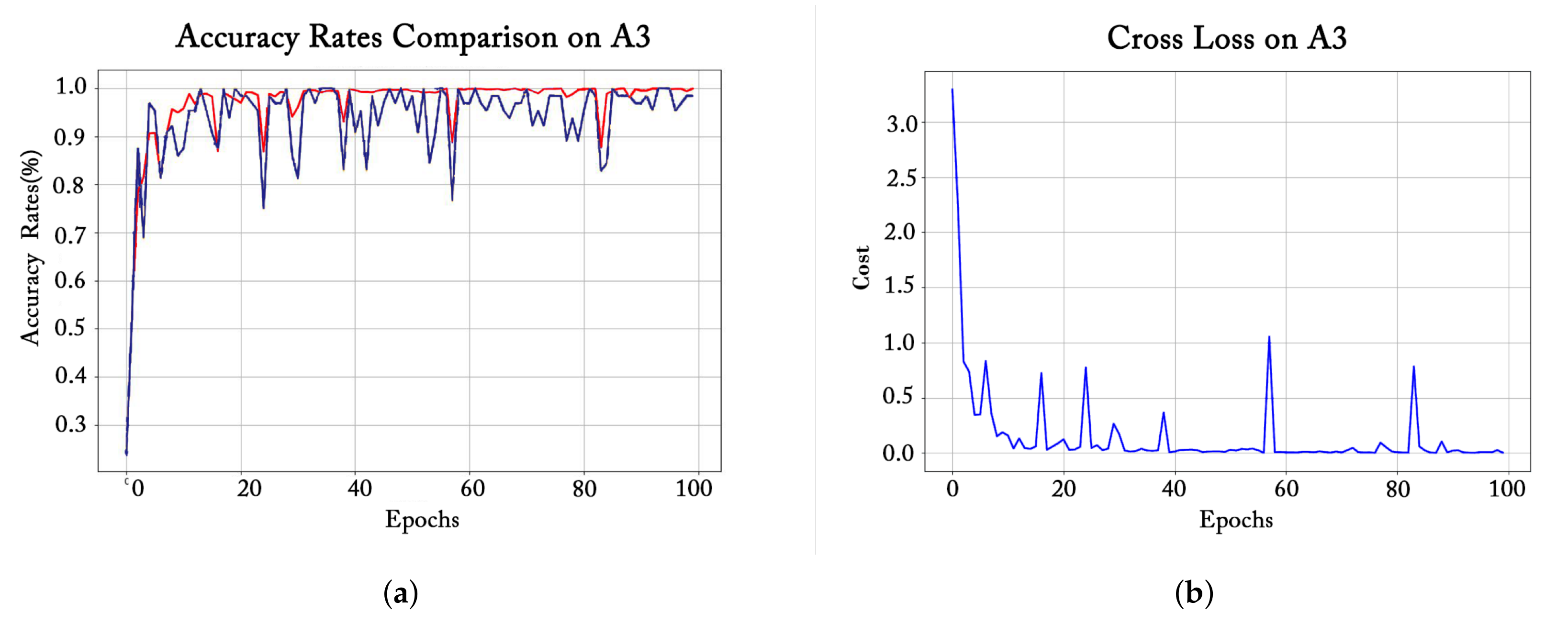
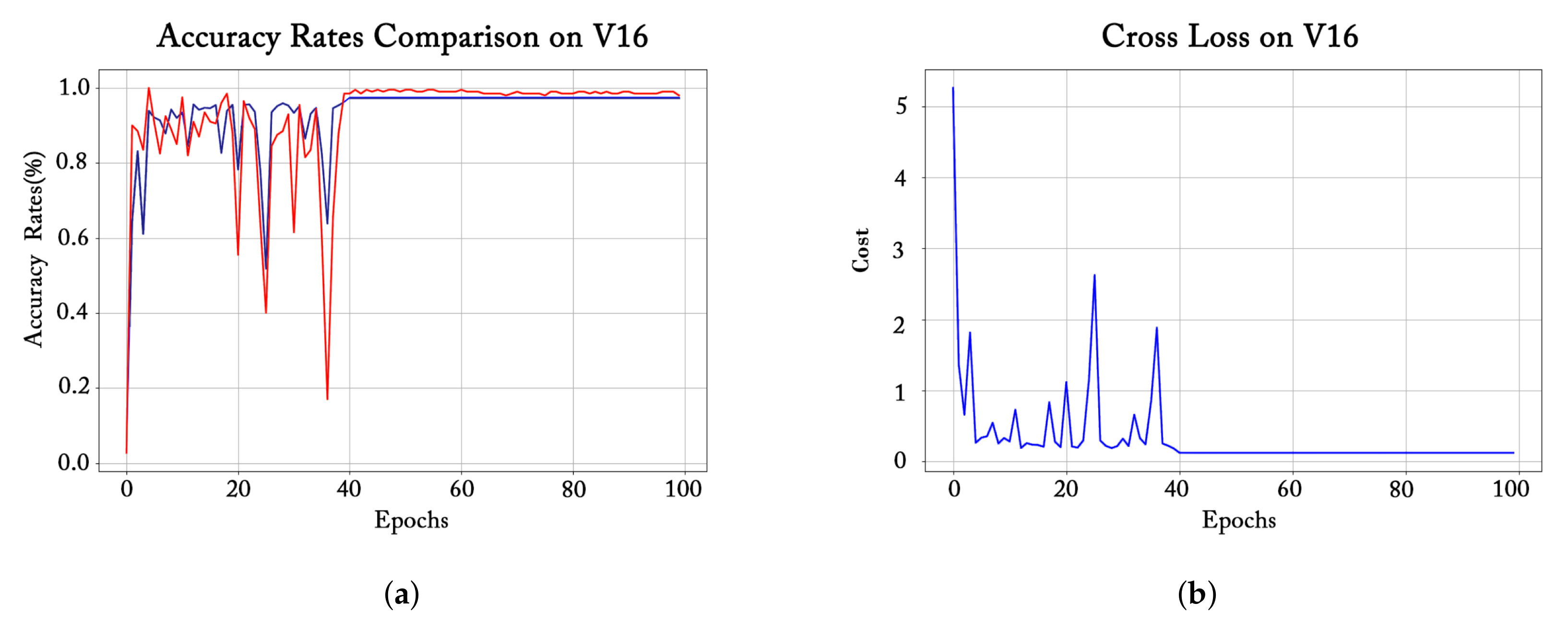
3.1. Training Process Observation
3.2. Parameter Effect Evaluation
3.3. Model Performance Overview
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Keightley, D.N. The Shang State as Seen in the Oracle-Bone Inscriptions. Early China 1980, 5, 25–34. [Google Scholar] [CrossRef]
- Flad, R.K. Divination and Power: A Multiregional View of the Development of Oracle Bone Divination in Early China. Curr. Anthropol. 2008, 49, 403–437. [Google Scholar] [CrossRef] [Green Version]
- Guo, J.; Wang, C.; Rangel, E.R.; Chao, H.; Rui, Y. Building Hierarchical Representations for Oracle Character and Sketch Recognition. IEEE Trans. Image Process. 2015, 25, 104–118. [Google Scholar] [CrossRef] [PubMed]
- Keightley, D.N. Graphs, Words, and Meanings: Three Reference Works for Shang Oracle-Bone Studies, with an Excursus on the Religious Role of the Day or Sun. J. Am. Orient. Soc. 1997, 117, 507–524. [Google Scholar] [CrossRef]
- Bazerman, C. Handbook of research on writing: History, society, school, individual, text. Delta Doc. Estud. Lingüística Teórica E Apl. 2008, 24, 419–420. [Google Scholar]
- Dress, A.; Grünewald, S.; Zeng, Z. A cognitive network for oracle bone characters related to animals. Int. J. Mod. Phys. B 2016, 30, 1630001. [Google Scholar] [CrossRef]
- Feng, Y. Recognition of jia gu wen based on graph theory. J. Electron. Inf. Technol. 1996, 18, 41–47. [Google Scholar]
- Li, Q.; Wu, Q.; Yang, Y. Dynamic Description Library for Jiaguwen Characters and the Reserch of the Characters Processing. Acta Sci. Nat. Univ. Pekin. 2013, 49, 61–67. [Google Scholar]
- Lu, X.; Li, M.; Cai, K.; Wang, X.; Tang, Y. A graphic-based method for Chinese Oracle-bone classification. J. Beijing Inf. Sci. Technol. Univ. 2010, 25, 92–96. [Google Scholar]
- Gu, S. Identification of Oracle-bone Script Fonts Based on Topological Registration. Comput. Digit. Eng. 2016, 44, 2001–2006. [Google Scholar]
- Meng, L. Two-Stage Recognition for Oracle Bone Inscriptions. In Proceedings of the ICIAP, Catania, Italy, 11–15 September 2017. [Google Scholar]
- Meng, L. Recognition of Oracle Bone Inscriptions by Extracting Line Features on Image Processing. In Proceedings of the ICPRAM, Porto, Portugal, 24–26 February 2017. [Google Scholar]
- Liu, Y.; Liu, G. Oracle character recognition based on SVM. J. Anyang Norm. Univ. 2017, 2, 54–56. [Google Scholar]
- Gjorgjevikj, D.; Cakmakov, D. Handwritten Digit Recognition by Combining SVM Classifiers. In Proceedings of the Eurocon 2005—The International Conference on “computer as a Tool”, Belgrade, Serbia, 21–24 November 2005. [Google Scholar]
- Gao, F.; Xiong, J.; Liu, Y. Recognition of Fuzzy Characters on Oracle-Bone Inscriptions. In Proceedings of the IEEE International Conference on Computer & Information Technology; Ubiquitous Computing & Communications; Dependable, Autonomic and Secure Computing; Pervasive Intelligence and Computing, Liverpool, UK, 26–28 October 2015. [Google Scholar]
- Institute of Archaeology, Chinese Academy of Sciences. Oracle Bone Inscriptions Collection; Zhonghua Book Company: Beijing, China, 1965. [Google Scholar]
- Wang, B. 100 Cases of Classical Oracle Bone Inscription Rubbings; Beijing Arts and Crafts Publishing House: Beijing, China, 2015. [Google Scholar]
- Froment, J. Parameter-Free Fast Pixelwise Non-Local Means Denoising. Image Process. Line 2014, 4, 300–326. [Google Scholar] [CrossRef] [Green Version]
- Buades, A.; Coll, B.; Morel, J.M. Non-Local Means Denoising. Image Process. Line 2011, 1, 208–212. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Haralick, R.M. Recursive Erosion, Dilation, Opening, and Closing Transforms. IEEE Trans. Image Process. 1995, 4, 335–345. [Google Scholar] [CrossRef] [PubMed]
- Kim, P. Convolutional Neural Network In MATLAB Deep Learning: With Machine Learning, Neural Networks and Artificial Intelligence; Apress: Berkeley, CA, USA, 2017. [Google Scholar]
- Maitra, D.S.; Bhattacharya, U.; Parui, S.K. CNN based common approach to handwritten character recognition of multiple scripts. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015. [Google Scholar]
- Heaton, J. Deep learning. Genet. Program. Evolvable Mach. 2018, 19, 305–307. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning Deep Features for Scene Recognition using Places Database. Adv. Neural Inf. Process. Syst. 2015, 1, 487–495. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition. Agric. Eng. Int. Cigr J. Sci. Res. Dev. Manuscr. Pm 1995, 12, 1235–1242. [Google Scholar]
- Le Cun, Y.; Jackel, L.D.; Boser, B.; Denker, J.S.; Graf, H.P.; Guyon, I.; Henderson, D.; Howard, R.E.; Hubbard, W. Handwritten Digit Recognition: Applications of Neural Net Chips and Automatic Learning. IEEE Commun. Mag. 1989, 27, 41–46. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. VVery Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the ICCV, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ConvNet Configurations | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Framework | LeNet | AlexNet | VGGNet | |||||||
| Name of our proposed Models | L1 | L2 | A1 | A2 | A3 | V11 | V13 | V16 | V16-2 | V19 |
| Input | gray-scale images from OBI-100. | |||||||||
| Network Structure | conv5-6 | conv3-32 | conv11-64 | conv11-64 | conv11-64 | conv3-64 conv3-64 | conv3-32 conv3-32 | conv3-64 conv3-64 | conv3-64 conv3-64 | conv3-64 conv3-64 conv3-64 |
| maxpool: | maxpool: | maxpool: | maxpool: | |||||||
| conv5-16 | conv5-64 | conv5-192 | conv5-192 | conv5-192 | conv3-128 conv3-128 | conv3-64 conv3-64 | conv3-64 conv3-64 | conv3-64 conv3-64 | conv3-128 conv3-128 conv3-128 | |
| maxpool: | maxpool: | maxpool: | maxpool: | |||||||
| conv3-384 conv3-256 | conv3-384 conv3-256 conv3-256 | conv3-384 conv3-256 conv3-256 | conv3-256 conv3-256 | conv3-128 conv3-128 | conv3-128 conv3-128 conv3-128 | conv3-128 conv3-128 conv1-128 | conv3-256 conv3-256 conv3-256 | |||
| maxpool: | maxpool: | maxpool: | ||||||||
| conv3-256 conv3-256 | conv3-512 conv3-1024 conv3-1024 | conv3-512 conv3-512 | conv3-256 conv3-256 | conv3-256 conv3-256 conv3-256 | conv3-256 conv3-256 conv1-256 | conv3-512 conv3-512 conv3-512 | ||||
| maxpool: | maxpool: | |||||||||
| conv3-512 conv3-512 | conv3-512 conv3-512 conv3-512 | conv3-512 conv3-512 conv1-512 | conv3-512 conv3-512 conv3-512 conv3-512 | |||||||
| maxpool: | ||||||||||
| FC-120 | FC-512 | FC-4096 FC-4096 | FC-1024 FC-1024 | FC-4096 FC-4096 | FC-4096 FC-4096 | FC-4096 FC-4096 | FC-4096 FC-4096 | FC-1024 FC-1024 | FC-4096 FC-4096 | |
| FC-100 | ||||||||||
| softmax | ||||||||||
| Model | Data Augment | Method | Accuracy (%) | |
|---|---|---|---|---|
| Test (Max) | Test (Ave) | |||
| Based on LeNet | ||||
| LeNet | No | - | 71.23 | - |
| L1 | SF | 78.77 | 78.77 | |
| L2 | SF | 74.20 | - | |
| LeNet | Yes | - | 81.25 | 75.00 |
| SF + BN + DP | 85.41 | 82.37 | ||
| L1 | SF | 95.35 | 92.48 | |
| SF + BN | 97.15 | 96.56 | ||
| SF + BN + DP | 98.43 | 97.93 | ||
| L2 | SF | 93.75 | 87.50 | |
| SF + BN | 94.25 | 88.80 | ||
| SF + BN + DP | 96.88 | 86.93 | ||
| Model | Data Augment | Method | Accuracy (%) | |
|---|---|---|---|---|
| Test (Max) | Test (Ave) | |||
| Based on AlexNet | ||||
| AlexNet | No | - | 71.23 | - |
| A1 | DP | 84.47 | - | |
| A2 | DP + SF | 89.80 | - | |
| A3 | DP + SF | 91.32 | - | |
| AlexNet | Yes | - | 79.40 | 76.91 |
| DP + SF + BN | 91.66 | 89.97 | ||
| A1 | DP | 92.19 | 92.17 | |
| DP + SF | 94.12 | 93.11 | ||
| DP + SF + BN | 96.75 | 94.05 | ||
| A2 | DP + SF | 96.88 | 91.04 | |
| DP + SF + BN | 97.05 | 93.76 | ||
| A3 | DP + SF | 98.44 | 93.25 | |
| DP + SF + BN | 98.48 | 95.38 | ||
| Model | Data Augment | Method | Accuracy (%) | |
|---|---|---|---|---|
| Test (Max) | Test (Ave) | |||
| Based on VGGNet | ||||
| VGG11 | No | - | 84.88 | - |
| V11 | BN | 85.56 | - | |
| VGG13 | - | 85.03 | - | |
| V13 | BN + SF | 85.10 | - | |
| VGG16 | - | 93.75 | - | |
| V16 | BN + SF | 91.28 | - | |
| VGG19 | - | 90.35 | - | |
| V19 | BN + SF | 89.71 | - | |
| Based on VGGNet | ||||
| VGG11 | Yes | - | 91.10 | 90.39 |
| BN + SF + DP | 92.96 | 92.18 | ||
| V11 | BN | 91.20 | 91.10 | |
| BN + SF | 91.80 | 91.20 | ||
| BN + SF + DP | 94.66 | 92.50 | ||
| VGG13 | - | 92.88 | 90.67 | |
| BN + SF + DP | 94.31 | 93.21 | ||
| V13 | BN + SF | 93.20 | 91.75 | |
| BN + SF + DP | 95.85 | 95.10 | ||
| VGG16 | - | 96.24 | 93.75 | |
| BN + SF + DP | 97.75 | 95.65 | ||
| V16 | BN + SF | 99.49 | 99.00 | |
| BN + SF + DP | 99.50 | 99.50 | ||
| V16-2 | BN + SF | 95.30 | 94.13 | |
| BN + SF + DP | 95.60 | 94.38 | ||
| VGG19 | - | 96.67 | 96.28 | |
| BN + SF + DP | 98.26 | 97.75 | ||
| V19 | BN + SF | 98.40 | 98.20 | |
| BN + SF + DP | 98.75 | 98.61 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, X.; Yang, Z.; Zeng, Z.; Zhang, Y.; Zhou, Q. Improvement of Oracle Bone Inscription Recognition Accuracy: A Deep Learning Perspective. ISPRS Int. J. Geo-Inf. 2022, 11, 45. https://doi.org/10.3390/ijgi11010045
Fu X, Yang Z, Zeng Z, Zhang Y, Zhou Q. Improvement of Oracle Bone Inscription Recognition Accuracy: A Deep Learning Perspective. ISPRS International Journal of Geo-Information. 2022; 11(1):45. https://doi.org/10.3390/ijgi11010045
Chicago/Turabian StyleFu, Xuanming, Zhengfeng Yang, Zhenbing Zeng, Yidan Zhang, and Qianting Zhou. 2022. "Improvement of Oracle Bone Inscription Recognition Accuracy: A Deep Learning Perspective" ISPRS International Journal of Geo-Information 11, no. 1: 45. https://doi.org/10.3390/ijgi11010045
APA StyleFu, X., Yang, Z., Zeng, Z., Zhang, Y., & Zhou, Q. (2022). Improvement of Oracle Bone Inscription Recognition Accuracy: A Deep Learning Perspective. ISPRS International Journal of Geo-Information, 11(1), 45. https://doi.org/10.3390/ijgi11010045