
Deep Descriptor Learning with Auxiliary Classification Loss for Retrieving Images of Silk Fabrics in the Context of Preserving European Silk Heritage


Abstract
:1. Introduction
- To the best of our knowledge, ours is the first work exploiting class labels of multiple semantic variables for defining similarity for image retrieval in combination with in an auxiliary classification loss in an end-to-end training strategy. Existing works employing an auxiliary classification loss that we are aware of [22,23,24] do not exploit multiple variables and thus do not use a gradual concept of similarity.
- We use a gradual rather than a binary concept of similarity of images based on multiple semantic variables while taking into account the problem of missing annotations, which is important when dealing with collections of records harvested from the internet. Other works implicitly allow a different number of labels per image because the scene contains multiple objects, e.g., [12,13,14], which is not the case in our application.
- We transfer the gradual definition of the similarity status of image pairs into the triplet loss of [25] to learn fine-grained image representations so that the Euclidean distances of the learned descriptors are forced to reflect the different degrees of similarity without the need to carefully select a margin in the loss. The margin is adapted to the degree of similarity and uncertainty of the similarity status.
- Our formulation of the loss allows us to combine different concepts of similarity for training to obtain descriptors that are both visually as well as semantically similar.
- We present an extensive set of experiments based on a dataset of silk fabrics, using kNN classification for a quantitative evaluation, which also highlights the impact of the classification loss on the results. To show the transferability of the approach, we also present experiments for image retrieval based on the WikiArt dataset (http://www.wikiart.org, visited on 30 November 2021).
2. Related Work
2.1. Exploiting Semantic Annotations
2.2. Auxiliary Losses
2.3. Image Retrieval for Cultural Heritage
2.4. Discussion
3. Methodology
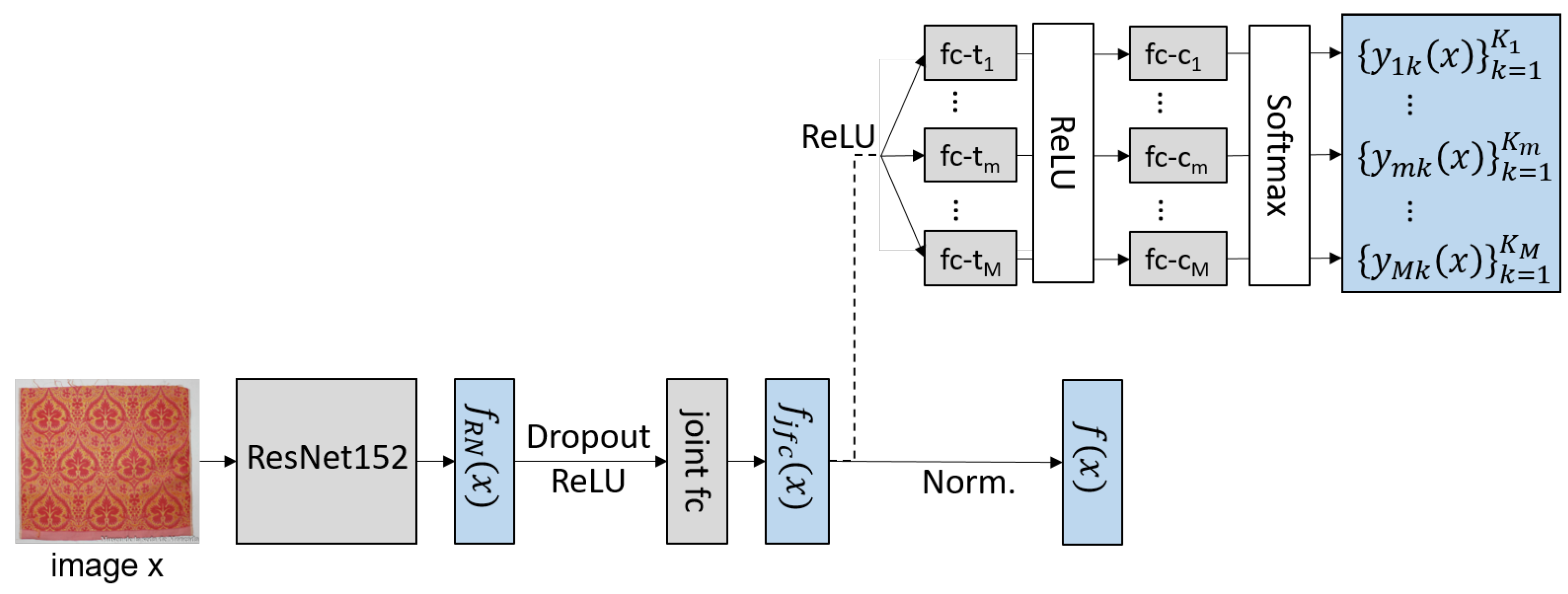
3.1. Network Architecture
3.2. Network Training
3.2.1. Image Retrieval Training Objective
Semantic Similarity Loss
Color Similarity Loss
Self-Similarity Loss
- If the dataset contains no such images or if it is not known whether it contains such images, the image is generated synthetically from , and in this case, the loss in Equation (14) could be seen as a variant of data augmentation; this is the only case considered in the self similarity loss of [21].
3.2.2. Auxiliary Multi-Task Learning Training Objective
3.3. Batch Generation
- The semantic similarity loss in Equation (9) requires triplets ∈. In a first step, all possible triplets with are generated for every image . As for a triplet to be valid, the positive sample has to be more similar to than the negative sample , only those triplets fulfilling the constraint related to the margin formulated in Equation (10) are presented to the network. As the number of is dependent on the margin calculated from the available class labels in a mini-batch, the loss is normalized by the number of triplets.
- The color similarity loss in Equation (13) requires pairs of images . For that purpose, all possible pairs in the mini-batch are generated, excluding all pairs with . Thus, the color similarity loss is calculated for pairs of training samples, where ! denotes the factorial of a number.
- The self similarity loss requires pairs of images . There is one such pair per image in the mini-batch; as described in Section 3.2.1, if there exist other images in the dataset that show the same object as , one of these images is randomly chosen to serve as the partner . Otherwise, is generated synthetically using a randomly drawn transformation as defined in Section 3.2.1.This results in pairs of images .
- The classification loss in Equation (16) requires a set of independent images with known classes for ideally all of the M variables in order to learn such that the predictions become optimal. Accordingly, all images in the mini-batch can be presented to the classification loss. As class labels are potentially not available for all M variables, there are potentially less than cross-entropy terms constituting the classification loss in case of mutually exclusive class labels per variable. Thus, the loss is normalized by the number of known class labels for the M variables; i.e., the number of terms constituting the loss.
4. Dataset
4.1. SILKNOW Dataset
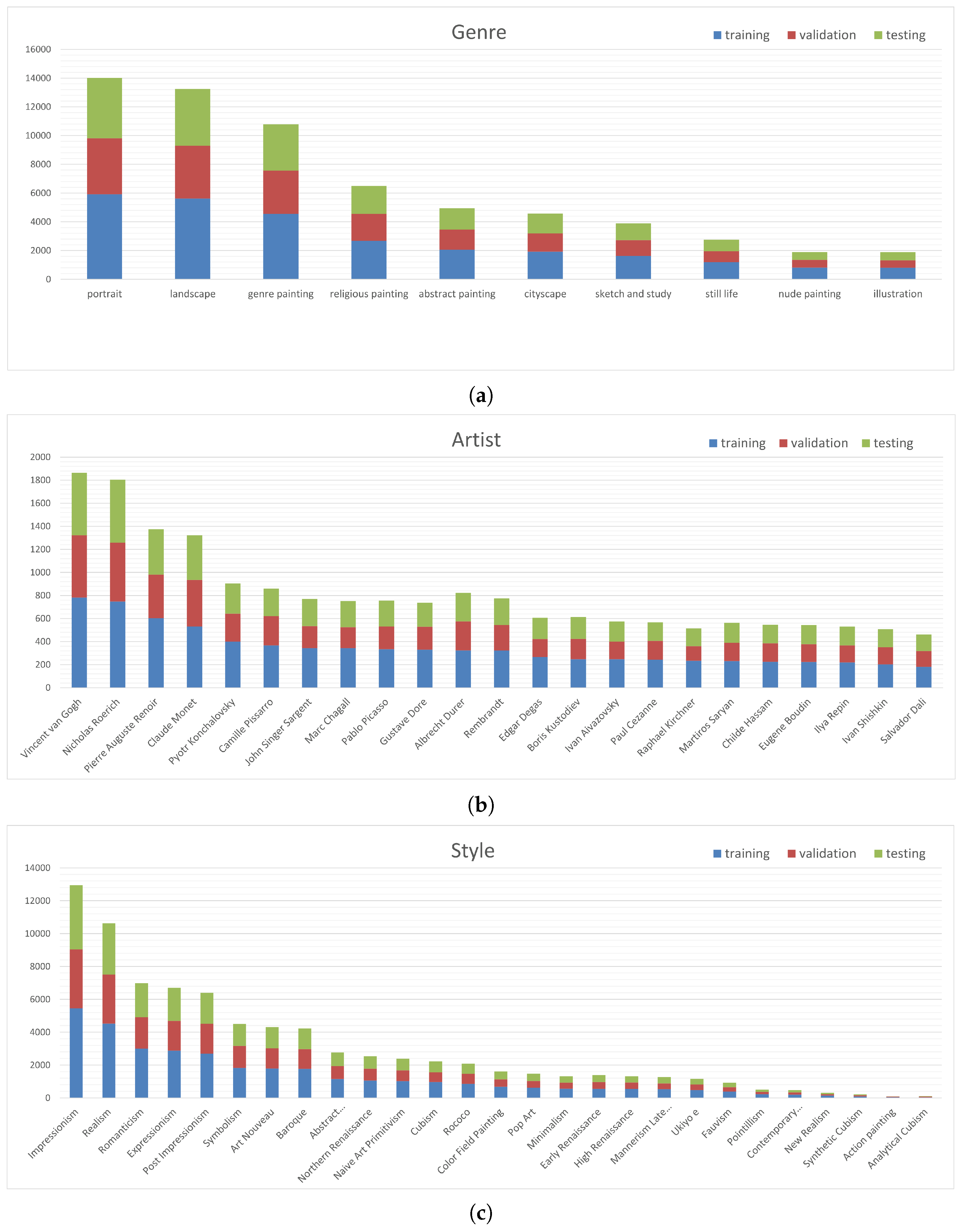
4.2. WikiArt Dataset
5. Experiments and Results
5.1. Test Setup and Evaluation Strategy
5.1.1. General Test Setup
5.1.2. Test Series
Evaluation Strategy
5.2. Results of the Experiments Using the SILKNOW Dataset
5.2.1. General Observations
5.2.2. Variable-Specific Analysis
5.3. Transferability of the Approach: Evaluation on the WikiArt Dataset
5.4. Qualitative Evaluation of the Results
6. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alba Pagán, E.; Gaitán Salvatella, M.; Pitarch, M.D.; León Muñoz, A.; Moya Toledo, M.; Marin Ruiz, J.; Vitella, M.; Lo Cicero, G.; Rottensteiner, F.; Clermont, D.; et al. From silk to digital technologies: A gateway to new opportunities for creative industries, traditional crafts and designers. The SILKNOW case. Sustainability 2020, 12, 8279. [Google Scholar] [CrossRef]
- Bentley, J. Multidimensional Binary Search Trees Used for Associative Searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Jain, A.K.; Vailaya, A. Image retrieval using color and shape. Pattern Recognit. 1996, 29, 1233–1244. [Google Scholar] [CrossRef]
- Gudivada, V.N.; Raghavan, V.V. Content based image retrieval systems. Computer 1995, 28, 18–22. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.C.; Lee, C.H. Image semantics discovery from web pages for semantic-based image retrieval using self-organizing maps. Expert Syst. Appl. 2008, 34, 266–279. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten ZIP code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 539–546. [Google Scholar] [CrossRef]
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; Wu, Y. Learning fine-grained image similarity with deep ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1386–1393. [Google Scholar] [CrossRef] [Green Version]
- Qi, Y.; Song, Y.Z.; Zhang, H.; Liu, J. Sketch-based image retrieval via siamese convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2460–2464. [Google Scholar] [CrossRef]
- Cao, Y.; Long, M.; Liu, B.; Wang, J. Deep cauchy hashing for hamming space retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1229–1237. [Google Scholar] [CrossRef]
- Zhao, F.; Huang, Y.; Wang, L.; Tan, T. Deep semantic ranking based hashing for multi-label image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1556–1564. [Google Scholar] [CrossRef]
- Wu, D.; Lin, Z.; Li, B.; Ye, M.; Wang, W. Deep supervised hashing for multi-label and large-scale image retrieval. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval (ICMR’17), Bucharest, Romania, 6–9 June 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 150–158. [Google Scholar] [CrossRef]
- Zhang, Z.; Zou, Q.; Lin, Y.; Chen, L.; Wang, S. Improved deep hashing with soft pairwise similarity for multi-label image retrieval. IEEE Trans. Multimed. 2019, 22, 540–553. [Google Scholar] [CrossRef] [Green Version]
- Gordo, A.; Larlus, D. Beyond Instance-Level Image Retrieval: Leveraging Captions to Learn a Global Visual Representation for Semantic Retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5272–5281. [Google Scholar] [CrossRef]
- Kim, S.; Seo, M.; Laptev, I.; Cho, M.; Kwak, S. Deep Metric Learning Beyond Binary Supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2283–2292. [Google Scholar] [CrossRef] [Green Version]
- Mao, H.; Cheung, M.; She, J. Deepart: Learning joint representations of visual arts. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1183–1191. [Google Scholar] [CrossRef]
- Stefanini, M.; Cornia, M.; Baraldi, L.; Corsini, M.; Cucchiara, R. Artpedia: A new visual-semantic dataset with visual and contextual sentences in the artistic domain. In International Conference on Image Analysis and Processing (ICIAP); Springer: Cham, Switzerland, 2019; pp. 729–740. [Google Scholar] [CrossRef] [Green Version]
- Garcia, N.; Renoust, B.; Nakashima, Y. ContextNet: Representation and exploration for painting classification and retrieval in context. Int. J. Multimed. Inf. Retr. 2020, 9, 17–30. [Google Scholar] [CrossRef] [Green Version]
- Clermont, D.; Dorozynski, M.; Wittich, D.; Rottensteiner, F. Assessing the semantic similarity of images of silk fabrics using convolutional neural network. In ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences; Copernicus GmbH: Göttingen, Germany, 2020; Volume V-2, pp. 641–648. [Google Scholar] [CrossRef]
- Schleider, T.; Troncy, R.; Ehrhart, T.; Dorozynski, M.; Rottensteiner, F.; Lozano, J.S.; Lo Cicero, G. Searching Silk Fabrics by Images Leveraging on Knowledge Graph and Domain Expert Rules. In Proceedings of the 3rd Workshop on Structuring and Understanding of Multimedia HeritAge Contents (SUMAC ’21), Association for Computing Machinery (ACM), Chengdu, China, 20 October 2021; pp. 41–49. [Google Scholar] [CrossRef]
- Li, J.; Ng, W.W.; Tian, X.; Kwong, S.; Wang, H. Weighted multi-deep ranking supervised hashing for efficient image retrieval. Int. J. Mach. Learn. Cybern. 2020, 11, 883–897. [Google Scholar] [CrossRef]
- Shen, C.; Zhou, C.; Jin, Z.; Chu, W.; Jiang, R.; Chen, Y.; Hua, X.S. Learning feature embedding with strong neural activations for fine-grained retrieval. In Proceedings of the on Thematic Workshops of ACM Multimedia, Mountain View, CA, USA, 23–27 October 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 424–432. [Google Scholar] [CrossRef]
- Jun, H.; Ko, B.; Kim, Y.; Kim, I.; Kim, J. Combination of multiple global descriptors for image retrieval. arXiv 2019, arXiv:1903.10663. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.S.; Huang, T.S. Relevance feedback in image retrieval: A comprehensive review. Multimed. Syst. 2003, 8, 536–544. [Google Scholar] [CrossRef]
- Chen, Z.; Wenyin, L.; Zhang, F.; Li, M.; Zhang, H. Web mining for web image retrieval. J. Am. Soc. Inf. Sci. Technol. 2001, 52, 831–839. [Google Scholar] [CrossRef]
- Sharif Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar] [CrossRef] [Green Version]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.; LeCun, Y.; Moore, C.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 669–688. [Google Scholar] [CrossRef] [Green Version]
- Dutta, A.; Akata, Z. Semantically Tied Paired Cycle Consistency for Zero-Shot Sketch-Based Image Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5084–5093. [Google Scholar] [CrossRef] [Green Version]
- Deng, Y.; Tang, F.; Dong, W.; Ma, C.; Huang, F.; Deussen, O.; Xu, C. Exploring the representativity of art paintings. IEEE Trans. Multimed. 2021, 23, 2794–2805. [Google Scholar] [CrossRef]
- Efthymiou, A.; Rudinac, S.; Kackovic, M.; Worring, M.; Wijnberg, N. Graph Neural Networks for Knowledge Enhanced Visual Representation of Paintings. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 3710–3719. [Google Scholar] [CrossRef]
- Hamreras, S.; Boucheham, B.; Molina-Cabello, M.A.; Benitez-Rochel, R.; Lopez-Rubio, E. Content based image retrieval by ensembles of deep learning object classifiers. Integr. Comput.-Aided Eng. 2020, 27, 317–331. [Google Scholar] [CrossRef]
- Liu, F.; Wang, B.; Zhang, Q. Deep Learning of Pre-Classification for Fast Image Retrieval. In Proceedings of the 2018 International Conference on Algorithms, Computing and Artificial Intelligence; Association for Computing Machinery, Sanya, China, 21–23 December 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Lin, H.; Fu, Y.; Lu, P.; Gong, S.; Xue, X.; Jiang, Y.G. Tc-net for isbir: Triplet classification network for instance-level sketch based image retrieval. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 2–25 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1676–1684. [Google Scholar] [CrossRef]
- Huang, J.; Feris, R.S.; Chen, Q.; Yan, S. Cross-Domain Image Retrieval With a Dual Attribute-Aware Ranking Network. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1062–1070. [Google Scholar] [CrossRef] [Green Version]
- Barz, B.; Denzler, J. Hierarchy-based image embeddings for semantic image retrieval. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 638–647. [Google Scholar] [CrossRef] [Green Version]
- Fellbaum, C. WordNet: Wiley online library. Encycl. Appl. Linguist. 1998, 7. [Google Scholar] [CrossRef]
- Mensink, T.; Van Gemert, J. The rijksmuseum challenge: Museum-centered visual recognition. In Proceedings of the International Conference on Multimedia Retrieval (ICMR’14), Glasgow, UK, 1–4 April 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 451–454. [Google Scholar] [CrossRef]
- Tan, W.R.; Chan, C.S.; Aguirre, H.E.; Tanaka, K. Ceci n’est pas une pipe: A deep convolutional network for fine-art paintings classification. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3703–3707. [Google Scholar] [CrossRef]
- Sur, D.; Blaine, E. Cross-Depiction Transfer Learning for Art Classification; Technical Report CS 231A and CS 231N; Stanford University: Stanford, CA, USA, 2017. [Google Scholar]
- Belhi, A.; Bouras, A.; Foufou, S. Towards a hierarchical multitask classification framework for cultural heritage. In Proceedings of the 2018 IEEE/ACS 15th International Conference on Computer Systems and Applications (AICCSA), Aqaba, Jordan, 28 October–1 November 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Strezoski, G.; Worring, M. Omniart: Multi-task deep learning for artistic data analysis. arXiv 2017, arXiv:1708.00684. [Google Scholar]
- Bianco, S.; Mazzini, D.; Napoletano, P.; Schettini, R. Multitask painting categorization by deep multibranch neural network. Expert Syst. Appl. 2019, 135, 90–101. [Google Scholar] [CrossRef] [Green Version]
- Castellano, G.; Vessio, G. Deep learning approaches to pattern extraction and recognition in paintings and drawings: An overview. Neural Comput. Appl. 2021, 33, 12263–12282. [Google Scholar] [CrossRef]
- Stalmann, K.; Wegener, D.; Doerr, M.; Hill, H.J.; Friesen, N. Semantic-based retrieval of cultural heritage multimedia objects. Int. J. Semant. Comput. 2012, 6, 315–327. [Google Scholar] [CrossRef]
- Castellano, G.; Lella, E.; Vessio, G. Visual link retrieval and knowledge discovery in painting datasets. Multimed. Tools Appl. 2021, 80, 6599–6616. [Google Scholar] [CrossRef]
- Jain, N.; Bartz, C.; Bredow, T.; Metzenthin, E.; Otholt, J.; Krestel, R. Semantic Analysis of Cultural Heritage Data: Aligning Paintings and Descriptions in Art-Historic Collections. In International Conference on Pattern Recognition (ICPR); Springer: Berlin/Heidelberg, Germany, 2021; pp. 517–530. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.W.; Sobue, S.; Huang, X. KANSEI based clothing fabric image retrieval. In International Workshop on Computational Color Imaging; Springer: Berlin/Heidelberg, Germany, 2009; pp. 71–80. [Google Scholar] [CrossRef] [Green Version]
- Corbiere, C.; Ben-Younes, H.; Rame, A.; Ollion, C. Leveraging Weakly Annotated Data for Fashion Image Retrieval and Label Prediction. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Venice, Italy, 22–29 October 2017; pp. 2268–2274. [Google Scholar] [CrossRef] [Green Version]
- D’Innocente, A.; Garg, N.; Zhang, Y.; Bazzani, L.; Donoser, M. Localized Triplet Loss for Fine-Grained Fashion Image Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 3910–3915. [Google Scholar] [CrossRef]
- Deng, D.; Wang, R.; Wu, H.; He, H.; Li, Q.; Luo, X. Learning deep similarity models with focus ranking for fabric image retrieval. Image Vis. Comput. 2018, 70, 11–20. [Google Scholar] [CrossRef] [Green Version]
- Xiang, J.; Zhang, N.; Pan, R.; Gao, W. Fabric image retrieval system using hierarchical search based on deep convolutional neural network. IEEE Access 2019, 7, 35405–35417. [Google Scholar] [CrossRef]
- Dorozynski, M.; Clermont, D.; Rottensteiner, F. Multi-task deep learning with incomplete training samples for the image-based prediction of variables describing silk fabrics. In ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences; Copernicus GmbH: Göttingen, Germany, 2019; Volume IV-2/W6, pp. 47–54. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar] [CrossRef] [Green Version]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning, 1st ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef] [Green Version]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Chen, L.; Chen, Y. Age Classification Using Convolutional Neural Networks with the Multi-class Focal Loss. IOP Conf. Ser. Mater. Sci. Eng. 2018, 428, 012043. [Google Scholar] [CrossRef]
- IMATEX. Centre de Documentació i Museu Tèxtil, CMDT’s Textilteca Online. 2018. Available online: http://imatex.cdmt.cat (accessed on 14 February 2019).
- Liu, Z.; Luo, P.; Qiu, S.; Wang, X.; Tang, X. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1096–1104. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; He, K. Exploring Simple Siamese Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar] [CrossRef]
- Garcia, N.; Vogiatzis, G. How to read paintings: Semantic art understanding with multi-modal retrieval. In Computer Vision—ECCV 2018 Workshops; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 676–691. [Google Scholar] [CrossRef] [Green Version]
- SILKNOW Knowledge Graph. https://doi.org/10.5281/zenodo.5743090 (accessed on 29 November 2021).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Class Name | Total | Train | Update | Stop | Val | Test |
|---|---|---|---|---|---|---|---|
| material | animal fibre | 27,252 | 16,700 | 12,546 | 4154 | 5330 | 5222 |
| (72.4%) | metal thread | 4208 | 2574 | 1943 | 631 | 684 | 950 |
| vegetal fibre | 3891 | 2407 | 1763 | 644 | 707 | 777 | |
| place | GB | 7998 | 5154 | 3908 | 1246 | 1282 | 1562 |
| (71.3%) | FR | 7379 | 4452 | 3346 | 1106 | 1527 | 1400 |
| ES | 4708 | 2847 | 2127 | 720 | 921 | 940 | |
| IT | 4700 | 2781 | 2131 | 650 | 995 | 924 | |
| IN | 2353 | 1441 | 1069 | 372 | 420 | 492 | |
| CN | 1399 | 866 | 636 | 230 | 276 | 257 | |
| IR | 1294 | 802 | 608 | 194 | 248 | 244 | |
| JP | 1097 | 794 | 588 | 206 | 163 | 140 | |
| BE | 648 | 405 | 305 | 100 | 71 | 172 | |
| TR | 593 | 342 | 240 | 102 | 94 | 157 | |
| DE | 592 | 388 | 291 | 97 | 96 | 131 | |
| GR | 479 | 281 | 206 | 75 | 69 | 129 | |
| NL | 455 | 310 | 226 | 84 | 85 | 60 | |
| US | 357 | 238 | 190 | 48 | 54 | 65 | |
| PK | 352 | 225 | 165 | 60 | 67 | 60 | |
| RU | 228 | 137 | 99 | 38 | 46 | 45 | |
| JM | 191 | 105 | 77 | 28 | 49 | 37 | |
| timespan | 19th century | 9975 | 6041 | 4569 | 1472 | 1938 | 1996 |
| (57.9%) | 18th century | 8423 | 5155 | 3819 | 1336 | 1539 | 1729 |
| 20th century | 4012 | 2447 | 1821 | 626 | 778 | 787 | |
| 17th century | 3378 | 2170 | 1649 | 521 | 482 | 726 | |
| 16th century | 1829 | 1154 | 873 | 281 | 332 | 343 | |
| 15th century | 685 | 433 | 338 | 95 | 100 | 152 | |
| technique | embroidery | 6861 | 4333 | 3237 | 1096 | 1217 | 1310 |
| (32.2%) | velvet | 3051 | 1854 | 1422 | 432 | 671 | 526 |
| damask | 2768 | 1615 | 1218 | 397 | 582 | 571 | |
| other technique | 2526 | 1585 | 1203 | 382 | 463 | 478 | |
| resist dyeing | 355 | 289 | 213 | 76 | 15 | 51 | |
| tabby | 185 | 98 | 70 | 28 | 37 | 50 |
| Experiment | |||||
|---|---|---|---|---|---|
| sem | 1 | 0 | 1.0 | 0.0 | 0.0 |
| co | 1 | 0 | 0.0 | 1.0 | 0.0 |
| sem + co | 1 | 0 | 0.5 | 0.5 | 0.0 |
| sem + slf | 1 | 0 | 1.0 | 0.0 | 0.5 |
| sem + co + slf | 1 | 0 | 0.5 | 0.5 | 0.5 |
| sem + C | 1 | 1 | 1.0 | 0.0 | 0.0 |
| sem + co + C | 1 | 1 | 0.5 | 0.5 | 0.0 |
| sem + slf + C | 1 | 1 | 1.0 | 0.0 | 0.5 |
| sem + co + slf + C | 1 | 1 | 0.5 | 0.5 | 0.5 |
| Quality Metric | Experiment | Mean | Std |
|---|---|---|---|
| OA [%] | sem | 61.2 | 0.18 |
| co | 54.7 | 0.20 | |
| sem + co | 60.9 | 0.17 | |
| sem + slf | 53.5 | 0.34 | |
| sem + co + slf | 56.5 | 0.21 | |
| sem + C | 63.9 | 0.11 | |
| sem + co + C | 63.7 | 0.11 | |
| sem + slf + C | 62.2 | 0.16 | |
| sem + co + slf + C | 62.2 | 0.15 | |
| F1 score [%] | sem | 37.3 | 0.34 |
| co | 32.1 | 0.39 | |
| sem + co | 38.0 | 0.48 | |
| sem + slf | 29.2 | 0.30 | |
| sem + co + slf | 32.4 | 0.51 | |
| sem + C | 42.9 | 0.31 | |
| sem + co + C | 42.7 | 0.30 | |
| sem + slf + C | 40.2 | 0.36 | |
| sem + co + slf + C | 40.0 | 0.40 |
| Experiment | Material | Place | Timespan | Technique | ||||
|---|---|---|---|---|---|---|---|---|
| mean | std | mean | std | mean | std | mean | std | |
| sem | 75.0 | 0.16 | 46.0 | 0.23 | 54.9 | 0.58 | 68.9 | 0.60 |
| co | 74.3 | 0.10 | 37.8 | 0.54 | 47.9 | 0.77 | 58.9 | 0.63 |
| sem + co | 74.9 | 0.25 | 46.1 | 0.41 | 54.3 | 0.36 | 68.4 | 0.50 |
| sem + slf | 74.2 | 0.29 | 35.4 | 0.22 | 46.0 | 1.14 | 58.4 | 0.36 |
| sem + co + slf | 74.3 | 0.31 | 39.5 | 0.80 | 49.8 | 0.58 | 62.3 | 0.62 |
| sem + C | 75.0 | 0.23 | 49.2 | 0.34 | 58.7 | 0.31 | 72.6 | 0.24 |
| sem + co + C | 75.1 | 0.16 | 49.3 | 0.11 | 58.6 | 0.44 | 71.7 | 0.26 |
| sem + slf + C | 74.8 | 0.27 | 47.5 | 0.44 | 56.5 | 0.81 | 69.9 | 0.61 |
| sem + co + slf + C | 74.7 | 0.09 | 47.5 | 0.31 | 56.9 | 0.39 | 69.7 | 0.38 |
| Experiment | Material | Place | Timespan | Technique | ||||
|---|---|---|---|---|---|---|---|---|
| mean | std | mean | std | mean | std | mean | std | |
| sem | 36.4 | 0.50 | 22.9 | 0.24 | 43.2 | 0.52 | 46.6 | 1.66 |
| co | 34.1 | 0.23 | 18.4 | 0.33 | 35.8 | 0.90 | 39.9 | 0.78 |
| sem + co | 37.3 | 0.67 | 23.7 | 0.75 | 42.4 | 0.42 | 48.5 | 1.51 |
| sem + slf | 33.7 | 1.20 | 14.8 | 0.62 | 31.6 | 0.74 | 36.7 | 0.50 |
| sem + co + slf | 34.9 | 0.77 | 17.4 | 0.51 | 36.5 | 0.52 | 40.9 | 1.58 |
| sem + C | 40.2 | 0.48 | 29.1 | 0.62 | 47.4 | 0.60 | 55.0 | 1.36 |
| sem + co + C | 40.3 | 0.51 | 28.9 | 0.53 | 47.4 | 0.76 | 54.3 | 0.77 |
| sem + slf + C | 39.5 | 0.59 | 27.3 | 0.48 | 44.7 | 1.23 | 49.2 | 1.10 |
| sem + co + slf + C | 38.8 | 0.20 | 26.2 | 0.60 | 44.7 | 0.39 | 50.3 | 1.21 |
| Quality Metric | Model | Style | Genre | Artist | Average |
|---|---|---|---|---|---|
| OA [%] | sem + C | 43.0 | 69.9 | 54.5 | 55.8 |
| sem + co + slf + C | 40.6 | 67.6 | 50.7 | 53.0 | |
| F1 score [%] | sem + C | 37.3 | 64.7 | 51.2 | 51.1 |
| sem + co + slf + C | 33.1 | 62.1 | 47.1 | 47.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dorozynski, M.; Rottensteiner, F. Deep Descriptor Learning with Auxiliary Classification Loss for Retrieving Images of Silk Fabrics in the Context of Preserving European Silk Heritage. ISPRS Int. J. Geo-Inf. 2022, 11, 82. https://doi.org/10.3390/ijgi11020082
Dorozynski M, Rottensteiner F. Deep Descriptor Learning with Auxiliary Classification Loss for Retrieving Images of Silk Fabrics in the Context of Preserving European Silk Heritage. ISPRS International Journal of Geo-Information. 2022; 11(2):82. https://doi.org/10.3390/ijgi11020082
Chicago/Turabian StyleDorozynski, Mareike, and Franz Rottensteiner. 2022. "Deep Descriptor Learning with Auxiliary Classification Loss for Retrieving Images of Silk Fabrics in the Context of Preserving European Silk Heritage" ISPRS International Journal of Geo-Information 11, no. 2: 82. https://doi.org/10.3390/ijgi11020082
APA StyleDorozynski, M., & Rottensteiner, F. (2022). Deep Descriptor Learning with Auxiliary Classification Loss for Retrieving Images of Silk Fabrics in the Context of Preserving European Silk Heritage. ISPRS International Journal of Geo-Information, 11(2), 82. https://doi.org/10.3390/ijgi11020082