
Geospatial Queries on Data Collection Using a Common Provenance Model



Abstract
1. Introduction
2. Provenance Model
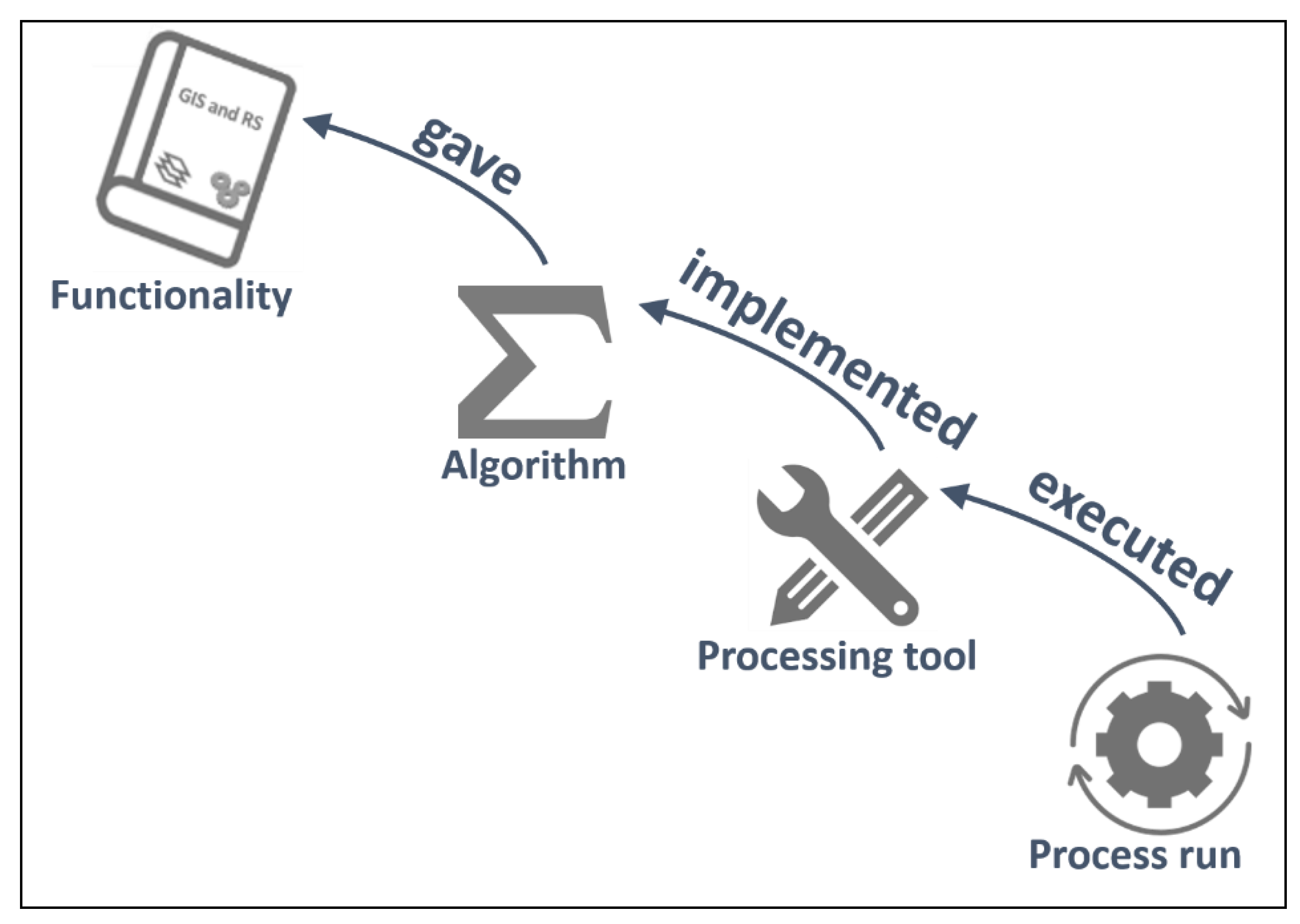
2.1. Levels of Abstraction of Process Steps
- Process run (process step): an individual execution of a processing tool with a specific set of parameters. It is a single GIS execution. Represented by LE_ProcessStep in ISO and as an Activity in PROV.
- Processing tool (executable or web service): a specific version of an implementation of an algorithm in a piece of software that can obviously be executed several times with different sources and parameters. This is what we can find in the GitHub, buy from a software vendor, use in a web processing service, etc. Represented by LE_Processing in ISO and as an Entity in PROV.
- Algorithm (model): a set of mathematical and logical steps that allow for transforming some inputs into some outputs. It can be implemented in software in different ways and programming languages. This is what a scientific paper usually describes. Represented by LE_Algorithm in ISO and as an Entity in PROV.
- Functionality (operation): an operation that transforms data into other data with spatial problem-solving orientation. This is a black box that can be implemented with different algorithms, potentially giving slightly different results. This is what a GIS and RS textbooks describe. It does not exist in ISO and is represented as an Entity in PROV.
- Represent together in a single provenance representation the origin of different datasets.
- Formalize provenance queries at different levels of abstraction. For instance, (from more abstract to more specific):
- ○
- What functionalities are used more frequently in my organization?
- ○
- What is the best algorithm that I can use for a quality test of my final products?
- ○
- How are my results affected by a specific processing tool version that has a bug?
- Translate a lineage description that is executed with one software vendor into another software product and reproduce the results.
2.2. Linking Geospatial Dataset Collections Through the Process History
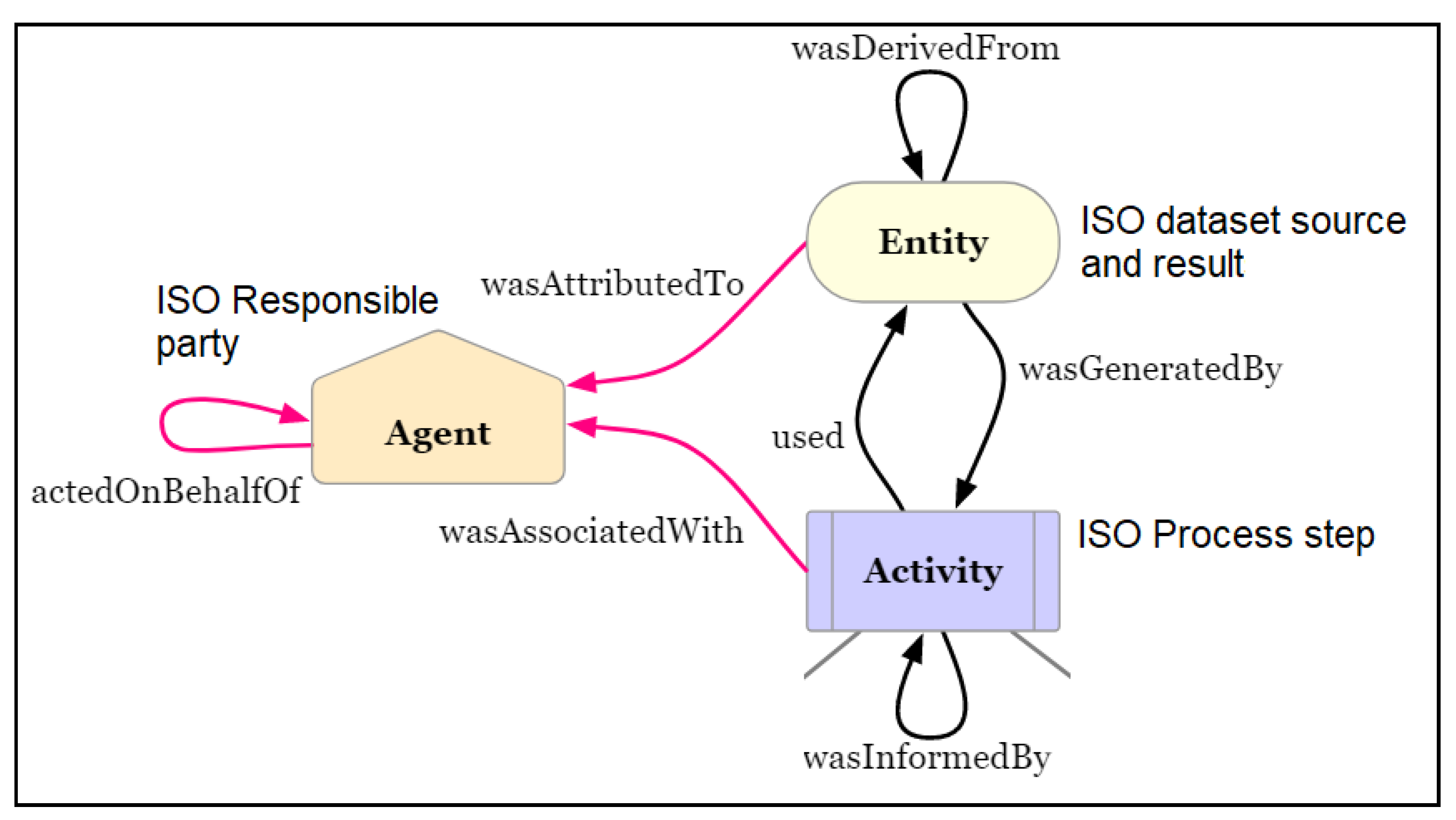
- PROV:used → Relates activities (PROV:Activity) with entities (PROV:Entity).
- PROV:wasAssociatedwith → Relates activities (PROV:Activity) with agents (PROV:Agent).
- PROV:wasGeneratedBy → Relates entities (PROV:Entity) with activities (PROV:Activity).
- PROV:wasAttributedTo → Relates entities (PROV:Entity) with agents (PROV:Agent).
- PROV:wasInformedBy (These PROV core relationships are not used in this proposal) → Relates activities (PROV:Activity) activities (PROV:Activity).
- PROV:wasDerivedFrom → Relates entities (PROV:Entity) with entities (PROV:Entity).
- PROV:actedOnBehalfOf (These PROV core relationships are not used in this proposal) → Relates agents (PROV:Agent) with agents (PROV:Agent).
2.3. W3C PROV for Representing the Process Abstraction Levels
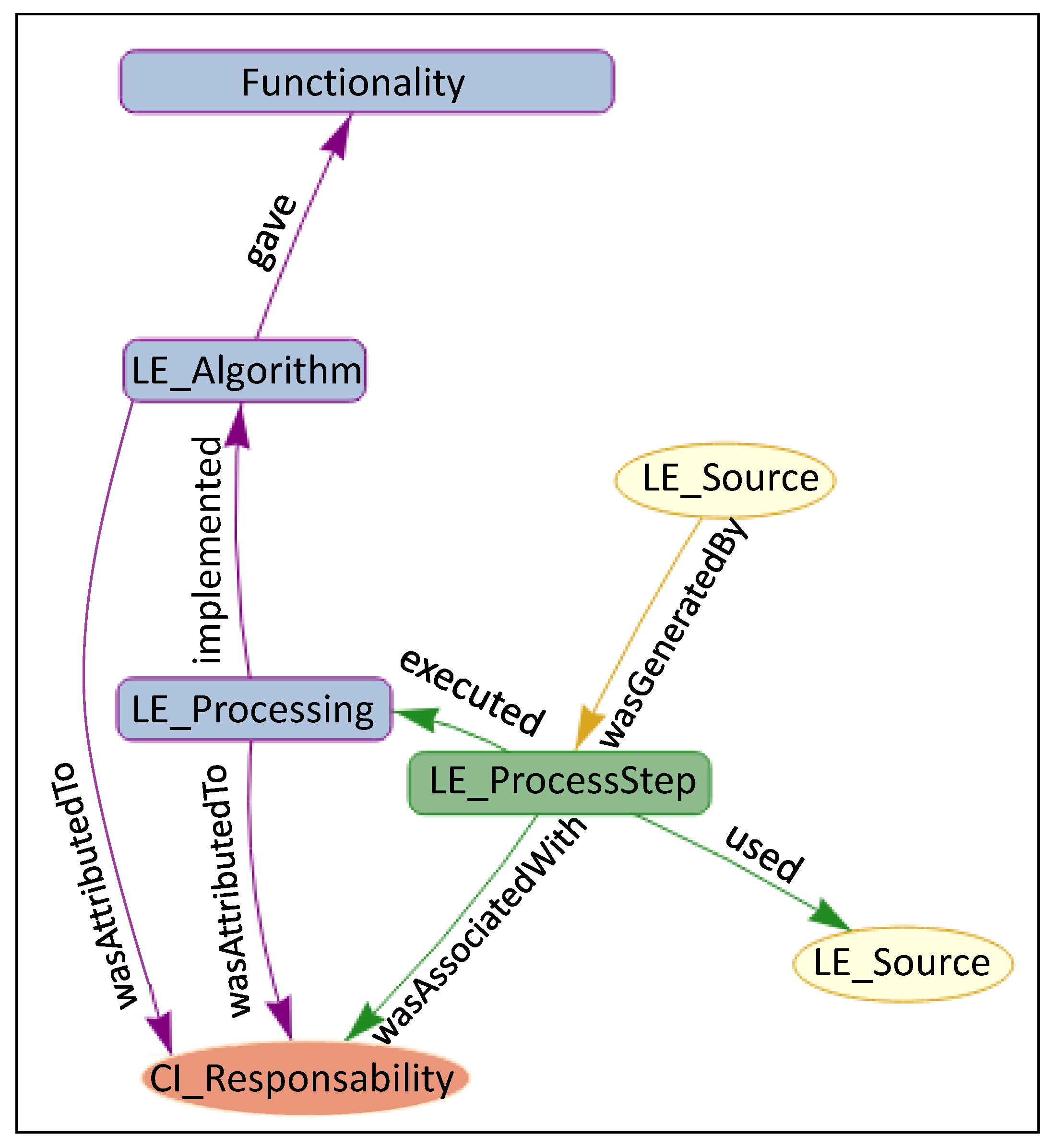
- executed → The subtype used:executed, is introduced to relate a LE_ProcessStep (PROV:Activity) with its LE_Processing tool (PROV:Entity). A LE_ProcessSet executed a LE_Processing tool once.
- implemented → The subtype wasDerivedFrom:implemented is used to relate the LE_Processing tool (PROV:Entity) with an LE_Algorithm (PROV:Entity). A LE_Processing tool implemented an LE_Algorithm.
- gave → The subtype wasDerivedFrom:gave is used to relate an LE_Algorithm (PROV:Entity) with a Functionality (PROV:Entity). An LE_Algorithm gave a Functionality.
2.3.1. Combining W3C PROV and ISO19115 to Represent Provenance
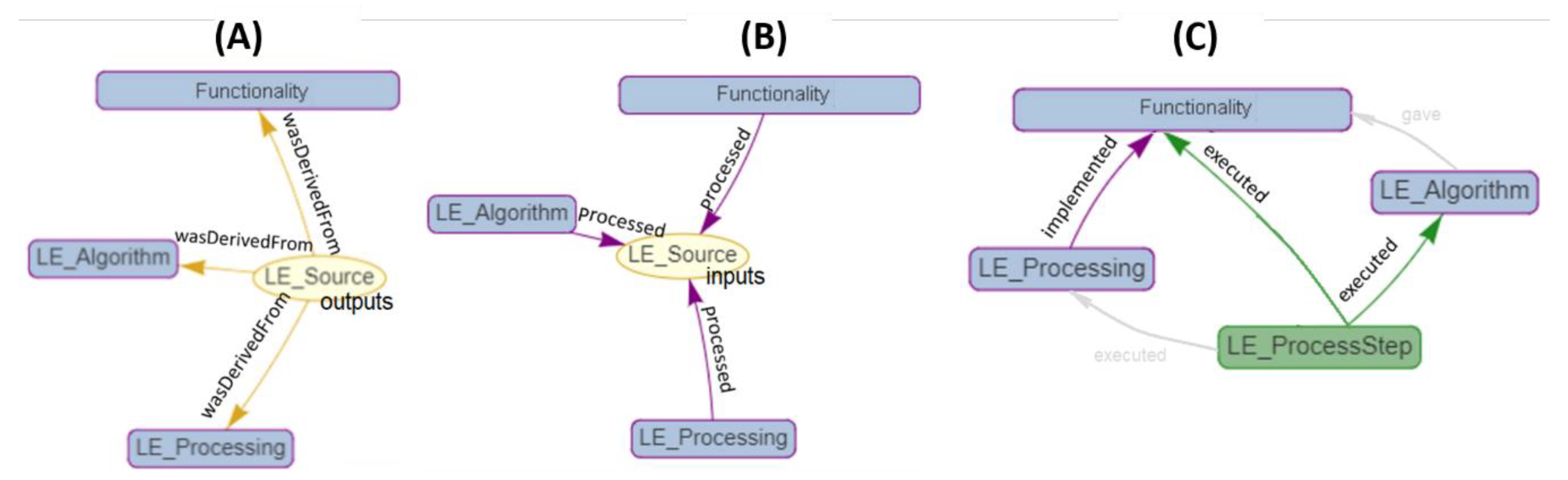
2.3.1.1. Relating Lineage Elements in Different Levels of Abstraction
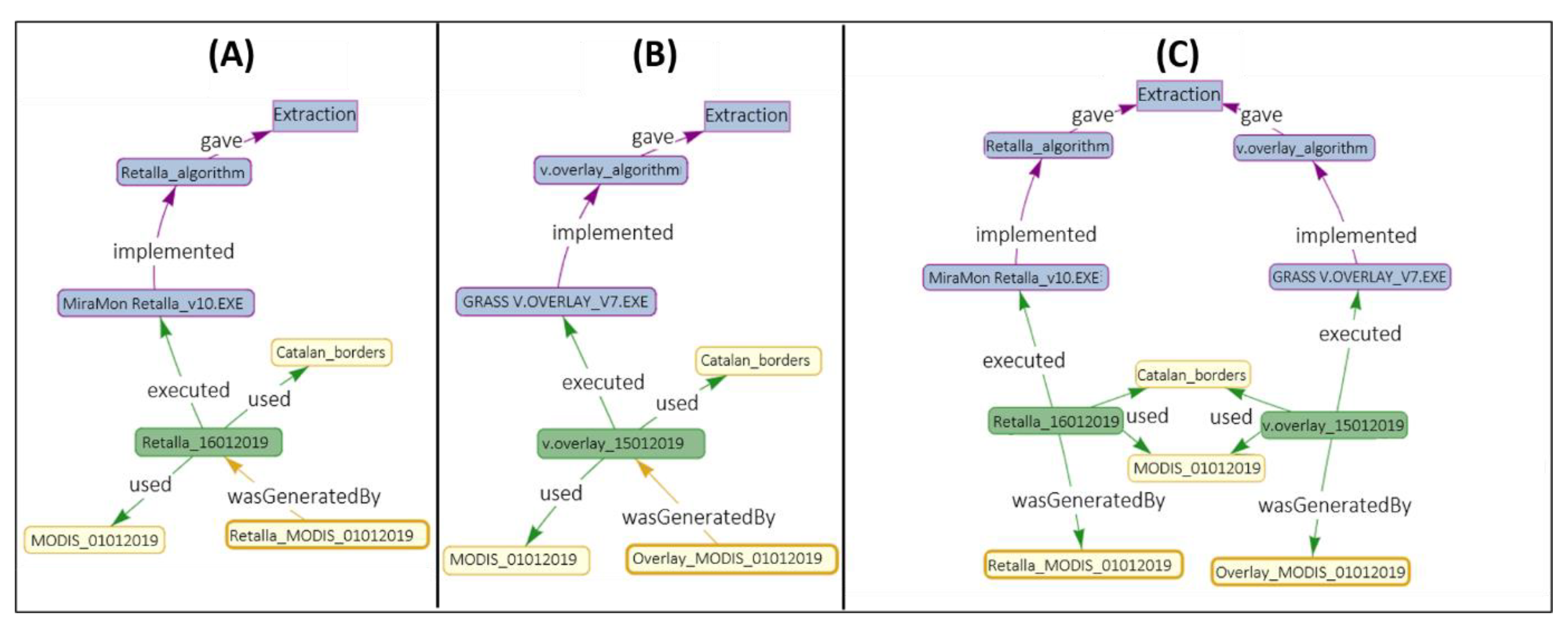
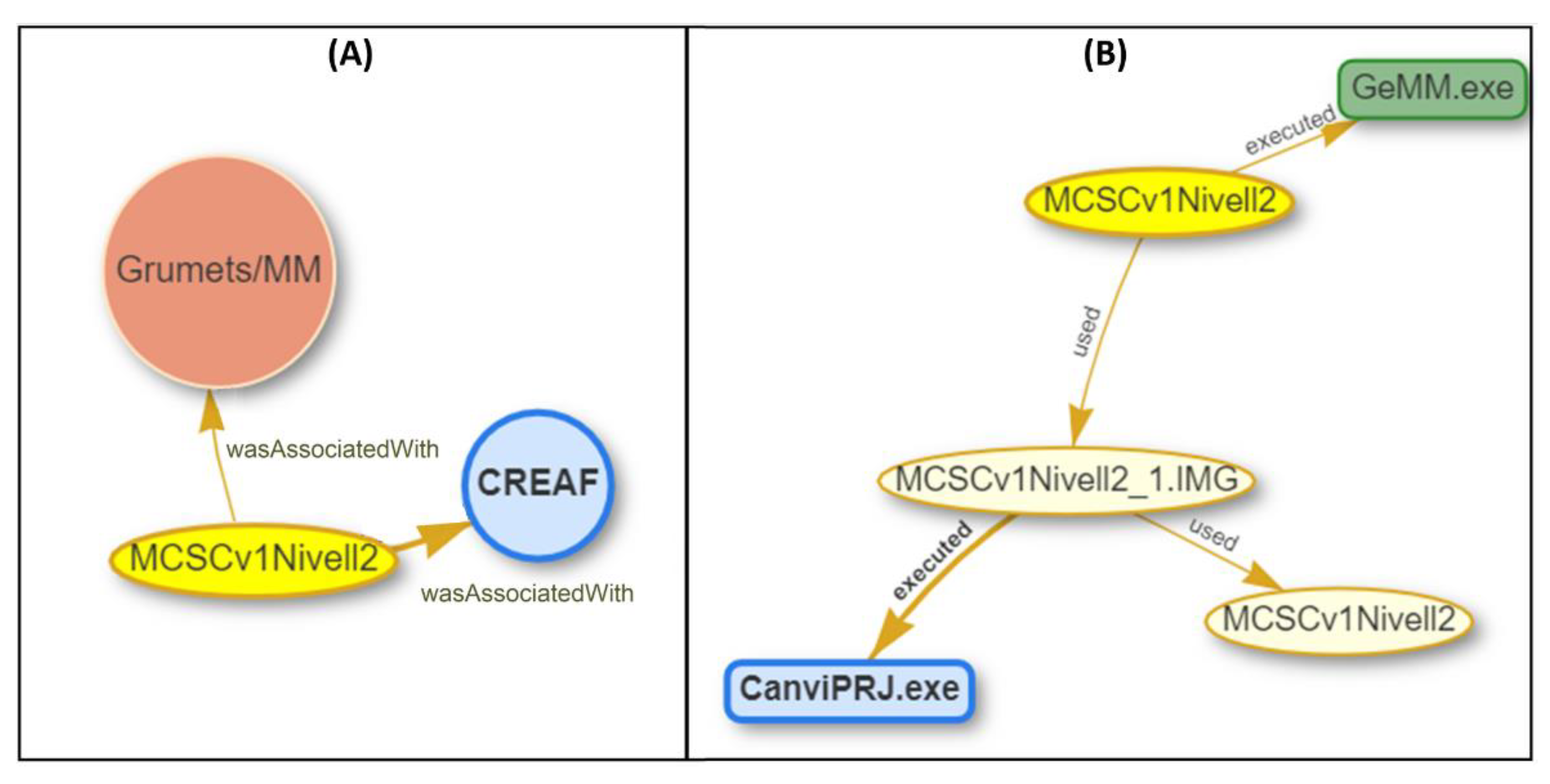
- Relating outputs (LE_Source) with the different levels of process step abstraction (Figure 5A). The PROV core type relation wasDerivedFrom is used with LE_Processing, LE_Algorithm and Funcionatily. The reason is that, while LE_ProcessStep can be assimilated to a PROV:Activity (and use wasGeneratedBy), the others are assimilated to a PROV: Entity.
- Relating inputs (LE_Source) with the different levels of abstraction (Figure 5B). The relationship processed is introduced, a subtyping of the PROV-DM core wasDerivedFrom. In this case, the relationship changes from connecting a PROV:Activity (LE:ProcessStep) with a PROV:entity (LE_Source), to connecting entities (LE_Processing, LE_Algorithm, Functionality) with entities (LE_Source).
- Relating the different levels of abstraction between themselves (Figure 5C). In this case, as there in no change in the relationship type (it is always a PROV:Entity to PROV:Entity), we are free to use the lowest level (in terms of process abstraction) provenance element connector.
3. Queries Facilitated by the Provenance Data Model
- Information and transparency: lineage allows for us to learn how datasets were developed.
- Trust and authority of the sources and tools used: the authority can help in determining liability.
- Data quality: the sources and processes involved can be used to estimate uncertainty and blunder propagation.
- Documentation and reproducibility: the documentation of the complete processing chain can help in the reproducibility, especially if provenance indicates the actual and exact datasets, parameters, and tools used.
- License and accessibility: related to the authorship rights of the sources used.
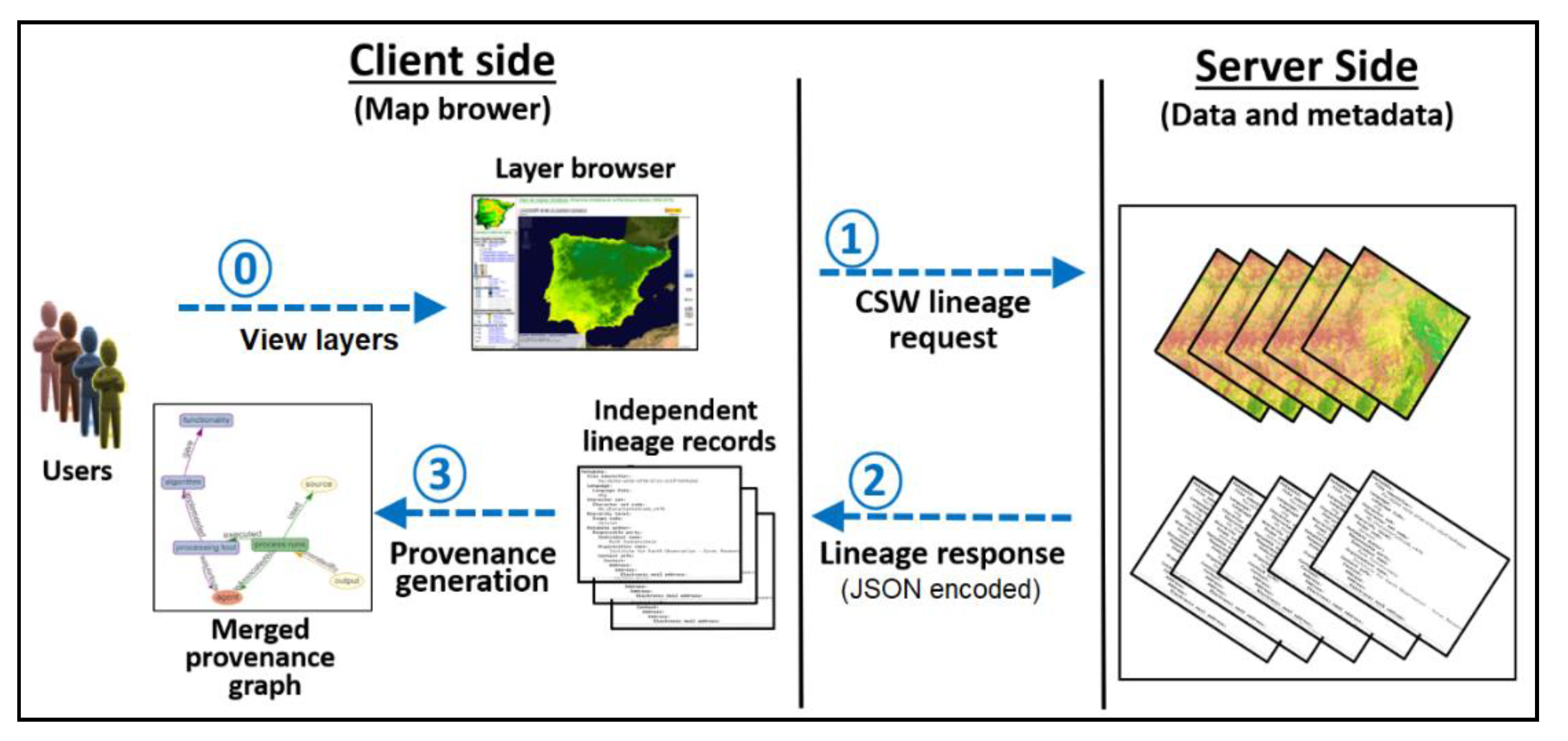
4. Representation and the Query Provenance Tool
4.1. Lineage Server
4.2. Provenance Interface
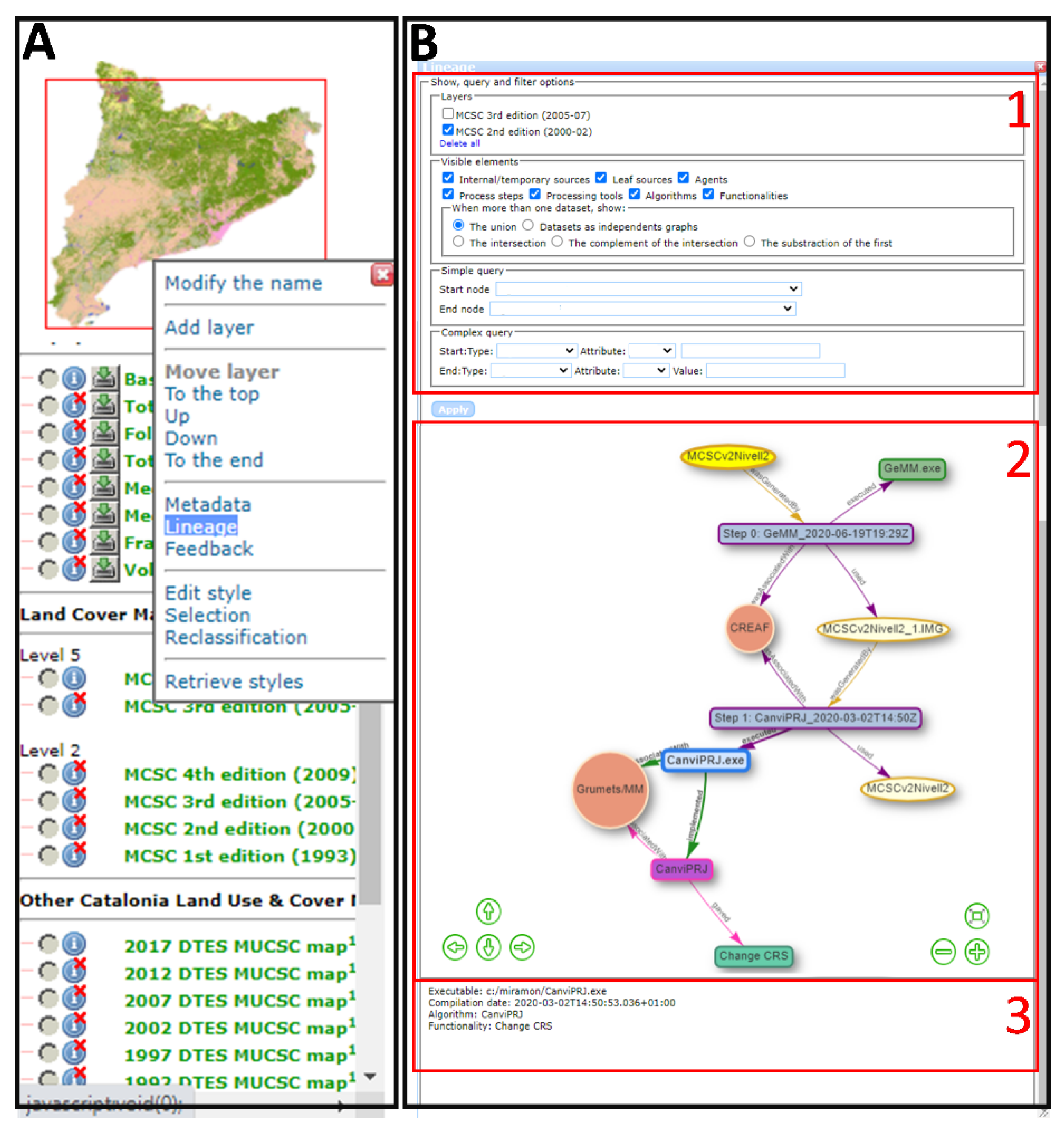
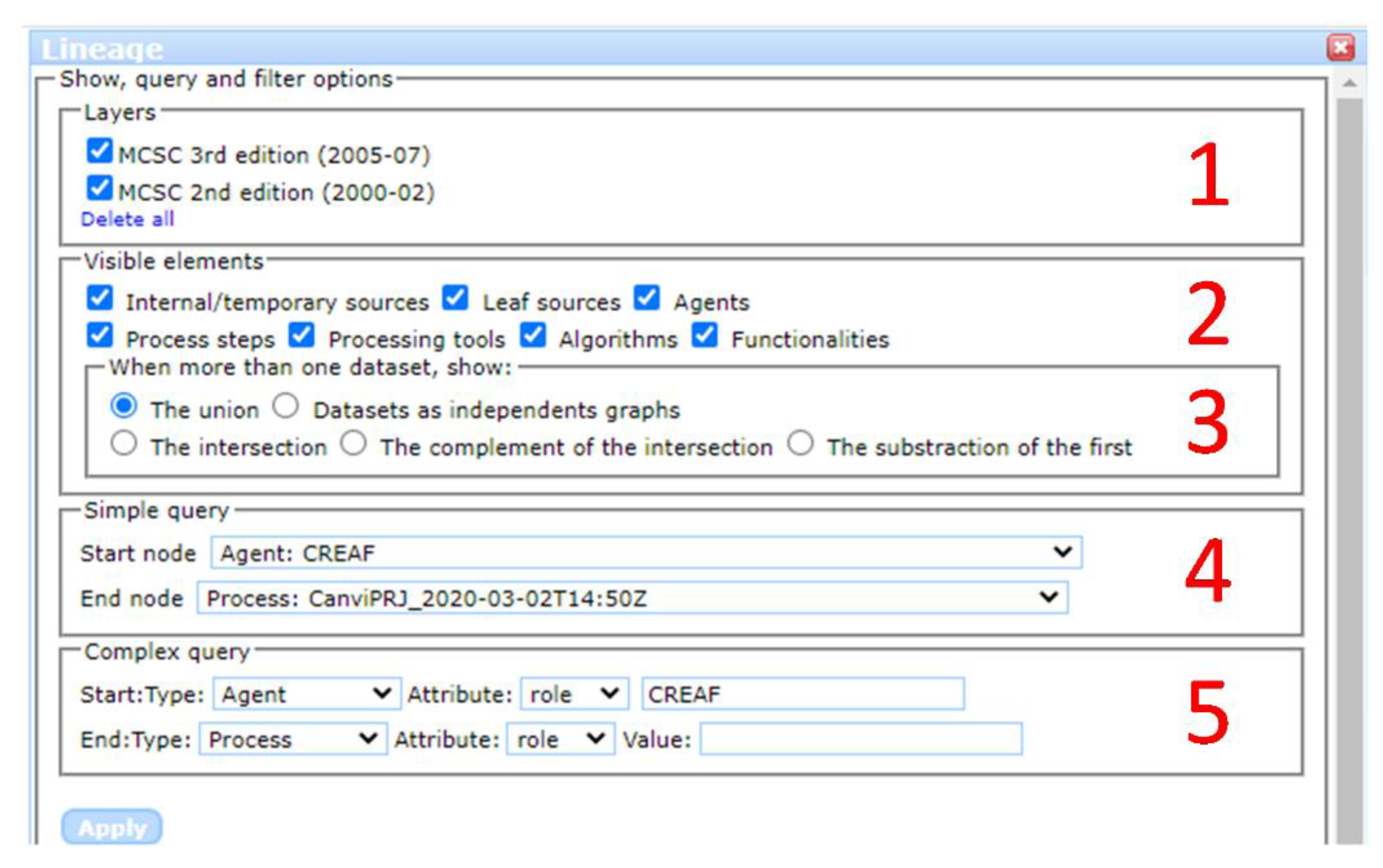
- Users can unselect some lineage element types to hide them in order to simplify the visualization (see Figure 10, panel 2):
- ○
- Agents can be hidden without consequences to simplify visualization.
- ○
- Leaf sources (sources that existed independently of the executed process step) can be removed from the view in order to make the process chain simpler.
- ○
- Internal and often temporary sources (datasets that were produced during the process chain execution) can be removed from the view in order to enhance the understanding of the process chain.
- ○
- Process steps can be removed, and processing tools take their place.
- ○
- Processing tools can be removed, and they are replaced by algorithms.
- ○
- Algorithms can be removed, and they are replaced by the functionality provided.
- ○
- Functionalities can be hidden with no consequences.
- Users can select and incorporate another dataset. The "incoming" lineage elements are accumulated in the provenance window. This combined graph can be represented in different ways (see Figure 10, panel 3):
- ○
- A new independent graph that is presented next to the previous one in the same window.
- ○
- The union of all lineage elements in a provenance graph: the common elements are represented only once, allowing for users to see the full picture of the provenance, including provenance connections between two production processes, such as shared sources, tools, agents, etc.
- ○
- The intersection between the two graphs: only the nodes that connect and are shared by both lineage graphs are presented. These elements are the ones that are most used.
- ○
- The subtraction of the first graph: only elements of the first lineage that are not present on the other lineage are represented. This places the emphasis on what is different in the first layer from the second one.
- ○
- The complement of the intersection: the elements that are not common in the two lineages are represented, placing the emphasis on the elements that are only used once.
- Users can right-click on the box of a process steps and request to group it with the previous step or with the next step. This creates a "virtual" process step that is the sequence of the previous two; in the same way as we create batch processes.
- Users can check the lineage statement by clicking with the right button on the resulting dataset (bright yellow ellipsis).
4.3. Provenance Query Tool
- The simple queries are facilitated by a simple query interface that offers two lists with all the objects that are present in the graph (classified per type). An algorithm determines whether the start object is connected with the end object and selects them as well as all intermediate nodes that connect them. For instance, we would like to check the activity of the agent “CREAF” regarding a specific “CanviPrj” processing tool (see Figure 10, panel 4).
- The complex query allows us to select two object types and their respective attribute values. This results in several start and end nodes being marked as selected. Not filling in the attribute value will result in selecting all of the nodes with the same attribute type as the start or end points. For instance, we would like to check the activities of the agent “CREAF” regarding all of the processing tools (see Figure 10, panel 5), whatever they may be. As in the previous case, the objects that match the query and all the objects that connect them are selected.
- A graph representing only the elements that were selected by the query. The result is simpler, but some relationships to other objects that are essential in understanding the graph might not be visible.
- A full graph with all elements, but with the selected elements emphasized. This option is more useful for graphs that contain a limited number of elements.
5. Use Case: Catalonia Land Use and Land Cover Map
- The MCSCs were made by photointerpretation of aerial photographs and, sometimes, by incorporating elements of other cartography. The base materials for the photointerpretation were a set of orthophotos in natural color from the Institut Cartogràfic i Geològic de Catalunya (ICGC). The legends of the MCSC 2005 and 2009 editions have hierarchical levels of complexity (the simplest is level 1 and the most complex is level 5) [49].
- MUCSCs were generated using automatic classification of satellite imagery and auxiliary cartography. While the 1987, 1992, 1997, and 2002 maps were generated by the ICGC, the 2007, 2012, and 2017 editions were generated by the Geography Department of the Universitat Autònoma de Barcelona (UAB). In addition, the 1987, 1992, 1997, 2002, and 2012 maps were created using Landsat imagery (Landsat 5, Landsat 7, or Landsat 8, depending on the edition), and the 2017 map was based on Sentinel 2 imagery [50,51]. The software used has evolved over the years, with new methodologies and new versions of the same applications. Finally, the maps have been manually edited to fix some unavoidable errors of the automatic classification.
5.1. Provenance Visualization Examples
- Example 1 (see Figure 11—Left): a provenance graph shows the agents that are involved in the generation of the MCSC version 1. The visibility, query, and filter options panel only has the layer MCSCv1Nivell2 selected and the agents as visible.
- Example 2 (see Figure 11—Right): the provenance graph panel shows the processing tools and sources involved in the generation of MCSC version 2. Process steps have been abstracted into used processing tools. The visibility query and filter options panel only has the layer MCSCv1Nivell2 selected and the internal sources, leaf sources, and processing tools as visible.
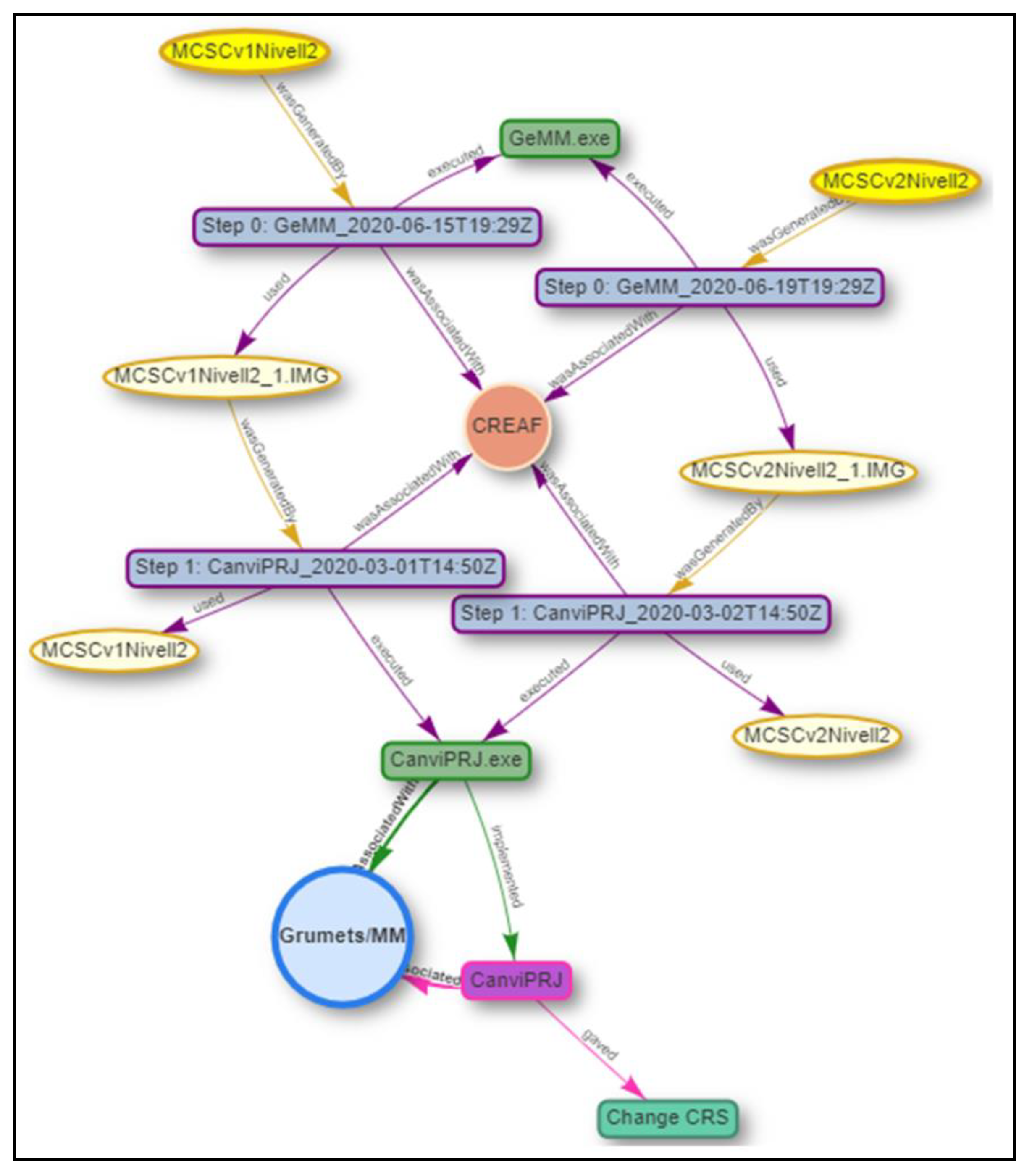
- Example 3 (see Figure 12): the provenance graph panel shows a representation of the combination of the lineage of the MCSC versions 1 and 2. The shared lineage elements are detected and represented only once. The visibility, query, and filter options panel have both layers, MCSCv1Nivell2 and MCSCv2Nivell2 selected, and all of the lineage elements are selected.
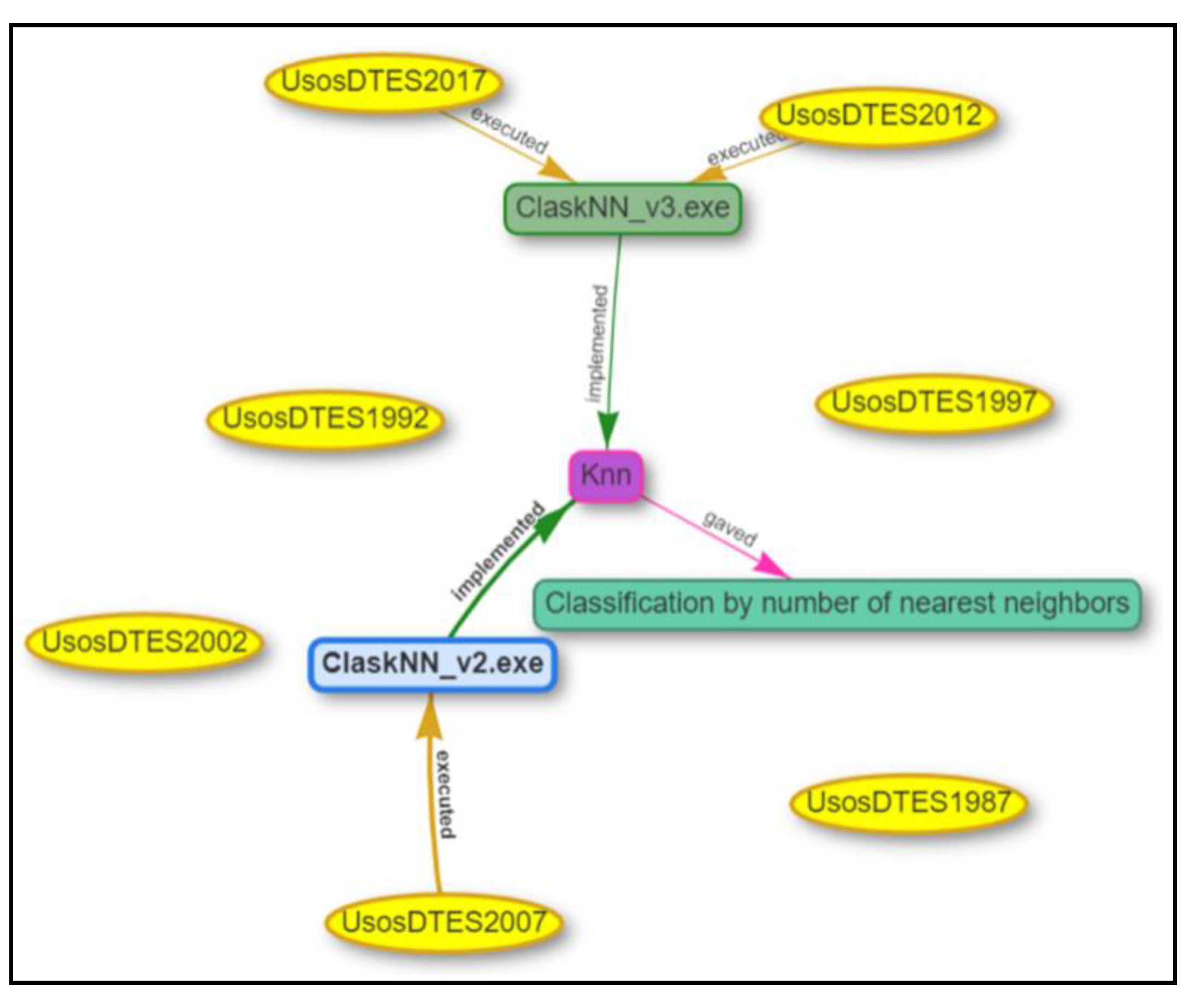
5.2. Provenance Query Examples
6. Discussion
- Information and transparency. These provide a better understanding and compare methodologies in Table 4 Q1, Q3, Q4, Q10, Q11, Q12, Q15, Q16, Q18, Q21, Q24 and Q25, Q27, Q28. Q32, Q33, Q39, Q42, and Q43.
- Trust and authority: agents and their responsibilities can be inferred based on the sources and tools used in Table 4 Q2, Q5, Q13, Q20, Q31, Q37, and Q38.
- Data quality can be deduced from the quality of the sources and precision of the processing tools used in Table 4 Q6, Q7, Q10, Q14, Q19, Q21 Q22, Q25, Q30, Q34, Q40, and Q44.
- Documentation and reproducibility can be achieved if all the necessary details about the actual dataset, metadata, or tools are present, such as in Table 4 Q9, Q16, Q17, Q23, Q24 Q29, and Q41.
- License and accessibility: information about the needed resources that were accessed, and licenses needed are present in Table 4 Q8, Q26, Q35, and Q36.
7. Future Work
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Baker, M. 1,500 scientists lift the lid on reproducibility. Nat. Cell Biol. 2016, 533, 452–454. [Google Scholar] [CrossRef]
- Lemos, M.C.; Kirchhoff, C.J.; Ramprasad, V. Narrowing the climate information usability gap. Nat. Clim. Chang. 2012, 2, 789–794. [Google Scholar] [CrossRef]
- Spiekermann, R.; Jolly, B.; Herzig, A.; Burleigh, T.; Medyckyj-Scott, D. Implementations of fine-grained automated data provenance to support transparent environmental modelling. Environ. Model. Softw. 2019, 118, 134–145. [Google Scholar] [CrossRef]
- Brinckman, A.; Chard, K.; Gaffney, N.; Hategan, M.; Jones, M.B.; Kowalik, K.; Stodden, V. Computing environments for reproducibility: Capturing the “Whole Tale”. Future Gener. Comput. Syst. 2019, 94, 854–867. [Google Scholar] [CrossRef]
- Lewis, A.; Lacey, J.; Mecklenburg, S.; Ross, J.; Siqueira, A.; Killough, B.; Szantoi, Z.; Tadono, T.; Rosenavist, A.; Goryl, P.; et al. CEOS Analysis Ready Data for Land (CARD4L) Overview. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7407–7410. [Google Scholar]
- Giuliani, G.; Chatenoux, B.; Bono, A.D.; Rodila, D.; Richard, J.P.; Allenbach, K.; Peduzzi, P. Building an Earth Observations Data Cube: Lessons learned from the Swiss Data Cube (SDC) on generating Analysis Ready Data (ARD). Big Earth Data 2017, 1, 100–117. [Google Scholar] [CrossRef]
- Fisher, P.F. Algorithm and Implementation Uncertainty: Any Advances? Int. J. Geogr. Inf. Sci. Syst. 2006, 225–228. [Google Scholar]
- Lutz, M.; Riedemann, C.; Probst, F. A Classification Framework for Approaches to Achieving Semantic Interoperability between GI Web Services. In Proceedings of the International Conference on Spatial Information Theory, Kartause Ittingen, Switzerland, 24–28 September 2008; Springer: Berlin/Heidelberg, Germany, 2003; pp. 186–203. [Google Scholar]
- CEOS Interoperability Terminology, Version 1.0. CEOS—WGISS Interoperability and Use Interest Group. 2020. Available online: https://ceos.org/document_management/Meetings/Plenary/34/Documents/CEOS_Interoperability_Terminology_Report.pdf (accessed on 20 October 2020).
- Jiang, L.; Yue, P.; Kuhn, W.; Zhang, C.; Yu, C.; Guo, X. Advancing interoperability of geospatial data provenance on the web: Gap analysis and strategies. Comput. Geosci. 2018, 117, 21–31. [Google Scholar] [CrossRef]
- Yue, P.; Wei, Y.; Di, L.; He, L.; Gong, J.; Zhang, L. Sharing geospatial provenance in a service-oriented environment. Comput. Environ. Urban Syst. 2011, 35, 333–343. [Google Scholar] [CrossRef]
- Zhang, M.; Yue, P.; Wu, Z.; Ziebelin, D.; Wu, H.; Zhang, C. Model provenance tracking and inference for integrated environmental modelling. Environ. Model. Softw. 2017, 96, 95–105. [Google Scholar] [CrossRef]
- He, L.; Yue, P.; Di, L.; Zhang, M.; Hu, L. Adding Geospatial Data Provenance into SDI—A Service-Oriented Approach. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 926–936. [Google Scholar] [CrossRef]
- Growth, P.; Moreau, L. PROV-Overview: An Overview of the PROV Family of Documents. W3C. 2013. Available online: https://eprints.soton.ac.uk/356854/ (accessed on 20 October 2020).
- Lanter, D.P. Design of a Lineage-Based Meta-Data Base for GIS. Cartogr. Geogr. Inf. Syst. 1991, 18, 255–261. [Google Scholar] [CrossRef]
- Spatial Data Transfer Standard (SDTS); American National Standards Institute’s (ANSI). ANSI/NCITS320.1998. 1998. Available online: https://www.fgdc.gov/standards/projects/SDTS/sdts_cadd/finalcadd.pdf (accessed on 15 October 2020).
- ISO. Geographic Information—Metadata; ISO 19115:2003; ISO: Geneva, Switzerland, May 2003; 140p. [Google Scholar]
- ISO. Geographic Information—Metadata—Part 1: Fundamentals; ISO 19115-1:2014; ISO: Geneva, Switzerland, April 2014; 167p. [Google Scholar]
- ISO. Geographic Information—Metadata—Part 2: Extensions for Acquisition and Processing; ISO 19115-2: 2019; ISO: Geneva, Switzerland, January 2019; 57p. [Google Scholar]
- Di, L.; Shao, Y.; Kang, L. Implementation of Geospatial Data Provenance in a Web Service Workflow Environment with ISO 19115 and ISO 19115-2 Lineage Model. IEEE Trans. Geosci. Remote Sens. 2013, 51, 5082–5089. [Google Scholar] [CrossRef]
- Di, L.; Yue, P.; Ramapriyan, H.K.; King, R.L. Geoscience Data Provenance: An Overview. IEEE Trans. Geosci. Remote Sens. 2013, 51, 5065–5072. [Google Scholar] [CrossRef]
- Ivánová, I.; Armstrong, K.; McMeekin, D. Provenance in the next-generation spatial knowledge infrastructure. In Proceedings of the 22nd International Congress on Modelling and simulation (MODSIM 2017), Hobart, Tasmania, Australia, 3–8 December 2017; pp. 410–416. [Google Scholar]
- Lopez-Pellicer, F.J.; Barrera, J. D16. 1 Call 2: Linked map VGI provenance schema. In Linked Map Subproject of Planet Data. Seventh Framework Programe; European Commission: Brussels, Belgium, 2014. [Google Scholar]
- Closa, G.; Masó, J.; Proß, B.; Pons, X. W3C PROV to describe provenance at the dataset, feature and attribute levels in a distributed environment. Comput. Environ. Urban Syst. 2017, 64, 103–117. [Google Scholar] [CrossRef]
- Closa, G.; Masó, J.; Zabala, A.; Pesquer, L.; Pons, X. A provenance metadata model integrating ISO geospatial lineage and the OGC WPS: Conceptual model and implementation. Trans. GIS 2019, 23, 1102–1124. [Google Scholar] [CrossRef]
- Salton, G.; Allan, J.; Buckley, C.; Singhal, A. Automatic analysis, theme generation, and summarization of machine-readable texts. Science 1994, 264, 1421–1426. [Google Scholar] [CrossRef]
- Konkol, M.; Kray, C. In-depth examination of spatiotemporal figures in open reproducible research. Cartogr. Geogr. Inf. Sci. 2019, 46, 412–427. [Google Scholar] [CrossRef]
- Yazici, I.M.; Karabulut, E.; Aktas, M.S. A Data Provenance Visualization Approach. In Proceedings of the 2018 14th International Conference on Semantics, Knowledge and Grids (SKG), Guangzhou, China, 12–14 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 84–91. [Google Scholar]
- Cohen-Boulakia, S.; Belhajjame, K.; Collin, O.; Chopard, J.; Froidevaux, C.; Gaignard, A.; Hinsen, K.; Larmande, P.; Le Bras, Y.; Lemoine, F.; et al. Scientific workflows for computational reproducibility in the life sciences: Status, challenges and opportunities. Future Gener. Comput. Syst. 2017, 75, 284–298. [Google Scholar] [CrossRef]
- Yue, P.; Zhang, M.; Guo, X.; Tan, Z. Granularity of geospatial data provenance. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec, QC, Canada, 13–18 July 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 4492–4495. [Google Scholar]
- Albrecht, J. Universal Analytical GIS Operations: A Task-Oriented Systematization of Data Structure-Independent GIS Functionality. Geogr. Inf. Res. Transatl. Perspect. 1998, 577–591. Available online: https://www.researchgate.net/publication/228530780_Universal_analytical_GIS_operations_a_task-oriented_systematization_of_data_structure-independent_GIS_functionality (accessed on 20 October 2020).
- Sun, Z.; Yue, P.; Di, L. GeoPWTManager: A task-oriented web geoprocessing system. Comput. Geosci. 2012, 47, 34–45. [Google Scholar] [CrossRef]
- Goodchild, M.F. Geographic information systems. Prog. Hum. Geogr. 1991, 15, 194–200. [Google Scholar] [CrossRef]
- Kuhn, W.; Ballatore, A. Designing a Language for Spatial Computing. In Proceedings of the Agile 2015, Washington, DC, USA, 3–7 August 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 309–326. [Google Scholar]
- Yue, C.; Baumann, P.; Bugbee, P.; Jiang, L. Towards intelligent giservices. Earth Sci. Inf. 2015, 8, 463–481. [Google Scholar] [CrossRef]
- ESRI. ArcGIS Desktop: Release 10; Environmental Systems Research Institute: Redlands, CA, USA, 2020. [Google Scholar]
- Pons, X. MiraMon: Geographical Information System and Remote Sensing Software; Centre de Recerca Ecològica i Aplicacions Forestals: Barcelona, Spain, 2020. [Google Scholar]
- GRASS Development Team. Geographic Resources Analysis Support System (GRASS) Software, Version 7.2. Open Source Ge-ospatial Foundation. 2017. Available online: http://grass.osgeo.org (accessed on 20 October 2020).
- SNAP—ESA. Sentinel Application Platform v8.0.0. 2020. Available online: http://step.esa.int (accessed on 20 October 2020).
- Lopez-Pellicer, F.J.; Lacasta, J.; Espejo, B.A.; Barrera, J.; Agudo, J.M. The standards bodies soup recipe: An experience of interoperability among ISO-OGC-W3C-IETF standards. In Proceedings of the Inspire-Geospatial World Forum, Lisbon, Portugal, 25–29 May 2015. [Google Scholar]
- Masó, J.; Pons, X.; Zabala, A. Building the World Wide Hypermap (WWH) with a RESTful architecture. Int. J. Digit. Earth 2012, 7, 175–193. [Google Scholar] [CrossRef]
- Erwig, M.; Schneider, M. Developments in spatio-temporal query languages. In Proceedings of the Tenth International Workshop on Database and Expert Systems Applications DEXA 99, Florence, Italy, 3 September 1999; IEEE: Piscataway, NJ, USA, 1999; pp. 441–449. [Google Scholar]
- Koubarakis, M.; Karpathiotakis, M.; Kyzirakos, K.; Nikolaou, C.; Sioutis, M. Data Models and Query Languages for Linked Geospatial Data. In Reasoning Web International Summer School; Springer: Berlin/Heidelber, Germany, 2012; pp. 290–328. [Google Scholar]
- Amann, B.; Scholl, M. Gram: A graph data model and query languages. In Proceedings of the ACM conference on Hypertext, Seattle, WA, USA, 14–18 November 1993; pp. 201–211. [Google Scholar]
- Maso, J. OGC JSON Best Practice Draft. 2018. Available online: https://github.com/opengeospatial/architecture-dwg/tree/master/json-best-practice (accessed on 15 October 2020).
- Masó, J.; Zabala, A.; Pons, X. Protected Areas from Space Map Browser with Fast Visualization and Analytical Operations on the Fly. Characterizing Statistical Uncertainties and Balancing Them with Visual Perception. ISPRS Int. J. Geo-Information 2020, 9, 300. [Google Scholar] [CrossRef]
- Vis.js. 2020. Available online: https://visjs.org/ (accessed on 25 October 2020).
- Generalitat de Catalunya; Departament de Territori i Sostenibilitat. Land Use and Cover Open Data Page. 2020. Available online: https://territori.gencat.cat/ca/01_departament/12_cartografia_i_toponimia/bases_cartografiques/medi_ambient_i_sostenibilitat/usos-del-sol/ (accessed on 20 October 2020).
- Ibàñez, J.J.; Burriel, J.A. Mapa de cubiertas del suelo de Cataluña: Características de la tercera edición y relación con SIOSE. In Tecnologías de la Información Geográfica: La Información Geográfica al Servicio de los Ciudadanos; Ojeda, J., Pita, M.F., Vallejo, I., Eds.; Secretariado de Publicaciones de la Universidad de Sevilla: Sevilla, Spain, 2010; pp. 179–198. ISBN 978-84-472-1294-1. [Google Scholar]
- González-Guerrero, Ò.; Pons, X.; Bassols-Morey, R.; Camps, F.X. Dinàmica de les Superfícies de Conreu a Catalunya Mitjançant Teledetecció en el període 1987–2012. Quaderns Agraris 2019, 59–91. [Google Scholar]
- González-Guerrero, Ò.; Pons, X. The 2017 Land Use/Land Cover Map of Catalonia based on Sentinel-2 images and auxiliary data. Revista de Teledetección 2020, 55, 81–92. [Google Scholar] [CrossRef]
- Zhao, J.; Goble, C.; Stevens, R.; Turi, D. Mining Taverna’s semantic web of provenance. Concurr. Comput. Pract. Exp. 2008, 20, 463–472. [Google Scholar] [CrossRef]
- Theoharis, Y.; Fundulaki, I.; Karvounarakis, G.; Christophides, V. On Provenance of Queries on Semantic Web Data. IEEE Internet Comput. 2010, 15, 31–39. [Google Scholar] [CrossRef]
- Viola, F.; Roffia, L.; Antoniazzi, F.; D’Elia, A.; Aguzzi, C.; Cinotti, T.S. Interactive 3D Exploration of RDF Graphs through Semantic Planes. Future Internet 2018, 10, 81. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GIS functionality | ArcGIS tool | MiraMon tool | GRASS tool |
| Geometric union | Union | CombiCapa | v.overlay(or) |
| Extraction | Clip | Retalla | v.overlay(and) |
| Proximity | Buffer | BufDist | v.buffer |
| Distance | Distance | BufDist | r.distance |
| Surface interpolation | Interpolation | InterPNT | r.resamp.interp |
| Slope | Slope | Pendent | r.slope.aspect |
| Aspect | Aspect | Pendent | r.slope.aspect |
| Shade | Hillshade | Illum | r.relief |
| Visibility | Viewshed | Visible | r.viewshed |
| Cell statistics | Cell statistics | EstRas | r.univar |
| Field statistics | Field statistics | EstCamp | v.vect.stats |
| Joining | Join | GestBD | v.db.join |
| Merging | Merge | GestBD | v.patch |
| Aggregation | Dissolve | Ciclar | v.disolve |
| Feature selection | Select by features | VecSelect | v.extract |
| RS functionality | SNAP | MiraMon tool | GRASS tool |
| Georeferencing | Orthorectification | CorrGeom | i.ortho.photo |
| Radiometric correction | Sen2Cor | CorRad | i.atcorr |
| W3C PROV Relationships | ISO 19115 Classes Connected |
|---|---|
| Used | LI_ProcessStep/source → LI_Source (or LE_Source) |
| Was Associated with | LI_ProcessStep/processor → CI_Responsability |
| Was Generated By | LI_ProcessStep/output → LE_Source |
| Was Attributed To | LE_ProcessStep/processingInformation/LE_Processing/softwareReference/CI_Citation/citedResponsibleParty→CI_Responsability |
| Was Derived From: gave | LE_ProcessStep/processingInformation/LE_Processing/procedureDescription →CharacterString (representing the Functionality; no existing in ISO) |
| Was Derived From: implemented | LE_ProcessStep/processingInformation/LE_Processing/algorithm → LE_Algorithm |
| Use: executed | LE_ProcessStep/processingInformation → LE_Processing |
| Process Run | Processing Tool | Algorithm | Functionality | Agent | Source | Time | Output | |
|---|---|---|---|---|---|---|---|---|
| Did any execution cover Africa? | Was version 3 of InterPNT used? | Was a kriging algorithm used? | Was a reprojection functionality used? | Did the user Bob have a role in the creation of this dataset? | Was a dataset called Rivers used? | Was something executed in 2013? | Was a rain dataset created? | |
| Process run | What was executed after Process step 5? | Did Process step 5 use version 3 of InterPNT? | Was Process step 5 a krigring interpolation? | What was the purpose of Process step 5? | Was Process step 5 executed by Bob? | Did Process step 5 use a DEM of 2 m? | How long did Process step 5 last? | Which data were generated with Process step 5? |
| Processing tool | Which tool is often used right after InterPNT? | Does version 3 of InterPNT support an IDW interpolation? | Did InterPNT and r.resamp.intep implement equivalent functionalities? | Which interpolation tools were developed by a trusted software vendor? | Did version 3 of InterPNT use a GeoJSON format? | Is version 3 of InterPNT the last version available? | Which outputs were created with version 3 of InterPNT? | |
| Algorithm | Which different versions of the buffer algorithm are used? | Did GRASS and MiraMon buffer tools use the same algorithm? | Was Bob the author of any of the algorithms used? | Is this algorithm suitable for categorical data? | When was this algorithm developed? | Which outputs were created using this algorithm? | ||
| Functionality | Have all the corrections been made with the same software? | Who did the radiometric corrections? | Which of the datasets used were reprojected? | Was something reprojected in 2015? | Which outputs were reprojected? | |||
| Agent | Who used tools developed by Bob? | Which of the sources used were produced by a public institution? | When did Bob make his first execution in this collection? | Which institution generated the resulting maps? | ||||
| Source | Which two sources were used together? | Are all the sources from the same temporal interval as the output? | Was a rain intensity dataset needed to create a river flow dataset? | |||||
| Time | How long did it take to complete production? | When was this output generated? | ||||||
| Output | Was this output a revision of another output? |
| Process Run | Processing Tool | Algorithm | Functionality | Agent | Source | Time | Output | |
|---|---|---|---|---|---|---|---|---|
(over a complete dataset) | Q1. Did any of the executions not use MiraMon software? | Q2. Was version 3 of ClassKnn used? | Q3. Was the Knn algorithm used? | Q4. Was the supervised classification functionality used? | Q5. Which roles did CREAF do? | Q6. Was a dataset called Orto25m used? | Q7. Was something executed before 2013? | Q8. Was any output not owned by CREAF? |
| Process run (over MUCSC 2017 generation) | Q9. What was executed after ClassKnn v. 5? | Q10. Did process Step 5 use version 3 of ClassKnn? | Q11. Was Process step 5 a Knn classification? | Q12. What is the functionality provided by Process step 5? | Q13. Which process steps were executed by Grumets? | Q14. Did Process step 5 use a DEM of 2m? | Q15. What was the last process step? | Q16. Which outputs were generated with Step 5 execution? |
| Processing tool (over MUCSC series generation) | Q17. Which tool was most often used right after the ClassKnn tool? | Q18. What algorithm implemented version 3 of ClassKnn? | Q19. Do the tools ClassKnn and IsoMM provide equivalent functionalities? | Q20. Were the tools used developed by trusted software vendors? | Q21. Did version 3 of ClasskNN tool need PIA (Pseudoinvariant areas) sources? | Q22. Was version 3 of ClassKnn tool the last version available? | Q23. Which versions of MUCSC used version 2 of the ClassKnn tool? | |
| Algorithm (over a complete dataset) | Q24. Which different versions of the Knn algorithm were used? | Q25. Did all the Sup.classification tools use the same algorithm? | Q26. Was CREAF the author and owner of any of the algorithms used? | Q27. Was the reclassification algorithm suitable for working with categorical data? | Q28. When was the current version of the Sup.classification developed? | Q29. Which versions of MUCSC were created using the Knn algorithm? | ||
| Functionality (over a complete dataset) | Q30. Were all radiometric corrections made with the same software? | Q31. Which institution performed the radiometric corrections? | Q32. Which of the datasets used were reclassified? | Q33. Were any of the datasets classified before 2015? | Q34. Which Land Cover Maps were photo-interpreted? | |||
| Agent (over a complete dataset) | Q35. Who used tools developed by CREAF? | Q36. Which of the sources used in this collection have open access licenses? | Q37. When did CREAF make their first execution in this collection? | Q38. Did CREAF create a MUCSC 2007dataset? | ||||
| Source (over 2012 and 2017 MUCSC series generation) | Q39. Which sources were used in all processing chains? | Q40. Did the orthos use the same temporal interval as the MUCSC outputs? | Q41 Which orthos were used in the generation of MUCSC of 2012 and 2017? | |||||
| Time (over 2017 MUCSC generation) | Q42. How long did the complete processing chain take to be completed? | Q43. When was the MUCSC map finalized? | ||||||
| Output (over 20017 MUCSC generation) | Q44. Was this LULC a revision of another MUCSC map? |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Closa, G.; Masó, J.; Julià, N.; Pons, X. Geospatial Queries on Data Collection Using a Common Provenance Model. ISPRS Int. J. Geo-Inf. 2021, 10, 139. https://doi.org/10.3390/ijgi10030139
Closa G, Masó J, Julià N, Pons X. Geospatial Queries on Data Collection Using a Common Provenance Model. ISPRS International Journal of Geo-Information. 2021; 10(3):139. https://doi.org/10.3390/ijgi10030139
Chicago/Turabian StyleClosa, Guillem, Joan Masó, Núria Julià, and Xavier Pons. 2021. "Geospatial Queries on Data Collection Using a Common Provenance Model" ISPRS International Journal of Geo-Information 10, no. 3: 139. https://doi.org/10.3390/ijgi10030139
APA StyleClosa, G., Masó, J., Julià, N., & Pons, X. (2021). Geospatial Queries on Data Collection Using a Common Provenance Model. ISPRS International Journal of Geo-Information, 10(3), 139. https://doi.org/10.3390/ijgi10030139