
A Hierarchical Spatial Network Index for Arbitrarily Distributed Spatial Objects

Abstract
:1. Introduction
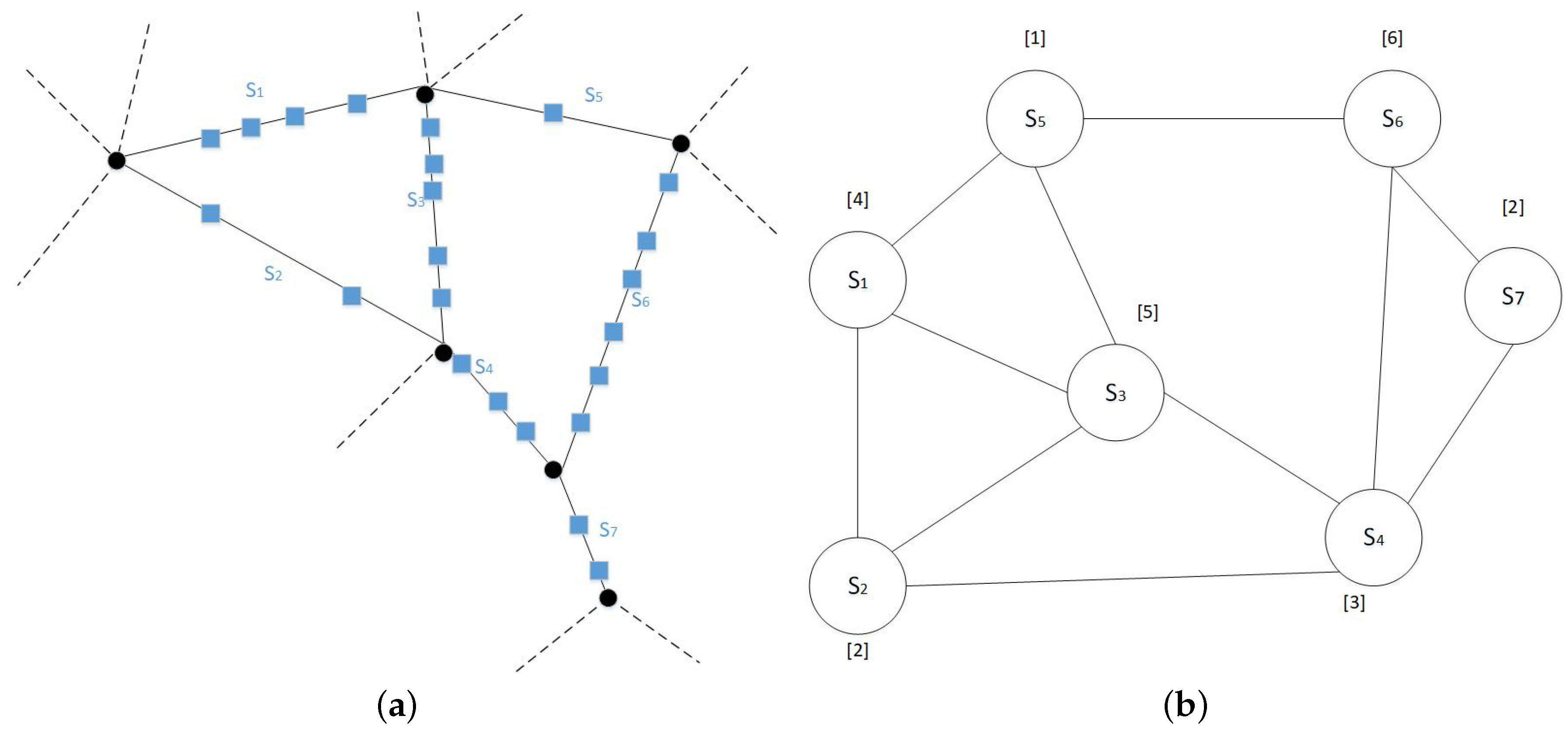
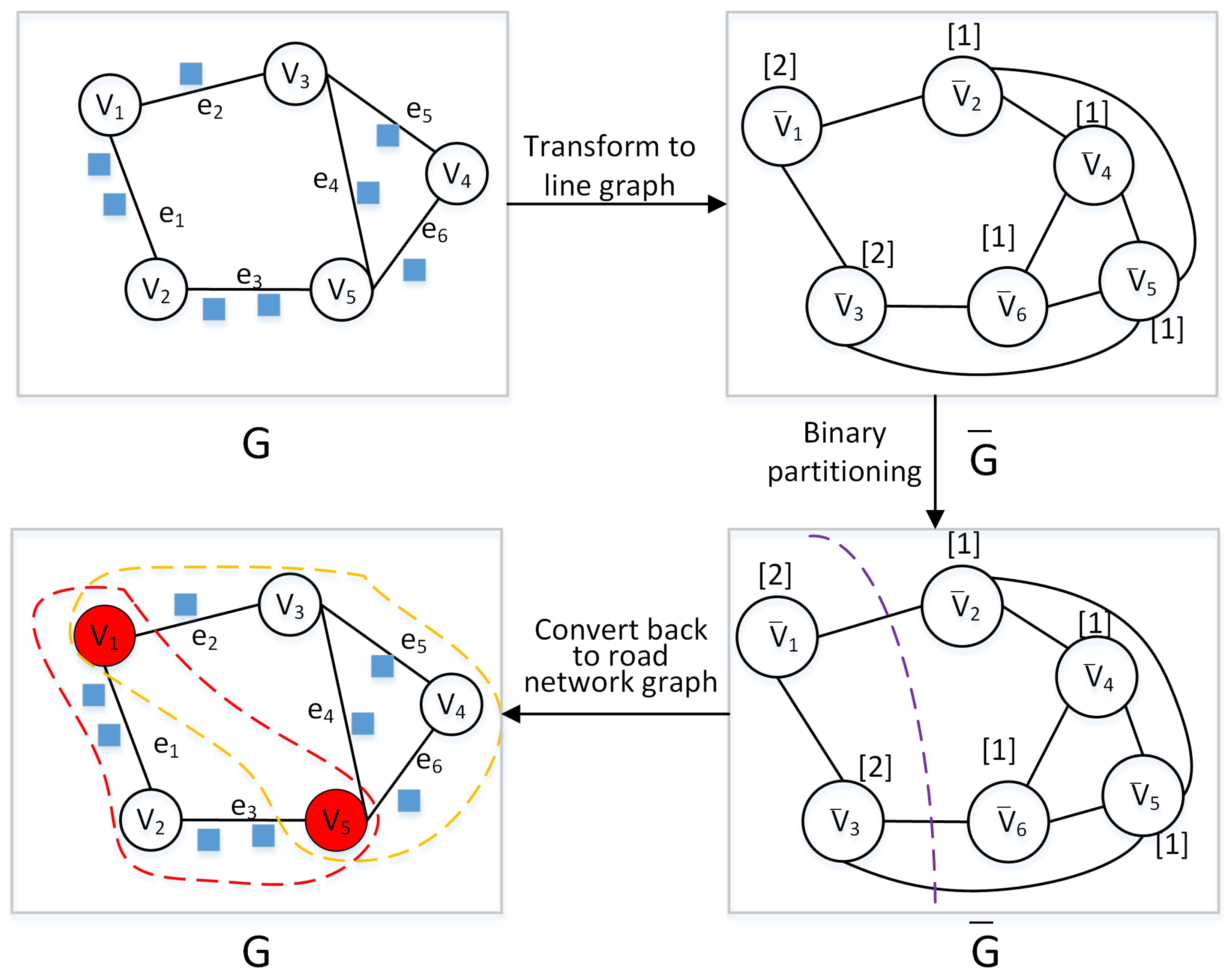
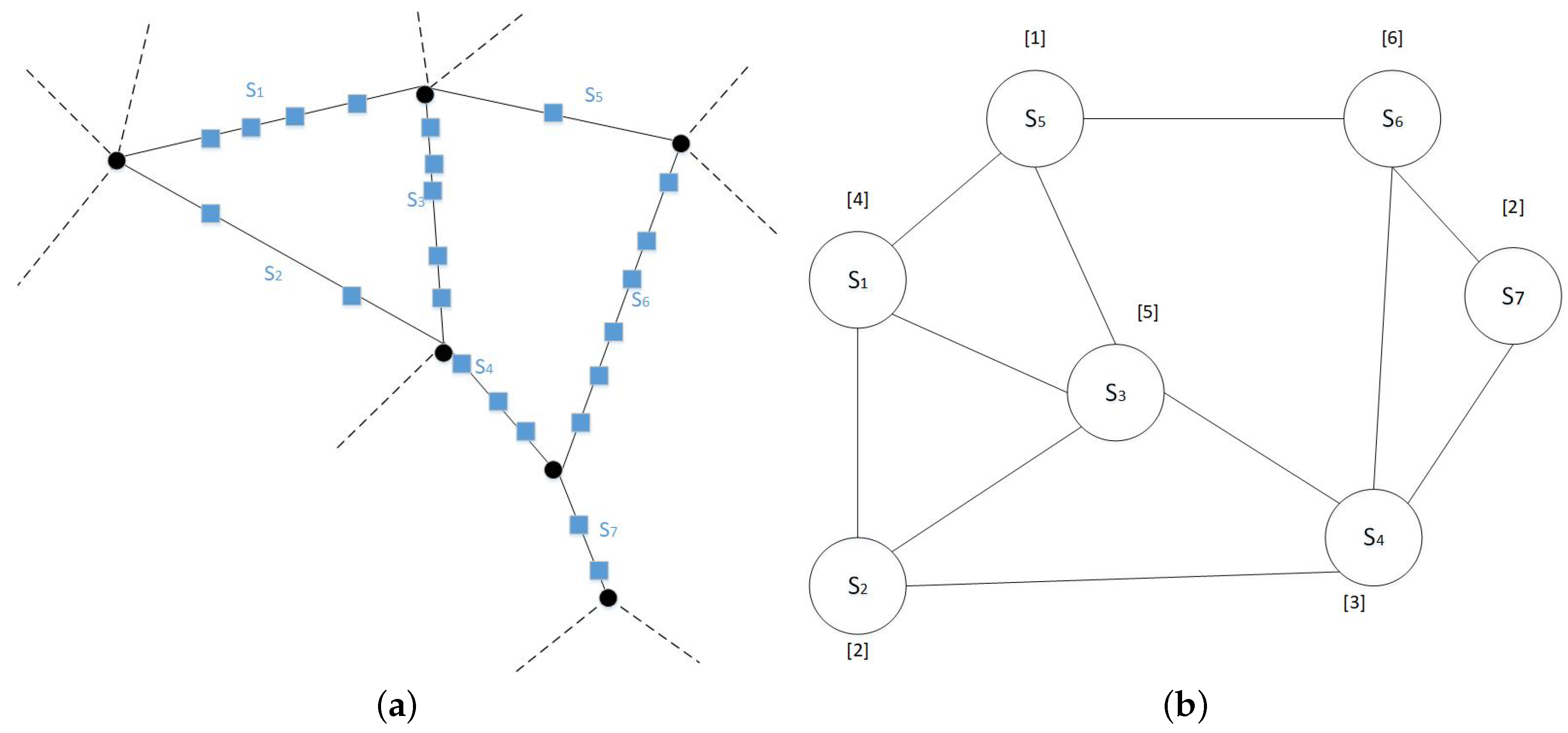
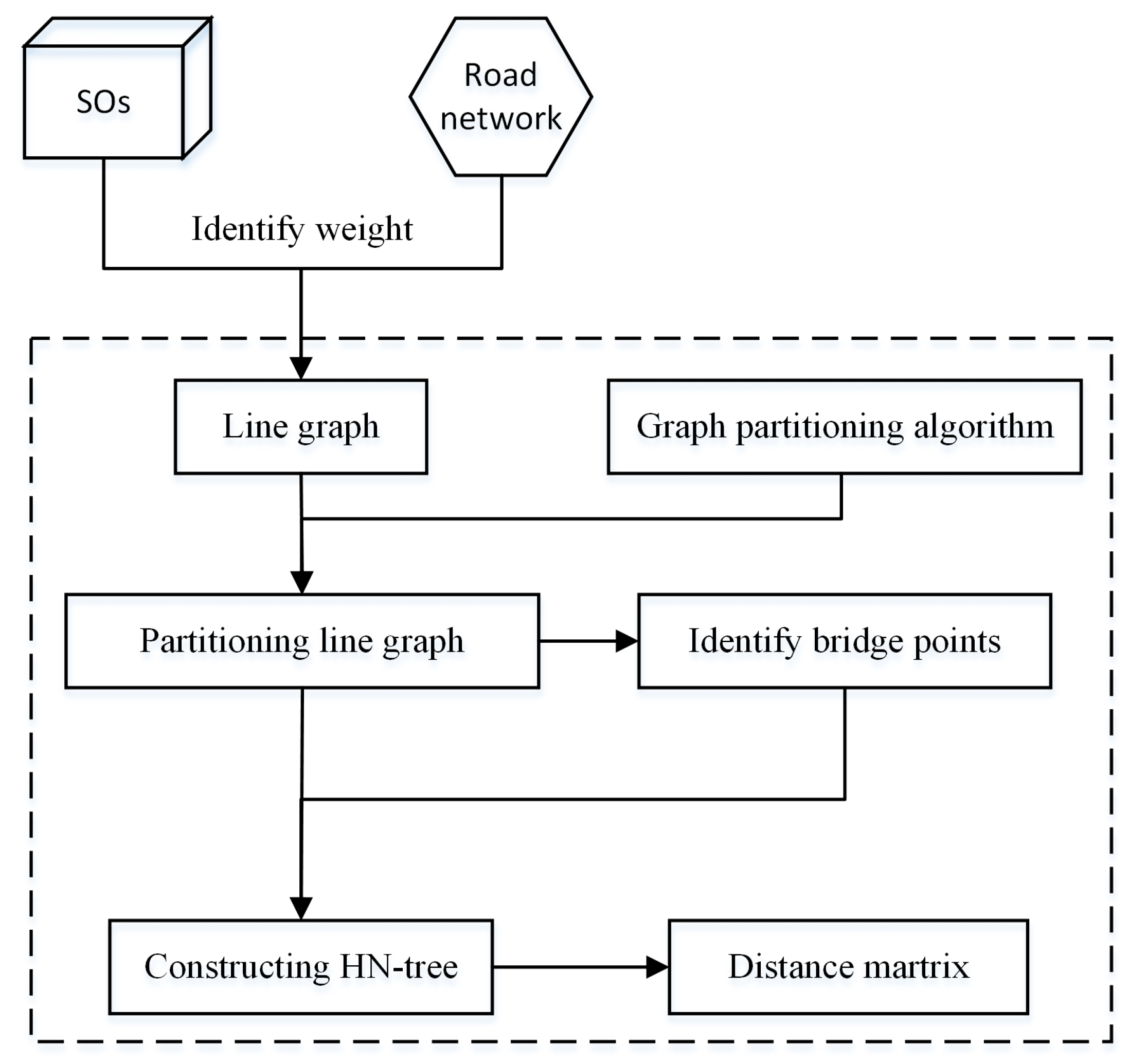
- We propose a hierarchical graph partitioning algorithm that preserves the edges between partitions. The main idea of this algorithm is to (1) transform the network into a line graph (switching nodes and edges); (2) utilize a traditional graph partitioning algorithm on the line graph; and (3) map the resulting partitions back to their spatial network representation.
- Leveraging this graph partitioning, we propose a novel hierarchical network index, the HN-tree, which recursively partitions the network based on the distribution of SOs.
- We devise a range query processing algorithm using our proposed HN-tree.
- Experimental results for three different datasets show that this HN-tree based method greatly outperforms state-of-the-art range query and indexing methods in terms of efficiency.
2. Related Work
3. Hierarchical Graph Partitioning
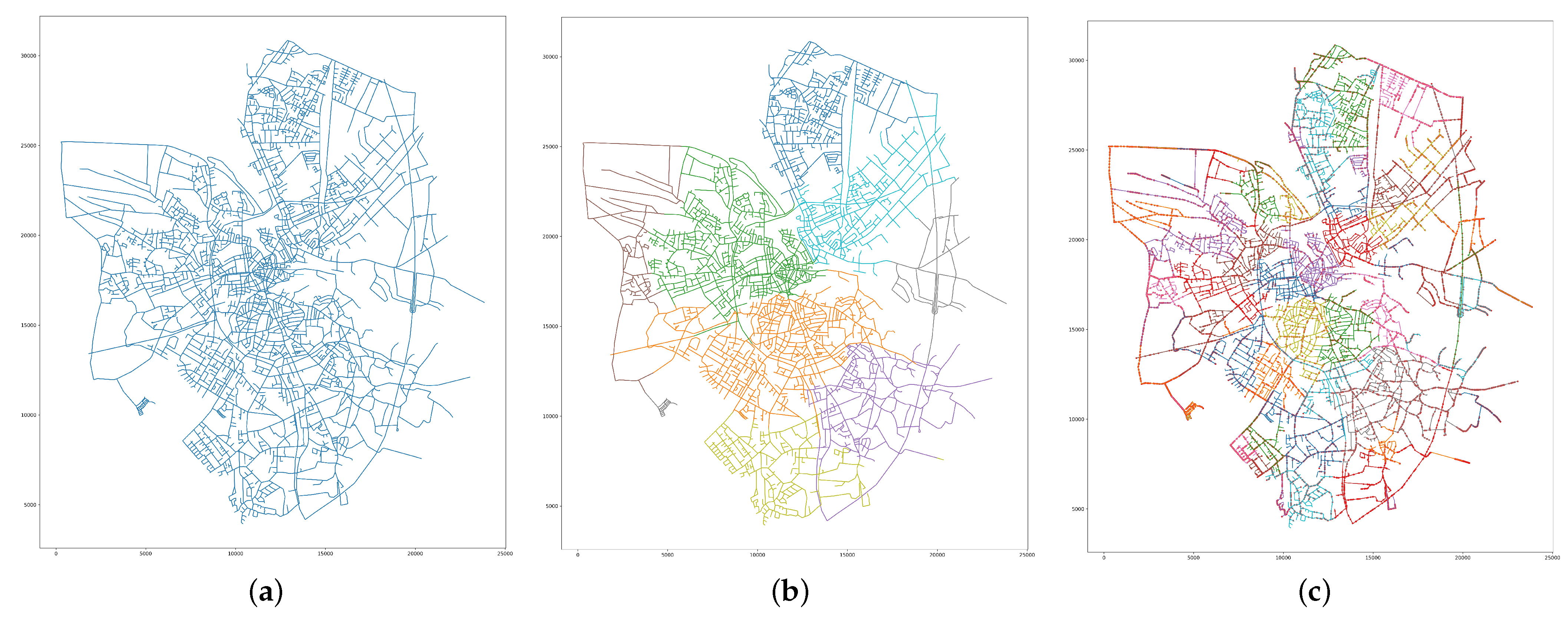
3.1. Road Networks
3.2. Graph Partitioning
- and ;
- ;
- .
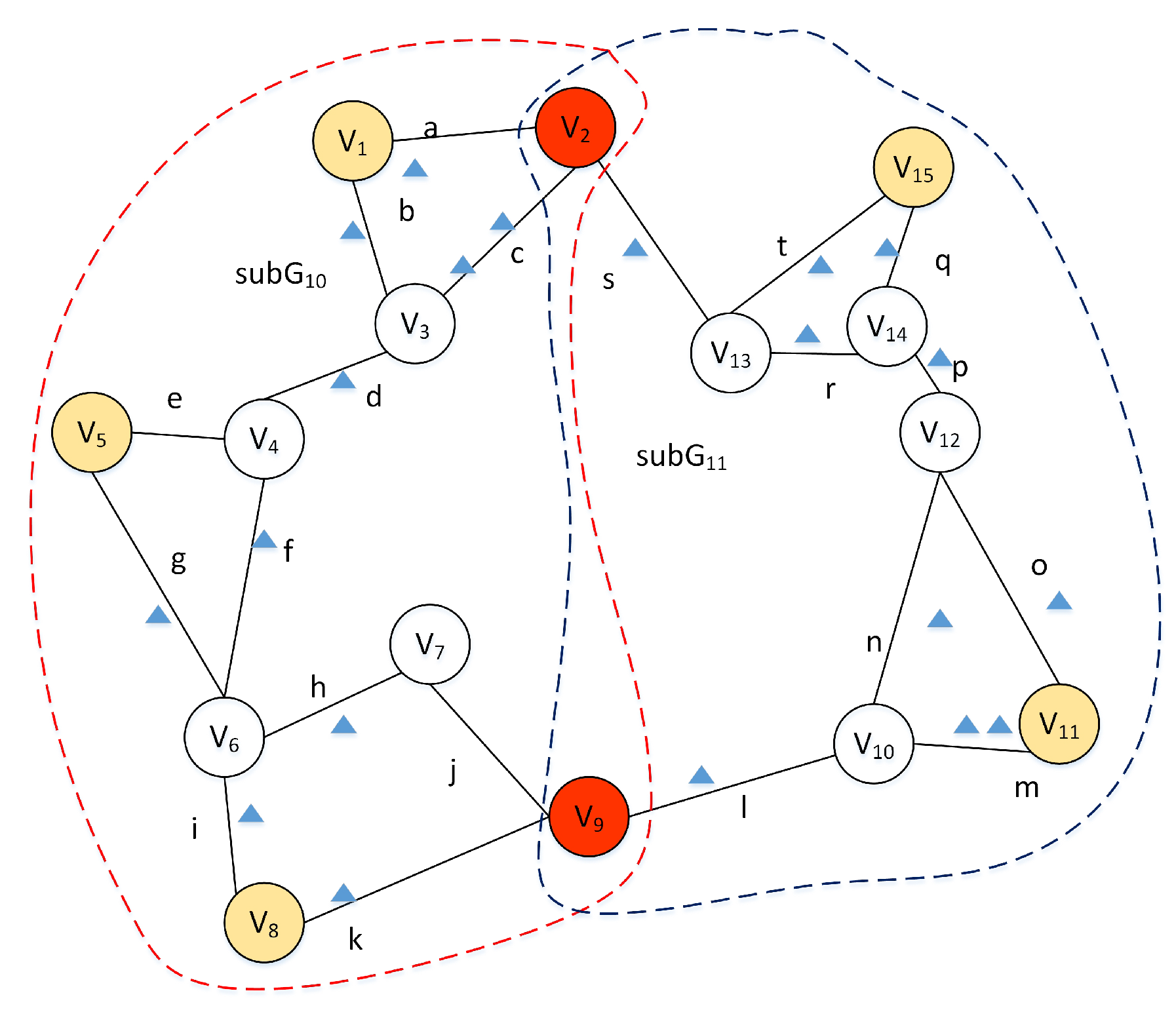
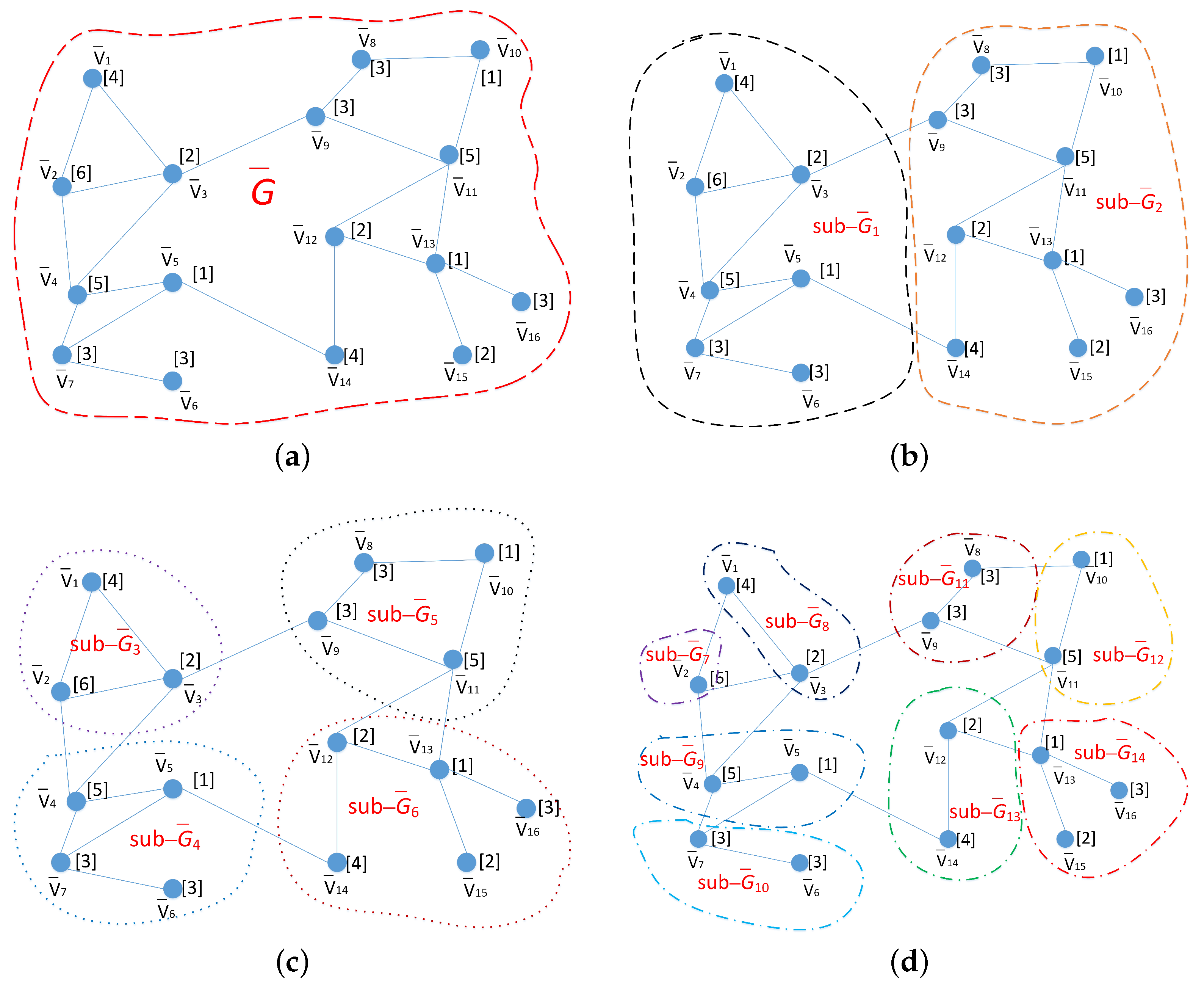
3.3. Hierarchical Graph Partitioning
4. HN-Tree
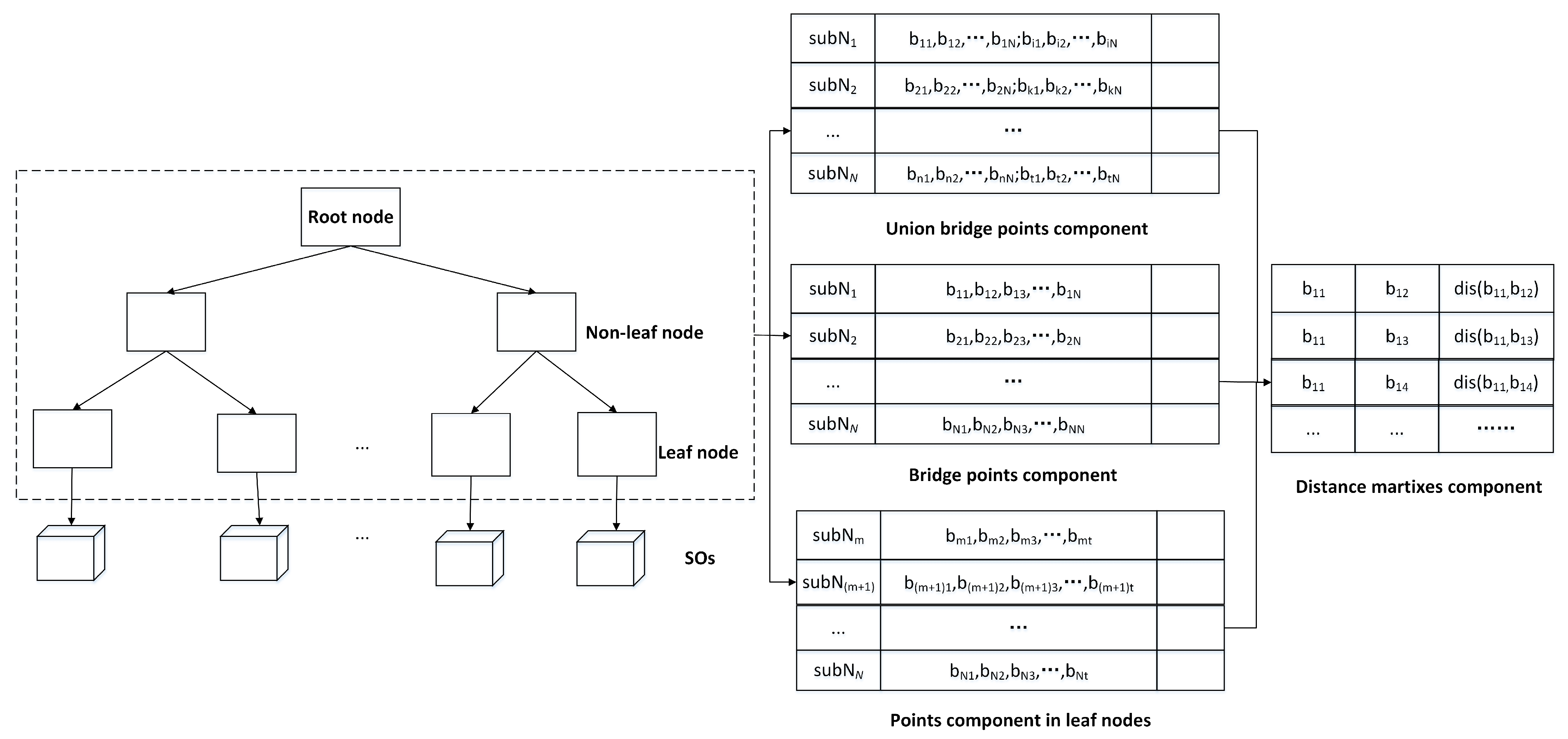
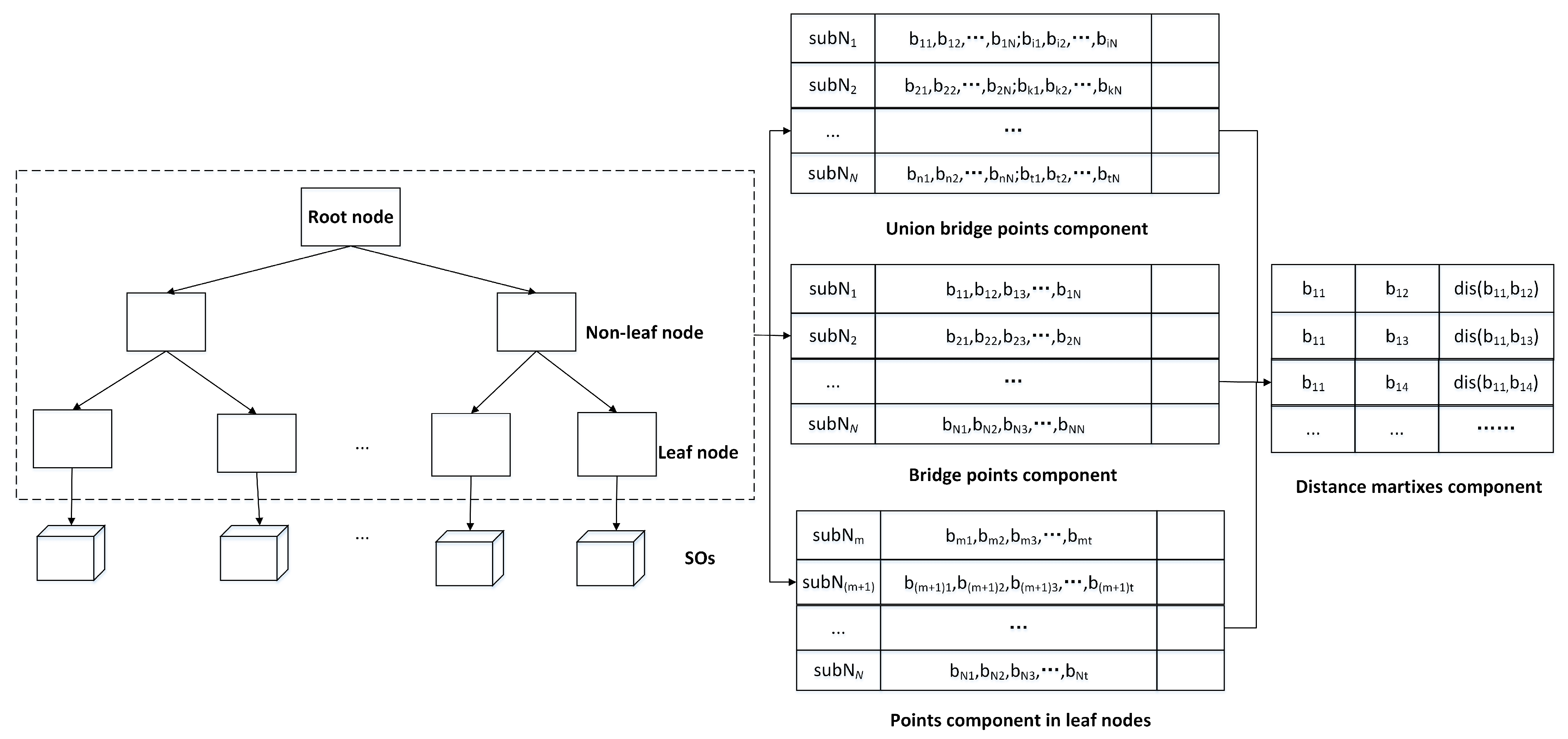
4.1. HN-Tree Index Definition
- (1)
- Each tree node captures a sub-network partition, the root node corresponds to the entire road network. The sub-network of the parent node is a super-network of its child nodes.
- (2)
- Each non-leaf node has at least 2) and at most M child nodes.
- (3)
- Each leaf node contains at most SOs. All leaf nodes appear at the same level.
- (4)
- Each tree node maintains bridge points and a distance matrix.
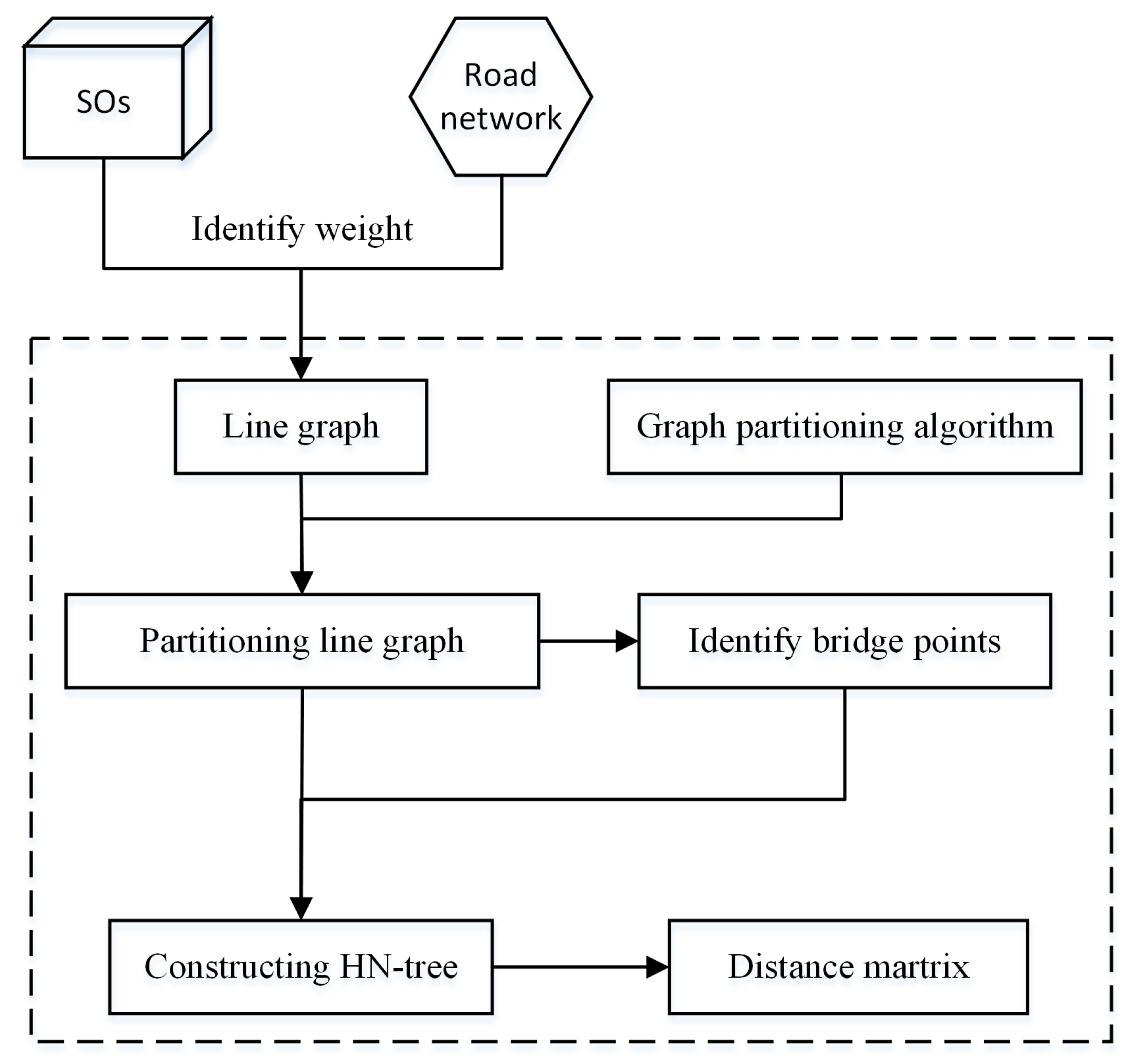
4.2. Index Construction
| Algorithm 1. HN-tree construction |
| Require:: the results of the hierarchical graph partition; G: road network; |
| Ensure: HN-tree; |
| 1: foreach do |
| 2: convert back to |
| 3: G is the root node of HN-tree; |
| 4: the of G are corresponding to root node’s child nodes; |
| 5: identify the bridge points of ; |
| 6: while ( is not the bottom partition) do |
| 7: add the next level’s of as its child nodes; |
| 8: identify the bridge points of ; |
| 9: end while foreach tree node HN-tree do |
| 10: compute the distance matrix of |
| 11: return HN-tree; |
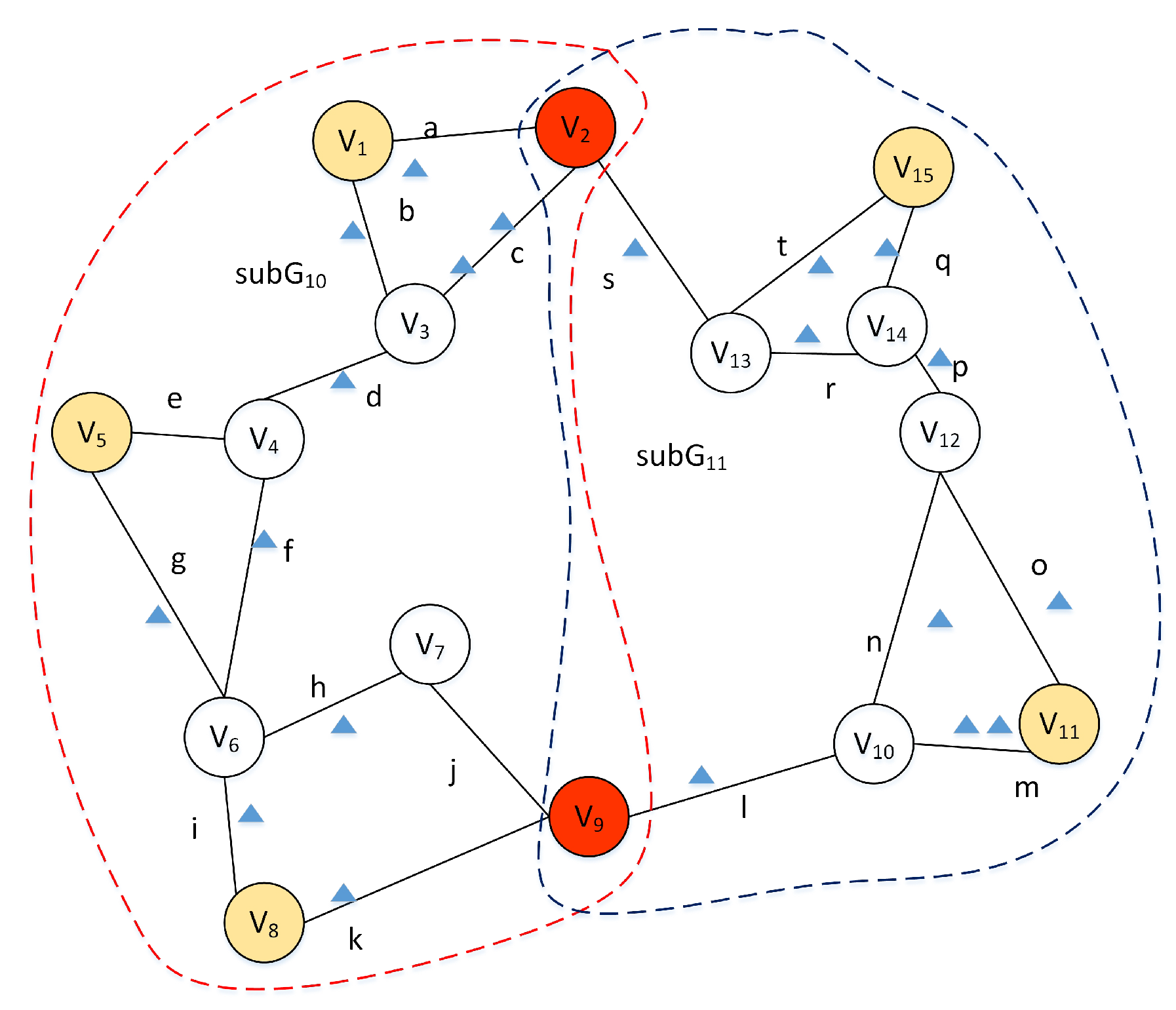
5. Range Query Processing
5.1. Concepts and Terminology
5.2. Range Query Algorithm
| Algorithm 2. Range query |
|
| Algorithm 3. Function NNV |
|
5.3. SPDis Function
6. Experimental Evaluation
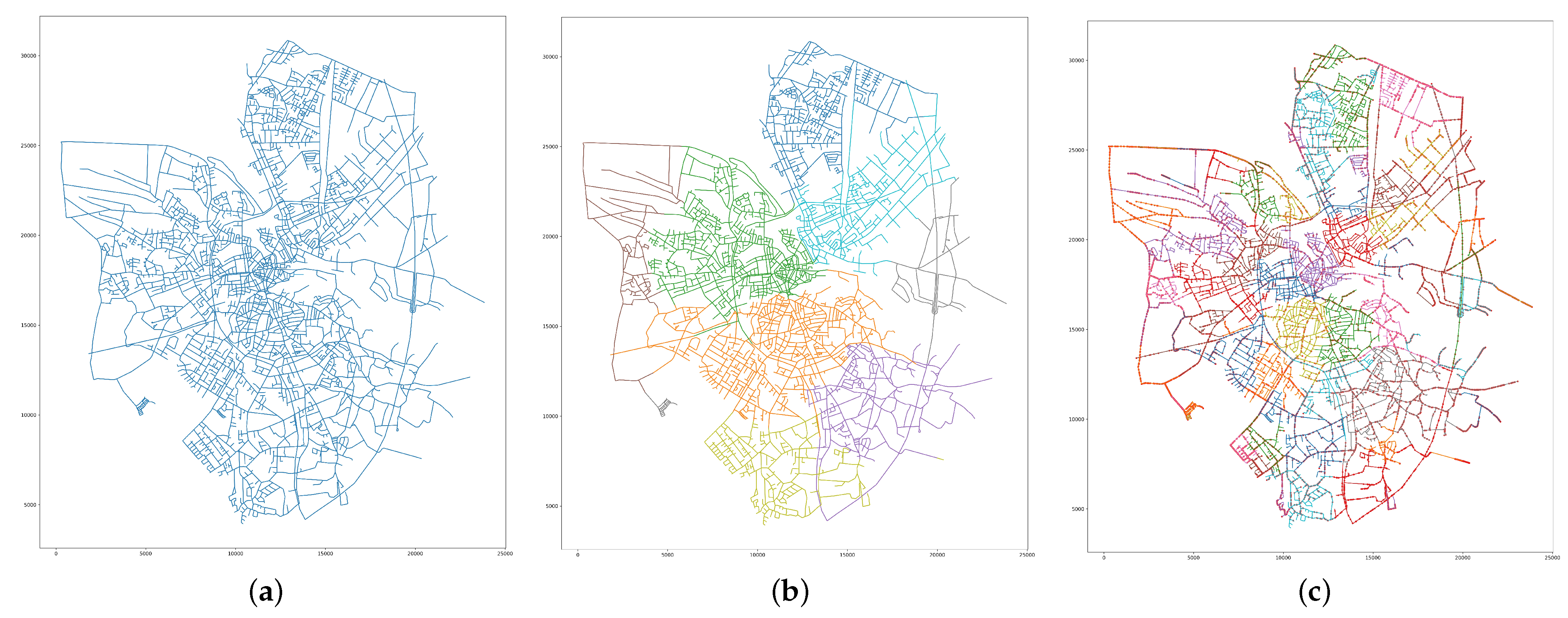
6.1. Datasets
6.2. Experimental Setup
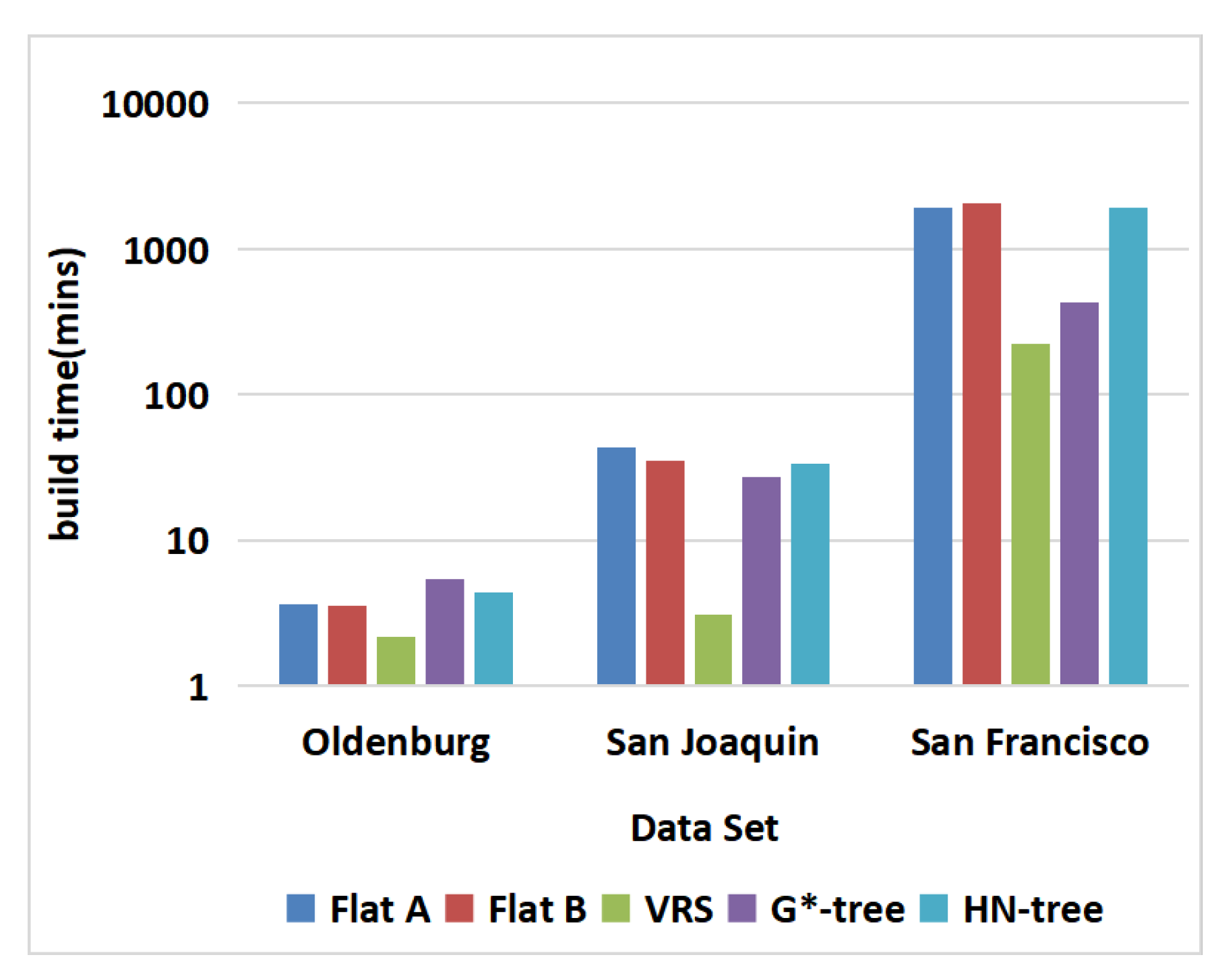
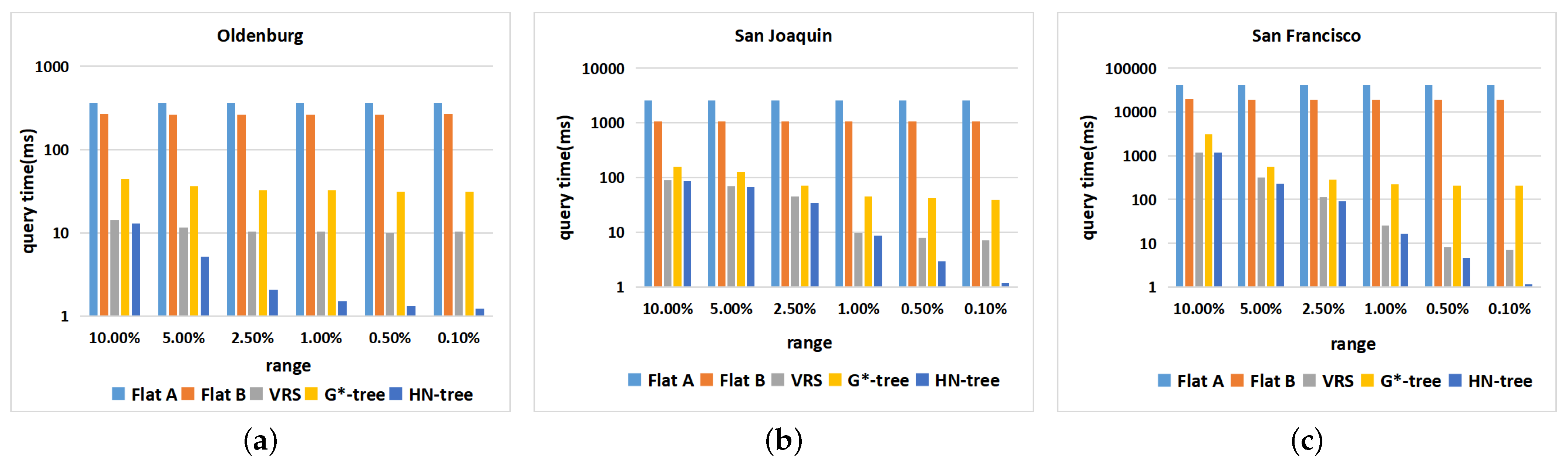
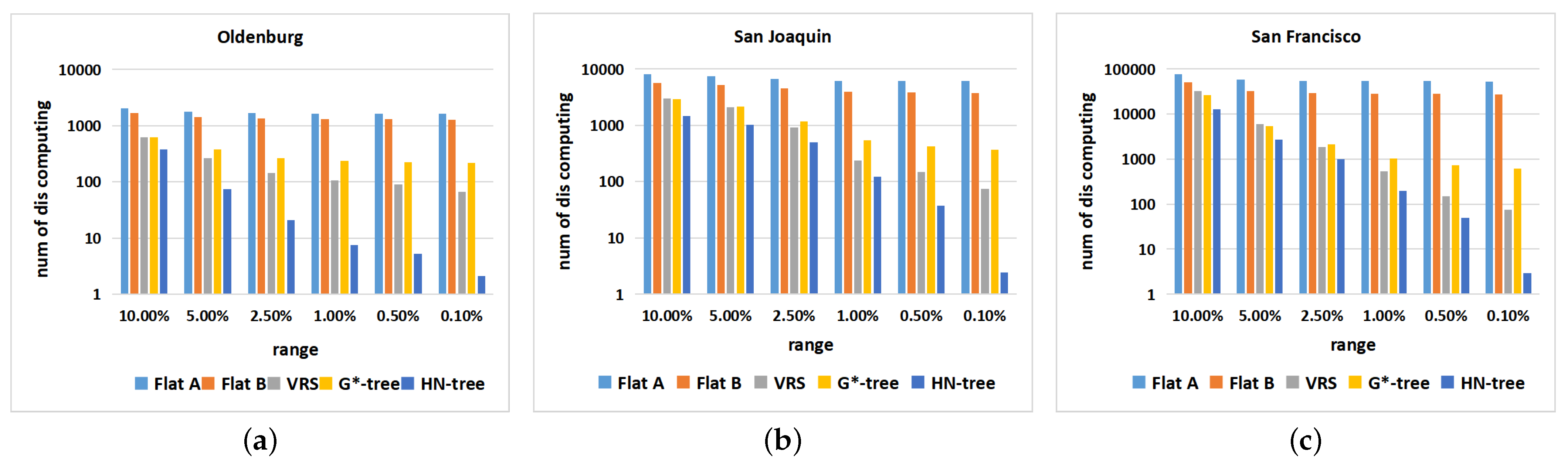
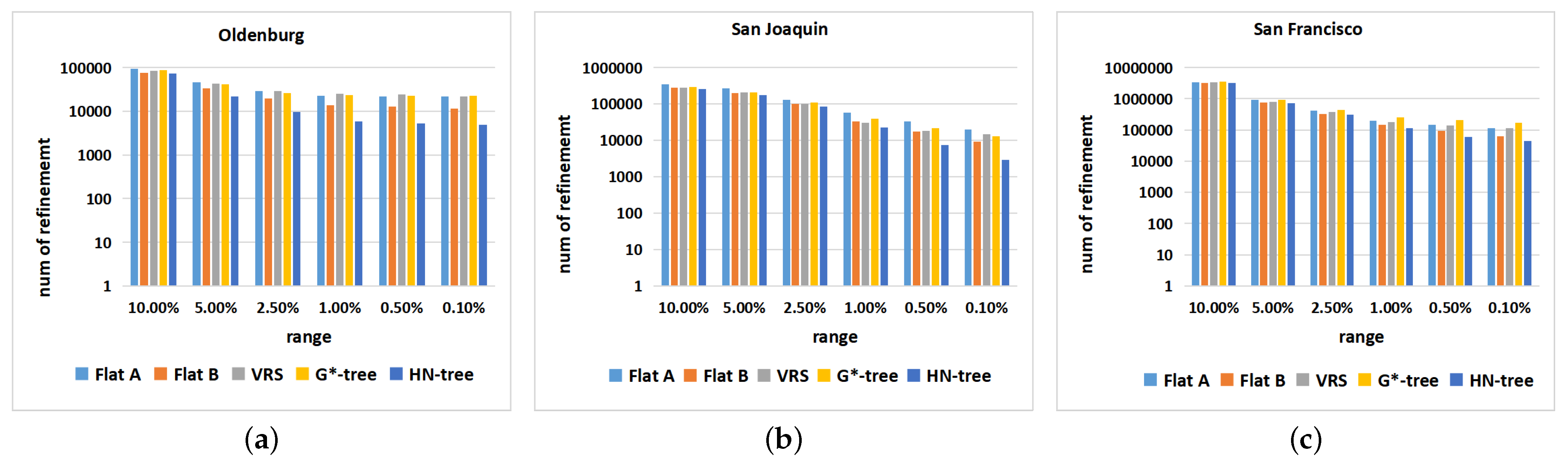
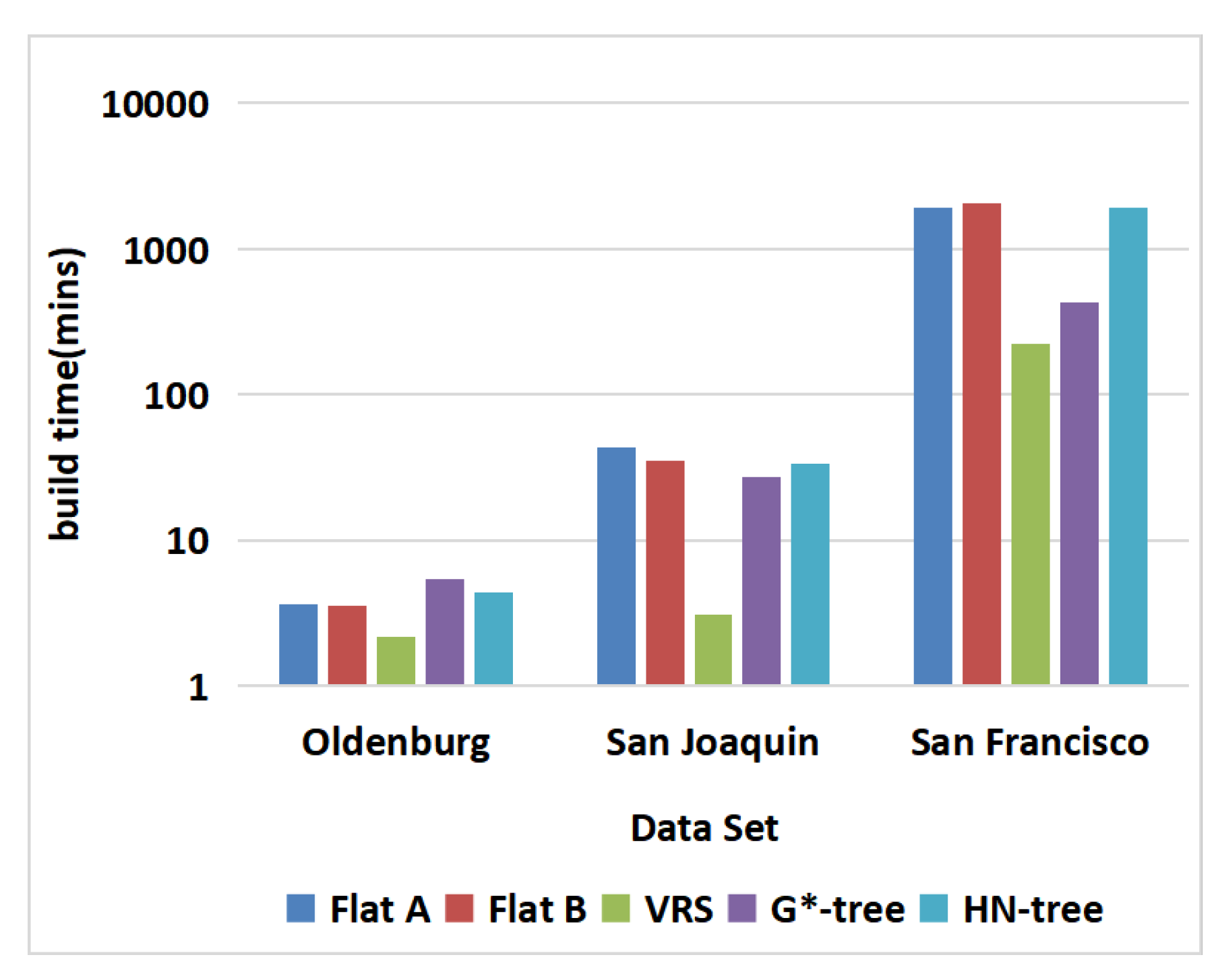
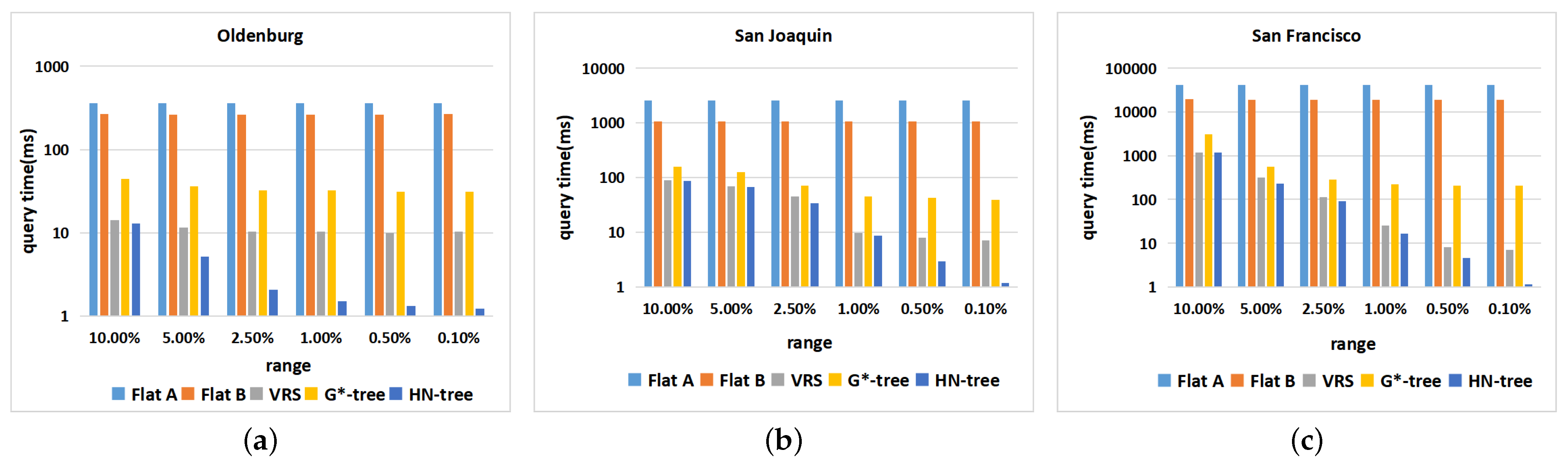
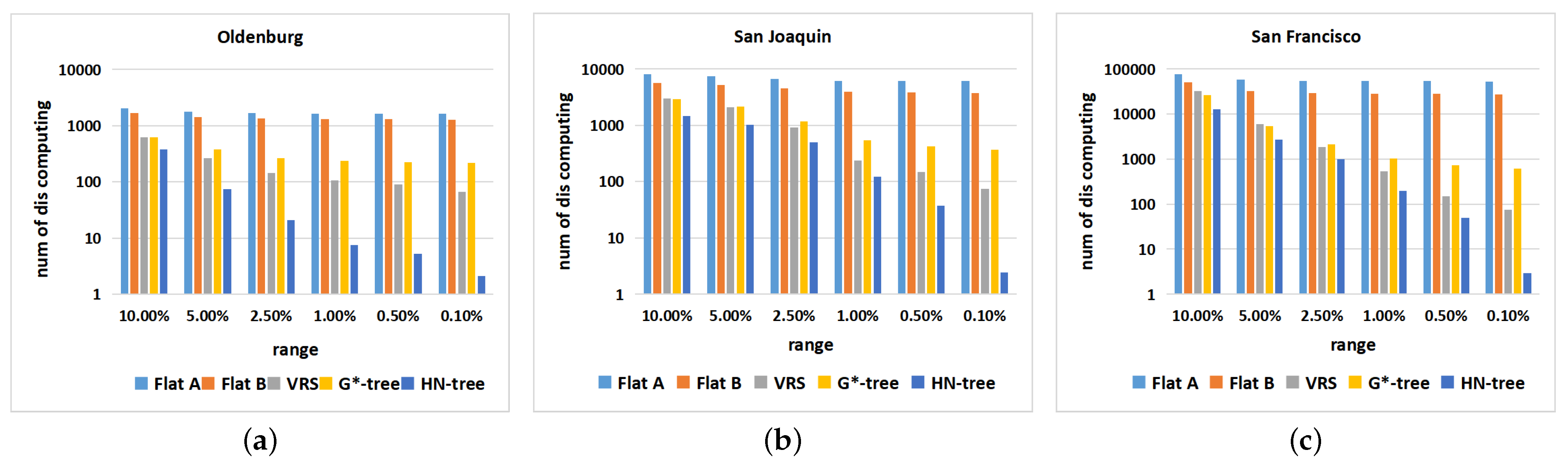
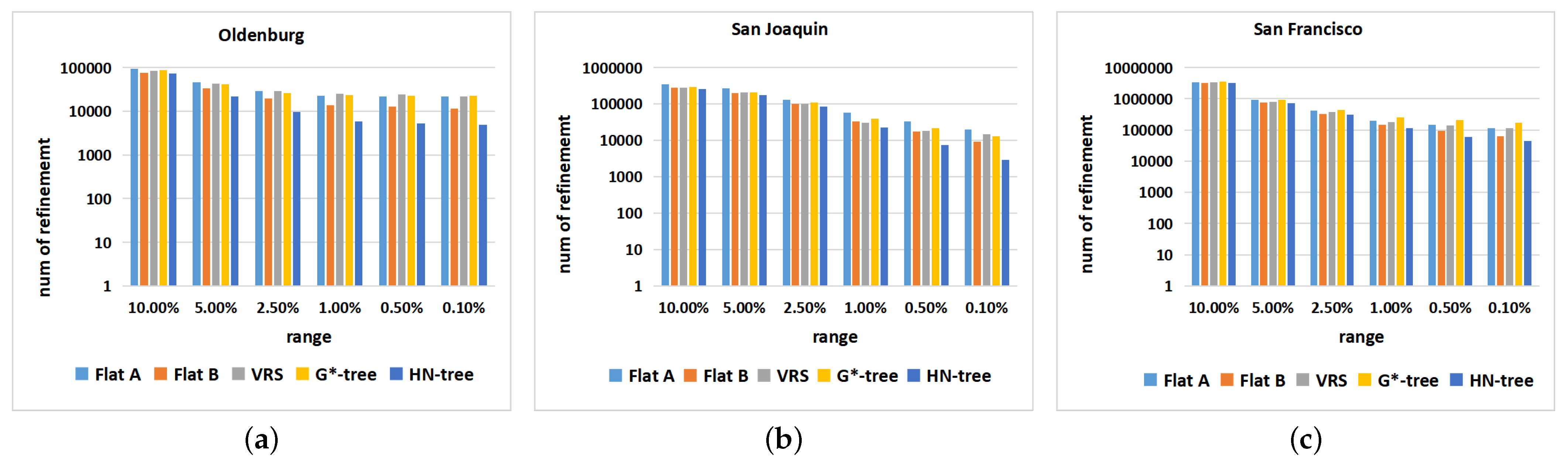
6.3. Dataset: Non-Uniform Distribution
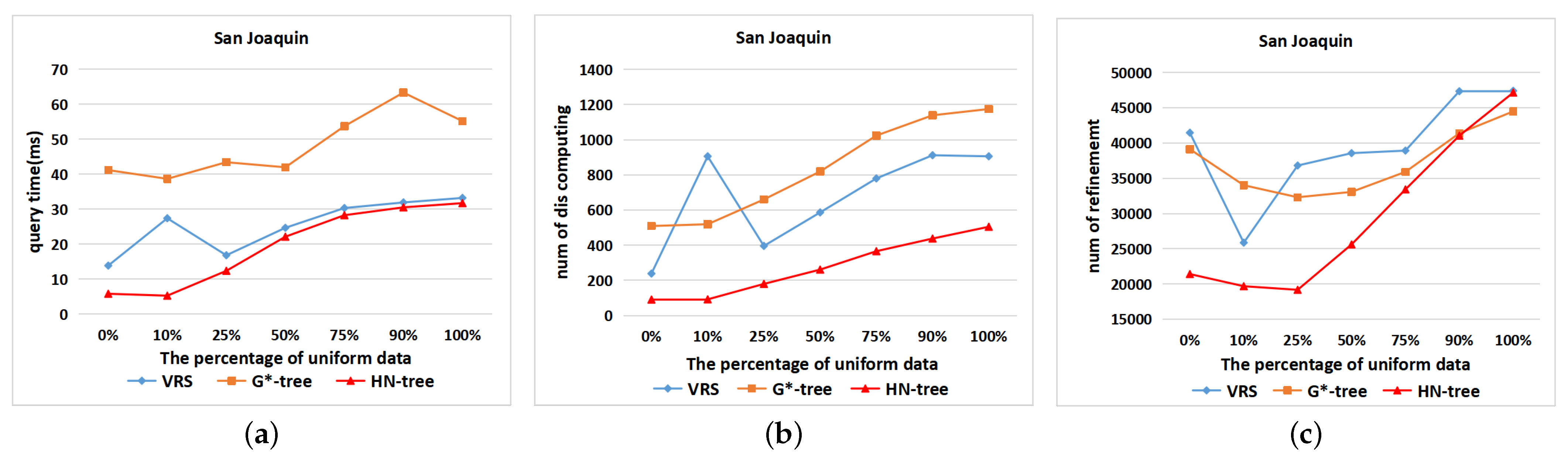
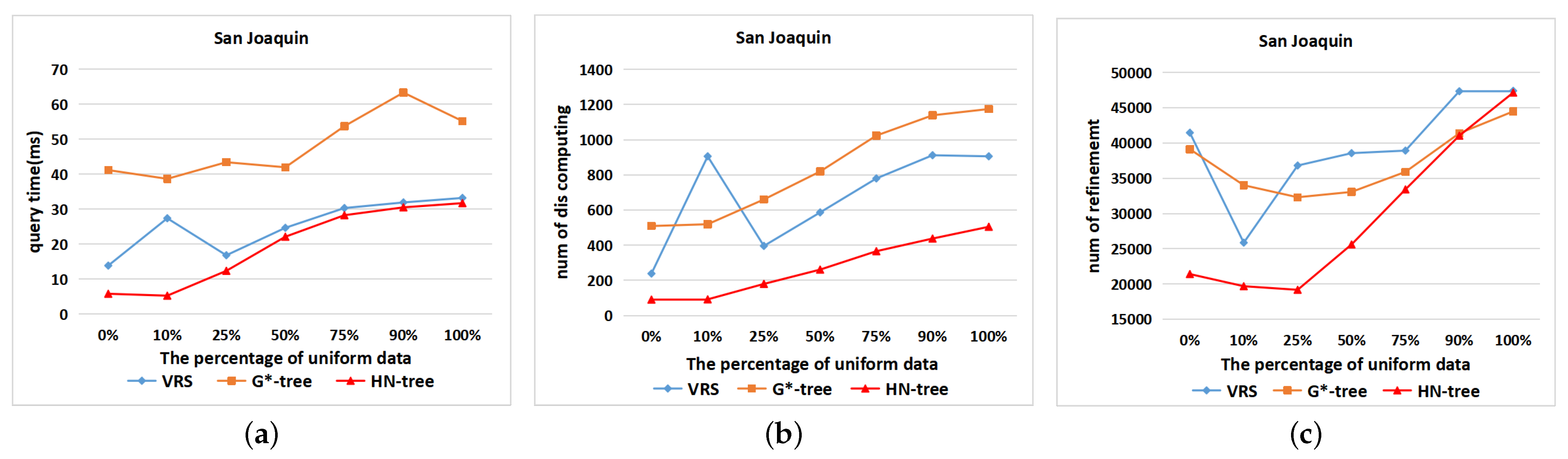
6.4. Datasets: Different Distributions
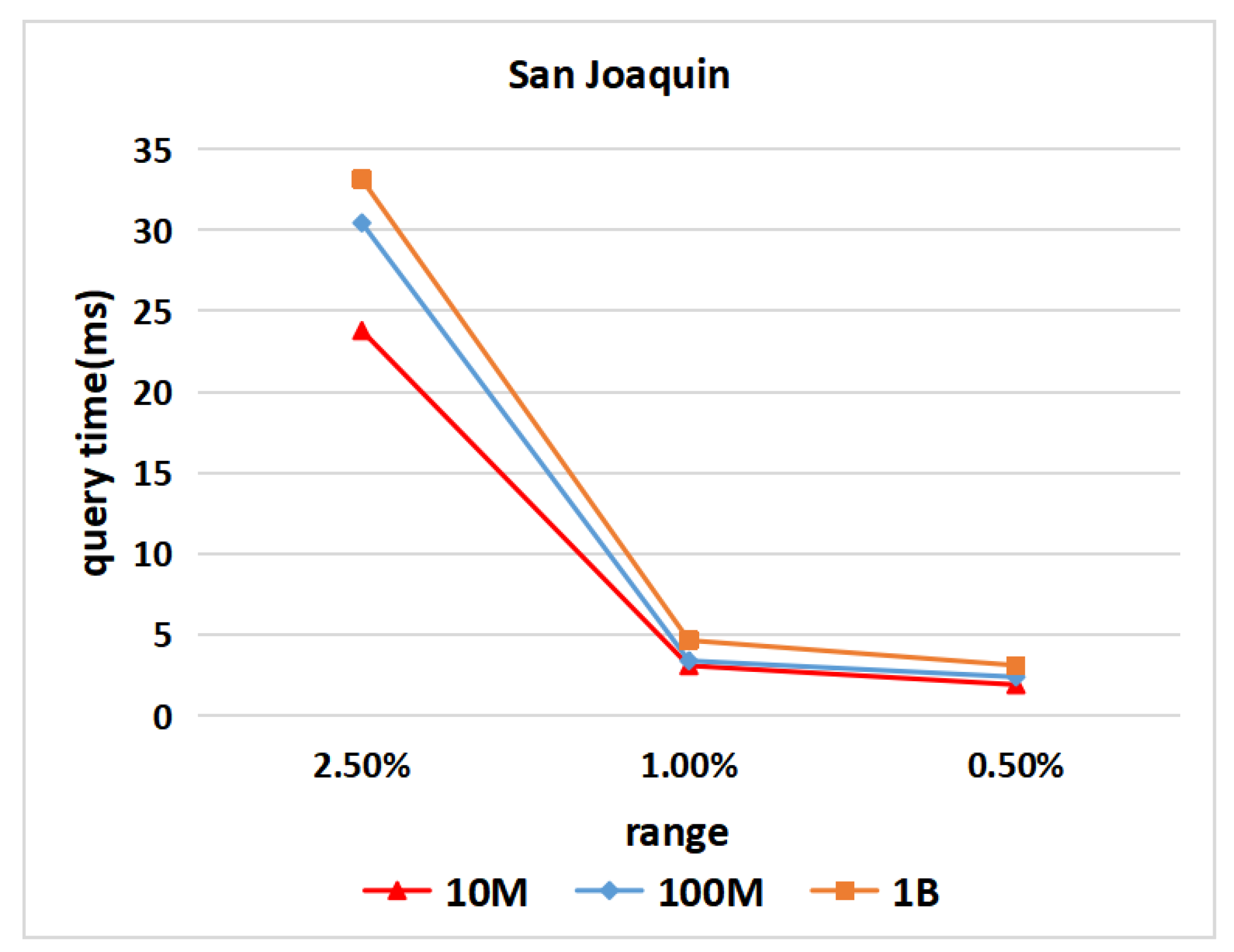
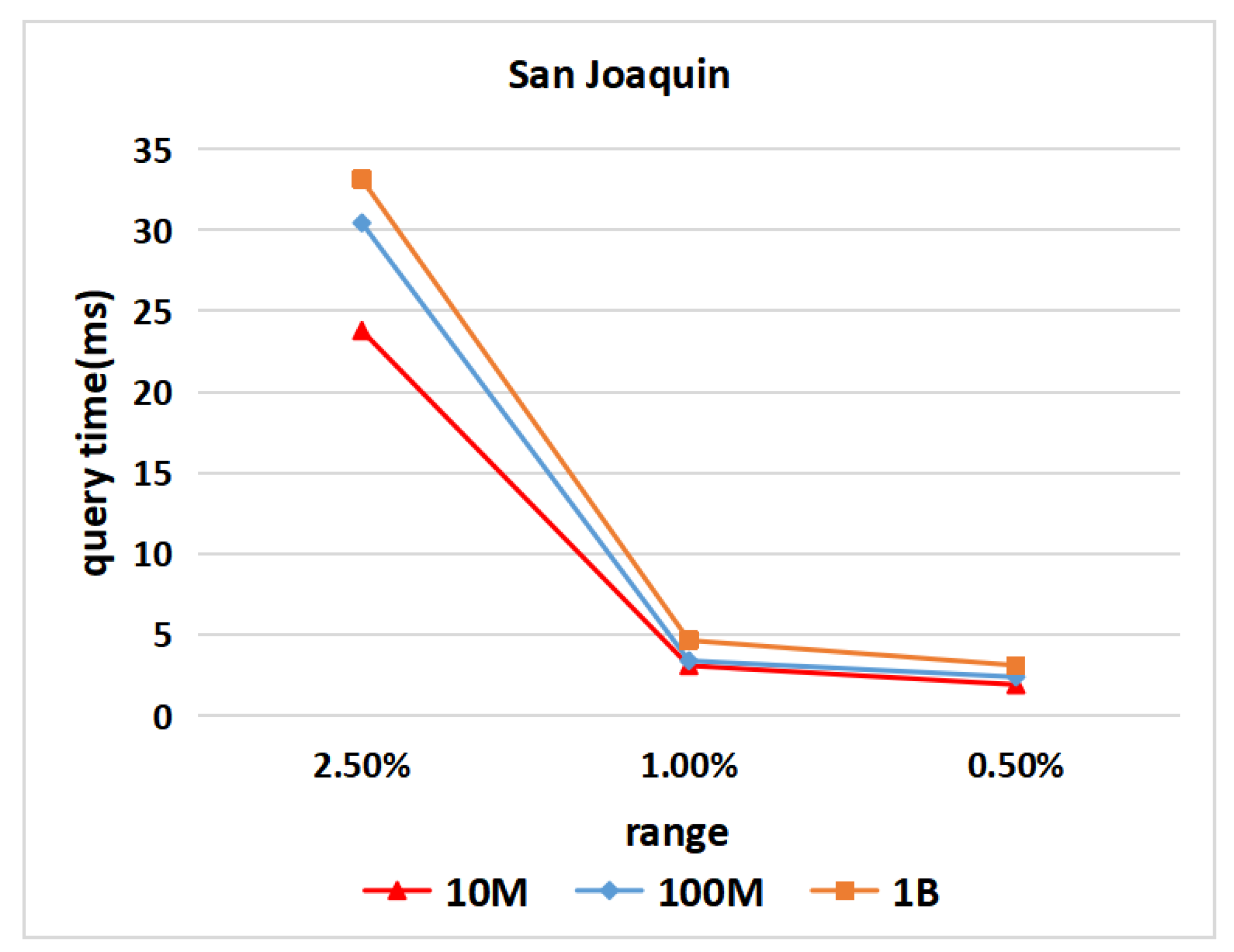
6.5. Query Time for Different Numbers of Spatial Objects
6.6. Experimentation Summary
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, S.; Dragicevic, S.; Castro, F.A.; Sester, M.; Winter, S.; Coltekin, A.; Pettit, C.; Jiang, B.; Haworth, J.; Stein, A.; et al. Geospatial big data handling theory and methods: A review and research challenges. ISPRS J. Photogramm. Remote Sens. 2016, 115, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Shekhar, S.; Chawla, S.; Ravada, S.; Fetterer, A.; Liu, X.; Lu, C.T. Spatial databases-accomplishments and research needs. IEEE Trans. Knowl. Data Eng. 1999, 11, 45–55. [Google Scholar] [CrossRef]
- Tong, Y.; Zhou, Z.; Zeng, Y.; Chen, L.; Shahabi, C. Spatial crowdsourcing: A survey. VLDB J. 2020, 29, 217–250. [Google Scholar] [CrossRef]
- Yan, Y.; Feng, C.C.; Huang, W.; Fan, H.; Wang, Y.C.; Zipf, A. Volunteered geographic information research in the first decade: A narrative review of selected journal articles in GIScience. Int. J. Geogr. Inf. Sci. 2020, 34, 1765–1791. [Google Scholar] [CrossRef]
- Lin, J.; Wu, Z.; Li, X. Measuring inter-city connectivity in an urban agglomeration based on multi-source data. Int. J. Geogr. Inf. Sci. 2019, 33, 1062–1081. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. KDD-96 Proc. 1996, 96, 226–231. [Google Scholar]
- Guttman, A. R-trees: A dynamic index structure for spatial searching. In Proceedings of the 1984 ACM SIGMOD International Conference on Management of Data, Boston, MA, USA, 18–21 June 1984; pp. 47–57. [Google Scholar]
- Sun, W.; Chen, C.; Zheng, B.; Chen, C.; Liu, P. An air index for spatial query processing in road networks. IEEE Trans. Knowl. Data Eng. 2014, 27, 382–395. [Google Scholar] [CrossRef]
- Hoffman, J. Q&A: The data visualizer. Nature 2012, 486, 33. [Google Scholar]
- Pfoser, D.; Jensen, C.S.; Theodoridis, Y. Novel approaches to the indexing of moving object trajectories. In Proceedings of the 26th VLDB Conference, Cairo, Egypt, 10–14 September 2000. [Google Scholar]
- Cudre-Mauroux, P.; Wu, E.; Madden, S. Trajstore: An adaptive storage system for very large trajectory data sets. In Proceedings of the 2010 IEEE 26th International Conference on Data Engineering (ICDE 2010), Long Beach, CA, USA, 1–6 March 2010; pp. 109–120. [Google Scholar]
- Al Aghbari, Z. cTraj: Efficient indexing and searching of sequences containing multiple moving objects. J. Intell. Inf. Syst. 2012, 39, 1–28. [Google Scholar] [CrossRef]
- Song, M.; Choo, H.; Kim, W. Spatial indexing for massively update intensive applications. Inf. Sci. 2012, 203, 1–23. [Google Scholar] [CrossRef]
- Gani, A.; Siddiqa, A.; Shamshirband, S.; Hanum, F. A survey on indexing techniques for big data: Taxonomy and performance evaluation. Knowl. Inf. Syst. 2016, 46, 241–284. [Google Scholar] [CrossRef]
- Pfoser, D.; Jensen, C.S. Trajectory indexing using movement constraints. GeoInformatica 2005, 9, 93–115. [Google Scholar] [CrossRef] [Green Version]
- Popa, I.S.; Zeitouni, K.; Oria, V.; Barth, D.; Vial, S. Indexing in-network trajectory flows. VLDB J. 2011, 20, 643. [Google Scholar] [CrossRef]
- Xuan, K.; Zhao, G.; Taniar, D.; Rahayu, W.; Safar, M.; Srinivasan, B. Voronoi-based range and continuous range query processing in mobile databases. J. Comput. Syst. Sci. 2011, 77, 637–651. [Google Scholar] [CrossRef] [Green Version]
- Papadias, D.; Zhang, J.; Mamoulis, N.; Tao, Y. Query processing in spatial network databases. In Proceedings 2003 VLDB Conference; Elsevier: Amsterdam, The Netherlands, 2003; pp. 802–813. [Google Scholar]
- Zhong, R.; Li, G.; Tan, K.L.; Zhou, L.; Gong, Z. G-tree: An efficient and scalable index for spatial search on road networks. IEEE Trans. Knowl. Data Eng. 2015, 27, 2175–2189. [Google Scholar] [CrossRef]
- Lee, K.C.; Lee, W.C.; Zheng, B.; Tian, Y. ROAD: A new spatial object search framework for road networks. IEEE Trans. Knowl. Data Eng. 2010, 24, 547–560. [Google Scholar] [CrossRef]
- Chen, L.; Tang, Y.; Lv, M.; Chen, G. Partition-based range query for uncertain trajectories in road networks. GeoInformatica 2015, 19, 61–84. [Google Scholar] [CrossRef]
- Teng, X.; Yang, J.; Kim, J.S.; Trajcevski, G.; Züfle, A.; Nascimento, M.A. Fine-grained diversification of proximity constrained queries on road networks. In Proceedings of the 16th International Symposium on Spatial and Temporal Databases, Vienna, Austria, 19–21 August 2019; pp. 51–60. [Google Scholar]
- Pfoser, D. Indexing the trajectories of moving objects. IEEE Data Eng. Bull. 2002, 25, 3–9. [Google Scholar]
- Bentley, J.L. Multidimensional binary search trees in database applications. IEEE Trans. Softw. Eng. 1979, 4, 333–340. [Google Scholar] [CrossRef]
- Beckmann, N.; Kriegel, H.P.; Schneider, R.; Seeger, B. The R*-tree: An efficient and robust access method for points and rectangles. In Proceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ, USA, 23–25 May 1990; pp. 322–331. [Google Scholar]
- Šumák, M.; Gurskỳ, P. R++-tree: An efficient spatial access method for highly redundant point data. In New Trends in Databases and Information Systems; Springer: Berlin/Heidelberg, Germany, 2014; pp. 37–44. [Google Scholar]
- Xu, J.; Güting, R.H.; Zheng, Y. The TM-RTree: An index on generic moving objects for range queries. GeoInformatica 2015, 19, 487–524. [Google Scholar] [CrossRef]
- Li, Z.; Chen, L.; Wang, Y. G*-Tree: An Efficient Spatial Index on Road Networks. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019. [Google Scholar]
- Zhang, H.; Lu, F.; Chen, J. A line graph-based continuous range query method for moving objects in networks. ISPRS Int. J. Geo-Inf. 2016, 5, 246. [Google Scholar] [CrossRef] [Green Version]
- Yin, X.; Ding, Z.; Li, J. Moving continuous k nearest neighbor queries in spatial network databases. In Proceedings of the 2009 WRI World Congress on Computer Science and Information Engineering, Washington, DC, USA, 31 March–2 April 2009; Volume 4, pp. 535–541. [Google Scholar]
- Jossé, G.; Schmid, K.A.; Züfle, A.; Skoumas, G.; Schubert, M.; Renz, M.; Pfoser, D.; Nascimento, M.A. Knowledge extraction from crowdsourced data for the enrichment of road networks. Geoinformatica 2017, 21, 763–795. [Google Scholar] [CrossRef]
- Skoumas, G.; Schmid, K.A.; Jossé, G.; Schubert, M.; Nascimento, M.A.; Züfle, A.; Renz, M.; Pfoser, D. Knowledge-enriched route computation. In International Symposium on Spatial and Temporal Databases; Springer: Berlin/Heidelberg, Germany, 2015; pp. 157–176. [Google Scholar]
- Wang, H.; Zimmermann, R. Processing of continuous location-based range queries on moving objects in road networks. IEEE Trans. Knowl. Data Eng. 2010, 23, 1065–1078. [Google Scholar] [CrossRef]
- Lee, K.C.; Lee, W.C.; Zheng, B. Fast object search on road networks. In Proceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology, Saint Petersburg, Russia, 24–26 March 2009; pp. 1018–1029. [Google Scholar]
- Frentzos, E. Indexing objects moving on fixed networks. In International Symposium on Spatial and Temporal Databases; Springer: Berlin/Heidelberg, Germany, 2003; pp. 289–305. [Google Scholar]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef] [Green Version]
- Karypis, G.; Kumar, V. A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM J. Sci. Comput. 1998, 20, 359–392. [Google Scholar] [CrossRef]
- Anwar, T.; Liu, C.; Vu, H.L.; Leckie, C. Partitioning road networks using density peak graphs: Efficiency vs. accuracy. Inf. Syst. 2017, 64, 22–40. [Google Scholar] [CrossRef]
- Hosseini, S.; Najafipour, S.; Cheung, N.M.; Yin, H.; Kangavari, M.R.; Zhou, X. TEAGS: Time-aware text embedding approach to generate subgraphs. Data Min. Knowl. Discov. 2020, 34, 1136–1174. [Google Scholar] [CrossRef]
- Najafipour, S.; Hosseini, S.; Hua, W.; Kangavari, M.R.; Zhou, X. SoulMate: Short-text author linking through Multi-aspect temporal-textual embedding. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef] [Green Version]
- Ashrafi-Payaman, N.; Kangavari, M.R.; Hosseini, S.; Fander, A.M. GS4: Graph stream summarization based on both the structure and semantics. J. Supercomput. 2021, 77, 2713–2733. [Google Scholar] [CrossRef]
- Brinkhoff, T. A Framework for Generating Network-Based Moving Objects. Geoinformatica 2002, 6, 153–180. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | # of Network Nodes | # of Links | # of SOs |
|---|---|---|---|
| Oldenburg | 6105 | 7034 | 1,248,212 |
| San Joaquin | 18,496 | 24,123 | 3,305,742 |
| San Francisco Bay Area | 175,343 | 223,606 | 37,808,266 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Min, X.; Pfoser, D.; Züfle, A.; Sheng, Y. A Hierarchical Spatial Network Index for Arbitrarily Distributed Spatial Objects. ISPRS Int. J. Geo-Inf. 2021, 10, 814. https://doi.org/10.3390/ijgi10120814
Min X, Pfoser D, Züfle A, Sheng Y. A Hierarchical Spatial Network Index for Arbitrarily Distributed Spatial Objects. ISPRS International Journal of Geo-Information. 2021; 10(12):814. https://doi.org/10.3390/ijgi10120814
Chicago/Turabian StyleMin, Xiangqiang, Dieter Pfoser, Andreas Züfle, and Yehua Sheng. 2021. "A Hierarchical Spatial Network Index for Arbitrarily Distributed Spatial Objects" ISPRS International Journal of Geo-Information 10, no. 12: 814. https://doi.org/10.3390/ijgi10120814
APA StyleMin, X., Pfoser, D., Züfle, A., & Sheng, Y. (2021). A Hierarchical Spatial Network Index for Arbitrarily Distributed Spatial Objects. ISPRS International Journal of Geo-Information, 10(12), 814. https://doi.org/10.3390/ijgi10120814