
The Societal Echo of Severe Weather Events: Ambient Geospatial Information (AGI) on a Storm Event



Abstract
1. Introduction
1.1. Ambient Geospatial Information (AGI) in Crisis Informatics
1.2. Objectives and Research Questions
2. Materials and Methods
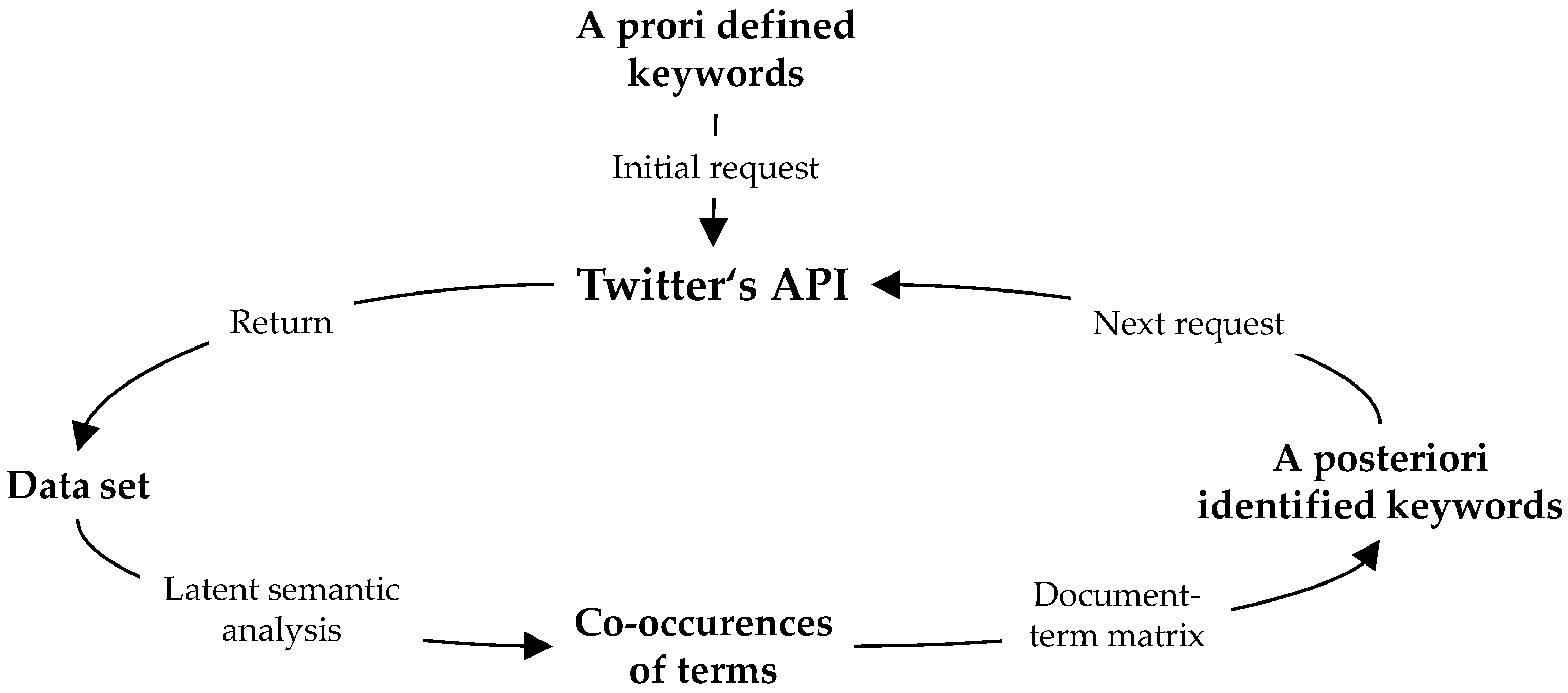
2.1. The Harvested Dataset
2.2. Wrangling and Filtering
2.3. Geocoding of Implicit Location Names (Toponyms)
2.4. Spatio-Temporal and Content-Related Patterns Analysis
3. Results
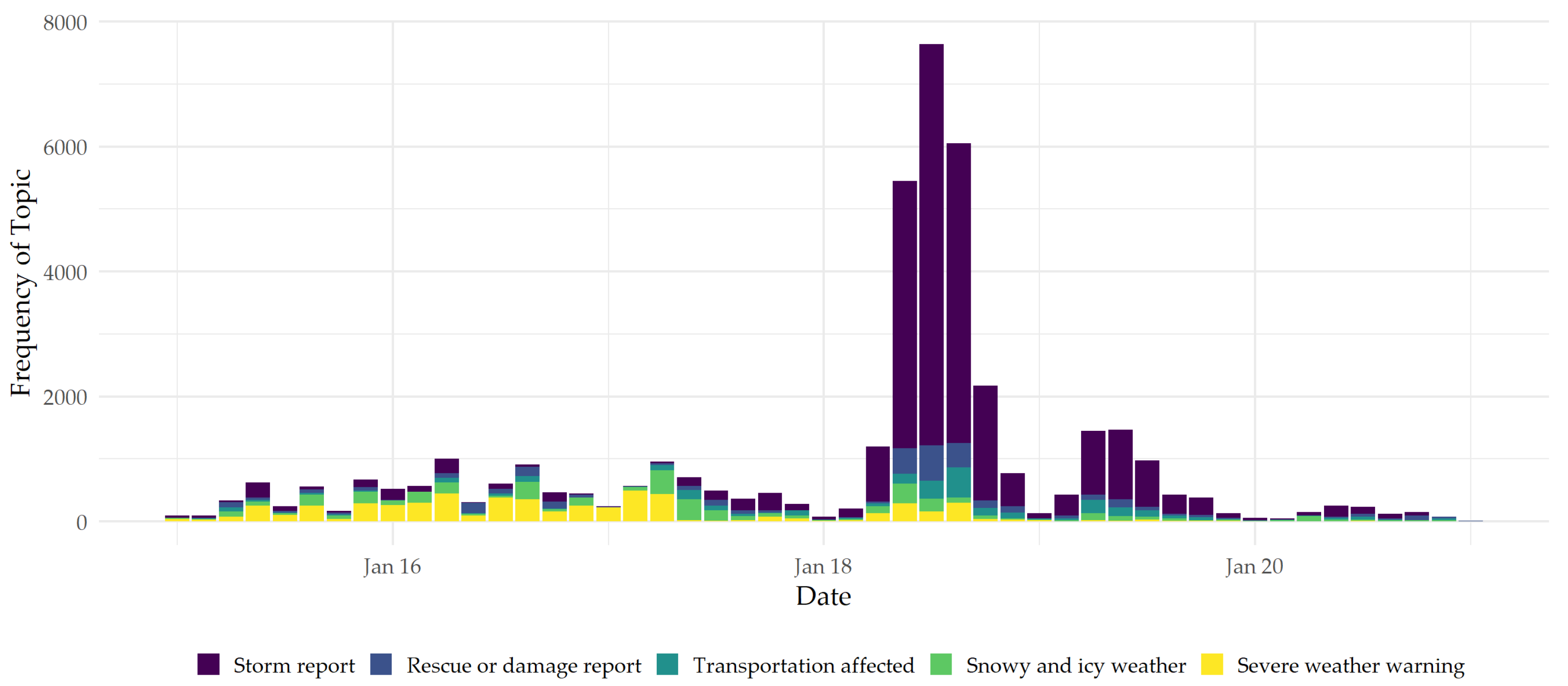
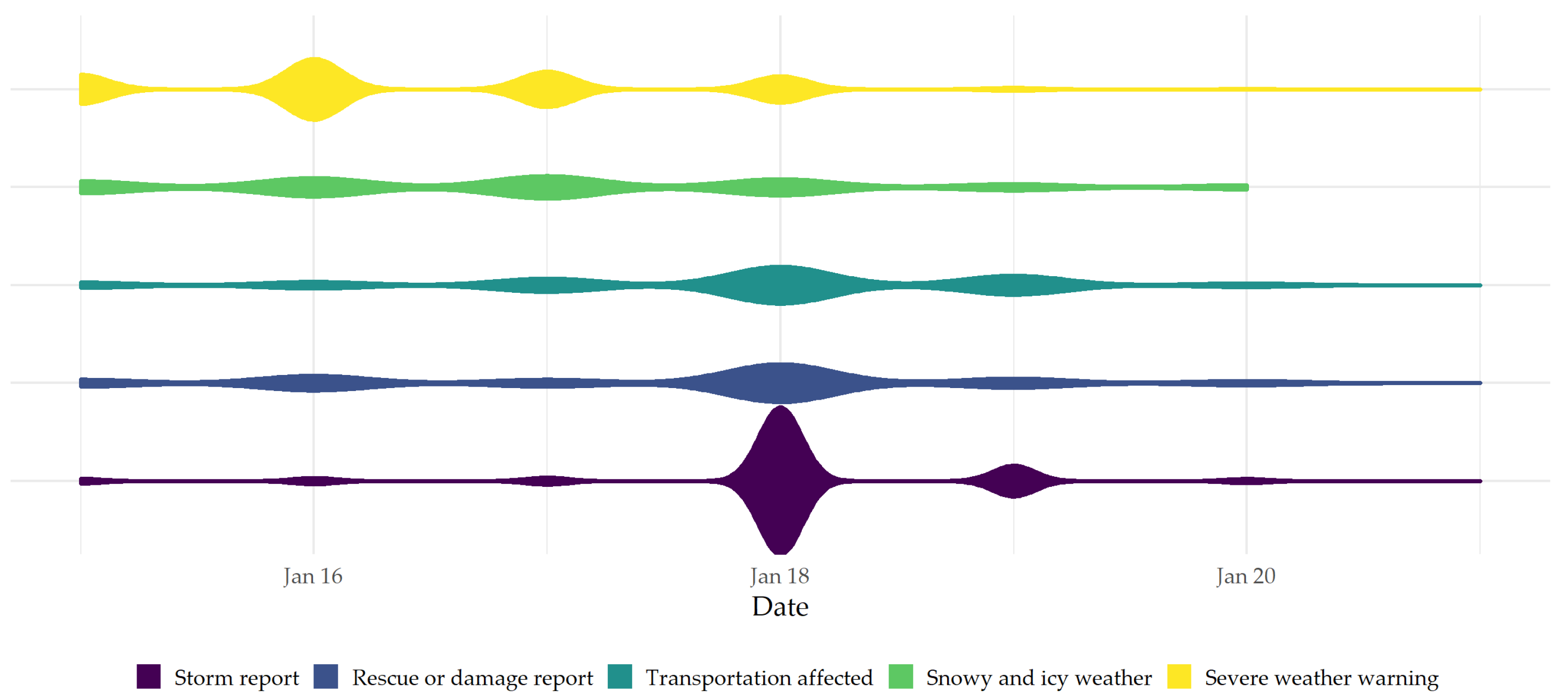
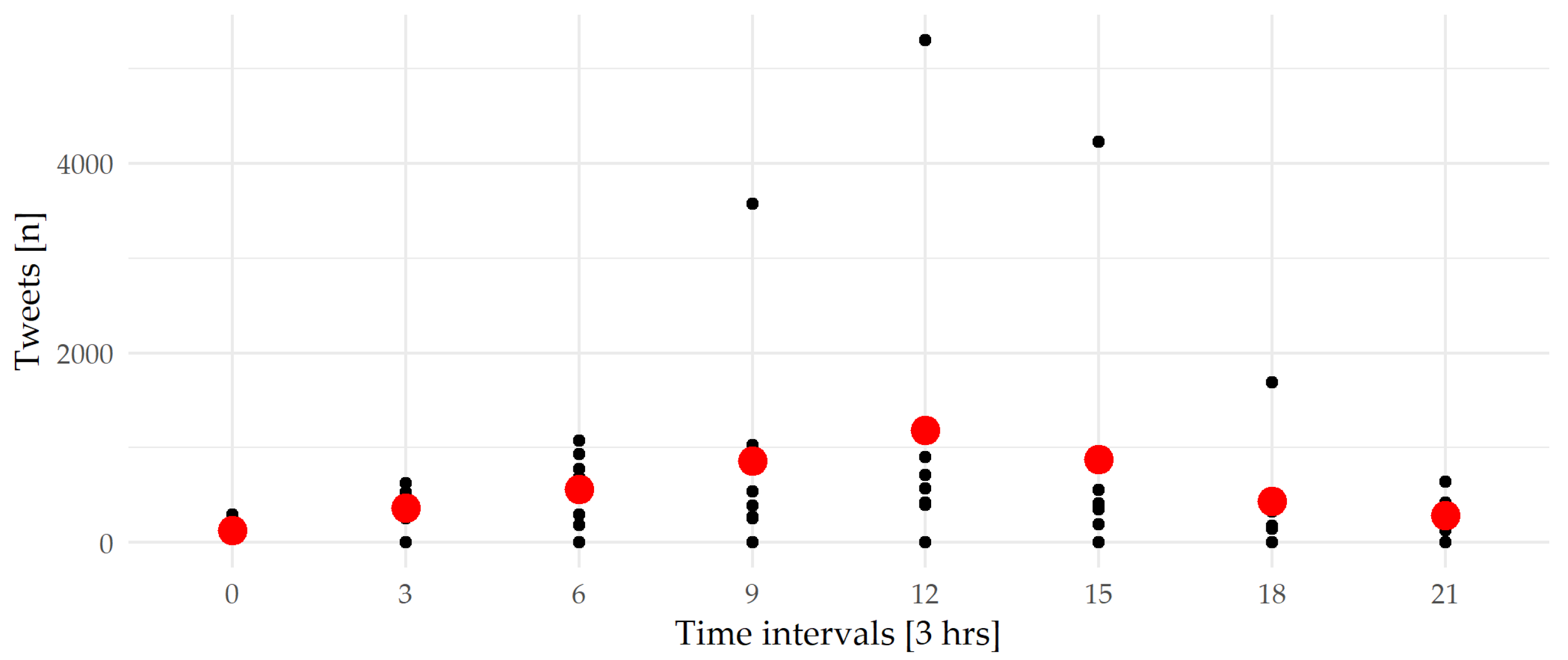
3.1. Central Topic Clusters and Their Temporal Density
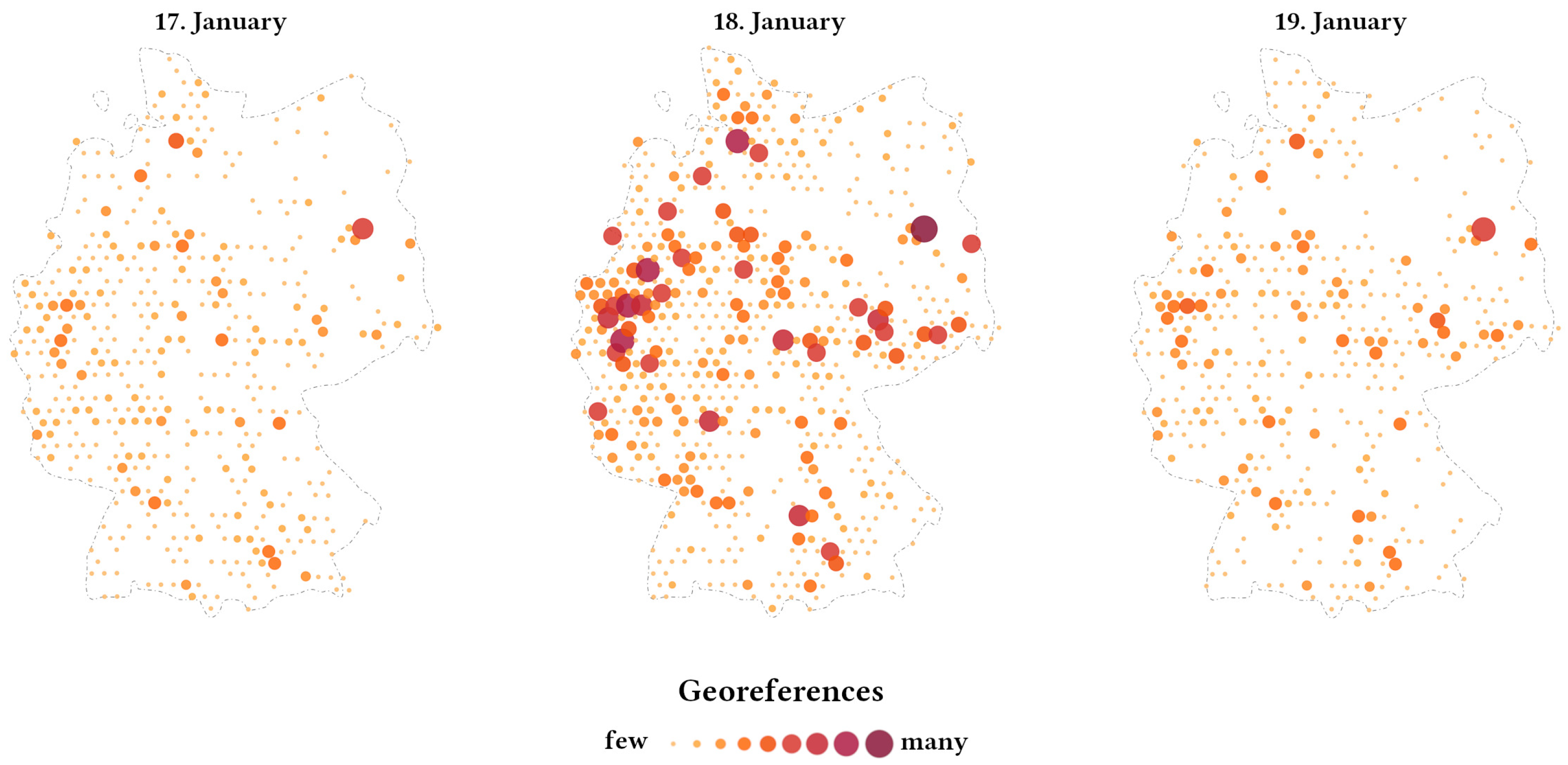
3.2. Implicit Toponyms of AGI
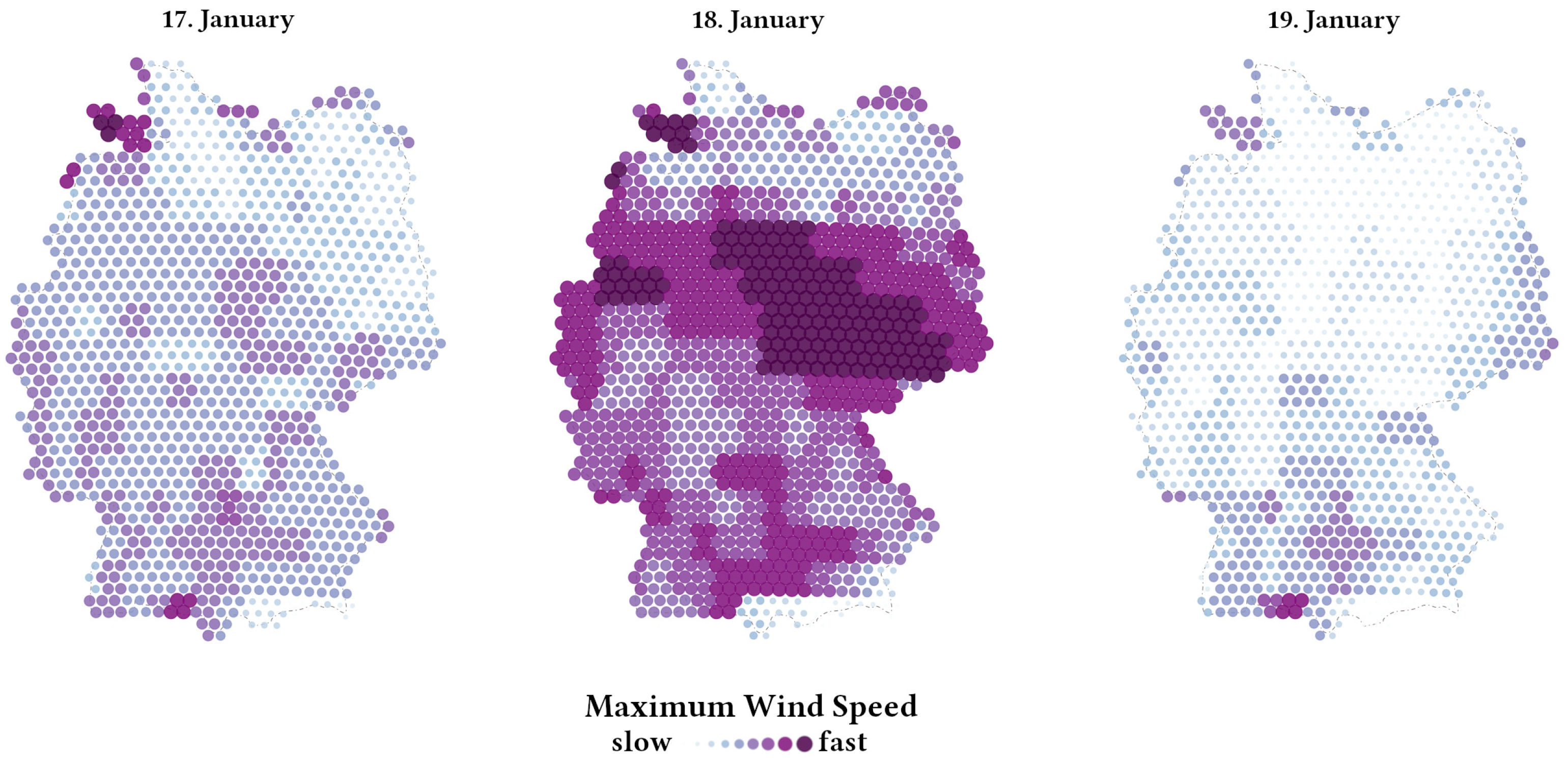
3.3. Spatial Patterns of AGI and Wind Speed Data
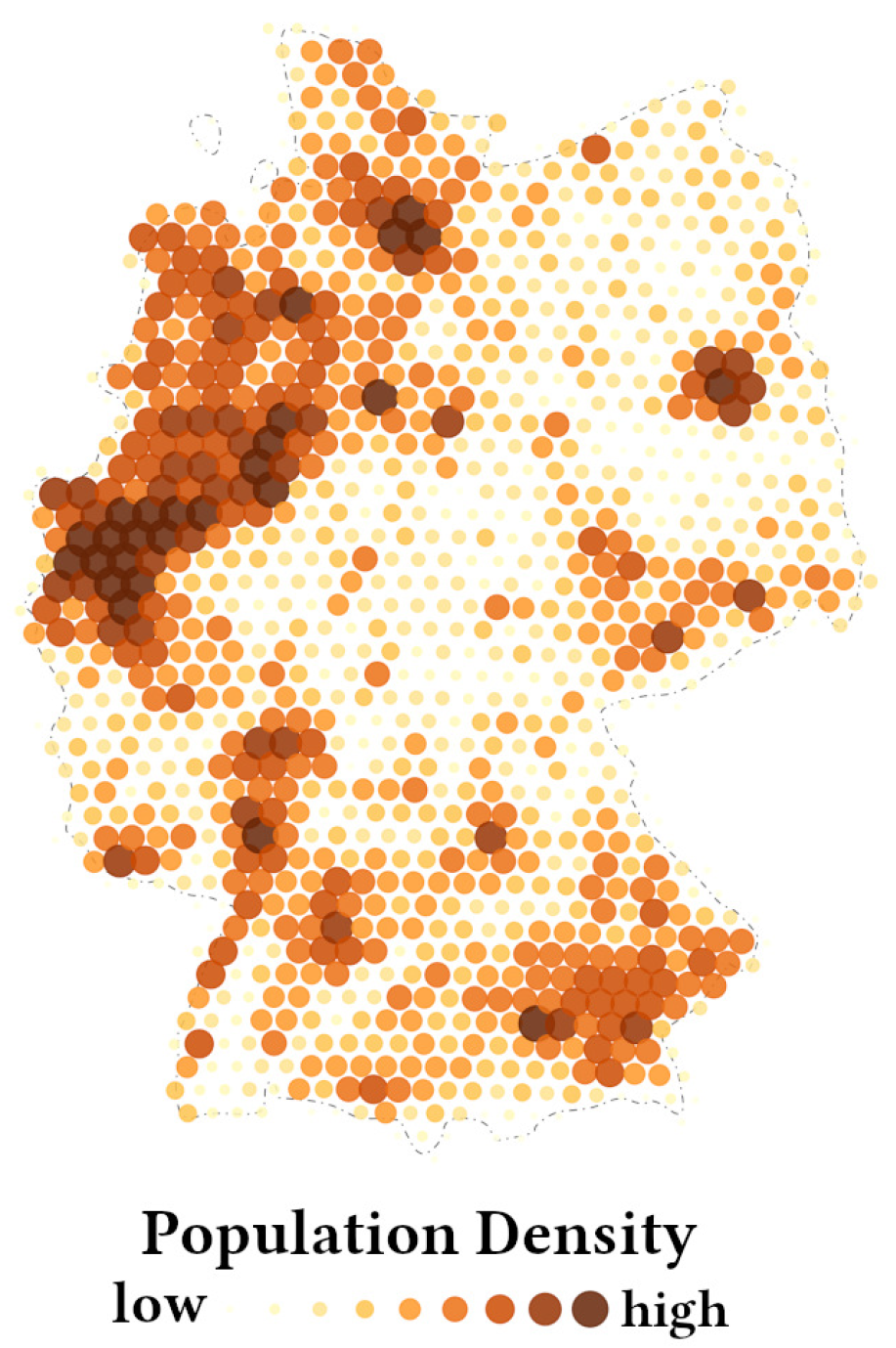
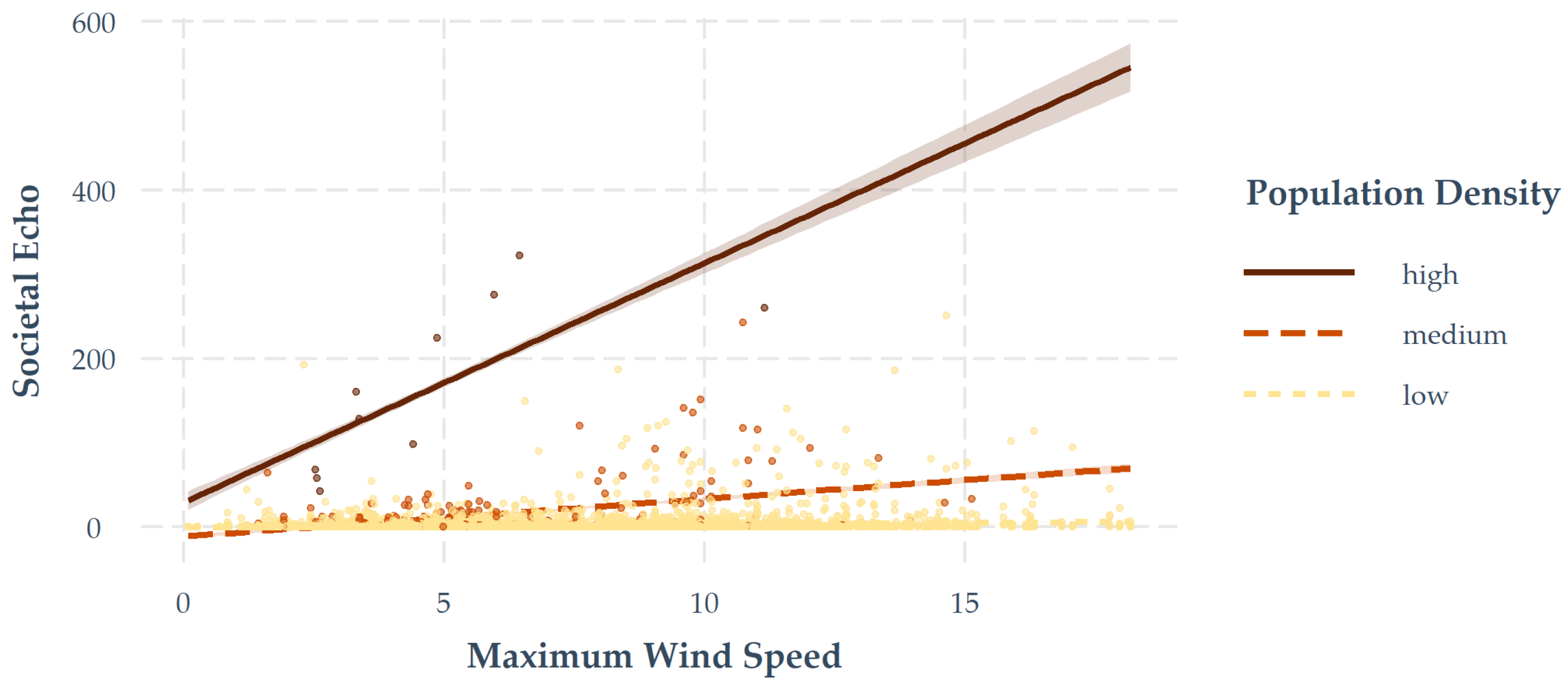
3.4. Synthesis of AGI, Wind, and Population Data
4. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AGI | Ambient Geospatial Information |
| API | Application Programming Interface |
| CGI | Citizen Contributed Geographic Information |
| GFS | Global Forecast System |
| GIS | Geographic Information System |
| GHSL | Global Human Settlement Layer |
| IR | Information Retrieval |
| LAU | Local Administrative Units |
| LSA | Latent Semantic Analysis |
| MAUP | Modifiable Areal Unit Problem |
| NUTS | Nomenclature of Territorial Units for Statistics |
| R | R Programming Language and Free Software Environment |
| VGI | Volunteered Geographic Information |
References
- O’Reilly, T. What is Web 2.0: Design Patterns and Business Models for the Next Generation of Software. Commun. Strateg. 2007, 1, 17–37. [Google Scholar]
- Hyvärinen, O.; Saltikoff, E. Social Media as a Source of Meteorological Observations. Mon. Weather. Rev. 2010, 138, 3175–3184. [Google Scholar] [CrossRef]
- Niforatos, E.; Vourvopoulos, A.; Langheinrich, M. Understanding the potential of human-machine crowdsourcing for weather data. Int. J. Hum. Comput. Stud. 2017, 102, 54–68. [Google Scholar] [CrossRef]
- Ratter, B.M.; Philipp, K.H.; Von Storch, H. Between hype and decline: Recent trends in public perception of climate change. Environ. Sci. Policy 2012, 18, 3–8. [Google Scholar] [CrossRef]
- Sisco, M.R.; Bosetti, V.; Weber, E.U. When do extreme weather events generate attention to climate change? Clim. Chang. 2017, 143, 227–241. [Google Scholar] [CrossRef]
- Shao, W.; Goidel, K. Seeing is Believing? An Examination of Perceptions of Local Weather Conditions and Climate Change Among Residents in the U.S. Gulf Coast. Risk Anal. 2016, 36, 2136–2157. [Google Scholar] [CrossRef]
- Starbird, K.; Palen, L. “Voluntweeters”. In Proceedings of the 2011 Annual Conference on Human Factors in Computing Systems—CHI ’11; ACM Press: New York, NY, USA, 2011; p. 1071. [Google Scholar] [CrossRef]
- See, L.; Mooney, P.; Foody, G.; Bastin, L.; Comber, A.; Estima, J.; Fritz, S.; Kerle, N.; Jiang, B.; Laakso, M.; et al. Geo-Information Crowdsourcing, Citizen Science or Volunteered Geographic Information? The Current State of Crowdsourced Geographic Information. ISPRS Int. J. Geo-Inf. 2016, 5, 55. [Google Scholar] [CrossRef]
- Harvey, F. To Volunteer or to Contribute Locational Information? Towards Truth in Labeling for Crowdsourced Geographic Information. In Crowdsourcing Geographic Knowledge: Volunteered Geographic Information (VGI) in Theory and Practice; Sui, D., Elwood, S., Goodchild, M., Eds.; Springer: Dordrecht, The Netherlands, 2013; pp. 31–42. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar]
- Fischer, F. VGI as Big Data. A New but Delicate Geographic Data-Source. GeoInformatics 2012, 15, 46–47. [Google Scholar]
- Spyratos, S.; Lutz, M.; Pantisano, F. Characteristics of Citizen—Contributed Geographic Information. In Proceedings of the International Conference on Geographic Information Science, Castellón, Spain, 3–6 June 2014; pp. 3–6. [Google Scholar] [CrossRef]
- Stefanidis, A.; Crooks, A.; Radzikowski, J. Harvesting Ambient Geospatial Information from social media feeds. GeoJournal 2013, 78, 319–338. [Google Scholar] [CrossRef]
- Palen, L.; Starbird, K.; Vieweg, S.; Hughes, A. Twitter-based Information Distribution during the 2009 Red River Valley Flood Threat by. Bull. Am. Soc. Inf. Sci. Technol. 2010, 36, 13–18. [Google Scholar] [CrossRef]
- Ghermandi, A.; Sinclair, M. Passive crowdsourcing of social media in environmental research: A systematic map. Glob. Environ. Chang. 2019, 55, 36–47. [Google Scholar] [CrossRef]
- Poblete, B.; Guzman, J.; Maldonado, J.; Tobar, F. Robust Detection of Extreme Events Using Twitter: Worldwide Earthquake Monitoring. IEEE Trans. Multimed. 2018, 20, 2551–2561. [Google Scholar] [CrossRef]
- Mendoza, M.; Poblete, B.; Valderrama, I. Nowcasting earthquake damages with Twitter. EPJ Data Sci. 2019, 8, 1–23. [Google Scholar] [CrossRef]
- Palen, L.; Vieweg, S.; Liu, S.B.; Hughes, A.L. Crisis in a Networked World. Soc. Sci. Comput. Rev. 2009, 27, 467–480. [Google Scholar] [CrossRef]
- Meier, P. Digital Humanitarians: How Big Data Is Changing the Face of Humanitarian Response; Routledge: London, UK, 2015; pp. 1–259. [Google Scholar] [CrossRef]
- Castillo, C. Big Crisis Data: Social Media in Disasters and Time-Critical Situations; Cambridge University Press: New York, NY, USA, 2016; pp. 1–212. [Google Scholar] [CrossRef]
- Palen, L.; Anderson, K.M. Crisis informatics: New data for extraordinary times. Science 2016, 353, 224–225. [Google Scholar] [CrossRef]
- Li, G.; Zhao, J.; Murray, V.; Song, C.; Zhang, L. Gap analysis on open data interconnectivity for disaster risk research. Geo-Spat. Inf. Sci. 2019, 22, 45–58. [Google Scholar] [CrossRef]
- Kitchin, R. Big data and human geography: Opportunities, challenges and risks. Dialogues Hum. Geogr. 2013, 3, 262–267. [Google Scholar] [CrossRef]
- Graham, M.; Shelton, T. Geography and the future of big data, big data and the future of geography. Dialogues Hum. Geogr. 2013, 3, 255–261. [Google Scholar] [CrossRef]
- De Longueville, B.; Smith, R.S.; Luraschi, G. OMG, from here, I can see the flames! In Proceedings of the 2009 International Workshopon Location Based Social Networks (LBSN), Seattle, WA, USA, 3 November 2009; pp. 73–80. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; ACM: New York, NY, USA, 2010; pp. 851–860. [Google Scholar] [CrossRef]
- Verma, S.; Vieweg, S.; Corvey, W.J.; Palen, L.; Martin, J.H.; Palmer, M.; Schram, A.; Anderson, K.M. Natural Language Processing to the Rescue? Extracting “Situational Awareness” Tweets During Mass Emergency. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Catalonia, Spain, 17–21 July 2011; pp. 385–392. [Google Scholar]
- Imran, M.; Castillo, C.; Diaz, F.; Vieweg, S. Processing Social Media Messages in Mass Emergency: Survey Summary. In Companion Proceedings of the the Web Conference 2018; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2018; pp. 507–511. [Google Scholar] [CrossRef]
- Anderson, J.; Casas Saez, G.; Anderson, K.; Palen, L.; Morss, R. Incorporating Context and Location Into Social Media Analysis: A Scalable, Cloud-Based Approach for More Powerful Data Science. In Proceedings of the 52nd Hawaii International Conference on System Sciences, Maui, HI, USA, 8–11 January 2019; Volume 6, pp. 2274–2283. [Google Scholar] [CrossRef]
- Kryvasheyeu, Y.; Chen, H.; Obradovich, N.; Moro, E.; Van Hentenryck, P.; Fowler, J.; Cebrian, M. Rapid assessment of disaster damage using social media activity. Sci. Adv. 2016, 2, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Eilander, D.; Trambauer, P.; Wagemaker, J.; Van Loenen, A. Harvesting Social Media for Generation of Near Real-time Flood Maps. Procedia Eng. 2016, 154, 176–183. [Google Scholar] [CrossRef]
- Kent, J.D.; Capello, H.T., Jr. Spatial patterns and demographic indicators of effective social media content during theHorsethief Canyon fire of 2012. Cartogr. Geogr. Inf. Sci. 2013, 40, 78–89. [Google Scholar] [CrossRef]
- Dong, Z.S.; Meng, L.; Christenson, L.; Fulton, L. Social media information sharing for natural disaster response. Nat. Hazards 2021, 107, 2077–2104. [Google Scholar] [CrossRef]
- Morss, R.E.; Demuth, J.L.; Lazrus, H.; Palen, L.; Barton, C.M.; Davis, C.A.; Snyder, C.; Wilhelmi, O.V.; Anderson, K.M.; Ahijevych, D.A.; et al. Hazardous weather prediction and communication in the modern information environment. Bull. Am. Meteorol. Soc. 2017, 98, 2653–2674. [Google Scholar] [CrossRef]
- Holderness, T.; Turpin, E. From Social Media to GeoSocial Intelligence: Crowdsourcing Civic Co-management for Flood Response in Jakarta, Indonesia. In Social Media for Government Services; Springer International Publishing: Cham, Switzerland, 2015; pp. 115–133. [Google Scholar] [CrossRef]
- Resch, B.; Usländer, F.; Havas, C. Combining machine-learning topic models and spatiotemporal analysis of social media data for disaster footprint and damage assessment. Cartogr. Geogr. Inf. Sci. 2018, 45, 362–376. [Google Scholar] [CrossRef]
- Niforatos, E.; Vourvopoulos, A.; Langheinrich, M. ‘Weather With You’: Evaluating Report Reliability in Weather Crowdsourcing. In Proceedings of the 14th International Conference on Mobile and Ubiquitous Multimedia, Linz, Austria, 30 November–2 December 2015; pp. 152–162. [Google Scholar] [CrossRef]
- Anderson, J.; Soden, R.; Keegan, B.; Palen, L.; Anderson, K.M. The Crowd is the Territory: Assessing Quality in Peer-Produced Spatial Data During Disasters. Int. J. -Hum.-Comput. Interact. 2018, 34, 295–310. [Google Scholar] [CrossRef]
- Elwood, S.; Goodchild, M.F.; Sui, D.Z. Researching Volunteered Geographic Information: Spatial Data, Geographic Research, and New Social Practice. Ann. Assoc. Am. Geogr. 2012, 102, 571–590. [Google Scholar] [CrossRef]
- Ahmouda, A.; Hochmair, H.H.; Cvetojevic, S. Analyzing the effect of earthquakes on OpenStreetMap contribution patterns and tweeting activities. Geo-Spat. Inf. Sci. 2018, 21, 195–212. [Google Scholar] [CrossRef]
- Florczyk, A.J.; Corbane, C.; Ehrlich, D.; Freire, S.; Kemper, T.; Maffenini, L.; Melchiorri, M.; Pesaresi, M.; Politis, P.; Schiavina, M.; et al. GHSL Data Package 2019; Technical Report; EU: Luxembourg, 2019. [Google Scholar] [CrossRef]
- Leetaru, K.H.; Shaowen, W.; Guofeng, C.; Padmanabhan, A.; Shook, E. Mapping the global Twitter hearbeat: The geography of Twitter. First Monday 2013, 18, 5–6. [Google Scholar] [CrossRef]
- Zappavigna, M. Ambient affiliation: A linguistic perspective on Twitter. New Media Soc. 2011, 13, 788–806. [Google Scholar] [CrossRef]
- Kearney, M.W. rtweet: Collecting and analyzing Twitter data. J. Open Source Softw. 2019, 4, 1829. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schutze, H. An Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2009; p. 569. [Google Scholar] [CrossRef]
- Zipf, G.K. Selected Studies of the Principle of Relative Frequency in Language; Harvard University Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Evert, S.; Baroni, M. zipfR: Word Frequency Distributions in R. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Posters and Demonstrations Sessions, Prague, Czech Republic, 25–27 June 2007; pp. 29–32. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2016. [Google Scholar]
- He, W.; Zha, S.; Li, L. Social media competitive analysis and text mining: A case study in the pizza industry. Int. J. Inf. Manag. 2013, 33, 464–472. [Google Scholar] [CrossRef]
- Hahmann, S.; Purves, R.S.; Burghardt, D. Twitter location (Sometimes) matters: Exploring the relationship between georeferenced tweet content and nearby feature classes. J. Spat. Inf. Sci. 2014, 9, 1–36. [Google Scholar] [CrossRef]
- Ogie, R.I.; Forehead, H. Investigating the accuracy of georeferenced social media data for flood mapping: The PetaJakarta.org case study. In Proceedings of the 2017 4th International Conference on Information and Communication Technologies for Disaster Management, ICT-DM Münster, Germany, 11–13 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ribeiro, S.; Pappa, G.L. Strategies for combining Twitter users geo-location methods. GeoInformatica 2018, 22, 563–587. [Google Scholar] [CrossRef]
- Craglia, M.; Ostermann, F.; Spinsanti, L. Digital Earth from vision to practice: Making sense of citizen-generated content. Int. J. Digit. Earth 2012, 5, 398–416. [Google Scholar] [CrossRef]
- Granell, C.; Ostermann, F.O. Beyond data collection: Objectives and methods of research using VGI and geo-social media for disaster management. Comput. Environ. Urban Syst. 2016, 59, 231–243. [Google Scholar] [CrossRef]
- Zhang, C.; Fan, C.; Yao, W.; Hu, X.; Mostafavi, A. Social media for intelligent public information and warning in disasters: An interdisciplinary review. Int. J. Inf. Manag. 2019, 49, 190–207. [Google Scholar] [CrossRef]
- Robinson, D. Fuzzyjoin: Join Tables Together on Inexact Matching. 2020. R Package Version 0.1.6. Available online: https://cran.r-project.org/web/packages/fuzzyjoin/ (accessed on 26 August 2020).
- Goodchild, M.F. GIScience, geography, form, and process. Ann. Am. Assoc. Geogr. 2004, 94, 709–714. [Google Scholar]
- Birch, C.P.; Oom, S.P.; Beecham, J.A. Rectangular and hexagonal grids used for observation, experiment and simulation in ecology. Ecol. Model. 2007, 206, 347–359. [Google Scholar] [CrossRef]
- Global Forecast System Data. 2021. Available online: https://www.ncei.noaa.gov/products/weather-climate-models/global-forecast (accessed on 5 February 2021).
- Fernández-López, J.; Schliep, K. rWind: Download, edit and include wind data in ecological and evolutionary analysis. Ecography 2019, 42, 804–810. [Google Scholar] [CrossRef]
- Pebesma, E. Simple Features for R: Standardized Support for Spatial Vector Data. R J. 2018, 10, 439–446. [Google Scholar] [CrossRef]
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016. [Google Scholar]
- Silge, J.; Robinson, D. tidytext: Text Mining and Analysis Using Tidy Data Principles in R. J. Open Source Softw. 2016, 1, 37. [Google Scholar] [CrossRef]
- Müller, K.; Wickham, H. tibble: Simple Data Frames. 2020. Available online: https://cran.r-project.org/package=tibble (accessed on 2 May 2021).
- Andrienko, G.; Andrienko, N.; Bosch, H.; Ertl, T.; Fuchs, G.; Jankowski, P.; Thom, D. Thematic patterns in georeferenced tweets through space-time visual analytics. Comput. Sci. Eng. 2013, 15, 72–82. [Google Scholar] [CrossRef]
- Crampton, J.W.; Graham, M.; Poorthuis, A.; Shelton, T.; Stephens, M.; Wilson, M.W.; Zook, M. Beyond the geotag: Situating ‘big data’ and leveraging the potential of the geoweb. Cartogr. Geogr. Inf. Sci. 2013, 40, 130–139. [Google Scholar] [CrossRef]
- Lachlan, K.A.; Spence, P.R.; Lin, X.; Greco, M.D. Screaming into the Wind: Examining the Volume and Content of Tweets Associated with Hurricane Sandy. Commun. Stud. 2014, 65, 500–518. [Google Scholar] [CrossRef]
- Spruce, M.; Arthur, R.; Williams, H.T. Using social media to measure impacts of named storm events in the United Kingdom and Ireland. Meteorol. Appl. 2020, 27, e1887. [Google Scholar] [CrossRef]
- Beevolve. An Exhaustive Study of Twitter Users Across the World—Social Media Analytics|Beevolve. 2012. Available online: http://www.beevolve.com/twitter-statistics (accessed on 15 August 2020).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spatial Scale | Georeferences | Tweets |
|---|---|---|
| Country (NUTS-0) | 528 | 528 |
| States (NUTS-1) | 2134 | 1899 |
| Government regions (NUTS-2) | 3106 | 2886 |
| Districts (NUTS-3) | 10,214 | 7093 |
| Municipalities (NUTS-4) | 31,557 | 13,241 |
| Total | 47,539 | 25,647 |
| Unique | 13,241 |
| Hexagonwide | Countrywide | ||
|---|---|---|---|
| Temporal Aggregation | Tweets (n)∼ Population (%) | Tweets (n)∼ Wind Speed (Max) | Tweets (n)∼ Wind Speed (Max) |
| 3 h | 0.20 | 0.15 | 0.54 |
| 6 h | 0.25 | 0.20 | 0.55 |
| 12 h | 0.30 | 0.25 | 0.60 |
| 24 h | 0.31 | 0.25 | 0.68 |
| 7 days | 0.46 | 0.01 | - |
| Time Interval | 0–3 | 3–6 | 6–9 | 9–12 | 12–15 | 15–18 | 18–21 | 21–0 |
|---|---|---|---|---|---|---|---|---|
| rho | 0.89 | 0.67 | 0.28 | 0.60 | 0.53 | 0.92 | 0.53 | 0.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hologa, R.; Glaser, R. The Societal Echo of Severe Weather Events: Ambient Geospatial Information (AGI) on a Storm Event. ISPRS Int. J. Geo-Inf. 2021, 10, 815. https://doi.org/10.3390/ijgi10120815
Hologa R, Glaser R. The Societal Echo of Severe Weather Events: Ambient Geospatial Information (AGI) on a Storm Event. ISPRS International Journal of Geo-Information. 2021; 10(12):815. https://doi.org/10.3390/ijgi10120815
Chicago/Turabian StyleHologa, Rafael, and Rüdiger Glaser. 2021. "The Societal Echo of Severe Weather Events: Ambient Geospatial Information (AGI) on a Storm Event" ISPRS International Journal of Geo-Information 10, no. 12: 815. https://doi.org/10.3390/ijgi10120815
APA StyleHologa, R., & Glaser, R. (2021). The Societal Echo of Severe Weather Events: Ambient Geospatial Information (AGI) on a Storm Event. ISPRS International Journal of Geo-Information, 10(12), 815. https://doi.org/10.3390/ijgi10120815