
Optimization-Based Reference Generator for Nonlinear Model Predictive Control of Legged Robots


Abstract
1. Introduction
1.1. Related Work
1.2. Proposed Approach and Contribution
- the presentation of a novel reference generator that drives the robot to accomplish a task (optionally in a user-defined time interval), taking into account the underactuation of statically unstable gaits, like the trot. Footholds are heuristically computed to be coherent with the CoM motion, and optimized GRFs are obtained in order to follow those trajectories. The formulation is lightweight enough to maintain the replanning frequency of 25 of the NMPC;
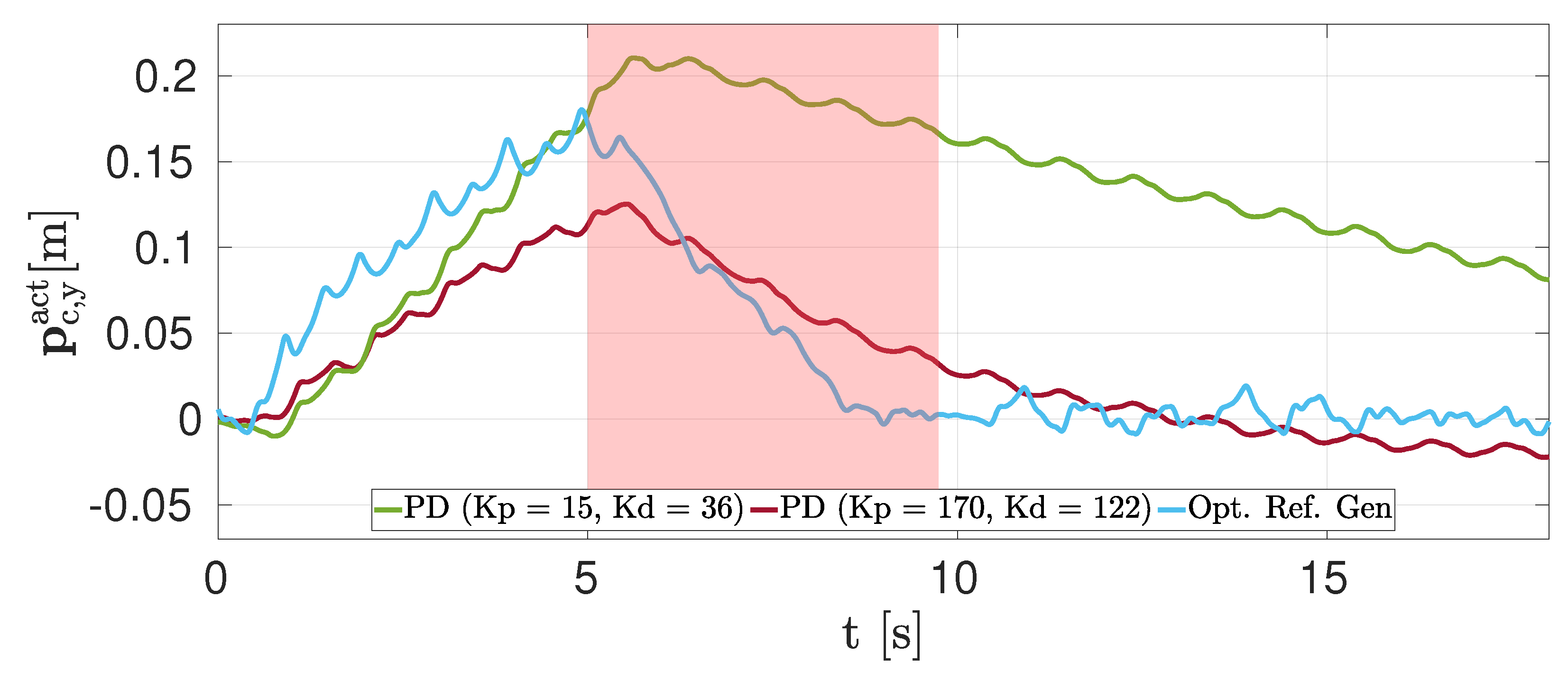
- simulations and experiments to demonstrate the effectiveness of the proposed approach in three different scenarios: (a) straight motion, (b) fixed lateral goal, and (c) recovery after a push. We also compared in simulation our algorithm with a state-of-the-art approach (NMPC + PD action) for the scenario (c); and
- as an additional minor contribution, we demonstrate the generality of the approach, showing it was able to deal with different dynamic gaits, i.e., trot and pace.
1.3. Outline
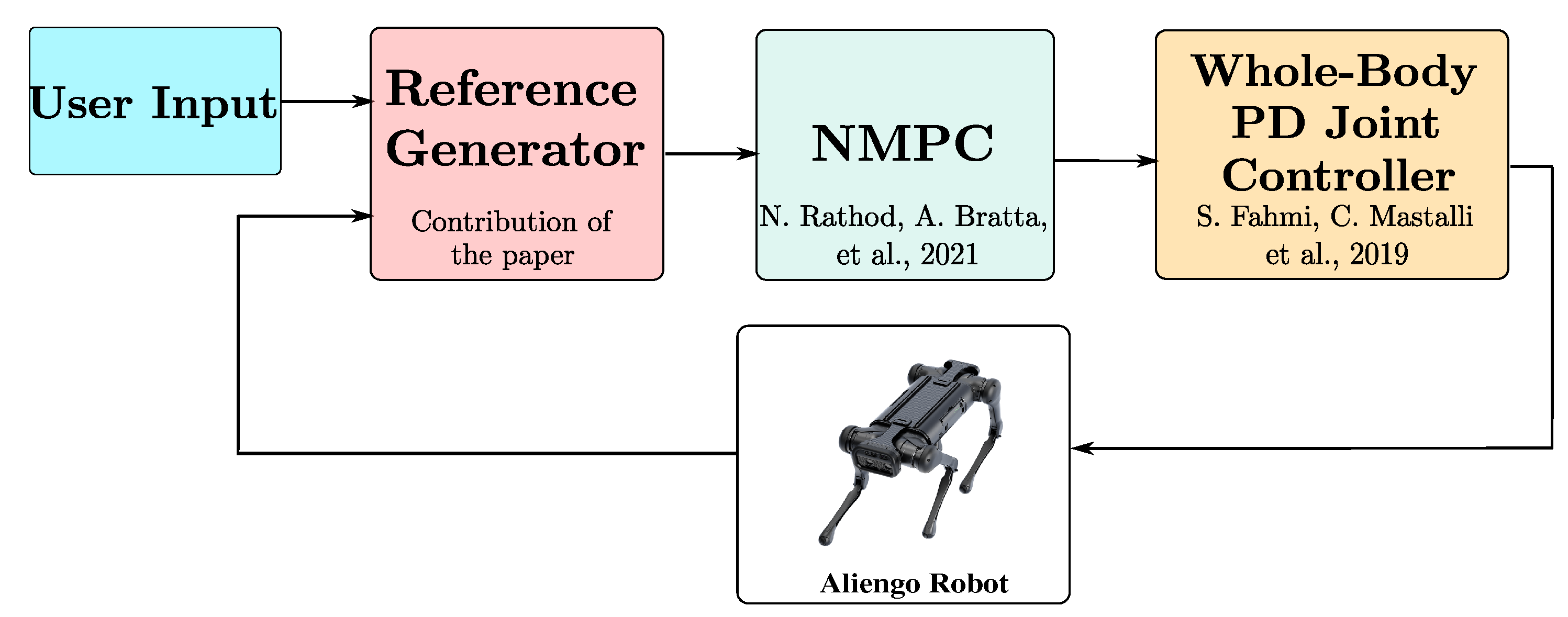
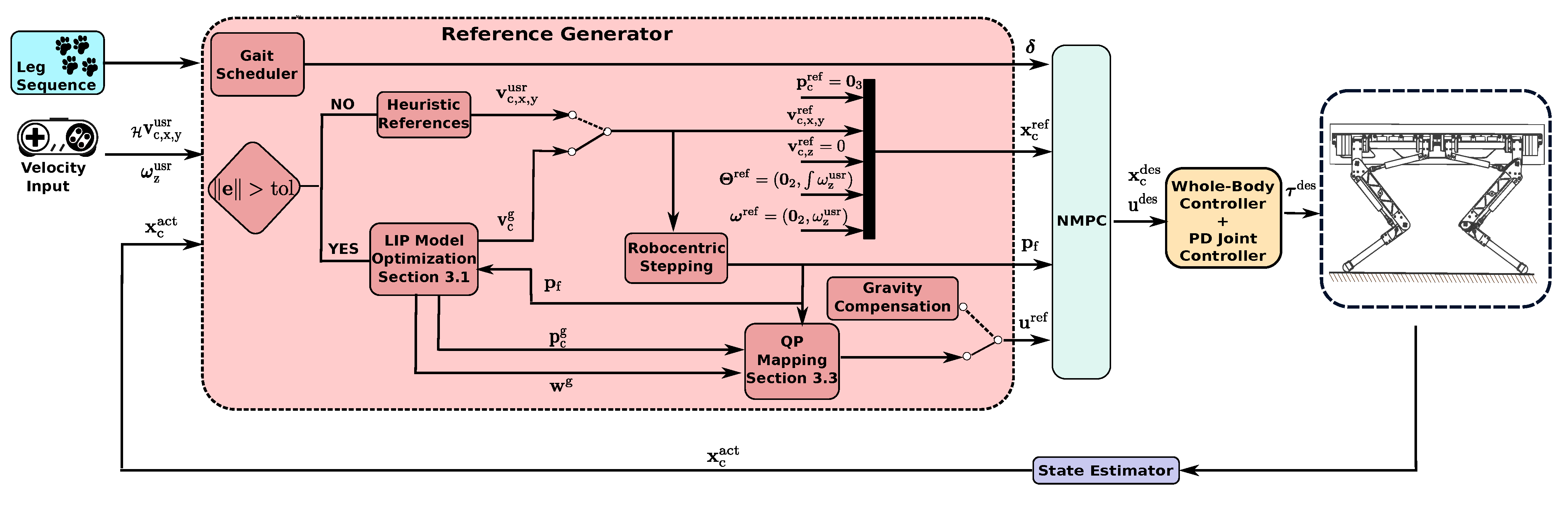
2. Locomotion Framework Description
2.1. Goal Setting and Status of the Reference Generator
| Algorithm 1 Reference generator |
|
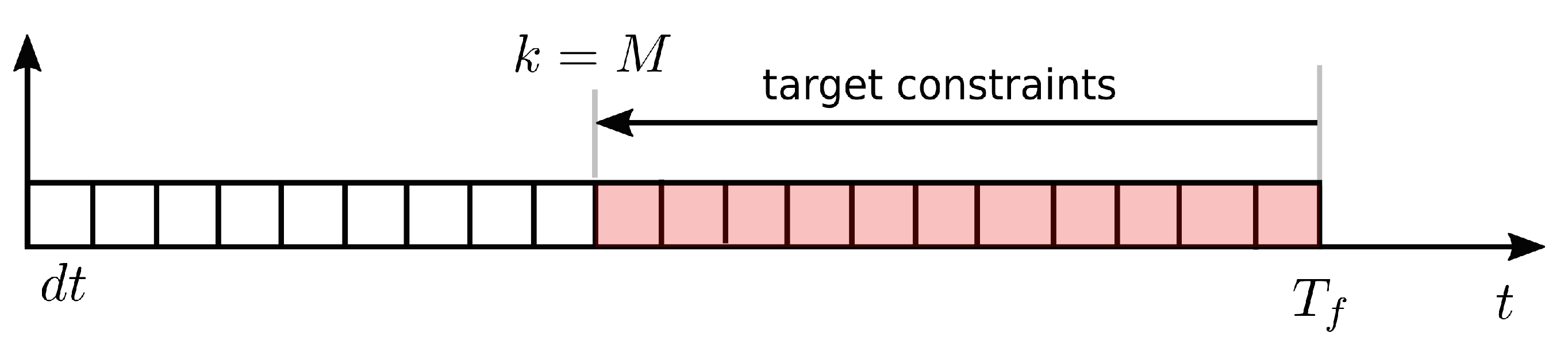
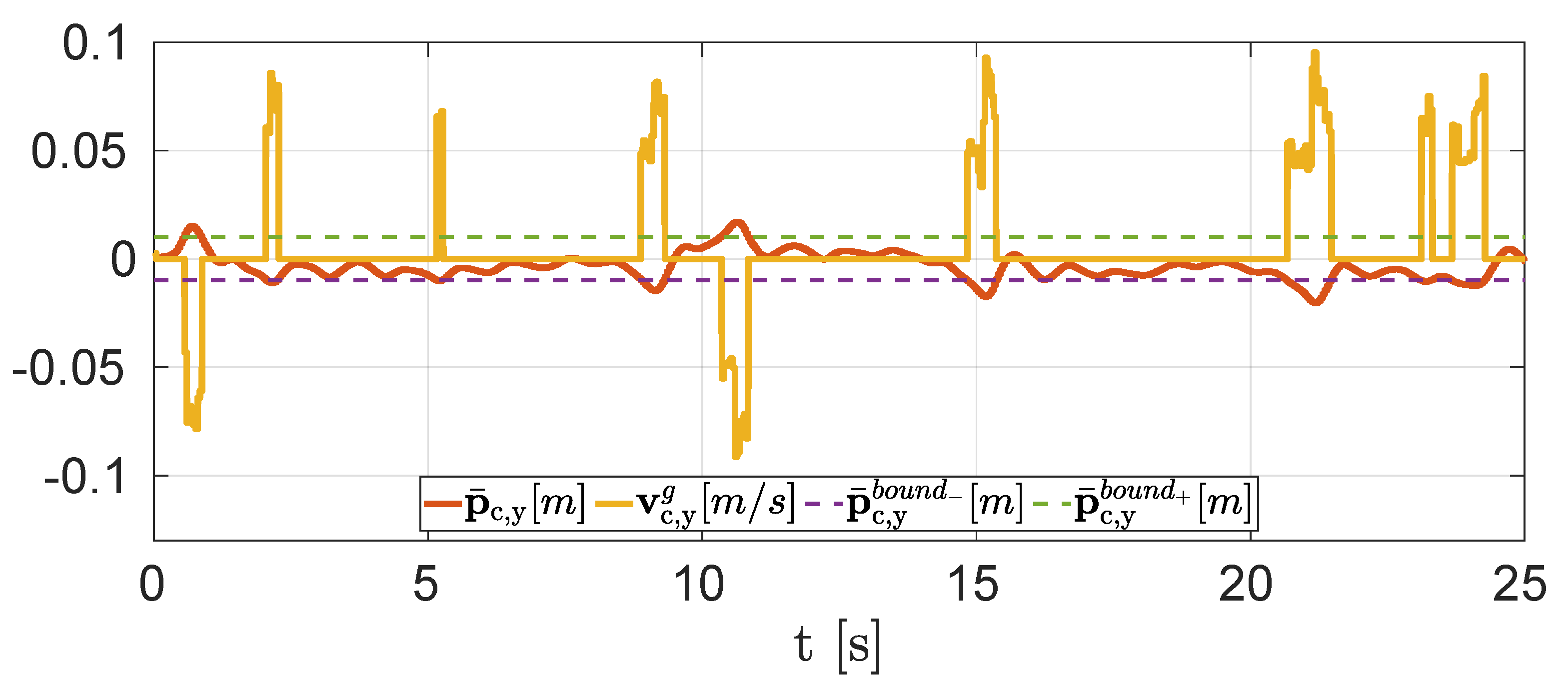
2.2. Formal Guarantees on Response Time
3. Optimized Reference Generator
3.1. LIP Model Optimization
3.2. QP Mapping
4. Simulation and Experimental Results
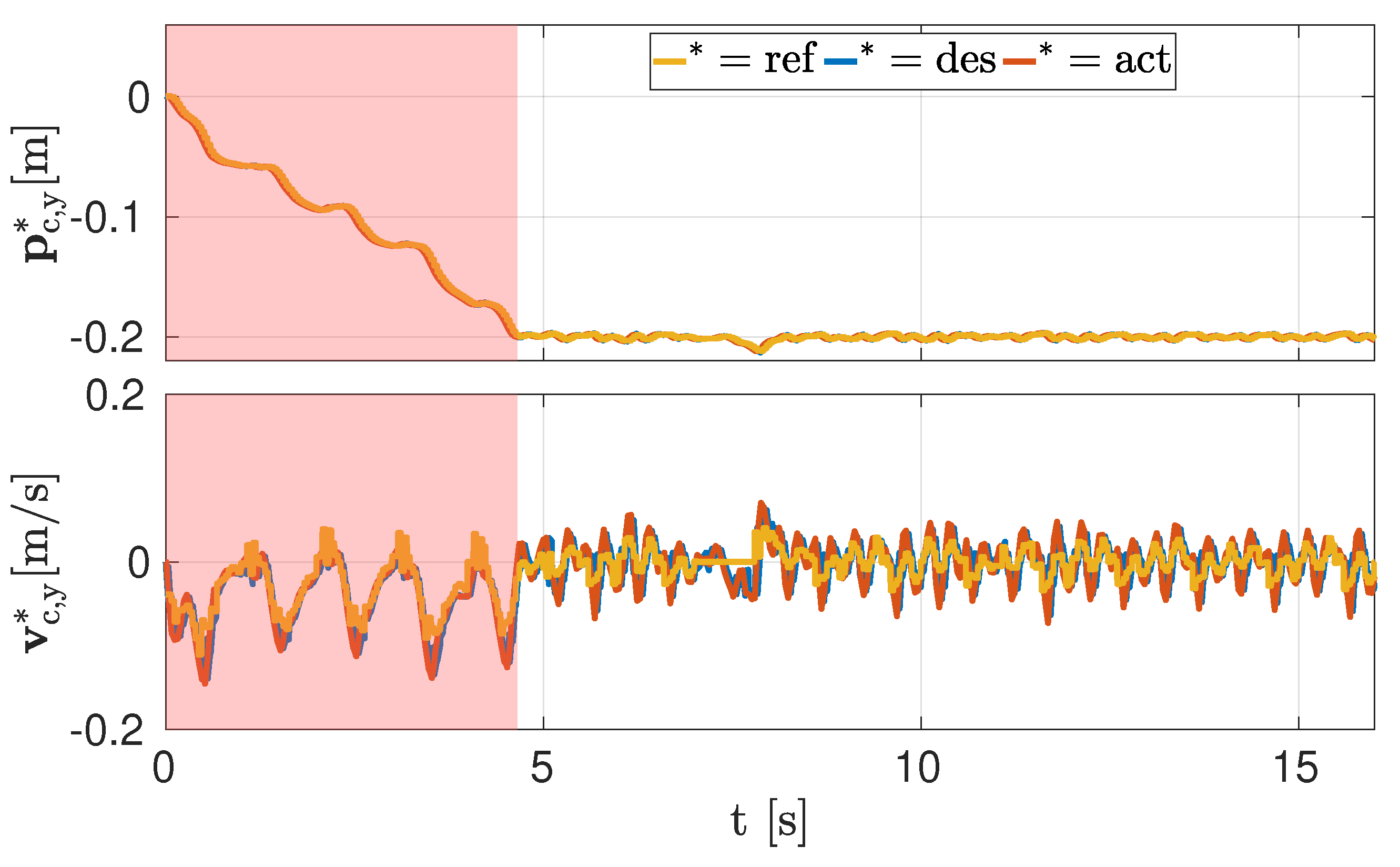
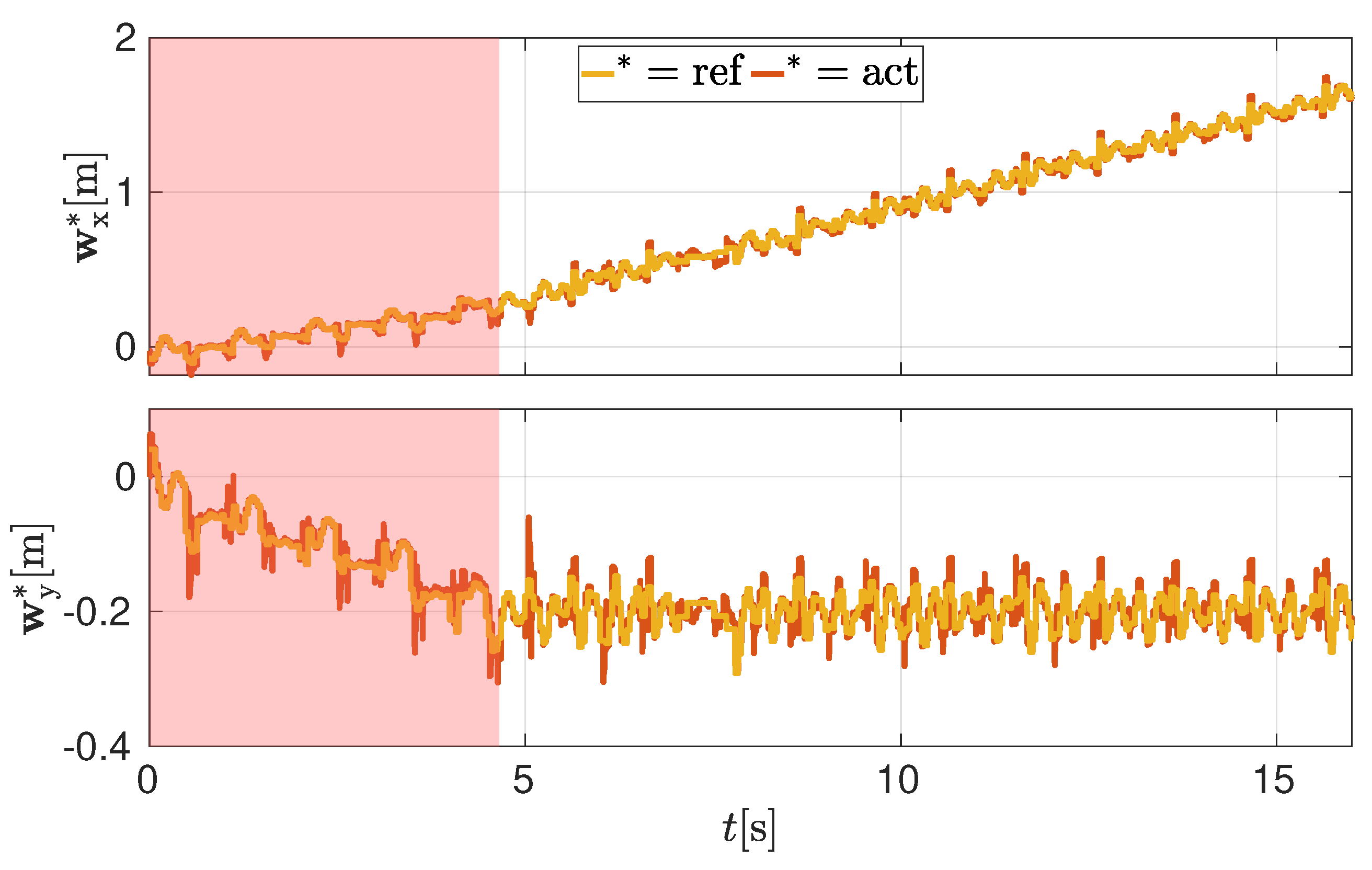
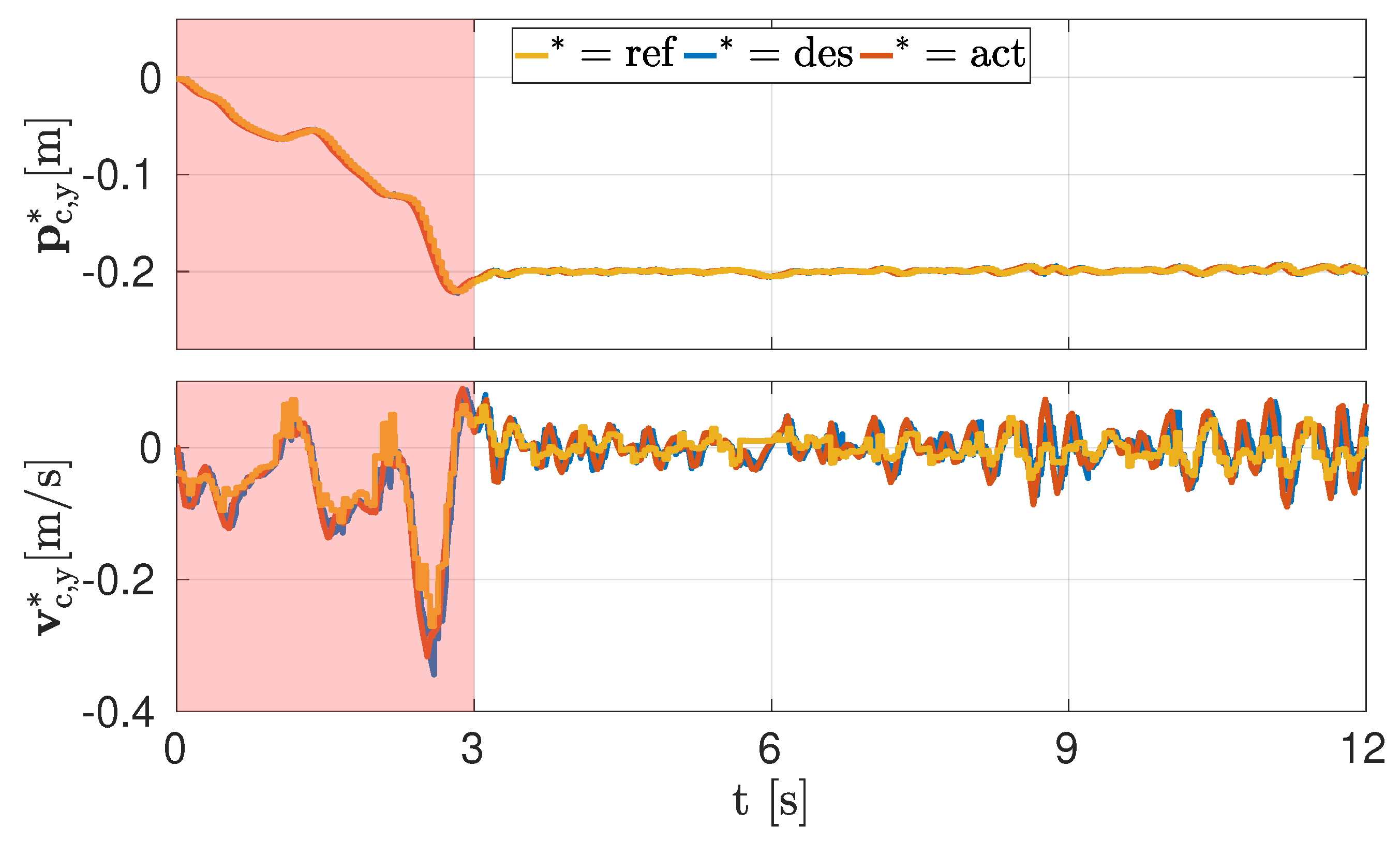
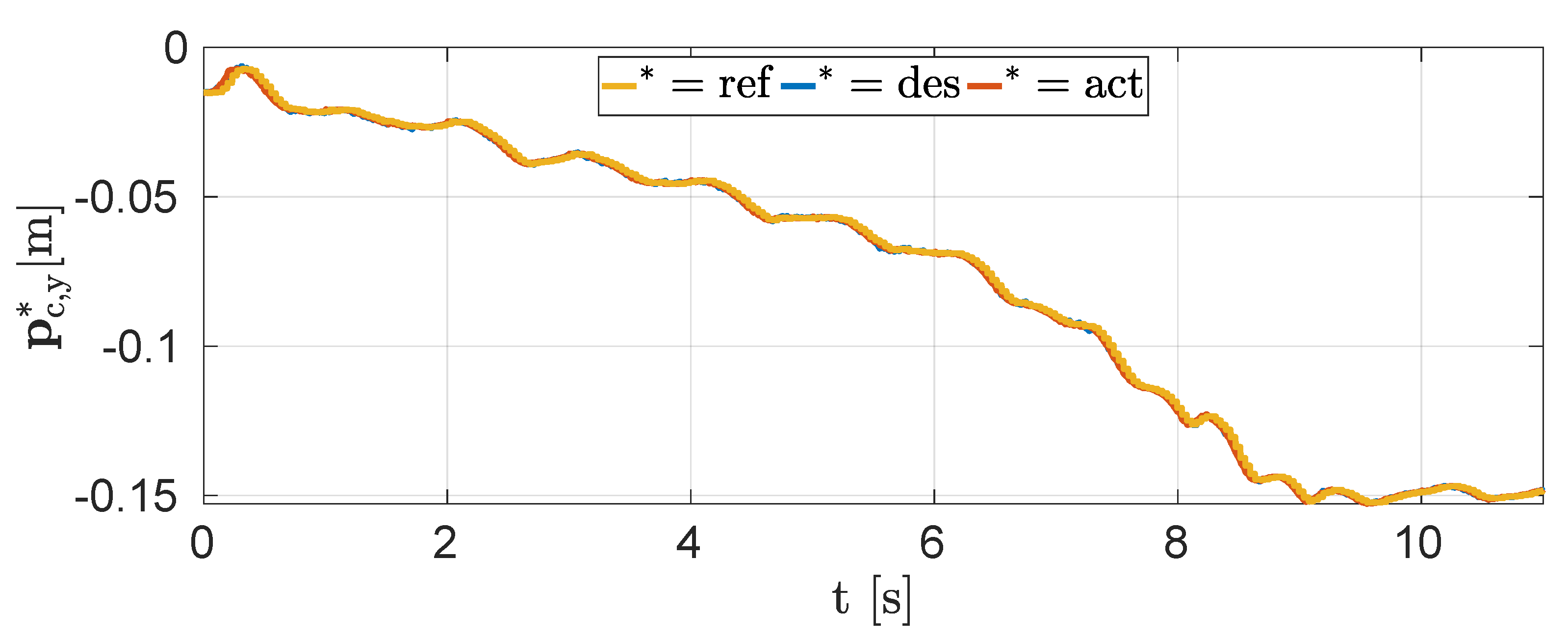
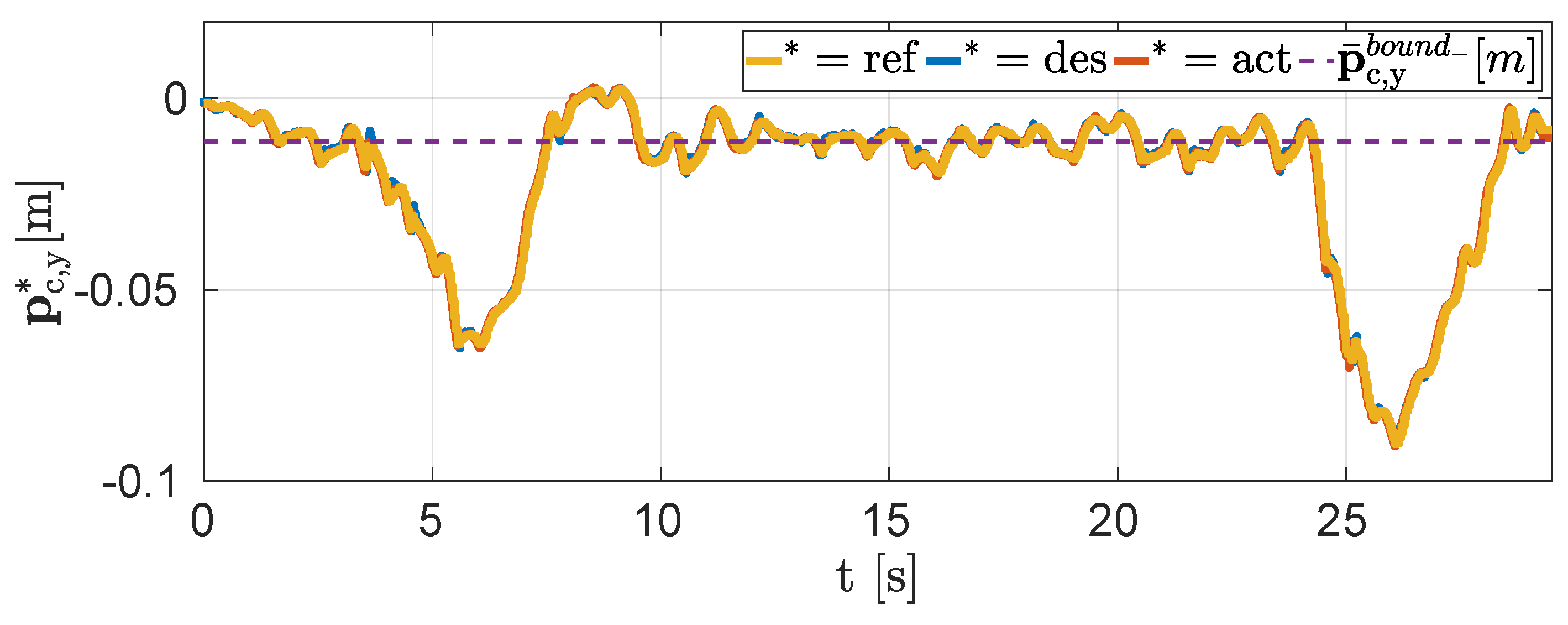
4.1. Simulations
4.2. Experiments
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Notation
| NMPC horizon. | |
| Reference horizon. | |
| Sequence of gait status. | |
| Footholds sequence. | |
| State of the optimized reference generator. | |
| X-Y COM reference position at time k. | |
| X-Y COM reference velocity at time k. | |
| ZMP position at time k. | |
| slack variables at time k. | |
| GRFs computed by the QP Mapping. | |
| Predicted GRFs by the NMPC. | |
| Predicted states by the NMPC. | |
| Actual robot state. | |
| Average X-Y COM position. |
References
- Raibert, M.H.; Tello, E.R. Legged Robots That Balance. IEEE Expert 1986, 1, 89. [Google Scholar] [CrossRef]
- Winkler, A.W.; Bellicoso, C.D.; Hutter, M.; Buchli, J. Gait and Trajectory Optimization for Legged Systems Through Phase-Based End-Effector Parameterization. IEEE Robot. Autom. Lett. (RA-L) 2018, 3, 1560–1567. [Google Scholar] [CrossRef]
- Bratta, A.; Orsolino, R.; Focchi, M.; Barasuol, V.; Muscolo, G.G.; Semini, C. On the Hardware Feasibility of Nonlinear Trajectory Optimization for Legged Locomotion based on a Simplified Dynamics. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–1 August 2020; pp. 1417–1423. [Google Scholar] [CrossRef]
- Li, H.; Wensing, P.M. Hybrid Systems Differential Dynamic Programming for Whole-Body Motion Planning of Legged Robots. IEEE Robot. Autom. Lett. (RA-L) 2020, 5. [Google Scholar] [CrossRef]
- Rathod, N.; Bratta, A.; Focchi, M.; Zanon, M.; Villarreal, O.; Semini, C.; Bemporad, A. Model Predictive Control with Environment Adaptation for Legged Locomotion. IEEE Access 2021, 9, 145710–145727. [Google Scholar] [CrossRef]
- Semini, C.; Tsagarakis, N.G.; Guglielmino, E.; Focchi, M.; Cannella, F.; Caldwell, D.G. Design of HyQ—A Hydraulically and Electrically Actuated Quadruped Robot. IMechE Part I J. Syst. Control. Eng. 2011, 225, 831–849. [Google Scholar] [CrossRef]
- Minniti, M.V.; Grandia, R.; Farshidian, F.; Hutter, M. Adaptive CLF-MPC With Application to Quadrupedal Robots. IEEE Robot. Autom. Lett. (RA-L) 2022, 7, 565–572. [Google Scholar] [CrossRef]
- Hong, S.; Kim, J.H.; Park, H.W. Real-Time Constrained Nonlinear Model Predictive Control on SO(3) for Dynamic Legged Locomotion. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 3982–3989. [Google Scholar] [CrossRef]
- Amatucci, L.; Kim, J.H.; Hwangbo, J.; Park, H.W. Monte Carlo Tree Search Gait Planner for Non-Gaited Legged System Control. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 4701–4707. [Google Scholar] [CrossRef]
- Meduri, A.; Shah, P.; Viereck, J.; Khadiv, M.; Havoutis, I.; Righetti, L. BiConMP: A Nonlinear Model Predictive Control Framework for Whole Body Motion Planning. IEEE Trans. Robot. (T-RO) 2022. [Google Scholar] [CrossRef]
- Di Carlo, J.; Wensing, P.M.; Katz, B.; Bledt, G.; Kim, S. Dynamic Locomotion in the MIT Cheetah 3 Through Convex Model-Predictive Control. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Grimminger, F.; Meduri, A.; Khadiv, M.; Viereck, J.; Wuthrich, M.; Naveau, M.; Berenz, V.; Heim, S.; Widmaier, F.; Flayols, T.; et al. An Open Torque-Controlled Modular Robot Architecture for Legged Locomotion Research. Robot. Autom. Lett. (RA-L) 2020, 5, 3650–3657. [Google Scholar] [CrossRef]
- Barasuol, V.; Buchli, J.; Semini, C.; Frigerio, M.; De Pieri, E.R.; Caldwell, D.G. A reactive controller framework for quadrupedal locomotion on challenging terrain. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; pp. 2554–2561. [Google Scholar] [CrossRef]
- Cebe, O.; Tiseo, C.; Xin, G.; Lin, H.C.; Smith, J.; Mistry, M.N. Online Dynamic Trajectory Optimization and Control for a Quadruped Robot. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 12773–12779. [Google Scholar] [CrossRef]
- Bouyarmane, K.; Kheddar, A. On Weight-Prioritized Multitask Control of Humanoid Robots. IEEE Trans. Autom. Control 2018, 63, 1632–1647. [Google Scholar] [CrossRef]
- Bledt, G.; Kim, S. Implementing Regularized Predictive Control for Simultaneous Real-Time Footstep and Ground Reaction Force Optimization. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 6316–6323. [Google Scholar] [CrossRef]
- Bjelonic, M.; Grandia, R.; Geilinger, M.; Harley, O.; Medeiros, V.S.; Pajovic, V.; Jelavic, E.; Coros, S.; Hutter, M. Offline motion libraries and online MPC for advanced mobility skills. Int. J. Robot. Res. 2022, 41, 903–924. [Google Scholar] [CrossRef]
- Bemporad, A. Reference governor for constrained nonlinear systems. IEEE Trans. Autom. Control 1998, 43, 415–419. [Google Scholar] [CrossRef]
- Kolmanovsky, I.; Garone, E.; Di Cairano, S. Reference and command governors: A tutorial on their theory and automotive applications. In Proceedings of the 2014 American Control Conference, Portland, OR, USA, 4–6 June 2014; pp. 226–241. [Google Scholar] [CrossRef]
- Garone, E.; Di Cairano, S.; Kolmanovsky, I. Reference and command governors for systems with constraints: A survey on theory and applications. Automatica 2017, 75, 306–328. [Google Scholar] [CrossRef]
- Kajita, S.; Kanehiro, F.; Kaneko, K.; Yokoi, K.; Hirukawa, H. The 3D linear inverted pendulum mode: A simple modeling for a biped walking pattern generation. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 239–246. [Google Scholar] [CrossRef]
- Orin, D.E.; Goswami, A.; Lee, S.H. Centroidal dynamics of a humanoid robot. Auton. Robot. 2013, 35, 161–176. [Google Scholar] [CrossRef]
- Mastalli, C.; Merkt, W.; Xin, G.; Shim, J.; Mistry, M.; Havoutis, I.; Vijayakumar, S. Agile Maneuvers in Legged Robots: A Predictive Control Approach. arXiv 2022, arXiv:2203.07554. [Google Scholar]
- Fahmi, S.; Mastalli, C.; Focchi, M.; Semini, C. Passive Whole-Body Control for Quadruped Robots: Experimental Validation Over Challenging Terrain. IEEE Robot. Autom. Lett. (RA-L) 2019, 4, 2553–2560. [Google Scholar] [CrossRef]
- Unitree Robotics. Available online: https://www.unitree.com/en/aliengo/ (accessed on 22 November 2022).
- Focchi, M.; Orsolino, R.; Camurri, M.; Barasuol, V.; Mastalli, C.; Caldwell, D.G.; Semini, C. Heuristic Planning for Rough Terrain Locomotion in Presence of External Disturbances and Variable Perception Quality. In Advances in Robotics Research: From Lab to Market; Springer Tracts in Advanced Robotics Series; Springer: New York, NY, USA, 2020; pp. 165–209. [Google Scholar] [CrossRef]
- Nobili, S.; Camurri, M.; Barasuol, V.; Focchi, M.; Caldwell, D.G.; Semini, C.; Fallon, M. Heterogeneous Sensor Fusion for Accurate State Estimation of Dynamic Legged Robots. In Proceedings of the Robotics: Science and Systems, Cambridge, MA, USA, 12–16 July 2017. [Google Scholar] [CrossRef]
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Nowicki, M.; Belter, D.; Kostusiak, A.; Cížek, P.; Faigl, J.; Skrzypczyński, P. An experimental study on feature-based SLAM for multi-legged robots with RGB-D sensors. Ind. Robot. 2017, 44, 428–441. [Google Scholar] [CrossRef]
- Hult, R.; Zanon, M.; Gros, S.; Falcone, P. Optimal Coordination of Automated Vehicles at Intersections: Theory and Experiments. IEEE Trans. Control. Syst. Technol. 2019, 27, 2510–2525. [Google Scholar] [CrossRef]
- Chignoli, M.; Wensing, P.M. Variational-Based Optimal Control of Underactuated Balancing for Dynamic Quadrupeds. IEEE Access 2020, 8, 49785–49797. [Google Scholar] [CrossRef]
- Harada, K.; Kajita, S.; Kaneko, K.; Hirukawa, H. ZMP analysis for arm/leg coordination. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 27 October–1 November 2003; pp. 75–81. [Google Scholar] [CrossRef]
- Vukobratovic, M.; Borovac, B. Zero-Moment-Point—Thirty five years of its life. Int. J. Hum. Robot. 2004, 01, 157–173. [Google Scholar] [CrossRef]
- Bellicoso, C.D.; Jenelten, F.; Gehring, C.; Hutter, M. Dynamic Locomotion Through Online Nonlinear Motion Optimization for Quadrupedal Robots. IEEE Robot. Autom. Lett. (RA-L) 2018, 3, 2261–2268. [Google Scholar] [CrossRef]
- Frison, G.; Diehl, M. HPIPM: A high-performance quadratic programming framework for model predictive control. IFAC-PapersOnLine 2020, 53, 6563–6569. [Google Scholar] [CrossRef]
- Verschueren, R.; Frison, G.; Kouzoupis, D.; van Duijkeren, N.; Zanelli, A.; Novoselnik, B.; Frey, J.; Albin, T.; Quirynen, R.; Diehl, M. Acados—A modular open-source framework for fast embedded optimal control. Math. Prog. Comp. 2021. [Google Scholar] [CrossRef]
- Guennebaud, G.; Furfaro, A.; Gaspero, L.D. Available online: https://github.com/fx74/uQuadProg (accessed on 22 November 2022).
- Video of the Experiments. Available online: https://www.youtube.com/watch?v=Jp0D8_AKiIY (accessed on 22 November 2022).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cost | Weight | Value |
|---|---|---|
| Velocities LIP | ) | |
| ZMP | ||
| Slack | ||
| Forces QP mapping | ||
| Angular Momentum Rate |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bratta, A.; Focchi, M.; Rathod, N.; Semini, C. Optimization-Based Reference Generator for Nonlinear Model Predictive Control of Legged Robots. Robotics 2023, 12, 6. https://doi.org/10.3390/robotics12010006
Bratta A, Focchi M, Rathod N, Semini C. Optimization-Based Reference Generator for Nonlinear Model Predictive Control of Legged Robots. Robotics. 2023; 12(1):6. https://doi.org/10.3390/robotics12010006
Chicago/Turabian StyleBratta, Angelo, Michele Focchi, Niraj Rathod, and Claudio Semini. 2023. "Optimization-Based Reference Generator for Nonlinear Model Predictive Control of Legged Robots" Robotics 12, no. 1: 6. https://doi.org/10.3390/robotics12010006
APA StyleBratta, A., Focchi, M., Rathod, N., & Semini, C. (2023). Optimization-Based Reference Generator for Nonlinear Model Predictive Control of Legged Robots. Robotics, 12(1), 6. https://doi.org/10.3390/robotics12010006