1. Introduction
Facial attributes represent intuitive semantic features such as “male”, “female”, “person with eyeglasses” and “smiling” that describe the biological identity or expression of a person. Extensive research has been conducted on the biological identity of human faces in the field of computer vision, from face identification and detection [
1,
2,
3,
4] to face-attribute modification [
5,
6,
7]. These approaches were successful based on three factors: (i) access to numerous publicly available training data with labels, (ii) the high computational capabilities of GPUs, and (iii) access to open-source libraries. The availability of the aforementioned resources made it possible for researchers to perform a large amount of work in the fields of face identification, detection, and attribute modification. The prominent facial-attribute modification task is, however, more challenging as compared to those of face recognition and detection, wherein a careful description of the semantic aspects of the face is required while modifying the required attributes, in addition to keeping the face identity intact. For example, if we want to modify a specific attribute, such as hair color, we need to have semantic information about the hair and modify only that part of the image without changing any facial details.
Extensive studies have been conducted on facial attribute modification and image-to-image translation in computer graphics in terms of various applications such as color modification [
8], content modification [
9], image wrapping [
10,
11], image translation [
12,
13,
14,
15,
16,
17], and interpretation [
18]. The image editing problem has been handled using two types of approaches: example-based [
19,
20,
21] and model-based approaches [
11,
22,
23]. In the example-based approach, the required attribute is searched for in the given reference image and transferred to the target image. This makes the image editing dependent on the available reference image in many ways [
19,
20,
21]. However, the reference image must be of the same person with an appropriate face alignment and the same lighting conditions. In the model-based approach, the model of the required face is first built and the image is then modified accordingly [
11,
22,
23]. Although these approaches have proven to be successful in the modification of particular attributes, they are task-specific, and thus, it is impossible to apply them to arbitrary attribute-modification problems.
Several face-attribute modification approaches [
6,
24] and distortion-removal approaches for real images [
24] have been developed based on recent developments in deep neural networks, such as generative adversarial networks (GANs) [
25] and variational autoencoders (VAEs) [
26]. Both GANs and VAEs are powerful models and are capable of generating images. GANs generate more realistic images as compared to VAEs. However, the GAN cannot encode images as it uses random noise as an input. In contrast, the VAE is capable of encoding the image to its corresponding latent representation although its generated image is blurry as compared to that of the GAN. A combination of the GAN and autoencoder makes a powerful tool for image-attribute editing. In Invertable Conditional GAN (IcGAN) [
27] and Conditional GAN (cGAN) [
28], the GAN and autoencoder are combined for editing the attributes of an image. They modify the latent representation to reflect the expected attribute and then decode the modified image. The object transfiguration is learned by GeneGAN [
5] from two unpaired sets of images: one set of images with specific attributes and the other without those attributes. The only constraint faced here is that the objects are located at approximately the same place. For example, the training data can comprise one set of reference images of faces with eyeglasses and another set of images of faces without eyeglasses, where both sets are spatially aligned using face landmarks. DNA-GAN [
29] shares similar traits with GeneGAN and provides “crossbreed” images by swapping the latent representation of the corresponding attributes between the given pair of images. Hence, the DNA-GAN can be considered as an extension of the GeneGAN. These methods have been proved to be useful in image editing tasks, but they require different models for different attributes, which is not practical in real-world applications owing to the corresponding time complexity. The proposed work is based on the attribute-dependent approach, wherein an attribute classification constraint is applied to the generated images. Attribute GAN (AttGAN) [
6] can change the required attribute while keeping the other details unchanged. The modified attributes, however, are not prominent, although the face identity is well preserved. In contrast, the proposed approach is focused on the prominent modification of the attributes while keeping the rest of the attributes unchanged. The proposed approach is different from the AttGAN because it has an additional discriminator that we call the refined discriminator. The refined discriminator takes the modified image from the generator as an input and helps the generator to refine it further to obtain a better output. Further explanation of the refined discriminator is presented in
Section 2. RelGAN in [
7] can effectively modify attributes simultaneously with an additional capability of interpolation. They obtain the relative attributes by determining the difference between the given and predefined target attributes. In contrast, the proposed approach does not consider the predefined attributes but uses the already-available target attributes with a further refinement, which is provided by the refined discriminator. Recently, a facial attribute modification network (FAMN) was proposed in [
30], which has an architecture style that is common with that of the AttGAN and the proposed approach. The FAMN has two generators and two discriminators, and both the generators share the same encoder part. The decoder part of both the generators takes the latent representation as its input along with the binary and mean attribute vectors, whereas each generator has its own discriminator. In contrast, the proposed approach consists of a single generator and two discriminators, where the role of the second discriminator is to refine the modified output further and, hence, to generate more realistic results with a lower computational complexity. In [
31], the authors proposed the Multimodal Unsupervised Image-to-Image Translation (MUNIT) framework, where they decomposed the image representation into a content code and a style code and then recombined the content code with a random style code sampled from the style space of the target domain to generate different style output. The cycle-consistent adversarial networks (CycleGANs) [
32] translate an input image from one domain to another domain in an unsupervised manner, where the corresponding target pair is not given. Both MUNIT and CycleGAN can effectively translate images from one domain to another domain. However, their focus is on the style of the whole image rather than a specific attribute. Considering the time efficiency, because the proposed network has a single generator and two discriminators while the AttGAN has a single generator and a single discriminator, the number of parameters in the proposed network are more than those of the AttGAN and thus the proposed network requires more training time than the AttGAN. However, the discriminator is only included in training as shown in
Figure 1 and does not affect the time complexity during the testing. The FAMN, on the other hand, has two discriminators and an extra decoder whereas the proposed approach does not have the extra decoder. Thus, the number of parameters in the proposed network are less than those of the FAMN and the proposed network requires less training time than the FAMN. The testing time for the AttGAN, the FAMN, and the proposed approach is same. The contribution of this work can be summarized as follows:
A novel network architecture that utilizes the latent representation of the given and modified outputs along with the given and required attributes is proposed to generate prominent modification in the given input.
The tuning and refining discriminators ensure the prominent modifications by guiding the generators.
A unified approach is proposed to effectively change the appearance of faces while preserving the identity.
Multiple experiments are carried out to validate the proposed approach.
2. Proposed Approach
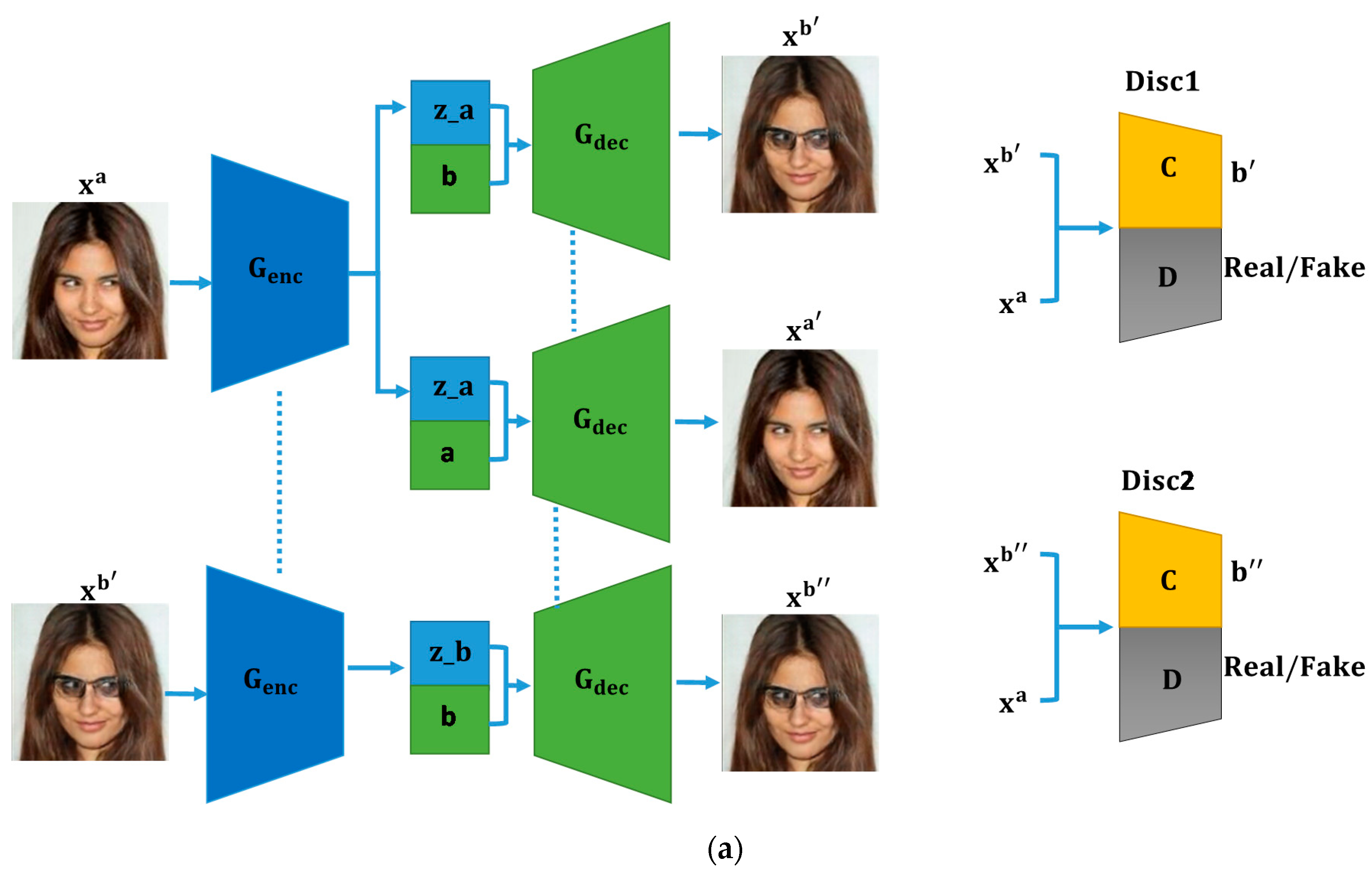
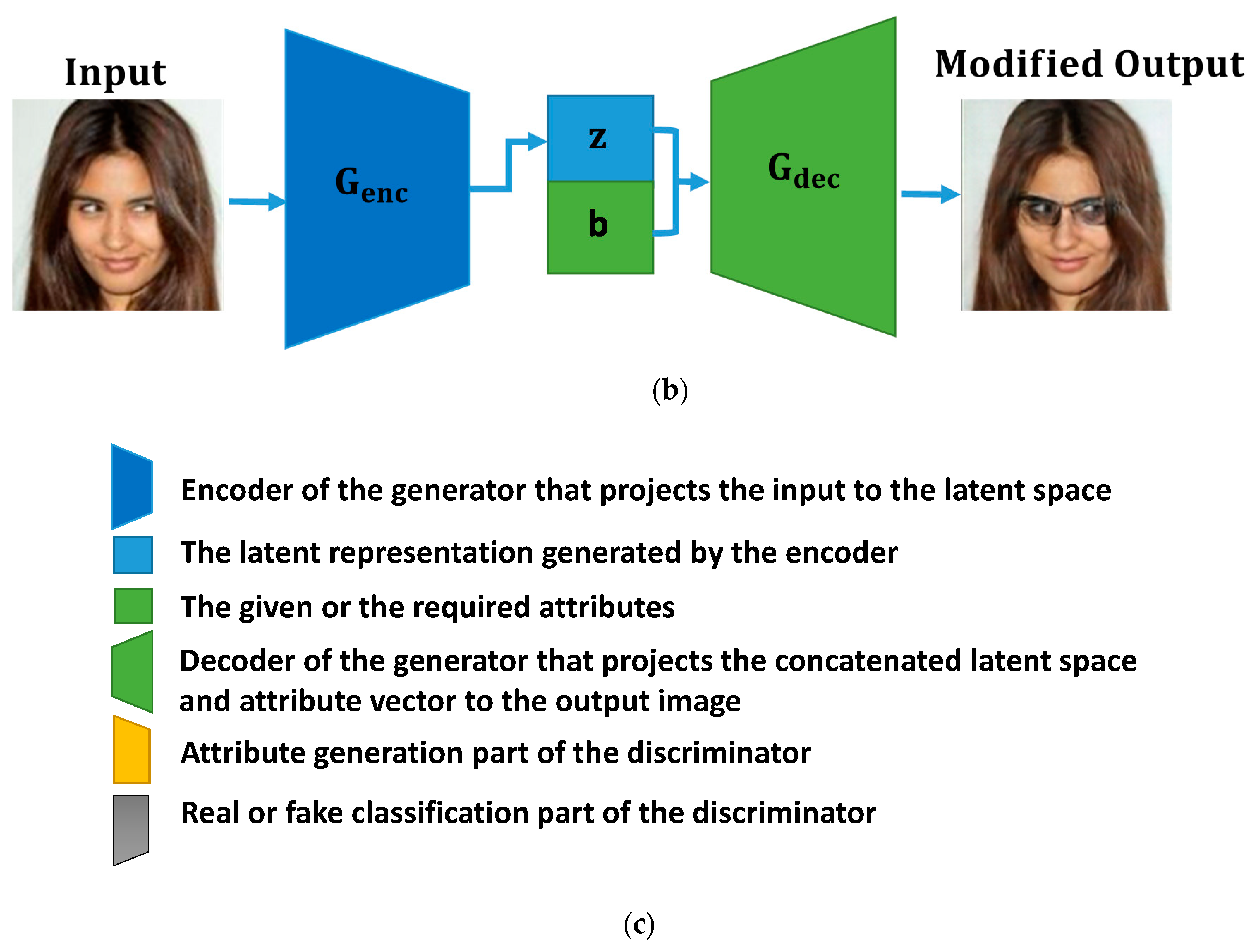
This section introduces the fine-tuned attribute-modification approach for editing facial attributes. The facial attributes are represented by a binary vector, where “1” represents the presence of a particular attribute in the given face image and ”0” represents its absence. The configuration of the proposed FTAMN is presented in
Figure 1. The FTAMN consists of a single generator with an encoder
and a decoder
, and two discriminators
and
. The generator takes the input face image in two different steps. In the first step, the encoder part
of the generator takes the face image
that is required to be modified and projects it to the latent representation
. The decoder
then takes the pair of the latent representation
and given attribute vector
and generates the image
. Similarly, the latent representation
and required attribute vector
are decoded back to the modified image
using
. In the second step,
takes the generated image
as its input and projects it to its corresponding latent representation
. Next,
takes the pair of the latent representation
and the required attribute vector
and then generates the modified image
. In terms of the discriminators, the first discriminator
takes either the real image
or fake image
generated by
and maps it to the attribute vectors
or
along with real and fake classification labels. It thus guides the generator to generate the modified image. Similarly, the second discriminator
is used as a tuning discriminator that takes the real image
or fake image
generated by
and maps it to the corresponding attribute vectors
or
along with real and fake classification labels. It thus guides the generator to generate the required modified image with prominent attributes.
3. Training
The purpose of the proposed FTAMN is to modify multiple attributes simultaneously using the attribute information available in the input data. The generator takes the required image as an input, and we modify some of its contents by decoding a different combination of attributes. In this approach, we selected thirteen attributes that are required to be modified. These attributes include baldness, bangs, black hair, blond hair, brown hair, bushy eyebrows, eyeglasses, gender, mouth open/closed, mustache, no beard, pale skin, and young. For example, if black hair and a mustache are the desired attributes in the input testing sample, this approach will make the hair black and put a mustache on the face in the given image. During the training, the attributes of each image are concatenated in three configurations. In the first configuration, the original attributes are concatenated with the latent representation of the input image, and the combination of the attributes and latent representation are then decoded back to the original image using . The original attribute objective along with the GAN objective is used to train and . In the second configuration, the input attributes are first shuffled and then concatenated with the latent representation of the input image. Next, the concatenated pair is decoded back to the modified image using . In the third configuration, the generated modified image is first fed back to the encoder and is projected to its corresponding latent representation. The latent representation and the required attributes are concatenated. Next, the concatenated pair is decoded back to the modified image using . The attribute objective along with the reconstruction and the GAN objectives are used to tune the parameters of the generator of the network.
The detailed explanation of this process and stepwise training procedure are as follows. For a given face input image
, its attributes are defined as a vector
as follows.
In the first step, the encoder part
of the FTAMN takes
as its input and transforms it into its corresponding latent representation
as follows.
During the first configuration, the decoder
translates the latent representation
along with its attribute vector
to
as follows.
During the second configuration, the attribute vector
a is first modified to reflect the required attributes as follows.
where
is a function used for changing the elements of a binary vector. The decoder
then translates the latent representation
along with the required attribute vector
to the modified image
as follows.
During the third configuration, the latent representation
is first obtained as follows.
The decoder
then translates the latent representation
along with the required attribute vector
to the refined modified image
.
The GAN objective functions are defined for training the discriminators
and
as follows.
where
and
, respectively, are the GAN losses for training each of the discriminators.
and
represent the real outputs of the discriminators for the given original input that is required to be modified.
and
represent the fake outputs of the discriminators for the given modified face image generated by
. The attribute objective for preserving the remaining attributes of the face image is defined as follows.
where
represents the sigmoid cross-entropy loss for the given attributes,
represents the target attribute, and
represents the generated predicted attributes.
where
represents the sigmoid cross-entropy loss for the given attributes, and
represents the generated predicted attributes.
The overall objective for training the discriminator
is defined as follows.
where
represents the control parameter for the original attribute objective. The overall objective for training the discriminator
is defined as follows.
Similarly, the training objective functions for the generator in the first and second steps are defined as follows.
where
and
are the GAN losses for training the generator in the first and second steps, respectively.
where
and
represent the sigmoid cross-entropy losses for the modified attributes
, where
represents the target binary attributes.
and
represent the corresponding generated predicted attributes.
where
represents the absolute reconstruction objective, where the aim is to preserve the remaining attributes of the face image during the modification of the required attribute objectives.
represents the input face image, and
represents the image reconstructed with the intention of preserving the remaining features of the given face image.
is the control parameter for the reconstruction objective that preserves the face identity.
where
represents the absolute refinement objective, where the aim is to further refine the modification in the given image while considering the provided attributes.
represents the generated modified image in the first step, and
represents the generated modified image in the second step.
The overall training objective for the generator part of the network is expressed as follows.
where
represents the control parameter for the required attribute objective, and
represents the total loss of the generator.
4. Experiments
For training the FTAMN, we used the CelebA dataset [
33]. The CelebA is a large-scale face dataset comprising 202,599 face images. We divided the CelebA dataset into training and testing sets. The training set comprises 182,000 images, and the testing set comprises the remaining 20,599 images. After the training, we evaluated the network for its ability to modify the input images according to the required attributes. We analyzed the experimental results qualitatively and quantitatively by defining the structural similarity index (SSIM) from the reconstructed images and the modified images as shown in
Table 1. The proposed network was implemented by using TensorFlow 1.7, an open-source deep learning framework, on the GPU-based PC, which was comprised of an Intel(R) Core i9-9940X CPU, 132.0 GB RAM, and four NVIDIA GeForce RTX 2080 Ti graphics cards.
In the first experimental analysis, we evaluated the proposed approach in terms of the baldness of the given input image. If the given image is not bald, the proposed approach will inverse the bald attribute and generate a bald image. The comparison of the qualitative results of the proposed approach with those of the AttGAN [
6] and the FAMN [
30] in terms of baldness is presented in
Figure 2.
Figure 2a–c shows the results obtained using the proposed FTAMN, the AttGAN, and the FAMN, respectively. The green frame indicates the required successful modification, the blue frame indicates the successful modification with lost identity, and the red frame indicates the failure of the required attribute modifications. Considering the modified images of the AttGAN, we can observe that the generated images are smooth but their smoothness affects the quality of the modified image, as indicated by the red frames in
Figure 2b. In other words, the baldness effect is not distinct in the results of the AttGAN as compared to our results. In the results of the FAMN, we can observe that the generated images show prominent baldness but the identity of the face is affected as indicated by the blue frames in
Figure 2c. In contrast, the FTAMN translates the attributes in a prominent manner with considerable smoothness and retains the face identity as compared to the FAMN, as indicated by the green frames in
Figure 2a. This proves that, as compared to the AttGAN and the FAMN, the proposed FTAMN is more effective in translating the required attributes to the given input face images.
In the second analysis, we evaluated the proposed approach in terms of the mouth open/closed attribute, where the given input image with an open mouth is modified to obtain an output image with a closed mouth. The comparative analysis of the proposed approach with the AttGAN and the FAMN is presented in
Figure 3.
Figure 3a–c presents the results obtained using the proposed FTAMN, the AttGAN, and the FAMN, respectively. From this analysis, we can observe that the AttGAN translates the input images with an open mouth into the required output images with a closed mouth. However, the attribute modification is not prominent, as indicated by the red frames in
Figure 3b. In contrast, the FTAMN translates the required attribute in a prominent manner in the output images, as indicated by the green frames in
Figure 3a. The modification performance of the FTAMN is comparable with that of the FAMN, but the FTAMN preserves the face identity in the images better than the FAMN.
In the third analysis, we evaluated the proposed approach in terms of the bangs attribute, where the given input image without bangs is modified to an output image that comprises bangs. The comparative analysis of the proposed approach with the AttGAN and the FAMN in terms of the bangs attribute translation is presented in
Figure 4. From this analysis, we can observe that the bangs attribute effect is applied well to the given input images on using the proposed FTAMN, as shown in
Figure 4a. In
Figure 4a, the first and second columns, respectively, comprise the candidate input images and generated images with the required bangs effect.
Figure 4b shows the results obtained from the AttGAN, where the given input images in the first column are translated to the output images in the second column with the required modification. The bangs effect is not prominent in the translated images with this approach as compared to the proposed FTAMN, although the face identity is preserved well.
Figure 4c shows the results obtained with the FAMN, where the given input images in the first column are also translated to the output images in the second column with the required modification. The bangs effect is not prominent in the majority of the translated images of the FAMN as compared to the proposed FTAMN, especially in the red frame of
Figure 4c. Furthermore, the FTAMN preserves the face identity better than the FAMN, as indicated by the green frame in
Figure 4a.
In the fourth analysis, we evaluated the proposed approach in terms of the eyeglasses attribute, where the given input image without eyeglasses is modified into the output image with eyeglasses. The comparative analysis of the FTAMN with the AttGAN and the FAMN is presented in
Figure 5, where
Figure 5a–c presents the results of the FTAMN, the AttGAN, and the FAMN, respectively. As shown in the second columns of each subfigure in
Figure 5, the FTAMN translates the eyeglasses attribute in more prominent manner in the case of a majority of the images as compared to the AttGAN and the FAMN, as indicated by the green frames in
Figure 5a. Furthermore, the FTAMN preserves the face identity better than the FAMN, as indicated by the green frames in
Figure 5a.
In the fifth analysis, we evaluated the proposed approach in terms of the mustache attribute, where the given input image without a mustache is modified into the output image with a mustache irrespective of the gender. For example, if the given input image comprises no mustache, whether its face is male or female, we modify the input image to have a mustache. We performed a comparative analysis of the proposed approach with the AttGAN and the FAMN in terms of putting a mustache in the image, as presented in
Figure 6. We can observe that the mustache attribute effect is applied well to the given input images by the FTAMN, as shown in
Figure 6a. The first and second columns in
Figure 6a show the candidate input images and the generated images with the required mustache on the face.
Figure 6b,c presents the results obtained using the AttGAN and the FAMN, respectively, where the given input images in the first column are translated to the output images in the second column with the required modification. In the case of the AttGAN, the effect of the mustache attribute is not prominent in the translated images as compared to the FTAMN, although the face identity is preserved well, as indicated by the red frames in
Figure 6b. In the case of the FAMN, as compared to the FTAMN, although the effect of the mustache attribute is prominent, the identity of the face image is affected, as indicated by the blue frames in
Figure 6c.
In the final analysis, we performed a comparative qualitative analysis of the proposed FTAMN with the AttGAN and the FAMN for all of the thirteen attributes, as shown in
Figure 7.
Figure 7a–c shows the results obtained using the AttGAN, the FAMN, and the proposed FTAMN, respectively. The input images in the first column are the candidate samples that are required to be modified according to the required attributes. The second column shows the reconstructed results obtained using the AttGAN, the FAMN, and the FTAMN, and the remaining columns comprise the modified results with the various aforementioned attributes ranging from bald to young. These results reflect that the proposed FTAMN is capable of modifying multiple attributes more efficiently as compared to the AttGAN and the FAMN.
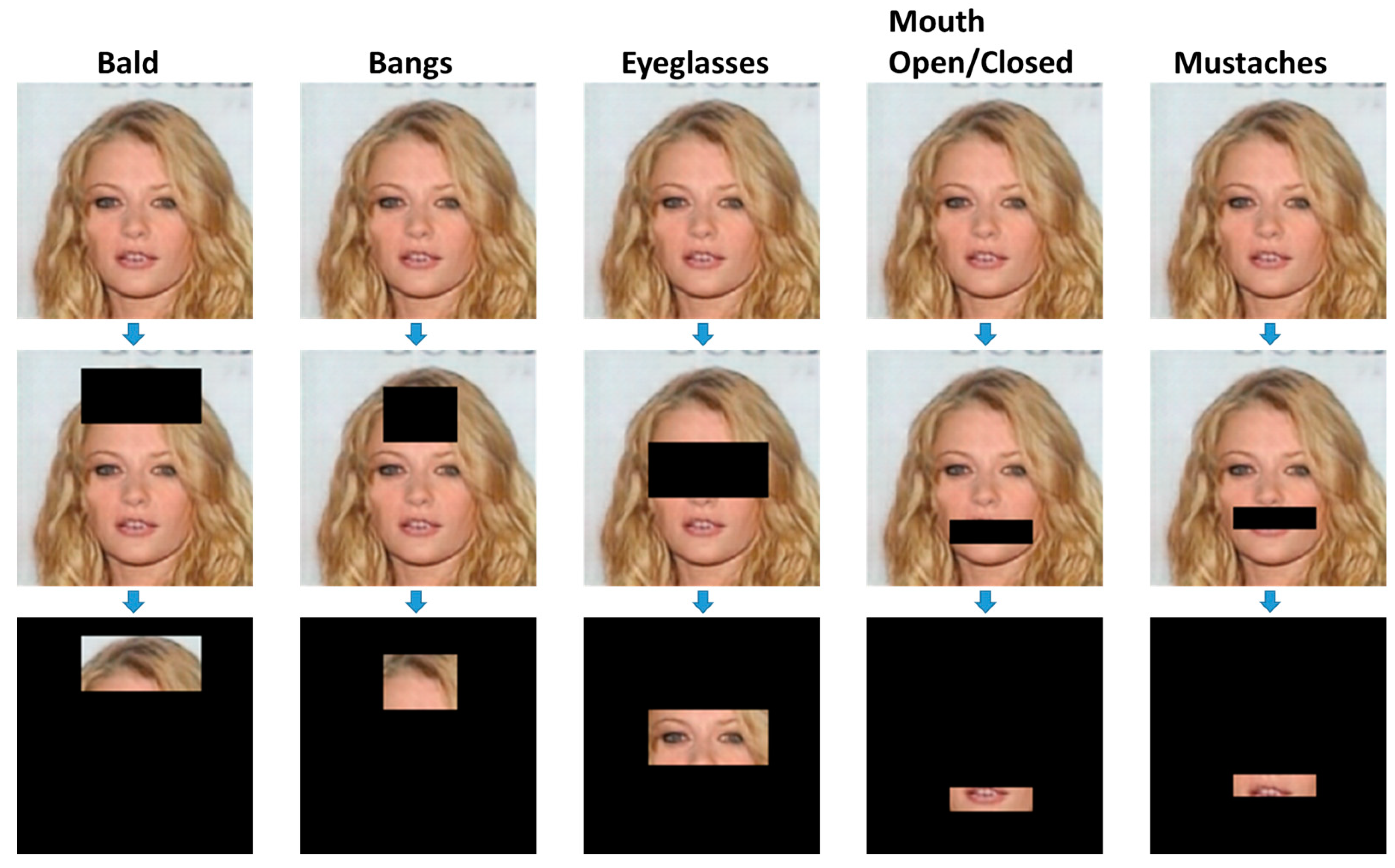
The qualitative results discussed above showed the effectiveness of the proposed network for realistically modifying the given input images to their corresponding required attributes, compared with the AttGAN and the FAMN approaches. However, for insight into the analysis of the proposed approach, we performed a quantitative analysis. We selected five attributes such as bald, mouth open/closed, bangs, eyeglasses, and mustache. First, we randomly selected the testing samples and then generated the reconstructed samples as well as the modified images using the proposed FTAMN, the FAMN and the AttGAN approaches. We analyzed the structure of the images generated by the proposed FTAMN, the FAMN and the AttGAN approaches with the SSIM. To perform specific attribute dependent analysis, we first located the required target attribute region in the input image and then cropped the attribute region for comparative analysis using the SSIM as shown in
Figure 8. The SSIM showed the structural similarity between the modified images and the corresponding reconstructed images. Under the rough estimation, the lower the SSIM was, the better the results were because we want prominent modification. The per-pixel and per-image SSIM results for the CelebA dataset are listed in
Table 1. The per-pixel and per-image SSIM values were lower for the proposed FTAMN than the FAMN and the AttGAN, showing that the proposed approach outperformed the FAMN and the AttGAN in terms of prominent attribute modification.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}