A Deep Reinforcement Learning-Based Power Resource Management for Fuel Cell Powered Data Centers


Abstract
:1. Introduction
- By jointly considering the applying of fuel cells and maximization of power resource use for data centers, we formulate this objective as a workload optimization problem and identify the key to achieving this target by mitigating the variation of energy consumption.
- We propose an effective use of the power resources approach by employing improved deep Q-learning methods. A real state experience pool is introduced in the DQN agent, aimed at reducing the number of redundant state calculations.
- We evaluate the performance of our approach through a simulation with real-world data center traces. Simulation results show that the proposed approach has good effectiveness and feasibility compared with state-of-the-art methods.
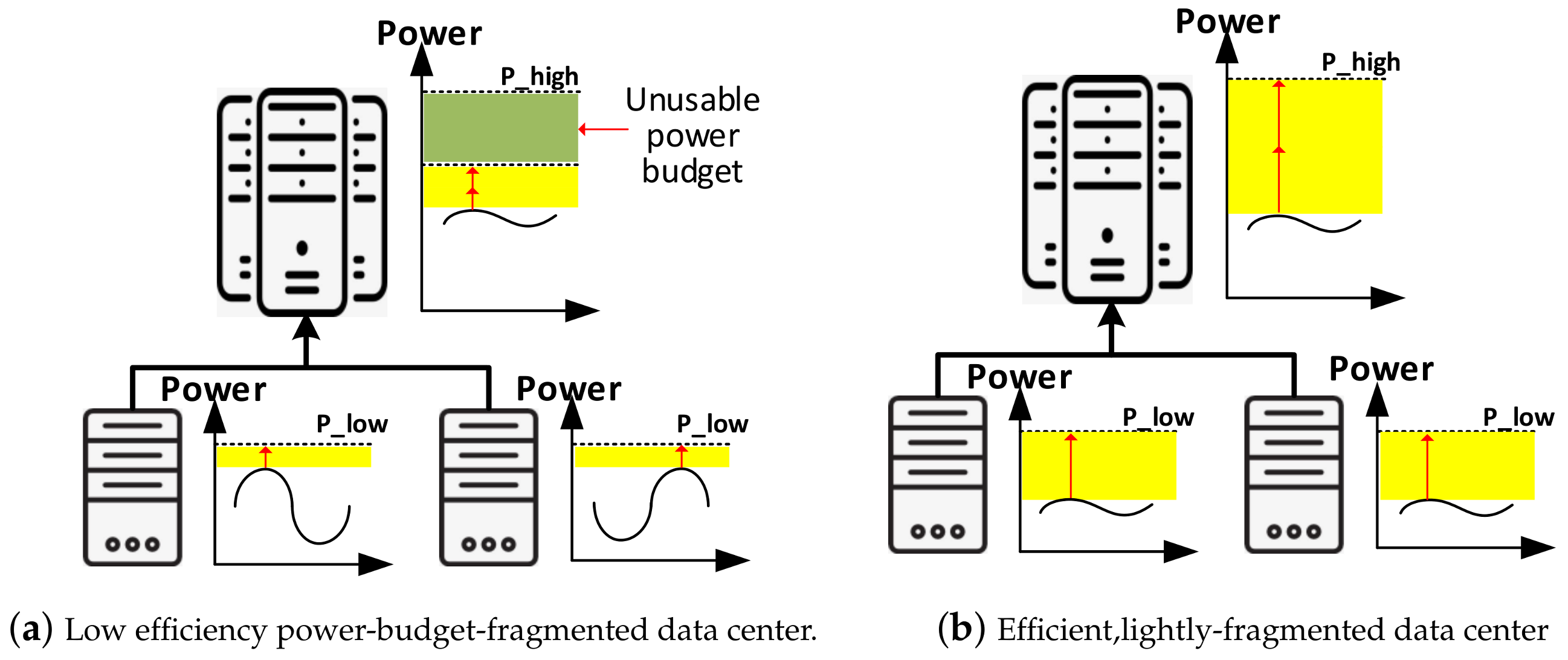
2. Motivation
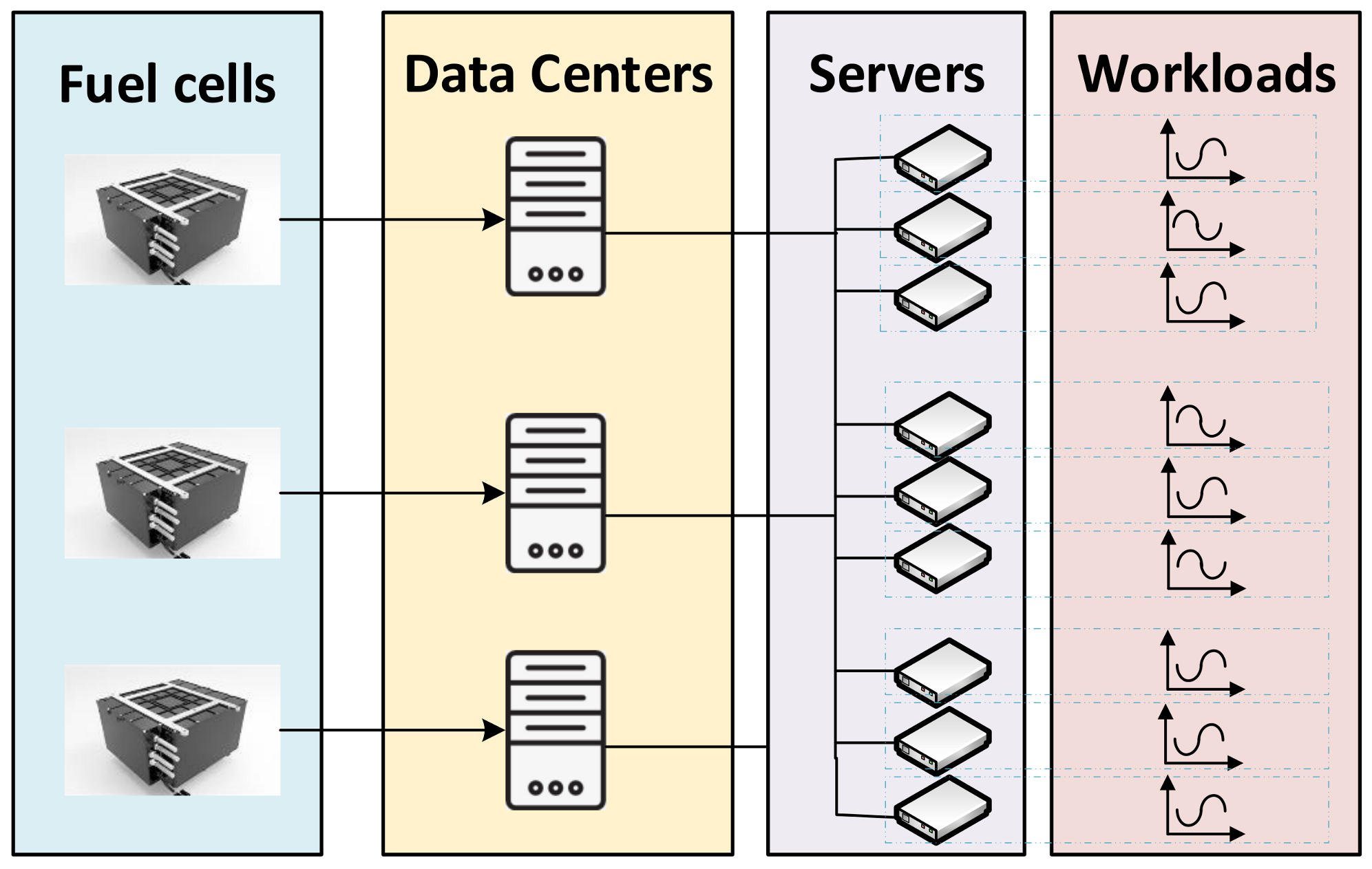
3. System Model
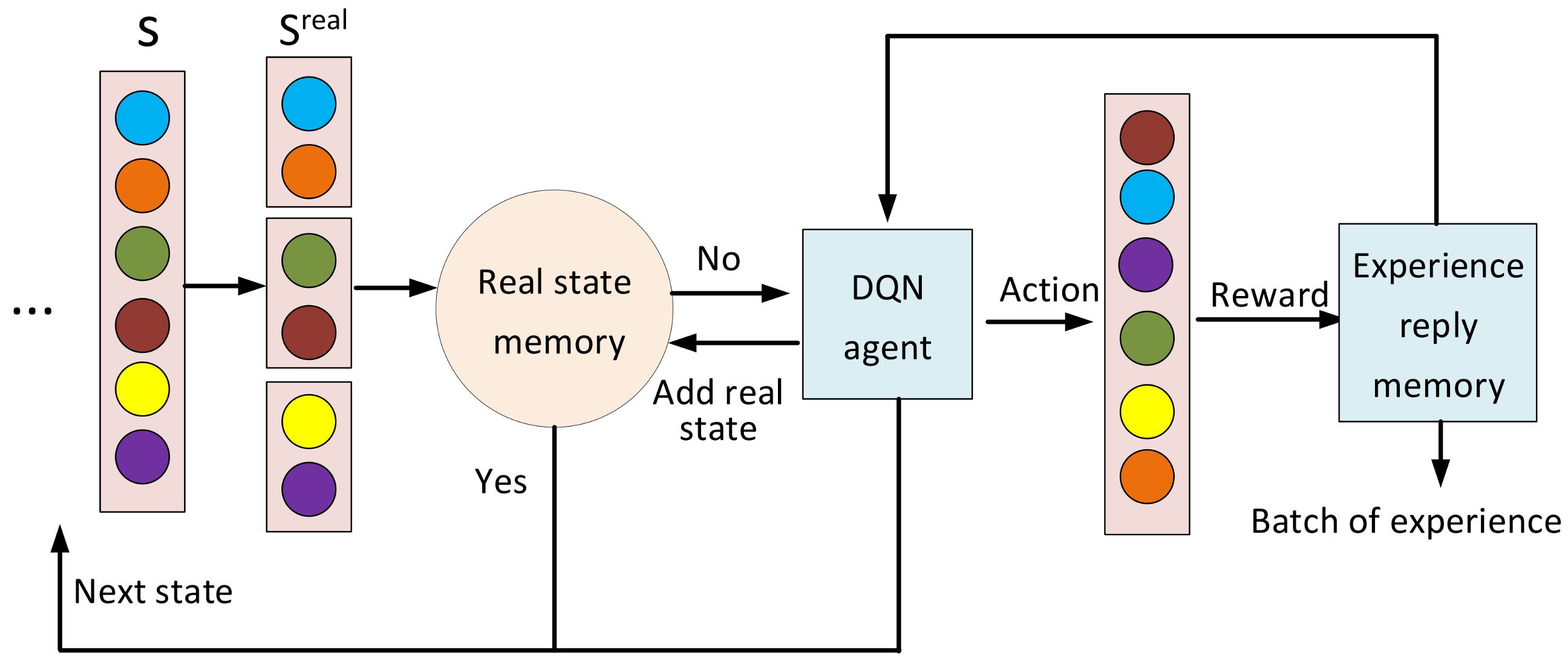
4. Deep Reinforcement Learning Based Distribution Method
4.1. Deep Reinforcement Learning Problem Formulation
- s is the state space. The goal of our proposal is to decide which data center is assigned to each request. n denotes the number of data centers in the previous section. Hence, we denote the state space
- a is the action space defined as choosing the data center n. Therefore, we also have
- In this problem, our goal is to mitigate the variation of power demand of all the data centers. The sum of all the data centers’ power demands in each time slot is defined as:where is the total power demand of data center n in each time slot, which can be calculated bywhere is the energy demand of each workload in time slot t, which was defined before. Then, the variation of power demand for all the data centers between the adjacent time slots isIn addition, the variation in power demand of all the data centers cannot exceed the capacity of fuel cells. Therefore, the reward function can be defined asFinally, the state transition samples of Reinforcement learning can be represented as
4.2. F-DQN Algorithm Design
5. Experimental Results
5.1. Simulation Settings
- Static: assuming the coming workloads are not changed to other servers.
- Random: The coming workloads in each time slot are changed randomly to all the servers.
- K-means: The coming workloads are transferred through k-means to get with the optimal variation of energy consumption. For each workload, the asynchrony score is calculated and each server will be considered to be a data point. Then we apply k-means clustering to these data points and obtain a set of cluster [12].
5.2. Simulation Results
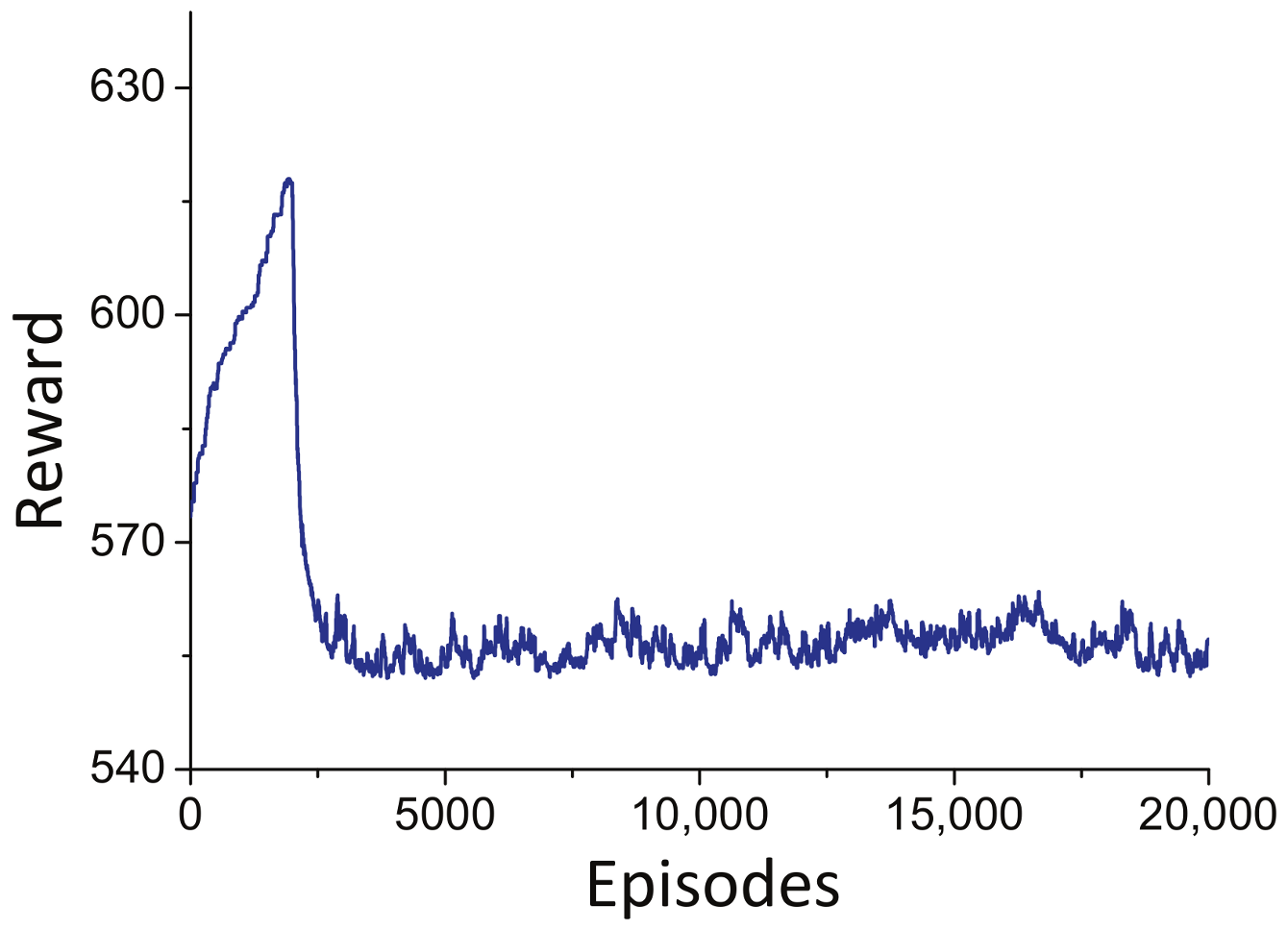
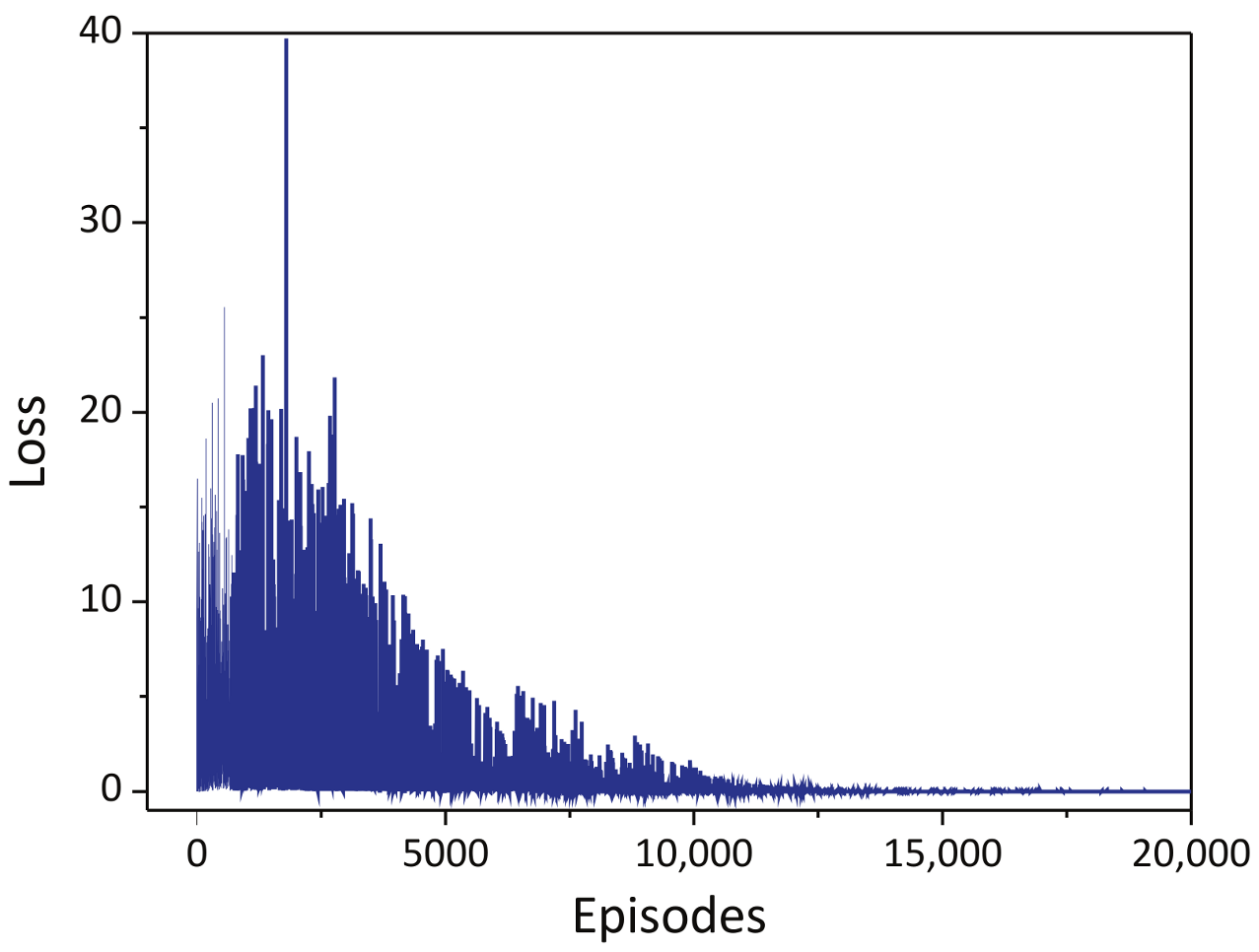
5.2.1. The Performance of F-DQN Algorithm
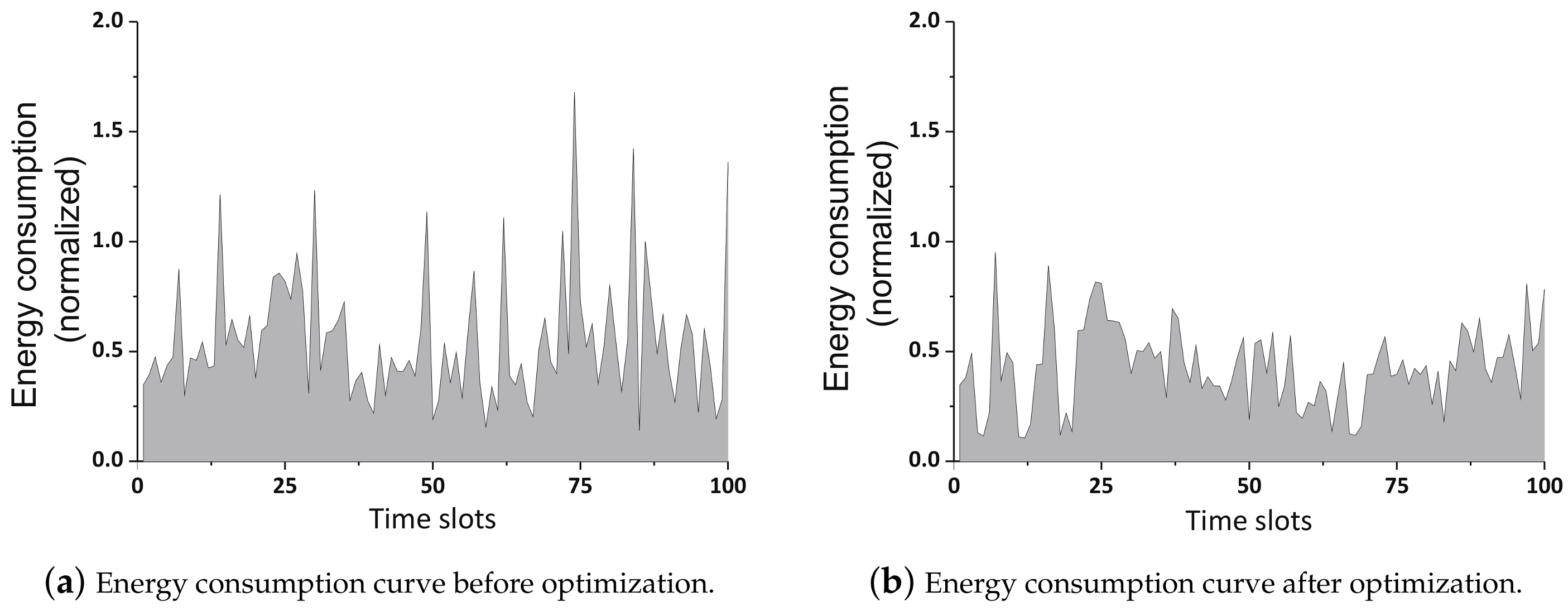
5.2.2. Energy Consumption Traces before and after Optimization
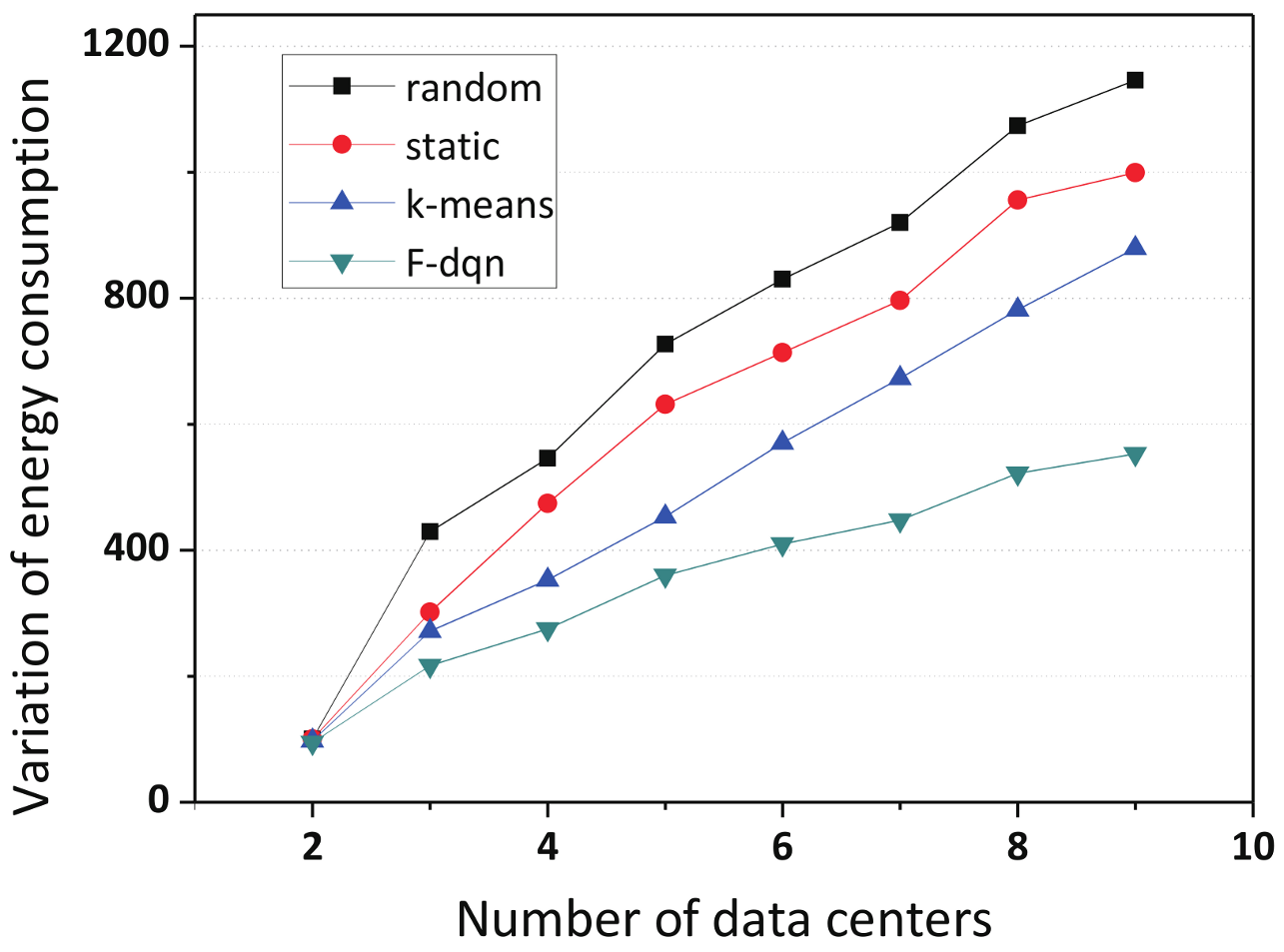
5.2.3. The Comparison of Variation of Energy Consumption among Different Number of Data Centers
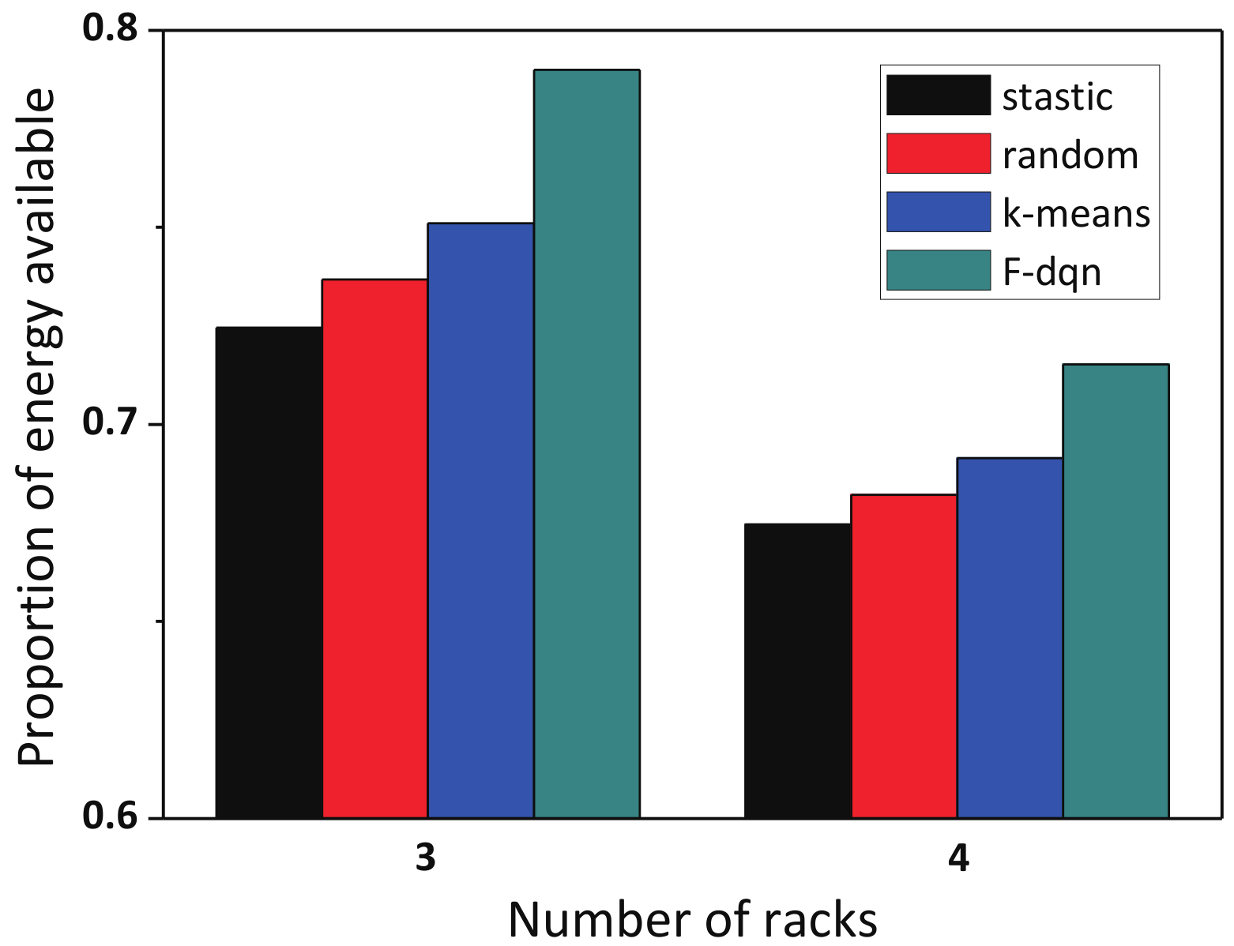
5.2.4. The Comparison of Proportion of Power Budget among Different Number of Racks
6. Related Work
6.1. Fuel Cells for Data Centers
6.2. Deep Reinforcement Learning for Data Centers
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wei, Z.; Yonggang, W.; Lei, L.L.; Fang, L.; Rui, F. Cost Optimal Data Center Servers: A Voltage Scaling Approach. IEEE Trans. Cloud Comput. 2018, 1. [Google Scholar] [CrossRef]
- Qureshi, A. Power-Demand Routing in Massive Geo-Distributed Systems. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2011. [Google Scholar]
- Ren, C.; Wang, D.; Urgaonkar, B.; Sivasubramaniam, A. Carbon-Aware Energy Capacity Planning for Datacenters. In Proceedings of the 2012 IEEE 20th International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems, Washington, DC, USA, 7–9 August 2012; pp. 391–400. [Google Scholar] [CrossRef]
- Seh, Z.W.; Kibsgaard, J.; Dickens, C.F.; Chorkendorff, I.; Norskov, J.K.; Jaramillo, T.F. Combining theory and experiment in electrocatalysis: Insights into materials design. Science 2017, 355, eaad4998. [Google Scholar] [CrossRef] [Green Version]
- Pelley, S.; Meisner, D.; Zandevakili, P.; Wenisch, T.; Underwood, J. Power Routing: Dynamic Power Provisioning in the Data Center. ACM SIGPLAN Not. 2010, 45, 231–242. [Google Scholar] [CrossRef]
- Qiang, W.; Deng, Q.; Ganesh, L.; Hsu, C.H.; Song, Y.J. Dynamo: Facebook’s Data Center-Wide Power Management System; IEEE: New York, NY, USA, 2012. [Google Scholar]
- Zhao, L.; Brouwer, J.; James, S.; Siegler, J.; Peterson, E.; Kansal, A.; Liu, J. Servers Powered by a 10kW In-Rack Proton Exchange Membrane Fuel Cell System. In Proceedings of the International Conference on Fuel Cell Science, Engineering and Technology, Boston, MA, USA, 30 June 2014. [Google Scholar] [CrossRef] [Green Version]
- Ng, M.F.; Zhao, J.; Yan, Q.; Conduit, G.J.; Seh, Z.W. Predicting the state of charge and health of batteries using data-driven machine learning. Nat. Mach. Intell. 2020, 2, 161–170. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wang, D.; Ghose, S.; Liu, J.; Govindan, S.; James, S.; Peterson, E.; Siegler, J.; Ausavarungnirun, R.; Mutlu, O. SizeCap: Efficiently Handling Power Surges in Fuel Cell Powered Data Centers. In Proceedings of the 2016 IEEE International Symposium on High Performance Computer Architecture (HPCA), Barcelona, Spain, 12–16 March 2016. [Google Scholar] [CrossRef]
- Miyazaki, M.R.; Sorensen, A.J.; Vartdal, B.J. Reduction of Fuel Consumption on Hybrid Marine Power Plants by Strategic Loading With Energy Storage Devices. IEEE Power Energy Technol. Syst. J. 2016, 3, 207–217. [Google Scholar] [CrossRef]
- Hu, X.; Li, P.; Wang, K.; Sun, Y.; Zeng, D.; Guo, S. Energy Management of Data Centers Powered by Fuel Cells and Heterogeneous Energy Storage. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018. [Google Scholar] [CrossRef]
- Hsu, C.H.; Deng, Q.; Mars, J.; Tang, L. SmoothOperator: Reducing Power Fragmentation and Improving Power Utilization in Large-scale Datacenters. ACM SIGPLAN Not. 2018, 53, 535–548. [Google Scholar] [CrossRef]
- Kontorinis, V.; Zhang, L.; Aksanli, B.; Sampson, J.; Homayoun, H.; Pettis, E.; Tullsen, D.; Rosing, T. Managing Distributed UPS Energy for Effective Power Capping in Data Centers. ACM SIGPLAN Not. 2012, 40, 488–499. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Jiang, T.; Cao, Y.; Qi, Q. Carbon-Aware Energy Cost Minimization for Distributed Internet Data Centers in Smart Microgrids. Internet Things J. IEEE 2014, 1, 255–264. [Google Scholar] [CrossRef]
- Guo, Y.; Gong, Y.; Fang, Y.; Khargonekar, P.P.; Geng, X. Energy and Network Aware Workload Management for Sustainable Data Centers with Thermal Storage. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 2030–2042. [Google Scholar] [CrossRef]
- Sun, P.; Wen, Y.; Han, R.; Feng, W.; Yan, S. GradientFlow: Optimizing Network Performance for Large-Scale Distributed DNN Training. IEEE Trans. Big Data 2019, 1. [Google Scholar] [CrossRef]
- Chen, L.; Lingys, J.; Chen, K.; Liu, F. AuTO: Scaling deep reinforcement learning for datacenter-scale automatic traffic optimization. In SIGCOMM ’18: Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Yang, J.; Xiao, W.; Chun, J.; Hossain, M.S.; Muhammad, G.; Amin, S. AI Powered Green Cloud and Data Center. IEEE Access 2018, 1. [Google Scholar] [CrossRef]
- Ran, Y.; Hu, H.; Zhou, X.; Wen, Y. DeepEE: Joint Optimization of Job Scheduling and Cooling Control for Data Center Energy Efficiency Using Deep Reinforcement Learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 645–655. [Google Scholar] [CrossRef]
- Yi, D.; Zhou, X.; Wen, Y.; Tan, R. Toward Efficient Compute-Intensive Job Allocation for Green Data Centers: A Deep Reinforcement Learning Approach. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019. [Google Scholar] [CrossRef]
- OpenComputeProject. Available online: https://www.opencompute.org/ (accessed on 21 November 2019).
- Hu, X.; Li, P.; Wang, K.; Sun, Y.; Zeng, D.; Wang, X.; Guo, S. Joint Workload Scheduling and Energy Management for Green Data Centers Powered by Fuel Cells. IEEE Trans. Green Commun. Netw. 2019, 3, 397–406. [Google Scholar] [CrossRef]
- Zhang, Y.; Prekas, G.; Fumarola, G.M.; Fontoura, M.; Goiri, I.; Bianchini, R. History-Based Harvesting of Spare Cycles and Storage in Large-Scale Datacenters. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 755–770. [Google Scholar]
- Yu, L.; Jiang, T.; Cao, Y. Energy Cost Minimization for Distributed Internet Data Centers in Smart Microgrids Considering Power Outages. IEEE Trans. Parallel Distrib. Syst. 2014, 26, 120–130. [Google Scholar] [CrossRef]
- Shi, W.; Li, N.; Chu, C.C.; Gadh, R. Real-Time Energy Management in Microgrids. IEEE Trans. Smart Grid 2015, 8, 228–238. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Wiki dump data. Available online: http://dumps.wikimedia.org/other/pagecounts-raw/ (accessed on 24 December 2018).
- Kalhoff, N. Integration of fuel cell applications into the power supply for information and telecommunications technology. In Proceedings of the INTELEC 07 - 29th International Telecommunications Energy Conference, Rome, Italy, 30 September–4 October 2007; pp. 444–448. [Google Scholar] [CrossRef]
- Riekstin, A.; James, S.; Kansal, A.; Liu, J.; Peterson, E. No More Electrical Infrastructure: Towards Fuel Cell Powered Data Centers. In Proceedings of the Workshop on Power-Aware Computing and Systems, HotPower 2013, Farmington, PA, USA, 3–6 November 2013. [Google Scholar] [CrossRef]
- Zhou, Z.; Liu, F.; Li, B.; Li, B.; Jin, H.; Zou, R.; Liu, Z. Fuel Cell Generation in Geo-Distributed Cloud Services: A Quantitative Study. In Proceedings of the International Conference on Distributed Computing Systems, Madrid, Spain, 30 June–3 July 2014; pp. 52–61. [Google Scholar] [CrossRef]
- Sevencan, S.; Lindbergh, G.; Lagergren, C.; Alvfors, P. Economic feasibility study of a fuel cell-based combined cooling, heating and power system for a data centre. Energy Build. 2016, 111, 218–223. [Google Scholar] [CrossRef] [Green Version]
- Yi, D.; Zhou, X.; Wen, Y.; Tan, R. Efficient Compute-Intensive Job Allocation in Data Centers via Deep Reinforcement Learning. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1474–1485. [Google Scholar] [CrossRef]
- Gao, J.; Wang, H.; Shen, H. Smartly Handling Renewable Energy Instability in Supporting A Cloud Datacenter. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), New Orleans, LA, USA, 18–22 May 2020; pp. 769–778. [Google Scholar] [CrossRef]
- Li, Y.; Wen, Y.; Guan, K.; Tao, D. Transforming Cooling Optimization for Green Data Center via Deep Reinforcement Learning. IEEE Trans. Cybern. 2017. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| (hour) | 600 | 0.01 | |
| n | 2–9 | 0.1 | |
| m | 3–4 | memory cappacity | 2000 |
| (kw/h) | 10 | target update frequency | 100 |
| (kw/h) | 5 | batch size | 128 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, X.; Sun, Y. A Deep Reinforcement Learning-Based Power Resource Management for Fuel Cell Powered Data Centers. Electronics 2020, 9, 2054. https://doi.org/10.3390/electronics9122054
Hu X, Sun Y. A Deep Reinforcement Learning-Based Power Resource Management for Fuel Cell Powered Data Centers. Electronics. 2020; 9(12):2054. https://doi.org/10.3390/electronics9122054
Chicago/Turabian StyleHu, Xiaoxuan, and Yanfei Sun. 2020. "A Deep Reinforcement Learning-Based Power Resource Management for Fuel Cell Powered Data Centers" Electronics 9, no. 12: 2054. https://doi.org/10.3390/electronics9122054
APA StyleHu, X., & Sun, Y. (2020). A Deep Reinforcement Learning-Based Power Resource Management for Fuel Cell Powered Data Centers. Electronics, 9(12), 2054. https://doi.org/10.3390/electronics9122054