Episodic Self-Imitation Learning with Hindsight


Abstract
1. Introduction
2. Related Work
3. Background
3.1. Reinforcement Learning
3.2. Proximal Policy Optimization
3.3. Hindsight Experiences and Goals
4. Methodology
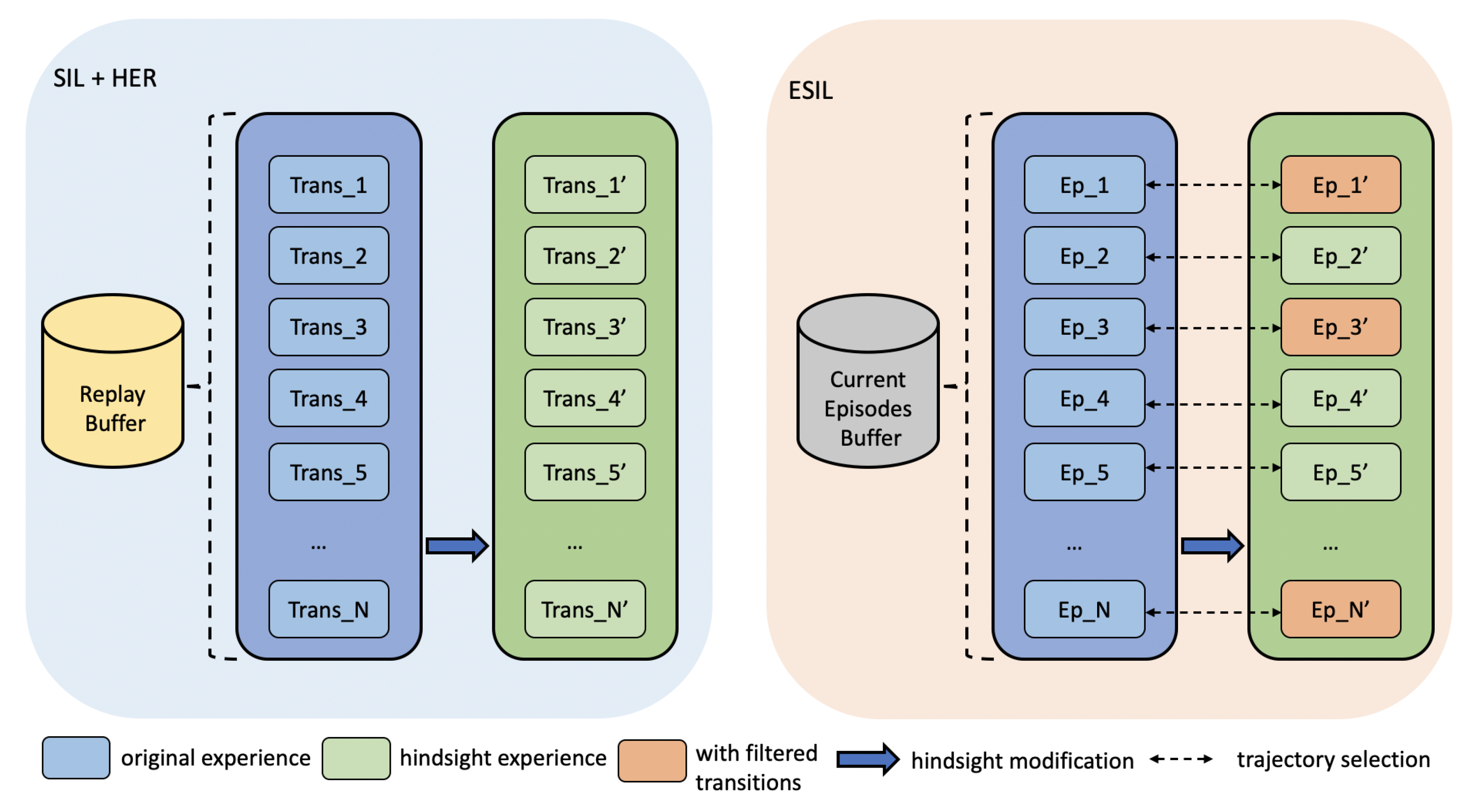
4.1. Episodic Self-Imitation Learning
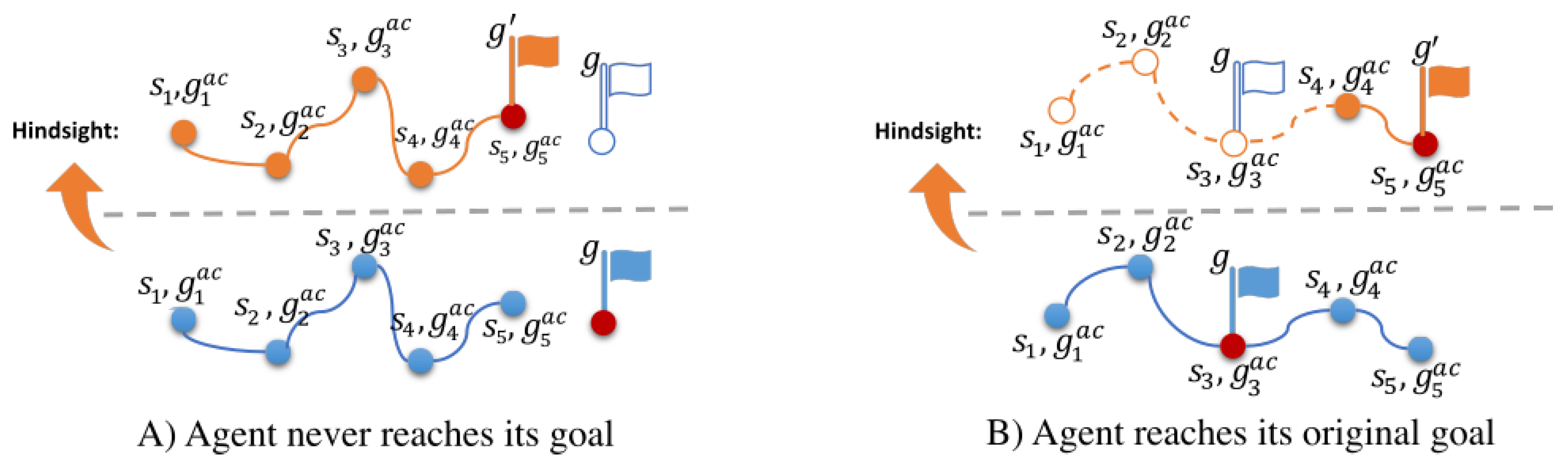
4.2. Episodic Update with Hindsight
| Algorithm 1 Proximal policy optimization (PPO) with Episodic Self-Imitation Learning (ESIL) |
Require: an actor network , a critic network , the maximum steps T of an episode, a reward function r
|
5. Experiments and Results
5.1. Setup
5.2. Network Structure and Hyperparameters
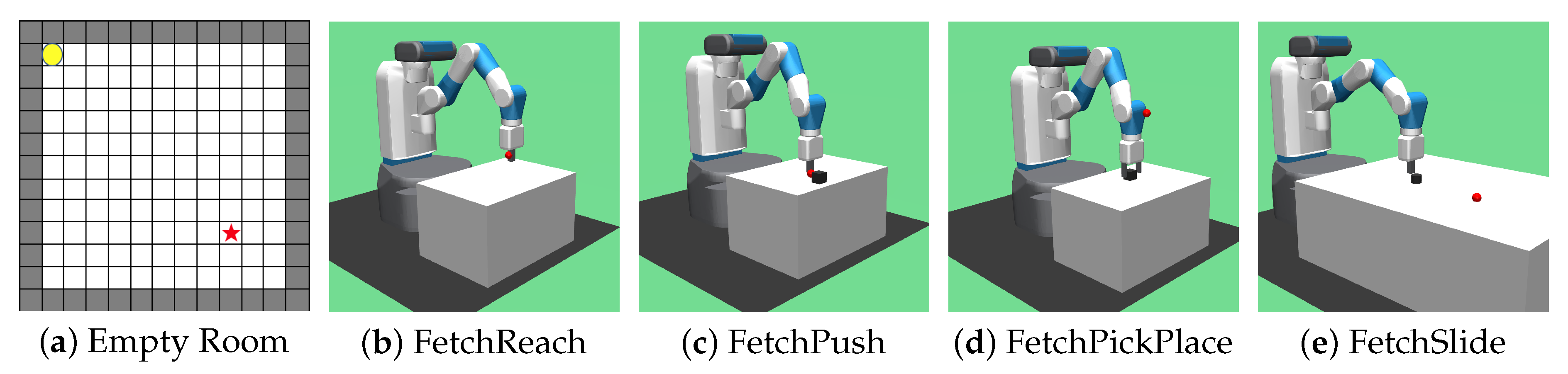
5.3. Grid-World Environments
- PPO: vanilla PPO [46] for discrete action spaces;
- PPO+SIL/PPO+SIL+HER: Self-imitation learning (SIL) is used with PPO to solve hard exploration environments by imitating past good experiences [14]. In order to solve sparse rewards tasks, hindsight experience replay (HER) is applied to sampled transitions;
- DQN+HER: Hindsight experience replay (HER), designed for sparse reward problems, is combined with a deep Q-learning network (DQN) [15]; this is an off policy algorithm;
- Hindsight Policy Gradients (HPG): the vanilla implementation of HPG that is only suitable for discrete action spaces [40].
5.4. Continuous Environments
- PPO: the vanilla PPO [46] for continuous action spaces;
- PPO+SIL/PPO+SIL+HER: Self-imitation learning is used with PPO to solve hard exploration environments by imitating past good experiences [14]. For sparse rewards tasks, hindsight experience replay (HER) is applied to sampled transitions;
- DDPG+HER: this is the state-of-the-art off-policy RL algorithm for the Fetch tasks. Deep deterministic policy gradient (DDPG) is trained with HER to deal with the sparse reward problem [15].
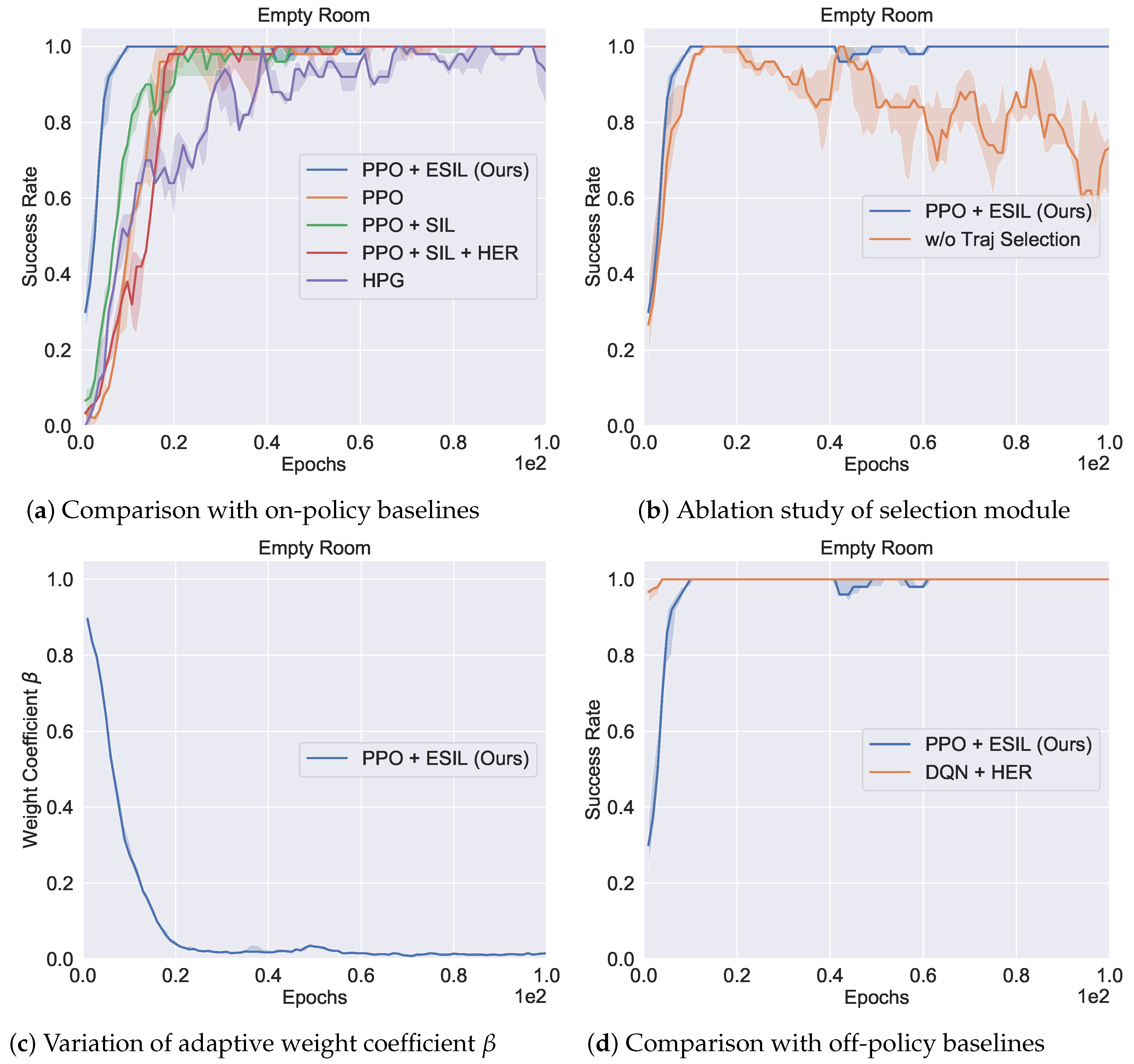
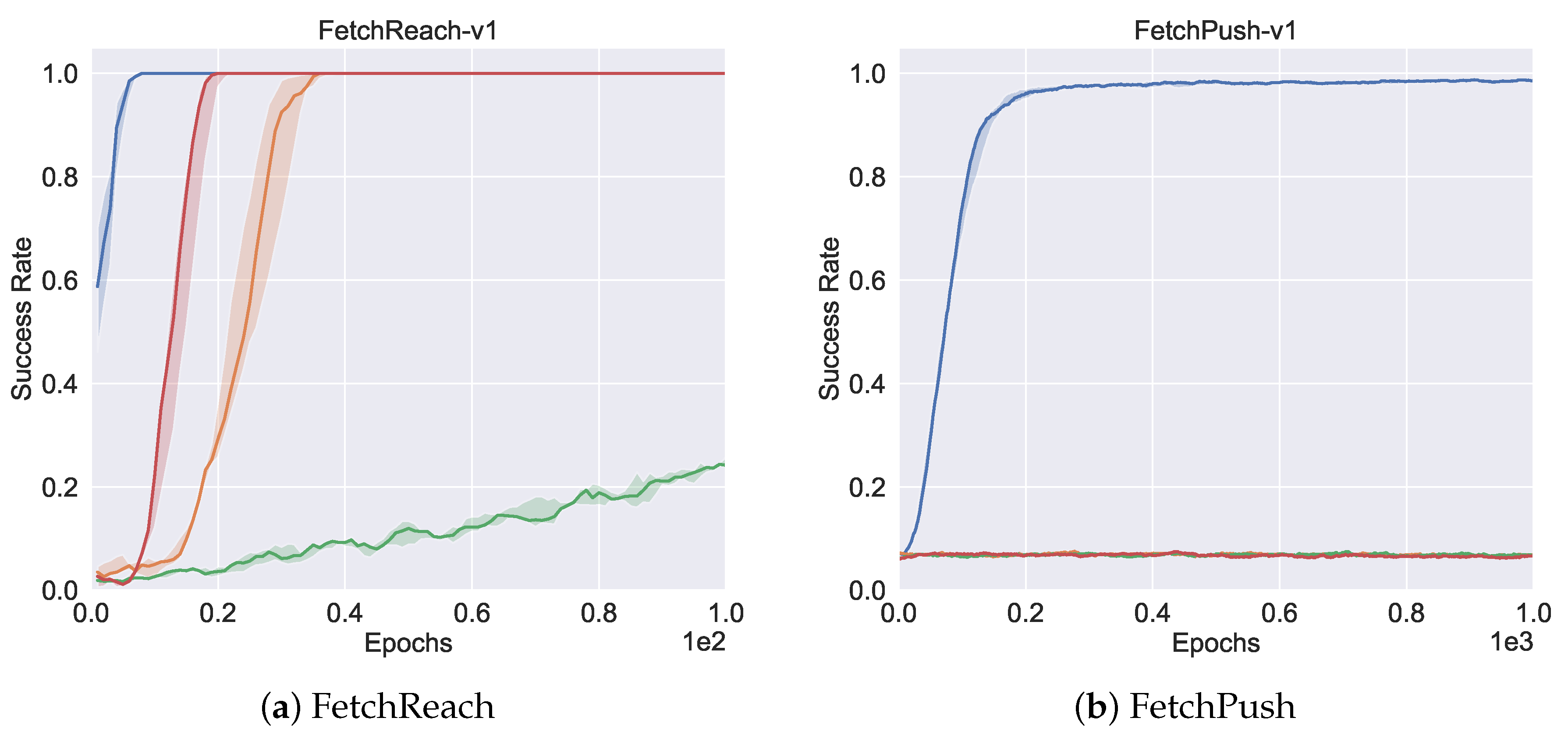
5.4.1. Comparison to On-Policy Baselines
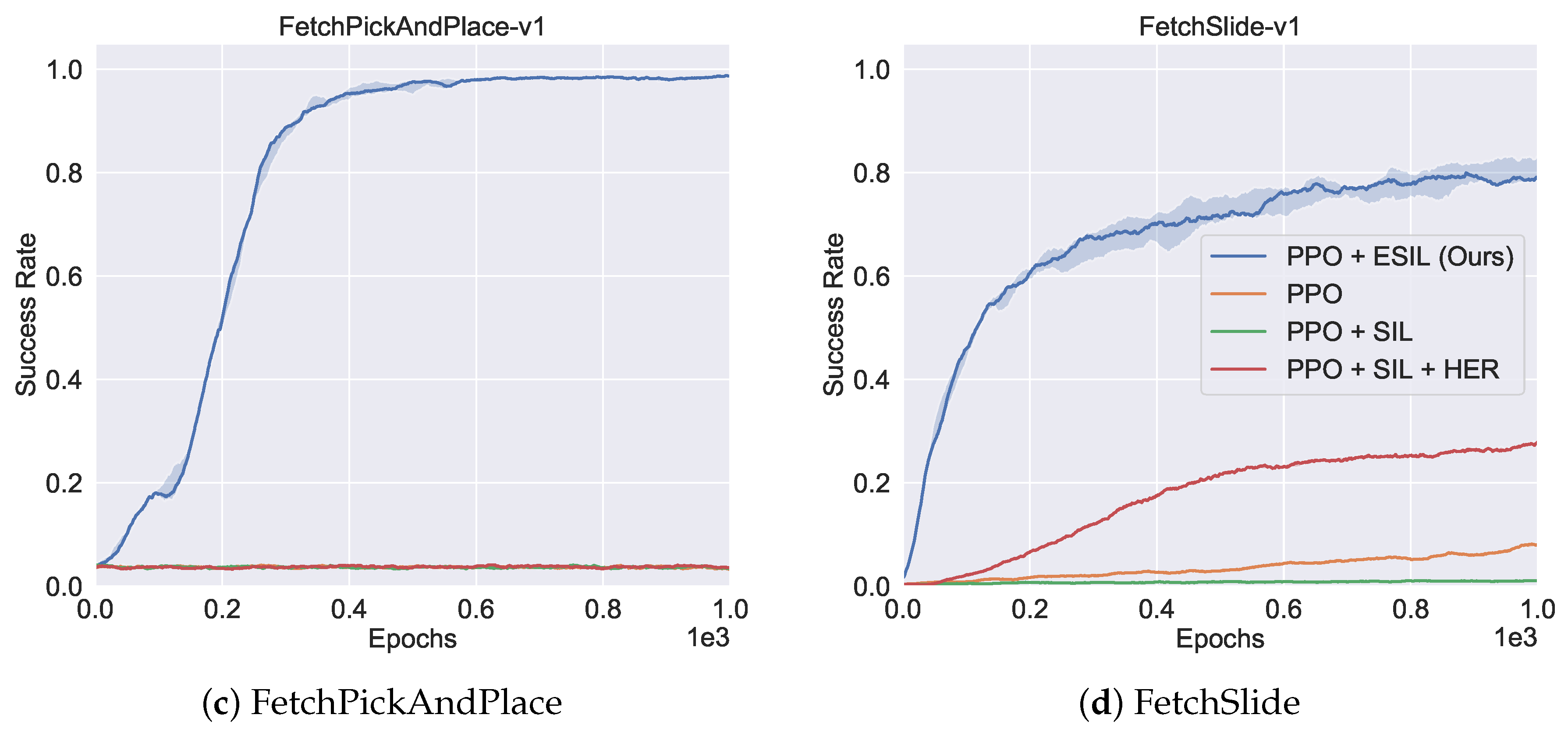
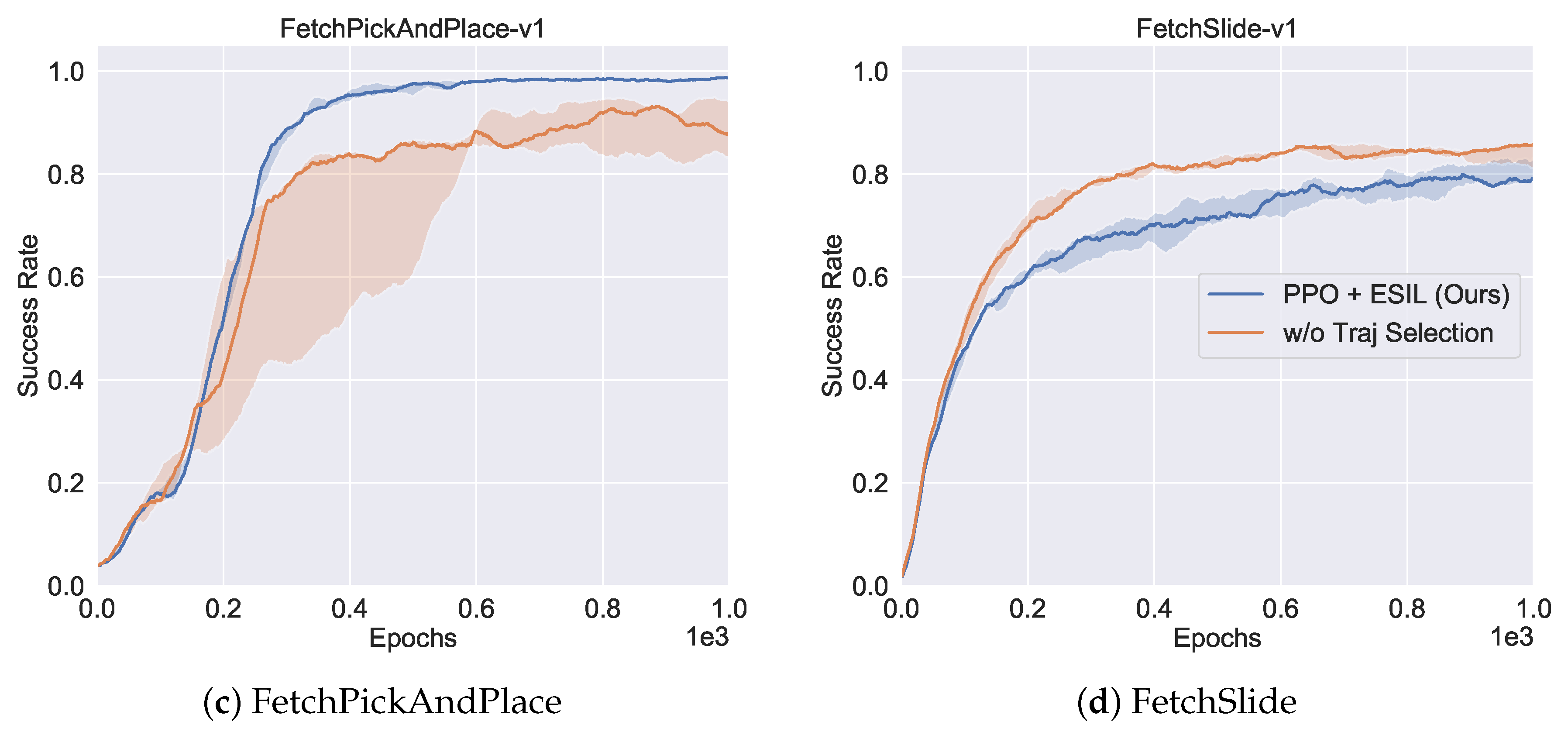
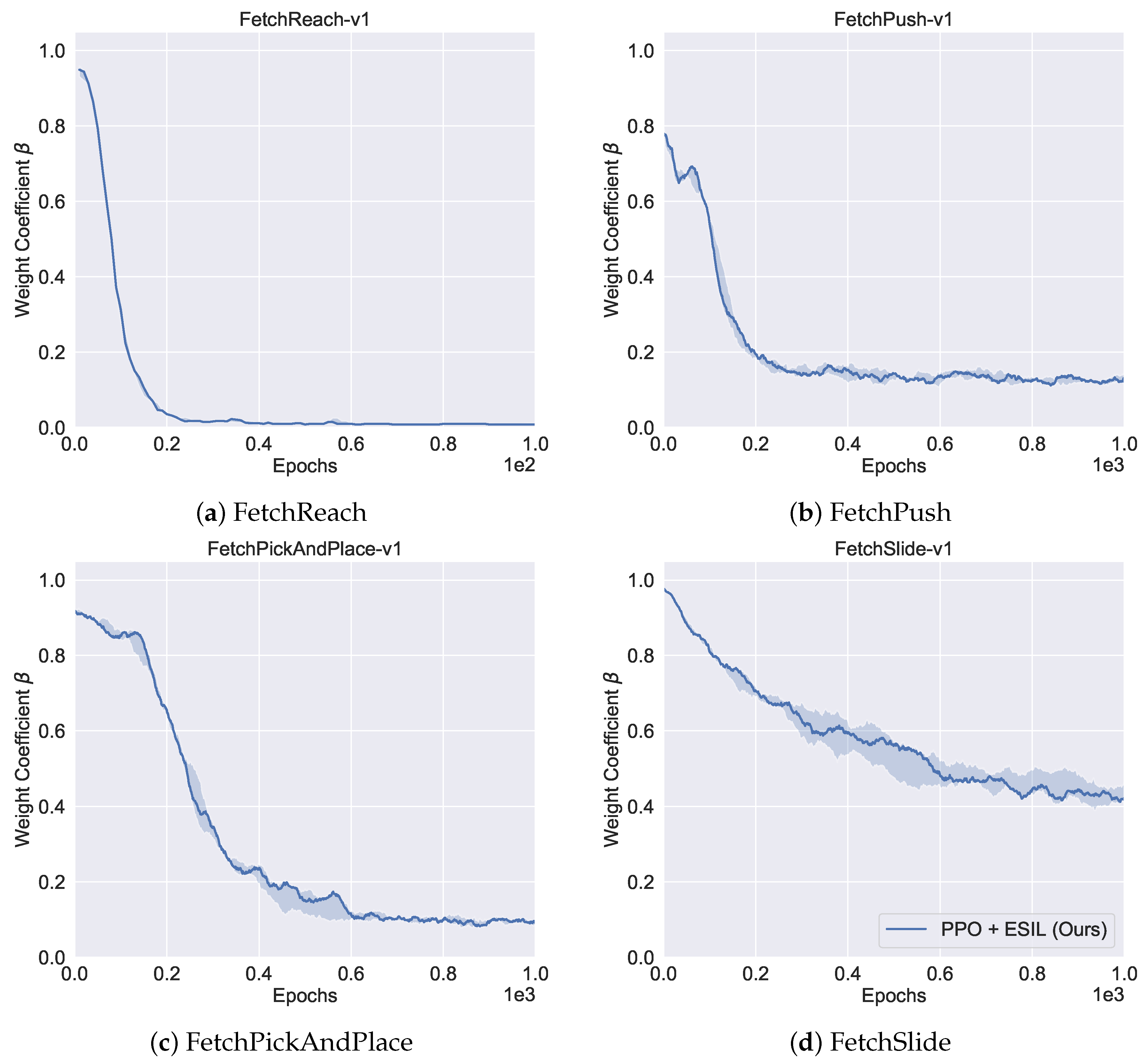
5.4.2. Ablation Study of Trajectory Selection Module
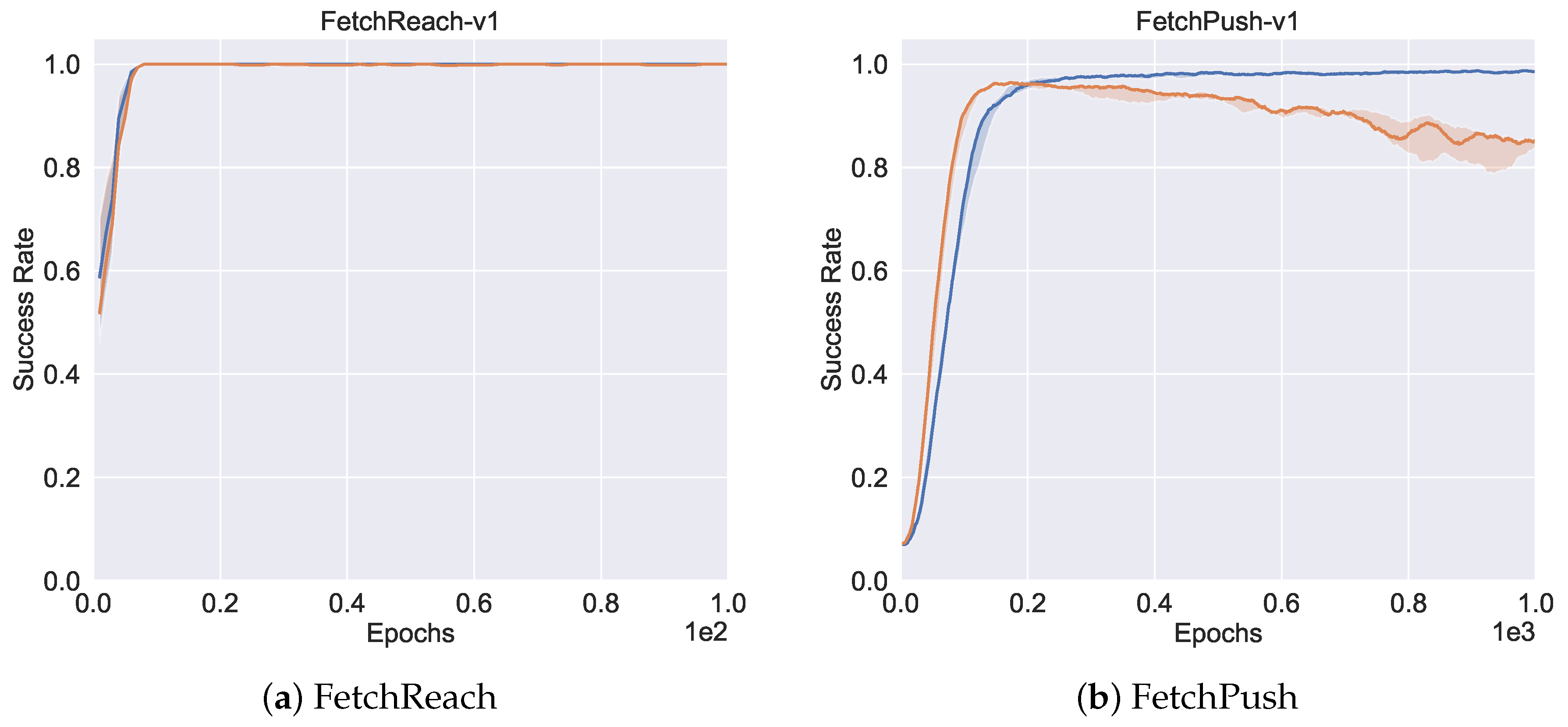
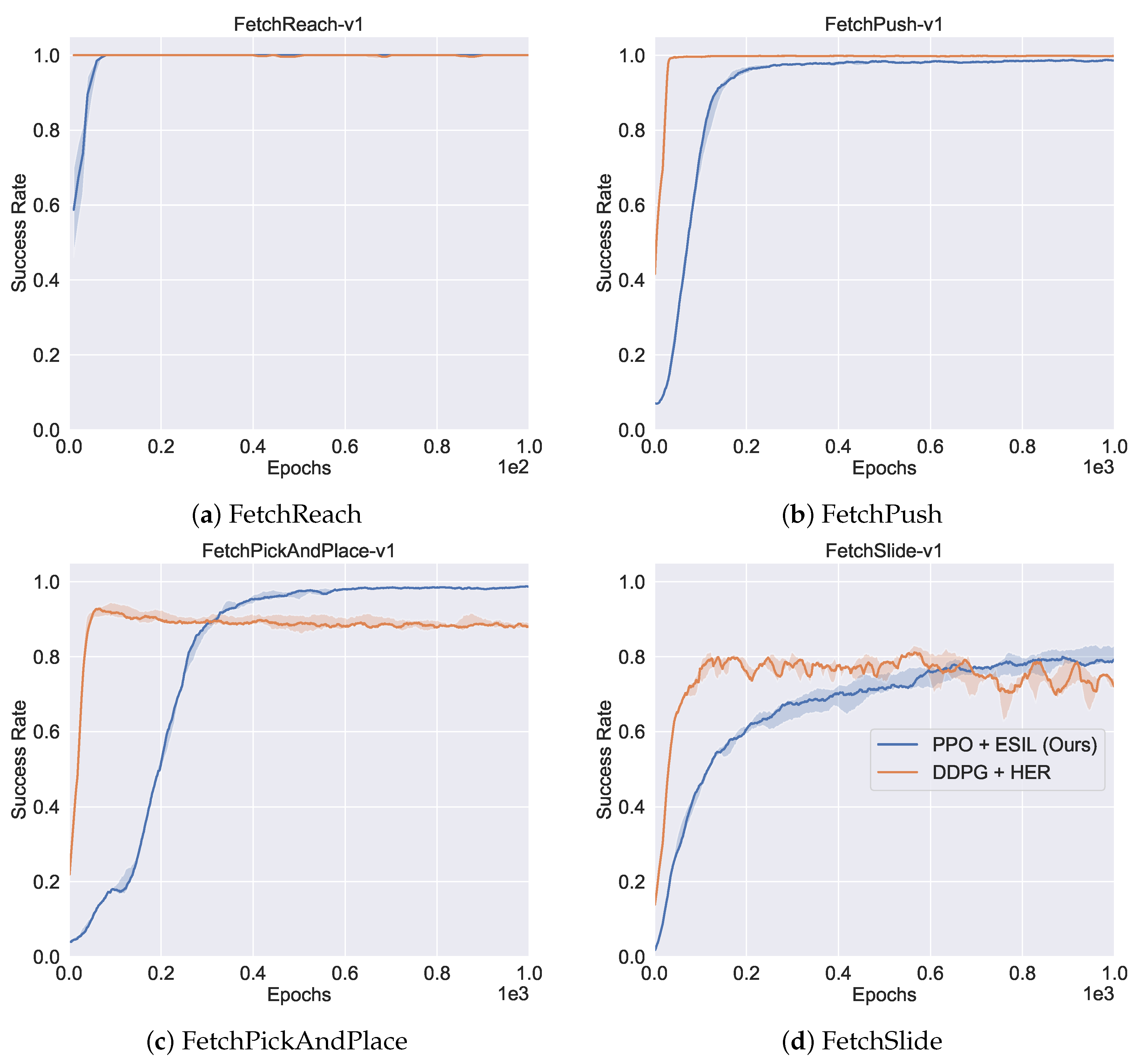
5.4.3. Comparison to Off-Policy Baselines
5.5. Overall Performance
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Ng, A.Y.; Harada, D.; Russell, S. Policy Invariance under Reward Transformations: Theory and Application to Reward Shaping. In International Conference on Machine Learning; ACM: New York, NY, USA, 1999; Volume 99, pp. 278–287. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Florensa, C.; Held, D.; Wulfmeier, M.; Zhang, M.; Abbeel, P. Reverse curriculum generation for reinforcement learning. arXiv 2017, arXiv:1707.05300. [Google Scholar]
- Hester, T.; Vecerik, M.; Pietquin, O.; Lanctot, M.; Schaul, T.; Piot, B.; Horgan, D.; Quan, J.; Sendonaris, A.; Osband, I.; et al. Deep Q-learning from demonstrations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Gao, Y.; Lin, J.; Yu, F.; Levine, S.; Darrell, T. Reinforcement learning from imperfect demonstrations. arXiv 2018, arXiv:1802.05313. [Google Scholar]
- Rajeswaran, A.; Kumar, V.; Gupta, A.; Vezzani, G.; Schulman, J.; Todorov, E.; Levine, S. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. arXiv 2017, arXiv:1709.10087. [Google Scholar]
- Večerík, M.; Hester, T.; Scholz, J.; Wang, F.; Pietquin, O.; Piot, B.; Heess, N.; Rothörl, T.; Lampe, T.; Riedmiller, M. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards. arXiv 2017, arXiv:1707.08817. [Google Scholar]
- Nair, A.; McGrew, B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Overcoming exploration in reinforcement learning with demonstrations. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018; pp. 6292–6299. [Google Scholar]
- James, S.; Bloesch, M.; Davison, A.J. Task-Embedded Control Networks for Few-Shot Imitation Learning. In Proceedings of the 2nd Annual Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018. [Google Scholar]
- Oh, J.; Guo, Y.; Singh, S.; Lee, H. Self-Imitation Learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Abbeel, O.P.; Zaremba, W. Hindsight experience replay. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5048–5058. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Liu, H.; Trott, A.; Socher, R.; Xiong, C. Competitive experience replay. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Lee, S.Y.; Sungik, C.; Chung, S.Y. Sample-efficient deep reinforcement learning via episodic backward update. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 2112–2121. [Google Scholar]
- Plappert, M.; Andrychowicz, M.; Ray, A.; McGrew, B.; Baker, B.; Powell, G.; Schneider, J.; Tobin, J.; Chociej, M.; Welinder, P.; et al. Multi-goal reinforcement learning: Challenging robotics environments and request for research. arXiv 2018, arXiv:1802.09464. [Google Scholar]
- Hussein, A.; Gaber, M.M.; Elyan, E.; Jayne, C. Imitation learning: A survey of learning methods. ACM Comput. Surv. 2017, 50, 21. [Google Scholar] [CrossRef]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-to-end learning of driving models from large-scale video datasets. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2174–2182. [Google Scholar]
- Torabi, F.; Warnell, G.; Stone, P. Behavioral cloning from observation. arXiv 2018, arXiv:1805.01954. [Google Scholar]
- Ross, S.; Gordon, G.; Bagnell, D. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 627–635. [Google Scholar]
- Ho, J.; Ermon, S. Generative adversarial imitation learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4565–4573. [Google Scholar]
- Wang, Z.; Merel, J.S.; Reed, S.E.; de Freitas, N.; Wayne, G.; Heess, N. Robust imitation of diverse behaviors. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5320–5329. [Google Scholar]
- Ng, A.Y.; Russell, S.J. Algorithms for Inverse Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; pp. 663–670. [Google Scholar]
- Abbeel, P.; Ng, A.Y. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the International Conference on Machine Learning, Louisville, KY, USA, 16–18 December 2004; p. 1. [Google Scholar]
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. Maximum entropy inverse reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008; Volume 8, pp. 1433–1438. [Google Scholar]
- Finn, C.; Levine, S.; Abbeel, P. Guided cost learning: Deep inverse optimal control via policy optimization. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 49–58. [Google Scholar]
- Zhang, T.; McCarthy, Z.; Jowl, O.; Lee, D.; Chen, X.; Goldberg, K.; Abbeel, P. Deep imitation learning for complex manipulation tasks from virtual reality teleoperation. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Finn, C.; Yu, T.; Zhang, T.; Abbeel, P.; Levine, S. One-Shot Visual Imitation Learning via Meta-Learning. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; Volume 78, pp. 357–368. [Google Scholar]
- Fang, B.; Jia, S.; Guo, D.; Xu, M.; Wen, S.; Sun, F. Survey of imitation learning for robotic manipulation. Int. J. Intell. Robot. Appl. 2019, 3, 362–369. [Google Scholar] [CrossRef]
- Ding, Y.; Florensa, C.; Abbeel, P.; Phielipp, M. Goal-conditioned imitation learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 15324–15335. [Google Scholar]
- Gangwani, T.; Liu, Q.; Peng, J. Learning self-imitating diverse policies. arXiv 2018, arXiv:1805.10309. [Google Scholar]
- Wu, Y.H.; Charoenphakdee, N.; Bao, H.; Tangkaratt, V.; Sugiyama, M. Imitation Learning from Imperfect Demonstration. In Proceedings of the International Conference on Machine learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Tang, Y. Self-imitation learning via generalized lower bound q-learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Guo, Y.; Choi, J.; Moczulski, M.; Bengio, S.; Norouzi, M.; Lee, H. Self-Imitation Learning via Trajectory-Conditioned Policy for Hard-Exploration Tasks. arXiv 2019, arXiv:1907.10247. [Google Scholar]
- Rauber, P.; Ummadisingu, A.; Mutz, F.; Schmidhuber, J. Hindsight policy gradients. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Fang, M.; Zhou, C.; Shi, B.; Gong, B.; Xu, J.; Zhang, T. DHER: Hindsight Experience Replay for Dynamic Goals. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Liu, N.; Lu, T.; Cai, Y.; Li, B.; Wang, S. Hindsight Generative Adversarial Imitation Learning. arXiv 2019, arXiv:1903.07854. [Google Scholar]
- Zhao, R.; Tresp, V. Energy-based hindsight experience prioritization. arXiv 2018, arXiv:1810.01363. [Google Scholar]
- Fang, M.; Zhou, T.; Du, Y.; Han, L.; Zhang, Z. Curriculum-guided hindsight experience replay. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 12623–12634. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Andrychowicz, O.M.; Baker, B.; Chociej, M.; Jozefowicz, R.; McGrew, B.; Pachocki, J.; Petron, A.; Plappert, M.; Powell, G.; Ray, A.; et al. Learning dexterous in-hand manipulation. Int. J. Robot. Res. 2020, 39, 3–20. [Google Scholar] [CrossRef]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Dębiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with large scale deep reinforcement learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Empty Room | Reach | Push | Pick | Slide | |
|---|---|---|---|---|---|
| PPO | 1.000 ± 0.000 | 1.000 ± 0.000 | 0.070 ± 0.001 | 0.033 ± 0.001 | 0.077 ± 0.001 |
| PPO+SIL | 0.998 ± 0.002 | 0.225 ± 0.016 | 0.071 ± 0.001 | 0.036 ± 0.002 | 0.011 ± 0.001 |
| PPO+SIL+HER | 0.996 ± 0.013 | 1.000 ± 0.000 | 0.066 ± 0.011 | 0.035 ± 0.004 | 0.276 ± 0.011 |
| DQN+HER | 1.000 ± 0.000 | - | - | - | - |
| DDPG+HER | - | 1.000 ± 0.000 | 0.996 ± 0.001 | 0.888 ± 0.008 | 0.733 ± 0.013 |
| HPG | 0.964 ± 0.012 | - | - | - | - |
| PPO+ESIL (Ours) | 1.000 ± 0.000 | 1.000 ± 0.000 | 0.984 ± 0.003 | 0.986 ± 0.002 | 0.812 ± 0.015 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, T.; Liu, H.; Anthony Bharath, A. Episodic Self-Imitation Learning with Hindsight. Electronics 2020, 9, 1742. https://doi.org/10.3390/electronics9101742
Dai T, Liu H, Anthony Bharath A. Episodic Self-Imitation Learning with Hindsight. Electronics. 2020; 9(10):1742. https://doi.org/10.3390/electronics9101742
Chicago/Turabian StyleDai, Tianhong, Hengyan Liu, and Anil Anthony Bharath. 2020. "Episodic Self-Imitation Learning with Hindsight" Electronics 9, no. 10: 1742. https://doi.org/10.3390/electronics9101742
APA StyleDai, T., Liu, H., & Anthony Bharath, A. (2020). Episodic Self-Imitation Learning with Hindsight. Electronics, 9(10), 1742. https://doi.org/10.3390/electronics9101742