1. Introduction
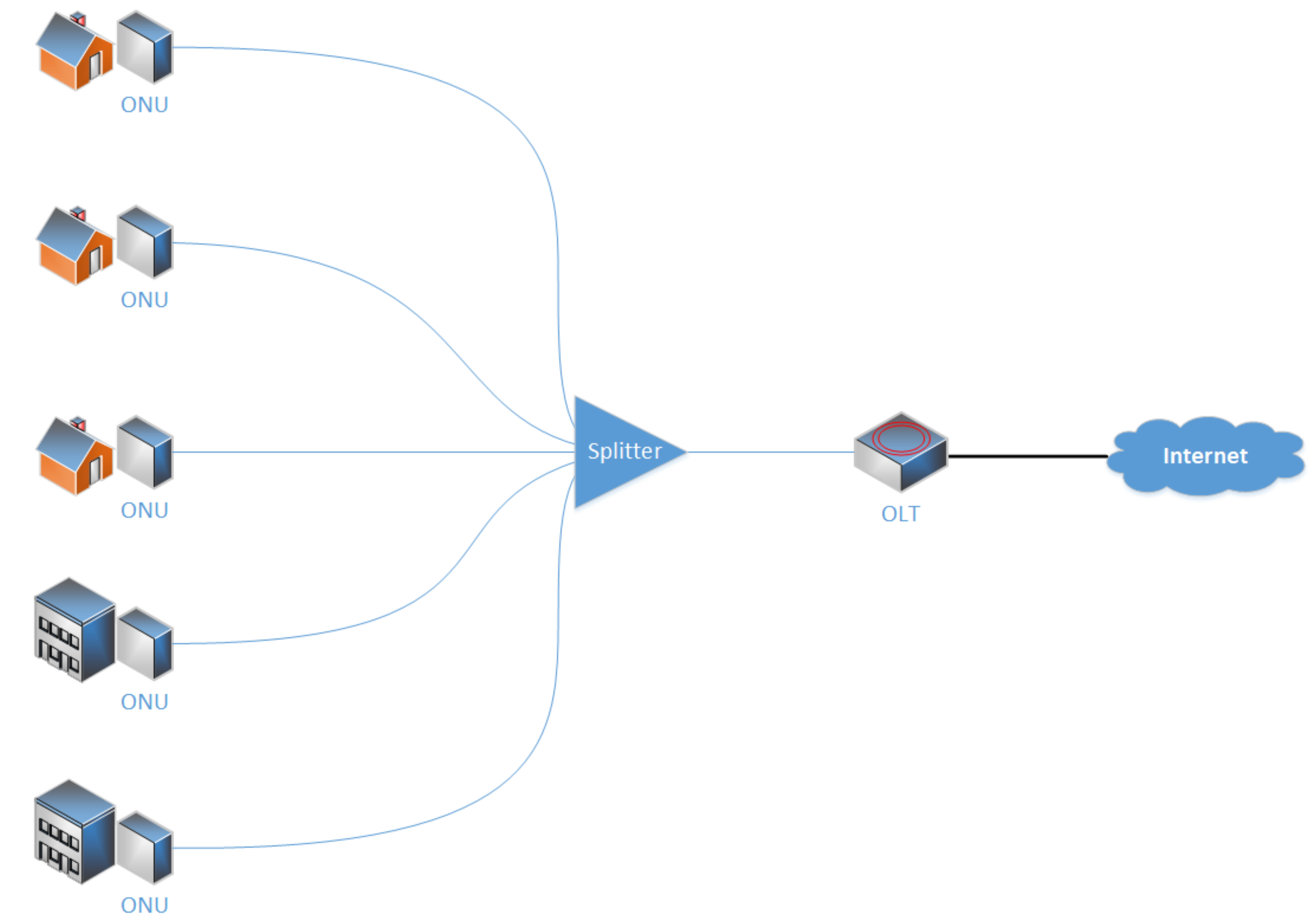
Passive optical network (PON) provides the advantage of having no active elements in its optical path [
1,
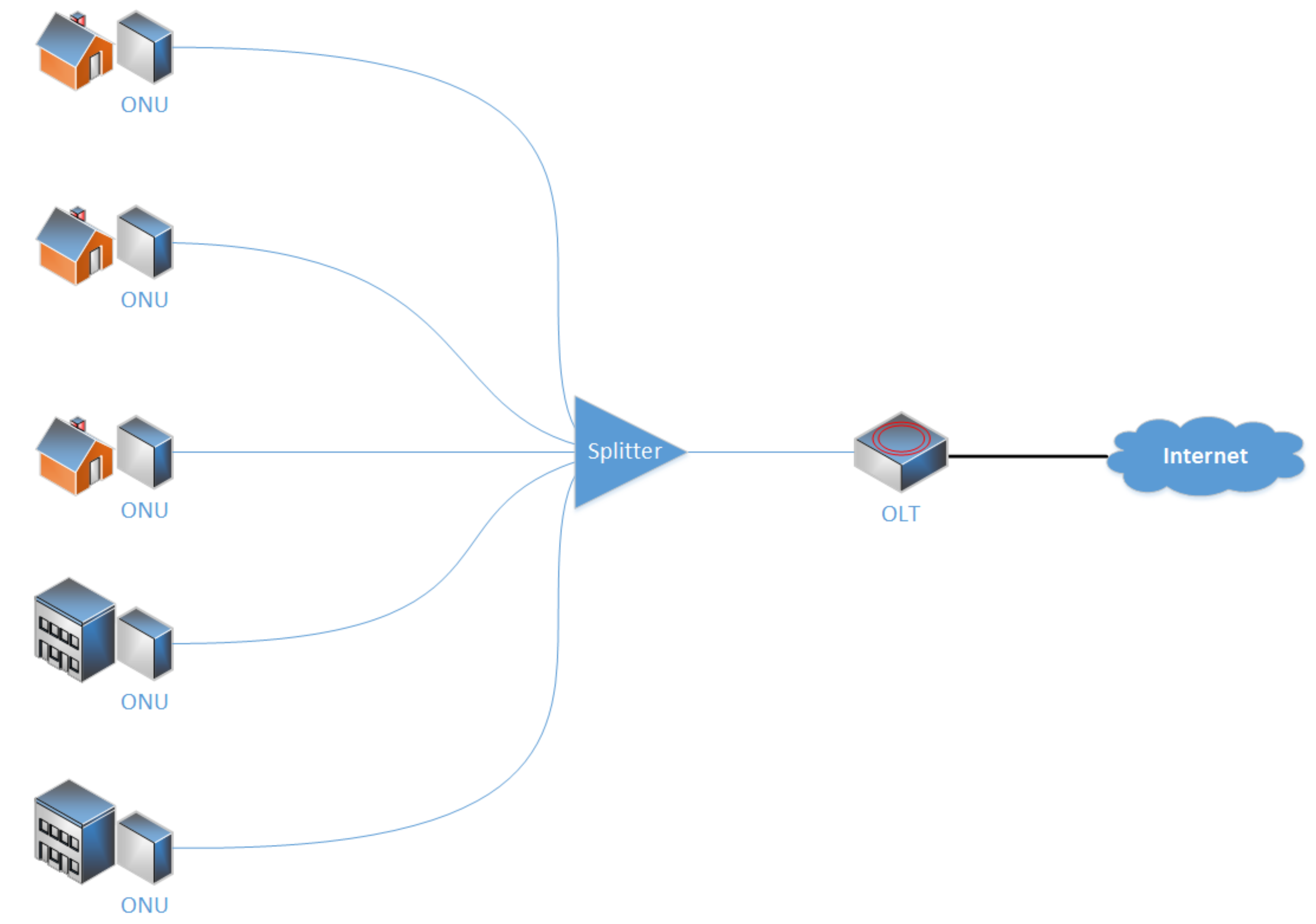
2]. Moreover, it offers a possibility of using a single optical fiber for all end units, even for bidirectional communication. The network consists of a central unit called optical line terminal (OLT) that is owned by the internet service provider (ISP), and other units connected to it called optical network unit (ONU) that are located with customers. The only other elements used in an optical network, called optical distribution network (ODN), are the so-called splitters, which are passive optical hubs that make it possible to connect several ONUs to a single optical fiber. Such a network is then referred to as point-to-multipoint (P2MP) network; see
Figure 1 [
3,
4].
Passive optical networks (PONs) cannot work without any sophisticated dynamic bandwidth allocation (DBA) algorithm. OLT would implement the undemanding algorithm as a static assignment. OLT thus allocates bandwidth only when an ONU is connected to the ODN. Bandwidth amount would be split among between all connected ONUs [
5,
6]. Presently, network flows are very unstable and static assignment is thus completely unacceptable in unstable networks.
XG-PON network expects implementation of DBA. XG-PON defines two methods for the detection for the current ONU load. One is called status reporting (SR) and the other is called traffic monitoring (TM) [
7].
DBA algorithms have quite accurate information about ONUs load. Introduced DBA algorithms used in our approach are based on this information. With sophisticated DBA algorithms an XG-PON network can quickly change bandwidth in very unstable networks.
The main contribution of this paper is testing DBA algorithms, which are currently available. We have developed our XG-PON simulator specially for testing DBA algorithms performance. In the simulator we implemented the static assignment, and three DBA algorithms, namely hybrid reporting allocation (HYRA) [
8], gigaPON access network (GIANT) [
9], and modified Max–Min [
10]. Algorithms were tested for transmission delay and amount of bandwidth waste.
The rest of this paper is structured as follows.
Section 2 provides an overview of the related works.
Section 3 introduces the selected and implemented algorithms from the theoretical point of the view.
Section 4 presents our simulator and simulation results. Finally,
Section 5 concludes the paper.
2. Related Work
Assuming a continued annual relative growth ranging from 5.6 to 6.9 %, ICT’s relative contribution would exceed 14 % of the 2016-level worldwide global greenhouse gas emissions (GHGE) by 2040 [
11]. A present phenomenon is energy efficiency during sleep cycles and bandwidth allocation for ONUs in Institute of Electrical and Electronics Engineers (IEEE) or International Telecommunication Union (ITU) PONs [
12,
13,
14].
In [
15] the demand forecasting DBA algorithm for reducing packet delay is discussed. The propagation delay between OLT and ONU is about 0.3 ms which contains propagation delay, processing time and whole windows of the OLT unit of one frame. Current DBA algorithms rely on the request-grant cycle. The authors proposed a new DBA algorithm based on demand forecasting with the prediction of ONU future demand by statistical modeling of the demand patterns.
The article [
16] deals with the next-generation Ethernet passive optical network (NG-EPON). These networks use optical distribution networks with wavelength sharing by ONUs; however, there are two different design architectures for NG-EPONs—the single scheduling domain (SSD) and multi-scheduling domain (MSD) ethernet passive optical network (EPON). Their algorithm works up to 10 Gbit/s but the NG-EPON will use more than 10 Gbit/s in final specification such as 2× 50 Gbit/s or 4× 25 Gbit/s. The proposed algorithm also fits the current 10 Gbit/s PONs.
The future of passive optical networks is in the multi-OLTs platform and it will be necessary to deal with a novel DBA algorithm for the downstream channel. The authors proposed weight factors of bandwidth demand of different users [
17]. They also proposed a bandwidth-transfer process between OLTs in ODN and they reduced the delay of the system while massively improving the system throughput.
The article [
18] introduces a modular dynamic bandwidth allocation for flexible PON. This concept should be adopted for the virtual OLT hardware abstraction (VOLTHA) [
19]. The VOLTHA is an open source project to create a hardware abstraction for broadband access equipment.
We also dealt with DBA algorithms in next-generation passive optical network stage 2 (NG-PON2) networks [
20,
21]. First, we introduced an implementation of the transmission convergence (TC) layer because the DBA uses the TC layer for allocation structures with grant size, start time, stop time, and other fields. The second article dealt with static bandwidth allocation in comparison with dynamic bandwidth algorithms. Furthermore, we proposed the modification for low load ONU units (for example during midnight or other scenarios).
The passive optical network can support bandwidth-intensive as well as low-latency services for 5th generation mobile networks by using channel bonding and low-latency oriented DBA [
22]. Next application of time and wavelength division multiplexed PON (TWDM-PON) is in front hauls streams in the centralized radio access network (C-RAN) architecture of mobile networks [
23,
24].
4. Simulation Description and Simulation Results Discussion
We use C++ language for development of our XG-PON simulator for testing DBA algorithms. This programming language allows the writing of object-oriented code, so we used this option and whole simulator is thus object-oriented. Every frame flowing through network or every ONU connected to ODN of XG-PON is an object made from one class for frame and one class for ONU. In object-oriented programming language it is much simpler to add additional DBA algorithms, which is also a big plus.
The simulator does not need full implementation for testing DBA algorithms. Functions such as encryption of each frame transmitted through ODN are unnecessary and their implementation would only take up computational resources such as processor time and random access memory (RAM). As some algorithms how to treat all T-CONT are not clearly defined, we decided the following. T-CONT 1 does not need any dynamic allocation, because it has fixed bandwidth. T-CONT 3 and 4 have lower QoS priority. So we decided to focus on T-CONT 2, and generate traffic only on this T-CONT for saving computing resources (central processor unit (CPU) i5-3230M 2.60 GHz, 8 GB random access memory (RAM) double data rate (DDR3), 256 GB solid state drive). This simulator also ignores different distances of ONUs from the OLT. Simulator thus places all ONUs to the same distance [
7]. A real passive optical network (in general point of view not only XG-PON or older/newer) uses an activation process of each ONU [
25]. During this phase, the ONUs have to be aligned to the same distance from the optical line termination (OLT) point of view. It leads to assigning a unique value of the equalization delay. The ONUs seem at the same distance (virtually) of the OLT, which allows the OLT to control the upstream by a time slot duration for each ONU. The propagation delay between OLT and ONU (up to 20 km) will be around picoseconds, but the OLT has hundreds of microseconds to process all traffic. This phenomenon must be discussed for long-reach passive optical networks.
Nevertheless, all functions can be skipped in the implementation. At first glance on service data unit (SDU) fragmentation, someone might skip this feature. However, that would cause big problem in some situations. When DBA allocates smaller amounts of bandwidth than the size of SDU in buffer, ONU cannot send this SDU and it must wait for higher allocation.
The simulator of XG-PON is controlled through command line. Parameters such as network load from ONU, used DBA, simulation time, and number of connected ONUs to ODN are set through command line. After the program finishes a simulation, it generates all results and events during simulation to text files. ONUs have one function in addition to the physical ONU. This feature represents a complete client devices simulation. It is unnecessary to simulate connected client devices to ONU, such as computers, smart phones, etc. Traffic is generated directly on ONU device as if it were a client device [
7].
Simulation starts from the point when all ONUs are properly connected to ODN, and they fully communicate with the OLT. So, the simulator skips all activation steps and starts in the Operating state (O5) [
7].
Simulation was run for every DBA algorithm separately. All common simulation parameters were set equally. Traffic flow generated in the simulations was 1 kB/s per ONU. So, every ONU generates every second 1024 B SDU. SDUs go directly to buffers and wait. This is not the correct value which is transmitted through ODN. To this we must add the overhead from XGEM and XG-PON transmission convergence layer (XGTC) frame, to which the SDU is encapsulated. In simulation we observe a lot of fragmentation, so this process adds some overhead data too.
Not all algorithms used in our simulation clearly describe how to allocate non-assured bandwidth and best-effort bandwidth. So, we decided not to simulate this bandwidth. We focus on allocation-identifier (Alloc-ID) 2, because this Alloc-ID uses only Assured bandwidth which all algorithms describe clearly.
4.1. Static Assignment
DBA algorithm in this simulation was set to static assignment. This pseudo DBA algorithm only assigns grants at the begin of the simulation. After that the algorithm does not make any changes in allocated bandwidth. For 10 ONUs the algorithm allocates 242 grants for all Alloc-IDs on every connected ODN.
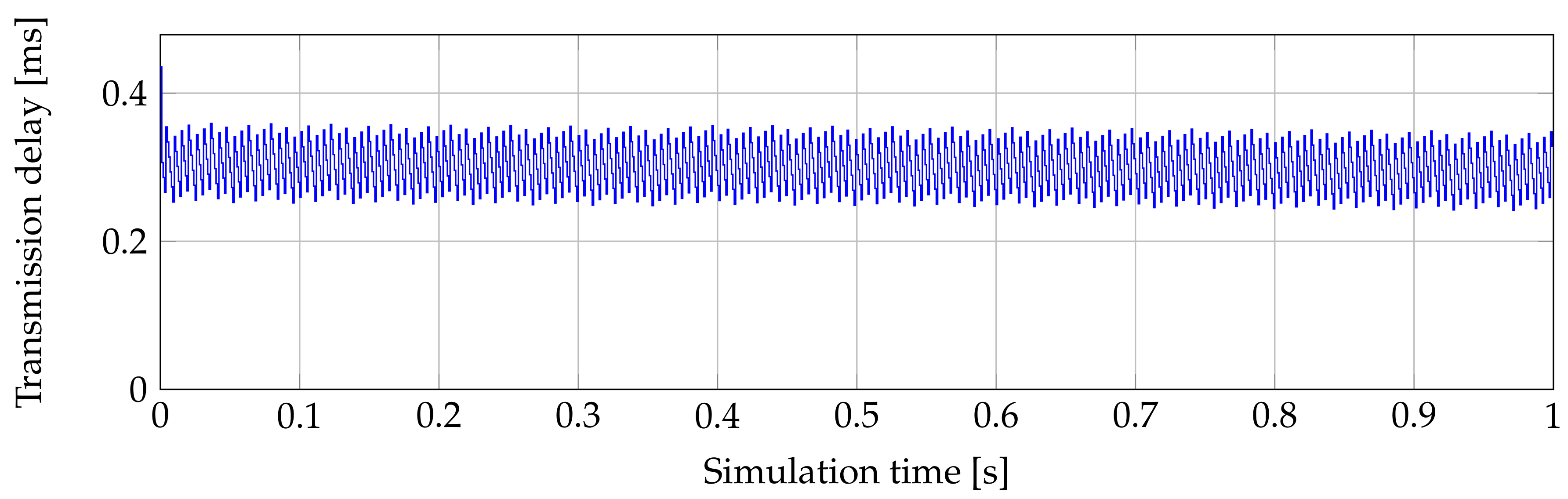
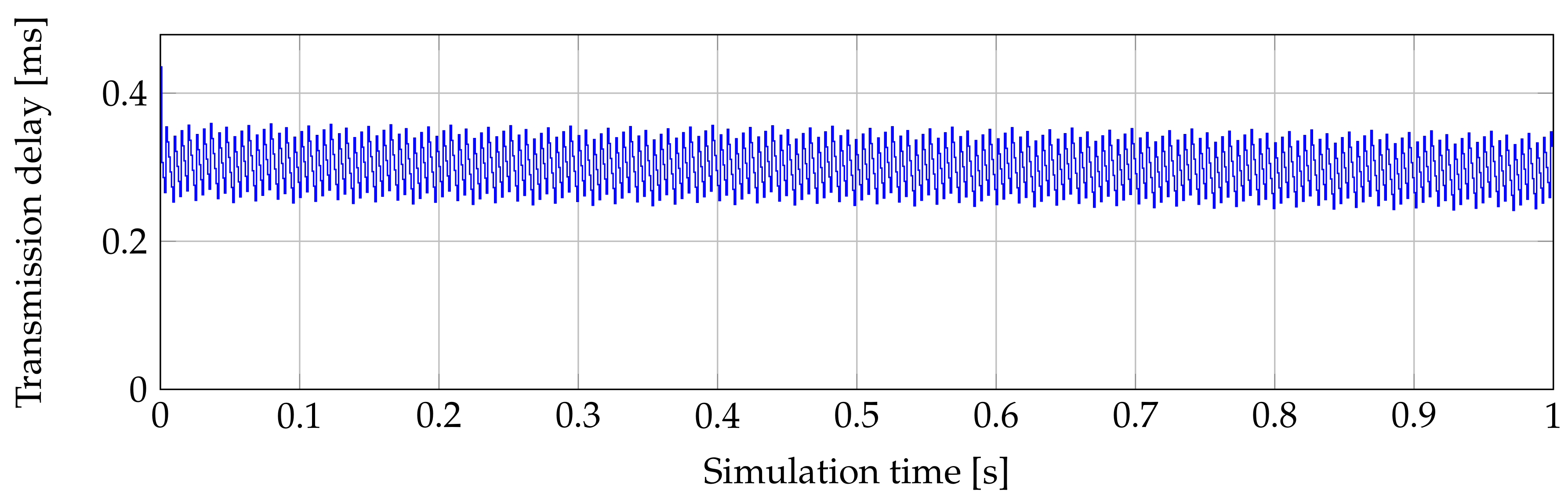
When we look at
Figure 2 at first we see a peak of 435.442
s. This is caused by waiting for the first allocation. After the OLT allocates bandwidth, the delay fluctuates between 250
s and 350
s. Fluctuations are caused by waiting time of SDUs in the buffer. ONU must wait for its allocated time slot. To this delay we must add the delay in the OLT buffer. When OLT processes an arrived SDU, OLT puts it to the downstream buffer. In the downstream buffer the SDU must wait until the next downstream XGTC frame is created. This process could take maximally 125
s.
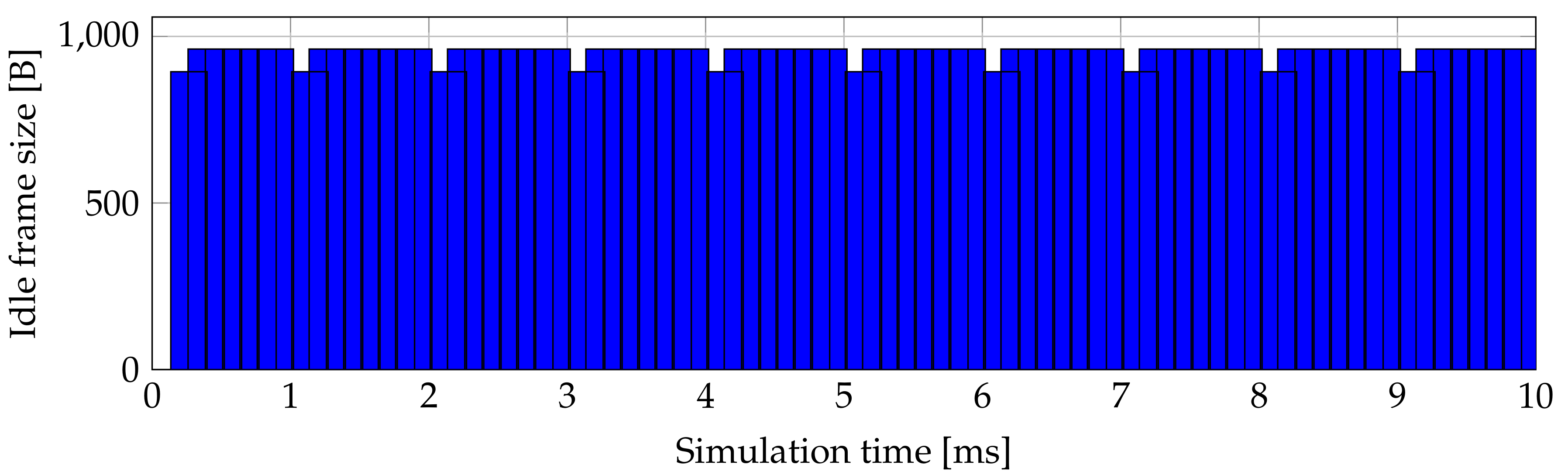
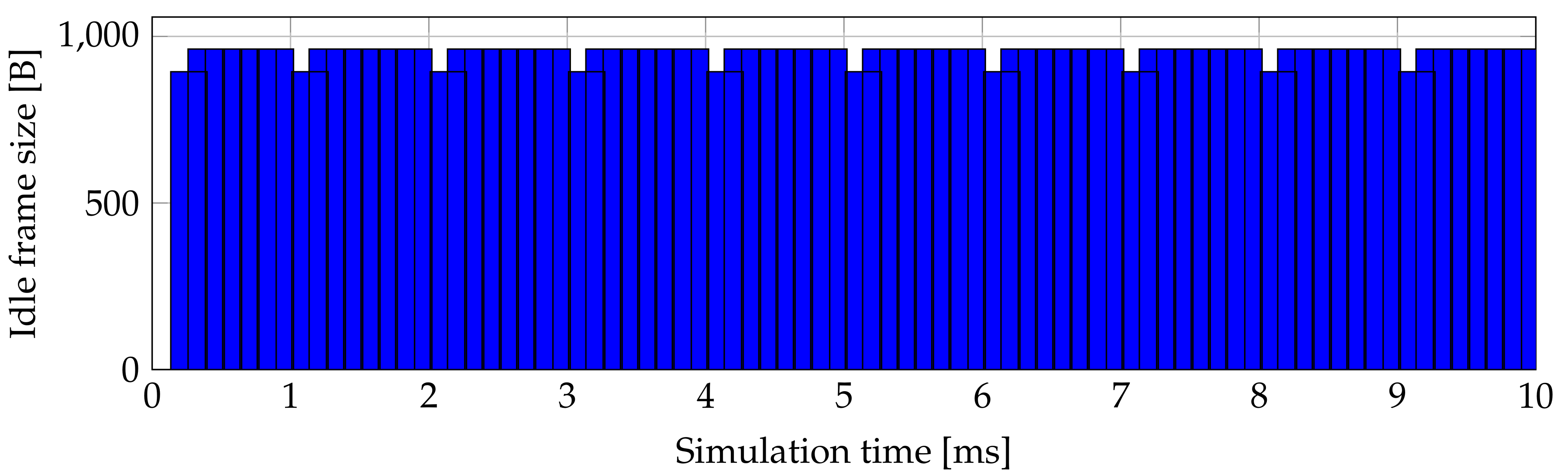
Figure 3 shows time and size of idle XGEM frames generated by the second ONU. It is clear for static assignment that the value fluctuates between 894 B and 962 B. Value 962 B represents the situation when the ONUs upstream buffer is empty and the ONU does not have data to send. ONU cannot transmit whole SDU with size 1024 B if its bandwidth allocation is smaller than 1024 B, so it must use fragmentation. The ONU first sends upstream XGTC frame filled with XGEM frame, which contains SDU of maximal size that was allocated to the ONU. After that, the ONU processes the second fragment of SDU and fills remaining bandwidth with an idle frame with length of 894 B. Static assignment lead to generation of many idle frames. When we counted it, it was 69 idle frames generated in 1 ms of simulation. In whole 1 s simulation all ONUs generate 6.67 MB—see
Table 2. Assignment of DBA was not changed during simulation, so all ONUs generate the same value. These values are the worst, respectively the highest of all algorithms tested in our simulations. When we look at
Table 3, we find out that with static assignment transmission the delay through ODN is the smallest, when we compare the value with real DBA algorithms, because ONUs do not wait for assignment sufficient bandwidth and ONUs can send SDUs immediately to OLT. This works only in case that traffic load of that ONU is not higher than the allocated bandwidth.
This pseudo DBA algorithm is useful in real deployment only in special cases, such as when ONUs have same traffic flow at all time while traffic load of ODN is not higher than maximum capacity of XG-PON. In other cases, this algorithm is not useful, because it wastes a lot of bandwidth. This wastes of bandwidth can be eliminated through real DBA algorithms. There is also a case when load of an ONU is higher than allocated bandwidth, and other ONUs are not fully loaded. In that case the loaded ONU delayed SDUs. When a network uses a real DBA algorithm, it can allocate higher bandwidth for certain time by reduction of bandwidth allocated to no loaded ONUs. Loaded ONU thus gains an opportunity to faster emptying the buffer and not to delay SDUs. Then the DBA algorithm shrinks bandwidth and other ONUs have an opportunity to get more bandwidth to allocate.
4.2. Max–Min DBA
In our implementation of this algorithm, we decided to set the fixed bandwidth to three grants. Fixed bandwidth is allocated to Alloc-ID 1 of all ONUs regardless the current network load to Alloc-ID one [
10]. We implement the first type, which computes the value from previously allocated grants. The authors of this algorithm claim the Max–Min DBA algorithm is hybrid, so it uses SR and TM methods for detection of the current buffer occupancy of every ONU. However, they do not describe how. So our implementation uses only the TM method.
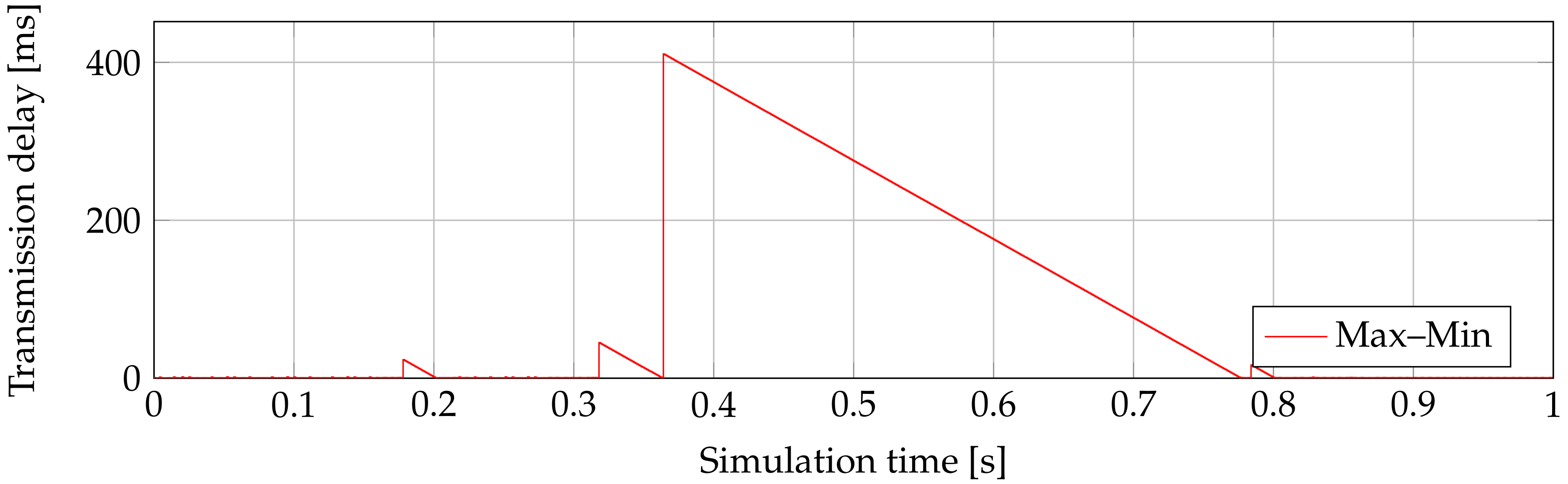
Our implementation of the Max–Min DBA algorithm provides the worst average transmission delay compared with all tested DBAs.
Table 3 clearly shows that the value of 109 ms is the maximum average delay. This value was measured on first ONU. The lowest average delay of 28 ms was made by the fifth ONU. This delay is also the worst if we compare this highest value with all highest delays measured in all tested DBA algorithms.
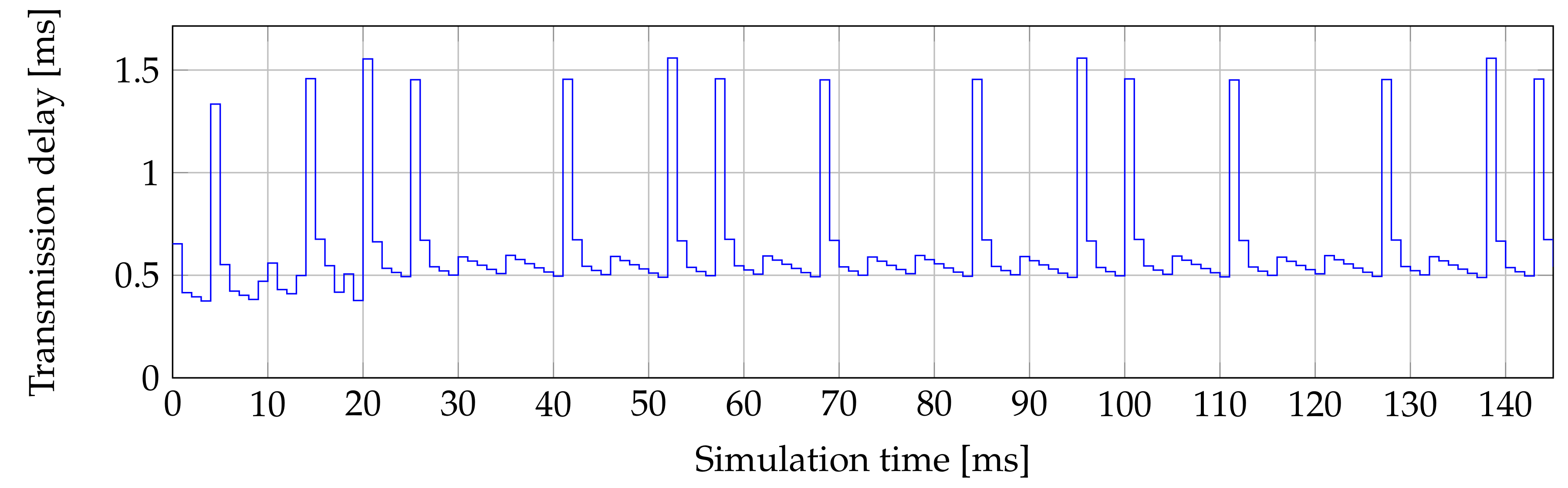
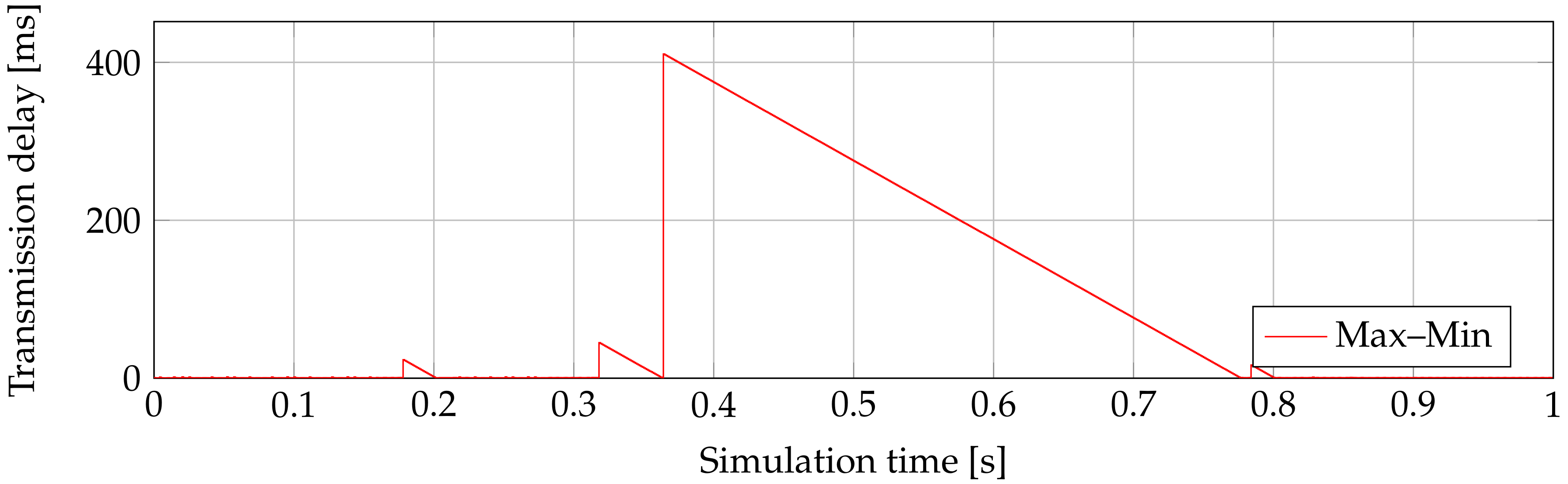
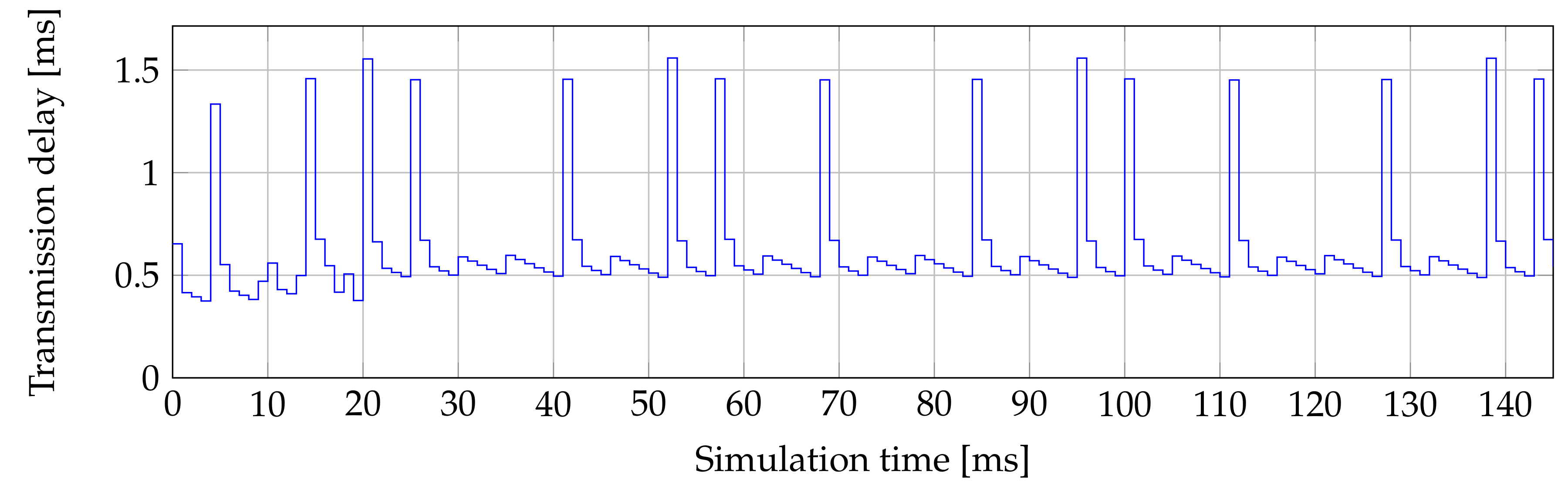
Figure 4 shows the transmission delay for the second ONU, where peaks of 1.85 ms are in 150 ms of simulation. This issue occurs in the whole 1 s simulation. Delays can reach 360 ms in maximal values. These values then make the worst average delay.
However, this algorithm is not the worst at all. It is the second-best DBA algorithm to save bandwidth as
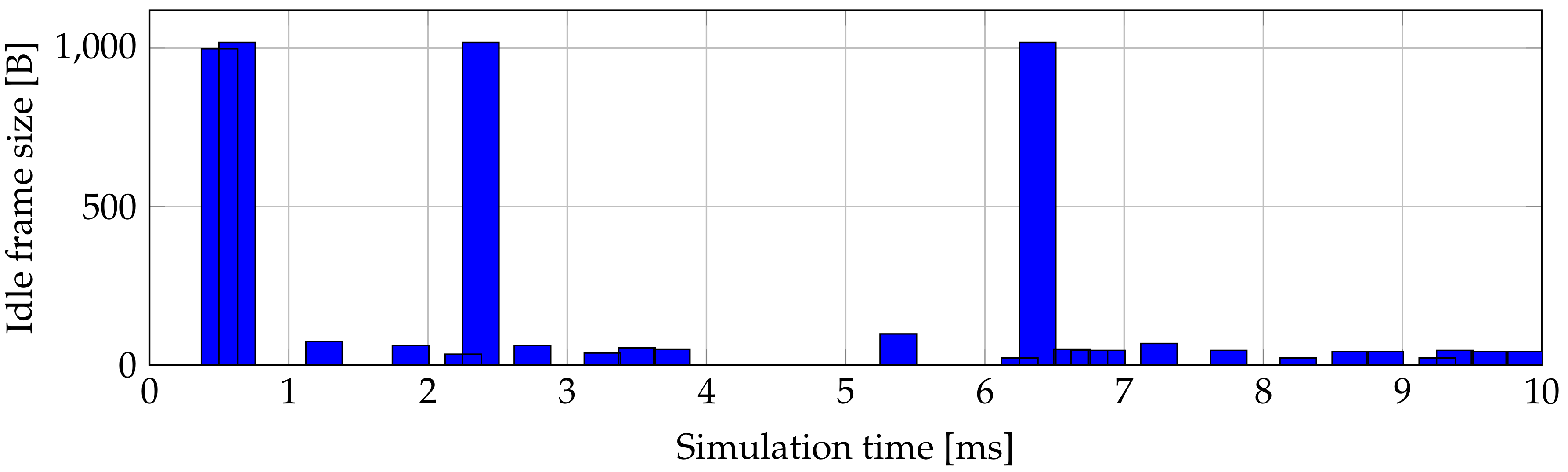
Table 2 shows. Sum of all idle XGEM frames generated by the sixth ONU is 1 MB, which is the highest value for that DBA algorithm. The lowest value generates the first ONU, where the sum is 0.45 MB. Second ONU generates 26 idle XGEM frames in 10 ms of simulation. Size of these frames is described in
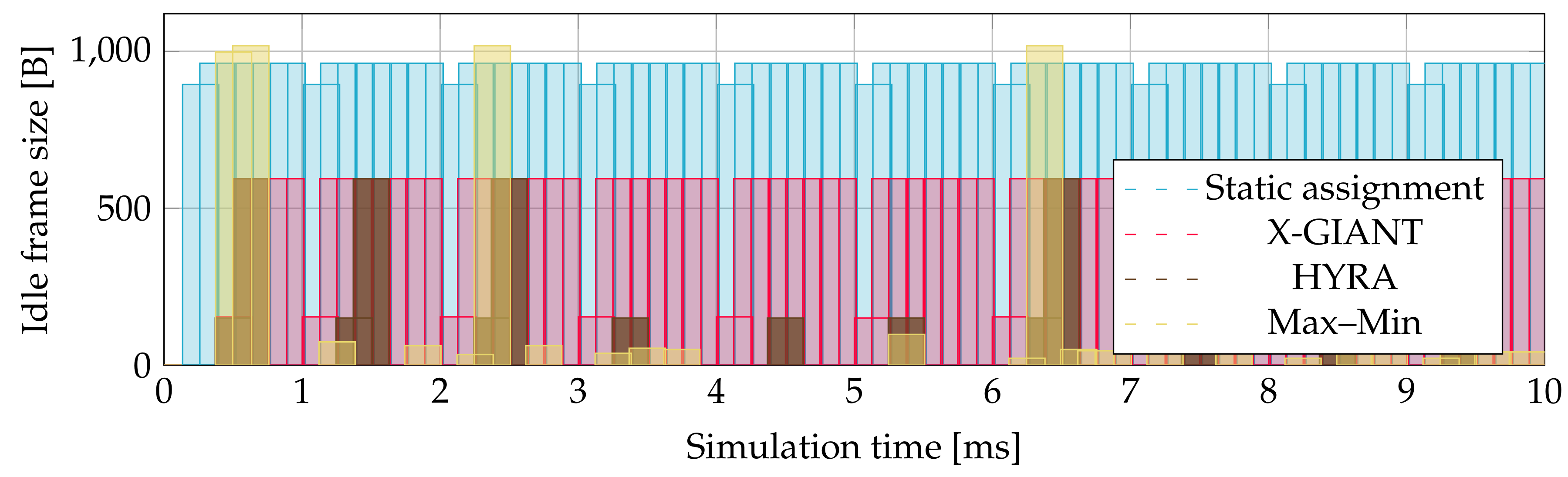
Figure 5. All ONUs generate similar number of IDLE frames of similar size in 10 ms of simulation. Average size of IDLE frames in whole simulation was between 0.45 and 1.125 MB, we decided to present the results of the second ONU which is in the middle of these Figures.
4.3. Hybrid Reporting Allocation
In our implementation of this algorithm, we decided to set the fixed bandwidth to six grants. Assured bandwidth was set as authors in the paper [
8] did to 125 words. Max bandwidth was set to 150 words. Values
L and
a were same as the authors proposed in their paper, so
L was set to 0.1 and
a to
.
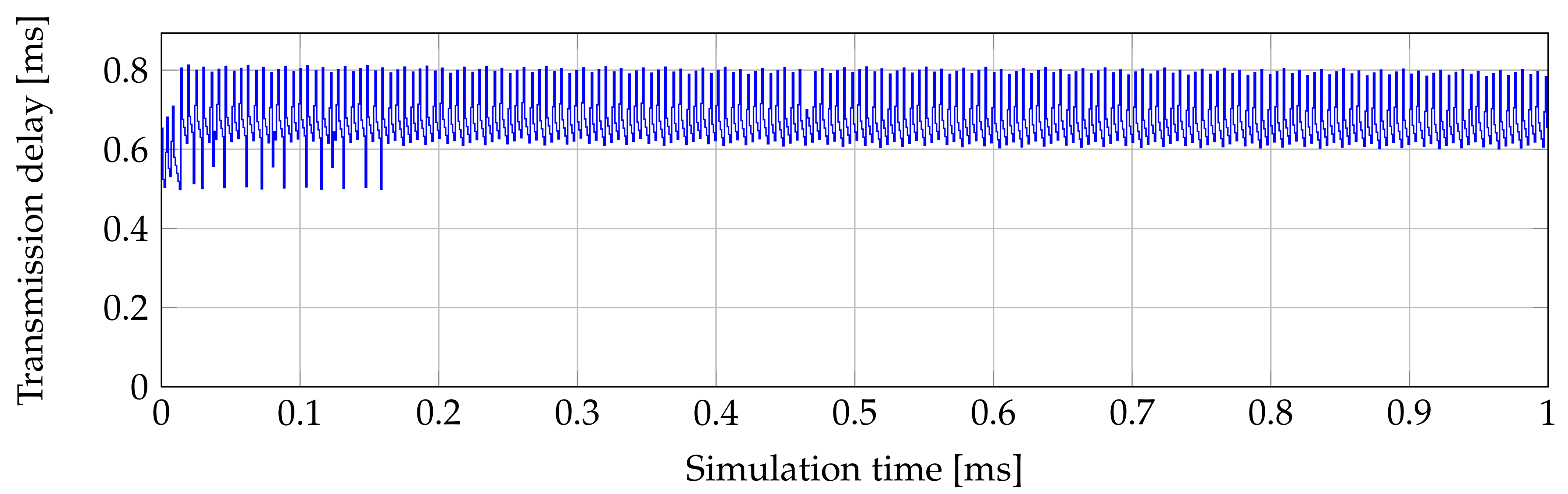
Figure 6 shows the SDU delay of transmission from the second ONU to OLT and back to ONU. The learning period of the algorithm, which takes less than 200 ms is clearly visible. After the algorithm learned the probabilities, the delay fluctuates between 600
s and 800
s with a tendency to decline. This algorithm makes the lowest jitter in tested real DBA algorithms, after the algorithm learns the probabilities, but a static assignment can generate the lowest jitter.
Grants allocated to the second ONU were very varied with the maximum value of 150 words, as can be seen in
Figure 7. 150 words is the correct value because we set the maximum allocated bandwidth to 150 words. There are no values between 150 and one grant. This is also correct, because we generate 1024 B SDUs, so it is 250 words without the overhead. So, when an SDU arrived at the buffer, ONU sent its buffer occupancy to the OLT and HYRA has enough bandwidth to allocate the maximum bandwidth. When the ONUs buffer is empty, ONU starts sending idle XGEM bursts with the value of buffer occupancy equal to zero. HYRA decided to allocate the minimal bandwidth which is one word. One word is minimal because ONU needs to report periodically its buffer occupancy. If we set this value to zero, ONUs will lose opportunities to send any upstream XGTC bursts, so the OLT will decide that this ONU does not need any bandwidth, and thus the ONU will be forever without bandwidth.
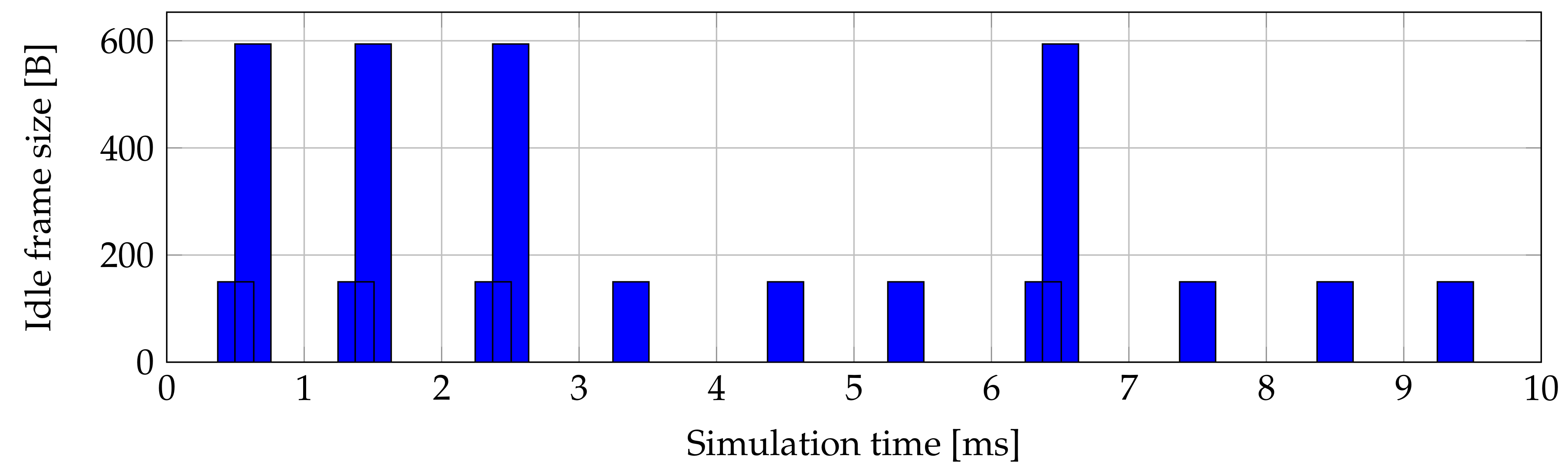
Figure 7 shows the size and when the second ONU sends idle XGEM in 150 ms of simulation. It is clearly visible that firstly there are not sent any XGEM idle frames, because the whole XGTC frame was filled with an XGEM frame that the contains SDU with maximum value of allocated bandwidth. After that, the ONU sends a fragment of SDU and adds to the XGTC frame an idle XGEM frame with the size of 150 B. An idle XGEM frame is also sent when the ONU has empty buffer and the ONU has still allocated bandwidth from previous buffer occupancy. Total number of sent idle frames in 10 ms of simulation was 15.
HYRA is the best choice for minimal waste of bandwidth in the selection of real DBAs. As described
Table 2, the average size of generated ONUs is between 0.29 and 0.43 MB. It is not the best choice for minimal delay. Delay with the HYRA algorithm is between 0.68 and 0.9 ms, as described in
Table 3.
4.4. X-GIANT DBA
The X-GIANT DBA algorithm works with 6 parameters. We used same values as the authors of the paper [
9]. However, authors in [
9] experimented with SiMax and SiMin. So, we decided to set the parameters as described in
Table 4.
When we compared this algorithm with Max–Min we found that the delay of every ONU is much smaller. Comparing two maximal average transmission delays, we found out that both are by first ONU and values differ by 108.81 ms. Maximal average transmission delay of all algorithms was made by the Max–Min DBA algorithm. When we compare average transmission delay from second ONU with static assignment and again transmission delay of first ONU with Max–Min, then we found extremes. These values differ by 108.94 ms. All average values of delays with X-GIANT algorithm are summarized in
Table 3.
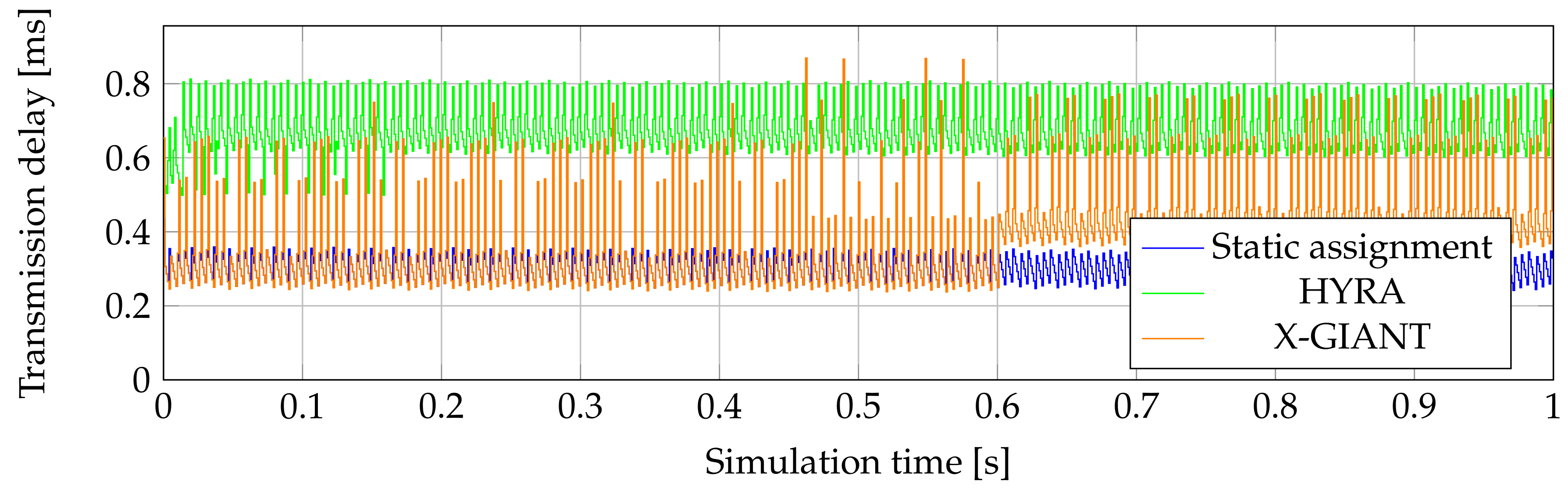
Average delay of the second ONU with algorithm X-GIANT in first 150 ms shows
Table 3. Values are comparable to static assignment, except peaks. Peaks can reach 0.89 ms in the whole 1 s simulation. In first 150 ms peaks reach maximum value of 0.65 ms. Considering the average delay, the algorithm took the first place in real DBAs. When comparing it with static assignment, static assignment is still better. Maximal average value was measured on the first ONU, with the value of 0.43 ms. Minimal average delay was on the third ONU, with 0.35 ms. First 150 ms of simulation are shown in
Figure 8.
Considering use of bandwidth, the algorithm is the worst of real DBAs. However, it is still better than static assignment, which took twice the value. The lowest sum of generated idle frames in whole simulations, was measured on the fourth ONU with the value 3.06 ms. The highest value was 3.12 ms, measured on the ninth ONU. All values are shown in
Table 2. In 10 ms of simulation the second ONU transmits 66 idle XGEM frames, which is not the highest. The highest value generates static assignment. First 150 ms of simulation are shown in
Figure 9.
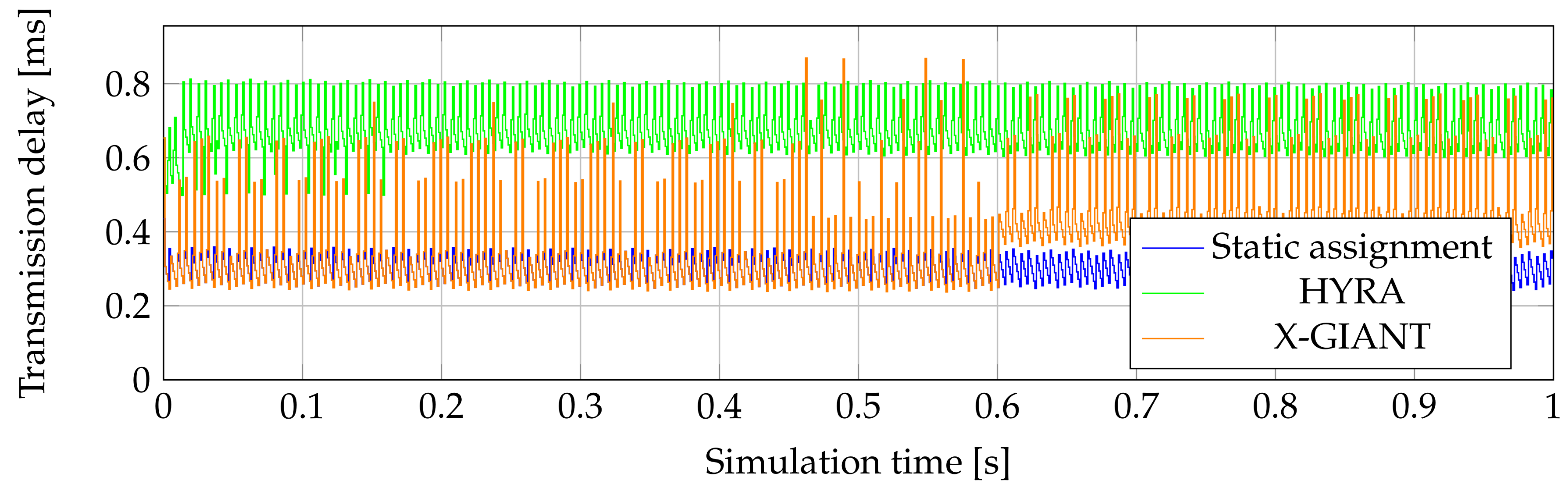
Figure 10 and
Figure 11 show transmission delay from second ONU in 1 s simulation. Max–Min DBA algorithm was separated, because algorithm generates a more significant transmission delay in comparison with other algorithms. It is clearly visible from Figures that X-GIANT generates the lowest average transmission delay, if we compare real DBA algorithms. The lowest values reach values same as static assignment. HYRA generated the second highest delay. This delay still does not make any problems, because the values were larger by about 400
s when compared with static assignment. The advantage of the HYRA DBA algorithm shows
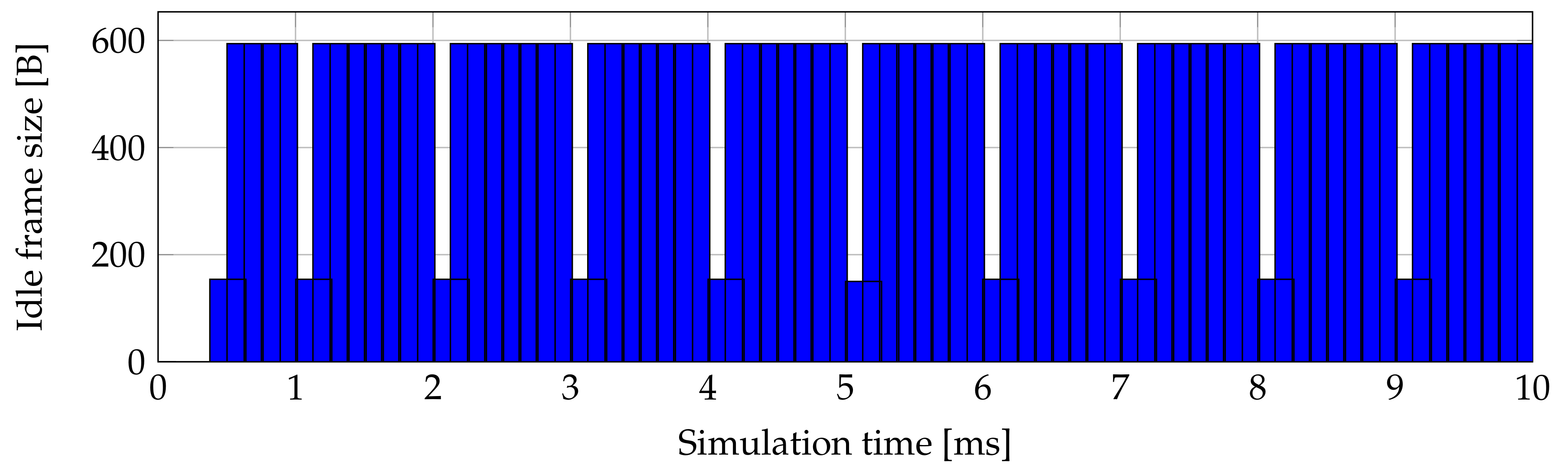
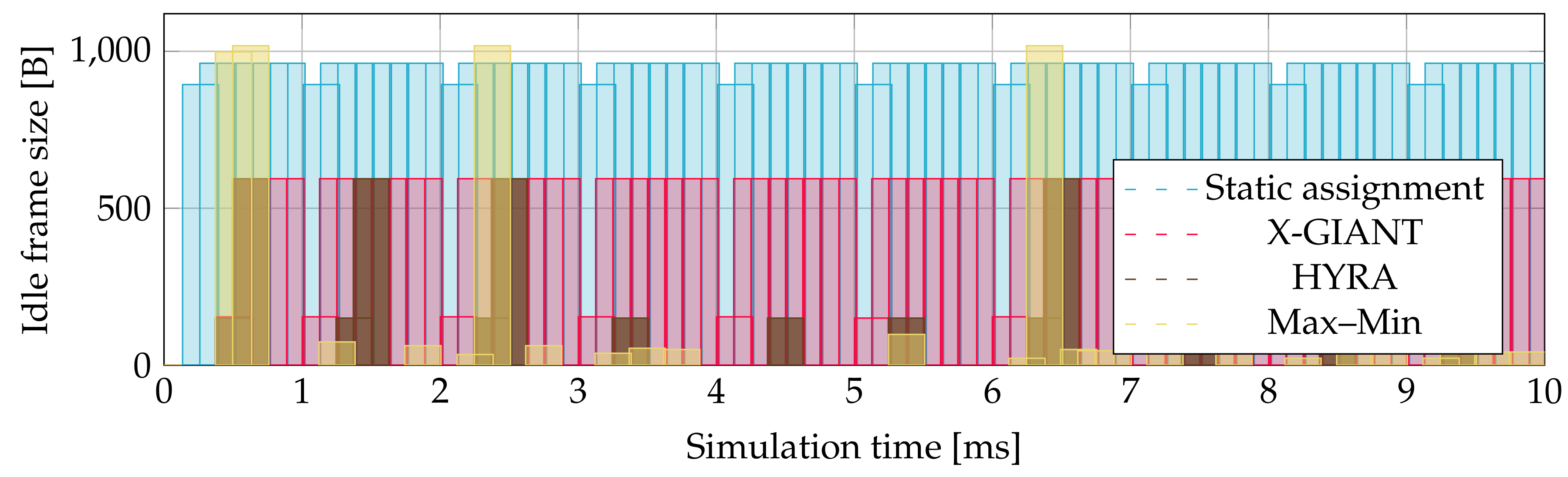
Figure 12, which shows generated idle frames and their size by second ONU in 10 ms of simulation. The advantage is that this algorithm generates small amount of unnecessary traffic flow.
5. Conclusions
Today’s networks have very variable network flow. Without sophisticated DBA algorithms, XG-PON networks cannot achieve fast adjustment to current conditions. Static assignment has some advantages, as that ONUs have the lowest transmission delay, but only in some cases. When network load of at least one ONU is higher than the allocated bandwidth, for example in our case with 10 ONUs, 969 B for one allocation is sufficient to gradually overflow the buffer. XG-PON networks need a DBA algorithm which is fair, generates lowest delay on ODN and minimally wastes the bandwidth. In our simulation approach with tested DBAs, we found two options. Both two options are a compromise in higher delay or higher waste of bandwidth. The Max–Min DBA algorithm has lower waste of bandwidth, but transmission delay was very high. For it we decided not to choose this algorithm at all. The HYRA DBA algorithm is a proper choice when the major network requirement is the low bandwidth waste. The X-GIANT DBA algorithm is a proper choice when the major network requirement is the low delay.
The future work will be an implementation of our modification of the algorithm and improvement the current implementation with an activation process with tuning process for NG-PON2 networks.

 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}