Wearable Travel Aid for Environment Perception and Navigation of Visually Impaired People


Abstract
:1. Introduction
- Design a lightweight Convolutional Neural Network (CNN)-based 2.5D object-recognition module which combines depth image-based object-detection method to provide obstacles’ category, location, and orientation information, and integrate this module into our previous work [10,11] to improve the environment perception ability of VIP and promote navigation.
- Propose an adaptive ground segmentation algorithm that uses an adaptive threshold computation algorithm and uses ground height continuity among adjacent frames.
- Present a walkable direction search method to guide VIP to his/her destination.
2. Related Work
2.1. Vision-Based Assistive Systems for VIPs
2.2. Deep Learning-Based Object Recognition for VIPs
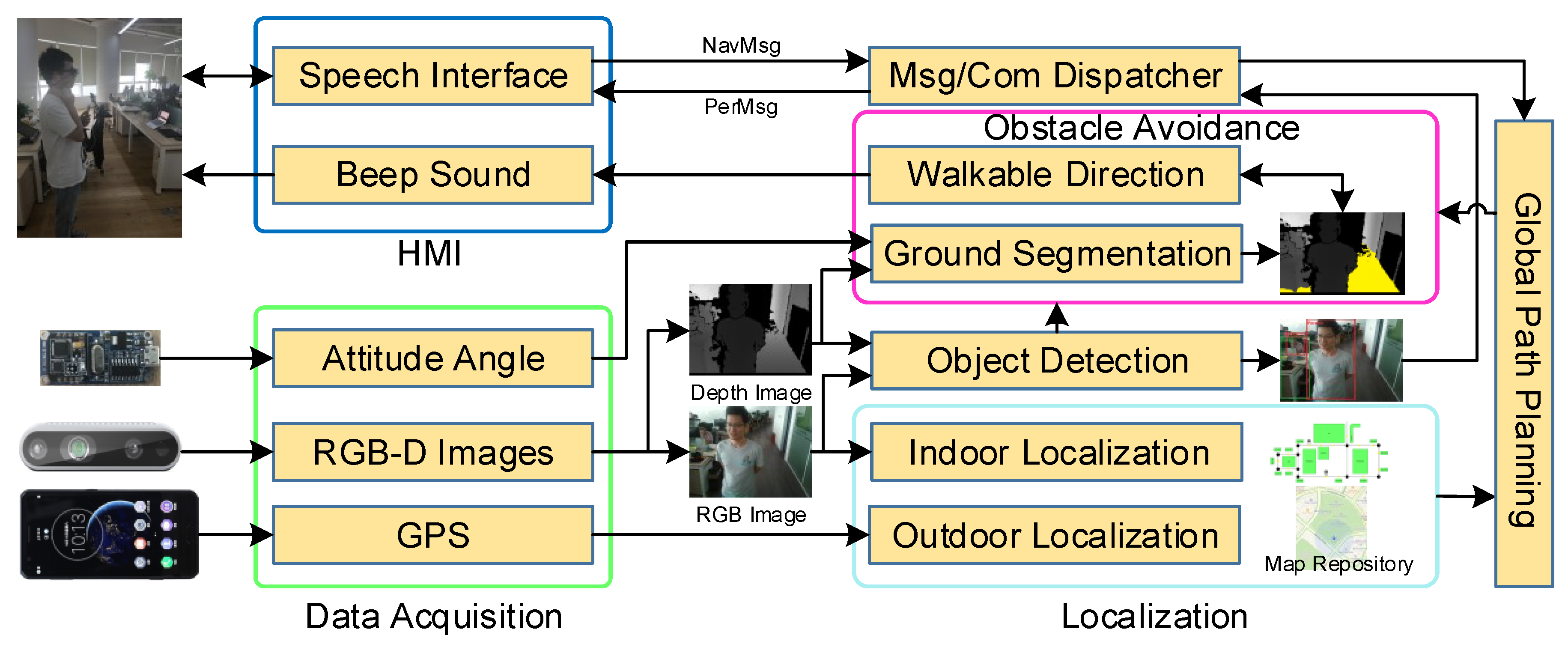
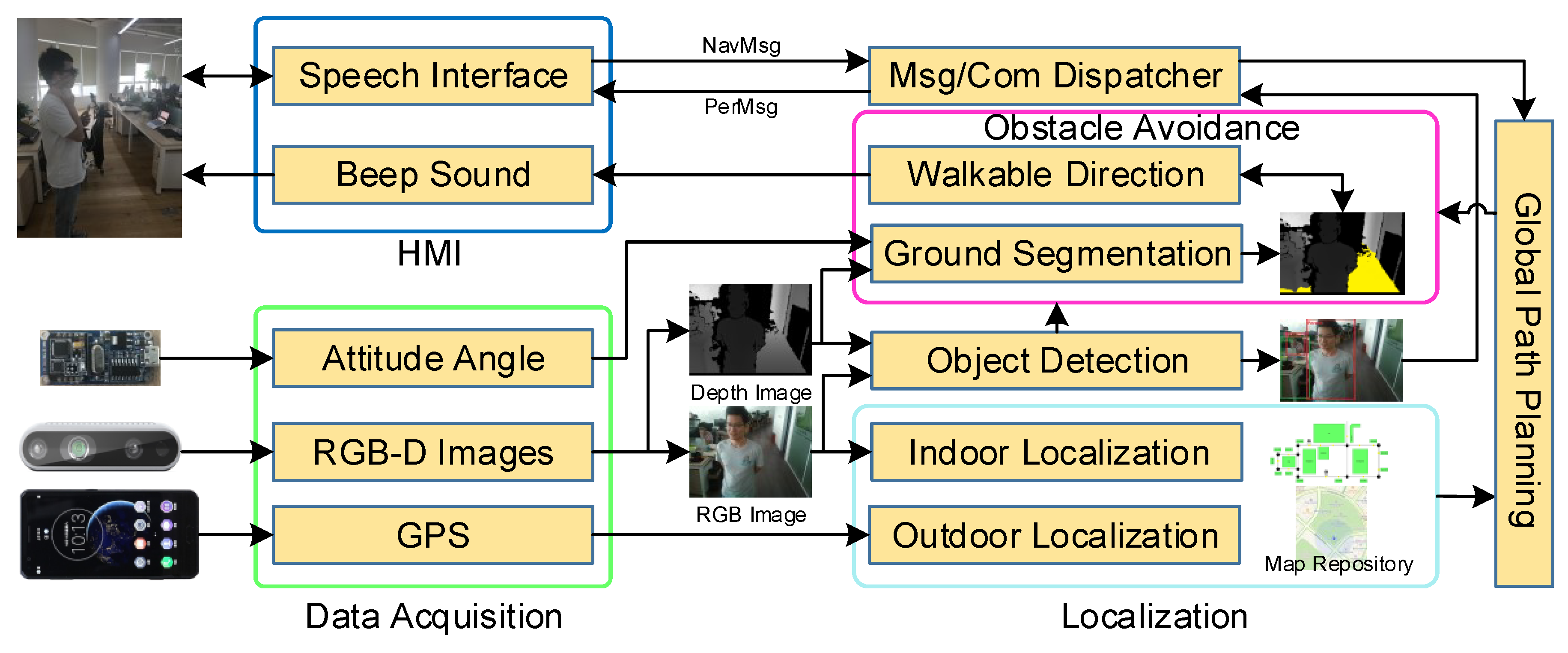
3. System Design
- A speech interface module, which acquires and recognizes verbal instructions from the user, e.g., to indicate a desired destination.
- An RGB-D camera (Intel RealSense D435), which captures the depth and color images in both indoor and outdoor scenarios and forwards the images to the navigation or recognition system.
- An IMU sensor, used to acquire the attitude angle of the camera.
- A smartphone, used to obtain the current position of the user in the outdoor environment, perform the navigation and object-recognition algorithms, and play the audio feedback.
- A dataset including many common objects such as chairs, desks, cars, pedestrians, etc., used in the recognition system.
- A speech interface module to convert the output of navigation system into a beeping sound and the output of recognition system into speech.
- The recognition system outputs the object’s category, distance, and orientation.
3.1. Navigation System
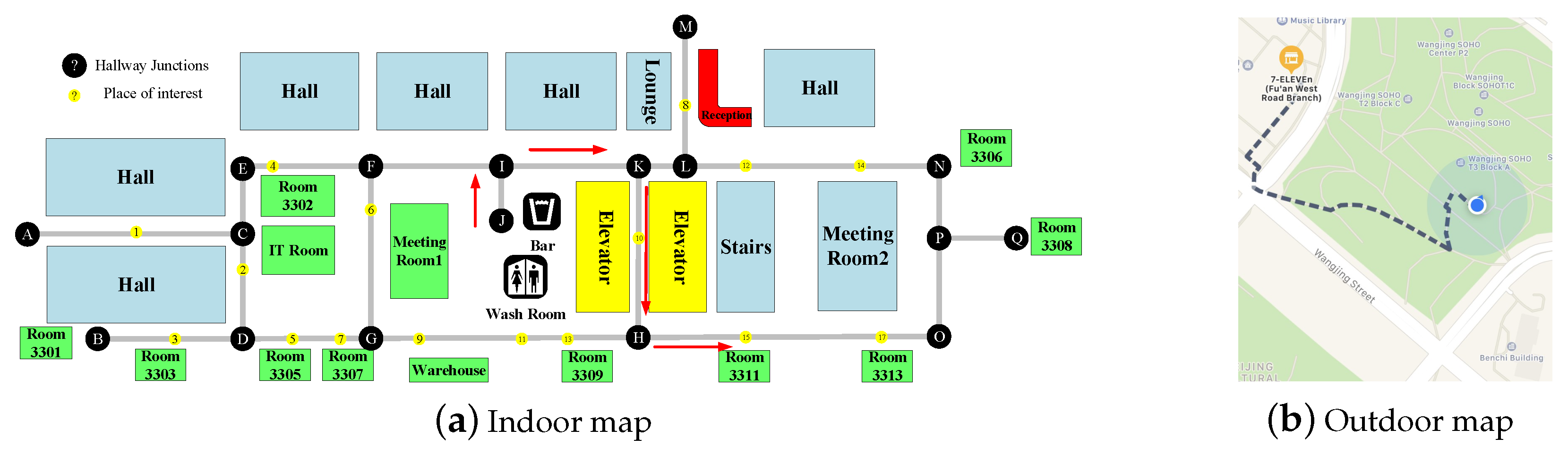
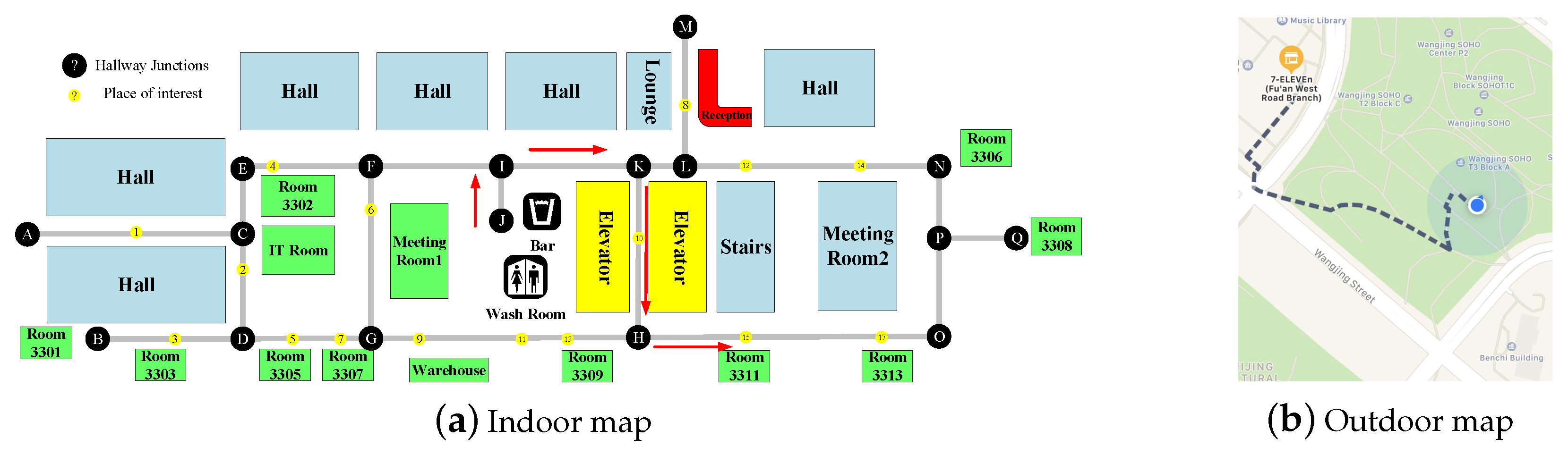
3.1.1. Localization Module
3.1.2. Global Path-Planning Module
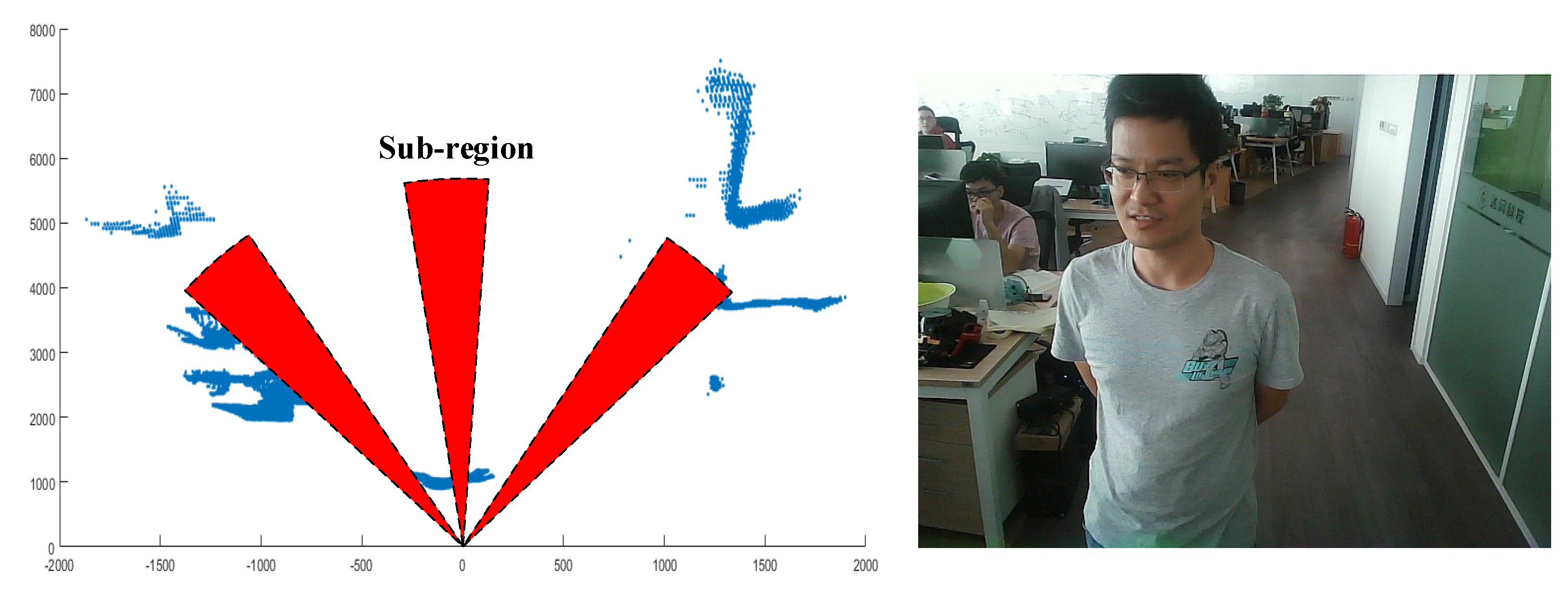
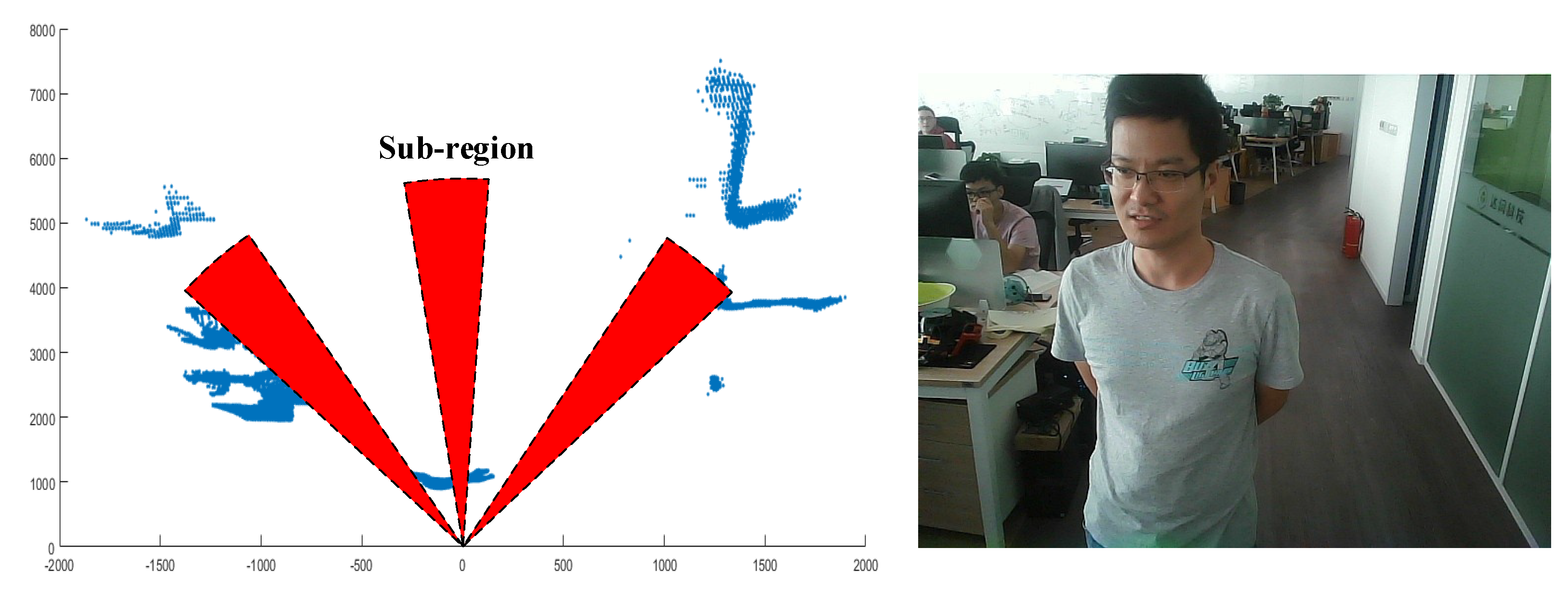
3.1.3. Obstacle-Avoidance Module
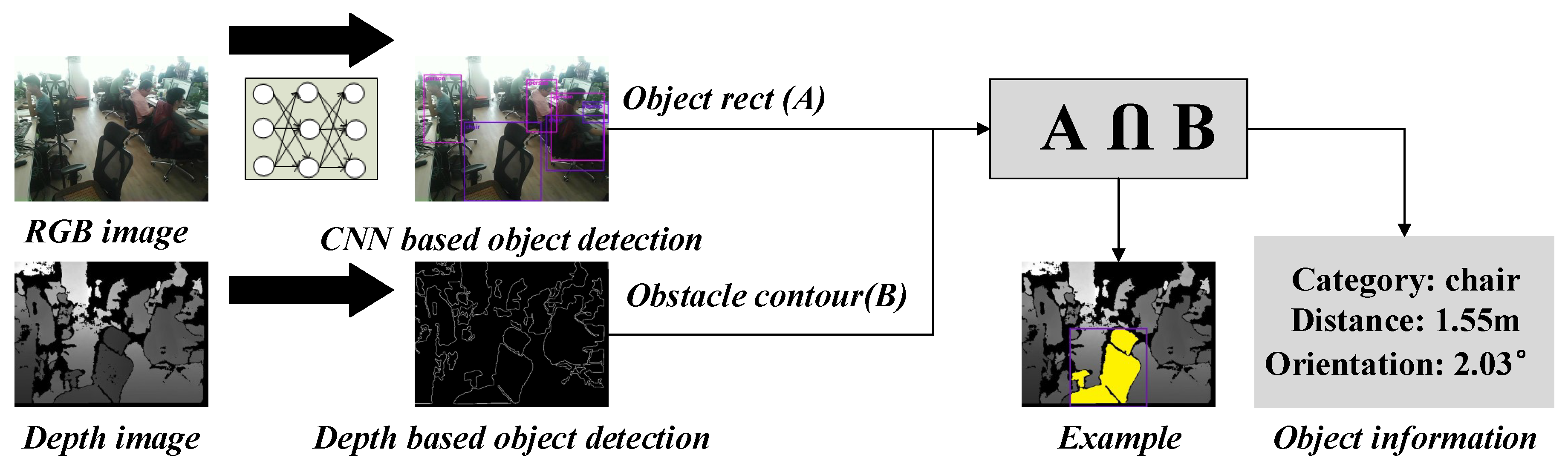
3.2. Recognition System
3.2.1. CNN-Based Object Detection
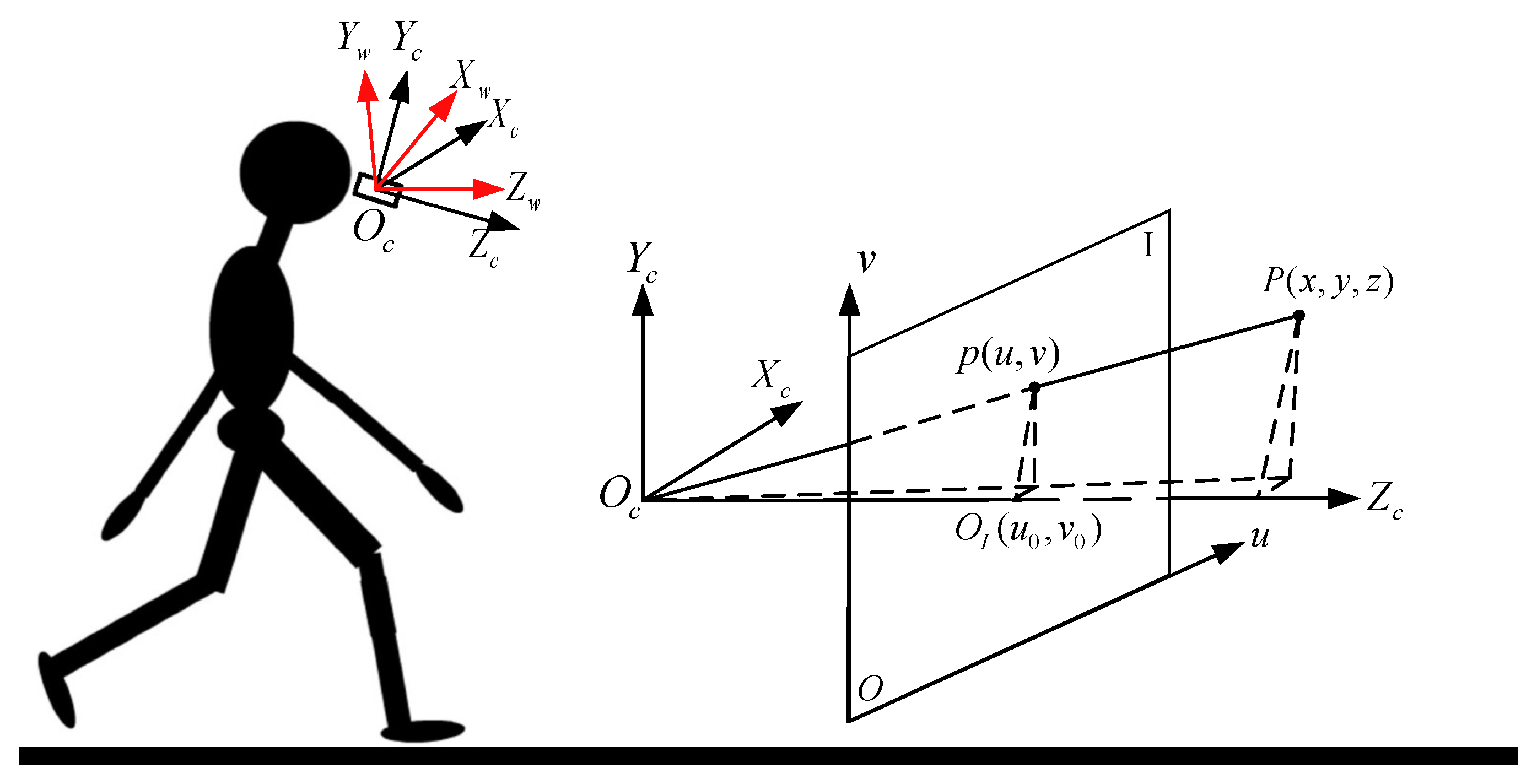
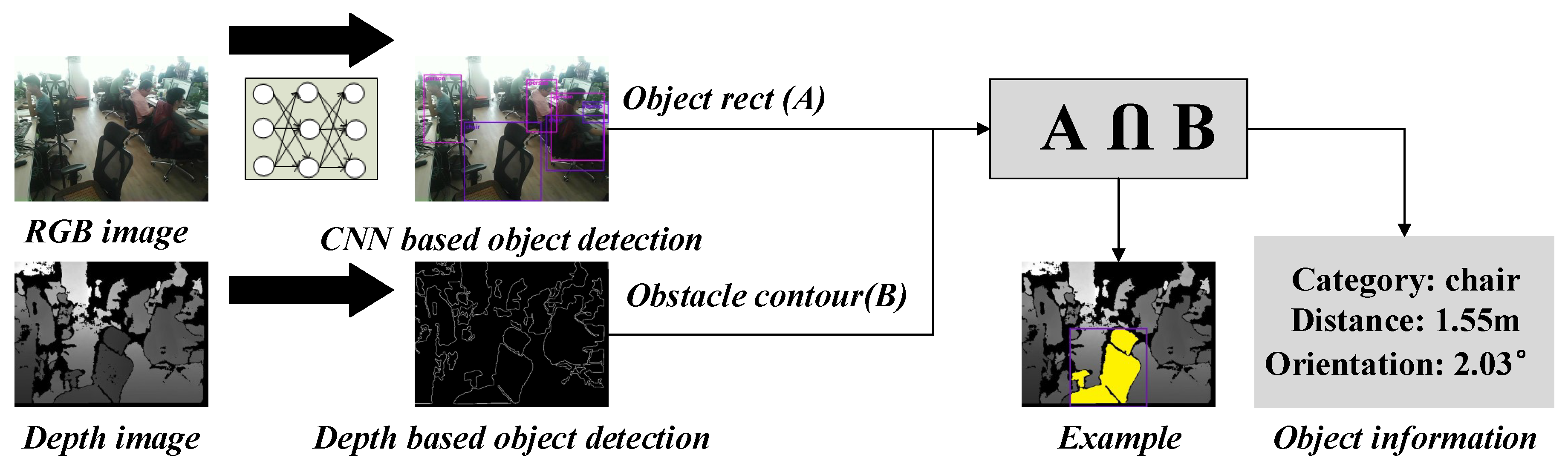
3.2.2. Depth-Based Object Detection
- Remove the ground area from the depth image.
- Fill the holes and perform close morphological processing to reduce the noise, isolate individual elements, and join disparate elements in the depth image.
- Extract the external contours of the objects and compute the corresponding area.
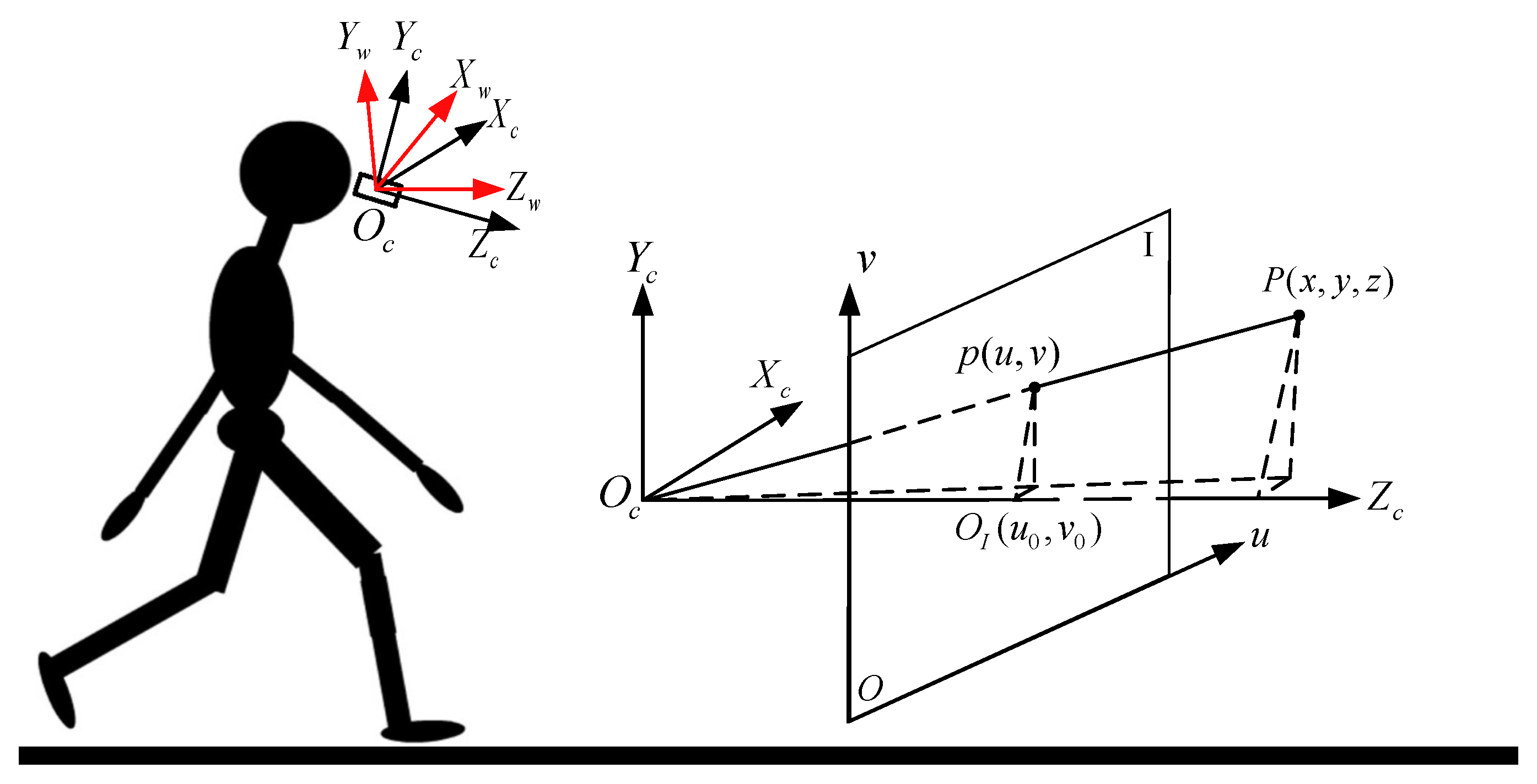
- If the contour area is less than a threshold S, the corresponding contour will be taken as noise; otherwise, the zero-order moment and the first-order moment of each contour is obtained. Then the centroid of the contour is calculated through:
- Based on the contour centroid and the mapped object box, the intersection (see the yellow region in Figure 8) can be obtained:
- If ( represents the area of region i) is greater than a threshold (e.g., 0.7), it means the mapped box and the detected contour is the same object. Then the object distance is the minimum non-zero depth value within the intersection area C, and the object location and orientation information relative to the user can be obtained by:where is the contour centroid, and are the camera intrinsic parameters which are the same with Equation (1).
3.3. Human–Machine Interaction
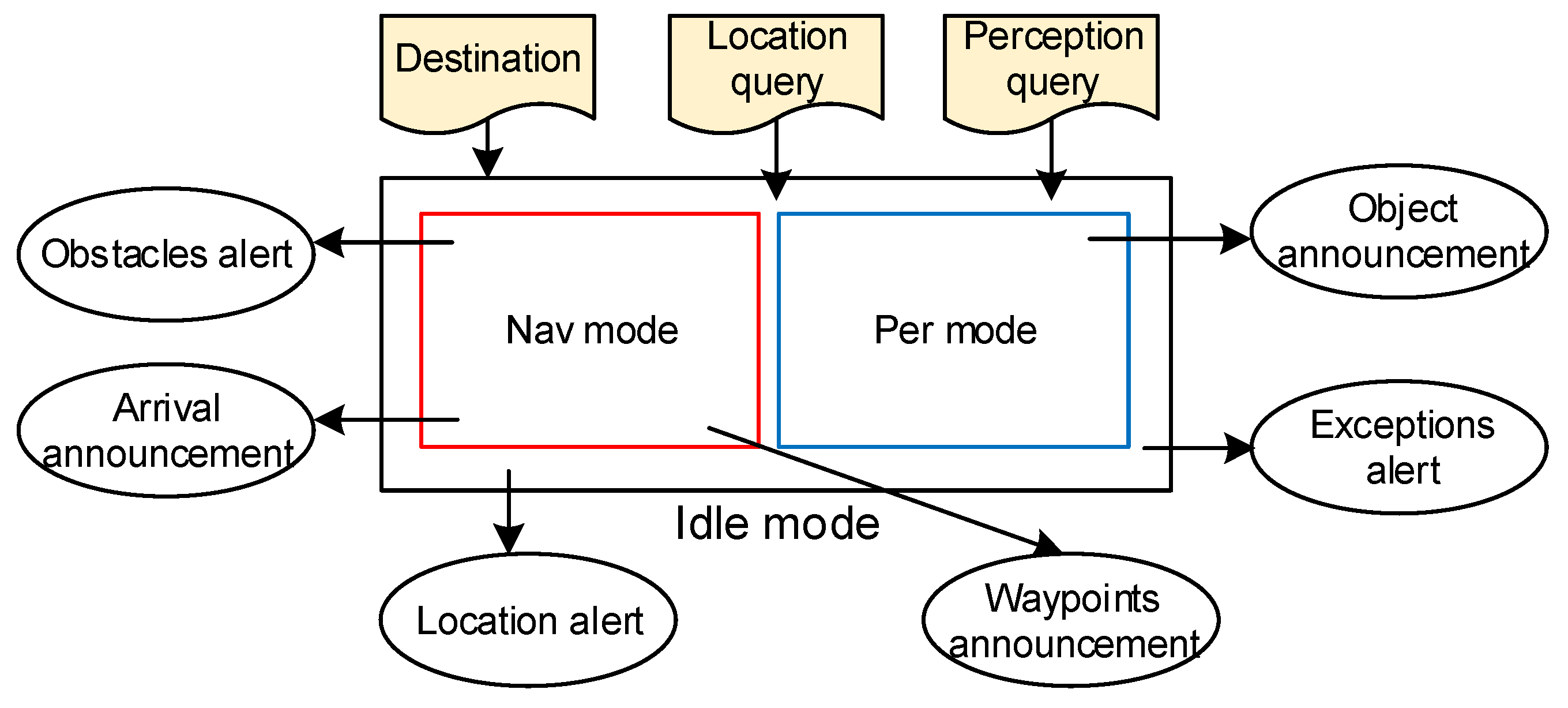
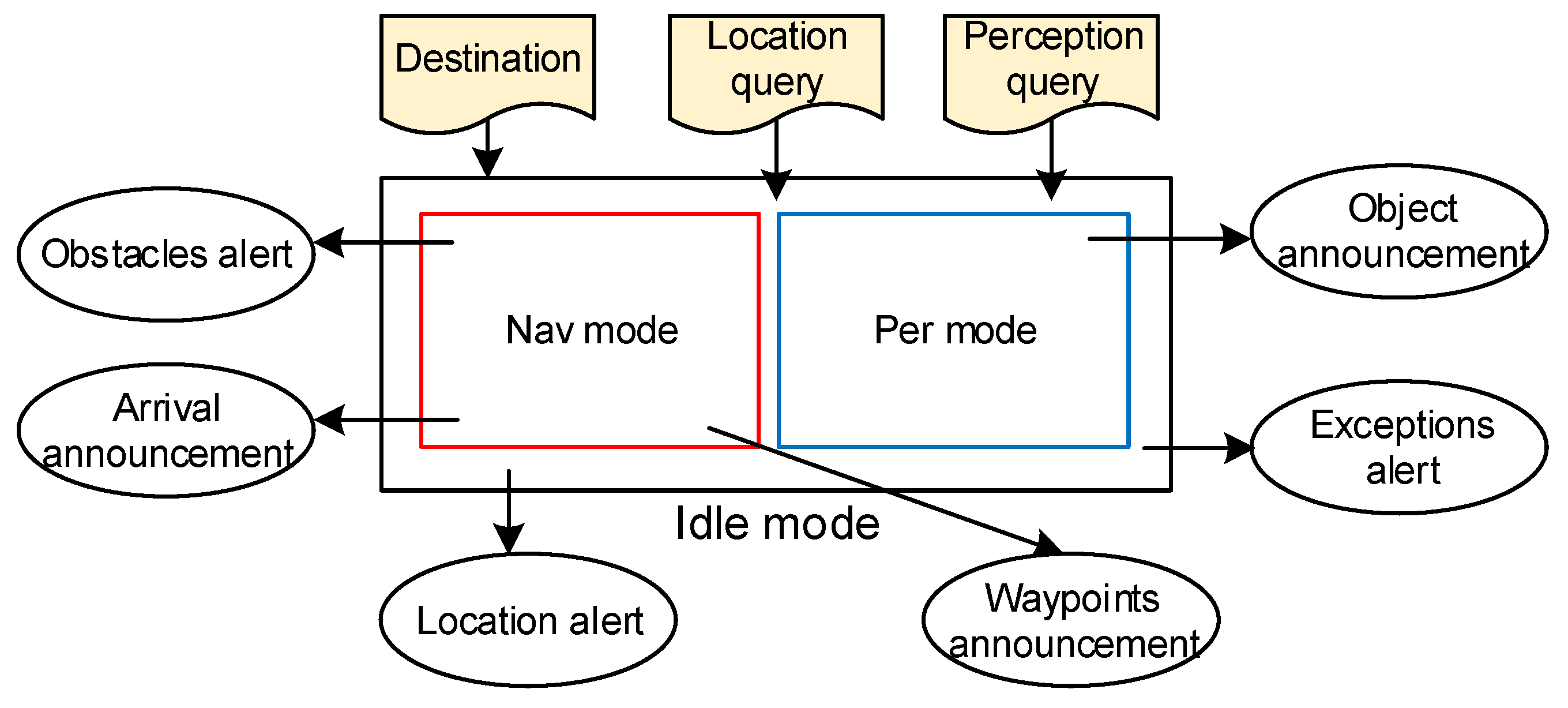
3.3.1. Operational Mode
3.3.2. Speech and Audio HMI
4. Experimental Results and Discussions
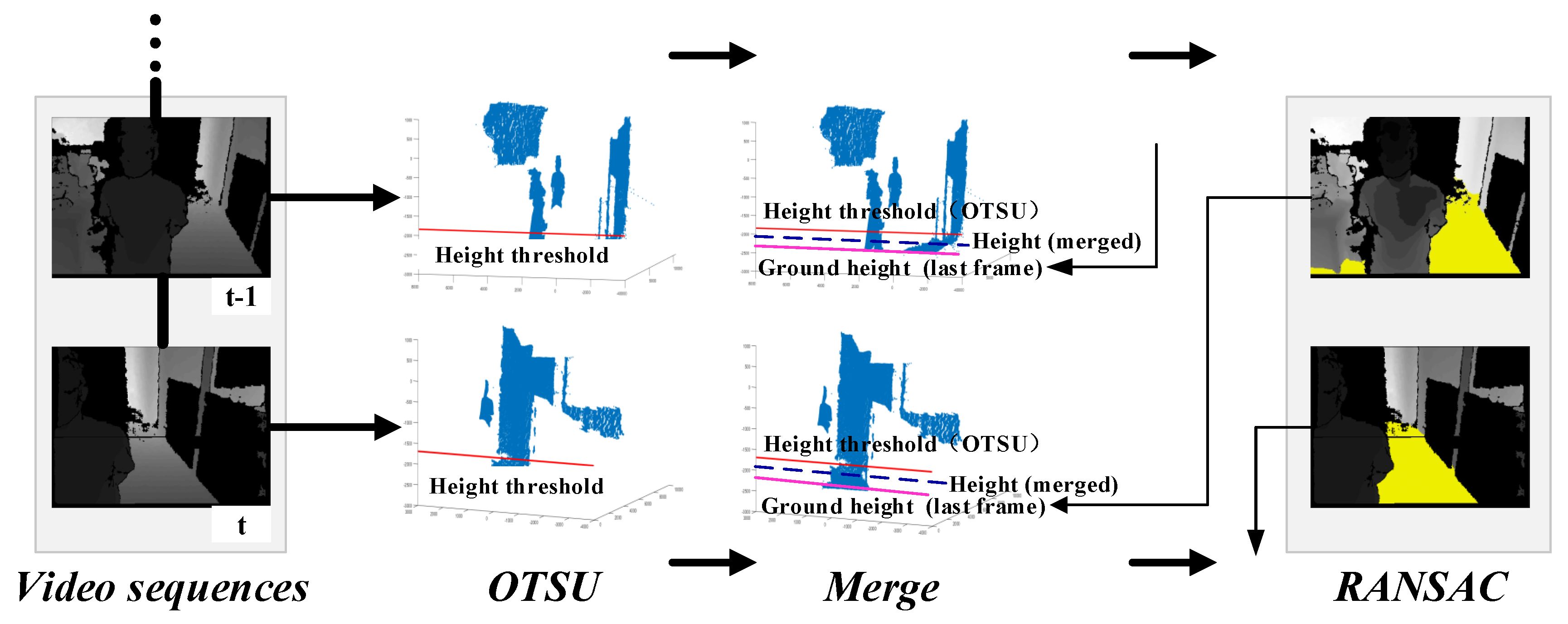
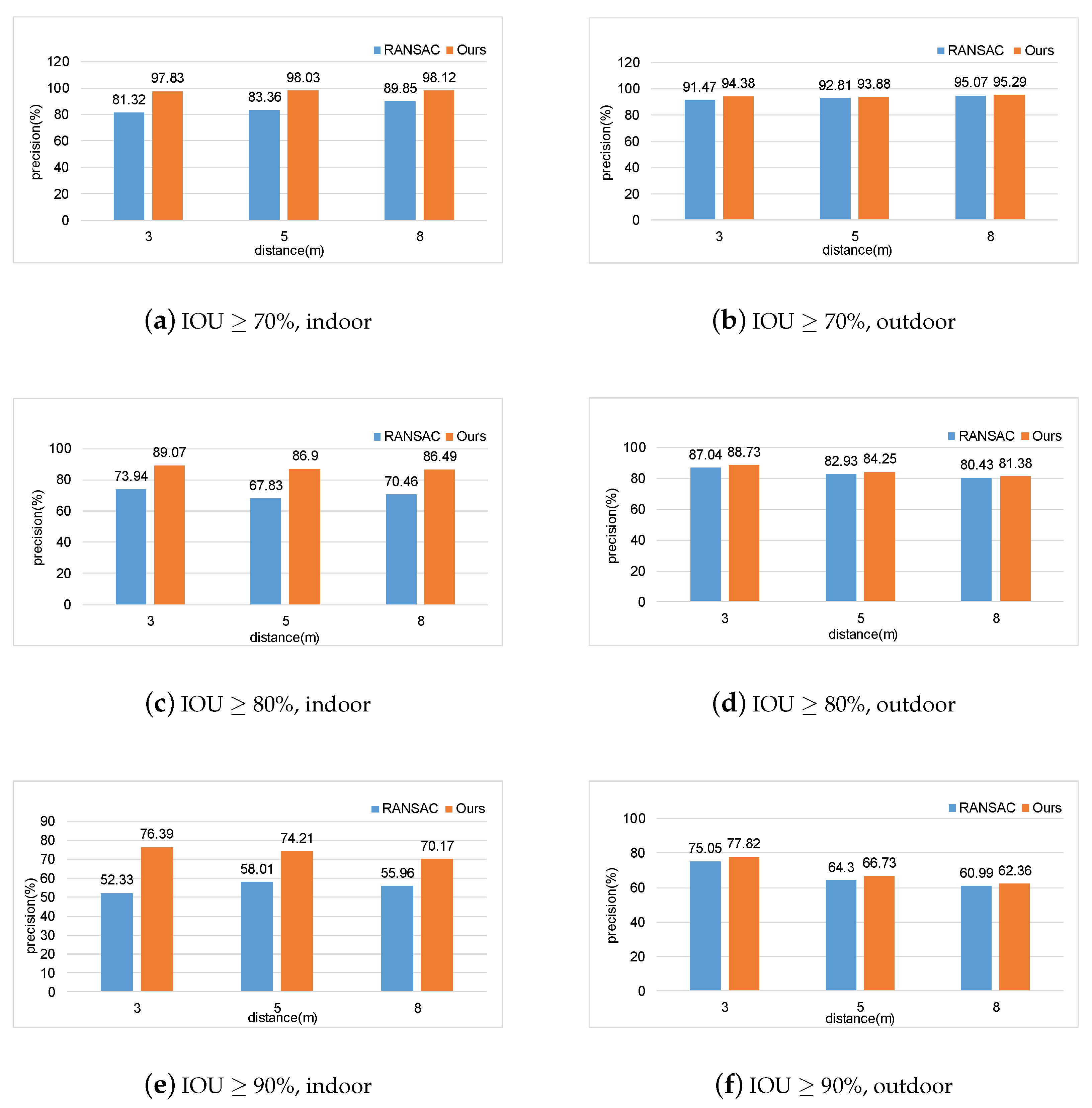
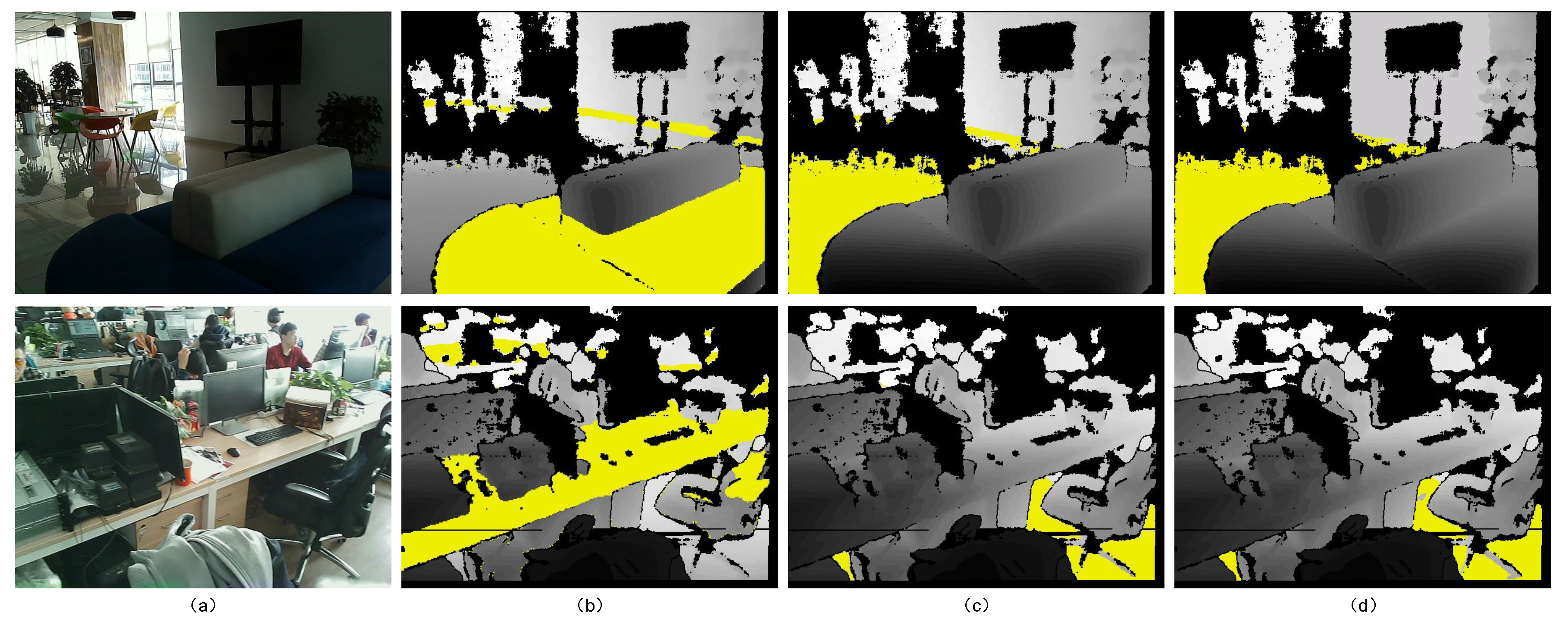
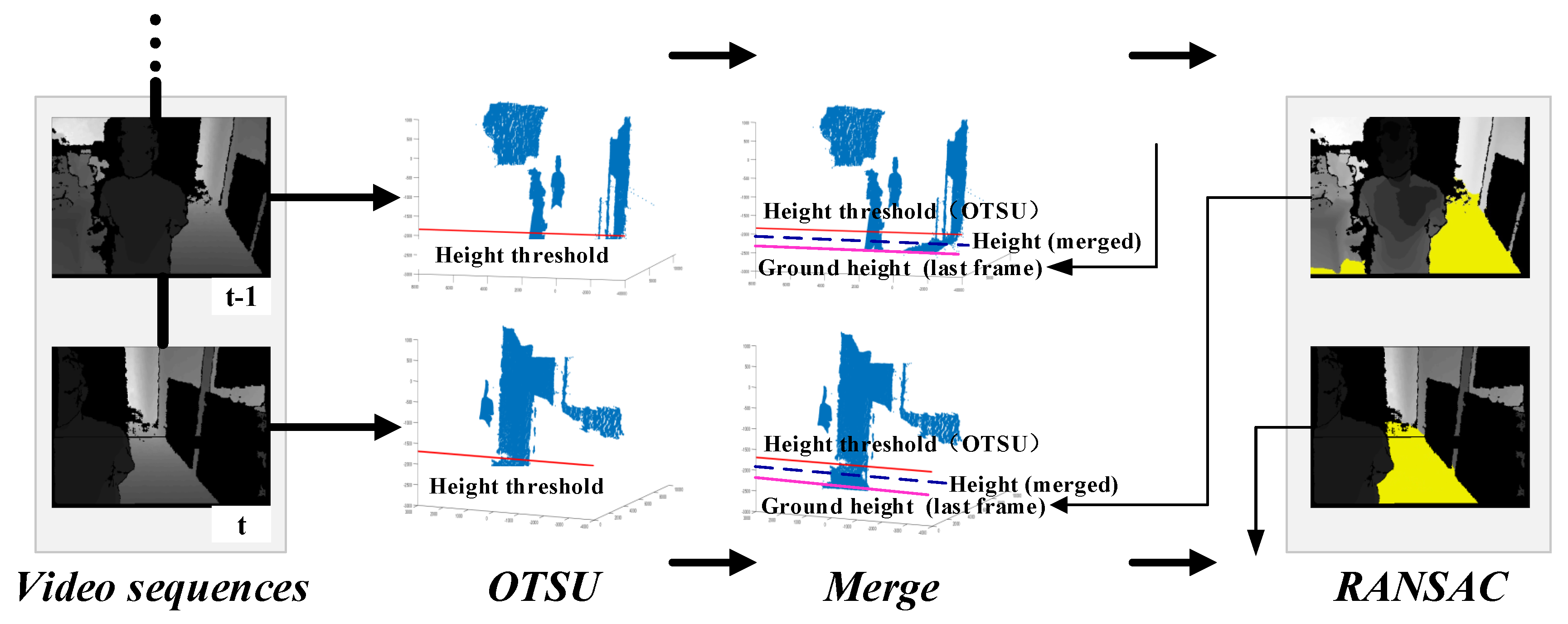
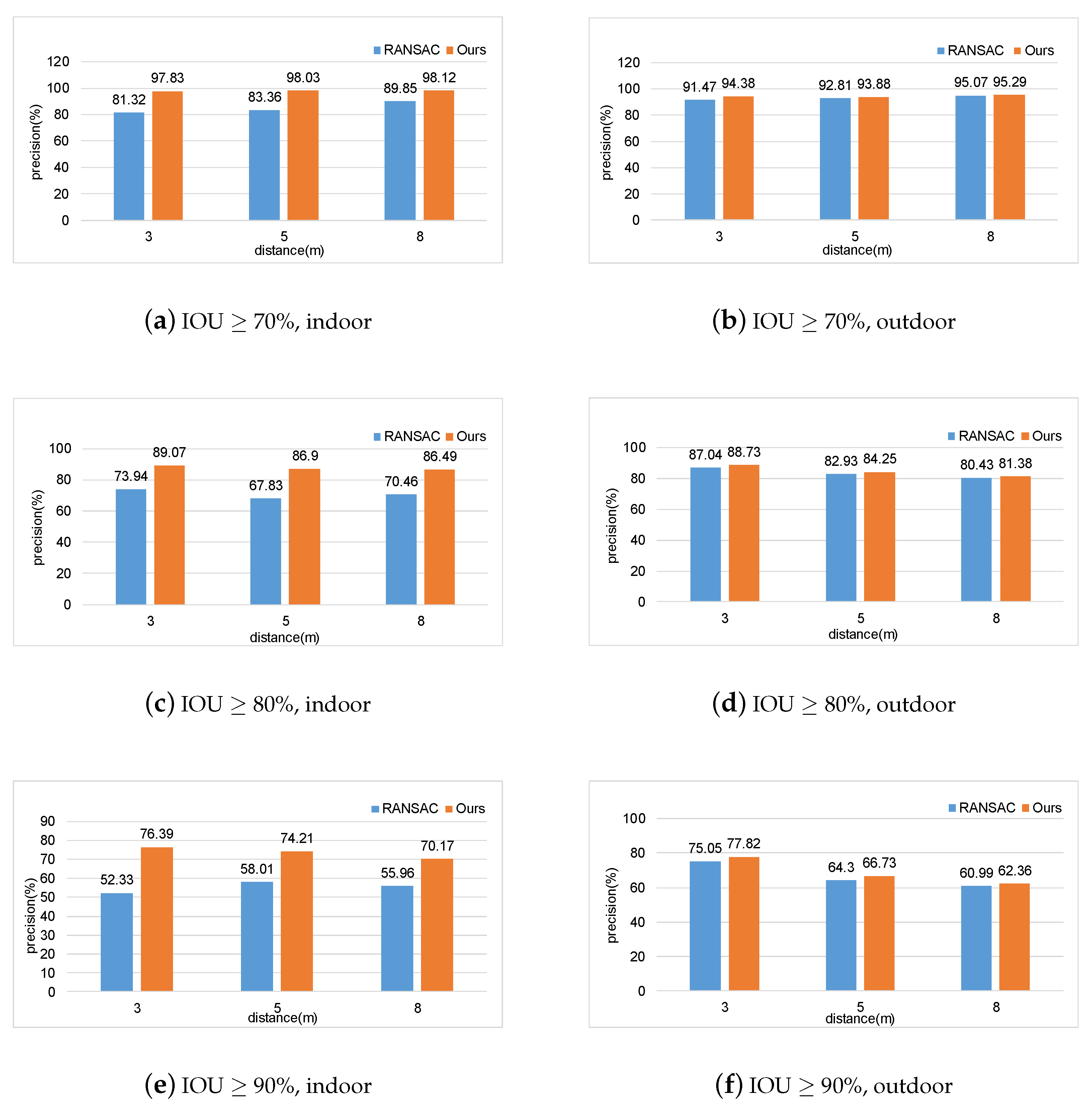
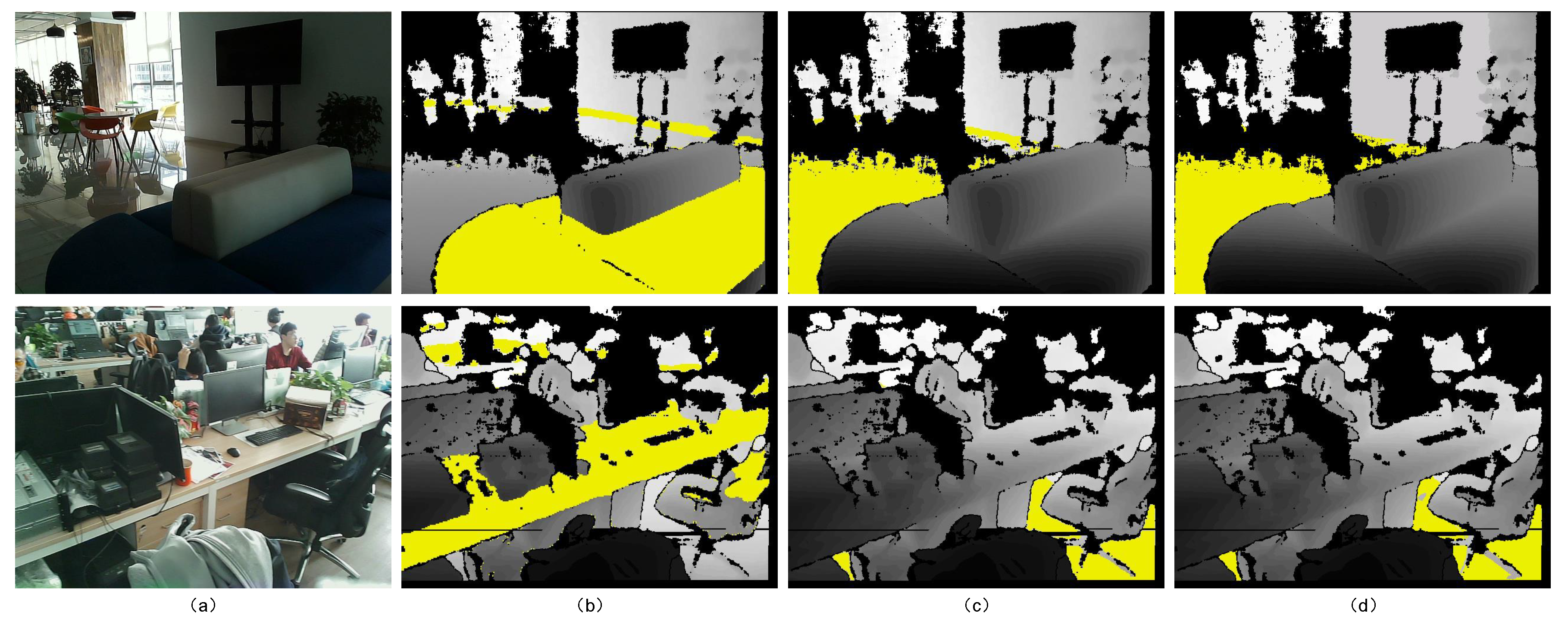
4.1. Experiments on Ground Segmentation
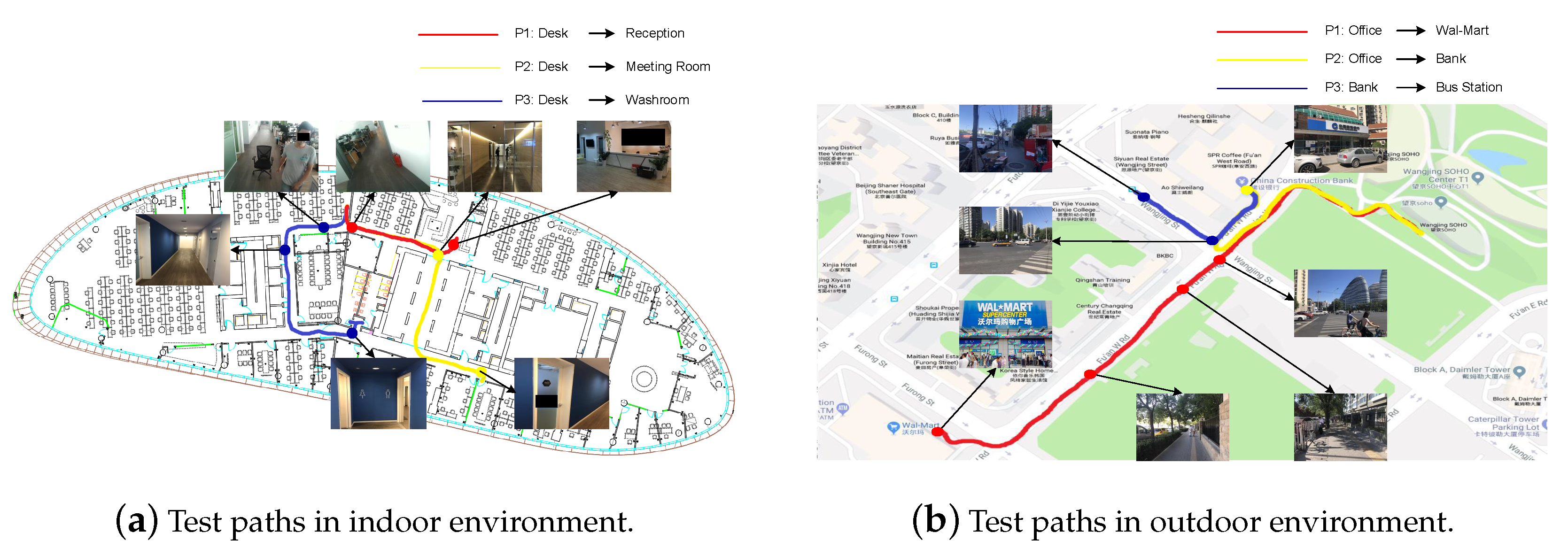
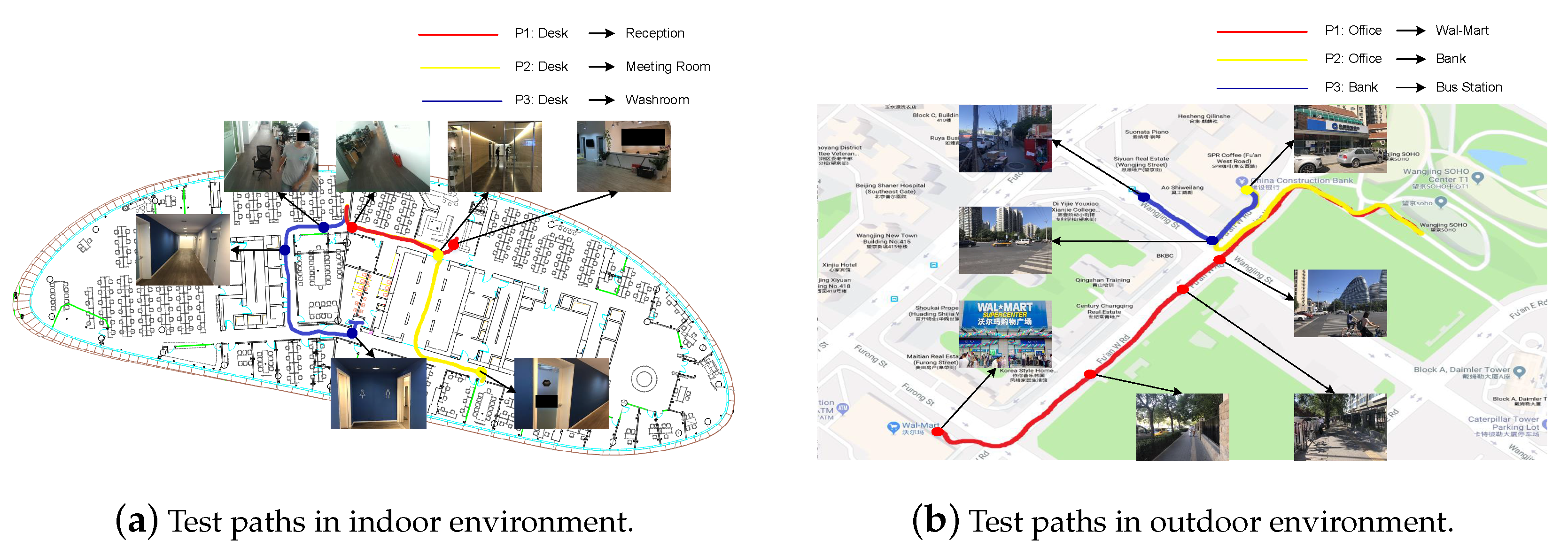
4.2. Experiments on Real-World Scenarios
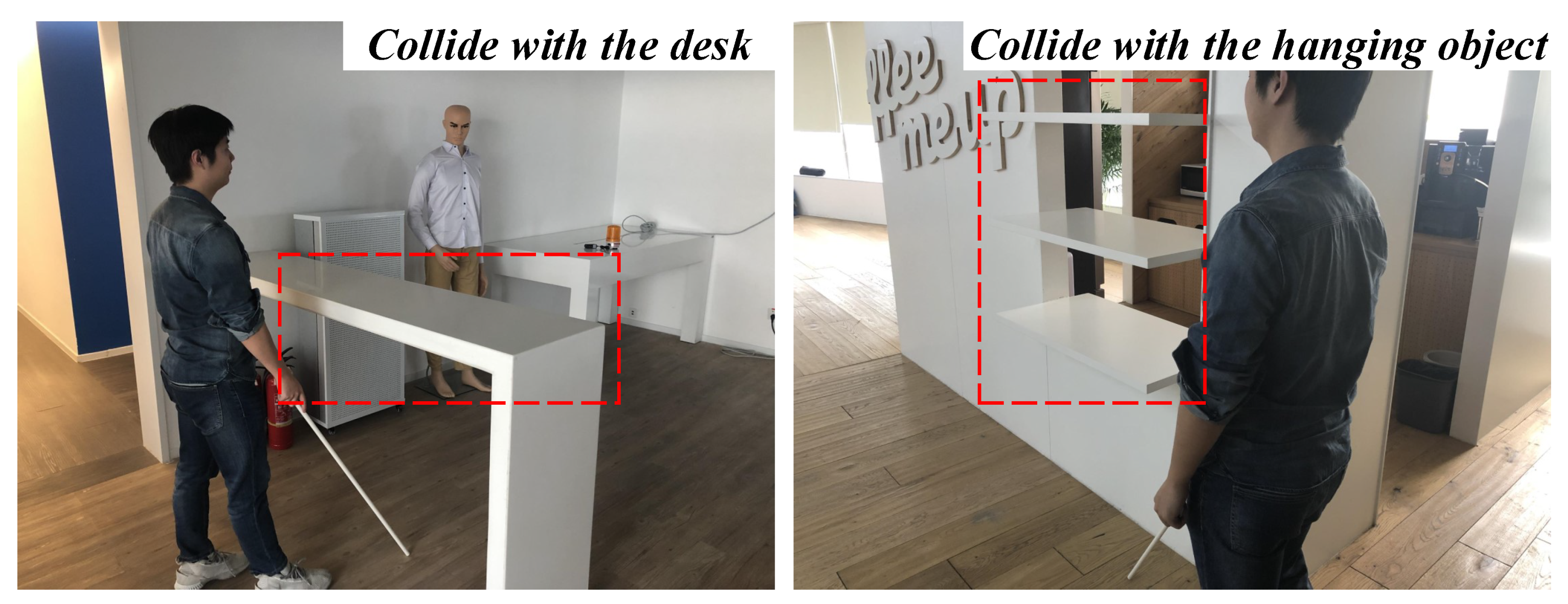
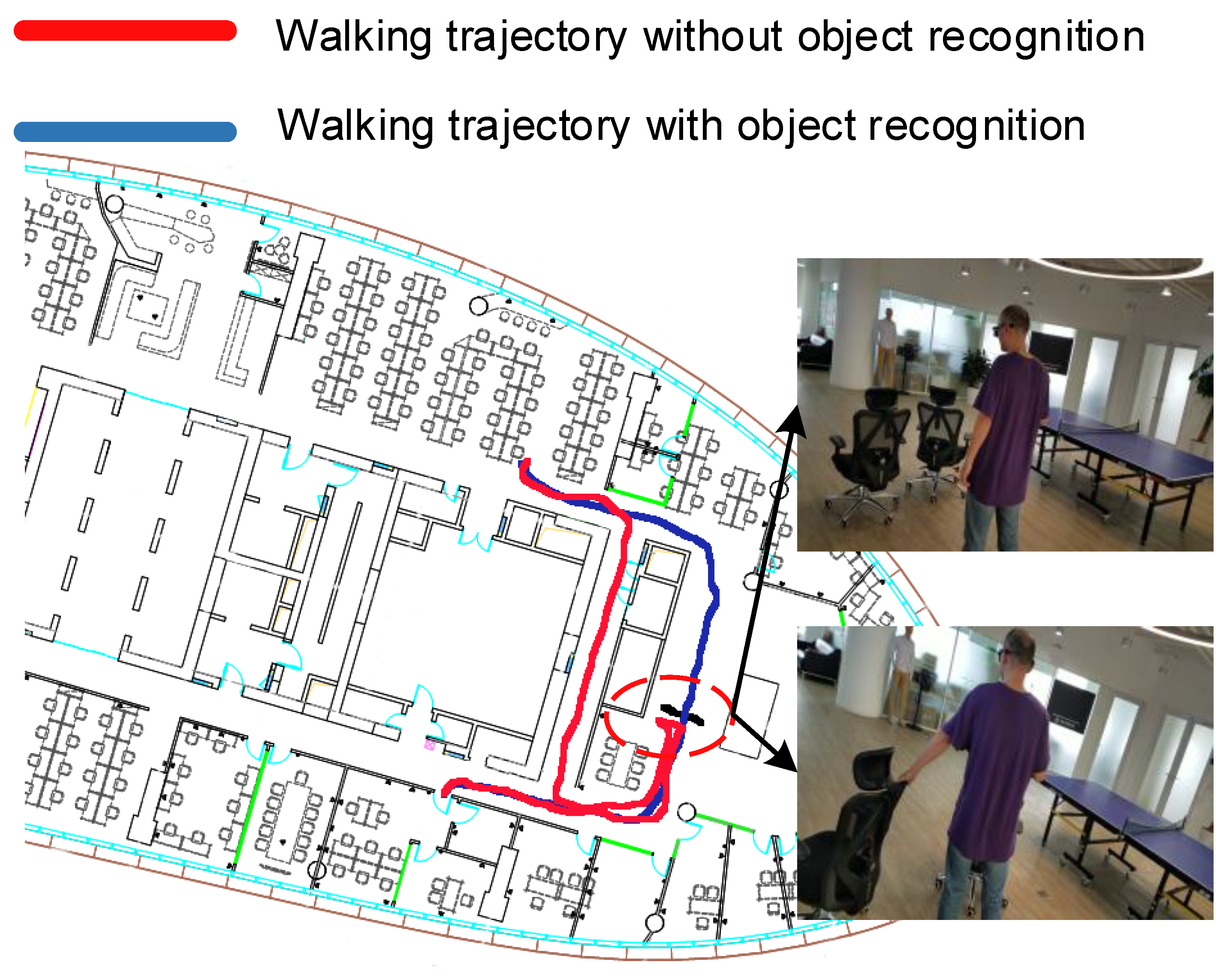
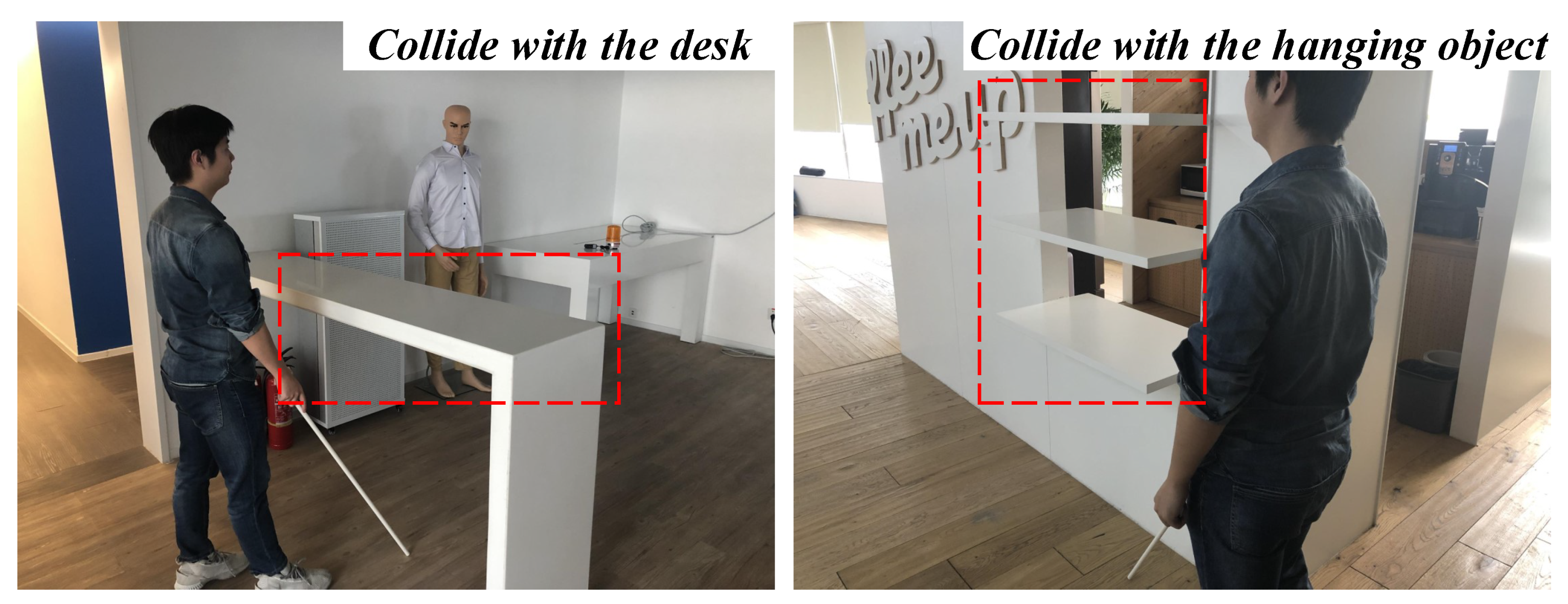
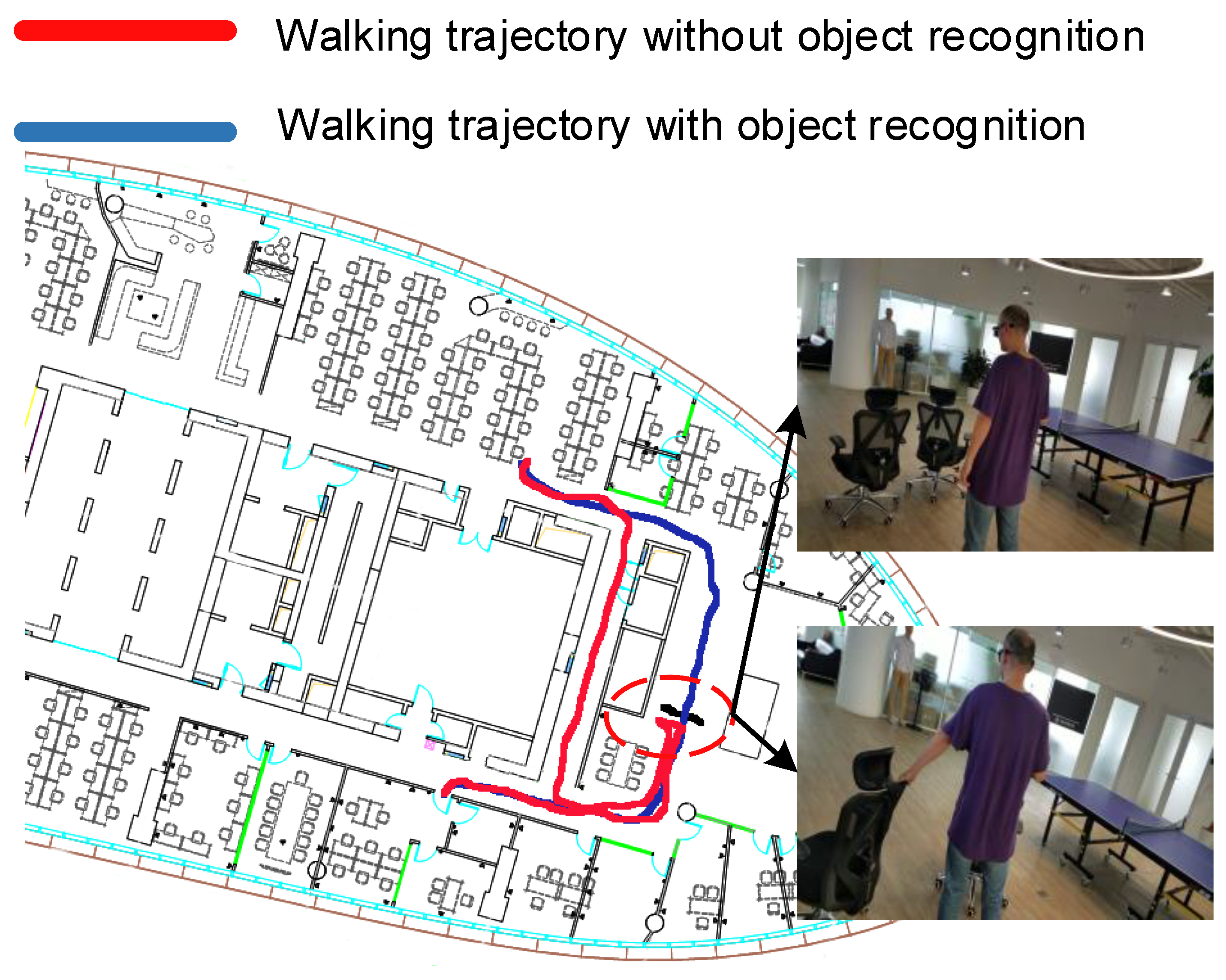
4.3. Qualitative Analysis
4.4. Computational Cost
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| WHO | World Health Organization |
| VIP | Visually Impaired Person |
| RGB-D | Red, Green, Blue and Depth |
| IMU | Inertial Measurement Unit |
| CNN | Convolutional Neural Network |
| RANSAC | RANdom SAmple Consensus |
| GPU | Graphics Processing Unit |
| GPR | Gaussian Process Regressors |
| ICP | Iterative Closest Point |
| GMM | Gaussian Mixture Model |
| TTS | Text-to-Speech |
| POI | Points of Interest |
| RCNN | Recursive Convolutional Neural Network |
| HMI | Human–Machine Interaction |
| VSLAM | Visual Simultaneous Localization and Mapping |
| IOU | Intersection Over Union |
References
- WHO. Available online: https://www.who.int/news-room/fact-sheets/detail/blindness-and-visual-impairment (accessed on 11 October 2018).
- Mekhalfi, M.L.; Melgani, F.; Zeggada, A.; De Natale, F.G.; Salem, M.A.M.; Khamis, A. Recovering the sight to blind people in indoor environments with smart technologies. Expert Syst. Appl. 2016, 46, 129–138. [Google Scholar] [CrossRef]
- Bhatlawande, S.; Mahadevappa, M.; Mukherjee, J.; Biswas, M.; Das, D.; Gupta, S. Design, development, and clinical evaluation of the electronic mobility cane for vision rehabilitation. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 1148–1159. [Google Scholar] [CrossRef]
- Islam, M.M.; Sadi, M.S.; Zamli, K.Z.; Ahmed, M.M. Developing walking assistants for visually impaired people: A review. IEEE Sens. J. 2019, 19, 2814–2828. [Google Scholar] [CrossRef]
- Sivan, S.; Darsan, G. Computer vision based assistive technology for blind and visually impaired people. In Proceedings of the International Conference on Computing Communication and Networking Technologies, Dallas, TX, USA, 6–8 July 2016. [Google Scholar]
- Fei, Z.; Yang, E.; Hu, H.; Zhou, H. Review of machine vision-based electronic travel aids. In Proceedings of the 2017 23rd International Conference on Automation and Computing (ICAC), Huddersfield, UK, 7–8 September 2017; pp. 1–7. [Google Scholar]
- Jafri, R.; Ali, S.A.; Arabnia, H.R.; Fatima, S. Computer vision-based object recognition for the visually impaired in an indoors environment: A survey. Vis. Comput. 2014, 30, 1197–1222. [Google Scholar] [CrossRef]
- Tian, Y. RGB-D sensor-based computer vision assistive technology for visually impaired persons. In Computer Vision and Machine Learning with RGB-D Sensors; Shao, L., Han, J., Kohli, P., Zhang, Z., Eds.; Springer: Cham, Switzerland, 2014; pp. 173–194. [Google Scholar]
- Aladrén, A.; López-Nicolás, G.; Puig, L.; Guerrero, J.J. Navigation assistance for the visually impaired using RGB-D sensor with range expansion. IEEE Syst. J. 2016, 10, 922–932. [Google Scholar] [CrossRef]
- Bai, J.; Lian, S.; Liu, Z.; Wang, K.; Liu, D. Virtual-blind-road following-based wearable navigation device for blind people. IEEE Trans. Consum. Electron. 2018, 64, 136–143. [Google Scholar] [CrossRef]
- Bai, J.; Lian, S.; Liu, Z.; Wang, K.; Liu, D. Smart guiding glasses for visually impaired people in indoor environment. IEEE Trans. Consum. Electron. 2017, 63, 258–266. [Google Scholar] [CrossRef]
- Söveny, B.; Kovács, G.; Kardkovács, Z.T. Blind guide—A virtual eye for guiding indoor and outdoor movement. In Proceedings of the 2014 5th IEEE Conference on Cognitive Infocommunications (CogInfoCom), Vietri sul Mare, Italy, 5–7 November 2014; pp. 343–347. [Google Scholar]
- Kanwal, N.; Bostanci, E.; Currie, K.; Clark, A.F. A navigation system for the visually impaired: A fusion of vision and depth sensor. Appl. Bionics Biomech. 2015, 2015, 479857. [Google Scholar] [CrossRef]
- Kang, M.C.; Chae, S.H.; Sun, J.Y.; Yoo, J.W.; Ko, S.J. A novel obstacle detection method based on deformable grid for the visually impaired. IEEE Trans. Consum. Electron. 2015, 61, 376–383. [Google Scholar] [CrossRef]
- Kang, M.C.; Chae, S.H.; Sun, J.Y.; Lee, S.H.; Ko, S.J. An enhanced obstacle avoidance method for the visually impaired using deformable grid. IEEE Trans. Consum. Electron. 2017, 63, 169–177. [Google Scholar] [CrossRef]
- Yang, K.; Wang, K.; Hu, W.; Bai, J. Expanding the detection of traversable area with RealSense for the visually impaired. Sensors 2016, 16, 1954. [Google Scholar] [CrossRef]
- Yang, K.; Wang, K.; Bergasa, L.M.; Romera, E.; Hu, W.; Sun, D.; Sun, J.; Cheng, R.; Chen, T.; López, E. Unifying terrain awareness for the visually impaired through real-time semantic segmentation. Sensors 2018, 18, 1506. [Google Scholar] [CrossRef]
- Ye, C.; Hong, S.; Qian, X.; Wu, W. Co-robotic cane: A new robotic navigation aid for the visually impaired. IEEE Syst. Man Cybern. Mag. 2016, 2, 33–42. [Google Scholar] [CrossRef]
- Zhang, H.; Ye, C. An indoor wayfinding system based on geometric features aided graph SLAM for the visually impaired. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 1592–1604. [Google Scholar] [CrossRef]
- Ye, C.; Qian, X. 3-D object recognition of a robotic navigation aid for the visually impaired. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 441–450. [Google Scholar] [CrossRef]
- Ţepelea, L.; Gavriluţ, I.; Gacsádi, A. Smartphone application to assist visually impaired people. In Proceedings of the 2017 14th International Conference on Engineering of Modern Electric Systems (EMES), Oradea, Romania, 1–2 June 2017; pp. 228–231. [Google Scholar]
- Vera, D.; Marcillo, D.; Pereira, A. Blind guide: Anytime, anywhere solution for guiding blind people. In World Conference on Information Systems and Technologies; Springer: Cham, Switerland, 2017; pp. 353–363. [Google Scholar]
- Wang, H.C.; Katzschmann, R.K.; Teng, S.; Araki, B.; Giarré, L.; Rus, D. Enabling independent navigation for visually impaired people through a wearable vision-based feedback system. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 6533–6540. [Google Scholar]
- Mancini, A.; Frontoni, E.; Zingaretti, P. Mechatronic system to help visually impaired users during walking and running. IEEE Trans. Intell. Transp. Syst. 2018, 19, 649–660. [Google Scholar] [CrossRef]
- Eckert, M.; Blex, M.; Friedrich, C.M. Object detection featuring 3D audio localization for Microsoft HoloLens. In Proceedings of the 11th International Joint Conference on Biomedical Engineering Systems and Technologies, Funchal, Portugal, 19–21 January 2018; Volume 5, pp. 555–561. [Google Scholar]
- Long, N.; Wang, K.; Cheng, R.; Yang, K.; Hu, W.; Bai, J. Assisting the visually impaired: Multitarget warning through millimeter wave radar and RGB-depth sensors. J. Electron. Image 2019, 28, 013028. [Google Scholar] [CrossRef]
- Li, B.; Munoz, J.P.; Rong, X.; Chen, Q.; Xiao, J.; Tian, Y.; Arditi, A.; Yousuf, M. Vision-based mobile indoor assistive navigation aid for blind people. IEEE Trans. Mob. Comput. 2019, 18, 702–714. [Google Scholar] [CrossRef]
- Tapu, R.; Mocanu, B.; Bursuc, A.; Zaharia, T. A smartphone-based obstacle detection and classification system for assisting visually impaired people. In Proceedings of the 2013 IEEE ICCV Workshops, Sydney, Australia, 2–8 December 2013; pp. 444–451. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. IJCV 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Tapu, R.; Mocanu, B.; Zaharia, T. DEEP-SEE: Joint object detection, tracking and recognition with application to visually impaired navigational assistance. Sensors 2017, 17, 2473. [Google Scholar] [CrossRef]
- Lin, B.; Lee, C.; Chiang, P. Simple smartphone-based guiding system for visually impaired people. Sensors 2017, 17, 1371. [Google Scholar] [CrossRef]
- Parikh, N.; Shah, I.; Vahora, S. Android smartphone based visual object recognition for visually impaired using deep learning. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 3–5 April 2018; pp. 0420–0425. [Google Scholar]
- Bashiri, F.S.; LaRose, E.; Badger, J.C.; D’Souza, R.M.; Yu, Z.; Peissig, P. Object detection to assist visually impaired people: A deep neural network adventure. In International Symposium on Visual Computing; Springer: Cham, Switerland, 2018; pp. 500–510. [Google Scholar]
- Trabelsi, R.; Jabri, I.; Melgani, F.; Smach, F.; Conci, N.; Bouallegue, A. Indoor object recognition in rgbd images with complex-valued neural networks for visually-impaired people. Neurocomputing 2019, 330, 94–103. [Google Scholar] [CrossRef]
- Kaur, B.; Bhattacharya, J. A scene perception system for visually impaired based on object detection and classification using multi-modal DCNN. arXiv 2018, arXiv:1805.08798. [Google Scholar]
- Forrest, N.I.; Song, H.; Matthew, W.M.; Khalid, A.; William, J.D.; Kurt, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 1800–1807. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Wang, R.J.; Li, X.; Ling, C.X. Pelee: A real-time object detection system on mobile devices. In Proceedings of the Advances in Neural Information Processing Systems, NIPS 2018, Montréal, QC, Canada, 2–8 December 2018; pp. 1963–1972. [Google Scholar]
- Mur-Artal, R.; Tardos, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Tong, Q.; Peiliang, L.; Shaojie, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar]
- QQMAP. Available online: https://lbs.qq.com/android_v1/index.html (accessed on 25 March 2019).
- Caron, F.; Duflos, E.; Pomorski, D.; Vanheeghe, P. GPS/IMU data fusion using multisensor kalman filtering: Introduction of contextual aspects. Inf. Fusion 2006, 7, 221–230. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Alkhanifer, A.; Ludi, S. Towards a situation awareness design to improve visually impaired orientation in unfamiliar buildings: Requirements elicitation study. In Proceedings of the IEEE 22nd International Requirements Engineering Conference (RE), Karlskrona, Sweden, 25–29 August 2014; pp. 23–32. [Google Scholar]
- Endsley, M.R. Toward a theory of situation awareness in dynamic systems. Hum. Factors 1995, 37, 32–64. [Google Scholar] [CrossRef]
- Arditi, A.; Tian, Y. User interface preferences in the design of a camera-based navigation and wayfinding aid. J. Vis. Impair. Blind. 2013, 107, 118–129. [Google Scholar] [CrossRef]
- Golledge, R.G.; Marston, J.R.; Loomis, J.M.; Klatzky, R.L. Stated preferences for components of a personal guidance system for nonvisual navigation. J. Vis. Impair. Blind. 2004, 98, 135–147. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Works | Year | Sensors | Feedback | Indoor/outdoor | Weight | Cost | Capabilities | Limitations | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Localization | Obstacle Avoidance | Object Detection/Recognition | ||||||||
| Söveny et al. [12] | 2014 | Two RGB cameras | Audio | Both | Light | Low | - | Yes | Yes | Ground texture changes or other large plane such as wall in indoor scenarios may cause errors of free path detection. |
| Kanwal et al. [13] | 2015 | RGB-D camera | Audio | Both | Bulky | Low | - | Yes | - | The system has no recognition capability and the obstacle detection performance degrades severely under strong sunlight. |
| Kang et al. [14,15] | 2015, 2017 | RGB camera | Stereophonic | Both | Light | High | - | Yes | - | The system cannot detect obstacles that are closed to non-textured regions such as a door or a wall. |
| Yang et al. [16,17] | 2016, 2018 | RGB-D camera | Stereophonic | Both | Light | High | - | Yes | Yes | The system needs GPU to accelerate the semantic segmentation and detects obstacles only in a short range. |
| Mekhalfi et al. [2] | 2016 | RGB-D camera, IMU and laser sensor | Speech | Indoor | Bulky | High | - | Yes | Yes | The system requires the prior information about indoor environment to train the GPR, which limits its universal application in other scenarios. |
| Aladrén et al. [9] | 2016 | RGB-D camera | Speech and stereo beeps | Indoor | Light | High | - | Yes | - | The algorithm is complicated and only operates in indoor environment. |
| Ye et al. [18,19,20] | 2016, 2017 | RGB and IR camera | Speech | Indoor | Bulky | High | Yes | Yes | Yes | The navigation and recognition systems perform separately. |
| Tepelea et al. [21] | 2017 | RGB camera, MEMS and ultrasonic sensors | Audio | Both | Light | Low | Yes | Yes | - | The system is not tested in buildings and outdoor environment to find the optimum obstacle detection distance. |
| Vera et al. [22] | 2017 | RGB camera and ultrasonic sensors | Audio | Both | Bulky | Low | - | Yes | Yes | The system can only works in the scene with internet access and the recognition works well only with good light conditions. |
| Wang et al. [23] | 2017 | Depth camera | Vibration | Indoor | Light | Low | - | Yes | Yes | The system applies to only indoor environment and recognizes only some common objects in engineered indoor scenes, such as tables, chairs, and loungers. |
| Mancini et al. [24] | 2018 | RGB camera | Vibration | Outdoor | Light | High | - | - | Yes | The system is not suitable in crowded scenarios due to its weak obstacle-avoidance capability. |
| Eckert et al. [25] | 2018 | RGB-D camera and IMU sensors | Audio | Indoor | Light | High | - | - | Yes | The system has low recognition accuracies on small objects and needs network connection to provide the recognition service, which limits its mobility. |
| Long et al. [26] | 2019 | RGB-D camera and MMW radar | Stereophonic | Both | Bulky | High | - | Yes | - | The prototype still runs on a PC, which is not portable for navigation application. |
| Li et al. [27] | 2019 | RGB-D camera | Audio | Indoor | Light | High | Yes | Yes | - | The semantic map needs annotation functionality of adding POI, which is not easily accessible for VIP. |
| Our previous works [10,11] | 2017, 2018 | RGB camera and ultrasonic sensors | Audio | Indoor | Light | Low | Yes | Yes | - | The system has no recognition capability and only works in indoor environment. |
| Category | Speech | Description |
|---|---|---|
| User’s commands | “Go to” + destination | The user tells the system to guide him/her to the destinations, such as toilet, Room3301, supermarket |
| “Where am I” | The user queries his/her current location. | |
| System instructions | “Will you start navigation to” + destination | Ask the user to make sure the destination is his/her desired one. |
| “You are in the” + current location. | Tell the user his/her current location, such as hall, XXX road. | |
| “There is a” + an object + distance + “meters ahead of your” + orientation | Inform the user about the perception information, including objects category location, and orientation. For example, “There is a chair one point eight meters ahead of your left side two degree.” | |
| “Walk” + distance + ”meters then take a” + turn direction + “Walk” + ...+ “arrive at the destination” | Allow the user to have a holistic cognition about the whole path. For example, “Walk 30 m then take a left, then walk 20 m then take a right, then walk ten meters and then arrive at the destination.” | |
| “The destination is arrived, the navigation is over.” | Inform the user that he/she arrives at the destination. | |
| System exceptions | “The camera is not connected.” “The IMU is not connected” “The power is lower than ten percent” | Alert the user about the status of the key hardware components. |
| Scenario | Path | Length (m) | Obstacles | Average Time (s) | Total Collisions | ||
|---|---|---|---|---|---|---|---|
| Ours | Cane | Ours | Cane | ||||
| Indoor | P1 (Desk→Reception) | ∼21 | 3 (avg) | 60.8 | 61.5 | 0 | 0 |
| P2 (Desk→Meeting Room) | ∼52 | 8 (avg) | 172.3 | 183.2 | 0 | 32 | |
| P3 (Desk→Washroom) | ∼ 30 | 5 (avg) | 101.1 | 108.3 | 3 | 22 | |
| Outdoor | P1 (Office→Wal-Mart) | ∼860 | 81 (sum) | 2157.5 | 2204.2 | 0 | 5 |
| P2 (Office→Bank) | ∼450 | 74 (sum) | 1112.3 | 1208.2 | 5 | 20 | |
| P3 (Bank→Bus Station) | ∼190 | 57 (sum) | 485.1 | 502.3 | 0 | 12 | |
| Users | Totally Blind or Partially Sighted | Easy to Wear? | Useful? | Feedback in Time? | Advice for Future Improvement |
|---|---|---|---|---|---|
| User1 | Partially sighted | Yes | Yes | Yes | |
| User2 | Partially sighted | Yes | Yes | Yes | Provide a detailed tutorial |
| User3 | Totally blind | Yes | Yes | Yes | Add tactile feedback |
| User4 | Partially sighted | No | Yes | Yes | Design the device in a backpack |
| User5 | Partially sighted | Yes | Yes | Yes | |
| User6 | Totally blind | Yes | Yes | Yes | Add face recognition |
| User7 | Totally blind | Yes | Yes | Yes | Feedback about staircases |
| User8 | Partially sighted | Yes | Yes | Yes | |
| User9 | Totally blind | Yes | Yes | Yes | Add character recognition, cash recognition |
| User10 | Partially sighted | Yes | Yes | Yes |
| Processing Step | Average Time (ms) |
|---|---|
| Data acquisition | 38.06 |
| Ground segmentation | 13.53 |
| Moving direction search | 7.19 |
| Global path planning | 18.22 |
| Indoor localization | 45.36 |
| Outdoor localization | 13.08 |
| Object detection | 114.13 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, J.; Liu, Z.; Lin, Y.; Li, Y.; Lian, S.; Liu, D. Wearable Travel Aid for Environment Perception and Navigation of Visually Impaired People. Electronics 2019, 8, 697. https://doi.org/10.3390/electronics8060697
Bai J, Liu Z, Lin Y, Li Y, Lian S, Liu D. Wearable Travel Aid for Environment Perception and Navigation of Visually Impaired People. Electronics. 2019; 8(6):697. https://doi.org/10.3390/electronics8060697
Chicago/Turabian StyleBai, Jinqiang, Zhaoxiang Liu, Yimin Lin, Ye Li, Shiguo Lian, and Dijun Liu. 2019. "Wearable Travel Aid for Environment Perception and Navigation of Visually Impaired People" Electronics 8, no. 6: 697. https://doi.org/10.3390/electronics8060697
APA StyleBai, J., Liu, Z., Lin, Y., Li, Y., Lian, S., & Liu, D. (2019). Wearable Travel Aid for Environment Perception and Navigation of Visually Impaired People. Electronics, 8(6), 697. https://doi.org/10.3390/electronics8060697