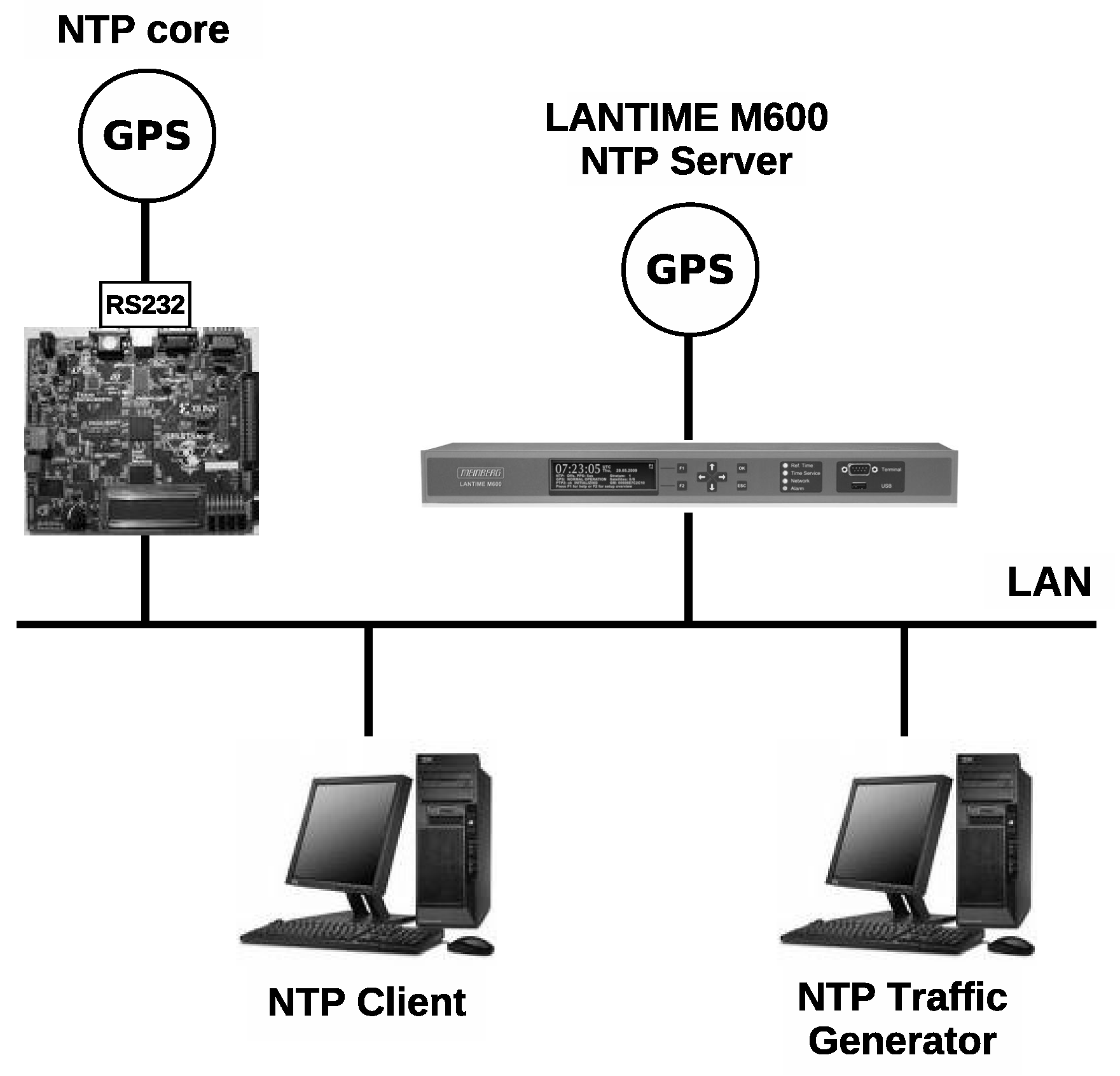
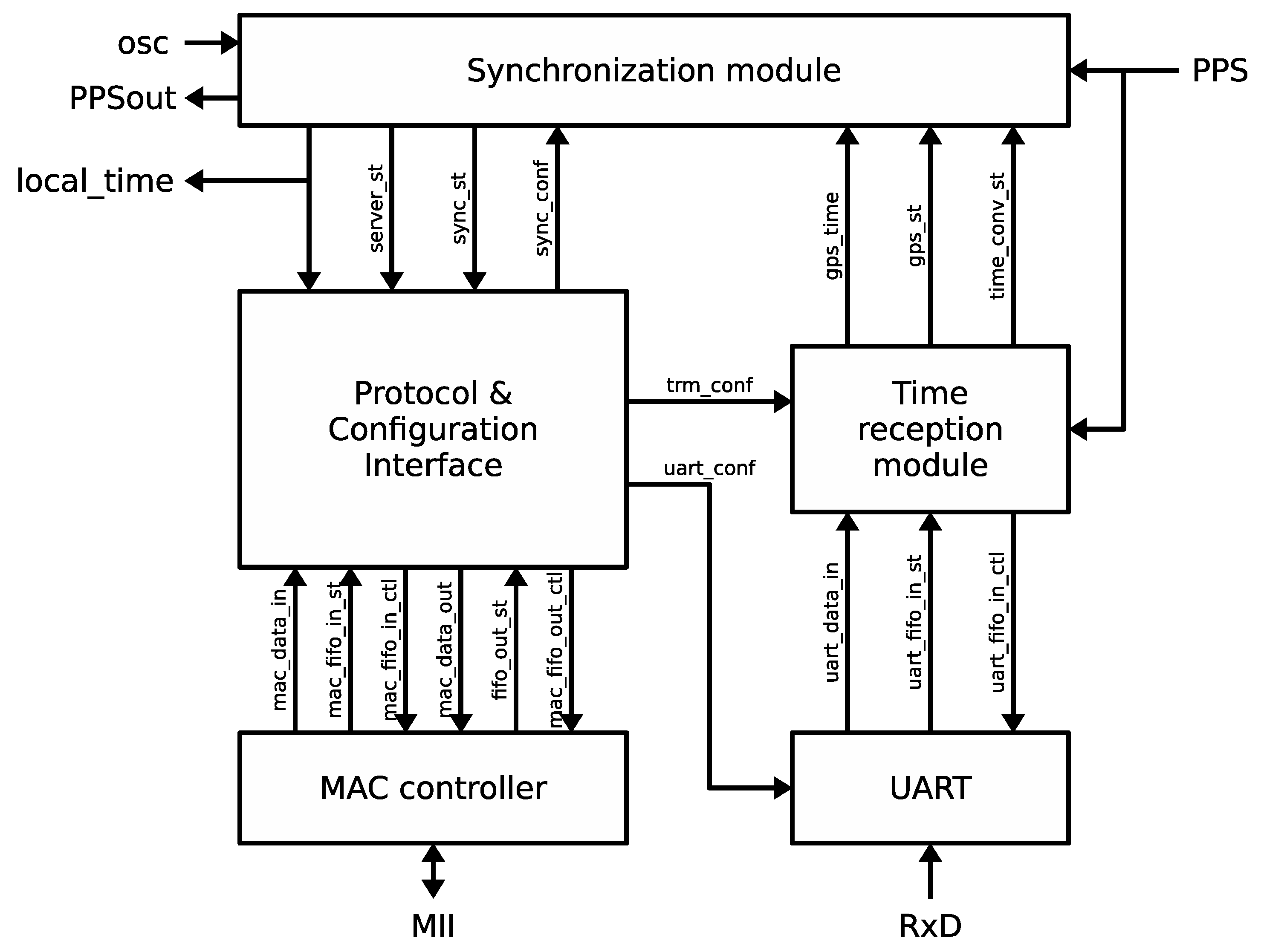
The synchronization module is the core of the timekeeping subsystem, in which the UART and the time reception modules are working as an interface to the GPS receiver. These modules are described in this section.
5.2. Time Reception Module
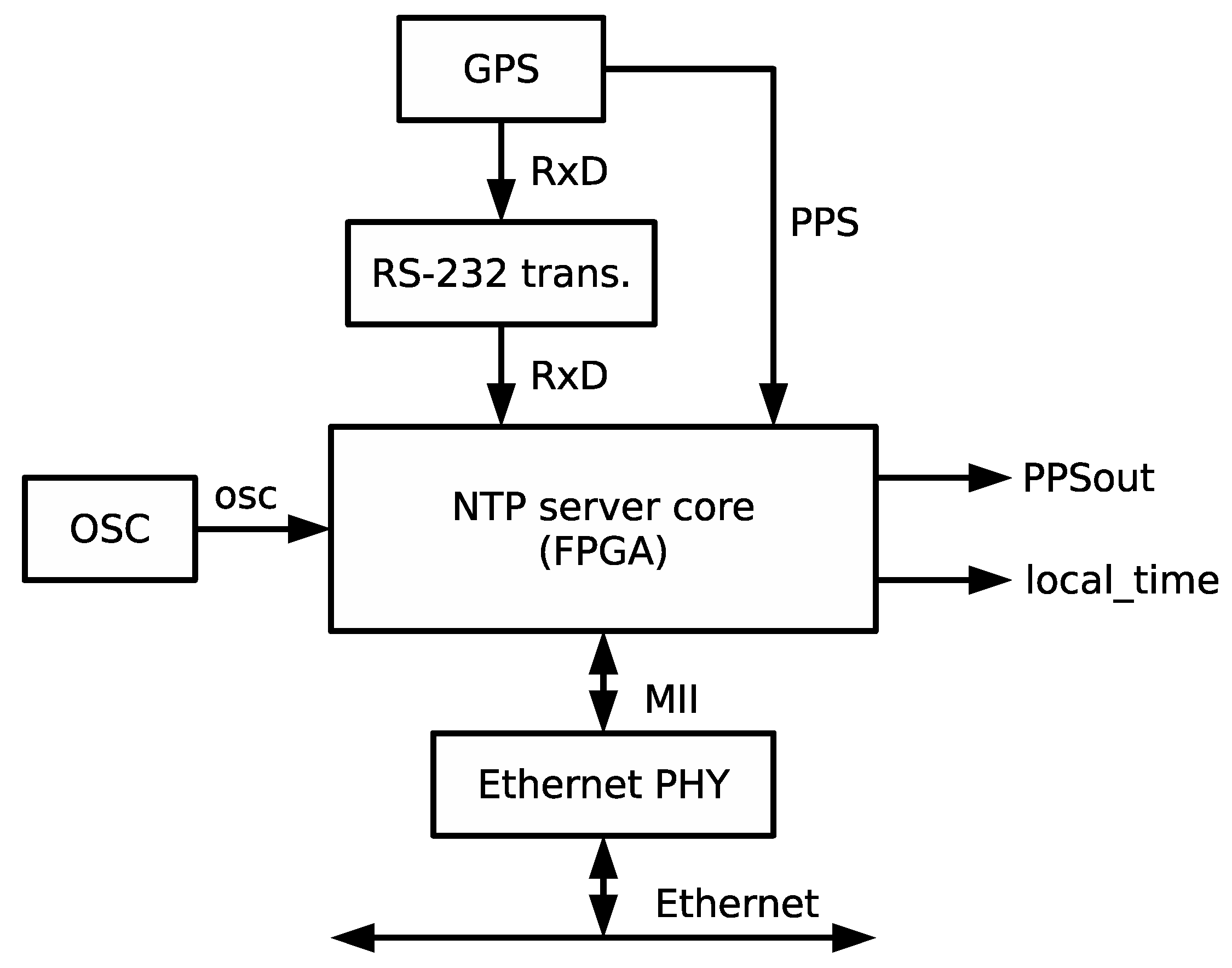
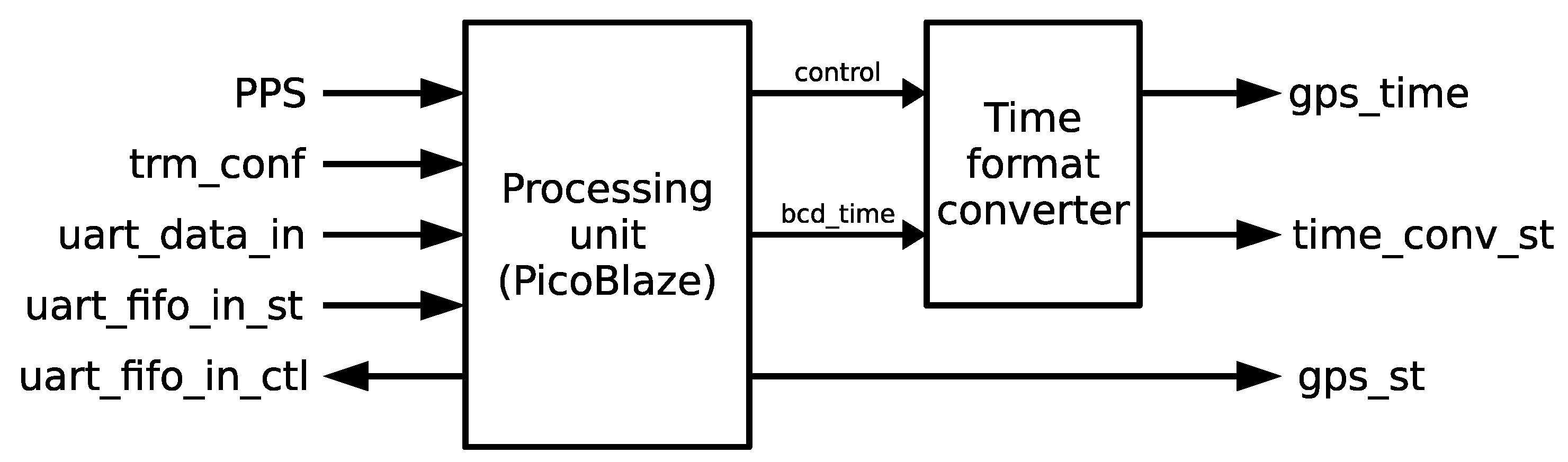
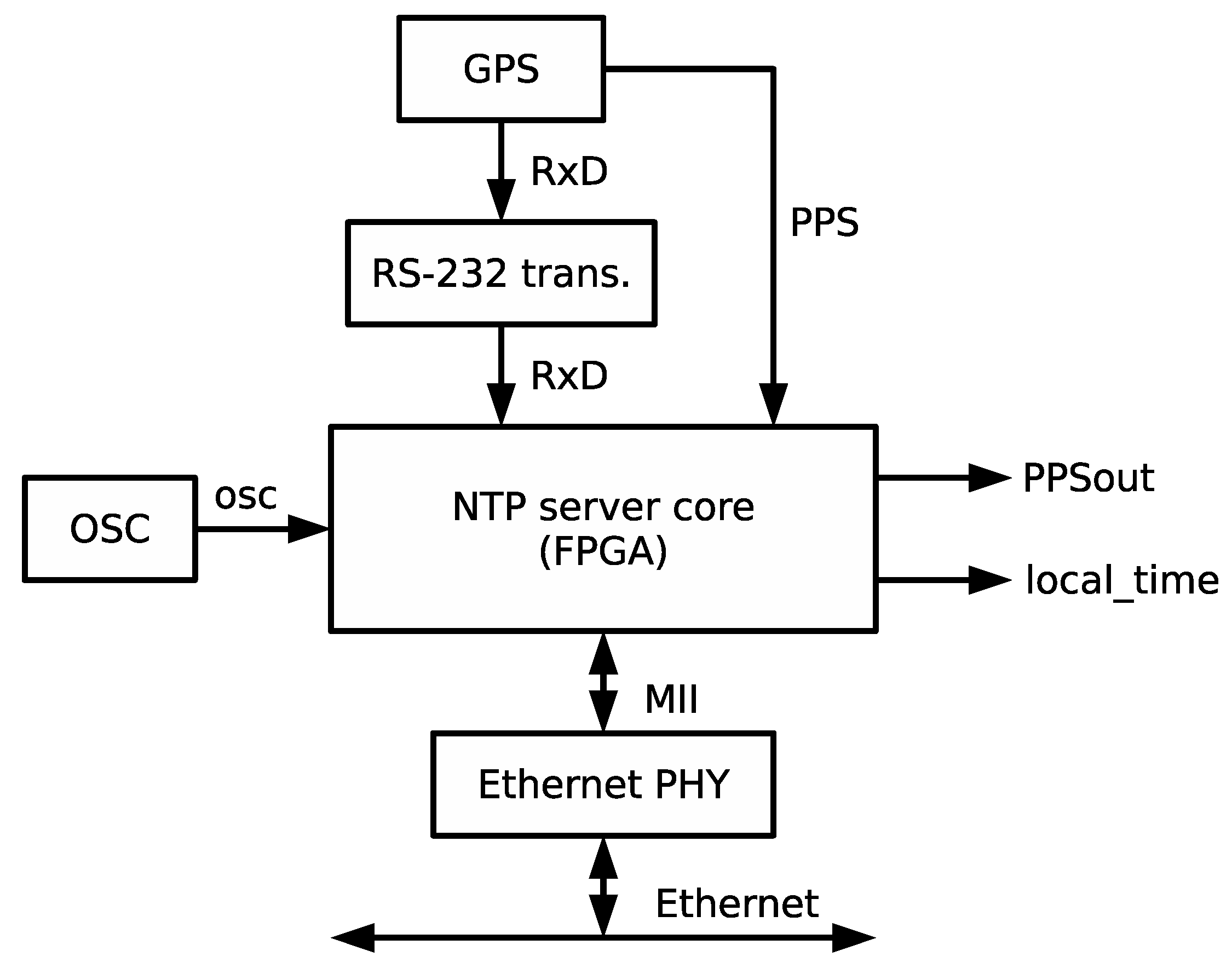
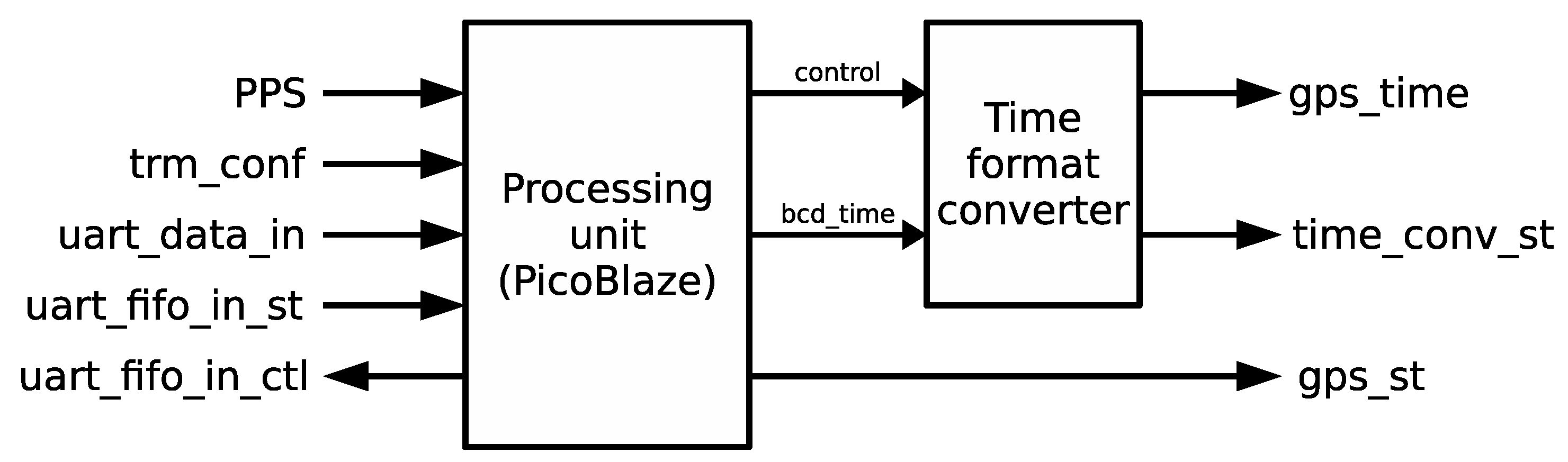
The mission of the time reception module is to collect information from the GPS receiver and transform it into time data and control signals that can be used by the synchronization module to maintain an accurate time in the local clock. The time reception module has two main blocks depicted in
Figure 6: (i) Processing unit; and (ii) time format converter. The module operates as follows: the GPS receiver signals the starting of a new second with an active edge of the PPS signal. Following the edge, the GPS receiver emits a set of NMEA-0183 messages encoded in plain ASCII text. The message that is relevant for time synchronization applications is the recommended minimum sentence C (RMC), which covers date and time corresponding to the active edge of the PPS signal. The time reception module operation is triggered by the active edge of the PPS signal. Furthermore, a 1-bit configuration parameter included within the trm_conf bus indicates whether the expected active edge is a rising (1) or a falling (0) edge. Next, the time reception module starts receiving data from the UART, identifies the RMC frame and extracts time, GPS status and date information that is encoded in frame fields 1, 2 and 7, respectively.
Figure 7 shows a sample RMC frame with decoded fields. After processing the RMC frame, date and time information is converted into NTP time format (seconds 00:00, 1 January 1900) and handed to the synchronization module through the 32-bit signal gps_time. Both the status of the GPS (active or not active) and the status of time conversion (correct or not correct) are also made available to the synchronization module through output signals gps_st and time_conv_st, respectively.
Most of the work in the time reception module is carried out by the processing unit, which is implemented by a Picoblaze 8-bit microcontroller [
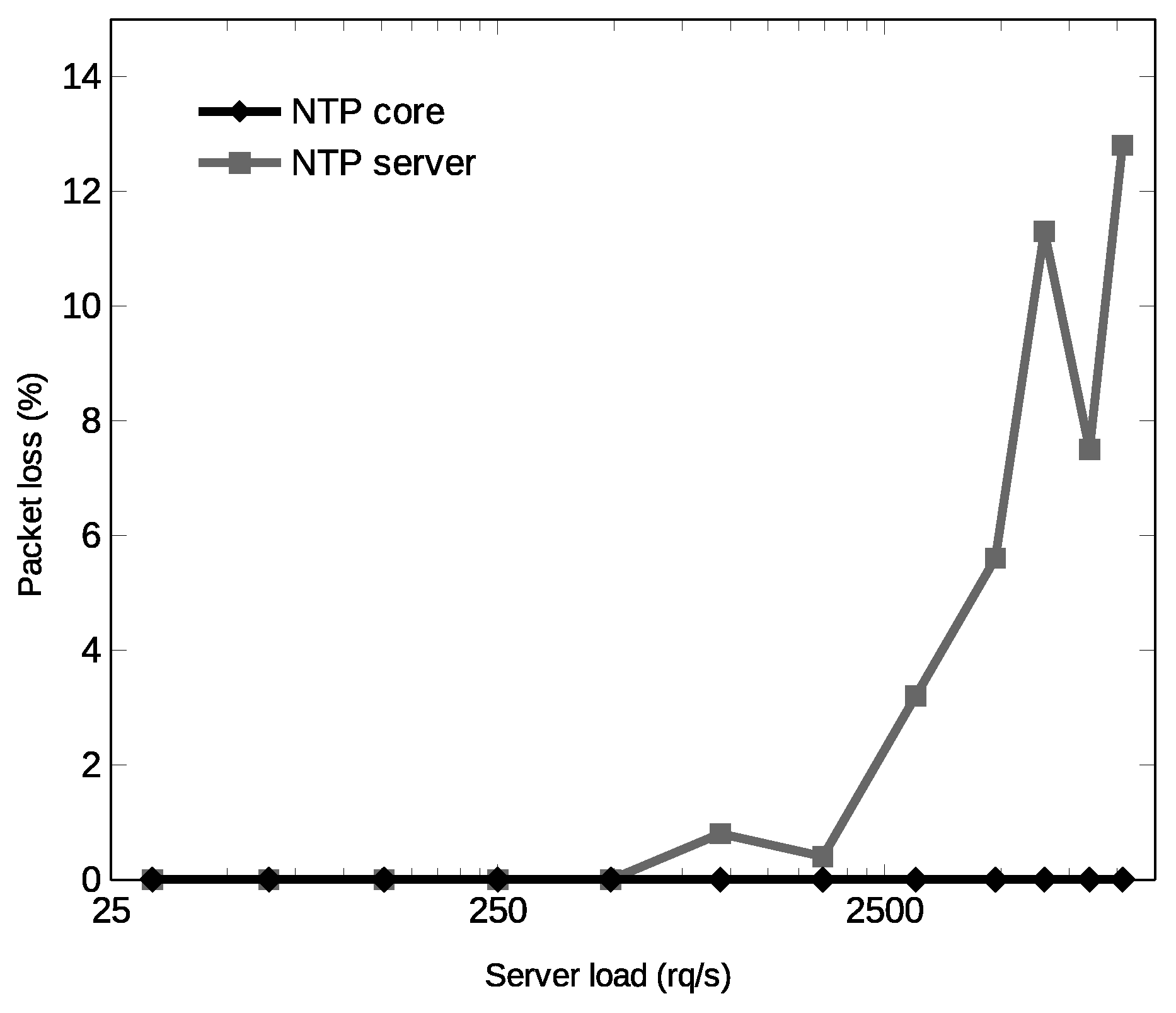
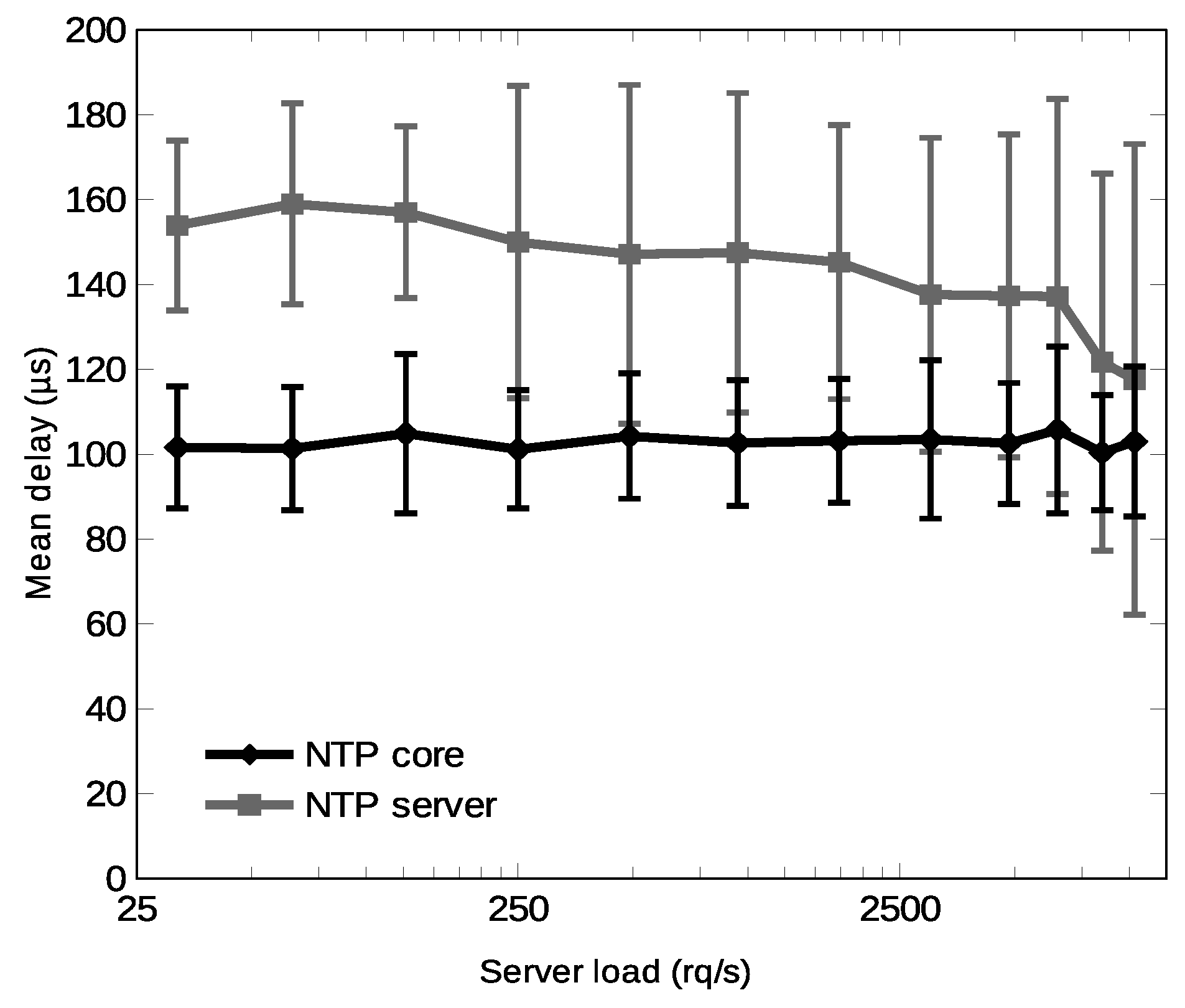
36] running a small program that is written in assembly language. Picoblaze is a tiny microcontroller and this programmatic approach greatly simplifies data extraction from the ASCII stream and control of the UART without having a significant impact on the overall resources utilization, as observed in
Section 7.1. In addition, the use of a microcontroller here makes it much easier to deal with GPS communication debugging. Extracted date and time are stored in a set of binary-coded decimal (BCD) registers forming the bcd_time signal in day-month-year (DD-MM-YY) in the first case, and hour-minute-second (HH:MM:SS) format, in the second case.
The time format converter translates the BCD date and time data into NTP time format when signaled by the processing unit. This module has been implemented in HDL: a control unit manages a data path that processes the BCD registers sequentially and accumulates the total number of seconds represented by each register in the 32-bit output register gps_time.
The time reception module has been tested using KPicoSim [
37] Picoblaze development environment and ISim logic-level simulator included within Xilinx ISE Design Suite [
38].
5.3. Synchronization Module
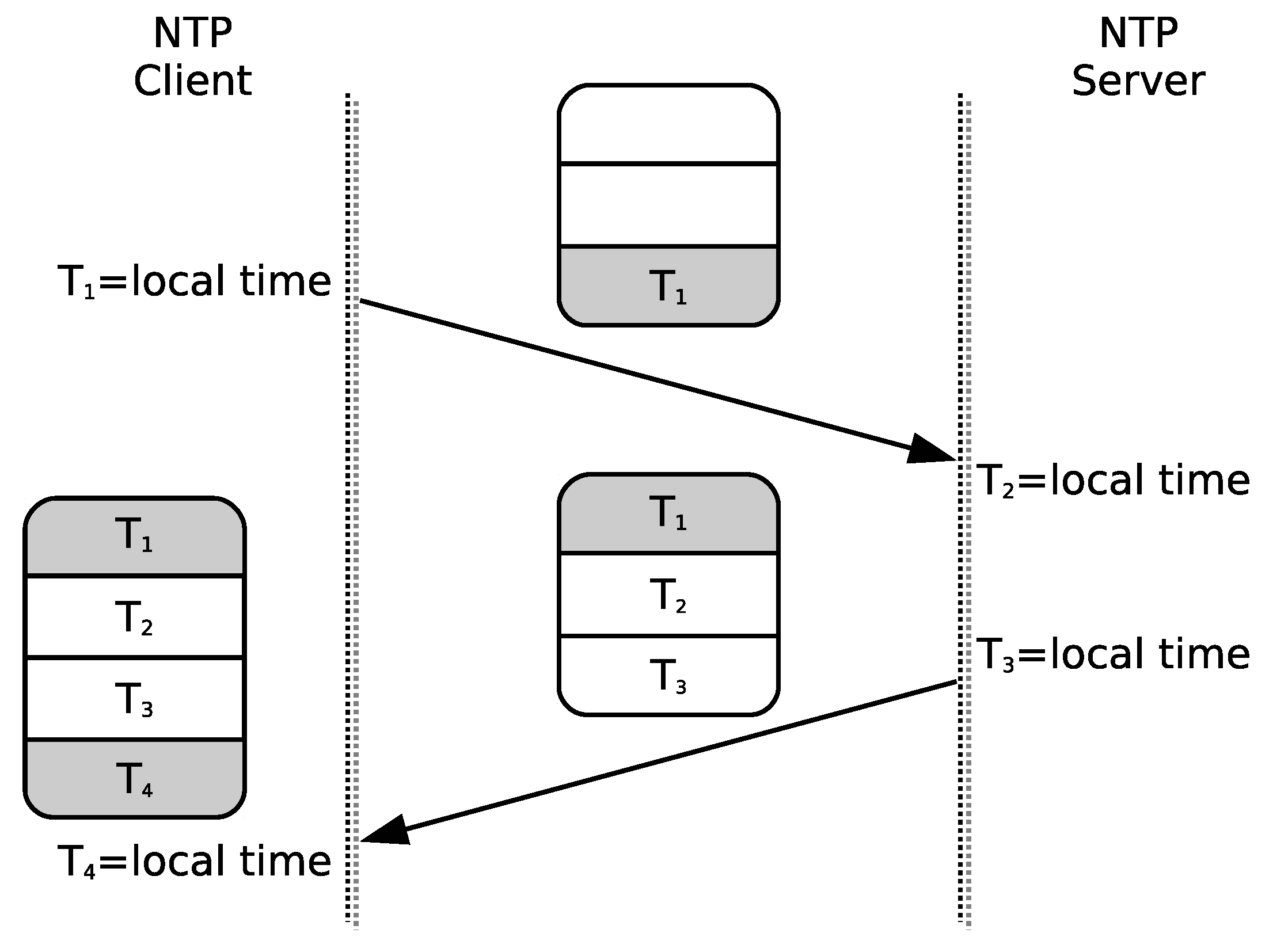
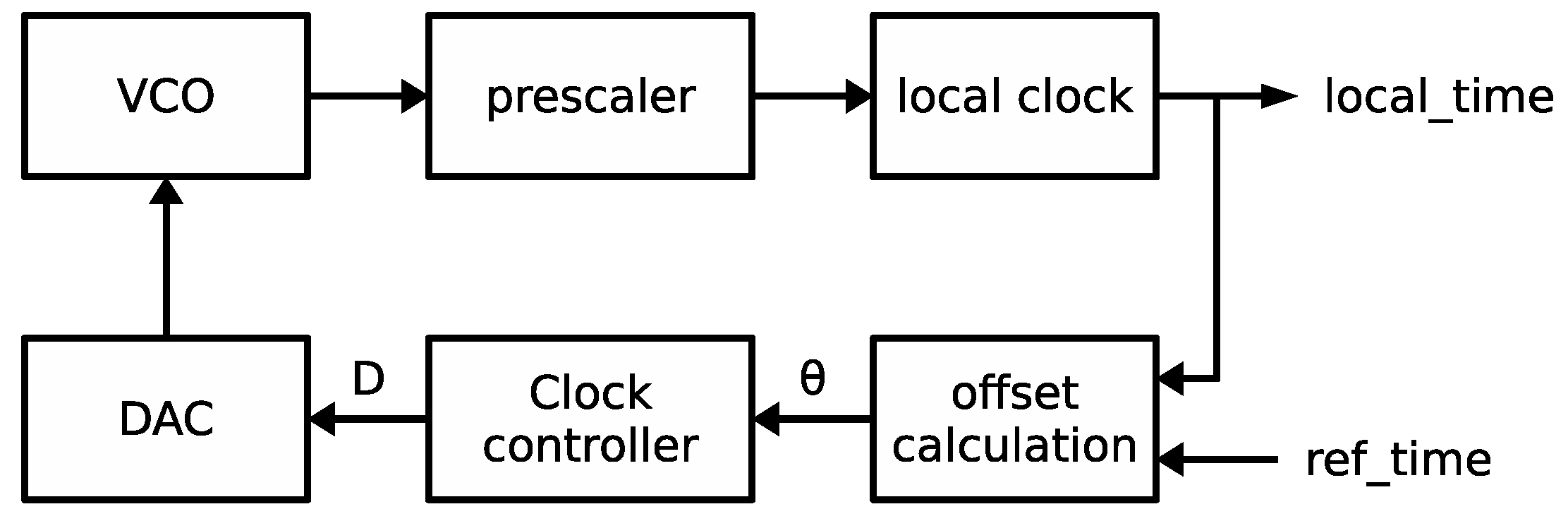
The task of the synchronization module is to maintain the local clock time as accurate and stable as possible by taking the GPS time as reference. This module is based on a clock model and a set of algorithms for continuously adjusting the local clock. It is the most complex one in the system after the P&CI. NTP implementations are typically based on the computer clock model introduced in [
39] and shown in
Figure 8. In this model, a voltage-controlled oscillator (VCO) generates a clock signal with a base frequency that a prescaler circuit turns into a proportional frequency better suited to drive the local clock. At each iteration of the control algorithm, the offset between local time and reference time (
) is calculated. Thereafter, a clock controller uses a clock discipline algorithm to adjust the control voltage of the VCO through a digital-to-analog converter (DAC) circuit in order to maintain the local clock correctly synchronized with the reference.
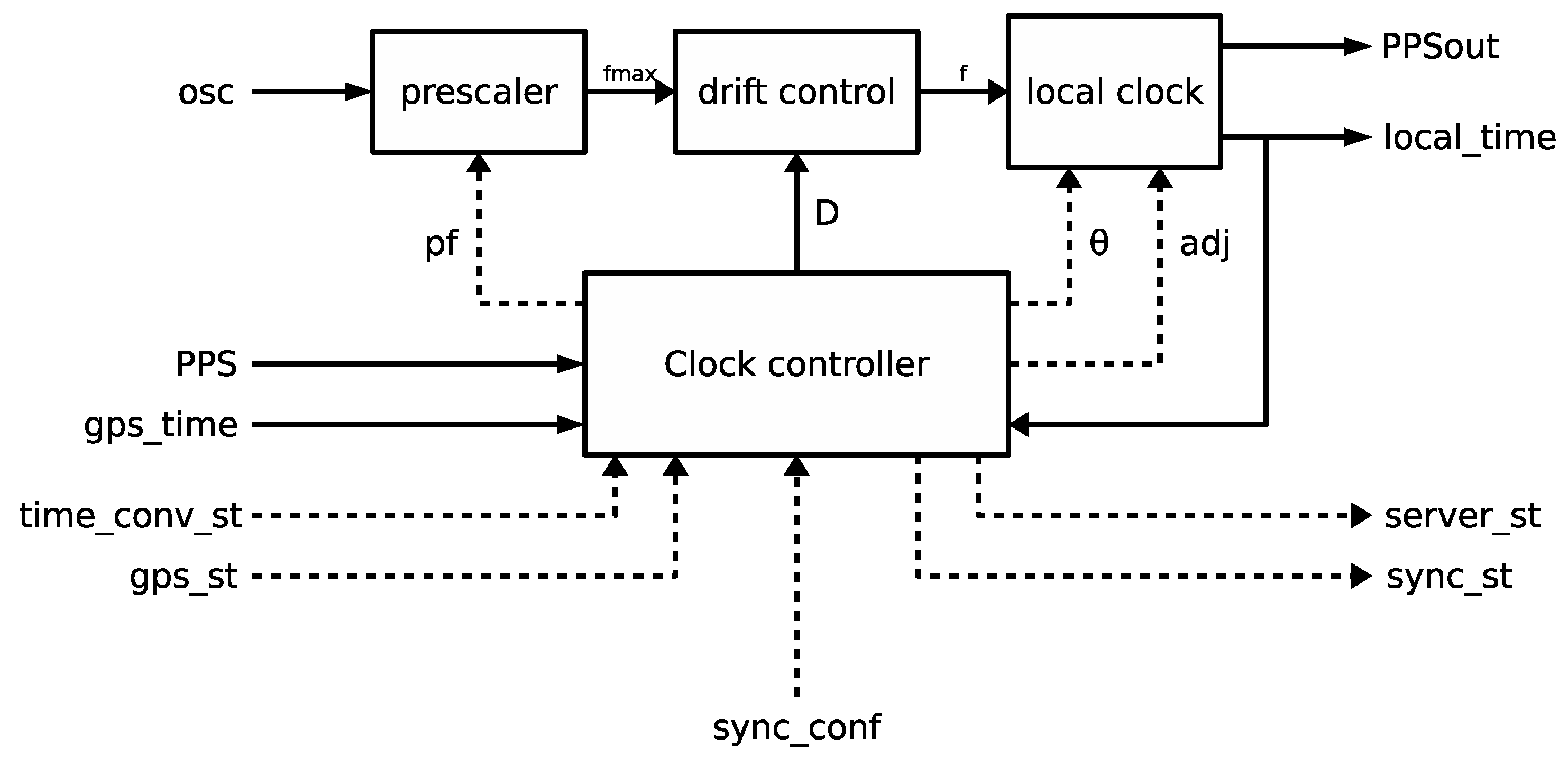
The synchronization module uses a different approach focused on the all-digital clock model introduced in [
24] and adapted to the NTP server core, as
Figure 9 shows. Compared to the traditional clock model, the most remarkable difference is that the VCO has been substituted by a completely digital drift control block, therefore eliminating the need of external components, like VCO and DAC. Solid lines in
Figure 9 correspond to signals used by the synchronization module during a normal operation, when the local clock is synchronized with the reference clock and only slight modifications of the local clock frequencies are necessary to maintain the synchronization. Dashed lines are related to signals that are relevant during the initial configuration phase of the module or when the synchronization has been lost and the local clock needs to be re-adjusted.
The base frequency comes from a fixed-frequency clock signal that is divided by the prescaler into a new frequency , where is an 8-bit prescaler factor included in the sync_conf configuration bus. This factor can be modified to accommodate a wide range of external oscillator frequencies in order to produce a that is close, but slightly higher, than the nominal frequency at which the local clock would run with no drift (). Afterwards, the drift control block selectively introduces a small time shift in by skipping a scattered fraction of the input cycles, given by input D. As a result, the average frequency at the output of the drift control block (the frequency applied to the local clock) can be adjusted.
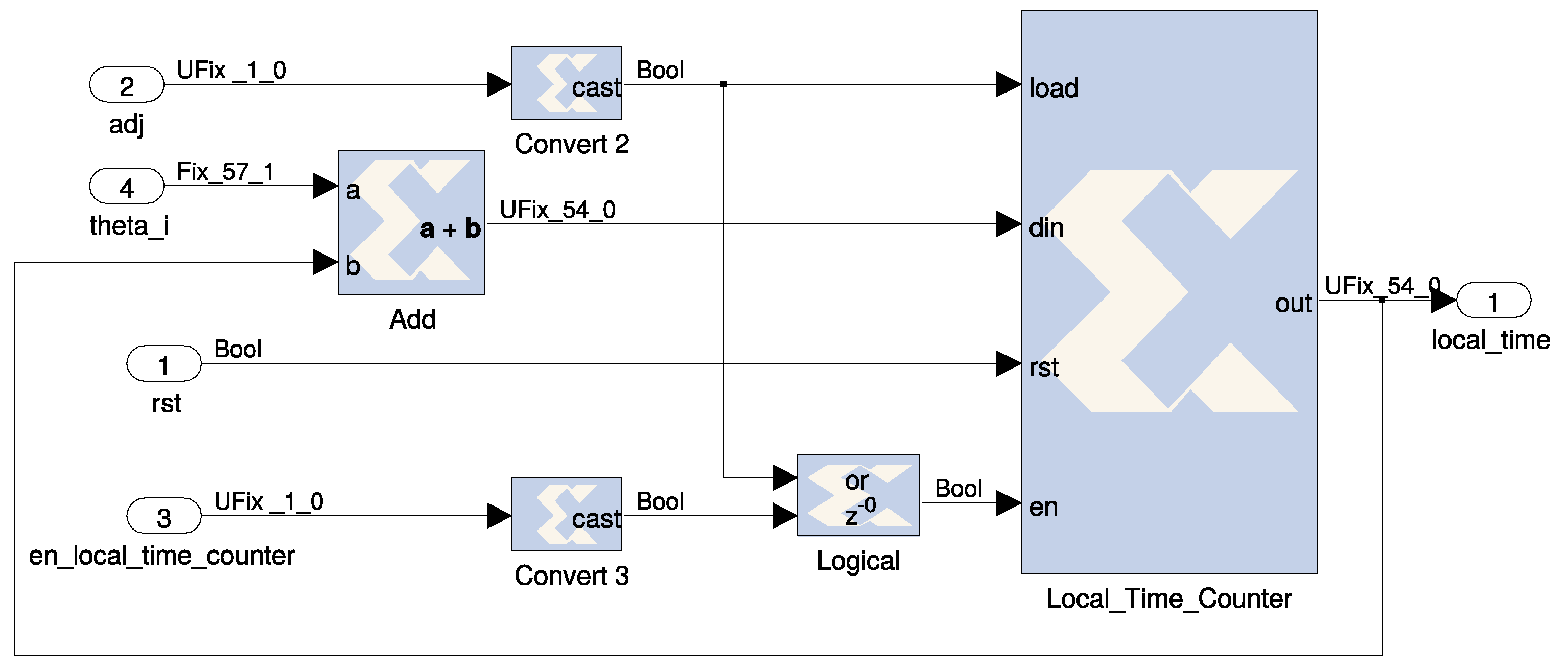
The local clock stores the time in NTP format using 32 bits for the integer part of the second and
n bits for the fractional part. The resolution and tuning capabilities of the system are derived from
n. The internal time resolution of the local clock is
s and the nominal operating frequency
that would make the local clock run synchronized is
. The drift control unit is designed so that it can skip
D cycles every
cycles, consequently:
but, since the prescaler is configured as
, the previous equation can be approximated by:
In the current implementation,
,
is approximately
MHz and time resolution is 238 ns, as can be seen in the local clock internal diagram in
Figure 10. It means that the minimum frequency adjustment is about one quarter of the microhertz. This resolution is intended to provide local clock accuracy in the range of
s. Furthermore, a system clock of 50 MHz is used to drive
with a prescaler factor of
that yields a maximum frequency (
) of
MHz. It means that the average frequency of the local clock can be adjusted in a range of
with respect to the nominal clock frequency. Due to this range, small corrections can be performed to the local clock during normal operation.
It is along normal operation (solid lines in
Figure 9) that the clock controller periodically compares the local time with the GPS time coming from the time reception module through the
signal and calculates the offset
. Because the GPS time is only precisely known at the active edge of the PPS signal, this is taken as the trigger to run the adjustment process. At this point, the GPS time at
signal actually corresponds to the previous active edge of the PPS signal, since NMEA-0183 frames are only sent by the GPS unit after the active edge. Nevertheless, as the active edge occurs at the beginning of the second, the offset can be calculated right after identifying the edge as:
A new value of the adjustment parameter
D is calculated at every adjustment interval to keep the local clock tuned to GPS time. This adjustment process is controlled by the clock discipline algorithm specially designed for hardware implementation, as introduced in [
24]. The algorithm tries to maintain the exactitude of the local clock, the stability of the clock frequency and a minimum drift of the local time when the GPS reference is not available for any reason. For that purpose, the clock discipline algorithm constantly computes the best value of
D (
), which would make the local clock run at the nominal frequency
, and the additional correction to
D, in order to make the local clock converge on the reference time in a smooth way. The actual implementation details of the algorithm are shown in
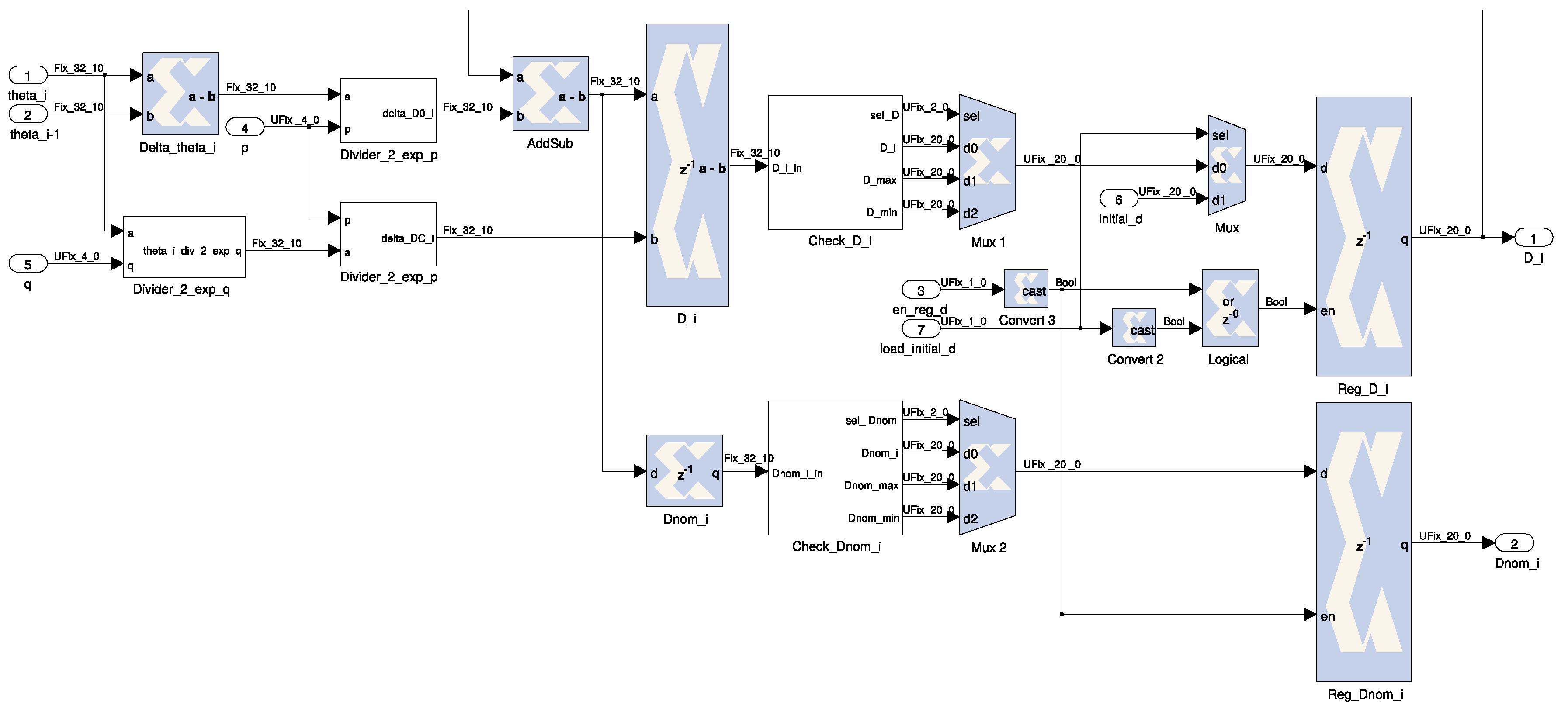
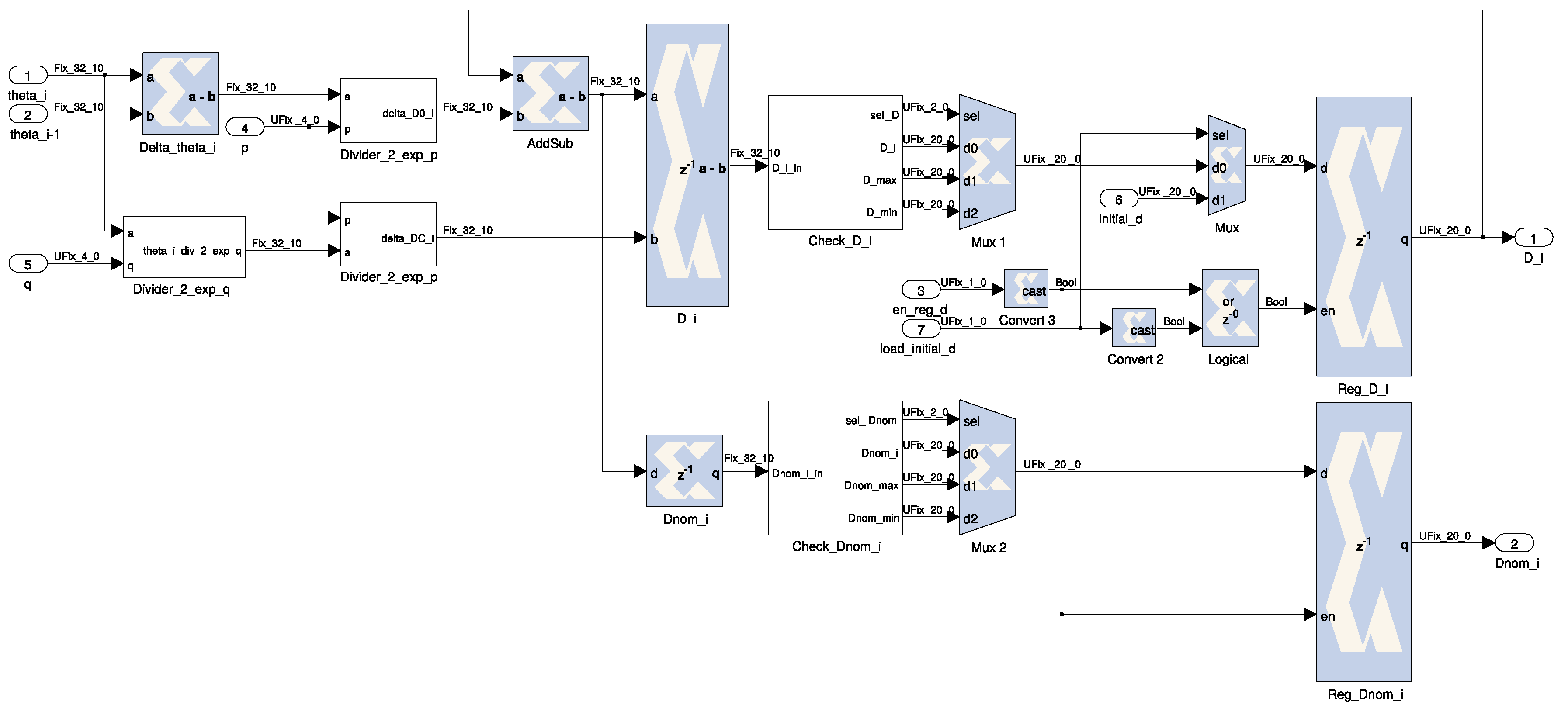
Figure 11 where
theta_i and
theta_i-1 are the current and previous offset values, respectively;
p and
q are two convergence factors, which can be altered for testing and/or fine-tuning purposes; and
D_i is the calculated correction. The module is implemented by using regular logic like shifters (power of 2 dividers), registers and simple arithmetic. Please refer to the work of Viejo et al. [
24] for additional details.
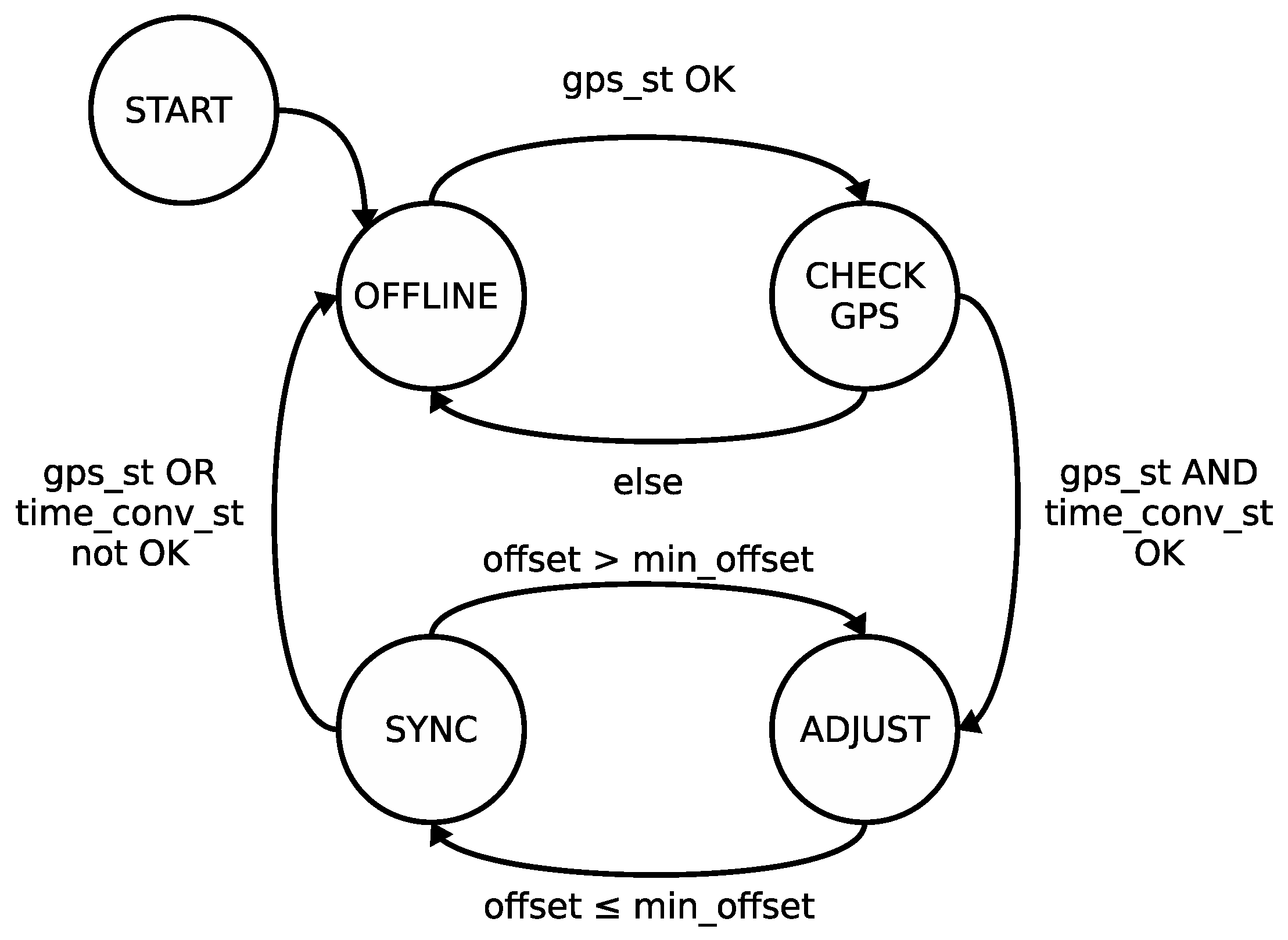
Furthermore, from the normal synchronized operation described in the previous paragraphs, the clock controller also handles the initial configuration and synchronization recovery by following the synchronization algorithm summarized in
Figure 12. Upon system initialization, the controller is in
START state and it is provided with the configuration for the synchronization module coming from the P&CI module through the sync_conf bus. This bus not only contains the information about the active edge of the
PPS signal, the prescaler factor and two 4-bit convergence factors for the clock discipline algorithm, as previously mentioned, but also a 20-bit initial value of parameter
D (see
Figure 11).
Once configured, the controller moves to offline state. Afterwards, the following state transitions are triggered by the active edge of the PPS signal or by a watchdog signal set a few instants after the expected PPS edge, in case the GPS becomes unavailable. The GPS on-line state is checked through the gps_st signal coming from the time reception module. When the GPS is on-line, the system transitions to check GPS state, where the time conversion executed by the time reception module after the last active edge of the PPS signal is checked through the time_conv_st signal. If the conversion succeeds and the GPS receiver is still on-line, then there is a transition to adjust state, else the system returns to offline state.
Adjust state is intended to set the local clock to the reference time for the first time, once the system has been initialized, or when the local clock has drifted considerably from the reference clock after a long period of off-line operation. In this state, if the clock offset calculated as Equation (
4) is within a minimum value
min_offset, then the system is considered synchronized and moves to sync state. Otherwise, the clock controller activates the adj signal of the local clock causing it to add the offset to the local time, which sets the local time equal to the current GPS time (one second more than the previous GPS time in the gps_time signal). Since this hard adjustment is likely to be non-monotonic, it should be avoided in most cases by setting
min_offset to the maximum offset value tolerated by the intended application, commonly in the range of a few seconds. Later, the system is synchronized and moves to sync state.
While in sync state, the system runs normally as described at the beginning of this subsection. If the offset overcomes min_offset, then the system moves back to adjust state and a hard adjustment of the local clock is forced. Nevertheless, this situation hardly ever happens in an already synchronized system and may reflect either a malfunction of the GPS receiver or a wrong operation of the clock discipline algorithm implemented by the clock controller. In case that either the GPS receiver becomes off-line or the time conversion does not work correctly, the system moves to offline state and waits for a correct GPS output to be available. While in this state, the clock discipline algorithm sets the drift control parameter to , in order to minimize the wandering of the local clock whenever the time reference is not available.
The clock controller also generates two state signals that are useful to build an NTP reply according to the NTP specification [
5]. The sync_st indicates whether the synchronization module is currently synchronized or not with the time reference and can be used to determine the present stratum of the server. The server_st is a bundle of state signals including whether the local clock has been synchronized with the reference since startup, as well as the last time it happened. It also includes an estimation of the actual accuracy of the local clock.
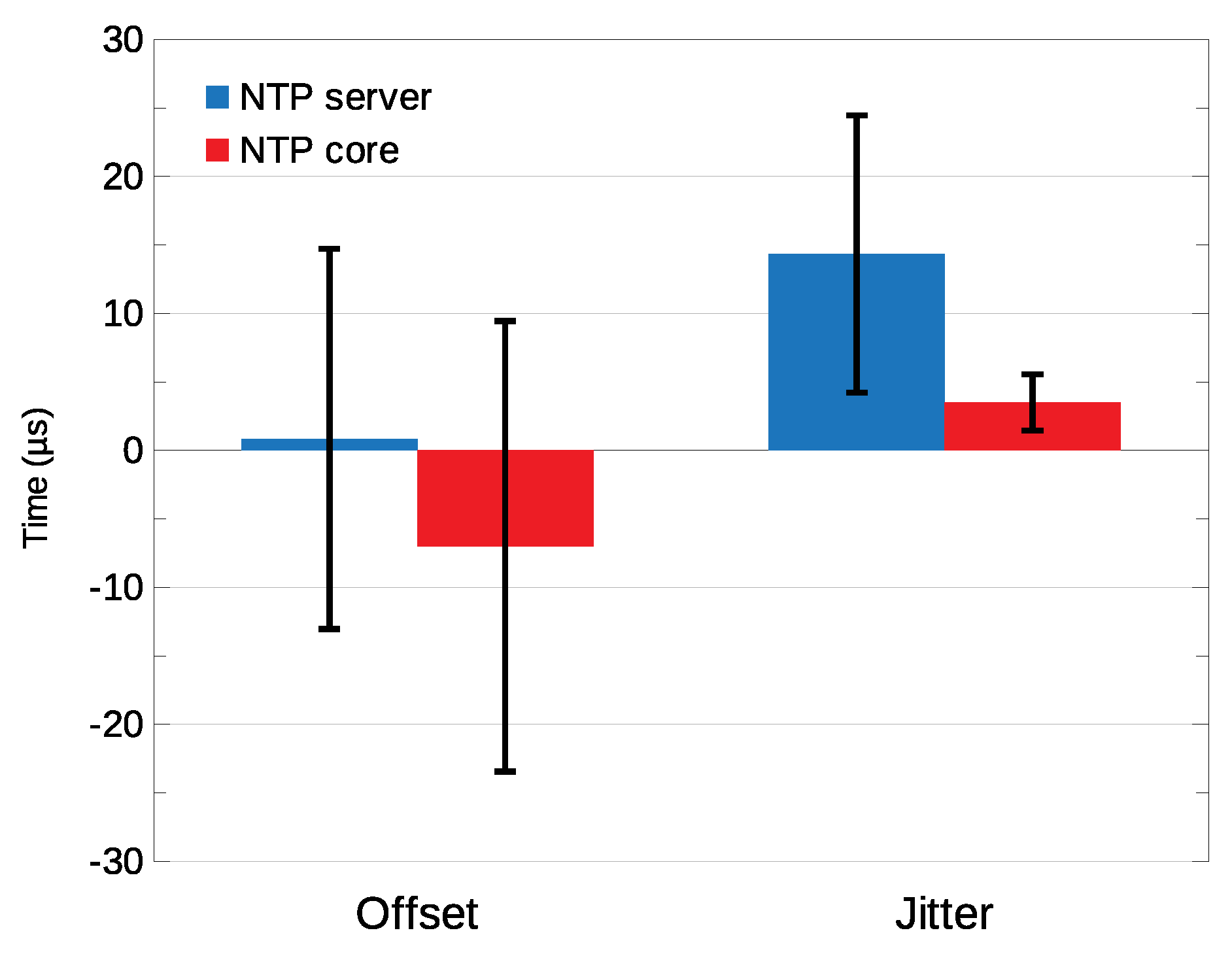
As referred above, the current implementation uses 50 MHz global clock signal of the system to drive the reference clock signal of the synchronization module (osc). However, this signal is made externally available in case the stability of the system under a failure of the GPS needs to be improved by using a more accurate external reference, such as temperature compensated or oven-controlled crystal oscillator.
The synchronization algorithm in
Figure 12 was been implemented using a finite state machine (FSM) coded in HDL. Data processing inside the clock controller includes extensive arithmetic operations for offset and control parameters calculations. Xilinx system generator for DSP has been used to model and implement the data processing part, which has been tested through Xilinx’s supported design flow based on MATLAB [
40] and Simulink [
41].

 ,
, 





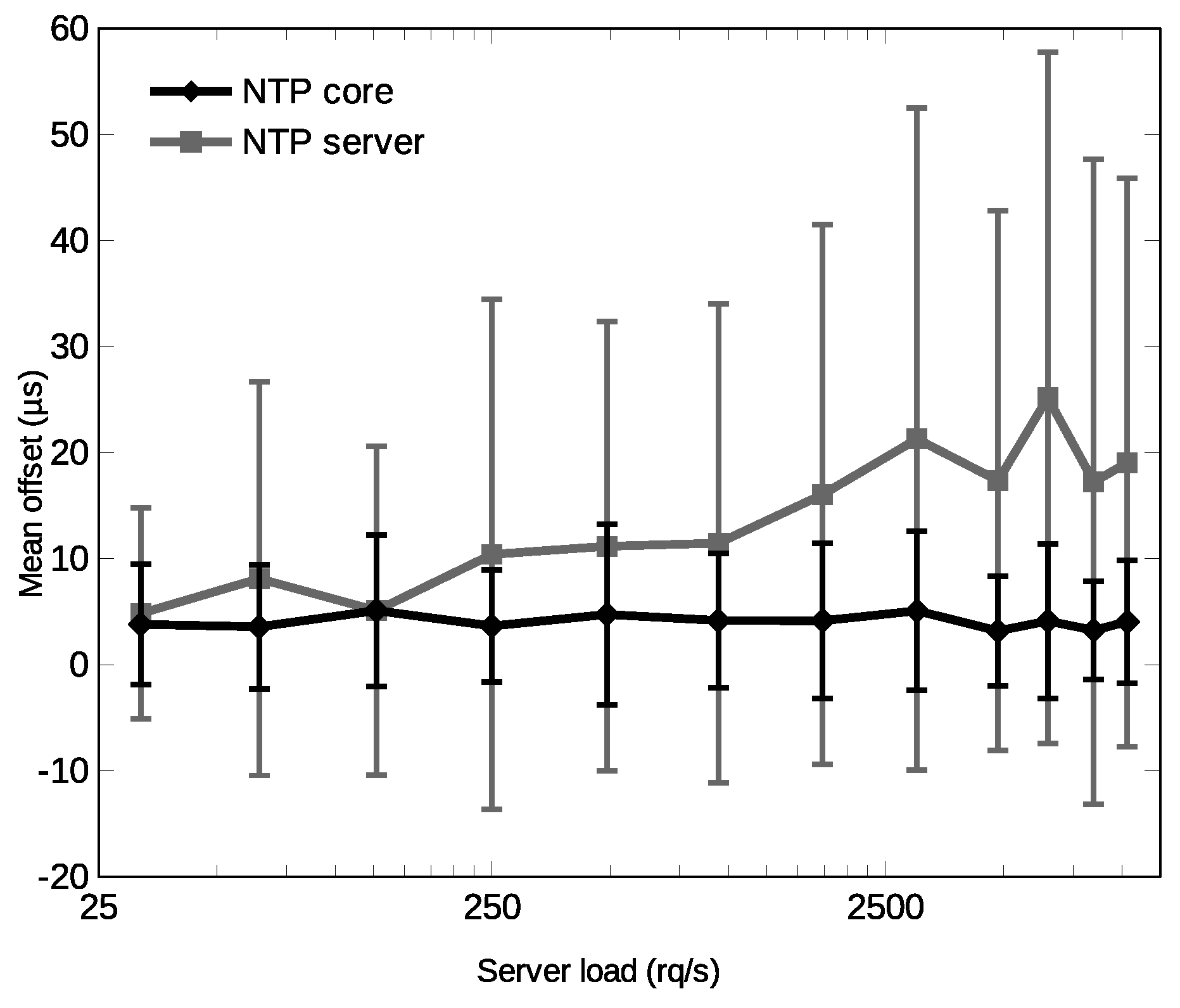
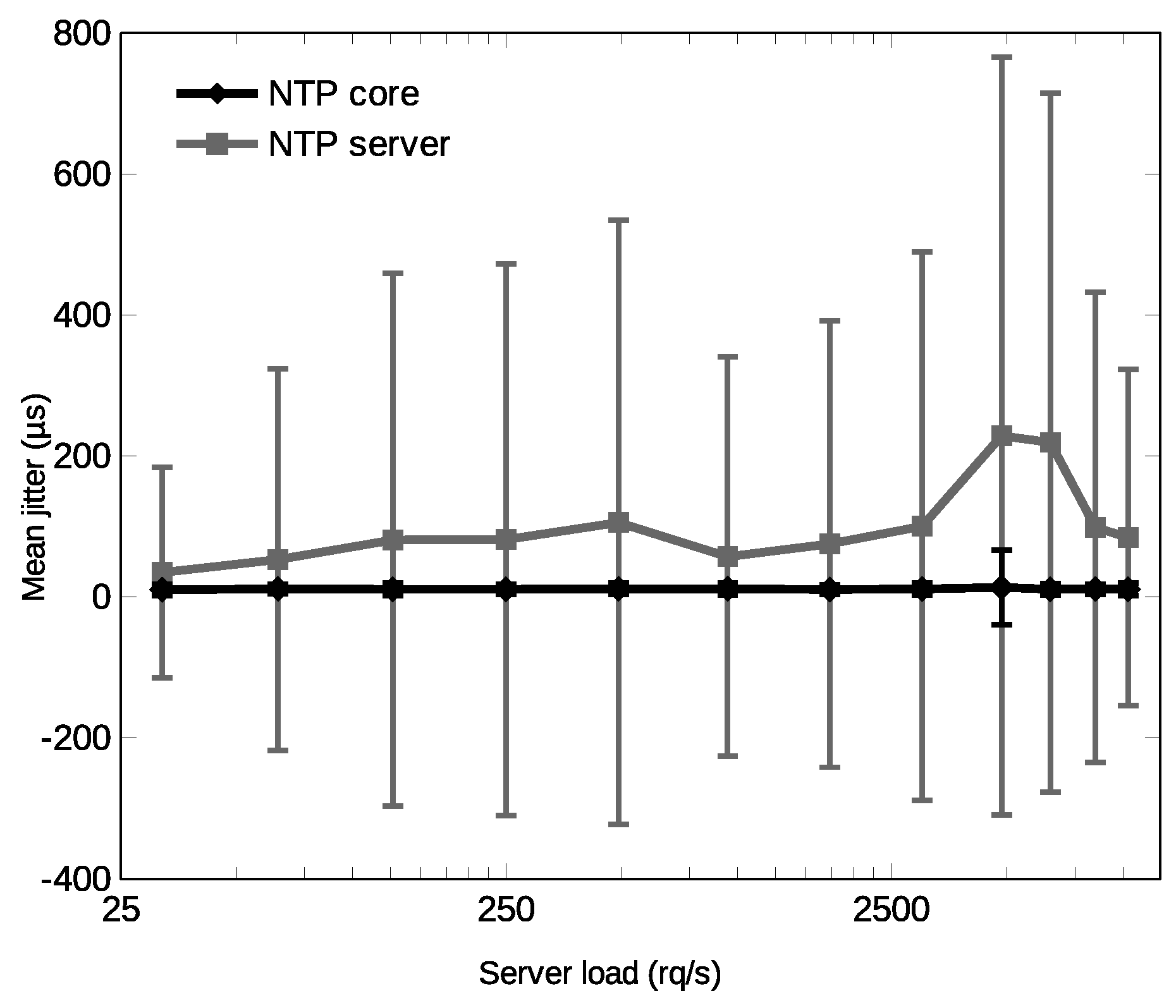

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}