Chromosome Image Classification Based on Improved Differentiable Architecture Search


Abstract
1. Introduction
2. Materials and Methods
2.1. The Dataset
2.1.1. CIFAR-10
2.1.2. ImageNet
2.1.3. Copenhagen
2.2. Methods
2.2.1. Overall Framework
2.2.2. Principle of DARTS
2.2.3. Search Space of E-DARTS
- Architecture parameters indicate the importance of candidate operators in transformation operations.
- The architecture parameters are relaxed to normalize them within the (0, 1) interval, with the sum of the parameters for all candidate operations on a directed edge constrained to equal 1.
2.2.4. Search Algorithm of E-DARTS
3. Experiments
3.1. Results on CIFAR-10
3.2. Results on ImageNet
3.3. Results on Copenhagen
3.4. Ablation Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Meenakshisundaram, N.; Ramkumar, G. A combined deep CNN-LSTM network for chromosome classification for metaphase selection. In Proceedings of the 2022 International Conference on Inventive Computation Technologies (ICICT), Lalitpur, Nepal, 20–22 July 2022; pp. 1005–1010. [Google Scholar]
- Somasundaram, D.; Madian, N.; Goh, K.M.; Suresh, S. Chromosome segmentation and classification: An updated review. Knowl. Inf. Syst. 2025, 67, 977–1011. [Google Scholar] [CrossRef]
- Menaka, D.; Vaidyanathan, S.G. Chromenet: A CNN architecture with comparison of optimizers for classification of human chromosome images. Multidimens. Syst. Signal Process. 2022, 33, 747–768. [Google Scholar] [CrossRef]
- Piper, J.; Granum, E. On fully automatic feature measurement for banded chromosome classification. Cytom. J. Int. Soc. Anal. Cytol. 1989, 10, 242–255. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Sharma, M.; Saha, O.; Sriraman, A.; Hebbalaguppe, R.; Vig, L.; Karande, S. Crowdsourcing for chromosome segmentation and deep classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 34–41. [Google Scholar]
- Jindal, S.; Gupta, G.; Yadav, M.; Sharma, M.; Vig, L. Siamese networks for chromosome classification. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 72–81. [Google Scholar]
- Lin, C.; Zhao, G.; Yang, Z.; Yin, A.; Wang, X.; Guo, L.; Chen, H.; Ma, Z.; Zhao, L.; Luo, H. Cir-net: Automatic classification of human chromosome based on inception-resnet architecture. IEEE/ACM Trans. Comput. Biol. Bioinform. 2020, 19, 1285–1293. [Google Scholar] [CrossRef]
- Liu, X.; Fu, L.; Chun-Wei Lin, J.; Liu, S. SRAS-net: Low-resolution chromosome image classification based on deep learning. IET Syst. Biol. 2022, 16, 85–97. [Google Scholar] [CrossRef]
- Xiao, L.; Luo, C. DEEPACC: Automate chromosome classification based on metaphase images using deep learning framework fused with priori knowledge. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 607–610. [Google Scholar]
- Sun, X.; Li, J.; Ma, J.; Xu, H.; Chen, B.; Zhang, Y.; Feng, T. Segmentation of overlapping chromosome images using U-Net with improved dilated convolutions. J. Intell. Fuzzy Syst. 2021, 40, 5653–5668. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Ang, K.M.; Lim, W.H.; Tiang, S.S.; Sharma, A.; Towfek, S.; Abdelhamid, A.A.; Alharbi, A.H.; Khafaga, D.S. MTLBORKS-CNN: An innovative Approach for automated convolutional neural Network design for image classification. Mathematics 2023, 11, 4115. [Google Scholar] [CrossRef]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 4780–4789. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. DARTS: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Chitty-Venkata, K.T.; Emani, M.; Vishwanath, V.; Somani, A.K. Neural architecture search benchmarks: Insights and survey. IEEE Access 2023, 11, 25217–25236. [Google Scholar] [CrossRef]
- Miahi, E.; Mirroshandel, S.A.; Nasr, A. Genetic Neural Architecture Search for automatic assessment of human sperm images. Expert Syst. Appl. 2022, 188, 115937. [Google Scholar] [CrossRef]
- Lu, Z.; Liang, S.; Yang, Q.; Du, B. Evolving block-based convolutional neural network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–21. [Google Scholar] [CrossRef]
- Fu, P.; Liang, X.; Qian, Y.; Guo, Q.; Zhang, Y.; Huang, Q.; Tang, K. Multi-Scale Features Are Effective for Multi-Modal Classification: An Architecture Search Viewpoint. IEEE Trans. Circuits Syst. Video Technol. 2024, 35, 1070–1083. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 20 March 2025).
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lundsteen, C.; Lind, A.M.; Granum, E. Visual classification of banded human chromosomes. I. Karyotyping compared with classification of isolated chromosomes. Ann. Hum. Genet. 1976, 40, 87–97. [Google Scholar] [CrossRef]
- Shu, Y.; Wang, W.; Cai, S. Understanding architectures learnt by cell-based neural architecture search. arXiv 2019, arXiv:1909.09569. [Google Scholar]
- Chen, X.; Xie, L.; Wu, J.; Tian, Q. Progressive differentiable architecture search: Bridging the depth gap between search and evaluation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1294–1303. [Google Scholar]
- Xie, S.; Zheng, H.; Liu, C.; Lin, L. SNAS: Stochastic neural architecture search. arXiv 2018, arXiv:1812.09926. [Google Scholar]
- Pham, H.; Guan, M.; Zoph, B.; Le, Q.; Dean, J. Efficient neural architecture search via parameters sharing. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4095–4104. [Google Scholar]
- Ye, P.; Li, B.; Li, Y.; Chen, T.; Fan, J.; Ouyang, W. b-DARTS: Beta-decay regularization for differentiable architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10874–10883. [Google Scholar]
- Yang, Z.; Wang, Y.; Chen, X.; Shi, B.; Xu, C.; Xu, C.; Tian, Q.; Xu, C. Cars: Continuous evolution for efficient neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1829–1838. [Google Scholar]
- Xu, Y.; Xie, L.; Zhang, X.; Chen, X.; Qi, G.-J.; Tian, Q.; Xiong, H. PC-DARTS: Partial channel connections for memory-efficient architecture search. arXiv 2019, arXiv:1907.05737. [Google Scholar]
- Zhang, B.; Wu, X.; Miao, H.; Guo, C.; Yang, B. Dependency-Aware Differentiable Neural Architecture Search. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 219–236. [Google Scholar]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.-J.; Li, F.-F.; Yuille, A.; Huang, J.; Murphy, K. Progressive neural architecture search. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 19–34. [Google Scholar]
- Li, J.; Chen, B.; Sun, X.; Feng, T.; Zhang, Y. Banded chromosome images recognition based on dense convolutional network with segmental recalibration. J. Biomed. Eng. 2021, 38, 122–130. [Google Scholar]
- Qin, Y.; Wen, J.; Zheng, H.; Huang, X.; Yang, J.; Song, N.; Zhu, Y.-M.; Wu, L.; Yang, G.-Z. Varifocal-net: A chromosome classification approach using deep convolutional networks. IEEE Trans. Med. Imaging 2019, 38, 2569–2581. [Google Scholar] [CrossRef]
- Hussain, T.; Shouno, H.; Hussain, A.; Hussain, D.; Ismail, M.; Mir, T.H.; Hsu, F.R.; Alam, T.; Akhy, S.A. EFFResNet-ViT: A Fusion-based Convolutional and Vision Transformer Model for Explainable Medical Image Classification. IEEE Access 2025, 13, 54040–54068. [Google Scholar] [CrossRef]

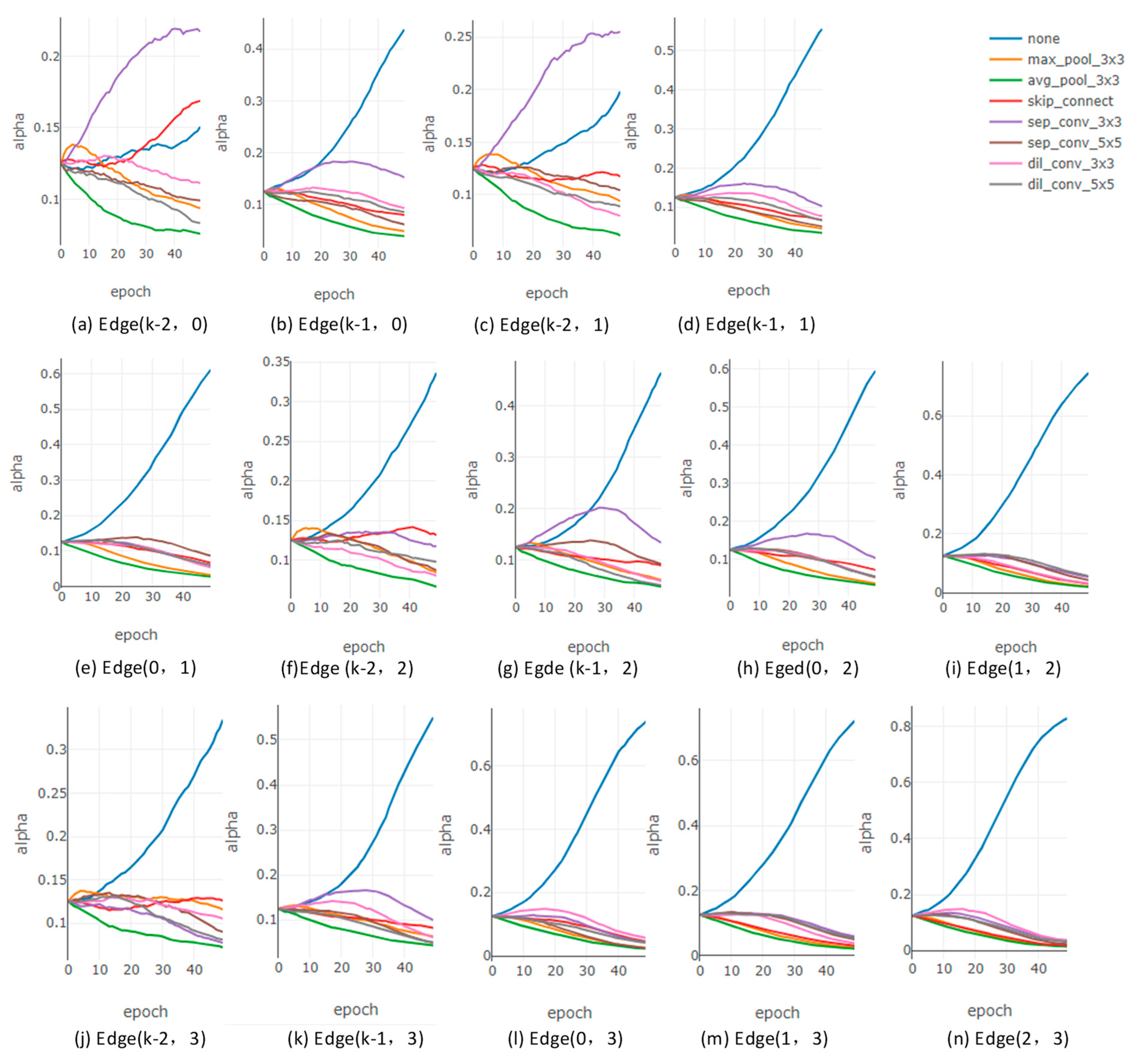

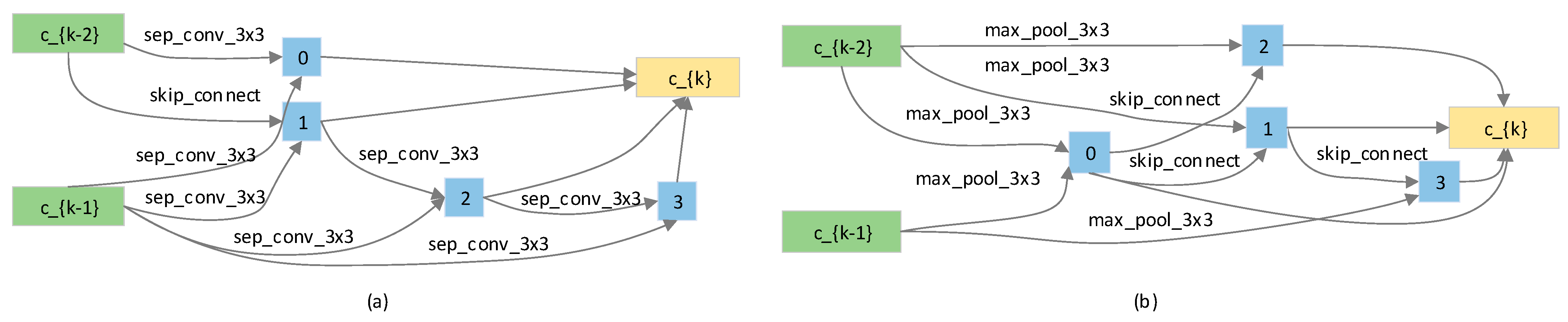
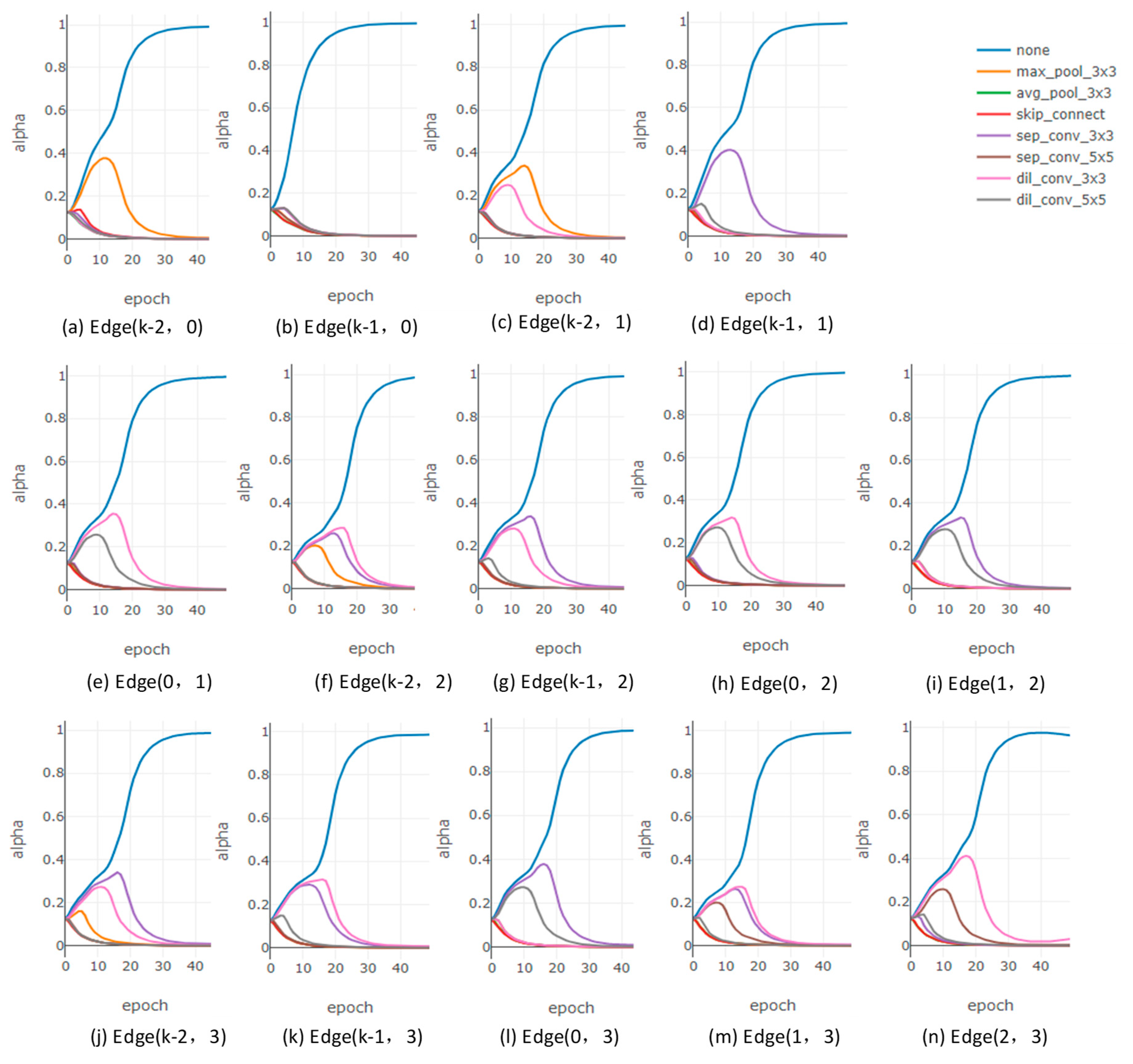

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Params (M) | Search Cost (GPU·Days) | Search Method |
|---|---|---|---|---|
| NASNet-A | 97.35 | 3.3 | 2000 | RL |
| ENAS | 97.11 | 4.6 | 0.5 | RL |
| DARTS_V1 | 3.3 | 1.5 | Gradient-based | |
| SNAS | 2.8 | 1.5 | Gradient-based | |
| R-DARTS | 96.95 | - | - | Gradient-based |
| FairDARTS-a | 97.46 | 2.8 | - | Gradient-based |
| P-DARTS | 97.50 | 3.4 | 0.3 | Gradient-based |
| PC-DARTS | 0.07 | 3.6 | 0.1 | Gradient-based |
| β-DARTS | 0.08 | 3.75 | 0.4 | Gradient-based |
| E-DARTS_S | 0.17 | 3.2 | 0.3 | Gradient-based |
| E-DARTS | 3.8 | 0.3 | Gradient-based |
| Model | Top1 Acc (%) | Top5 Acc (%) | Params (M) | Search Cost (GPU·Days) | +×(M) | Method |
|---|---|---|---|---|---|---|
| Inception-v1 | 69.8 | 89.9 | 6.6 | - | 1448 | manual |
| MobileNets | 70.6 | 89.5 | 4.2 | - | 569 | manual |
| ShuffleNet 2× | 73.7 | - | ~5 | - | 524 | manual |
| DARTS 1 | 73.3 | 91.3 | 4.7 | 0.4 | 574 | gradient-based |
| SNAS | 72.7 | 90.8 | 4.3 | 1.5 | 522 | gradient-based |
| NASNet-A | 74 | 91.6 | 5.3 | 2000 | 564 | RL |
| NASNet-B | 72.8 | 91.3 | 5.3 | 1800 | 488 | RL |
| NASNet-C | 72.5 | 91.0 | 4.9 | 1800 | 558 | RL |
| AmoebaNet-A | 74.5 | 92.0 | 5.1 | 3150 | 555 | evolution |
| AmoebaNet-B | 74 | 91.5 | 5.3 | 3150 | 555 | evolution |
| AmoebaNet-C | 75.7 | 92.4 | 6.4 | 3150 | 570 | evolution |
| CARS-I | 75.2 | 92.5 | 5.1 | 0.4 | 591 | evolution |
| PNAS | 74.2 | 91.9 | 5.1 | 225 | 588 | SMBO |
| MnasNet | 74.8 | 92.0 | 4.4 | - | 388 | RL |
| P-DARTS | 75.6 | 92.6 | 4.9 | 0.3 | 557 | gradient-based |
| PC-DARTS | 74.9 | 92.2 | 5.3 | 0.1 | 586 | gradient-based |
| DaNas | 75.8 | 92.9 | 5.5 | 0.3 | - | gradient-based |
| β-DARTS | 76.1 | 93.0 | 5.5 | 0.4 | 609 | gradient-based |
| E-DARTS | 75.4 | 92.5 | 5.3 | 0.3 | 602 | gradient-based |
| Model | Accuracy (%) | Layers |
|---|---|---|
| AlexNet | 96.55 | 8 |
| Sharma | 97.53 | 11 |
| VGG16 | 97.53 | 16 |
| ResNet18 | 98.03 | 18 |
| DenseNet | 98.03 | 121 |
| G-Net | 98.64 | 28 |
| E-DARTS | 98.64 | 59 |
| Model | Search Space | Entropy | CIFAR-10 (Avg) | CIFAR-10 (Best) | ImageNet (Best) |
|---|---|---|---|---|---|
| DARTS | 96.88 | 97.07 | 73.30 | ||
| E-DARTS-S 1 | √ | 97.00 | 97.21 | 74.40 | |
| E-DARTS-R 2 | √ | 96.71 | 96.12 | 73.71 | |
| E-DARTS 3 | √ | √ | 97.09 | 97.27 | 75.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zeng, C.; Zhou, M.; Shang, Z.; Zhu, J. Chromosome Image Classification Based on Improved Differentiable Architecture Search. Electronics 2025, 14, 1820. https://doi.org/10.3390/electronics14091820
Li J, Zeng C, Zhou M, Shang Z, Zhu J. Chromosome Image Classification Based on Improved Differentiable Architecture Search. Electronics. 2025; 14(9):1820. https://doi.org/10.3390/electronics14091820
Chicago/Turabian StyleLi, Jianming, Changchang Zeng, Min Zhou, Zeyi Shang, and Jiangang Zhu. 2025. "Chromosome Image Classification Based on Improved Differentiable Architecture Search" Electronics 14, no. 9: 1820. https://doi.org/10.3390/electronics14091820
APA StyleLi, J., Zeng, C., Zhou, M., Shang, Z., & Zhu, J. (2025). Chromosome Image Classification Based on Improved Differentiable Architecture Search. Electronics, 14(9), 1820. https://doi.org/10.3390/electronics14091820