
How to Use Redundancy for Memory Reliability: Replace or Code?


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. System Model
3. Error Protection from Hard Faults
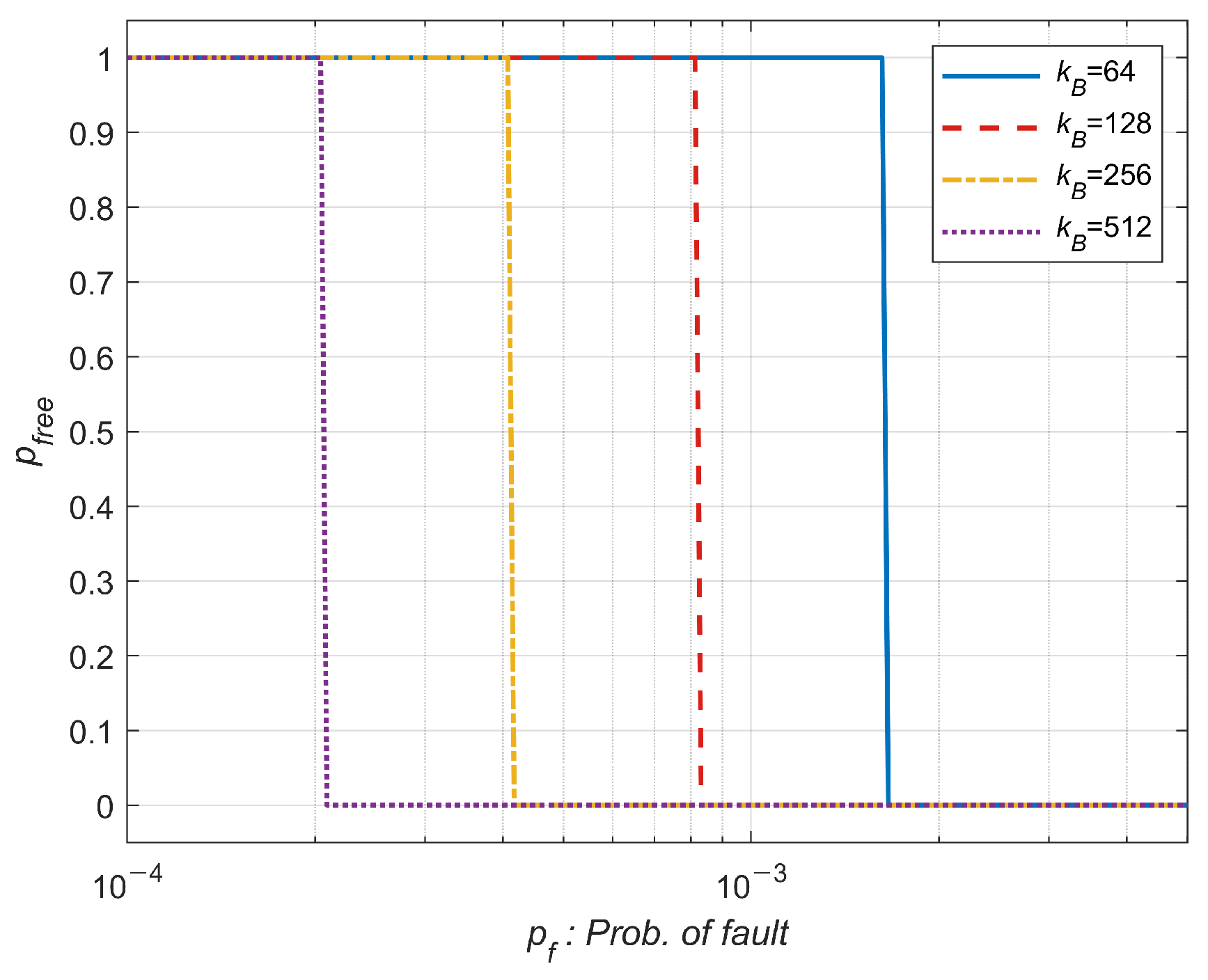
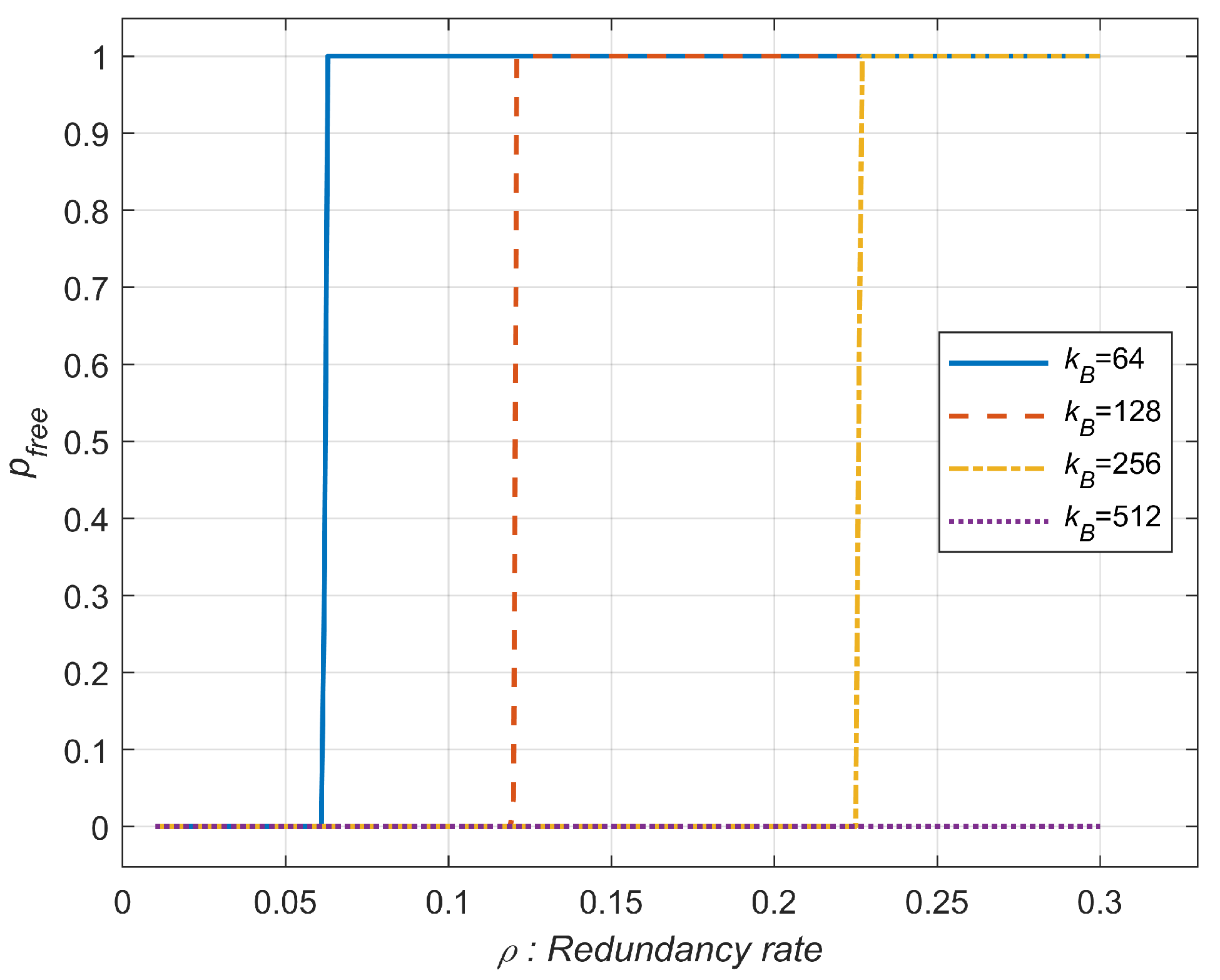
3.1. Replacement Approach
3.2. Error Correction Coding Approach
4. Error Protection from Soft Errors
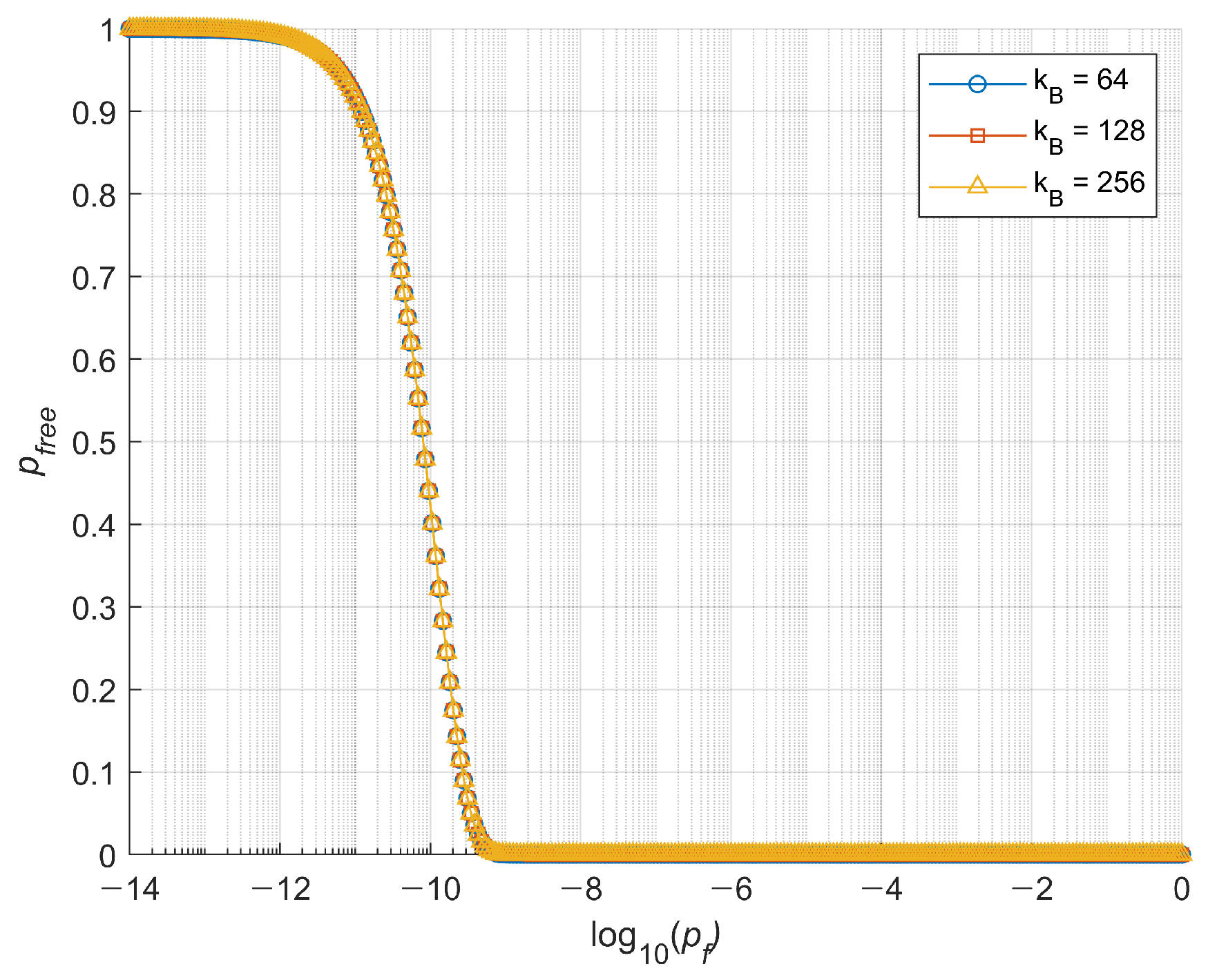
4.1. Soft Error Only Scenario
4.2. How to Handle the Mixture of Hard Faults and Soft Errors
- Assign replacement cells fitted to the target . (We assume aging can increase , and the repair process can be conducted after production.)
- The block length can be optimized in terms of the final BLER.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CLT | central limit theorem |
| EC | error correction |
| ECC | error-correcting code |
| ED | error detection |
| IECC | in-DRAM error correction code |
| PPR | post-packaging repair |
References
- Schroeder, B.; Pinheiro, E.; Weber, W.D. DRAM errors in the wild: A large-scale field study. In Proceedings of the 11th International Joint Conference on Measurement and Modeling of Computer Systems (SIGMETRICS), Seattle, WA, USA, 15–19 June 2009; pp. 193–204. [Google Scholar]
- Grupp, L.M.; Davis, J.D.; Swanson, S. The bleak future of NAND flash memory. In Proceedings of the 10th USENIX Conference on File and Storage Technologies (FAST), San Jose, CA, USA, 15–17 February 2012; p. 2. [Google Scholar]
- Mielke, N.; Marquart, T.; Wu, N.; Kessenich, J.; Cubert, H.; Cadien, K.; Hankinson, J.; Nevill, R. Bit error rate in NAND flash memories. In Proceedings of the 2008 IEEE International Reliability Physics Symposium, Phoenix, AZ, USA, 27 April–1 May 2008; pp. 9–19. [Google Scholar]
- Kim, Y.; Daly, R.; Kim, J.; Fallin, C.; Lee, J.H.; Lee, D.; Wilkerson, C.; Lai, K.; Mutlu, O. Flipping bits in memory without accessing them: An experimental study of DRAM disturbance errors. In Proceedings of the 41st International Symposium on Computer Architecture (ISCA), Minneapolis, MN, USA, 14–18 June 2014; pp. 361–372. [Google Scholar]
- Patel, M.; Kim, J.; Mutlu, O. The Reach Profiler (REAPER): Enabling the mitigation of DRAM retention failures via profiling at aggressive conditions. In Proceedings of the 44th International Symposium on Computer Architecture (ISCA), Toronto, ON, Canada, 24–28 June 2017; pp. 255–266. [Google Scholar]
- Masashi, H.; Itoh, K. Nanoscale Memory Repair; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Hou, C.S.; Chen, Y.X.; Li, J.F.; Lo, C.Y.; Kwai, D.M.; Chou, Y.F. A built-in self-repair scheme for DRAMs with spare rows, columns, and bits. In Proceedings of the 2016 IEEE International Test Conference (ITC), Fort Worth, TX, USA, 15–17 November 2016; pp. 1–7. [Google Scholar]
- Gu, B.; Coughlin, T.; Maxwell, B.; Griffith, J.; Lee, J.; Cordingley, J.; Johnson, S.; Karaginiannis, E.; Ehmann, J. Challenges and future directions of laser fuse processing in memory repair. In Proceedings of the Semicon China, Shanghai, China, 12 March 2003. [Google Scholar]
- Kim, D.-H.; Milor, L.S. ECC-ASPIRIN: An ECC-assisted post-package repair scheme for aging errors in DRAMs. In Proceedings of the 2016 IEEE 34th VLSI Test Symposium (VTS), Las Vegas, NV, USA, 25–27 April 2016; pp. 1–6. [Google Scholar]
- Jung, G.; Na, H.J.; Kim, S.H.; Kim, J. Dual-axis ECC: Vertical and horizontal error correction for storage and transfer errors. In Proceedings of the 2024 IEEE 42nd International Conference on Computer Design (ICCD), Milan, Italy, 18–20 November 2024. [Google Scholar]
- Lee, D.; Cho, E.; Kim, S.H. On the performance of SEC and SEC-DED-DAEC codes over burst error channels. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 20–22 October 2021. [Google Scholar]
- Gong, S.L.; Kim, J.; Lym, S.; Sullivan, M.; David, H.; Erez, M. DUO: Exposing On-Chip Redundancy to Rank-Level ECC for High Reliability. In Proceedings of the 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; pp. 683–695. [Google Scholar]
- Kwon, S.; Son, Y.H.; Ahn, J.H. Understanding DDR4 in pursuit of In-DRAM ECC. In Proceedings of the 2014 International SoC Design Conference (ISOCC), Jeju, Republic of Korea, 3–6 November 2014; pp. 276–277. [Google Scholar]
- Polyanskiy, Y.; Poor, H.V.; Verdú, S. Channel coding rate in the finite blocklength regime. IEEE Trans. Inf. Theory 2010, 56, 2307–2359. [Google Scholar] [CrossRef]
- Bose, R.C.; Ray-Chaudhuri, D.K. On A Class of Error Correcting Binary Group Codes. Inf. Control 1960, 3, 68–79. [Google Scholar] [CrossRef]
- Cha, S.; Shin, S.O.H.; Hwang, S.; Park, K.; Jang, S.J.; Choi, J.S.; Jin, G.Y.; Son, Y.H.; Cho, H.; Ahn, J.H.; et al. Defect analysis and cost-effective resilience architecture for future DRAM devices. In Proceedings of the 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA), Austin, TX, USA, 4–8 February 2017. [Google Scholar]
- Ju, H.; Park, J.; Lee, D.; Jang, M.; Lee, J.; Kim, S.-H. On improving the design of parity-check polar codes. IEEE Open J. Commun. Soc. (OJCOMS) 2024, 5, 5552–5566. [Google Scholar] [CrossRef]
- Hamming, R.W. Error correcting and error detecting codes. Bell Syst. Tech. J. 1950, 29, 147–160. [Google Scholar] [CrossRef]
- Hsiao, M.Y. A class of optimal minimum odd-weight-column SECDED codes. IBM J. Res. Develop. 1970, 14, 301–395. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ju, H.; Kong, D.-H.; Lee, K.; Lee, M.-K.; Cho, S.; Kim, S.-H. How to Use Redundancy for Memory Reliability: Replace or Code? Electronics 2025, 14, 1812. https://doi.org/10.3390/electronics14091812
Ju H, Kong D-H, Lee K, Lee M-K, Cho S, Kim S-H. How to Use Redundancy for Memory Reliability: Replace or Code? Electronics. 2025; 14(9):1812. https://doi.org/10.3390/electronics14091812
Chicago/Turabian StyleJu, Hyosang, Dong-Hyun Kong, Kijun Lee, Myung-Kyu Lee, Sunghye Cho, and Sang-Hyo Kim. 2025. "How to Use Redundancy for Memory Reliability: Replace or Code?" Electronics 14, no. 9: 1812. https://doi.org/10.3390/electronics14091812
APA StyleJu, H., Kong, D.-H., Lee, K., Lee, M.-K., Cho, S., & Kim, S.-H. (2025). How to Use Redundancy for Memory Reliability: Replace or Code? Electronics, 14(9), 1812. https://doi.org/10.3390/electronics14091812