


Side-Scan Sonar Image Classification Based on Joint Image Deblurring–Denoising and Pre-Trained Feature Fusion Attention Network

Abstract
1. Introduction
2. Related Work
2.1. The Imaging Principle and Characteristics of Sonar Images
2.2. Traditional SSS Image Classification Methods
2.3. Deep Learning-Based SSS Image Classification Method
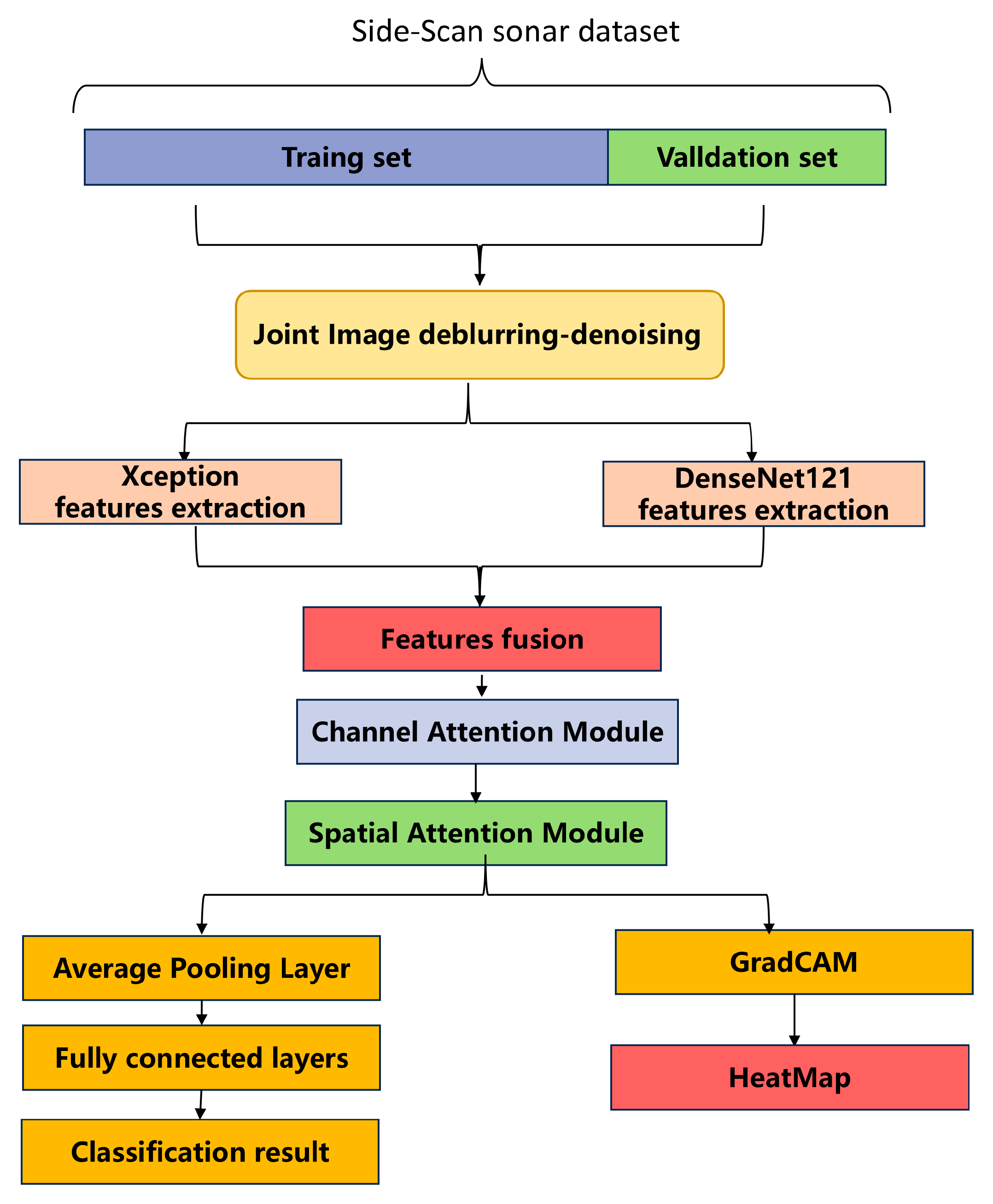
3. Methods
3.1. Joint Image Deblurring–Denoising Method
3.2. Feature Fusion Attention Network Based on Transfer Learning
3.2.1. Transfer Learning Method
3.2.2. Introduction of DenseNet and Xception
3.2.3. Feature Fusion Process Based on Spatial and Channel Attention Mechanisms
3.3. Grad CAM
4. Results and Discussions
4.1. Data Description and Experimental Environment
4.2. Model Performance Metrics
- True Positive (TP): Samples correctly identified as positive.
- True Negative (TN): Samples correctly identified as negative.
- False Positive (FP): Samples incorrectly identified as positive (actual negatives).
- False Negative (FN): Samples incorrectly identified as negative (actual positives).
- Precision measures the accuracy of the model’s positive predictions, defined as the proportion of true positives among all predicted positives.
- Recall measures the proportion of actual positives that were correctly identified by the model.
- The F1 score is the harmonic mean of precision and recall, providing a balanced measure of both.
- Specificity measures the proportion of actual negatives that were correctly identified as negative.
- Overall Accuracy (OA) measures the proportion of all samples that were correctly classified.
4.3. Ablation Study
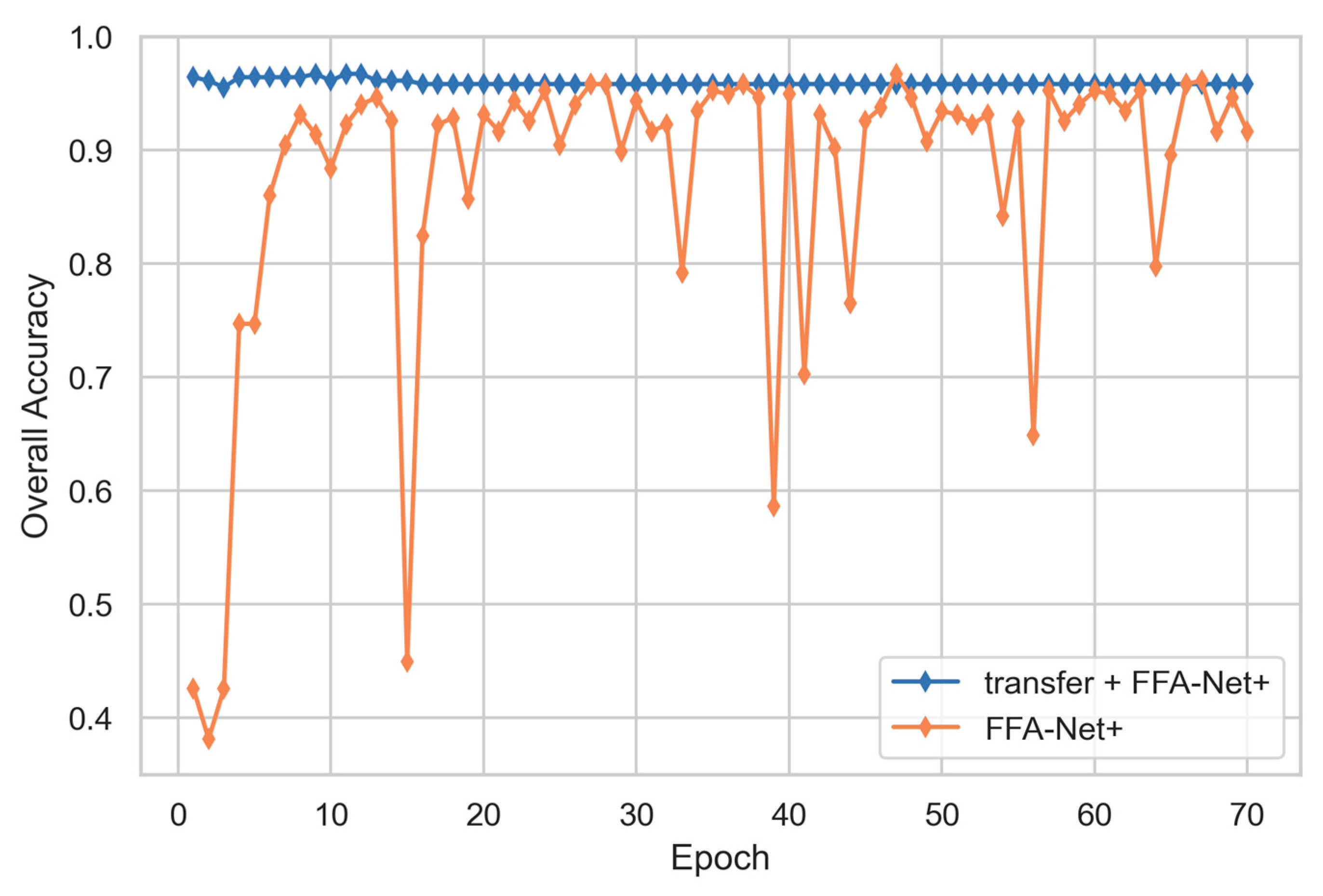
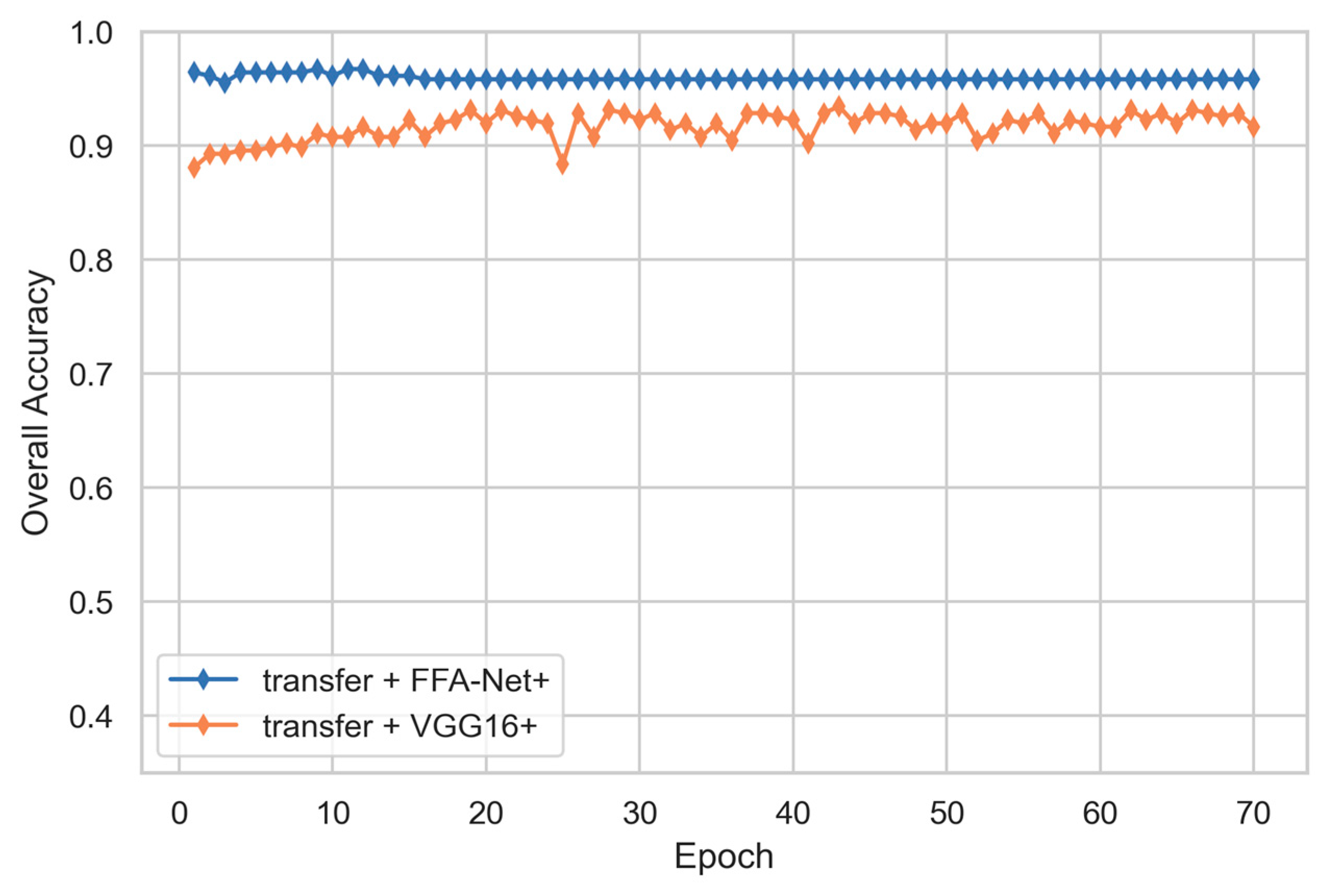
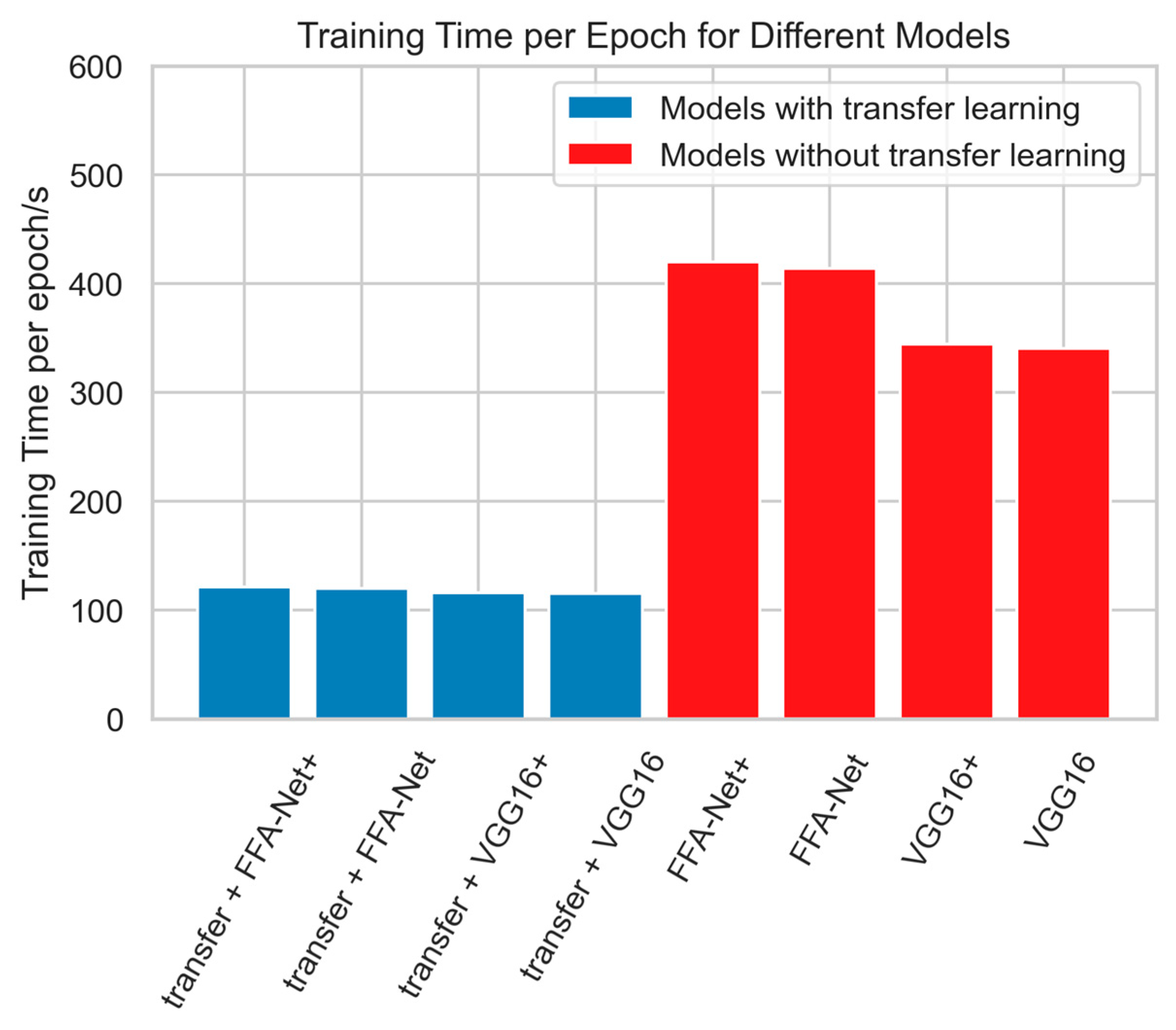
4.4. Comparative Experiment
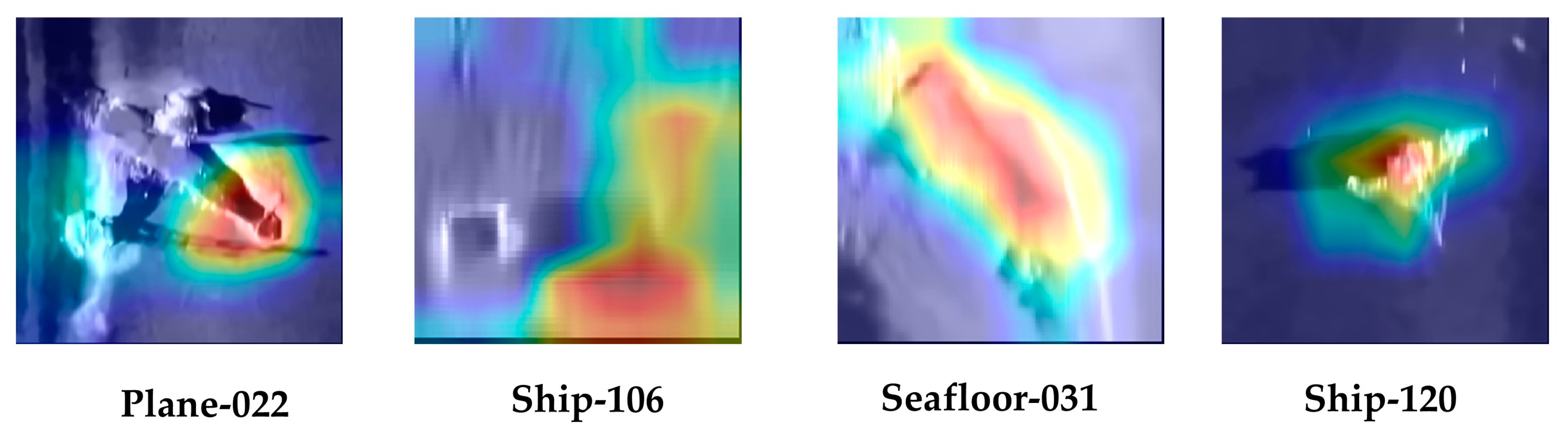
4.5. Case Study and Grad-CAM Result
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| SSS | Side-scan sonar |
| RRDB | Residual in Residual Dense Block |
| FFA-Net | Feature fusion attention network |
| F1-Score | Harmonic mean of precision and recall |
| Precision | The ratio of true positive observations to the total predicted positives |
| Recall | The ratio of true positive observations to the total actual positives |
| Grad-CAM | Gradient-weighted Class Activation Mapping |
| TP | True positives |
| TN | True negatives |
| FP | False positives |
| FN | False negatives |
References
- Greene, A.; Rahman, A.F.; Kline, R.; Rahman, M.S. Side scan sonar: A cost-efficient alternative method for measuring seagrass cover in shallow environments. Estuar. Coast. Shelf Sci. 2018, 207, 250–258. [Google Scholar] [CrossRef]
- Boretti, A. Unmanned surface vehicles for naval warfare and maritime security. J. Def. Model. Simul. 2024, 15485129241283056. [Google Scholar] [CrossRef]
- Silarski, M.; Nowakowski, M. Performance of the SABAT neutron-based explosives detector integrated with an unmanned ground vehicle: A simulation study. Sensors 2022, 22, 9996. [Google Scholar] [CrossRef]
- Munteanu, D.; Moina, D.; Zamfir, C.G.; Petrea, Ș.M.; Cristea, D.S.; Munteanu, N. Sea mine detection framework using YOLO, SSD and EfficientDet deep learning models. Sensors 2022, 22, 9536. [Google Scholar] [CrossRef]
- Niemikoski, H.; Söderström, M.; Kiljunen, H.; Östin, A.; Vanninen, P. Identification of degradation products of sea-dumped chemical warfare agent-related phenylarsenic chemicals in marine sediment. Anal. Chem. 2020, 92, 4891–4899. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Wang, L.; Jin, S.; Zhao, J.; Huang, C.; Yu, Y. AUV-based side-scan sonar real-time method for underwater-target detection. J. Mar. Sci. Eng. 2023, 11, 690. [Google Scholar] [CrossRef]
- Li, C.; Ye, X.; Xi, J.; Jia, Y. A texture feature removal network for sonar image classification and detection. Remote Sens. 2023, 15, 616. [Google Scholar] [CrossRef]
- McMahon, J.; Plaku, E. Autonomous data collection with timed communication constraints for unmanned underwater vehicles. IEEE Robot. Autom. Lett. 2021, 6, 1832–1839. [Google Scholar] [CrossRef]
- Ling, H.; Zhu, T.; He, W.; Zhang, Z.; Luo, H. Cooperative search method for multiple AUVs based on target clustering and path optimization. Nat. Comput. 2021, 20, 3–10. [Google Scholar]
- Cao, X.; Ren, L.; Sun, C. Research on obstacle detection and avoidance of autonomous underwater vehicle based on forward-looking sonar. IEEE Trans. Neural Networks Learn. Syst. 2022, 34, 9198–9208. [Google Scholar]
- Fan, X.; Lu, L.; Shi, P.; Zhang, X. A novel sonar target detection and classification algorithm. Multimed. Tools. Appl. 2022, 81, 10091–10106. [Google Scholar]
- Chen, Z.; Wang, Y.; Tian, W.; Liu, J.; Zhou, Y.; Shen, J. Underwater sonar image segmentation combining pixel-level and region-level information. Comput. Electr. Eng. 2022, 100, 107853. [Google Scholar]
- Karimanzira, D.; Renkewitz, H.; Shea, D.; Albiez, J. Object detection in sonar images. Electronics 2020, 9, 1180. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Li, Q.; Xiao, Y.; Ban, X. Passive sonar target tracking based on deep learning. J. Mar. Sci. Eng. 2022, 10, 181. [Google Scholar] [CrossRef]
- Zou, S.; Lin, J.; Wang, X.; Li, G.; Wang, Z.; Xie, X. An object enhancement method for forward-looking sonar images based on multi-frame fusion. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Republic of Korea, 22–28 May 2021; pp. 1–5. [Google Scholar]
- Li, S.; Zhao, J.; Zhang, H.; Bi, Z.; Qu, S. A non-local low-rank algorithm for sub-bottom profile sonar image denoising. Remote Sens. 2020, 12, 2336. [Google Scholar] [CrossRef]
- Yang, C.; Li, Y.; Jiang, L.; Huang, J. Foreground enhancement network for object detection in sonar images. Mach. Vis. Appl. 2023, 34, 56. [Google Scholar]
- Najibzadeh, M.; Mahmoodzadeh, A.; Khishe, M. Active sonar image classification using deep convolutional neural network evolved by robust comprehensive grey wolf optimizer. Neural Process Lett. 2023, 55, 8689–8712. [Google Scholar]
- Shi, P.; Sun, H.; Fan, X.; He, Q.; Zhou, X.; Lu, L. An effective automatic object detection algorithm for continuous sonar image sequences. Multimed. Tools. Appl. 2024, 83, 10233–10246. [Google Scholar]
- Goodman, J.W. Speckle Phenomena in Optics: Theory and Applications; Roberts and Company Publishers: Greenwood Village, CO, USA, 2007. [Google Scholar]
- Cheng, Z.; Huo, G.; Li, H. A multi-domain collaborative transfer learning method with multi-scale repeated attention mechanism for underwater side-scan sonar image classification. Remote Sens. 2022, 14, 355. [Google Scholar] [CrossRef]
- Liu, T.; Yan, S.; Wang, G. Remove and recover: Two stage convolutional autoencoder based sonar image enhancement algorithm. Multimed. Tools. Appl. 2024, 83, 55963–55979. [Google Scholar]
- Rao, J.; Peng, Y.; Chen, J.; Tian, X. Various Degradation: Dual Cross-Refinement Transformer For Blind Sonar Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–14. [Google Scholar]
- Yuan, F.; Xiao, F.; Zhang, K.; Huang, Y.; Cheng, E. Noise reduction for sonar images by statistical analysis and fields of experts. J. Vis. Commun. Image Represent. 2021, 74, 102995. [Google Scholar]
- Vishwakarma, A. Denoising and inpainting of sonar images using convolutional sparse representation. IEEE Trans. Instrum. Meas. 2023, 72, 1–9. [Google Scholar]
- Zhou, T.; Si, J.; Wang, L.; Xu, C.; Yu, X. Automatic detection of underwater small targets using forward-looking sonar images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar]
- Klaucke, I. Sidescan Sonar; Springer: Berlin/Heidelberg, Germany, 2018; pp. 13–24. [Google Scholar]
- Sadjadi, F.A. Studies in adaptive automated underwater sonar mine detection and classification-part 1: Exploitation methods. In Proceedings of the Automatic Target Recognition XXV, Baltimore, MD, USA, 19 June 2015; pp. 157–172. [Google Scholar]
- Jiao, W.; Zhang, J. Sonar images classification while facing long-tail and few-shot. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–20. [Google Scholar]
- Ye, X.; Yang, H.; Li, C.; Jia, Y.; Li, P. A gray scale correction method for side-scan sonar images based on retinex. Remote Sens. 2019, 11, 1281. [Google Scholar] [CrossRef]
- Ge, Q.; Ruan, F.; Qiao, B.; Zhang, Q.; Zuo, X.; Dang, L. Side-scan sonar image classification based on style transfer and pre-trained convolutional neural networks. Electronics 2021, 10, 1823. [Google Scholar] [CrossRef]
- Kapetanović, N.; Mišković, N.; Tahirović, A. Saliency and anomaly: Transition of concepts from natural images to side-scan sonar images. IFAC-PapersOnLine 2020, 53, 14558–14563. [Google Scholar]
- Yu, G.; Sapiro, G. DCT image denoising: A simple and effective image denoising algorithm. Image Process. Line 2011, 1, 292–296. [Google Scholar]
- Danielyan, A.; Katkovnik, V.; Egiazarian, K. BM3D frames and variational image deblurring. IEEE Trans. Image Process 2011, 21, 1715–1728. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process 2017, 26, 3142–3155. [Google Scholar]
- Chen, P.; Xu, Z.; Zhao, D.; Guo, X. Despeckling for forward looking sonar image based on ANLResNet. J. Chin. Comput. Syst. 2022, 43, 355–361. [Google Scholar]
- Tian, C.; Xiao, J.; Zhang, B.; Zuo, W.; Zhang, Y.; Lin, C.-W. A self-supervised network for image denoising and watermark removal. Neural Netw. 2024, 174, 106218. [Google Scholar]
- Tang, H.; Zhang, W.; Zhu, H.; Zhao, K. Self-supervised real-world image denoising based on multi-scale feature enhancement and attention fusion. IEEE Access 2024, 12, 49720–49734. [Google Scholar]
- Fan, L.; Cui, J.; Li, H.; Yan, X.; Liu, H.; Zhang, C. Complementary blind-spot network for self-supervised real image denoising. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 10107–10120. [Google Scholar]
- Zhou, X.; Yu, C.; Yuan, X.; Luo, C. Deep denoising method for side scan sonar images without high-quality reference data. In Proceedings of the 2022 2nd International Conference on Computer, Control and Robotics (ICCCR), Shanghai, China, 18–20 March 2022; pp. 241–245. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtually, 11–17 October 2021; pp. 1905–1914. [Google Scholar]
- Yan, Y.; Liu, C.; Chen, C.; Sun, X.; Jin, L.; Peng, X.; Zhou, X. Fine-grained attention and feature-sharing generative adversarial networks for single image super-resolution. IEEE Trans. Multimed. 2021, 24, 1473–1487. [Google Scholar]
- Lu, Z.; Zhu, T.; Zhou, H.; Zhang, L.; Jia, C. An image enhancement method for side-scan sonar images based on multi-stage repairing image fusion. Electronics 2023, 12, 3553. [Google Scholar] [CrossRef]
- Peng, C.; Jin, S.; Bian, G.; Cui, Y. SIGAN: A Multi-Scale Generative Adversarial Network for Underwater Sonar Image Super-Resolution. J. Mar. Sci. Eng. 2024, 12, 1057. [Google Scholar] [CrossRef]
- Zhu, B.; Wang, X.; Chu, Z.; Yang, Y.; Shi, J. Active learning for recognition of shipwreck target in side-scan sonar image. Remote Sens. 2019, 11, 243. [Google Scholar] [CrossRef]
- Karine, A.; Lasmar, N.; Baussard, A.; El Hassouni, M. Sonar image segmentation based on statistical modeling of wavelet subbands. In Proceedings of the 2015 IEEE/ACS 12th International Conference of Computer Systems and Applications (AICCSA), Marrakech, Morocco, 17–20 November 2015; pp. 1–5. [Google Scholar]
- Kumar, N.; Mitra, U.; Narayanan, S.S. Robust object classification in underwater sidescan sonar images by using reliability-aware fusion of shadow features. IEEE J. Ocean. Eng. 2014, 40, 592–606. [Google Scholar]
- Zhu, M.; Song, Y.; Guo, J.; Feng, C.; Li, G.; Yan, T.; He, B. PCA and kernel-based extreme learning machine for side-scan sonar image classification. In Proceedings of the 2017 IEEE Underwater Technology (UT), Busan, Republic of Korea, 21–24 February 2017; pp. 1–4. [Google Scholar]
- Liu, X.; Zhu, H.; Song, W.; Wang, J.; Yan, L.; Wang, K. Research on improved VGG-16 model based on transfer learning for acoustic image recognition of underwater search and rescue targets. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 18112–18128. [Google Scholar]
- Williams, D.P.; Fakiris, E. Exploiting environmental information for improved underwater target classification in sonar imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6284–6297. [Google Scholar]
- Peng, C.; Jin, S.; Bian, G.; Cui, Y.; Wang, M. Sample Augmentation Method for Side-Scan Sonar Underwater Target Images Based on CBL-sinGAN. J. Mar. Sci. Eng. 2024, 12, 467. [Google Scholar] [CrossRef]
- Tang, J.; Liu, D.; Jin, X.; Peng, Y.; Zhao, Q.; Ding, Y.; Kong, W. BAFN: Bi-direction attention based fusion network for multimodal sentiment analysis. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1966–1978. [Google Scholar]
- Wang, H.; Liu, J.; Tan, H.; Lou, J.; Liu, X.; Zhou, W.; Liu, H. Blind image quality assessment via adaptive graph attention. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 10299–10309. [Google Scholar]
- Dai, Z.; Liang, H.; Duan, T. Small-sample sonar image classification based on deep learning. J. Mar. Sci. Eng. 2022, 10, 1820. [Google Scholar] [CrossRef]
- Shi, Y.; Chen, M.; Yao, C.; Li, X.; Shen, L. Seabed Sediment Classification for Sonar Images Based on Deep Learning. Comput. Inform. 2022, 41, 714–738. [Google Scholar]
- Ge, Q.; Liu, H.; Ma, Y.; Han, D.; Zuo, X.; Dang, L. Shuffle-RDSNet: A method for side-scan sonar image classification with residual dual-path shrinkage network. J. Supercomput. 2024, 80, 19947–19975. [Google Scholar]
- Xu, Y.; Wang, X.; Wang, K.; Shi, J.; Sun, W. Underwater sonar image classification using generative adversarial network and convolutional neural network. IET Image Process 2020, 14, 2819–2825. [Google Scholar]
- Yang, Y.; Wang, Y.; Yang, Z.; Yang, J.; Deng, L. Research on the classification of seabed sediments sonar images based on MoCo self-supervised learning. In Proceedings of the Journal of Physics: Conference Series, Changsha, China, 13–15 October 2024; p. 012058. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Huo, G.; Wu, Z.; Li, J. Underwater object classification in sidescan sonar images using deep transfer learning and semisynthetic training data. IEEE Access 2020, 8, 47407–47418. [Google Scholar]
- Zhang, P.; Tang, J.; Zhong, H.; Ning, M.; Liu, D.; Wu, K. Self-trained target detection of radar and sonar images using automatic deep learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtually, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 11976–11986. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Output Size | DenseNet-121 |
|---|---|---|
| Convolution | 112 × 112 | 7 × 7 conv, stride 2 |
| Pooling | 56 × 56 | 3 × 3 max pool, stride 2 |
| Dense Block(1) | 56 × 56 | × 6 |
| Transition Layer(1) | 56 × 56 | |
| 28 × 28 | 2 × 2 average pool, stride 2 | |
| Dense Block(2) | 28 × 28 | × 12 |
| Transition Layer(2) | 28 × 28 | |
| 14 × 14 | 2 × 2 average pool, stride 2 | |
| Dense Block(3) | 14 × 14 | × 24 |
| Transition Layer(3) | 14 × 14 | |
| 7 × 7 | 2 × 2 average pool, stride 2 | |
| Dense Block(4) | 7 × 7 | × 16 |
| Categories | Drowning Victim | Aircraft | Seafloor | Shipwreck |
|---|---|---|---|---|
| Numbers | 17 | 66 | 487 | 578 |
| Component | Description |
|---|---|
| Processor | 12th Gen Intel® Core™ i5—12400F (Intel Corporation, Santa Clara, CA, USA) |
| Clock Speed | 2.5 GHz |
| RAM | 16 GB |
| Software Environment | Python version: 3.11.7 | packaged by Anaconda, Inc. (Austin, TX, USA) | (main, 15 December 2023, 18:05:47) [MSC v.1916 64 bit (AMD64)] TensorFlow version: 2.12.0 NumPy version: 1.23.5 |
| Model | Transfer Learning | Deblurring– Denoising | OA | AP | AR | F1 | AS | Training Time (s/epoch) | Validation Time (ms/per image) | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | FFA-Net | × | × | 87.56% | 87.56% | 88.16% | 88.60% | 92.47% | 414 | 160 |
| 2 | FFA-Net | × | √ | 89.13% | 89.12% | 89.91% | 89.51% | 93.37% | 420 | 152 |
| 3 | FFA-Net | √ | × | 95.21% | 95.21% | 95.25% | 95.23% | 96.71% | 120 | 159 |
| 4 | FFA-Net | √ | √ | 96.80% | 96.80% | 96.87% | 96.83% | 98.07% | 121 | 154 |
| 5 | VGG16 | × | × | 84.24% | 84.24% | 85.79% | 84.96% | 87.78% | 340 | 143 |
| 6 | VGG16 | × | √ | 88.02% | 88.02% | 88.90% | 88.44% | 94.42% | 344 | 143 |
| 7 | VGG16 | √ | × | 89.42% | 89.41% | 89.22% | 89.31% | 92.15% | 115 | 148 |
| 8 | VGG16 | √ | √ | 91.86% | 91.86% | 92.09% | 91.98% | 93.78% | 116 | 141 |
| Model | VGG16 | VGG16+ | Transfer +VGG16 | Transfer+ VGG16+ | FFA-Net | FFA-Net+ | Transfer+ FFA-Net |
|---|---|---|---|---|---|---|---|
| P | 1.8 × 10−3 | 3.65 × 10−4 | 5.02 × 10−7 | 5.02 × 10−8 | 2.61 × 10−5 | 4.29 × 10−7 | 2.29 × 10−5 |
| Model | OA | AP | AR | F1 | AS |
|---|---|---|---|---|---|
| FFA-Net | 96.80% | 96.80% | 96.87% | 96.83% | 98.07% |
| VGG16 | 91.86% | 91.86% | 91.68% | 91.77% | 94.27% |
| MobileNetV2 | 93.31% | 93.31% | 93.28% | 93.30% | 95.54% |
| DenseNet121 | 94.48% | 94.47% | 94.65% | 94.56% | 96.24% |
| InceptionV3 | 94.77% | 94.77% | 94.82% | 94.80% | 96.41% |
| Model | OA | AP | AR | F1 | AS |
|---|---|---|---|---|---|
| Xception+DenseNet121 | 96.80% | 96.80% | 96.87% | 96.83% | 98.07% |
| InceptionV3+MobileNetV2 | 94.77% | 94.83% | 94.80% | 94.77% | 96.10% |
| Xception+InceptionV3 | 95.35% | 95.35% | 95.40% | 95.37% | 96.64% |
| Xception+MobileNetV2 | 95.64% | 95.64% | 95.67% | 95.65% | 97.20% |
| DenseNet121+MobileNetV2 | 93.90% | 93.89% | 93.96% | 93.93% | 95.73% |
| Model | True Class | Predicted Class | |||
|---|---|---|---|---|---|
| Shipwreck | Aircraft | Seafloor | Drowning Victim | ||
| Xception+DenseNet121 | Shipwreck | 143 | 2 | 1 | 0 |
| Aircraft | 1 | 19 | 0 | 0 | |
| Seafloor | 6 | 0 | 167 | 0 | |
| Drowning Victim | 0 | 0 | 0 | 5 | |
| InceptionV3+MobileNetV2 | Shipwreck | 142 | 1 | 3 | 0 |
| Aircraft | 9 | 11 | 0 | 0 | |
| Seafloor | 4 | 0 | 169 | 0 | |
| Drowning Victim | 1 | 0 | 0 | 4 | |
| Xception+InceptionV3 | Shipwreck | 140 | 2 | 4 | 0 |
| Aircraft | 2 | 18 | 0 | 0 | |
| Seafloor | 8 | 0 | 165 | 0 | |
| Drowning Victim | 0 | 0 | 0 | 5 | |
| Xception+MobileNetV2 | Shipwreck | 142 | 2 | 2 | 0 |
| Aircraft | 5 | 15 | 0 | 0 | |
| Seafloor | 6 | 0 | 167 | 0 | |
| Drowning Victim | 0 | 0 | 0 | 5 | |
| DenseNet121+MobileNetV2 | Shipwreck | 142 | 2 | 2 | 0 |
| Aircraft | 9 | 11 | 0 | 0 | |
| Seafloor | 8 | 0 | 165 | 0 | |
| Drowning Victim | 0 | 0 | 0 | 5 | |
| Model | OA | AP | AR | F1 | AS |
|---|---|---|---|---|---|
| proposed | 96.80% | 96.80% | 96.87% | 96.83% | 98.07% |
| CAM | 95.64% | 95.64% | 95.77% | 95.70% | 97.10% |
| SAM | 96.22% | 96.22% | 96.31% | 96.27% | 97.53% |
| Model | OA | AP | AR | F1 | AS |
|---|---|---|---|---|---|
| Proposed | 96.80% | 96.80% | 96.87% | 96.83% | 98.07% |
| Adaptive mean filtering | 93.60% | 93.60% | 93.77% | 93.69% | 95.63% |
| Bilateral filtering | 92.15% | 92.15% | 92.62% | 92.39% | 94.54% |
| Wavelet filtering | 95.64% | 95.64% | 95.62% | 95.63% | 97.05% |
| Model | OA | AP | AR | F1 | AS |
|---|---|---|---|---|---|
| FFA-Net | 96.80% | 96.80% | 96.87% | 96.83% | 98.07% |
| CovnNext [65] | 95.93% | 96.11% | 95.93% | 95.99% | 97.82% |
| Swin Transformer [66] | 95.06% | 95.24% | 95.06% | 95.13% | 97.37% |
| Model | True Class | Predicted Class | |||
|---|---|---|---|---|---|
| Shipwreck | Aircraft | Seafloor | Drowning Victim | ||
| Proposed (pre-trained FFA-Net with joint image deblurring–denoising) | Shipwreck | 143 | 2 | 1 | 0 |
| Aircraft | 1 | 19 | 0 | 0 | |
| Seafloor | 6 | 0 | 167 | 0 | |
| Drowning Victim | 0 | 0 | 0 | 5 | |
| Pre-trained FFA-Net (without joint image deblurring–denoising) | Shipwreck | 141 | 2 | 3 | 0 |
| Aircraft | 7 | 13 | 0 | 0 | |
| Seafloor | 5 | 0 | 168 | 0 | |
| Drowning Victim | 1 | 0 | 0 | 4 | |
| FFA-Net with joint image deblurring–denoising (without transfer learning) | Shipwreck | 145 | 1 | 0 | 0 |
| Aircraft | 16 | 2 | 2 | 0 | |
| Seafloor | 14 | 0 | 159 | 0 | |
| Drowning Victim | 3 | 0 | 0 | 2 | |
| Pre-trained VGG16 with joint image deblurring–denoising | Shipwreck | 139 | 3 | 4 | 0 |
| Aircraft | 11 | 9 | 0 | 0 | |
| Seafloor | 8 | 0 | 165 | 0 | |
| Drowning Victim | 1 | 0 | 0 | 4 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, B.; Zhang, H.; Wang, W. Side-Scan Sonar Image Classification Based on Joint Image Deblurring–Denoising and Pre-Trained Feature Fusion Attention Network. Electronics 2025, 14, 1287. https://doi.org/10.3390/electronics14071287
Xie B, Zhang H, Wang W. Side-Scan Sonar Image Classification Based on Joint Image Deblurring–Denoising and Pre-Trained Feature Fusion Attention Network. Electronics. 2025; 14(7):1287. https://doi.org/10.3390/electronics14071287
Chicago/Turabian StyleXie, Baolin, Hongmei Zhang, and Weihan Wang. 2025. "Side-Scan Sonar Image Classification Based on Joint Image Deblurring–Denoising and Pre-Trained Feature Fusion Attention Network" Electronics 14, no. 7: 1287. https://doi.org/10.3390/electronics14071287
APA StyleXie, B., Zhang, H., & Wang, W. (2025). Side-Scan Sonar Image Classification Based on Joint Image Deblurring–Denoising and Pre-Trained Feature Fusion Attention Network. Electronics, 14(7), 1287. https://doi.org/10.3390/electronics14071287