1. Introduction
The maritime industry is rapidly increasing the size and complexity of internal ship networks due to the combined use of cutting-edge technologies such as satellite communications, maritime IoT, and automated navigation systems [
1]. These technological advancements provide various benefits in terms of operational efficiency, safety, and economy, but at the same time, they also bring new threats in terms of cybersecurity [
2,
3,
4].
In fact, as various devices and sensors inside the ship, crew work systems, and remote control modules are interconnected, attackers are more likely to target the maritime environment and attempt ransomware, spoofing, radio frequency (RF) jamming, and supply chain attacks [
5,
6,
7]. These threats can directly affect ships’ safety and operational efficiency at sea [
8,
9]. In particular, since it is difficult to receive external assistance when a ship is sailing in open waters after leaving the port, there is a greater risk as sailors may struggle to respond immediately in the event of a security incident [
10,
11].
A real-world example of such a threat is the 2023 ransomware attack on the Norwegian classification society DNV, which compromised its ShipManager system, a widely used fleet management software. The attack led to a system shutdown, affecting nearly 1000 vessels worldwide and disrupting critical onboard operations, forcing shipowners to rely on offline procedures [
12]. Similarly, in 2022, the Port of Lisbon fell victim to a ransomware attack by the LockBit group, disrupting administrative and operational networks. While core shipping activities remained functional, the attack exposed security gaps in port infrastructure, demonstrating how cybercriminals can target maritime logistics hubs to disrupt trade and demand ransoms [
13].
Another significant case occurred in 2022, when CMA CGM, one of the largest shipping companies, was hit by the Ragnar Locker ransomware attack, forcing a two-week system shutdown that delayed container operations and disrupted global logistics chains. This attack demonstrated the severe operational risks posed by ransomware in the maritime industry and how prolonged recovery times can exacerbate financial losses and supply chain disruptions [
14]. These incidents underscore the urgency of rapid threat response in maritime cybersecurity. Given the interconnected nature of modern shipping and port operations, delays in addressing cyber threats can escalate into widespread operational failures, financial losses, and compromised safety at sea.
To prevent this, many shipping companies and shipowners are introducing Intrusion Detection System (IDS) and Intrusion Prevention System (IPS) solutions into ship internal networks. Among these, Suricata is in the spotlight for its network traffic analysis capabilities, supported by an active open-source community. Suricata monitors network flow in real-time and generates alert logs using predefined signature rules or anomaly detection methods [
15,
16]. Although Suricata and similar IDS tools can detect potential threats, they lack automated context-aware analysis or advanced summarization functions, requiring security experts to interpret logs and decide on responses.
However, in situations where large-scale alert logs are generated, there are usually no security experts on board, and crew members—who typically have only basic user-level IT knowledge—often have to analyze these logs independently. Unlike trained cybersecurity professionals, most seafarers are not well-versed in network security protocols, log analysis, or advanced threat detection techniques, making it difficult for them to interpret complex security alerts accurately. Large-scale alert logs generated by IDS solutions such as Suricata can appear in diverse and extensive forms due to the characteristics of the ship’s internal environment (e.g., satellite communication, limited bandwidth, and maritime IoT).
This places a significant burden on crew members, who have limited manpower and time resources to manually assess security events. Misinterpreting or overlooking critical alerts due to a lack of cybersecurity expertise can result in delayed or inadequate responses, potentially exposing vessels to serious threats such as ransomware, GPS spoofing, or unauthorized access. In addition, providing immediate remote assistance from land is challenging because communication bandwidth with the land control center is limited during long voyages. As a result, crew members may struggle to identify high-priority threats amid the overwhelming daily torrent of alerts and determine the appropriate actions to take, increasing the likelihood of delayed threat responses and serious security incidents [
17]. Moreover, the absence of real-time cybersecurity guidance forces crew members to rely on their limited IT knowledge and experience, heightening the risk of misjudgments in critical situations.
Recently, large language models (LLMs) have been actively introduced in the field of cybersecurity to address these challenges [
18,
19]. However, leading LLMs such as GPT-4 [
20], LLaMA3 [
21], and Gemini [
22] have limitations in that they require enormous computing resources. Therefore, attempts to introduce small language models (SLMs) to alleviate the high resource demands of LLMs and achieve optimized performance for specific purposes or environments are increasing [
23]. SLM not only saves memory and computational resources by using relatively small parameter sizes but also maintains efficiency and high performance through fine-tuning and quantization techniques tailored to specific domains. Due to these characteristics, they are gaining attention as cost-effective solutions that can be implemented in resource-constrained environments.
In this paper, we propose an Adaptive Threat Intelligence and Response Recommendation System (ATIRS), an intelligent log summary and automatic response recommendation system utilizing SLMs to address the constraints of the ship environment and security operation challenges. Unlike traditional IDS solutions—which focus primarily on detecting suspicious traffic and raising alerts—the ATIRS summarizes network alert logs and provides users with response recommendations based on these summaries. Specifically, the ATIRS aims to dramatically improve the efficiency of security operations through the following process. First, network warning logs collected inside the ship are preprocessed, and key information is analyzed and concisely summarized through the SLM-based summary module. Through this, essential data such as attack type, risk level, source/destination IP, and occurrence time are extracted to help the SLM-based response recommendation module interpret them more effectively.
Additionally, to address the limitations of rule-based analysis, SLM’s natural language understanding and generation capabilities are leveraged to capture the context of complex security logs and intuitively generate signature summaries. Then, the SLM-powered response recommendation module automatically suggests follow-up actions such as IP blocking, account locking, and network segment separation, allowing crews to respond swiftly and efficiently even in environments without dedicated security personnel. Furthermore, ATIRS continuously enhances recommendation accuracy when similar or new alerts occur by applying Adaptive Learning, which continuously incorporates users’ response choices and new threat data.
Automated Network Alert Log Summarization: The system automatically analyzes and summarizes key information such as major attack types, severity levels, and timestamps from large volumes of logs, enabling crew members with limited security expertise to understand them more easily. Additionally, the SLM-based response recommendation module utilizes this information to suggest appropriate response actions.
Automated Response Recommendation: Instead of relying on traditional rule-based approaches, the system leverages SLM inference capabilities based on alert log summaries to recommend response actions automatically. This helps mitigate the lack of security expertise among crew members while reducing the burden caused by excessive alerts.
Performance Evaluation Based on a Ship Environment: The proposed system is implemented and evaluated using network alert logs collected from an actual ship environment. The effectiveness of the system is verified by measuring quantitative benefits such as reduced Mean Time to Response (MTTR) and alleviation of the crew’s alert analysis workload.
Section 2 reviews related work on IDS/IPS systems, the application of LLMs in cybersecurity, and LLM fine-tuning techniques.
Section 3 describes the overall architecture of the proposed ATIRS system.
Section 4 introduces the dataset, experimental settings, and evaluation methods used in the study.
Section 5 presents the experimental results and analysis. Finally,
Section 6 provides conclusions and discusses potential future research directions.
3. Methodology
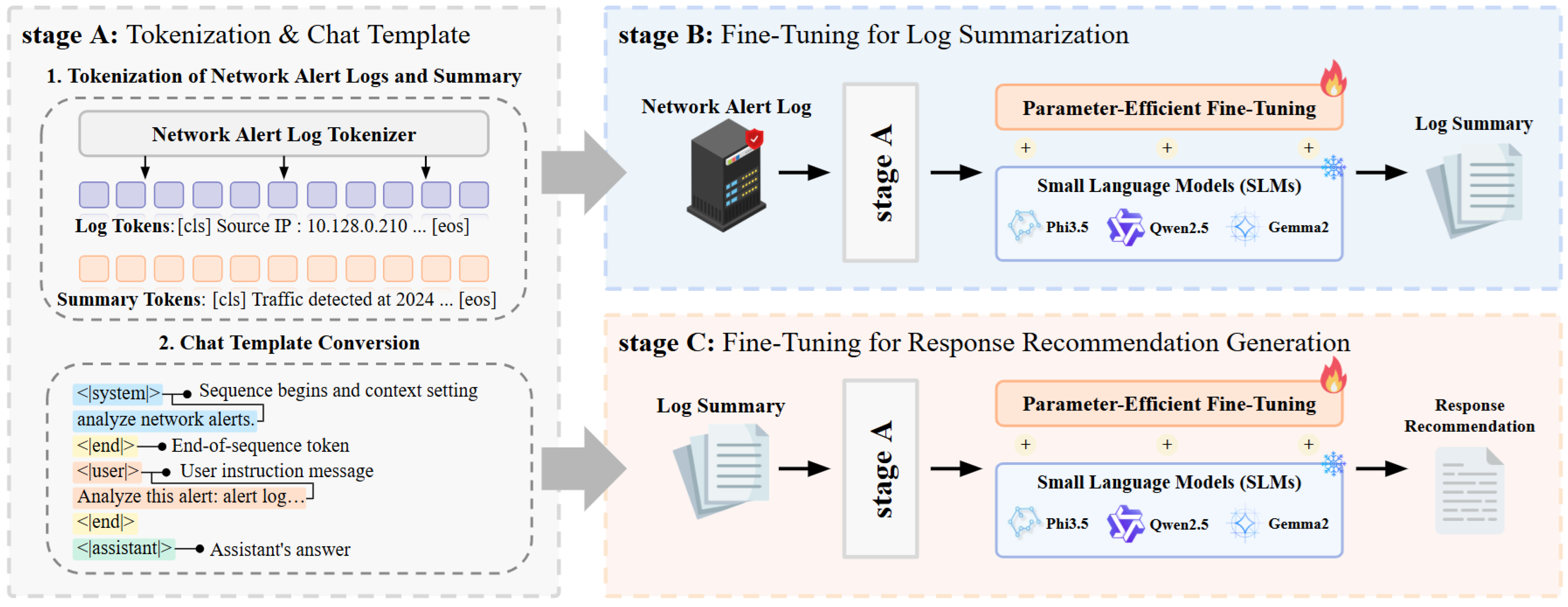
This section describes the methodology of ATIRS, which consists of Tokenization & Chat Template Conversion, and Fine-Tuning for Network Alert Log Summarization and Response Recommendation Generation.
3.1. Overview
The overall structure of the ATIRS is illustrated in
Figure 3.
The ATIRS is designed to process network alert logs and generate log summaries and response recommendations efficiently using a fine-tuned transformer-based SLM. To effectively handle security-related tasks while maintaining computational efficiency, ATIRS employs a multi-stage processing pipeline consisting of the following:
The fine-tuning process follows a two-stage approach:
Stage B (Network Alert Log Summarization): Converts network alert logs into structured summaries, improving interpretability.
Stage C (Response Recommendation): Uses the summarized logs to generate appropriate security response actions, assisting personnel without cybersecurity expertise in making informed decisions.
By structuring the pipeline in this manner, the ATIRS effectively processes security alerts, reduces computational overhead, and improves response efficiency in resource-constrained environments.
3.2. Network Alert Logs and Summary Tokenization
To effectively process network security alerts, the ATIRS employs a specialized tokenization mechanism designed to bridge the modality gap between structured log data and natural language. This approach enhances token efficiency, ensuring that network alert logs are formatted optimally for downstream tasks such as log summarization and response recommendation. A comparative example of base tokenization versus ATIRS tokenization is illustrated in
Figure 4.
Unlike standard tokenization, which often results in excessive token length and redundant segmentation of structured data, the ATIRS introduces a domain-specific tokenization strategy. The base tokenization method, as shown in
Figure 4, produces a tokenized output with excessive fragmentation and the redundant splitting of critical fields such as timestamps, IP addresses, and protocol descriptions. This results in an inflated token length (
1040), increasing computational overhead and reducing model efficiency.
Conversely, ATIRS tokenization optimizes the processing of network alert logs by preserving the structural integrity of key fields. As shown in
Figure 4, the ATIRS tokenizer processes the same alert log while maintaining proper formatting of numerical values, network-related terms, and timestamps, reducing the overall token length to
604. This optimized representation allows for more efficient fine-tuning while retaining essential contextual information.
To achieve this, the ATIRS employs a domain-adapted Byte Pair Encoding (BPE) tokenizer, trained specifically on network security text. This tokenizer extends the vocabulary of standard SLM tokenizers, incorporating network-specific terminology, security-related event codes, and structured log patterns. As a result, the ATIRS tokenization approach ensures that network security alerts are effectively transformed into concise yet informative token sequences, reducing token redundancy and enhancing processing efficiency.
This specialized tokenization not only improves model efficiency by reducing token length but also enhances downstream tasks such as log summarization and response recommendation. By applying this technique, the ATIRS ensures that network alert logs are optimally formatted for large-scale processing, making it well suited for resource-constrained environments.
3.3. Chat Template Conversion
To standardize the input format for different language models, the ATIRS incorporates a chat template conversion mechanism. Since each SLM (e.g., Phi-3.5, Qwen2.5, Gemma-2) utilizes distinct chat formatting rules, a unified conversion step is necessary to ensure consistency in prompt structure.
Figure 5 illustrates how the same input is adapted to different chat templates for these models.
The conversion process involves restructuring the network alert log prompts into the specific format required by each model. In the case of Phi-3.5, the template follows a structured format with designated <system>, <user>, and <assistant> tags, ensuring that system instructions and user queries are properly distinguished. Similarly, Qwen2.5 adopts a comparable format but uses <im_start> and <im_end> markers instead. On the other hand, Gemma-2 structures its interactions using <start_of_turn> and <end_of_turn> markers.
This template conversion serves several key functions: (I) Since each SLM interprets input differently, standardizing prompts eliminates formatting inconsistencies that could impact response quality. (II) Properly formatted prompts help models better distinguish between system messages, user queries, and expected responses. (III) By automating chat template adaptation, the ATIRS streamlines the training process across multiple models without requiring manual intervention.
By applying these structured chat templates, the ATIRS ensures seamless integration with different SLMs, optimizing performance in both network alert log summarization and response recommendation tasks. The automated chat template conversion mechanism is essential for maintaining model adaptability and robustness in processing network security alerts.
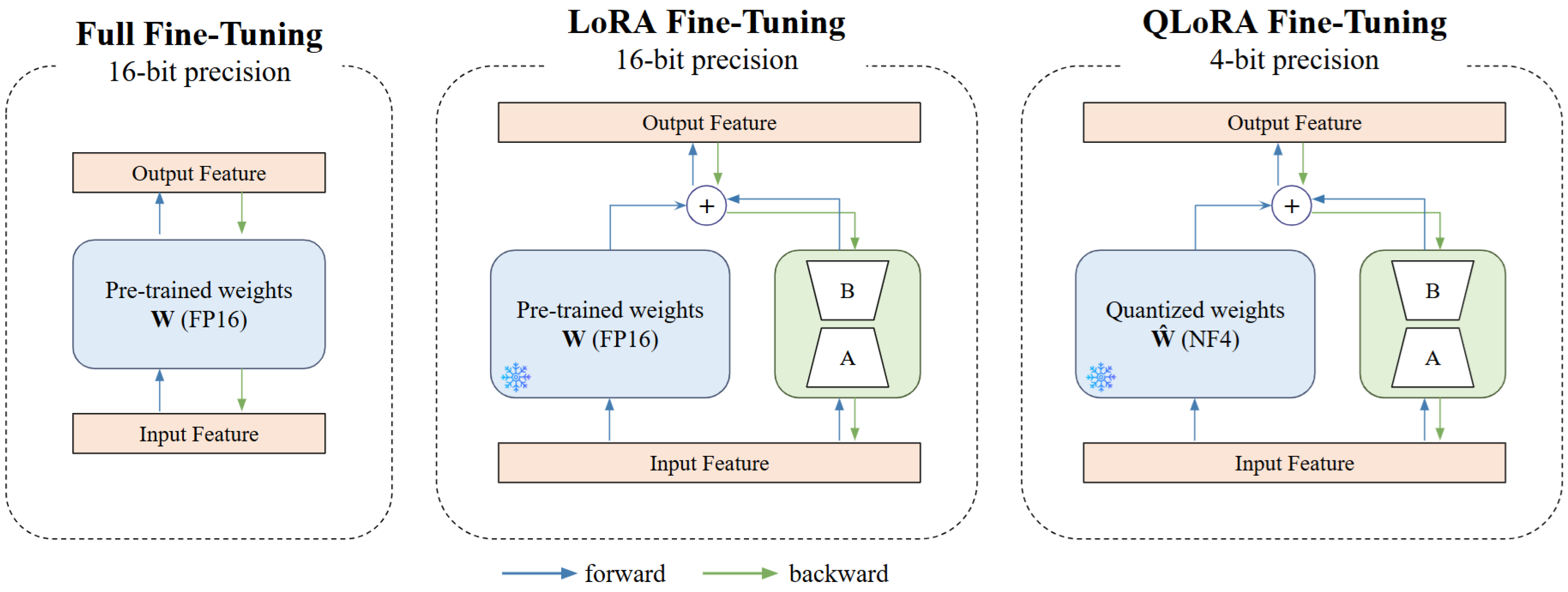
3.4. Fine-Tuning and PEFT
To enhance the adaptability of the ATIRS in resource-constrained environments, we employ a PEFT approach using LoRA. This method enables efficient optimization by fine-tuning only a small subset of additional trainable parameters while keeping the majority of the pre-trained model frozen.
The fine-tuning process in the ATIRS consists of two key stages: network alert log summarization, referred to as the ATIRS-Summarization Model (ATIRS-SM), and response recommendation, referred to as the ATIRS-Response Recommendation Model (ATIRS-RM). Both stages leverage LoRA-based PEFT techniques to optimize SLMs for cybersecurity tasks while maintaining computational efficiency.
Figure 6 illustrates how LoRA is integrated into the transformer architecture during fine-tuning, ensuring effective adaptation to the specific needs of each stage.
LoRA modifies the transformer’s self-attention mechanism by introducing low-rank matrices into the key (K), query (Q), and value (V) projections. Instead of updating the full weight matrices, LoRA injects trainable rank-decomposed matrices ( for Q; for K; and for V) while keeping the pre-trained parameters frozen.
This approach significantly reduces memory consumption and computational complexity while enabling effective domain adaptation. The residual connection helps preserve the Base model’s general knowledge while allowing the LoRA layers to specialize in cybersecurity-related tasks, minimizing the risk of catastrophic forgetting.
ATIRS-SM transforms raw network alert logs into concise summaries. The model processes network security alerts, which often contain complex and unstructured information. Using parameter-efficient fine-tuning, particularly LoRA, pre-trained SLMs such as Phi-3.5, Qwen2.5, and Gemma-2 are adapted to generate structured and informative summaries. These summaries provide essential contextual information that assists ATIRS-RM in generating accurate and relevant response recommendations.
Once the logs are summarized, ATIRS-RM utilizes these summaries to fine-tune pre-trained models for response recommendation. Rather than relying on raw network alert logs, ATIRS-RM learns from structured summaries, enabling a more effective mapping between security events and corresponding response actions. The response generation process involves analyzing summarized alerts and selecting the most suitable security measures, ensuring that the recommended actions are both contextually appropriate and actionable.
By employing hierarchical fine-tuning, ATIRS-RM optimizes its response recommendation process, leveraging LoRA-based adaptation to enhance efficiency while maintaining high-quality recommendations. The integration of ATIRS-SM and ATIRS-RM establishes a streamlined cybersecurity workflow, where security alerts are first condensed into structured summaries and then mapped to corresponding response actions.
3.5. Adaptive Learning Strategy
Maritime vessels typically lack dedicated cybersecurity experts onboard, requiring crew members to execute response actions based on the recommendations generated by the ATIRS. To enhance performance and adaptability, the ATIRS integrates an adaptive learning strategy, allowing the model to refine its response recommendation capabilities based on real-world feedback.
Once the ATIRS generates a response recommendation, onboard personnel review and execute the suggested actions. Their final decisions serve as implicit feedback, which, along with metadata such as alert severity and response modifications, is securely stored in the onboard system. Due to intermittent network connectivity, security experts periodically access these feedback data via satellite communication and synchronize them with the central security management system, where they are aggregated and analyzed to improve future recommendations.
To efficiently adapt to evolving threats, the ATIRS employs a periodic fine-tuning approach based on accumulated feedback, ensuring continuous improvement without requiring full model retraining. Instead of updating the entire model, the ATIRS utilizes QLoRA to modify only the low-rank adaptation layers while keeping the pre-trained model weights largely unchanged. This enables the ATIRS to rapidly integrate response strategies based on validated user feedback, improving the accuracy of response recommendations for both recurring and emerging threats, while minimizing computational overhead.
4. Experiment
4.1. Datasets
In this study, we deployed the Suricata IDS on an actual ship’s internal network to monitor security events in a real-world maritime environment. High-severity (Severity 1 and 2) alert log data collected through this system were used to train and evaluate the proposed ATIRS-SM and ATIRS-RM models. These logs were sourced from a real-world maritime cybersecurity environment, capturing security events that occurred while the ship was actively operating. The dataset used in our experiments consists of network alert logs generated during the following period:
The collected dataset contains security logs reflecting various cyber threats encountered in maritime operations, including unauthorized access attempts, network scanning activities, potential malware infections, abnormal traffic patterns, and other intrusion attempts. Suricata logs generally classify severity into three levels. Severity 1 indicates the highest level of threat, encompassing critical security events that require immediate response and action. Severity 2 represents medium-level threats that require additional monitoring and analysis. In contrast, Severity 3 indicates low-level threats, including minor or potential risk factors. This study focuses exclusively on Severity 1 and 2 alerts to effectively summarize significant security events and recommend appropriate response strategies.
To ensure high-quality data for model training and evaluation, redundant and low-relevance logs were filtered during preprocessing. Identical logs with the same timestamp, source/destination IP, and threat signatures were removed to prevent duplication. Additionally, security experts reviewed and validated false positives, eliminating incorrect alerts. Based on these findings, Suricata IDS rules were updated to minimize false detections in future monitoring. By reducing false detections and filtering out duplicate and low-relevance logs, these preprocessing steps refined the dataset to focus on high-severity security events, ensuring that the model is trained to provide effective response recommendations for critical threats.
The types, descriptions, and distributions of the collected network alert log data are summarized in
Table 1. The dataset encompasses a variety of alert categories, including information leakage attempts, privilege escalation attempts, network scanning activities, and other cyber threats encountered in the ship’s network.
However, the initial analysis revealed several limitations in the existing classification system. Some alert categories were excessively detailed, adding unnecessary complexity, while others had very few occurrences, making statistical analysis unreliable and potentially leading to biased model training. Sparse alert categories also posed challenges in learning effective response strategies, as there were insufficient instances for the model to generalize appropriate recommendations.
Additionally, the presence of semantically overlapping categories made it difficult to clearly distinguish different types of security events, potentially causing inconsistencies in response mapping. To address these issues, we systematically reconstructed the alert categories based on similarity, frequency, and analytical feasibility.
Some alert types with fundamentally similar meanings were grouped. For instance, both Attempted Information Leak and Information Leak pertain to data exposure events. To simplify classification and improve analytical efficiency, they were merged into a single category, “Information Leak and Attempted Information Leak”.
Similarly, Attempted User Privilege Gain, Successful User Privilege Gain, Attempted Administrator Privilege Gain, and Successful Administrator Privilege Gain all indicate privilege escalation attempts or successes. These were consolidated into the category “User and Administrator Privilege Escalation Attempts and Successes”.
Certain alert types with very low occurrences were also reorganized for better analysis. For example, Successful Administrator Privilege Gain was recorded only twice. However, it is closely related to Attempted Administrator Privilege Gain (27 occurrences) and Successful User Privilege Gain (2 occurrences). Therefore, rather than being classified separately, these alerts were grouped under the category “User and Administrator Privilege Escalation Attempts and Successes”.
Likewise, Device Retrieving External IP Address Detected (7 occurrences) and Attempted Denial of Service (6 occurrences) were integrated into a broader category, “Miscellaneous Anomalous Traffic and Malicious Code Detection”, to improve analytical efficiency. The reconstructed alert categories are summarized in
Table 2.
The reconstructed alert logs were manually reviewed by security experts, who applied clear criteria to eliminate false positives. Additionally, they conducted a detailed analysis of alert categories and signatures to structure the dataset as follows:
Network Alert Log Summary Dataset (NALSD): This dataset consists of raw network alert logs and summaries that have been manually written and validated by security experts. It is used to train ATIRS-SM, enabling the model to generate concise and informative summaries from network alert logs. Security experts meticulously review each log entry to ensure that the summaries accurately capture key aspects of security incidents while maintaining clarity and relevance.
Network Alert Summarization-based Response Recommendation Dataset (NASR-RD): This dataset consists of summaries generated by ATIRS-SM from raw network alert logs, along with their corresponding response recommendations. Security experts rigorously review and validate both the summaries and the recommendations to ensure accuracy and effectiveness. Representative examples of response actions included in the dataset are blocking suspicious IP addresses, isolating compromised devices, disabling or locking user accounts, and revoking access privileges. These expert-validated actions provide a practical foundation for training ATIRS-RM, enabling it to learn how to generate contextually appropriate and operationally feasible response strategies based on summarized security logs.
Network Alert Log Response Recommendation Dataset (NALRD): This dataset is used to evaluate the effectiveness of the ATIRS by comparing it against baseline models. Unlike dataset (II), which trains ATIRS-RM using summaries generated by ATIRS-SM, this dataset consists of raw network alert logs that have been manually reviewed by security experts and paired with recommended responses.
To establish a baseline for comparison, a baseline model is trained directly on this dataset using a “raw network alert log → recommended response” approach, bypassing the summarization step. In contrast, the ATIRS follows a “raw network alert log → summary → recommended response” flow. By comparing the performance of both models, researchers can quantify the impact of the summarization process on response recommendation accuracy. This evaluation ensures that the ATIRS provides a tangible improvement in security operations by generating more effective and context-aware responses.
Additionally, this study aims to develop a summarization and response recommendation system based on high-severity alert logs, offering a robust solution for effective real-time security threat response. Accordingly, the dataset is partitioned into 70% for training, 15% for testing, and 15% for validation to ensure a well-balanced evaluation of the proposed approach.
4.2. Settings
This section describes the training configurations of the ATIRS-SM and ATIRS-RM models. The experiments were conducted using Phi-3.5, Qwen2.5, and Gemma-2 as backbone models, with all models sharing the same hyperparameters and training settings.
Additionally, QLoRA-based 4-bit and 8-bit quantization were applied for model optimization, allowing efficient fine-tuning even in resource-constrained environments. The key hyperparameters used in the ATIRS experiments are summarized in
Table 3.
A batch size of 4 was selected to balance memory efficiency and training stability, as larger batch sizes were impractical on the NVIDIA A30 HBM2 (24 GB) GPU due to the additional memory overhead introduced by quantization and low-rank adaptation. The learning rate of was empirically chosen based on its stability across different backbone models, ensuring effective gradient updates while avoiding catastrophic forgetting. Since QLoRA introduces trainable low-rank weight matrices on top of the quantized pre-trained model, updates are efficiently applied while minimizing memory overhead. Unlike full fine-tuning, QLoRA allows gradient computation through the quantized model while primarily adapting the newly introduced low-rank matrices.
AdamW was used as the optimizer due to its robust weight decay properties, which help maintain generalization when fine-tuning pre-trained language models with quantization. A warmup ratio of 0.1 was applied to gradually adjust the learning rate, preventing sudden gradient spikes that could arise from quantized training. The training process was controlled by setting max_steps to 1000, ensuring a predefined number of optimization updates for efficient task-specific adaptation. This step-based approach helps maintain computational efficiency while preventing unnecessary overtraining. Although training_epochs was set to 1, max_steps took precedence, meaning that training could conclude before completing a full pass through the dataset if the step limit was reached. This step-based approach is particularly useful in QLoRA fine-tuning, where a full dataset pass is often unnecessary for effective adaptation, allowing for more controlled and efficient training.
For LoRA-specific configurations, a rank (r) of 8 and a LoRA alpha of 16 were chosen, as they provide a good trade-off between parameter efficiency and model expressiveness, allowing effective adaptation without excessive computational overhead. A LoRA dropout rate of 0.1 was applied to enhance generalization and prevent overfitting, ensuring stable adaptation across both high- and low-resource settings. Additionally, all linear layers were selected as target modules to ensure comprehensive adaptation of critical model components, while the bias parameter was set to None to maintain training efficiency. Furthermore, the training and evaluation of the ATIRS models were conducted in a PyTorch 2.6.0 and Python 3.9.21 environment. All experiments were performed on a server equipped with two Intel Xeon Gold 5317 processors, an NVIDIA A30 HBM2 (24 GB) GPU, and 128 GB of RAM, ensuring efficient execution of QLoRA-based fine-tuning while accommodating large-scale alert log processing.
4.3. Evaluation Metrics
To evaluate the performance of the trained model, we used Bilingual Evaluation Understudy (BLEU), Recall-Oriented Understudy for Gisting Evaluation (ROUGE)-N, ROUGE-L, ROUGE-Lsum, and Metric for Evaluation of Translation with Explicit ORdering (METEOR) [
52,
53,
54,
55]. The equations for performance evaluation are as follows.
The BLEU formula is shown as follows:
(Additional) Brevity penalty (BP) is defined as follows:
BLEU is a widely used metric in machine translation and text generation that evaluates the similarity between generated text and reference text. It calculates the precision of overlapping word sequences, known as n-grams, and combines them using a weighted geometric mean. Here, N represents the highest n-gram order considered, typically set to 4 to account for unigrams, bigrams, trigrams, and 4-grams. The weights determine the relative contribution of each n-gram precision score and are usually distributed equally as , ensuring that all n-grams influence the final BLEU score in a balanced manner.
To prevent artificially high scores from overly short outputs, BLEU applies a brevity penalty (BP). If the generated text (c) is at least as long as the reference text (r), no penalty is applied, and BP remains 1. However, if the generated text is shorter than the reference, BP applies an exponential penalty, reducing the BLEU score proportional to the length discrepancy.
(I) Widely used in text generation and translation: BLEU is a standard benchmark metric in NLP research. (II) Computationally efficient: It provides a quick and reliable measure without requiring human annotations. (III) Language-independent: It can be applied to multiple languages without modification. (IV) Handles multiple reference texts: BLEU allows comparison against multiple reference translations, improving evaluation robustness. (V) Prevents length bias: The brevity penalty ensures that shorter outputs are not unfairly advantaged.
The ROUGE-1 and ROUGE-2 (ROUGE-N) formulas are as follows:
ROUGE is a widely used metric in text summarization and evaluates how much of the reference summary is covered by the generated summary. measures the recall-based overlap of n-grams between the generated and reference texts. uses unigrams, while uses bigrams.
(I) Effectively assesses how much key information from the reference summary is retained. (II) Simple and computationally efficient for large-scale evaluations. (III) Adaptable for both recall-based and precision-based evaluations (e.g., ROUGE-P). (IV) Widely adopted in summarization research, facilitating comparison with existing models.
The ROUGE-L formula is shown as follows:
ROUGE-L measures the similarity between the generated text and the reference text using the Longest Common Subsequence (LCS). Unlike n-gram-based metrics, LCS-based evaluation considers sequence order while allowing gaps in matches.
(recall) represents the proportion of the reference text covered by the LCS, while (precision) measures the proportion of the generated text that matches the LCS. The final ROUGE-L score is computed as an F-measure that balances recall and precision, where determines the relative importance of recall and precision. A typical choice is , giving equal weight to both recall and precision.
(I) Captures sentence structure by considering the longest common subsequence rather than isolated n-grams. (II) Accounts for sequence order, favoring outputs that preserve logical flow. (III) More flexible than strict n-gram overlap, allowing partial matches within longer text sequences.
The ROUGE-Lsum formula is shown as follows:
where
ROUGE-Lsum extends ROUGE-L to multi-sentence or document-level summaries by applying the LCS-based recall and precision over the entire text rather than at the single-sentence level. Specifically, all sentences from the reference and generated summaries are treated as continuous token sequences (), and the Longest Common Subsequence is computed on these full sequences. Then, and are calculated as above, leading to a single F-measure (with balancing recall vs. precision).
(I) Offers a holistic, document-level evaluation of summarization quality. (II) Preserves sequence order, rewarding coherent text structures. (III) More robust for longer or multi-paragraph summaries than single-sentence ROUGE-L.
The METEOR formula is shown as follows:
METEOR improves upon BLEU by considering recall (R) and precision (P) at the word level, while applying a penalty if matching words are fragmented into separate chunks. The more disjointed the matches (C), the higher the penalty, reducing the overall score. Unlike BLEU, METEOR enhances evaluation by incorporating synonym matching, stemming, and paraphrasing, enabling a more flexible and linguistically informed assessment that better aligns with human judgments. The parameters , , and are empirically optimized to enhance performance.
(I) Demonstrates a strong correlation with human evaluations due to its linguistic considerations. (II) More flexible than BLEU, as it accounts for synonyms, stemming, and paraphrasing, providing a more comprehensive evaluation. (III) Includes recall, which is crucial for summarization and translation evaluation. (IV) Applies a penalty for fragmented matches, favoring outputs with better word sequence alignment, thus improving overall coherence.
In this study, we leverage the strengths and unique characteristics of multiple evaluation metrics, by adopting BLEU, ROUGE (ROUGE-1, ROUGE-2, ROUGE-L, ROUGE-Lsum), and METEOR to comprehensively assess our models. Each metric provides a distinct perspective: BLEU focuses on n-gram precision, ROUGE measures recall-based coverage and sequence overlap, while METEOR captures broader lexical and semantic variations by incorporating synonym matching and stemming.
By analyzing results from multiple metrics, we aim to gain a holistic understanding of our models’ performance and mitigate potential biases that may arise from relying on a single metric. Ultimately, a model that consistently achieves high scores across these evaluation measures will be regarded as robust and well-balanced.
5. Results
In this study, we evaluated the performance of the proposed ATIRS-SM and ATIRS-RM using BLEU, ROUGE-N, ROUGE-L, ROUGE-Lsum, and METEOR metrics. The backbone models used were Phi-3.5, Qwen2.5, and Gemma-2, and each model was evaluated under 4-bit and 8-bit QLoRA settings. The following sections present detailed experimental results and analyses for each model.
5.1. Performance Evaluation of ATIRS-SM
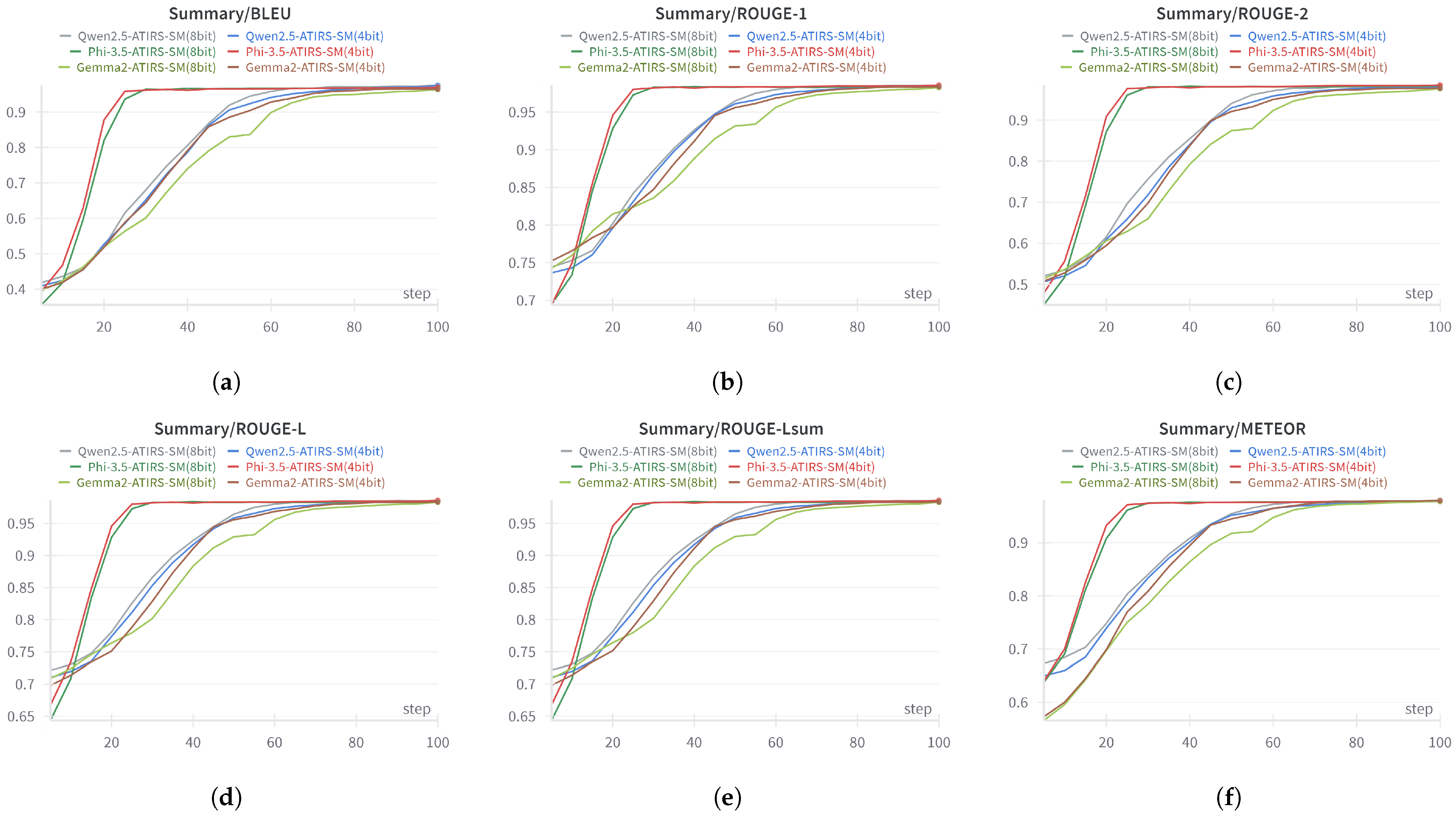
Figure 7 and
Table 4 present the overall performance metrics and comparative results of ATIRS-SM in both visual and numerical formats.
According to
Table 4, Phi-3.5 (4-bit) achieved the highest performance on the primary ROUGE metrics (ROUGE-1, ROUGE-2, ROUGE-L, ROUGE-Lsum), indicating that the summarized text effectively preserves the structure and key information of the original text. In particular, the superiority of Phi-3.5 is prominent in environments that require high accuracy, such as the summarization of security alert logs. Furthermore, the minimal performance degradation observed in the 4-bit QLoRA setting compared to the 8-bit setting suggests that high-quality summarization is achievable even in environments with limited computational and memory resources.
Meanwhile, in the BLEU index, Qwen2.5 (8-bit) recorded the highest BLEU score of 0.9761, and in the METEOR index, Gemma-2 (4-bit) recorded 0.9797, showing a slight advantage. This means that the performance of the models may vary somewhat depending on the specific evaluation criteria, but Phi-3.5 (4-bit) showed the most balanced results in overall ROUGE performance. That is, it was confirmed that it can maintain competitive performance in terms of fluency and semantic consistency, and provide stable performance in applications such as security log summarization that require real-time processing.
5.2. Performance Evaluation of ATIRS-RM
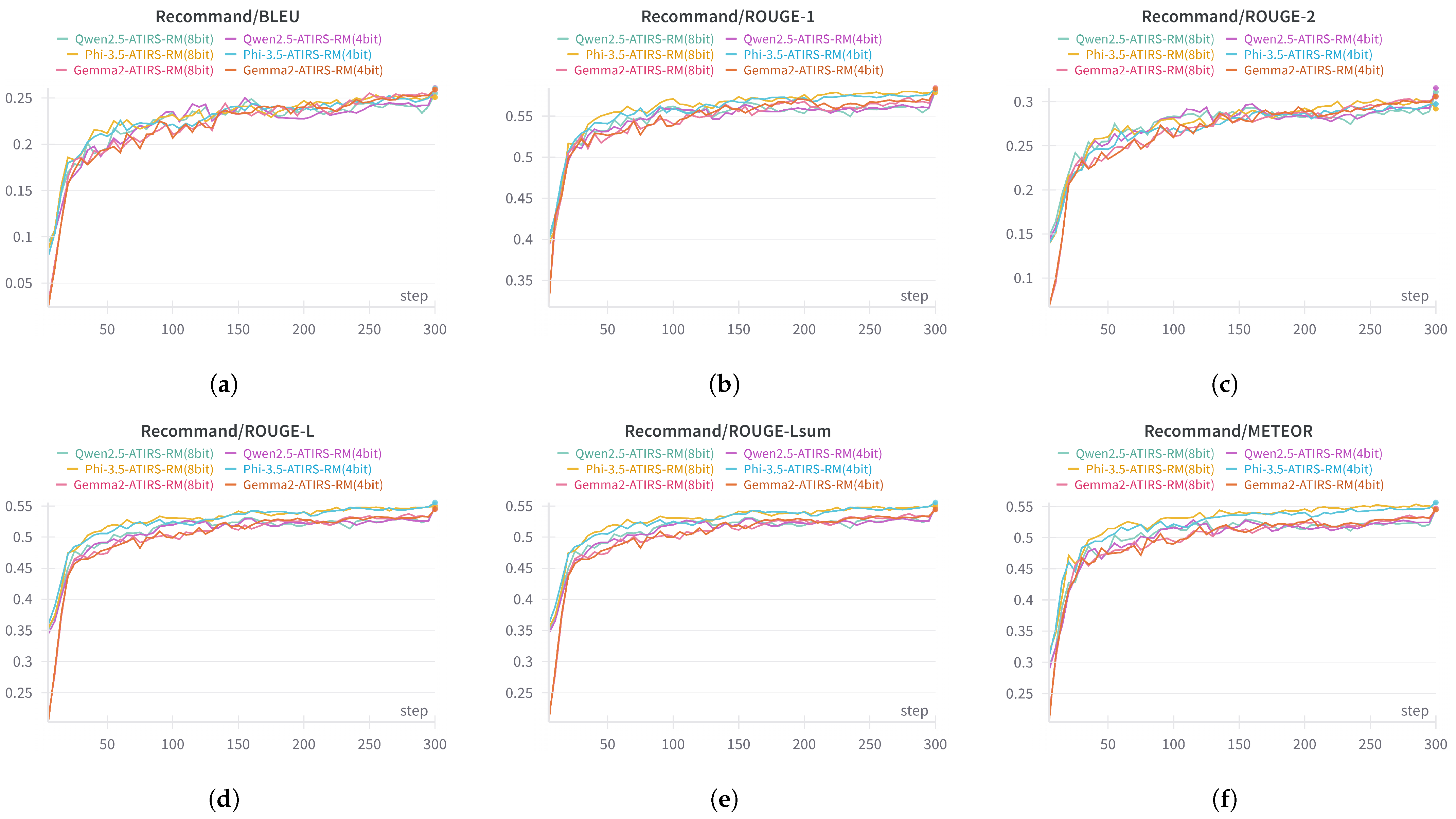
Figure 8 and
Table 5 summarize the performance metrics and relative improvements of ATIRS-RM in both visual and numerical forms.
The 4-bit quantized backbone models were fine-tuned using data in the format “network alert logs → response recommendation” derived from network alert logs, while the proposed ATIRS-RM was fine-tuned using data in the format “summary → response recommendation” derived from summaries generated by ATIRS-SM. This allowed for a comparative analysis of the performance differences between using the original log data and the summarized data.
The results presented in
Table 5 show that the overall performance of ATIRS-RM (4-bit/8-bit) significantly improved compared to the Base model. Moreover, the performance differences between the 4-bit and 8-bit versions were very minimal for each backbone model, with some metrics even showing slightly higher scores for the 4-bit version. This indicates that when applying the QLoRA technique, 4-bit quantization can substantially reduce memory usage and computational cost while minimizing accuracy loss.
Compared to the Base model, ATIRS-RM (4-bit) improved ROUGE-1 from 0.4361 to 0.5831 (+33.71%) and ROUGE-2 from 0.2245 to 0.2974 (+36.17%). This indicates that the model produced response recommendations that closely align with the reference responses in terms of structure and key information. Additionally, between the 4-bit and 8-bit versions, the 4-bit version achieved higher scores in certain metrics such as ROUGE-1, ROUGE-L, and ROUGE-Lsum, while ROUGE-2 and METEOR were either slightly higher for the 8-bit version or nearly identical. Consequently, the model achieved up to a 36% improvement over the Base model, while simultaneously delivering memory and computational efficiency in a 4-bit environment.
Qwen2.5 (4-bit) achieved slightly higher scores on most metrics, including BLEU (0.2609), ROUGE-1 (0.5836), ROUGE-2 (0.3158), and METEOR (0.5471), compared to Qwen2.5 (8-bit). It recorded up to a 26.17% improvement (in ROUGE-2) over the Base model, confirming that it generates much more accurate and comprehensive response recommendations.
Gemma-2 (4-bit) also exhibited performance improvements of up to 28.97% (in ROUGE-Lsum) over the Base model. The performance between the 4-bit and 8-bit versions was very similar, with some metrics favoring the 4-bit version and others the 8-bit version. For example, ROUGE-1 was slightly higher for the 8-bit version (0.5843), whereas BLEU was marginally higher for the 4-bit version (0.2593).
All three models, when fine-tuned using the proposed ATIRS-RM with “summary → response recommendation” data, showed significant improvements across BLEU, ROUGE, and METEOR metrics. This indicates that utilizing ATIRS-SM based data enables the learning of much more refined response recommendations compared to the Base model that relies solely on the original network alert logs.
To support these results, a statistical analysis was conducted based on the findings presented in
Table 5. Specifically, each Base model was compared with its corresponding ATIRS-RM model, fine-tuned using the QLoRA technique. A paired
t-test was performed to determine whether the improvements in BLEU, ROUGE, and METEOR scores achieved by the ATIRS-RM models were statistically significant.
Table 6 presents the results of this analysis. The findings indicate that the Phi-3.5-based and Qwen2.5-based ATIRS-RM models, in both 4-bit and 8-bit configurations, demonstrated statistically significant improvements over their respective Base models (
). This confirms that the observed performance gains are unlikely to be due to random variations, reinforcing that QLoRA-based fine-tuning effectively enhances response recommendation capabilities.
In contrast, the Gemma-2-based ATIRS-RM models exhibited numerical improvements over their respective Base models; however, these differences were not statistically significant (). This suggests that, unlike Phi-3.5 and Qwen2.5, the adaptation of Gemma-2 using QLoRA did not yield sufficiently consistent performance gains across multiple runs. The lack of statistical significance could be attributed to the model’s inherent architectural differences, the impact of low-rank adaptation on its internal representations, or limitations in dataset alignment with its pre-trained knowledge.
Although ATIRS tokenization introduces a slight increase in tokenization time compared to the Base model (1.963 ms vs. 1.187 ms per text), it significantly reduces the token sequence length from 1040 to 604. This reduction is particularly beneficial for Transformer-based models, where inference complexity scales with sequence length. As a result, while tokenization takes marginally longer, overall computational efficiency in downstream processing, including model inference, is improved. This makes ATIRS-RM not only more effective in response recommendation generation but also more scalable for real-time cybersecurity applications.
In summary, ATIRS-RM exhibited substantial performance enhancements over the Base model, and applying 4-bit QLoRA can reduce memory usage while maintaining or even improving the accuracy of response recommendations. In particular, the Phi-3.5-based ATIRS-RM demonstrated consistently superior performance across all metrics. To further analyze the efficiency of different models under QLoRA-based fine-tuning, inference speed and memory usage were measured across multiple backbone models. The results are presented in
Table 7.
These results indicate that while the Qwen2.5-based ATIRS-RM 4-bit achieves faster inference speed (2737.28 ms), it requires significantly more GPU memory (8.5681 GB) compared to the Phi-3.5-based ATIRS-RM 4-bit (3896.89 ms, 3.9668 GB). This makes the Phi-3.5-based ATIRS-RM 4-bit the most memory-efficient choice for real-time applications in constrained environments, where reducing memory consumption is crucial.
Additionally, while the Qwen2.5-based ATIRS-RM 8-bit achieves significantly faster inference time (1903.26 ms) compared to the Phi-3.5-based ATIRS-RM 8-bit (4735.03 ms), it comes at the cost of higher GPU memory usage (12.2661 GB vs. 5.5861 GB). This trade-off suggests that the Phi-3.5-based ATIRS-RM 8-bit remains a viable option for environments where memory constraints outweigh processing speed.
Furthermore, the Gemma-2-based ATIRS-RM 4-bit and 8-bit models exhibit significantly longer inference times in both settings, with the slowest performance across all tested configurations. This suggests that they may not be suitable for real-time applications in maritime and edge computing scenarios, where low-latency responses are critical.
Overall, these findings validate that the Phi-3.5-based ATIRS-RM 4-bit provides the best balance between inference efficiency and memory footprint, making it the most practical model for deployment in resource-constrained maritime cybersecurity environments.
6. Conclusions and Further Research
In this study, we proposed an ATIRS, a framework designed for real-time network alert log summarization and response recommendation in resource-constrained environments. The ATIRS integrates network alert log summarization (ATIRS-SM) and response recommendation (ATIRS-RM) to assist crew members with limited cybersecurity expertise in understanding and responding to security threats. Experimental results demonstrated that Phi-3.5 (4-bit)-based ATIRS-SM achieved the highest performance in ROUGE metrics, ensuring accurate security log summarization. Additionally, ATIRS-RM significantly improved response recommendation accuracy, outperforming the base model by up to 36.17%.
Traditionally, security incidents occurring during voyages cannot be addressed immediately, as responses are typically handled by security personnel after docking. However, the ATIRS automates log summarization and provides real-time response recommendations, enabling crew members without prior security expertise to take immediate action. In actual testing, analyzing 10 security incidents manually required an average response time of 30 min, whereas the ATIRS reduced this response time to 5–10 min, significantly improving operational efficiency.
In conclusion, the ATIRS has been experimentally validated as an effective solution for overcoming the limitations of conventional maritime security operations. By enabling real-time threat detection and response in constrained hardware environments, the ATIRS enhances cybersecurity operations with minimal computational overhead.
In future work, we aim to improve the ATIRS by expanding the dataset with real-time network data and applying data augmentation techniques to enhance the model’s generalization capability. Additionally, we plan to refine the feedback integration process—building on the adaptive learning strategy described in
Section 3.5—by introducing automated validation mechanisms to ensure higher-quality user feedback before incorporating it into fine-tuning cycles.
Furthermore, we will explore reinforcement learning-based optimization techniques to enhance the ATIRS’s ability to dynamically adapt to real-time security incidents and refine response recommendations based on long-term incident resolution outcomes. To further improve real-time adaptation, we will investigate integrating Retrieval-Augmented Generation (RAG), enabling the ATIRS to leverage up-to-date security intelligence from external threat databases while maintaining a lightweight model adaptation process. These enhancements will ensure that the ATIRS continuously refines its recommendations and remains effective in rapidly evolving maritime cybersecurity environments.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}