
CSP-DCPE: Category-Specific Prompt with Deep Contextual Prompt Enhancement for Vision–Language Models

Abstract
1. Introduction
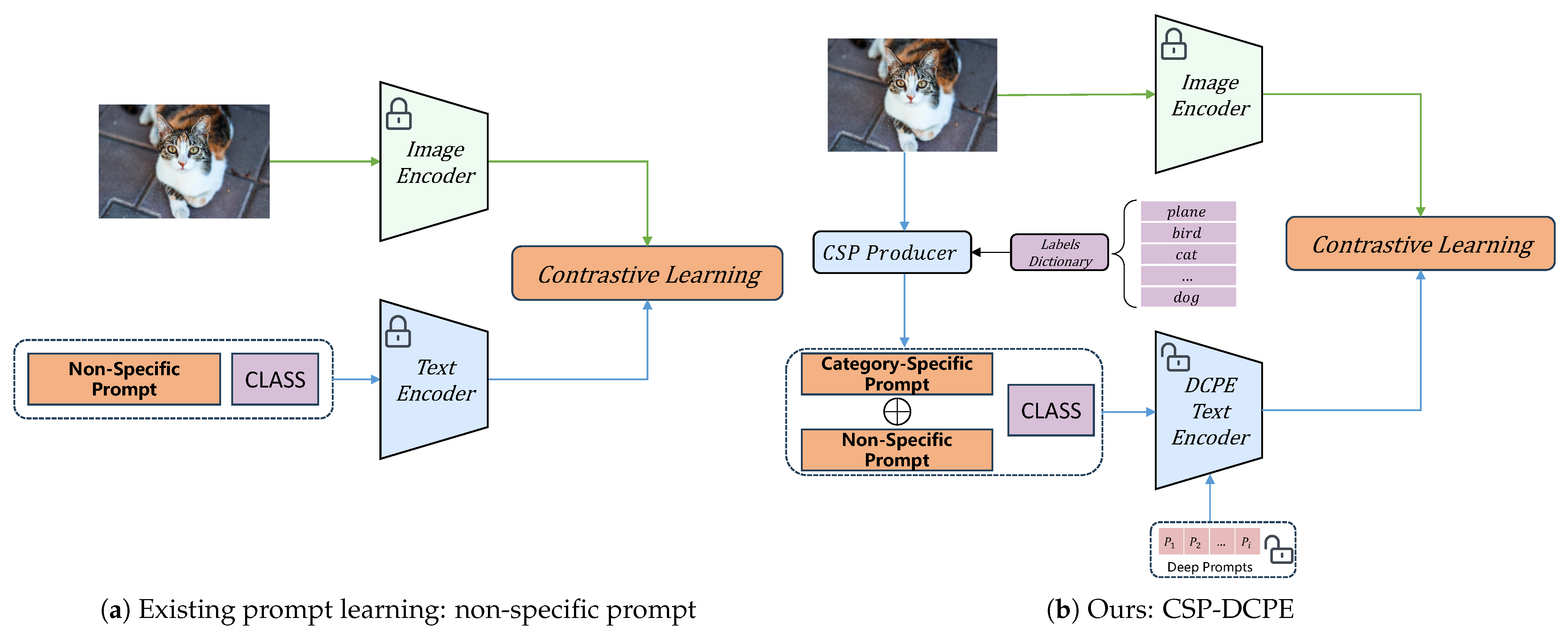
- We examine the function of prompt learning in image-classification tasks and suggest a new prompt-learning structure, the Category-Specific Prompt (CSP). As far as we are aware, this marks the inaugural endeavor to leverage a combination of non-specific and Category-Specific Prompts in the domain of image classification.
- In order to enhance the exploitation of features derived from the preceding layer and to optimize the utilization of the combination of category-specific and non-specific prompts, we propose a novel deep prompt-learning approach, Deep Contextual Prompt Enhancement (DCPE). This approach represents the input text in a more comprehensive manner, thereby optimizing the extraction process.
- Our proposed CSP-DCPE architecture combines both instance-oriented and task-oriented data. We evaluated our proposed architecture on 11 benchmark image-classification datasets, achieving optimal outcomes.
2. Related Work
2.1. Pre-Trained VLMs
2.2. Few-Shot Learning
2.3. Prompt Tuning in Pre-Trained VLMs
3. Method
3.1. Revisit CLIP
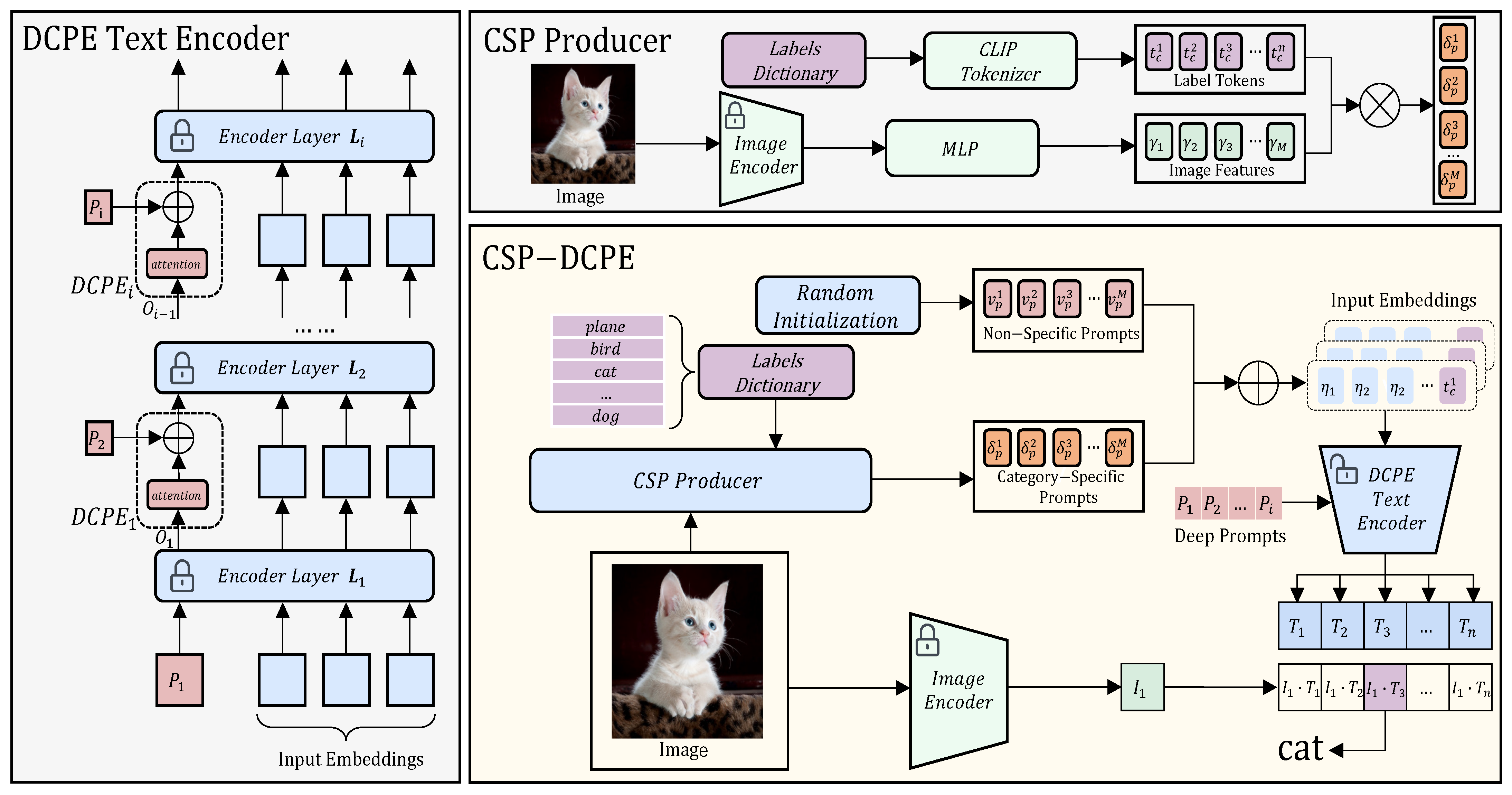
3.2. Category-Specific Prompt
3.3. Textual Input Embeddings
3.4. Deep Contextual Prompt Enhancement
3.5. Loss Function
4. Experiment
- Datasets
- Implementation details
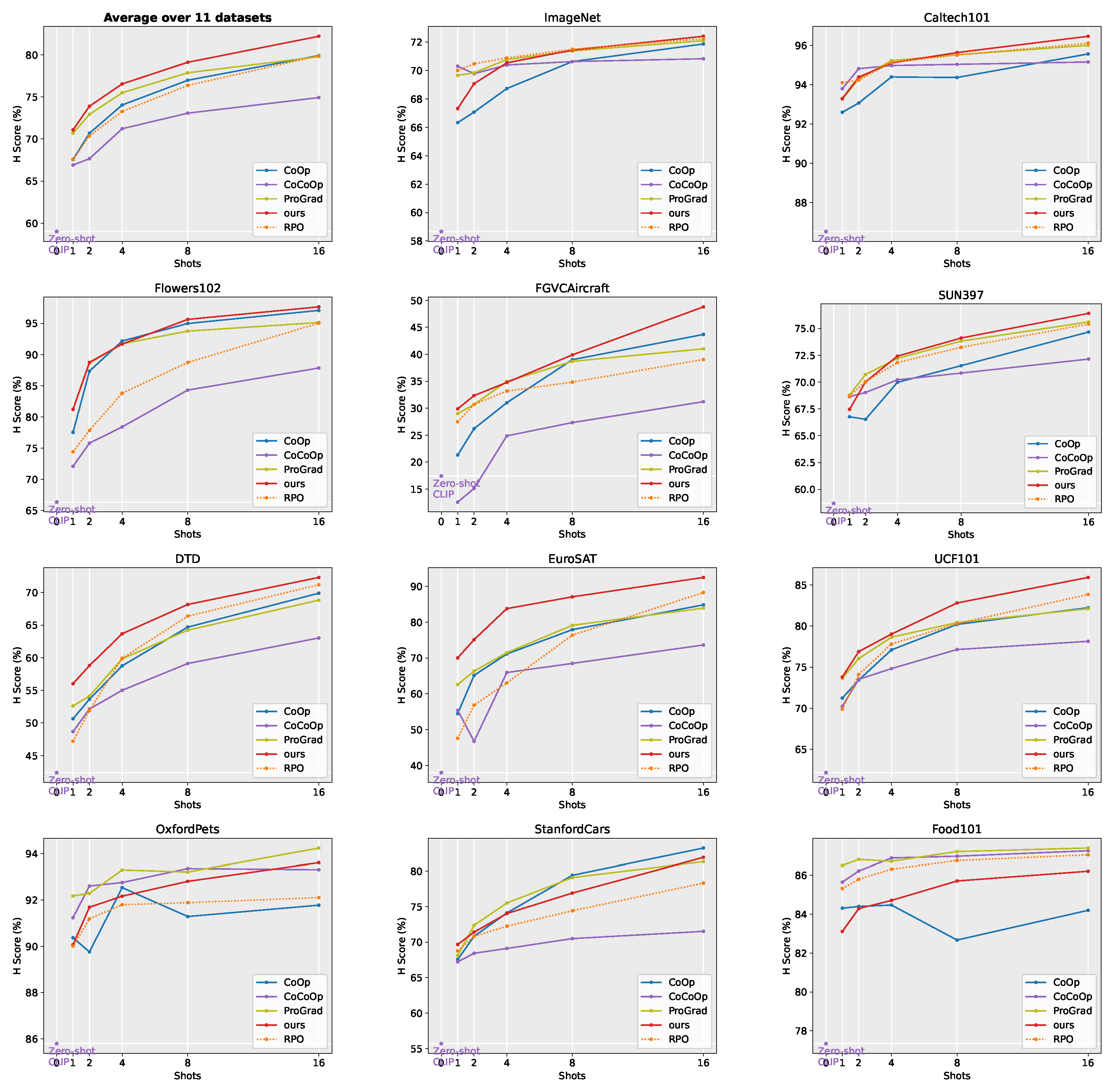
4.1. Few-Shot Learning
4.2. Base-to-Novel Generalization
- Overall assessment:
- Detailed assessment:
4.3. Ablation Experiments
- Assessment of Module Effectiveness:
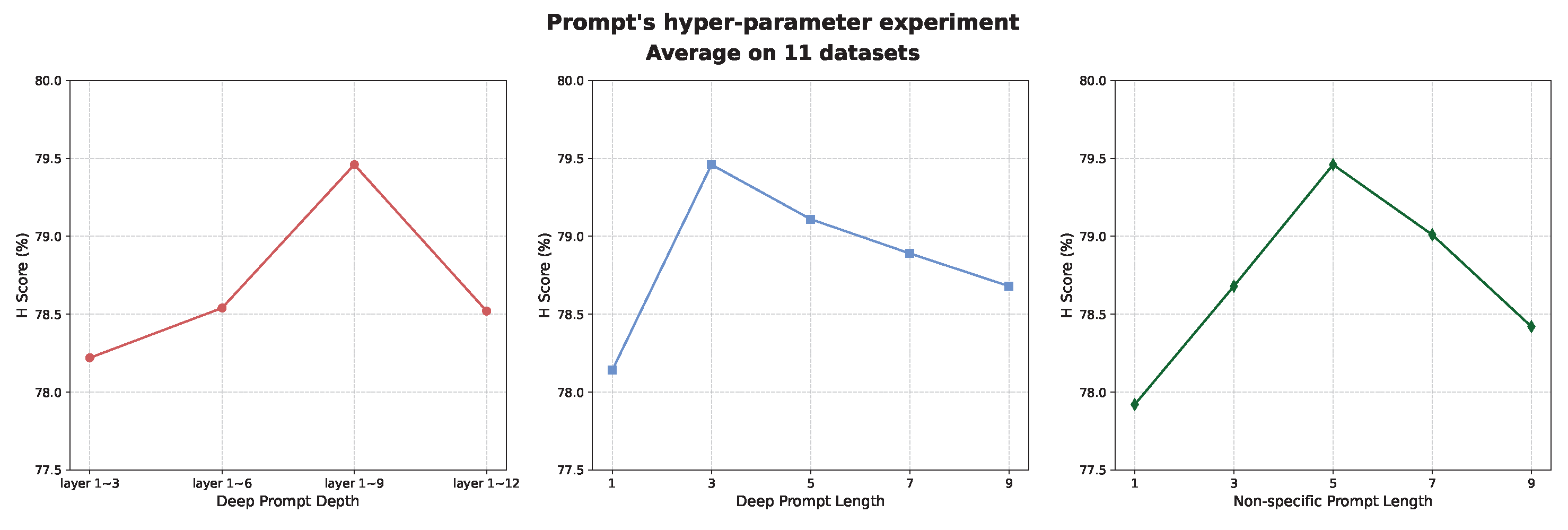
- Experiment on Prompt Hyper-Parameter:
- Ablation on Deep Structure:
- Experiment on Computational Efficiency:
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to prompt for vision–language models. Int. J. Comput. Vis. 2022, 130, 2337–2348. [Google Scholar] [CrossRef]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling up visual and vision–language representation learning with noisy text supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Conditional prompt learning for vision–language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16816–16825. [Google Scholar]
- Yao, L.; Huang, R.; Hou, L.; Lu, G.; Niu, M.; Xu, H.; Liang, X.; Li, Z.; Jiang, X.; Xu, C. Filip: Fine-grained interactive language-image pre-training. arXiv 2021, arXiv:2111.07783. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. arXiv 2021, arXiv:2101.00190. [Google Scholar]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT understands, too. AI Open 2024, 5, 208–215. [Google Scholar] [CrossRef]
- Lester, B.; Al-Rfou, R.; Constant, N. The power of scale for parameter-efficient prompt tuning. arXiv 2021, arXiv:2104.08691. [Google Scholar]
- Gu, Y.; Han, X.; Liu, Z.; Huang, M. Ppt: Pre-trained prompt tuning for Few-Shot Learning. arXiv 2021, arXiv:2109.04332. [Google Scholar]
- Xu, C.; Shen, H.; Shi, F.; Chen, B.; Liao, Y.; Chen, X.; Wang, L. Progressive Visual Prompt Learning with Contrastive Feature Re-formation. arXiv 2023, arXiv:2304.08386. [Google Scholar] [CrossRef]
- Khattak, M.U.; Rasheed, H.; Maaz, M.; Khan, S.; Khan, F.S. Maple: Multi-modal prompt learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19113–19122. [Google Scholar]
- Miao, Y.; Li, S.; Tang, J.; Wang, T. MuDPT: Multi-modal Deep-symphysis Prompt Tuning for Large Pre-trained Vision-Language Models. arXiv 2023, arXiv:2306.11400. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Desai, K.; Kaul, G.; Aysola, Z.; Johnson, J. RedCaps: Web-curated image–text data created by the people, for the people. arXiv 2021, arXiv:2111.11431. [Google Scholar]
- Srinivasan, K.; Raman, K.; Chen, J.; Bendersky, M.; Najork, M. Wit: Wikipedia-based image text dataset for multimodal multilingual machine learning. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, Canada, 11–15 July 2021; pp. 2443–2449. [Google Scholar]
- Schuhmann, C.; Beaumont, R.; Vencu, R.; Gordon, C.; Wightman, R.; Cherti, M.; Coombes, T.; Katta, A.; Mullis, C.; Wortsman, M.; et al. Laion-5b: An open large-scale dataset for training next generation image–text models. Adv. Neural Inf. Process. Syst. 2022, 35, 25278–25294. [Google Scholar]
- Hu, X.; Gan, Z.; Wang, J.; Yang, Z.; Liu, Z.; Lu, Y.; Wang, L. Scaling up vision–language pre-training for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17980–17989. [Google Scholar]
- Kim, W.; Son, B.; Kim, I. Vilt: Vision-and-language transformer without convolution or region supervision. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 18–24 July 2021; pp. 5583–5594. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Adv. Neural Inf. Process. Syst. 2019, 32, 13–23. [Google Scholar]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. Vl-bert: Pre-training of generic visual-linguistic representations. arXiv 2019, arXiv:1908.08530. [Google Scholar]
- Li, J.; Selvaraju, R.; Gotmare, A.; Joty, S.; Xiong, C.; Hoi, S.C.H. Align before fuse: Vision and language representation learning with momentum distillation. Adv. Neural Inf. Process. Syst. 2021, 34, 9694–9705. [Google Scholar]
- Huo, Y.; Zhang, M.; Liu, G.; Lu, H.; Gao, Y.; Yang, G.; Wen, J.; Zhang, H.; Xu, B.; Zheng, W.; et al. WenLan: Bridging vision and language by large-scale multi-modal pre-training. arXiv 2021, arXiv:2103.06561. [Google Scholar]
- Gao, P.; Geng, S.; Zhang, R.; Ma, T.; Fang, R.; Zhang, Y.; Li, H.; Qiao, Y. Clip-adapter: Better vision–language models with feature adapters. Int. J. Comput. Vis. 2024, 132, 581–595. [Google Scholar] [CrossRef]
- Kim, K.; Laskin, M.; Mordatch, I.; Pathak, D. How to Adapt Your Large-Scale Vision-and-Language Model. 2022. Available online: https://openreview.net/forum?id=EhwEUb2ynIa (accessed on 1 February 2025).
- Zhang, R.; Fang, R.; Zhang, W.; Gao, P.; Li, K.; Dai, J.; Qiao, Y.; Li, H. Tip-adapter: Training-free clip-adapter for better vision–language modeling. arXiv 2021, arXiv:2111.03930. [Google Scholar]
- Feng, C.; Zhong, Y.; Jie, Z.; Chu, X.; Ren, H.; Wei, X.; Xie, W.; Ma, L. Promptdet: Towards open-vocabulary detection using uncurated images. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 701–717. [Google Scholar]
- Gu, X.; Lin, T.Y.; Kuo, W.; Cui, Y. Open-vocabulary object detection via vision and language knowledge distillation. arXiv 2021, arXiv:2104.13921. [Google Scholar]
- Maaz, M.; Rasheed, H.; Khan, S.; Khan, F.S.; Anwer, R.M.; Yang, M.H. Class-agnostic object detection with multi-modal transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 512–531. [Google Scholar]
- Bangalath, H.; Maaz, M.; Khattak, M.U.; Khan, S.H.; Shahbaz Khan, F. Bridging the gap between object and image-level representations for open-vocabulary detection. Adv. Neural Inf. Process. Syst. 2022, 35, 33781–33794. [Google Scholar]
- Zang, Y.; Li, W.; Zhou, K.; Huang, C.; Loy, C.C. Open-vocabulary detr with conditional matching. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 106–122. [Google Scholar]
- Zhou, X.; Girdhar, R.; Joulin, A.; Krähenbühl, P.; Misra, I. Detecting twenty-thousand classes using image-level supervision. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 350–368. [Google Scholar]
- Ding, J.; Xue, N.; Xia, G.S.; Dai, D. Decoupling zero-shot semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11583–11592. [Google Scholar]
- Lüddecke, T.; Ecker, A. Image segmentation using text and image prompts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7086–7096. [Google Scholar]
- Rao, Y.; Zhao, W.; Chen, G.; Tang, Y.; Zhu, Z.; Huang, G.; Zhou, J.; Lu, J. Denseclip: Language-guided dense prediction with context-aware prompting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18082–18091. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on Few-Shot Learning. ACM Comput. Surv. (csur) 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Jiang, W.; Huang, K.; Geng, J.; Deng, X. Multi-scale metric learning for Few-Shot Learning. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1091–1102. [Google Scholar] [CrossRef]
- Hao, F.; He, F.; Cheng, J.; Wang, L.; Cao, J.; Tao, D. Collect and select: Semantic alignment metric learning for few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8460–8469. [Google Scholar]
- Li, H.; Ge, S.; Gao, C.; Gao, H. Few-shot object detection via high-and-low resolution representation. Comput. Electr. Eng. 2022, 104, 108438. [Google Scholar] [CrossRef]
- Sun, Q.; Liu, Y.; Chua, T.S.; Schiele, B. Meta-transfer learning for Few-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 403–412. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-learning in neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5149–5169. [Google Scholar] [CrossRef]
- Wang, J.X. Meta-learning in natural and artificial intelligence. Curr. Opin. Behav. Sci. 2021, 38, 90–95. [Google Scholar] [CrossRef]
- Lei, S.; Dong, B.; Shan, A.; Li, Y.; Zhang, W.; Xiao, F. Attention meta-transfer learning approach for few-shot iris recognition. Comput. Electr. Eng. 2022, 99, 107848. [Google Scholar] [CrossRef]
- Yao, H.; Zhang, R.; Xu, C. Visual-language prompt tuning with knowledge-guided context optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6757–6767. [Google Scholar]
- Zhu, B.; Niu, Y.; Han, Y.; Wu, Y.; Zhang, H. Prompt-aligned gradient for prompt tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 15659–15669. [Google Scholar]
- Lu, Y.; Liu, J.; Zhang, Y.; Liu, Y.; Tian, X. Prompt distribution learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5206–5215. [Google Scholar]
- Zhang, Y.; Fei, H.; Li, D.; Yu, T.; Li, P. Prompting through prototype: A prototype-based prompt learning on pretrained vision–language models. arXiv 2022, arXiv:2210.10841. [Google Scholar]
- Jia, M.; Tang, L.; Chen, B.C.; Cardie, C.; Belongie, S.; Hariharan, B.; Lim, S.N. Visual prompt tuning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 709–727. [Google Scholar]
- Lee, D.; Song, S.; Suh, J.; Choi, J.; Lee, S.; Kim, H.J. Read-only Prompt Optimization for Vision-Language Few-Shot Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 1401–1411. [Google Scholar]
- Liu, X.; Tang, W.; Lu, J.; Zhao, R.; Guo, Z.; Tan, F. Deeply Coupled Cross-Modal Prompt Learning. arXiv 2023, arXiv:2305.17903. [Google Scholar]
- Cho, E.; Kim, J.; Kim, H.J. Distribution-Aware Prompt Tuning for Vision-Language Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 22004–22013. [Google Scholar]
- Ju, C.; Han, T.; Zheng, K.; Zhang, Y.; Xie, W. Prompting visual-language models for efficient video understanding. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 105–124. [Google Scholar]
- Yu, X.; Yoo, S.; Lin, Y. CLIPCEIL: Domain Generalization through CLIP via Channel rEfinement and Image–text aLignment. In Proceedings of the Thirty-Eighth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Fei-Fei, L.; Fergus, R.; Perona, P. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004; IEEE: Piscataway, NJ, USA, 2004; p. 178. [Google Scholar]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-grained visual classification of aircraft. arXiv 2013, arXiv:1306.5151. [Google Scholar]
- Nilsback, M.E.; Zisserman, A. Automated flower classification over a large number of classes. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Bhubaneswar, India, 16–19 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 722–729. [Google Scholar]
- Bossard, L.; Guillaumin, M.; Van Gool, L. Food-101–mining discriminative components with random forests. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part VI 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 446–461. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A.; Jawahar, C. Cats and dogs. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3498–3505. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3d object representations for fine-grained categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3606–3613. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. Sun database: Large-scale scene recognition from abbey to zoo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 3485–3492. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbones | Methods | K = 4 | K = 8 | K = 16 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Base | Novel | H | Base | Novel | H | Base | Novel | H | ||
| CoOp [1] | 78.44 | 68.01 | 72.85 | 80.74 | 68.40 | 74.06 | 82.72 | 68.00 | 74.64 | |
| CoCoOp [4] | 76.71 | 73.33 | 74.98 | 78.56 | 72.01 | 75.14 | 80.52 | 71.72 | 75.87 | |
| ViT-B/16 | ProGrad [45] | 79.20 | 71.13 | 74.95 | 80.63 | 71.03 | 75.53 | 82.69 | 70.43 | 76.07 |
| KgCoOp [44] | 79.90 | 73.10 | 76.35 | 78.37 | 73.89 | 76.06 | 80.55 | 73.52 | 76.87 | |
| RPO [49] | 74.11 | 74.30 | 74.20 | 77.10 | 74.39 | 75.72 | 81.06 | 75.01 | 77.92 | |
| Ours | 77.25 | 75.71 | 76.47 | 80.28 | 75.86 | 78.00 | 82.81 | 76.38 | 79.46 | |
| (a) Average over 11 datasets. | |||
| Methods | Base | Novel | H |
| CLIP | 69.34 | 74.22 | 71.70 |
| CoCoOp | 80.52 | 71.72 | 75.87 |
| KgCoOp | 80.55 | 73.52 | 76.87 |
| CoOp | 82.72 | 68.00 | 74.64 |
| ProGrad | 82.69 | 70.43 | 76.07 |
| RPO | 81.06 | 75.01 | 77.92 |
| Ours | 82.81 | 76.38 | 79.46 |
| (b) ImageNet. | |||
| Methods | Base | Novel | H |
| CLIP | 72.43 | 68.14 | 70.22 |
| CoCoOp | 75.95 | 70.45 | 73.09 |
| KgCoOp | 75.80 | 69.94 | 72.75 |
| CoOp | 76.48 | 66.32 | 71.03 |
| ProGrad | 77.05 | 66.68 | 71.49 |
| RPO | 76.62 | 71.59 | 74.01 |
| Ours | 76.51 | 71.02 | 73.66 |
| (c) Food101. | |||
| Methods | Base | Novel | H |
| CLIP | 90.10 | 91.22 | 90.66 |
| CoCoOp | 90.72 | 91.28 | 90.99 |
| KgCoOp | 90.51 | 91.71 | 91.10 |
| CoOp | 89.43 | 87.49 | 88.44 |
| ProGrad | 90.36 | 89.60 | 89.97 |
| RPO | 90.32 | 90.82 | 90.56 |
| Ours | 90.41 | 91.49 | 90.94 |
| (d) FGVCAircraft. | |||
| Methods | Base | Novel | H |
| CLIP | 27.19 | 36.29 | 31.09 |
| CoCoOp | 33.42 | 23.72 | 27.74 |
| KgCoOp | 36.22 | 33.54 | 34.82 |
| CoOp | 39.25 | 30.48 | 34.31 |
| ProGrad | 40.55 | 27.56 | 32.81 |
| RPO | 37.32 | 34.21 | 35.69 |
| Ours | 39.32 | 34.56 | 36.78 |
| (e) SUN397. | |||
| Methods | Base | Novel | H |
| CLIP | 69.36 | 75.35 | 72.23 |
| CoCoOp | 79.75 | 76.85 | 78.27 |
| KgCoOp | 80.28 | 76.54 | 78.36 |
| CoOp | 80.84 | 68.35 | 74.07 |
| ProGrad | 81.25 | 74.18 | 77.55 |
| RPO | 80.61 | 77.79 | 79.17 |
| Ours | 81.03 | 78.01 | 79.49 |
| (f) DTD. | |||
| Methods | Base | Novel | H |
| CLIP | 53.24 | 59.90 | 56.37 |
| CoCoOp | 77.32 | 56.77 | 65.47 |
| KgCoOp | 77.09 | 54.01 | 63.51 |
| CoOp | 80.02 | 47.99 | 59.99 |
| ProGrad | 77.91 | 52.98 | 63.07 |
| RPO | 76.99 | 62.64 | 69.07 |
| Ours | 80.69 | 63.94 | 71.34 |
| (g) EuroSAT. | |||
| Methods | Base | Novel | H |
| CLIP | 56.48 | 64.05 | 60.03 |
| CoCoOp | 87.98 | 60.47 | 71.67 |
| KgCoOp | 85.32 | 64.78 | 73.64 |
| CoOp | 91.23 | 54.11 | 67.92 |
| ProGrad | 90.89 | 60.02 | 72.29 |
| RPO | 86.12 | 68.23 | 76.13 |
| Ours | 94.58 | 82.58 | 88.17 |
| (h) UCF101. | |||
| Methods | Base | Novel | H |
| CLIP | 70.53 | 77.50 | 73.85 |
| CoCoOp | 82.78 | 73.89 | 78.08 |
| KgCoOp | 82.11 | 76.34 | 79.11 |
| CoOp | 85.47 | 64.99 | 73.83 |
| ProGrad | 84.62 | 74.23 | 79.08 |
| RPO | 83.99 | 75.77 | 79.66 |
| Ours | 84.96 | 79.01 | 81.87 |
| (i) OxfordPets. | |||
| Methods | Base | Novel | H |
| CLIP | 91.17 | 97.26 | 94.12 |
| CoCoOp | 95.87 | 97.34 | 96.59 |
| KgCoOp | 94.98 | 97.45 | 96.19 |
| CoOp | 94.78 | 96.13 | 95.45 |
| ProGrad | 95.32 | 97.19 | 96.24 |
| RPO | 94.21 | 97.89 | 96.01 |
| Ours | 95.59 | 97.55 | 96.56 |
| (j) Caltech101. | |||
| Methods | Base | Novel | H |
| CLIP | 96.84 | 94.00 | 95.40 |
| CoCoOp | 97.67 | 93.99 | 95.79 |
| KgCoOp | 97.21 | 94.38 | 95.77 |
| CoOp | 98.13 | 93.12 | 95.55 |
| ProGrad | 98.03 | 93.34 | 95.62 |
| RPO | 97.34 | 94.34 | 95.81 |
| Ours | 98.36 | 94.02 | 96.14 |
| (k) StanfordCars. | |||
| Methods | Base | Novel | H |
| CLIP | 63.37 | 74.89 | 68.65 |
| CoCoOp | 70.01 | 73.03 | 71.48 |
| KgCoOp | 71.23 | 75.06 | 73.09 |
| CoOp | 76.31 | 69.99 | 73.01 |
| ProGrad | 77.78 | 68.02 | 72.57 |
| RPO | 73.45 | 75.61 | 74.51 |
| Ours | 73.28 | 73.62 | 73.44 |
| (l) Flowers102. | |||
| Methods | Base | Novel | H |
| CLIP | 72.08 | 77.80 | 74.83 |
| CoCoOp | 94.32 | 71.23 | 81.16 |
| KgCoOp | 95.34 | 74.98 | 83.94 |
| CoOp | 97.99 | 69.12 | 81.06 |
| ProGrad | 95.89 | 71.01 | 81.59 |
| RPO | 94.78 | 76.23 | 84.49 |
| Ours | 96.23 | 74.38 | 83.90 |
| Methods | Base (Mean ± Stds) | Base (95% CI) | Novel (Mean ± Stds) | Novel (95% CI) |
|---|---|---|---|---|
| CoOp | 82.72 ± 0.03 | [82.70, 82.74] | 68.00 ± 0.31 | [67.65, 68.35] |
| CoCoOp | 80.52 ± 0.27 | [80.31, 80.73] | 71.72 ± 0.17 | [71.47, 71.97] |
| ProGrad | 82.69 ± 0.14 | [82.53, 82.85] | 70.43 ± 0.45 | [69.92, 70.94] |
| KgCoOp | 80.55 ± 0.21 | [80.32, 80.78] | 73.52 ± 0.27 | [73.31, 73.73] |
| RPO | 81.06 ± 0.06 | [81.02, 81.10] | 75.01 ± 0.13 | [74.88, 75.14] |
| Ours | 82.81 ± 0.28 | [82.59, 83.03] | 76.38 ± 0.11 | [76.27, 76.49] |
| Methods | Base | Novel | H |
|---|---|---|---|
| non-specific+deep (baseline) | 79.78 | 74.34 | 76.96 |
| CSP | 80.32 | 74.40 | 77.23 |
| CSP+deep | 80.75 | 74.79 | 77.65 |
| DCPE | 81.12 | 75.64 | 78.28 |
| CSP-DCPE | 82.81 | 76.38 | 79.46 |
| Methods | Base | Novel | H |
|---|---|---|---|
| CSP+deep | 80.75 | 74.79 | 77.65 |
| CSP+single attention | 81.04 | 75.11 | 77.96 |
| CSP+multi MLP | 81.61 | 75.92 | 78.66 |
| CSP+multi LSTM | 82.15 | 76.1 | 79.01 |
| CSP+multi attention (CSP-DCPE) | 82.81 | 76.38 | 79.46 |
| Methods | Epochs | Additional Params (K) | FLOPS (G) | H |
|---|---|---|---|---|
| CoOp | 100 | 2.05 | 20.96 | 74.64 |
| CoCoOp | 10 | 35.36 | 20.96 | 75.87 |
| non-specific+deep | 8 | 16.38 | 20.96 | 76.96 |
| CSP | 8 | 35.48 | 20.96 | 77.23 |
| CSP+deep | 8 | 49.30 | 20.96 | 77.65 |
| DCPE | 8 | 8421.38 | 33.76 | 78.28 |
| CSP-DCPE | 8 | 8454.29 | 33.76 | 79.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.; Wu, Y.; Xu, Q.; Zi, X. CSP-DCPE: Category-Specific Prompt with Deep Contextual Prompt Enhancement for Vision–Language Models. Electronics 2025, 14, 673. https://doi.org/10.3390/electronics14040673
Wu C, Wu Y, Xu Q, Zi X. CSP-DCPE: Category-Specific Prompt with Deep Contextual Prompt Enhancement for Vision–Language Models. Electronics. 2025; 14(4):673. https://doi.org/10.3390/electronics14040673
Chicago/Turabian StyleWu, Chunlei, Yixiang Wu, Qinfu Xu, and Xuebin Zi. 2025. "CSP-DCPE: Category-Specific Prompt with Deep Contextual Prompt Enhancement for Vision–Language Models" Electronics 14, no. 4: 673. https://doi.org/10.3390/electronics14040673
APA StyleWu, C., Wu, Y., Xu, Q., & Zi, X. (2025). CSP-DCPE: Category-Specific Prompt with Deep Contextual Prompt Enhancement for Vision–Language Models. Electronics, 14(4), 673. https://doi.org/10.3390/electronics14040673