Abstract
Entity alignment in knowledge graphs plays a crucial role in ensuring the consistency and integration of data across different domains. For example, in power topology, accurate entity matching is essential for optimizing system design and control. However, traditional approaches to entity alignment often rely heavily on language models to extract general features, which can overlook important logical aspects such as temporal and event-centric relationships that are crucial for precise alignment.To address this issue, we propose EAL (Entity Alignment with Logical Capturing), a novel and lightweight RNN-based framework designed to enhance logical feature learning in entity alignment tasks. EAL introduces a logical paradigm learning module that effectively models complex-event relationships, capturing structured and context-aware logical patterns that are essential for alignment. This module encodes logical dependencies between entities to dynamically capture both local and global temporal-event interactions. Additionally, we integrate an adaptive logical attention mechanism that prioritizes influential logical features based on task-specific contexts, ensuring the extracted features are both relevant and discriminative. EAL also incorporates a key feature alignment framework that emphasizes critical event-centric logical structures. This framework employs a hierarchical feature aggregation strategy combining low-level information on temporal events with high-level semantic patterns, enabling robust entity matching while maintaining computational efficiency. By leveraging a multi-stage alignment process, EAL iteratively refines alignment predictions, optimizing both precision and recall. Experimental results on benchmark datasets demonstrate the effectiveness and robustness of EAL, which not only achieves superior performance in entity alignment tasks but also provides a lightweight yet powerful solution that reduces reliance on large language models.
1. Introduction
Knowledge graphs are increasingly applied across various domains, including power topology, where they model the complex relationships between components in power grids such as generators, transformers, and switches. In these domains, accurate entity alignment is crucial for integrating data from diverse sources, ensuring consistency, and supporting informed decision-making. However, current models for knowledge graph entity alignment heavily rely on language models for general feature extraction. These approaches often fail to address the challenge of identifying and utilizing critical information within complex and sparse knowledge graph structures. Existing approaches often struggle when applied to sparse knowledge graphs due to their reliance on dense relational structures, which limits their ability to capture meaningful patterns in data with fewer connections. This challenge has been addressed in several studies [1,2], which have demonstrated the limitations of traditional models in sparse graph settings. These models fail to effectively leverage the sparse nature of the graph, often leading to suboptimal performance when the graph contains missing or incomplete relationships.
Entity alignment involves identifying equivalent entities across different knowledge graphs, which often have heterogeneous schemes and varying structural representations [3]. The task becomes particularly challenging when entities are represented differently and the relationships between them differ in terms of naming conventions, types, or even semantic interpretation. Furthermore, knowledge graphs often contain missing or incomplete information, making it difficult to identify exact matches between entities. This situation is exacerbated when entities share similar semantics but differ in their temporal or event-based contexts. Entity alignment in knowledge graphs can be achieved through various approaches, each with its own unique strengths and limitations. The primary methods for entity alignment include Embedding-Based Methods, Rule-Based Reasoning, and GNN-Based Models.
Embedding-based alignment approaches such as JE [4], MTransE [5], and IPTransE [6] learn low-dimensional vector representations for entities and relations, which captures global semantic similarities. While these models are scalable, they struggle with temporal or event-based dependencies, which limits their use in dynamic environments.
Rule-based alignment approaches include Neural Logic Programming [7], Neural Theorem Provers [8], and RNNLogic [9]. They focus on explicit logical rules, offering higher precision and interpretability. Approaches such as SEA [10] integrate semi-supervised learning, but are less adaptable to large or evolving graphs with complex undefined relationships.
GNN-based alignment approaches such as HGCN [11] and RDGCN [12] leverage message-passing to capture both structural and semantic features, which excels in large-scale graph alignment. Advances such as GCN-Align [13] and HMEA [14] improve alignment through multilingual and multimodal features, but can still struggle with temporal or event-based alignments. Models such as MMEA [15] and EVA [16] address these issues by incorporating visual and multimodal data. However, global feature propagation in GNN models can lead to inefficiencies, with solutions such as MultiJAF [17] still needing refinement for better balance between accuracy and efficiency.
While recent advancements in knowledge graph entity alignment have achieved notable improvements in accuracy and efficiency, many existing methods fall short in addressing nuanced temporal-event logical features and their dependencies. This limitation often hinders the alignment of entities in scenarios where precise reasoning over temporal and event-based contexts is critical, leading to suboptimal alignment results.
As shown in Figure 1, effective entity alignment relies heavily on capturing temporal and event-centric dependencies between entities across different knowledge graphs. In the example:
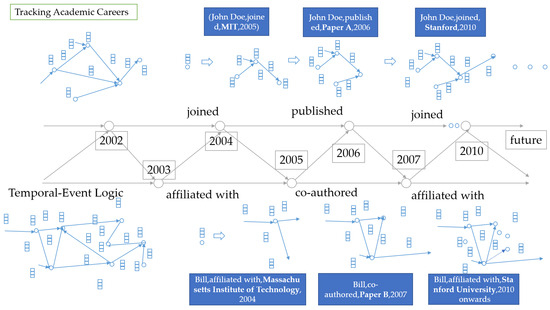
Figure 1.
Key message structure for reasoning.
- Time Consistency: The temporal overlap in affiliations (2005–2010 at MIT, 2010 onwards at Stanford) validates the alignment between “John Doe” in KG1 and “J. Doe” in KG2, ensuring that the entity’s temporal affiliations are consistent across both graphs.
- Event Linkage: The publication of “Paper A” in 2006 links “John Doe” in KG1 with “J. Doe” in KG2 through the shared event of authoring the paper. This ensures that critical events such as publications are aligned even when they are not explicitly tied to affiliations.
- Transitions: The movement from MIT to Stanford in 2010 is observed in both graphs, showing a continuity in the academic trajectory. The transition is represented as “J. Doe was affiliated with MIT until joining Stanford”.
- Temporal Path Pruning: EAL prioritizes temporal paths linking “2005–2010 at MIT” to “2010 onwards at Stanford” for alignment, ensuring that only relevant temporal paths are considered.
- Event Reasoning: The model focuses on critical events such as the publication of “Paper A” to strengthen the alignment of “John Doe” with “J. Doe”.
- Adaptive Attention: During inference, temporal paths that do not align (e.g., affiliations outside 2005–2010) are pruned to optimize reasoning efficiency by focusing only on the relevant temporal-event relationships.
Building on these insights, we introduce EAL, a novel framework that leverages a lightweight RNN-based architecture designed to prioritize key temporal-event features that are essential for precise entity alignment. Unlike previous methods that focus primarily on global semantic similarity or structural matching, EAL explicitly captures the temporal and event-centric dependencies between entities. This allows the model to handle the complexities of sparse and heterogeneous graph structures, significantly improving its alignment accuracy in dynamic and event-driven domains.
2. Related Work
The core objective of entity alignment in knowledge graphs is to accurately identify and align semantically equivalent entities across heterogeneous knowledge graphs. This requires capturing structural, semantic, and contextual features while addressing challenges such as data incompleteness, heterogeneous schemes, and noisy data. Existing approaches have made significant strides in improving entity alignment through techniques that leverage embedding learning, rule-based reasoning, and graph neural networks (GNNs).
2.1. Alignments Methods
Over the past decade, entity alignment methods have evolved to better address the inherent complexity of knowledge graph data. These methods can be broadly categorized into three main approaches: embedding-based alignment models, rule-based alignment methods, and structure-based alignment models utilizing GNNs [18].
Embedding-based alignment approaches such as JE [4], MTransE [5], and IPTransE [6] are translation-based methods that focus on learning low-dimensional vector representations for entities and relations. These methods embed entities and relations into continuous vector spaces, optimizing alignment through techniques such as positive and negative sampling. One of the main advantages of embedding-based models is their ability to capture global semantic similarities, which makes them efficient for matching entities based on their general meaning. This approach is scalable and works well in domains where semantic similarity plays a dominant role in entity alignment.
However, embedding-based methods have notable drawbacks. They often fail to account for critical logical dependencies such as temporal and event-based relationships [19,20]. As a result, these methods struggle in scenarios where precise alignment requires reasoning about contextual or temporal relationships between entities. This limitation makes embedding-based methods less effective in complex and dynamic environments where entities need to be aligned based on their temporal or event-centric context.
Rule-based alignment approaches, including Neural Logic Programming [7], Neural Theorem Provers [8], and RNNLogic [9], focus on leveraging logical rules to guide entity alignment. These models explicitly learn logical rules that capture the relationships between entities, offering a higher level of interpretability and alignment precision. The key strength of rule-based reasoning lies in its ability to model and reason about explicit logical dependencies, which can significantly enhance alignment accuracy, particularly when the relationships between entities are governed by clear and predefined rules or logical structures.
For example, approaches such as SEA [10] have demonstrated notable performance in entity alignment tasks by incorporating specific logical rules into their alignment procedures. These methods explicitly model structural dependencies, enabling a more interpretable process for aligning entities across knowledge graphs. SEA in particular uses semi-supervised learning, which helps in aligning entities even when only partial supervision is available. However, while rule-based methods excel at reasoning about logical structures, they are often limited by their reliance on predefined frameworks. This makes them less adaptable to large, dynamic, and evolving knowledge graphs where the relationships may not always be well defined or may require dynamic learning.
Despite their strengths, rule-based models face scalability issues when applied to large-scale knowledge graphs. For example, SEA and IPTransE struggle with graphs where entity relationships are more complex and evolving. This restricts their ability to handle the wide variety of structures found in real-world applications. As such, the general applicability of rule-based approaches is often constrained to scenarios where the underlying graph structures remain relatively stable and where clear logical rules are available for learning.
GNN-based models, such as HGCN [11] and RDGCN [12], utilize Graph Neural Networks (GNNs) to propagate information across graph structures. These models are particularly effective at capturing both topological and semantic features through message-passing mechanisms. By leveraging the rich structural dependencies between entities, GNN-based models are highly suited for global entity alignment tasks, especially when graph connectivity plays a crucial role. Their ability to scale to large and complex graphs makes them effective in handling a wide range of real-world knowledge graph alignment tasks [21,22].
Recent advancements such as GCN-Align [13] and HMEA [14] have improved the efficiency of GNNs by incorporating additional mechanisms that refine the alignment process. For example, GCN-Align has proven effective in cross-lingual knowledge graph alignment by leveraging graph convolutional networks to propagate alignment information across multilingual graphs. Similarly, HMEA integrates multimodal features to capture rich relationships between entities, further improving alignment accuracy in multimodal knowledge graphs. However, while efficient at capturing structural dependencies, these models can sometimes struggle with scenarios where explicit temporal or event-based logical dependencies play a critical role in entity alignment.
To address such limitations, models such as MMEA [15] and EVA [16] have integrated additional modalities such as visual and multimodal information, further enhancing their ability to align entities across different graph structures. For instance, MMEA focuses on the alignment of entities in multimodal knowledge graphs, improving performance in scenarios where simple structural or semantic alignment is insufficient. Similarly, the inclusion of visual features in EVA helps to capture more nuanced relationships between entities that traditional GNN-based models may miss. Despite these advancements, the general reliance on global feature propagation in RNN-based models such as those used in GCN-Align and MMEA can sometimes result in computational inefficiencies. Models such as MultiJAF [17] aim to address this by optimizing the message-passing process; however, these models still require further refinement to balance efficiency with alignment precision.
GNN-based approaches often underutilize logical interrelations, which are critical for aligning entities in complex scenarios involving multi-hop reasoning and contextual dependencies. Inspired by these insights, our proposed framework integrates a logical feature learning mechanism within an RNN-based entity alignment architecture. This mechanism emphasizes capturing and propagating logical dependencies, enhancing the model’s ability to align entities based on relational and contextual reasoning. Furthermore, we incorporate a dynamic pruning strategy to refine message propagation paths, selectively focusing on logical propagation routes that contribute most to alignment accuracy. By combining logical reasoning with structural and semantic embeddings, our approach achieves a significant improvement in both efficiency and interpretability for entity alignment tasks.
In summary, while embedding-based, rule-based, and structure-based methods have all advanced the field of entity alignment, they often lack the ability to fully leverage logical reasoning within graph structures. By addressing this gap, our work provides a novel perspective on the integration of logical feature learning into RNN-based entity alignment, setting a new benchmark for reasoning-driven alignment in heterogeneous knowledge graphs.
2.2. Motivating Example
The limitations of existing entity alignment approaches is crucial for appreciating the novelty of the proposed EAL framework. Many traditional methods, including embedding-based and GNN-based models, fail to effectively capture logical dependencies, particularly in event-driven scenarios. Figure 1 presents an illustrative case that highlights the logical challenges faced by conventional methods. On this basis, we can draw the following conclusions.
2.2.1. Limitations of Existing Methods
Despite notable advances in entity alignment, many existing methods suffer from the following limitations:
- Limited Logical Reasoning: Most embedding-based models focus on semantic similarity and fail to capture critical logical dependencies such as temporal or event-based relationships.
- Inefficient Handling of Sparse Graphs: Many methods struggle with sparse graphs in which entities and relations are not densely connected.
- Lack of Scalability: Existing methods often do not scale well with large knowledge graphs, as they rely on exhaustive pairwise comparisons or inefficient message propagation.
2.2.2. Key Contributions of EAL for Entity Alignment
Entity alignment in knowledge graphs remains a challenging task due to the limitations of existing methods in logical reasoning, handling sparse structures, and scalability. To overcome these challenges, we propose EAL (Entity Alignment with Logical Capturing), a novel framework that integrates logical reasoning into the alignment process. The key innovations of our work are summarized as follows:
- Logic-Enhanced Feature Learning: Unlike conventional embedding-based and GNN-based models that primarily rely on semantic similarity, EAL introduces an RNN-based logical feature learning mechanism to explicitly capture temporal-event dependencies. This enables a deeper understanding of complex entity relationships, resulting in significantly improved alignment accuracy.
- Adaptive Hierarchical Attention for Sparse Graphs: Many existing methods struggle with entity alignment in sparsely connected knowledge graphs. To address this, EAL incorporates a hierarchical logical attention mechanism that dynamically prioritizes informative relationships, ensuring robust performance even in cases of missing or incomplete entity connections.
- Scalable and Efficient Entity Alignment: Traditional GNN-based approaches often suffer from high computational costs due to excessive message passing. EAL overcomes this issue by employing a dynamic path pruning strategy, which selectively propagates only the most relevant logical paths. This reduces computational overhead while maintaining high alignment precision, making the proposed framework scalable for large-scale knowledge graphs.
By systematically integrating logical reasoning, adaptive attention, and efficient path pruning, EAL presents a novel and highly effective approach to entity alignment, outperforming previous methods in terms of both accuracy and scalability.
3. Methodology
Within the domain of knowledge graph (KG) reasoning, entity alignment plays a pivotal role in enabling accurate relational inference. Let represent a knowledge graph, where E and R denote the sets of entities and relations, respectively. Each directed edge in G is represented as a triplet , where represent the head and tail entities and represents the relation between them. In entity alignment tasks, the goal is to map entities across different knowledge graphs and while ensuring semantic consistency and structural integrity.
Problem Definition
For two knowledge graphs and , entity alignment aims to identify a set of aligned entity pairs such that and refer to the same real-world concept. Formally, given a partial set of pre-aligned entity pairs , the task is to learn a mapping function (or vice versa) that maximizes the alignment accuracy [23]:
where the similarity score is often computed based on structural, semantic, and logical features extracted from the respective knowledge graphs.
Entity alignment in knowledge graphs presents several challenges:
Structural Heterogeneity: Knowledge graphs often exhibit differing graph structures, with variations in node degrees, relation types, and edge densities. These differences make direct comparison of entity neighborhoods nontrivial [24].
Semantic Inconsistencies: Entities across knowledge graphs may have overlapping but nonidentical labels or attributes, complicating the alignment process. For instance, one graph may label an entity as “NYC” while another uses “New York City”.
Incomplete and Noisy Data: Real-world knowledge graphs are often incomplete and may contain erroneous information, further hampering the ability to find accurate alignments.
Logical Dependencies: Entities may be related through complex logical paths, (e.g., transitive or hierarchical relationships), that are not explicitly captured in simple embeddings or similarity metrics [25].
3.1. Proposed Framework for Entity Alignment
To address these challenges, we propose an RNN-based framework that leverages logical reasoning and dynamic propagation strategies to effectively align entities. To enhance clarity, we introduce Figure 2, which provides a structured overview of the methodology. This figure outlines the logical feature learning module and entity alignment steps along with their interconnections. By following this structured pipeline, the proposed EAL framework ensures efficient and accurate entity alignment.
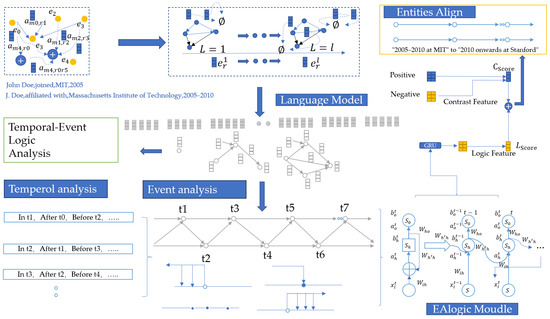
Figure 2.
Main structure of the EAL model, illustrating the integration of the time-event analysis and EAL modules to process logical propagation paths in knowledge graph reasoning.
Figure 2 presents a step-by-step breakdown of our methodology. The main steps include:
- Feature Extraction: Initial processing of knowledge graph entities and relations in order to obtain their representations.
- Logical Feature Learning: Capturing logical dependencies using an RNN-based reasoning mechanism.
- Attention Mechanism: Prioritizing the most relevant logical connections for effective alignment.
- Entity Alignment Optimization: Refining alignment predictions using an iterative learning process.
The framework is parameterized as , where w represents model parameters and denotes the set of propagation paths for feature aggregation.
The logical feature propagation mechanism ensures that the alignment process captures both local and global structural dependencies. Given an entity , the propagation process involves iteratively aggregating features from its neighboring entities and relations. Let represent the feature representation of entity e at layer l and let denote the neighbors of e. In addition, let represent the relation feature between e and its neighbor , and let represent the aggregation function, such as a mean or attention-weighted sum.
The feature propagation process aggregates the neighboring node features while preserving semantic dependencies:
where represents the feature of entity e at layer l and A denotes the aggregation function (e.g., mean or attention-weighted sum).
To clarify the relationship between feature propagation and attention score, we explicitly illustrate how these formulas interact. Feature propagation ensures that information flows through the knowledge graph structure by aggregating features from neighboring nodes. Meanwhile, the attention score mechanism selectively prioritizes the most relevant propagation paths, ensuring that both semantic and structural relevance are preserved. This interaction enables our model to capture entity relationships more effectively while maintaining the graph’s inherent structural integrity.
To ensure that feature propagation does not indiscriminately aggregate information, we introduce an attention score mechanism to prioritize the most informative paths:
where represents the attention weight for a given propagation path, is an activation function, and is a learnable weight matrix for relation features. This attention mechanism ensures that feature propagation captures meaningful relationships rather than propagating noise.
To mitigate computational overhead and focus on relevant paths, we employ a dynamic path pruning strategy. Inspired by adaptive sampling methods, the framework selectively propagates features along high-utility paths identified through attention scores. For a query entity , the pruned propagation set is defined as
where is a threshold determining the minimum attention score for path inclusion. The pruned set reduces the computational complexity by focusing on the most informative paths for entity alignment.
By integrating logical reasoning and dynamic feature propagation, our framework addresses key challenges in entity alignment, ensuring improved semantic consistency and structural alignment across knowledge graphs. This approach not only enhances alignment accuracy but also provides interpretability by emphasizing logical dependencies and high-utility propagation paths.
3.2. RNN-Based Logical Path Capture and Attention for Entity Alignment
The RNN-based Logical Path Capture and Attention module enhances the capabilities of entity alignment by integrating Recurrent Neural Networks (RNNs) with a temporal and event-driven logic attention mechanism. This approach prioritizes temporal and structural relationships between entities, ensuring that logical paths that are semantically relevant to the query are emphasized. The RNN-based message passing process in this module is defined as folows:
where is the feature representation for node i after applying the RNN-based propagation mechanism, R denotes the set of relations, and represents the set of neighboring nodes connected to node i via message . The function aggregates node and relation features from the previous layer to refine the message representation, and represents the learned attention weight for each relation path.
The attention weight is computed as follows:
where represents the message feature, is the relation representation, and is the entity feature. Because these components belong to different vector spaces, we apply layer normalization prior to summation to ensure scale compatibility.
In our model, we sum heterogeneous concepts such as message features and entity representations within the attention mechanism in order to generate a unified attention score. The rationale for this summation lies in the need to integrate both local context (message features) and individual entity characteristics (entity representations) for effective alignment. Although these components represent different types of information, they are normalized before summation to ensure compatibility and to prevent any one term from dominating the computation. Specifically, we apply layer normalization to each component to ensure that they have similar scales and contribute meaningfully to the final attention weight. By combining these features, the model is able to capture a richer and more holistic representation of the entity’s context, thereby improving the alignment process.
3.2.1. Logical Path Capture and Encoding with EAL
In the RNN-based Logical Path Capture Mechanism, temporal-event dependencies between nodes in the knowledge graph are learned through recurrent propagation. This mechanism iteratively processes temporal and structural relationships by utilizing RNNs to model dynamic logical paths. The process consists of three key stages: path initialization, logical path capture, and multi-hop logical fusion.
Path Initialization
Logical paths are initialized based on the query’s entities and relations. Given a query entity and target relation , the initialization step identifies candidate paths connecting to its neighboring entities . Each initial path is represented as , where . The embedding for each path is computed as
where ⊙ represents element-wise multiplication, is a learned relation transformation matrix, and are the embeddings of the query entity and its neighbor, respectively.
Logical Path Capture with RNN
The RNN model is employed to dynamically capture significant logical relationships between entities. To determine the relevance of each path, the model assigns attention scores to paths based on their similarity to the query embedding. This is expressed as
where denotes the attention score for path computed by using a softmax function over all neighboring paths. The RNN process recursively updates the path representations by incorporating temporal-event logic, allowing the model to focus on paths that are logically relevant for entity alignment.
3.2.2. RNN-Logics for Temporal-Event Reasoning in EAL
To address the limitations of traditional methods that rely primarily on general feature extraction, we introduce the RNN-Logic Paradigm within the EAL framework, which explicitly incorporates temporal-event reasoning. Leveraging the RNN architecture, we model logical dependencies between entities and their interactions over time, capturing both local and global interactions for precise alignment.
Temporal Logic Discovery
EAL introduces specialized temporal and event-centric logic operators that are integrated into the RNN architecture to handle the evolution of relationships and events across time. These operators allow for reasoning about continuity, transitions, and future predictions. They are encoded and dynamically processed by the RNN to capture entity dependencies.
- Always Operator (□): The Always operator ensures the persistence of a condition over time, represented asThis operator ensures that the model retains a consistent state for logical conditions across all future temporal entities. For instance, in a health KG, it could capture the persistence of a chronic disease state across time periods.
- Until Operator (U): The Until operator models transitions in logical states, and is defined asThis operator models transitions in conditions, such as when a machine remains in an “operational” state until a “maintenance” event is triggered in a manufacturing KG.
- Eventually Operator (♢): The Eventually operator ensures that a condition holds at some point in the future, as expressed byThis supports reasoning about future occurrences of conditions, such as predicting future events in a social network KG.
Dynamic Logical Feature Encoding
In the RNN-Logic framework, these temporal operators are embedded into an adaptive RNN attention mechanism. The features for each node are dynamically updated by aggregating neighbor information and attention weights, as follows:
where represents the attention score for path computed based on the relevance of temporal-event relationships. This mechanism enables the model to capture critical logical structures, improving the model’s interpretability and alignment precision.
Hierarchical Feature Propagation with RNN
To further enhance feature integration, the RNN-based framework employs hierarchical feature aggregation. This aggregation allows for the combination of temporal-event information with semantic patterns across multiple layers of the RNN network. For a node i at layer l, the updated feature representation is provided by
where and are trainable parameters and is a nonlinear activation function such as ReLU. This process allows the RNN model to capture long-range dependencies across temporal-event relationships.
Logical Triple Scoring with EAL
To evaluate the plausibility of the inferred triples , we introduce a scoring function that integrates RNN-based logical path information with relational context:
where ∘ denotes element-wise multiplication, is the scoring weight matrix, and is the logical score based on accumulated logical paths. This scoring mechanism enables the model to rank and select the most plausible triples, offering both high alignment performance and insights into the underlying reasoning process.
The core strength of EAL lies in its logical feature learning mechanism, where temporal-event relationships are treated as fundamental logical paradigms. In contrast to traditional models that rely predominantly on general feature extraction, EAL focuses on the logical learning of these critical temporal-event dependencies. By explicitly modeling these key logical structures, EAL captures the interdependencies between entities in a way that global semantic or structural similarity-based methods cannot. This ability to learn logical features ensures that the model can identify and prioritize relevant temporal-event relationships that are vital for accurate alignment.
Logical learning in EAL plays a pivotal role in distinguishing between critical and irrelevant information, allowing the model to focus on the essential paths that truly influence the alignment process. This is especially crucial in environments where entities’ relationships are governed by events or temporal transitions rather than just their structural proximity.
A significant advantage of EAL is its ability to selectively capture essential logical features from complex graph structures. While many existing entity alignment models primarily rely on embedding-based methods or shallow feature extraction, EAL’s focus on logical learning allows it to achieve higher alignment accuracy. This is because the model is able to explicitly capture and reason about the temporal-event relationships that many traditional models overlook. Specifically, learning time-event relationships allows the model to form a more nuanced understanding of entity interrelations, further improving the alignment precision.
Through its integration of these mechanisms, EAL offers a more focused, efficient, and precise approach to knowledge graph entity alignment by its emphasis on learning temporal-event logical features. Experimental results validate that EAL outperforms traditional models in both alignment accuracy and computational efficiency, demonstrating the significant benefits of integrating logical paradigms into entity alignment tasks.
4. Experimental Results and Analysis
4.1. Datasets Overview
To comprehensively evaluate the effectiveness of the proposed EAL framework, we conducted experiments on widely adopted datasets that provide diverse and challenging knowledge graph structures. The FB15K-DB15K and FB15K-YAGO15K datasets represent complex real-world entity relationships, offering an ideal testbed for analyzing the model’s ability to capture and utilize logical patterns for entity alignment tasks.
4.1.1. FB15K-DB15K
This dataset is derived from the integration of Freebase and DBpedia, and consists of entities and relations that span overlapping knowledge domains. Its intricate structural dependencies challenge the model’s capacity for accurate entity alignment in heterogeneous graphs.
4.1.2. FB15K-YAGO15K
Combining Freebase with YAGO, this dataset emphasizes scalability and alignment precision in scenarios involving large-scale entity mappings. This dataset includes a broad array of semantic and temporal relations, making it a suitable benchmark for evaluating logical reasoning capabilities.
4.2. Experimental Setup
To ensure the reproducibility of our experiments, we provide a detailed description of the experimental setup, including hyperparameter settings and optimization strategies.
4.2.1. Hyperparameter Settings
The following hyperparameters were used during model training:
- Learning Rate: We use an initial learning rate of , with exponential decay applied after every 10,000 steps to prevent overfitting and ensure convergence.
- Batch Size: The model was trained using a batch size of 32 for better memory utilization and training efficiency.
- Embedding Dimension: The entity and relation embeddings were set to a dimension of 100 to capture sufficient semantic information without introducing excessive model complexity.
- Number of Epochs: The model was trained for 50 epochs, with early stopping applied to prevent overfitting if the validation performance plateaued.
- Optimization Strategy: The model was trained with the Adam optimizer.
These hyperparameters were chosen based on empirical results and prior research. The learning rate of has been shown to provide a good balance between convergence speed and stability, while the batch size of 32 helps to prevent memory overflow in large graphs. The Adam optimizer with the chosen hyperparameters ensures efficient learning, particularly in sparse graphs, and the weight decay parameter helps regularize the model to prevent overfitting.
We employ the Adam optimizer due to its efficiency in handling sparse gradients and its ability to dynamically adapt learning rates for different parameters. Given that entity alignment tasks often involve high-dimensional knowledge graph embeddings, traditional stochastic gradient descent (SGD) may struggle with slow convergence and inconsistent updates. Adam’s adaptive moment estimation helps to stabilize learning by adjusting step sizes based on first-order and second-order moments of past gradients, leading to faster and more stable convergence.
The EAL model is specifically designed to prioritize logical reasoning pathways, leveraging a hierarchical logical feature aggregation strategy and adaptive logical attention. The key experimental configurations are provided below.
The training and evaluation processes were conducted on a high-performance computing platform equipped with an NVIDIA RTX3090 GPU, enabling efficient handling of large-scale datasets.
Table 1 presents the comparative performance of EAL against several baseline models, including traditional translational embeddings (TransE) and GNN-based approaches (GCN-Align, SEA, etc.). The evaluation metrics include Hits@1, Hits@3, Hits@10, and Mean Reciprocal Rank (MRR), which collectively measure alignment precision and ranking quality.

Table 1.
Performance comparison on the FB15K-DB15K and FB15K-YAGO15K datasets. Bold indicates the highest precision, and underline indicates the second-highest precision.
4.2.2. Evaluation Metrics
To assess the effectiveness of our proposed entity alignment approach, we employ the following widely used evaluation metrics:
- Hits@K: This metric measures the proportion of correctly aligned entities ranked within the top-K predictions. A higher Hits@K score indicates better retrieval performance. We report Hits@1, Hits@5, and Hits@10 to evaluate the alignment accuracy across different ranking thresholds.
- Mean Reciprocal Rank (MRR): This metric evaluates the ranking quality of the correct entity by computing the average of the reciprocal ranks of the correct matches. Given a set of queries, MRR is defined aswhere N is the total number of test instances and represents the position of the correct entity in the ranked list. Higher MRR values indicate better ranking performance.
4.2.3. Baseline Comparisons
EAL’s performance was compared against a wide array of existing approaches:
- IPTransE [6]: IPTransE is an iterative extension of traditional translational embedding models like TransE.
- SEA [10]: A semantic-enhanced alignment framework that integrates additional linguistic features to improve alignment performance. It uses semi-supervised learning to better handle incomplete or noisy data.
- GCN-Align [13]: A graph convolutional network-based model that leverages structural information from knowledge graphs. GCN-Align combines both structural and semantic features of the graph for improved entity alignment.
- PoE-Ini [18]: A multimodal entity alignment model that incorporates visual and textual data sources, with an emphasis on aligning multimodal knowledge graphs. This method combines different knowledge sources for enhanced alignment performance.
- HMEA [14]: A multimodal entity alignment approach that explores various types of data, such as textual and visual, in order to enhance alignment accuracy. HMEA focuses on handling multimodal information to improve the alignment results in complex knowledge graphs.
- MMEA [15]: Multimodal entity alignment that combines multiple sources of knowledge (such as text, image, and structured data) to improve the accuracy of entity matching across different graphs. This method achieves a high level of alignment by fusing multimodal information.
- EVA [16]: A method focused on visual alignment, particularly for tasks where the visual properties of entities play a crucial role in aligning knowledge graphs. EVA uses visual features to complement traditional alignment techniques.
- MultiJAF [17]: A multimodal joint alignment framework that combines different types of data sources and structures to improve the accuracy of entity alignment across diverse knowledge graphs. It emphasizes a joint attention mechanism to optimize alignment precision.
The summarized results in Table 1 illustrate that EAL achieves superior performance across all key metrics, including Hits@1, Hits@5, Hits@10, and Mean Reciprocal Rank (MRR).
4.3. Experimental Results and Analysis
To rigorously validate the efficacy of EAL, we conducted experiments across the FB15K-DB15K and FB15K-YAGO15K benchmark datasets. These datasets present unique challenges in terms of scale, heterogeneity, and semantic complexity, making them suitable for evaluating both the precision and generalization capabilities of EAL.
4.3.1. Superior Accuracy on FB15K-DB15K
EAL achieves state-of-the-art performance, significantly surpassing previous models such as MMEA and MultiJAF. Notably, it records a Hits@1 score of 0.491 and an MRR of 0.532, indicating the model’s robust ability to prioritize logical pathways and ensure accurate predictions in complex alignment tasks.
4.3.2. Scalability and Effectiveness on FB15K-YAGO15K
The results on FB15K-YAGO15K (a larger dataset than FB15K-DB15K) highlight EAL’s scalability and adaptability on large-scale knowledge graphs. With a Hits@10 score of 0.748 and MRR of 0.560, EAL outperforms all competing approaches, demonstrating its ability to capture intricate entity relationships while maintaining computational efficiency.
In terms of generalization across relational diversity, EAL consistently outperforms baseline methods across datasets with varying structural properties. This indicates its robustness and adaptability to diverse knowledge graph topologies, including those with sparse or highly interconnected relational structures.
4.3.3. Computational Efficiency Analysis
To further assess the efficiency of our proposed EAL framework, we conducted additional experiments comparing its computational cost against several baseline models. Specifically, we evaluated peak GPU memory usage during model training and inference.
Table 2 presents the comparative analysis of memory usage across different models. Our proposed EAL framework achieves the lowest computational cost, reducing memory consumption by 19%. These improvements can be attributed to our efficient logical feature learning module as well as to the adaptive attention mechanism, which selectively propagates features without unnecessary redundancy.
Table 2.
Comparison and memory usage (GB) on FB15K-DB15K.
This scalability advantage demonstrates that EAL is well suited for large-scale entity alignment tasks, making it both computationally efficient and effective.
4.4. Ablation Study
To evaluate the contribution of the different components in our model, we conducted an ablation study by systematically removing key modules and varying the hyperparameters. The results demonstrate how each component influences model performance.
4.4.1. Impact of Model Components
We analyzed the effect of removing each major module from our model:
- Without Logical Feature Learning (w/o LFL): The logical feature learning module is removed, leaving only structural and semantic features.
- Without Attention Mechanism (w/o Att): The attention mechanism is disabled, treating all paths equally in feature propagation.
4.4.2. Hyperparameter Sensitivity
We further investigated the impact of key hyperparameters onmodel performance:
- Embedding Dimension: The embedding size of 300 was varied to observe its effect on alignment accuracy.
- Learning Rate: We tested learning rates of {0.0001, 0.001, 0.01} to assess training stability.
Table 3 shows the performance drop when removing different components. The logical feature learning module (w/o LFL) has the most significant impact, demonstrating its importance in capturing logical dependencies. The attention mechanism (w/o Att) also contributes significantly to improving entity alignment accuracy.
Table 3.
Ablation study results on the FB15K-DB15K dataset.
Overall, the ablation study validates the effectiveness of each component, reinforcing our model’s design choices.
4.5. Results of Entity Alignment with Complex-Event Logic
As shown in Figure 3, the results of entity alignment with complex-event logic demonstrate the effectiveness of our method. Methods (1), (2), and (3) are shown in the figure, and methods (4) and (5) are additional examples.
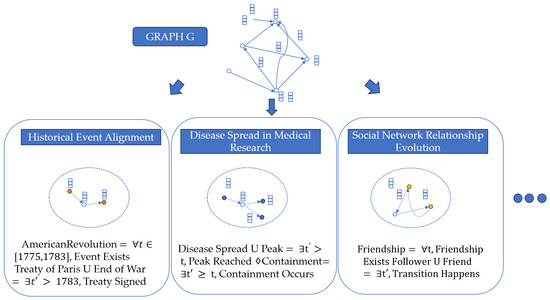
Figure 3.
Results of entity alignment with complex-event logic.
1. Historical Event Alignment
In historical knowledge graphs, events such as “American Revolution” can be represented with different time labels in different databases. Temporal-event logic ensures consistency across these graphs.
The □ operator is used to ensure the persistence of the event during its time span (e.g., from 1775 to 1783) and the U (Until) operator to model the event’s relationship with other events, such as the signing of the Treaty of Paris in 1783, as shown below.
2. Disease Spread in Medical Research
In medical graphs, the spread of a disease is modeled across different time intervals, which might vary across datasets. Temporal logic helps to ensure accurate alignment of disease spread events.
We use U to model disease spread until it reaches a peak or containment and ♢ (Eventually) to predict the eventual containment or eradication of the disease, as shown below.
3. Social Network Relationship Evolution
In social networks, user relationships (e.g., friends or followers) evolve over time. Temporal-event logic can align entities by modeling the evolution of these relationships.
We use □ to represent continuous friendship over time and U to capture the transition from one type of relationship to another, such as from “follower” to “friend”, as shown below.
4. Scientific Research Citation Graph Alignment
In citation-based knowledge graphs, papers are linked through citations over time. Temporal-event logic is used to model the citation patterns across different datasets.
We use □ to indicate that a foundational paper continues to be cited over time and ♢ to model the eventual citation of a paper in the future, as shown below.
5. Event-Driven Financial Data Alignment
In financial graphs, market events such as stock crashes or market recoveries occur over time. Temporal-event logic can ensure that entities and events related to the market are consistently aligned.
We use U to model market recovery after a crash and ♢ to predict the eventual recovery after a financial downturn, as shown below.
4.6. Error Analysis
Despite its strengths, EAL exhibits limitations in aligning entities with ambiguous labels or those lacking sufficient contextual information. For example,
- entities with generic labels, such as “National Park”, are occasionally misaligned due to insufficient distinguishing features.
- In sparse knowledge graphs, the absence of strong logical dependencies impacts the performance of temporal operators.
Addressing these challenges will involve exploring enhanced pretraining strategies, incorporation of external contextual embeddings, and integration of domain-specific ontologies to enrich the logical representation space.
The experimental findings underscore the following advantages of EAL:
- Logical Feature Prioritization: By embedding logical operators and leveraging adaptive attention, EAL effectively captures both temporal and event-centric dependencies, which are often overlooked by traditional methods.
- Generalizability Across Graph Structures: The model exhibits consistent performance across datasets with varying levels of complexity, indicating its robustness and versatility in handling diverse knowledge graph scenarios.
- Enhanced Hierarchical Reasoning: EAL’s hierarchical feature aggregation mechanism enables it to integrate local and global relational patterns, providing a more comprehensive understanding of entity alignments.
EAL represents a significant leap forward in knowledge graph entity alignment, offering unparalleled accuracy and efficiency through its logical paradigm learning framework. Future research could focus on extending this approach to dynamic and continuously evolving knowledge graphs, further solidifying its utility in real-world applications.
5. Conclusions and Future Work
This study presents EAL, a novel framework for enhancing knowledge graph reasoning through the extraction and utilization of logical message structures. Central to EAL is the Logical Message Attention Mechanism, which employs progressive propagation to dynamically prioritize salient logical paths, enabling nuanced understanding of entity relationships in large and complex knowledge graphs. By integrating a strategic sampling scheme for path pruning, the model achieves an efficient balance between computational overhead and reasoning quality, offering a refined methodology for tasks requiring precise entity alignment. Experimental results across multiple benchmark datasets demonstrate EAL’s superior performance in both accuracy and computational efficiency, affirming its potential to address critical challenges in knowledge graph reasoning.
While our proposed EAL framework provides significant improvements in entity alignment, several avenues for future research remain. In particular, we propose the following specific and actionable research directions:
- Scalability Improvements: Although EAL shows good performance on existing benchmarks, its scalability can be further enhanced to handle extremely large knowledge graphs. Future work could focus on optimizing the feature propagation and attention mechanisms to ensure efficient alignment in highly sparse and large-scale graphs.
- Exploration of Additional Logical Reasoning Techniques: Our current approach primarily focuses on temporal and event-centric logical dependencies. Further research could explore other logical reasoning techniques, such as causal reasoning or spatial relationships, to help improve alignment accuracy in more complex scenarios.
- Extension to Temporal Reasoning: One promising direction is to extend the EAL framework to handle explicit temporal reasoning, thereby enabling it to effectively model dynamic knowledge graphs where entities evolve over time. This could be particularly useful in domains such as healthcare, finance, and social networks.
- Integration with Multimodal Knowledge Graphs: Another interesting direction is to extend EAL to multimodal knowledge graphs, where entities and relations are described using different data types such as text, images, and sensor data. Incorporating multimodal reasoning could significantly enhance the alignment of heterogeneous knowledge sources.
These directions align with the increasing complexity of real-world knowledge graphs, which often require reasoning over not just structural and semantic relationships but also temporal and multimodal data. By extending EAL to address these challenges, we aim to make the framework more versatile and applicable to a broader range of applications, including predictive modeling, multi-source data integration, and real-time entity alignment.
Author Contributions
Y.Z.: Writing—original draft, software, methodology, conceptualization. X.H.: Writing—review and editing, supervision, formal analysis. X.W.: Validation, software. J.L.: Writing—review and editing, formal analysis. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 12171073.
Data Availability Statement
The data used in this study are publicly available.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Xia, Y.; Lan, M.; Luo, J.; Chen, X.; Zhou, G. Iterative rule-guided reasoning over sparse knowledge graphs with deep reinforcement learning. Inf. Process. Manag. 2022, 59, 103040. [Google Scholar] [CrossRef]
- Anelli, V.W.; Di Noia, T.; Di Sciascio, E.; Ferrara, A.; Mancino, A.C.M. Sparse feature factorization for recommender systems with knowledge graphs. In Proceedings of the Proceedings of the 15th ACM Conference on Recommender Systems, Amsterdam, The Netherlands, 27 September–1 October 2021; pp. 154–165. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the NIPS’13: 27th International Conference on Neural Information Processing Systems, Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; Volume 26. [Google Scholar]
- Hao, Y.; Zhang, Y.; He, S.; Liu, K.; Zhao, J. A Joint Embedding Method for Entity Alignment of Knowledge Bases. In Knowledge Graph and Semantic Computing: Semantic, Knowledge, and Linked Big Data; Chen, H., Ji, H., Sun, L., Wang, H., Qian, T., Ruan, T., Eds.; Springer: Singapore, 2016; p. 314. [Google Scholar]
- Chen, M.; Tian, Y.; Yang, M.; Zaniolo, C. Multilingual Knowledge Graph Embeddings for Cross-lingual Knowledge Alignment. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; AAAI Press: Washington, DC, USA, 2017; pp. 1511–1517. [Google Scholar]
- Zhu, H.; Xie, R.; Liu, Z.; Sun, M. Iterative Entity Alignment via Joint Knowledge Embeddings. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, Melbourne, Australia, 19–25 August 2017; pp. 4258–4264. [Google Scholar] [CrossRef]
- Qu, M.; Tang, J. Probabilistic logic neural networks for reasoning. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Sen, P.; de Carvalho, B.W.; Riegel, R.; Gray, A. Neuro-symbolic inductive logic programming with logical neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Pomona, CA, USA, 24–28 October 2022; Volume 36, pp. 8212–8219. [Google Scholar]
- Qu, M.; Chen, J.; Xhonneux, L.P.; Bengio, Y.; Tang, J. RNNLogic: Learning Logic Rules for Reasoning on Knowledge Graphs. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Pei, S.; Yu, L.; Hoehndorf, R.; Zhang, X. Semi-supervised Entity Alignment via Knowledge Graph Embedding with Awareness of Degree Difference. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3130–3136. [Google Scholar]
- Wu, Y.; Liu, X.; Feng, Y.; Wang, Z.; Zhao, D. Jointly Learning Entity and Relation Representations for Entity Alignment. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 240–249. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, X.; Feng, Y.; Wang, Z.; Yan, R.; Zhao, D. Relation-aware Entity Alignment for Heterogeneous Knowledge Graphs. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19), Macao, China, 10–16 August 2019; pp. 5278–5284. [Google Scholar]
- Wang, Z.; Lv, Q.; Lan, X.; Zhang, Y. Cross-lingual Knowledge Graph Alignment via Graph Convolutional Networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 349–357. [Google Scholar] [CrossRef]
- Guo, H.; Tang, J.; Zeng, W.; Zhao, X.; Liu, L. Multi-modal Entity Alignment in Hyperbolic Space. Neurocomputing 2021, 461, 598–607. [Google Scholar] [CrossRef]
- Chen, L.; Li, Z.; Wang, Y.; Xu, T.; Wang, Z.; Chen, E. Mmea: Entity Alignment for Multi-modal Knowledge Graph. In Knowledge Science, Engineering and Management; Li, G., Shen, H., Yuan, Y., Wang, X., Liu, H., Zhao, X., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 134–147. [Google Scholar]
- Liu, F.; Chen, M.; Roth, D.; Collier, N. Visual Pivoting for (Unsupervised) Entity Alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Cheng, B.; Zhu, J.; Guo, M. MultiJAF: Multi-modal joint entity alignment framework for multi-modal knowledge graph. Neurocomputing 2022, 500, 581–591. [Google Scholar] [CrossRef]
- Liu, Y.; Li, H.; Garcia-Duran, A.; Niepert, M.; Onoro-Rubio, D.; Rosenblum, D. Mmkg: Multi-modal Knowledge Graphs. In The Semantic Web; Hitzler, P., Fernández, M., Janowicz, K., Zaveri, A., Gray, A., Lopez, V., Haller, A., Hammar, K., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 459–474. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Talukdar, P. Composition-based Multi-Relational Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Li, Z.; Huang, W.; Gong, X.; Luo, X.; Xiao, K.; Deng, H.; Zhang, M.; Zhang, Y. Decoupled semantic graph neural network for knowledge graph embedding. Neurocomputing 2025, 611, 128614. [Google Scholar] [CrossRef]
- Zhao, X.; Zeng, W.; Tang, J.; Wang, W.; Suchanek, F.M. An experimental study of state-of-the-art entity alignment approaches. IEEE Trans. Knowl. Data Eng. 2020, 34, 2610–2625. [Google Scholar] [CrossRef]
- Ge, C.; Liu, X.; Chen, L.; Zheng, B.; Gao, Y. Make it easy: An effective end-to-end entity alignment framework. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 777–786. [Google Scholar]
- Zeng, W.; Zhao, X.; Tang, J.; Li, X.; Luo, M.; Zheng, Q. Towards entity alignment in the open world: An unsupervised approach. In Proceedings of the Database Systems for Advanced Applications: 26th International Conference, DASFAA 2021, Taipei, Taiwan, 11–14 April 2021; Proceedings, Part I 26. Springer: Cham, Switzerland, 2021; pp. 272–289. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).