


Recent Developments in Image-Based 3D Reconstruction Using Deep Learning: Methodologies and Applications

 ,
,  ,
,  ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Methods
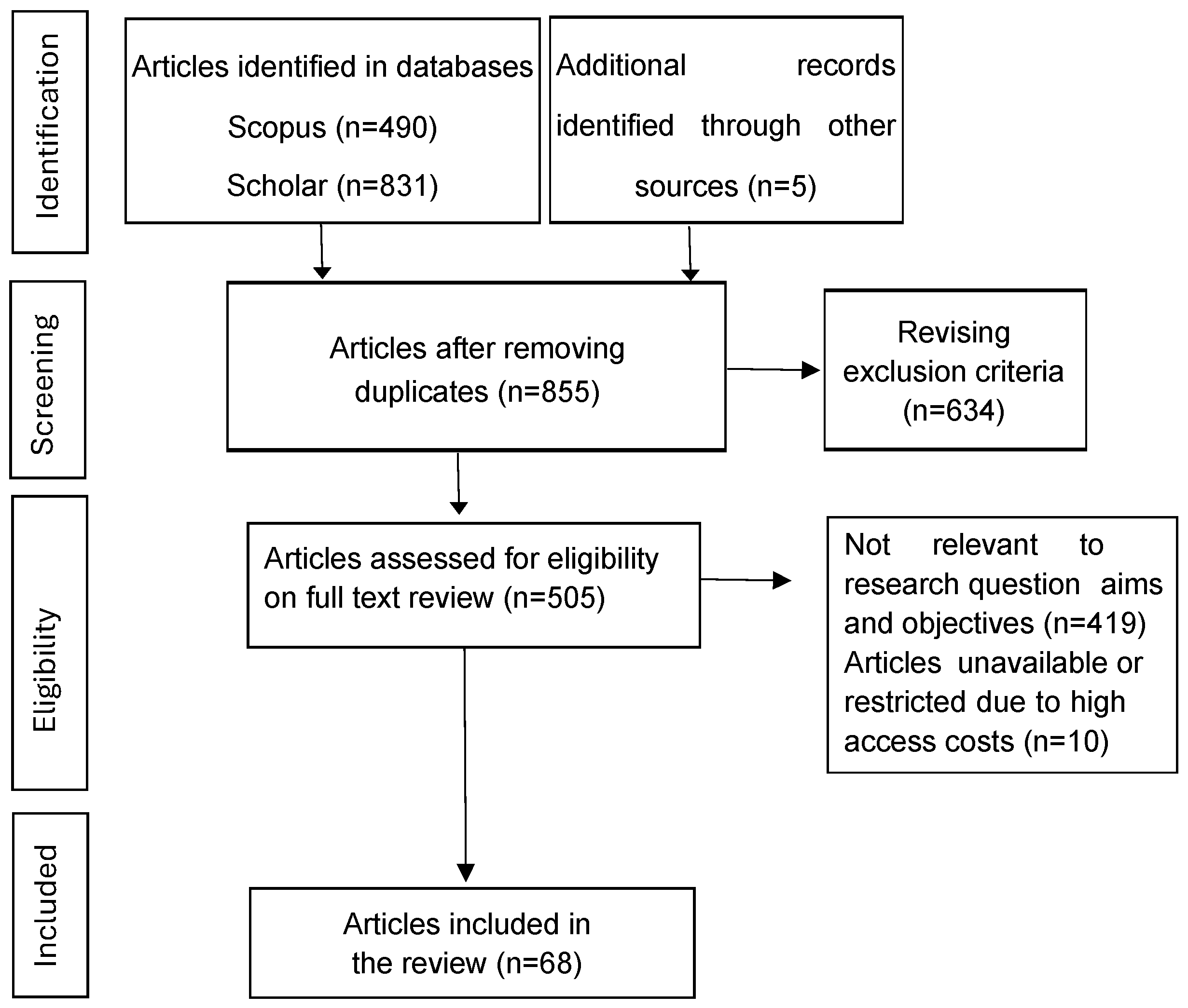
2.1. Data Selection
- Inclusion criteria:
- Articles that apply deep learning models for 3D reconstruction, depth estimation, or structure-from-motion tasks;
- Articles that use images or video frames (from monocular, stereo, catadioptric, omnidirectional, or drone-based cameras);
- Articles that aim to reconstruct or estimate 3D geometry, depth maps, disparity maps, or point clouds;
- Only peer-reviewed conference papers and journal articles;
- Articles written in English;
- Articles published from 2019 to 2025.
- Exclusion criteria:
- Articles not available in English, as this language is required to ensure understanding of the content and proper analysis;
- Articles published before 2019 will focus on recent advancements and relevance;
- Documents other than peer-reviewed journal articles, including theses, conference proceedings, and reports, are maintained to maintain a consistent level of academic rigor;
- Articles behind a high-cost paywall to ensure that all selected studies were readily accessible for a comprehensive review.
2.2. Data Extraction
3. Results
3.1. Evaluation Metrics
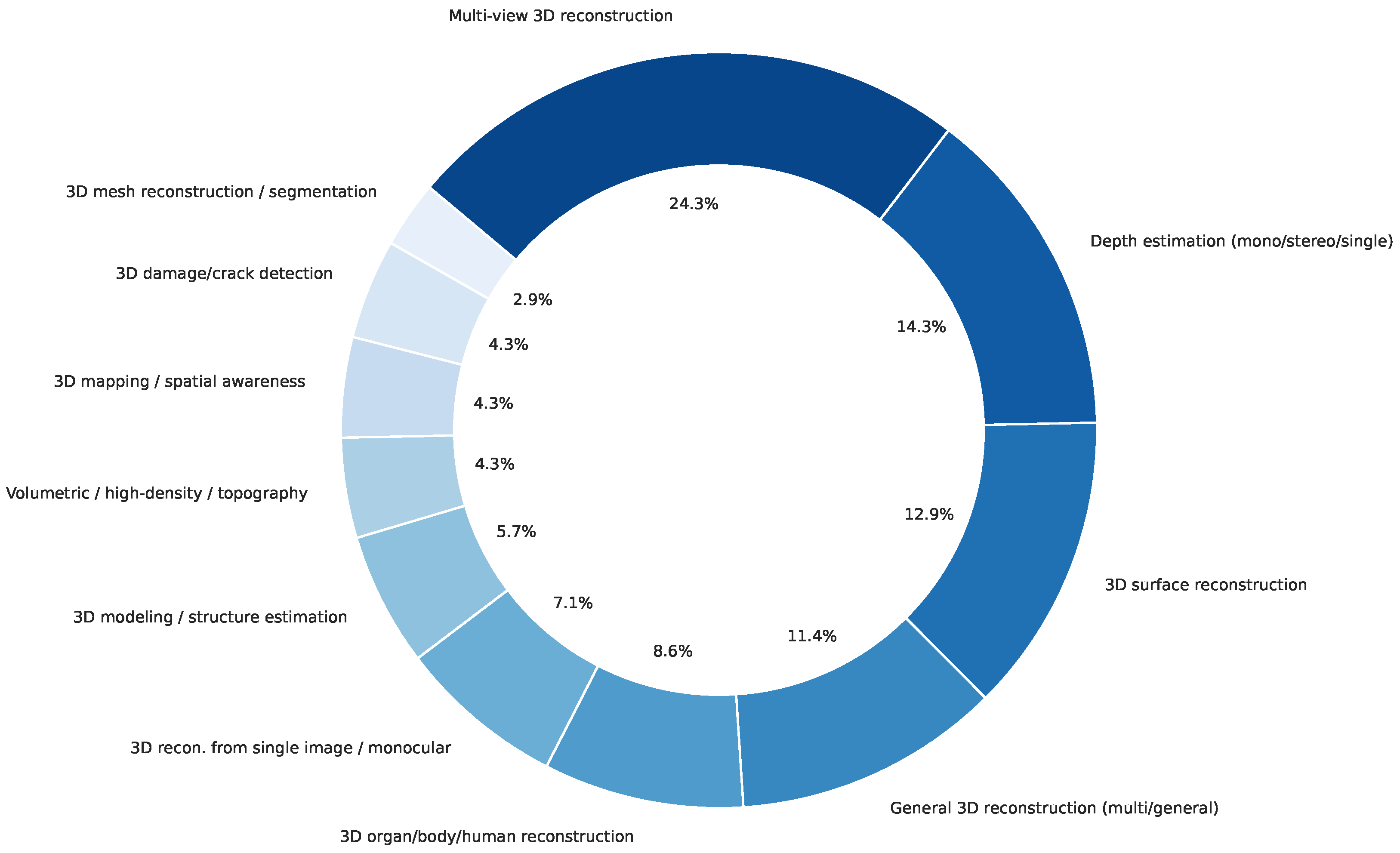
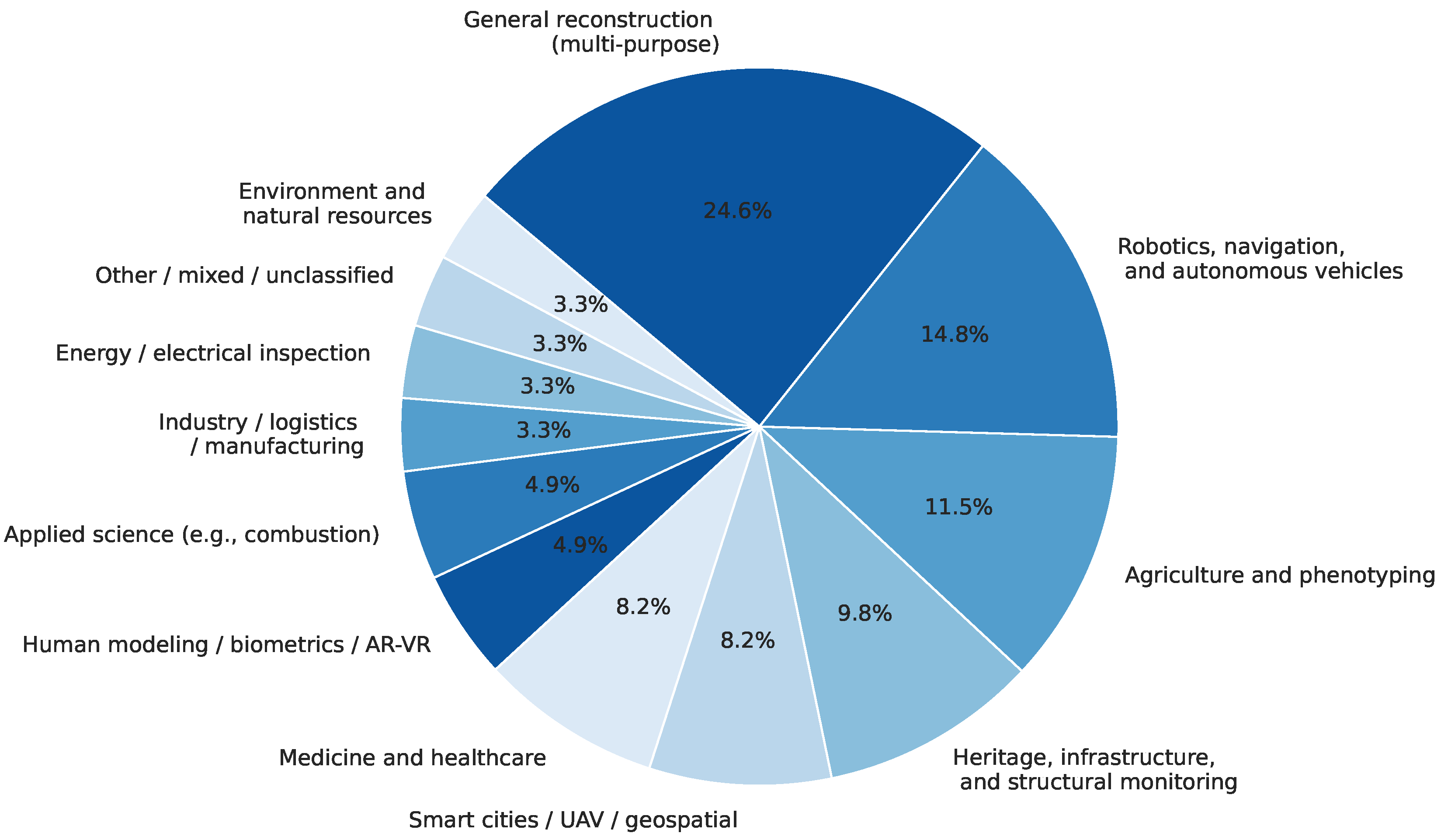
3.2. Emerging Research and Topical Landscape
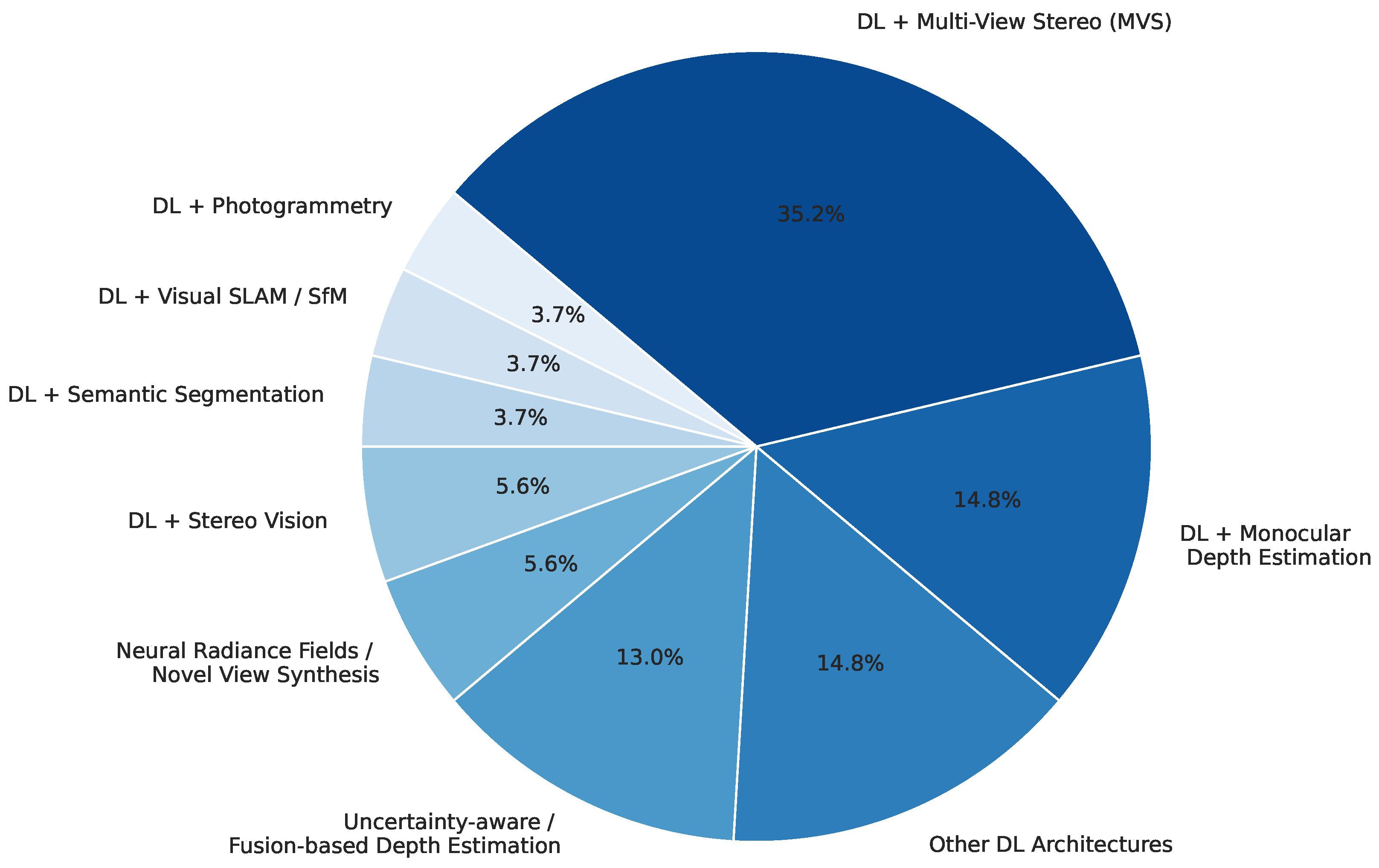
3.3. Network Architectures Employed
3.4. Cameras or Sensor Types
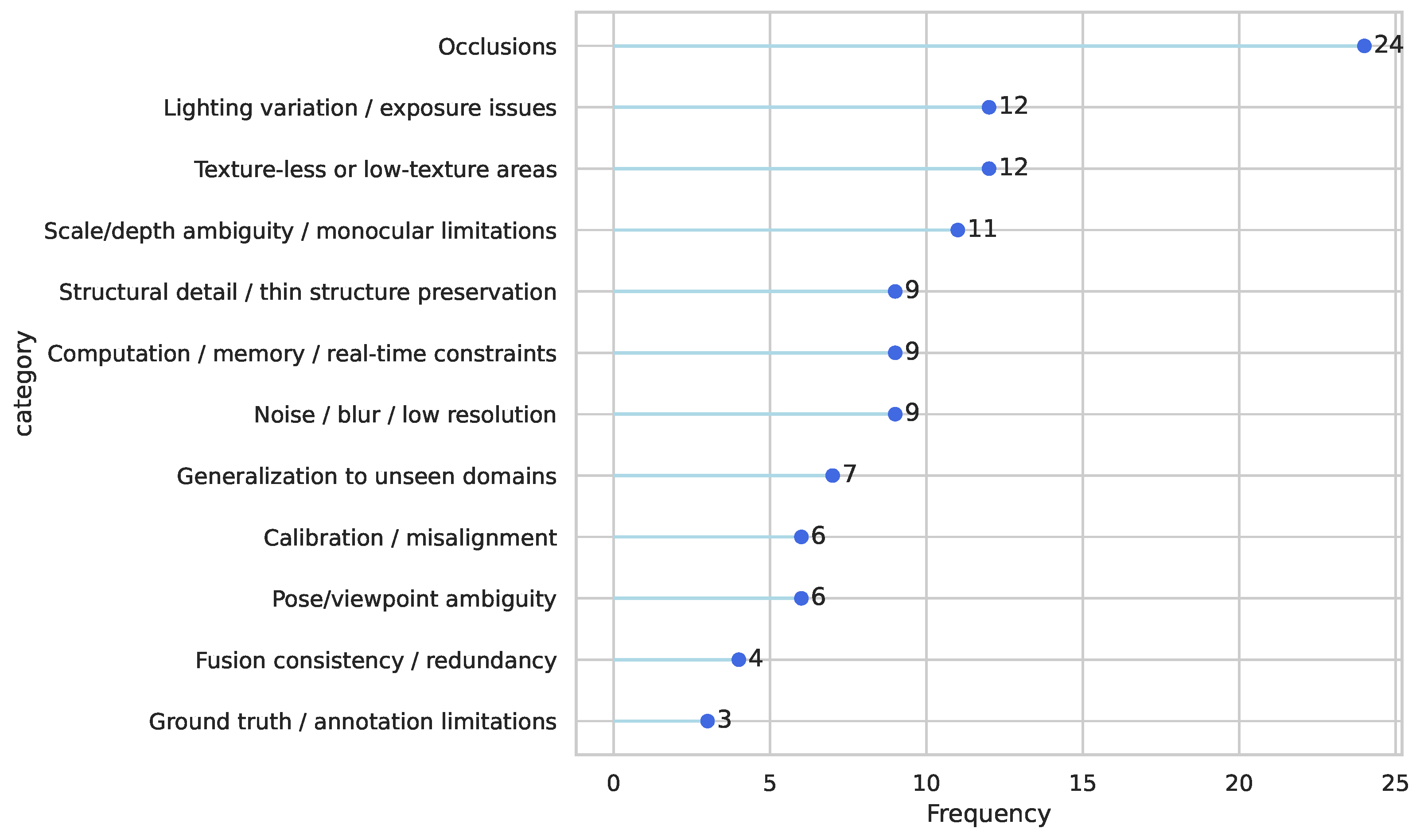
3.5. Principal Challenges
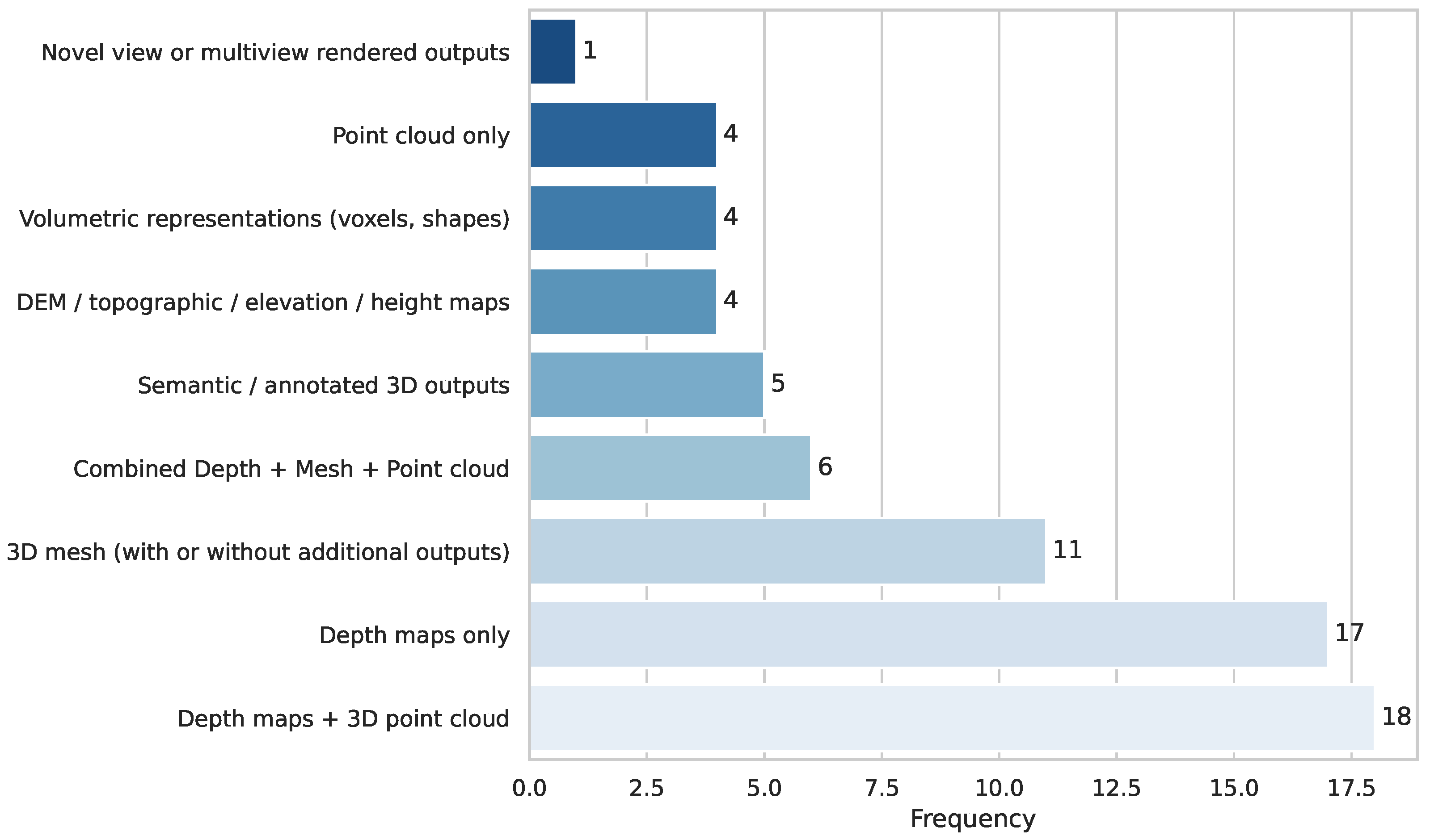
3.6. Output Formats in 3D Reconstruction Studies
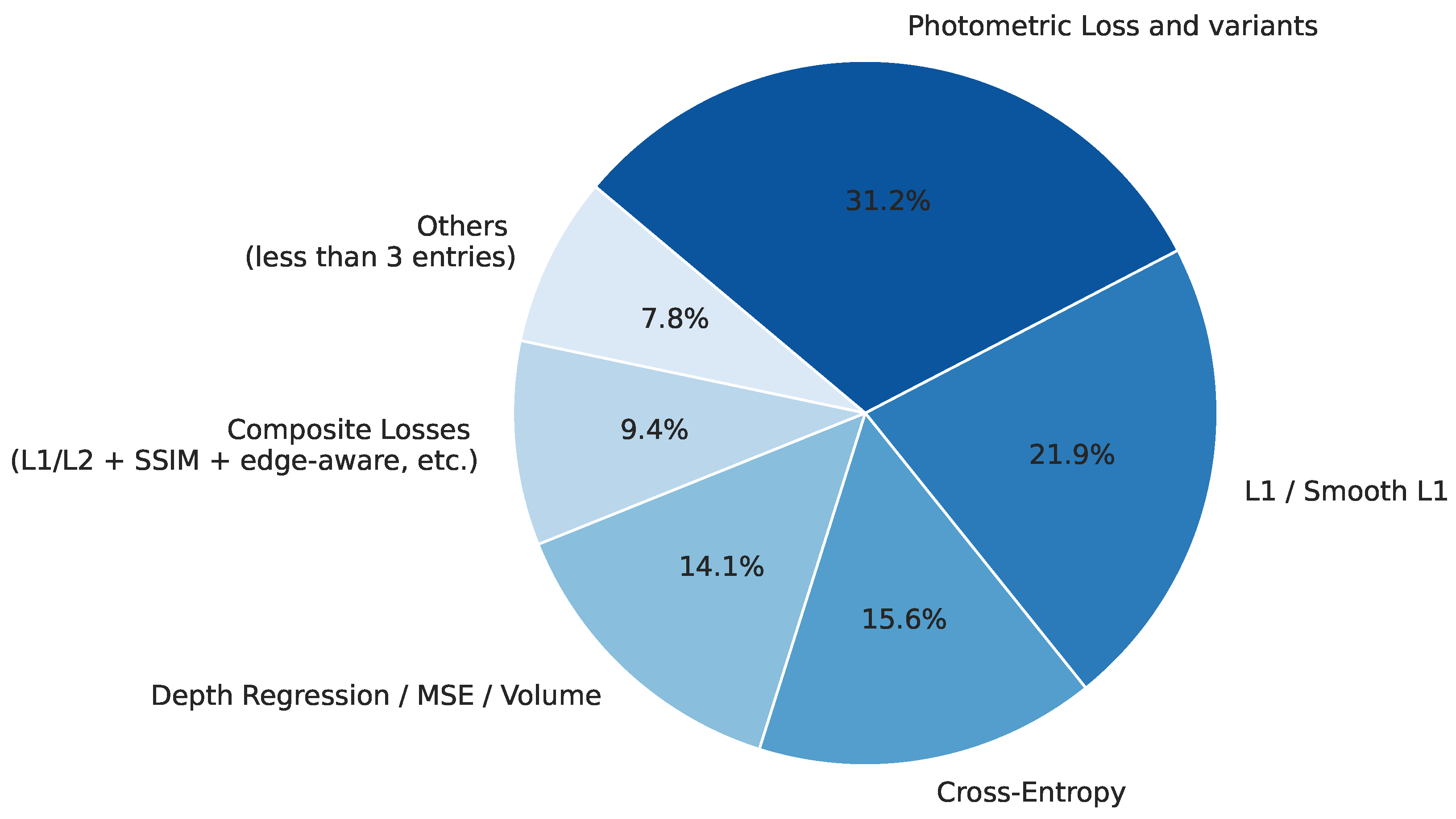
3.7. Loss Functions
3.8. Methods Observed
3.9. Geometric Model
3.10. Distribution of Dataset Sources
3.11. Performance Trade-Offs
4. Discussion and Conclusions
4.1. Core Contributionsand Performance Highlights
4.2. Methodological Gaps, Limitations, and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kompis, Y.; Bartolomei, L.; Mascaro, R.; Teixeira, L.; Chli, M. Informed sampling exploration path planner for 3d reconstruction of large scenes. IEEE Robot. Autom. Lett. 2021, 6, 7893–7900. [Google Scholar] [CrossRef]
- Ren, R.; Fu, H.; Xue, H.; Sun, Z.; Ding, K.; Wang, P. Towards a fully automated 3d reconstruction system based on lidar and gnss in challenging scenarios. Remote Sens. 2021, 13, 1981. [Google Scholar] [CrossRef]
- Hu, S.; Liu, Q. Fast underwater scene reconstruction using multi-view stereo and physical imaging. Neural Netw. 2025, 189, 107568. [Google Scholar] [CrossRef]
- Yu, Z.; Shen, Y.; Zhang, Y.; Xiang, Y. Automatic crack detection and 3D reconstruction of structural appearance using underwater wall-climbing robot. Autom. Constr. 2024, 160, 105322. [Google Scholar] [CrossRef]
- Maken, P.; Gupta, A. 2D-to-3D: A review for computational 3D image reconstruction from X-ray images. Arch. Comput. Methods Eng. 2023, 30, 85–114. [Google Scholar] [CrossRef]
- Zi, Y.; Wang, Q.; Gao, Z.; Cheng, X.; Mei, T. Research on the application of deep learning in medical image segmentation and 3d reconstruction. Acad. J. Sci. Technol. 2024, 10, 8–12. [Google Scholar] [CrossRef]
- Yu, S.; Liu, X.; Tan, Q.; Wang, Z.; Zhang, B. Sensors, systems and algorithms of 3D reconstruction for smart agriculture and precision farming: A review. Comput. Electron. Agric. 2024, 224, 109229. [Google Scholar] [CrossRef]
- Gu, W.; Wen, W.; Wu, S.; Zheng, C.; Lu, X.; Chang, W.; Xiao, P.; Guo, X. 3D reconstruction of wheat plants by integrating point cloud data and virtual design optimization. Agriculture 2024, 14, 391. [Google Scholar] [CrossRef]
- Lu, Y.; Wang, S.; Fan, S.; Lu, J.; Li, P.; Tang, P. Image-based 3D reconstruction for Multi-Scale civil and infrastructure Projects: A review from 2012 to 2022 with new perspective from deep learning methods. Adv. Eng. Inform. 2024, 59, 102268. [Google Scholar] [CrossRef]
- Muhammad, I.B.; Omoniyi, T.M.; Omoebamije, O.; Mohammed, A.G.; Samson, D. 3D Reconstruction of a Precast Concrete Bridge for Damage Inspection Using Images from Low-Cost Unmanned Aerial Vehicle. Disaster Civ. Eng. Archit. 2025, 2, 46–62. [Google Scholar] [CrossRef]
- Banerjee, D.; Yu, K.; Aggarwal, G. Robotic arm based 3D reconstruction test automation. IEEE Access 2018, 6, 7206–7213. [Google Scholar] [CrossRef]
- Sumetheeprasit, B.; Rosales Martinez, R.; Paul, H.; Shimonomura, K. Long-range 3D reconstruction based on flexible configuration stereo vision using multiple aerial robots. Remote Sens. 2024, 16, 234. [Google Scholar] [CrossRef]
- Wang, H.; Sun, S.; Ren, P. Underwater color disparities: Cues for enhancing underwater images toward natural color consistencies. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 738–753. [Google Scholar] [CrossRef]
- Wang, H.; Sun, S.; Chang, L.; Li, H.; Zhang, W.; Frery, A.C.; Ren, P. INSPIRATION: A reinforcement learning-based human visual perception-driven image enhancement paradigm for underwater scenes. Eng. Appl. Artif. Intell. 2024, 133, 108411. [Google Scholar] [CrossRef]
- Samavati, T.; Soryani, M. Deep learning-based 3D reconstruction: A survey. Artif. Intell. Rev. 2023, 56, 9175–9219. [Google Scholar] [CrossRef]
- Vinodkumar, P.K.; Karabulut, D.; Avots, E.; Ozcinar, C.; Anbarjafari, G. Deep learning for 3d reconstruction, augmentation, and registration: A review paper. Entropy 2024, 26, 235. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 2002, 86, 2278–2324. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Shi, Z.; Meng, Z.; Xing, Y.; Ma, Y.; Wattenhofer, R. 3d-retr: End-to-end single and multi-view 3d reconstruction with transformers. arXiv 2021, arXiv:2110.08861. [Google Scholar]
- Ding, C.; Dai, Y.; Feng, X.; Zhou, Y.; Li, Q. Stereo vision SLAM-based 3D reconstruction on UAV development platforms. J. Electron. Imaging 2023, 32, 013041. [Google Scholar] [CrossRef]
- Huang, J.; Xu, F.; Chen, T.; Zeng, Y.; Ming, J.; Niu, X. Real-Time Ocean Waves Three-Dimensional Reconstruction Research Based on Deep Learning. In Proceedings of the 2023 2nd International Conference on Robotics, Artificial Intelligence and Intelligent Control (RAIIC), Mianyang, China, 11–13 August 2023; pp. 334–339. [Google Scholar] [CrossRef]
- Lu, G. Bird-view 3d reconstruction for crops with repeated textures. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 4263–4270. [Google Scholar] [CrossRef]
- Cheng, Y.; Liu, Z.; Lan, G.; Xu, J.; Chen, R.; Huang, Y. Edge_MVSFormer: Edge-Aware Multi-View Stereo Plant Reconstruction Based on Transformer Networks. Sensors 2025, 25, 2177. [Google Scholar] [CrossRef]
- Chen, Q.; Song, L.; Zhang, X.; Zhang, G.; Lu, H.; Liu, J.; Pan, Y.; Luo, W. Accurate 3D anthropometric measurement using compact multi-view imaging. Measurement 2025, 247, 116777. [Google Scholar] [CrossRef]
- Ma, D.; Wang, N.; Fang, H.; Chen, W.; Li, B.; Zhai, K. Attention-optimized 3D segmentation and reconstruction system for sewer pipelines employing multi-view images. Comput.-Aided Civ. Infrastruct. Eng. 2025, 40, 594–613. [Google Scholar] [CrossRef]
- Yu, J.; Yin, W.; Hu, Z.; Liu, Y. 3D reconstruction for multi-view objects. Comput. Electr. Eng. 2023, 106, 108567. [Google Scholar] [CrossRef]
- Liu, J.; Bajraktari, F.; Rausch, R.; Pott, P.P. 3D Reconstruction of Forearm Veins Using NIR-Based Stereovision and Deep Learning. In Proceedings of the 2023 IEEE 36th International Symposium on Computer-Based Medical Systems (CBMS), L’Aquila, Italy, 22–24 June 2023; pp. 57–60. [Google Scholar] [CrossRef]
- Niri, R.; Gutierrez, E.; Douzi, H.; Lucas, Y.; Treuillet, S.; Castañeda, B.; Hernandez, I. Multi-view data augmentation to improve wound segmentation on 3D surface model by deep learning. IEEE Access 2021, 9, 157628–157638. [Google Scholar] [CrossRef]
- Chen, R.; Yin, X.; Yang, Y.; Tong, C. Multi-view Pixel2Mesh++: 3D reconstruction via Pixel2Mesh with more images. Vis. Comput. 2023, 39, 5153–5166. [Google Scholar] [CrossRef]
- Kui, X.; Xiaoran, G. SinHuman3D: Novel Multi-View Synthesis and 3D Reconstruction from a Single Human Image. In Proceedings of the 2024 IEEE 4th International Conference on Data Science and Computer Application (ICDSCA), Dalian, China, 22–24 November 2024; pp. 355–359. [Google Scholar] [CrossRef]
- Hermann, M.; Weinmann, M.; Nex, F.; Stathopoulou, E.; Remondino, F.; Jutzi, B.; Ruf, B. Depth estimation and 3D reconstruction from UAV-borne imagery: Evaluation on the UseGeo dataset. ISPRS Open J. Photogramm. Remote Sens. 2024, 13, 100065. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, Y.; Sun, Y.; Liu, N.; Sun, F.; Fang, B. Artificial Skin Based on Visuo-Tactile Sensing for 3D Shape Reconstruction: Material, Method, and Evaluation. Adv. Funct. Mater. 2025, 35, 2411686. [Google Scholar] [CrossRef]
- Gao, T.; Hong, Z.; Tan, Y.; Sun, L.; Wei, Y.; Ma, J. HC-MVSNet: A probability sampling-based multi-view-stereo network with hybrid cascade structure for 3D reconstruction. Pattern Recognit. Lett. 2024, 185, 59–65. [Google Scholar] [CrossRef]
- Zhu, Z.; Yang, L.; Lin, X.; Yang, L.; Liang, Y. Garnet: Global-aware multi-view 3d reconstruction network and the cost-performance tradeoff. Pattern Recognit. 2023, 142, 109674. [Google Scholar] [CrossRef]
- de Queiroz Mendes, R.; Ribeiro, E.G.; dos Santos Rosa, N.; Grassi Jr, V. On deep learning techniques to boost monocular depth estimation for autonomous navigation. Robot. Auton. Syst. 2021, 136, 103701. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Dong, Z.; Gao, M.; Lin, H.; Miao, Q. SABV-Depth: A biologically inspired deep learning network for monocular depth estimation. Knowl.-Based Syst. 2023, 263, 110301. [Google Scholar] [CrossRef]
- Madhuanand, L.; Nex, F.; Yang, M.Y. Deep learning for monocular depth estimation from UAV images. In Proceedings of the XXIVth ISPRS Congress 2020. International Society for Photogrammetry and Remote Sensing (ISPRS), Nice, France, 31 August–2 September 2020; pp. 451–458. [Google Scholar]
- Abdullah, R.M. A deep learning-based framework for efficient and accurate 3D real-scene reconstruction. Int. J. Inf. Technol. 2024, 16, 4605–4609. [Google Scholar] [CrossRef]
- Teng, J.; Sun, H.; Liu, P.; Jiang, S. An Improved TransMVSNet Algorithm for Three-Dimensional Reconstruction in the Unmanned Aerial Vehicle Remote Sensing Domain. Sensors 2024, 24, 2064. [Google Scholar] [CrossRef] [PubMed]
- Nex, F.; Zhang, N.; Remondino, F.; Farella, E.; Qin, R.; Zhang, C. Benchmarking the extraction of 3D geometry from UAV images with deep learning methods. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-ISPRS Arch. 2023, 48, 123–130. [Google Scholar] [CrossRef]
- Dhanushkodi, K.; Bala, A.; Chaplot, N. Single-View Depth Estimation: Advancing 3D Scene Interpretation with One Lens. IEEE Access 2025, 13, 20562–20573. [Google Scholar] [CrossRef]
- Hu, Y.; Fu, T.; Niu, G.; Liu, Z.; Pun, M.O. 3D map reconstruction using a monocular camera for smart cities. J. Supercomput. 2022, 78, 16512–16528. [Google Scholar] [CrossRef]
- Izadmehr, Y.; Satizábal, H.F.; Aminian, K.; Perez-Uribe, A. Depth estimation for egocentric rehabilitation monitoring using deep learning algorithms. Appl. Sci. 2022, 12, 6578. [Google Scholar] [CrossRef]
- Hong, Z.; Yang, Y.; Liu, J.; Jiang, S.; Pan, H.; Zhou, R.; Zhang, Y.; Han, Y.; Wang, J.; Yang, S.; et al. Enhancing 3D reconstruction model by deep learning and its application in building damage assessment after earthquake. Appl. Sci. 2022, 12, 9790. [Google Scholar] [CrossRef]
- Li, G.; Li, K.; Zhang, G.; Zhu, Z.; Wang, P.; Wang, Z.; Fu, C. Enhanced multi view 3D reconstruction with improved MVSNet. Sci. Rep. 2024, 14, 14106. [Google Scholar] [CrossRef]
- Wang, B.; Chen, W.; Qian, J.; Feng, S.; Chen, Q.; Zuo, C. Single-shot super-resolved fringe projection profilometry (SSSR-FPP): 100,000 frames-per-second 3D imaging with deep learning. Light Sci. Appl. 2025, 14, 70. [Google Scholar] [CrossRef]
- Duan, Z.; Chen, Y.; Yu, H.; Hu, B.; Chen, C. RGB-Fusion: Monocular 3D reconstruction with learned depth prediction. Displays 2021, 70, 102100. [Google Scholar] [CrossRef]
- Dai, L.; Chen, Z.; Zhang, X.; Wang, D.; Huo, L. CPH-Fmnet: An Optimized Deep Learning Model for Multi-View Stereo and Parameter Extraction in Complex Forest Scenes. Forests 2024, 15, 1860. [Google Scholar] [CrossRef]
- Dalai, R.; Dalai, N.; Senapati, K.K. An accurate volume estimation on single view object images by deep learning based depth map analysis and 3D reconstruction. Multimed. Tools Appl. 2023, 82, 28235–28258. [Google Scholar] [CrossRef]
- Knyaz, V.A.; Kniaz, V.V.; Remondino, F.; Zheltov, S.Y.; Gruen, A. 3D reconstruction of a complex grid structure combining UAS images and deep learning. Remote Sens. 2020, 12, 3128. [Google Scholar] [CrossRef]
- Jiang, S.; Zhang, Y.; Wang, F.; Xu, Y. Three-dimensional reconstruction and damage localization of bridge undersides based on close-range photography using UAV. Meas. Sci. Technol. 2024, 36, 015423. [Google Scholar] [CrossRef]
- Wang, J.; Ma, D.; Wang, Q.; Wang, J. CSA-MVSNet: A Cross-Scale Attention Based Multi-View Stereo Method With Cascade Structure. IEEE Trans. Consum. Electron. 2025, 1. [Google Scholar] [CrossRef]
- Song, L.; Liu, T.; Jiang, D.; Li, H.; Zhao, D.; Zou, Q. 3D multi views reconstruction of flame surface based on deep learning. J. Phys. Conf. Ser. 2023, 2593, 012006. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, Q.; Rao, X.; Xie, L.; Ying, Y. OrangeStereo: A navel orange stereo matching network for 3D surface reconstruction. Comput. Electron. Agric. 2024, 217, 108626. [Google Scholar] [CrossRef]
- Wei, R.; Guo, J.; Lu, Y.; Zhong, F.; Liu, Y.; Sun, D.; Dou, Q. Scale-aware monocular reconstruction via robot kinematics and visual data in neural radiance fields. Artif. Intell. Surg. 2024, 4, 187–198. [Google Scholar] [CrossRef]
- Niknejad, N.; Bidese-Puhl, R.; Bao, Y.; Payn, K.G.; Zheng, J. Phenotyping of architecture traits of loblolly pine trees using stereo machine vision and deep learning: Stem diameter, branch angle, and branch diameter. Comput. Electron. Agric. 2023, 211, 107999. [Google Scholar] [CrossRef]
- Zhao, G.; Cai, W.; Wang, Z.; Wu, H.; Peng, Y.; Cheng, L. Phenotypic parameters estimation of plants using deep learning-based 3-D reconstruction from single RGB image. IEEE Geosci. Remote Sens. Lett. 2022, 19, 2506705. [Google Scholar] [CrossRef]
- Engin, S.; Mitchell, E.; Lee, D.; Isler, V.; Lee, D.D. Higher order function networks for view planning and multi-view reconstruction. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 11486–11492. [Google Scholar] [CrossRef]
- Wu, J.; Thomas, D.; Fedkiw, R. Sparse-View 3D Reconstruction of Clothed Humans via Normal Maps. In Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Tucson, AZ, USA, 26 February–6 March 2025; pp. 11–22. [Google Scholar] [CrossRef]
- Zhang, Z.; Cheng, J.; Xu, G.; Wang, X.; Zhang, C.; Yang, X. Leveraging consistent spatio-temporal correspondence for robust visual odometry. Proc. AAAI Conf. Artif. Intell. 2025, 39, 10367–10375. [Google Scholar] [CrossRef]
- Gao, S.; Xu, Z. Efficient 3DGS object segmentation via COLMAP point cloud. In Proceedings of the Eighth International Conference on Computer Graphics and Virtuality (ICCGV 2025), Chengdu, China, 21–23 February 2025; Volume 13557, pp. 65–76. [Google Scholar] [CrossRef]
- Medhi, M.; Ranjan Sahay, R. Adversarial learning for unguided single depth map completion of indoor scenes. Mach. Vis. Appl. 2025, 36, 30. [Google Scholar] [CrossRef]
- Cai, Y.; Cao, Y. Positional tracking study of greenhouse mobile robot based on improved Monodepth2. IEEE Access 2025, 13, 106690–106702. [Google Scholar] [CrossRef]
- Habib, Y.; Papadakis, P.; Le Barz, C.; Fagette, A.; Gonçalves, T.; Buche, C. Densifying SLAM for UAV navigation by fusion of monocular depth prediction. In Proceedings of the 2023 9th International Conference on Automation, Robotics and Applications (ICARA), Abu Dhabi, United Arab Emirates, 10–12 February 2023; pp. 225–229. [Google Scholar] [CrossRef]
- Fu, W.; Lv, B.; Tong, S. DTR-Map: A Digital Twin-Enabled Real-Time Mapping System Based on Multi-View Stereo. In Proceedings of the 2023 China Automation Congress (CAC), Chongqing, China, 17–19 November 2023; pp. 4273–4278. [Google Scholar] [CrossRef]
- Feng, Y.; Wu, R.; Li, P.; Wu, W.; Lin, J.; Liu, X.; Chen, L. Multi-view high-dynamic-range 3D reconstruction and point cloud quality evaluation based on dual-frame difference images. Appl. Opt. 2024, 63, 7865–7874. [Google Scholar] [CrossRef]
- Zhang, J.; Fu, X.D.T.; Srigrarom, S. Depth Estimation in Static Monocular Vision with Stereo Vision Assisted Deep Learning Approach. In Proceedings of the 2024 4th International Conference on Computer, Control and Robotics (ICCCR), Shanghai, China, 19–21 April 2024; pp. 101–107. [Google Scholar] [CrossRef]
- Al-Selwi, M.; Ning, H.; Gao, Y.; Chao, Y.; Li, Q.; Li, J. Enhancing object pose estimation for RGB images in cluttered scenes. Sci. Rep. 2025, 15, 8745. [Google Scholar] [CrossRef]
- Lu, L.; Bu, C.; Su, Z.; Guan, B.; Yu, Q.; Pan, W.; Zhang, Q. Generative deep-learning-embedded asynchronous structured light for three-dimensional imaging. Adv. Photonics 2024, 6, 046004. [Google Scholar] [CrossRef]
- Zuo, Y.; Hu, Y.; Xu, Y.; Wang, Z.; Fang, Y.; Yan, J.; Jiang, W.; Peng, Y.; Huang, Y. Learning Guided Implicit Depth Function with Scale-aware Feature Fusion. IEEE Trans. Image Process. 2025, 34, 3309–3322. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Liu, T.; Wang, X. Advanced pavement distress recognition and 3D reconstruction by using GA-DenseNet and binocular stereo vision. Measurement 2022, 201, 111760. [Google Scholar] [CrossRef]
- Padkan, N.; Battisti, R.; Menna, F.; Remondino, F. Deep learning to support 3d mapping capabilities of a portable vslam-based system. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, 48, 363–370. [Google Scholar] [CrossRef]
- Zhang, R.; Jing, M.; Yi, X.; Li, H.; Lu, G. Dense reconstruction for tunnels based on the integration of double-line parallel photography and deep learning. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 43, 1117–1123. [Google Scholar] [CrossRef]
- Liu, L.; Wang, C.; Feng, C.; Gong, W.; Zhang, L.; Liao, L.; Feng, C. Incremental SFM 3D Reconstruction Based on Deep Learning. Electronics 2024, 13, 2850. [Google Scholar] [CrossRef]
- Luo, W.; Lu, Z.; Liao, Q. LNMVSNet: A low-noise multi-view stereo depth inference method for 3D reconstruction. Sensors 2024, 24, 2400. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L. Multi-View Reconstruction of Landscape Images Considering Image Registration and Feature Mapping. In Proceedings of the 2025 International Conference on Multi-Agent Systems for Collaborative Intelligence (ICMSCI), Erode, India, 20–22 January 2025; pp. 1349–1354. [Google Scholar] [CrossRef]
- Ding, Y.; Lin, L.; Wang, L.; Zhang, M.; Li, D. Digging into the multi-scale structure for a more refined depth map and 3D reconstruction. Neural Comput. Appl. 2020, 32, 11217–11228. [Google Scholar] [CrossRef]
- Yang, Y.; Cao, J.; Zhao, H.; Chang, Z.; Wang, W. High frequency domain enhancement and channel attention module for multi-view stereo. Comput. Electr. Eng. 2025, 121, 109855. [Google Scholar] [CrossRef]
- Wang, T.; Gan, V.J. Multi-view stereo for weakly textured indoor 3D reconstruction. Comput.-Aided Civ. Infrastruct. Eng. 2024, 39, 1469–1489. [Google Scholar] [CrossRef]
- Kamble, T.U.; Mahajan, S.P. 3D Image reconstruction using C-dual attention network from multi-view images. Int. J. Wavelets, Multiresolut. Inf. Process. 2023, 21, 2250044. [Google Scholar] [CrossRef]
- Gong, L.; Gao, B.; Sun, Y.; Zhang, W.; Lin, G.; Zhang, Z.; Li, Y.; Liu, C. preciseSLAM: Robust, Real-Time, LiDAR–Inertial–Ultrasonic Tightly-Coupled SLAM With Ultraprecise Positioning for Plant Factories. IEEE Trans. Ind. Inform. 2024, 20, 8818–8827. [Google Scholar] [CrossRef]
- Kumar, R.; Luo, J.; Pang, A.; Davis, J. Disjoint pose and shape for 3d face reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 3107–3117. [Google Scholar] [CrossRef]
- Chuah, W.; Tennakoon, R.; Hoseinnezhad, R.; Bab-Hadiashar, A. Deep learning-based incorporation of planar constraints for robust stereo depth estimation in autonomous vehicle applications. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6654–6665. [Google Scholar] [CrossRef]
- Hu, G.; Zhao, H.; Huo, Q.; Zhu, J.; Yang, P. Multi-view 3D Reconstruction by Fusing Polarization Information. In Pattern Recognition and Computer Vision–7th Chinese Conference, PRCV 2024, Urumqi, China, October 18–20, 2024, Proceedings, Part XIII; Lecture Notes in Computer Science; Springer: Singapore, 2024; Volume 15043, pp. 181–195. [Google Scholar] [CrossRef]
- Yang, R.; Miao, W.; Zhang, Z.; Liu, Z.; Li, M.; Lin, B. SA-MVSNet: Self-attention-based multi-view stereo network for 3D reconstruction of images with weak texture. Eng. Appl. Artif. Intell. 2024, 131, 107800. [Google Scholar] [CrossRef]
- Lai, H.; Ye, C.; Li, Z.; Yan, P.; Zhou, Y. MFE-MVSNet: Multi-scale feature enhancement multi-view stereo with bi-directional connections. IET Image Process. 2024, 18, 2962–2973. [Google Scholar] [CrossRef]
- Ignatov, D.; Ignatov, A.; Timofte, R. Virtually Enriched NYU Depth V2 Dataset for Monocular Depth Estimation: Do We Need Artificial Augmentation? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 6177–6186. [Google Scholar] [CrossRef]
- Ding, Y.; Li, K.; Zhang, G.; Zhu, Z.; Wang, P.; Wang, Z.; Fu, C.; Li, G.; Pan, K. Multi-step depth enhancement refine network with multi-view stereo. PLoS ONE 2025, 20, e0314418. [Google Scholar] [CrossRef] [PubMed]
- Abderrazzak, S.; Omar, S.; Abdelmalik, B. Supervised depth estimation for visual perception on low-end platforms. In Proceedings of the 2020 IEEE International Conference on Technology Management, Operations and Decisions (ICTMOD), Marrakech, Morocco, 24–27 November 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Qiao, J.; Hong, H.; Cui, G. Spatial Ranging and Distance Recognition of Electrical Targets and Distribution Lines Based on Stereo Vision and Deep Learning. In Proceedings of the 2024 5th International Conference on Clean Energy and Electric Power Engineering (ICCEPE), Yangzhou, China, 9–11 August 2024; pp. 815–819. [Google Scholar] [CrossRef]
- Xie, Q.; Xin, Y.; Sun, K.; Zeng, X. Fusion Multi-scale Features and Attention Mechanism for Multi-view 3D Reconstruction. In Proceedings of the 2023 IEEE 3rd International Conference on Electronic Technology, Communication and Information (ICETCI), Changchun, China, 26–28 May 2023; pp. 1120–1123. [Google Scholar] [CrossRef]
- Freller, A.; Turk, D.; Zwettler, G.A. Using deep learning for depth estimation and 3d reconstruction of humans. In Proceedings of the 32nd European Modeling and Simulation Symposium, Vienna, Austria, 16–18 September 2020; pp. 281–287. [Google Scholar] [CrossRef]
- Cui, D.; Liu, P.; Liu, Y.; Zhao, Z.; Feng, J. Automated Phenotypic Analysis of Mature Soybean Using Multi-View Stereo 3D Reconstruction and Point Cloud Segmentation. Agriculture 2025, 15, 175. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Academic Database | Keywords |
|---|---|
| Scopus | TITLE-ABS-KEY(“deep learning” AND (“3D reconstruction” OR “depth estimation” OR “structure from motion”) AND (“stereo vision” OR “multi-view” OR “camera system”)) AND PUBYEAR > 2019 |
| Google Scholar | “deep learning” “3D reconstruction” “stereo vision” after:2019 intitle:“deep learning” intitle:“3D reconstruction” OR intitle:“deep learning” intitle:“depth estimation” after:2019 |
| Author | Year | RMSE (m) | MAE (m) | IoU | DSC | Accuracy | Precision | Recall |
|---|---|---|---|---|---|---|---|---|
| [35] | 2021 | 4.6320 | – | – | – | – | – | – |
| [36] | 2023 | 3.9020 | – | – | – | – | – | – |
| [37] | 2020 | 3.8400 | – | – | – | – | – | – |
| [38] | 2024 | 1.0300 | 0.7200 | – | – | 0.8830 | – | – |
| [39] | 2024 | 0.7500 | – | 0.8100 | – | 0.8750 | – | – |
| [40] | 2023 | 0.5480 | 0.3090 | – | – | – | – | – |
| [41] | 2025 | 0.5120 | – | – | – | – | – | – |
| [42] | 2022 | 0.4900 | – | – | – | – | – | – |
| [43] | 2022 | 0.2940 | – | – | – | – | – | – |
| [44] | 2022 | 0.1500 | – | – | – | – | – | – |
| [45] | 2024 | 0.0730 | 0.0420 | – | – | – | – | – |
| [46] | 2025 | 0.0573 | - | – | – | – | – | – |
| [47] | 2021 | 0.0450 | 0.0230 | – | – | – | – | – |
| [48] | 2024 | 0.0422 | 0.0215 | – | – | – | – | – |
| [49] | 2023 | 0.0390 | – | – | – | – | – | – |
| [50] | 2020 | 0.0210 | – | – | – | – | – | – |
| [21] | 2023 | 0.0091 | 0.0065 | – | – | – | – | – |
| [51] | 2024 | 0.0073 | – | – | – | – | – | – |
| [52] | 2025 | 0.0046 | 0.0023 | – | – | 0.0039 | – | – |
| [22] | 2023 | 0.0024 | 0.0018 | – | – | – | – | – |
| [24] | 2025 | 0.0019 | 0.0015 | – | – | – | – | – |
| [23] | 2025 | 0.0018 | 0.0014 | – | – | – | – | – |
| [53] | 2023 | 0.0007 | – | – | – | – | – | – |
| [54] | 2024 | 0.0004 | 0.0003 | – | – | – | – | – |
| [55] | 2024 | – | 0.0350 | – | – | – | – | – |
| [56] | 2023 | – | 0.0130 | – | – | – | – | – |
| [57] | 2022 | – | 0.0120 | – | – | – | – | – |
| [27] | 2023 | – | – | – | 0.9120 | – | 0.9250 | 0.9080 |
| Author | Chamfer Distance (mm) | Year |
|---|---|---|
| [58] | 0.68 (proposed]), 0.74 (baseline) | 2020 |
| [29] | 0.384 (multi-view Pixel2Mesh++), 0.471 (baseline Pixel2Mesh++) | 2023 |
| [59] | 0.81 (proposed), vs. 0.93 (PIFuHD), 0.91 (PaMIR) | 2025 |
| [30] | 0.79 | 2024 |
| [55] | Relative improvement: −23% vs. vanilla NeRF (value not directly provided) | 2024 |
| Focus Area | Estimated Frequency | Authors |
|---|---|---|
| Real-world validation | 8 | [31,38,51,65,68,71,72,73] |
| Hybrid classical–DL approaches | 7 | [50,53,70,73,74,75,76] |
| Low-texture and repetitive pattern handling | 6 | [22,52,69,77,78,79] |
| Biomedical applications | 5 | [25,27,28,35,43] |
| Edge–device optimization | 5 | [42,53,67,80,81] |
| Structure filtering via segmentation | 5 | [26,27,46,50,53] |
| Model compression for deployment | 3 | [20,34,82] |
| CNN–transformer hybrids | 2 | [36,41] |
| Author | Year | Architecture | Time |
|---|---|---|---|
| [89] | 2020 | Lightweight CNN | 26.0 ms/frame |
| [47] | 2021 | RGB-FusionNet | 25.0 ms/frame |
| [35] | 2021 | U-Net + attention | 35.0 ms/frame |
| [34] | 2023 | GARNet (2D+3D CNNs) | 1.205 s/view |
| [91] | 2023 | BFC-MVSNet | 1.480 s/view |
| [21] | 2023 | CNN regression net | 33.3 ms/frame |
| [81] | 2024 | EKF + sensor fusion | 33.3 ms/frame |
| [90] | 2024 | YOLOv8 + disparity map | 41.7 ms/frame |
| [45] | 2024 | Modified MVSNet w/ adaptive cost volume | 0.120 s/view |
| [33] | 2024 | HC-MVSNet | 1.100 s/view |
| [85] | 2024 | SA-MVSNet | 1.100 s/view |
| [75] | 2024 | LN-MVSNet | 1.150 s/view |
| [86] | 2024 | MFE-MVSNet | 1.180 s/view |
| [23] | 2025 | Edge-MVSFormer | 0.080 s/view |
| [88] | 2025 | MSDERNet | 1.200 s/view |
| [68] | 2025 | CNN + attention fusion | 29–35 ms/frame |
| [41] | 2025 | Monodepth2, DPT, BTS | 50.0 ms/frame |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Lira, D.-C.; Córdova-Esparza, D.-M.; Terven, J.; Romero-González, J.-A.; Alvarez-Alvarado, J.M.; González-Barbosa, J.-J.; Ramírez-Pedraza, A. Recent Developments in Image-Based 3D Reconstruction Using Deep Learning: Methodologies and Applications. Electronics 2025, 14, 3032. https://doi.org/10.3390/electronics14153032
Rodríguez-Lira D-C, Córdova-Esparza D-M, Terven J, Romero-González J-A, Alvarez-Alvarado JM, González-Barbosa J-J, Ramírez-Pedraza A. Recent Developments in Image-Based 3D Reconstruction Using Deep Learning: Methodologies and Applications. Electronics. 2025; 14(15):3032. https://doi.org/10.3390/electronics14153032
Chicago/Turabian StyleRodríguez-Lira, Diana-Carmen, Diana-Margarita Córdova-Esparza, Juan Terven, Julio-Alejandro Romero-González, José Manuel Alvarez-Alvarado, José-Joel González-Barbosa, and Alfonso Ramírez-Pedraza. 2025. "Recent Developments in Image-Based 3D Reconstruction Using Deep Learning: Methodologies and Applications" Electronics 14, no. 15: 3032. https://doi.org/10.3390/electronics14153032
APA StyleRodríguez-Lira, D.-C., Córdova-Esparza, D.-M., Terven, J., Romero-González, J.-A., Alvarez-Alvarado, J. M., González-Barbosa, J.-J., & Ramírez-Pedraza, A. (2025). Recent Developments in Image-Based 3D Reconstruction Using Deep Learning: Methodologies and Applications. Electronics, 14(15), 3032. https://doi.org/10.3390/electronics14153032