
Dynamic Vulnerability Knowledge Graph Construction via Multi-Source Data Fusion and Large Language Model Reasoning

Abstract
1. Introduction
- Data Fragmentation and Static Limitations: Traditional methods that depend heavily on established vulnerability databases (such as the National Vulnerability Database (NVD) or the China National Vulnerability Database (CNVD)) suffer from data fragmentation. Information is distributed across multiple databases and formats, making unified integration difficult [4]. Moreover, these structured databases often provide incomplete coverage and fail to capture implicit relationships (e.g., causal or prerequisite links between vulnerabilities). They also tend to remain static, lacking real-time updates or dynamic insights.
- Challenges in Unstructured Data Extraction: Researchers have used NLP methods, such as Named Entity Recognition (NER) and relation extraction, to mine vulnerabilities from unstructured sources (e.g., bulletins, blogs, threat reports). However, cybersecurity texts contain specialized jargon, non-standard abbreviations, and ambiguous or noisy language, which impedes accurate extraction and normalization. As a result, merging these unstructured insights with structured databases is prone to errors and demands tailored solutions.
- Heterogeneous Data Fusion and Dynamic Update Issues: Attempts to fuse structured and unstructured data into knowledge graphs—via TransH embeddings or Graph Neural Networks—are hampered by data heterogeneity. Existing security ontologies lack the flexibility to represent the full spectrum of vulnerability information, and even advanced embeddings fail to capture many implicit links. Consequently, most graphs remain static snapshots that do not auto-update with new vulnerabilities or attack patterns, reducing their real-time threat-prediction and analysis utility.
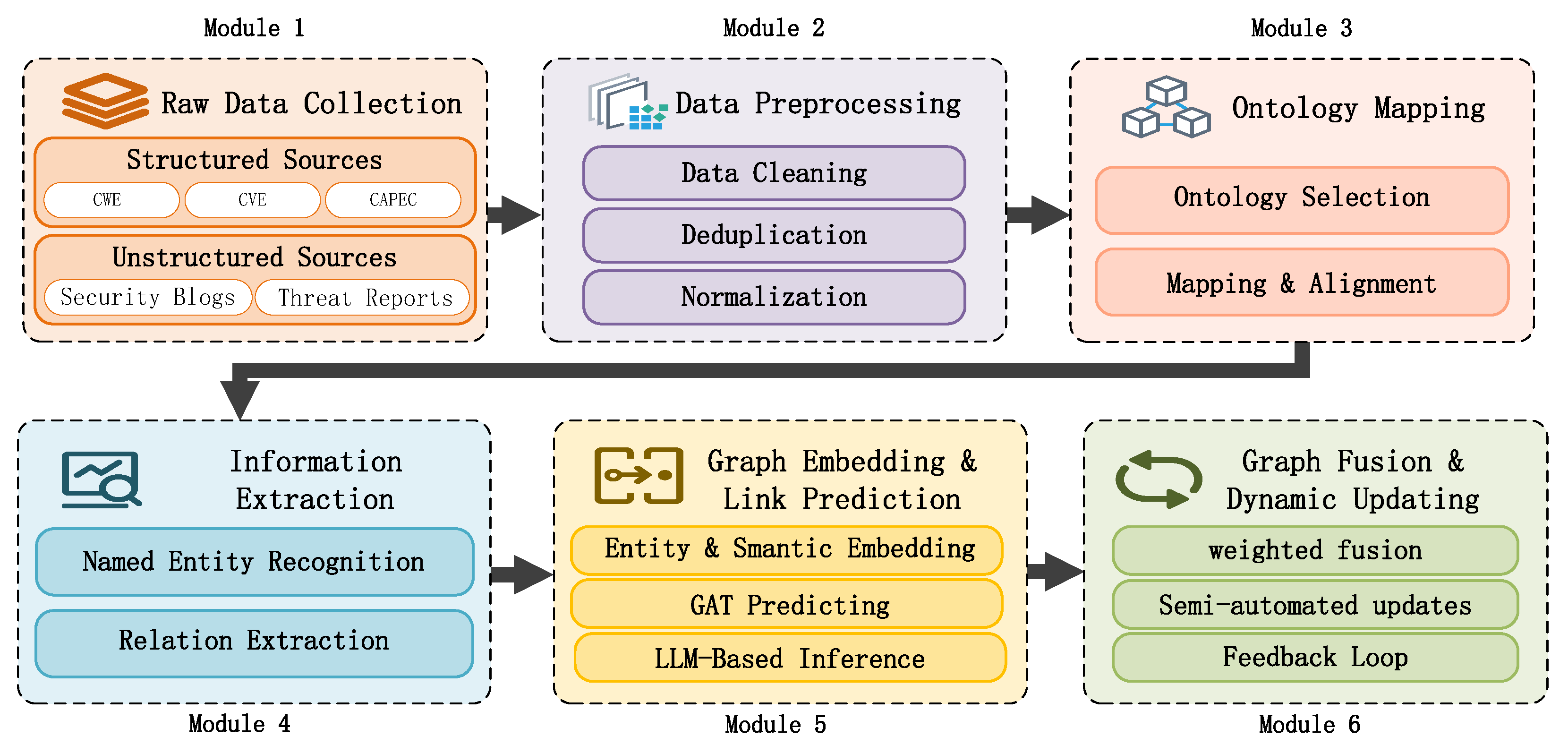
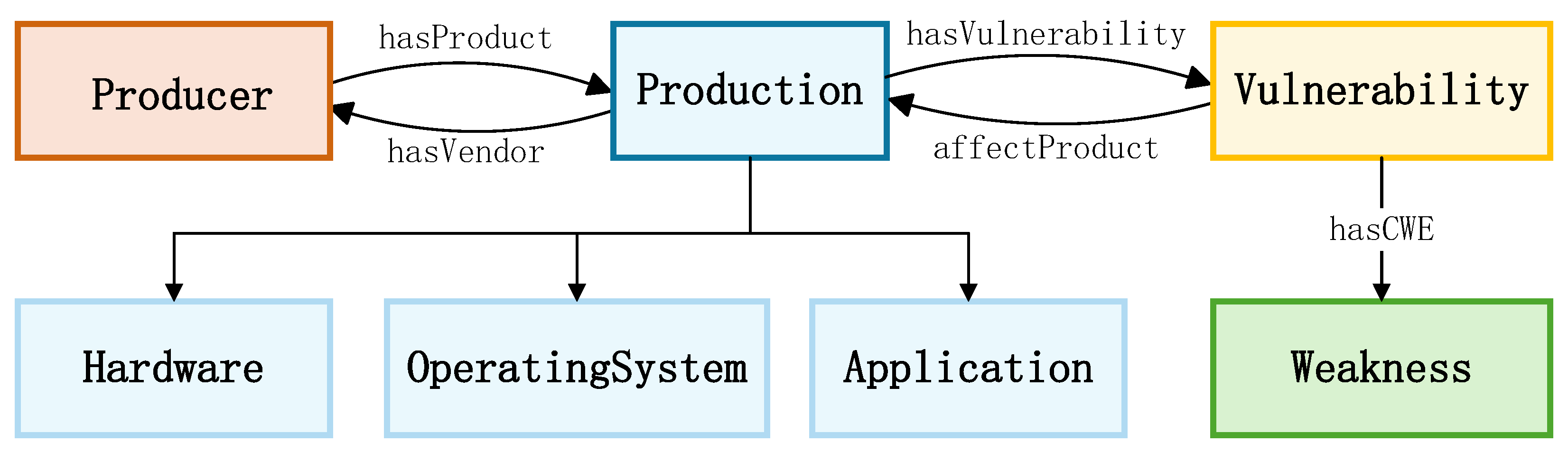
- Multi-Source Data Integration: We aggregate vulnerability data from both structured sources (e.g., NVD, CNVD) and unstructured web content, then map everything to a unified cybersecurity ontology built by extending the UCO [10] and IDS frameworks [11]. This ontology standardizes entities (Vulnerability, Weakness, Product, Attack) and relation types. Finally, we apply cleaning, deduplication, and entity normalization to ensure consistent, high-quality integration across all sources.
- Domain-Specific Knowledge Extraction: For unstructured text, we use a BiLSTM-CRF NER model augmented with a dictionary of over 150 cybersecurity terms to accurately extract CVE identifiers, product and vendor names, and weakness categories. An attention-based CNN then identifies relations such as “affects”, “has weakness”, and “exploited by”, converting free text into structured triples ready for knowledge graph ingestion.
- Link Prediction via Graph Embedding and LLM Reasoning: Even a high-quality initial knowledge graph can miss important connections, so we employ a two-pronged link prediction strategy. First, we combine TransH-based KG embeddings with BERT-derived textual node vectors to power a text-enhanced Graph Attention Network (GAT) that uncovers structural relationships. Second, we leverage large language models—GPT-3 [12], GPT-4 [13], or open-source alternatives like LLaMA [14]—to generate candidate links from vulnerability descriptions, which are then validated via BERT semantic similarity checks. Finally, a weighted fusion of GAT and LLM confidence scores integrates both structural and semantic evidence, yielding a more complete and reliable cybersecurity knowledge graph [15].
- Dynamic Graph Updating: Our system is designed to operate as an autonomous agent. It continuously monitors new vulnerability data, updates the knowledge graph by re-running the extraction and prediction pipelines, and ensures that the graph remains current and relevant for ongoing threat analysis.
- Integration Framework: We present an ontology-driven integration method that seamlessly fuses structured vulnerability databases and unstructured textual sources into a unified knowledge graph.
- Enhanced Extraction: We develop a domain-enhanced NER model and an attention-based relation extraction model, which together improve the accuracy and completeness of extracted vulnerability information compared to generic NLP approaches.
- Hybrid Link Prediction: We introduce a novel combination of graph-based and LLM-based reasoning for link prediction. By fusing a text-enhanced GAT with GPT-3-generated insights, our method can infer missing relationships that neither approach could fully capture alone.
- Dynamic Updating: We design a system capable of making continuous, autonomous updates to the knowledge graph as new data emerge.
2. Related Work
3. Methodology
3.1. Data Collection and Preprocessing
3.1.1. Data Sources and Ontology Integration
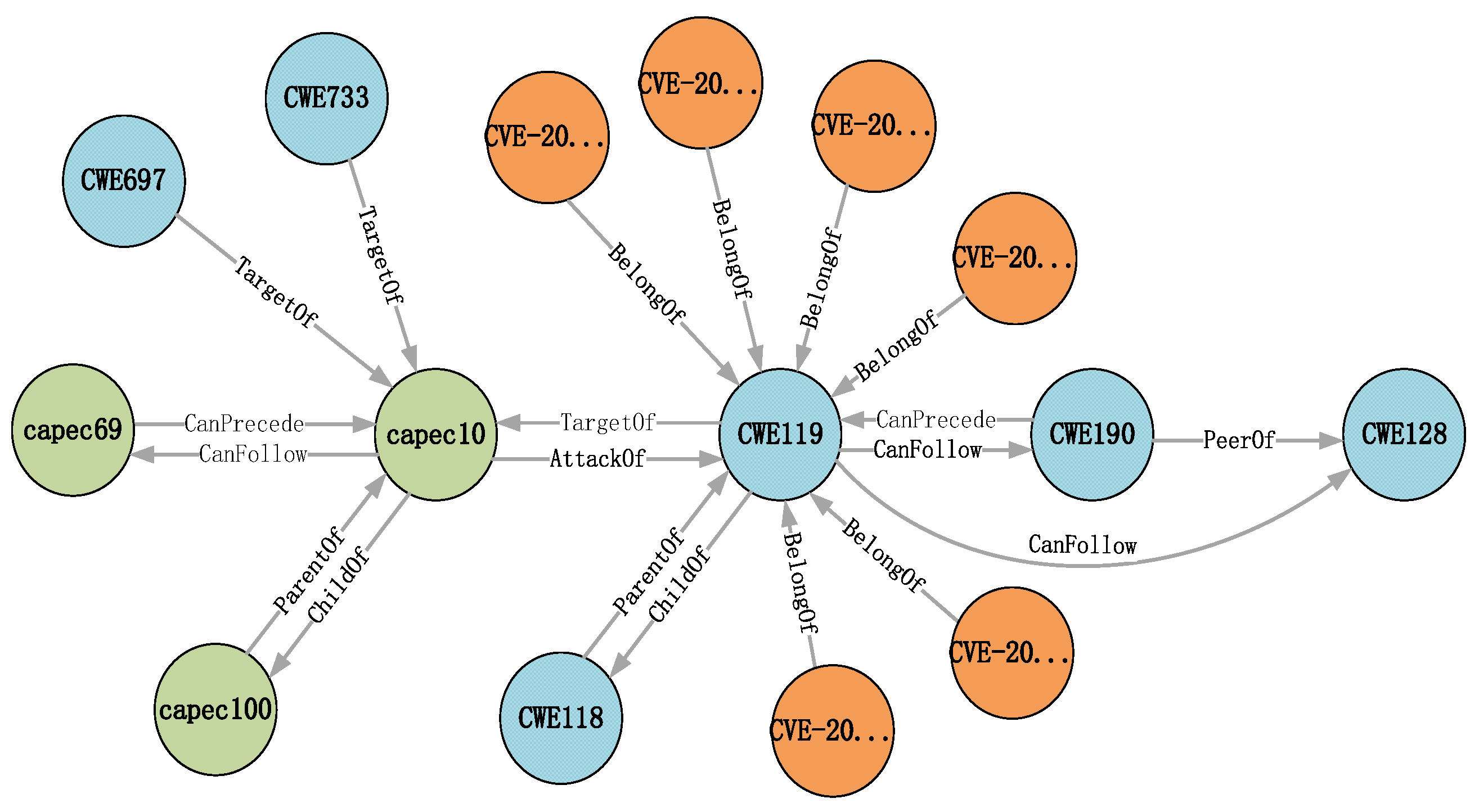
- Structured Sources: These include established databases such as the National Vulnerability Database (NVD). For structured data, a total of 4003 CVE entities, 891 CWE entities [28], and 522 CAPEC entities were obtained. These entities constitute the nodes in the knowledge graph. The obtained nodes are stored in csv files, and the dataset is preprocessed to construct subsequent triples.
- Unstructured Sources: We also harvested data via web crawling from security blogs, threat intelligence reports, and exploit databases [29].
3.1.2. Data Cleaning and Normalization
- Format Unification: Diverse records are transformed into a standardized JSON schema aligned with our ontology.
- Text Cleaning: We remove HTML tags, boilerplate content, and non-informative text segments to isolate relevant information.
- Deduplication and Entity Normalization: Duplicate entries (e.g., the same CVE reported in multiple sources) are merged, and variant expressions (e.g., “Windows 10” vs. “Microsoft Windows 10”) are normalized using a curated dictionary.
3.2. Domain-Specific Information Extraction
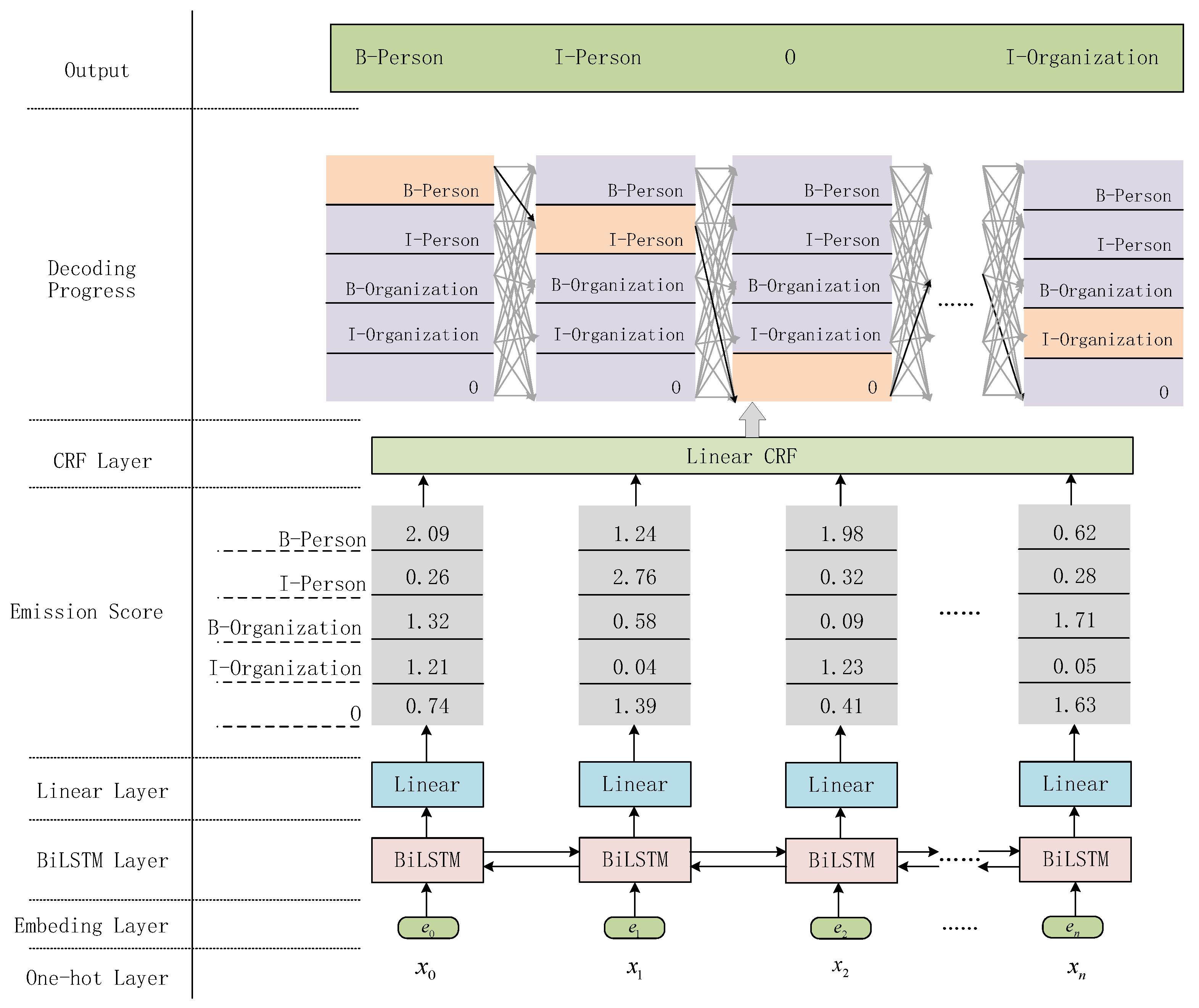
Named Entity Recognition (NER)
- Embedding Layer
- BiLSTM Layer
- CRF Layer
- Domain Dictionary Correction
| Algorithm 1 Bi-Directional Maximum Match (BMM). |
| Require: Dictionary sequence Ensure:forwardResult, backwardResult
|
3.3. Graph Embedding and Link Prediction
3.3.1. Relation Extraction (RE)
3.3.2. TransH Embedding
3.3.3. Text-Enhanced Graph Attention Network (GAT)
3.4. LLM-Based Relation Inference and Fusion
- (i)
- Graph-based module: A text-enhanced Graph Attention Network (GAT) that leverages the structure of the existing knowledge graph (nodes and known links) and node textual descriptions to predict potential relations.
- (ii)
- LLM-based module: A large language model (GPT-3) that generates candidate relations by reasoning over vulnerability descriptions in natural language (as described in Section 3.4.1).
- (iii)
- Validation module: A BERT-based semantic matcher that evaluates each candidate relation’s plausibility by measuring contextual similarity, filtering out spurious suggestions (Section 3.4.2).
- (iv)
- Fusion mechanism: A weighted integration strategy that combines the confidence scores from the GAT and the LLM (Section 3.4.3).
3.4.1. GPT-3 Candidate Generation
CVE-2023-1231 is a buffer overflow vulnerability that mainly affects Windows systems and may lead to memory corruption and data leakage. This vulnerability may interact with other vulnerabilities, leading to more widespread attacks. Based on the description above, predict which other vulnerabilities might be related to this one, and output the candidate relationships in the form of triples, ensuring that each triple is formatted as ⟨head, entity, relation, tail, entity⟩.
3.4.2. BERT-Based Validation
3.4.3. Knowledge Completion and Fusion Strategy
- Structural score : obtained by the GAT model from entity and relation vectors via cosine similarity or Euclidean distance, reflecting local graph connectivity.
- Language-model score : returned by GPT-3 and adjusted by BERT’s semantic matching verification, indicating the plausibility and trustworthiness of the generated relation.
- Complementarity: GAT captures local structural cues, while the large model leverages global semantic knowledge, yielding richer relation hypotheses.
- Adaptivity: By dynamically adjusting and , the system can favor structural or semantic evidence according to the data density and ambiguity.
- Validation loop: BERT semantic matching provides feedback to filter spurious outputs and reinforce contextually valid relations.
3.5. System Deployment and Update Strategy
- Data Ingestion: New structured and unstructured data are preprocessed .
- Triple Extraction: The NER/RE pipeline extracts new entities and relations from the incoming data.
- Embedding Update: Node embeddings are recalculated, and the GAT predicts new links between existing and new nodes.
- LLM Inference: Ambiguous or novel cases are processed through the GPT-3 module, with BERT validation applied.
- Graph Merging: Newly predicted relations are merged into the existing knowledge graph with provenance logs for auditing.
- Performance and Scalability: The pipeline must handle high-volume data streams (e.g., surges of vulnerability reports) in near real-time, which requires efficient parallel processing and optimization of each module (our design allows the NER/RE, GAT, and LLM components to run in parallel or be distributed across servers to scale).
- Integration with Existing Workflows: The knowledge graph should integrate with enterprise security dashboards and incident response systems, which may require developing APIs or adapters and ensuring data format compatibility.
- Latency and Cost of LLM Calls: Relying on a large language model (GPT-3/4) can incur latency and usage costs; caching frequent queries and using local fine-tuned models for less critical tasks are strategies to mitigate this.
- Data Quality and Maintenance: Ensuring the continuous quality of the graph is non-trivial, as newly ingested data might introduce noise or inconsistencies, so we implement validation steps (like the BERT-based check) and maintain provenance metadata for auditing.
3.6. Security Knowledge Graph Construction
3.7. Data Modeling and Storage
- Vulnerability type
- Identifier (ID)
- Description
- Related vulnerabilities
3.8. Dynamic Updates and Front-End Visualization
4. Results
4.1. Experimental Environment Setup
4.2. Domain-Dictionary Corrected BiLSTM-CRF Experiments
4.2.1. Dataset and Experimental Setup
4.2.2. Evaluation Metrics
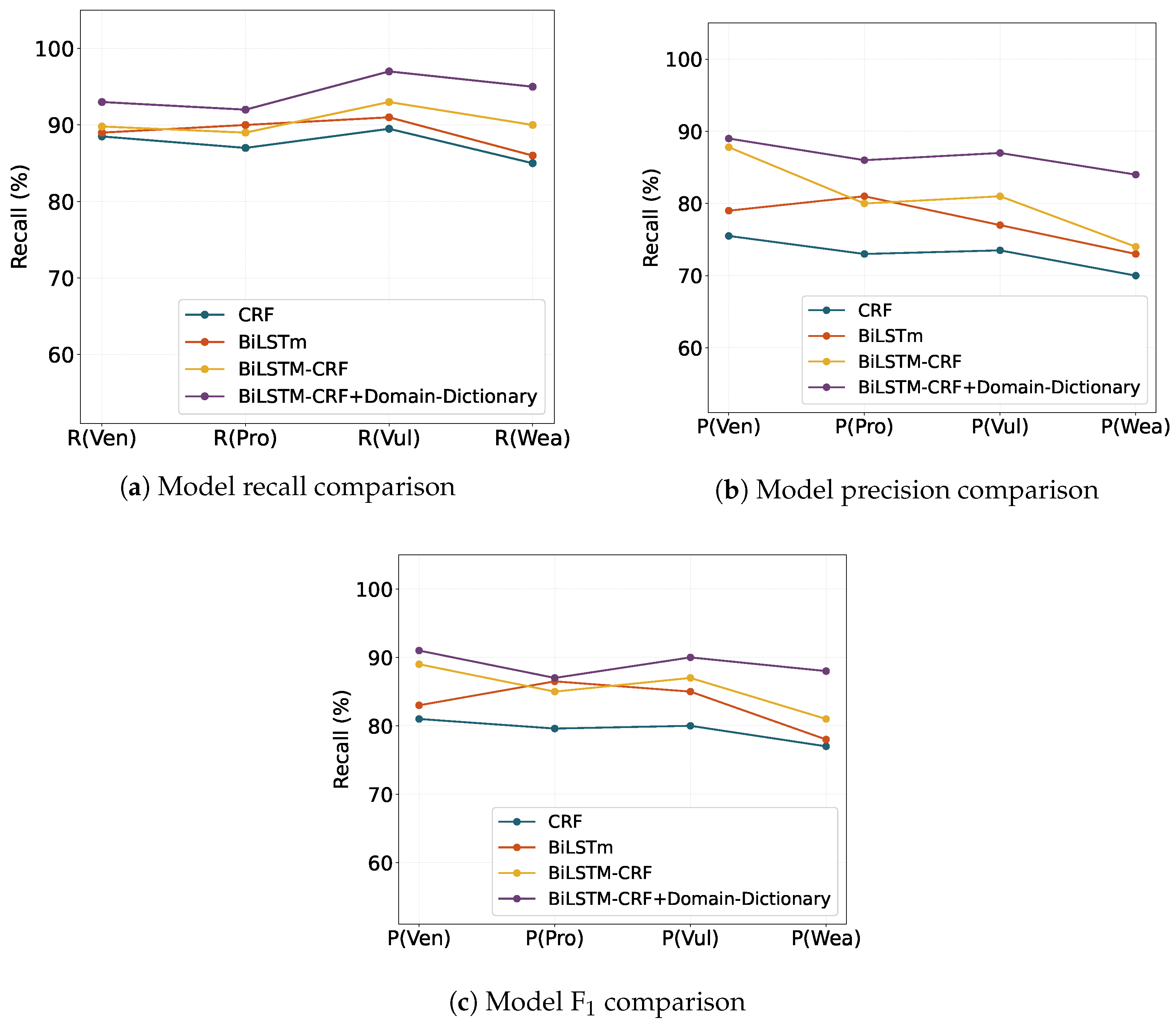
4.2.3. Experimental Results
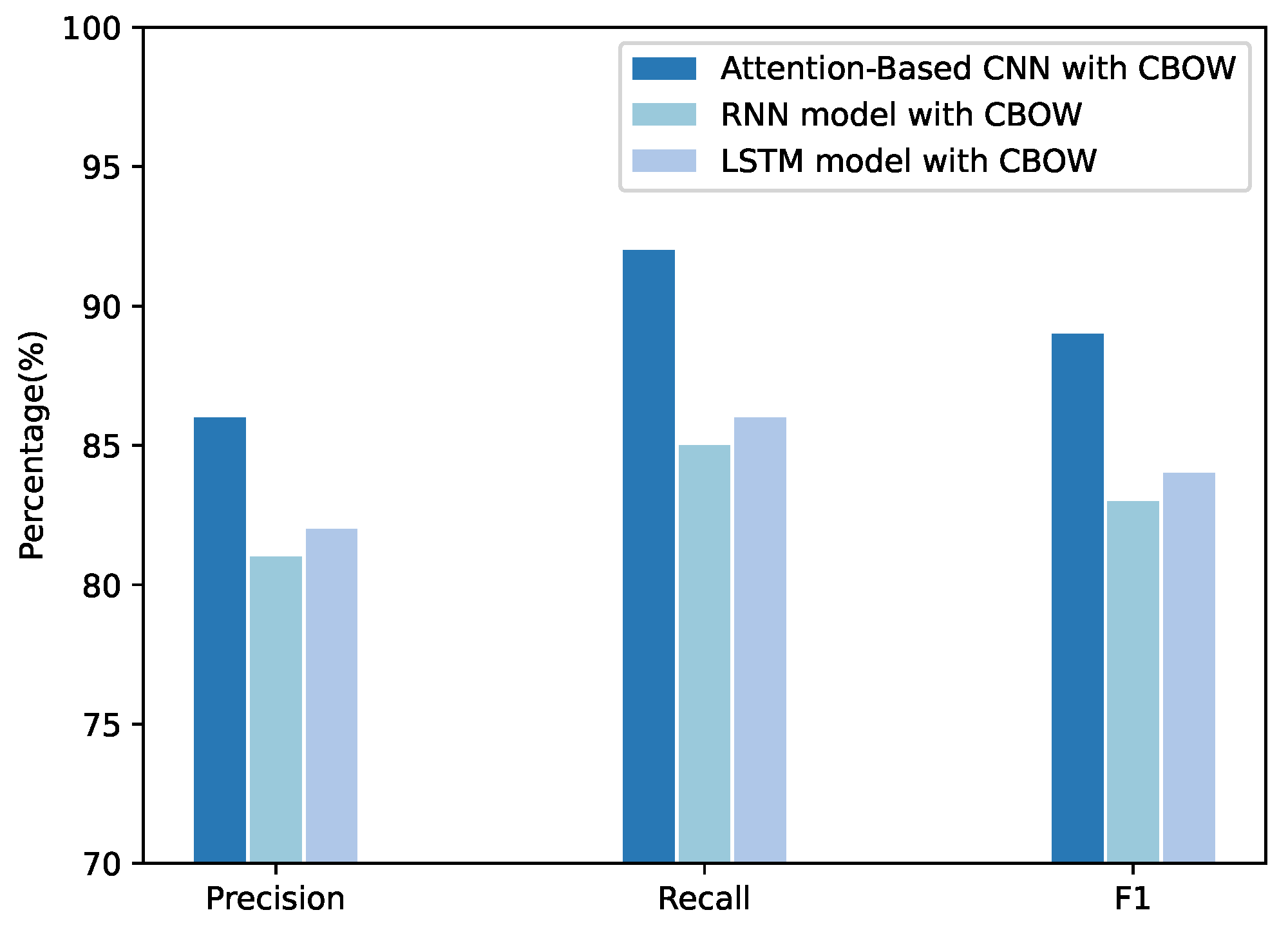
4.3. Attention-Based CNN Experiments
4.3.1. Dataset and Experimental Setup
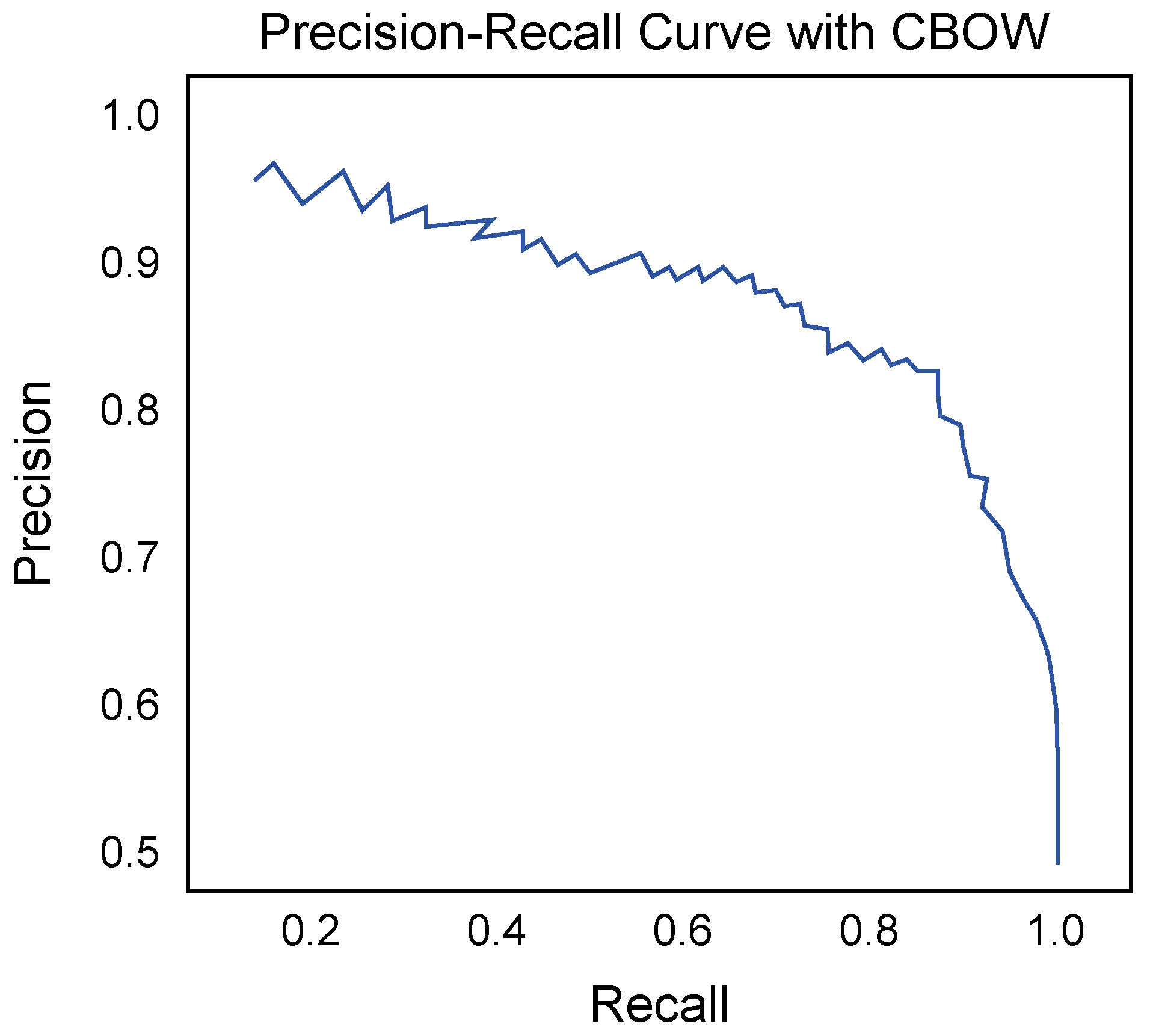
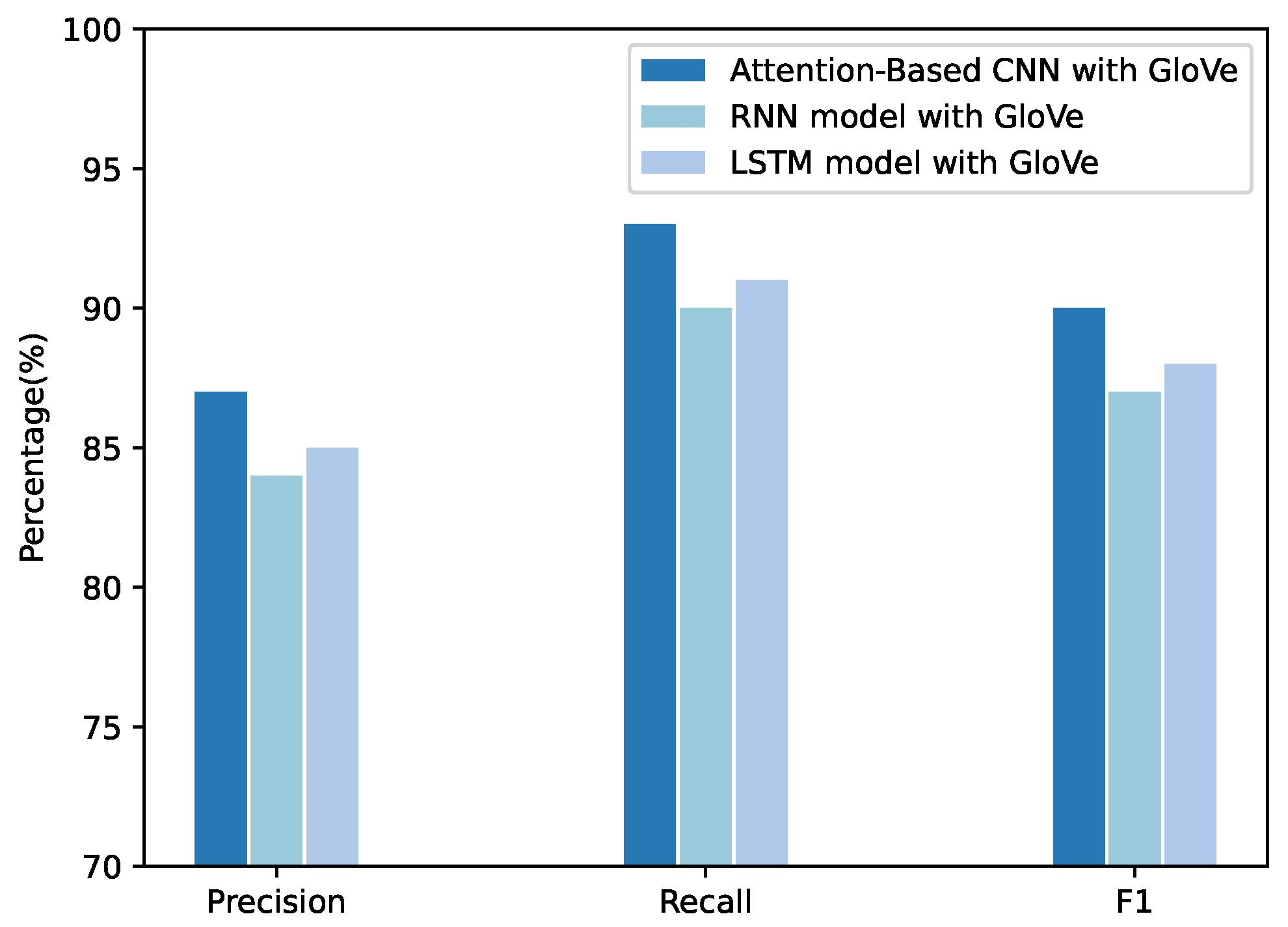
4.3.2. Experimental Results
4.4. GAT and LLM–Based Vulnerability Relation Prediction
4.4.1. Dataset and Experimental Setup
4.4.2. Evaluation Metrics
4.4.3. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xue, R.; Tang, P.; Fang, S. Prediction of computer network security situation based on association rules mining. Wirel. Commun. Mob. Comput. 2022, 2022, 1–9. [Google Scholar] [CrossRef]
- Zeng, Z.R.; Peng, W.; Zeng, D.; Chen, Y. Intrusion detection framework based on causal reasoning for DDoS. J. Inf. Secur. Appl. 2022, 65, 103124. [Google Scholar] [CrossRef]
- Yu, D.; Zhu, C.; Yang, Y.; Zengmm, M. Jaket: Joint pre-training of knowledge graph and language understanding. In Proceedings of the 36th AAAI Conference on Artificial Intelligence, Virtual Event, 22 February–1 March 2022; pp. 11630–11638. [Google Scholar]
- Zhao, X.; Jiang, R.; Han, Y.; Li, A.; Peng, Z. A survey on cybersecurity knowledge graph construction. Comput. Secur. 2024, 136, 103524. [Google Scholar] [CrossRef]
- Jiao, J.; Li, W.; Guo, D. The Vulnerability Relationship Prediction Research for Network Risk Assessment. Electronics 2024, 13, 3350. [Google Scholar] [CrossRef]
- Rastogi, N.; Dutta, S.; Zaki, M.J.; Gittens, A.; Aggarwal, C. Malont: An ontology for malware threat intelligence. In Proceedings of the International Workshop on Deployable ML for Security Defense, Virtual Event, 24 August 2020; pp. 28–44. [Google Scholar]
- Zhao, J.; Yan, Q.; Li, J.; Shao, M.; He, Z.; Bo Li, B. TIMiner: Automatically extracting and analyzing categorized cyber threat intelligence from social data. Comput. Secur. 2020, 95, 101867. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Z.; Huang, C.; Liu, J.; Jing, W.; Wang, Z.; Wang, Y. CyberRel: Joint entity and relation extraction for cybersecurity concepts. In Proceedings of the 23rd International Conference on Information and Communications Security (ICICS), Part I, Chongqing, China, 19–22 August 2021; pp. 447–463. [Google Scholar]
- Bouarroudj, W.; Boufaida, Z.; Bellatreche, L. Named entity disambiguation in short texts over knowledge graphs. Knowl. Inf. Syst. 2022, 64, 325–351. [Google Scholar] [CrossRef]
- Mahdisoltani, F.; Biega, J.; Suchanek, F.M. YAGO3: A Knowledge Base from Multilingual Wikipedias. In Proceedings of the 9th Biennial Conference on Innovative Data Systems Research (CIDR), Asilomar, CA, USA, 6–9 January 2013. [Google Scholar]
- Can, O.; Unalır, M.Ö.; Sezer, E.; Akar, G. An Ontology Based Approach for Host Intrusion Detection Systems. In Proceedings of the Metadata Semantic Research: 11th Int. Conf. MTSR 2017, Tallinn, Estonia, 28 November–1 December 2017; pp. 80–86. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774.
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Zhang, J.; Bu, H.; Wen, H.; Liu, Y.; Fei, H.; Xi, R.; Li, L.; Yang, Y.; Zhu, H.; Meng, D. When LLMs meet cybersecurity: A systematic literature review. Cybersecurity 2025, 8, 55. [Google Scholar] [CrossRef]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A nucleus for a web of open data. In Proceedings of the 6th International Semantic Web Conference, Busan, Korea, 11–15 November 2007; pp. 722–735. [Google Scholar]
- Vrandečić, D. Wikidata: A new platform for collaborative data collection. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 1063–1064. [Google Scholar]
- Färber, M.; Bartscherer, F.; Menne, C.; Rettinger, A. Linked Data Quality of DBpedia, Freebase, OpenCyc, Wikidata, and YAGO. Semant. Web 2018, 9, 77–129. [Google Scholar] [CrossRef]
- Xu, B.; Xu, Y.; Liang, J.; Xie, C.; Liang, B.; Cui, W.; Xiao, Y. CN-DBpedia: A never-ending Chinese knowledge extraction system. In Proceedings of the 30th International Conference on Industrial Engineering and Other Applications of Applied Intelligent Systems, Arras, France, 27–30 June 2017; pp. 428–438. [Google Scholar]
- Jia, Y.; Qi, Y.; Shang, H.; Jiang, R. A Practical Approach to Constructing a Knowledge Graph for Cybersecurity. Engineering 2018, 4, 53–60. [Google Scholar] [CrossRef]
- Sun, Y.; Lin, D.; Song, H.; Yan, M.; Cao, L. A Method to Construct Vulnerability Knowledge Graph based on Heterogeneous Data. In Proceedings of the 16th International Conference on Mobility, Sensing and Networking (MSN), Tokyo, Japan, 17–19 December 2020. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; Garcia-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-Relational Data. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 26. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the 28th AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014; Volume 28, p. 1. [Google Scholar]
- Yin, J.; Chen, G.; Hong, W.; Wang, H.; Cao, J.; Miao, Y. Empowering Vulnerability Prioritization: A Heterogeneous Graph-Driven Framework for Exploitability Prediction. In Proceedings of the 24th International Conference on Web Information Systems Engineering–WISE 2023, Melbourne, VIC, Australia, 25–27 October 2023; pp. 289–299. [Google Scholar]
- Yue, P.; Tang, H.; Li, W.; Zhang, W.; Yan, B. MLKGC: Large Language Models for Knowledge Graph Completion Under Multimodal Augmentation. Mathmatics 2025, 13, 1463. [Google Scholar] [CrossRef]
- Han, Z.; Li, X.; Liu, H.; Sun, F.; Zhang, N. Deepweak: Reasoning Common Software Weaknesses via Knowledge Graph Embedding. In Proceedings of the IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER), Campobasso, Italy, 20–23 March 2018; pp. 456–466. [Google Scholar]
- Wei, Y.; Huang, Q.; Zhang, Y.; Kwok, J.T. KICGPT: Large Language Model with Knowledge in Context for Knowledge Graph Completion. In Proceedings of the Findings ACL EMNLP 2023, Singapore, 6–10 December 2023; pp. 8667–8683. [Google Scholar]
- Cheng, X.; Sun, X.; Bo, L.; Wei, Y. KVS: A tool for knowledge-driven vulnerability searching. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), Singapore, 14–18 November 2022; pp. 1731–1735. [Google Scholar]
- Guo, Y.; Liu, Z.; Huang, C.; Wang, N.; Min, H.; Guo, W.; Liu, J. A Framework for Threat Intelligence Extraction and Fusion. Comput. Secur. 2023, 132, 103371. [Google Scholar] [CrossRef]
- Host, A.M.; Lison, P.; Moonen, L. Constructing a Knowledge Graph from Textual Descriptions of Software Vulnerabilities in the National Vulnerability Database. arXiv 2023, arXiv:2305.00382. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Sorokoletova, O.; Antonioni, E.; Colò, G. Towards a scalable AI-driven framework for data-independent Cyber Threat Intelligence Information Extraction. arXiv 2025, arXiv:2501.06239. [Google Scholar]
- Wang, J.; Zhu, T.; Xiong, C.; Chen, Y. MultiKG: Multi-Source Threat Intelligence Aggregation for High-Quality Knowledge Graph Representation of Attack Techniques. arXiv 2024, arXiv:2411.08359. [Google Scholar]
- Wåreus, E.; Hell, M. Automated CPE Labeling of CVE Summaries with Machine Learning. In Proceedings of the Detection of Intrusions and Malware, and Vulnerability Assessment: 17th Int. Conf. DIMVA 2020, Lisbon, Portugal, 24–26 June 2020; pp. 3–22. [Google Scholar]
- Wu, H.; Li, X.; Gao, Y. An Effective Approach of Named Entity Recognition for Cyber Threat Intelligence. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; Volume 1, pp. 1370–1374. [Google Scholar]
- Ma, P.; Jiang, B.; Lu, Z.; Xue, M.; Shi, X. Cybersecurity Named Entity Recognition Using Bidirectional Long Short-Term Memory with Conditional Random Fields. Tsinghua Sci. Technol. 2020, 26, 259–265. [Google Scholar] [CrossRef]
- Wang, X.; El-Gohary, N. Deep Learning-Based Relation Extraction and Knowledge Graph-Based Representation of Construction Safety Requirements. Autom. Constr. 2023, 147, 104696. [Google Scholar] [CrossRef]
- Geng, Z.; Chen, G.; Han, Y.; Liu, X.; Shi, C. Semantic Relation Extraction Using Sequential and Tree-Structured LSTM with Attention. Inf. Sci. 2020, 509, 183–192. [Google Scholar] [CrossRef]
- Li, Q.; Chen, Z.; Ji, C.; Jiang, S.; Li, J. LLM-based Multi-Level Knowledge Generation for Few-Shot Knowledge Graph Completion. In Proceedings of the 33rd International Joint Conference on Artificial Intelligence (IJCAI 2024), Yokohama, Japan, 3–9 August 2024; pp. 2135–2143. [Google Scholar]
- Li, Y.; Yang, Y.; Zhu, J.; Chen, H.; Wang, H. LLM-Empowered Few-Shot Node Classification on Incomplete Graphs with Real Node Degrees. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM), Boise, ID, USA, 18–22 October 2024. [Google Scholar]
- Wen, M.; Mei, H.; Wang, W.; Zhang, X. Enhanced Temporal Knowledge Graph Completion via Learning High-Order Connectivity and Attribute Information. Appl. Sci. 2023, 13, 12392. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware Component | Specification |
|---|---|
| Operating System | Ubuntu 22.04.1 LTS |
| Processor | Intel Xeon® Gold 6146 @ 3.20 GHz |
| Memory | 128 GB RAM |
| Storage | 256 GB SSD |
| GPU | NVIDIA GeForce RTX 3090, NVIDIA Corporation, Santa Clara, CA, USA |
| Abbreviation | Definition |
|---|---|
| TP (True Positives) | Number of correctly identified positive samples |
| FP (False Positives) | Number of incorrectly identified positive samples |
| FN (False Negatives) | Number of incorrectly identified negative samples |
| Hyperparameter | Value |
|---|---|
| Dropout rate | 0.5 |
| Word embedding dimension | 300 |
| Position embedding dimension | 50 |
| POS embedding dimension | 15 |
| Optimizer and Epoch | SGD, as set per experiment |
| Relation | Description | Count |
|---|---|---|
| ChildOf | hierarchical child | 1436 |
| ParentOf | hierarchical parent | 1436 |
| CanPrecede | may precede another | 156 |
| CanFollow | may follow another | 220 |
| PeerOf | peer relation | 196 |
| Semantic | semantic similarity | 654 |
| Relation | Description | Count |
|---|---|---|
| BelongOf | CVE → CWE | 3975 |
| AttackOf | CWE → CAPEC | 2486 |
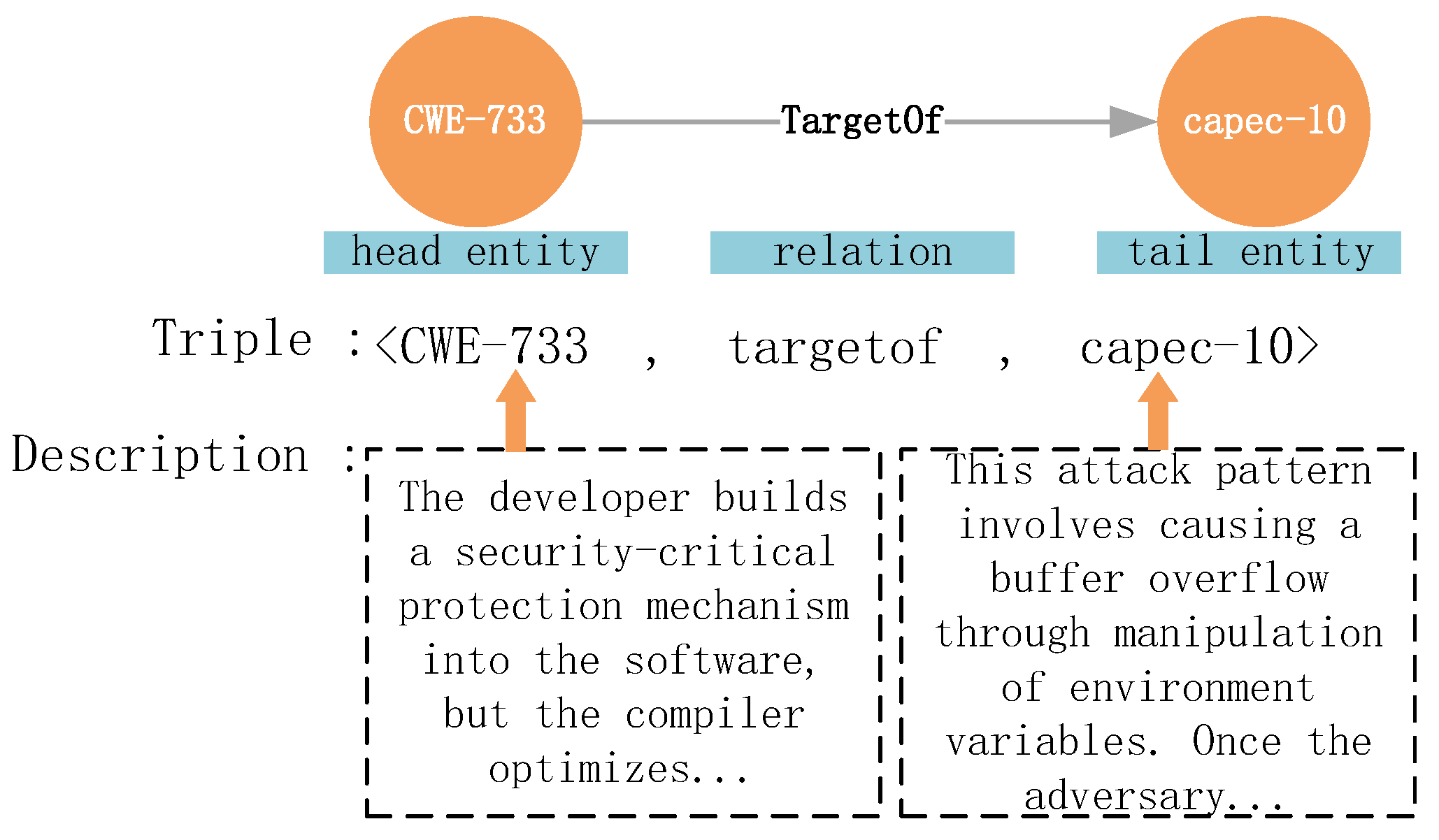
| TargetOf | CWE → CAPEC | 3215 |
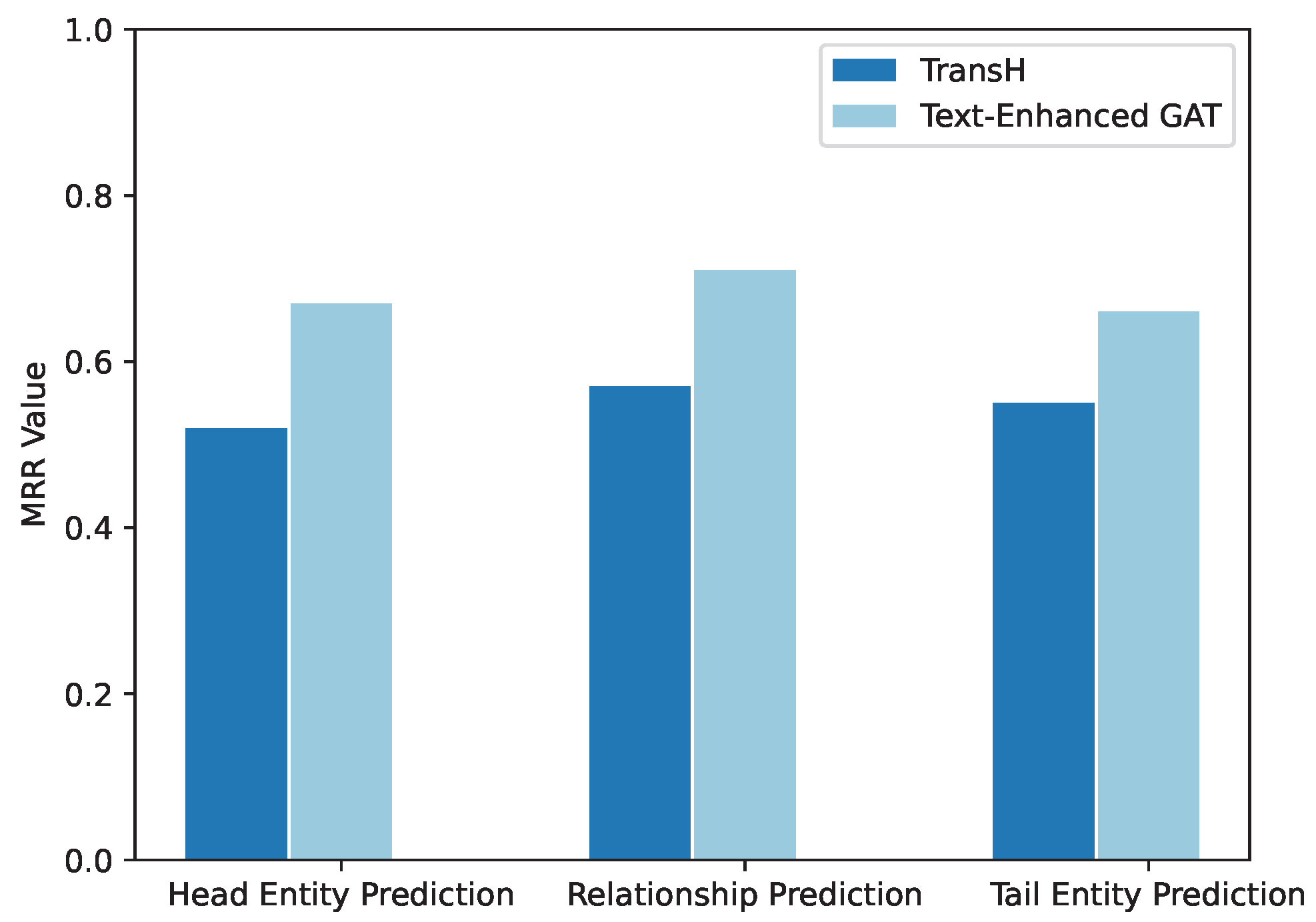
| Prediction | Model | Hits@1 | Hits@3 | Hits@10 |
|---|---|---|---|---|
| Head Entity | TransH | 0.458 | 0.567 | 0.632 |
| Text-Enhanced GAT | 0.588 | 0.632 | 0.726 | |
| Relation | TransH | 0.432 | 0.543 | 0.691 |
| Text-Enhanced GAT | 0.569 | 0.659 | 0.792 | |
| Tail Entity | TransH | 0.451 | 0.581 | 0.612 |
| Text-Enhanced GAT | 0.579 | 0.702 | 0.796 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, R.; Xie, Y.; Dang, Z.; Hao, J.; Quan, X.; Xiao, Y.; Peng, C. Dynamic Vulnerability Knowledge Graph Construction via Multi-Source Data Fusion and Large Language Model Reasoning. Electronics 2025, 14, 2334. https://doi.org/10.3390/electronics14122334
Liu R, Xie Y, Dang Z, Hao J, Quan X, Xiao Y, Peng C. Dynamic Vulnerability Knowledge Graph Construction via Multi-Source Data Fusion and Large Language Model Reasoning. Electronics. 2025; 14(12):2334. https://doi.org/10.3390/electronics14122334
Chicago/Turabian StyleLiu, Ruitong, Yaxuan Xie, Zexu Dang, Jinyi Hao, Xiaowen Quan, Yongcai Xiao, and Chunlei Peng. 2025. "Dynamic Vulnerability Knowledge Graph Construction via Multi-Source Data Fusion and Large Language Model Reasoning" Electronics 14, no. 12: 2334. https://doi.org/10.3390/electronics14122334
APA StyleLiu, R., Xie, Y., Dang, Z., Hao, J., Quan, X., Xiao, Y., & Peng, C. (2025). Dynamic Vulnerability Knowledge Graph Construction via Multi-Source Data Fusion and Large Language Model Reasoning. Electronics, 14(12), 2334. https://doi.org/10.3390/electronics14122334