1. Introduction
During training, a deep neural network (DNN) learns the output probability, which indicates the DNN’s confidence in the results. Some recent work has found that the confidence of a DNN is not consistent with its accuracy [
1,
2,
3]. These works point out that DNNs suffer from overconfidence. An overconfident DNN gives high confidence in wrong predictions. The problem of overconfidence poses a huge challenge to the deployment of DNNs in real-world applications. For example, in health care, criminal justice, and autonomous driving applications, we expect models to have a certain degree of confidence in their predictions in order to make more informed decisions. Confidence calibration not only enhances the model’s ability to generalize and minimizes potential risks but also greatly aids in its interpretability [
4,
5].
Confidence calibration is the process of adjusting the predicted probabilities of a model to better reflect the true likelihood of its predictions being correct [
2,
6]. More formally, a completely calibrated classification model is one in which the probability of the predicted outcome
being equal to the actual outcome
Y is defined as
, where
p falls within the range of
, and
is the model’s associated confidence. It is expected that
will be calibrated, indicating that it accurately reflects an actual probability. An accurately-calibrated classifier is a probabilistic classifier that can be directly interpreted in terms of confidence score through its predicted probability output. To illustrate, a precisely calibrated (binary) classifier that yields 100 samples with a confidence score of
for every prediction indicates that 60 samples will be accurately classified. Confidence calibration refers to a model’s capacity to accurately assign probabilities to its predictions [
7]. In recent years, multiple techniques have been introduced to generate predictive confidence scores through calibration [
2,
8,
9], including post-processing, Bayesian neural networks, and deep ensemble methods. Temperature scaling is a post-processing calibration method proposed by Guo et al. [
2]. The main principle revolves around the utilization of a singular scalar parameter,
, denoting the temperature, to modify the logit score prior to the implementation of the softmax function. The method cannot effectively handle out-of-distribution data because
T is computed on the validation set. The idea behind the Bayesian neural network approach is to infer the probability distribution of the DNN parameters. This distribution is used to sample the parameters for single forward propagation, resulting in random predictions that are influenced by diverse model weights. However, precise Bayesian inference is computationally difficult for neural networks and incurs extremely expensive computational and memory costs [
3].
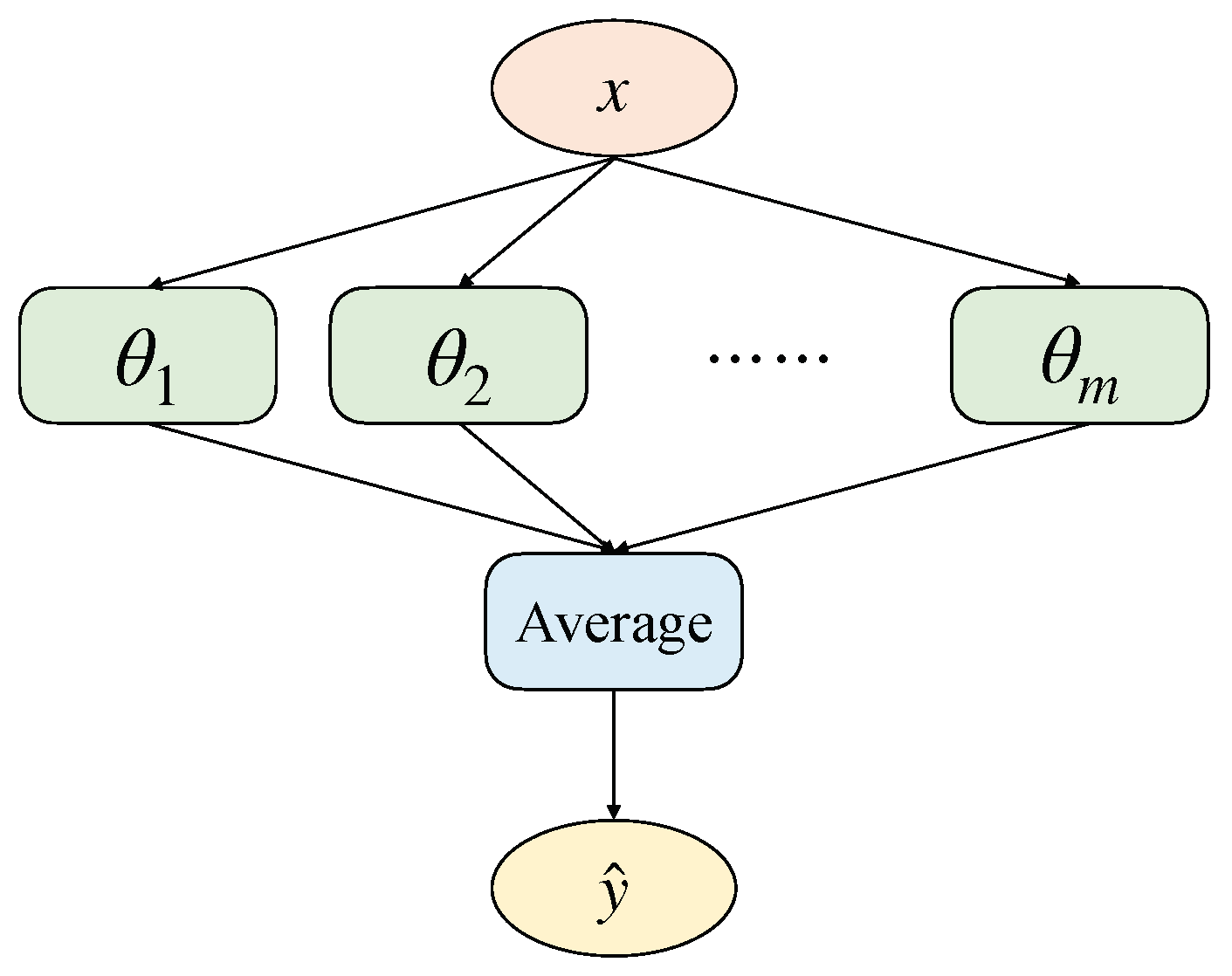
Deep ensemble learning [
10] combines the predictions of several base estimators to reduce the variance of predictions and reduce generalization errors. The concept of ensembling is based on the idea that a group of models can work together to enhance the strengths and minimize the weaknesses of individual base learners. Deep ensembles were originally proposed and discussed to improve the prediction performance of DNNs. In [
11], the authors, through the experimental analysis of several regression and classification tasks, showed that averaging the predictions of ensemble models can also be used to derive useful uncertainty estimates. Moreover, in [
12], deep ensembles were shown to be state-of-the-art for the domain shift (or out-of-distribution) setting. Compared to single-model methods [
2], the computational costs and memory consumption of the deep ensemble approach are significantly higher. Moreover, the additional computations increase linearly with the number of base learners. Some interesting methods, such as distillation, sub-ensembles, and batch ensembles, have been proposed to solve these problems. However, these approaches necessitate substantial changes to the training process and remain costly in regards to both time and computational resources. To overcome these challenges, work in [
13] presented an approximate method to implement an ensemble of models without increasing the training cost. During the training phase, multiple
snapshots of the model are periodically saved, and the predictions from the multiple
snapshots are averaged during the testing phase. Instead of training
M models from scratch, the snapshot ensembles in [
13] were created by changing the learning rate to allow the optimizer to reach the local minimum
M times during the optimization process. In [
14], the study demonstrated that simple curves connect the optima of complex loss functions, with consistent training and test accuracy. Based on this geometric finding, they proposed a new approximate ensembling procedure called fast geometric ensembling (FGE). The FGE algorithm uncovers various networks by taking small steps in the weight space while remaining in a low test error region. FGE allows training of highly effective ensembles in the same amount of time it takes to train a single model. However, these single-model multiple-weight methods were initially proposed to improve the accuracy of the DNN but with little attention paid to confidence in the output. It remains unclear whether these methods are effective in reducing confidence errors.
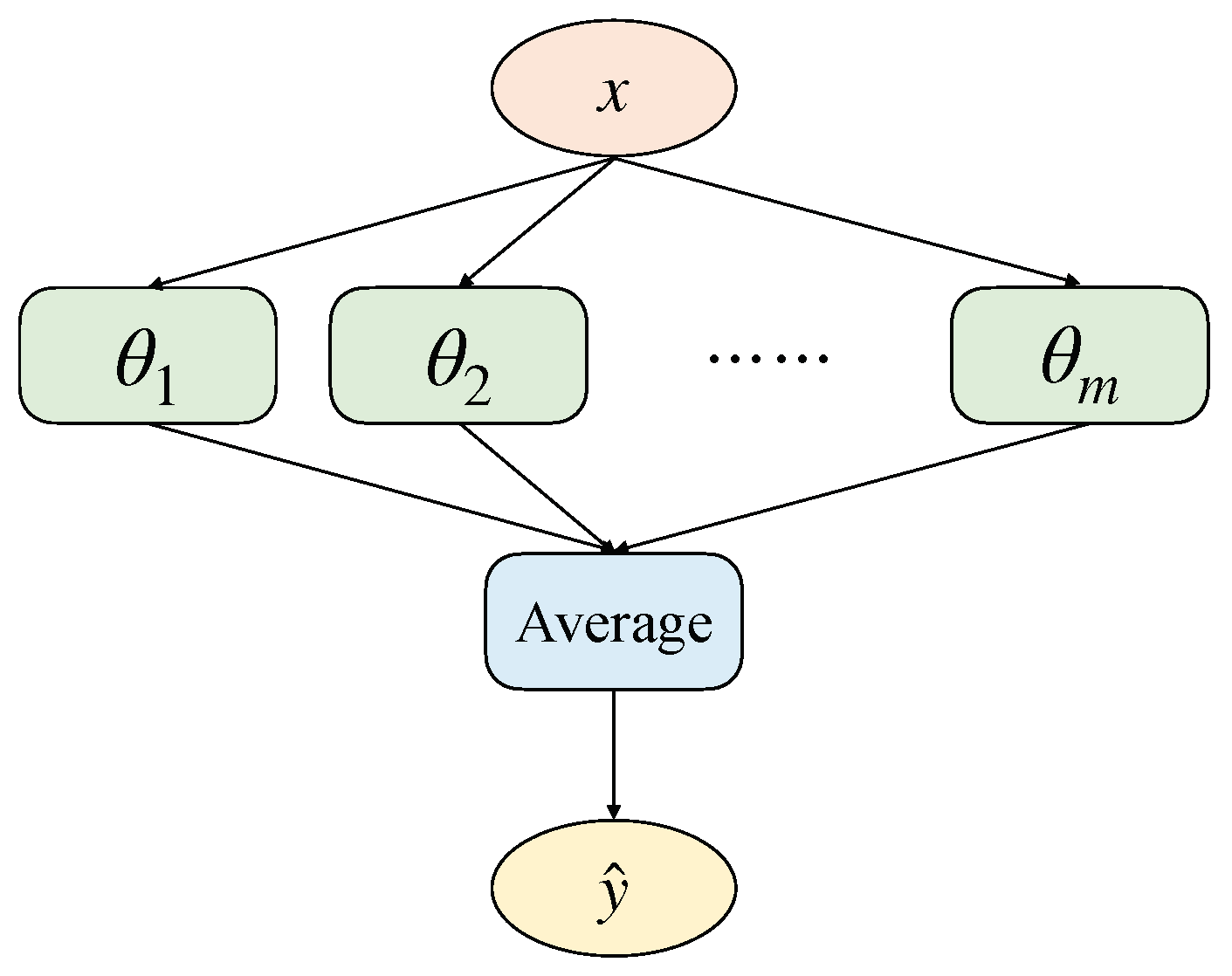
To fill this gap, we propose a confidence calibration method based on stochastic weight averaging. We achieve this by training a single DNN to converge to multiple local minima on the loss surface and to sample and save the model parameters by using a smart strategy. At a high level, the concept of averaging the stochastic gradient descent (SGD) iterations has been around for several decades in the field of convex optimization [
9,
15]. In convex optimization, researchers have primarily focused on optimizing convergence rates by implementing averaged SGD. In deep learning, the use of averaged SGD results in a smoother trajectory for SGD iterations but yields minimal differences in performance. By contrast, we are more concerned in this work with the effect of the method on the calibration error. Multiple locally optimal weights generated in the training phase are specially sampled, and then forward propagation is computed as new parameters for the base learner during the testing phase. We force the optimizer to explore a variety of models rather than converge on just one solution by using a modified learning rate strategy. We use a smart strategy to select relatively more meaningful weights from a large number of candidate weights. To summarize, instead of designing multiple sets of DNNs, the method simply trains a single model to obtain well-calibrated confidence output. We tested our method on two benchmarks with varying modalities, including static images and dynamic videos. Our experimental findings indicate that our method effectively minimizes calibration error and enhances the model’s precision. The code is publicly available at
github.com/zjcao/swaCal (accessed on 22 January 2024).
The main contributions of our work are summarized as follows.
- (1)
We propose an alternate ensemble learning approach to improve the quality of neural network uncertainty measures to overcome overconfidence without incurring additional computational costs.
- (2)
We evaluate our approach using two benchmarks with different modalities: static images and dynamic videos. The results of our experiments demonstrate that our approach successfully reduces calibration error and enhances the model’s accuracy.
The remainder of this paper is structured as follows.
Section 2 discusses related studies on deep ensemble learning and confidence calibration.
Section 3 describes our proposed approach in detail. The experiments and results are presented in
Section 4.
Section 5 is the conclusion and suggests further studies.
4. Experiment Results
We evaluated our approach using two benchmark datasets with different modalities: static images and dynamic videos. In both cases, we followed standard training, validation, and testing protocols. We evaluated the quality of the confidence score estimation and the accuracy of the prediction. We show across two different datasets that our method improves confidence scores without reducing classification error.
4.1. Evaluation Calibration Quality
Before showing experiments to recalibrate the classifier, the metrics for evaluating the effectiveness of the calibration of the classifier need to be presented. Proper scoring rules measure the quality of predictive uncertainty. A scoring rule assigns a numerical score to a predictive distribution,
, rewarding better-calibrated predictions over worse ones. Negative log-likelihood (NLL) is a popular and proper scoring rule for multi-class classification tasks when measuring the accuracy of predicted probabilities. Given probabilistic model
and
n samples, NLL is defined as follows:
In the field of deep learning, NLL is also known as cross-entropy loss. In this work, we use NLL as a training criterion.
To quantify the quality of the given model’s confidence calibration, we use the following evaluation metrics: expected calibration error (ECE), maximum calibration error (MCE), and root mean square calibration error (RMSCE) [
24]. ECE measures the correspondence between the probability and the accuracy of the prediction. It is computed as the average gap between within-bin accuracy, and within-bin predicted probability for
m bins and can be expressed as follows:
where
indicates the fraction of data points in bin
i,
presents the average accuracy in bin
i, and
indicates the average confidence in bin
i.
In contrast to evaluation metrics, reliability diagrams are a visual representation of the quality of the model’s confidence calibration. It plots the true frequency of a classifier’s correctly classified labels against the predicted probability. Note that if a DNN is perfectly calibrated, the diagram should plot the identity function.
4.2. Application 1: Gesture Recognition Task
Computers can interpret human gestures as commands through gesture recognition, which is a form of perceptual computing user interface. The main objective of gesture recognition is to categorize a gesture video clip into a specific action group. Gesture recognition technology is highly applicable in various industries, including robot control, autonomous driving, and virtual reality. The gesture recognition model should not only correctly understand the command of the gesture but should also have a certain confidence in the prediction. Unlike static images, the uncertainty of the deep learning model on dynamic video is usually more difficult to capture. To evaluate the effectiveness of our method more comprehensively, we first tested it on a video-based gesture recognition dataset. A precisely calibrated gesture recognition system functions as a probabilistic classifier, allowing for the direct interpretation of the predicted probability output as a confidence score. This probability gives a certain level of confidence in the prediction.
The publicly available Jester dataset [
25] was used to asses the proposed method. It contains 148,092 videos of people making standard hand gestures in front of a laptop or webcam. We split the dataset into two categories (a closed set and an open set) and proceeded to create smaller sets by randomly selecting data from the closed set at a ratio of approximately 1:4. There are 20 class gestures within the closed mini-datasets, with a split of 8:1:1 for training, validation, and testing. The training, validation, and testing sets contain 22,000, 2400, and 2240 gesture samples, respectively. We trained, validated, and tested all models on the closed Jester mini-dataset in this study.
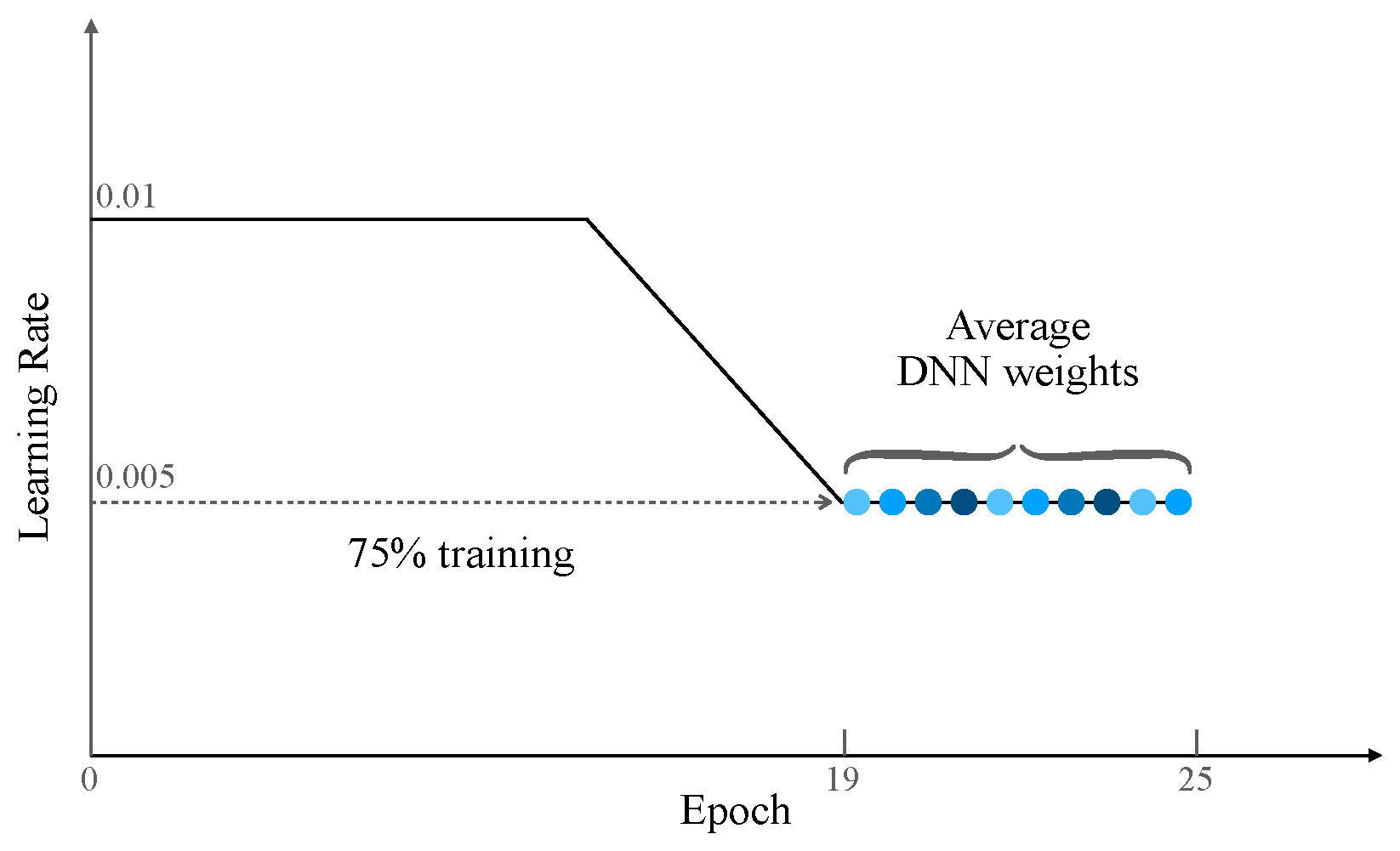
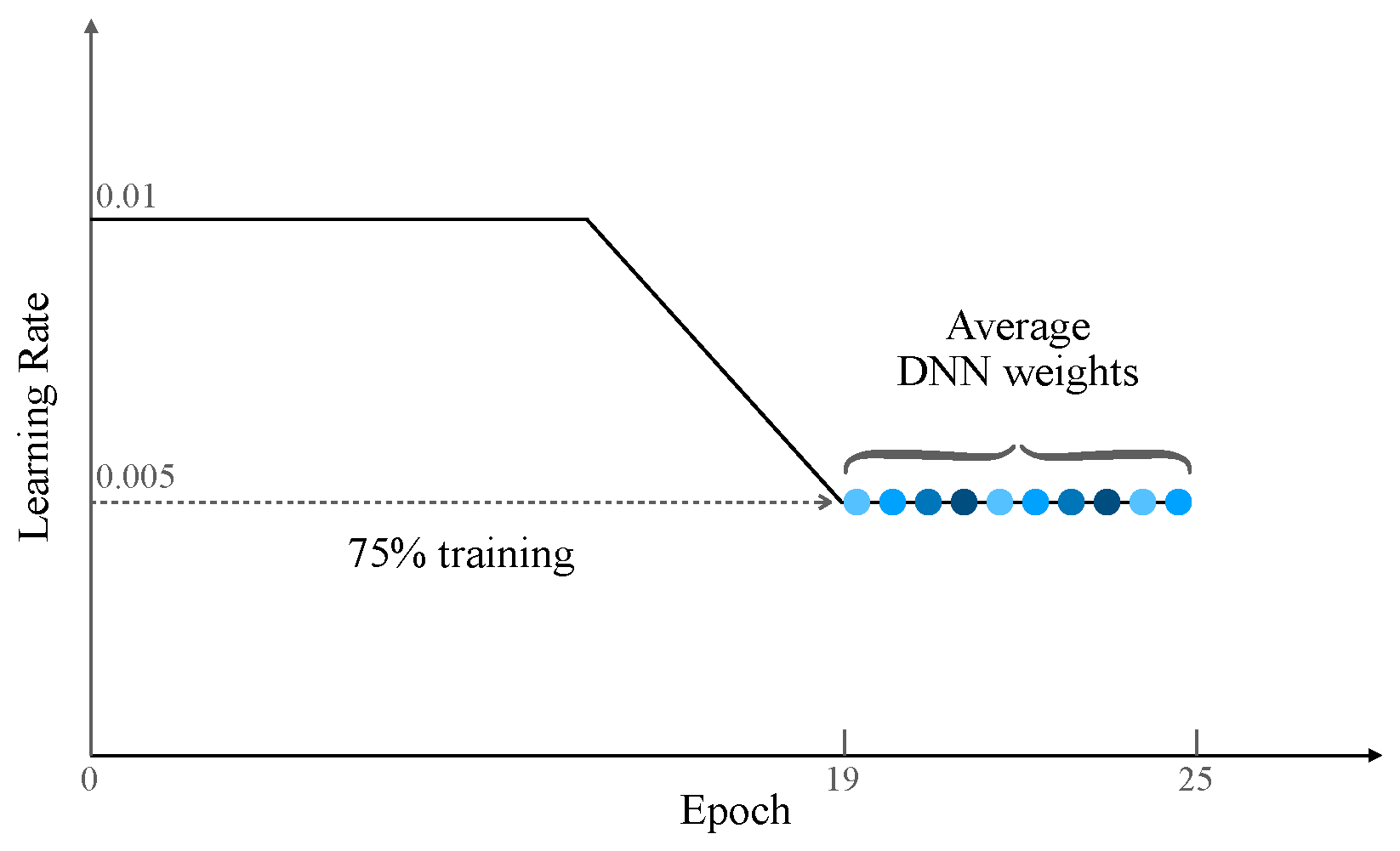
We utilized the PyTorch 2.1 deep learning framework to implement the proposed network. The training and validation were conducted on a server containing four NVIDIA GeForce RTX 3090 GPUs. In our study, we employed a 3D ResNet-18 model that was initially trained on Kinetics-400. We then proceeded to fine-tune this model using the Jester training set. We utilized SGD with a momentum of
as the optimizer and conducted training on the model for 25 epochs with a batch size of 16. Following the settings from [
15], during the first
of training, we adopted the standard decaying learning rate strategy, followed by a consistent and high learning rate for the remaining
(as shown in
Figure 3). The use of a modified learning rate scheme is expected to keep the optimizer bouncing around the optimum, exploring different models rather than simply converging to a single solution. Our model obtained
accuracy on the training set at the 25th epoch, with a corresponding cross-entropy loss of approximately
. At the same time, the validation set achieved its best rate of
at the 21st epoch.
In addition to evaluating the expected calibration error using ECM, MCE, and RMSCE, we also report the accuracy and average confidence in the model’s classifications. The results obtained from the Jester test dataset are summarized in
Table 1. We evaluated our method on multiple scoring functions, including SGD (baseline), MC-Dropout [
16], and Logits-Scaling [
26]. On the Jester test set, our method reduced the ECE error from
to
. Meanwhile, we observed that our method not only significantly reduced ECE and MCE but also improved the prediction accuracy of the model to a certain extent. For example, classification accuracy increased from
to
. The experiment report further illustrates the effectiveness of our method in improving the quality of the confidence estimation from DNNs in gesture recognition tasks.
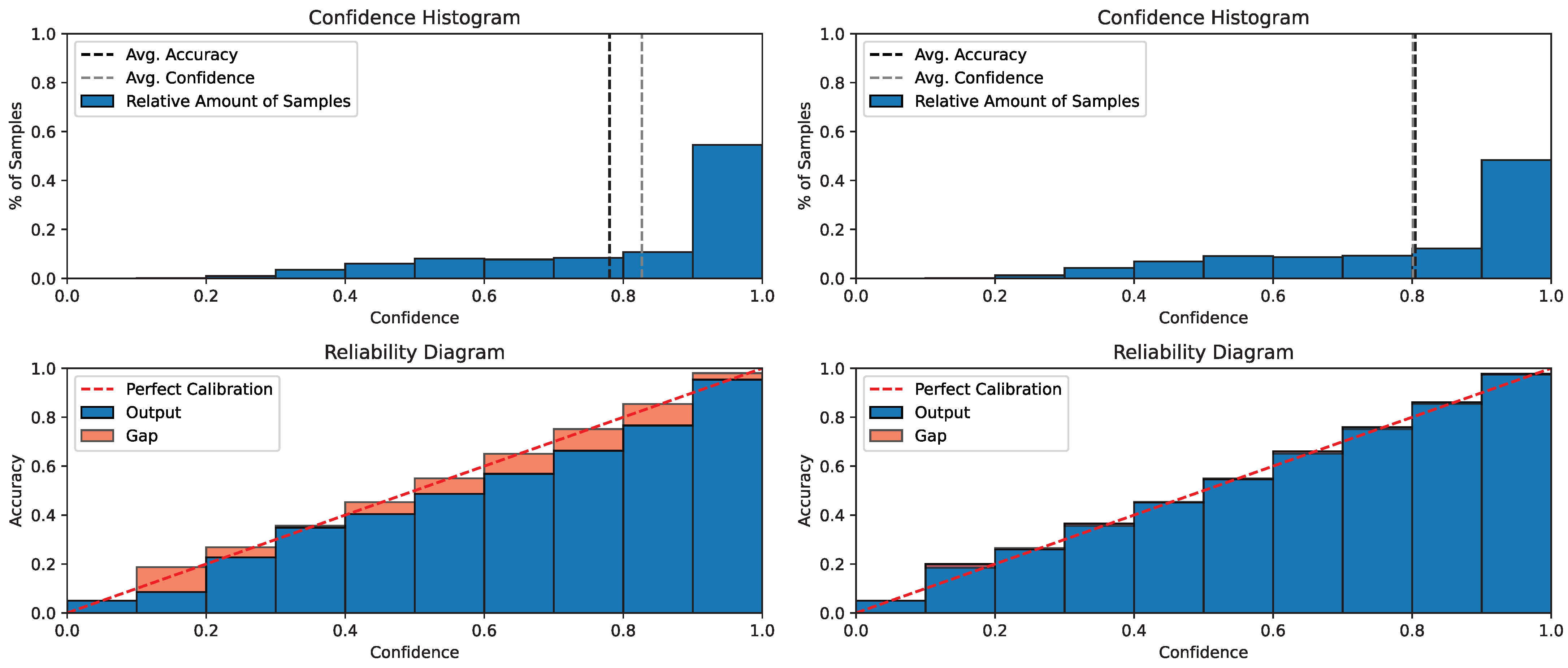
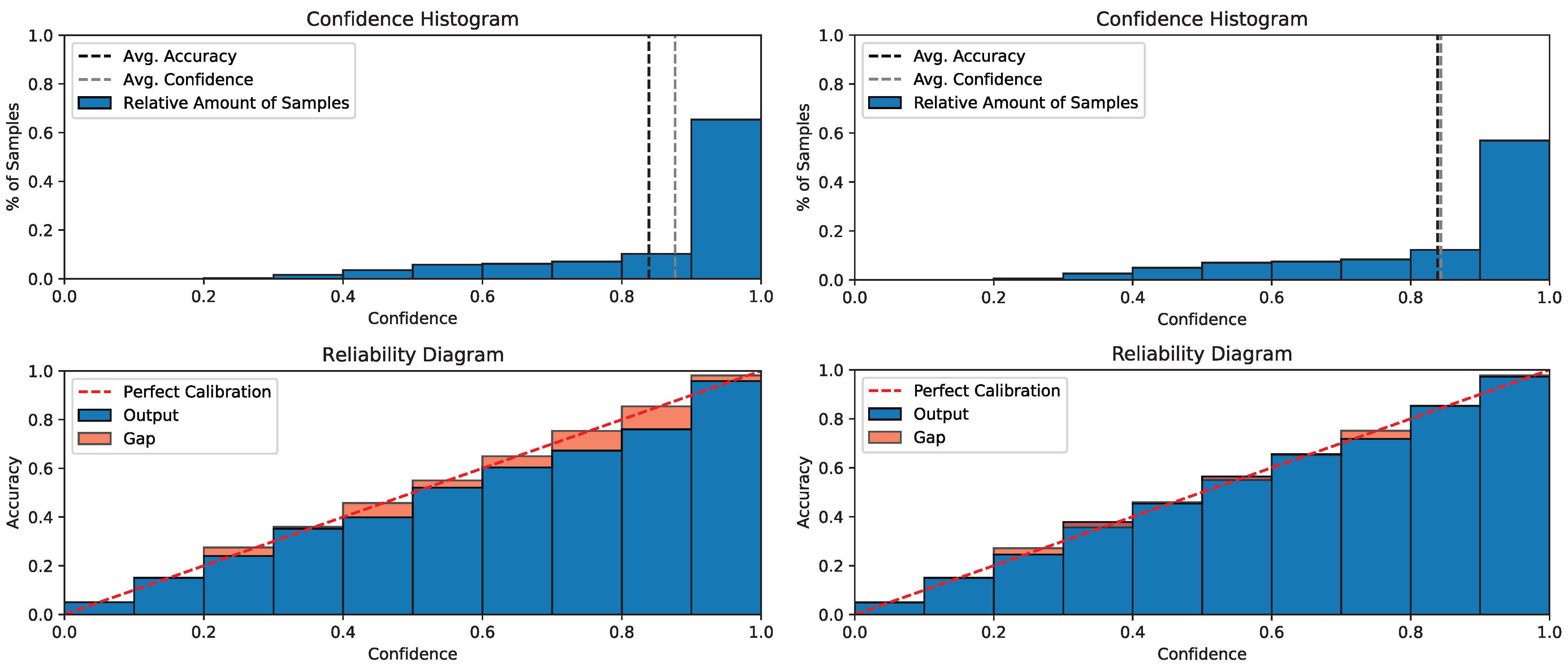
We used visualization to gain an intuitive understanding of the calibration of the predicted probabilities. The reliability diagram illustrates the degree of calibration in the probabilistic predictions of a classifier. The reliability diagram displays the average predicted probability on the
x-axis for each bin, while the
y-axis reflects the fraction of positive samples, indicating the proportion of samples with positive categories in each bin. The diagram should represent the identity function if the model is accurately calibrated. If the diagonal is not perfect, it suggests the model was not calibrated correctly. The comparison diagrams in
Figure 4 show that after using our method, the gap was effectively reduced, and the reliability diagram is closer to an identity function. The upper charts in the figure are visualizations of the average confidence and accuracy, and below them are reliability diagrams.
4.3. Application 2: Image Classification Task
To evaluate the performance of the model in different tasks, we tested our proposed method in an image classification task using the CINIC-10 datasets [
27]. They were compiled by combining CIFAR-10 with images selected and downsampled from the ImageNet database. The CINIC-10 datasets had 270,000 images and were divided into three groups for training, validation, and testing. In each subset, there were 10 categories, each with 90,000 images. We used three architectures that were pre-trained on ImageNet for a backbone network (ResNet-50 [
28], Wide-ResNet-50 [
29], and VGG-16 [
30]), and we then fine-tuned them on the CINIC-10 training set using the transfer learning approach. The experimental setup and training strategy are consistent with those presented in
Section 4.2.
Comparisons of classification accuracy, average confidence, RMSCE, MCE, and ECE of the different architectures and methods on the CINIC-10 test set are summarized in
Table 2. We evaluated our method using the same scoring function as in
Section 4.2, including: SGD (baseline), MC-Dropout [
16], and Logits-Scaling [
26]. We observed that the VGG16-based architecture yielded the best confidence calibration, with improved classification accuracy. The other two architectures significantly improved accuracy by about
on average, compared with the SGD optimization approach. Comparative results demonstrate that our approach decreases the model’s calibration error while also increasing its accuracy.
The MC-dropout method can be viewed as an approximation of Bayesian neural networks. The method requires modification of the original network architecture and in the testing phase. It is also necessary to perform multiple forward propagation and average multiple predictions during the testing phase. In contrast, our method can be regarded as a trainable method. There is no need to modify the model structure, and only one forward propagation is required in the test phase, which greatly reduces the inference time. The Logits-scaling method requires recalculating a hyperparameter T based on the validation set after training and using T to modify the output of softmax during inference on new inputs. An obvious shortcoming of this method is that it is very dependent on data sets and has relatively less generality.
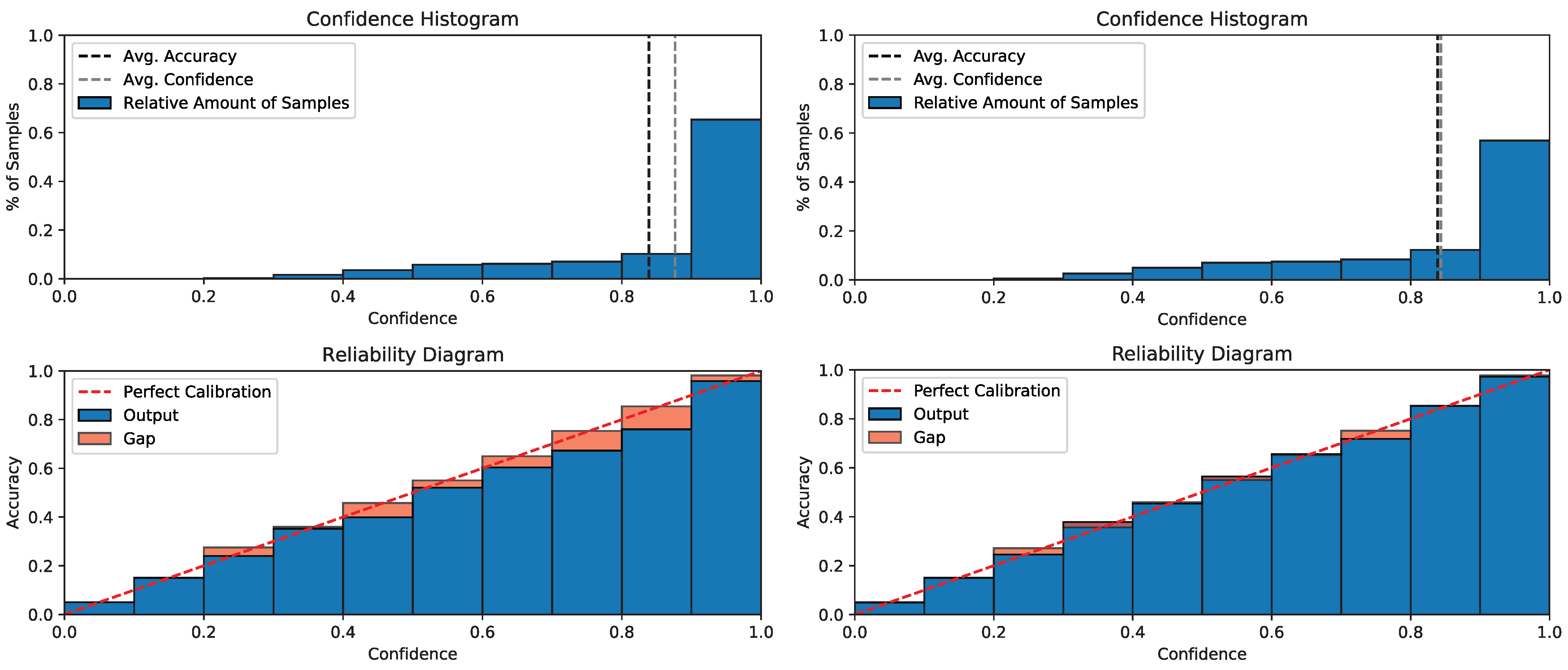
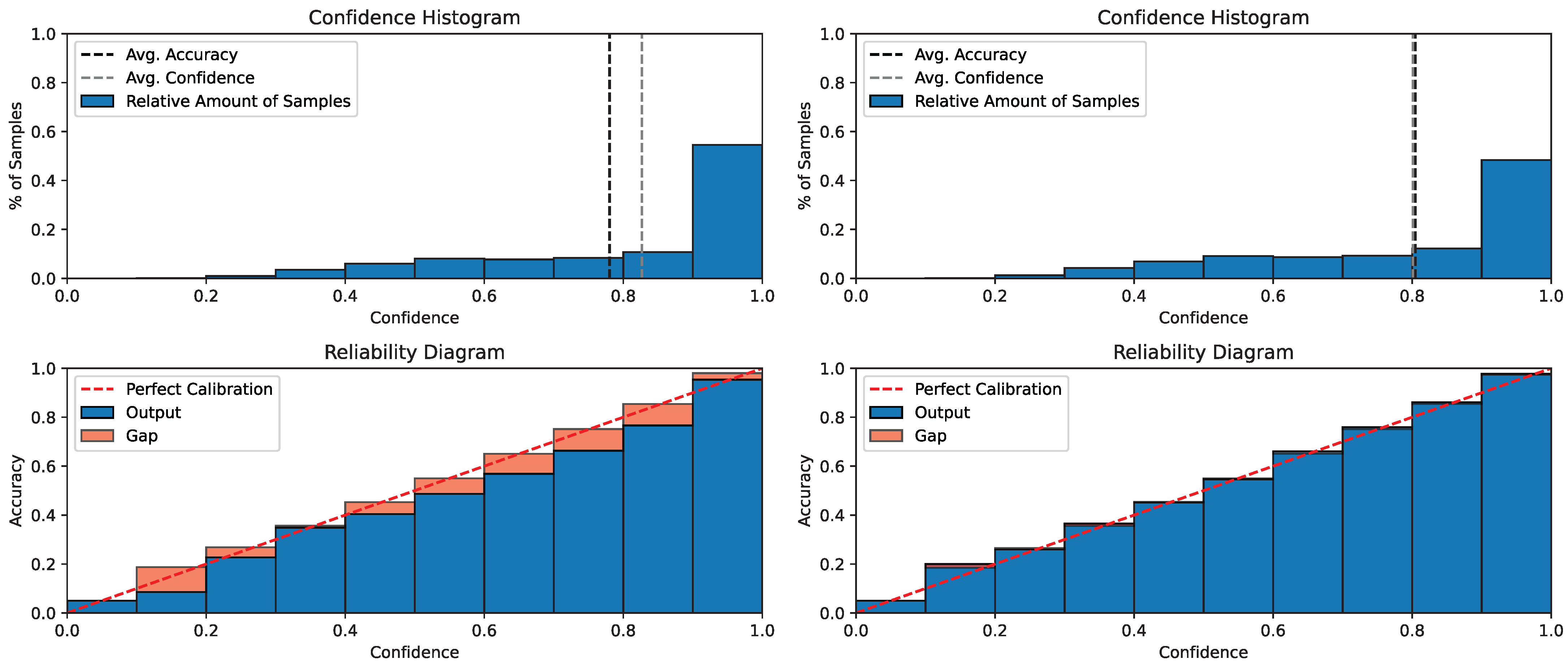
To visualize the calibration effect of our method on the CINIC-10 dataset, we also visualized the calibration curves. The reliability diagram before and after confidence calibration is shown in
Figure 5. The red dashed line indicates the best calibration, where the output confidence precisely reflects the accuracy. In the confidence histogram (upper left), we observe a large gap between the mean confidence and the confidence; while in the upper right graph (our method), we can see that this gap is greatly reduced. Comparing the left and right reliability diagrams, we can also visualize that our approach is closer to the red dashed line. These results are consistent with what we observed in application 1 in
Section 4.2.
5. Discussion and Future Work
We believe that there are three important factors that make our proposed approach work. First, our method uses a modified learning rate schedule. This allows the optimizer to continuously explore the optimal weights for high performance rather than just reaching or limiting itself to a single solution. For example, we use a standard decaying learning rate strategy for the first 75% of iterations, and a cyclical learning rate for the remaining 25% of iterations. Second, we choose to save the corresponding model weights when the learning rate decays to its lowest value rather then saving model weights according to the validation accuracy. Note that we are using a cyclical learning rate, so the learning rate will decay to the lowest value multiple times; that is, we obtain multiple sets of model weight parameters. The third is to average the model weight parameters traversed by the optimizer. The key idea behind this is to leverage deep learning’s unique training objectives flatness [
14] to improve generalization and reduce overconfidence.
DNNs are usually learned through a stochastic training algorithm, which means the DNN is sensitive to the training data and may learn a different set of weights at the end of the training session, resulting in different predictions. The goal of machine learning is to develop methods and algorithms to learn from the data; that is, extract the residing information from the data. In fact, learning parameters from data is an inverse problem; we need to infer the cause (parameters) from the result (observed data). In this work, we proposed an approximate deep ensemble method to calibrate the confidence of DNNs. The ambiguity in target y for a given x was captured by obtaining a probabilistic model with appropriate scoring rules. In addition, the approximate combination of ensembles was used to predict the output for x in an attempt to capture model uncertainty. Through experiments on two benchmark datasets for image classification and gesture recognition, we demonstrated that our method obtained well-calibrated confidence estimates. Removing correlations from individual network predictions to promote ensemble diversity and further improve performance is left to future work. It would be meaningful to refine multiple ensemble models into a simpler single model to obtain a model with good confidence calibration.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}