



Analysis of Function Approximation and Stability of General DNNs in Directed Acyclic Graphs Using Un-Rectifying Analysis



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
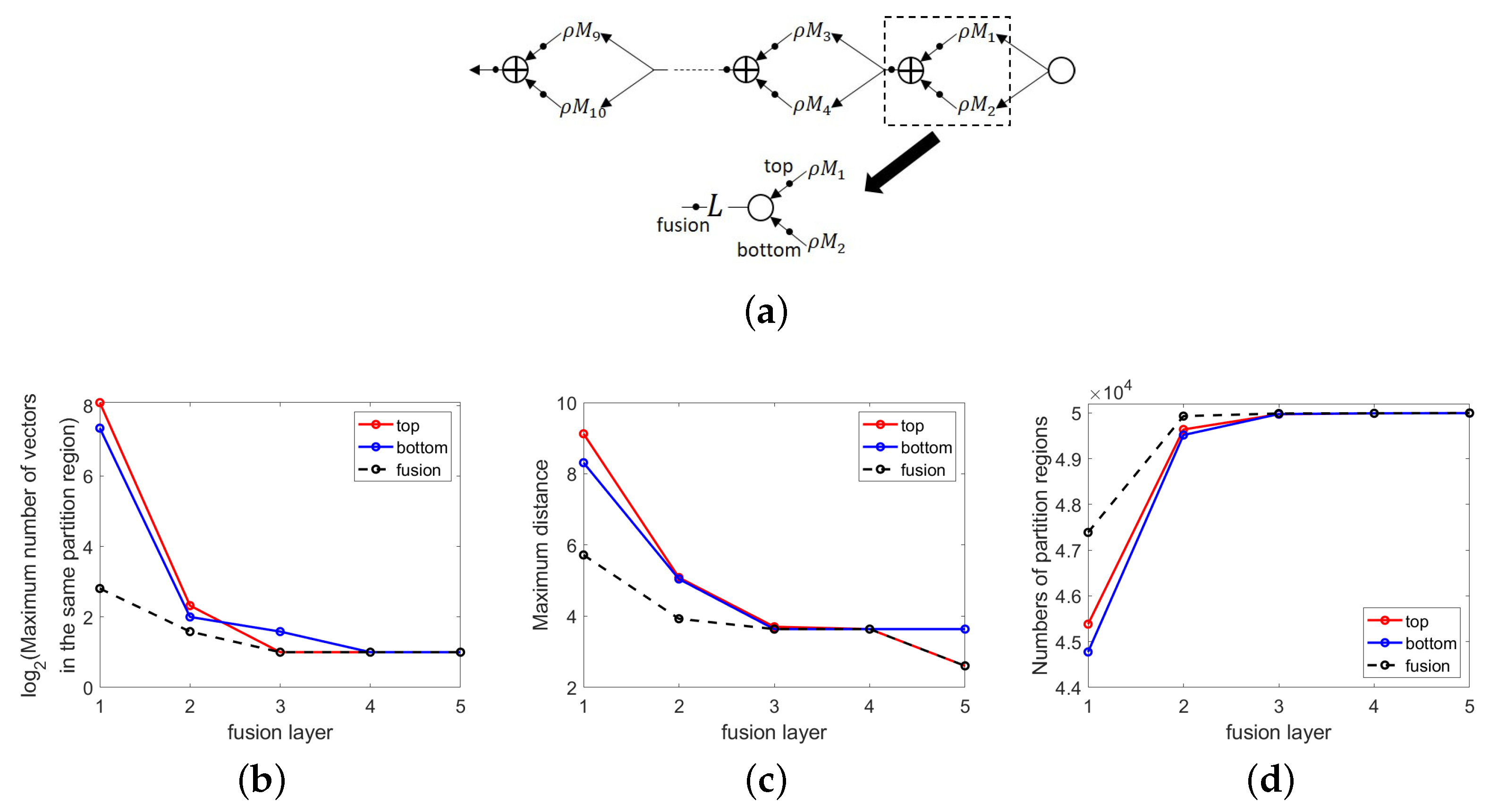
- A DNN DAG divides the input space via partition refinement using either a composition of activation functions along a path or a fusion operation combining inputs from more than one path in the graph. This makes it possible to approximate a target function in a coarse-to-fine manner by applying a local approximating function to each partitioning region in the input space. Furthermore, the fusion operation means that domain partition tends not to be a tree-like process.
- Under mild assumptions related to point-wise CPWL activation functions and non-linear transformations, the stability of a DNN against local input perturbations can be maintained using sparse/compressible weight coefficients associated with incident arcs to a node.
2. Related Works
Un-Rectifying Analysis
3. DNNs and DAG Representations
3.1. Activation Functions and Non-Linear Transformations
- (A1)
- can be expressed as (16).
- (A2)
- There exists a bound that for any activation function () regardless of input (). This corresponds to the assumption that
- (A3)
- There exists a uniform Lipschitz constant bound () with respect to norm for any non-linear transformation function () and any inputs ( and ) in :
3.2. Proposed Axiomatic Method
- O1.
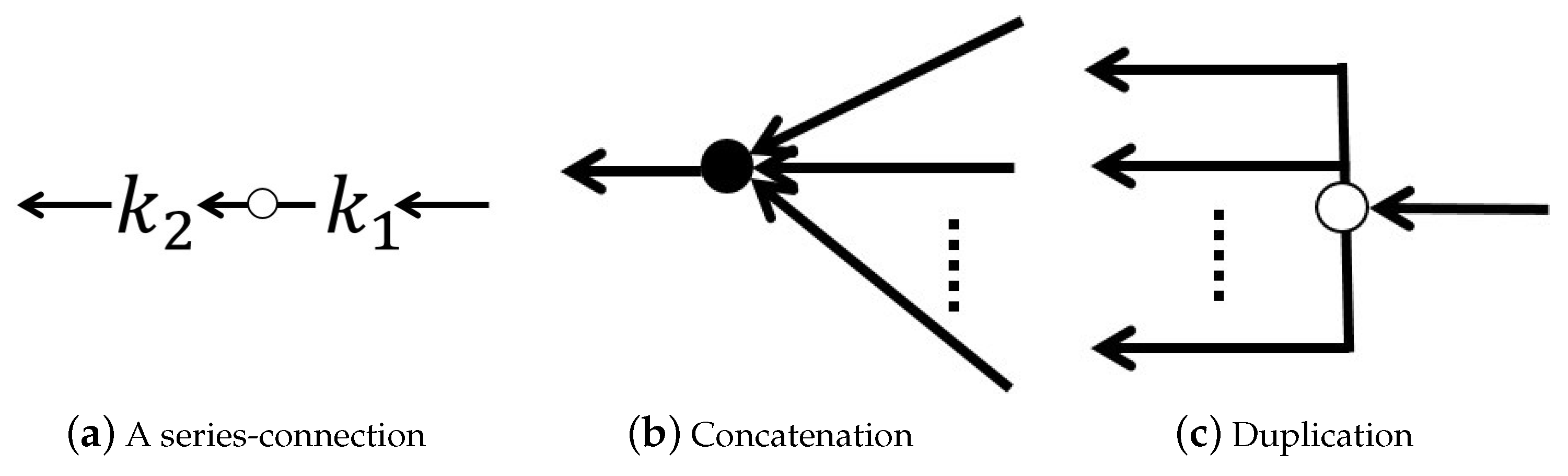
- Series connection (∘): We combine and by letting the output of be the input of , where
- O2.
- Concatenation: We combine multichannel inputs into a vector as follows:
- O3.
- Duplication: We duplicate an input to generate m copies of itself as follows:
- R.
- DAG closure: We apply O1–O3 to in accordance with
3.3. Useful Modules
- (i)
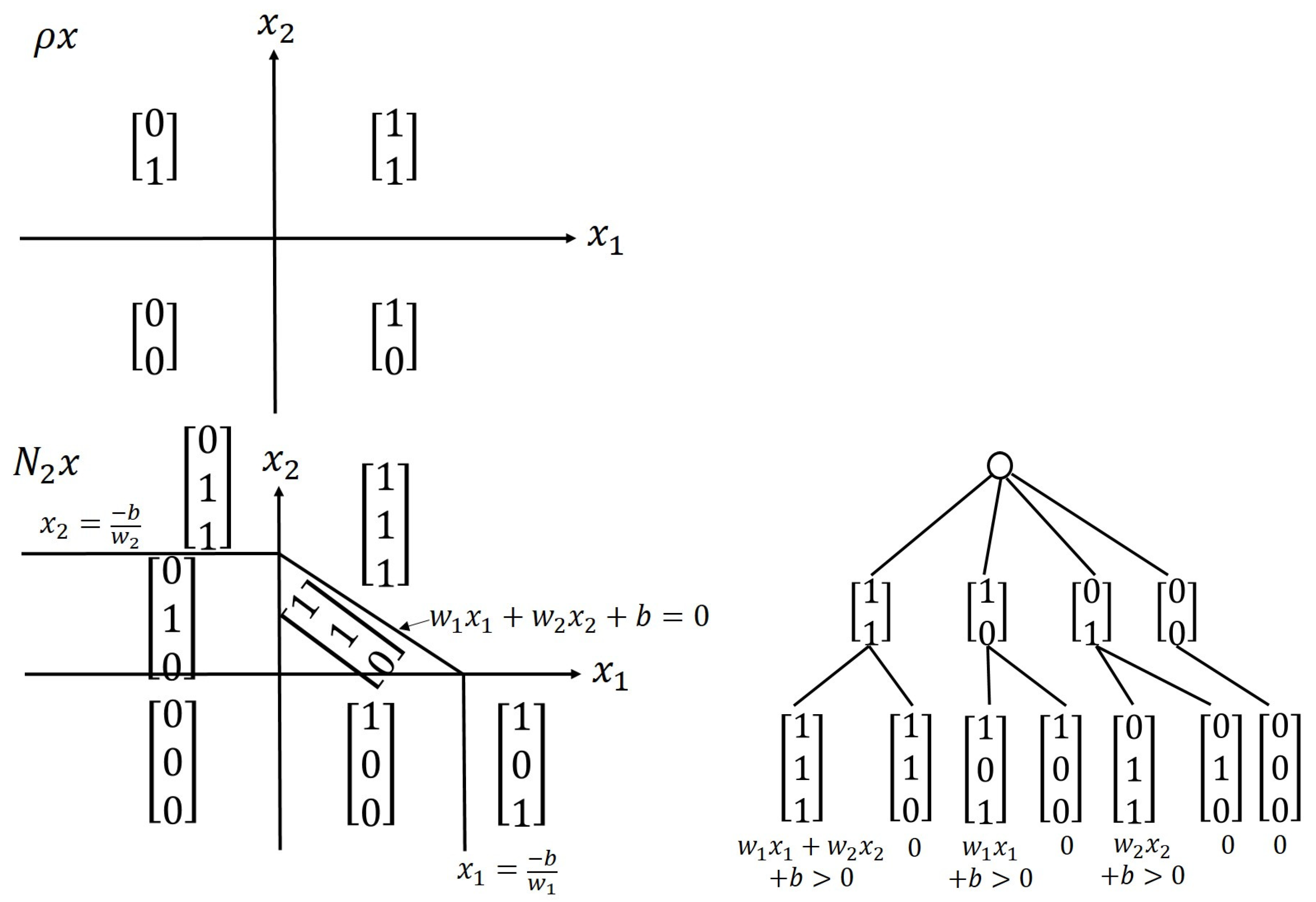
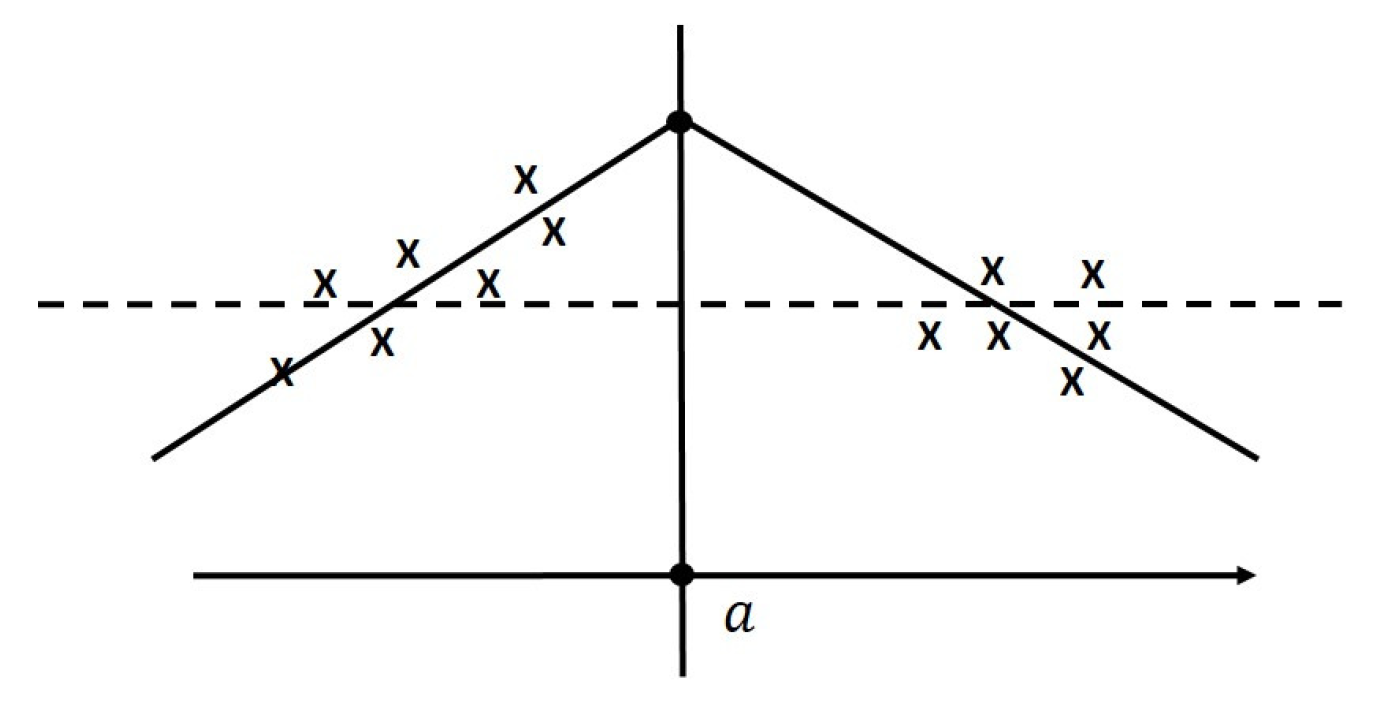
- refines (any partition region in can be subsumed to one and only one partition region in ).
- (ii)
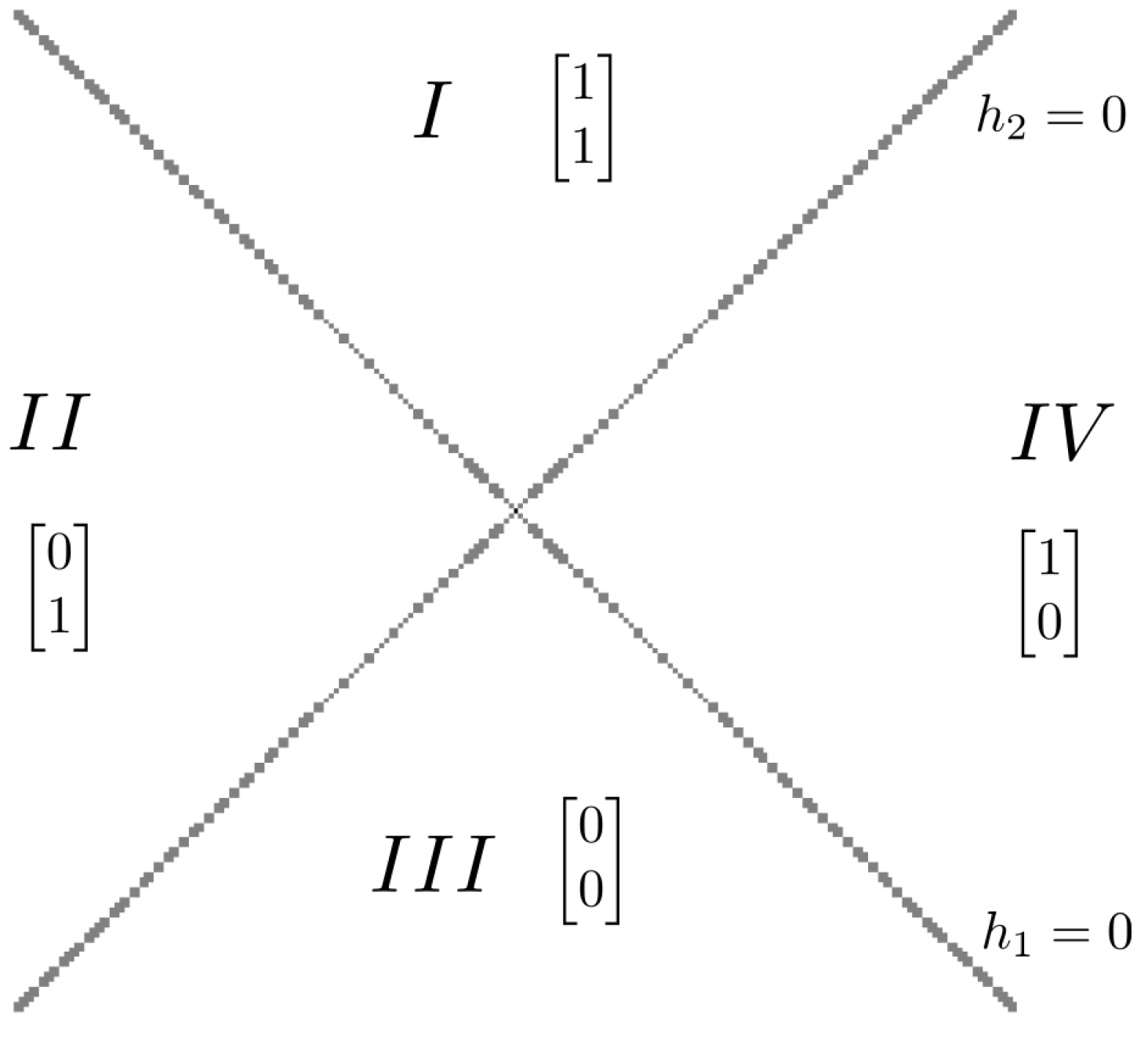
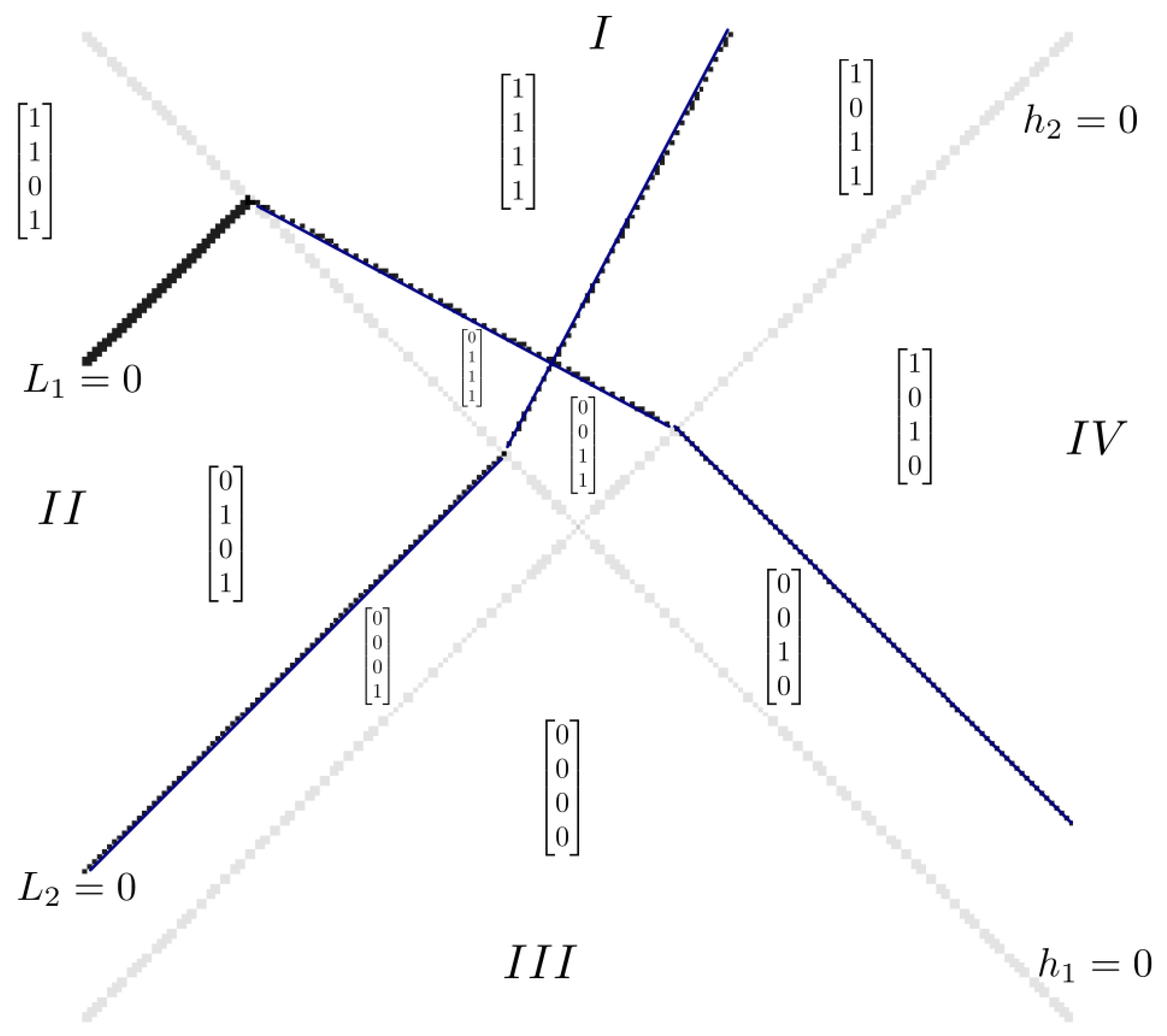
- The affine linear mappings of can be expressed as , where is an un-rectifying matrix of ReLU. This means that if , then there must be a j in which , such that , where the un-rectifying matrix () depends on .
4. Properties of General DNNs
4.1. Function Approximation via Partition Refinement
4.2. Stability via Sparse/Compressible Weight Coefficients
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proof of Lemma 5
Appendix B. Theorem 2
References
- Yang, Y.; Sun, J.; Li, H.; Xu, Z. Deep ADMM-Net for compressive sensing MRI. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Monga, V.; Li, Y.; Eldar, Y.C. Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing. IEEE Signal Process. Mag. 2021, 38, 18–44. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning. Lulu.com. 2020. Available online: https://christophmolnar.com/books/interpretable-machine-learning/ (accessed on 9 September 2023).
- Balestriero, R.; Cosentino, R.; Aazhang, B.; Baraniuk, R. The Geometry of Deep Networks: Power Diagram Subdivision. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 15806–15815. [Google Scholar]
- Hwang, W.L.; Heinecke, A. Un-rectifying non-linear networks for signal representation. IEEE Trans. Signal Process. 2019, 68, 196–210. [Google Scholar] [CrossRef]
- Li, Q.; Lin, T.; Shen, Z. Deep learning via dynamical systems: An approximation perspective. arXiv 2019, arXiv:1912.10382. [Google Scholar] [CrossRef]
- Baraniuk, R. The local geometry of deep learning (Power Pointer slides). In Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (Plentary Speech), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]
- Sun, W.; Tsiourvas, A. Learning Prescriptive ReLU Networks. arXiv 2023, arXiv:2306.00651. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Duvenaud, D.; Maclaurin, D.; Aguilera-Iparraguirre, J.; Gómez-Bombarelli, R.; Hirzel, T.; Aspuru-Guzik, A.; Adams, R.P. Convolutional networks on graphs for learning molecular fingerprints. arXiv 2015, arXiv:1509.09292. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Weinan, E. A proposal on machine learning via dynamical systems. Commun. Math. Stat. 2017, 1, 1–11. [Google Scholar]
- Lu, Y.; Zhong, A.; Li, Q.; Dong, B. Beyond finite layer neural networks: Bridging deep architectures and numerical differential equations. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 3276–3285. [Google Scholar]
- Haber, E.; Ruthotto, L. Stable architectures for deep neural networks. Inverse Probl. 2017, 34, 014004. [Google Scholar] [CrossRef]
- Chang, B.; Chen, M.; Haber, E.; Chi, E.H. AntisymmetricRNN: A dynamical system view on recurrent neural networks. arXiv 2019, arXiv:1902.09689. [Google Scholar]
- Ascher, U.M.; Petzold, L.R. Computer Methods for Ordinary Differential Equations and Differential-Algebraic Equations; SIAM: Philadelphia, PA, USA, 1998; Volume 61. [Google Scholar]
- Mallat, S. Group invariant scattering. Commun. Pure Appl. Math. 2012, 65, 1331–1398. [Google Scholar] [CrossRef]
- Bruna, J.; Mallat, S. Invariant scattering convolution networks. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1872–1886. [Google Scholar] [CrossRef] [PubMed]
- Kuo, C.C.J.; Chen, Y. On data-driven saak transform. J. Vis. Commun. Image Represent. 2018, 50, 237–246. [Google Scholar]
- Gregor, K.; LeCun, Y. Learning fast approximations of sparse coding. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 399–406. [Google Scholar]
- Zhang, J.; Ghanem, B. ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1828–1837. [Google Scholar]
- Chan, S.H. Performance analysis of plug-and-play ADMM: A graph signal processing perspective. IEEE Trans. Comput. Imaging 2019, 5, 274–286. [Google Scholar] [CrossRef]
- Heinecke, A.; Ho, J.; Hwang, W.L. Refinement and universal approximation via sparsely connected ReLU convolution nets. IEEE Signal Process. Lett. 2020, 27, 1175–1179. [Google Scholar] [CrossRef]
- Arora, R.; Basu, A.; Mianjy, P.; Mukherjee, A. Understanding deep neural networks with rectified linear units. arXiv 2016, arXiv:1611.01491. [Google Scholar]
- Goodfellow, I.; Warde-Farley, D.; Mirza, M.; Courville, A.; Bengio, Y. Maxout networks. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1319–1327. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Gao, B.; Pavel, L. On the properties of the softmax function with application in game theory and reinforcement learning. arXiv 2017, arXiv:1704.00805. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Geman, S.; Bienenstock, E.; Doursat, R. Neural networks and the bias/variance dilemma. Neural Comput. 1992, 4, 1–58. [Google Scholar] [CrossRef]
- Belkin, M.; Hsu, D.; Ma, S.; Mandal, S. Reconciling modern machine-learning practice and the classical bias–variance trade-off. Proc. Natl. Acad. Sci. USA 2019, 116, 15849–15854. [Google Scholar] [CrossRef] [PubMed]
- Cao, Y.; Chen, Z.; Belkin, M.; Gu, Q. Benign overfitting in two-layer convolutional neural networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2022; Volume 35, pp. 25237–25250. [Google Scholar]
- Hwang, W.L. Representation and decomposition of functions in DAG-DNNs and structural network pruning. arXiv 2023, arXiv:2306.09707. [Google Scholar]




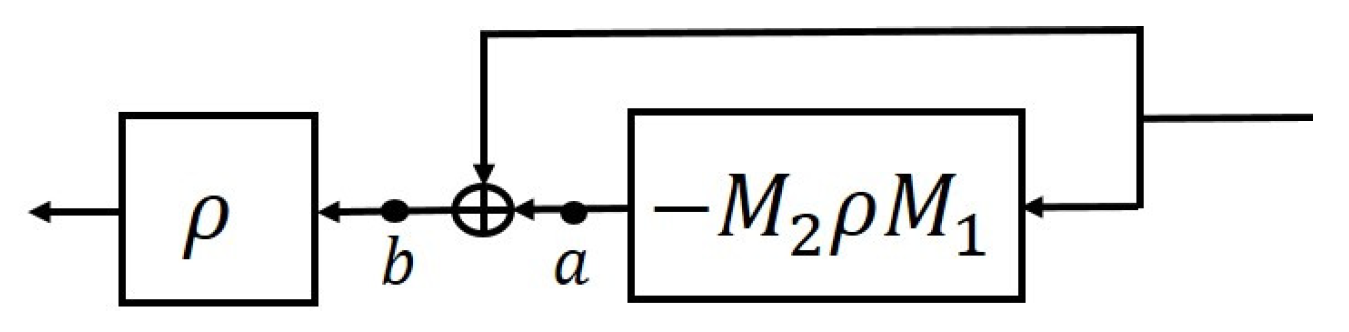




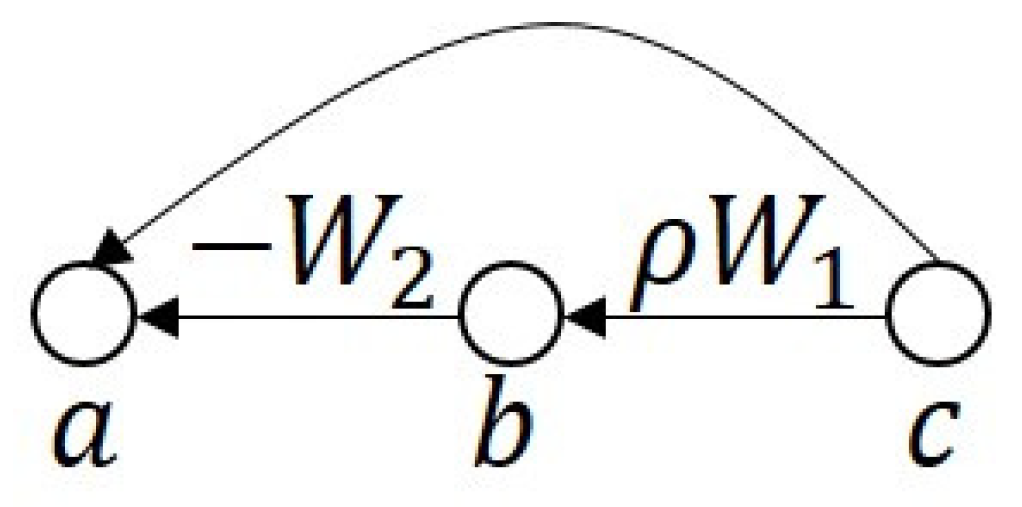

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, W.-L.; Tung, S.-S. Analysis of Function Approximation and Stability of General DNNs in Directed Acyclic Graphs Using Un-Rectifying Analysis. Electronics 2023, 12, 3858. https://doi.org/10.3390/electronics12183858
Hwang W-L, Tung S-S. Analysis of Function Approximation and Stability of General DNNs in Directed Acyclic Graphs Using Un-Rectifying Analysis. Electronics. 2023; 12(18):3858. https://doi.org/10.3390/electronics12183858
Chicago/Turabian StyleHwang, Wen-Liang, and Shih-Shuo Tung. 2023. "Analysis of Function Approximation and Stability of General DNNs in Directed Acyclic Graphs Using Un-Rectifying Analysis" Electronics 12, no. 18: 3858. https://doi.org/10.3390/electronics12183858
APA StyleHwang, W.-L., & Tung, S.-S. (2023). Analysis of Function Approximation and Stability of General DNNs in Directed Acyclic Graphs Using Un-Rectifying Analysis. Electronics, 12(18), 3858. https://doi.org/10.3390/electronics12183858