

A Smart Control System for the Oil Industry Using Text-to-Speech Synthesis Based on IIoT

 ,
,  ,
,  and
and 
Abstract
1. Introduction
- We built a novel extension intelligent control system utilizing IIoT and a text-to-speech model for industrial purposes (particularly oil refineries).
- We successfully designed a TTS model that can run on low computational resources: Raspberry Pi 4 (RPi).
- Speaker adaptation was used to customize the synthesized speech for the two target speakers (male and female) using only a small adaptation dataset.
- We proposed a real-time end-to-end TTS model using the cache mechanism technique to increase the efficiency of our design inspired by [20]. Our results reveal that TTS is no longer an issue in real-time applications.
2. Related Studies
2.1. IIoT in Oil and Gas Industry
2.2. Converging Speech Processing in Industry 4.0
2.3. Speaker Adaptation
3. Methods
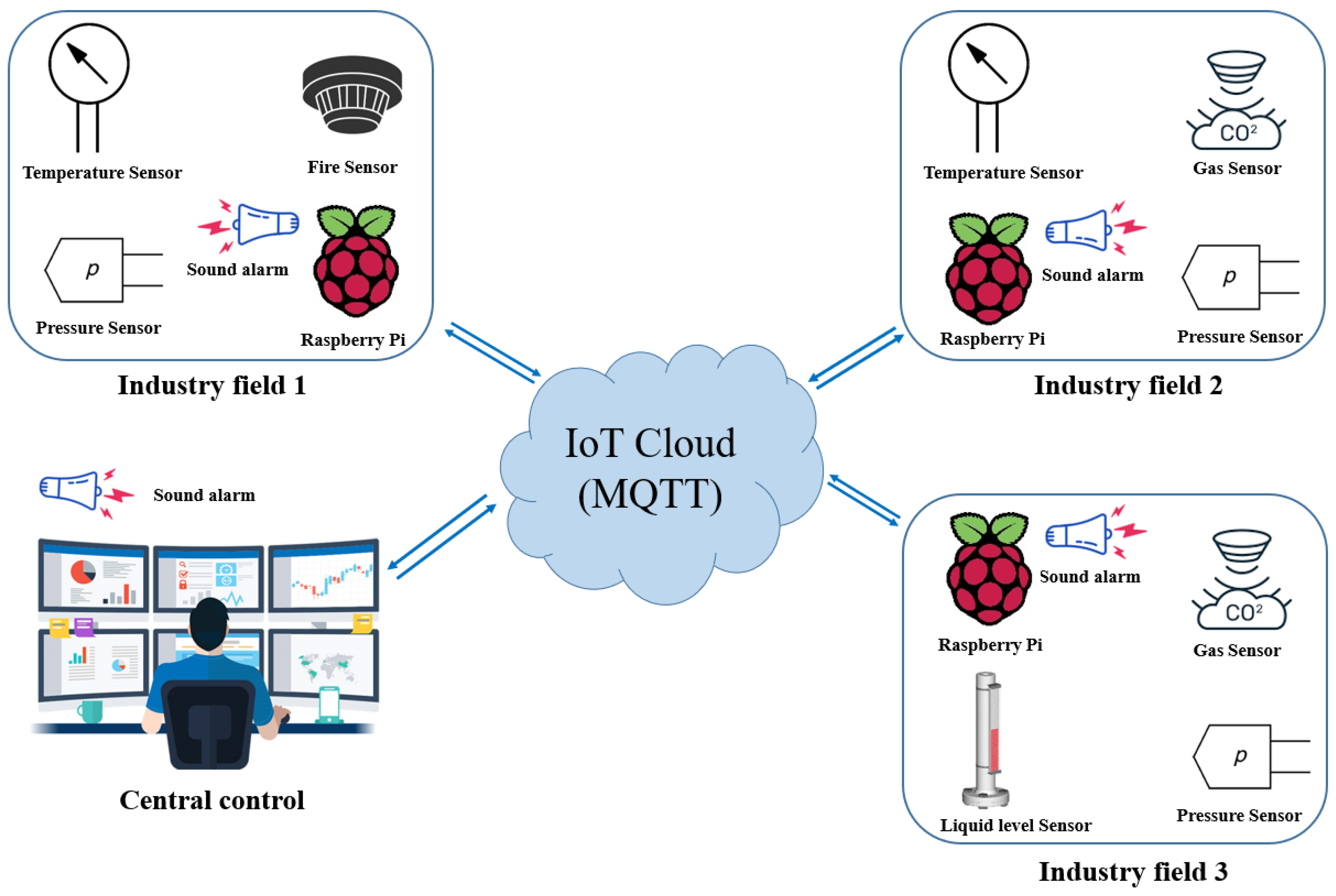
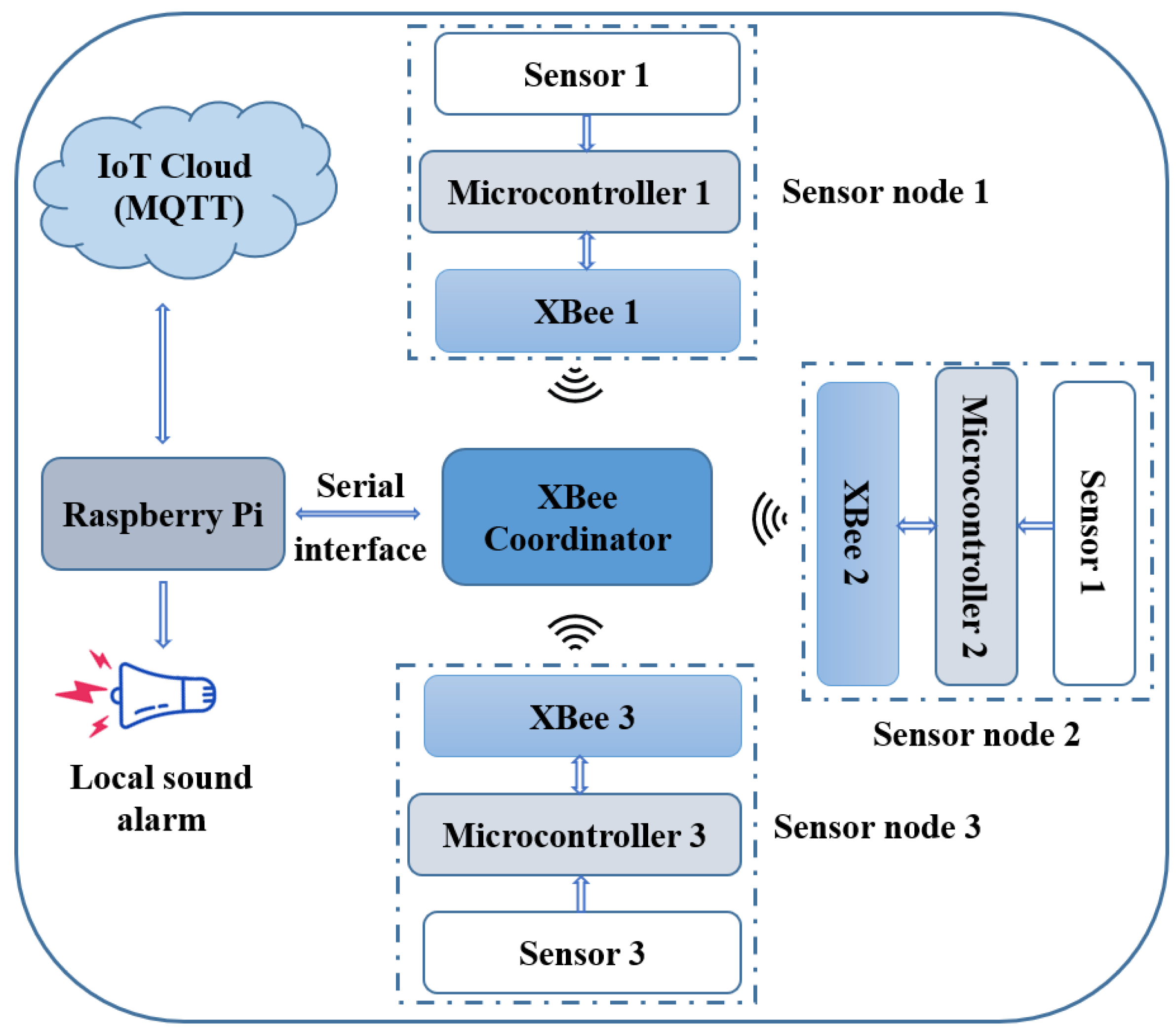
3.1. Hardware and IoT System Design
3.1.1. XBee
- CE: Coordinator Enable (to be a coordinator module)
- CE: End Devices (to be an end device module)
3.1.2. Raspberry Pi
3.1.3. MQTT and HiveMQ
3.2. Text-to-Speech Model Architecture
3.2.1. End-to-End TTS: FastSpeech 2
3.2.2. Neural Vocoders: HiFi-GAN and MelGAN
3.3. Speech Corpora
3.4. Training Topology and Speaker Adaptation
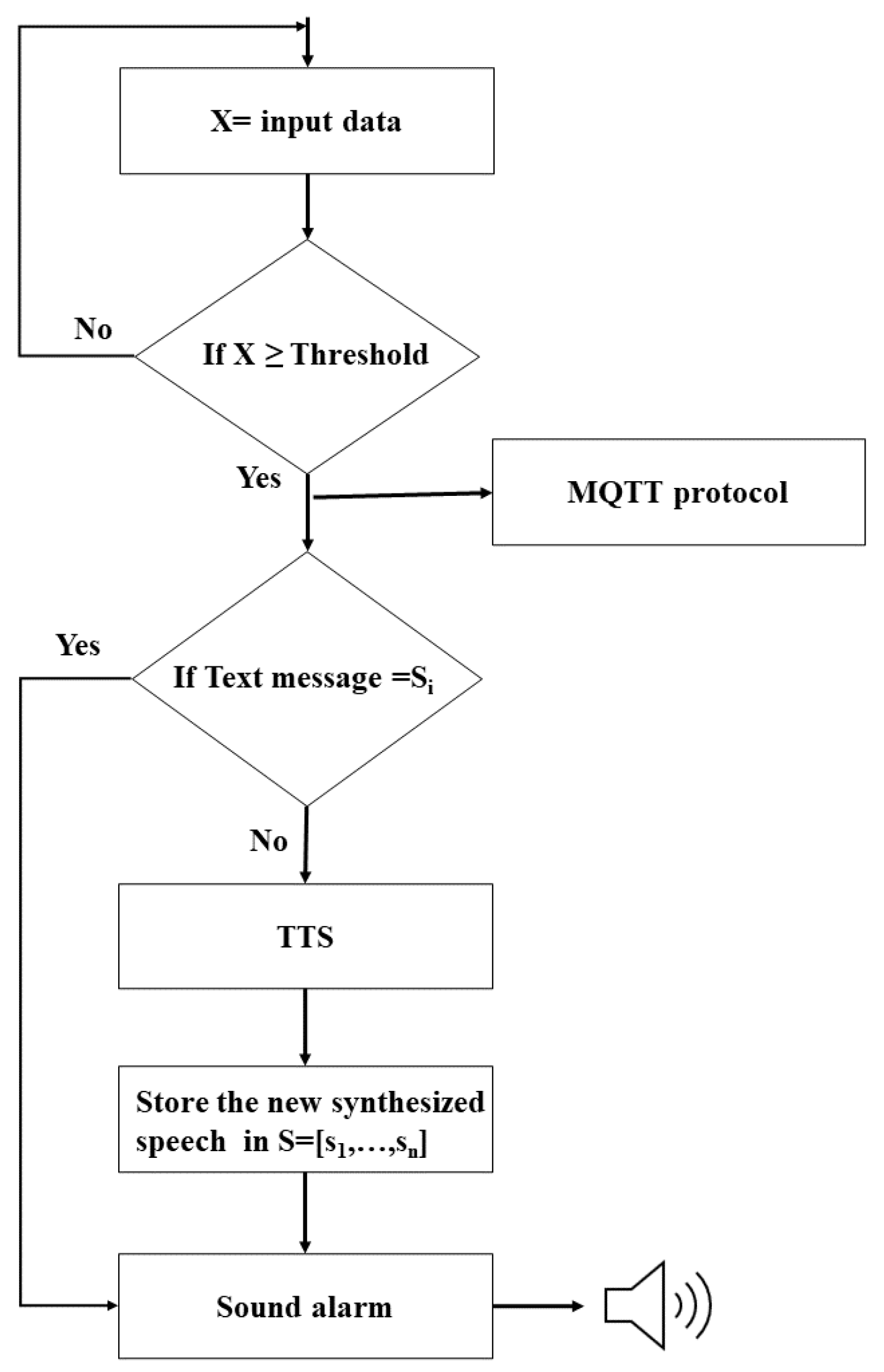
3.5. Cache Mechanism Implementation
| Algorithm 1 Field-Side |
INPUT: ; ; T; TTS; A; U; P; Hs; Mt; R; Hi; Mp;
|
| Algorithm 2 Supervisor Side |
INPUT: ; ; TTS; A; U; P; Hs; Mt; R; Hi; Mp;
|
4. Results
4.1. IoT System Design Efficiency
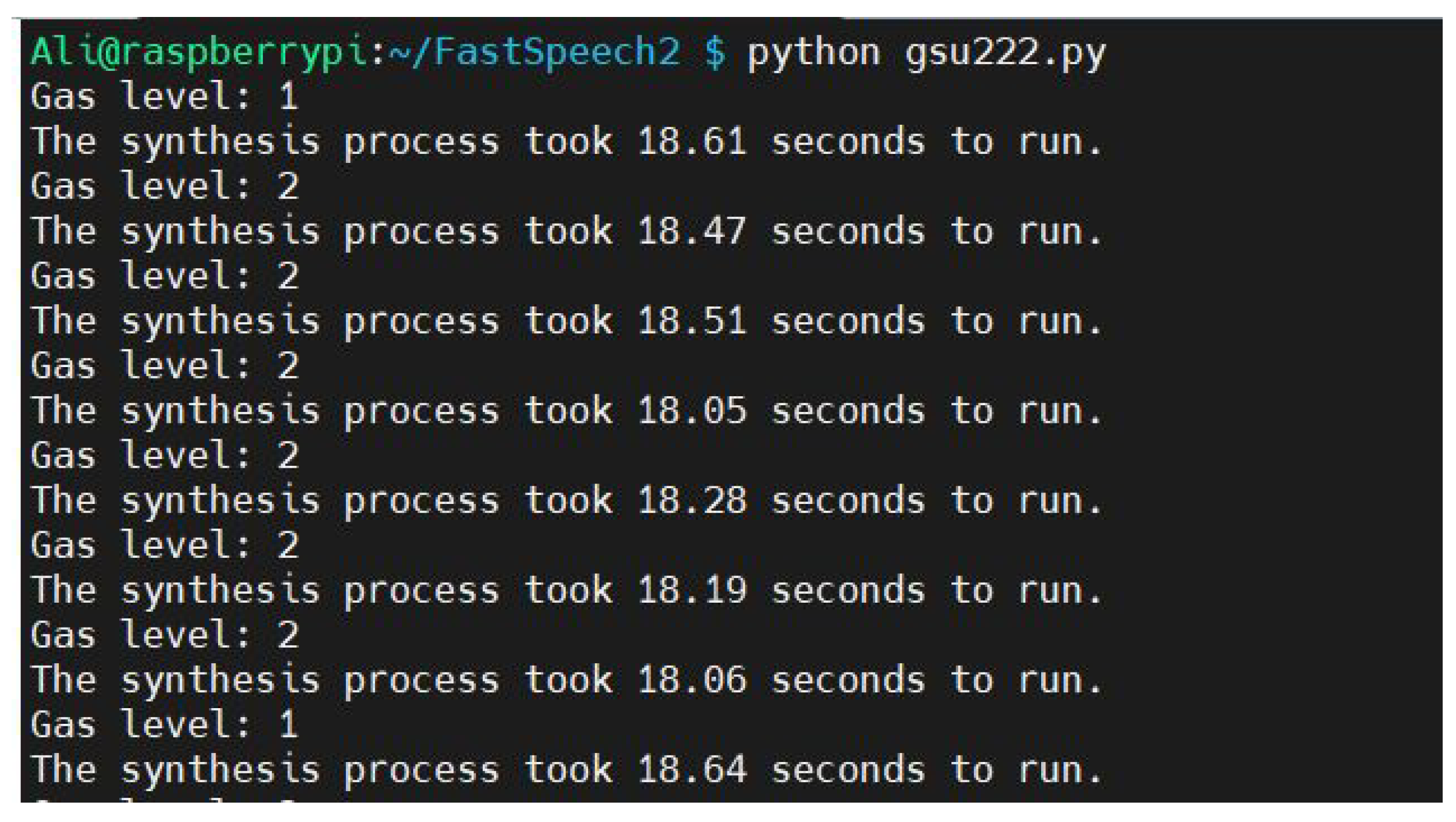
4.2. Real-Time System Evaluation and Runtime Analysis
4.3. Complexity Analysis
- INPUT: ; ; TTS; A; U; P; Hs; Mt; R; Hi; Mp: O(1)
- While the reading data from the sensor node (X) is not null, go to the next step: O(1)
- If input data (xi) ≥ the threshold (T), then go to the next step: O(1)
- Check if “Text message” exists in the list of previously stored values: O(1)
- If “Text message” is equal to saved synthesized speech (S), then go to the alarm step: O(1)
- Synthesize the input text using the TTS model: O(n)
- Store the data in the stack: O(1)
- Alarm step: O(1)
- MQTT step: secured MQTT connection: O(1)
- Send data to HiveMQ: O(1)
- From this analysis, the computational complexity of Algorithm 1 is O(n) without using the cache mechanism, and it is O(1) using the cache mechanism. The complexity calculation of Algorithm 2 is explained below:
- INPUT: ; ; TTS; A; U; P; Hs; Mt; R; Hi; Mp: O(1)
- Secured MQTT connection: O(1)
- Check if “Text message” exists in the list of previously stored values: O(1)
- If “Text message” = saved synthesized speech (S), then go to the alarm step: O(1)
- Synthesize the input text using the TTS model: O(n)
- Store the data in the stack: O(1)
- Alarm step: O(1)
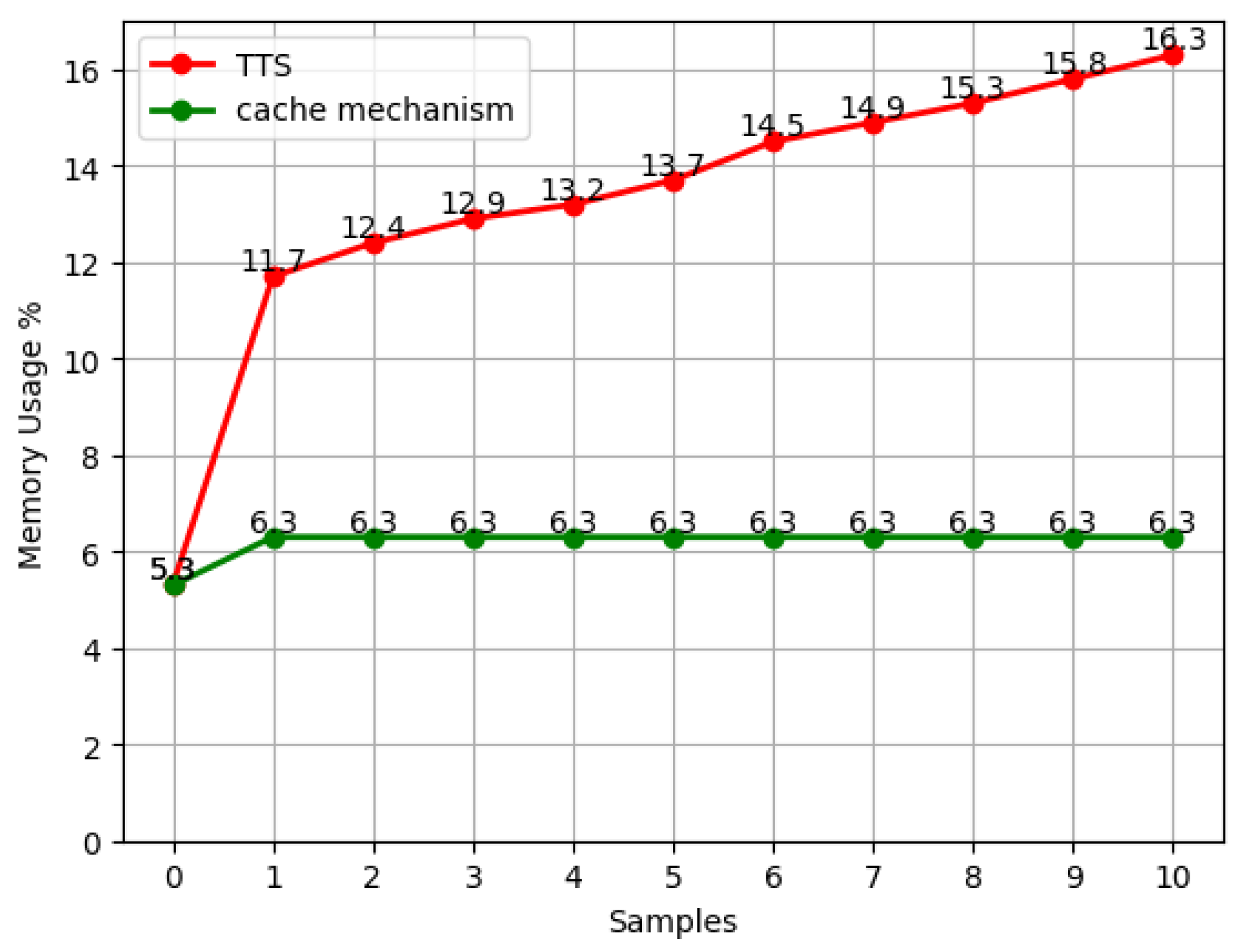
4.4. Memory Experiment
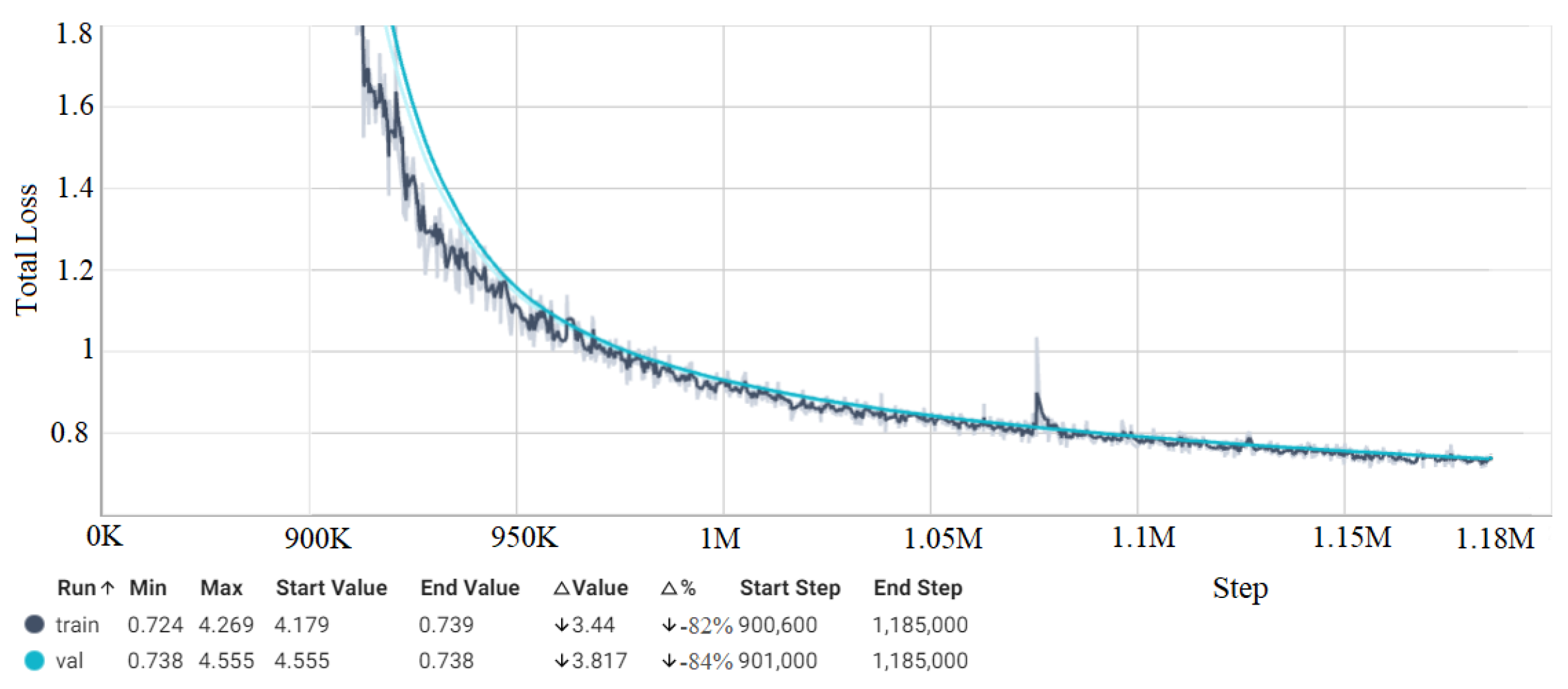
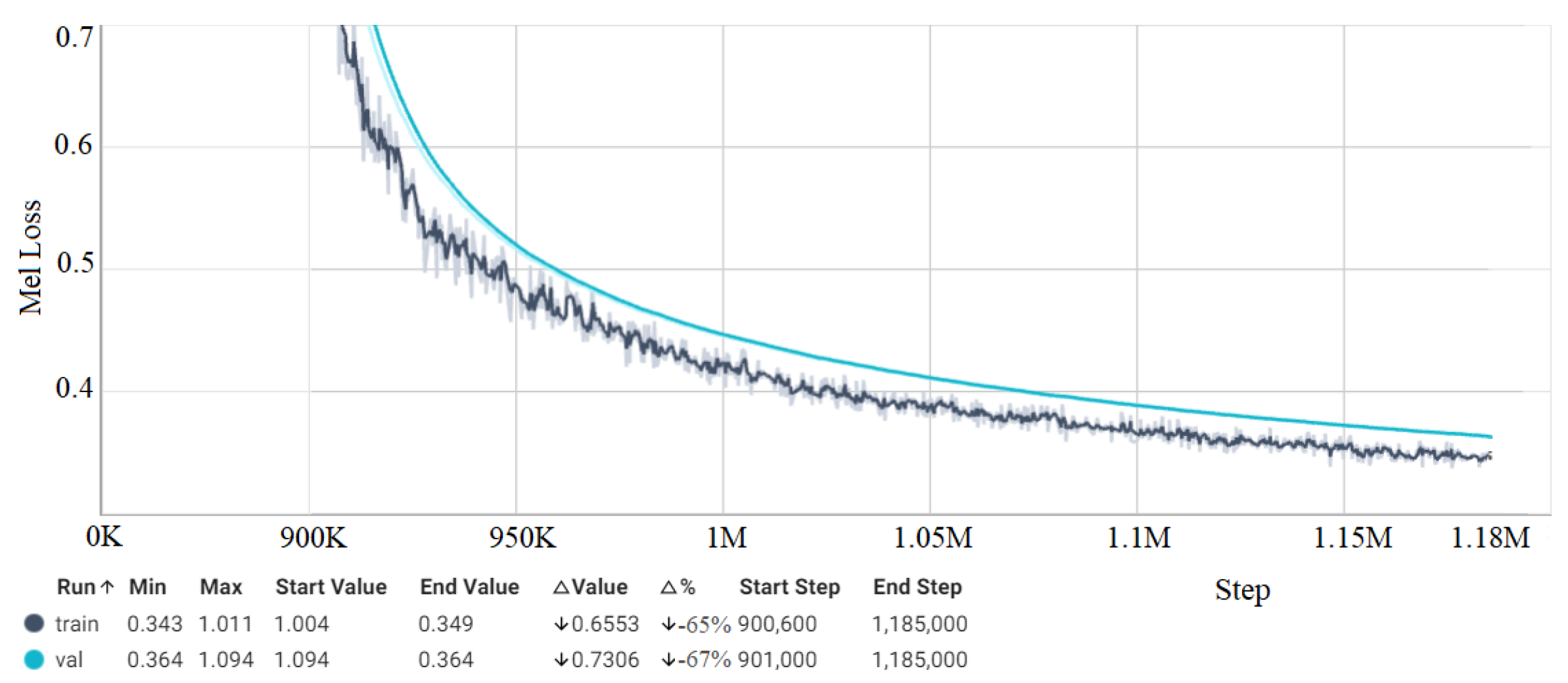
4.5. Loss Measurement
4.6. Synthesized Speech Objective Evaluation
- MCD (dB):
- 2.
- FwSNRseg (dB):
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| X | Data from the sensor node |
| S | Saved synthesized speech |
| Si | The stored value element in the memory |
| T | Threshold value |
| TTS | Text-to-Speech model |
| U | HiveMQ user ID |
| P | HiveMQ password |
| Hs | HiveMQ hostname |
| R | connection port |
| Hi | HiveMQ cluster credentials |
| A | The Alarm |
| Mt | MQTT topic |
| Mp | MQTT protocol |
| D | Data received via MQTT |
References
- Sisinni, E.; Saifullah, A.; Han, S.; Jennehag, U.; Gidlund, M. Industrial Internet of Things: Challenges, Opportunities, and Directions. IEEE Trans. Ind. Inform. 2018, 14, 4724–4734. [Google Scholar] [CrossRef]
- Gosine, R.; Warrian, P. Digitalizing extractive industries: The state-of-the-art to the art-of-the possible. In Munk School of Global Affairs Innovation Policy Lab White Paper Series 2017–004; University of Toronto: Toronto, ON, Canada, 2017. [Google Scholar]
- Hazra, A.; Adhikari, M.; Amgoth, T.; Srirama, S.N. A Comprehensive Survey on Interoperability for IIoT: Taxonomy, Standards, and Future Directions. ACM Comput. Surv. 2021, 55, 9. [Google Scholar] [CrossRef]
- Ramos, M.A.; Droguett, E.L.; Mosleh, A.; Moura, M.D.C. A Human Reliability Analysis Methodology for Oil Refineries and Petrochemical Plants Operation: Phoenix-PRO Qualitative Framework. Reliab. Eng. Syst. Saf. 2020, 193, 106672. [Google Scholar] [CrossRef]
- Yoo, B.-T.; Shim, W.S. Evaluating the Efficiency of the Process Safety Management System through Analysis of Major Industrial Accidents in South Korea. Processes 2023, 11, 2022. [Google Scholar] [CrossRef]
- Bloch, K.P.; Wurst, D.M. Process Safety Management Lessons Learned from a Petroleum Refinery Spent Caustic Tank Explosion. Process Saf. Prog. 2010, 29, 332–339. [Google Scholar] [CrossRef]
- U.S. Chemical Safety and Hazard Investigation Board. Investigation Report Catastrophic Rupture of Heat Exchanger (Seven Fatalities)—Report 2010–08-I-WA2014; U.S. Chemical Safety and Hazard Investigation Board: Washington, DC, USA, 2014.
- Nwankwo, C.D.; Arewa, A.O.; Theophilus, S.C.; Esenowo, V.N. Analysis of accidents caused by human factors in the oil and gas industry using the HFACS-OGI framework. Int. J. Occup. Saf. Ergon. 2021, 28, 1642–1654. [Google Scholar] [CrossRef] [PubMed]
- U.K. Health and Safety Executive (HSE). Core Topic 3: Identifying Human Failures; U.K. Health and Safety Executive (HSE): London, UK, 2005.
- Mandapaka, P.V.; Lo, E.Y. Assessing Shock Propagation and Cascading Uncertainties Using the Input–Output Framework: Analysis of an Oil Refinery Accident in Singapore. Sustainability 2023, 15, 1739. [Google Scholar] [CrossRef]
- Foley, L.; Anderson, C.J.; Schutz, M. Re-Sounding Alarms: Designing Ergonomic Auditory Interfaces by Embracing Musical Insights. Healthcare 2020, 8, 389. [Google Scholar] [CrossRef]
- Chikara, R.K.; Ko, L.W. Modulation of the Visual to Auditory Human Inhibitory Brain Network: An EEG Dipole Source Localization Study. Brain Sci. 2019, 9, 216. [Google Scholar] [CrossRef]
- Webster, C.S.; Sanderson, P. Need for a New Paradigm in the Design of Alarms for Patient Monitors and Medical Devices. Br. J. Anaesth. 2021, 127, 677–680. [Google Scholar] [CrossRef]
- Haslwanter, J.D.H.; Heiml, M.; Wolfartsberger, J. Lost in translation: Machine translation and text-to-speech in industry 4.0. In Proceedings of the 12th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Rhode Island, Greece, 5–7 June 2019; pp. 333–342. [Google Scholar]
- Ning, Y.; He, S.; Wu, Z.; Xing, C.; Zhang, L.-J. A Review of Deep Learning Based Speech Synthesis. Appl. Sci. 2019, 9, 4050. [Google Scholar] [CrossRef]
- Luo, R.; Tan, X.; Wang, R.; Qin, T.; Li, J.; Zhao, S.; Chen, E.; Liu, T.-Y. Lightspeech: Lightweight and Fast Text to Speech with Neural Architecture Search. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar] [CrossRef]
- Yang, G.; Yang, S.; Liu, K.; Fang, P.; Chen, W.; Xie, L. Multi-Band Melgan: Faster Waveform Generation for High-Quality Text-To-Speech. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021. [Google Scholar] [CrossRef]
- Kawamura, M.; Shirahata, Y.; Yamamoto, R.; Tachibana, K. Lightweight and High-Fidelity End-to-End Text-to-Speech with Multi-Band Generation and Inverse Short-Time Fourier Transform. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar] [CrossRef]
- Achanta, S.; Antony, A.; Golipour, L.; Li, J.; Raitio, T.; Rasipuram, R.; Rossi, F.; Shi, J.; Upadhyay, J.; Winarsky, D.; et al. On-Device Neural Speech Synthesis. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021. [Google Scholar] [CrossRef]
- Zainkó, C.; Bartalis, M.; Németh, G.; Olaszy, G. A Polyglot Domain Optimised Text-to-Speech System for Railway Station Announcements. In Proceedings of the Interspeech 2015, Dresden, Germany, 6–10 September 2015. [Google Scholar] [CrossRef]
- Mandeel, A.R.; Aggar, A.A.; Al-Radhi, M.S.; Csapó, T.G. Implementing a Text-to-Speech Synthesis Model on a Raspberry Pi for Industrial Applications. In Proceedings of the 1st Workshop on Intelligent Infocommunication Networks, Systems and Services, Budapest, Hungary, 7 February 2023. [Google Scholar] [CrossRef]
- Ramzey, H.; Badawy, M.; Elhosseini, M.; Elbaset, A.A. I2OT-EC: A Framework for Smart Real-Time Monitoring and Controlling Crude Oil Production Exploiting IIOT and Edge Computing. Energies 2023, 16, 2023. [Google Scholar] [CrossRef]
- Priyanka, E.; Maheswari, C.; Ponnibala, M.; Thangavel, S. SCADA Based Remote Monitoring and Control of Pressure & Flow in Fluid Transport System Using IMC-PID Controller. Adv. Syst. Sci. Appl. 2019, 19, 140–162. [Google Scholar] [CrossRef]
- Priyanka, E.B.; Maheswari, C.; Thangavel, S. A Smart-integrated IoT Module for Intelligent Transportation in Oil Industry. Int. J. Numer. Model. Electron. Netw. Devices Fields 2020, 34, e2731. [Google Scholar] [CrossRef]
- Henry, N.F.; Henry, O.N. Wireless Sensor Networks Based Pipeline Vandalisation and Oil Spillage Monitoring and Detection: Main Benefits for Nigeria Oil and Gas Sectors. SIJ Trans. Comput. Sci. Eng. Its Appl. (CSEA) 2019, 7, 1–7. [Google Scholar] [CrossRef]
- Wanasinghe, T.R.; Gosine, R.G.; James, L.A.; Mann, G.K.; De Silva, O.; Warrian, P.J. The Internet of Things in the Oil and Gas Industry: A Systematic Review. IEEE Internet Things J. 2020, 7, 8654–8673. [Google Scholar] [CrossRef]
- Carroll, K.; Chandramouli, M. Scaling IoT to Meet Enterprise Needs—Balancing Edge and Cloud Computing; Deloitte: London, UK, 2019. [Google Scholar]
- Hossain, M.S.; Rahman, M.; Sarker, M.T.; Haque, M.E.; Jahid, A. A Smart IoT Based System for Monitoring and Controlling the Sub-Station Equipment. Internet Things 2019, 7, 100085. [Google Scholar] [CrossRef]
- Parjane, V.A.; Gangwar, M. Corrosion Detection and Prediction Approach Using IoT and Machine Learning Techniques; Lecture Notes in Networks and Systems; Springer: Berlin/Heidelberg, Germany, 2022; pp. 205–215. [Google Scholar] [CrossRef]
- Singh, R.; Baz, M.; Narayana, C.L.; Rashid, M.; Gehlot, A.; Akram, S.V.; Alshamrani, S.S.; Prashar, D.; AlGhamdi, A.S. Zigbee and Long-Range Architecture Based Monitoring System for Oil Pipeline Monitoring with the Internet of Things. Sustainability 2021, 13, 10226. [Google Scholar] [CrossRef]
- Spandonidis, C.; Theodoropoulos, P.; Giannopoulos, F. A Combined Semi-Supervised Deep Learning Method for Oil Leak Detection in Pipelines Using IIoT at the Edge. Sensors 2022, 22, 4105. [Google Scholar] [CrossRef]
- Lade, P.; Ghosh, R.; Srinivasan, S. Manufacturing Analytics and Industrial Internet of Things. IEEE Intell. Syst. 2017, 32, 74–79. [Google Scholar] [CrossRef]
- Ijiga, O.E.; Malekian, R.; Chude-Okonkwo, U.A. Enabling Emergent Configurations in the Industrial Internet of Things for Oil and Gas Explorations: A Survey. Electronics 2020, 9, 1306. [Google Scholar] [CrossRef]
- Javadi, S.H.; Mohammadi, A. Fire Detection by Fusing Correlated Measurements. J. Ambient. Intell. Humaniz. Comput. 2017, 10, 1443–1451. [Google Scholar] [CrossRef]
- AlSuwaidan, L. The Role of Data Management in the Industrial Internet of Things. Concurr. Comput. Pract. Exp. 2020, 33, e6031. [Google Scholar] [CrossRef]
- Ahmed, S.; Le Mouël, F.; Stouls, N.; Lipeme Kouyi, G. Development and Analysis of a Distributed Leak Detection and Localisation System for Crude Oil Pipelines. Sensors 2023, 23, 4298. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Chen, X.; Fan, C. Research on a Safety Assessment Method for Leakage in a Heavy Oil Gathering Pipeline. Energies 2020, 13, 1340. [Google Scholar] [CrossRef]
- Liu, R.; Ding, S.; Ju, G. Numerical Study of Leakage and Diffusion of Underwater Oil Spill by Using Volume-of-Fluid (VOF) Technique and Remediation Strategies for Clean-Up. Processes 2022, 10, 2338. [Google Scholar] [CrossRef]
- Varga, P.; Bácsi, S.; Sharma, R.; Fayad, A.; Mandeel, A.R.; Soos, G.; Franko, A.; Fegyo, T.; Ficzere, D. Converging Telco-Grade Solutions 5G and Beyond to Support Production in Industry 4.0. Appl. Sci. 2022, 12, 7600. [Google Scholar] [CrossRef]
- Zhao, W.; Yang, Z. An Emotion Speech Synthesis Method Based on VITS. Appl. Sci. 2023, 13, 2225. [Google Scholar] [CrossRef]
- Kiangala, K.S.; Wang, Z. An Experimental Safety Response Mechanism for an Autonomous Moving Robot in a Smart Manufacturing Environment Using Q-Learning Algorithm and Speech Recognition. Sensors 2022, 22, 941. [Google Scholar] [CrossRef]
- Du, G.; Chen, M.; Liu, C.; Zhang, B.; Zhang, P. Online Robot Teaching with Natural Human–Robot Interaction. IEEE Trans. Ind. Electron. 2018, 65, 9571–9781. [Google Scholar] [CrossRef]
- Stefaniak, P.; Stachowiak, M.; Koperska, W.; Skoczylas, A.; Śliwiński, P. Application of Wearable Computer and ASR Technology in an Underground Mine to Support Mine Supervision of the Heavy Machinery Chamber. Sensors 2022, 22, 7628. [Google Scholar] [CrossRef]
- Chen, H.; Leu, M.C.; Yin, Z. Real-Time Multi-Modal Human–Robot Collaboration Using Gestures and Speech. J. Manuf. Sci. Eng. 2022, 144, 101007. [Google Scholar] [CrossRef]
- Mo, D.-H.; Tien, C.-L.; Yeh, Y.-L.; Guo, Y.-R.; Lin, C.-S.; Chen, C.-C.; Chang, C.-M. Design of Digital-Twin Human-Machine Interface Sensor with Intelligent Finger Gesture Recognition. Sensors 2023, 23, 3509. [Google Scholar] [CrossRef]
- Siyaev, A.; Jo, G.-S. Towards Aircraft Maintenance Metaverse Using Speech Interactions with Virtual Objects in Mixed Reality. Sensors 2021, 21, 2066. [Google Scholar] [CrossRef]
- Latif, S.; Qadir, J.; Qayyum, A.; Usama, M.; Younis, S. Speech Technology for Healthcare: Opportunities, Challenges, and State of the Art. IEEE Rev. Biomed. Eng. 2021, 14, 342–356. [Google Scholar] [CrossRef]
- Silvestri, R.; Holmes, A.; Rahemtulla, R. The Interaction of Cognitive Profiles and Text-to-Speech Software on Reading Comprehension of Adolescents with Reading Challenges. J. Spec. Educ. Technol. 2021, 37, 498–509. [Google Scholar] [CrossRef]
- Kato, S.; Yasuda, Y.; Wang, X.; Cooper, E.; Takaki, S.; Yamagishi, J. Modeling of Rakugo Speech and Its Limitations: Toward Speech Synthesis That Entertains Audiences. IEEE Access 2020, 8, 138149–138161. [Google Scholar] [CrossRef]
- Chung, Y.-A.; Wang, Y.; Hsu, W.-N.; Zhang, Y.; Skerry-Ryan, R.J. Semi-Supervised Training for Improving Data Efficiency in End-to-End Speech Synthesis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar] [CrossRef]
- Mandeel, A.R.; Al-Radhi, M.S.; Csapó, T.G. Speaker Adaptation with Continuous Vocoder-Based DNN-TTS; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2021; pp. 407–416. [Google Scholar] [CrossRef]
- Mandeel, A.R.; Al-Radhi, M.S.; Csapó, T.G. Investigations on Speaker Adaptation Using a Continuous Vocoder within Recurrent Neural Network Based Text-to-Speech Synthesis. Multimed. Tools Appl. 2023, 82, 15635–15649. [Google Scholar] [CrossRef]
- Schnell, B.; Garner, P.N. Investigating a Neural All Pass Warp in Modern TTS Applications. Speech Commun. 2022, 138, 26–37. [Google Scholar] [CrossRef]
- Eren, E.; Demiroglu, C. Deep Learning-Based Speaker-Adaptive Postfiltering with Limited Adaptation Data for Embedded Text-to-Speech Synthesis Systems. Comput. Speech Lang. 2023, 81, 101520. [Google Scholar] [CrossRef]
- Mandeel, A.R.; Al-Radhi, M.S.; Csapó, T.G. Speaker Adaptation Experiments with Limited Data for End-to-End Text-To-Speech Synthesis Using Tacotron2. Infocommun. J. 2022, 14, 55–62. [Google Scholar] [CrossRef]
- Huang, S.-F.; Lin, C.-J.; Liu, D.-R.; Chen, Y.-C.; Lee, H.-Y. Meta-TTS: Meta-Learning for Few-Shot Speaker Adaptive Text-to-Speech. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1558–1571. [Google Scholar] [CrossRef]
- Wang, X. Embedded Task System and Gaussian Mixture Model in the Analysis and Application of User Behavior in Marketing Management. Wirel. Netw. 2021, 1–13. [Google Scholar] [CrossRef]
- Karami, M.; McMorrow, G.V.; Wang, L. Continuous Monitoring of Indoor Environmental Quality Using an Arduino-Based Data Acquisition System. J. Build. Eng. 2018, 19, 412–419. [Google Scholar] [CrossRef]
- Leonard, B. (Ed.) Advances on P2P, Parallel, Grid, Cloud and Internet Computing; Lecture Notes in Networks and Systems; Springer: Berlin/Heidelberg, Germany, 2023. [Google Scholar] [CrossRef]
- Champaty, B.; Nayak, S.K.; Thakur, G.; Mohapatra, B.; Tibarewala, D.N.; Pal, K. Development of Bluetooth, Xbee, and Wi-Fi-Based Wireless Control Systems for Controlling Electric-Powered Robotic Vehicle Wheelchair Prototype. In Robotic Systems: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2020; pp. 1048–1079. [Google Scholar] [CrossRef]
- Dewanta, F. A Study of Secure Communication Scheme in MQTT: TLS vs. AES Cryptography. J. Infotel 2022, 14, 269–276. [Google Scholar] [CrossRef]
- Fadhil, T.Z.; Mandeel, A.R. Live Monitoring System for Recognizing Varied Emotions of Autistic Children. In Proceedings of the International Conference on Advanced Science and Engineering (ICOASE), Duhok, Iraq, 9–11 October 2018. [Google Scholar] [CrossRef]
- Di Paolo, E.; Bassetti, E.; Spognardi, A. Security Assessment of Common Open Source MQTT Brokers and Clients. In ITASEC; ITASEC: São Paulo, Brazil, 2021; pp. 475–487. [Google Scholar]
- Paris IL, B.M.; Habaebi, M.H.; Zyoud, A.M. Implementation of SSL/TLS Security with MQTT Protocol in IoT Environment. Wirel. Pers. Commun. 2023, 1–20. [Google Scholar] [CrossRef]
- Hyperscale with HiveMQ: Learn about Scale from Our 200 Million Benchmark. Available online: https://www.hivemq.com/blog/hyperscale-iot-iiot-applications-up-to-200-mil-connections-with-hivemq/ (accessed on 21 May 2023).
- Koziolek, H.; Grüner, S.; Rückert, J. A Comparison of MQTT Brokers for Distributed IoT Edge Computing; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; pp. 352–368. [Google Scholar] [CrossRef]
- Ren, Y.; Hu, C.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.-Y. Fastspeech 2: Fast and High-Quality End-to-End Text to Speech. In ICLR. OpenReview.net. 2021. Available online: https://openreview.net/forum?id=piLPYqxtWuA (accessed on 8 July 2021).
- Kong, J.; Kim, J.; Bae, J. HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis. Adv. Neural Inf. Process. Syst. 2020, 33, 17022–17033. [Google Scholar]
- Kumar, K.; Kumar, R.; De Boissiere, T.; Gestin, L.; Teoh, W.Z.; Sotelo, J.; De Brebisson, A.; Bengio, Y.; Courville, A.C. Melgan: Generative adversarial networks for conditional waveform synthesis. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Ito, K.; Johnson, L. The LJ Speech Dataset. 2017. Available online: https://keithito.com/LJ-Speech-Dataset/ (accessed on 22 December 2020).
- Bakhturina, E.; Lavrukhin, V.; Ginsburg, B.; Zhang, Y. Hi-Fi Multi-Speaker English TTS Dataset. In Proceedings of the Interspeech, Brno, Czech Republic, 30 August–3 September 2021. [Google Scholar] [CrossRef]
- McAuliffe, M.; Socolof, M.; Mihuc, S.; Wagner, M.; Sonderegger, M. Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar] [CrossRef]
- Takieldeen, A.E.; El-kenawy, E.S.M.; Hadwan, M.; Zaki, R.M. Dipper Throated Optimization Algorithm for Unconstrained Function and Feature Selection. Comput. Mater. Contin. 2022, 72, 1465–1481. [Google Scholar] [CrossRef]
- Philip, M.A.; Vaithiyanathan. A Survey on Lightweight Ciphers for IoT Devices. In Proceedings of the International Conference on Technological Advancements in Power and Energy (TAP Energy), Kollam, India, 21–23 December 2017. [Google Scholar] [CrossRef]
- Homicskó, Á. (Ed.) Egyes Modern Technológiák Etikai, Jogi és Szabályozási Kihívásai. Acta Caroliensia Conventorum Scientiarum Iuridico-Politicarum XXII; KRE: Budapest, Hungary, 2018; p. 223. [Google Scholar]
- Rothstein, N.; Kounios, J.; Ayaz, H.; de Visser, E.J. Assessment of Human-Likeness and Anthropomorphism of Robots: A Literature Review. Adv. Intell. Syst. Comput. 2020, 28, 190–196. [Google Scholar] [CrossRef]
- Otto, M. Regulation (EU) 2016/679 on the Protection of Natural Persons with Regard to the Processing of Personal Data and on the Free Movement of Such Data (General Data Protection Regulation—GDPR). In International and European Labour Law; Nomos Verlagsgesellschaft mbH & Co. KG: Baden-Baden, Germany, 2018; pp. 958–981. [Google Scholar] [CrossRef]
- Webber, J.J.; Valentini-Botinhao, C.; Williams, E.; Henter, G.E.; King, S. Autovocoder: Fast Waveform Generation from a Learned Speech Representation Using Differentiable Digital Signal Processing. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Contribution | Techniques | Results |
|---|---|---|---|
| [33] | Enhance oil industry business interactions |
| EC and SDN-based IIoT improve the oil extraction procedures |
| [34] | Reducing fire accidents by using IIoT | The copula theory to integrate the sensors | It surpasses two baseline methods in fire detection |
| [35] | Data management for IIoT systems. | Machine learning techniques | IIoT is used for tracking the oil and gas industry operations flow |
| [31] | Leak detection in oil pipelines utilizing IIoT |
| Efficient wireless sensor system for leakage detection in the metallic pipeline |
| [36] | Leak detection in oil pipelines utilizing IIoT | Hybrid localization and distributed leakage detection techniques |
|
| [37] | Risk oil pipelines evaluation without failure data |
| Control risks and avoid leakage consequences |
| [38] | Spilled oil diffusion underwater distance prediction |
| Provide an emergency treatment plan for offshore oil spill accidents |
| Ref. | Techniques | Contribution | Limitation |
|---|---|---|---|
| [14] | TTS model | Using a TTS model to help workers in the assembly industries. | It did not customize the target speakers. |
| [40] | TTS model | Developed Emo-VITS | It was not tested in a real IoT application. |
| [41] | ASR model | A safety method to stop small plants working in emergencies. | It has yet to benefit from IoT to extend the coverage. |
| [42] | ASR model | Control robots with a user’s voice | It needs to address incorrect human instructions. |
| [43] | ASR model | Using ASR in the underground mining industry | The average accuracy of form completion was 70–80% which may be insufficient for the critical tasks. |
| [44] | ASR model | ASR & gestures recognizer to control an industrial robot | Environmental constraints: noise, lighting conditions, and moving objects. |
| [45] | TTS model | Digital-twin human-machine interface sensors enable the control of digital devices using gestures. Speech synthesis feedback expresses the operational requirements of inconvenient work. | Validations of real-world scenarios were excluded. |
| [46] | ASR model | It mixed reality and speech interactions to improve aircraft maintenance. | System latency and response time were overlooked. |
| Communication Technology | Transmission Range | Power Consumption | Cost |
|---|---|---|---|
| ZigBee | 10–100 m | Low | Low |
| Bluetooth | 8–10 m | Low | Low |
| WiFi | 20–100 m | High | High |
| WiMAX | Less than 50 Km | Medium | High |
| Mobile Communication | Entire Cellular Region | Medium | Medium |
| Model | Hidden Dimension | Transposed Convolutions Kernel Sizes | Kernel Sizes | Dilation Rates |
|---|---|---|---|---|
| V1 | 512 | [16, 16, 4, 4] | [3, 7, 11] | [[1, 1], [3, 1], [5, 1]] × 3 |
| V3 | 256 | [16, 16, 8] | [3, 5, 7] | [[1], [2]], [[2], [6]], [[3], [12]] |
| Sentence
Duration | FastSpeech 2 + HiFi-GAN V3 | FastSpeech 2 + MelGAN | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| R1 | R2 | R3 | Avg. sec | RTF | R1 | R2 | R3 | Avg. sec | RTF | |
| 1 | 20.2 | 20.3 | 20.4 | 20.3 | 6.4 | 23.0 | 22.8 | 23.4 | 23.1 | 7.5 |
| 2 | 21.2 | 21.9 | 21.3 | 21.4 | 25.5 | 27.1 | 25.5 | 26.0 | ||
| 3 | 21.7 | 21.7 | 21.7 | 21.7 | 24.8 | 25.4 | 25.6 | 25.2 | ||
| 4 | 22.6 | 22.5 | 22.8 | 22.7 | 25.6 | 26.1 | 26.5 | 26.1 | ||
| 5 | 22.1 | 22.0 | 22.0 | 22.0 | 25.4 | 26.8 | 25.1 | 25.8 | ||
| 6 | 22.9 | 23.1 | 22.9 | 23.0 | 26.4 | 27.5 | 28.1 | 27.3 | ||
| 7 | 23.9 | 23.7 | 23.8 | 23.8 | 28.6 | 29.8 | 28.3 | 28.9 | ||
| 8 | 24.4 | 24.3 | 24.3 | 24.3 | 31.6 | 31.5 | 28.2 | 30.4 | ||
| 9 | 24.9 | 24.9 | 25.1 | 25.0 | 31.3 | 30.2 | 29.2 | 30.2 | ||
| 10 | 25.2 | 24.8 | 24.9 | 24.9 | 33.8 | 29.8 | 39.9 | 34.5 | ||
| No. of Stored Samples in the Memory | R1 sec | R2 sec | R3 sec | Average Time sec | RTF |
|---|---|---|---|---|---|
| 250 | 0.58 | 0.62 | 0.65 | 0.62 | 0.16 |
| 500 | 0.71 | 0.76 | 0.85 | 0.77 | 0.19 |
| 1000 | 0.89 | 1.04 | 1.08 | 1.00 | 0.29 |
| Speaker | Modified TTS Model | Baseline TTS Model | ||
|---|---|---|---|---|
| MCD | FwSNRseg | MCD | FwSNRseg | |
| F | 5.17 | 1.0 | 5.76 | 0.8 |
| M | 6.0 | 0.67 | 7.13 | 0.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mandeel, A.R.; Aggar, A.A.; Al-Radhi, M.S.; Csapó, T.G. A Smart Control System for the Oil Industry Using Text-to-Speech Synthesis Based on IIoT. Electronics 2023, 12, 3380. https://doi.org/10.3390/electronics12163380
Mandeel AR, Aggar AA, Al-Radhi MS, Csapó TG. A Smart Control System for the Oil Industry Using Text-to-Speech Synthesis Based on IIoT. Electronics. 2023; 12(16):3380. https://doi.org/10.3390/electronics12163380
Chicago/Turabian StyleMandeel, Ali Raheem, Ammar Abdullah Aggar, Mohammed Salah Al-Radhi, and Tamás Gábor Csapó. 2023. "A Smart Control System for the Oil Industry Using Text-to-Speech Synthesis Based on IIoT" Electronics 12, no. 16: 3380. https://doi.org/10.3390/electronics12163380
APA StyleMandeel, A. R., Aggar, A. A., Al-Radhi, M. S., & Csapó, T. G. (2023). A Smart Control System for the Oil Industry Using Text-to-Speech Synthesis Based on IIoT. Electronics, 12(16), 3380. https://doi.org/10.3390/electronics12163380