Abstract
In the upcoming 6G era, edge artificial intelligence (AI), as a key technology, will be able to deliver AI processes anytime and anywhere by the deploying of AI models on edge devices. As a hot issue in public safety, person re-identification (Re-ID) also needs its models to be urgently deployed on edge devices to realize real-time and accurate recognition. However, due to complex scenarios and other practical reasons, the performance of the re-identification model is poor in practice. This is especially the case in public places, where most people have similar characteristics, and there are environmental differences, as well other such characteristics that cause problems for identification, and which make it difficult to search for suspicious persons. Therefore, a novel end-to-end suspicious person re-identification framework deployed on edge devices that focuses on real public scenarios is proposed in this paper. In our framework, the video data are cut images and are input into the You only look once (YOLOv5) detector to obtain the pedestrian position information. An omni-scale network (OSNet) is applied through which to conduct the pedestrian attribute recognition and re-identification. Broad learning systems (BLSs) and cycle-consistent adversarial networks (CycleGAN) are used to remove the noise data and unify the style of some of the data obtained under different shooting environments, thus improving the re-identification model performance. In addition, a real-world dataset of the railway station and actual problem requirements are provided as our experimental targets. The HUAWEI Atlas 500 was used as the edge equipment for the testing phase. The experimental results indicate that our framework is effective and lightweight, can be deployed on edge devices, and it can be applied for suspicious person re-identification in public places.
1. Introduction
The rapid development of artificial intelligence (AI) in recent years has resulted in an increasing amount of data being transferred to cloud data centers, thus leading to data transmission, delays, privacy breaches, and other problems. However, edge AI, as a key technology by which to achieve 6G, will contribute to a decrease in cloud services issues by the deploying of training and testing AI models on edge networks []. In the future, 6G wireless communication technology will be designed to allow people to engage with AI anytime and anywhere [,]. For example, in the public security field, when suspicious people appear in multiple surveillance videos, edge devices need to be used quickly and accurately to find out where they are; this is a typical pedestrian re-identification (Re-ID) problem. Person Re-ID can apply in many real scenarios, such as railway stations and shopping malls, and identification problems in these scenarios are usually regarded as a retrieval picture problem. Given a pedestrian who is known, a query is generated on whether they have appeared at different times and on different cameras. In practice, several instances of video surveillance data are given before the original data is collected, and the corresponding bounding box is generated using person detection technology.Then, the obtained training data are annotated. Finally, the pedestrians are retrieved through the training Re-ID models to find their location and time information.
The research on pedestrian Re-ID began in the 1990s. Researchers focused on simple classification through some mature pattern recognition algorithms. Most image-based person Re-ID models mainly have three learning strategies: 1. Global feature learning. In [,], these methods extract a global feature vector from each image via feature learning. They are also applied to early image classification. 2. Local feature learning. These methods include a bilinear pool [], a multiple-scale context aware convolution [], and a multi-channel aggregation []. These methods learn the local features of partial aggregation by combining local with global pedestrian image features. 3. The feature representation of auxiliary information assists person Re-ID to improve accuracy by combining person attribute recognition [] and enhanced training samples [,]. In the past decade, with deep learning progressing rapidly, the research of pedestrian Re-ID has developed. Many excellent models can now achieve more than 90% accuracy on the public Market-1501 dataset. Examples of these models are part-based convolutional baseline (PCB) model [], the omni-scale network (OSNet) [], the batch DropBlock (BDB) model [], and the interaction and aggregation network (IANet) [].
Although pedestrian Re-ID technology has developed rapidly in recent years, there are still various problems in its practical application: 1. Under different cameras, the viewpoint of the same person image changes and leads to different kinds of pedestrian orientations in the pictures [,]. 2. The same pedestrian features do not match due to occlusions, which is a challenge for the Re-ID models’ learning ability. 3. Due to the light changes in environments [], the same person can have a color mismatch problem when caught under different cameras. 4. Background interference [], the same person can produce an interference problem when in a complex environment. These are the practical problems that are encountered in the application of person re-identification technology. Therefore, there are still enormous differences between theoretical research and practical application. Furthermore, few articles have been published on the practical applications of pedestrian Re-ID. A night-time scene for person re-identification is a specific application. Ref. [] aims to deal with pedestrian Re-ID in a night-time scenario. Ref. [] combined detection and Re-ID technology, and proposed an end-to-end algorithm to test in a real scene. In addition, these methods are trained and tested centrally in the cloud. Massive amounts of data are transferred from the terminal devices to the cloud data center, which may result in a higher latency due to the bandwidth and long transmission distance. This is unfavorable in an actual scenario. Therefore, it is still necessary to research the application of pedestrian Re-ID in the context of practical problems.
To meet the needs of actual scenarios, we propose a complete application framework that includes person detection, image classification, and enhanced data to person attribute recognition and person Re-ID. Our approach is different from the ones that have come before. Although the cloud can provide many computing resources, its disadvantage is that the transmission distance is too long, which is not conducive to developing 6G wireless communication technology. Therefore, in the context of the 6G era, we deploy the proposed framework on edge devices in order to achieve low latency and efficient resource utilization. To realize the pedestrian Re-ID problem in real scenarios at the edge level, we also provide a real-world data set and simulate the actual problem requirements. The specific actual needs are as follows: 1. To Detect, track, and Re-ID suspicious persons through personal characteristics. 2. Define and describe personnel anomaly information. 3. Search for the characteristics of suspicious persons. 4. The person Re-ID results are backtracked according to the time axis. To address the actual requirements, the implementation process of our framework is as follows. First, we cut the frame of the video, then we detect the pedestrians through You only look once (YOLOv5), and then we generate the corresponding bounding box and cut the detection results on each image. Second, to remove the noise data, the broad learning system (BLS) [] is used to classify the detection results. Then, the style migration cycle-consistent adversarial network algorithm (CycleGAN) [] is used to unify the image styles under different cameras. Finally, we label the training data and use OSNet for the person attribute recognition and Re-ID.
Our framework is lightweight overall; we used the YOLOv5 detection model, which is faster and more convenient to deploy, the BLS for fast classification, and the OSNet model with a deep separable convolution. Therefore, our framework is convenient to deploy and implement. In short, the contribution of our work can be summarized to the following points:
- A novel end-to-end framework that has strong integrity is proposed to Re-ID suspicious pedestrians. Then, this framework is deployed on a HUAWEI Atlas 500 edge device for testing, which relieves the cloud computing pressure and improves the response time of Re-ID;
- Our framework combines the classification algorithm BLS to remove the noise data, and the style migration algorithm CycleGAN is used to unify the image style under different cameras, thus improving the Re-ID model recognition performance;
- The real-world data set of the railway station is provided to Re-ID the suspicious pedestrians in real scenarios. Compared with other baseline models, the results indicate the proposed framework is lightweight and effective.
The other organizational structures of this paper are as follows: In Section 2, the relevant work will be reviewed. Then, the proposed end-to-end framework is introduced in Section 3. Next, we verify the framework effectiveness via experiments, which are deployed on the HUAWEI Atlas 500 edge device in order to solve the practical suspicious person re-identification problems in public places. In the end, we conclude this paper with a summary and an account of the development of future work.
2. Related Work
In this section, we will review some related works on person Re-ID, including Re-ID with deep learning, the generative adversarial network (GAN) and Re-ID, attribute recognition and Re-ID, as well as edge computing and Re-ID.
2.1. Person Re-ID Based on Deep Learning
In recent years, deep learning-based person Re-ID algorithms have been rapidly developed. In [], the author proposed the PCB network and RPP adaptive pooling method to be applied to Re-ID by learning the part-informed features with a strong discrimination ability. A deep architecture PyrNet [] can better deal with Re-ID by using pyramid information. The OSNet [] improves the ability of person recognition by learning omni-scale features. In addition, this method also be applies to other vision tasks. In [], the author designed an interaction and association network to improve the features extracted by a CNN representation ability and used it for Re-ID. VAL [] is different from the direction of separation research between perspective and different identities as it uses viewpoint information to further improve performance. Second-order nonlocal attention [] is proposed as a module to deal with the multi-part problems as a whole. These deep learning-based models not only were successfully applied to pedestrian Re-ID, but also achieved great performance.
2.2. GAN and Person Re-ID
Generative adversarial networks as auxiliary information can improve the Re-ID model recognition ability. Zheng [] applied GAN to pedestrian Re-ID models for the first time by using newly generated person images to improve the feature learning ability. To solve the problem of changes between different camera styles, image generation was applied in [] to enhance the data while smoothing the differences in the image styles. In [], a pose-normalization GAN was used to normalize the attitudes found in Re-ID. The generated image can provide a depth recognition feature and has little impact on attitude changes. The multi-camera transfer model GAN [] transfers the tagged training data to each video of the target data. This model realizes the training under different data sets. PAC-GAN [] is an unsupervised framework for Re-ID, it improves the detection ability of Re-ID by enhancing the various postures of pedestrians in the picture. To cope with the decline of Re-ID performance in different environments, the spatial awareness generation countermeasure network [] not only adapts to different images at the pixel level, but also completes the adaptation at the spatial level, reducing the difference of image styles in the same environment.
2.3. Person Attribute Recognition and Re-ID
Pedestrian attribute recognition refers to selecting a group of attributes from a series of predefined attributes in order to describe personal characteristics. Person attributes are a kind of high-level semantic auxiliary information that are required to complete pedestrian Re-ID tasks. Combining person attribute recognition and person Re-ID helps identity verification to enhance Re-ID model recognition ability. In Ref. [], person attribute tags were combined with Re-ID, and the model accuracy was raised by fine-tuning the CNN features. In Ref. [], an end-to-end deep learning framework baseline for the simultaneous learning of pedestrian attribute recognition and Re-ID tasks was provided. In Ref. [], an architecture that integrated person attributes into the pedestrian Re-ID framework was designed. Multi-task loss fusion co-variance uncertainty learning and end-to-end joint learning were also used to improve the Re-ID model performance.
2.4. Edge Computing and Person Re-ID
Most of the existing Re-ID models have been trained and tested in the cloud. Due to continuous data transmission to the cloud, privacy leakage and poor real-time performance are generated. However, deploying the model on an edge networkdoes not require data transmission, which not only improves the real-time capability of Re-ID [], but also protects pedestrian privacy []. Therefore, migrating Re-ID models from the cloud to an edge network is becoming a new trend. In [], the author proposes an end-to-end Re-ID system based on an edge–cloud network. In this system, raw video data are processed from the edge devices; then, the processed data are sent to the cloud for inference. This method aims to protect privacy and real-time prediction. In Ref. [], a trained model on an edge device is deployed. This approach overcomes the difficulty of updating model parameters, and improves the response time of Re-ID. However, due to the large number of parameters in the AI models, the resource consumption of edge computing is too large when processing this model. Therefore, in [], the Re-ID system was placed on the AloT EC gateway, raising the computing resources of the Re-ID process.
3. Proposed Method
In this part, the novel end-to-end framework applied in the public place for Re-ID and detail of each model will be introduced, including the person detection model YOLOv5, the classifier BLS, the style transfer model CycleGAN, person Re-ID, and the attribute recognition model OSNet. The complete framework structure is shown in Figure 1. The detailed algorithm is shown in Algorithm 1.
| Algorithm 1 End-to-end suspicious pedestrian Re-ID framework |
|
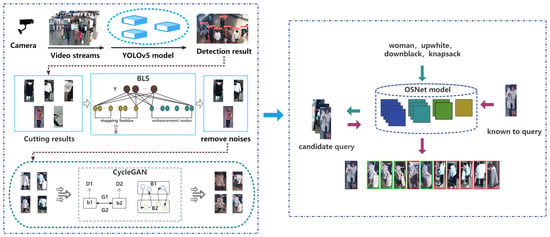
Figure 1.
The end-to-end suspicious pedestrian re-identification (Re-ID) framework in a public place.
3.1. Person Detection
The target detection model YOLOv5 is an improvement of YOLOv3, and it consists of YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. We used the YOLOv5s model to extract and calculate the features of each person, and also positioned and classified them. The classification mainly included two parts: person and non-person. The process includes the following:
- (1)
- The calculation method for adaptive picture downsizing is as follows: Firstly, the scale of adaptive scaling is calculated. The original size is , and the original target size of the adaptive scaling is . The scaling coefficients and are calculated by the following formula.If , we choose as the final scaling coefficient Z; otherwise, we choose .The second step is to calculate the size after adaptive scaling. Multiply the original image length and width with scaling coefficient Z to obtain the corresponding filled image length and width . If , is selected as the position to be filled; otherwise, we select .Finally, the fill value of the black edge is calculated. Taking as the position to be filled as an example, calculate the height that needs to be filled originally, the value that needs to be filled at both ends of the picture, and the size and of the scaled image.
- (2)
- Extraction feature map. In this part, the input image of size is obtained, and the feature map of size is obtained by a slicing operation, where the convolution kernel is b, and a new feature map of size is obtained by convolution .
- (3)
- Loss. The loss in the person detection stage includes three parts. The first is the bounding box loss, which is a loss of the predicted and real bounding box. The second is the confidence loss, which is the key to distinguishing between the negative and positive samples. Finally, the classification loss is used to predict the category information. The bounding box loss function is defined as follows.where d is the distance from the real and predicted bounding box to the center point, h is the similarity of the aspect ratio of the two bounding boxes, is the influence factor of h, and are the areas of the two boxes, and l is the minimum diagonal length of the enclosed rectangle. The following loss function is used to define confidence loss.where C and V are the confidence label matrix and predicted confidence matrix, respectively. , and z represent the matrix dimension. The classification loss is defined with the following loss function.where G represents the number of categories, and is a smoothing coefficient.
By using the YOLOv5 algorithm, we can detect as many pedestrians as possible and cut down the numberof detected pedestrians for the next classification operation.
3.2. Classifier
BLS is a framework proposed by Chen et al. to replace deep networks. The advantages of BlS are that it has a simple model structure and a fast training speed. Therefore, BLS is excellent for some simple classification tasks. The BLS algorithm is as follows:
- (1)
- Feature mapping. The following formula is used for the feature mapping of input data X.where and are both randomly generated matrices, and is a linear function that is not unique. We can select different linear functions for different input data or different feature mapping combinations. We will obtain s that are different to Z and which are combined to obtain the s group feature node, ; this indicates that all mapping features are extracted from X through network mapping.
- (2)
- Computation of enhanced nodes. The enhancement node are calculated with the following formula.where and are, still, randomly generated matrices and represents a nonlinear function. In addition, different can be selected here, and is in a matrix form. By combining the different H we can obtain the final l group of the enhanced nodes , which represents all the enhanced nodes we obtain from the mapping feature.
- (3)
- Calculation output. The final output is obtained by multiplying the combined matrix of the mapping features and the enhanced nodes with the weight of the network connection., which is the matrix of and combined. As the connection weight of the network, W is represented as follows:where we usually let , I is the identity matrix, and calculates the pseudoinverse of matrix P. The network connection weight W is obtained according to multiplying P by the output matrix Y.
We substitute the calculated W into the formula to obtain the final output Y. With the BLS, we can quickly classify the complete person images and reduce the influence of noise data.
3.3. Style Transfer
Due to different camera locations and environments, there will be differences in image styles. Therefore, the same pedestrian features may be varied under different cameras. To cope with this problem, we used CycleGAN algorithm to unify the parts of the image styles. The CycleGAN algorithm is as follows:
- (1)
- Training generator. When training generators and , fix discriminator and parameters, and adjust parameters in the hope that the quality of the image generated by generator will be better. The higher the score of the opposing discriminator on the image that is generated by generator , the higher the score ; then, adjust the parameters. The quality of the generated images is expected to be better. The higher the rating is of the image , which is produced by generator , then the more the discriminator is against it.
- (2)
- Training discriminator. The training discriminator allows and to better distinguish the image produced by generator and . If the similarity between the produced by generator and the image in dataset is not high, then the discriminator should be given a low score, with a minimum score of 0. Otherwise, it should be given a high score, with a maximum score of 1. Similarly, if the similarity between the produced by generator and the image in dataset is not high, then the discriminator should be given a low score. Otherwise, it should be given a high score.The parameters of generator , , and discriminator are fixed. When training the discriminator , the value of should be maximized so that the discriminator can give a higher score to . The value of should be minimized so that the discriminator can give a lower score to the image generated by . Thus, the ability of the discriminator is improved (the training of the discriminator was similar).
- (3)
- Loss. This step is shown by the following two loss functions. The loss of the first part is to ensure the mutual learning and confrontation between the generator and discriminator, this is performed in order to ensure that the generator can generate more high-quality images. This first part is recorded as . The second part is to ensure that the input and output images are only different in style, while the image content should be the same. This part loss is recorded as , which is specifically expressed by the following formula.
By applying the CycleGAN algorithm, we reduce the impact of different camera shooting environments on the same person and improve recognition accuracy.
3.4. Suspicious Person Re-ID and Attribute Recognition
In this part, the OSNet model was used for suspicious person re-identification and attribute recognition. Deep separable convolution was used instead of ordinary convolution, and the parameters were decreased. In addition, several bottlenecks were used to extract the omni-scale features in the same picture, as shown in Figure 2.
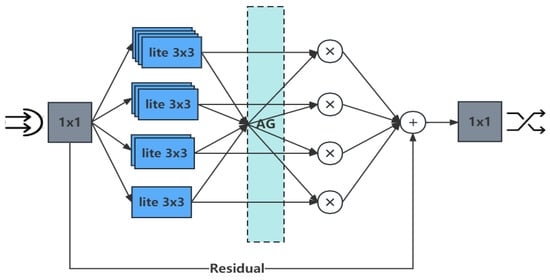
Figure 2.
Bottleneck.
The 1 × 1 convolution of the beginning and the end was used to reduce and recover the feature size. Lite 3 × 3 represents the depth separable convolution. By stacking lite 3 × 3, not only were the smaller scale features of the previous layer retained, but the final feature captured the whole spatial scale range. The aggregation gate (AG) approach was then combined with the output of different streams dynamically. Finally, the bottleneck as a whole resulted in residual learning.
For the person Re-ID, each pedestrian identity was treated as a class, and the cross-entropy losses were overseen using label smoothing and then fine-tuned from the imageNet pre-training weights. After we trained the Re-ID model, when given a suspicious person image, the model could analyze the characteristics of the suspicious person and could compare the characteristics of each person in the test set. It could also rank candidates from high to low according to the similarity of the characteristics.
The OSNet model is still used for person attribute recognition because its omni-scale features are crucial for attribute learning. It can recognize not only global attribute features such as short sleeves and trousers, but also local attributes such as clothing logos and people wearing glasses. In addition to the aforementioned, we also marked 37 attribute labels for each person, including gender, age, hat, coat, pants, backpack, etc., for person attribute recognition. Person attributes can not only describe the feature information of abnormal person images, but they can also use be used as a feature retrieval item to search for suspicious persons conforming to a certain feature. It is used for re-identification that should only meet the suspicious pedestrian information.
4. Experiments
4.1. Data Sets and Task Demands
In this section, the real-world railway station data set is introduced. Then, the actual task requirements in real scenarios as our experiment target is given.
4.1.1. Data Set
Our data set is obtained from the real data of a railway station, and it was captured by the eight surveillance videos in the waiting hall, before and after the security check. As shown in Figure 3, pink represents the monitoring range of the eight cameras, while the blue and gray represent specific scenes (security checks, waiting halls) at the railway station. Everyone on the video is guaranteed to appear under at least two cameras. In addition, due to environmental impacts such as lighting, the monitoring video data are divided into two styles: strong exposure and weak exposure. Among them, the data of the weak exposure style appears in six cameras, and the strong exposure data only appears in two cameras. Cam1, Cam2, Cam3, and Cam4 are the four camera distributions in the first railway station. Cam1 and Cam2 are monitored before the person security check, and Cam3 and Cam4 are monitored after the person security check. Here, Cam1, Cam2, and Cam3 are in the same environment, and their camera styles are generally the same. Cam4 is in a low-exposure environment, and the personal features it captures are different from the other cameras. Cam5, Cam6, Cam7, and Cam8 are the four camera distributions in the second railway station. The monitoring range of Cam5 is after the person security check, while the monitoring ranges of Cam6, Cam7, and Cam8 are in the waiting hall. The four cameras are in the same environment and have the same camera style.
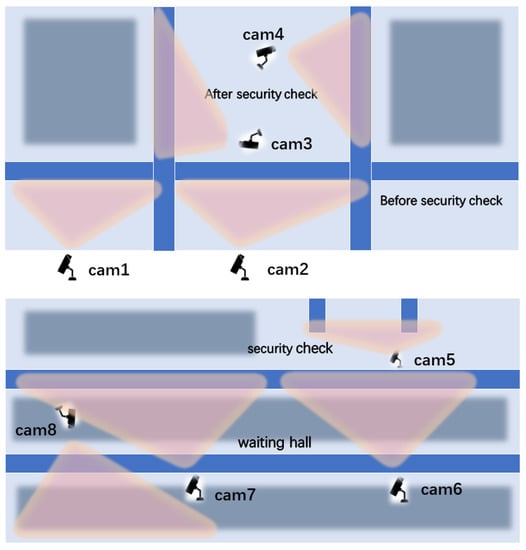
Figure 3.
Camera positions.
We first cut the frames of the video data and took pictures at 24-frame intervals. Then, we used YOLOv5 to detect the person, to mark them, and then cut the bounding box. These data contain 1362 identities and at least 20,000 boundary boxes. Since many of the staff served as extra noise data—and they always appeared in the video—we only took the staff as data in the training phase, whereas the passengers were used in the training and test data; this was done to avoid affecting the performance when evaluating the model. Through processing, there are a total of 15,294 person images, and it was ensured that every person had at least six track images from each camera. In addition, we took 12,394 and 2900 pedestrian images as the training and test data sets, respectively. Further, we took one picture of each person by each camera in the test set as the query set. Among them, there are 982 and 212 pedestrians in the training and test sets, respectively. Finally, in the way of image naming, the label is composed of person number, camera number, and time information.
4.1.2. Person Re-ID Task Demands
- The definition and description of personal exception information. Person abnormal information can be understood as personal characteristics. At the attribute recognition stage, the definition can include most of the characteristics, such as long sleeves, trousers, skirts, shorts, handbags, luggage, clothes of various colors, etc.
- Searching for the characteristics of suspicious persons. After providing the characteristics of the suspicious person, we can use the person attribute recognition model to detect the candidates of the suspicious person.
- Detect, track, and Re-ID suspicious persons by analyzing personal characteristics. Suspicious persons can be lost on old people, criminals, children, etc. We thus use the person Re-ID model to track suspicious persons across cameras.
- The pedestrian Re-ID results are backtracked by the time axis. When suspicious person images are provided, we will Re-ID them in all videos, find the qualified person Re-ID track, and obtain the current video time.
4.2. Experimental Setup
In the training phase, we used a Windows 10 operating system, NVIDIA GeForce RTX 3080 Ti graphics card, 32G memory, and Python as the programming language. All the pedestrian Re-ID models were implemented with PyTorch. In addition, to better achieve 6G, we used MindSpore as the underlying framework and a HUAWEI Atlas 500 (which was equipped with the AI chip of the Synovate 310, 16 TOPS AI computing power, and 4G memory) as an edge device for the testing phase.
In terms of person detection and attribute recognition, we used recall, accuracy, mean average precision, and precision as the common indicators. The calculation method used was as follows: for each category . Accuracy , indicates the samples that are predicted correctly, and indicates the total predicted samples (this represents the number of samples predicted correctly in the prediction result). Precision . and are the correct and false positive samples, respectively (this represents several real positive samples among predictions). Recall , where are the false negative samples (this represents the several positive samples predicted correctly). The mean average precision and recall indicators can be calculated as follows:
Average precision (AP) can be obtained by the precision–recall curve area. By averaging the AP and the sum of the number of all categories, the mAP can be represented as follows.
In addition, another significant indicator of Re-ID is the cumulative match characteristic (CMC) curve. The specific meaning of the CMC curve is to retrieve the pedestrians to be queried in the candidate person database (gallery) and the ratio of correct matching results in the first r search results. Among them, rank-1 indicates the average correct rate of the first match. Moreover, there is also rank-5, rank-10, and rank-20. This curve indicator shows the true recognition capability of the models.
4.3. Experimental Result
The first result is for person detection, the training results of YOLOv5 are shown in Figure 4. When IOU = 0.5, then mAP = 78.3% is the area enclosed by the P–R curve. We also show the detection results before and after the security check, as shown in Figure 5. YOLOv5 can detect most pedestrians before the security check, and the probability of detecting pedestrians was around 0.5. For distant locations, YOLOv5 does not need to detect. After the security check, the monitoring range is close to pedestrians, and YOLOv5 can detect all pedestrians passing the security check with a detection probability of 0.7–0.9. However, YOLOv5 also detects some noise. For example, when the probability of detection is 0.23, then the detected person occlusion is serious. To detect more people in the detection stage of YOLOv5, we can try to lower the value of IOU to detect more pedestrians. Then, we can cut the person detection results and cut out complete persons, as shown in Figure 6. According to the detection results of YOLOv5, only a single person was retained. Then, we used a classifier to filter the results, and the clipping results would eventually be used for person Re-ID.
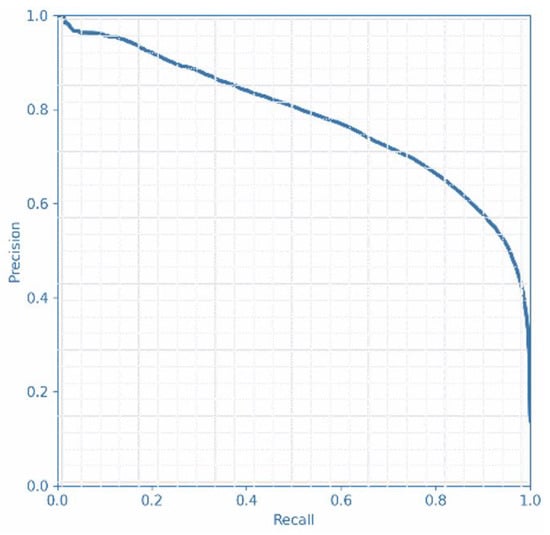
Figure 4.
Precision–recall curve.

Figure 5.
Person detection results.

Figure 6.
Cutting results.
After the YOLOv5 detection is complete, we cut the data according to the results. At this time, we not only obtained single and completed person pictures, but also captured some noisy pictures. As shown in Figure 7, the results only included part of the body, such as half a leg, a single arm, half a body, and even no person at all. At this point, we needed a model that can categorize results quickly. The function of BLS is to classify results and remove noise data. When there is no person in the cut pictures or only the arms or feet of pedestrians appear, we use BLS to classify them and discard noise data. The final results indicate that the BLS classifier accuracy was and the training time was only 2 s.

Figure 7.
Noise data.
After using BLS to remove the noise results, we used the CycleGAN algorithm to convert the images from different camera styles. Here, we had the same person data under two high and low exposure conditions, as shown in Figure 8, (the same person in front of the security check with a yellow jacket and white pants). After the security check, the shirt was shown as orange, and the pants were gray. Due to the environmental differences in the images, the Re-ID model recognition ability was poor in a real scenario. Therefore, we used the CycleGAN algorithm to alleviate this problem. As shown in the figure, a trained CycleGAN algorithm can convert the two styles of images into each other. From the results, we can see that the CycleGAN algorithm can not only unify the colors of the same person under different cameras, but it can also make up for the environment in which it is located. For our practical problems, background interference is a considerable factor. Therefore, in the proposed framework, we used the CycleGAN algorith to effectively enhance some of the data to better compensate for differences in different environments. Thus, this method improves the subsequent suspicious pedestrian Re-ID model accuracy.

Figure 8.
Style transfer results.
After, we show the results of a suspicious person attribute recognition and Re-ID according to actual demands. Person attribute recognition is mainly used to describe the abnormal feature information of a suspicious person, and it will attempt to find candidates of pedestrians with the suspicious person’s characteristics to be queried. These pedestrians are used for subsequent Re-ID investigations. The training results of the person attribute recognition model are as follows: accuracy is , precision is , and recall is . Figure 9 shows the person attribute recognition results.

Figure 9.
Person attribute recognition result.
The attributes of this person are female, age 18–60, has a handbag, has long sleeves, has pants, upper body is black, and lower body is black. In addition, when we needed to find a suspicious person who was aged 18–60, had long sleeves, and a red coat, the partial detection results obtained by the OSNet model are shown in Figure 10. Since the distinctive signs given by us were a person aged 18–60, had long sleeves, and a red coat, the candidates in the figure all have these characteristic attributes. When more feature information is provided, the search range of the locked distinctive person becomes smaller.

Figure 10.
Specific person search results.
When we only know the suspicious person’s information, we can use the person attribute recognition model to find pictures that satisfy the characteristic information from video data. Then, these images are used as the query set for the Re-ID models, which are utilized to track the suspicious pedestrian’s actions in a test data set; these actions are then backtracked along the time axis. At the same time, these images can also be used to describe all the suspicious pedestrian characteristics.
Finally, we show the suspicious person Re-ID results based on the railway station data set to solve the practical problems. As shown in Table 1, when we do not use the CycleGAN algorithm to unify the style of partial exposure data, the map of the OSNet model reaches 63.6%, rank-1 is 72.4%, rank-5 is 89.2%, and rank-10 is 94.1%. However, after we used the CycleGAN algorithm, the performance of the OSNet was improved. The mAP was promoted to 64.2%, rank-1 to 73.6%, rank-5 to 89.2%, and rank-10 to 94.3%. More importantly, when compared with other existing person Re-ID baseline models, not only did the OSNet improve the performance after using the CycleGAN algorithm, but other models (such as ResNet50, PCB, Densenet, and MLFN) were also improved. In addition, our method also has a small number of parameters (2,193,616) and computation (978,878,352) results, which is an order of magnitude less than other methods. We also compared the computing time and power consumption. As shown in Table 2, the computation time of our method is 24.068 s, which is faster than other methods. In terms of GPU power consumption, our method is 75.086 W, which is much lower than other methods. In conclusion, our method saves computing time, reduces resource consumption, and can be efficiently deployed on an edge device (e.g., HUAWEI Atlas 500).

Table 1.
Person re-identification (Re-ID) result. The bold contents are the results of our method.
Table 2.
Comparison of computing time and power consumption. The bold contents are the results of our method.
Figure 11 shows the visualization results of the suspicious person Re-ID. It shows the OSNet Re-ID results for four different groups of pedestrians. The four groups of images on the left show the Re-ID results of the four pedestrians to be queried as they rank in the top ten when classified under the original camera style. On the right is the Re-ID result of the same person after the camera style change. We can see from the results with id = 00246 that when not using the CycleGAN algorithm, four people in the OSNet matching results were matched correctly, and the correct person rank was 2, 3, 5, and 9. After using the CycleGAN algorithm, the rank of the people who matched correctly increases to 1, 2, 4, and 5. In addition, through a style transform method, the OSNet model can match more correct pedestrians, such as the person with id = 00337, 00342, and 00397, as shown in the figure. Without using the CycleGAN algorithm, the OSNet model only matches the 1, 3, and 3right people. With the CycleGAN algorithm, the number of correct matches increased to 4, 6, and 4. They all improved their matching ranks. In summary, when using the CycleGAN algorithm, the Re-ID model can recognize more person tracks and improves accuracy. We can find the specific time under the corresponding camera by the Re-ID visualization result to complete the cross-border tracking and time backtracking.

Figure 11.
Person re-identification (Re-ID) visualization results. Green and red boxes represent pedestrians who matched correctly and incorrectly, respectively.
5. Conclusions
This paper proposes a lightweight framework deployed in an edge network for recognizing suspicious persons in a public place. First, we used YOLOv5 to detect the pedestrians in the monitoring data that was provided by a real-world data set; in addition, the complete person detection results were cut. Then, we used the classification algorithm BLS to remove the noise data and the style transfer algorithm CycleGAN was used to unify the styles of pictures under different cameras, improving the person Re-ID model recognition ability. Finally, we applied the OSNet model for person attribute recognition and for the Re-ID to meet the task requirements in a real scenario. In addition, we also used the HUAWEI Atlas 500 as an edge device for the testing phase. In the future 6G era, we will continue to research pedestrian Re-ID processes in many different, real scenarios and will use edge AI technology to narrow the gap between its use in theory and in actual practice.
Author Contributions
Writing—original draft preparation, Y.W.; Writing—review and editing, X.P. and X.Z.; Supervision, S.B.; Funding acquisition, H.Y. and X.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Natural Science Foundation of Liaoning Province (Grant No. LJKZ0136), Basic scientific research Project of the Education Department of Liaoning Province (Grant LJKFZ20220184), Science and Technology Plan Project of Liaoning Province (2022JH2/101300243), Part of National Natural Science Foundation of China (Grant No. 62001313), Liaoning Provincial Natural Science Foundation of China (Grant No. 2020-MS-211, 2022-YGJC-11, 2022-YGJC-29, 2022-YGJC-35), Key project of Liaoning Provincial Department of Education (Grant No. LJKZ0133), Key Project of Liaoning Provincial Department of Science and Technology (Grant No. 2021JH2/10300134), Science and Technology Project of Shenyang City (Grant No. 22-321-32-09).
Data Availability Statement
The data are unavailable for sharing due to privacy.
Acknowledgments
The authors are thankful to the anonymous reviewers and editors for their valuable comments and suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, C.; Yu, X.; Xu, L.; Wang, W. Energy Efficient Task Scheduling Based on Traffic Mapping in Heterogeneous Mobile Edge Computing: A Green IoT Perspective. IEEE Trans. Green Commun. Netw. 2022. [Google Scholar] [CrossRef]
- Wang, C.; Yu, X.; Xu, L.; Wang, Z.; Wang, W. Multimodal semantic communication accelerated bidirectional caching for 6G MEC. Future Gener. Comput. Syst. 2023, 140, 225–237. [Google Scholar] [CrossRef]
- Zhao, L.; Yin, Z.; Yu, K.; Tang, X.; Xu, L.; Guo, Z.; Nehra, P. A fuzzy logic based intelligent multi-attribute routing scheme for two-layered SDVNs. IEEE Trans. Netw. Serv. Manag. 2022, 19, 4189–4200. [Google Scholar] [CrossRef]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3754–3762. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Lee, K.M. Part-aligned bilinear representations for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 402–419. [Google Scholar]
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Learning deep context-aware features over body and latent parts for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 384–393. [Google Scholar]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person re-identification by multi-channel parts-based cnn with improved triplet loss function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1335–1344. [Google Scholar]
- Lin, Y.; Zheng, L.; Zheng, Z.; Wu, Y.; Hu, Z.; Yan, C.; Yang, Y. Improving person re-identification by attribute and identity learning. Pattern Recognit. 2019, 95, 151–161. [Google Scholar] [CrossRef]
- Huang, H.; Li, D.; Zhang, Z.; Chen, X.; Huang, K. Adversarially occluded samples for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5098–5107. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-scale feature learning for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3702–3712. [Google Scholar]
- Dai, Z.; Chen, M.; Gu, X.; Zhu, S.; Tan, P. Batch dropblock network for person re-identification and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3691–3701. [Google Scholar]
- Hou, R.; Ma, B.; Chang, H.; Gu, X.; Shan, S.; Chen, X. Interaction-and-aggregation network for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9317–9326. [Google Scholar]
- Karanam, S.; Li, Y.; Radke, R.J. Person re-identification with discriminatively trained viewpoint invariant dictionaries. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4516–4524. [Google Scholar]
- Bak, S.; Zaidenberg, S.; Boulay, B.; Bremond, F. Improving person re-identification by viewpoint cues. In Proceedings of the 2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Seoul, Republic of Korea, 26–29 August 2014; pp. 175–180. [Google Scholar]
- Huang, Y.; Zha, Z.J.; Fu, X.; Zhang, W. Illumination-invariant person re-identification. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 365–373. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-guided contrastive attention model for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1179–1188. [Google Scholar]
- Zhang, J.; Yuan, Y.; Wang, Q. Night person re-identification and a benchmark. IEEE Access 2019, 7, 95496–95504. [Google Scholar] [CrossRef]
- Ke, X.; Lin, X.; Qin, L. Lightweight convolutional neural network-based pedestrian detection and re-identification in multiple scenarios. Mach. Vis. Appl. 2021, 32, 1–23. [Google Scholar] [CrossRef]
- Chen, C.P.; Liu, Z. Broad learning system: An effective and efficient incremental learning system without the need for deep architecture. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 10–24. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Martinel, N.; Luca Foresti, G.; Micheloni, C. Aggregating deep pyramidal representations for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Zhu, Z.; Jiang, X.; Zheng, F.; Guo, X.; Huang, F.; Sun, X.; Zheng, W. Aware loss with angular regularization for person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13114–13121. [Google Scholar]
- Xia, B.N.; Gong, Y.; Zhang, Y.; Poellabauer, C. Second-order non-local attention networks for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3760–3769. [Google Scholar]
- Zhong, Z.; Zheng, L.; Zheng, Z.; Li, S.; Yang, Y. Camera style adaptation for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5157–5166. [Google Scholar]
- Qian, X.; Fu, Y.; Xiang, T.; Wang, W.; Qiu, J.; Wu, Y.; Jiang, Y.G.; Xue, X. Pose-normalized image generation for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 650–667. [Google Scholar]
- Zhou, S.; Ke, M.; Luo, P. Multi-camera transfer GAN for person re-identification. J. Vis. Commun. Image Represent. 2019, 59, 393–400. [Google Scholar] [CrossRef]
- Zhang, C.; Zhu, L.; Zhang, S.; Yu, W. PAC-GAN: An Effective Pose Augmentation Scheme for Unsupervised Cross-View Person Re-Identification. Neurocomputing 2020, 387, 22–39. [Google Scholar] [CrossRef]
- Zhan, F.; Zhang, C. Spatial-aware gan for unsupervised person re-identification. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6889–6896. [Google Scholar]
- Matsukawa, T.; Suzuki, E. Person Re-Identification Using CNN Features Learned from Combination of Attributes. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2428–2433. [Google Scholar]
- Tay, C.P.; Roy, S.; Yap, K.H. Aanet: Attribute attention network for person re-identifications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7134–7143. [Google Scholar]
- Wang, C.Y.; Chen, P.Y.; Chen, M.C.; Hsieh, J.W.; Liao, H.Y.M. Real-time video-based person re-identification surveillance with light-weight deep convolutional networks. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–8. [Google Scholar]
- Yrjänäinen, J.; Ni, X.; Adhikari, B.; Huttunen, H. Privacy-aware edge computing system for people tracking. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Virtual, 25–28 October 2020; pp. 2096–2100. [Google Scholar]
- Gaikwad, B.; Karmakar, A. End-to-end person re-identification: Real-time video surveillance over edge-cloud environment. Comput. Electr. Eng. 2022, 99, 107824. [Google Scholar] [CrossRef]
- Chen, X.; Li, Z.; Tang, C.; Xiao, S.; Chen, Y. Person re-identification in the edge computing system: A deep square similarity learning approach. Concurr. Comput. Pract. Exp. 2021, 33, 1. [Google Scholar] [CrossRef]
- Chen, C.H.; Liu, C.T. Person re-identification microservice over artificial intelligence internet of things edge computing gateway. Electronics 2021, 10, 2264. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).