In this section, we first investigated the efficiency of our memory reconstruction strategy. The experiments for this were set in two scenarios: (1) using the network architecture of iCaRL in [
22] and our proposed memory reconstruction strategy (random-sample memory), and (2) using the proposed architecture with loss combination of CNN models and random-sample memory (as shown in
Figure 1). The results of the first scenario were compared with those of iCaRL method to show the better performance of our memory reconstruction strategy in comparison with iCaRL. In the second scenario, the performance of our memory reconstruction strategy with loss combination was evaluated with the different cases of the
coefficient in Formula (
14). Based on this, the best
value was chosen for further comparative evaluations with other SOTA methods.
The experiments were conducted at different memory sizes and numbers of classes in the CIFAR-10, CIFAR-100, and CORE-50 datasets. The memory size with the best result was chosen for the evaluation of the continual learning of NC and NCI cases. The proposed framework for continual learning was also evaluated and compared with other SOTA methods. The evaluation schemes were written in Python on a Pytorch deep learning framework and run on a workstation with a NVIDIA GPU 11G. The optimal function was stochastic gradient descent (SGD). The learning rate () was equal to 2.0 and automatically reduced after each 30 epochs. Resnet18 was used as the backbone model.
4.3. Evaluations with NC Type
In this section, two classification strategies are deployed: (1) end-to-end Resnet18 classification, and (2) a discrete method with a Resnet18 feature extractor and KNN classifier. The first strategy was implemented in [
7,
22,
38] with the LwF, iCaRL, and AOP methods, respectively. In this work, we compare these methods with the solutions named
RiCaRL-Resnet (using the proposed memory reconstruction strategy and Resnet backbone as in [
7] or [
22]) and
RLC-Resnet (using the proposed memory reconstruction strategy and loss combination of Resnet18 models). The second classification strategy is tested on three solutions:
iCaRL-Knn,
RiCaRL-Knn, and
RLC-Knn. The evaluations are deployed on the four above datasets, and the data protocols are applied for the incremental NC type.
Firstly, the CORE-50 and CIFAR-100 datasets are used in the experimental results presented in
Figure 3 and
Figure 4, respectively.
Figure 3a and
Figure 4a show the results for the first classification strategy. The results for the second strategy are presented in
Figure 3b and
Figure 4b. It can be seen from these figures that the experimented methods show decreases in accuracy as the number of classes increases. This happens for both classification strategies. However, the RLC-Resnet method has the least reduction compared with the other methods. This is indicated more clearly in the first classification strategy (
Figure 3a and
Figure 4a) than in the second one (
Figure 3b and
Figure 4b). In a comparison between the two classification strategies on the same experimental dataset, either CORE-50 or CIFAR-100, in general, we find that the second strategy has higher accuracy than the first one for all class numbers. This is remarkable for all solutions but not the RiCaRL-Resnet and RLC-Resnet methods. In practical applications, an end-to-end architecture is more prefered than a discrete one. This means that our end-to-end solutions, RiCaRL-Resnet and RLC-Resnet, balance both high recognition accuracy and applicability.
In a detailed analysis of the CORE-50 dataset, we see that, with the first classification strategy (
Figure 3a), the LwF method has the lowest accuracy, with 86.72% for 10 classes, followed by the methods of iCaRL-Resnet, with 98.21%; AOP, with 98.42%; RiCaRL-Resnet, with 99.75%; and the highest one, RLC-Resnet, with 100%. These results are reduced significantly when the class number increases. For 50 classes, LwF gains only 54.49%, iCaRL-Resnet gains 71.05%, AOP gains 80.53%, RiCaRL-Restnet and RLC-Resnet gains 84.87% and 88.22%, respectively. In the second classification strategy ((
Figure 3b), iCaRL-Knn has the lowest accuracy, with 99.43% and 87.74% for 10 and 50 class numbers, respectively. These are 1.22% and 16.69% higher than those of the first strategy. RiCaRL-Knn and RLC-Knn have higher accuracy compared with iCaRL-Knn, with 99.81% and 100% for 10 classes, and 86.05% and 91.03% for 50 classes, respectively. In comparison with the ones from the first strategy, these numbers are only about 2% to 3% higher.
The experimental results on the CIFAR-100 dataset also show the same progress as CORE-50.
Figure 4a shows the results of the first classification strategy. It can be seen that LwF has the lowest accuracy, with 84.51%, for 10 classes compared with the other four methods: AOP (86.31%), iCaRL-Resnet (87.92%), RiCaRL-Resnet (88%), and RLC-Resnet (88.92%). However, for 100 classes, these numbers decrease significantly to 39.04%, 51.38%, 49.19%, 49.48%, and 52.56% for each. In the second classification strategy (
Figure 4b), we see slight decreases in accuracy for 10 classes of iCaRL-Knn (86%) and RiCaRL-Knn (86.1%) compared with the ones with the first strategy. However, RLC-Knn has a tiny increase in accuracy of 89.9% in comparison with 88.92% for the first strategy. The modest reduction also occurs in class numbers 20, 30, and 40 for the methods RiCaRL-Knn and RLC-Knn, but for other class numbers, the trend increases slightly. For 100 classes, iCaRL-Knn has an accuracy of 49.79%, while RiCaRL-Knn and RLC-Knn have accuracies of 54.74% and 58.32%, respectively. These numbers are all higher than the those of the first classification strategy.
In addition to experiments on two commonly used databases for continual learning, CORE-50 and CIFAR-100, the NC incremental evaluation is also investigated on two hand gesture datasets: KinectLeap and Creative Senz3D. The memory size is 500 images, and down-sampling of the buffer is implemented as presented in
Section 3.2. The two data protocols for these datasets are deployed as shown in
Section 4.1. The learning rate (
) is equal to 2.0, which is then reduced after 30 epochs. Resnet18 is used as the backbone for both models.
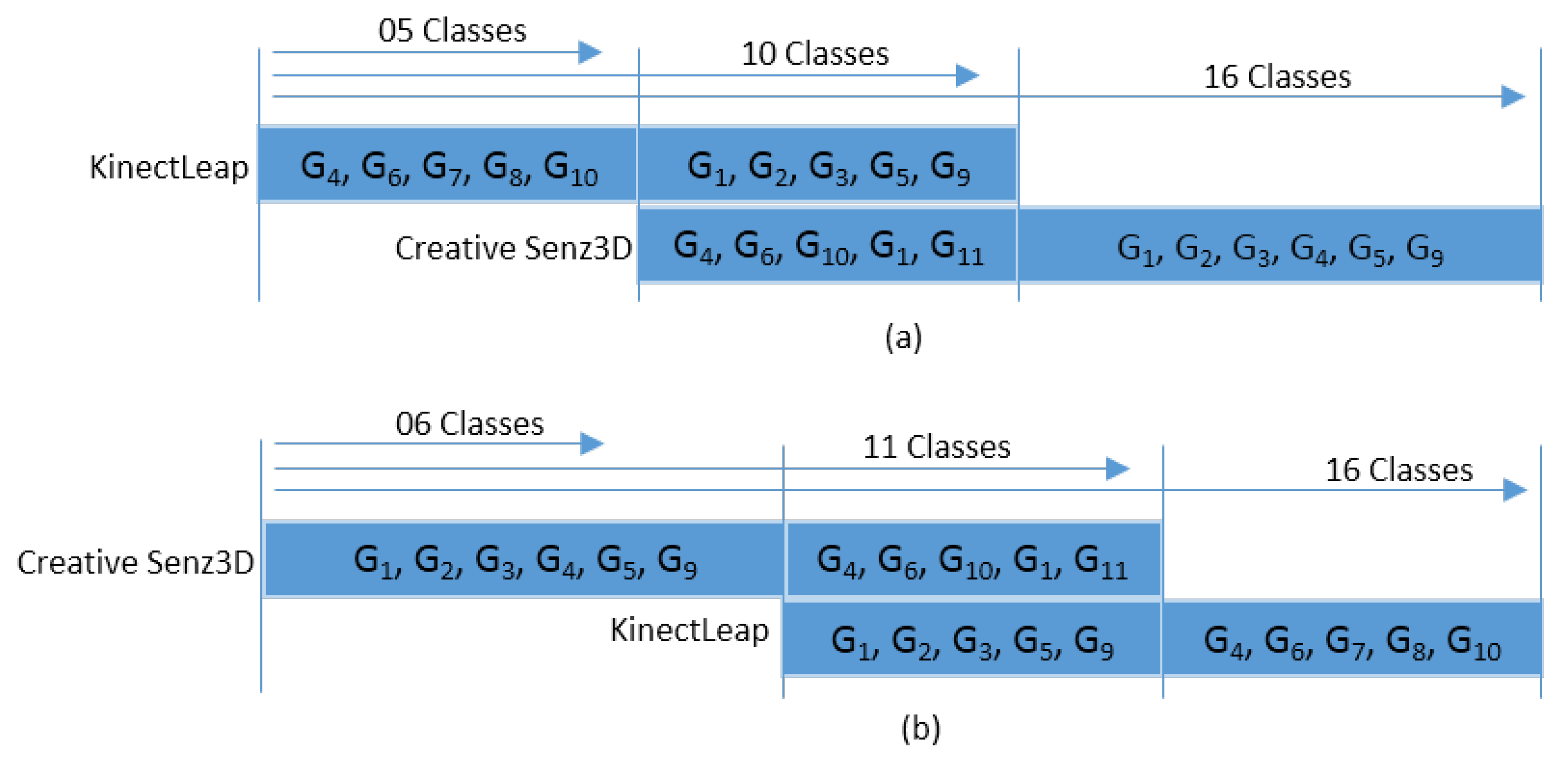
Table 5 shows the recognition accuracy of the various continual learning methods with two data protocols: KinectLeapCreative Senz3D (the left side of
Table 5), and Creative Senz3D - KinectLeap (the right side of
Table 5). In the first data protocol for NC type, three tasks are set up, in which task 1 contains 5 classes, task 2 includes 10 classes, and task 3 has 16 classes (as shown in
Figure 2a). The second data protocol for the NC type also has three tasks: task 1 contains 6 classes, task 2 has 11 classes, and task 3 has 16 classes (as indicated in
Figure 2b). All values of recognition accuracy in
Table 5 are the averages of five runs, with the standard deviation shown beside each result.
It can be seen from
Table 5 that the RLC-Resnet method obtains a higher accuracy on both data protocols, as well as the entire continual learning step of the tasks. For protocol 1, for tasks with 5, 10, and 16 classes, the RLC-Resnet method stably reduces from 94.06% to 86.58%. For a task with five classes, it is slightly higher than the LwF, iCaRL, and AOP methods. However, for tasks sizes of 10 and 16, it is extremely larger than the LwF method and about 6% higher than the iCaRL method. This trend is similar to protocol 2, with the RLC-Resnet method obtaining 98.61%, 92.37%, and 85.85% for task sizes of 6, 11, and 16, respectively.
The experimental results on KinectLeapCreative and Senz3Dshow with two data protocols for the NC type show the prospect of our RLC-Resnet method for improving the hand gesture recognition system on various hand gesture datasets of the NC type. This also shows its meaning in the practical implementation of hand gesture recognition systems, in which the hand gesture datasets belong mainly to the NC case.
Further evaluations are shown in
Table 6 to show the comparative results between the RLC-Resnet method and other solutions on the CIFAR-10 and CIFAR-100 datasets. The memory sizes and task sizes for these experiments are chosen as the best ones in [
25], with memory sizes of 5000 and 1000 and task sizes of 10 and 5 for the CIFAR-100 and CIFAR-10 datasets, respectively. In addition, in this work, we also evaluate the proposed solution of RLC-Resnet on the CORE-50 dataset, with a memory size of 4000 and a task size of 5. All experimental results are averaged over fifteen runtimes, and the standard deviation is shown beside each result.
It can be seen that, in comparison with the results of the best methods—OCM [
25], with
for the CORE-50 dataset, and AOP [
38], with
and
for the CIFAR-10 and the CIFAR-100 datasets, respectively—the results obtained with our RLC-Resnet method are higher, with
,
, and
for the CORE-50, CIFAR-10, and CIFAR-100 datasets, respectively.
4.4. Evaluations with NCI Type
This evaluation is implemented on two hand gesture datasets. For the NCI type, the data protocols and the optimization function are presented in detail in
Section 3.1.2,
Section 4.1.2 and
Section 3.2. The memory size, learning rate, and Resnet18 model are similar to the ones in the previous section. The task size is 16 for both data protocols: KinectLeap-Creative Senz3D and Creative Senz3D-KinectLeap.
The continual learning methods of LwF, iCaRL, AOP, and RLC-Resnet are compared with the original transfer learning of Resnet18 [
33], as illustrated in
Table 7. In the case of the pre-trained Resnet model on KinectLeap dataset and testing on Creative Senz3D, the recognition result is 30.38%. Compared with the continual leaning methods with
being KinectLeap and
being Creative Senz3D, this result is a little higher than that for LwF (29.75% for the NC case and 30.25% for the NCI case) but much lower than that for the iCaRL (80.88% for the NC case and 81.74% for the NCI case), AOP (81.67% for the NC case and 83.03% for the NCI case), and RLC-Resnet (86.58% for NC and 88.21% for NCI case) method. This also happens to the case of
with Creative Senz3D and
with KinectLeap. Transfer learning of ResNet18 obtains only 32.08% compare with LwF, with 28.56% and 30.26%; iCaRL, with 79.59% and 81.40%; AOP, with 80.46% and 82.34%; and RLC-ResNet, with 85.85% and 87.91%, for the cases of NC and NCI, respectively.
The cross-dataset evaluation results of Resnet18 on two different datasets—KinectLeap and Creative Senz3D—are much lower than the cases of training and testing ResNet on one dataset. For KinectLeap, the recognition result of ResNet is 72%, and for Creative Senz3D, the result is 72.04%. This is obvious in classification problems, in which cross-dataset evaluation is much more challenging than using a unified dataset for evaluation. However, when deploying these datasets for our continual learning method RLC-Resnet, the hand gesture recognition results are higher than those of ResNet18. In the case of being KinectLeap and being Creative Senz3D, the recognition results are 86.58% for the NC type and 88.21% for the NCI type. In the case of being Creative Senz3D and being KinectLeap, RLC-ResNet obtains 85.85% and 87.91% for NC and NCI, respectively. All values of recognition accuracy are the averages of five runs with the standard deviation, shown beside each result.
Based on the above analysis of experimental results, we see that the RLC-Resnet method not only outperforms other continual learning methods such as LwF, iCaRL, and AOP but also is extremely higher than the cross-dataset evaluation of ResNet18.
In addition,
Table 7 shows that the scenario of NCI incremental data obtains a little higher accuracy than the NC type for a task size of 16 classes. For KinectLeap-Creative Senz3D, the NCI type obtains 30.25%, 81.71%, 83.03%, and 88.21% for the LwF, iCaRL, AOP, and RLC-Resnet methods, respectively. They are approximately 1% higher than those of the NC type. For Creative Senz3D-KinectLeap, the results for NCI types are 30.26% for the LwF method, 81.40% for the iCaRL method, 82.34% for AOP, and 87.91% for the RLC method. The corresponding results for the NC type are 28.56%, 79.59%, 80.46%, and 85.85%.
From the above analysis of the experimental results, we see the efficiency of our RLC-Resnet method in incremental learning on two different datasets: KinectLeap and Creative Senz3D. Although these datasets have some similar labels for hand gestures, they were captured by different camera types at distinctive environments. When deploying these datasets for our RLC-Resnet method in both the NC and NCI types, the performance of hand gesture recognition is remarkably improved in comparison with other methods and even with a one-dataset evaluation of ResNet18. In addition, the higher recognition performance of the NCI type compared with the NC type proves the efficiency of our framework for continual learning, even for the more complex case of NCI. This result also shows the meaning of adding source task samples with similar class labels to the target task into the memory. This helps boost the performance of hand gesture recognition.









{kind=link}
{kind=link}
{kind=link}
{kind=link}