
Transfer Learning-Based Automatic Hurricane Damage Detection Using Satellite Images

 ,
, 
Abstract
:1. Introduction
- Addition of a newer set of layers to the pre-trained models for classification of the satellite images of hurricanes into damaged and undamaged categories;
- To generalize the model by applying data augmentation techniques to images;
- To perform a comparative study based on accuracy, precision, recall and F1-score for the four pre-trained models, which include VGG16, MobileNetV2, InceptionV3 and DenseNet121, at a learning rate of 0.0001 and 40 epochs.
- To compare the best performing models for various optimizers, which include SGD, Adadelta, Adam and RMSprop.
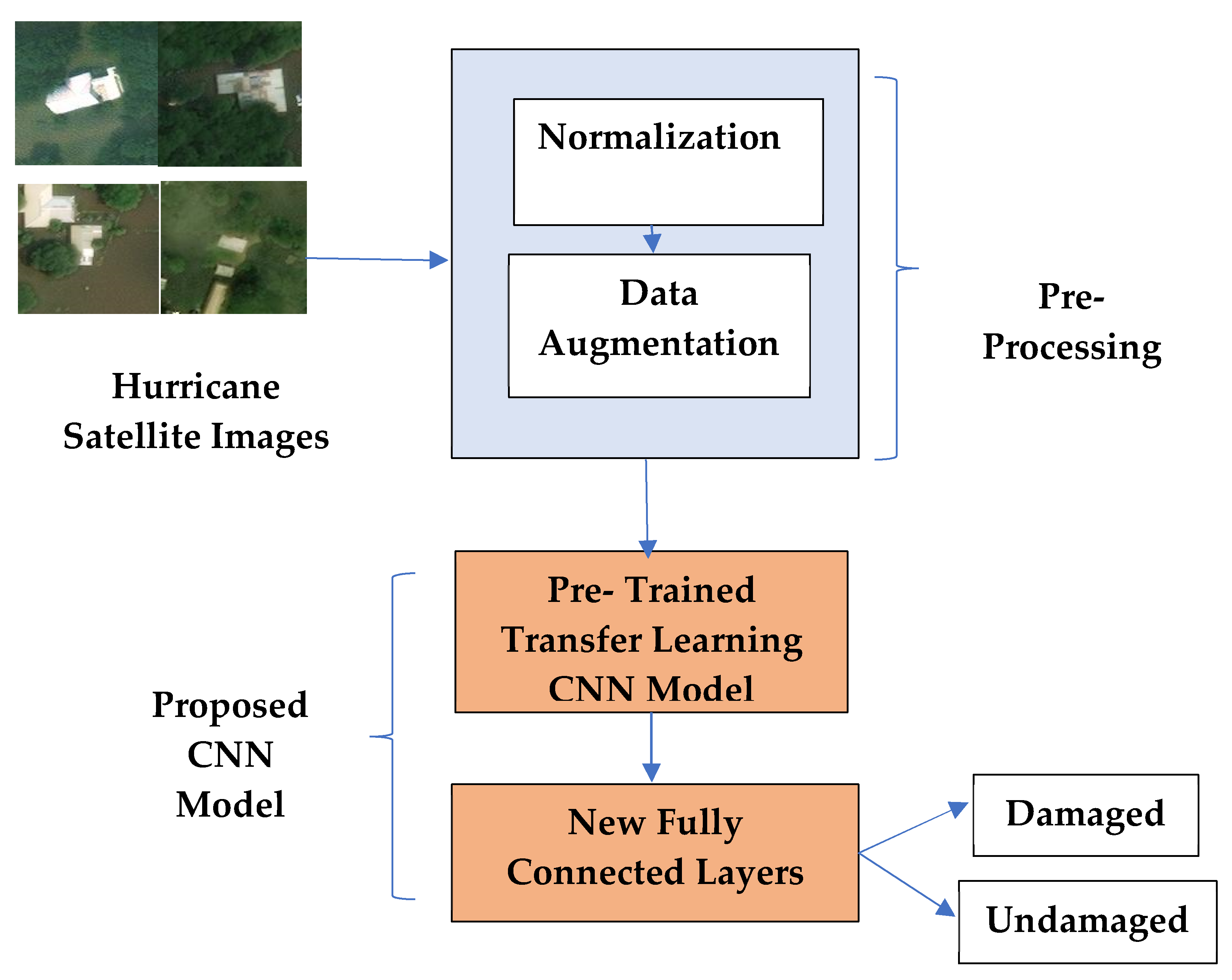
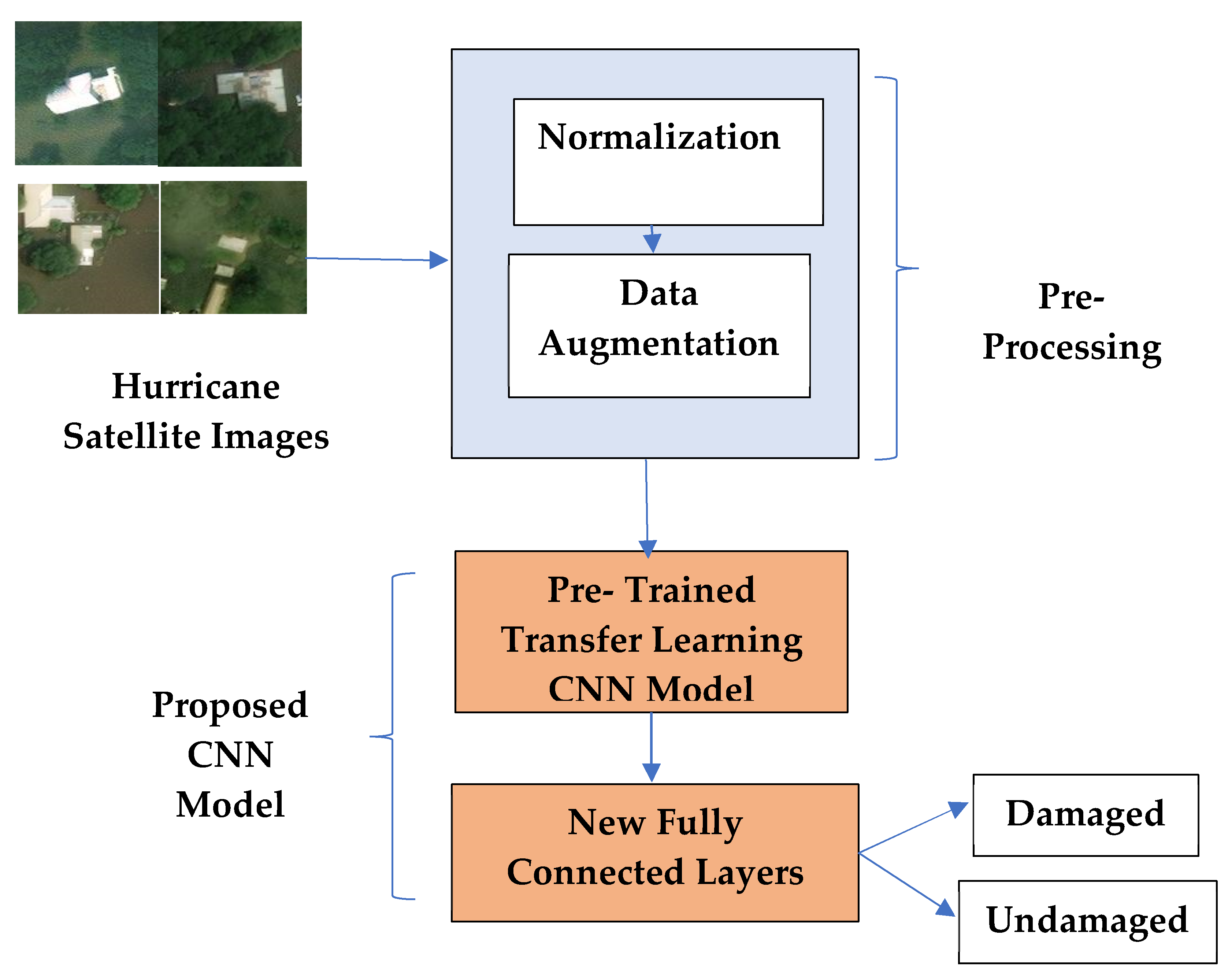
2. Proposed Methodology
2.1. Preprocessing
2.1.1. Normalization
2.1.2. Data Augmentation
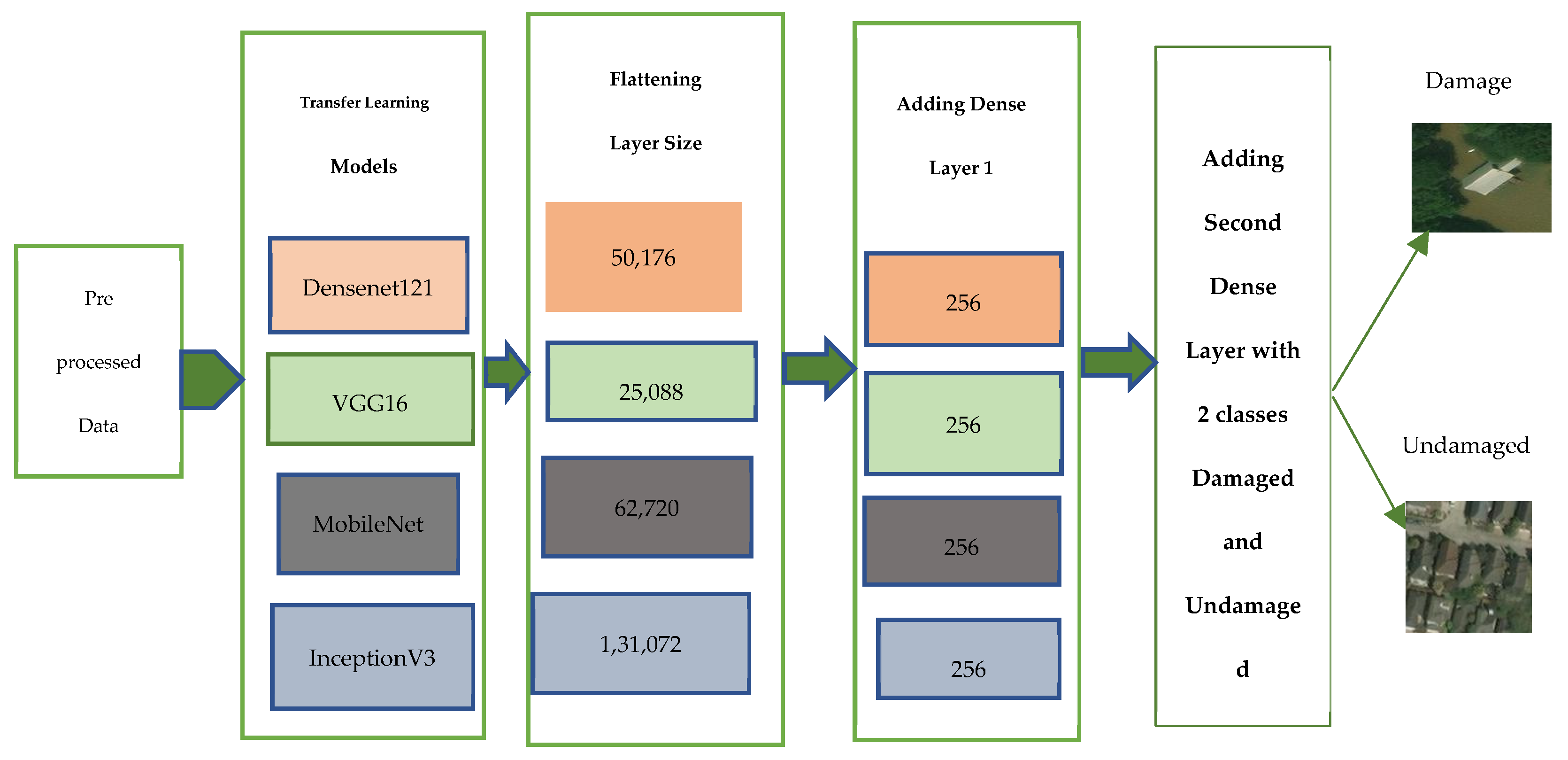
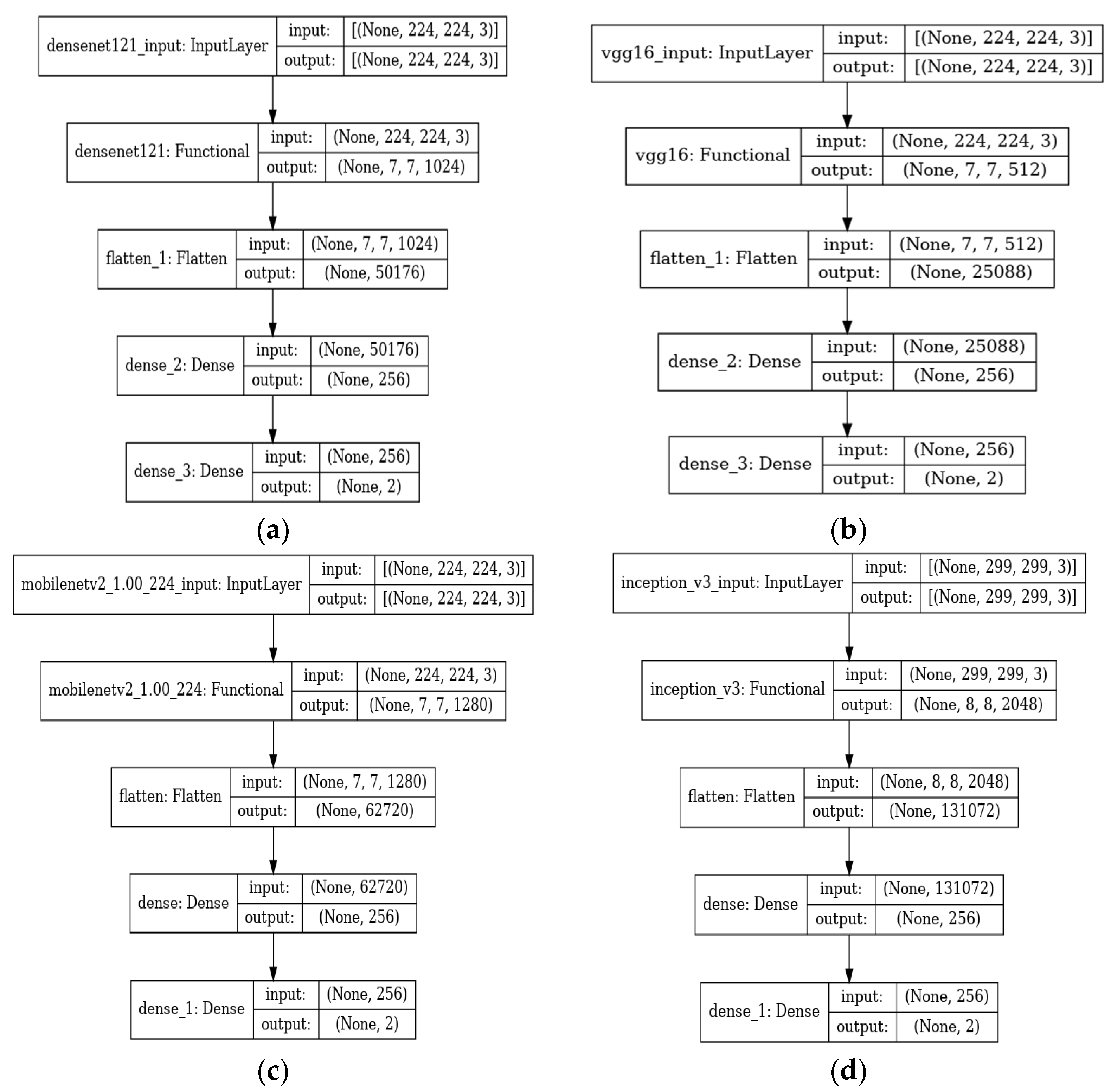
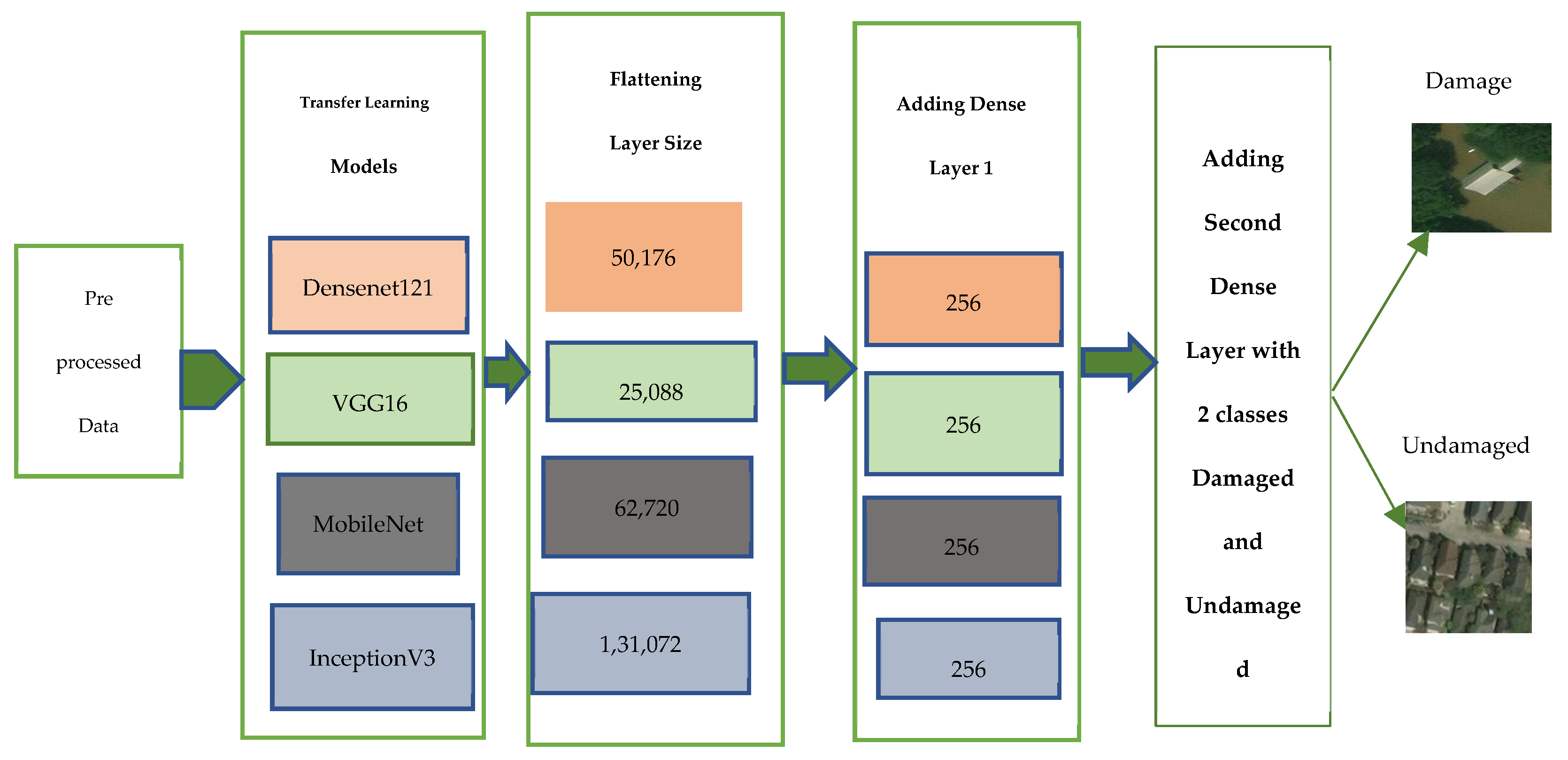
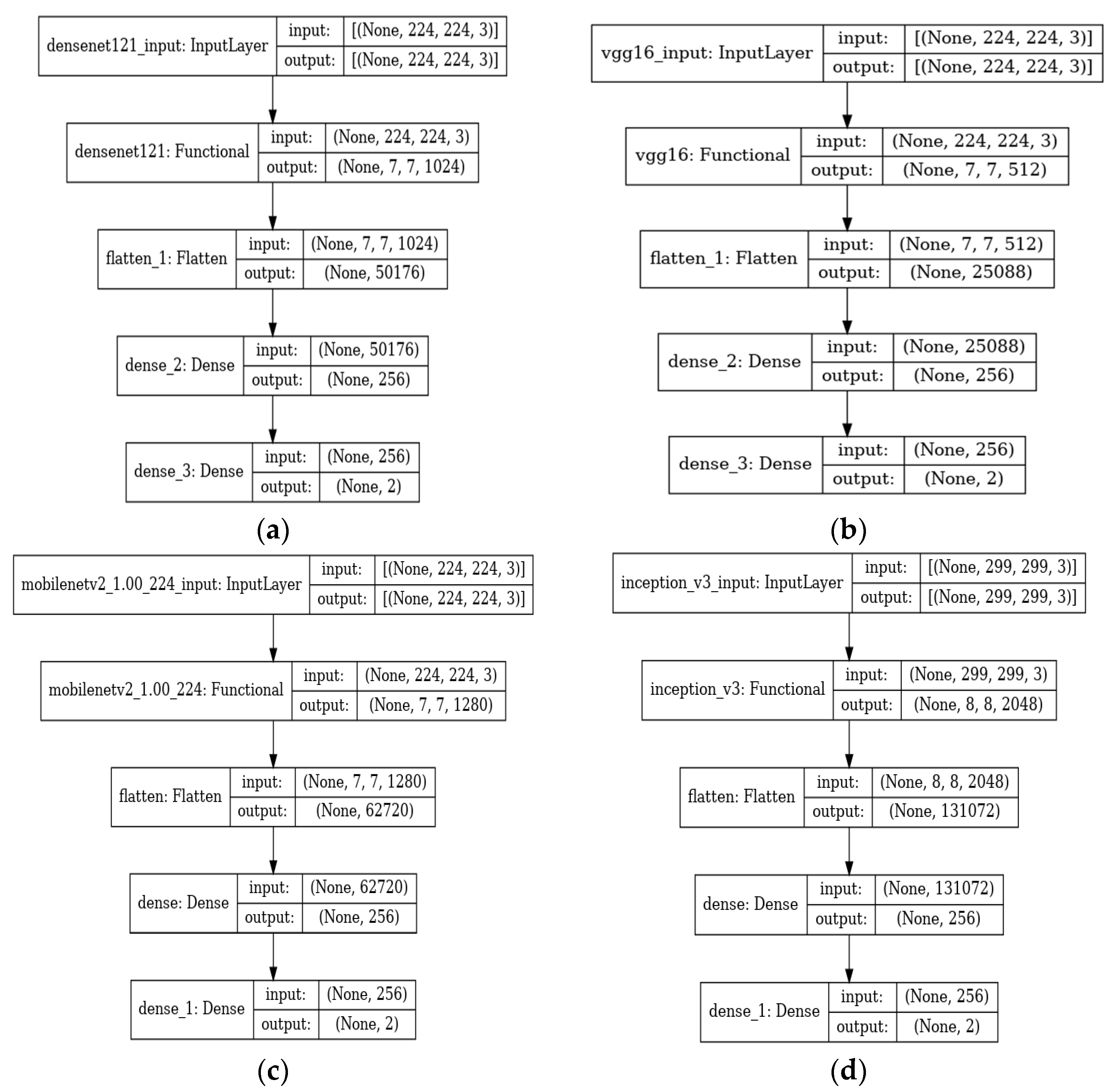
2.2. Hurricane Damage Detection Using Pre-Trained CNN Models
2.3. Tuning the Hyper-Parameters
3. Results and Discussion
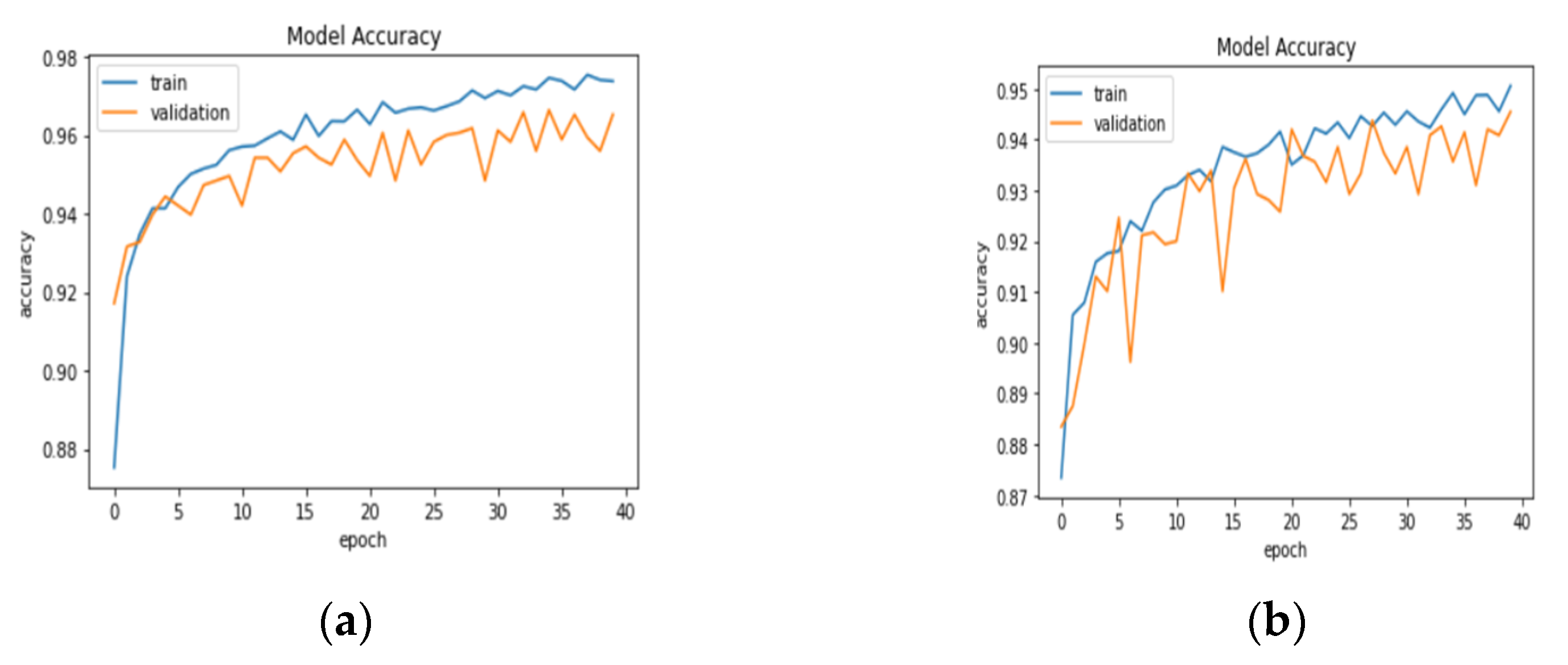
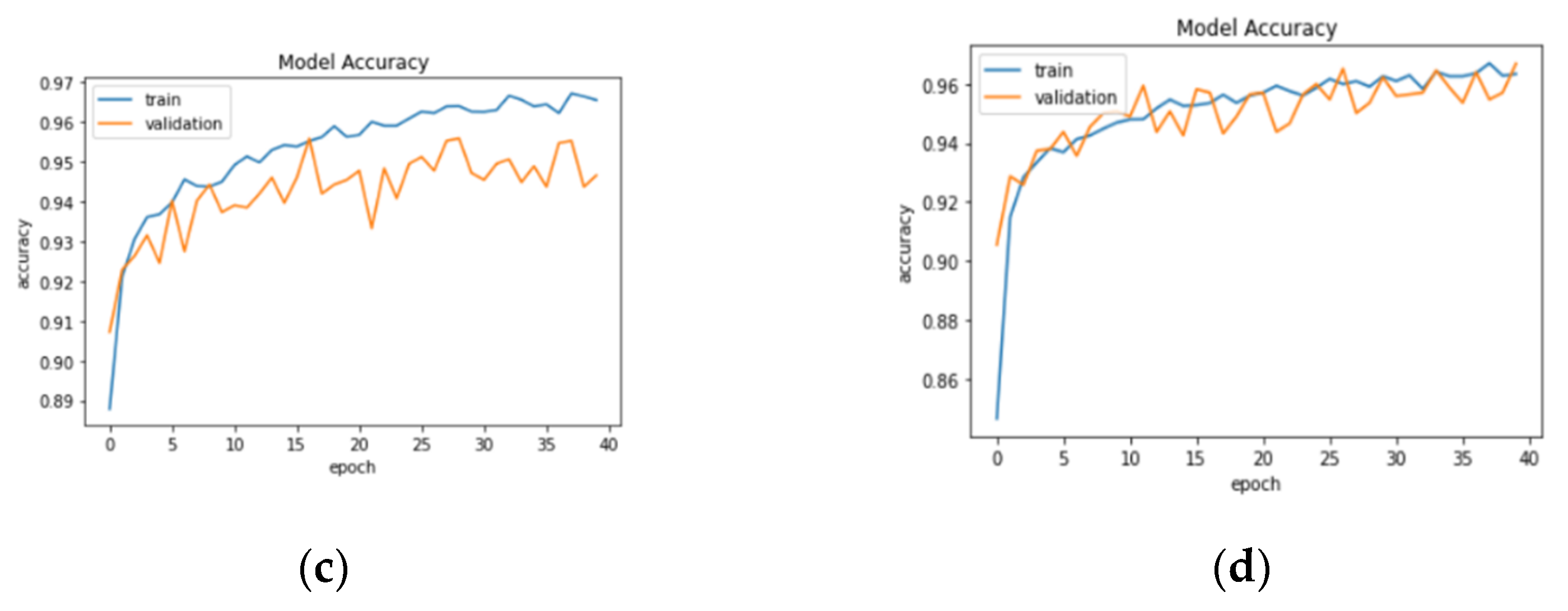
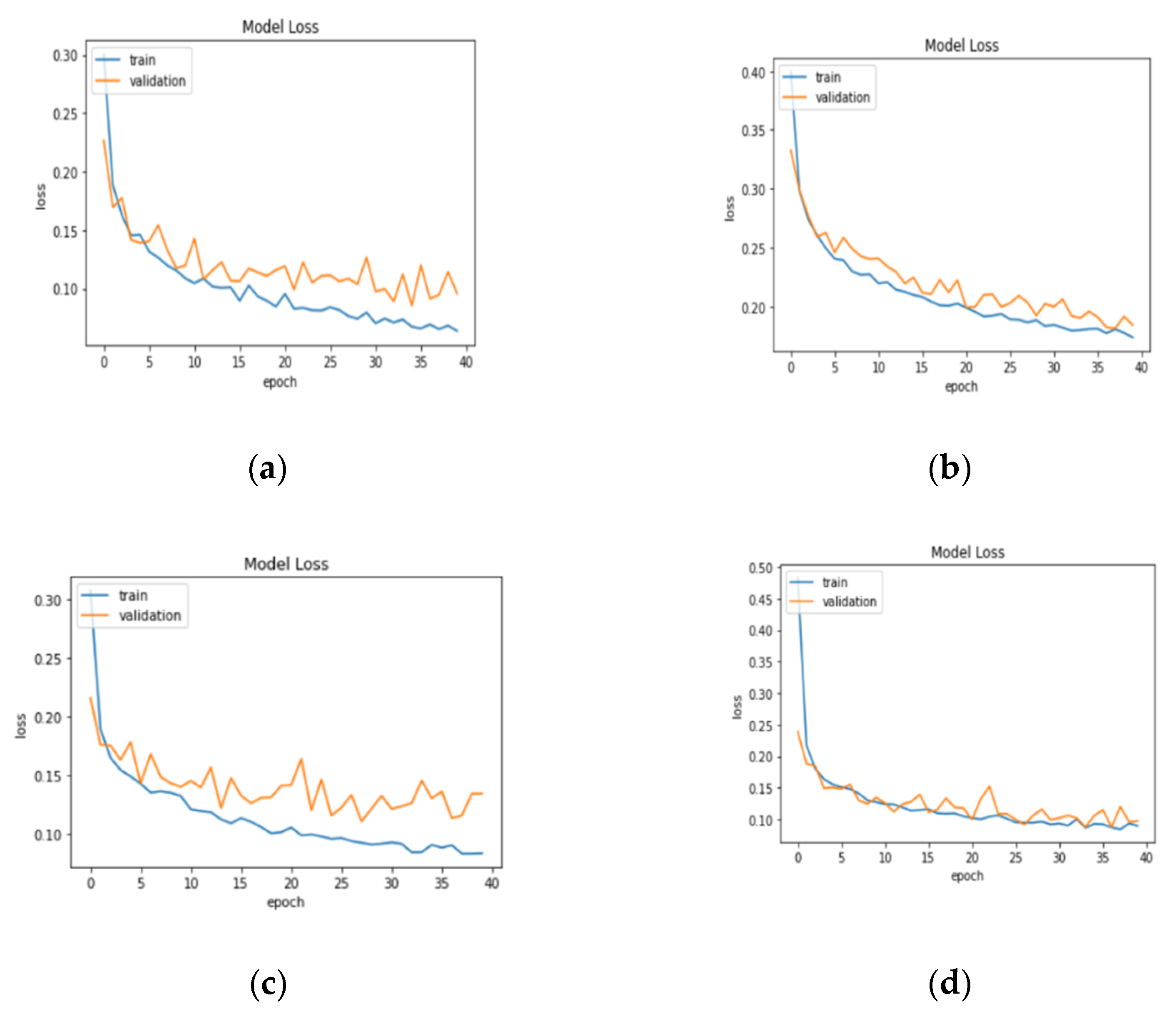
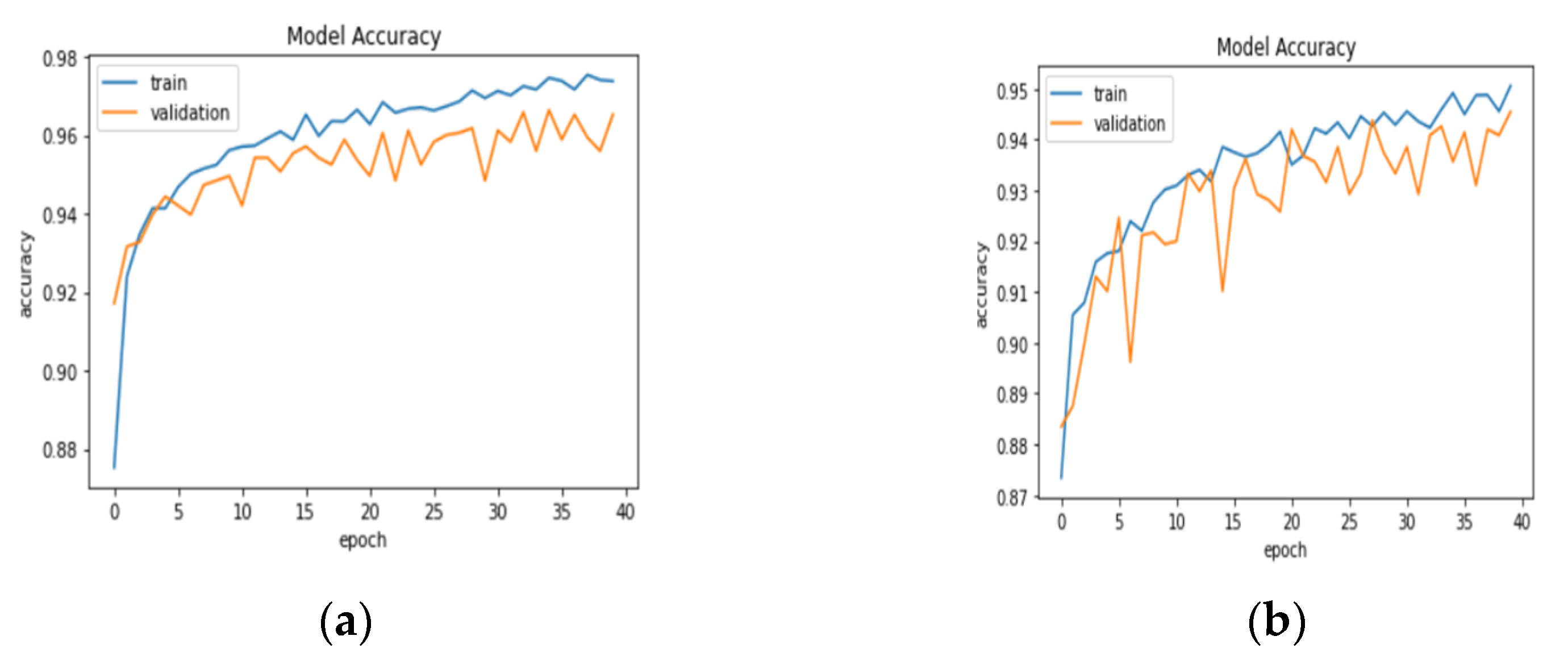
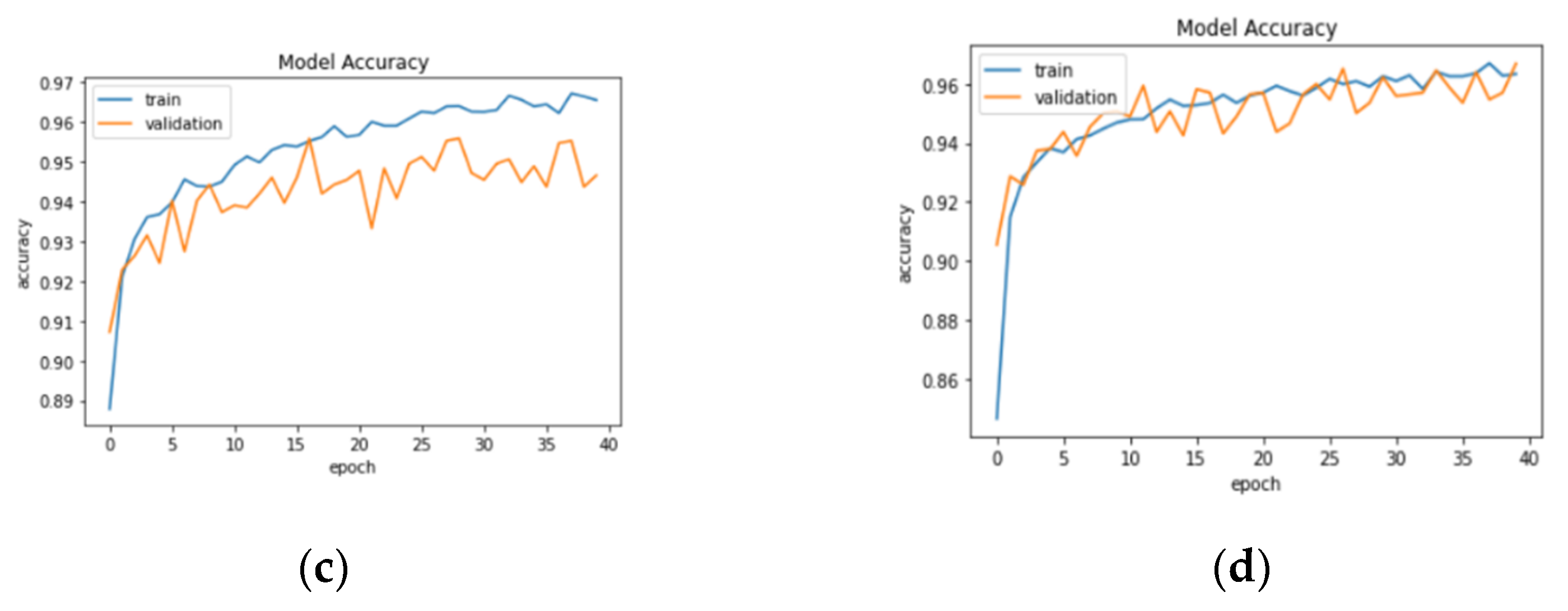
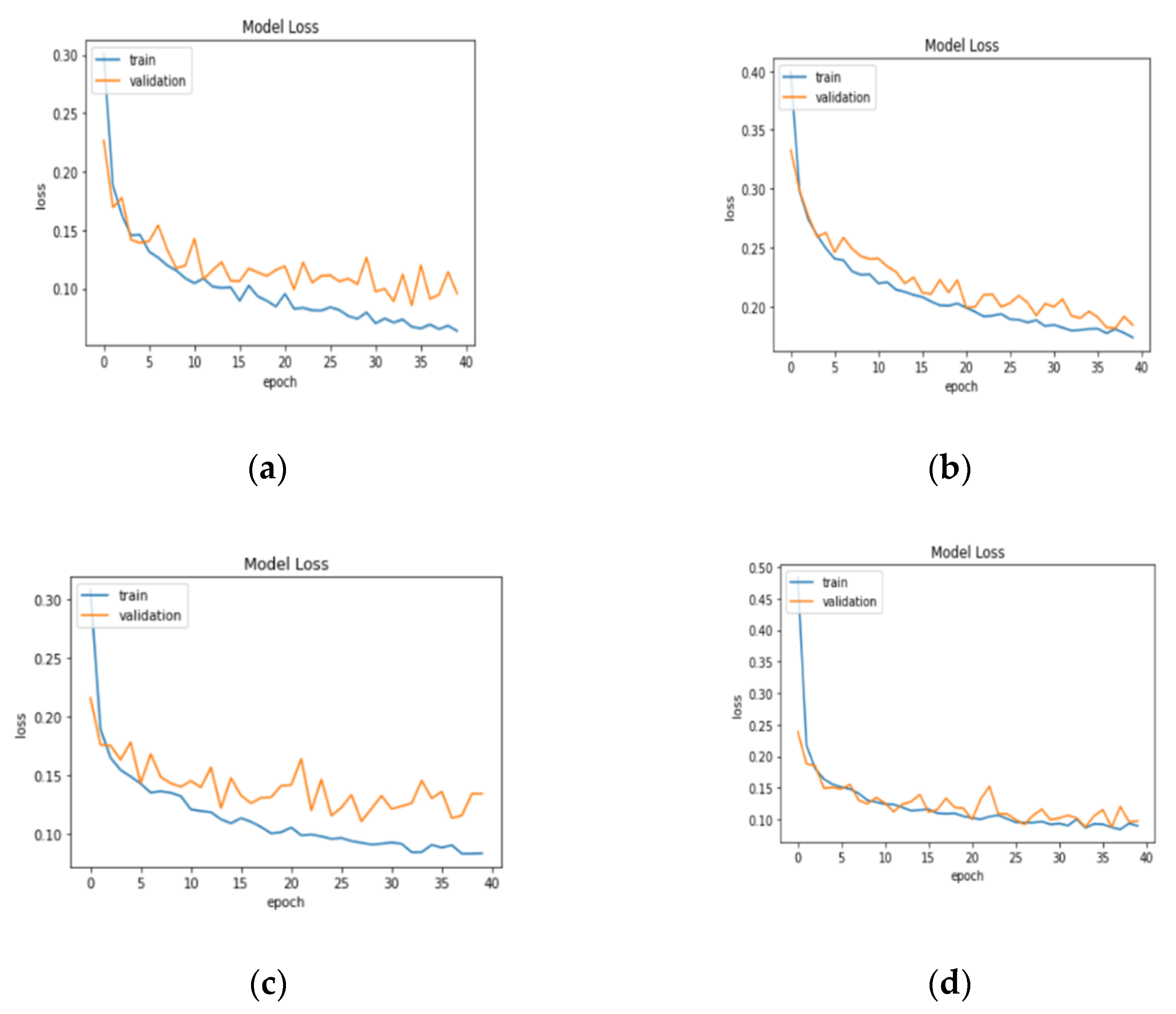
3.1. Result Analysis in Terms of Loss and Accuracy
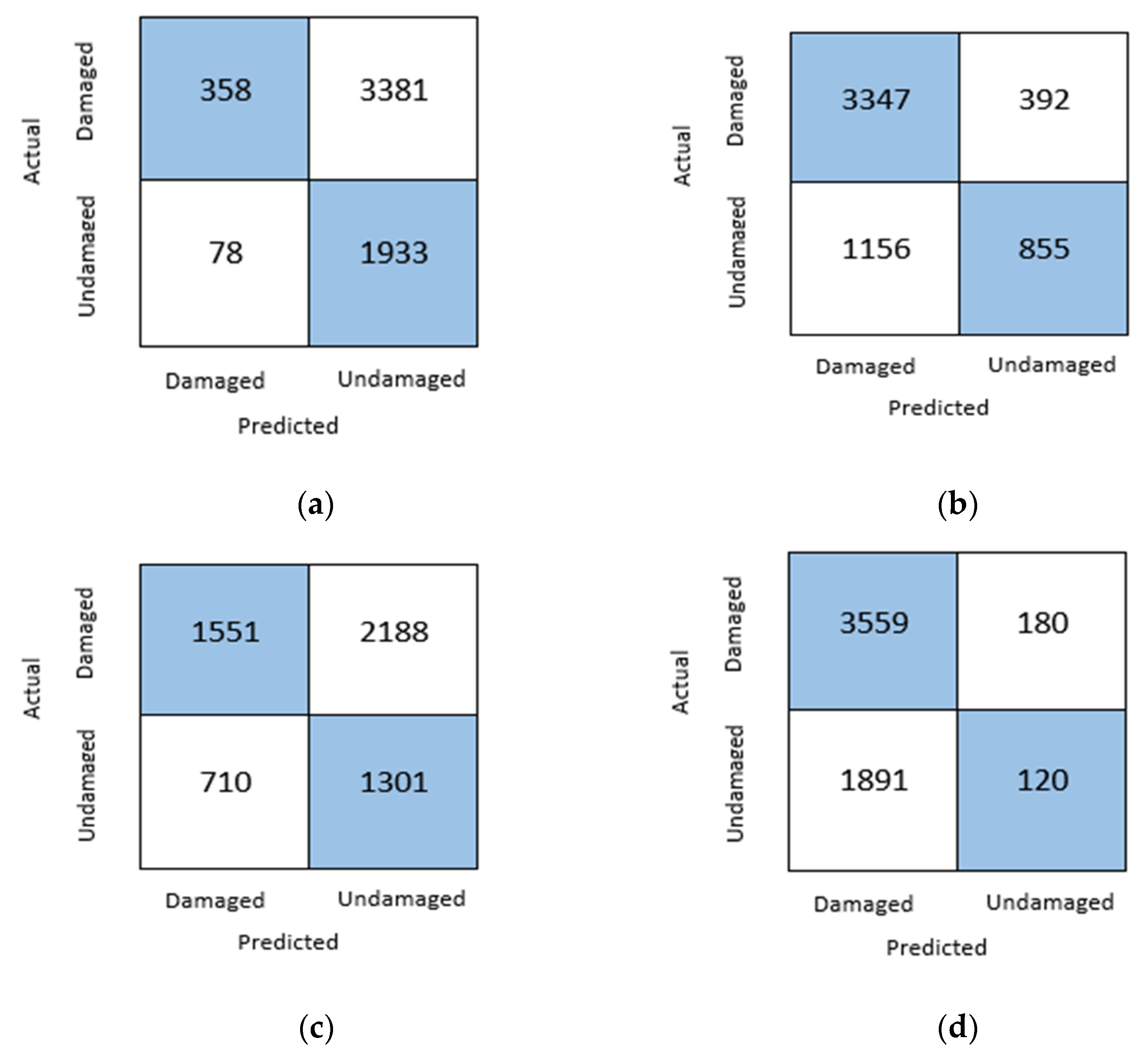
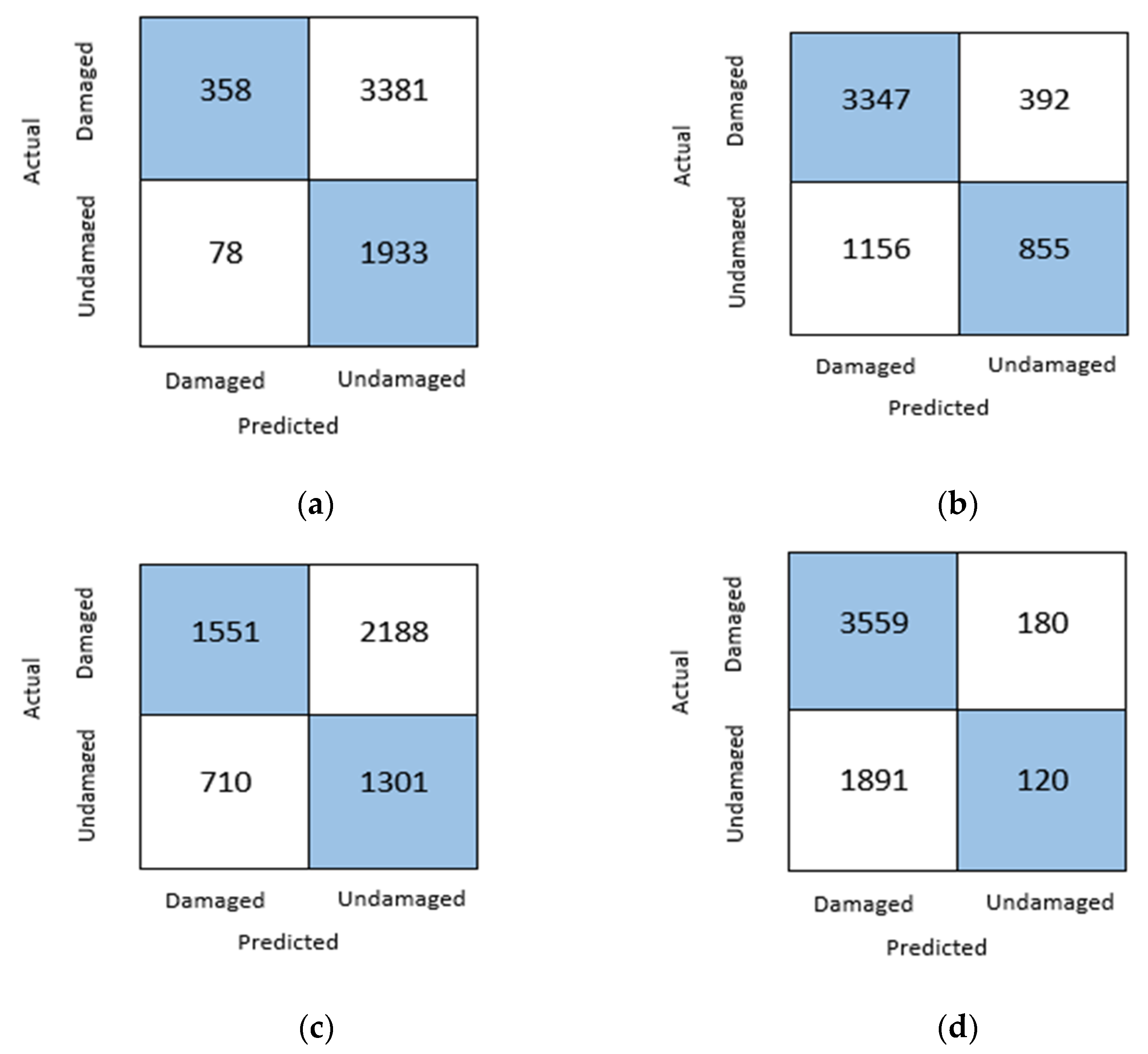
3.2. Confusion Matrix Parameter Result Analysis
3.3. Comparison of Results of Various Optimizers
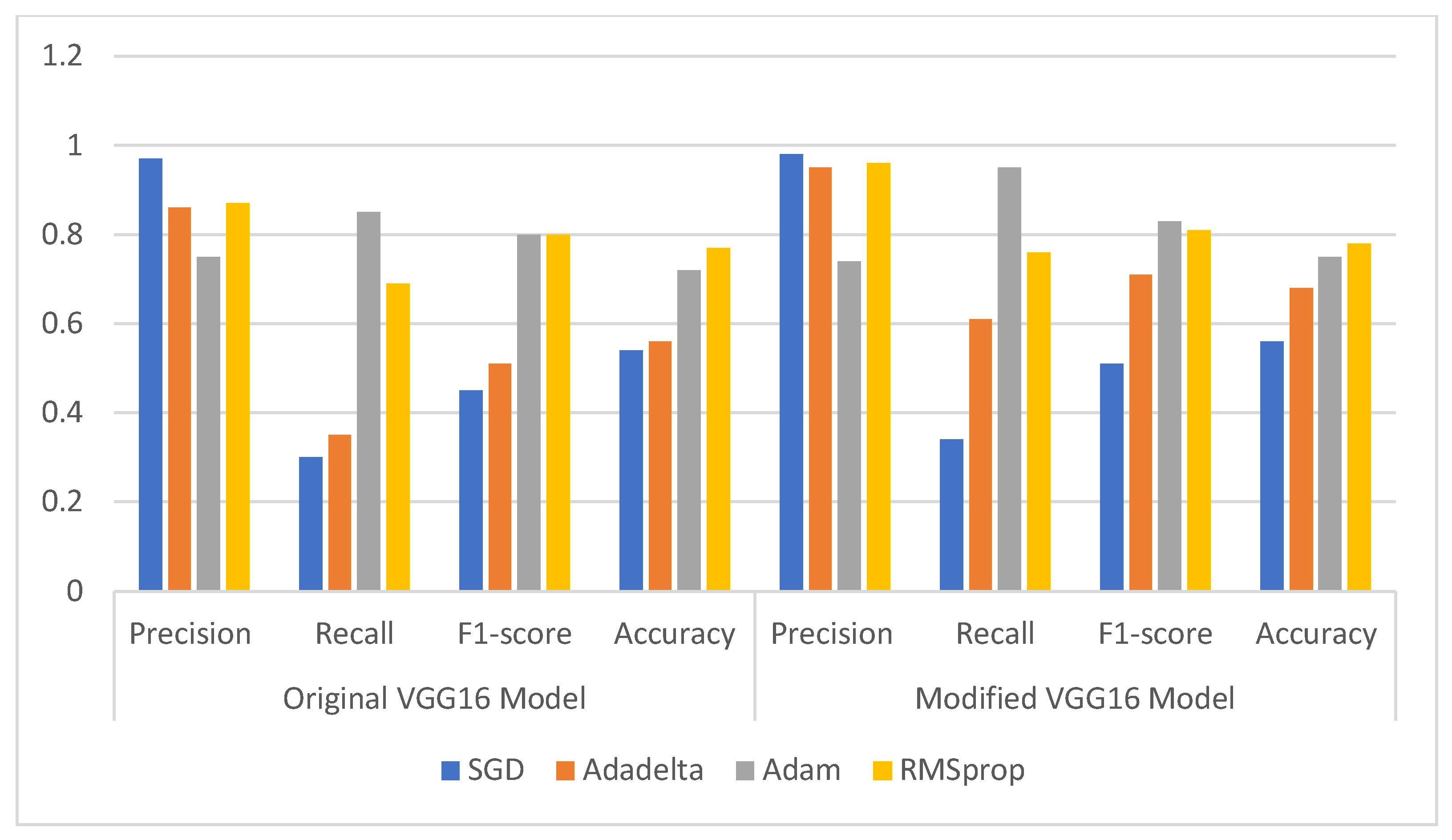
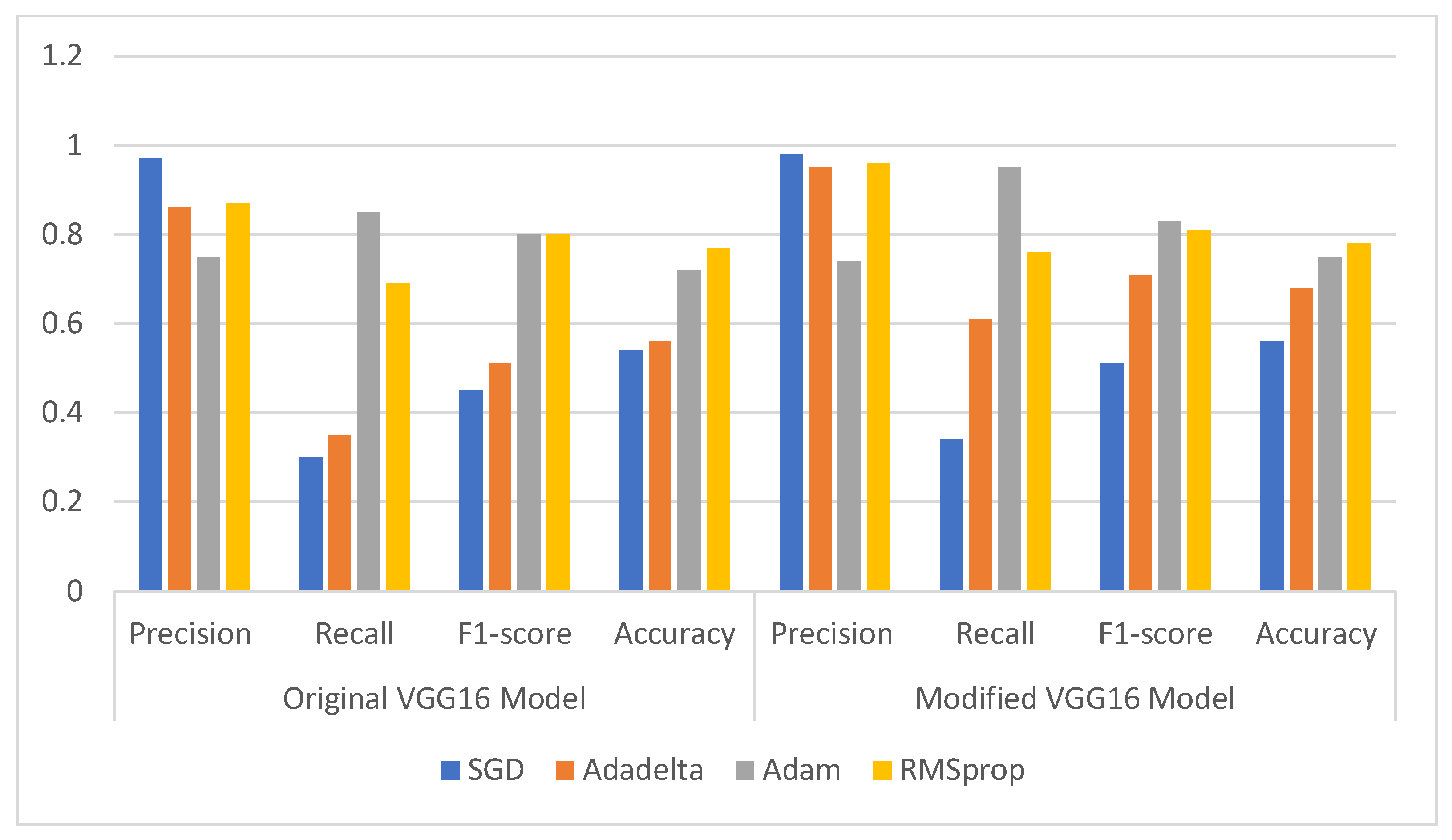
3.3.1. Comparison of Original and Modified VGG16 Model
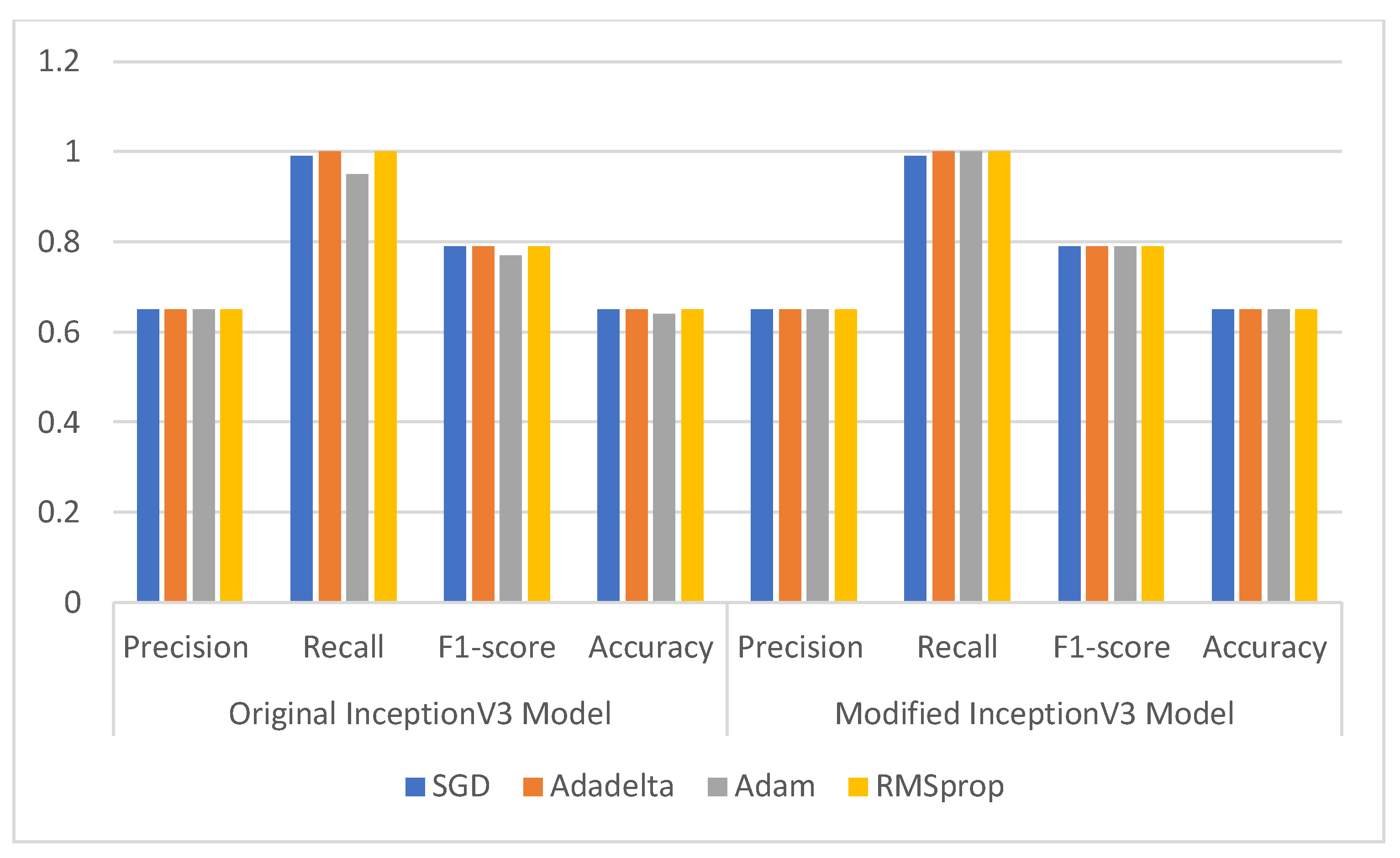
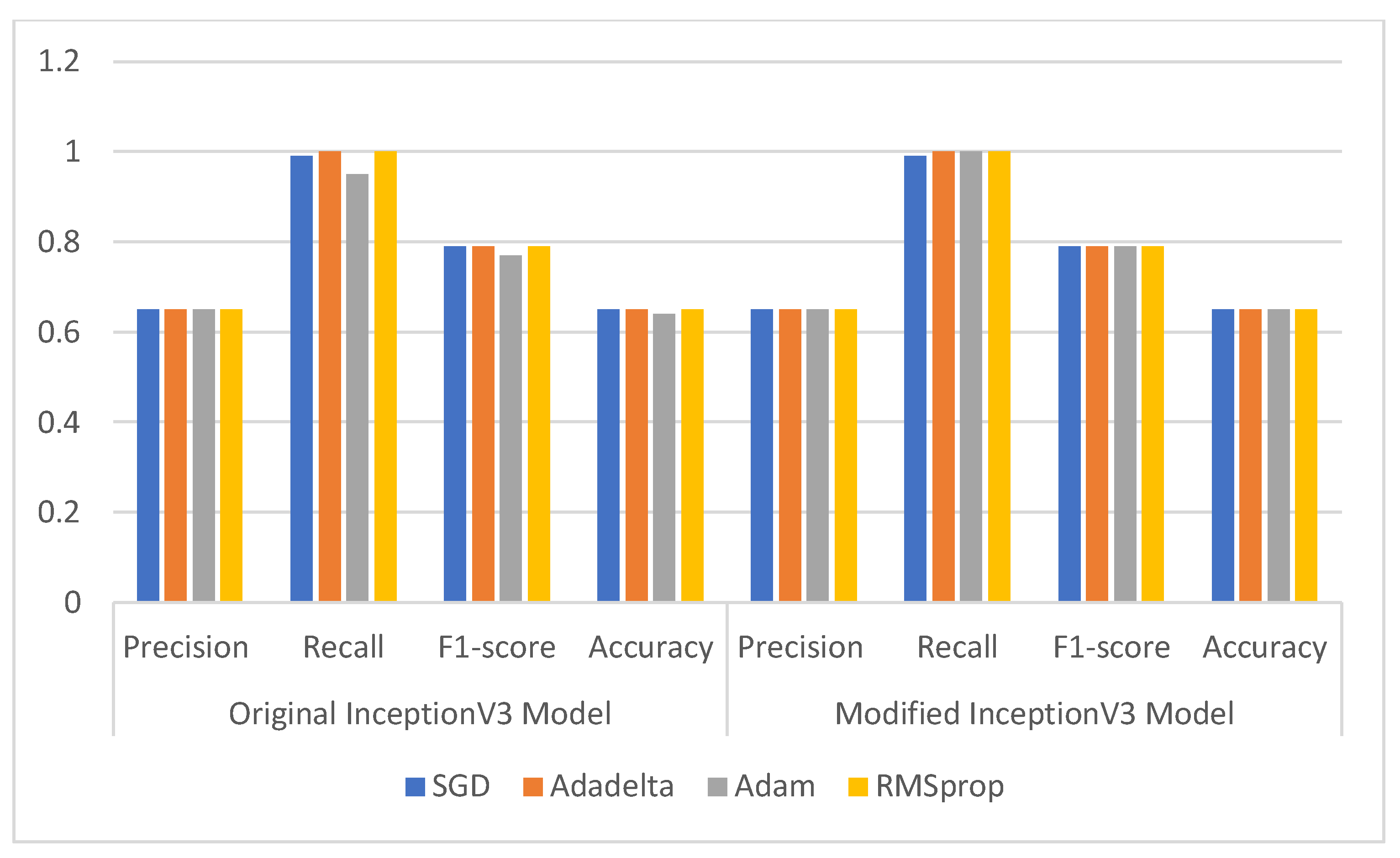
3.3.2. Comparison of Original and Modified InceptionV3 Model
3.4. Classification and Misclassification Results
3.5. Comparison with Present State-of-Art Deep Learning Models
3.6. Comparison with Present State-of-Art Machine Learning Models
4. Conclusions and Future Scope
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pi, Y.; Nath, N.D.; Behzadan, A.H. Convolutional neural networks for object detection in aerial imagery for disaster response and recovery. Adv. Eng. Inform. 2020, 43, 101009. [Google Scholar] [CrossRef]
- Dawood, M.; Asif, A. Deep-PHURIE: Deep learning-based hurricane intensity estimation from infrared satellite imagery. Neural Comput. Appl. 2019, 32, 1–9. [Google Scholar] [CrossRef]
- Dotel, S.; Shrestha, A.; Bhusal, A.; Pathak, R.; Shakya, A.; Panday, S.P. Disaster Assessment from Satellite Imagery by Analysing Topographical Features Using Deep Learning. In Proceedings of the 2020 2nd International Conference on Image, Video and Signal Processing, Singapore, 20–22 March 2020; pp. 86–92. [Google Scholar]
- Ng, H.W.; Nguyen, V.D.; Vonikakis, V.; Winkler, S. Deep learning for emotion recognition on small datasets using transfer learning. In Proceedings of the 2015 ACM on international conference on multimodal interaction, Seattle, WA, USA, 9–13 November 2015; pp. 443–449. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef] [Green Version]
- Pradhan, R.; Aygun, R.S.; Maskey, M.; Ramachandran, R.; Cecil, D.J. Tropical cyclone intensity estimation using a deep convolutional neural network. IEEE Trans. Image Process. 2017, 27, 692–702. [Google Scholar] [CrossRef]
- Resch, B.; Usländer, F.; Havas, C. Combining machine-learning topic models and spatiotemporal analysis of social media data for disaster footprint and damage assessment. Cartogr. Geogr. Inf. Sci. 2018, 45, 362–376. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Hu, W.; Dong, H.; Zhang, X. Building damage detection from post-event aerial imagery using single shot multibox detector. Appl. Sci. 2019, 9, 1128. [Google Scholar] [CrossRef] [Green Version]
- Doshi, J.; Basu, S.; Pang, G. From satellite imagery to disaster insights. arXiv 2018, arXiv:1812.07033. [Google Scholar]
- Chen, S.A.; Escay, A.; Haberland, C.; Schneider, T.; Staneva, V.; Choe, Y. Benchmark dataset for automatic damaged building detection from post-hurricane remotely sensed imagery. arXiv 2018, arXiv:1812.05581. [Google Scholar]
- Cheng, C.S.; Behzadan, A.H.; Noshadravan, A. Deep learning for post-hurricane aerial damage assessment of buildings. Comput. Aided Civ. Infrastruct. Eng. 2021, 36, 695–710. [Google Scholar] [CrossRef]
- Solano-Rojas, B.; Villalón-Fonseca, R.; Marín-Raventós, G. Alzheimer’s Disease Early Detection Using a Low Cost Three-Dimensional Densenet-121 Architecture. In International Conference on Smart Homes and Health Telematics; Springer: Cham, Switzerland, 2020; pp. 3–15. [Google Scholar]
- Bhalla, K.; Koundal, D.; Sharma, B.; Hu, Y.C.; Zaguia, A. A Fuzzy Convolutional Neural Network for Enhancing Multi-Focus Image Fusion. J. Vis. Commun. Image Represent. 2022, 84, 103485. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Wang, C.; Chen, D.; Hao, L.; Liu, X.; Zeng, Y.; Chen, J.; Zhang, G. Pulmonary image classification based on inception-v3 transfer learning model. IEEE Access 2019, 7, 146533–146541. [Google Scholar] [CrossRef]
- Scannell, C.M.; Veta, M.; Villa, A.D.; Sammut, E.C.; Lee, J.; Breeuwer, M.; Chiribiri, A. Deep-learning-based preprocessing for quantitative myocardial perfusion MRI. J. Magn. Reson. Imaging 2020, 51, 1689–1696. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.; Wang, M.; Ordieres-Meré, J. Comparison of data preprocessing approaches for applying deep learning to human activity recognition in the context of industry 4.0. Sensors 2018, 18, 2146. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ouahabi, A. A review of wavelet denoising in medical imaging. In Proceedings of the IEEE 2013 8th International Workshop on Systems, Signal Processing and Their Applications (WoSSPA), Algiers, Algeria, 12–15 May 2013; pp. 19–26. [Google Scholar]
- Mahdaoui, A.E.; Ouahabi, A.; Moulay, M.S. Image Denoising Using a Compressive Sensing Approach Based on Regularization Constraints. Sensors 2022, 22, 2199. [Google Scholar] [CrossRef]
- Kaur, S.; Gupta, S.; Singh, S.; Koundal, D.; Zaguia, A. Convolutional Neural Network based Hurricane Damage Detection using Satellite Images. Soft Comput. 2022. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Buiu, C.; Dănăilă, V.R.; Răduţă, C.N. MobileNetV2 ensemble for cervical precancerous lesions classification. Processes 2020, 8, 595. [Google Scholar] [CrossRef]
- Lin, C.; Li, L.; Luo, W.; Wang, K.C.; Guo, J. Transfer learning based traffic sign recognition using inception-v3 model. Period. Polytech. Transp. Eng. 2019, 47, 242–250. [Google Scholar] [CrossRef] [Green Version]
- Aral, R.A.; Keskin, Ş.R.; Kaya, M.; Hacıömeroğlu, M. Classification of trashnet dataset based on deep learning models. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2058–2062. [Google Scholar]
- He, F.; Liu, T.; Tao, D. Control batch size and learning rate to generalize well: Theoretical and empirical evidence. Adv. Neural Inf. Process. Syst. 2019, 32, 1143–1152. [Google Scholar]
- Aftab, M.; Amin, R.; Koundal, D.; Aldabbas, H.; Alouffi, B.; Iqbal, Z. Classification of COVID-19 and Influenza Patients Using Deep Learning. Contrast Media Mol. Imaging 2022, 2022, 8549707. [Google Scholar] [CrossRef]
- Rawat, R.; Patel, J.K.; Manry, M.T. Minimizing validation error with respect to network size and number of training epochs. In Proceedings of the 2013 international joint conference on neural networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–7. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for activation functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Bhalla, K.; Koundal, D.; Bhatia, S.; Khalid, M.; Rahmani, I.; Tahir, M. Fusion of infrared and visible images using fuzzy based siamese convolutional network. Comput. Mater. Con 2022, 70, 5503–5518. [Google Scholar] [CrossRef]
- Fürnkranz, J.; Flach, P.A. An analysis of rule evaluation metrics. In Proceedings of the 20th international conference on machine learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 202–209. [Google Scholar]
- Zhou, J.; Gandomi, A.H.; Chen, F.; Holzinger, A. Evaluating the quality of machine learning explanations: A survey on methods and metrics. Electronics 2021, 10, 593. [Google Scholar] [CrossRef]
- Duda, J. SGD momentum optimizer with step estimation by online parabola model. arXiv 2019, arXiv:1907.07063. [Google Scholar]
- Lydia, A.; Francis, S. Adagrad—An optimizer for stochastic gradient descent. Int. J. Inf. Comput. Sci. 2019, 6, 566–568. [Google Scholar]
- Kumar, A.; Sarkar, S.; Pradhan, C. Malaria disease detection using cnn technique with sgd, rmsprop and adam optimizers. In Deep Learning Techniques for Biomedical and Health Informatics; Springer: Cham, Switzerland, 2020; pp. 211–230. [Google Scholar]
- Wichrowska, O.; Maheswaranathan, N.; Hoffman, M.W.; Colmenarejo, S.G.; Denil, M.; Freitas, N.; Sohl-Dickstein, J. Learned optimizers that scale and generalize. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3751–3760. [Google Scholar]
- Robertson, B.W.; Johnson, M.; Murthy, D.; Smith, W.R.; Stephens, K.K. Using a combination of human insights and ‘deep learning’ for real-time disaster communication. Prog. Disaster Sci. 2019, 2, 100030. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Ofli, F.; Imran, M.; Mitra, P. Damage assessment from social media imagery data during disasters. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Sydney, Australia, 31 July–3 August 2017; pp. 569–576. [Google Scholar]
- Pandey, N.; Natarajan, S. How social media can contribute during disaster events? Case study of Chennai floods 2015. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 1352–1356. [Google Scholar]
- Lamovec, P.; Velkanovski, T.; Mikos, M.; Osir, K. Detecting flooded areas with machine learning techniques: Case study of the Selška Sora river flash flood in September 2007. J. Appl. Remote Sens. 2013, 7, 073564. [Google Scholar] [CrossRef] [Green Version]
- Bahrepour, M.; Meratnia, N.; Poel, M.; Taghikhaki, Z.; Havinga, P.J. Distributed event detection in wireless sensor networks for disaster management. In Proceedings of the 2010 International Conference on Intelligent Networking and Collaborative Systems, Thessalonika, Greece, 24–26 November 2010; pp. 507–512. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of the Model | No. of Layers | Parameters (Millions) | Size of Input Layer |
|---|---|---|---|
| VGG 16 | 16 | 138 | (224, 224, 3) |
| MobileNetV2 | 53 | 3.4 | (224, 224, 3) |
| InceptionV3 | 42 | 24 | (299, 299, 3) |
| DenseNet121 | 121 | 8 | (224, 224, 3) |
| Model Name | Epoch | Training Loss | Training Accuracy | Training Recall | Validation Loss | Validation Accuracy | Validation Recall |
|---|---|---|---|---|---|---|---|
| DenseNet121 | 1 | 0.4231 | 0.8259 | 0.8266 | 0.2266 | 0.9171 | 0.9130 |
| … | … | … | … | … | … | ||
| 39 | 0.0690 | 0.9736 | 0.9732 | 0.1141 | 0.9559 | 0.9588 | |
| 40 | 0.0666 | 0.9727 | 0.9735 | 0.0956 | 0.9652 | 0.9635 | |
| VGG 16 | 1 | 0.3726 | 0.8309 | 0.8269 | 0.2628 | 0.8835 | 0.8829 |
| … | … | … | … | … | … | ||
| 39 | 0.1335 | 0.9435 | 0.9429 | 0.1505 | 0.9409 | 0.9391 | |
| 40 | 0.1191 | 0.9480 | 0.9480 | 0.1373 | 0.9455 | 0.9443 | |
| MobileNetV2 | 1 | 0.5143 | 0.8462 | 0.8416 | 0.2155 | 0.9072 | 0.8986 |
| … | … | … | … | … | … | ||
| 39 | 0.0838 | 0.9660 | 0.9662 | 0.1341 | 0.9438 | 0.9420 | |
| 40 | 0.0801 | 0.9662 | 0.9659 | 0.1341 | 0.9467 | 0.9478 | |
| InceptionV3 | 1 | 1.0183 | 0.7676 | 0.7526 | 0.2388 | 0.9055 | 0.9090 |
| … | … | … | … | … | … | ||
| 39 | 0.0923 | 0.9634 | 0.9638 | 0.0962 | 0.9571 | 0.9594 | |
| 40 | 0.0866 | 0.9648 | 0.9651 | 0.0972 | 0.9670 | 0.9658 |
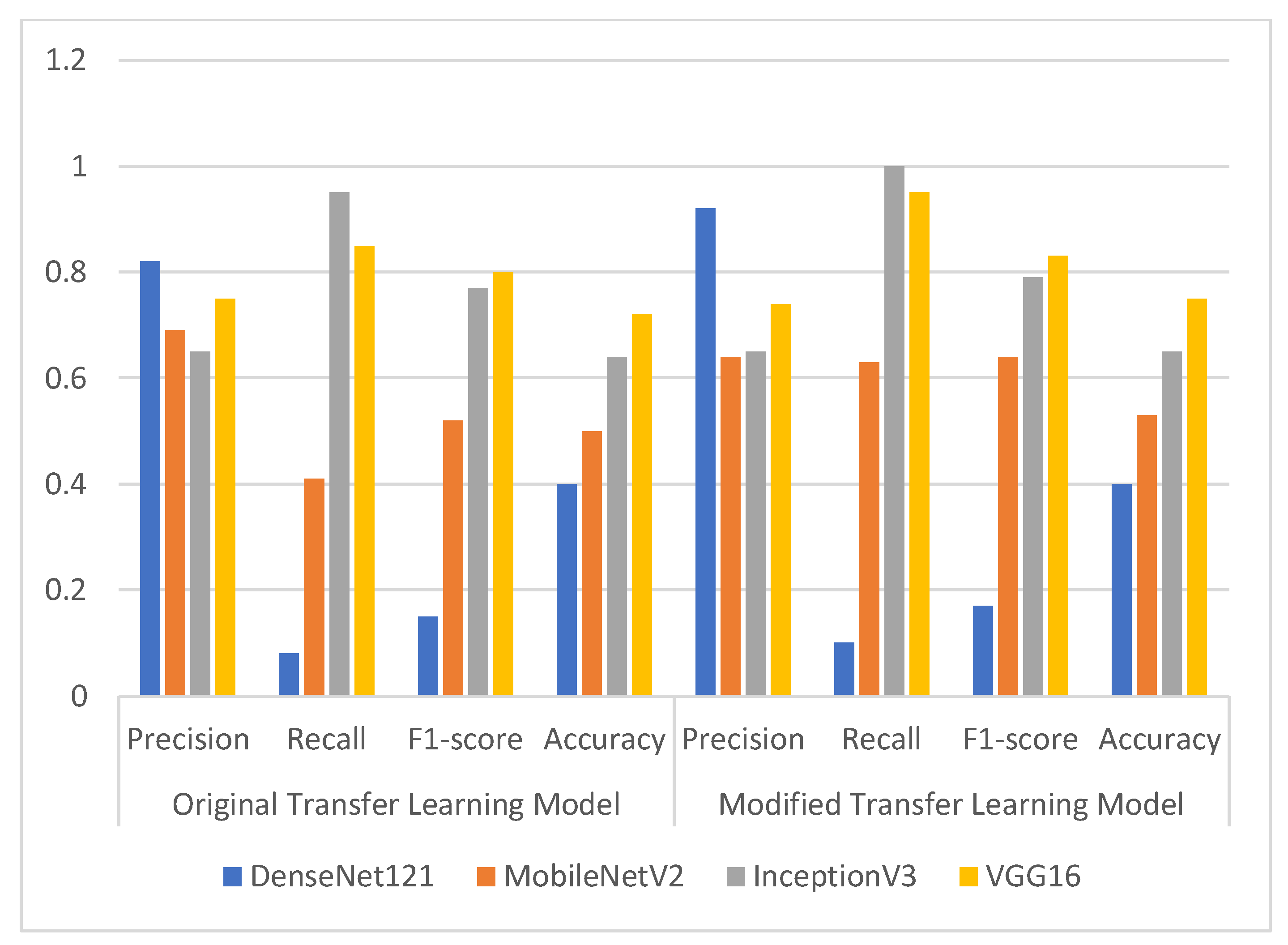
| Model Name | Original Transfer Learning Model | Modified Transfer Learning Model | ||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | Accuracy | |
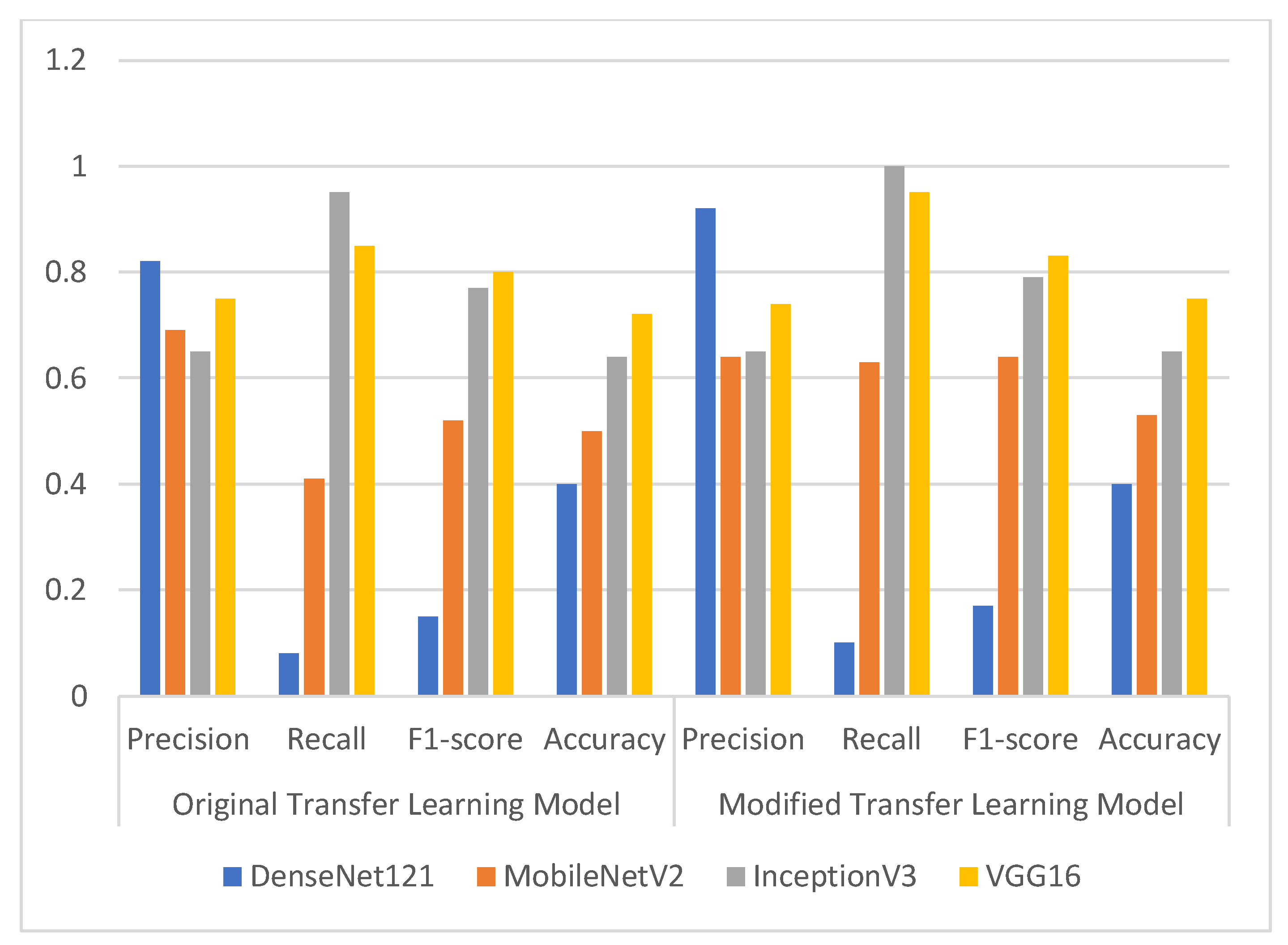
| DenseNet121 | 0.82 | 0.08 | 0.15 | 0.40 | 0.92 | 0.10 | 0.17 | 0.40 |
| MobileNetV2 | 0.69 | 0.41 | 0.52 | 0.50 | 0.64 | 0.63 | 0.64 | 0.53 |
| InceptionV3 | 0.65 | 0.95 | 0.77 | 0.64 | 0.65 | 1.00 | 0.79 | 0.65 |
| VGG16 | 0.75 | 0.85 | 0.80 | 0.72 | 0.74 | 0.95 | 0.83 | 0.75 |
| Optimizer | Original VGG16 Model | Modified VGG16 Model | ||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | Accuracy | |
| SGD | 0.97 | 0.30 | 0.45 | 0.54 | 0.98 | 0.34 | 0.51 | 0.56 |
| Adadelta | 0.86 | 0.35 | 0.51 | 0.56 | 0.95 | 0.61 | 0.71 | 0.68 |
| Adam | 0.75 | 0.85 | 0.80 | 0.72 | 0.74 | 0.95 | 0.83 | 0.75 |
| RMSprop | 0.87 | 0.69 | 0.80 | 0.77 | 0.96 | 0.76 | 0.81 | 0.78 |
| Optimizer | Original InceptionV3 Model | Modified InceptionV3 Model | ||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | Accuracy | |
| SGD | 0.65 | 0.99 | 0.79 | 0.65 | 0.65 | 0.99 | 0.79 | 0.65 |
| Adadelta | 0.65 | 1.00 | 0.79 | 0.65 | 0.65 | 1.00 | 0.79 | 0.65 |
| Adam | 0.65 | 0.95 | 0.77 | 0.64 | 0.65 | 1.00 | 0.79 | 0.65 |
| RMSprop | 0.65 | 1.00 | 0.79 | 0.65 | 0.65 | 1.00 | 0.79 | 0.65 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaur, S.; Gupta, S.; Singh, S.; Hoang, V.T.; Almakdi, S.; Alelyani, T.; Shaikh, A. Transfer Learning-Based Automatic Hurricane Damage Detection Using Satellite Images. Electronics 2022, 11, 1448. https://doi.org/10.3390/electronics11091448
Kaur S, Gupta S, Singh S, Hoang VT, Almakdi S, Alelyani T, Shaikh A. Transfer Learning-Based Automatic Hurricane Damage Detection Using Satellite Images. Electronics. 2022; 11(9):1448. https://doi.org/10.3390/electronics11091448
Chicago/Turabian StyleKaur, Swapandeep, Sheifali Gupta, Swati Singh, Vinh Truong Hoang, Sultan Almakdi, Turki Alelyani, and Asadullah Shaikh. 2022. "Transfer Learning-Based Automatic Hurricane Damage Detection Using Satellite Images" Electronics 11, no. 9: 1448. https://doi.org/10.3390/electronics11091448
APA StyleKaur, S., Gupta, S., Singh, S., Hoang, V. T., Almakdi, S., Alelyani, T., & Shaikh, A. (2022). Transfer Learning-Based Automatic Hurricane Damage Detection Using Satellite Images. Electronics, 11(9), 1448. https://doi.org/10.3390/electronics11091448