
Transfer Learning Improving Predictive Mortality Models for Patients in End-Stage Renal Disease





Abstract
:1. Introduction
- •
- Explore the benefits of using a DL approach to TL in the clinical setting;
- •
- Improve predictive models of mortality in ESRD patients by incorporating knowledge from a more extensive data set;
- •
- Tackle the class imbalance issue through a solution based on TL.
2. Materials and Methods
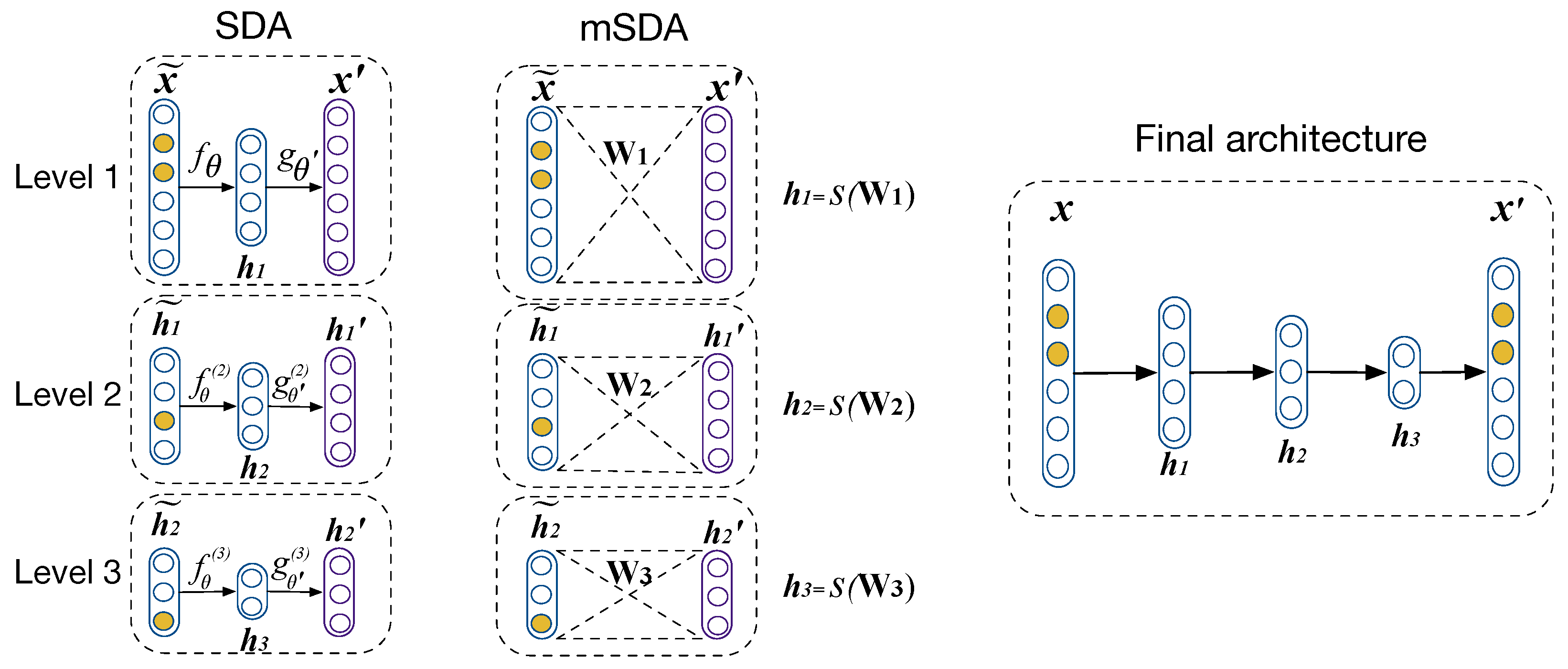
2.1. Autoencoders
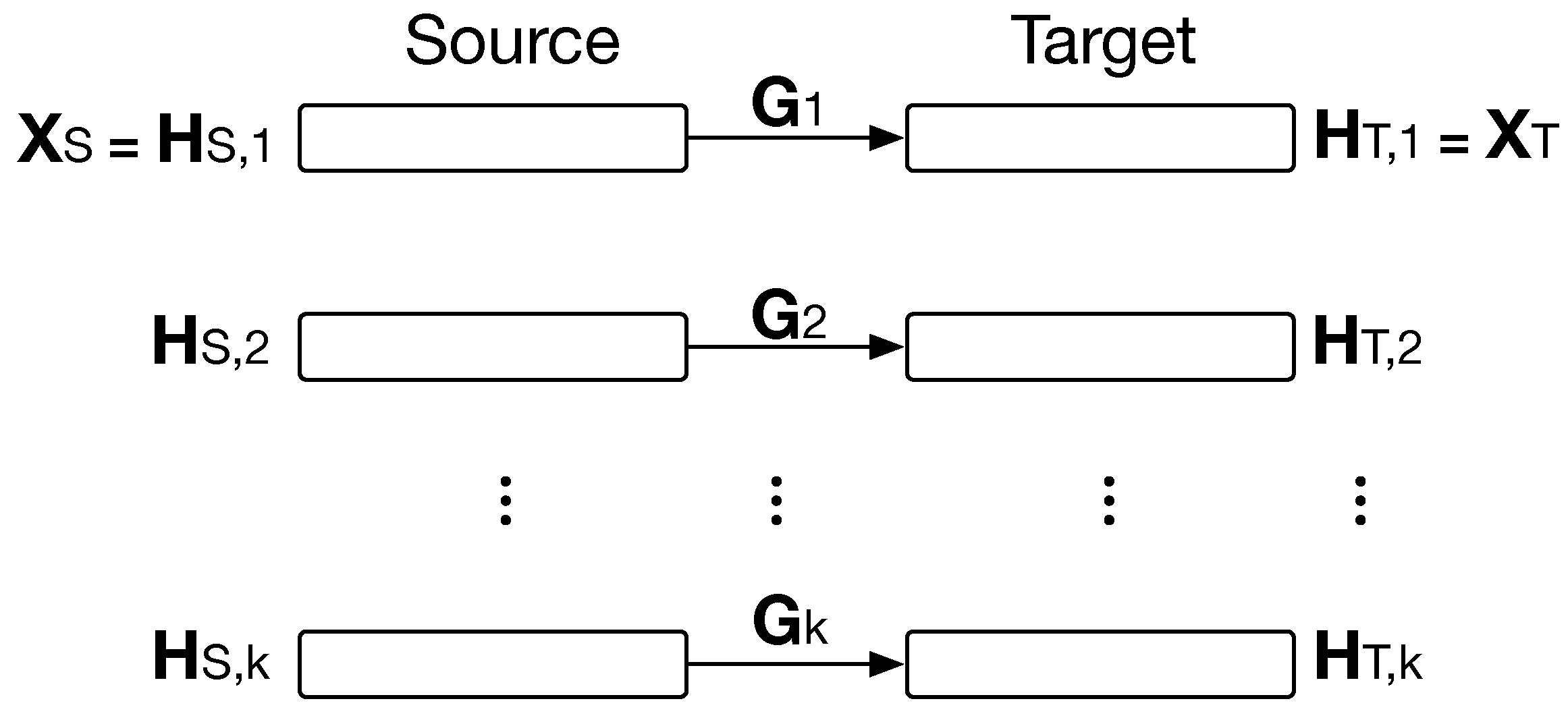
2.2. Hybrid Heterogeneous Transfer Learning
2.3. Problem Definition
- Transfer samples from one domain to another through the computation of a feature mapping matrix , as in HHTL.
- Map codes from one domain to the other one using .
- Transfer a sample to through , where is the code of .
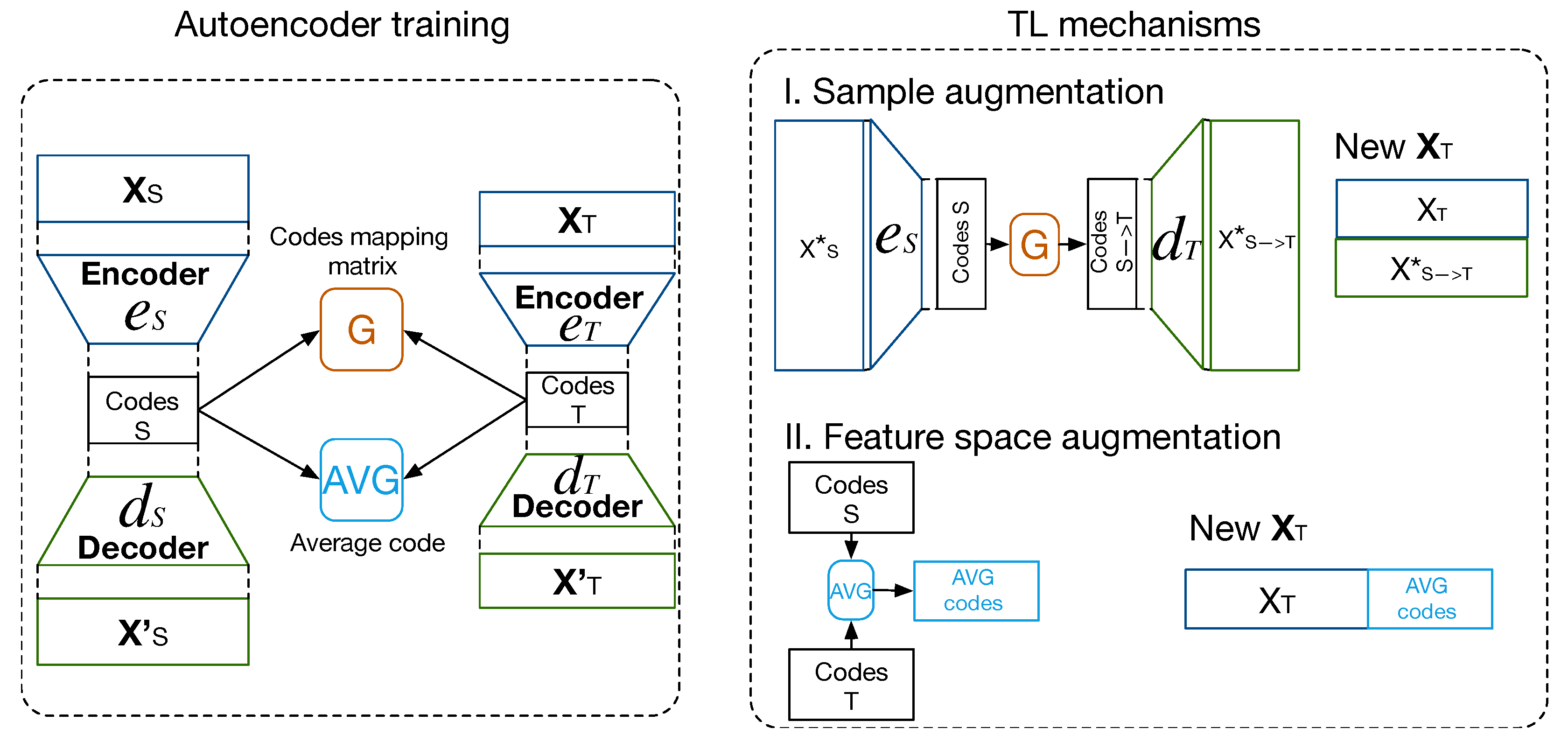
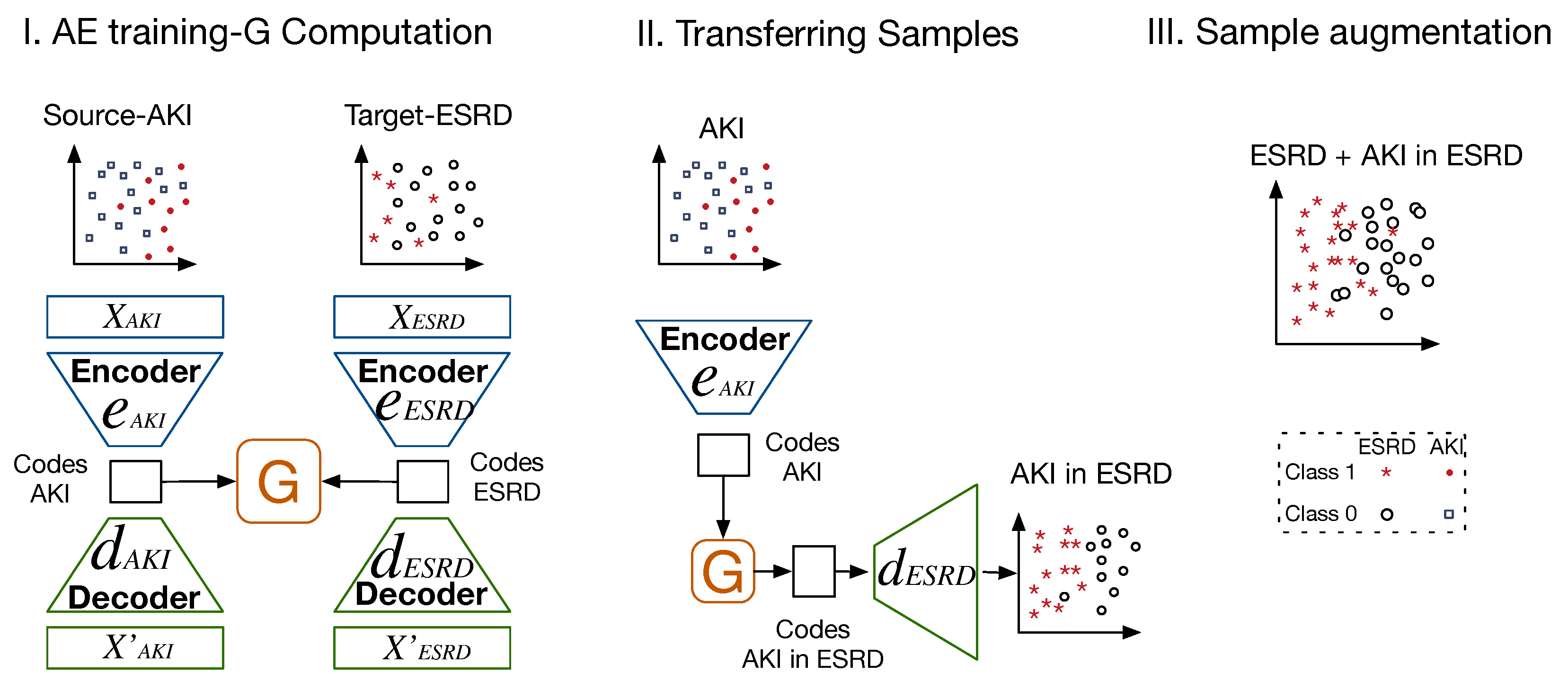
2.4. Proposed Method
- Sample augmentation using a mapping matrix , encoder and decoder functions in both domains to transfer and reconstruct codes from in ;
- Feature space augmentation based on the computation of the average of the most similar codes.
2.4.1. Sample Augmentation—TLCO
| Algorithm 1: Increasing samples using TLCO |
Input: Data from both domains, : ,
Output: Classifier f |
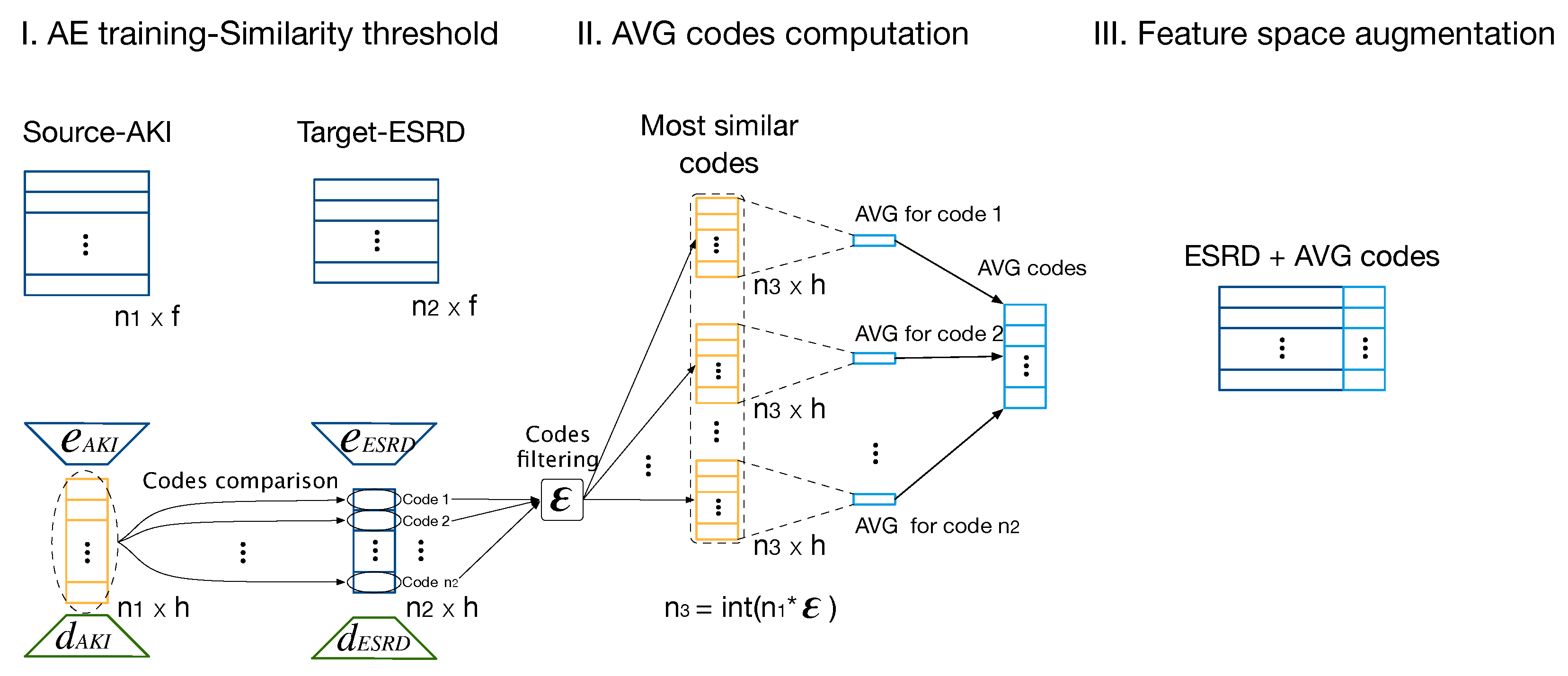
2.4.2. Feature Space Augmentation—TLAV
2.5. Experimental Setup
Datasets
3. Results
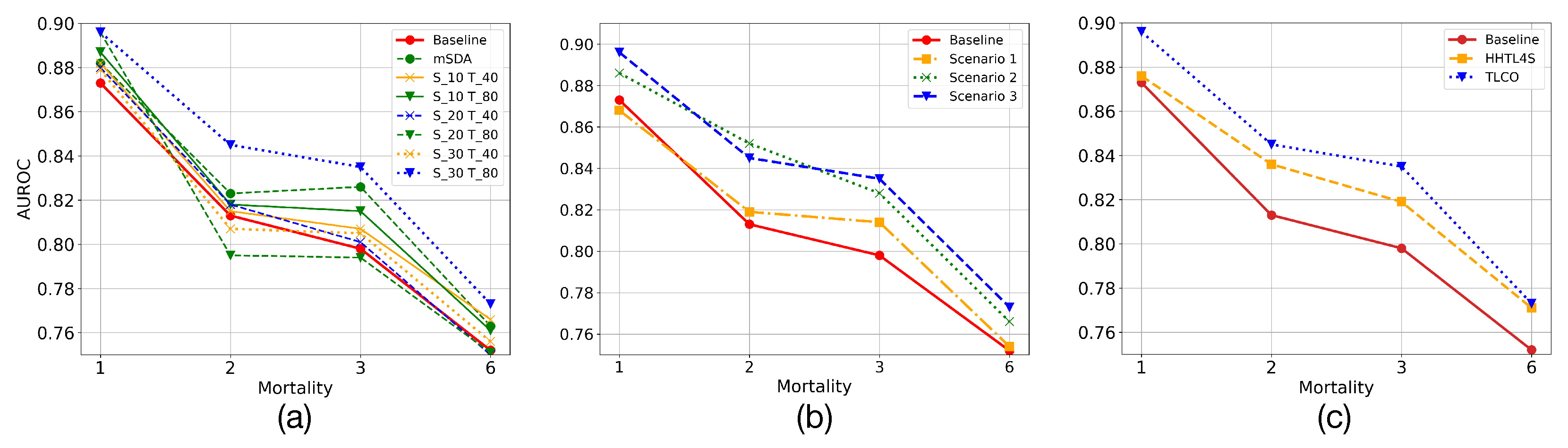
- Deep AE vs. mSDA: We designed a baseline to choose which type of AE better suits the data. We train deep AEs with two hidden layers for the encoder and decoder functions. Then a two-level mSDA is trained. The codes are extracted from the deep AE to perform TLCO and TLAV. For mSDA, the hidden representations from the second level are extracted as codes, and TLCO and TLAV are applied to them.
- HHTL: HHTL has been widely compared with other approaches in the TL literature, showing a better performance than its competitors [22]. The modified versions of HHTL, for sample and feature space augmentation are based on the management of the hidden representations for the levels of the trained mSDAs. As stated in Section 2.2, such hidden representations are extracted from hidden layers to create new feature spaces:then sample augmentation is carried out adding samples from AKI to ESRD in their respective new feature space, i.e., . As HHTL is a method to transfer samples, for feature space augmentation, as in the proposed approach, we use the averages of the most similar hidden representations from to augment , i.e., .
3.1. TLCO—Sample Augmentation
- Code dimension: The dimensions of codes in both domains are evaluated to find a high-level representation of the data that allows us to transfer valuable information. Thus, the combination of dimensions that presents the best overall performance for the prediction task is empirically found. In Figure 7a, it is denoted the dimension of the codes for the deep AE in AKI and ESRD as and , where * refers to the dimensions of the code, e.g., and refers to the combination of having trained AEs with codes of dimension 30 and 40 for AKI and ESRD, respectively. It is also shown the performance of mSDA. Moreover, it should be noted that in mSDA, the dimension of the codes has the same input data dimension, which is why only one predictor is observed for mSDA in the figure. In addition, it can be appreciated that most of the combinations present a higher performance than the baseline one. Although mSDA outperforms better than most predictors, the deep AE with 30 and 80 codes in AKI and ESRD offers a better predictive capacity than mSDA.
- Sample augmentation in ESRD: This experiment evaluates how the increase in samples in the training set affects the predictive models of mortality in ESRD. For this experiment, three possible scenarios were defined. Initially, the data imbalance in ESRD is intentionally increased. Thus, only Class 0 in AKI samples are transferred to the ESRD training set. This transfer is carried out to evaluate whether an adverse effect is linked to the increase in data imbalance. In the second scenario, the training set samples are increased, but only those that belong to AKI Class 1 are transferred. In this case, the aim is to balance the imbalanced class. Finally, in a third scenario, both classes are transferred from AKI to ESRD. Therefore, we evaluate both the effect of the increase in samples and the reduction in the data imbalance in the predictive models. Table 2 shows how the data imbalance varies for each scenario. In Figure 7b, it can be appreciated that increasing samples in the training set of the ESRD data does not imply, in most of the scenarios, a reduction in the predictive models performance. On the other hand, when the number of samples increases, the learning models present a better predictive capacity considering the imbalance ratio.
- Comparing with HHTL: To evaluate the performance of HHTL, the number of transferred samples was adjusted following the third scenario in the previous experiment. Thus, in Figure 7c it can be appreciated that although HHTL for upsampling or HHTL4S improves the base predictive models, it has a lower performance than that found by deep AE.
3.2. TLAV—Feature Space Augmentation
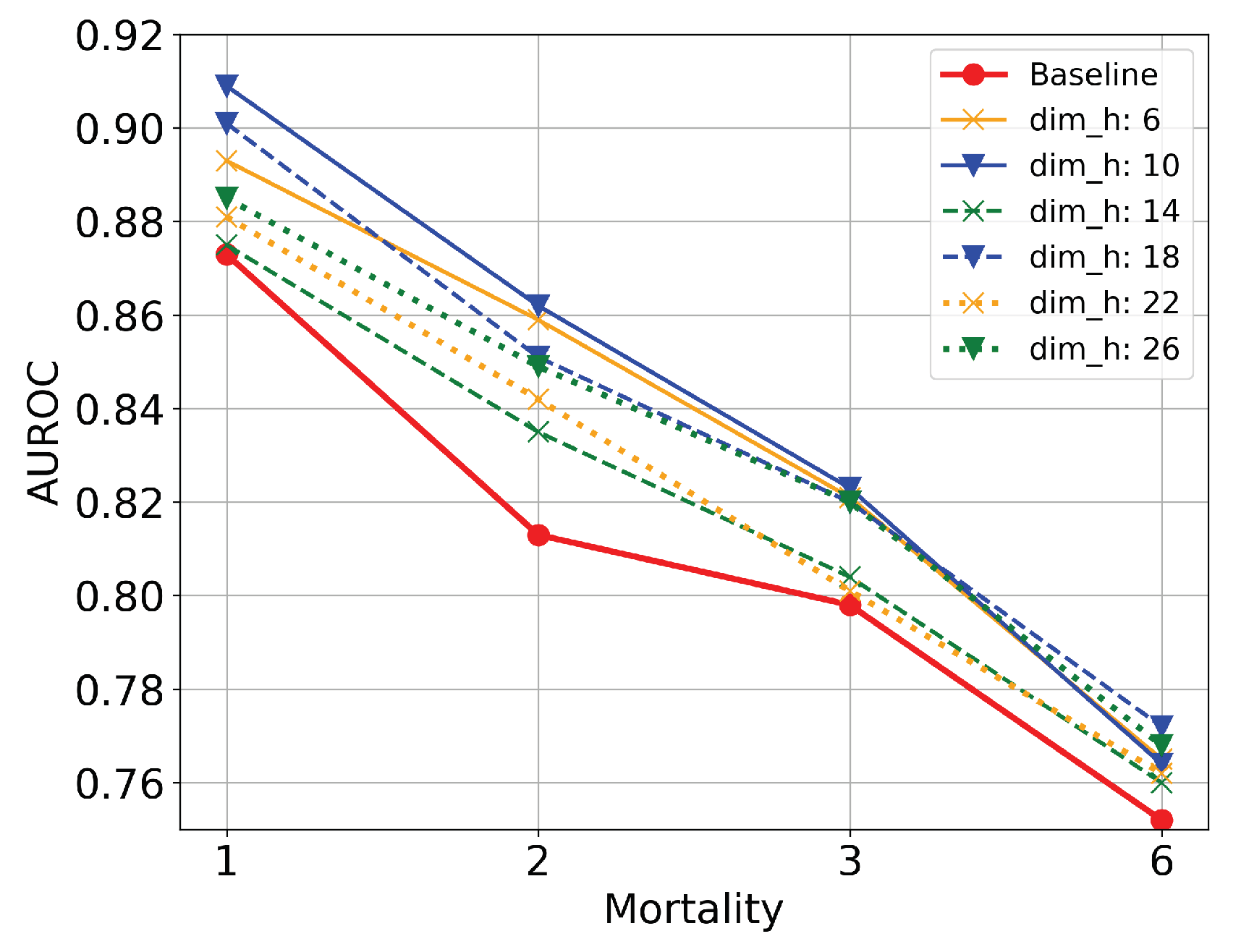
- Code dimension: The first parameter that controls the behavior of TLAV is the dimension of the codes (). This parameter reflects the ability of AEs to represent information in latent spaces under the TL methodology of TLAV. In this experiment, is set to 0.4. Figure 8 shows scenarios where the input information is compressed or dispersed according to the value of . It can be appreciated that bottleneck type deep AEs offer better overall performance than sparse type deep AEs. The best solution is the one with .
- Tuning similarity threshold (): With Euclidean distances from ESRD and AKI codes, a proportion of these codes is chosen using . controls the amount of more similar AKI codes used to compute the average one. Once every set of codes from AKI are extracted, their are computed and used to increase the feature space for each ESRD sample. Table 3 shows the performance of the predictive models varying . It can be appreciated that increasing the number of codes for the computation of their average reflects a slight improvement in the predictive models. However, from an of 0.3 or 0.4, more codes do not imply a considerable increase in the predictive models. Compared with its competitors, TLAV based on deep AEs presents a better performance when more codes are included for the average computation. Using the three methods, taking 40% of the most similar AKI codes for each ESRD code presents the most balanced performance for mortality prediction. TLAV with deep AEs is the best option to increase the feature space in ESRD.
3.3. TLAV—HHTLM
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ching, T.; Himmelstein, D.S.; Beaulieu-Jones, B.K.; Kalinin, A.A.; Do, B.T.; Way, G.P.; Ferrero, E.; Agapow, P.M.; Zietz, M.; Hoffman, M.M.; et al. Opportunities and obstacles for deep learning in biology and medicine. J. R. Soc. Interface 2018, 15, 20170387. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Piccialli, F.; Somma, V.D.; Giampaolo, F.; Cuomo, S.; Fortino, G. A survey on deep learning in medicine: Why, how and when? Inf. Fusion 2021, 66, 111–137. [Google Scholar] [CrossRef]
- Yu, Y.; Li, M.; Liu, L.; Li, Y.; Wang, J. Clinical big data and deep learning: Applications, challenges, and future outlooks. Big Data Min. Anal. 2019, 2, 288–305. [Google Scholar] [CrossRef] [Green Version]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Lopes, R.R.; Bleijendaal, H.; Ramos, L.A.; Verstraelen, T.E.; Amin, A.S.; Wilde, A.A.; Pinto, Y.M.; de Mol, B.A.; Marquering, H.A. Improving electrocardiogram-based detection of rare genetic heart disease using transfer learning: An application to phospholamban p.Arg14del mutation carriers. Comput. Biol. Med. 2021, 131, 104262. [Google Scholar] [CrossRef]
- Lv, J.; Li, G.; Tong, X.; Chen, W.; Huang, J.; Wang, C.; Yang, G. Transfer learning enhanced generative adversarial networks for multi-channel MRI reconstruction. Comput. Biol. Med. 2021, 134, 104504. [Google Scholar] [CrossRef]
- Choudhary, T.; Mishra, V.; Goswami, A.; Sarangapani, J. A transfer learning with structured filter pruning approach for improved breast cancer classification on point-of-care devices. Comput. Biol. Med. 2021, 134, 104432. [Google Scholar] [CrossRef]
- Shickel, B.; Davoudi, A.; Ozrazgat-Baslanti, T.; Ruppert, M.; Bihorac, A.; Rashidi, P. Deep Multi-Modal Transfer Learning for Augmented Patient Acuity Assessment in the Intelligent ICU. Front. Digit. Health 2021, 3, 11. [Google Scholar] [CrossRef]
- Maqsood, M.; Nazir, F.; Khan, U.; Aadil, F.; Jamal, H.; Mehmood, I.; Song, O.y. Transfer Learning Assisted Classification and Detection of Alzheimer’s Disease Stages Using 3D MRI Scans. Sensors 2019, 19, 2645. [Google Scholar] [CrossRef] [Green Version]
- Byra, M.; Wu, M.; Zhang, X.; Jang, H.; Ma, Y.J.; Chang, E.Y.; Shah, S.; Du, J. Knee menisci segmentation and relaxometry of 3D ultrashort echo time cones MR imaging using attention U-Net with transfer learning. Magn. Reson. Med. 2020, 83, 1109–1122. [Google Scholar] [CrossRef] [Green Version]
- Marcus, D.S.; Fotenos, A.F.; Csernansky, J.G.; Morris, J.C.; Buckner, R.L. Open access series of imaging studies: Longitudinal MRI data in nondemented and demented older adults. J. Cogn. Neurosci. 2010, 22, 2677–2684. [Google Scholar] [CrossRef] [PubMed]
- Desautels, T.; Calvert, J.; Hoffman, J.; Mao, Q.; Jay, M.; Fletcher, G.; Barton, C.; Chettipally, U.; Kerem, Y.; Das, R. Using transfer learning for improved mortality prediction in a data-scarce hospital setting. Biomed. Inform. Insights 2017, 9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Estiri, H.; Vasey, S.; Murphy, S.N. Generative transfer learning for measuring plausibility of EHR diagnosis records. J. Am. Med. Inform. Assoc. 2020, 28, 559–568. [Google Scholar] [CrossRef] [PubMed]
- Macias, E.; Boquet, G.; Serrano, J.; Vicario, J.; Ibeas, J.; Morel, A. Novel Imputing Method and Deep Learning Techniques for Early Prediction of Sepsis in Intensive Care Units. In Proceedings of the 2019 Computing in Cardiology (CinC), Singapore, 8–11 September 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Macias, E.; Morell, A.; Serrano, J.; Vicario, J. Knowledge Extraction Based on Wavelets and DNN for Classification of Physiological Signals: Arousals Case. In Proceedings of the 2018 Computing in Cardiology Conference (CinC), Maastricht, The Netherlands, 23–26 September 2018; Volume 45, pp. 1–4. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Macias, E.; Morell, A.; Serrano, J.; Vicario, J.L.; Ibeas, J. Mortality prediction enhancement in end-stage renal disease: A machine learning approach. Inform. Med. Unlocked 2020, 19, 100351. [Google Scholar] [CrossRef]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Li-wei, H.L.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Chen, M.; Xu, Z.; Weinberger, K.; Sha, F. Marginalized denoising autoencoders for domain adaptation. arXiv 2012, arXiv:1206.4683. [Google Scholar]
- Zhou, J.T.; Pan, S.J.; Tsang, I.W. A deep learning framework for Hybrid Heterogeneous Transfer Learning. Artif. Intell. 2019, 275, 310–328. [Google Scholar] [CrossRef]
- Inker, L.A.; Astor, B.C.; Fox, C.H.; Isakova, T.; Lash, J.P.; Peralta, C.A.; Tamura, M.K.; Feldman, H.I. KDOQI US commentary on the 2012 KDIGO clinical practice guideline for the evaluation and management of CKD. Am. J. Kidney Dis. 2014, 63, 713–735. [Google Scholar] [CrossRef] [PubMed] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mortality | Class 0 | Class 1 | Imbalance (%) |
|---|---|---|---|
| 1 | 7734 | 495 | 93.6 |
| 2 | 7488 | 741 | 90.1 |
| 3 | 7251 | 978 | 86.5 |
| 6 | 6632 | 1597 | 75.9 |
| Mortality | Generated Data Imbalance (%) | ||
|---|---|---|---|
| Scenario 1 | Scenario 2 | Scenario 3 | |
| 1 | 95.2 | 73.4 | 80.0 |
| 2 | 92.6 | 69.2 | 77.1 |
| 3 | 90.1 | 74.9 | 74.2 |
| 6 | 82.7 | 52.3 | 65.7 |
| Mortality | |||||
|---|---|---|---|---|---|
| TL Method | 1 | 2 | 3 | 6 | |
| mSDA | 0.857 | 0.839 | 0.816 | 0.761 | |
| 0.01 | HHTL4F | 0.878 | 0.824 | 0.820 | 0.757 |
| TLAV | 0.887 | 0.849 | 0.816 | 0.758 | |
| mSDA | 0.856 | 0.840 | 0.809 | 0.761 | |
| 0.1 | HHTL4F | 0.879 | 0.831 | 0.818 | 0.759 |
| TLAV | 0.891 | 0.854 | 0.816 | 0.763 | |
| mSDA | 0.859 | 0.834 | 0.811 | 0.760 | |
| 0.2 | HHTL4F | 0.891 | 0.834 | 0.819 | 0.758 |
| TLAV | 0.901 | 0.857 | 0.820 | 0.761 | |
| mSDA | 0.863 | 0.841 | 0.820 | 0.760 | |
| 0.3 | HHTL4F | 0.895 | 0.837 | 0.822 | 0.758 |
| TLAV | 0.906 | 0.860 | 0.823 | 0.765 | |
| mSDA | 0.877 | 0.842 | 0.819 | 0.758 | |
| 0.4 | HHTL4F | 0.894 | 0.835 | 0.821 | 0.760 |
| TLAV | 0.909 | 0.862 | 0.823 | 0.763 | |
| mSDA | 0.875 | 0.842 | 0.818 | 0.759 | |
| 0.5 | HHTL4F | 0.891 | 0.836 | 0.819 | 0.759 |
| TLAV | 0.904 | 0.861 | 0.821 | 0.765 | |
| Mortality | Baseline | TLCO | TLAV | TLAV-TLCO |
|---|---|---|---|---|
| 1 | 0.873 | 0.891 | 0.909 | 0.939 |
| 2 | 0.813 | 0.845 | 0.862 | 0.909 |
| 3 | 0.798 | 0.838 | 0.823 | 0.853 |
| 6 | 0.752 | 0.778 | 0.765 | 0.764 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Macias, E.; Lopez Vicario, J.; Serrano, J.; Ibeas, J.; Morell, A. Transfer Learning Improving Predictive Mortality Models for Patients in End-Stage Renal Disease. Electronics 2022, 11, 1447. https://doi.org/10.3390/electronics11091447
Macias E, Lopez Vicario J, Serrano J, Ibeas J, Morell A. Transfer Learning Improving Predictive Mortality Models for Patients in End-Stage Renal Disease. Electronics. 2022; 11(9):1447. https://doi.org/10.3390/electronics11091447
Chicago/Turabian StyleMacias, Edwar, Jose Lopez Vicario, Javier Serrano, Jose Ibeas, and Antoni Morell. 2022. "Transfer Learning Improving Predictive Mortality Models for Patients in End-Stage Renal Disease" Electronics 11, no. 9: 1447. https://doi.org/10.3390/electronics11091447
APA StyleMacias, E., Lopez Vicario, J., Serrano, J., Ibeas, J., & Morell, A. (2022). Transfer Learning Improving Predictive Mortality Models for Patients in End-Stage Renal Disease. Electronics, 11(9), 1447. https://doi.org/10.3390/electronics11091447