
A Partial-Reconfiguration-Enabled HW/SW Co-Design Benchmark for LTE Applications



Abstract
:1. Introduction
- We developed an efficient HLS based-module for each kernel in PHY-Bench and WiBench benchmark suites using Vivado HLS. Furthermore, to improve the concurrency and parallelization in each kernel, we refactored the C/C++ implementations and changed them to apply dataflow optimization. We made the source code available, and researchers can easily modify kernels and regenerate all kernels with different sizes.
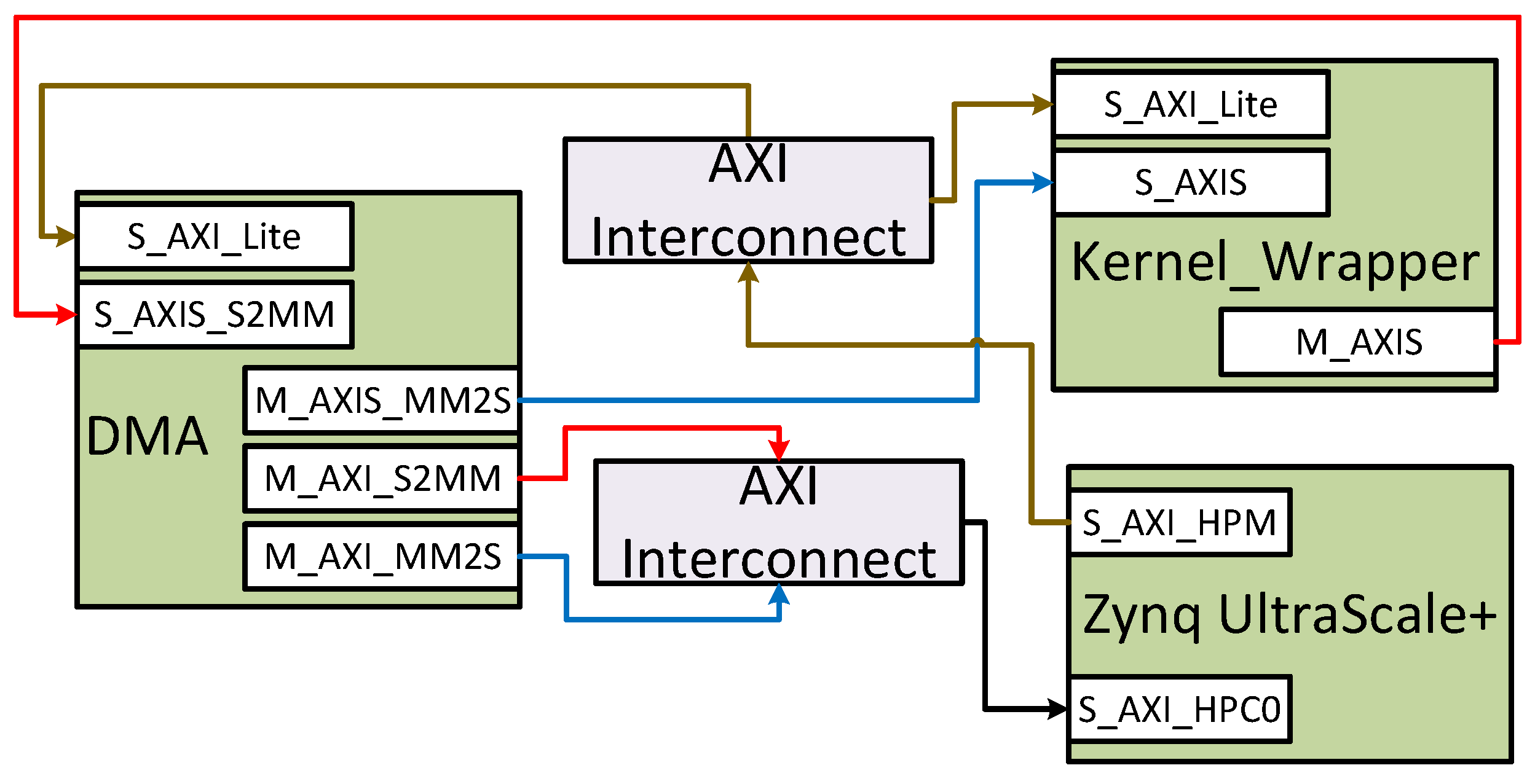
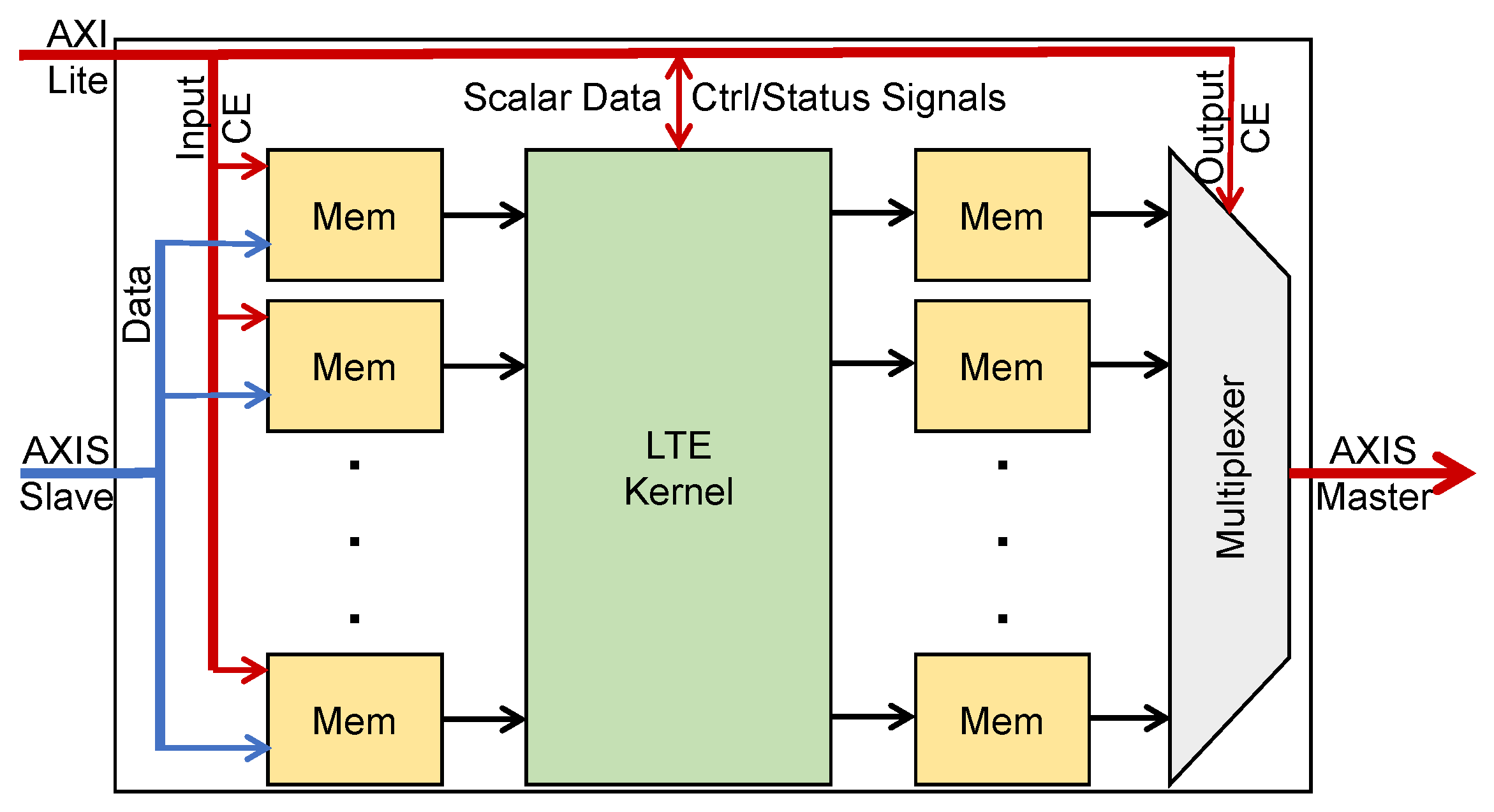
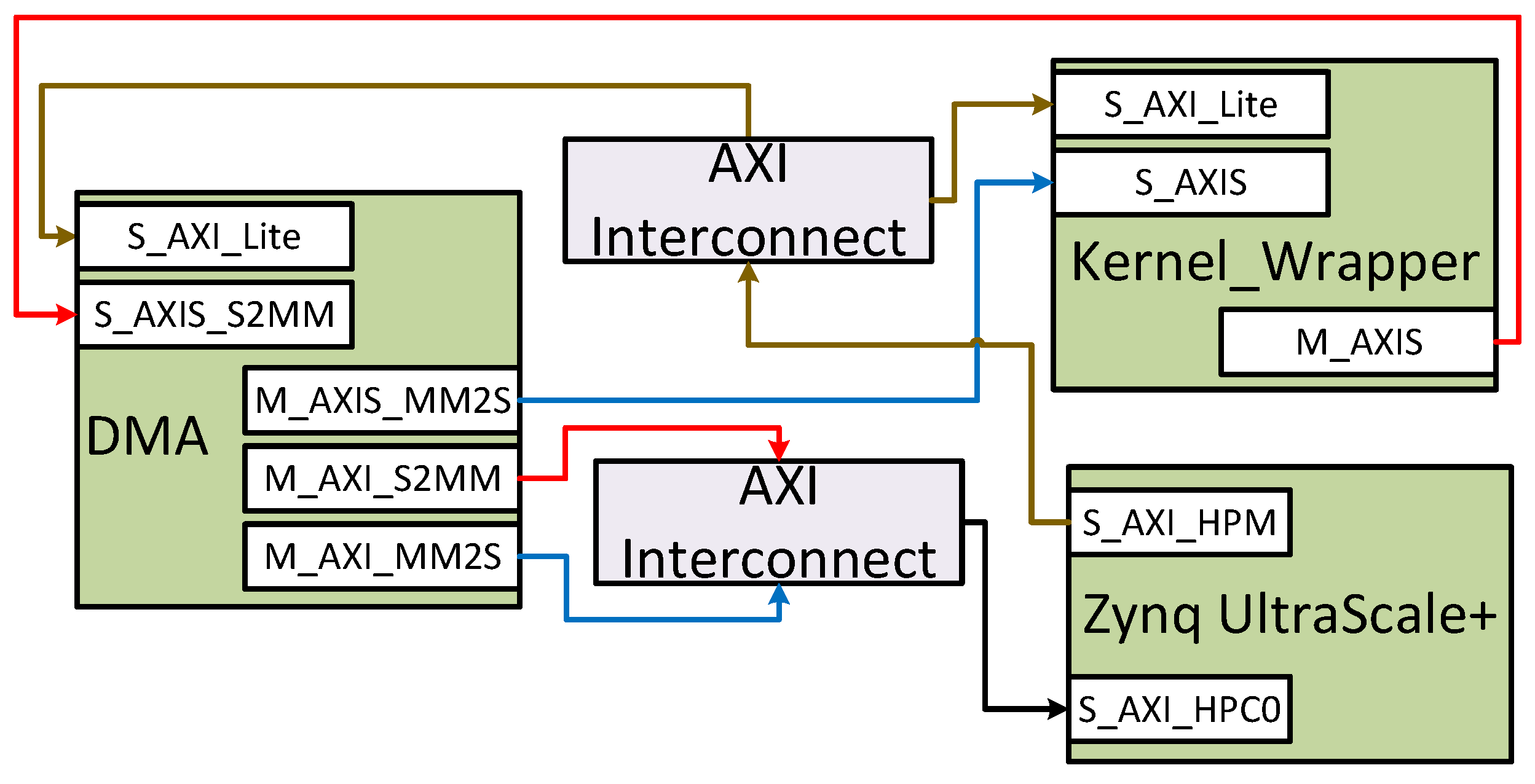
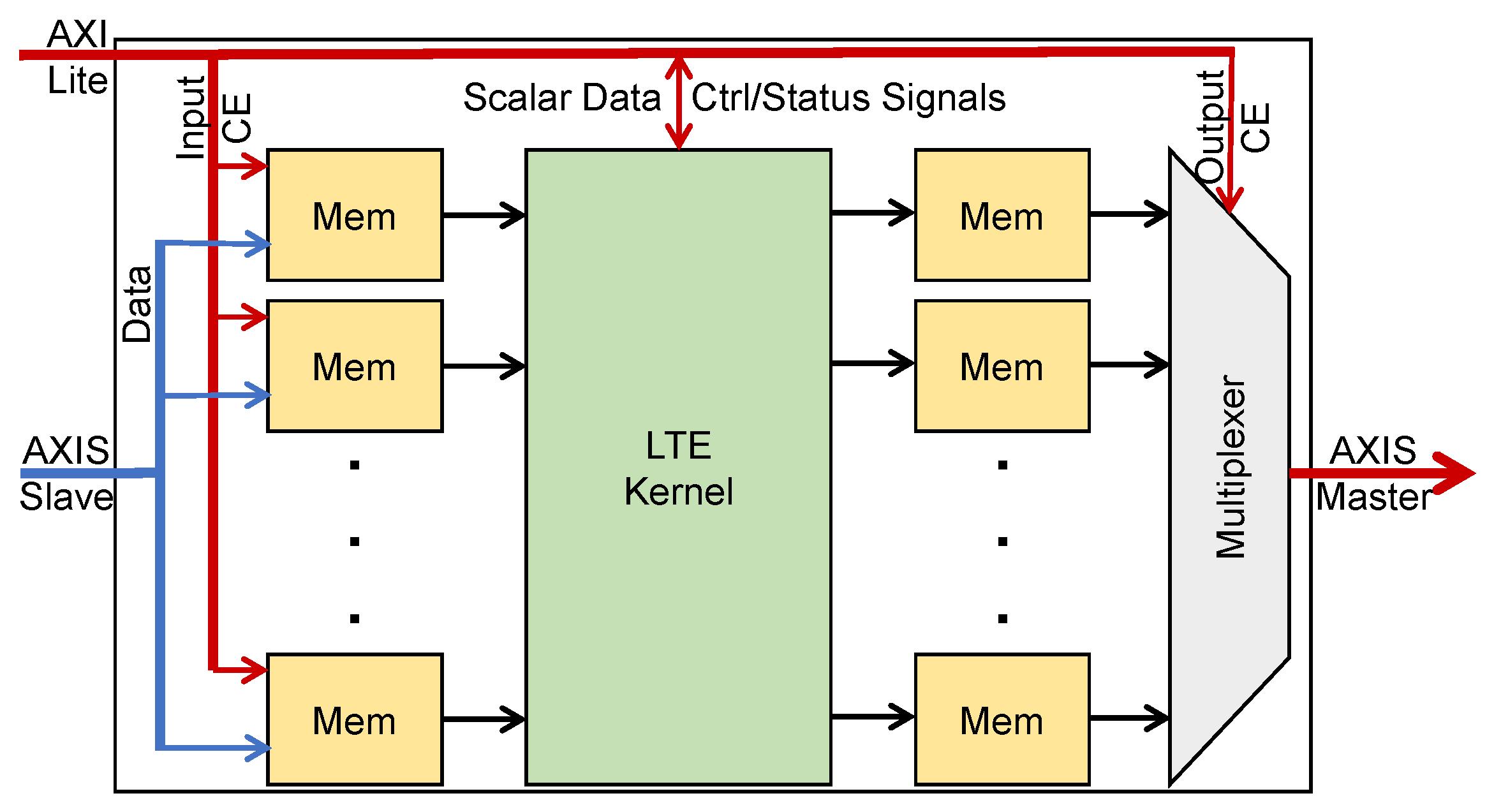
- We provided an HDL wrapper for each kernel with two AXI-Stream interfaces to receive input data and send output data through DMA. The wrapper also has an AXI-Lite interface to send and receive control and status signals. The wrappers for all kernels have the same interface ports. Therefore, we can swap all kernels in the FPGA during the run time with the help of partial reconfiguration.
- We compared each kernel’s execution time and power consumption during execution on the ARM processor and on the ZynqMP SoC. To this end, we exploited the Ultra96-V2 by Avnet, which is an ARM-based, Xilinx Zynq UltraScale+ MPSoC development board [14], to run different kernels on an XCZU3EG-SBVA484 FPGA and an ARM Cortex-A53 processor. It is important to mention that both the ARM Cortex-A53 and XCZU3EG-SBVA484 FPGA are integrated on the same chip.
2. Preliminaries
2.1. Zynq UltraScale+ MPSoC
2.2. Partial Reconfiguration
2.3. Advanced Extensible Interface (AXI) Bus Interface
3. Related Work
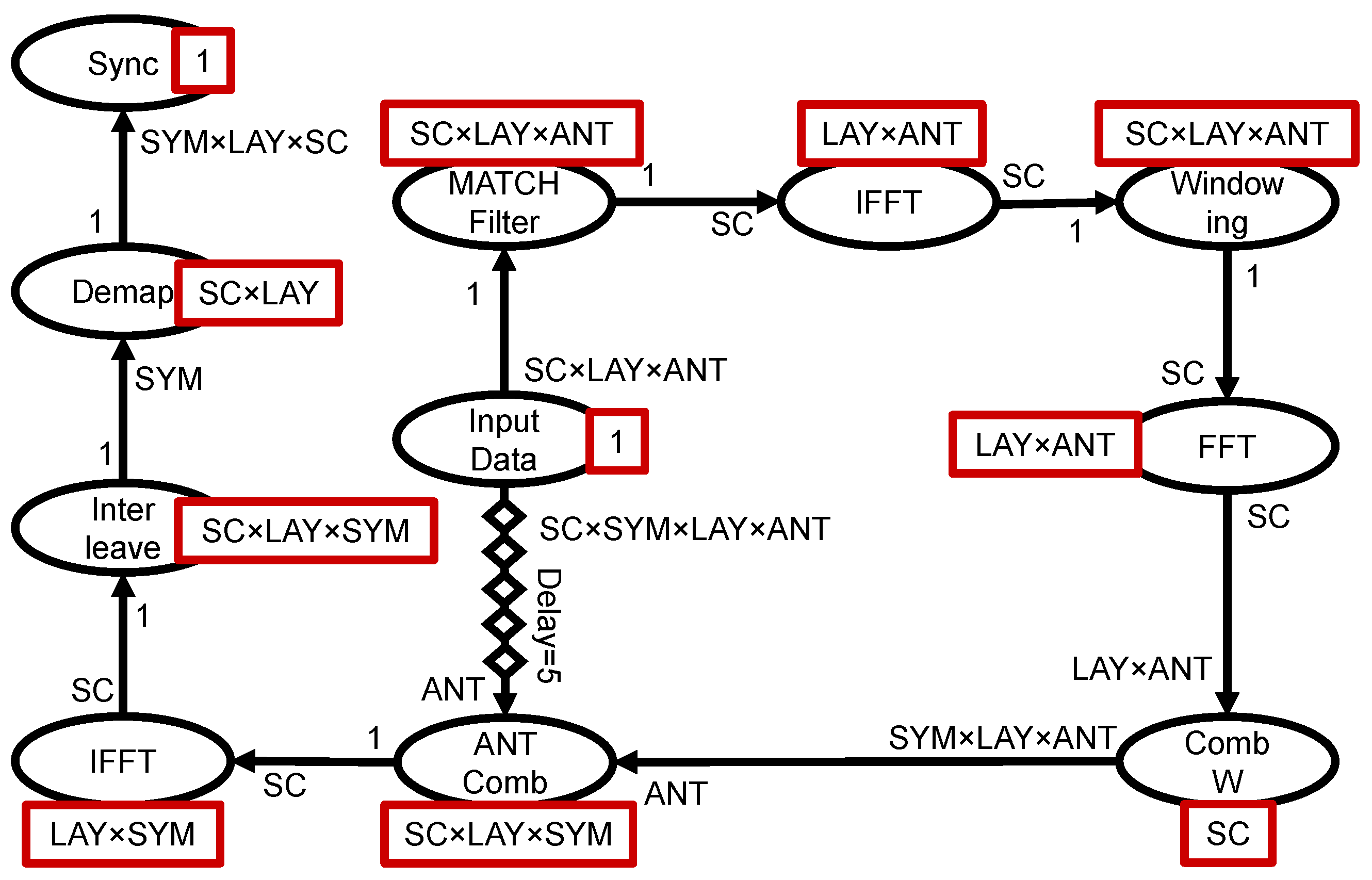
4. Kernel Characteristics
- Loop unroll: this directive takes a variable called “Factor” which indicates how much the designer wants to unroll the loop. Assuming that Factor is set to N, then the HLS compiler creates N copies of the loop body. Therefore, the generated RTL module runs N iterations of the loop concurrently. Hence, the number of sequential iterations is reduced by factor of N.
- Pipeline: this directive divides the body of loop or function into a set of pipes (sections) and allows all sections to be run in a concurrent manner. This directive does not improve the execution time of a single iteration of a loop. However, it improves the input interval of the loop. This directive is very effective for loops where the dependency between operations is low and the number of iterations is high.
- Array partition: by default, the HLS compiler implements each array in the code with one large memory with one or two ports to access the data. The array partitioning divides the array into two or more smaller memories, which increases the number of access ports to the array.
5. Execution Time and Power Comparison for Hardware and Software on a Real Platform
6. Partial Reconfiguration Effect
6.1. Effect of Partial Reconfiguration on Power Consumption: A Case Study on FFT
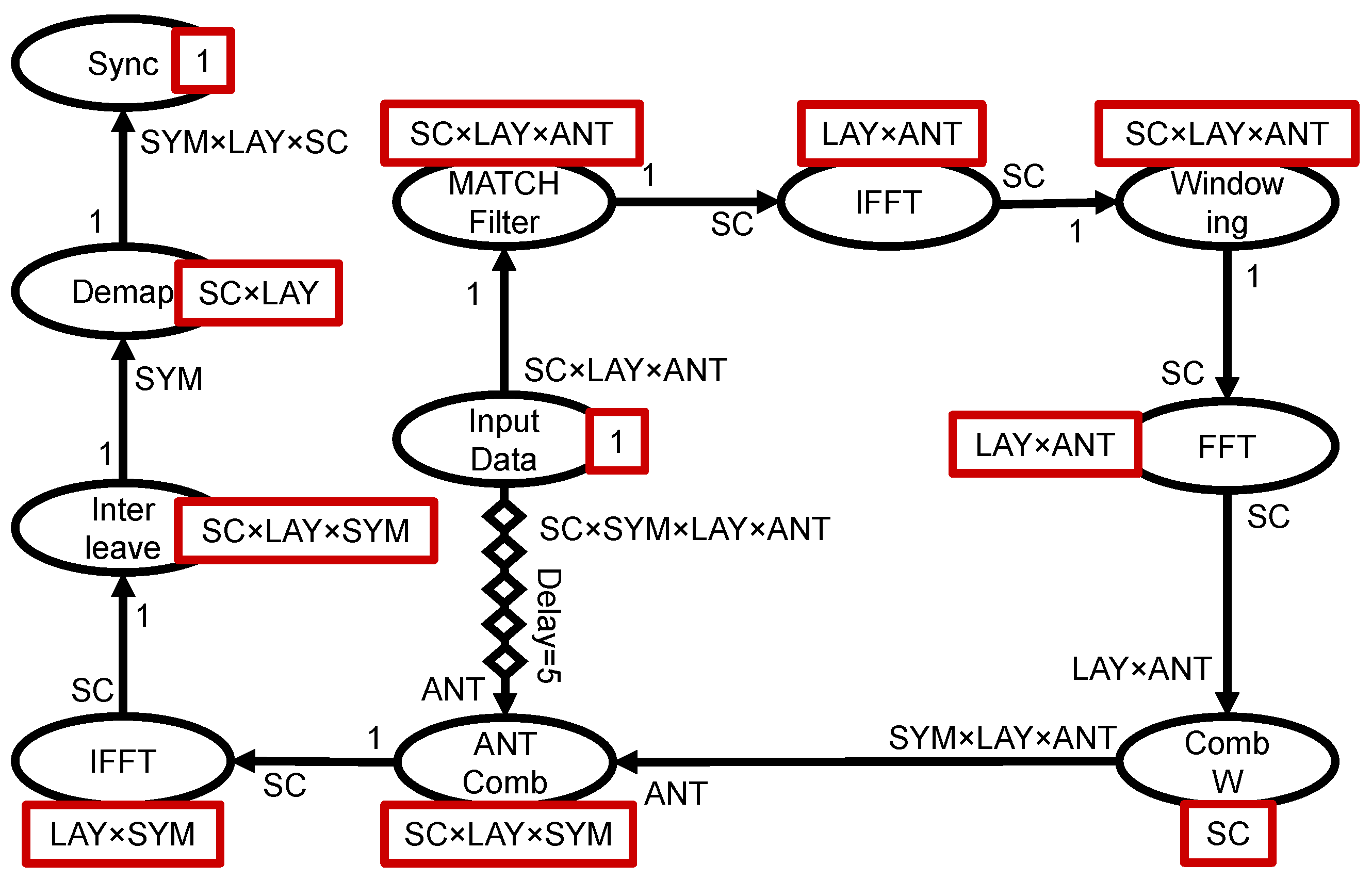
6.2. Effect of Partial Reconfiguration on Time and Area: A Real-World Application Example
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANT | Antennas |
| ASIC | Application-Specific Integrated Circuit |
| AXI | Advanced eXtensible Interface |
| BRAM | Block Random Access Memory |
| CE | Chip Enable |
| DFT | Discrete Fourier Transform |
| DFX | Dynamic Function Exchange |
| DMA | Direct Memory Access |
| FF | Flipflop |
| FFT | Fast Fourier Transform |
| FIFO | First In First Out |
| FPGA | Field Programmable Gate Array |
| HDL | Hardware Description Language |
| HLS | High-Level Synthesis |
| IFFT | Inverse Fast Fourier Transform |
| IoT | Internet of Things |
| ILP | Integer Linear Programming |
| LAY | Layers |
| LTE | Long-Term Evolution |
| MOD | Modulation Scheme |
| MPSoC | Multi-Processor System on Chip |
| NoC | Network on Chip |
| PR | Partial Reconfiguration |
| PRR | Partially Reconfigurable Regions |
| RTL | Register Transfer Level |
| SC | Sub-Carriers |
| SDF | Synchronous Data Flow |
| SYM | Symbols |
| TL | Transform Length |
| WCDMA | Wideband Code Division Multiple Access |
References
- Khasanov, R.; Robledo, J.; Menard, C.; Goens, A.; Castrillon, J. Domain-specific hybrid mapping for energy-efficient baseband processing in wireless networks. ACM Trans. Embed. Comput. Syst. (TECS) 2021, 20, 1–26. [Google Scholar] [CrossRef]
- Slalmi, A.; Saadane, R.; Chehri, A.; Kharraz, H. How will 5G transform industrial IoT: Latency and reliability analysis. In Human Centred Intelligent Systems; Springer: Singapore, 2021; pp. 335–345. [Google Scholar]
- Ha, S.; Teich, J.; Haubelt, C.; Glaß, M.; Mitra, T.; Dömer, R.; Eles, P.; Shrivastava, A.; Gerstlauer, A.; Bhattacharyya, S.S. Introduction to hardware/software codesign. In Handbook of Hardware/Software Codesign; Springer: Dordrecht, The Netherlands, 2017; pp. 3–26. [Google Scholar]
- Xilinx. Vivado Design Suite User Guide, Partial Reconfiguration. 2019. Available online: https://www.xilinx.com/support/documentation/sw_manuals/xilinx2018_1/ug909-vivado-partial-reconfiguration.pdf (accessed on 21 February 2022).
- Vipin, K.; Fahmy, S.A. FPGA dynamic and partial reconfiguration: A survey of architectures, methods, and applications. ACM Comput. Surv. (CSUR) 2018, 51, 1–39. [Google Scholar] [CrossRef] [Green Version]
- Lopes Ferreira, M.; Canas Ferreira, J. An FPGA-oriented baseband modulator architecture for 4G/5G communication scenarios. Electronics 2019, 8, 2. [Google Scholar] [CrossRef] [Green Version]
- Visconti, P.; Velazquez, R.; Del-Valle-Soto, C.; de Fazio, R. FPGA based technical solutions for high throughput data processing and encryption for 5G communication: A review. Telkomnika 2021, 19, 1291–1306. [Google Scholar] [CrossRef]
- Barlee, K.W.; Stewart, R.W.; Crockett, L.H.; MacEwen, N.C. Rapid prototyping and validation of FS-FBMC dynamic spectrum radio with simulink and ZynqSDR. IEEE Open J. Commun. Soc. 2020, 2, 113–131. [Google Scholar] [CrossRef]
- Själander, M.; McKee, S.A.; Brauer, P.; Engdal, D.; Vajda, A. An LTE uplink receiver PHY benchmark and subframe-based power management. In Proceedings of the International Symposium on Performance Analysis of Systems & Software, New Brunswick, NJ, USA, 1–3 April 2012; pp. 25–34. [Google Scholar]
- Zheng, Q.; Chen, Y.; Dreslinski, R.; Chakrabarti, C.; Anastasopoulos, A.; Mahlke, S.; Mudge, T. WiBench: An open source kernel suite for benchmarking wireless systems. In Proceedings of the International Symposium on Workload Characterization (IISWC), Portland, OR, USA, 22–24 September 2013; pp. 123–132. [Google Scholar]
- Xilinx. Vitis High-Level Synthesis User Guide. 2021. Available online: https://www.xilinx.com/support/documentation/sw_manuals/xilinx2020_2/ug1399-vitis-hls.pdf (accessed on 21 February 2022).
- Chen, Y.; He, J.; Zhang, X.; Hao, C.; Chen, D. Cloud-DNN: An open framework for mapping DNN models to cloud FPGAs. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019; pp. 73–82. [Google Scholar]
- Lahti, S.; Sjövall, P.; Vanne, J.; Hämäläinen, T.D. Are we there yet? A study on the state of high-level synthesis. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 38, 898–911. [Google Scholar] [CrossRef]
- Xilinx. Zynq UltraScale+ Device Technical Reference Manual. 2020. Available online: https://www.xilinx.com/support/documentation/user_guides/ug1085-zynq-ultrascale-trm.pdf (accessed on 21 February 2022).
- Venkataramani, V.; Kulkarni, A.; Mitra, T.; Peh, L.S. SPECTRUM: A Software-defined Predictable Many-core Architecture for LTE/5G Baseband Processing. ACM Trans. Embed. Comput. Syst. (TECS) 2020, 19, 1–28. [Google Scholar] [CrossRef]
- Gustavsson, U.; Frenger, P.; Fager, C.; Eriksson, T.; Zirath, H.; Dielacher, F.; Studer, C.; Pärssinen, A.; Correia, R.; Matos, J.N.; et al. Implementation challenges and opportunities in beyond-5G and 6G communication. IEEE J. Microwaves 2021, 1, 86–100. [Google Scholar] [CrossRef]
- Venkataramani, V.; Bodin, B.; Kulkarni, A.; Mitra, T.; Peh, L.S. Time-Predictable Software-Defined Architecture with Sdf-Based Compiler Flow for 5g Baseband Processing. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1553–1557. [Google Scholar]
- Wittig, R.; Goens, A.; Menard, C.; Matus, E.; Fettweis, G.P.; Castrillon, J. Modem Design in the Era of 5G and Beyond: The Need for a Formal Approach. In Proceedings of the 27th International Conference on Telecommunications (ICT), Bali, Indonesia, 5–7 October 2020; pp. 1–5. [Google Scholar]
- Chamola, V.; Patra, S.; Kumar, N.; Guizani, M. Fpga for 5g: Re-configurable hardware for next generation communication. IEEE Wirel. Commun. 2020, 27, 140–147. [Google Scholar] [CrossRef]
- Dhar, A.; Yu, M.; Zuo, W.; Wang, X.; Kim, N.S.; Chen, D. Leveraging Dynamic Partial Reconfiguration with Scalable ILP Based Task Scheduling. In Proceedings of the 33rd International Conference on VLSI Design and 19th International Conference on Embedded Systems (VLSID), Bangalore, India, 4–8 January 2020; pp. 201–206. [Google Scholar]
- Liang, Y.; Wang, S. Quantitative performance and power analysis of LTE using high level synthesis. In Proceedings of the 11th International Conference on ASIC (ASICON), Chengdu, China, 3–6 November 2015; pp. 1–4. [Google Scholar]
- Xilinx. AXI DMA LogiCORE IP Product Guide. 2019. Available online: https://www.xilinx.com/support/documentation/ip_documentation/axi_dma/v7_1/pg021_axi_dma.pdf (accessed on 21 February 2022).
- Lee, E.A.; Messerschmitt, D.G. Synchronous data flow. Proc. IEEE 1987, 75, 1235–1245. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Kernel | Implementation | Latency | Resources (%) | |||||
|---|---|---|---|---|---|---|---|---|
| Clk | Speedup 1 | BRAM | DSP | FF | LUT | |||
| WiBench | Equalizer | No-Directive | 619,276 | – | 0.00 | 18.89 | 17.83 | 38.09 |
| (LAY = 2, ANT = 2, | Primary-Directive | 607,351 | 1.02 | 0.00 | 34.44 | 22.54 | 44.86 | |
| SYM = 14, MDFT = 75) | Dataflow | 95,371 | 6.49 | 2.78 | 47.78 | 25.82 | 42.07 | |
| Demodulation | No-Directive | 1,821,604 | – | 0.00 | 3.06 | 2.94 | 5.03 | |
| (LAY = 2, ANT = 2, | Primary-Directive | 748,804 | 2.43 | 0.00 | 2.78 | 3.13 | 5.17 | |
| SYM = 14, MDFT = 75) | Dataflow | 349,274 | 5.22 | 0.23 | 5.00 | 4.29 | 8.17 | |
| Modulation | No-Directive | 16,203 | – | 0.00 | 0.83 | 0.53 | 1.16 | |
| (LAY = 2, ANT = 2, | Primary-Directive | 16,203 | 1.00 | 0.00 | 0.83 | 0.53 | 1.16 | |
| SYM = 14, MDFT = 75) | Dataflow | 16,203 | 1.00 | 0.00 | 0.83 | 0.53 | 1.16 | |
| WiBench | Descramble | No-Directive | 64,803 | – | 0.00 | 1.67 | 0.52 | 0.69 |
| (LAY = 2, ANT = 2, | Primary-Directive | 7211 | 8.99 | 0.00 | 1.67 | 0.59 | 0.78 | |
| SYM = 14, MDFT = 75) | Dataflow | 7211 | 8.99 | 0.00 | 1.67 | 0.59 | 0.78 | |
| Scramble | No-Directive | 14,403 | – | 0.00 | 0.83 | 0.33 | 0.45 | |
| (LAY = 2, ANT = 2, | Primary-Directive | 7204 | 2.00 | 0.00 | 0.83 | 0.31 | 0.48 | |
| SYM = 14, MDFT = 75) | Dataflow | 7204 | 2.00 | 0.00 | 0.83 | 0.31 | 0.48 | |
| RxRateMatch | No-Directive | 2486097 | – | 27.31 | 2.78 | 8.96 | 17.08 | |
| (LAY = 2, ANT = 2, | Primary-Directive | 2,395,848 | 1.04 | 27.31 | 9.72 | 12.89 | 22.87 | |
| SYM = 14, MDFT = 75) | Dataflow | 197,861 | 12.56 | 31.48 | 9.72 | 12.99 | 23.44 | |
| TxRateMatch | No-Directive | 1,923,250 | – | 27.31 | 4.44 | 9.29 | 17.77 | |
| (LAY = 2, ANT = 2, | Primary-Directive | 1,907,485 | 1.01 | 27.31 | 10.00 | 13.08 | 23.25 | |
| SYM = 14, MDFT = 75) | Dataflow | 158,678 | 12.12 | 31.25 | 15.28 | 20.60 | 35.35 | |
| SubCarrierDemap | No-Directive | 4992 | – | 0.46 | 0.56 | 0.87 | 1.93 | |
| (LAY = 2, ANT = 2, | Primary-Directive | 2621 | 1.90 | 0.46 | 2.22 | 1.11 | 2.46 | |
| SYM = 14, MDFT = 75) | Dataflow | 2621 | 1.90 | 0.46 | 2.22 | 1.11 | 2.46 | |
| SubCarrierMap | No-Directive | 6529 | – | 0.46 | 0.56 | 0.72 | 1.76 | |
| (LAY = 2, ANT = 2, | Primary-Directive | 2355 | 2.77 | 0.46 | 2.50 | 0.99 | 2.11 | |
| SYM = 14, MDFT = 75) | Dataflow | 2355 | 2.77 | 0.46 | 2.50 | 0.99 | 2.11 | |
| PHY-Bench | AntennaCombining | No-Directive | 9601 | – | 0.00 | 4.44 | 0.47 | 0.63 |
| (LAY = 4, ANT = 4, | Primary-Directive | 4805 | 2.00 | 0.00 | 4.44 | 0.50 | 0.65 | |
| SC = 1200) | Dataflow | 4805 | 2.00 | 0.00 | 4.44 | 0.50 | 0.65 | |
| Windowing | No-Directive | 2403 | – | 0.00 | 0.56 | 0.40 | 0.94 | |
| (LAY = 1, ANT = 1, | Primary-Directive | 1208 | 1.99 | 0.00 | 0.56 | 0.44 | 1.01 | |
| SC = 1200) | Dataflow | 1208 | 1.99 | 0.00 | 0.56 | 0.44 | 1.01 | |
| MatchFilter | No-Directive | 6001 | – | 0.00 | 1.67 | 0.33 | 0.45 | |
| (LAY = 1, ANT = 1, | Primary-Directive | 1205 | 4.98 | 0.00 | 1.67 | 0.44 | 0.55 | |
| SC = 1200) | Dataflow | 1205 | 4.98 | 0.00 | 1.67 | 0.44 | 0.55 | |
| CombinerWeights | No-Directive | 149,601 | – | 0.46 | 8.89 | 7.09 | 15.43 | |
| (LAY = 4, ANT = 4, | Primary-Directive | 123,501 | 1.21 | 0.69 | 15.00 | 8.91 | 22.03 | |
| SC = 100) | Dataflow | 28,964 | 5.17 | 3.80 | 18.83 | 13.13 | 24.96 | |
| Demap | No-Directive | 134,401 | – | 0.00 | 3.33 | 1.74 | 4.82 | |
| (LAY = 4, SYM = 6, | Primary-Directive | 28,809 | 4.67 | 0.00 | 3.33 | 2.57 | 9.13 | |
| SC = 50, MOD = 64QAM) | Dataflow | 28,809 | 4.67 | 0.00 | 3.33 | 2.57 | 9.13 | |
| Interleave | No-Directive | 4064 | – | 0.00 | 1.39 | 0.64 | 1.32 | |
| (LAY = 1, SYM = 1, | Primary-Directive | 1267 | 3.21 | 0.00 | 1.39 | 2.16 | 8.03 | |
| SC = 1200) | Dataflow | 1267 | 3.21 | 0.00 | 1.39 | 2.16 | 8.03 | |
| Kernel | Latency (s) | HW Speedup | Power (mW) | Energy (mJ) | ||||
|---|---|---|---|---|---|---|---|---|
| HW | SW | HW | SW | HW | SW | |||
| WiBench | Equalizer | 495.9 | 6210.8 | 12.5 | 405.0 | 968.7 | 201 | 6016 |
| Demodulation | 1760.3 | 21,694.2 | 12.3 | 375.0 | 968.7 | 660 | 21,015 | |
| Modulation | 111.5 | 1933.8 | 17.3 | 315.2 | 968.7 | 35 | 1873 | |
| Descramble | 41.0 | 764.1 | 18.7 | 315.2 | 968.7 | 13 | 740 | |
| Scramble | 54.5 | 771.2 | 14.2 | 315.2 | 968.7 | 17 | 747 | |
| RxRateMatch | 815.2 | 2702.6 | 3.3 | 405.0 | 968.7 | 330 | 2618 | |
| TxRateMatch | 641.1 | 2662.0 | 4.2 | 405.0 | 968.7 | 260 | 2579 | |
| Turbo Encoder | 385.6 | 1204.0 | 3.1 | 406.2 | 968.7 | 157 | 1166 | |
| SubCarrierDemap | 20.1 | 382.6 | 19.0 | 315.2 | 968.7 | 6 | 371 | |
| SubCarrierMap | 21.9 | 407.2 | 18.6 | 315.2 | 968.7 | 7 | 394 | |
| PHY-Bench | AntennaCombining | 19.8 | 339.1 | 17.1 | 405.0 | 968.7 | 8 | 328 |
| Windowing | 5.4 | 40.5 | 7.4 | 315.2 | 968.7 | 2 | 39 | |
| MatchFilter | 5.5 | 83.3 | 15.1 | 315.2 | 968.7 | 2 | 81 | |
| CombinerWeights | 111.9 | 461.2 | 4.1 | 405.0 | 968.7 | 45 | 447 | |
| Demap | 115.8 | 2247.4 | 19.4 | 360.5 | 968.7 | 42 | 2177 | |
| Interleave | 5.5 | 53.2 | 9.7 | 315.2 | 968.7 | 2 | 52 | |
| Transform Length | Latency (Clk) | Power Consumption of One FFT (mW) | Power Consumption of Ten FFTs All with the Same Transform Length (mW) |
|---|---|---|---|
| Idle | 0 | 312.50 | 312.50 |
| 8 | 94 | 343.75 | 343.75 |
| 16 | 146 | 343.75 | 343.75 |
| 32 | 242 | 343.75 | 375.00 |
| 64 | 434 | 359.25 | 375.00 |
| 128 | 834 | 359.25 | 406.25 |
| 256 | 1682 | 375.00 | 406.25 |
| 512 | 3490 | 375.00 | 437.50 |
| 1024 | 7346 | 375.00 | 437.50 |
| 2048 | 15,554 | 375.00 | 437.50 |
| 4086 | 32,978 | 406.25 | 500.00 |
| 8192 | 69,858 | 437.50 | 625.00 |
| Kernel | Time | Runs | Res | Fully Sequential | Fully Parallel | ||
|---|---|---|---|---|---|---|---|
| (s) | (#) | (%) | Time (s) | Res (%) | Time (s) | Res (%) | |
| MatchFilter | 19.2 | 1.0 | 2.0 | 19.2 | 2.0 | 19.2 | 2.0 |
| IFFT | 62.2 | 4.0 | 1.5 | 248.9 | 1.5 | 62.2 | 6.0 |
| Windowing | 19.2 | 1.0 | 1.0 | 19.2 | 1.0 | 19.2 | 1.0 |
| FFT | 62.2 | 4.0 | 1.5 | 248.9 | 1.5 | 62.2 | 6.0 |
| CombW | 44.2 | 20.0 | 8.0 | 884.8 | 8.0 | 44.2 | 160.0 |
| AntComb | 20.5 | 1.0 | 5.0 | 20.5 | 5.0 | 20.5 | 5.0 |
| IFFT | 62.2 | 12.0 | 1.5 | 746.6 | 1.5 | 62.2 | 18.0 |
| Interleave | 20.4 | 6.0 | 5.0 | 122.4 | 5.0 | 20.4 | 30.0 |
| Demap | 58.2 | 12.0 | 6.0 | 698.8 | 6.0 | 58.2 | 72.0 |
| Total Time () | - | - | - | 3.0 | - | 0.4 | - |
| Total Res (%) | - | - | - | - | 31.5 | - | 300.0 |
| Kernel | Partially Parallel | Partial Reconfiguration | ||||
|---|---|---|---|---|---|---|
| Time (s) | Res (%) | PF | Time (s) | Res (%) | PF | |
| MatchFilter | 19.2 | 2.0 | 1.0 | 19.2 | 2.0 | 1.0 |
| IFFT | 62.2 | 6.0 | 4.0 | 62.2 | 6.0 | 4.0 |
| Windowing | 19.2 | 1.0 | 1.0 | 19.2 | 1.0 | 1.0 |
| FFT | 62.2 | 6.0 | 4.0 | 62.2 | 6.0 | 4.0 |
| CombW | 221.2 | 32.0 | 4.0 | 177.0 | 40.0 | 5.0 |
| AntComb | 20.5 | 5.0 | 1.0 | 20.5 | 5.0 | 1.0 |
| IFFT | 186.6 | 6.0 | 4.0 | 62.2 | 18.0 | 12.0 |
| Interleave | 122.4 | 5.0 | 1.0 | 20.4 | 30.0 | 6.0 |
| Demap | 232.9 | 18.0 | 3.0 | 116.5 | 36.0 | 6.0 |
| Total Time () | 0.9 | - | - | 0.6 | - | - |
| Total Res (%) | - | 81.0 | - | - | 80.0 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hosseinghorban, A.; Kumar, A. A Partial-Reconfiguration-Enabled HW/SW Co-Design Benchmark for LTE Applications. Electronics 2022, 11, 978. https://doi.org/10.3390/electronics11070978
Hosseinghorban A, Kumar A. A Partial-Reconfiguration-Enabled HW/SW Co-Design Benchmark for LTE Applications. Electronics. 2022; 11(7):978. https://doi.org/10.3390/electronics11070978
Chicago/Turabian StyleHosseinghorban, Ali, and Akash Kumar. 2022. "A Partial-Reconfiguration-Enabled HW/SW Co-Design Benchmark for LTE Applications" Electronics 11, no. 7: 978. https://doi.org/10.3390/electronics11070978
APA StyleHosseinghorban, A., & Kumar, A. (2022). A Partial-Reconfiguration-Enabled HW/SW Co-Design Benchmark for LTE Applications. Electronics, 11(7), 978. https://doi.org/10.3390/electronics11070978