
A Survey on Efficient Convolutional Neural Networks and Hardware Acceleration




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
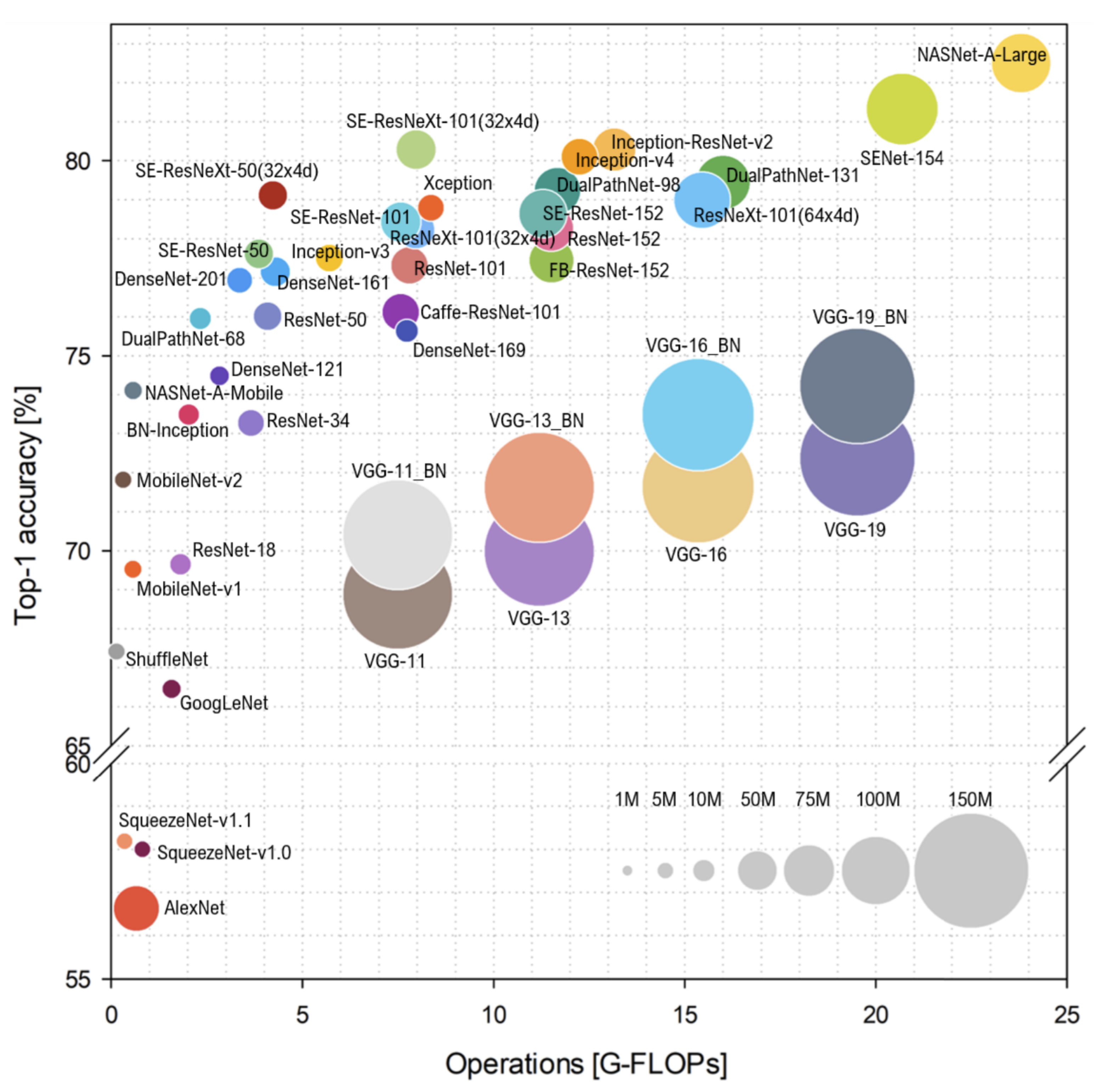
:1. Introduction
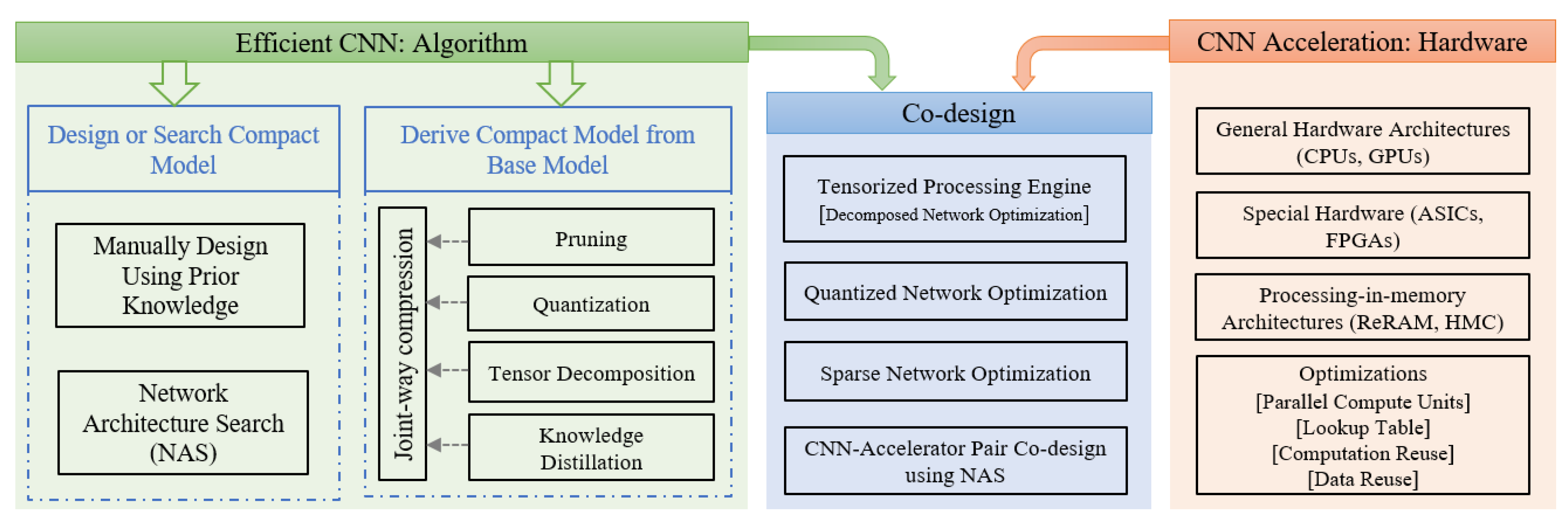
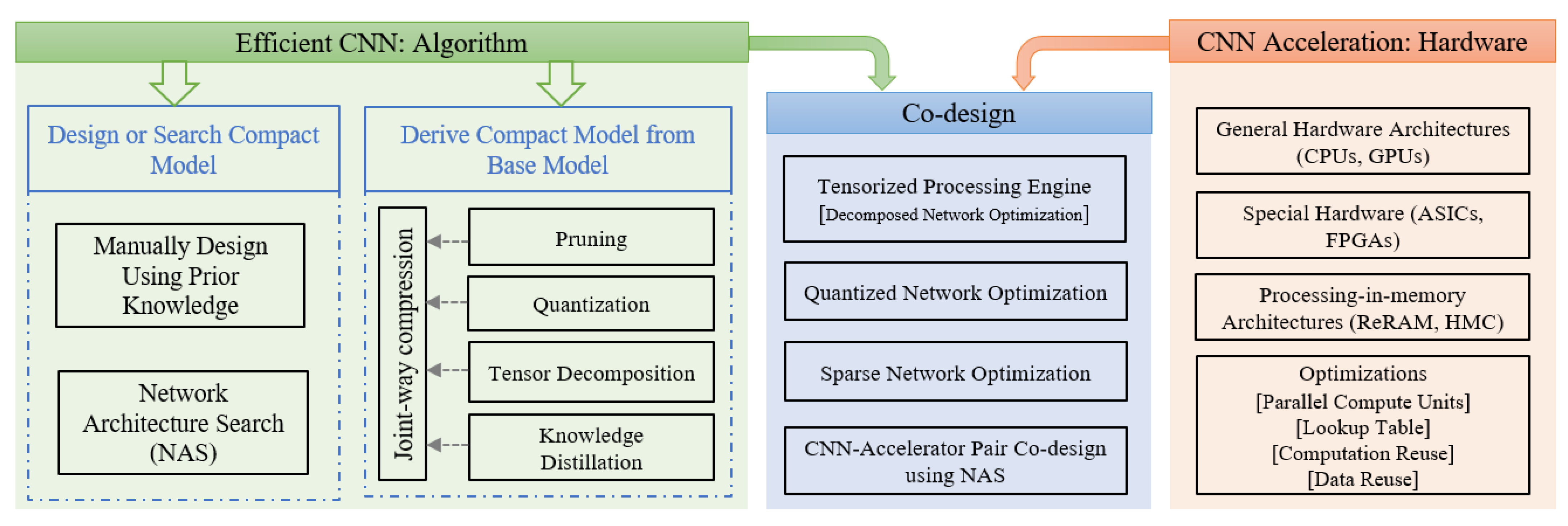
2. Efficient Convolutional Neural Networks
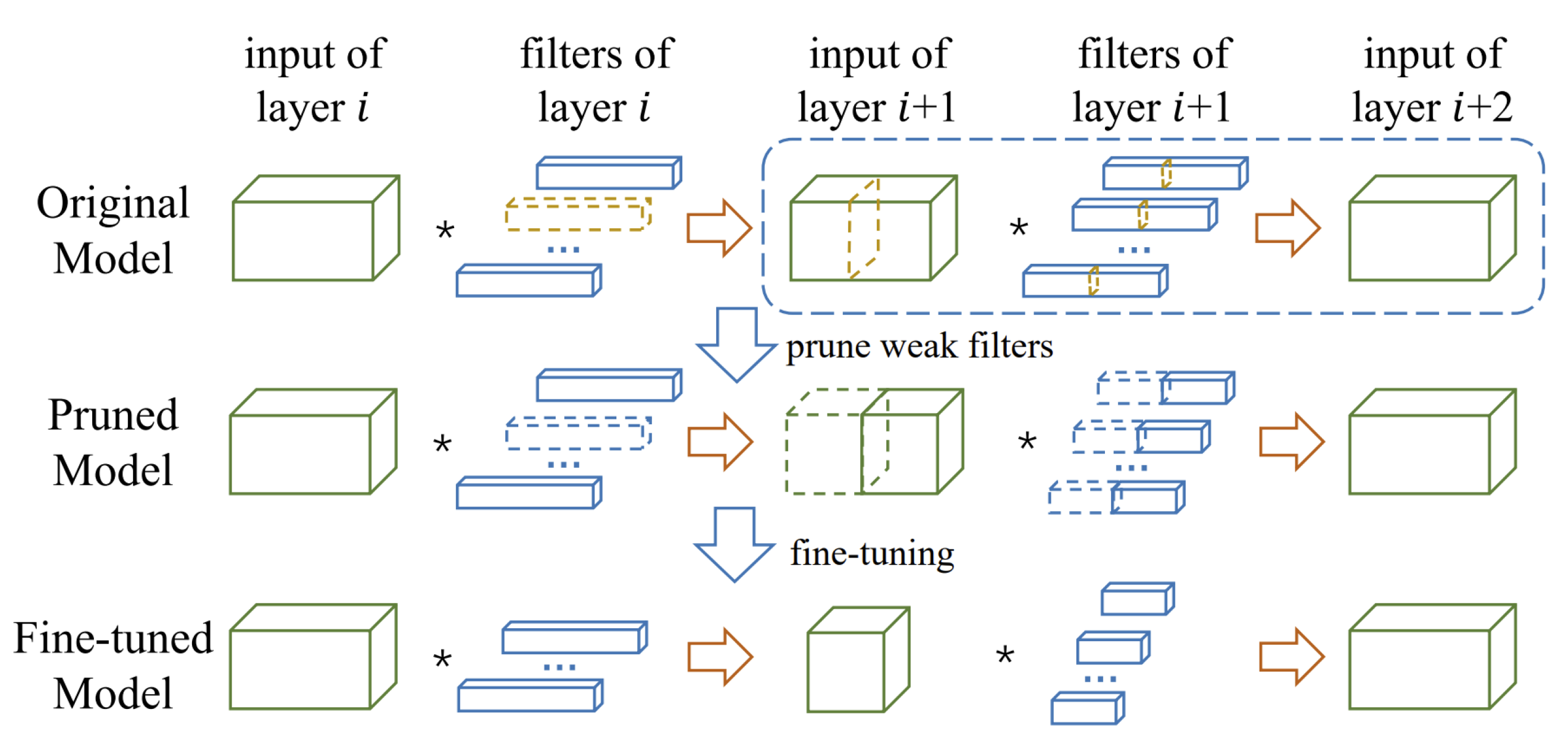
2.1. Pruning
2.1.1. Weight Pruning
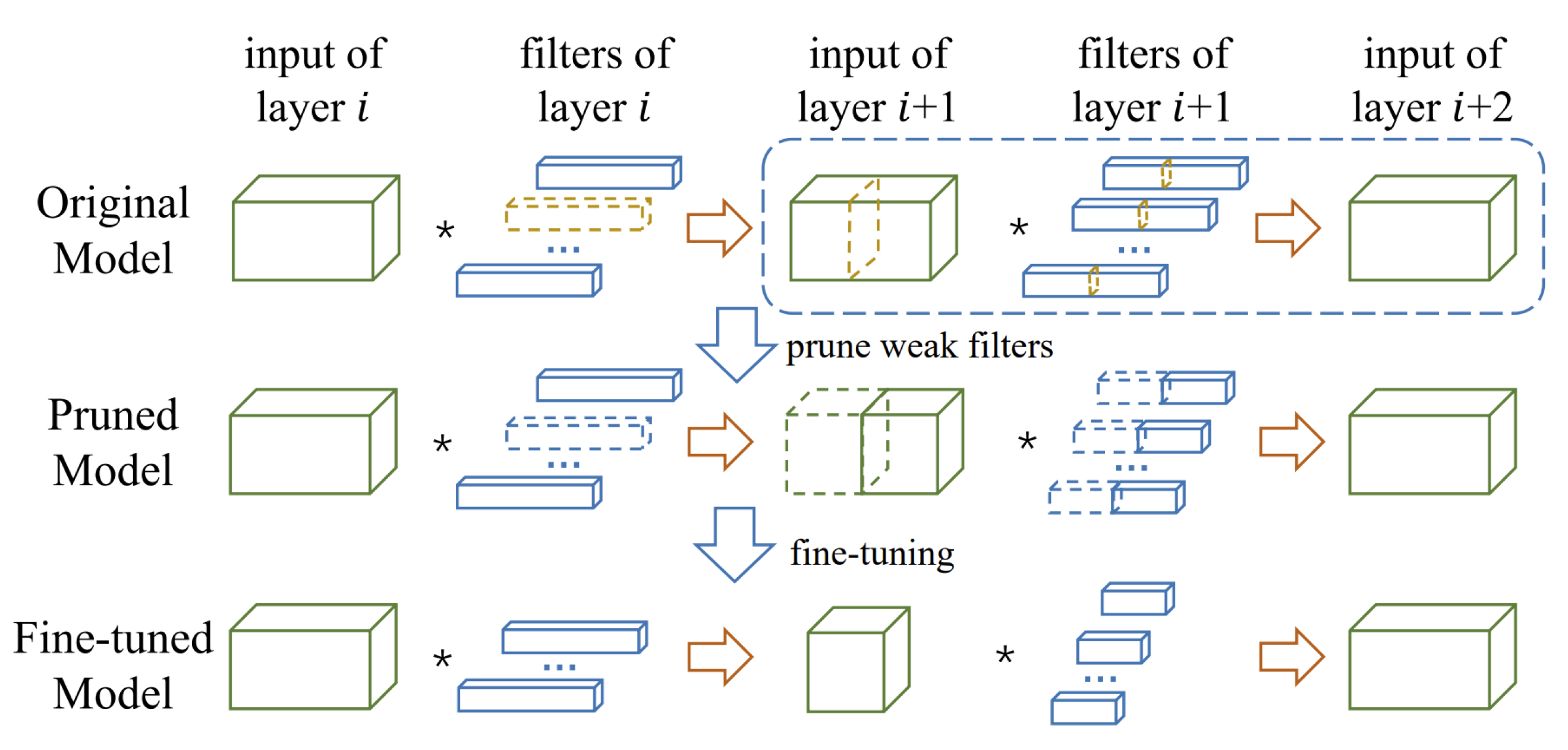
2.1.2. Structural Pruning
2.2. Quantization
Binarization
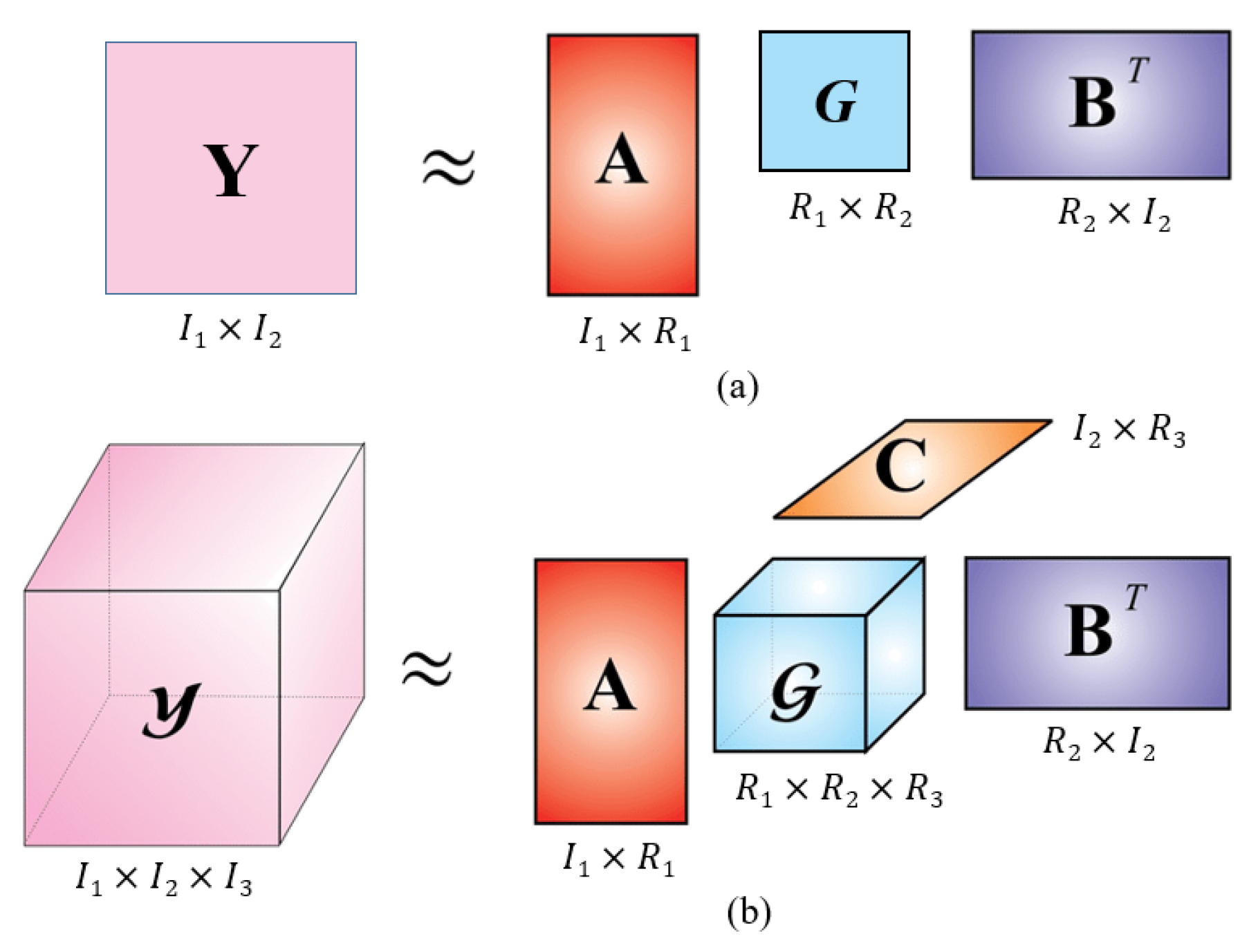
2.3. Tensor Decomposition
2.3.1. Low-Rank Matrix Decomposition
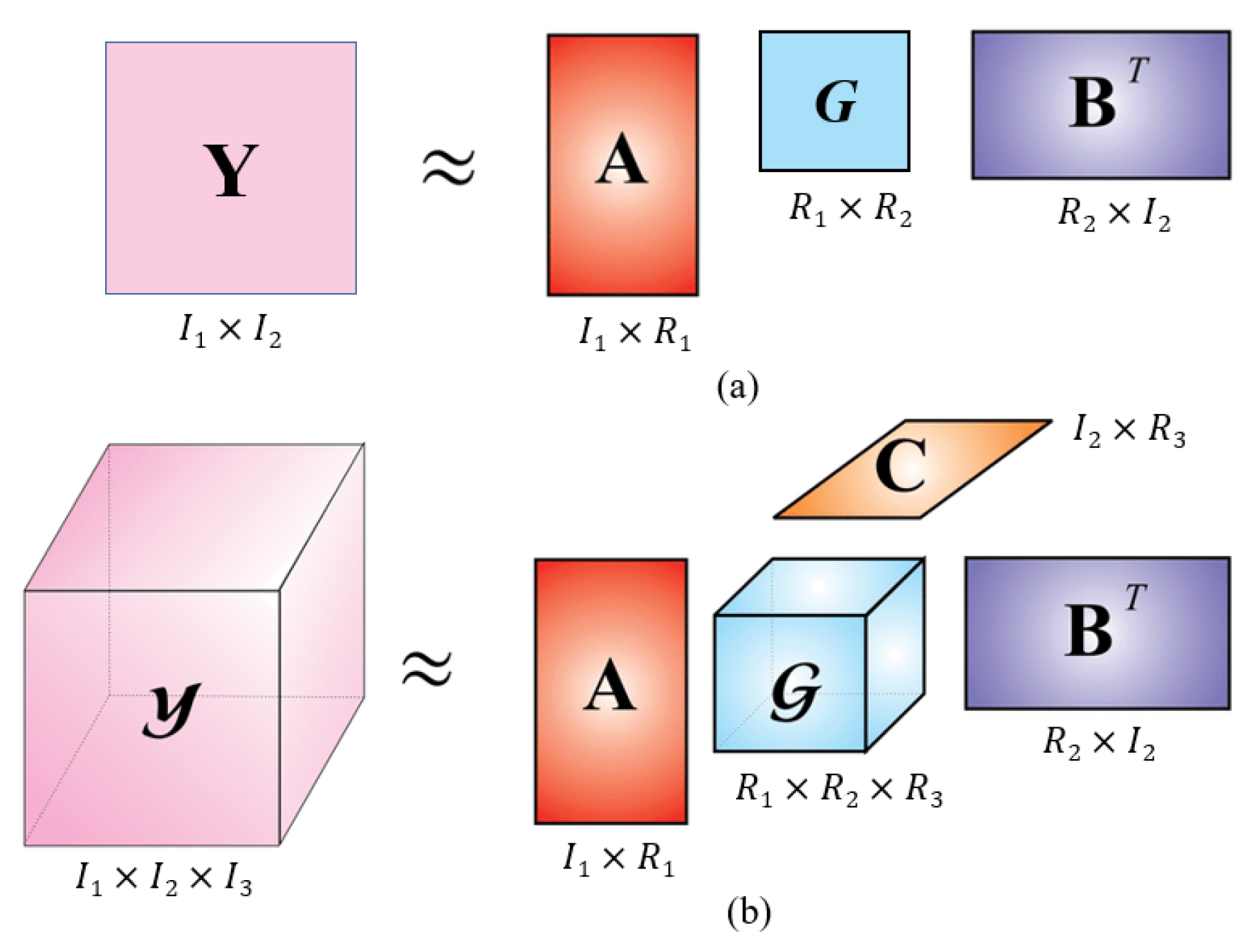
2.3.2. Tensorized Decomposition
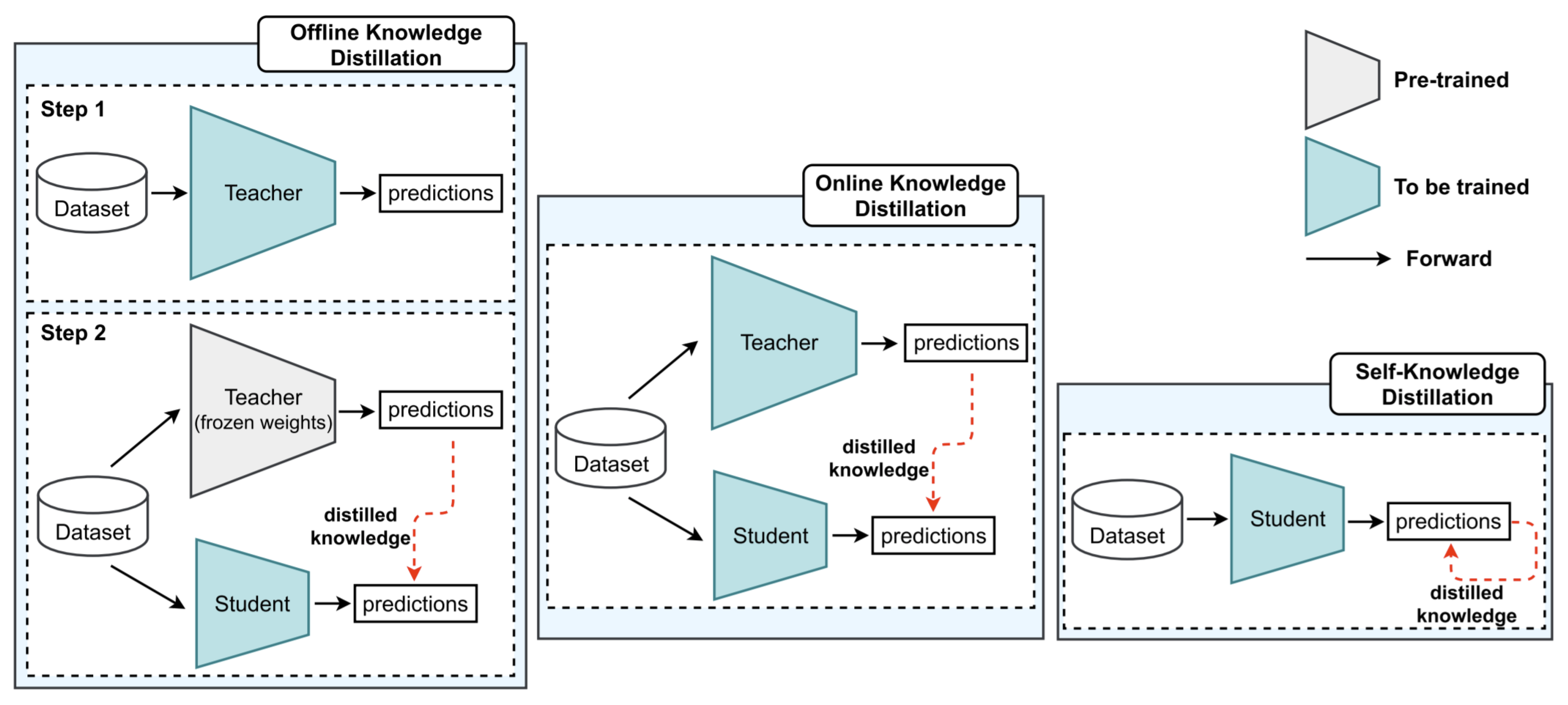
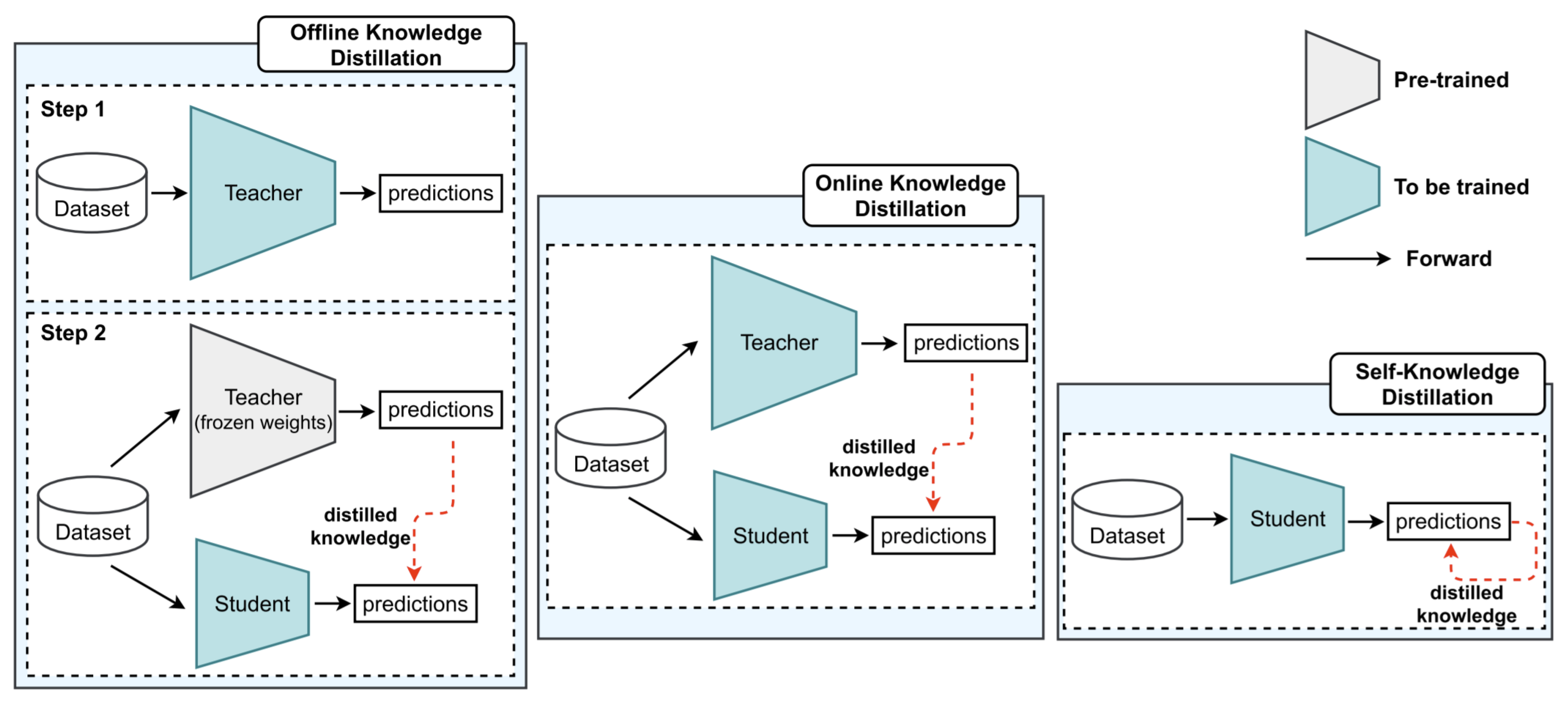
2.4. Knowledge Distillation
2.5. Neural Architecture Search
2.5.1. Search Space
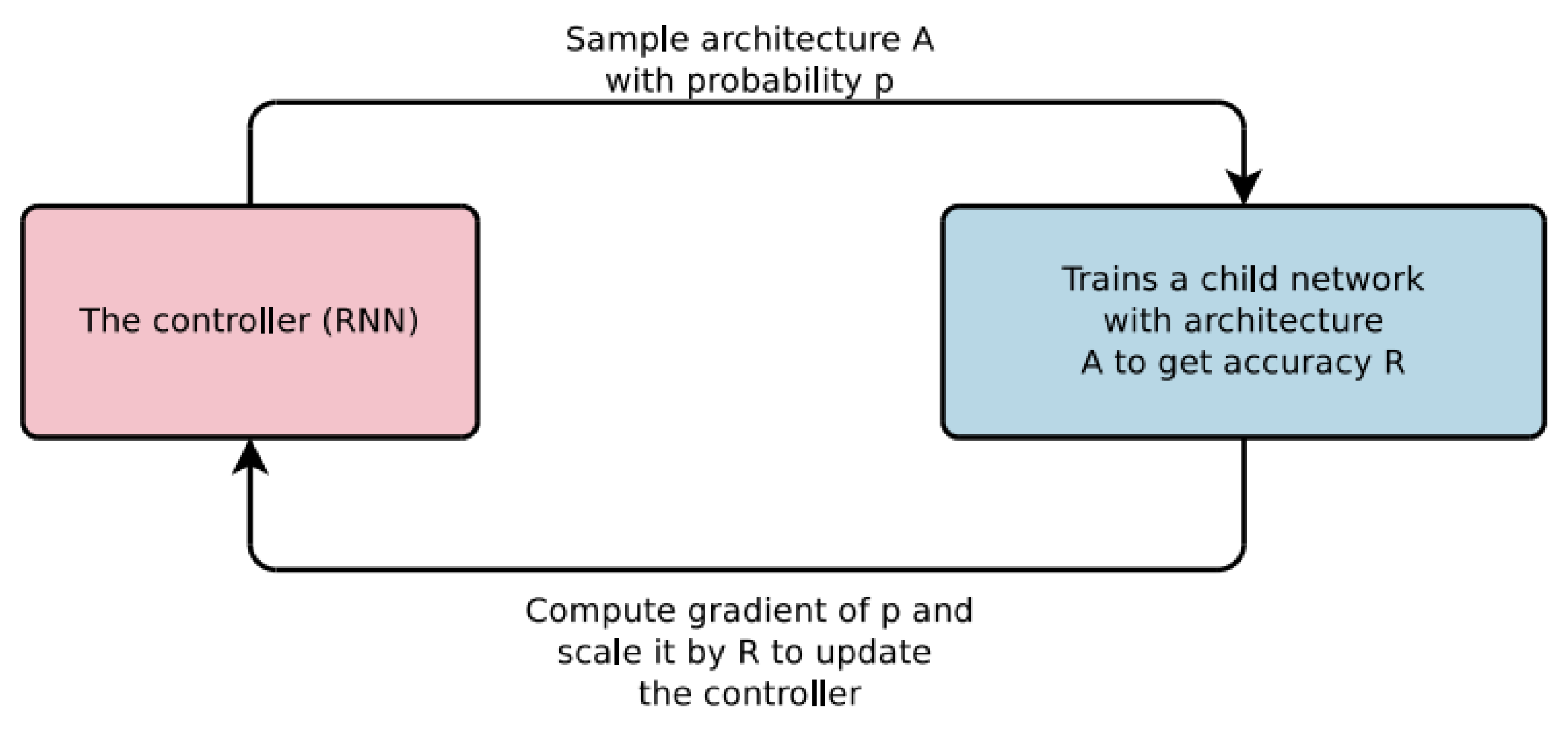
2.5.2. Search Algorithm
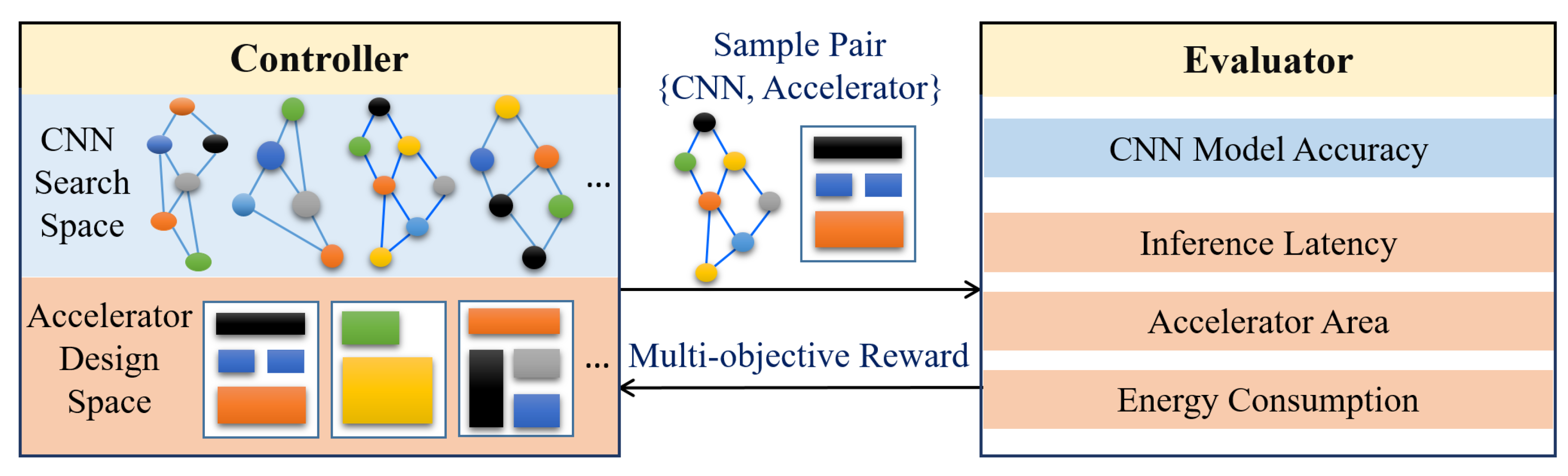
2.5.3. Performance Evaluation Strategy
3. Hardware Acceleration of Convolutional Neural Networks
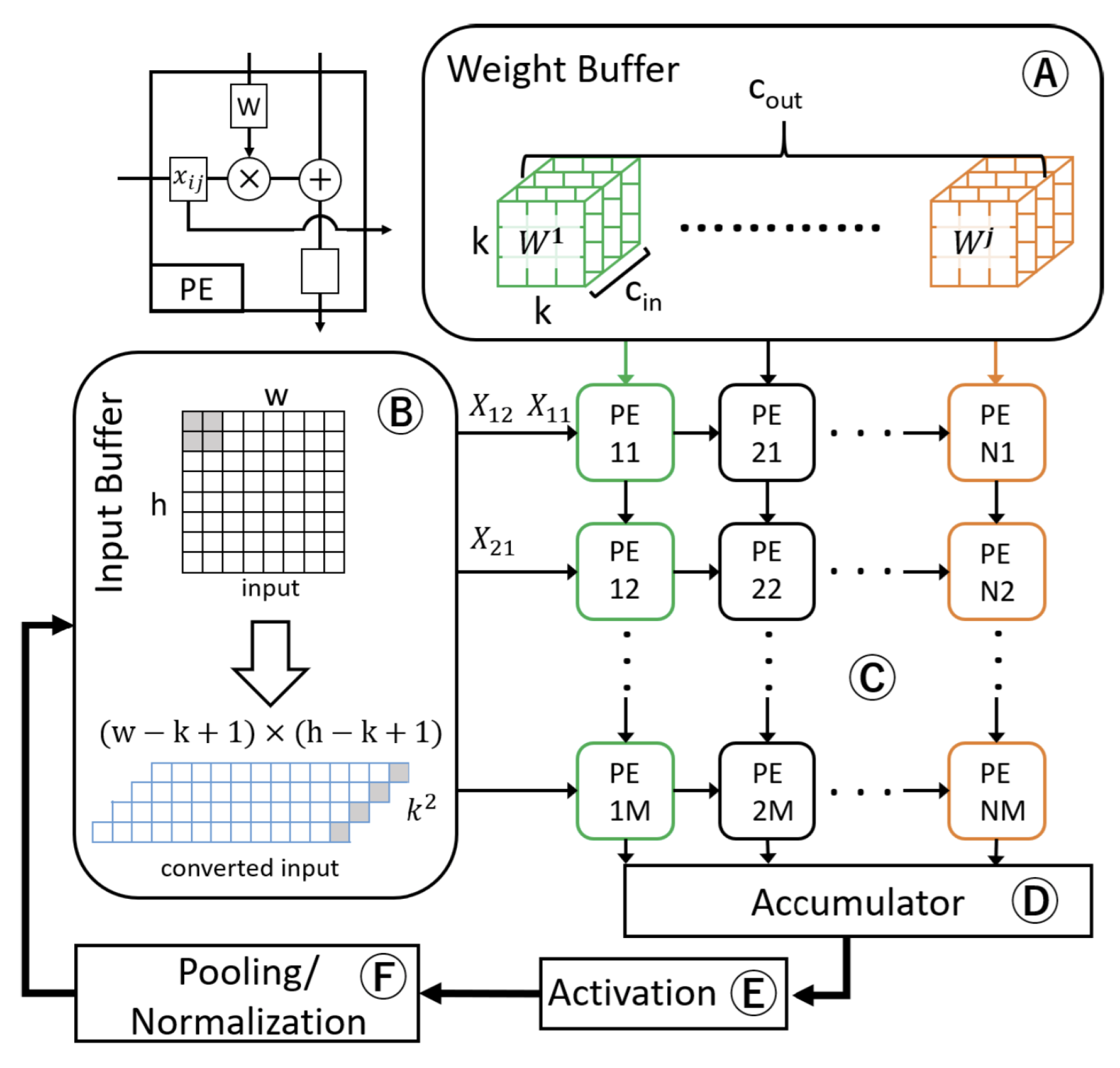
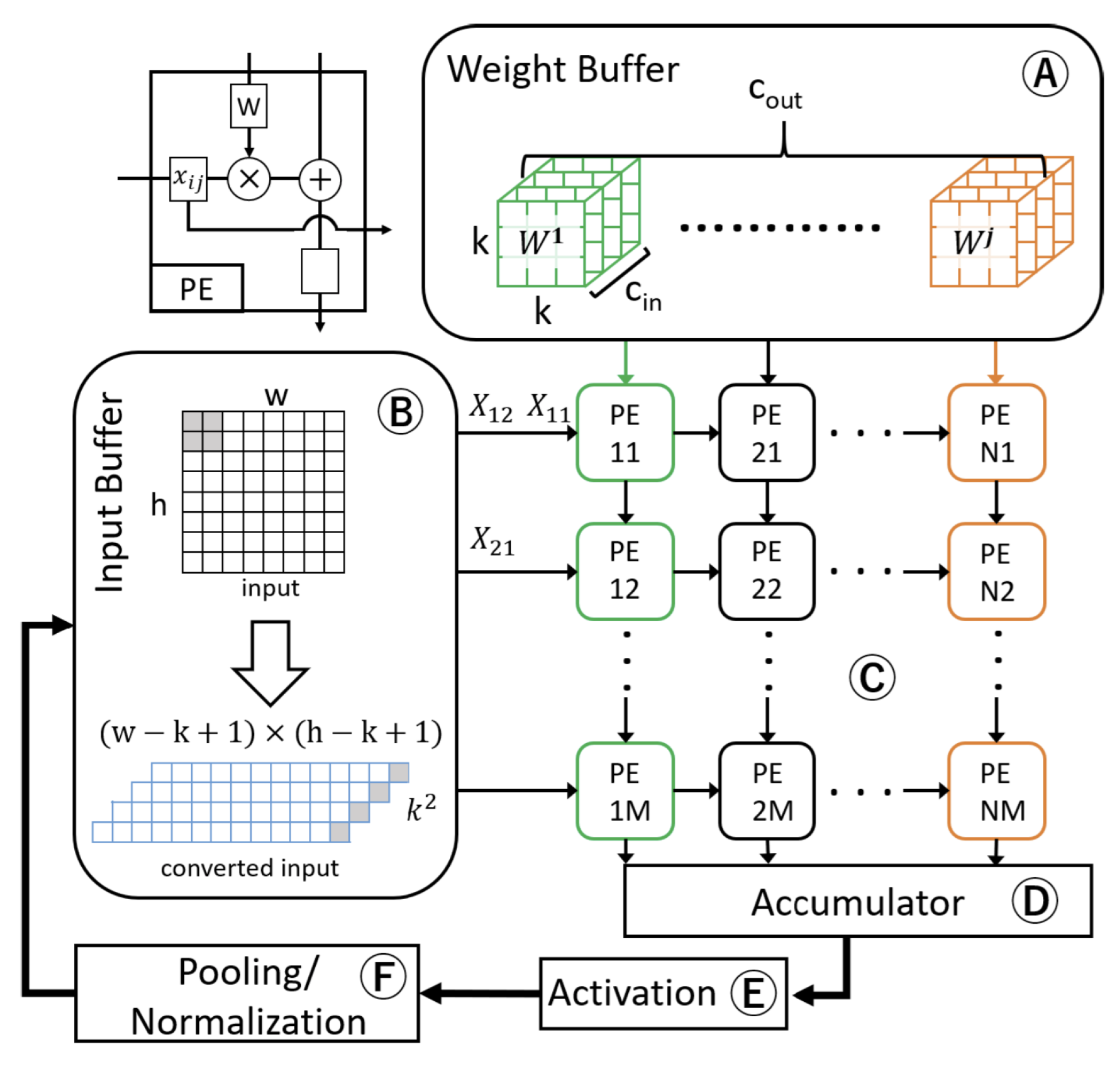
3.1. Temporal and Spatial Hardware Architectures
3.2. Processing-in-Memory (PIM) Architectures
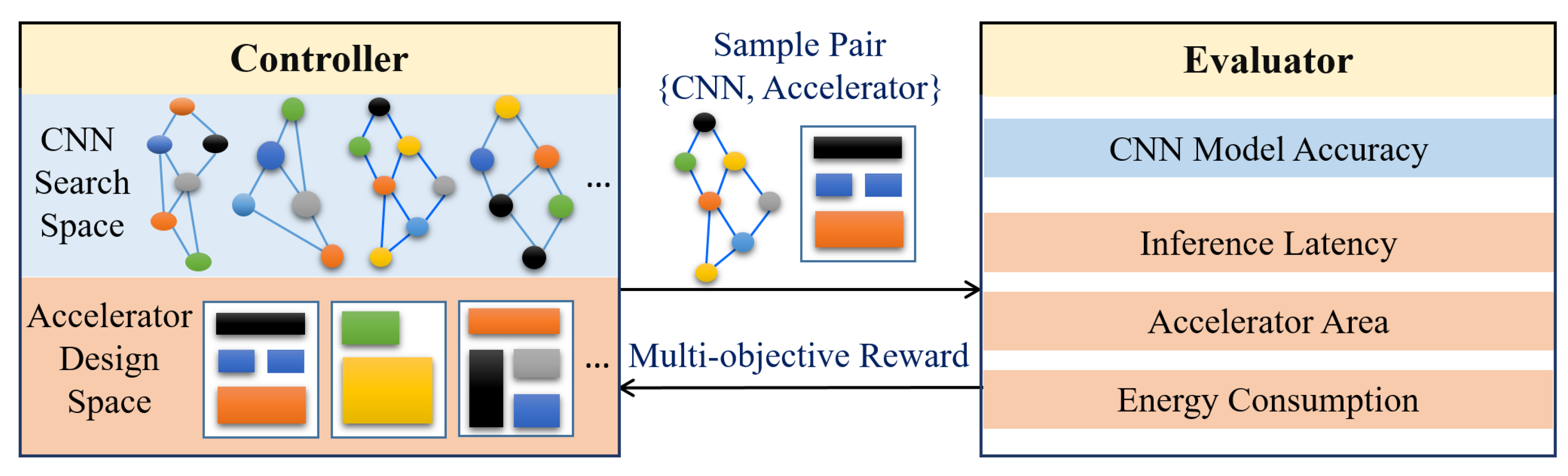
3.3. Co-Design of Hardware Architecture and Compression Algorithm
3.4. Practical Applications: Case Study
4. Discussions
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, J. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, J. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A Large-scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Bianco, S.; Cadene, R.; Celona, L.; Napoletano, T. Benchmark Analysis of Representative Deep Neural Network Architectures. IEEE Access. 2018, 6, 64270–67277. [Google Scholar] [CrossRef]
- Xiao, L.; Bahri, Y.; Sohl-Dickstein, J.; Schoenholz, S.; Pennington, J. Dynamical isometry and a mean field theory of cnns: How to train 10,000-layer vanilla convolutional neural networks. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Iandola, F.; Han, S.; Moskewicz, M.-G.; Ashraf, K.; Dally, W.; Keutzer, K. Squeezenet: Alexnet-level Accuracy with 50× fewer Parameters and <0.5 MB Model Size. arXiv 2017, arXiv:1602.07360. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake, UT, USA, 19–21 June 2018. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Xiangyu, Z.; Shaoqing, R.; Jian, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, T.; Wang, K.; Cai, H.; Lin, J.; Liu, Z.; Wang, H.; Lin, Y.; Han, S. APQ: Joint Search for Network Architecture, Pruning and Quantization Policy. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–10 June 2020. [Google Scholar]
- Zoph, B.; Li, Q.-V. Neural Architecture Search with Reinforcement Learning. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. Smash: One-shot model architecture search through hypernetworks. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, M.; Li, H.; Pan, S.; Chang, X.; Zhou, C.; Ge, Z.; Su, S. One-Shot Neural Architecture Search: Maximising Diversity to Overcome Catastrophic Forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2921–2935. [Google Scholar] [CrossRef]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.J.; Li, F.-F.; Yuille, A.; Huang, J.; Murphy, K. Progressive neural architecture search. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xu, Y.; Wang, Y.; Han, K.; Tang, Y.; Jui, S.; Xu, C.; Xu, C. Renas: Relativistic evaluation of neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Cai, H.; Gan, C.; Wang, T.; Zhang, Z.; Han, S. Once-for-all: Train one network and specialize it for efficient deployment. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 26 April–1 May 2020. [Google Scholar]
- Xia, X.; Xiao, X.; Wang, X.; Zheng, M. Progressive Automatic Design of Search Space for One-Shot Neural Architecture Search. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2022. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In Proceedings of the 30th International Conference on Machine Learning (ICML), Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing neural network architectures using reinforcement learning. arXiv 2016, arXiv:1611.02167. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake, UT, USA, 18–22 June 2018. [Google Scholar]
- Stanley, K.O.; Miikkulainen, R. Evolving neural networks through augmenting topologies. Evol. Comput. 2002, 10, 99–127. [Google Scholar] [CrossRef]
- Real, E.; Moore, S.; Selle, A.; Saxena, S.; Suematsu, Y.L.; Tan, J.; Le, Q.V.; Kurakin, A. Large-scale evolution of image classifiers. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Suganuma, M.; Shirakawa, S.; Nagao, T. A genetic programming approach to designing convolutional neural network architectures. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), Berlin, Germany, 15–19 July 2017. [Google Scholar]
- Liu, H.; Simonyan, K.; Vinyals, O.; Fernando, C.; Kavukcuoglu, K. Hierarchical representations for efficient architecture search. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Aging Evolution for Image Classifier Architecture Search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Miikkulainen, R.; Liang, J.; Meyerson, E.; Rawal, A.; Fink, D.; Francon, O.; Raju, B.; Shahrzad, H.; Navruzyan, A.; Duffy, N.; et al. Evolving deep neural networks. In Artificial Intelligence in the Age of Neural Networks and Brain Computing; Academic Press: Cambridge, MA, USA, 2019; pp. 293–312. [Google Scholar]
- Pham, H.; Guan, M.; Zoph, B.; Le, Q.; Dean, J. Efficient neural architecture search via parameters sharing. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Saikia, T.; Marrakchi, Y.; Zela, A.; Hutter, F.; Brox, T. Autodispnet: Improving disparity estimation with automl. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 17 October–2 November 2019. [Google Scholar]
- Yang, T.J.; Liao, Y.L.; Sze, V. Netadaptv2: Efficient neural architecture search with fast super-network training and architecture optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Korea, 27 October–30 November 2019. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning both weights and connections for efficient neural networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS), Montréal, QC, Canada, 7–10 December 2015. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the 4th International Conference on Learning Representations (ICLR), San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Liu, Z.; Xu, J.; Peng, X.; Xiong, R. Frequency-Domain Dynamic Pruning for Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Zhu, M.; Gupta, S. To prune, or not to prune: Exploring the efficacy of pruning for model compression. In Proceedings of the Sixth International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Alford, S.; Robinett, R.; Milechin, L.; Kepner, J. Training Behavior of Sparse Neural Network Topologies. In Proceedings of the IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 24–26 September 2019. [Google Scholar]
- Frankle, J.; Carbin, M. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Ding, X.; Ding, G.; Zhou, X.; Guo, Y.; Han, J.; Liu, J. Global Sparse Momentum SGD for Pruning Very Deep Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Lee, E.; Hwang, Y. Layer-Wise Network Compression Using Gaussian Mixture Model. Electronics 2021, 10, 72. [Google Scholar] [CrossRef]
- Yang, T.-J.; Chen, Y.-H.; Sze, V. Designing energy-efficient convolutional neural networks using energy-aware pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- He, Y.; Kang, G.; Dong, X.; Fu, Y.; Yang, Y. Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Lin, M.; Ji, R.; Wang, Y.; Zhang, Y.; Zhang, B.; Tian, Y.; Shao, L. HRank: Filter Pruning using High-Rank Feature Map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020. [Google Scholar]
- Hu, H.; Peng, R.; Tai, Y.-W.; Tang, C.-K. Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures. arXiv 2016, arXiv:1607.03250. [Google Scholar]
- Luo, J.-H.; Wu, J.; Lin, W. ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yu, R.; Li, A.; Chen, C.-F.; Lai, H.-H.; Morariu, V.I.; Han, X.; Gao, M.; Lin, C.-Y.; Davis, L.S. NISP: Pruning Networks Using Neuron Importance Score Propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- He, Y.; Liu, P.; Wang, Z.; Hu, Z.; Yang, Y. Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhou, Z.; Zhou, W.; Hong, R.; Li, H. Online Filter Clustering and Pruning for Efficient Convnets. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–18 October 2018. [Google Scholar]
- Chen, S.; Zhao, Q. Shallowing deep networks: Layer-wise pruning based on feature representations. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 3048–3056. [Google Scholar] [CrossRef]
- Elkerdawy, S.; Elhoushi, M.; Singh, A.; Zhang, H.; Ray, N. To filter prune, or to layer prune, that is the question. In Proceedings of the Asian Conference on Computer Vision (ACCV), Virtual, 30 November–4 December 2020. [Google Scholar]
- Xu, P.; Cao, J.; Shang, F.; Sun, W.; Li, P. Layer Pruning via Fusible Residual Convolutional Block for Deep Neural Networks. arXiv 2020, arXiv:2011.14356. [Google Scholar]
- Jung, S.; Son, C.; Lee, S.; Son, J.; Kwak, Y.; Han, J.-J.; Hwang, S.J.; Choi, C. Learning to Quantize Deep Networks by Optimizing Quantization Intervals with Task Loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 December 2017. [Google Scholar]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the value of network pruning. In Proceedings of the Seventh International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wang, Y.; Zhang, X.; Xie, L.; Zhou, J.; Su, H.; Zhang, B.; Hu, X. Pruning from scratch. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Fiesler, E.; Choudry, A.; Caulfield, H.J. Weight discretization paradigm for optical neural networks. In Proceedings of the International Congress on Optical Science and Engineering (ICOSE), The Hague, The Netherlands, 12–16 March 1990. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Miyashita, D.; Lee, E.H.; Murmann, B. Convolutional neural networks using logarithmic data representation. arXiv 2016, arXiv:1603.01025. [Google Scholar]
- Wu, H.; Judd, P.; Zhang, X.; Isaev, M.; Micikevicius, P. Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation. arXiv 2020, arXiv:2004.09602. [Google Scholar]
- Banner, B.; Nahshan, Y.; Hoffer, E.; Soudry, D. Post training 4-bit quantization of convolutional networks for rapid-deployment. In Proceedings of the 33rd International Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Quantized neural networks: Training neural networks with low precision weights and activations. J. Mach. Learn. Res. 2017, 18, 6869–6898. [Google Scholar]
- Zhou, Q.; Guo, S.; Qu, Z.; Guo, J.; Xu, Z.; Zhang, J.; Guo, T.; Luo, B.; Zhou, J. Octo: INT8 Training with Loss-aware Compensation and Backward Quantization for Tiny On-device Learning. In Proceedings of the 2021 USENIX Annual Technical Conference (USENIX ATC), Virtual, 14–16 July 2021. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J.P. Binaryconnect: Training deep neural networks with binary weights during propagations. In Proceedings of the 29th International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Hou, L.; Yao, Q.; Kwok, J.T. Loss-aware binarization of deep networks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental network quantization: Towards lossless cnns with low-precision weights. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Qin, H.; Gong, R.; Liu, X.; Shen, M.; Wei, Z.; Yu, F.; Song, J. Forward and backward information retention for accurate binary neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020. [Google Scholar]
- Denil, M.; Shakibi, B.; Dinh, L.; Ranzato, M.; de Freitas, N. Binaryconnect: Predicting parameters in deep learning. In Proceedings of the 29th International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Klema, V.; Laub, A. The singular value decomposition: Its computation and some applications. IEEE Trans. Autom. Control 1980, 25, 164–176. [Google Scholar] [CrossRef] [Green Version]
- Xue, J.; Li, J.; Yu, D.; Seltzer, M.; Gong, Y. Singular value decomposition based low-footprint speaker adaptation and personalization for deep neural network. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar]
- Masana, M.; van de Weijer, J.; Herranz, L.; Bagdanov, A.D.; Alvarez, J.M. Domain-adaptive deep network compression. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Swaminathan, S.; Garg, D.; Kannan, R.; Andres, F. Sparse low rank factorization for deep neural network compression. Neurocomputing 2020, 398, 185–196. [Google Scholar] [CrossRef]
- Zhang, X.; Zou, J.; He, K.; Sun, J. Accelerating very deep convolutional networks for classification and detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1943–1955. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Tang, M.; Wen, W.; Yan, F.; Hu, D.; Li, A.; Li, H.; Chen, Y. Learning low-rank deep neural networks via singular vector orthogonality regularization and singular value sparsification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Virtual, 14–19 June 2020. [Google Scholar]
- Chen, S.; Zhou, J.; Sun, W.; Huang, L. Joint Matrix Decomposition for Deep Convolutional Neural Networks Compression. arXiv 2021, arXiv:2107.04386. [Google Scholar]
- Kim, Y.-D.; Park, E.; Yoo, S.; Choi, T.; Yang, L.; Shin, D. Compression of deep convolutional neural networks for fast and low power mobile applications. In Proceedings of the 4th International Conference on Learning Representations (ICLR), San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Lebedev, V.; Ganin, Y.; Rakhuba, M.; Oseledets, I.; Lempitsky, V. Speeding-up convolutional neural networks using fine-tuned CP-decomposition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Astrid, M.; Lee, S.-I. CP-decomposition with tensor power method for convolutional neural networks compression. In Proceedings of the International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Korea, 13–16 February 2017. [Google Scholar]
- Phan, A.H.; Sobolev, K.; Sozykin, K.; Ermilov, D.; Gusak, J.; Tichavský, P.; Glukhov, V.; Oseledets, I.; Cichocki, A. Stable low-rank tensor decomposition for compression of convolutional neural network. In Proceedings of the European Conference on Computer Vision (ECCV), Virtual, 23–28 August 2020. [Google Scholar]
- Yang, Y.; Krompass, D.; Tresp, V. Tensor-train recurrent neural networks for video classification. In Proceedings of the International Conference on Machine Learning (PMLR), Stockholm, Sweden, 10–15 July 2017. [Google Scholar]
- Yin, M.; Sui, Y.; Liao, S.; Yuan, B. Towards Efficient Tensor Decomposition-Based DNN Model Compression with Optimization Framework. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Wang, D.; Zhao, G.; Li, G.; Deng, L.; Wu, Y. Compressing 3DCNNs based on tensor train decomposition. Neural Netw. 2020, 131, 215–230. [Google Scholar] [CrossRef] [PubMed]
- Bucilua, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Fukuda, T.; Suzuki, M.; Kurata, G.; Thomas, S.; Cui, J.; Ramabhadran, B. Efficient Knowledge Distillation from an Ensemble of Teachers. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Polino, A.; Pascanu, R.; Alistarh, D. Model compression via distillation and quantization. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Nayak, G.K.; Mopuri, K.R.; Shaj, V.; Radhakrishnan, V.B.; Chakraborty, A. Zero-shot knowledge distillation in deep networks. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Jin, X.; Peng, B.; Wu, Y.; Liu, Y.; Liu, J.; Liang, D.; Yan, J.; Hu, X. Knowledge distillation via route constrained optimization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–30 November 2019. [Google Scholar]
- Guo, Q.; Wang, X.; Wu, Y.; Yu, Z.; Liang, D.; Hu, X.; Luo, P. Online knowledge distillation via collaborative learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020. [Google Scholar]
- Li, H.-T.; Lin, S.-C.; Chen, C.-Y.; Chiang, C.-K. Layer-Level Knowledge Distillation for Deep Neural Network Learning. Appl. Sci. 2019, 9, 1966. [Google Scholar] [CrossRef] [Green Version]
- Walawalkar, D.; Shen, Z.; Savvides, M. Online ensemble model compression using knowledge distillation. In Proceedings of the European Conference on Computer Vision (ECCV), Virtual, 23–24 August 2020. [Google Scholar]
- Ji, M.; Shin, S.; Hwang, S.; Park, G.; Moon, I.C. Refine myself by teaching myself: Feature refinement via self-knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Vu, D.Q.; Le, N.; Wang, J.C. Teaching yourself: A self-knowledge distillation approach to action recognition. IEEE Access 2021, 9, 105711–105723. [Google Scholar] [CrossRef]
- Jouppi, N.P.; Young, C.; Patil, N. In-Datacenter Performance Analysis of a Tensor Processing Unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture (ISCA), Toronto, ON, Canada, 24–28 June 2017. [Google Scholar]
- Prost-Boucle, A.; Bourge, A.; Pétrot, F.; Alemdar, H.; Caldwell, N.; Leroy, V. Scalable high-performance architecture for convolutional ternary neural networks on FPGA. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017. [Google Scholar]
- Deng, C.; Sun, F.; Qian, X.; Lin, J.; Wang, Z.; Yuan, B. TIE: Energy-efficient Tensor Train-based Inference Engine for Deep Neural Network. In Proceedings of the ACM/IEEE 46th Annual International Symposium on Computer Architecture (ISCA), Phoenix, AZ, USA, 22–26 June 2019. [Google Scholar]
- LeCun, Y.; Denker, J.S.; Solla, S.A. Optimal brain damage. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Denver, CO, USA, 27–30 November 1989. [Google Scholar]
- Hassibi, B.; Stork, D.G.; Com, S.C.R. Second order derivatives for network pruning: Optimal brain surgeon. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Denver, CO, USA, 30 November–3 December 1992. [Google Scholar]
- Li, N.; Pan, Y.; Chen, Y.; Ding, Z.; Zhao, D.; Xu, Z. Heuristic rank selection with progressively searching tensor ring network. Complex Intell. Syst. 2021, 1–15. [Google Scholar] [CrossRef]
- Achararit, P.; Hanif, M.A.; Putra, R.V.W.; Shafique, M.; Hara-Azumi, Y. APNAS: Accuracy-and-performance-aware neural architecture search for neural hardware accelerators. IEEE Access 2020, 8, 165319–165334. [Google Scholar] [CrossRef]
- Parashar, A.; Rhu, M.; Mukkara, A.; Puglielli, A.; Venkatesan, R.; Khailany, B.; Emer, J.; Keckler, S.W. SCNN: An accelerator for compressed-sparse convolutional neural networks. In Proceedings of the 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), Toronto, ON, Canada, 24–28 June 2017. [Google Scholar]
- Cavigelli, L.; Benini, L. Origami: A 803-GOp/s/W convolutional network accelerator. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 2461–2475. [Google Scholar] [CrossRef] [Green Version]
- Yin, S.; Ouyang, P.; Tang, S.; Tu, F.; Li, X.; Zheng, S.; Lu, T.; Gu, J.; Liu, L.; Wei, S. A high energy efficient reconfigurable hybrid neural network processor for deep learning applications. IEEE J. Solid-State Circuits 2017, 53, 968–982. [Google Scholar] [CrossRef]
- Chen, Y.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.H.; Yang, T.J.; Emer, J.; Sze, V. Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 292–308. [Google Scholar] [CrossRef] [Green Version]
- Strukov, D.B.; Snider, G.S.; Stewart, D.R.; Williams, R.S. The missing memristor found. Nature 2008, 453, 80–83. [Google Scholar] [CrossRef] [PubMed]
- Pawlowski, J.T. Hybrid memory cube (HMC). In Proceedings of the 2011 IEEE Hot Chips 23 Symposium, Stanford, CA, USA, 17–19 August 2011. [Google Scholar]
- Deng, Q.; Jiang, L.; Zhang, Y.; Zhang, M.; Yang, J. DrAcc: A DRAM based Accelerator for Accurate CNN Inference. In Proceedings of the 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 24–28 June 2018. [Google Scholar]
- Chi, P.; Li, S.; Xu, C.; Zhang, T.; Zhao, J.; Liu, Y.; Wang, Y.; Xie, Y. Prime: A novel processing-in-memory architecture for neural network computation in reram-based main memory. ACM SIGARCH Comput. Archit. News 2016, 44, 27–39. [Google Scholar] [CrossRef]
- Zhang, Y.; Jia, Z.; Du, H.; Xue, R.; Shen, Z.; Shao, Z. A Practical Highly Paralleled ReRAM-based DNN Accelerator by Reusing Weight Pattern Repetitions. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2021. [Google Scholar] [CrossRef]
- Kim, D.; Kung, J.; Chai, S.; Yalamanchili, S.; Mukhopadhyay, S. Neurocube: A programmable digital neuromorphic architecture with high-density 3D memory. ACM SIGARCH Comput. Archit. News 2016, 44, 380–392. [Google Scholar] [CrossRef]
- Abdelfattah, M.S.; Dudziak, Ł.; Chau, T.; Lee, R.; Kim, H.; Lane, N.D. Best of both worlds: Automl codesign of a cnn and its hardware accelerator. In Proceedings of the 57th ACM/IEEE Design Automation Conference (DAC), Virtual, 20–24 July 2020. [Google Scholar]
- Zhang, S.; Du, Z.; Zhang, L.; Lan, H.; Liu, S.; Li, L.; Guo, Q.; Chen, T.; Chen, T. Cambricon-X: An accelerator for sparse neural networks. In Proceedings of the 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016. [Google Scholar]
- Zhou, X.; Du, Z.; Guo, Q.; Liu, S.; Liu, C.; Wang, C.; Zhou, X.; Li, L.; Chen, T.; Chen, Y. Cambricon-S: Addressing irregularity in sparse neural networks through a cooperative software/hardware approach. In Proceedings of the 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Fukuoka, Japan, 20–24 October 2018. [Google Scholar]
- Zhang, J.F.; Lee, C.E.; Liu, C.; Shao, Y.S.; Keckler, S.W.; Zhang, Z. Snap: An efficient sparse neural acceleration processor for unstructured sparse deep neural network inference. IEEE J. Solid-State Circuits 2021, 56, 636–647. [Google Scholar] [CrossRef]
- Judd, P.; Albericio, J.; Hetherington, T.; Aamodt, T.M.; Moshovos, A. Stripes: Bit-serial deep neural network computing. In Proceedings of the 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016. [Google Scholar]
- Sharma, H.; Park, J.; Suda, N.; Lai, L.; Chau, B.; Chandra, V.; Esmaeilzadeh, H. Bit fusion: Bit-level dynamically composable architecture for accelerating deep neural network. In Proceedings of the ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 1–6 June 2018. [Google Scholar]
- Lee, J.; Kim, C.; Kang, S.; Shin, D.; Kim, S.; Yoo, H.J. UNPU: An energy-efficient deep neural network accelerator with fully variable weight bit precision. IEEE J. Solid-State Circuits 2019, 54, 173–185. [Google Scholar] [CrossRef]
- Ryu, S.; Kim, H.; Yi, W.; Kim, E.; Kim, Y.; Kim, T.; Kim, J.J. BitBlade: Energy-Efficient Variable Bit-Precision Hardware Accelerator for Quantized Neural Networks. IEEE J. Solid-State Circuits 2022. [Google Scholar] [CrossRef]
- Lee, J.; Kim, C.; Kang, S.; Shin, D.; Kim, S.; Yoo, H.J. XNOR neural engine: A hardware accelerator IP for 21.6-fJ/op binary neural network inference. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 2940–2951. [Google Scholar]
- Andri, R.; Cavigelli, L.; Rossi, D.; Benini, L. YodaNN: An architecture for ultralow power binary-weight CNN acceleration. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 48–60. [Google Scholar] [CrossRef] [Green Version]
- Preußer, T.B.; Gambardella, G.; Fraser, N.; Blott, M. Inference of quantized neural networks on heterogeneous all-programmable devices. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018. [Google Scholar]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. Finn: A framework for fast, scalable binarized neural network inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 March 2017. [Google Scholar]
- Cho, J.; Jung, Y.; Lee, S.; Jung, Y. Reconfigurable Binary Neural Network Accelerator with Adaptive Parallelism Scheme. Electronics 2021, 10, 230. [Google Scholar] [CrossRef]
- Qu, Z.; Deng, L.; Wang, B.; Chen, H.; Lin, J.; Liang, L.; Li, G.; Zhang, Z.; Xie, Y. Hardware-Enabled Efficient Data Processing with Tensor-Train Decomposition. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2022, 41, 372–385. [Google Scholar] [CrossRef]
- Hosseini, M.; Mohsenin, T. QS-NAS: Optimally quantized scaled architecture search to enable efficient on-device micro-AI. IEEE J. Emerg. Sel. Top. Circuits Syst. 2021, 11, 597–610. [Google Scholar] [CrossRef]
- Bashivan, P.; Tensen, M.; DiCarlo, J.J. Teacher guided architecture search. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghimire, D.; Kil, D.; Kim, S.-h. A Survey on Efficient Convolutional Neural Networks and Hardware Acceleration. Electronics 2022, 11, 945. https://doi.org/10.3390/electronics11060945
Ghimire D, Kil D, Kim S-h. A Survey on Efficient Convolutional Neural Networks and Hardware Acceleration. Electronics. 2022; 11(6):945. https://doi.org/10.3390/electronics11060945
Chicago/Turabian StyleGhimire, Deepak, Dayoung Kil, and Seong-heum Kim. 2022. "A Survey on Efficient Convolutional Neural Networks and Hardware Acceleration" Electronics 11, no. 6: 945. https://doi.org/10.3390/electronics11060945
APA StyleGhimire, D., Kil, D., & Kim, S.-h. (2022). A Survey on Efficient Convolutional Neural Networks and Hardware Acceleration. Electronics, 11(6), 945. https://doi.org/10.3390/electronics11060945