3.3. Fuzzy Sets and Fuzzy Inference Systems
Fuzzy Set theory was proposed by Lotfi Zadeh in 1965 as an extension to the classical set theory, in which elements are described by fuzzy numbers. Fuzzy logic was introduced to approach a more realistic way of human thinking in a way that could provide tools for dealing with vagueness and imprecision of data in decision making. In fuzzy logic, knowledge representation is “interpreted as a collection of elastic or, equivalently fuzzy constraint on a collection of variables [
68]”. Consequently, “inference is viewed as a process of propagation of elastic constraints [
68]”.
In fuzzy set theory, elements can belong to more than one fuzzy set, using the notion of set membership. These relations are represented by a degree of membership, and it describes the degree of truth of an element. According to [
69], given a non-empty set
X, a
fuzzy set in
X is characterized by a membership function
:
and it is described as set of ordered pairs
:
where the first entity represents the element
x of
X, and the second one represents the membership value
ranging from [0, 1]. This membership value defines the degree of membership of element
x in the fuzzy set
for each
. In this way, a fuzzy set
is defined by a set of tuples. It is worth noting that a membership value of 0 for an element would denote the complete non-membership of the element in the fuzzy set, whereas a value of 1 would represent full membership. Similarly, intermediate values ranging in
represent a partial belonging of an element to a fuzzy set. Additionally, membership functions can take many shapes, such as triangular, trapezoidal, Gaussian, etc. Essentially, classical set theory is now considered a special case of fuzzy sets; a classical set is a fuzzy set whose membership value is either 0 or 1.
To capture the imprecision of data through natural language, Zadeh introduced the idea of linguistic variables in 1975, which was a core concept of fuzzy systems [
70,
71,
72]. These are variables “whose values are not numbers but words or sentences in a natural or artificial language [
70]”. According to him, linguistic variables are associated with fuzzy sets using adjectives and hedges [
73]. A full description of a linguistic variable requires the quintuple:
or the name
x of the variable, the set of terms
, the universe of discourse
U, the syntactic grammar
G, and the semantic rules
M [
70].
To introduce inference from linguistic variable operations, fuzzy logic uses a set of statements, called fuzzy rules, of the following structure:
where condition statements concern the input variables, conclusion statements concern the output variable/s and usually both take the form of “
is
” [
74].
In general, there are three major types of fuzzy inference rules: the Mamdani fuzzy rules [
75,
76], the Takagi-Sugeno (TSK) fuzzy rules [
77,
78], and the Tsukamoto fuzzy rules [
79], depending on the nature of <condition> and <conclusion>. In the Mamdani inference method, which is the most common one and can be found with multiple variations in literature, both <condition> and <conclusion> are fuzzy sets. In the TSK model, the output is a function of the input variable(s) and the idea is to generate the fuzzy rules based on an existing dataset of the dependent and independent variables. Lastly, in the Tsukamoto method, the output variable is a fuzzy set of a monotonic membership function.
Once all parameters for the inference model have been determined, e.g., type of the model, input/output variables, linguistic terms (or the fuzzy sets to be associated with them), fuzzy rules and shape of membership functions, the system is ready to accept crisp inputs and proceed to fuzzy operations that lead to intelligent decisions. This process is better known as a fuzzy inference system (FIS) and it is generally described by three main blocks:
Fuzzification: Translate input into truth values.
Evaluation: Compute output truth values.
Defuzzification: Transfer truth values into output.
It is worth noting that both TSK and Tsukamoto models avoid the costly defuzzification computations that are present in the Mamdani method. This is achieved by the fact that the outputs of their fuzzy rules are crisp numbers, which in turns facilitates the aggregation computations during the defuzzification part of the FIS.
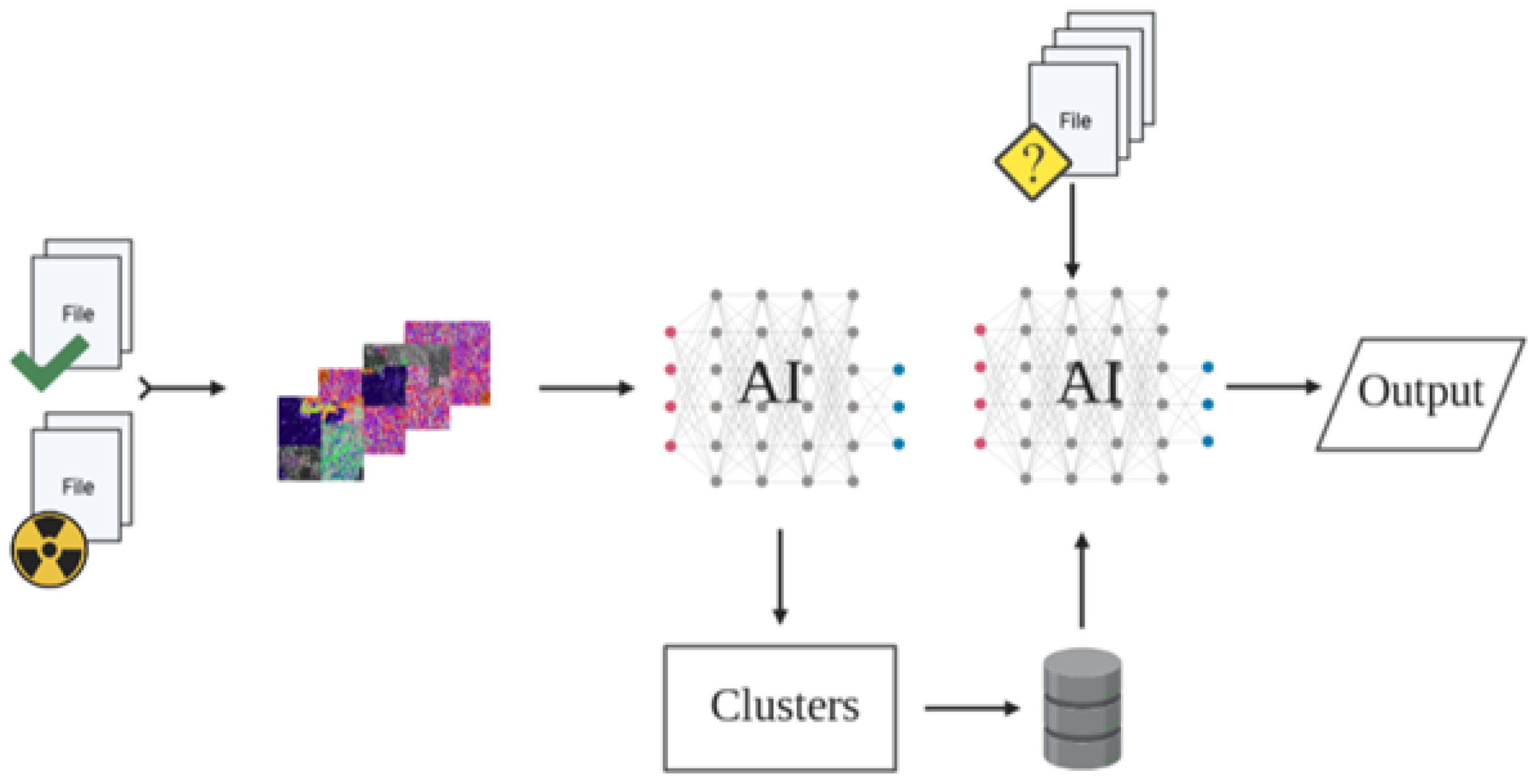
3.4. SAGMAD
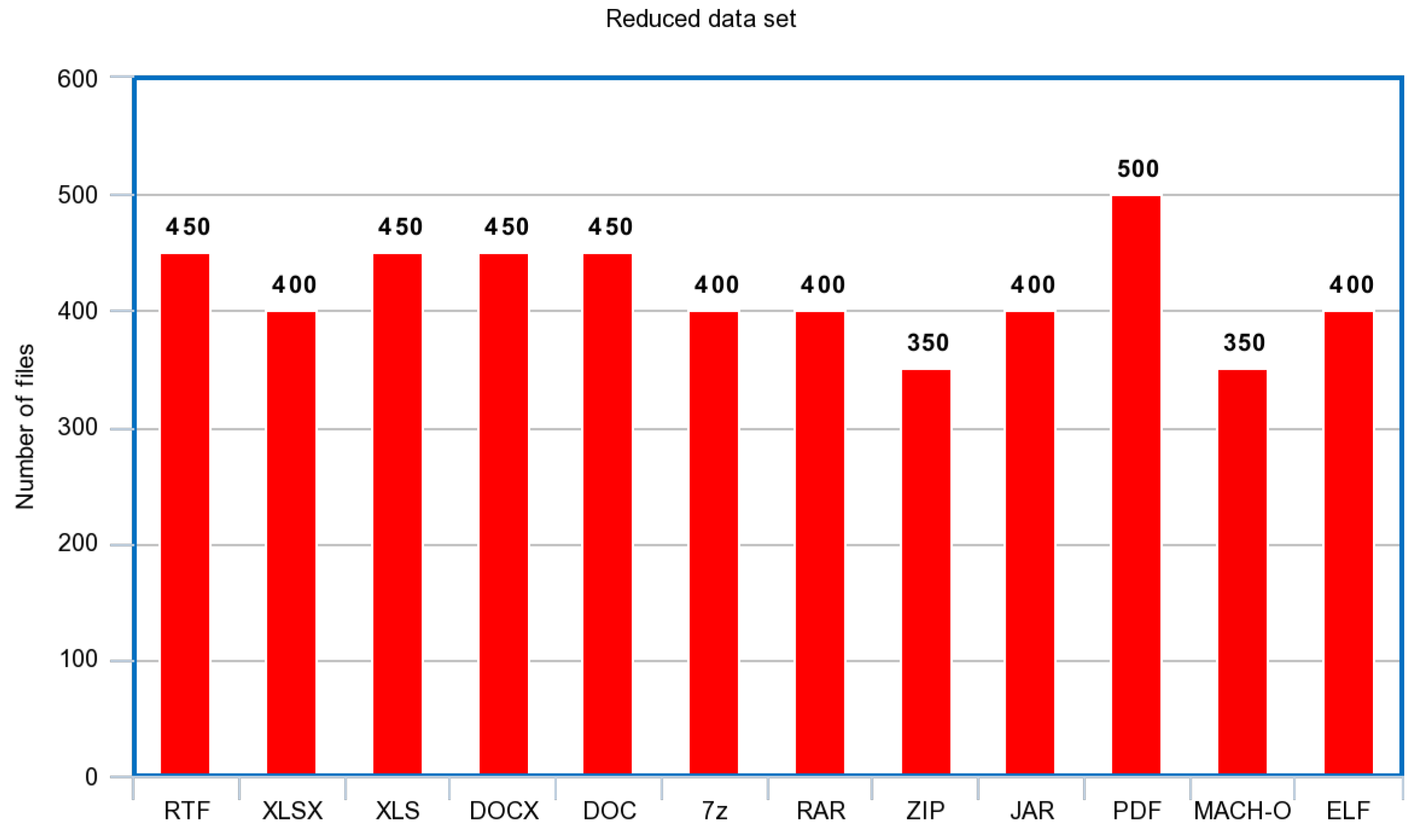
SAGMAD is a novel method based on the code provided by BinVis, that tries to intelligently capture byte sequence patterns through different tones of colour values. This is achieved by introducing the concept of colour tone to the already used colour value-as-per-class assignment.
According to our method, the colour tone of each byte is determined by the class types of its adjacent bytes. As previously discussed, BinVis assigns a colour value to each byte based on its ASCII value representation. In the case of SAGMAD, the colour assignment process remains the same, except that the algorithm is now evaluating a particular number of bytes that lay before and after the newly coloured pixel. It is worth noting that the algorithm sees the set of bytes arriving before the current byte and the set of bytes coming after it as two separate sets. It then continues by measuring the similarity of each collection to the current byte, with each similarity value contributing to its colour tone using fuzzy-based rules. In each case, the comparison of adjacent bytes is presented through the positioning of the array and before the space-filling clustering procedure is applied.
Essentially, SAGMAD adjusts the colour tone for each byte concerning whether n bytes located on either side of it belong to the same class, and assigns this value as a colour tint or shade. While BinVis tries to reveal patterns in code by visualising the byte class, the goal of SAGMAD is to make those areas stand out and facilitate image processing models. This is concerned with the fact that benign files appear to have a homogeneous distribution of printable (blue) and extended (red) ASCII characters, whereas malicious files present clustered areas of null (black) and orange (green) characters. In this way, broad homogeneous areas have their colour standards toned down, while “islands” of the malicious areas become more visible by becoming darker. With SAGMAD, each byte is currently affected by both its type and its environment.
To equate the set of bytes placed next (left or right-separate) to the byte to which we are assigning colour value and tone, we add the concept of similarity. We define the similarity as the ratio of the number of bytes within this set (left or right) that belong to the same class as the byte that we are currently interested in, over the total number of n bytes in the set.
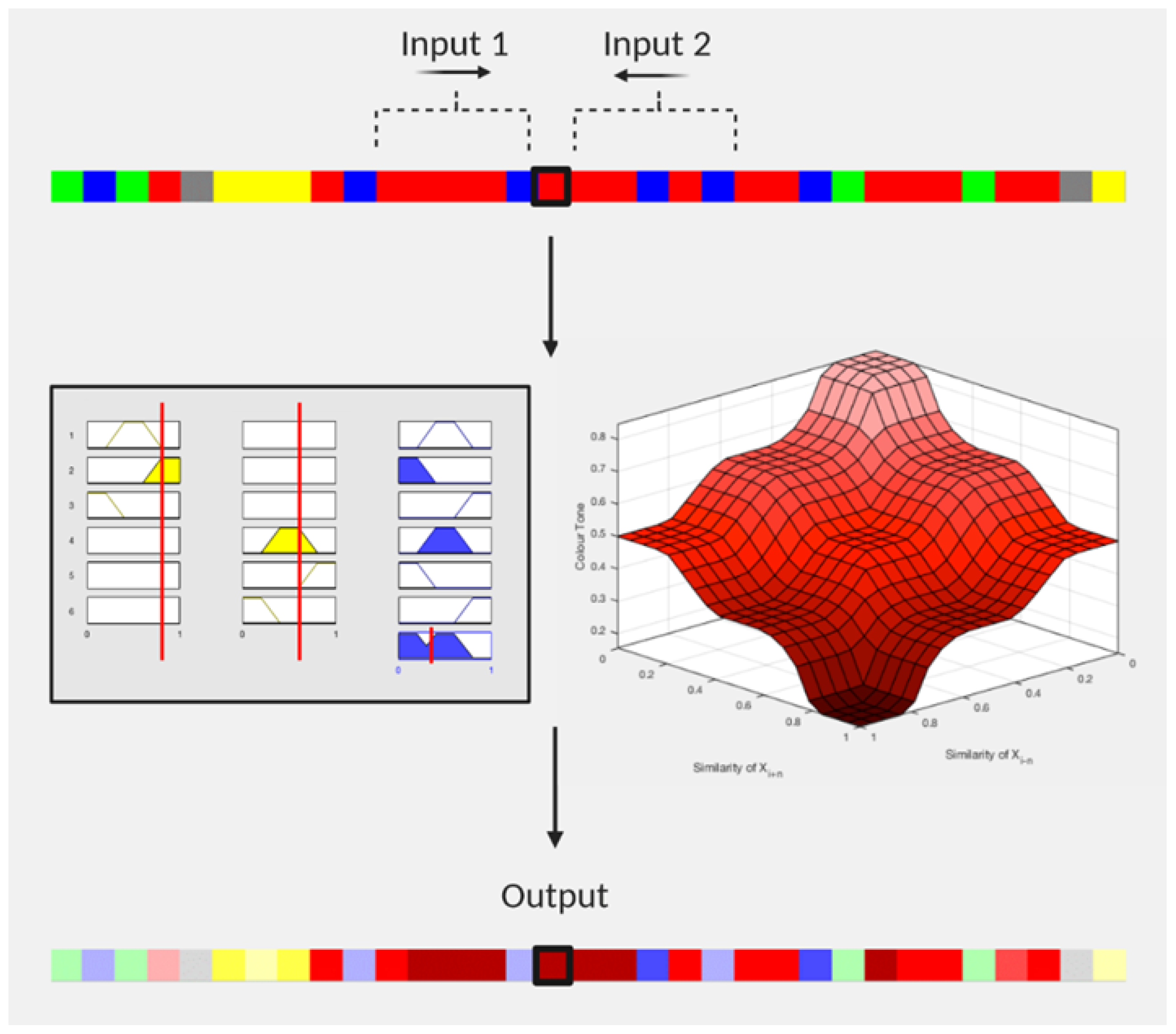
As illustrated in
Figure 2, let us assume that we are involved in assigning colour value and tone to byte
, which is an extended ASCII character, and for which we consider five adjacent bytes per side, i.e.,
. The byte is first given the red colour value and we begin to analyse the five bytes on each side to have its colour tone adjusted. On the left side, we find that four bytes out of the five are extended ASCII characters too, or, in other words, they belong in the “red” byte class as well, and calculate the similarity as
(left similarity). In the same sense, we move on to the right side, counting once again the number of bytes that belong to the same class, and we find that three out of the five bytes are also in the red category. Hence, we measure a similarity of
(right similarity). The two similarities are then given as inputs into a fuzzy inference system (FIS) where the colour tone is given as an output value of 0.35. As a result, the red (extended) character darkens because it resembles its environment. We should note that in the case of zero bytes belonging in the same byte class, the similarity would be 0. Accordingly, if all five bytes were in the “red” byte sequence, the similarity would be 1. It is a given that the colour adjustment of a red character will be within the red colour spectrum. The 3D shape in
Figure 2 represents the whole spectrum of the potential red colour tones, ranging from 1 (the most pale) to 0 (the darkest) according to the membership functions of the FIS (we define this FIS later). The same reasoning follows the bytes of the example that had their colours toned down. As we observed in our example, we consider two sides per byte so that the tone is influenced by two measures of similarity. The number
n, which specifies the number of objects we consider per collection, is always the same; in other words, we count the same number of bytes on the left and the same number of bytes on the right side of the byte
. Throughout the process, we keep
.
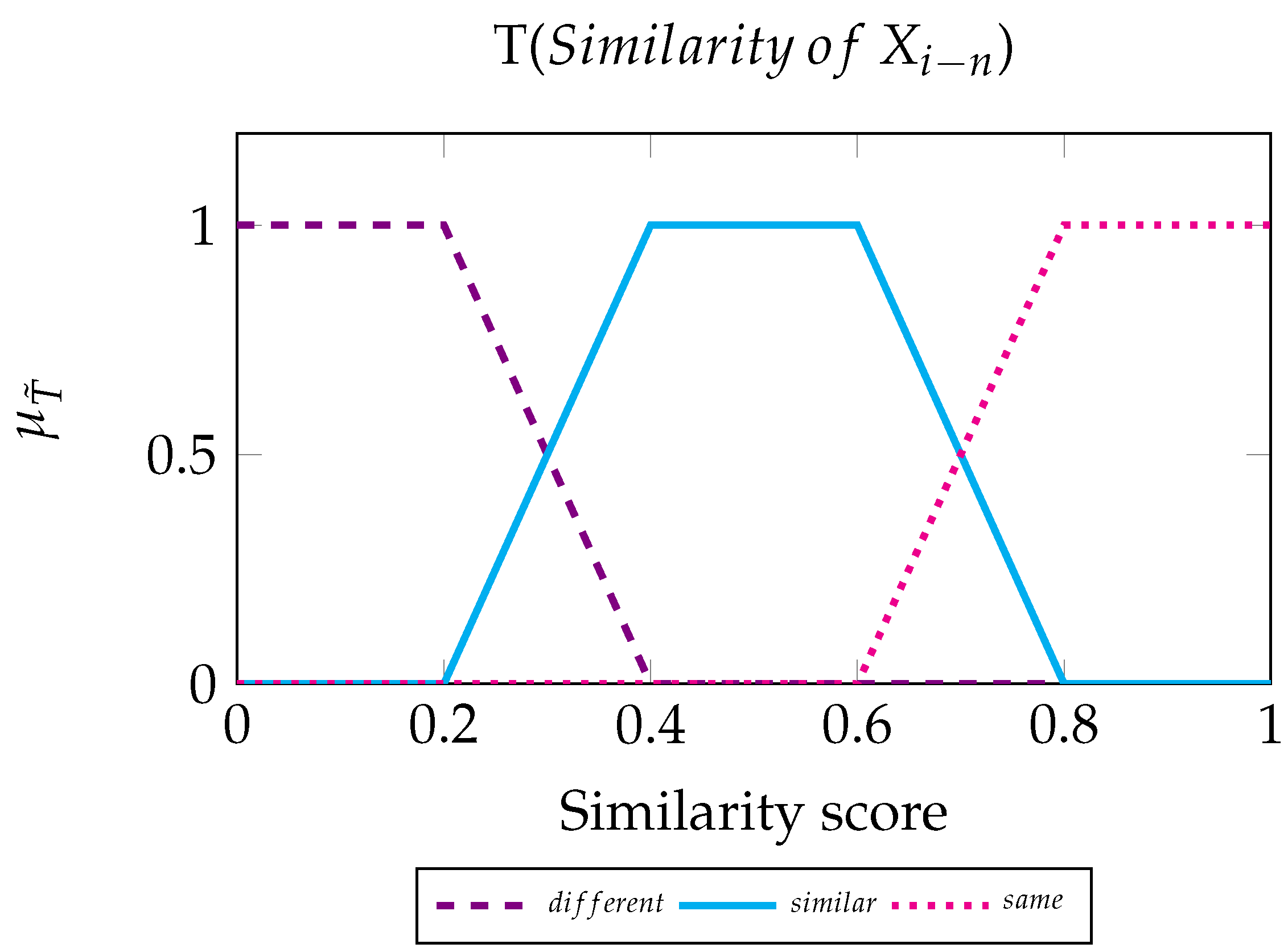
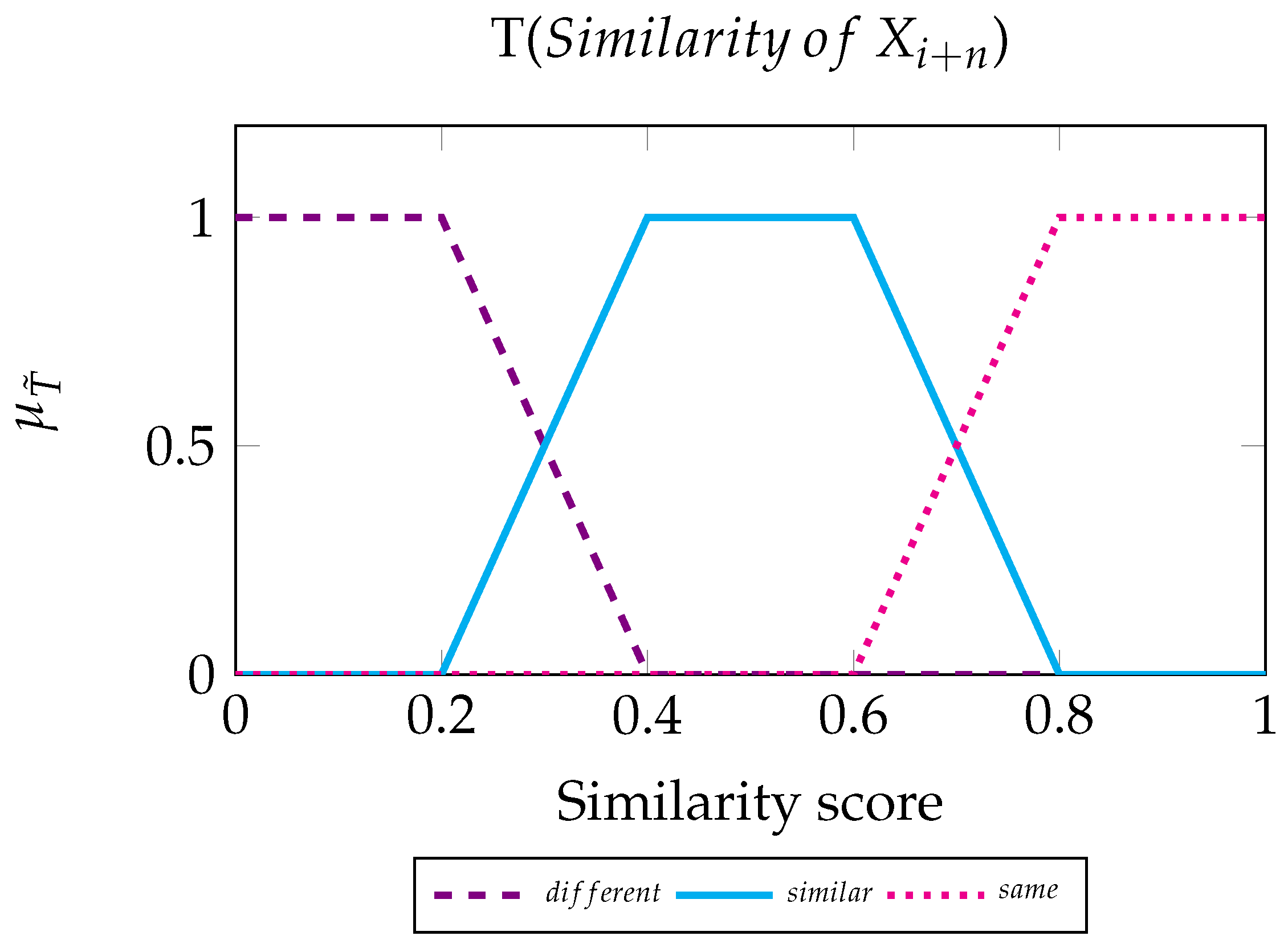
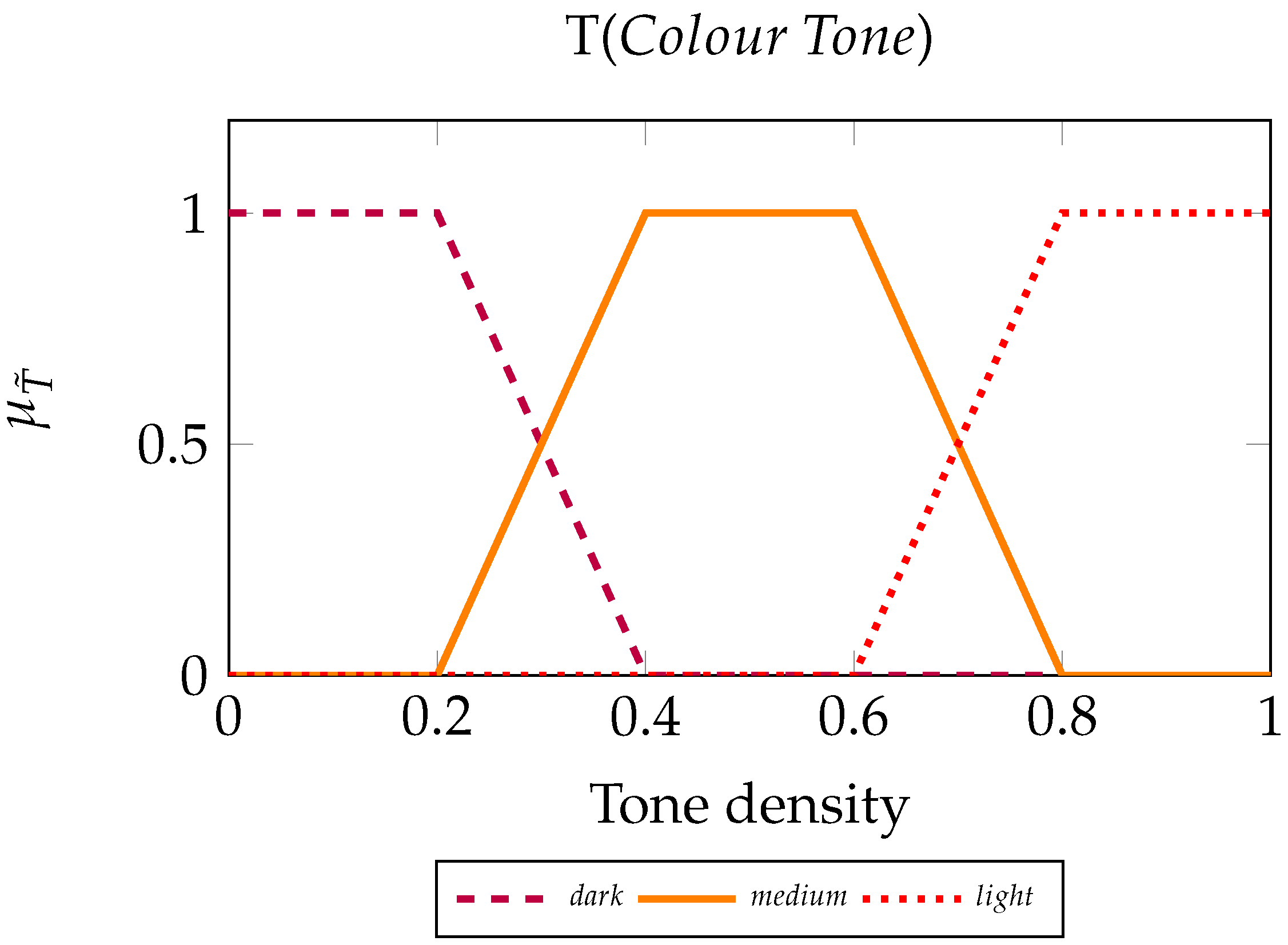
We now define the fuzzy inference system that determines the colour tone of the byte , based on the two similarities that relate to it. For our process, we call the set of bytes on the left and the set of bytes on the right. To create the FIS, we use two input variables and one output variable, which are the linguistic variables of the scheme. We describe a set of values for each linguistic element, the Fuzzy Sets.
Input variable. Linguistic variable values: Different, Similar, and Same.
Input variable. Linguistic variable values: Different, Similar, and Same.
Output variable. Linguistic variable values: Dark, Medium, and Light.
We also define the set of rules, which will constitute the machinery for the FIS.
Fuzzy rules for :
IF Similarity of IS Different THEN Tone is Light.
IF Similarity of IS Similar THEN Tone is Medium.
IF Similarity of IS Same THEN Tone is Dark.
Fuzzy rules for :
IF Similarity of IS Different THEN Tone is Light.
IF Similarity of IS Similar THEN Tone is Medium.
IF Similarity of IS Same THEN Tone is Dark.
Essentially, by employing an FIS, we measure how much each similarity contributes to the tone of byte . For instance, by examining how red byte should be, we ask what the degrees of truth are that byte belongs to the fuzzy sets Light, Medium, and Dark. As it was demonstrated in our example, the more a byte is surrounded by red class bytes, the darker it becomes. Similarly, bytes that find their surroundings dissimilar to them adopt pale tones.
To achieve the colour tone modification numerically, we pair the HSL (or Hue, Saturation, Lightness) colour model, firstly introduced in [
80], along with the RGB model; we first keep the assigned RGB values intact as described in
Section 3.2 to represent colors in their purest form. We then use HSL’s Lightness
to express the output FIS variable Colour Tone, without modifying Hue or Saturation. Shifting Lightness values towards 0 or 1, shifts a colour towards fully black or fully white, respectively.
Finally, for the formulation of the input/output mappings, we choose to apply the more intuitive Type-1 Mamdani FIS with the
implication and
aggregation methods. Then, to compute the output crisp value
we use the centroid defuzzification method, given by:
where
is the membership value for point
in the universe of discourse
U.
3.9. Machine Learning Metrics
To evaluate the contribution of SAGMAD towards accurate predictions of malicious patterns in unknown files, we will run the same machine learning algorithms that have been used in BinVis applications. The details of these experiments are discussed in
Section 3.10.
As in all mathematical learning methodologies, some output indicators help to determine the robustness of the model. At the same time, when we want to assess SAGMAD using the best-performing machine learning techniques of previous research projects, we can also evaluate the findings using the same criteria to allow for a similar comparison.
For this purpose, we employ the accuracy, precision, recall, and F-score functions. To explain what these terms stand for, we first need to describe the individual values that make them, namely the True Positive (), True Negative (), False Positive (), and False Negative () measures:
TP is equivalent to all elements of a class that the algorithm correctly predicted to belong in that class. In other words, it is the number of malicious files correctly identified as malicious.
TN is equivalent to all elements outside of a class that the algorithm correctly predicted to belong in a different class. In other words, it is the number of benign files correctly identified as benign.
FP is equivalent to all elements outside of a class that the algorithm has incorrectly predicted to belong in that class. In other words, it is the number of benign files incorrectly identified as malicious.
FN is equivalent to all elements of a class that the algorithm has incorrectly predicted to belong in a different class. In other words, it is the number of malicious files incorrectly identified as benign.
Next, we define the , , , and metrics:
Accuracy is the ratio of instances that were correctly predicted, or the ratio of the total hits (malicious and benign) of the algorithm. We provide the formula as:
Precision is the proportion of correct predictions of malicious cases over the total amount of predicted malicious cases, or the ratio of actual malicious cases from all cases predicted as malicious. We provide the formula as:
Recall is the proportion of correct predictions of malicious cases over the total amount of malicious cases, or the percentage of malicious cases detected. We provide the formula as:
F-score is the harmonic mean between precision and recall, and is indicative of the accuracy and robustness of the model. We provide the formula as:
3.10. Comparison with Previous Applications Based on BinVis
To properly analyse the efficiency of SAGMAD over the original BinVis tool, we need to do a comparative analysis against current BinVis methods. These experiments were originally mentioned in
Section 2. In their approach, the authors [
40,
41,
43,
44] used the BinVis algorithm to generate images which are used as input to the objective of feature classification. Their aim was to conduct either malware/benign filetype classification [
40], malware family classification [
41], or malware/benign IoT traffic classification [
43,
44].
In the next paragraphs, we will briefly present their top-performing solutions and explain the technical aspects of their approaches. This research will serve as the basic model requirements when comparing the classification output of the images provided by BinVis and SAGMAD.
3.10.1. Baptista et al.’s Experiment
Image classification through machine learning methods is a powerful technique for computers to recognize patterns, especially when paired with neural networks. To perform detection of malicious activity among various file types, Ref. [
40] employed a self organising incremental neural network (SOINN), a sophisticated neural network that uses only two layers. SOINN, which was initially proposed in [
91], adopts a minimalist approach that keeps computational costs at a minimum without undermining its ability to perform successful pattern recognition. The two layers focus on mapping a topological structure of the input data competitively while taking on different tasks. The first layer estimates the density distribution of the input vector by selecting a first and a second winner, and builds an undirected graph representation that is continuously being improved. The second layer can detect the different clusters by looking at the low-density areas between them. Many improved methods of SOINN have been proposed since its conception.
Regarding the construction of the feature vector, Ref. [
40] recognised the spatial distribution of malicious patterns in specific parts of the binary representation of a file, particularly on the top and the bottom of the image, and divided the clustered image into four parts; top, bottom, upper and lower middle. This was particularly important since they included multiple malware types within the infected files of their data set. In the feature vector, each of these areas was represented by a vector of length 256 to denote the histogram of the RGB colour space. Regional feature vectors were then put together following the corresponding order of the regions in the image, resulting in a feature vector of length 1024. It should be noted that while SOINN is a robust algorithm for unsupervised learning, parameterisation should be handled with care. Ref. [
40] was able to achieve an accuracy of 73.7% with 12% false positives and 14% false negatives for the overall malicious/benign file detection, with parameters lambda
= 290 (number of iterations) and max. age
A = 170 (age of communicating nodes). For this experiment, the rectangle-shaped image of the
scurve module was used.
3.10.2. O’Shaughnessy’s Experiment
Ref. [
41] recognized the need for AV programs to perform malware family classification, and employed computer vision techniques to provide a scalable solution. For this reason, he performed data conversion while experimenting with three factors of the image conversion and classification process: a variety of space-filling curves, different feature extraction techniques, and various statistical learning models. Ref. [
41] was the only one to try multiple space-filling curves offered by the
scurve module, other than the more widely used Hilbert curve; namely the Z-order, Gray-code, and the Hilbert curve mappings were employed, offering different representations for the same malicious file contents. Images were then given as input to models using the local binary patterns (LBP), Gabor filters and histogram of gradients (HOG). After malware family names were paired with the appropriate feature vector, Ref. [
41] tested three supervised machine learning algorithms, namely k-nearest neighbours (KNN), random forest (RF), and decision trees (DT).
Parameterisation has performed automatically for each model with the help of a Python module to evaluate the best parameter values. Out of all possible combinations, the best performing process proved to be the KNN-HOG Z-order model. The HOG method requires the tuning of various parameters, for which the author determined the best performance under orientation = 16, pixels-per-cell = 60 and cells-per-block = 1. To deal with changes in colour intensity, the L2-Hys normalisation was performed. Moving to KNN parameters, the number of neighbours was chosen to be k = 1, and the distance metric was the “cityblock” function. During the testing of the KNN-HOG Z-order method on unseen data, the model generalized well, with 82% precision, 80% recall, and 83% accuracy scores. It is important to note that for this experiment, the square-shaped image of the scurve module was used.
3.10.3. Shire et al.’s Experiment
IoT network traffic was monitored and cut in chunks by [
43] in an attempt to identify potential malware traffic from smart devices. Network traffic was collected in the form of .pcap files, which were then converted into 2D binary visualisations. The overall idea of the experiment was to test the model on various malicious network traffic scenarios, such as DDoS, botnet, trojan horse traffic, alongside normal traffic, and test if binary visualization was a promising solution on the getaway level of connected devices.
In this problem, the researchers chose convolutional neural networks (CNN) as the primary detection algorithm. More specifically, they used Tensorflow’s MobileNet module, where the data were trained for 500 batches. The PCAP files were inserted into the CNN by dividing each image into smaller tiles.
In the test that used the largest number of samples, they were able to achieve the highest values for the following metrics: 91.32% accuracy, 91.67% precision, 91.03% recall, and 91.35% F-score. In this experiment, the researchers performed their method on the rectangular layout of the scurve module.
3.10.4. Bendiab at al.’s Experiment
Continuing the works of [
40,
43,
44], the use of deep learning for classifying malicious/benign network traffic was proposed. Their best performing experiment employed the ResNet50 model, a CNN with 50 layers.
Their method tested 2D images of IoT traffic that represented a plethora of common attacks, such as DDoS, key loggers, back doors, and OS scans. For the training, the researchers iterated the model for 50 epochs with a batch size of six. They also incorporated the LRFinder function, a Python module that investigates the performance and finds the optimal parameters. According to this experimentation, they used a learning rate of 0.05.
Overall, deep learning outperformed previous efforts for classification; the experiment achieved 94.5% accuracy, 95.78% precision, 94.02% recall, and an F-score of 94.9%. Ref. [
44] used the rectangular-shaped form to construct the image samples.
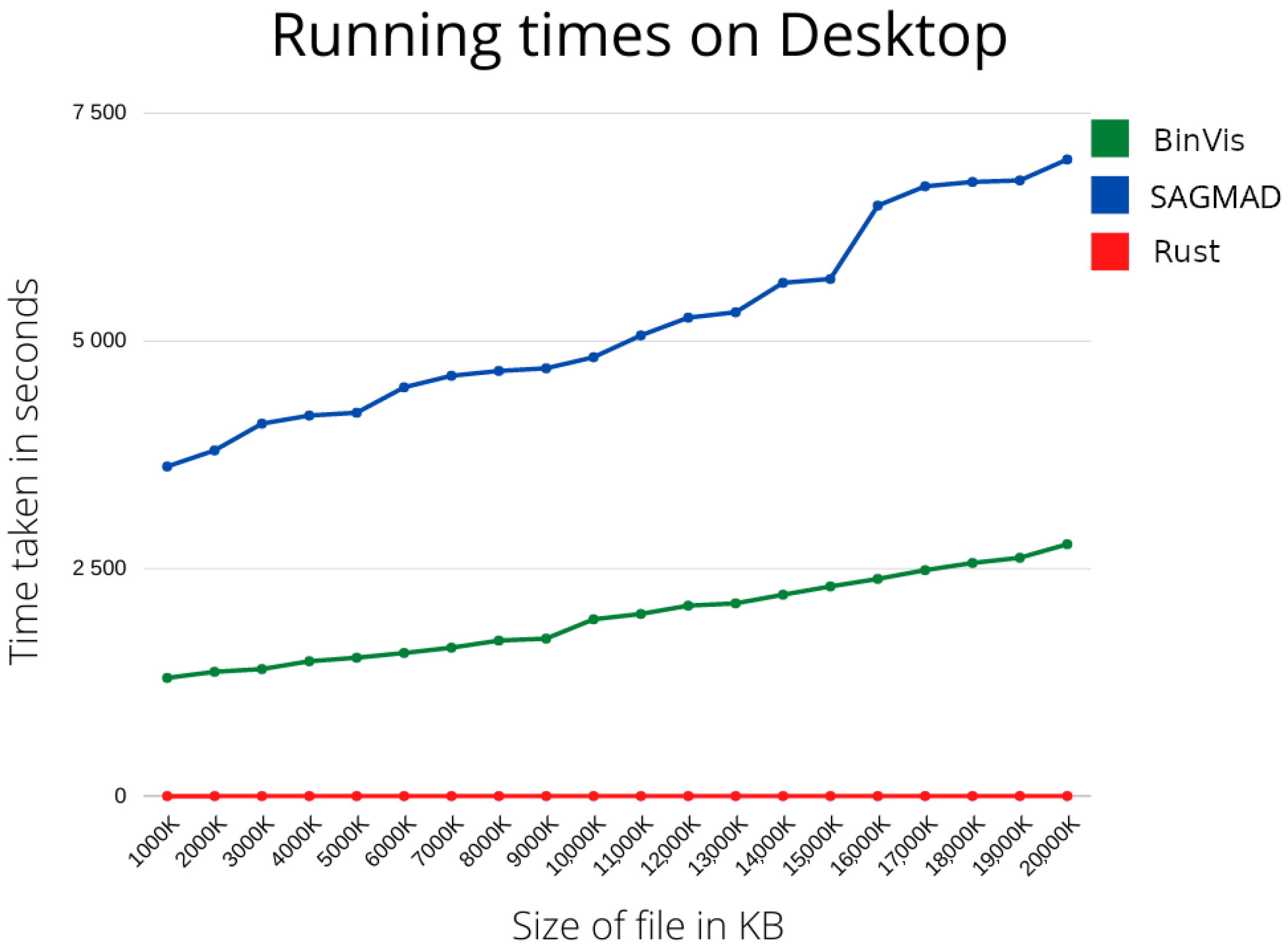
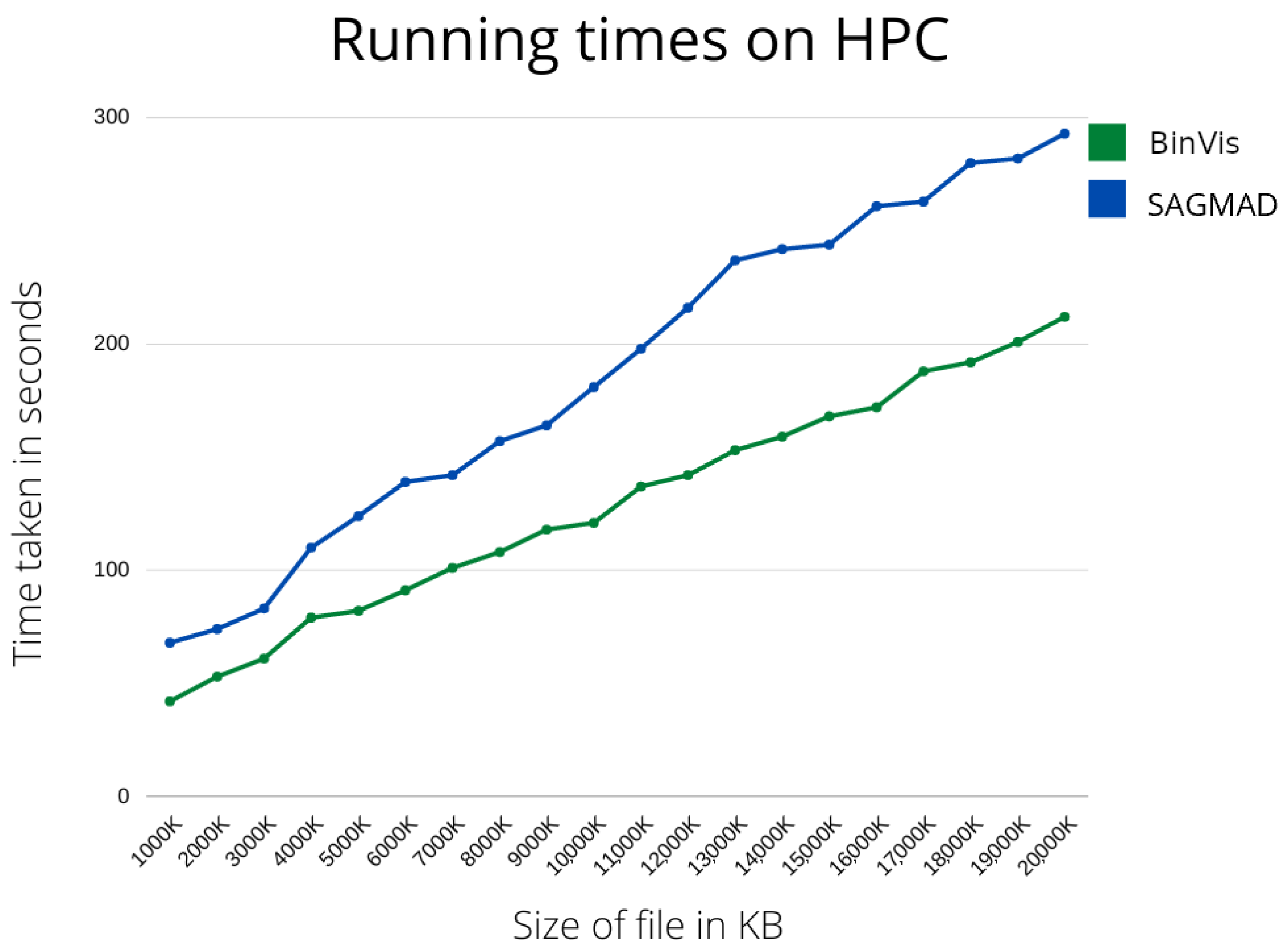
As previously stated, the main focus of our research has been the construction of a real-time malware detection system. In the next section, we are going to present the running times of our method and of the original package tested in different environments, as well as machine learning metrics to allow comparison with existing methods.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











