
Electricity Consumption Prediction in an Electronic System Using Artificial Neural Networks


Abstract
1. Introduction
- Seasonal models are developed to predict amount of consumed energy based on measured hourly-based consumption data provided for this purpose from a cold storage facility in Serbia;
- Data analysis is performed in order to select the inputs to different network structures;
- Several performance indicators are used to estimate performances of the proposed models. Based on these criteria, the best models are chosen.
2. Data and Methods
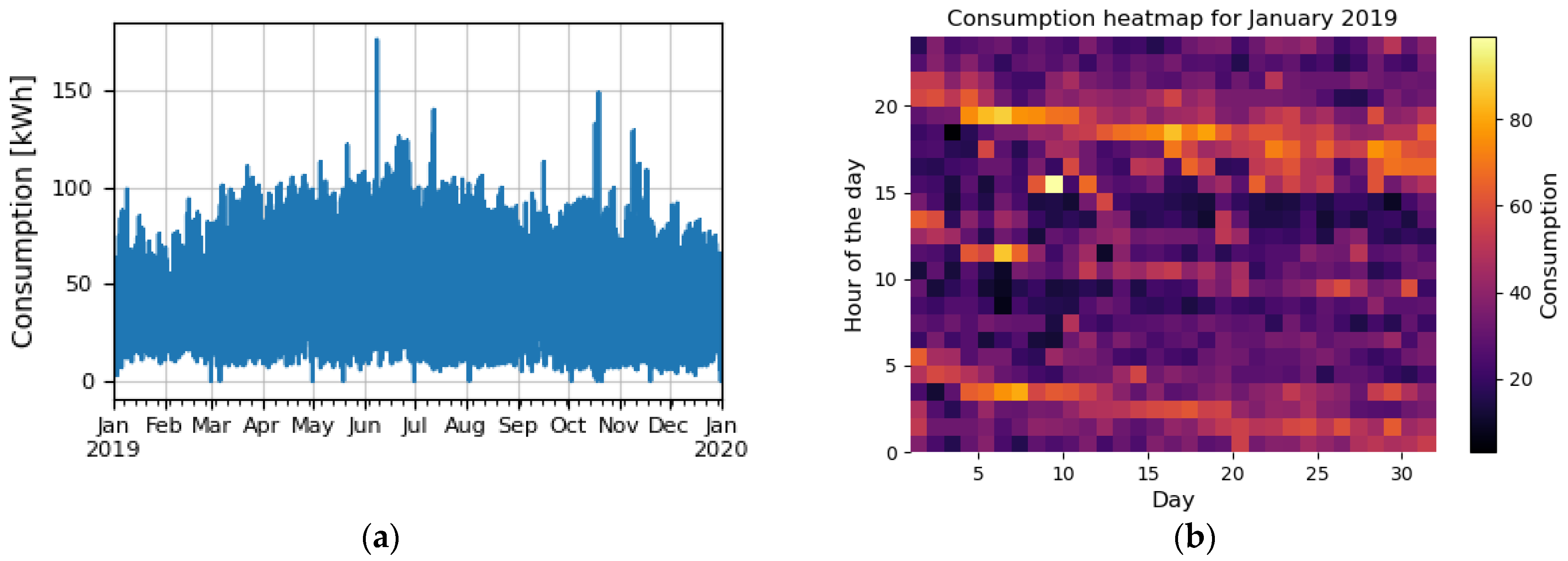
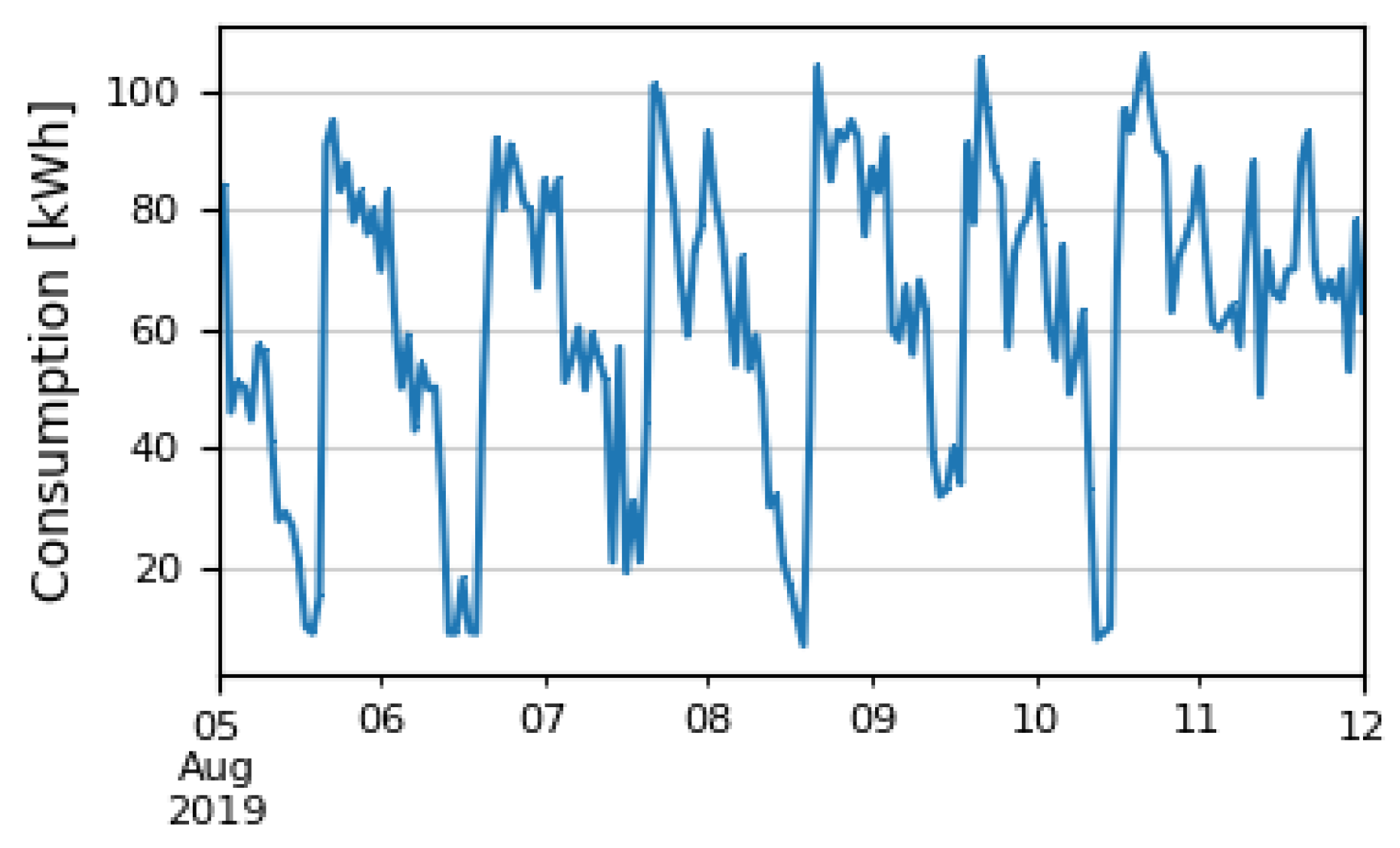
2.1. Consumption Dataset
2.2. Anomalies in Dataset
2.3. Preparation of Data for Training and Testing
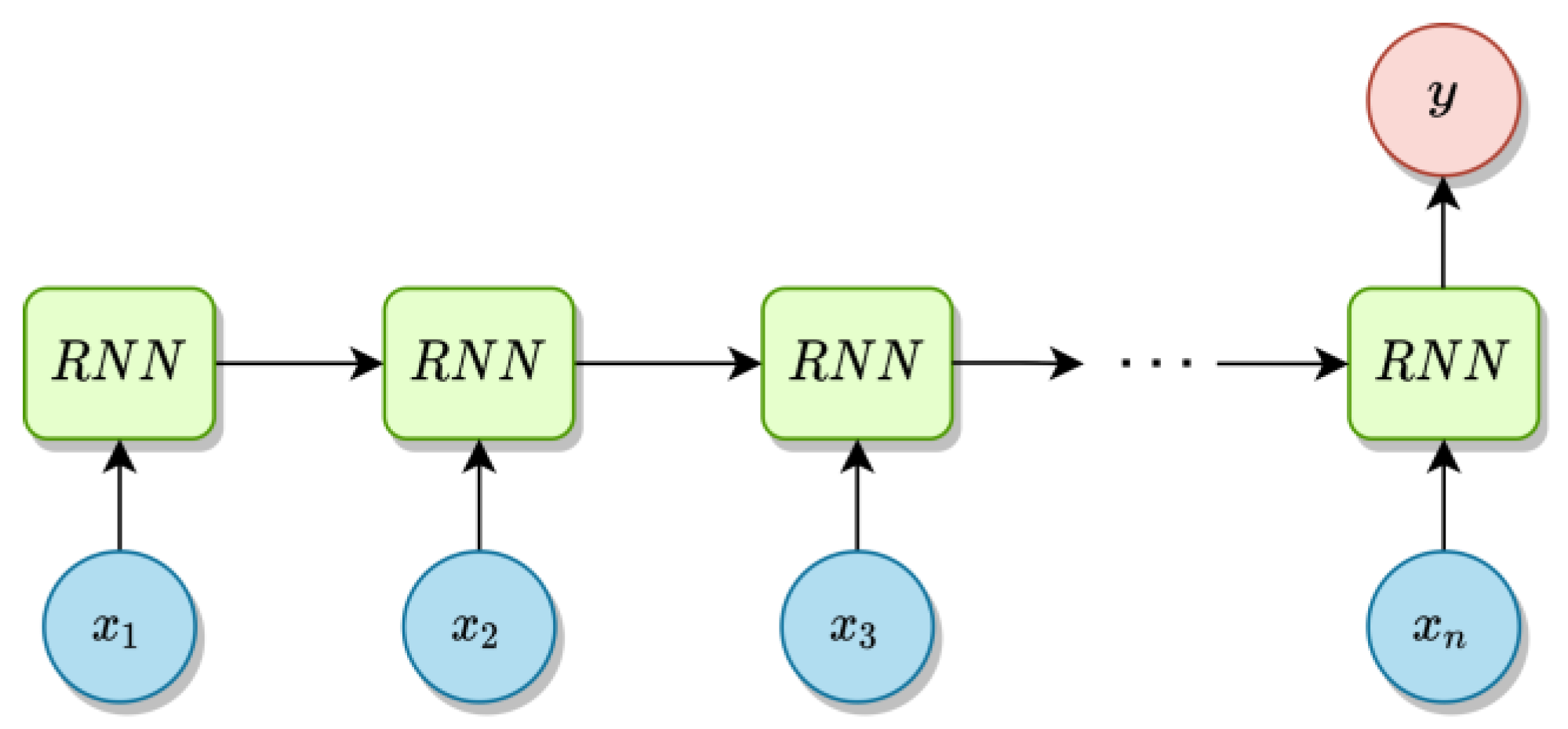
3. Choosing an Optimal ANN Structure
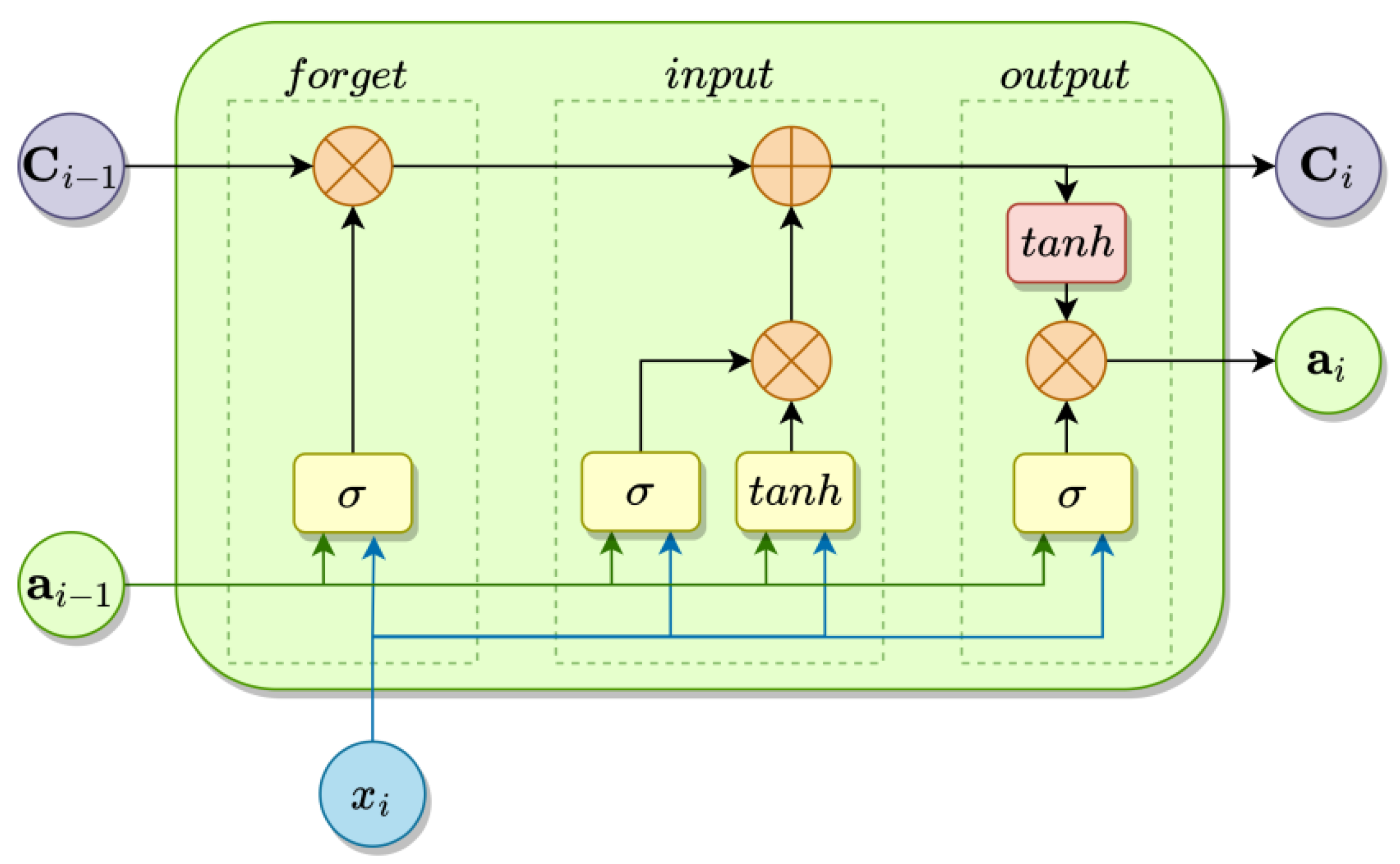
3.1. LSTM Structure
- (1)
- The forget gate is formed from a layer of neurons with a sigmoid activation function, so the activations of these neurons can have values between 0 and 1. The activations of the neurons are multiplied by the corresponding data in the array of cell states. If the activation is approximately 0, then the corresponding data from the cell state will be deleted, and if it is approximately 1, then the data will be kept.
- (2)
- The input gate examines whether some new information can be obtained from the current input and then whether this information is important for the state of the cells, i.e., if it should be added or ignored. The input gate consists of one sigmoid layer and one layer, activation function of which is the hyperbolic tangent. The hyperbolic tangent layer generates the information, and the σ layer decides which parts of the information should be passed to the cell state.
- (3)
- The output gate generates the output of the unit as well as the new internal state using the modified cell state. It consists of a σ layer that is applied to the input and the previous internal state and a layer, the activation of which is chosen as needed, generating the output data.
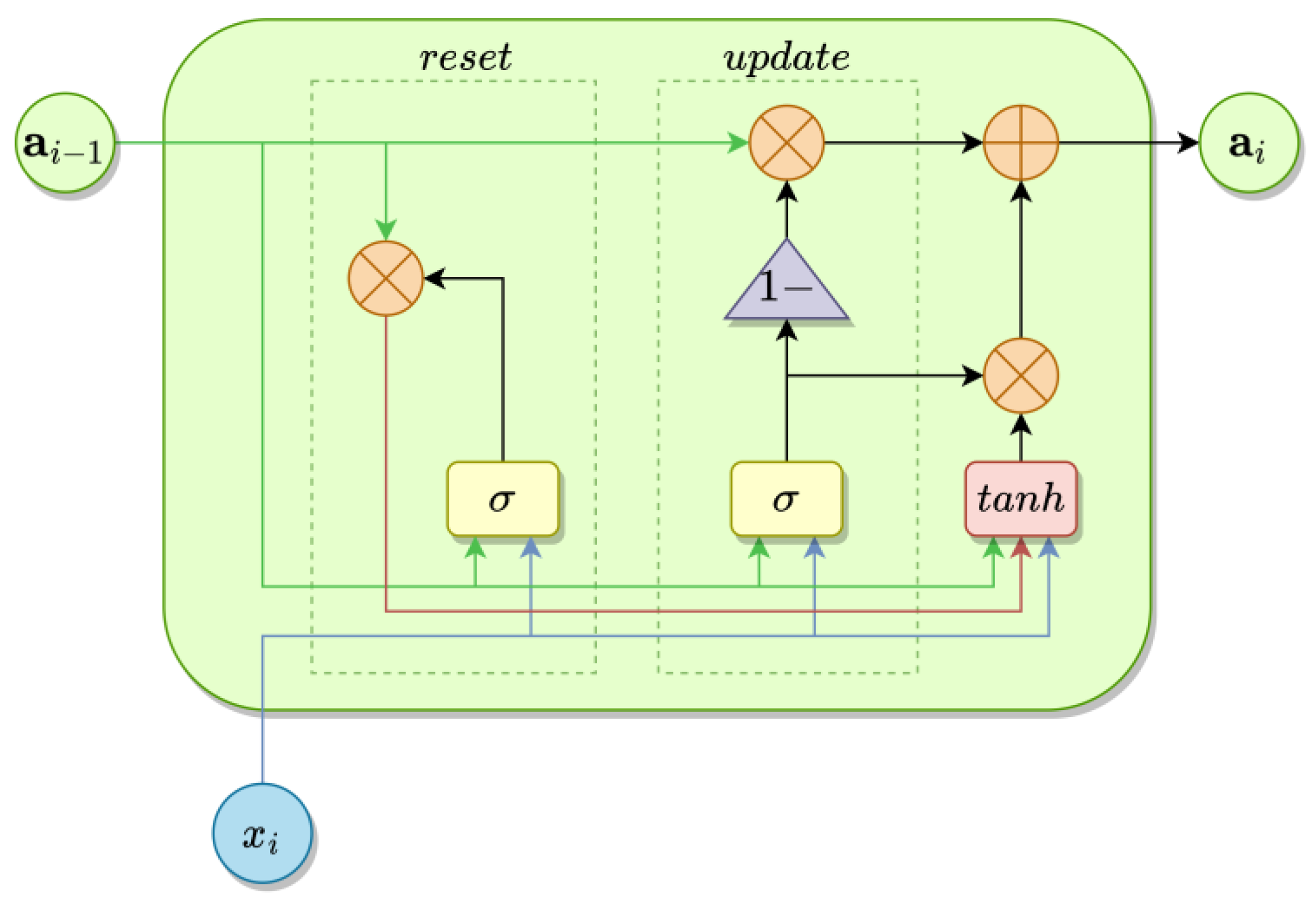
3.2. GRU Structure
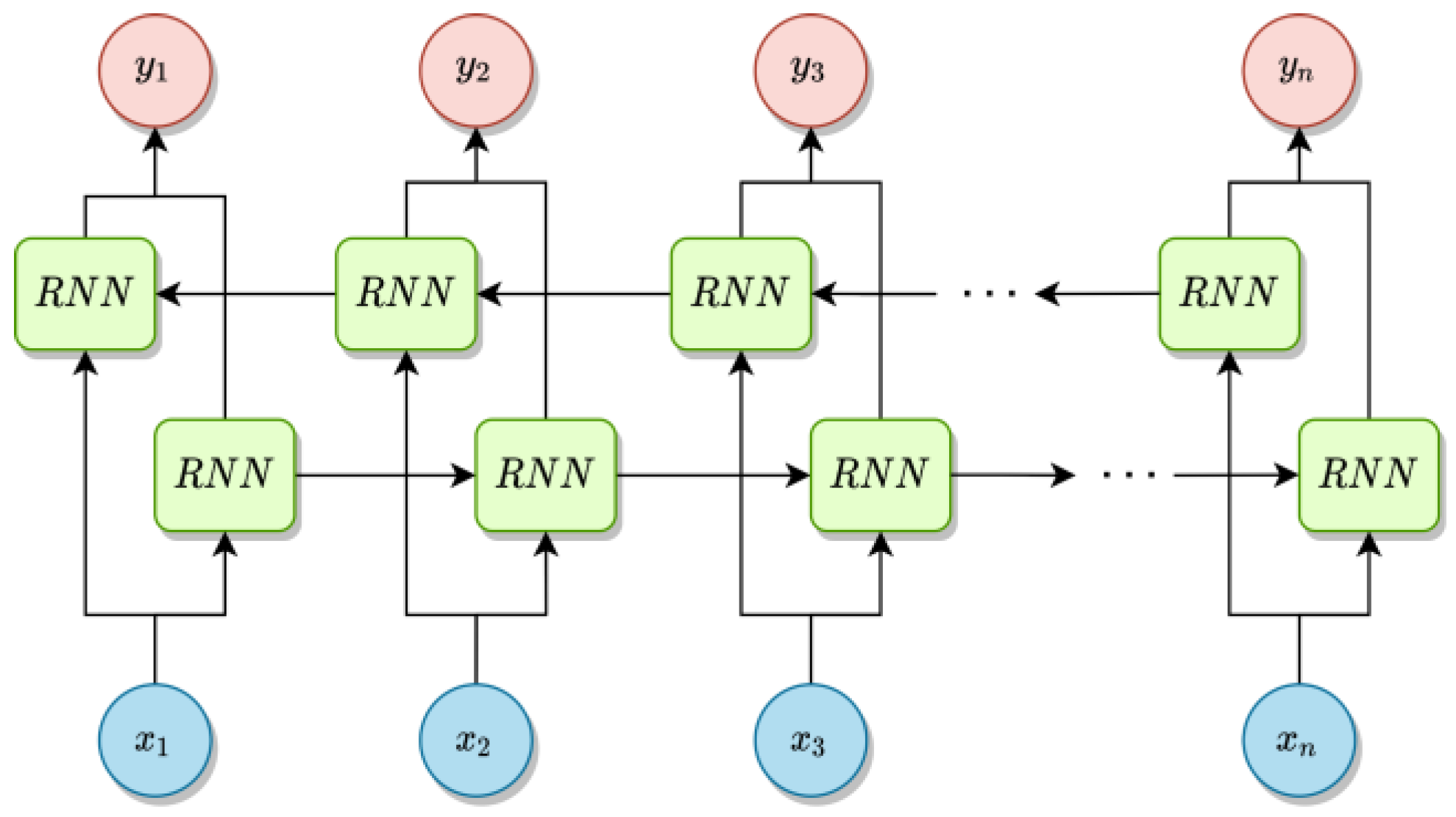
3.3. Bidirectional Recurrent Networks
3.4. Network Hyperparameters
- (1)
- Prediction horizon affects the structure of the network by determining the number of inputs. Different values of the horizon can affect the prediction results in several ways, e.g., it is intuitively felt that the prediction results could be better if the length of the input is 168 h (7 days) than e.g., a horizon of 48 h, since in that case the input data are more varied and there is more information in the memory (e.g., how consumption behaves on weekends);
- (2)
- Number of neurons in all hidden layers;
- (3)
- Number of network training iterations;
- (4)
- Batch size—the number of input vectors that are entered into the network at each iteration;
- (5)
- Method of initialization of the weight coefficients—it is also known that the initial values of the coefficients have a great influence on the optimization of the network, and that in most cases it is not convenient to simply set them to zero. Often, these initial values are randomly determined, for which different probability distribution functions can be used. Different functions can give different results, so several of them can be taken as hyperparameters;
- (6)
- Dropout factor—dropout is a technique that is often used in FF structures, but it can also be successfully applied in recurrent ones. During each training phase of the network, the influence of some neurons is completely ignored—a number of randomly selected neurons are excluded from the network during a training phase, so their weights are not updated. This technique is applied to prevent the problem of overfitting [52].
4. Results
4.1. Hyperparameter Optimization and Cross-Validation
- (1)
- Prediction horizon can be 24 h, 48 h, 96 h, 168 h and 336 h, i.e., one day, two days, four days, one week and two weeks (five values in total);
- (2)
- The number of neurons in the hidden layers is from the set: 80, 120, 160 or 200 (four in total);
- (3)
- Number of training iterations: 100, 150, 200, 250 and 300 (5 in total);
- (4)
- Batch size: 20 (fixed value);
- (5)
- Probability distribution for initialization: uniform, normal, glorot_uniform, lecun_uniform (four in total);
- (6)
- Dropout factor: 0.2 (fixed value).
- (1)
- Full grid search—examines all possible combinations of parameter values. This type of cross-validation is usually performed when there are fewer hyperparameters or simpler networks. However, as the total number of possible combinations for a given case is 400, this technique is not suitable.
- (2)
- Randomized grid search—a fixed number of random combinations are selected, and the best result among them is then selected and good results are given when a large set of hyperparameters is included. For the given case, a randomized grid search was carried out with 8-fold cross-validation for each network type.
4.2. Performance Indices
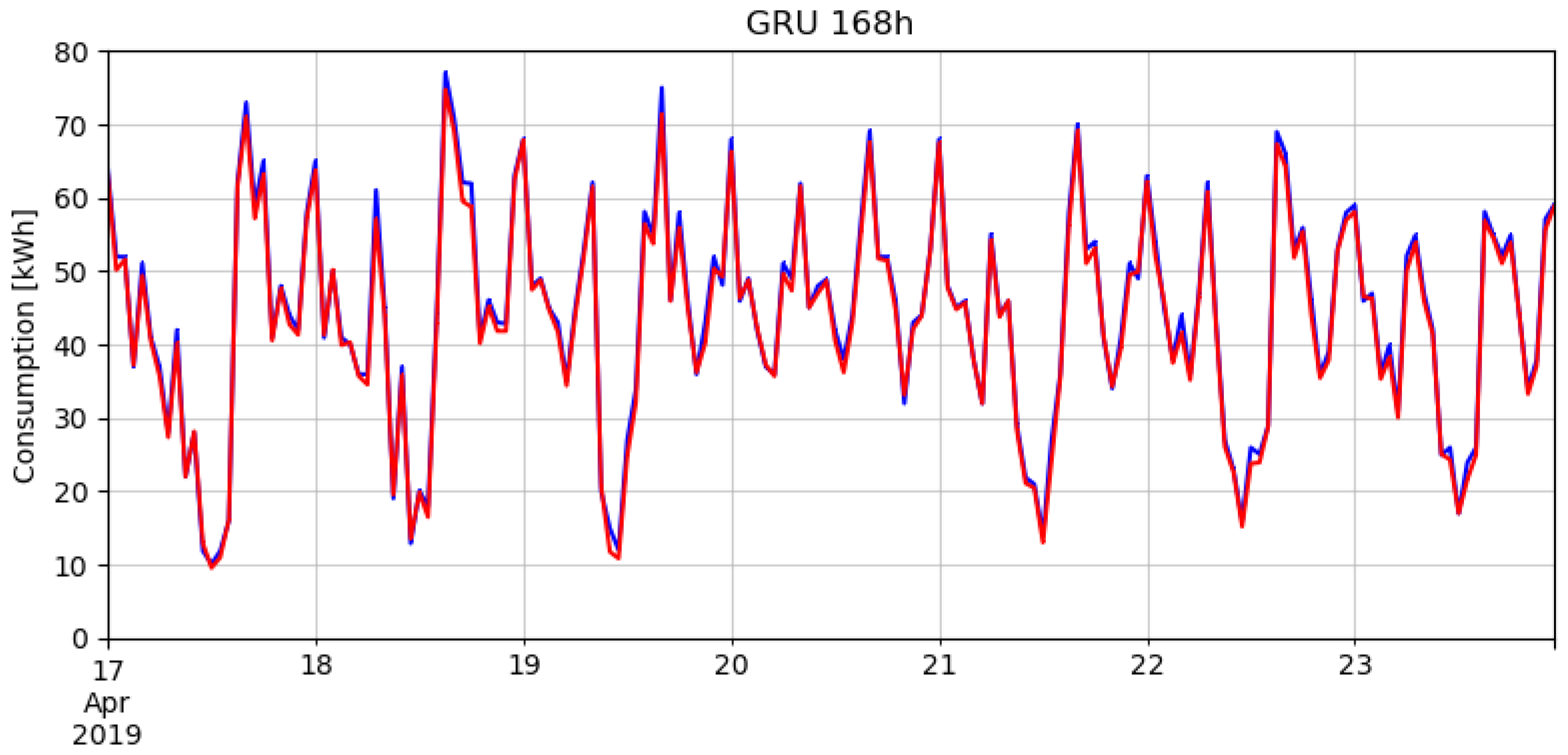
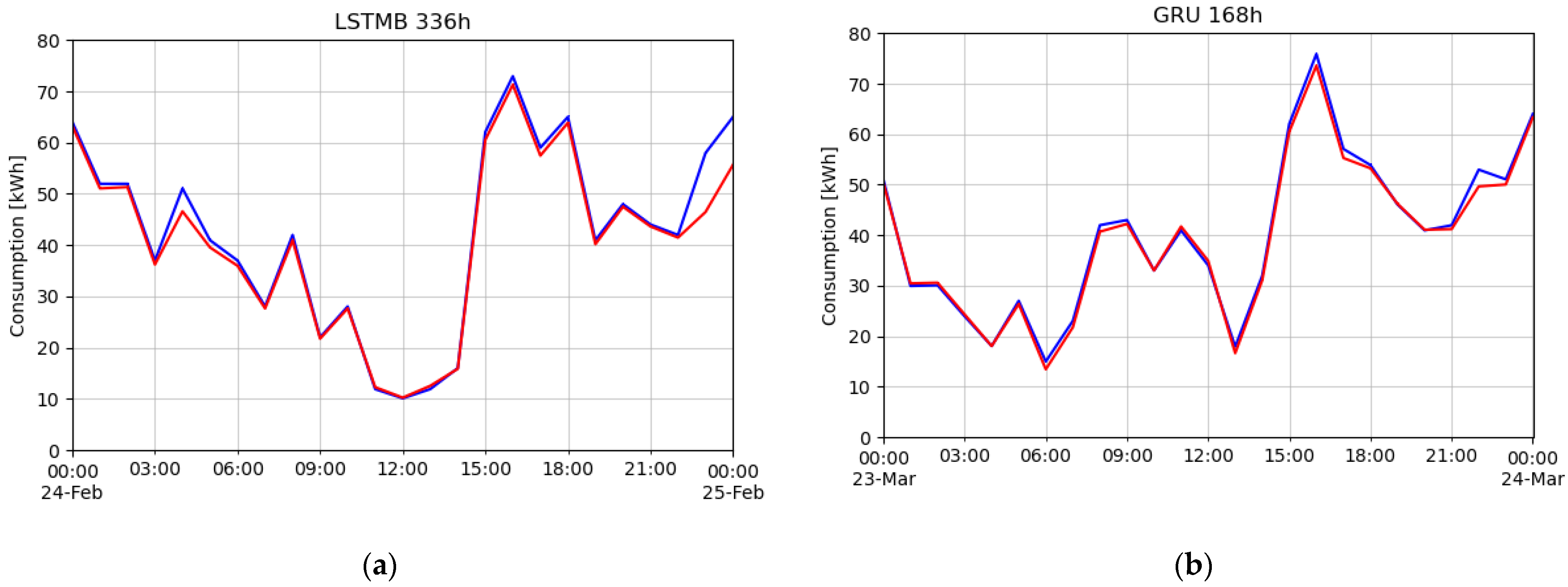
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Nomenclature
| ANN | Artificial Neural Network |
| FF | Feed-forward network |
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory |
| GRU | Gated Recurrent Unit |
| LSTMB | Long Short-Term Memory, Bidirectional |
| GRUB | Gated Recurrent Unit, Bidirectional |
| MAE | Mean Absolute Error |
| MSE | Mean Square Error |
| RMSE | Root Mean Square Error |
| MAPE | Mean Absolute Percentage Error |
| STLF | Short-Term Electrical Load Forecasting |
| TSO | Transmission System Operator |
| ENTSO-E | European Network of Transmission System Operators for Electricity |
| ARMA | Autoregressive Moving Average Model |
| ARIMA | Autoregressive Integrated Moving Average Model |
| k-NN | K-Nearest Neighbor Algorithm |
| SVM | Support Vector Machine |
References
- Pepermans, G. European energy market liberalization: Experiences and challenges. IJEPS 2019, 13, 3–26. [Google Scholar] [CrossRef]
- Rajbhandari, Y.; Marahatta, A.; Ghimire, B.; Shrestha, A.; Gachhadar, A.; Thapa, A.; Chapagain, K.; Korba, P. Impact study of temperature on the time series electricity demand of urban nepal for short-term load forecasting. Appl. Syst. Innov. 2021, 4, 43. [Google Scholar] [CrossRef]
- Javed, U.; Ijaz, K.; Jawad, M.; Ansari, E.A.; Shabbir, N.; Kütt, L.; Husev, O. Exploratory Data Analysis Based Short-Term Electrical Load Forecasting: A Comprehensive Analysis. Energies 2021, 14, 5510. [Google Scholar] [CrossRef]
- Javed, U.; Ijaz, K.; Jawad, M.; Khosa, I.; Ansari, E.A.; Zaidi, K.S.; Rafiq, M.N.; Shabbir, N. A novel short receptive field based dilated causal convolutional network integrated with Bidirectional LSTM for short-term load forecasting. Expert Syst. Appl. 2022, 205, 117689. [Google Scholar] [CrossRef]
- Jawad, M.; Ali, S.M.; Khan, B.; Mehmood, C.A.; Farid, U.; Ullah, Z.; Usman, S.; Fayyaz, A.; Jadoon, J.; Tareen, N.; et al. Genetic algorithm-based non-linear auto-regressive with exogenous inputs neural network short-term and medium-term uncertainty modelling and prediction for electrical load and wind speed. J. Eng. 2018, 2018, 721–729. [Google Scholar] [CrossRef]
- Van der Veen, R.A.C.; Hakvoort, R.A. Balance responsibility and imbalance settlement in Northern Europe—An evaluation. In Proceedings of the 6th International Conference on the European Energy Market, Leuven, Belgium, 27–29 May 2009; pp. 1–6. [Google Scholar]
- van der Veen, R.A.C.; Hakvoort, R.A. The electricity balancing market: Exploring the design challenge. Util. Policy 2016, 43, 186–194. [Google Scholar] [CrossRef]
- ENTSO-E Balancing Report. 2022. Available online: https://eepublicdownloads.blob.core.windows.net/strapi-test-assets/strapi-assets/2022_ENTSO_E_Balancing_Report_Web_2bddb9ad4f.pdf (accessed on 9 October 2022).
- Global Energy Review. 2021. Available online: https://iea.blob.core.windows.net/assets/d0031107-401d-4a2f-a48b-9eed19457335/GlobalEnergyReview2021.pdf (accessed on 7 October 2022).
- Daut, M.A.M.; Hassan, M.Y.; Abdullah, H.; Rahman, H.A.; Abdullah, P.; Hussin, F. Building electrical energy consumption forecasting analysis using conventional and artificial intelligence methods: A review. Renew. Sustain. Energy Rev. 2017, 70, 1108–1118. [Google Scholar] [CrossRef]
- Escrivá-Escrivá, G.; Álvarez-Bel, C.; Roldán-Blay, C.; Alcázar-Ortega, M. New artificial neural network prediction method for electrical consumption forecasting based on building end-uses. Energy Build. 2011, 43, 3112–3119. [Google Scholar] [CrossRef]
- Chen, S.X.; Gooi, H.B.; Wang, M.Q. Solar radiation forecast based on fuzzy logic and neural networks. Renew. Energy 2013, 60, 195–201. [Google Scholar] [CrossRef]
- Nowicka-Zagrajek, J.; Weron, R. Modeling electricity loads in California: ARMA models with hyperbolic noise. Signal Process. 2002, 82, 1903–1915. [Google Scholar] [CrossRef]
- Nichiforov, C.; Stamatescu, I.; Făgărăşan, I.; Stamatescu, G. Energy consumption forecasting using ARIMA and neural network models. In Proceedings of the 2017 5th International Symposium on Electrical and Electronics Engineering (ISEEE), Galati, Romania, 20–22 October 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Khashei, M.; Bijari, M.; Ardali, G.A.R. Improvement of auto-regressive integrated moving average models using fuzzy logic and artificial neural networks (ANNs). Neurocomputing 2009, 72, 956–967. [Google Scholar] [CrossRef]
- Fosso, O.B.; Gjelsvik, A.; Haugstad, A.; Mo, B.; Wangensteen, I. Generation scheduling in a deregulated system. The Norwegian case. IEEE Trans. Power Syst. 1999, 14, 75–81. [Google Scholar] [CrossRef]
- Bianco, V.; Manca, O.; Nardini, S. Electricity consumption forecasting in Italy using linear regression models. Energy 2009, 34, 1413–1421. [Google Scholar] [CrossRef]
- Abdel-Aal, R.E.; Al-Garni, A.Z. Forecasting monthly electric energy consumption in eastern Saudi Arabia using univariate time-series analysis. Energy 1997, 22, 1059–1069. [Google Scholar] [CrossRef]
- Akdi, Y.; Gölveren, E.; Okkaoğlu, Y. Daily electrical energy consumption: Periodicity, harmonic regression method and forecasting. Energy 2020, 191, 116524. [Google Scholar] [CrossRef]
- Gori, F.; Takanen, C. Forecast of energy consumption of industry and household & services in Italy. Int. J. Heat Technol. 2004, 22, 115–121. [Google Scholar]
- Verdejo, H.; Awerkin, A.; Becker, C.; Olguin, G. Statistic linear parametric techniques for residential electric energy demand forecasting. A review and an implementation to Chile. Renew. Sustain. Energy Rev. 2017, 74, 512–521. [Google Scholar] [CrossRef]
- Azadeh, A.; Ghaderi, S.F.; Sohrabkhani, S. Annual electricity consumption forecasting by neural network in high energy consuming industrial sectors. Energy Convers. Manag. 2008, 49, 2272–2278. [Google Scholar] [CrossRef]
- Amber, K.P.; Aslam, M.W.; Hussain, S.K. Electricity consumption forecasting models for administration buildings of the UK higher education sector. Energy Build. 2015, 90, 127–136. [Google Scholar] [CrossRef]
- UGE DOO NIŠ. Available online: https://united-green-energy.ls.rs/rs/ (accessed on 11 September 2022).
- Rahman, A.; Srikumar, V.; Smith, A.D. Predicting electricity consumption for commercial and residential buildings using deep recurrent neural networks. Appl. Energy 2018, 212, 372–385. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Yang, Z.; Feng, H.; Tripathi, S.; Dehmer, M. An Introductory Review of Deep Learning for Prediction Models with Big Data. Front. Artif. Intell. 2020, 3, 4. [Google Scholar] [CrossRef] [PubMed]
- Bontempi, G.; Taieb, S.B.; Le Borgne, Y.A. Machine Learning Strategies for Time Series Forecasting. In Business Intelligence. eBISS 2012. Lecture Notes in Business Information Processing; Aufaure, M.A., Zimányi, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 138. [Google Scholar] [CrossRef]
- Cerqueira, V.; Torgo, L.; Soares, C. Machine Learning vs Statistical Methods for Time Series Forecasting: Size Matters. arXiv 2019, arXiv:1909.13316. [Google Scholar]
- Abu Alfeilat, H.; Hassanat, A.; Lasassmeh, O.; Tarawneh, A.; Alhasanat, M.; Eyal-Salman, H.; Prasath, S. Effects of Distance Measure Choice on K-Nearest Neighbor Classifier Performance: A Review. Big Data 2019, 7, 221–248. [Google Scholar] [CrossRef] [PubMed]
- Tajmouati, S.; Bouazza, E.; Bedoui, A.; Abarda, A.; Dakkoun, M. Applying k-nearest neighbors to time series forecasting: Two new approaches. arXiv 2021, arXiv:2103.14200. [Google Scholar]
- Boubrahimi, S.F.; Ma, R.; Aydin, B.; Hamdi, S.M.; Angryk, R. Scalable kNN Search Approximation for Time Series Data. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 970–975. [Google Scholar] [CrossRef]
- Vrablecová, P.; Ezzeddine, A.B.; Rozinajová, V.; Šárik, S.; Sangaiah, A.K. Smart grid load forecasting using online support vector regression. Comput. Electr. Eng. 2018, 65, 102–117. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Support Vector Regression. In Efficient Learning Machines; Apress: Berkeley, CA, USA, 2015. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Predić, B.; Radosavljević, N.; Stojčić, A. Time Series Analysis: Forecasting Sales Periods in Wholesale Systems. Facta Univ. Ser. Autom. Control Robot. 2019, 18, 177–188. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks and Learning Machines; Pearson, Prentice Hall: Hoboken, NJ, USA, 2008. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Guo, C.; Wu, L. Gated Recurrent Unit with RSSIs from Heterogeneous Network for Mobile Positioning. Mob. Inf. Syst. 2021, 2021, 6679398. [Google Scholar] [CrossRef]
- Madrid, E.A.; Antonio, N. Short-Term Electricity Load Forecasting with Machine Learning. Information 2021, 12, 50. [Google Scholar] [CrossRef]
- Burg, L.; Gürses-Tran, G.; Madlener, R.; Monti, A. Comparative Analysis of Load Forecasting Models for Varying Time Horizons and Load Aggregation Levels. Energies 2021, 14, 7128. [Google Scholar] [CrossRef]
- Grzeszczyk, T.A.; Grzeszczyk, M.K. Justifying Short-Term Load Forecasts Obtained with the Use of Neural Models. Energies 2022, 15, 1852. [Google Scholar] [CrossRef]
- Islam, B.U.; Ahmed, S.F. Short-Term Electrical Load Demand Forecasting Based on LSTM and RNN Deep Neural Networks. Math. Probl. Eng. 2022, 2022, 2316474. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Neural Networks and Deep Learning: A Textbook, 1st ed.; Springer: Cham, Switzerland, 2018; ISBN-13: 978-3319944623. [Google Scholar]
- Mehlig, B. Machine Learning with Neural Networks. 2021. Available online: https://arxiv.org/pdf/1901.05639.pdf (accessed on 10 September 2022).
- Zhou, J.; Cao, Y.; Wang, X.; Li, P.; Xu, W. Deep recurrent models with fast-forward connections for neural machine translation. Trans. Assoc. Comput. Linguist. 2016, 4, 371–383. [Google Scholar] [CrossRef]
- Wang, Y. A new concept using LSTM Neural Networks for dynamic system identification. In Proceedings of the 2017 American Control Conference (ACC), Seattle, WA, USA, 24–26 May 2017; pp. 5324–5329. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Van Houdt, G.; Mosquera, C.; Nápoles, G. A review on the long short-term memory model. Artif. Intell. Rev. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]
- Le, X.-H.; Ho, H.V.; Lee, G.; Jung, S. Application of Long Short-Term Memory (LSTM) Neural Network for Flood Forecasting. Water 2019, 11, 1387. [Google Scholar] [CrossRef]
- Domb Alon, M.M.; Leshem, G. Satellite to Ground Station, Attenuation Prediction for 2.4–72 GHz Using LTSM, an Artificial Recurrent Neural Network Technology. Electronics 2022, 11, 541. [Google Scholar] [CrossRef]
- Liu, X.; Wang, Y.; Wang, X.; Xu, H.; Li, C.; Xin, X. Bi-directional gated recurrent unit neural network based nonlinear equalizer for coherent optical communication system. Opt. Express 2021, 29, 5923–5933. [Google Scholar] [CrossRef] [PubMed]
- Masters, T. Practical Neural Network Recipes in C++; Morgan Kaufmann: Burlington, MA, USA, June 2014; ISBN 9780080514338. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | i | X | Y | ||||||
|---|---|---|---|---|---|---|---|---|---|
| xi−h+1 | xi−h+2 | xi−h+3 | xi−h+4 | xi−h+5 | … | xi | xi+1 | ||
| 1 | h | 36.992 | 52.096 | 48 | 23.936 | 49.024 | … | 64 | 17.024 |
| 2 | h + 1 | 52.096 | 48 | 23.936 | 49.024 | 64 | … | 20.992 | 23.936 |
| 3 | h + 2 | 48 | 23.936 | 49.024 | 64 | 20.992 | … | 29.952 | 32 |
| 4 | h + 3 | 23.936 | 49.024 | 64 | 20.992 | 29.952 | … | 24.064 | 25.984 |
| 5 | h + 4 | 49.024 | 64 | 20.992 | 29.952 | 24.064 | … | 29.952 | 12.032 |
| … | … | … | … | … | … | … | … | … | … |
| n − h + 1 | n | 38.912 | 26.112 | 38.912 | 35.072 | 51.968 | … | 36.096 | 43.008 |
| Network Configuration | Number of Neurons |
|---|---|
| RNN | n2 + 2n |
| LSTM | 4·(n2 + 2n) |
| GRU | 3·(n2 + 2n) |
| Type of Network | Type of Error | 24 | 48 | 96 | 168 | 336 |
|---|---|---|---|---|---|---|
| GRU | MAE | 6.844952 | 6.841905 | 3.703619 | 1.929905 | 0.540190 |
| MAPE | 21.119003 | 20.980362 | 11.788948 | 6.265632 | 1.642816 | |
| MSE | 85.212794 | 99.907096 | 42.190848 | 5.377365 | 0.523995 | |
| RMSE | 9.231078 | 9.995354 | 6.495448 | 2.318915 | 0.723875 | |
| GRUB | MAE | 7.053714 | 6.287238 | 3.299810 | 1.033905 | 0.710095 |
| MAPE | 20.879806 | 19.450597 | 10.642182 | 3.435867 | 2.305570 | |
| MSE | 91.479869 | 93.981355 | 36.013885 | 1.587785 | 0.817835 | |
| RMSE | 9.564511 | 9.694398 | 6.001157 | 1.260073 | 0.904342 | |
| LSTM | MAE | 7.051429 | 6.472381 | 3.657905 | 0.849524 | 1.075810 |
| MAPE | 21.668491 | 19.099335 | 11.680444 | 2.920464 | 2.797340 | |
| MSE | 95.445480 | 105.017637 | 41.434453 | 1.098606 | 1.968030 | |
| RMSE | 9.769620 | 10.247811 | 6.436960 | 1.048144 | 1.402865 | |
| LSTMB | MAE | 6.878476 | 6.359619 | 3.995429 | 0.486095 | 0.561524 |
| MAPE | 20.545295 | 19.292223 | 13.531717 | 1.632134 | 1.615307 | |
| MSE | 89.904469 | 106.552856 | 41.896424 | 0.410185 | 0.485766 | |
| RMSE | 9.481797 | 10.322444 | 6.472745 | 0.640457 | 0.696969 | |
| RNN | MAE | 7.216000 | 7.094857 | 7.650286 | 4.026667 | 3.045333 |
| MAPE | 24.814516 | 22.877283 | 27.742101 | 13.739010 | 9.262036 | |
| MSE | 86.306914 | 84.897012 | 89.222290 | 27.050082 | 13.187267 | |
| RMSE | 9.290151 | 9.213957 | 9.445755 | 5.200969 | 3.631428 |
| Type of Network | Type of Error | 24 | 48 | 96 | 168 | 336 |
|---|---|---|---|---|---|---|
| GRU | MAE | 4.395429 | 2.355048 | 0.968381 | 0.787810 | 0.880000 |
| MAPE | 14.086003 | 7.365128 | 3.077262 | 2.542950 | 2.868073 | |
| MSE | 33.303893 | 10.051096 | 1.451252 | 1.064960 | 1.181111 | |
| RMSE | 5.770953 | 3.170346 | 1.204679 | 1.031969 | 1.086789 | |
| GRUB | MAE | 4.217905 | 1.866667 | 0.972190 | 0.954667 | 1.010286 |
| MAPE | 12.935179 | 6.540375 | 3.187603 | 3.453561 | 3.176468 | |
| MSE | 29.726818 | 7.193746 | 1.555895 | 1.379669 | 1.822525 | |
| RMSE | 5.452231 | 2.682116 | 1.247355 | 1.174593 | 1.350009 | |
| LSTM | MAE | 3.961905 | 1.907810 | 0.937905 | 1.087238 | 0.973714 |
| MAPE | 12.855625 | 6.345050 | 2.983061 | 3.489797 | 3.326173 | |
| MSE | 26.979962 | 6.901955 | 1.440719 | 1.917806 | 1.518641 | |
| RMSE | 5.194224 | 2.627157 | 1.200300 | 1.384849 | 1.232331 | |
| LSTMB | MAE | 3.278476 | 1.664000 | 0.826667 | 0.962286 | 1.334095 |
| MAPE | 10.639239 | 5.633171 | 2.750414 | 3.478291 | 3.561142 | |
| MSE | 17.068520 | 5.215963 | 1.098801 | 1.451057 | 2.993688 | |
| RMSE | 4.131406 | 2.283848 | 1.048237 | 1.204598 | 1.730228 | |
| RNN | MAE | 6.297143 | 5.829333 | 5.846857 | 5.356952 | 3.129905 |
| MAPE | 21.225944 | 20.429040 | 18.677578 | 18.459808 | 10.688008 | |
| MSE | 74.995127 | 57.958302 | 58.096299 | 47.486391 | 16.588800 | |
| RMSE | 8.659973 | 7.613035 | 7.622093 | 6.891037 | 4.072935 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stošović, M.A.; Radivojević, N.; Ivanova, M. Electricity Consumption Prediction in an Electronic System Using Artificial Neural Networks. Electronics 2022, 11, 3506. https://doi.org/10.3390/electronics11213506
Stošović MA, Radivojević N, Ivanova M. Electricity Consumption Prediction in an Electronic System Using Artificial Neural Networks. Electronics. 2022; 11(21):3506. https://doi.org/10.3390/electronics11213506
Chicago/Turabian StyleStošović, Miona Andrejević, Novak Radivojević, and Malinka Ivanova. 2022. "Electricity Consumption Prediction in an Electronic System Using Artificial Neural Networks" Electronics 11, no. 21: 3506. https://doi.org/10.3390/electronics11213506
APA StyleStošović, M. A., Radivojević, N., & Ivanova, M. (2022). Electricity Consumption Prediction in an Electronic System Using Artificial Neural Networks. Electronics, 11(21), 3506. https://doi.org/10.3390/electronics11213506