1. Introduction
The fruit industry is an important part of agriculture [
1]. Fruits are rich in more than a dozen trace elements and a lot of dietary fiber, which are very beneficial nutrients to our health [
2]. The vitamins and dietary fiber in fruits not only provide nutrients, but also promote an increase in beneficial bacteria in the gut [
3].
Wireless sensor networks, as a new kind of modem network, have been widely applied in the agricultural field. Farmers can place combination temperature and soil sensors in their fields so that the wireless sensors can calculate accurate irrigation and fertilization rates. Moreover, the sensor data required for this application are relatively small, and it is sufficient to equip an area of nearly tens of thousands of square meters with one sensor. Therefore, wireless sensor networks are playing an important role in the development of the fruit industry. However, there are many problems in sensor networks, such as those involving dynamic energy management and privacy protection. Many researchers have studied these issues. Ref. [
4] proposed respective dynamic energy management methods. Other researchers have proposed methods to protect the privacy and safety of the transmitters. Ref. [
5] proposed an index-based trust and reputation assessment system (ETRES). Ref. [
6] proposed a malicious node detection trust management scheme based on Dempster–Shafer evidence theory. Ref. [
7] proposed a malicious node detection trust management scheme based on Dempster–Shafer evidence theory. Ref. [
8] proposed a privacy and security framework (PPSF) for IoT-driven smart cities. Refs. [
9,
10] proposed a new scheme for handling MAX/MIN queries in a two-layer sensor network to protect privacy. These all have had positive effects on the fruit industry.
The fruit yield and planting area data for the calendar year in China are shown in
Table 1. As can be seen from the chart, the total output of fruit has been continuously increasing from 2008 to 2016, with the yield increasing from 17.9 tons/ha in 2008 to 21.84 tons/ha in 2016. Although the sown area has not changed much, it is also growing steadily. Fruit quality testing is one of the decisive factors in the development of the fruit trade, so the requirements for fruit quality testing are important. The annual import and export volumes and amounts of data for China are shown in
Table 2.
Based on
Table 1 and
Table 2, we can see that the export volume of fruits in China only accounted for 1.5% of the total output of fruits in 2016. Why did the export volume of fruits not increase significantly? One of the important reasons was that the quality testing of the fruits was not perfect enough to guarantee the high quality of the exported fruits. Therefore, if the quality of the fruits could be guaranteed, the export volume of the fruits would definitely be improved.
The rapid non-destructive testing of the intrinsic quality of fruits not only meets the increasingly diversified needs of Chinese consumers, but also meets the needs of China’s fruit exports. With the continuous improvements in living standards, consumers have not only put forward higher requirements for the shape, color, size, and other appearance factors of fruits, but have also paid greater attention to the taste, smell, quality, and other intrinsic qualities [
11]. This also determines the need for the non-destructive and rapid testing of fruits [
12].
The cherry tomato is one of the most important crops in the world, with a global production rate of 181 million tons of cherry tomatoes in 2019 [
13]. The fruit has an excellent flavor, attractive color, and high lycopene content. It represents to the consumer advantages from nutritional and sensorial points of view [
14]. According to the statistics from the FAO, the world’s total output of tomatoes in 2012 was 1.6179 × 108 t. The yield of tomatoes in China reached 5 × 107 t in 2012, accounting for 31% of the world’s total production [
15]. With this important position in the agricultural field, the quality testing of the cherry tomato has also attracted great attention. The sugar content of cherry tomatoes determines the quality of their growth. However, the conventional detection methods destroy the samples in order to complete the detection. Non-destructively determining the sugar content of cherry tomatoes is always a difficult problem [
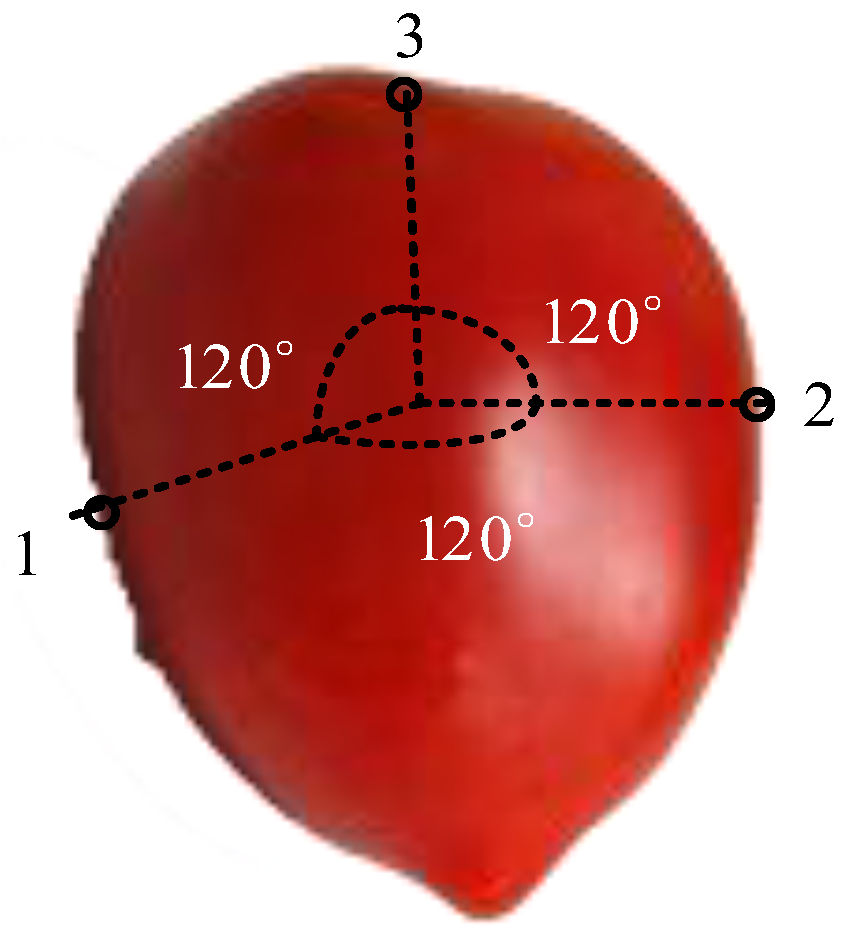
16]. As cherry tomatoes are rich in nutrition, this fruit is very popular. Therefore, this paper took cherry tomatoes as the samples to study the related sections.
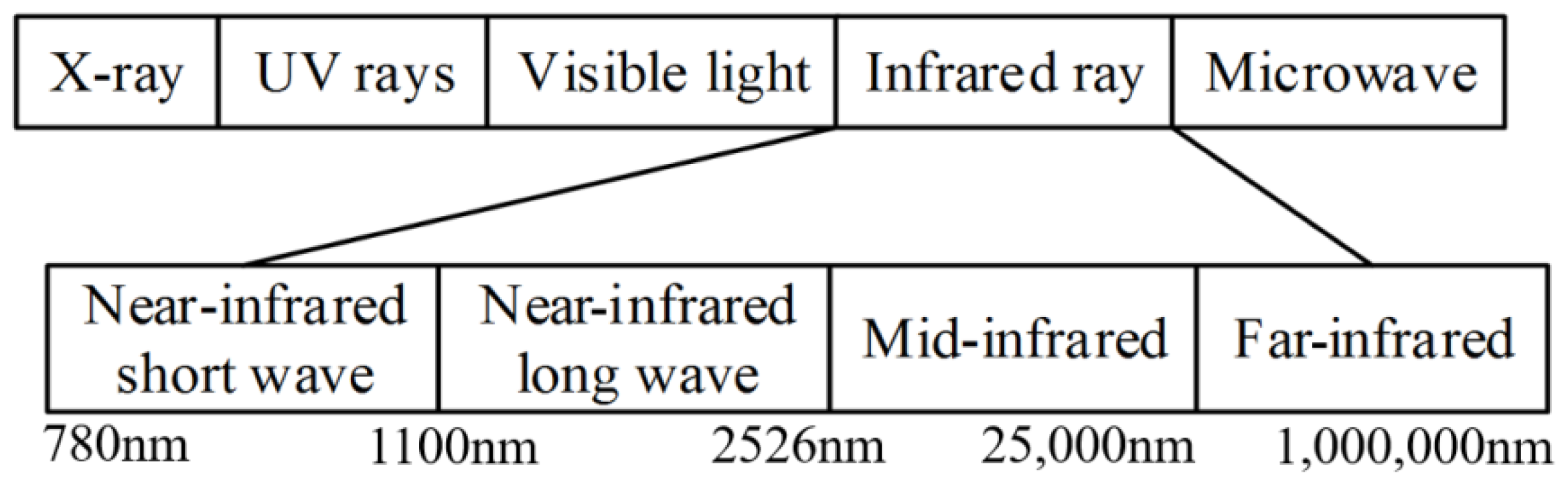
As a new non-destructive testing technology, near-infrared spectroscopy has broad application prospects in agriculture, food, and other fields [
17,
18,
19,
20]. As a fast, non-destructive, and efficient detection method, near-infrared spectroscopy can be used to analyze the physicochemical properties of all samples related to hydrogen radicals. NIR spectroscopy also enables rapid qualitative or quantitative analyses of specific components. Therefore, near-infrared technology can be considered for the non-destructive testing and detection analyses of fruits [
11,
12].
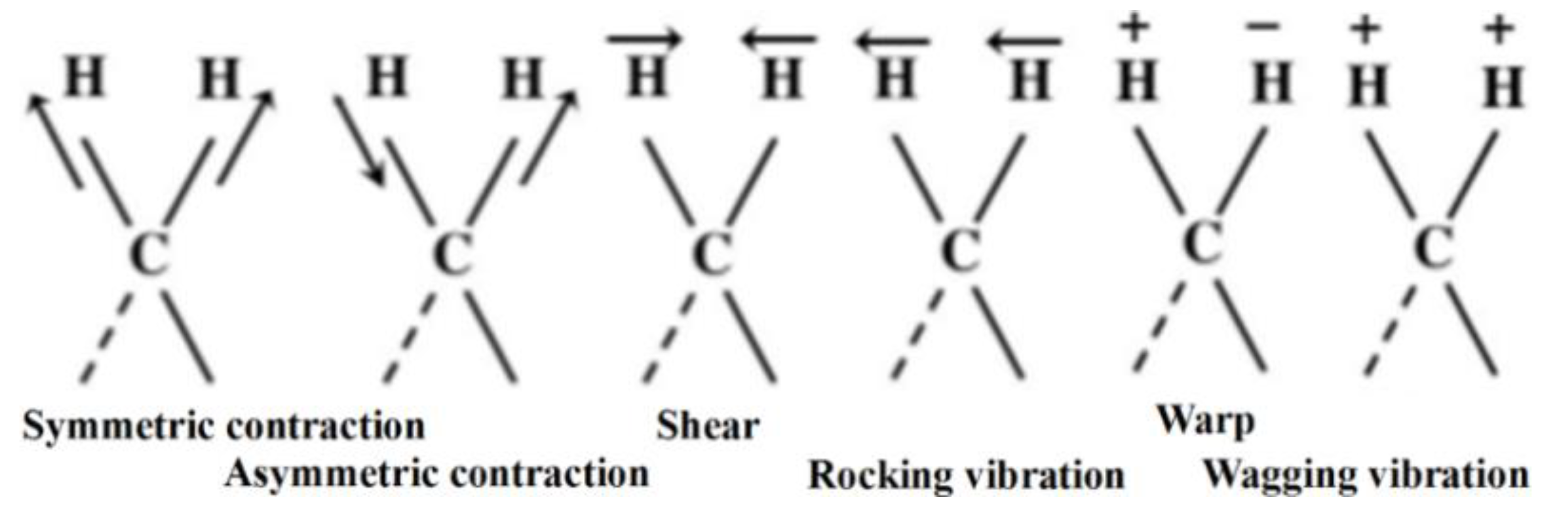
The NIR spectrum is mainly caused by the non-resonance of molecular vibrations. This leads to the oscillation of molecular vibrations from the ground state to a higher energy level. When molecules change from one excited state to another, they produce frequency-multiplying absorptions and combined frequency absorptions because of the absorptions at different fundamental frequencies [
21]. Near-infrared spectroscopy mainly reflects the frequency-doubled and total-frequency absorption information for hydrogen-containing groups (O-H, C-H, N-H, S-H, P-H) [
22]. When a molecule is exposed to infrared radiation, it is excited into resonance and the light’s energy is partially absorbed. We can measure the absorption of light and obtain an extremely complex spectrum that represents the properties of the substance [
23]. Examples of stretching vibrations and deformation vibrations of the measured material molecules are shown in
Figure 1. With the appropriate stoichiometry, the near-infrared absorption spectrum may be related to the substance’s composition or properties, and a corresponding model can be established.
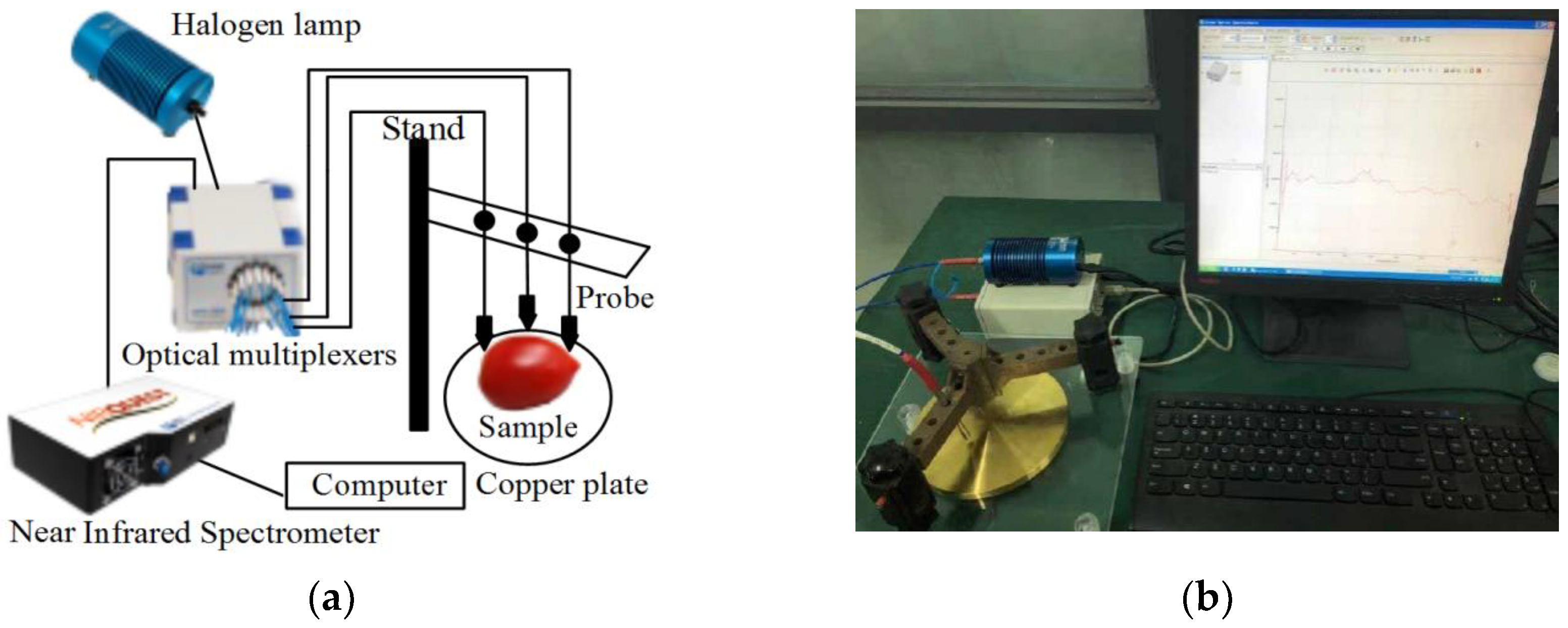
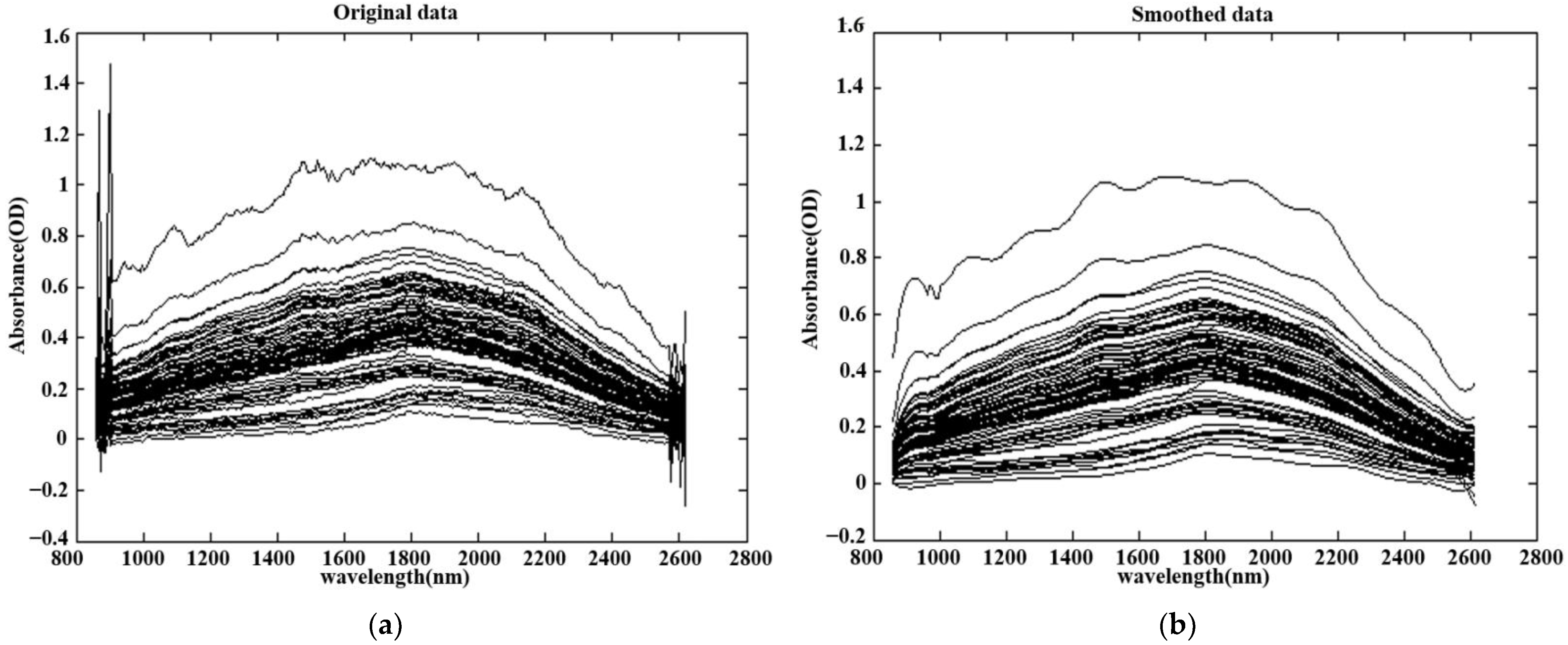
An intelligent near-infrared diffuse reflectance spectroscopy (INIS) method for the non-destructive testing of the sugar content in vegetables and fruits was designed on the basis of a near-infrared spectrum analysis technique. In the experimental part, cherry tomatoes were selected as the representative samples and a BP network model was established to study the sugar content. Spectral features were extracted from experimental the spectral data using smoothing and a principal component analysis (PCA). An intelligent near-infrared diffuse reflectance spectroscopy scheme (INIS) was the proposed for the non-destructive detection and prediction of the sugar content in the representative fruit.
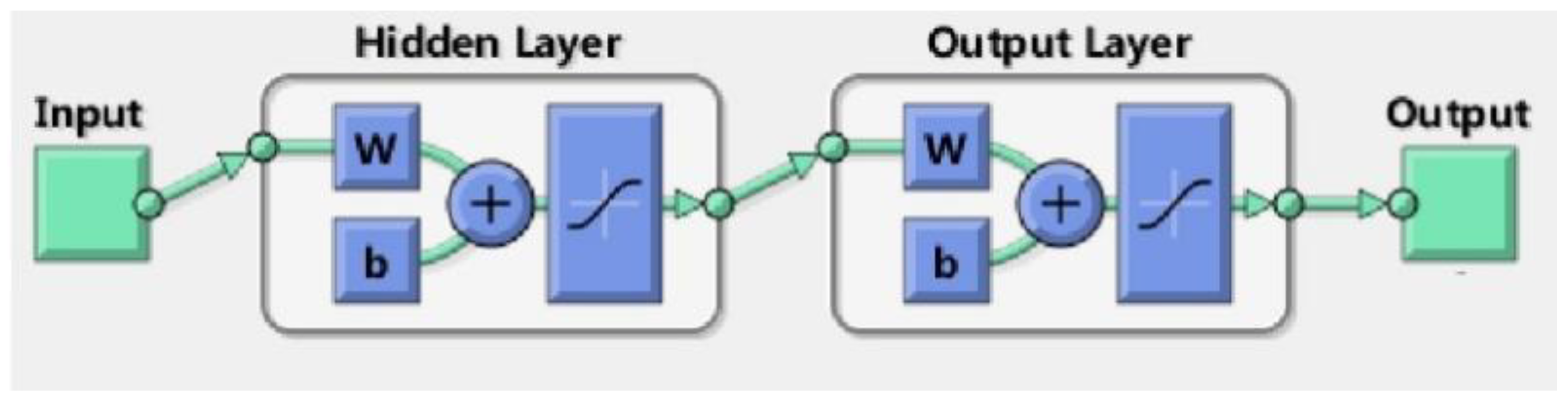
The BP neural network technology has broad application prospects in near-infrared non-destructive testing, and the prediction results are more accurate. In fruit detection, qualitative and quantitative analyses can be carried out on the fruits, including to assess the fruit types, regional classifications, fruit sugar contents, and so on. However, there is room for improvement in the accuracy of the results, and many fruits remain to be studied. Therefore, this paper combines near-infrared spectroscopy and a BP neural network to study the sugar content of cherry tomatoes and to improve the accuracy of the results.
The remainder of this paper is organized as follows.
Section 2 gives a brief introduction to the present situation regarding the domestic and foreign research. In
Section 3, we introduce the near-infrared spectroscopy technology, BP neural network, and model evaluation criteria. In
Section 4, the experimental materials and methods are presented. In
Section 5, we analyze and discuss the data collected from the experiments. In
Section 6, we draw conclusions and describe the future outlook.
2. The Related Work
As a new non-destructive testing technology, near-infrared spectroscopy has broad application prospects in agriculture, food, and other fields.
Ref. [
24] used visible near-infrared spectroscopy to predict soluble solids in Fuji apples. Ref. [
25] used near-infrared spectroscopy to calibrate models of soluble solids and moisture content in Cucurbitaceae. Ref. [
26] determined the chemical and sensory properties of tomatoes based on near-infrared spectroscopy. Ref. [
27] used near-infrared spectroscopy for the non-destructive prediction of the total soluble solids in strawberries. Ref. [
28] used near-infrared spectroscopy to improve the prediction of pear fruit moisture and soluble solid contents. Ref. [
29] conducted a non-contact assessment of intact mangoes using NIR spectroscopy. According to the existing research on non-destructive testing and detection testing, near-infrared spectroscopy technology could be used for the non-destructive testing of the sugar content of cherry tomatoes [
30,
31].
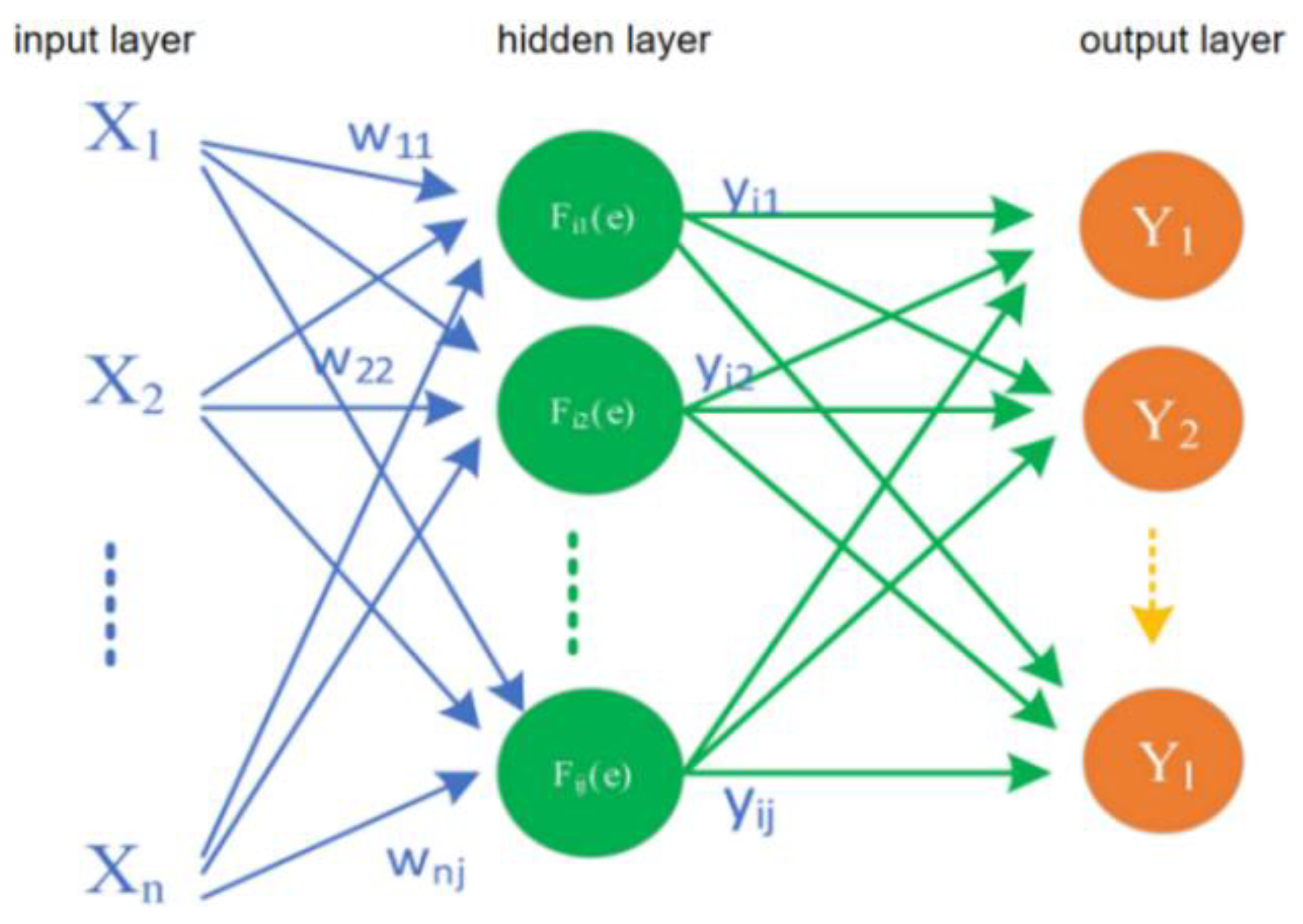
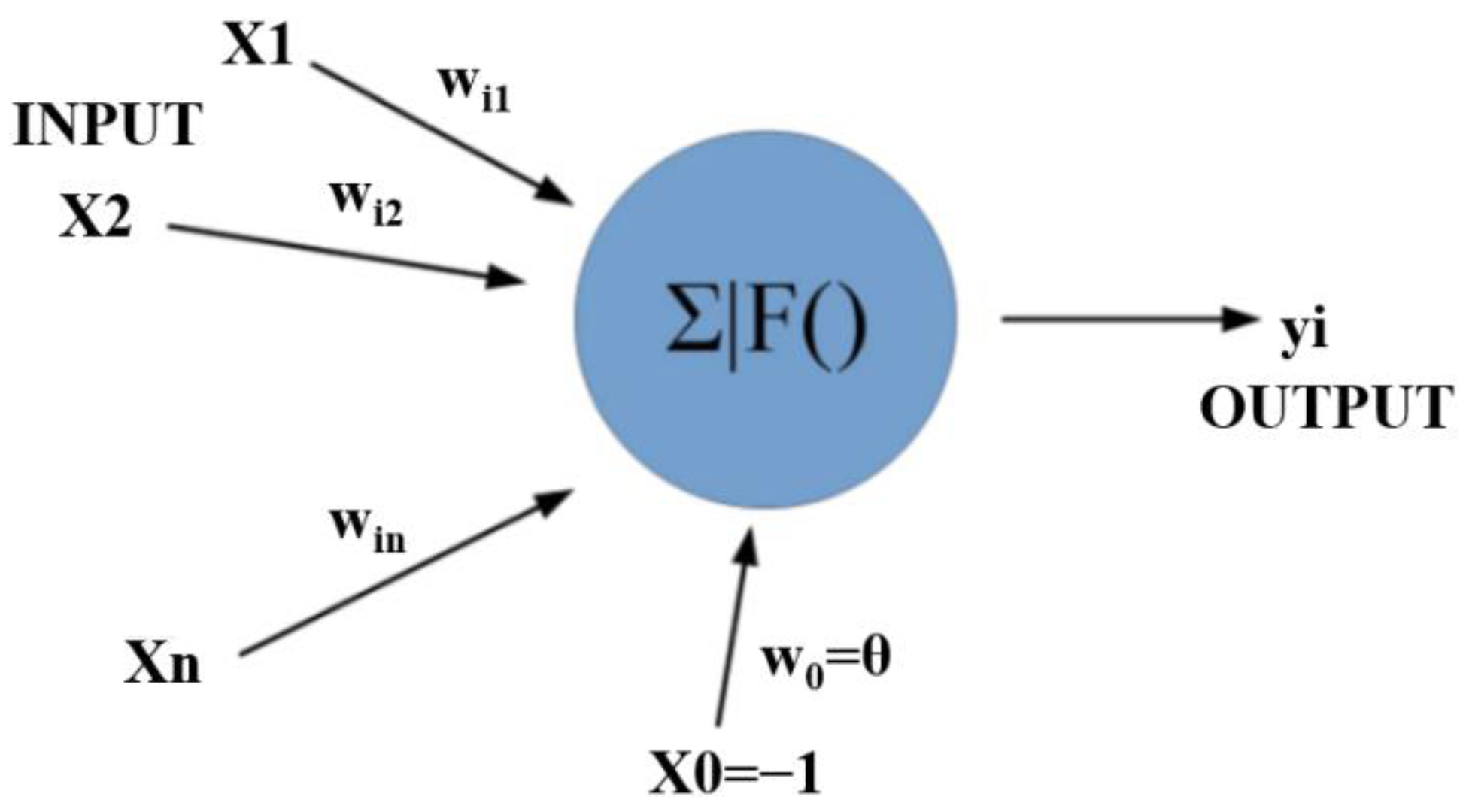
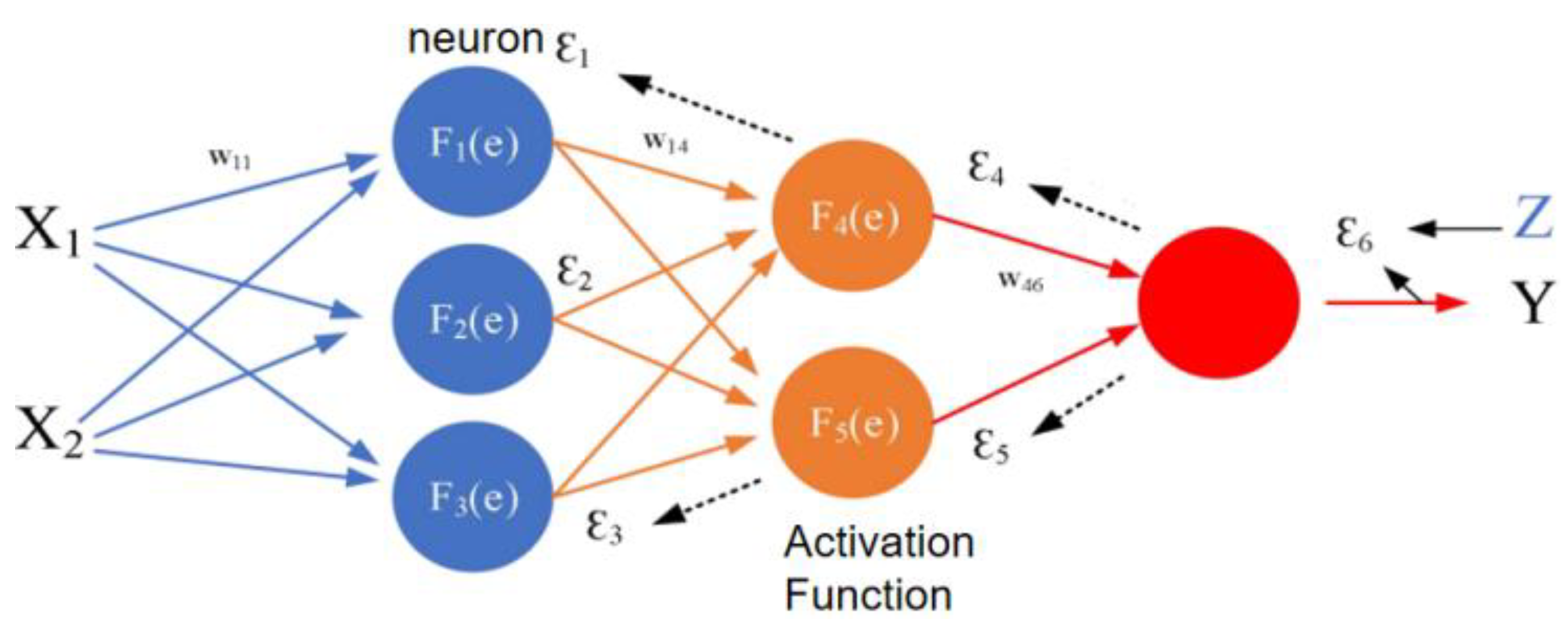
An artificial neural network (ANN) is a mathematical model that simulates animal neural networks and performs distributed parallel information processing. Such networks depend on the complexity of the system. The purpose of processing information is achieved by adjusting the mutual relationship between a large number of internal nodes. ANNs have the self-learning ability to adapt and have been connected with machine learning [
32], big data [
33], automatic processing [
34], analytics [
35], and algorithms [
36].
Ref. [
37] proposed a new method involving NIR-HSI combined with PLS. Ref. [
38] examined the FOS content in sun-dried banana syrup using NIR measurements. The PLS results indicated that the optimized wavelength range is better than the full wavelength. Ref. [
39] showed that VIS/NIR spectroscopy could be used to classify three varieties of tomatoes, as well as to determine their quality parameters, such as their SSC, TA, taste (SSC/TA), and firmness. Ref. [
40] used a PLS regression and wavenumber selections to perform non-destructive FT-NIR measurements and prediction models of texture. The results were that the R
2 values ranged from 0.70 to 0.97 and the RPD values from 1.8 to 6.1. Ref. [
41] used tropical papaya fruit as a raw material to produce pulp products. Based on a BP neural network, he predicted and verified the processing conditions for papaya pulp and meat products. The results showed that the products produced under certain conditions meet health and safety standards. Ref. [
42] established a model through a BP neural network and then combined this with near-infrared spectroscopy technology to predict the sugar content of cherry tomatoes. The results showed that this method can reasonably predict the sugar content.
In order to achieve the fast and non-destructive detection of the internal quality of cherry tomatoes, Refs. [
43,
44] established a cherry tomato transmission detection system. The correlation analysis and normalization treatment were used to correct the diameter of the cherry tomatoes. A rapid and non-destructive study was carried out on the soluble solid content (SSC) of cherry tomatoes based on this system. The results showed that the visible/near-infrared transmission spectrum combined with the normalization of the fruit diameter can be used to effectively predict the internal quality of cherry tomatoes and eliminate the errors caused by different fruit diameters. According to the existing research on the non-destructive testing [
30] of cherry tomatoes, artificial neural networks maybe good tools to resolve the problem.
Based on the previous research, we finished a literature review [
30], basic theory study, near-infrared diffuse reflection experiment, integrated environment experiment [
12], typical fruit selection experiment, typical fruit spectrum data collection study [
45], and a spectral data analysis of typical fruits. Based on the neural network design, we designed an intelligent near-infrared diffuse reflectance spectroscopy (INIS) scheme for the non-destructive testing of the sugar contents in fruits [
12].
Ref. [
46] proposed a weighting mechanism to connect samples with dictionary atoms. At the same time, traditional dictionary learning methods are prone to overfitting for patient classification with limited training datasets. Ref. [
45] introduced artificial neural networks based on a 1-D CNN (one-dimensional convolutional neural network) and Bi-LSTM (bidirectional long and short-term memory). Abstract features of different properties are obtained through preprocessed sensory data. Ref. [
47] proposed a new deep learning architecture called the recurrent 3D convolutional neural network (R3D). It is used to extract valid and discriminative spatiotemporal features for action recognition. This enables the capture of long-range time information by aggregating 3D convolutional network entries as inputs to LSTM (long short-term memory) architectures.
There are many known neural network algorithms, and each algorithm has its own characteristics. After reviewing the research status at home and abroad, it was found that BP algorithms can be used in the detection of many kinds of fruit, but the use of a BP neural network to predict the content of virgin fructose has great advantages. Therefore, in the next experiments, we choose the BP algorithm.
6. Conclusions and Future Work
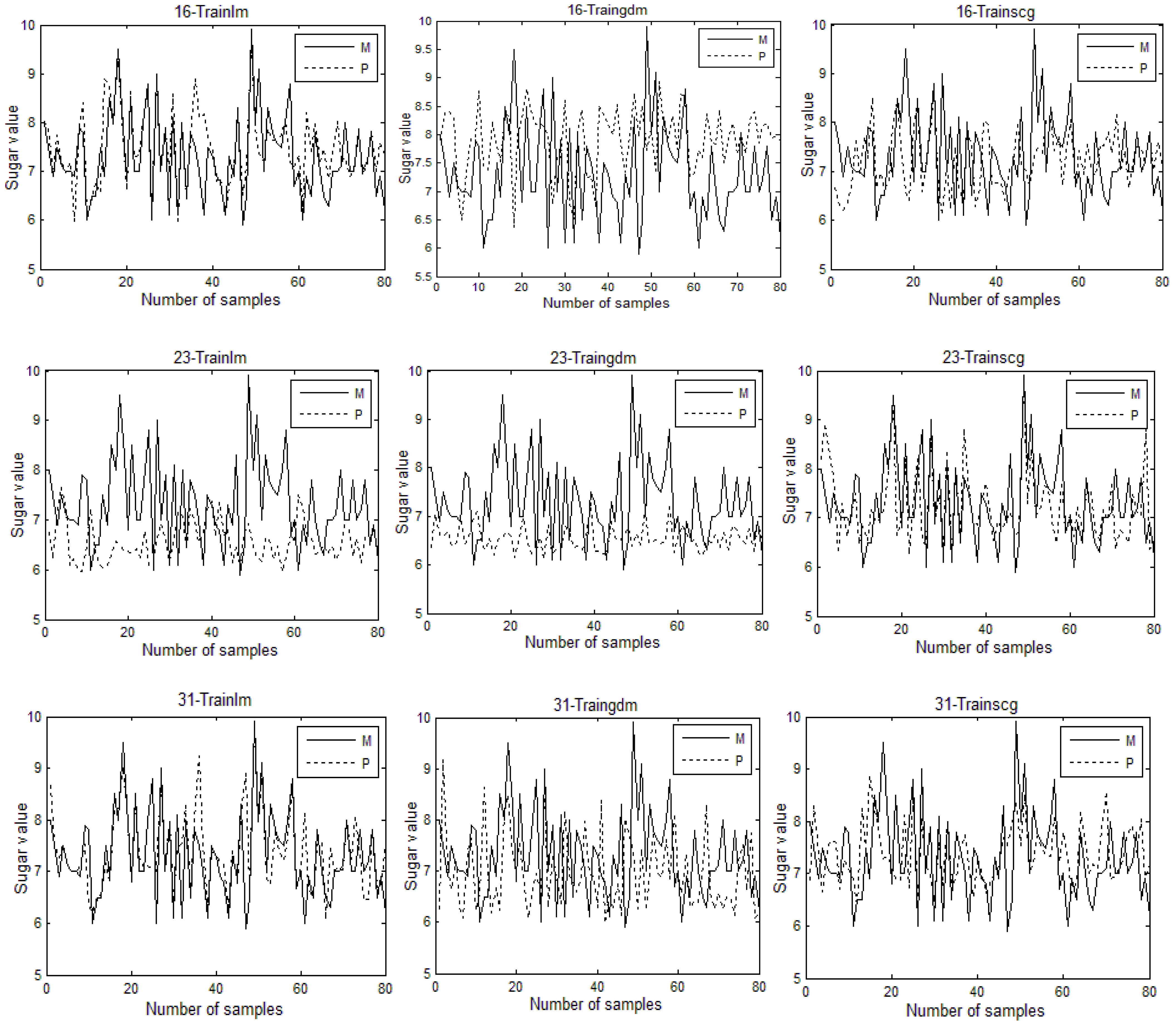
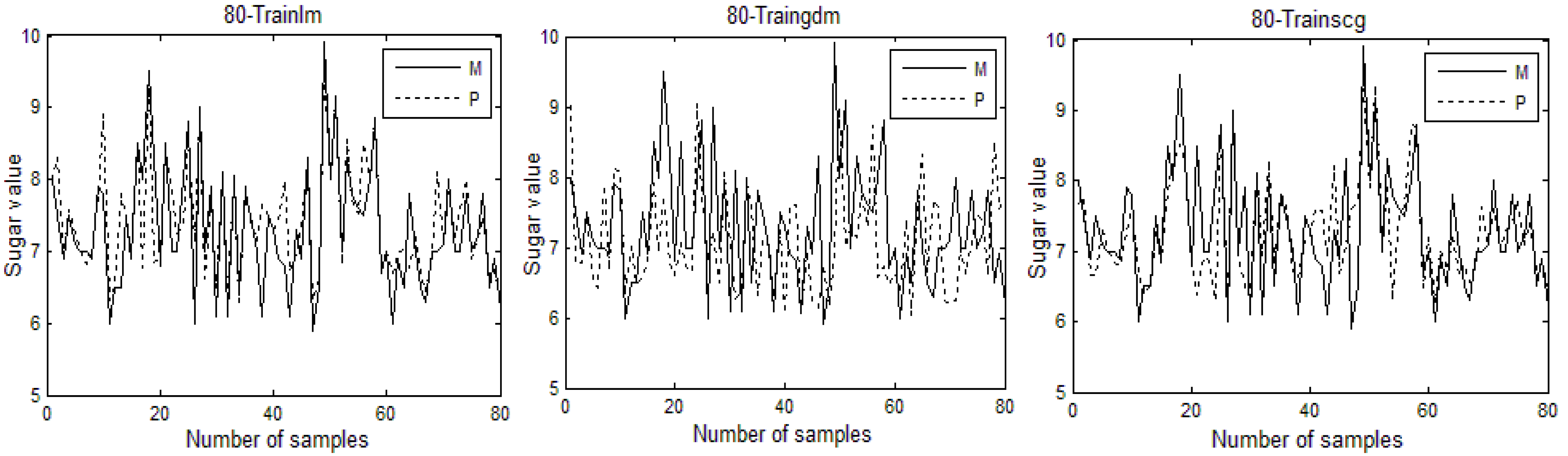
In this study, a near-infrared non-destructive testing method for the sugar content of cherry tomatoes was designed based on a BP neural network. An experimental system for near-infrared non-destructive testing was set up. The spectral data were preprocessed using the Savitzky–Golay algorithm and the principal component analysis method. The present study aimed to analyze the model prediction effects of the different parameters and to find the best model. The results show that when the network model structure of 80-12-1 is established and the network is trained using the training function Trainlm, the cross-validation determination coefficient of the model is 0.8328 and the average absolute deviation is 0.5711. Therefore, the model prediction effect is the best at this time.
The near-infrared non-destructive testing method based on the BP neural network proposed in this paper not only achieves the detection of the sugar content of cherry tomatoes, but also provides a foundation for the quality detection of cherry tomatoes, as well as for the quality detection of various other fruits and for fruit grading. However, the experimental process and the measurement of the sugar content will produce a certain error, and these errors will directly affect the accuracy of the results. Therefore, the challenge of reducing errors needs further research. In addition, due to the important role of fruit quality testing and grading in the agricultural field, a stable detection method that applies to all fruits is also a direction that needs to be studied.
In this paper, we selected the cherry tomato as the representative fruit. However, this method can be extended and optimized to be used in almost all fruits and vegetables. The optimal prediction model obtained in this paper is for cherry tomatoes. In order to improve the applicability of the model, other fruits can also be studied, so as to find the optimal prediction models for the sugar contents of a variety of fruits and to apply them in real life.
In this paper, the sugar content of cherry tomatoes was taken as the indicator to study the quality of the fruit. In addition, the indicators of fruit quality also included the acidity, PH value, and hardness, which can be combined to extract comprehensive indicators. Here, we have proposed a prediction model comprising comprehensive indicators and achieved comprehensive prediction results for fruit quality.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}