4. Machine Learning in the Teleoperated Robots PoC Development and Results
This section aims to provide the implementation details of a robotic solution that can efficiently detect the existence of inflammable gases in a room. A robot equipped with an MQ-2 gas sensor and a camera can search a specific room, creating graphs that help identify the root source of the gas leak and send data to the human operator about the amount of gas existing in the air. It is controlled remotely using a glove attached to an Arduino Nano board and an MPU6050 accelerometer module that allows the reading of hand gestures and translates them into robot movements.
Combustible gas leaks are dangerous to human health and can cause explosions if not detected on time. Olfactory robots can provide a feasible solution for gas detection because they read the data efficiently and limit human exposure to dangerous environments.
Methane has a variety of applications, including heating, industrial processes, and electricity generation. Naturally, methane does not have a specific odor. Thus, before distributing it to commercial use, methane is mixed with a pungent gas, which makes detecting leaks much easier. At concentrations that can be found in the natural environment, methane is not dangerous to human health. Nevertheless, exposure to low levels of methane, which is slightly above the natural limit, may cause headaches, dizziness, and fatigue. At high concentrations, the methane present in the air replaces oxygen and deprives the body of oxygen, which leads to asphyxiation.
At concentrations up to 1000 ppm (parts per million measuring unit), methane is considered safe and does not affect human health. At levels between 50,000 and 150,000 ppm, methane is considered combustible and extremely dangerous. Concentrations that exceed 150,000 ppm are not combustible because the gas replaces almost all the oxygen in the room, which contributes to the ignition process.
Room air quality plays an important role in human health and influences the productivity of workers and their well-being. Inadequate room quality may cause poor concentration, tiredness, and even some diseases. Air quality is evaluated based mostly on the levels of oxygen (O2), carbon monoxide (CO), carbon dioxide (CO2), and ozone (O3).
The first smoke detector was invented in 1940 and was based on the ionization of the air current using a radioactive source, americium-241. The alpha radiation ionizes the air and detects smoke based on a decrease in measurements when smoke particles are present in the sensing chamber. After further research, health issues occurred due to radioactivity, and these sources became unsafe for the population.
New smoke detectors have been developed that use light scattering and heat detection to measure smoke in a room. Most residential places use this type of smoke detector, which has been proven to be efficient. One aspect must be taken into consideration, although not all fires emit significant quantities of smoke, such as pure ethanol fires. The most common gaseous compounds emitted during a regular fire incident are CO, NO2, CO2, H2, ammonia, HCl, and many others. The main cause of human deaths during these fire incidents is not flames or heat, but poisonous gases that are released into the air by combustion.
Smoke detection devices have been developed to reduce the incidence of human casualties. There is a certain list of restrictions and requirements that a residential gas detection device must comply with: low costs that facilitate mass production, autonomous ability, reduced power consumption that will not influence the quality of data reading, sensitive to most important inflammable gases such as CO2, CO, H2, and a lifetime greater that ten years.
For a fire alarm to depend on the smoke detector alone, it must detect at least two gas types and distinguish between fire types, such as chemical fires and open fires. In addition, the smoke detector must be improved to reduce the number of false alarms caused by water vapor or dust accumulated inside the device.
The olfactory telerobots are machines provided with the sensory capabilities of a traditional teleoperated mobile robot capable of obtaining information about the surrounding environment (i.e., wind speed, smell, etc.) in addition to the common audio and video stream inputs.
As a concept, the sensors offer a rich variety of options for new and enhanced applications, among which we can count those related to gas-emission source localisation (GSL). This type of robot might thus allow human counterparts to identify a specific or several gas emissions sources, such as dangerous gas leaks in industrial plants or the survivors’ carbon imprint blocked in collapsed buildings.
Despite all the advantages that this technology might bring, the robot sensor capabilities as well as the smell-sensitive feedback interfaces aimed at helping the human operator are quite recent and still might not meet all the expectations for enhanced applications.
Numerous studies have been performed to assess the real utility of the olfactory telerobotic unit in addressing real-world GSL problems, and appropriately decide which aspects prevail as the most successful and important role, or otherwise, might negatively affect its versatility.
In several experiments, volunteer operators had to identify and locate specific hidden gas sources among several identical candidates equipped with an olfactory robot under real environmental conditions (i.e., natural gas distributions and uncontrolled).
The data were analyzed to determine the general search accuracy and intuitiveness of the system, considering that there were no operators with any previous experience. The second aim of the study was to determine the importance of the obtained sensor feedback and how they were used during the experiments.
Remote operation of mobile robots, also known as tele-robotics, is mainly the process of robot teleoperation of a machine that allows it to receive input and interact with the world from a certain distance. Its most important applications are usually those related to safety, as they imply conditions that are dangerous or limiting for humans, but on the other hand, they also demand more reliability than those offered by fully autonomous systems. This type of technology involves, among others, providing access to sites situated in difficult-to-reach locations (e.g., rescue missions in collapsed buildings), dangerous working environments (e.g., emergency response to nuclear accidents), and hazardous material manipulation (e.g., remote bomb disarming).
The situations in which tele-robotics may prove useful are limited, mainly among other factors, by the robot’s sensing capabilities. While it is usually sufficient for the robot to be provided with video access, audio, or tactile feedback, some applications may also demand additional and specialized sensors to be efficacious. This is the case for olfactory tele-robotics, where the robot needs to receive and send information about the surrounding air to solve smell or gas-related tasks, for example, searching for gas leaks related to dangerous chemicals (e.g., toxic or highly flammable) or tracing smoke-plumes to their origin (e.g., firefighting).
Although GSL tasks are one of the most relevant challenges in general for olfactory robotics, they have only been performed with autonomous mobile robots to render the search process automatically. However, because of the actual limited potential of autonomous robots and the complexity of the tasks required, works in this area have only been substantiated under very simple conditions (i.e., unidirectional and laminar wind fields, absence of obstacles in the environment, etc.) Therefore, a teleoperation concept that requires human reasoning capabilities seems to be a proper solution to address the inevitable drawbacks.
The most direct approach to allow chemometric data readings on a robot is the electronic nose (e-nose). The device comprises several small non-selective gas sensors that can respond to different chemical substances. Their combined information can be processed using a sorting algorithm designed to recognize and measure specific volatile substance parameters. The main advantages of electronic noses are their low cost and integration versatility in mobile robots. Gas sensors are usually expensive, and cheap sensors have limited sensing capabilities. This aspect limits electronic noses from providing essential information related to the spatial distribution of gases, especially if the natural spread of gases is considered. Owing to gas-specific properties, such as convection and air turbulence, the point of highest concentration may not correspond to the emission source. Thus, robots might require complementary sensor inputs, such as an anemometer or some sort of gas-mapping software, to chart their distribution in the environment.
Obviously, the delays in speed recognition and the range of the gas concentrations of these devices are still limited and not sophisticated enough for olfactory tele-robotics. Present-day user interfaces must therefore utilize a visual representation of the chemometric data, usually displayed as a simple intensity graph of different scents or as an image of the gas distribution map.
Scientists conducted a representative number of individual experiments with volunteer test subjects who had to find and identify a hidden alcohol diffuser situated in a ventilated area among the other five fake gas-source candidates. Human operators had to identify the scent sources using the telepresence system. Thus, a mobile robot supplied with an electronic nose and an anemometer, all controlled through a custom user interface that administered the robot’s video stream, sensor readings, navigation support, and a practical gas map of all previously inspected locations, was obtained. To replicate real-life conditions, none of the human operators had any previous experience regarding the teleoperation of the robot or knowledge about the test expected results. In the end, the human-operated robots succeeded in finding the source of a gas emission three out of four times. As a result, we might state that olfactory tele-robotics seems to be practically satisfactory for real-world GSL problems, but it is also reasonable to estimate that its efficiency can be increased if the operators are previously trained for the task.
Moreover, after analyzing the operator’s search strategy, we might state that the capabilities of teleoperated-GSL could be improved in the future due to the human tendency to actively explore the environment to determine the most likely locations of gas sources based on visual and semantically relevant information.
There was no evident correspondence between the accuracy and efficiency. The percentage of successfully localized gas sources seems to rely exclusively on the environment (i.e., the area of the source), but not on how long or intensively the operators searched for them. However, it seems to be a direct connection between the results of each experiment and the operator’s perception of their own conduct, which means that they are more likely to succeed if they feel confident. This might suggest that human intuition could provide a multi-hypothesis solution to GSL in the future by designating how much individual confidence each candidate holds before the experiment, instead of recruiting one.
Consequently, GSL with olfactory tele-robotics is still in its incipient development stages. The control interface must become more intuitive for the human operator by considering the human search strategy and by offering active assistance for the GSL. Thus, in future research, it is highly recommended to improve the gas maps that incorporate wind data, or to use suggestions of where to search next in an information-taxis-like approach that correlates with human intuition. In addition, the already collected dataset might be used to investigate new bioinspired GSL algorithms that, like human behaviour, may comply with the heterogeneous environments that describe real-life conditions without the need for an operator’s intervention.
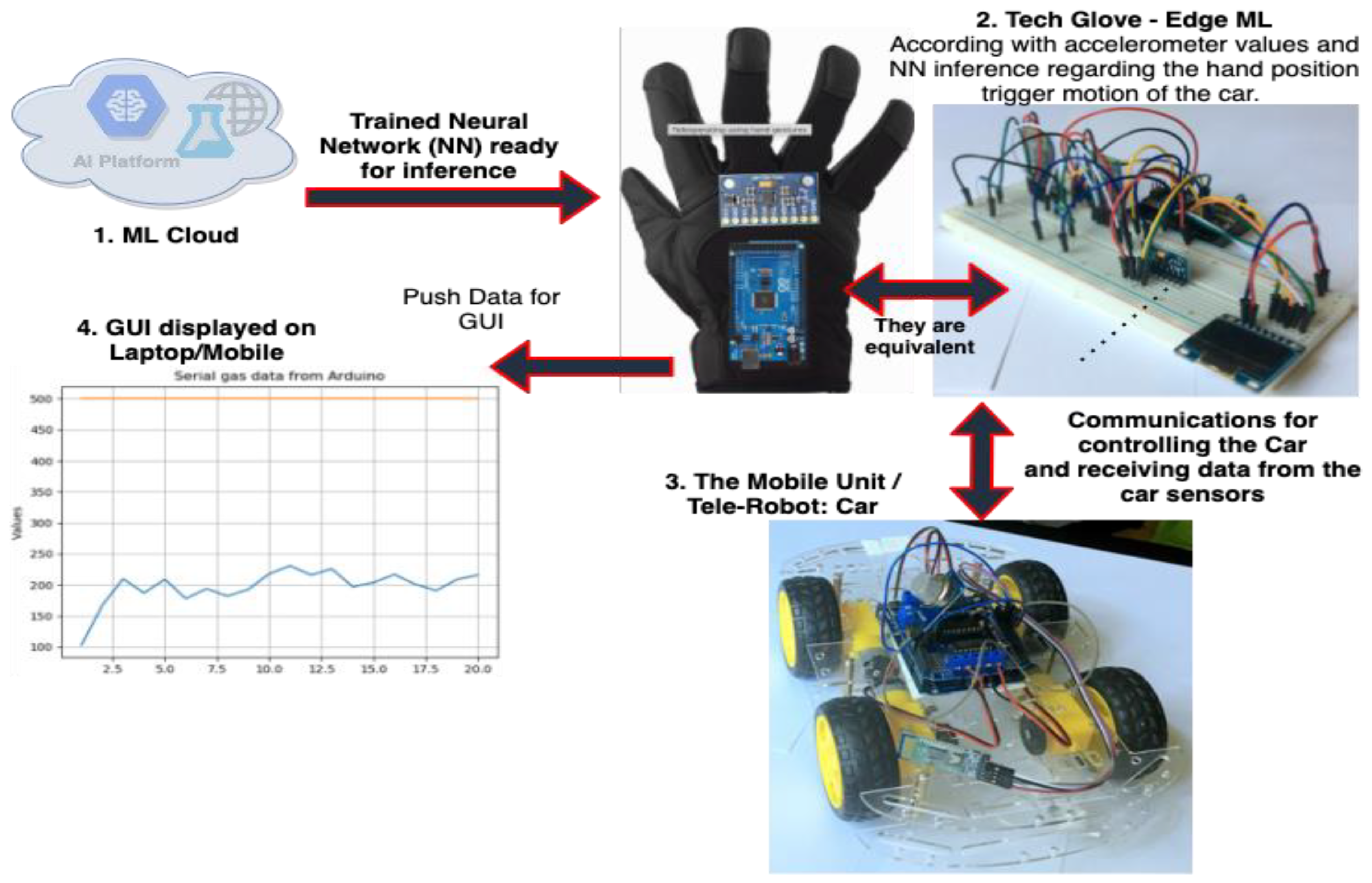
The proposed proof of concept (PoC) solution is a teleoperated robotic unit that can detect a variety of gases with the potential to become dangerous if they exceed the accepted limit, such as alcohol, CO, CO2, and methane. It consists of four main elements:
- ▪
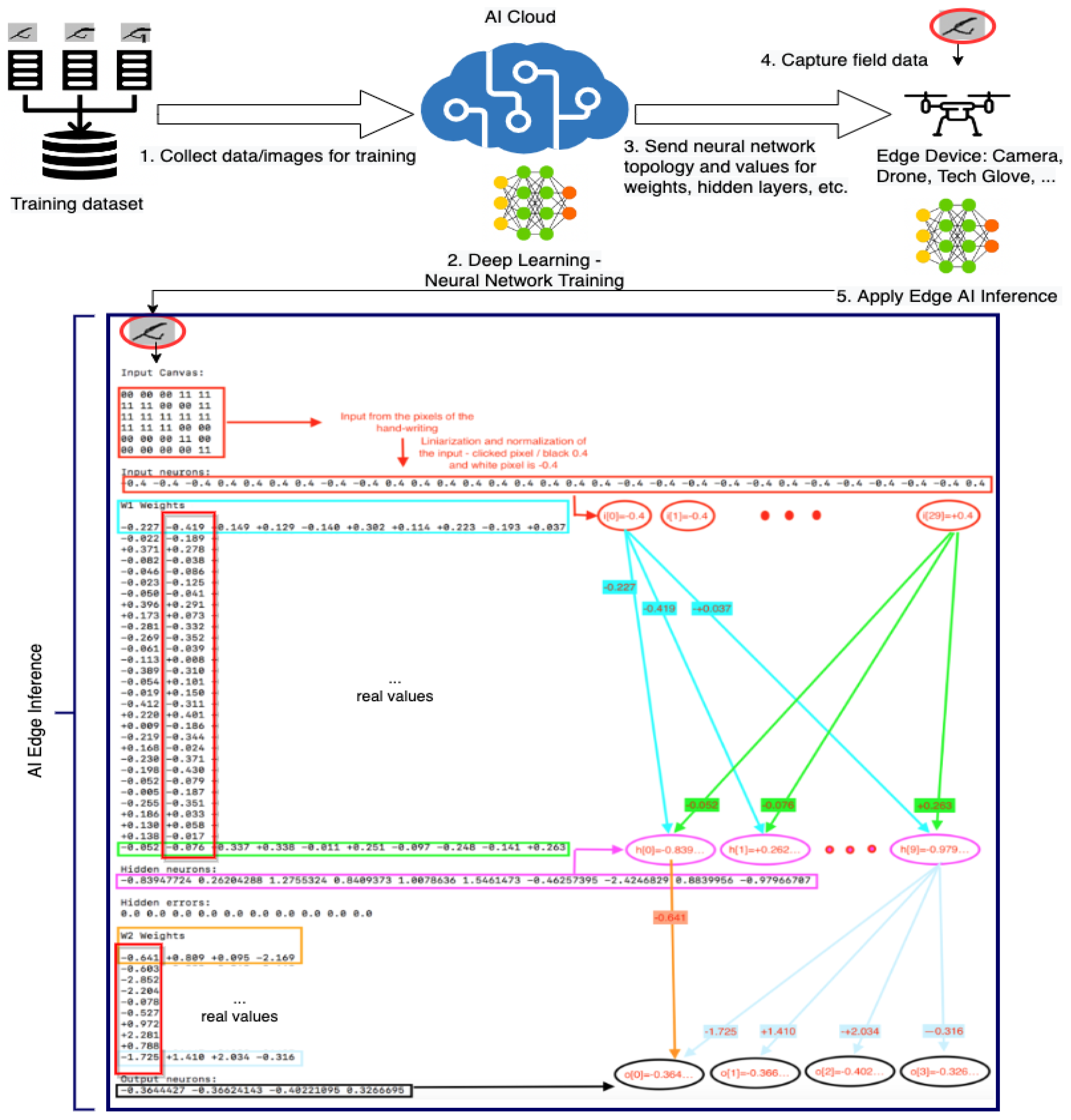
Machine Learning Cloud: It is used for training the neural network to improve the movement decision of the telerobot ordered by the tech glove according to the hand’s positions.
- ▪
Tech Glove: It is a glove that has attached an IoT smart device. The IoT smart device has a gyroscope sensor, Bluetooth modules, and a display. It communicates with the robotic car via Bluetooth and sends information about the direction in which the robot should move and receive gas data. For the tech glove, it is sufficient to have the values from the gyroscope and accelerometer, but with the use of the neural network inference, the control is more refined.
- ▪
Mobile unit/(Tele)Robot: This is a car robot that moves and detects gas sources by reading and interpreting atmospheric data. It has attached a gas sensor that detects gas leaks and sends it via a Bluetooth connection to the controller.
- ▪
User interface: the user interface is the graph generated by the data received from the car. It establishes a Bluetooth connection with the robotic glove and generates real-time graphs that plot the data. In addition, it receives a live-streaming video from the robotic car to visualize the environment.
In this way, the operator can guide the robotic unit to gather valuable gas data when human health is in danger. Gas leaks can be prevented in a secure manner, and users can visualize data in an interactive manner.
Figure 5 presents the components of the PoC.
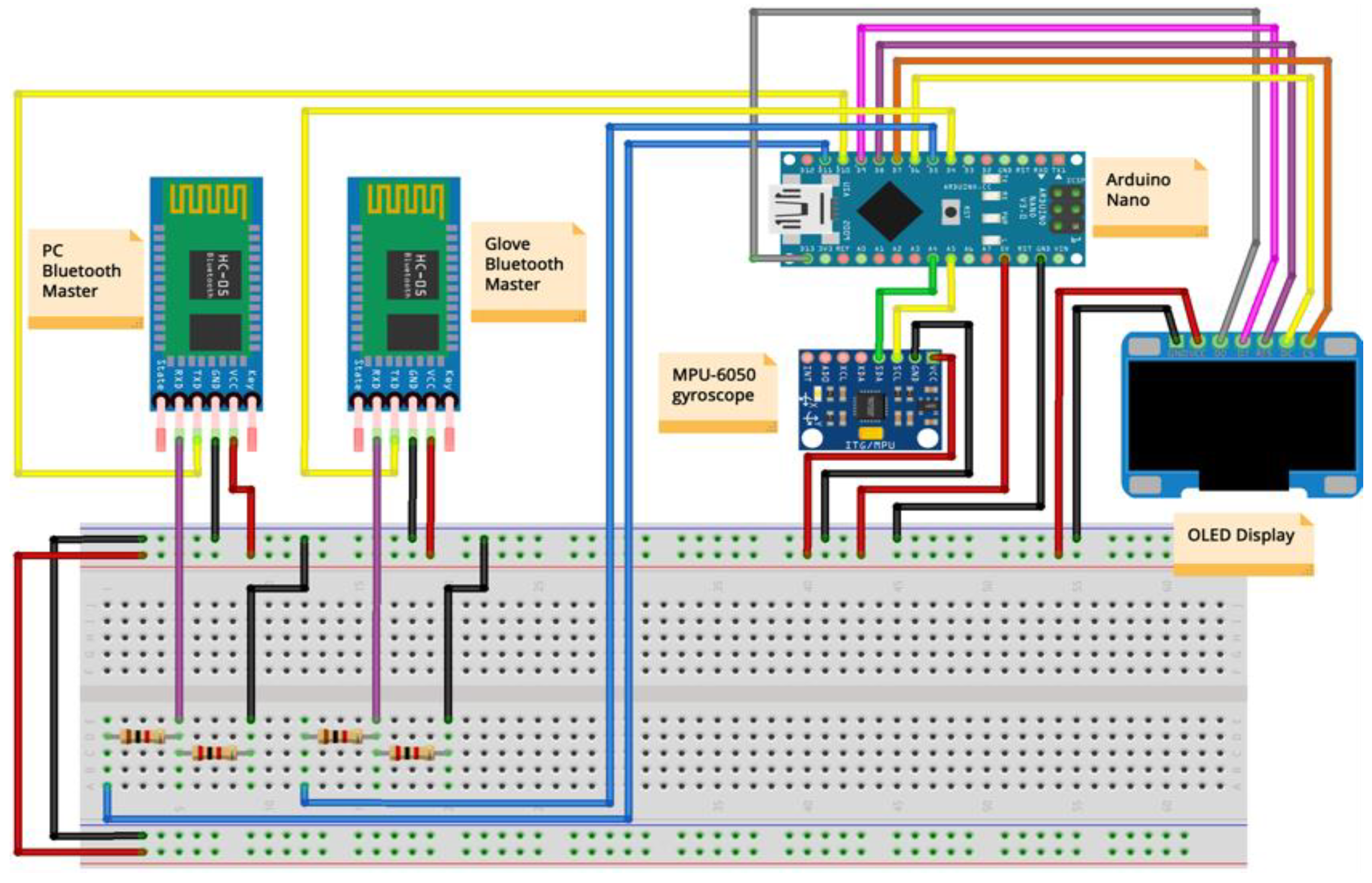
In terms of hardware for both the tech glove and the tele-robot car, one distinguishes a variety of elements that are used to build up the robots. Hardware includes Arduino UNO and Nano, two HC-05 Bluetooth modules, an MPU6050 gyroscope, MQ-2 gas sensor, an L293D motor driver shield, motors, wheels, chassis, and peripherals.
Arduino UNO is the most popular microcontroller board used in robotics PoC (not production ones). It has a large support community owing to its applicability. It is easy to comprehend, and it can be easily incorporated with other components, such as LEDs, sensors, or other development boards.
Arduino is an open-source platform that facilitates access to code written by other electronic enthusiasts. Projects available online differ in difficulty and capture all ideas of the community.
The Arduino UNO board is equipped with a power jack, reset button, 16 MHz resonator, 20 digital input/output pins, and an ICSP header. It is affordable and easy to replace when required. There are a variety of ‘shields’ that can be attached to the Arduino board to add more functionalities.
Arduino Nano is a smaller version of the Arduino UNO. It incorporates almost the same functionalities and can be easily integrated into a circuit. It has 14 digital pins and 8 analog inputs, supports I2C communication, an AREF pin for voltage reference, and a Reset pin used for adding a button to block the circuit. The board communicates via UART serial communication available on TX (1) and RX (2) digital pins and can be easily programmed via Arduino IDE.
Bluetooth module HC-05 is used for long-distance communication. It consumes low energy, and its small size makes it easy to incorporate in various projects. It has a signal radius of 10 m and can be used in robot-laptop communications or robot–robot communications. It can be configured in two modes: slave (pin value 0) and master (pin value 1). These are some common commands used to set up the modules.
- ▪
AT—verifies the connectivity to the module.
- ▪
AT+ROLE?—checks the role of the Bluetooth module; it returns 0 if it is in the slave configuration and 1 if it is in the master configuration.
- ▪
AT+RESET—resets the module configurations.
- ▪
AT+PSWD=—changes the password of the module. Note that the default password is ‘1234′; it is required for pairing the devices.
- ▪
AT+ADDR—returns the address of the module; it is also required for pairing the devices.
MPU6050 unit is a device equipped with a 3-axis accelerometer, 3-axis gyroscope and a digital motion processor that reads the orientation in a 3-dimensional space. It is used to detect the motion and orientation of the objects. It has three analog-to-digital pins used to convert to digital gyroscope outputs and three analog-to-digital pins that convert to digital accelerometer outputs. MPU6050 is small, flexible, and provides fast gesture conversion.
MQ-2 gas sensor was used to detect combustible gas leaks. The sensitivity of the sensor can be adjusted by a potentiometer, and it is fast responsive to gases such as H2, liquefied petroleum gas (LPG), methane (CH4), carbon monoxide (CO or smoke), alcohol (C2H5OH or ethanol), and propane (C3H8). It is a very fragile component, so there is a list of items that should be avoided when working with the MQ-2 gas sensor:
- ▪
Long-time storage without electrification should be avoided because it produces a reversible drift.
- ▪
It should not be exposed for long periods of time to high gas concentration environments because it may affect the sensor characteristics.
- ▪
Water condensation can affect the sensor performance.
- ▪
Concussion and vibrations should be avoided, as they may lead to hardware damage or down-lead responses.
L293D Motor Driver Shield is an integrated circuit that amplifies the low input current and provides a higher-current signal to the motors. It is a shield compatible with Arduino UNO, which can be easily attached to improve performance. Using this shield, different types of motors can be assembled to create a movable robotic unit. We can control four DC bi-directional motors with speed ranging from to 0–255, two stepper motors, or two servo motors at a time. The motor driver shield can be powered in three ways:
- ▪
Ensure a single DC power supply to the Arduino board, which supplies power to the shield.
- ▪
Two different DC power supplies, by plugging one of them into the DC power jack of the Arduino and one into the EXT_PWR block attached to the shield.
- ▪
A USB that provides power to the Arduino board and a DC power supply connected to the EXT_PWR block of the motor shield (recommended method).
Note: When supplying power to the EXT_PWR block, the power supply jumper must be removed. Otherwise, it may damage the shield and the Arduino.
OLED Display 128 × 64 SPI or I2C—this display module is small and compact, which makes it perfect for displaying small amounts of data (e.g., smart watches). It can display 128 × 64 points and consumes a low amount of power when it is used at full capacity. It can communicate with microcontrollers via a serial peripheral interface or inter-integrated circuit protocols.
In this project, it is used to display meaningful information and messages on the robotic glove, such as messages that let the user know whether the robots are connected via Bluetooth, or whether the robotic glove is powered on, the battery level, etc.
4.1. Motors, Wheels, and Chassis
The robot vehicle is equipped with four DC motors and wheels that allow movement on the terrain. DC motors convert direct current electrical energy into mechanical energy. The speed can be easily adjusted, and these motors are mostly used in toys and appliances. The four motors used in this project come together with a distinctive wheel that can be attached. All hardware used for the mobile robotic unit was mounted on a car chassis.
4.2. Peripherals
Peripheral components include jumper wires, soldering iron, 1 mm solder, four 9 V batteries, two 9 V battery connectors, breadboards for development, pin headers, buttons, and resistors. These peripherals connect the hardware components and provide a power supply to the robotic units.
Figure 7 and
Table 4 show the tele-robot/mobile unit/car hardware wiring schema.
The project involves two major parts: the robotic parts and the GUI plot generation. All these parts communicate via Bluetooth serial communication. Glove has two Bluetooth modules incorporated, one for linking with the robotic car and one for binding to the PC’s Bluetooth.
The glove has attached the MPU6050 gyroscope sensor, which is used to analyse the tilt and position of the hand. The starting position of the teleoperation begins with the hand relaxed, parallel to the ground, with the first open palm parallel to the ground and the inside of the hand oriented to the ground. MPU6050 reads the data and converges it into an XYZ-axis table. The X axes read whether the hand is in a parallel position with the hand raised or lowered in place from the fingers. The Y axes read whether the hand was in a horizontal position relative to the ground and was slightly rotated to either the left or right. The Z axes read the rotation of the whole hand when it has a palm parallel to the ground.
These XYZ values were tested for specific intervals, interpreted as movements. Therefore, we can distinguish five types of movement as presented in
Table 5.
For the SPIN and STOP movements, the Z-axis is insignificant because it depends only on the tilt of the hand to the right or to the left (Y-axis). For the START and BACK methods, the Z-axis is significant because once the fingers are lowered or raised to incline the hand up or down, you cannot rotate it to the left or right. This must be in a steady position.
For undefined or faulty data, glove sends 0 to the robotic car, which has the same effect as the STOP method.
Glove sends the code that is processed by the robotic car into movements. This car has four DC motors attached, which can be activated and deactivated, and set to a speed with values in the interval [0, 255] (0 is for STOP and 255 for full speed). Clockwise from the front left of the car, the motors are denoted as 1, 2, 3, and 4 to quickly identify which one must be activated or deactivated. For example, in a SPIN left motion, the left motors (1 and 4) run backward while the right motors (2 and 3) run forward, causing the car to spin in place.
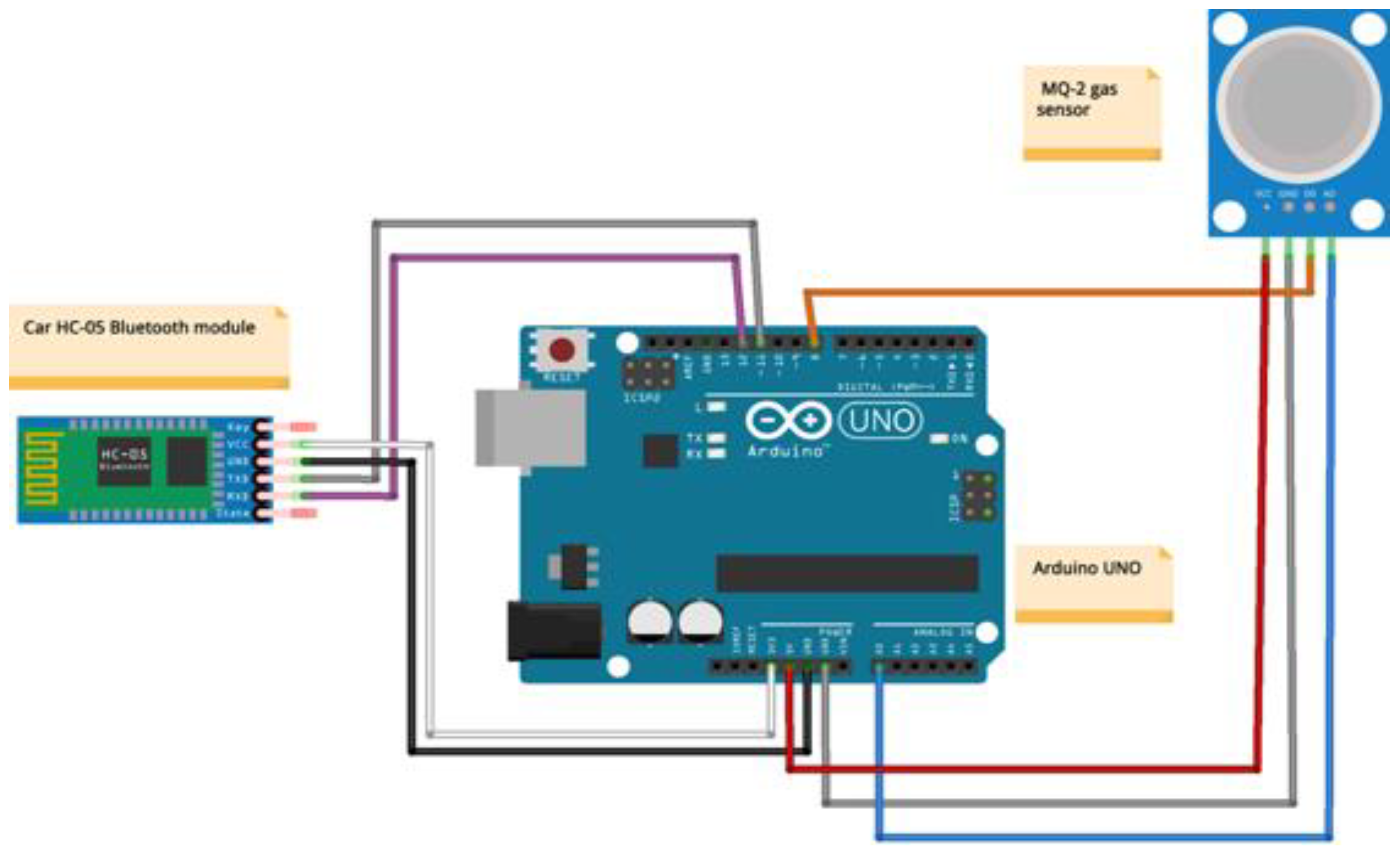
Once the robot Car can be remotely controlled, it can read and send data back to the glove. The MQ-2 gas sensor attached to the car reads and converts the voltage values into meaningful data and sends these values back to the glove via Bluetooth. It has also attached a mobile phone connected to the same Wi-Fi as the PC unit that streams live and records the car’s environment. Teleoperation would be blind without video streaming, which makes Wi-Fi connections a functional and important element in the project. Without establishing a secure and strong Wi-Fi signal, the operator has no visual feedback from the surroundings.
The converted gas values are received by the glove and passed to the PC via a separate serial Bluetooth communication. The PC unit connects to the HC-05 Bluetooth module, and the GUI module establishes a connection to this port. It constantly receives gas data values that are stored in an array based on the FIFO principle. The programme will constantly plot the new array of elements that create the effect of an endless line signifying the gas level at a certain moment of time.
To test this system, the level of security must be established. Compounds such as CO and CO2 are difficult to simulate at dangerous levels under safe conditions. As a result, acetone is considered an inflammable substance used to test the robot.
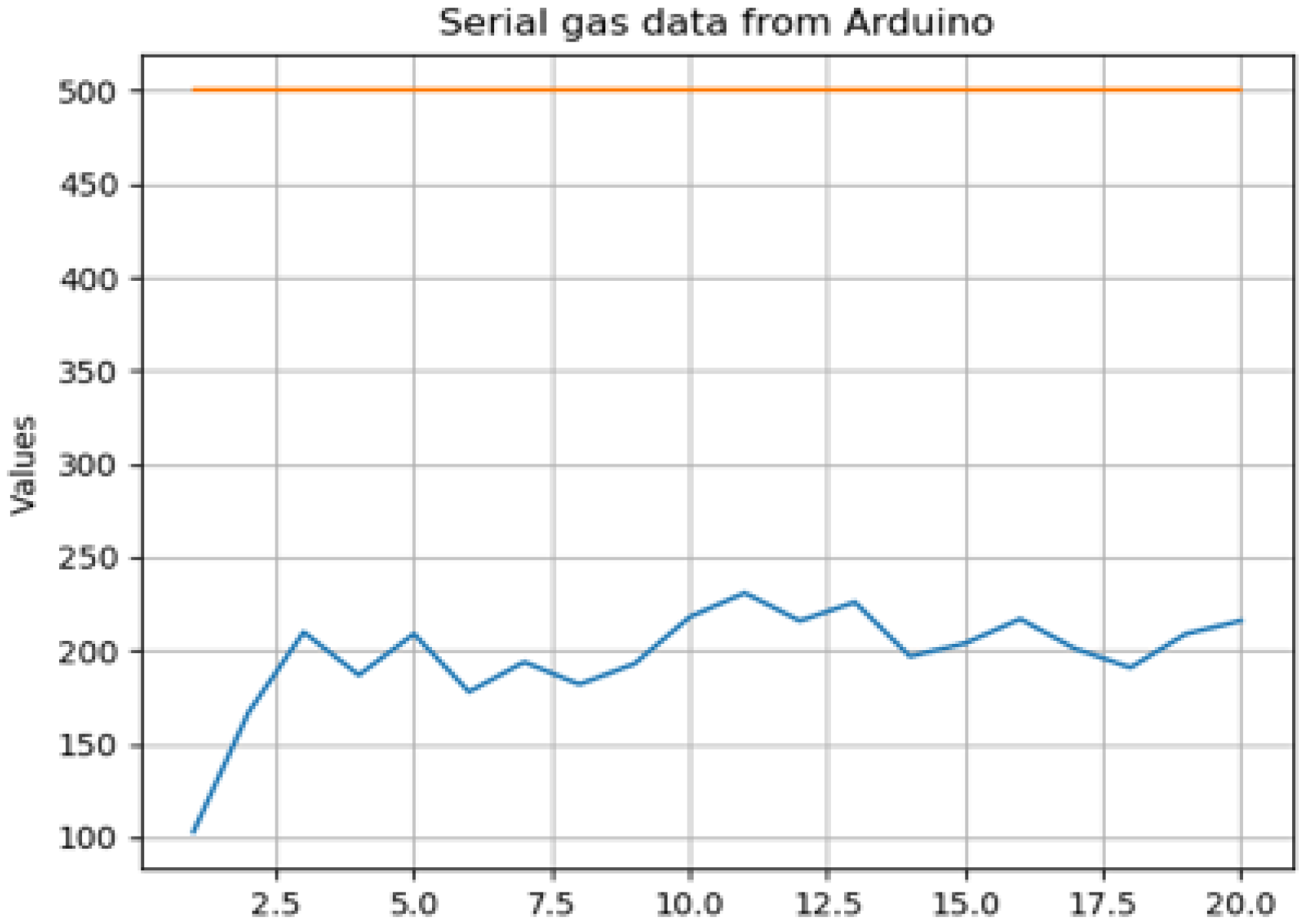
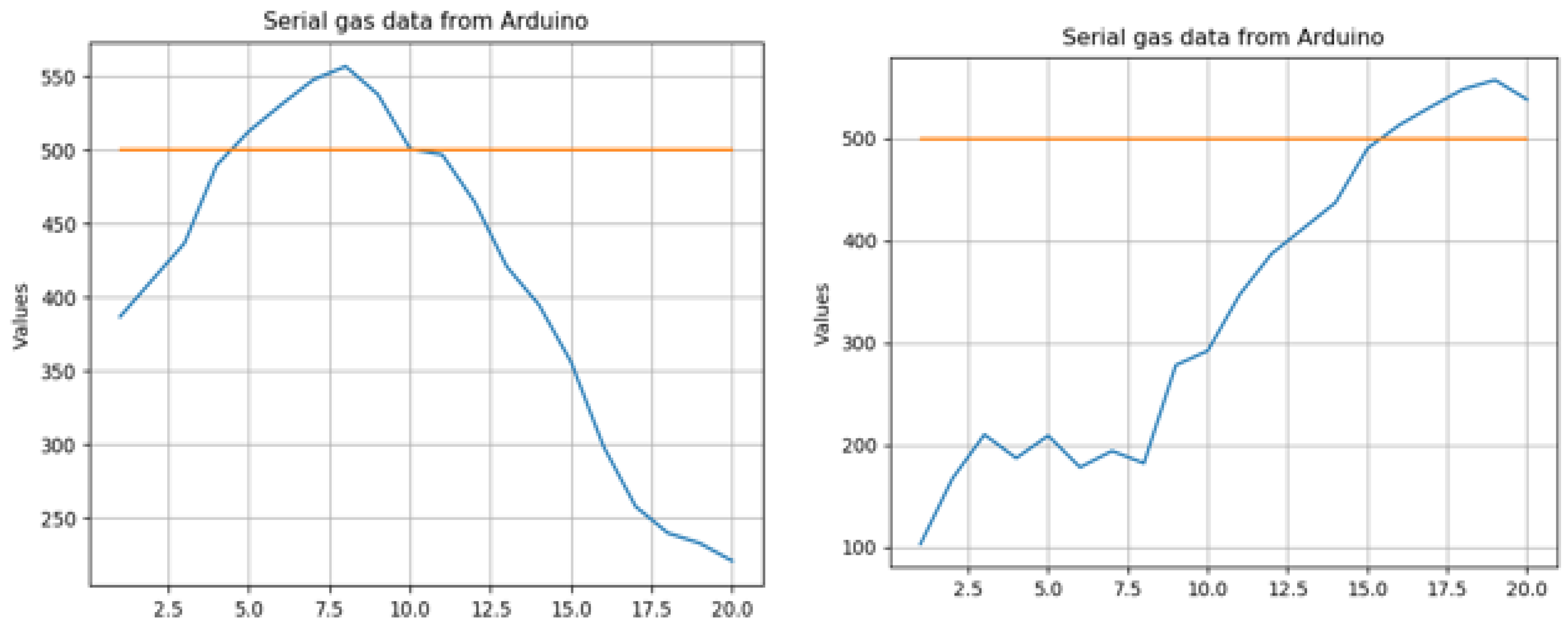
The graph in
Figure 8 shows a normal acetone gas curve with all values below 250 ppm. This level is safe and does not cause harm to human health. An orange line was drawn to display the accepted limit of moderate acetone ppm levels. To test the system, a cloth was soaked in acetone and left on the floor. When the robot car passed by it at a close distance, MQ-2 sensed the vapours and spiked above a 500-ppm level threshold for a short period of time,
Figure 9.
The
Table 6 gives a good understanding about the complexity of the entire solution from a different point of view.
The Edge ML can be used for the video stream feed as well, but we preferred to use it to enhance the reported values of the accelerometer from the tech glove and to do inference on the module from the glove. This allowed better refined values after the feed-forward neural network was applied, as presented in the second section of this paper.
5. Visual Computing of the UAV/Drone PoC Development, Experiments and Results
The aim of this section is to present how machine learning and drones can be used to facilitate the control of an unmanned aerial vehicle through poses and gestures made by an individual, as opposed to the classical usage of remote controllers, smartphones, or other devices. To achieve this goal, the authors used a Raspberry Pi 4 Model B/4 GB and an MPU6050 6-DoF accelerometer and gyroscope to control a DJI Tello drone through hand movements and gestures. This topic is like the previous section of this paper; however, in addition to hand movements, pose estimation algorithms are used to recognize and classify the positions of multiple individuals’ bodies from the drone’s video feed.
One of the most interesting branches of deep learning is computer vision, in which convolutional neural networks (CNNs) are the most applied in practice. This allowed impressive feats of engineering, such as advances in autonomous vehicles through autopilot, autonomous anomaly detection in production lines, and cancer diagnosis through radiographies [
60]. Computer vision also helped in landing the NASA Perseverance Mars mission by analyzing the planet’s surface in real time and detecting the best place for landing.
The most common applications of computer vision are posed estimation, optical character recognition, facial recognition, gesture recognition, pattern recognition, and object recognition. Current usage is seen in classification problems, a subset of supervised learning. This is because of the reliability of the detection of the edges from images. Stacking detections on top of each other makes it easier to “recognize” the desired feature in an image. Furthermore, because videos are nothing but thousands of image frames that are changing rapidly, the same approaches have high performance for the videos as well.
A typical workflow of a Computer Vision solution could be structured as follows:
- ▪
The first stage involves image acquisition. The most important characteristic of an image is its illumination. Closely following in importance, in no particular order, comes the camera quality, contrast, and focus [
66].
- ▪
After acquisition, most images are pre-processed before any other work is done to make it easier for a model to extract features from this input. Pre-processing can be as easy as size reduction or as complex as hue, saturation, and gamma corrections. Often, these two steps can lead to either a successful model or an ever-failing model.
- ▪
Feature extraction is the next step in a typical computer vision pipeline. Usually, this refers to the detection of lines, edges, ridges, corners, etc., which remain the sole components of the processed image, by reducing all to a background. After extracting the relevant features, the pipeline then detects and segments the data into regions or sets, which contain the most important information for finding the optimal solution to the problem. These are the prerequisites needed to finally reach the crucial step in a pipeline that handles high-level processing. It validates the input data and estimates parameters, such as position, distance, and size.
- ▪
High-level processing is a step in which recognition or registration is performed [
66].
- ▪
The final step in a typical computer vision pipeline is the decision-making step. For example, in classification problems, this step aims to determine whether the input data is a match. For sensitive solutions, such as those from the medical field, this step depends on the notification of an approval performed by a human [
66].
It is not mandatory for all models to follow this structure; however, sometimes, the input data is in a format that allows for some steps to be skipped. The same step needs to be replicated at different points through the pipeline lifecycle. There are cases in which only using image processing is sufficient to obtain the solution. The effect stemming from the varied approaches to any single problem is prevalent in machine learning, not just computer vision. This is because most of the time, the best model is the one tailored to the input, rather than the one recommended by theory alone.
Keypoint detection, commonly referred to as pose estimation, is a superset of models used to detect and estimate the pose of one or more humans in images or videos. It can also be extended to the pose of other living beings, such as mammals or reptiles. Common approaches to this problem are models, such as convolutional pose machines or part affinity fields. They are commonly used in articulated body pose estimation, a set of algorithms concerned with recovering articulated body poses by using joints and rigid parts Ref. [
67].
The relatively recent lack of efficient, reliable, and scalable real-time estimation of two-dimensional body poses is a longstanding problem that allows machines to gain a more meaningful comprehension of people in images and videos [
68]. Some algorithms provided high accuracy at the expense of performance and hardware requirements, while others that mitigated those issues suffered from performance drops proportional to the increase in people in the input data.
Convolutional pose machines aim to resolve these problems by combining the benefits of both pose machines and convolutional architectures. Using convolution to extract features of the image and the spatial context directly from data, they used the sequential learning process of associating multi-part cues and the overarching image. Using multiple convolutional networks, each iteration diminishes ambiguity from the initial detection, reducing the final prediction to the relevant key points. This approach allows for end-to-end training through backward propagation, with predictions benefiting from spatial models that are dependent on the input image [
67].
Pair Affinity Fields is a term coined by the team of Zhe Cao et al. of Carnegie Mellon University’s Robotics Institute, whose members and works are presented in [
68] in more detail. It refers to a non-parametric representation of body parts that are associated with an individual. The representation is created through two-dimensional vector fields, where the position and direction of the body parts are encoded. This allows for more meaningful insight into the anatomy of a person’s body pose [
68].
Owing to the large number of algorithms, frameworks, and models that exist in this scientific study, this study focuses on what is currently considered the state-of-the-art model for key point detection. This model was developed by Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh of Carnegie Mellon University’s Robot Perception Lab from Pittsburgh, Pennsylvania. It is a model used to estimate 2D poses of multiple people in real time, including hands, feet, and faces, using partial affinity fields. Their model is considered in such a high regard that it is now included in multiple machine learning frameworks, such as Google’s TensorFlow or OpenCV’s Deep Neural Network module.
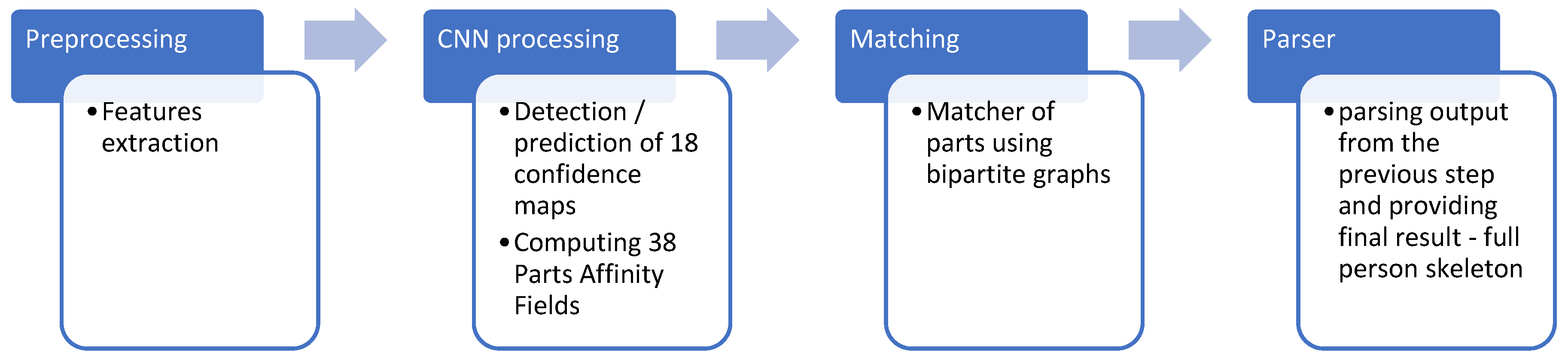
The architecture used by OpenPose comprises a pipeline with four steps. The first is tasked with receiving an input image. The second step has two sub-steps, which ran in parallel, one handling the detection and prediction of confidence maps, while the other handles the part affinity fields. The output is then processed by the next pipeline component, which runs a bipartitely matching the two results, creating the initial estimation result, which is then fed in the last step, which parses the result and provides the final estimation,
Figure 10.
The convolution employs a 3 × 3 kernel for each iteration in a 10-layer neural network. OpenPose supports hand and facial estimation and fully predicts the anatomy of the people in the input image(s) [
68].
The approach proposed and employed by [
68] provides great performance and efficiency, as it focuses on all the subjects in the input at once, and uses a bottom-up approach, first predicting body parts and associating them with everyone. After generating the part affinity fields, each iteration infers who owns each body part, reducing the time needed to estimate by half.
The primary hardware component of the solution was a drone. The DJI Tello drone model was used because of its availability to regular consumers, size and weight (which allows for no regulatory approval from the government for its usage), and affordable price. It benefits from an easy-to-use API, developed, provided, and documented by the DJI. To communicate, it broadcasts a Wi-Fi UDP connection that is accessible to any controller. The term controller represents any programme that sends commands to the drone. The architecture is composed of three layers: the command layer, the state layer, and the video stream layer, each using a different UDP server and port and accepting clear text commands/requests.
The second part of the architecture is composed of two separate hardware devices. The first is a Raspberry Pi 4 Model B/4 GB single-board computer. The other is an TDK InvenSense MPU6050 6-DoF (degrees of freedom) accelerometer and gyroscope: Invensense Manufacturer, USA. These components are connected through an HQ breadboard of 830 points using male-female-colored wire connectors. To see the live drone feed, the Raspberry Pi is connected through a USB-C cable to an Android device supporting USB tethering. The phone is then used to access the single-board computer through the VNC protocol, using the VNC Viewer client made by RealVNC. The Raspberry Pi hosts and runs a VNC server. In production, the Raspberry Pi single-board ARM computer is not recommended, but for the PoC is good enough, owing to its availability, price, and choice of embedded Linux operating system.
The MPU6050 addition was made because of its well-established accelerometer and gyroscope, having a technical sheet that is intuitive and has a low power consumption of 3.3–5 V.
The cables connecting the Raspberry Pi and MPU6050 are male-female-coloured wire connectors, which have a length of 20 cm. While the MPU6050 supports running on 3.3 V power, it is possible to use the standard 5 V power GPIO connector of the Raspberry Pi because no additional electronic components will be connected to the single-board computer, thus having no competing hardware “modules” to distribute electric current to. Owing to safety concerns, for most of the development, the accelerometer was rested on the breadboard to ensure that no conducting surfaces would touch it and to make it easier to handle, while analyzing the received data.
The approach of using the poses of the person facing the drone to control its flight showed its limitations early in the development process. Since the protocol used by the drone to communicate was UDP, this already meant that the video stream it was sending was unreliable. This means unreliable estimations of a person’s positions. In this situation, the control would either be sparse or wrong, and the computer vision algorithms have a high probability of running into difficulties predicting positions. Because of these concerns, the approach has been changed to employ both gesture interpretation using the accelerometer and gyroscope and pose recognition on the video stream. The major change from the initial idea was the computer vision component. Instead of using this feed to decide the path that the drone would take, it now detects the bodies and poses of people in front of the drone and displays it to the “pilot,” on a GUI.
Owing to these changes, the control drastically increased in reliability because the MPU6050 is connected directly to the Raspberry Pi, meaning little input lag and no data loss. Reliability also increases with longer travel distances from the person controlling the drone, allowing them to access any area within the drone’s maximum flight distance. Currently, drones are capable of surveying different areas, even those inaccessible to humans. This brings much more utility to the solution, as it can be used to find missing or trapped people, scout areas ahead of the person reaching them, or even provide cues to help position it in better suited places for different purposes, such as cinematography. Because the computer vision pipeline works even in above-normal bright or dim environments, it can still be used, even if human eyes are not able to properly identify the surroundings of the drone.
In terms of architecture, as mentioned above, there are several constraints that should be known, which influence the development and architecture of the PoC. First, the biggest constraint is the UDP protocol used by the drone to communicate. Because this is an unreliable connection, the video stream cannot be used as the sole method for piloting the drone because the computer vision pipeline would not be able to constantly determine the correct commands to send to the drone. This would not only be undesirable but also dangerous, as the drone would fly without control for varying periods of time.
The second constraint is the performance impact of the solution. Because it uses threads, networking, I2C, and a machine learning pipeline, the hardware required to run the programme needs to be sufficiently performant. This limited the options, leading to the choice of the Raspberry Pi 4 Model B/4 GB. While less performant single-board computers can handle the load, it is normal to ensure the best performance availability even for a PoC.
Another constraint comes from using the Raspberry Pi, along with the breadboard and short-length cable connectors. Because flexibility is important in prototyping the design, these components are needed. This means that the final product is not wearable because the wires are not soldered onto the breadboard, single-board computer, or MPU6050 MEMS. Without soldering, it is easy to accidentally unpin them, losing power, or connecting components. As the Raspberry Pi has a moderately high-power consumption, needing to be kept plugged into an electrical socket, this would also hinder wearing the device on one’s hand.
The orientation of the MEMS header pins creates another constraint, as they define the position and orientation of the gyroscope and accelerometer. This determines the logic for gesture detection, as it depends on which axis is placed parallel to the body and which one is placed perpendicularly, as well as on which plane, they are found. This limits the possible ways to wear the MPU6050, as well as how gestures are performed by the “pilot.” In addition, the header pin orientation also determines how the Raspberry Pi is positioned with respect to the MEMS. We decided to solder the MEMS header pins using a 90-degree pin connector, which allowed the MPU6050 to rest horizontally on a hand, parallel to it. We find this to be the most natural option. This meant that, from the perspective of the “pilot,” left and right are directions found on the Y axis, left being a positive value, right being a negative one, while forward and backward would be found on the X axis, with a negative value meaning forward and a positive one meaning backward. Up and down are found on the Z axis, with the natural expected directions, up meaning a positive value and down a negative value.
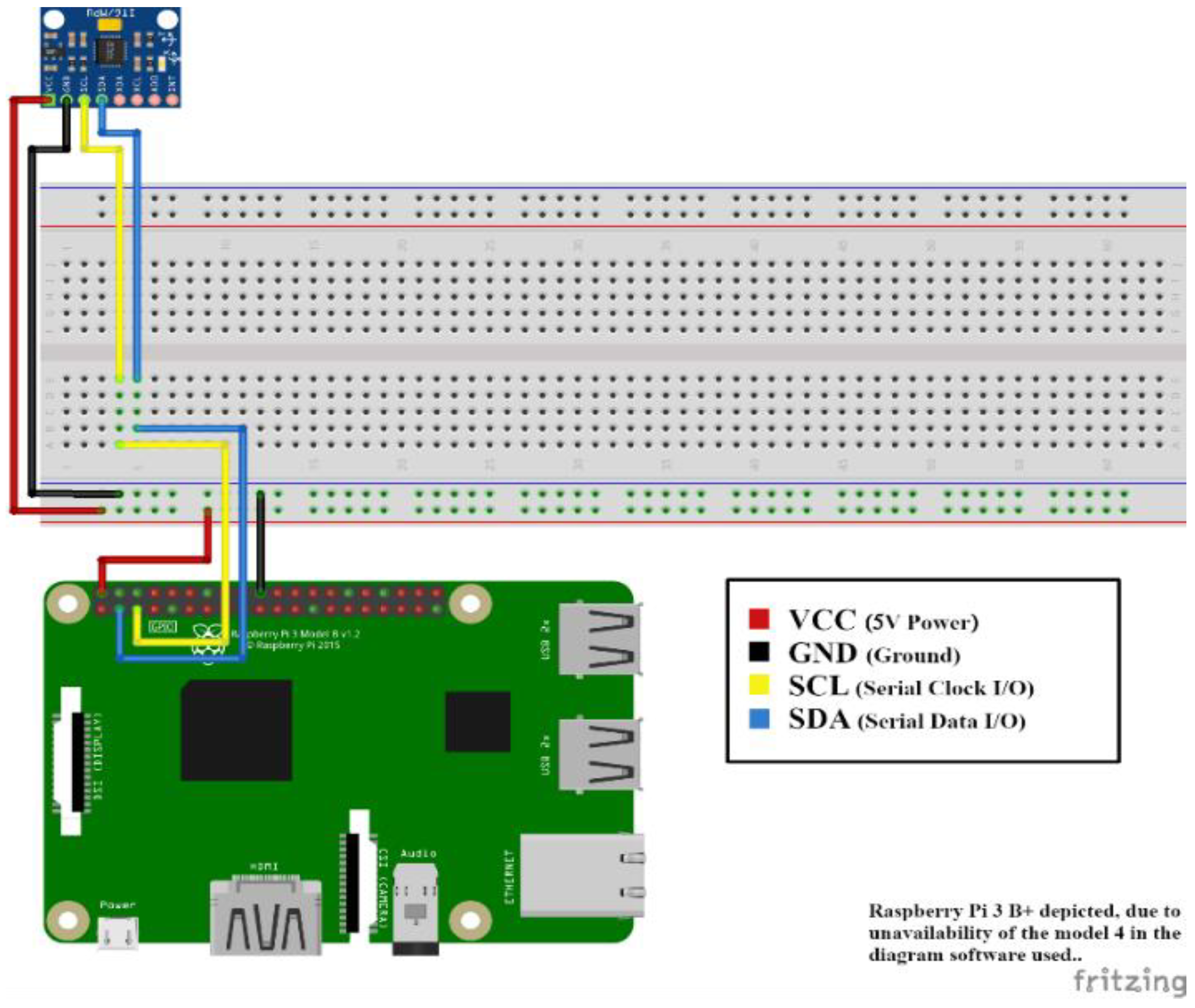
The following workflow is required to start the solution. First, the Raspberry Pi and the
MPU6050 need to be connected, as shown in
Figure 11, through male-female wire connectors placed on the breadboard. The Raspberry Pi needs to be powered on and, after a short wait, the Android smartphone used as a screen can connect to it, using the VNC protocol. There are several ways to obtain the IP of a single-board computer. Because Android no longer supports static IP addresses for USB tethering, the configured Raspberry Pi was connected to the same Wi-Fi network router where the mobile phone was connected. This allows the use of a static IP for this network. The configured Raspberry Pi uses the 192.168.1.71 IP v4 address, thus allowing the connection from the Android device via SSH. Finally, after connecting via SSH, one can obtain the USB tethering dynamic IP address and connect via the VNC Viewer client made by RealVNC.
The next step is to power the DJI Tello drone and connect it to its Wi-Fi network, using a smartphone to control the Raspberry Pi. Finally, the solution can start from a terminal. Once it is running, the device file is first opened, and the bus address of the MPU6050 is configured. Subsequently, the program calibrates the MEMS by reading the accelerometer and gyroscope data for several iterations and averaging it to compute the initial offset. The process and progress are shown in the terminal via standard output. After calibration, the terminal shows both the MPU6050 data and communication with the drone, such as what commands are sent, and the received responses. In addition, a GUI also starts to display the video stream of the drone, overlaid by the pose estimation resulting from the computer vision pipeline.
To fly the drone, a take-off command must be issued. This is performed via a special gesture recorded by the MPU6050. This gesture is unique to the previously mentioned command, and unless the drone is landed once more, it will not have any effect. To land the drone, a special secondary gesture is required. Both gestures were made on the Z-axis of the accelerometer. Flight is controlled via natural hand movements and gestures, such as raising the hand, leading to increasing altitude, lowering it leads to downward movement. Left and right flights are performed in a similar manner by rotating the hand on the X-axis of the gyroscope. The orientation of the drone is controlled by rotation of the hand on the Y-axis of the gyroscope.
To recognize a pose and display it on top of the raw video stream of the drone, a specialized service is created. To assign the drone live feed and use it in the recognition, the service exposes a setter method. Start and stop methods are also exposed to begin and end the process of displaying the graphical user interface, which will show the output of the machine learning pipeline. Because the process is generally slow, especially when the number of people for a given frame is large, and because the Raspberry Pi does not have a dedicated GPU or many resources and processing power, the entire recognition and display process is running on its dedicated thread, to allow the drone to be continuously controlled in real time through the movements of the accelerometer and gyroscope of the MPU6050.
To improve the performance of the pose recognition model, it uses only the general body model. OpenPose provides multiple specialized modules to create an accurate representation of the human body. These include complete facial recognition and complete hand and foot recognition models. However, to use these models, considerable computational power is required, and a dedicated GPU is recommended. Considering these issues, along with the technical specifications of the Raspberry Pi, it would be unrealistic to expect a complete human body model to be identified using this hardware. Because no significant benefits will result, based on the main applications of this solution, and because of the drawbacks, only the general outline of a body is presented.
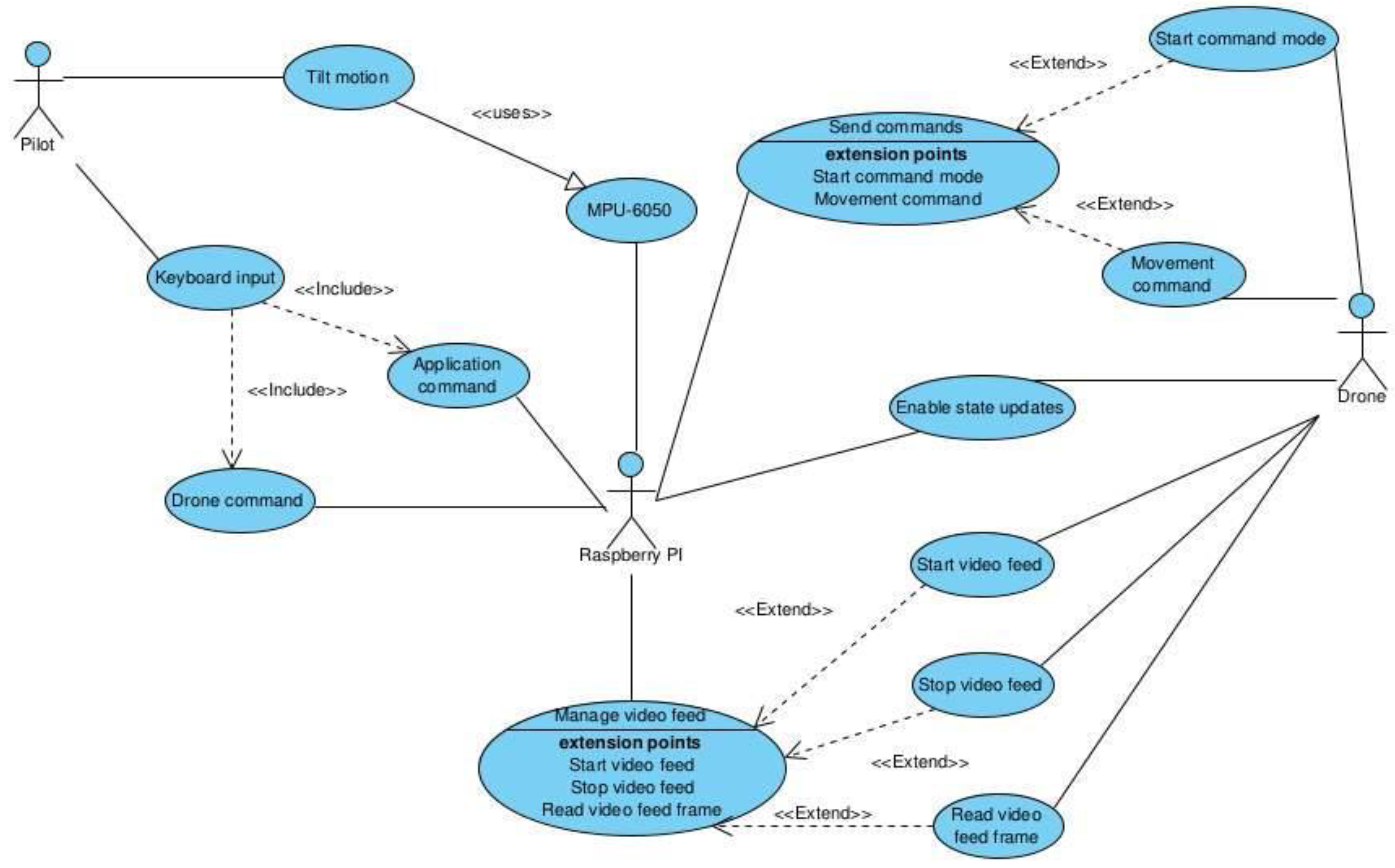
In terms of development,
Figure 12 shows the general UML use case diagram for the solution proposed in this study. The three main actors are the “pilot,” the Raspberry PI, and the drone.
The MPU6050 should not be classified as an actor, as it has no function on its own, only when paired with a single-board computer. Thus, it is used by the tilt motions and the Raspberry PI but cannot be identified as an independent actor. The pilot can make tilt motions, as described previously, or input direct commands through the keyboard to compensate for the reduced number of gestures available. The direct commands are of two types: the application commands, such as quitting the application and the drone commands, preceded by “c”, which are sent directly to the drone. The Raspberry PI, having those two inputs, manages sending commands, such as starting the command mode or movement commands, enables the state updates available from the drone and manages the video feed, by starting or stopping it and reading frames of the live stream. Finally, the drone executes each input received from the Raspberry PI and sends responses as detailed in its specific developer SDK manual.
The software components tasked with the behaviour are structured into multiple classes, interfaces, and Data Transfer Objects, such as AccelerometerData and GyroscopeData. The structure closely follows SOLID design principles and clean code practices. The MPU6050 class, for example, uses an I2C communication service that handles low-level information exchange between the Pi and the MEMS. This service is a member of a class and, following the dependency inversion principle, it is kept as a reference to an interface, decoupling implementation from usage. Configuration options for the MPU6050 are also provided via an options DTO, which has default values for all the required register addresses and system configurations, such as accelerometer and gyroscope ranges (both of which are further structured as individual DTOs). The default values are stored as public static members of an inner class.
The I2C service interface exposes only a few methods, the minimum required to communicate through this protocol. Specifically, the interface allows reading and writing byte data from and to a register address. The implementation of the interface uses its constructor to connect to the bus address of a device. This is done by providing the device number and bus address (as a hexadecimal value). If either operation fails, the respective custom exceptions are discarded. Continuing the topic of communication services, UDP communications are handled through a helper class, with static methods for socket API programming. Since the sockets API is a C API, it means that all calls are stateless; thus, we found no compelling argument to create a more advanced pattern. As with the previously mentioned service, the UDP helper methods throw custom exceptions in the case of failure. All exceptions that are thrown by the solution are custom exceptions, which inherit the runtime_exception base class available in the standard C++ library.
DTOs in the solution do not follow the strict rule of having only public members because of the extensibility of the C++ operators. To make code easier to follow and less verbose, all the DTOs have at least a couple of operators overloaded. For example, AccelerometerData and GyroscopeData DTOs have overloads for arithmetic operations, which are needed to process the respective sensor’s data to provide meaningful output. The arithmetic operations, which are referred to as division, addition, multiplication, or subtraction of values, and other DTO instances.
This allows clean, short, and easy approaches to understand, change, and debug operations.
To benefit from polymorphism, there is a usage of another recommended approach, employing smart pointers, throughout the C++ code. This is preferred to the classical C-like memory handling because the smart-pointers handle allocation and deallocation based on scopes and object lifetimes, following the RAII principle (Resource Allocation Is Initialization). Using a combination of unique pointers (which allow for only one reference to a single heap-allocated object) and shared pointers (allowing for multiple reference to the same heap-allocated object), this ensured that no memory leaks would occur and remove the memory management responsibilities from development. With the use of move semantics, one can pass ownership of a unique pointer, such as when providing an I2C service to the MPU6050 class, without violating the smart-pointer principles.
Because C++ is structured in header and source files, this leads to many files that need to be linked and compiled. Adding to the complexity, many compiler arguments are usually required for generating warnings and errors and for optimization, as well as libraries that need linking. For a complex project such as the one that is the subject of this chapter, this process is troublesome and highly verbose. To mitigate these issues, the best practice agreed in the industry is to use build systems. The most popular is the Make or CMake build system, which handles cross-platform, cross-architecture, and multiple compilers building of solutions. It can also handle the packaging and testing of solutions.
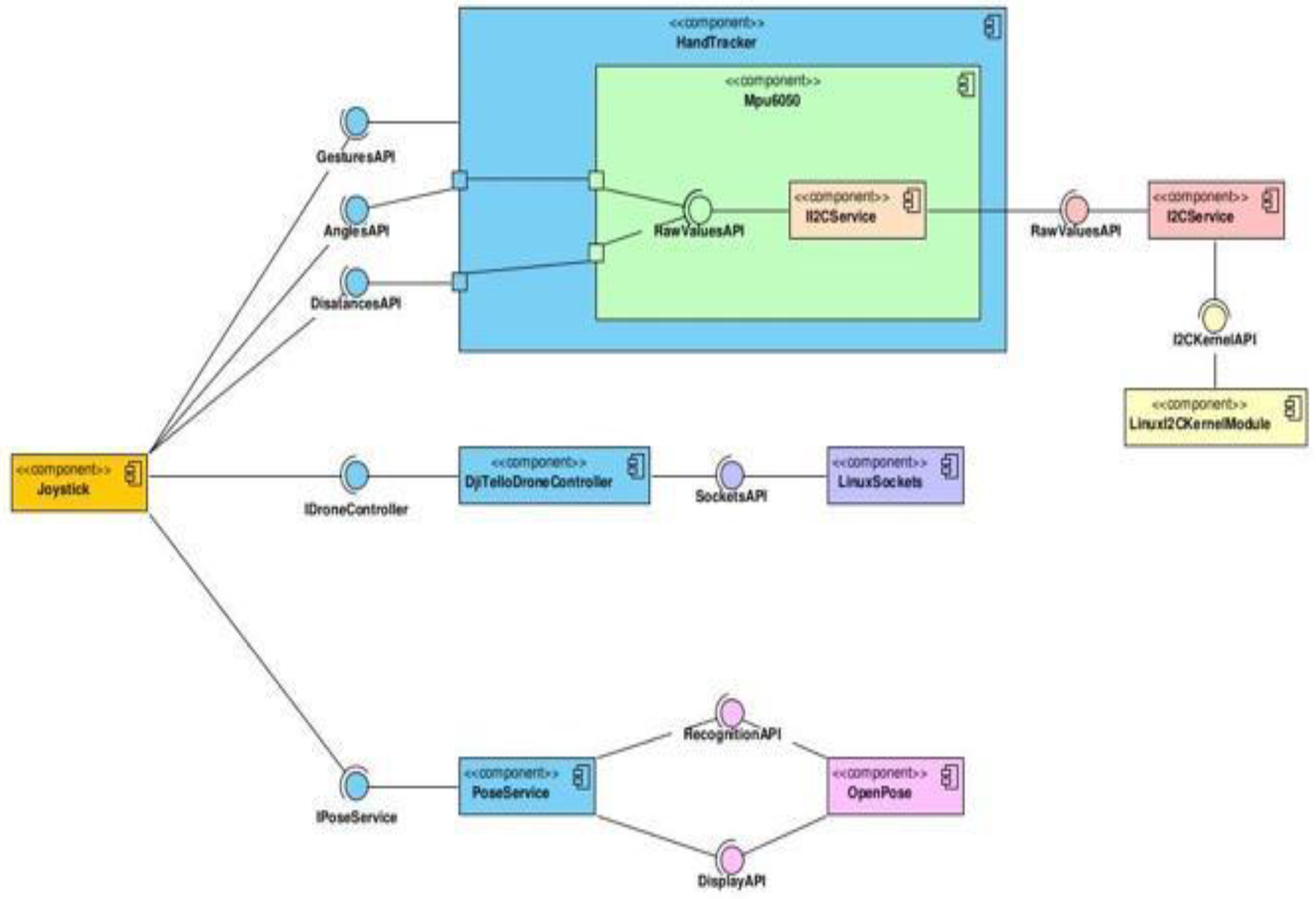
The diagram in
Figure 13 describes the general components of the solution. Not presented in it, is the subsystem used for the creation of drone controllers, as it is not tied directly into the joystick or main solution, as controllers can be instantiated without the factory mechanism available. As discussed above, is the entry point of the solution, that is, the
Joystick component. It is dependent on three others: the
PoseService, the
DjiTelloDroneController, generally any drone controller supported, and the
HandTracker.
The dependency on the PoseService is done through the IPoseService interface, which exposes the API required to recognise the bodies that exist in the video stream. Furthermore, this component is dependent on the underlying OpenPose library, using its recognition and frame-display APIs. The drone controller dependency is accomplished through the IDroneController interface, which exposes the APIs for sending commands, receiving responses, and state of the drone, as well as retrieving its video stream. In addition, this component uses the Linux sockets API to manage the sockets created for UDP communications with the drone. The final main component that the Joystick uses, the HandTracker, fulfils its dependent state through gestures, angles, and distances APIs. In addition, the MPU6050 component is responsible for obtaining and processing the values from the MPU6050 MEMS. The angles and distances API pass data directly to the MPU6050 component and its inner component. Inside it resides in its own dependency, the II2CService component, which is implemented in the I2CService implementation. This component exposes the required APIs to read and write to and from the MEMS, respectively, through the I2C communication protocol. This implementation relies on the Linux I2C kernel module as a dependency to communicate with the MPU6050.
To configure and use MPU6050, the register map is used to find the proper register addresses and the value range supported by each of them. The register addresses are all stored in the class holding the default values of the Mpu6050Options class, as static 8-bit unsigned integer variables, each address represented by its hexadecimal value. For the accelerometer and gyroscope configurations, two separate classes are created, containing an inner enumeration, which determines their respective possible values. The reasoning behind this structure is that C++ enumerations (enums) cannot have members, methods, or multiple values, with only one integer value per element. The wrapper class has a constructor that receives an enumeration value and initializes a private member with its value. The range classes also define private static 8-bit unsigned integer variables that contain the respective register value for each supported range and private static float variables representing the LSB sensitivity values of each range. The classes define appropriate methods and overloaded operators to retrieve those values based on the enumeration (enum) value the instance was given.
When initializing an MPU6050 object, it takes the MEMS out of sleep, using the I2C service, sets the accelerometer and gyroscope ranges, and configures a digital low-pass filter (DLPF) to calibrate the sensitivity regarding the natural forces the system is subject to. Options can be created with default values for the accelerometer and gyroscope ranges, or they can be provided to the constructor. The register values of the MPU6050 are initialized with the value at start-up, representing the initial positions of the accelerometer and gyroscope. To compute an initial offset and be able to measure changes in position at runtime, the MPU6050 class computes an average of values for the two sensors, with the number of iterations dictated by the options it receives. The results are stored and used to retrieve data after initialization. This initial calibration of offsets can be disabled through the options, and initial offset values can be provided instead. Offsets are computed using the same methods that retrieve the sensor data, which use the LSB sensitivity to compute the current positions and then round the result to a specified precision, which by default is three digits. Exposed are also the raw values of the accelerometer and gyroscope, as read from the MPU6050, as they are needed in the Kalman filter, which is presented in greater detail in the next section.
Gesture recognition is performed through the HandTracker class, which receives MPU6050 at initialization. It holds two SensorData instances, which are used to maintain the angles and distances per axis. The distances and angles are updated throughout the lifetime of the object by means of an update loop running on a secondary thread. To compute the distance of an axis, the loop keeps track of the start and end times of each iteration, gathering the accelerometer data from MPU6050. The data are then added to the existing value, after being multiplied by the delta time, as values are read in meters per second. The angle of an axis is computed similarly after reading the gyroscope data, which is added to the existing value, after the same multiplication as for distances. The accelerometer data were also read and converted to degrees, using the values for the other two axes to compute the arctangent. For the gyroscope angle, if the current iteration is the first one of the loops, the gyroscope angles are equated to the accelerometer angles, apart from the Z angle, which is assigned 0, as a starting value.
Following the Resource Acquisition Is Initialization (RAII), the thread is stopped and joined with the parent thread, where the HandTracker is initialized and safely disposed of. A mutex is used to try to lock resources shared across threads. Once the mutex is available, it is locked only during the operation, requiring shared access. The same behaviour is done at destruction to stop the thread, but the wait condition is whether the thread is joinable. The tracker exposes three different methods for retrieving its data: one for the angles, one for the distances, and one for the current gesture.
Gestures are retrieved as a 16-bit unsigned integer. The possible gestures that can be tracked are stored inside the Gesture enumeration, which also uses 16-bit unsigned integers for its values, with each gesture being represented by a different bit being set to 1. The tracker computes the current gestures by initializing 16 bits with 0 and then using the OR bitwise operation to set each performed gesture. This is done by comparing either angles or distances with different thresholds to determine whether a specific gesture was performed. To determine the commands that should be sent to the drone, the resulting integer is compared against the same Gesture values, using an AND bitwise operation, to determine if certain gestures were performed. Commands are added to a buffer for each gesture that was identified and sent to the drone through a given controller.
Because the solution is aimed at flight on no specific drone, the drone controller mechanism is highly extensible and abstracted. An abstract factory pattern was used in this study. For the DJI Tello drone used, a custom factory extends the abstract one and offers a method to construct a DJI Tello controller object. Upon construction, this controller opens three sockets and connects to the command server of the drone using one UDP socket as a client, while the remaining two sockets are used as servers for the drone state and receive its video feed. The destructor handles sending appropriate commands to land and shutdown the drone. This controller and any other controller will implement the IController interface, which defines methods for obtaining the video stream and sending commands to a drone. The feed is returned as an OpenCV Video Capture object, and the socket IDs are represented by integer values.
To control flight in a stable manner, the raw data of the
MPU6050 inertial measurement unit must be processed in a particular manner. The usual method used to control white noise, stemming from the influence of gravity on the sensor, as well as the slight, natural tremble of a hand, is to use filters on the data. Measuring only the gyroscope data and processing it yields unusable results because slight sequential movements lead to considerable variance between them. The second method, which is frequently used in such applications, is to use a complementary filter. A complementary filter is computed as follows:
where the angle is represented by
, gyroscope readings are represented by
, accelerometer readings are represented by
and
represents the time difference from the previous reading to the current one. Finally,
α is a constant that determines the weight of the gyroscope and accelerometer data in the result.
Both solutions, which are easy to implement, do not offer reliable data without additional processing of the input noise. Even after applying a digital low-pass filter directly to the MEMS, as well as setting a sample rate divider, the errors in the measurements were high. The optimal solution was a Kalman filter. The principal idea behind the Kalman filter is to use periodic measurements containing white noise to estimate the value of a variable. This is more accurate than the previous versions because it employs a joint probability distribution in the estimated computation. The computation considers both the predicted system state and the raw measurement and performs a weighted sum to output its estimate.
In a Kalman filter, the initial angles are set to the initial accelerometer readings, and the weights of the final sum are given from the covariance of the system. The covariance, in the context of the filter, represents the uncertainty of the estimation. The error and covariance are updated with each iteration of the filter, and the results are fine-tuned. Thus, the algorithm only depends on the values of the previous step to compute the next step. This is highly efficient, both in terms of runtime speed, as well as in memory usage, for an application running continuously and accepting input in real-time. Over time, the filter slowly accumulates gain, leading to erroneous results. To counteract this effect, checks are put in place, which verifies that the accelerometer and Kalman values for the x-axis do not have a difference of 180° between them. If the result is positive, then the Kalman angle is retrieved; otherwise, the accelerometer value is used for the current iteration and assigned to the Kalman angle.
The primary disadvantages of this approach are losing one of the axes, the z axis, also known as the yaw, and restricting the values of another, the y axis, also known as the pitch, to degrees. The lack of yaw is attributed to the inability to measure it using an accelerometer, owing to the influence of gravity. To gain access to this 3rd axis, a magnetometer is required, which comes with the MPU9250. The MPU6050 only comes with six degrees of freedom, and thus lacks this component. The second disadvantage is the mathematical solutions derived from the equations of the filter. Without restricting either the roll or the pitch, two independent solutions to the system can be found, thus making it impossible to choose the “correct” one. Limiting one of the two axes restricts the solution space to only one such solution to the system. This also allows the other axis to have a range between degrees. The choice was to restrict the pitch, as the PoC application will only check for a maximum of ±90° on any given axis.
The component responsible for handling communications between the HandTracker and drone controller is the Joystick. It contains a drone controller instance, a HandTracker instance, and a pose service instance. Exposing only one public method, the Run() method, starts a loop, similar to a game loop, meaning a centralized point where the flow control is described.
The main flow is defined as:
- ▪
Get the current gesture from the HandTracker.
- ▪
Use the drone controller to parse gestures into commands that the drone can understand; send each command to the drone.
- ▪
Wait for a few milliseconds to ensure the “pilot” has time to adjust their gesture. Alongside this loop, there is a second, on a different thread, which listens to keyboard input from the pilot, for commands lacking a specific gesture or for emergencies in which there is no room for error in command interpretation.
- ▪
Finally, before any of the two mentioned loops start, the pose service is used to start displaying the video feed of the drone by passing the video stream the drone controller can provide.
Pose recognition is handled through a specialized service that implements the IPoseService interface, which exposes methods for assigning a video stream, as an OpenCV VideoCapture instance, and for starting and stopping the recognition and display process. Starting the recognition and display process creates a thread on which a loop runs at each step, retrieving the current frame from the VideoCapture instance. The frame is then processed through the OpenPose API, which uses an asynchronous wrapper to extract the keypoints of the bodies in the frame and apply them to the raw data. The result is a complex OpenPose object that contains both the keypoints, the raw frame, the new one, and additional information concerning recognition. Finally, the new frame is passed to the display method, which validates that it is not empty, retrieves the new frame, converts it back to an OpenCV matrix instance, and uses the OpenCV API to display it in a GUI on the screen.
The
Table 7 gives a good understanding about the complexity of the entire solution from a different point of view.
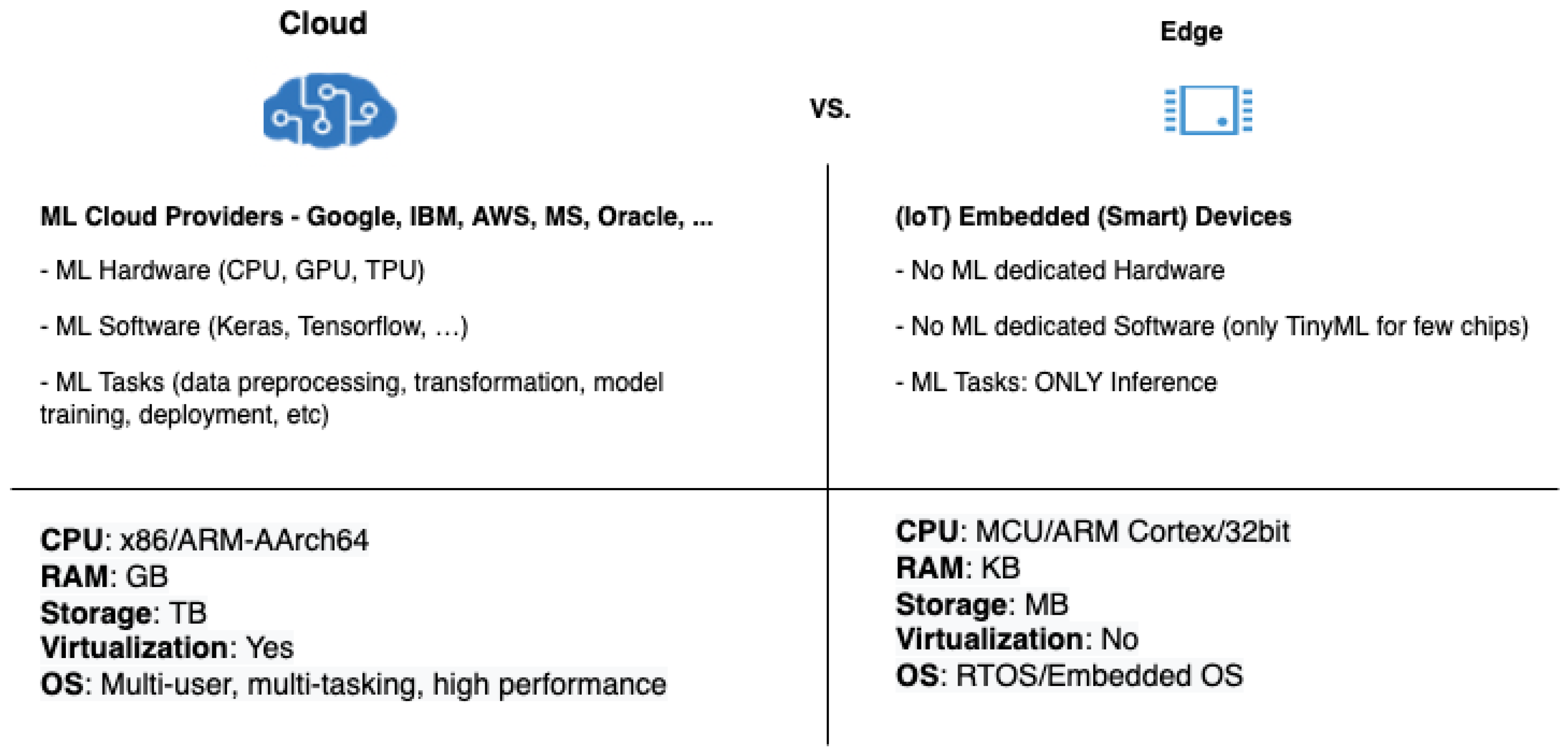
In addition to the OpenCV API, additional neural networks can be trained in the machine learning cloud to have a dedicated inference for the edge applied on the objects identified by the OpenCV API.


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}