




Algorithms for the Structural Analysis of Multimode Modelica Models


Abstract
:1. Introduction
- Initialization, in which initial conditions consistent with the multimode DAE system must be specified;
- Long modes, which are modes lasting for some positive duration, each one being governed by a specific DAE dynamics;
- Mode changes, which are events separating two successive long modes and possibly requiring a specific reset of the state of the system;
- Transient modes, which are modes with zero duration in which a specific dynamics is in force; such modes can occur in finite sequences called cascades. Transient modes occur, for example, with elastic impacts in contact mechanics: this is illustrated below by the Cup-and-Ball game example, a multimode variation of the celebrated pendulum in Cartesian coordinates.
2. Multimode Modelica Models
2.1. A Simple Two-Equation Model
- When p is true, x is a leading variable, meaning that it is the unknown that needs to be solved;
- When p is false, the leading variable is x′, the first-order time derivative of x, while x itself is a state variable.
2.2. A Simplified Water Tank Model

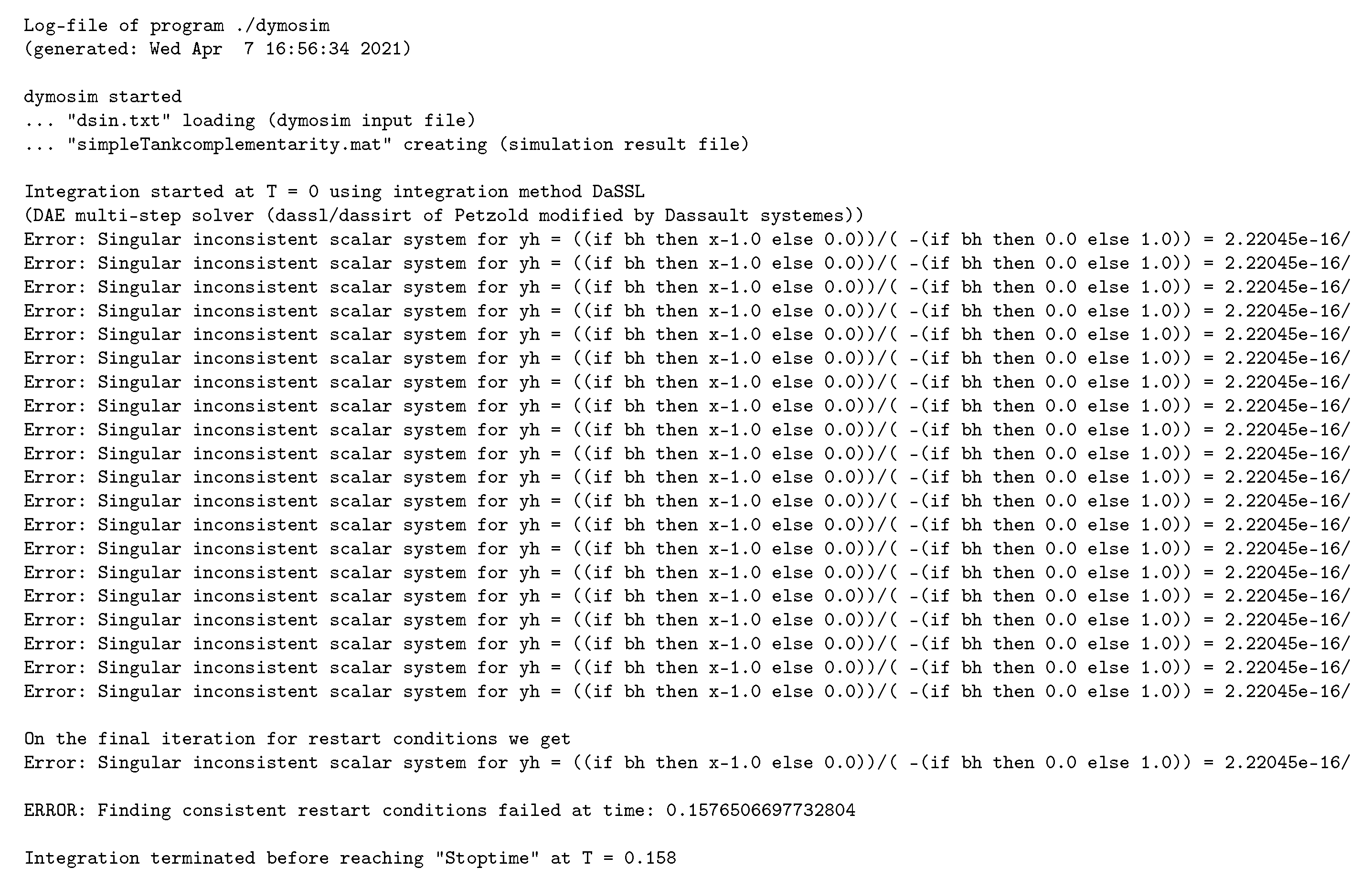
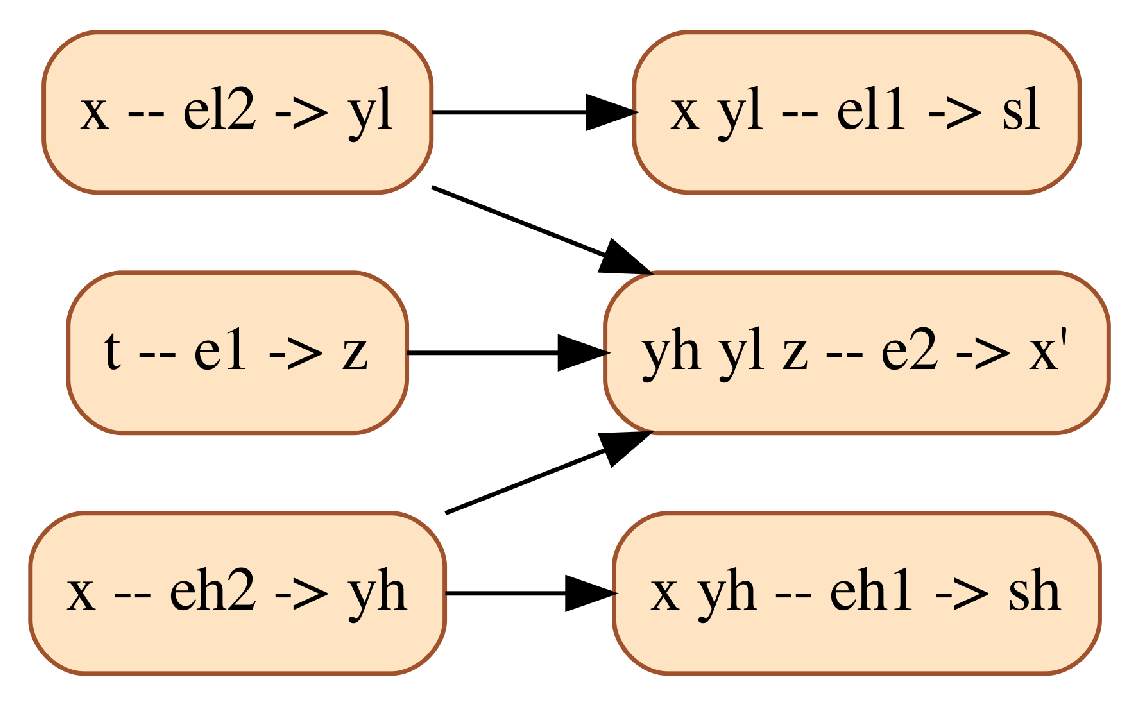
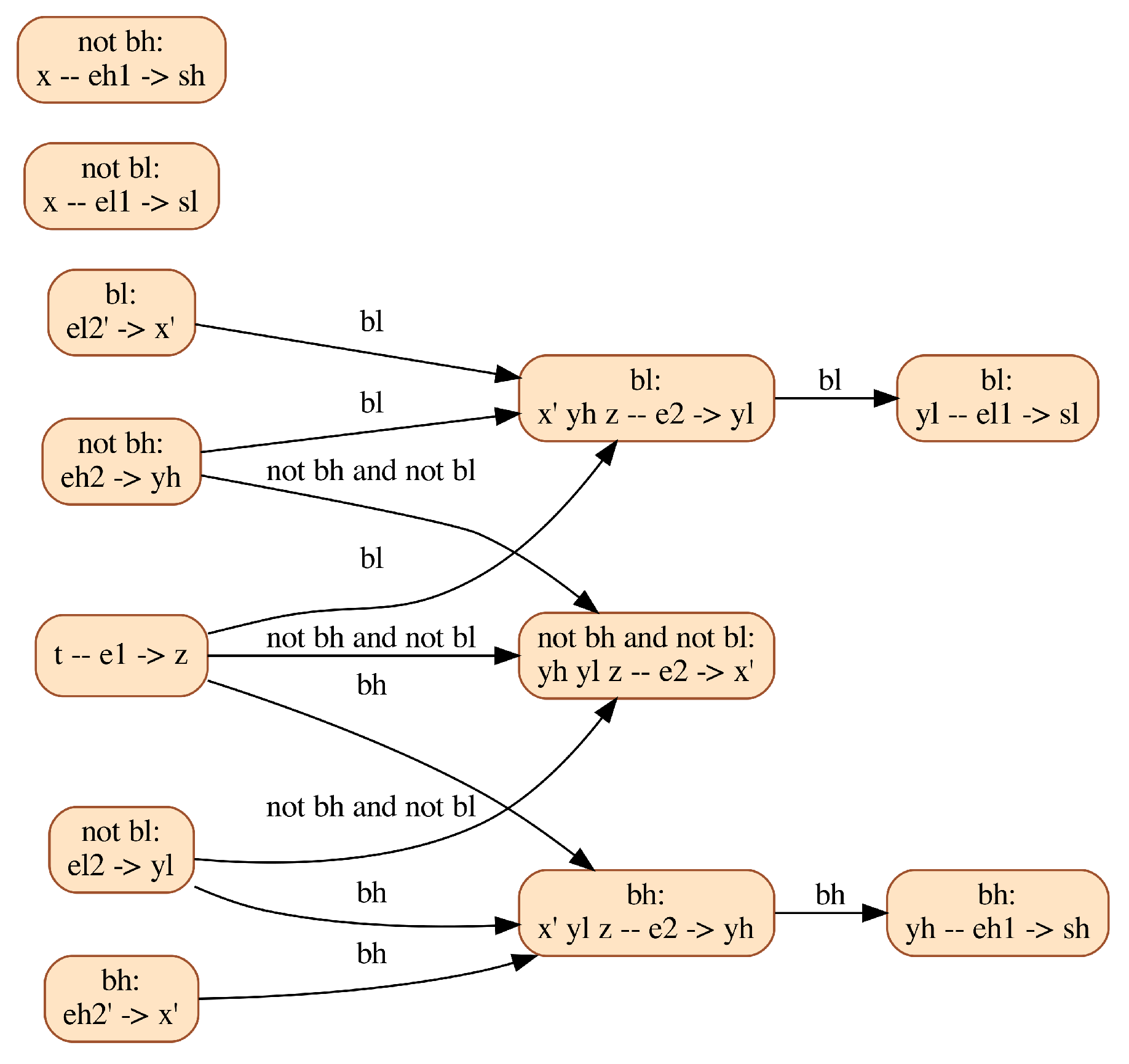
2.3. A Clutch Model
- The clutch in Modelica:
3. A Proposal for a Variable Dimension Extension of the Modelica Language
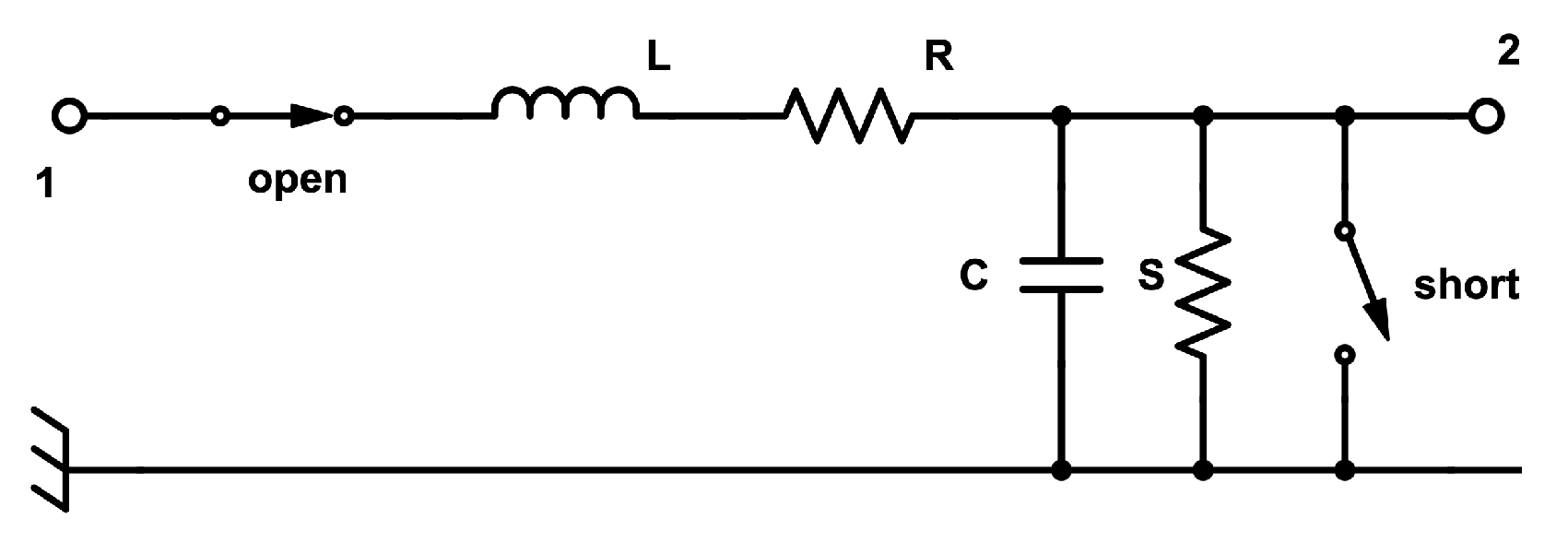
- Nominal mode, when the open switch is closed, and the short switch is open (in this mode, nominal behavior is expected, while the other two modes are related to faults);
- Open circuit mode, where both the open and short switches are open;
- Short circuit mode, where both the open and short switches are closed.
4. Algorithmic Building Blocks
- A concise representation of the mode-dependent structure of multimode systems, Section 4.1;
- A multimode extension of the Dulmage–Mendelsohn decomposition, Section 4.2;
- A multimode extension of Pryce’s -method, Section 4.3.
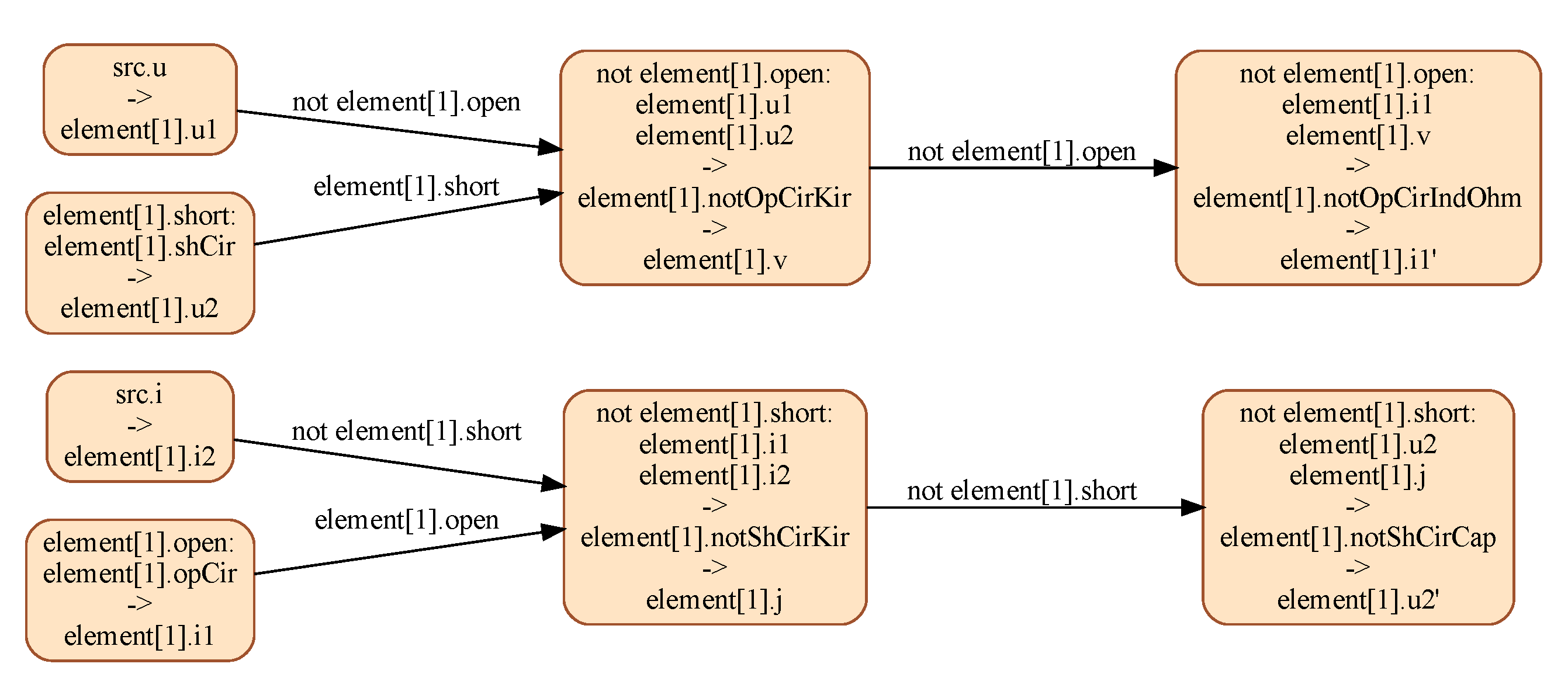
4.1. Dual Representation of Multimode Systems
4.2. A Multimode Dulmage–Mendelsohn Decomposition
- , , ;
- a maximum matching of G can only join a vertex of to a vertex of , a vertex of to a vertex of , a vertex of to a vertex of ;
- a maximum matching of G can always be restricted to a perfect matching between and ;
- there is no edge between a vertex in and a vertex in ;
- there is no edge between a vertex in and a vertex in .
- the total orders and are consistent with the DM decomposition, in the sense that the following conditions are met:
- (i)
- , and
- (ii)
- ;
- the incidence matrix of S, with respect to order on equations and order on variables, is in upper block-triangular form.
- and are the subsets of I and J (respectively) that are reachable via an alternating path from ;
- and are the subsets of I and J (respectively) that are reachable via an alternating path from ;
- and collect the remaining equations and variables.
- Multimode extension:
4.3. A Multimode Extension of Pryce’s -Method
- Initialize to the zero vector.
- For every ,
- For every ,
- Repeat Steps 2 and 3 until convergence is reached.
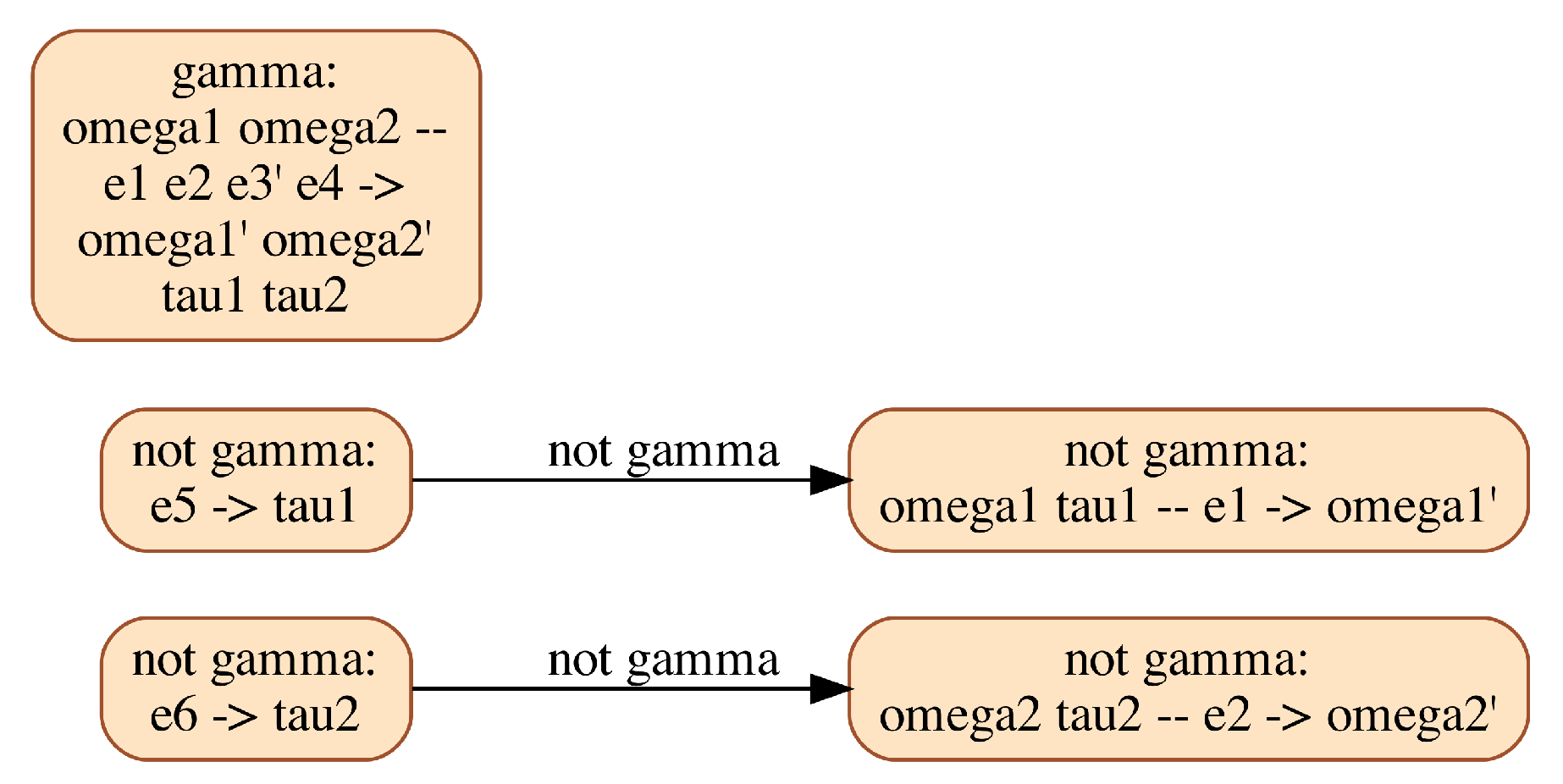
- Multimode extension:
- describes all perfect matchings in all valid modes; it can be computed as the conjunction of several functions, representing the uniqueness constraints on both equations and variables, as well as the constraint that only edges that are active in a given mode can be part of a matching in this mode.
- describes all MWPMs in all valid modes; it can be computed by pruning out from X every matching whose weight is not maximal, thanks to the use of a weight function computed from function .
- restricts S by selecting one and only one MWPM per valid mode; it can be efficiently computed by an inductive algorithm on the BDD encoding function S.
- For convenience, a function is computed for every edge , indicating the valid modes in which edge e is part of the chosen MWPM.
- Initialize to the zero function.
- For every ,
- For every ,
- Repeat Steps 2 and 3 until convergence is reached.
5. Addressing the Scalability Challenge with the CoSTreD Method
5.1. Related Work
5.2. Constraint Dependencies Follow Component Interconnections
5.3. Generic Single-Mode Formulation
- is a set of reward functions on set X; for any valuation , we denote .
- This set of functions expresses the quantity to be maximized. In the primal problem, the objective function given by (9a) is ; it can be kept as a monolithic constraint (in which case it would be the only element in ), or decomposed as the set of constraints for all . By definition of , both approaches yield the same objective function, but the second one ensures a better sparsity of the primal graph of the constraint system.
- is a set of Boolean constraints on the set X of propositional variables; for any valuation , we denote .
- This set of constraints is used to filter out valuations that do not meet the given criteria. In the primal problem, where the propositional variables are the ’s, set collects all constraints (9b) and (9c). Each of these constraints can be seen as a Boolean function that, given a valuation , returns if the constraint holds for , otherwise. As a result, returns if and only if encodes a perfect matching.
5.4. Generic Multimode Formulation
- a multimode Boolean constraint is of the form ;
- a multimode reward function is of the form ;
- the (mode-dependent) maximal weight is defined asand the relationship between this and the unsatisfiability of the set of Boolean constraints now reads
- finally, is similarly extended as
5.5. Unified Formulation
- for each Boolean constraint , we introduce a weighted constraint ;
- for each reward function , we introduce a weighted constraint by just extending the co-domain with .
- two sets of variables X and M, with the same meaning as above, and
- a set of weighted constraints , whose semantics is defined byRemark that the semantics of a constraint system is a constraint itself. In many cases, this allows us to reason on constraints, instead of constraint systems.
- First, we define a multimode valuation as a function , that is, a function that, for each mode, returns either a valuation or . Given a multimode constraint , we define as follows:
- Then, we say that a multimode valuation V is a multimode solution ifFor the solving of the multimode primal problem, this function returns for a given mode if no perfect matching exists in this mode; otherwise, it returns the encoding of a perfect matching.
- Finally, we say that a multimode valuation V is a maximal weight multimode solution ifOn may notice that V is, in particular, a multimode solution. By convention, maximal weight multimode solutions are denoted by . In particular, in the context of the multimode primal problem, is a function which, for each mode , returns an encoding of an MWPM if at least one perfect matching exists, otherwise.
5.6. Single-Mode Decompositional Approach
- Illustrative example
- Forward Reduction: Start from node , one of the leaves of the rooted tree. The constraint sitting in it undergoes two operations:
- Projection: Variables that only belong to node are eliminated in such a way that all necessary information about the maximal possible weight is preserved. This information is passed to node and combined with the constraint sitting in that node.
- Co-Projection: The original weighted constraint sitting in node is turned into a Boolean constraint describing conditions under which a valuation of the variables can be a maximal weight solution of the wCSP. To our knowledge, this operation was not introduced in message passing techniques; it is instrumental to the second stage of the method, the Back-Selection (see below).
This process is repeated toward the root, on node , then on node . In parallel, the other branch is handled in a similar fashion, from node 4 to node 1; the final constraint sitting in node 0, the root of the tree decomposition, combines the original weighted constraint sitting in node 0 with the constraints received from nodes and 1.Solving this constraint can actually be performed by applying the projection and co-projection operators. The former yields the global maximal weight, while the latter provides a Boolean constraint on the set of maximal weight solutions; any valuation of the variables of node 0 that satisfies this constraint is a partial solution, meaning that it can be extended into a maximal weight solution of the original wCSP. - Back-Selection: The Boolean constraints sitting in the nodes of the tree decomposition are the results of the co-projections performed during the Forward Reduction. As we shall see in the rest of this section, the design of the CoSTreD method ensures two important properties: any valuation of the variables that satisfy all these constraints at once is a maximal weight solution, and a partial solution can always be extended into such a solution.To do so, the Boolean constraints sitting in the nodes are taken into account in a top-down fashion, that is, from the root of the tree to its leaves. This extends, in successive steps, the partial solution computed in node 0 into a global maximal weight solution of the original wCSP.
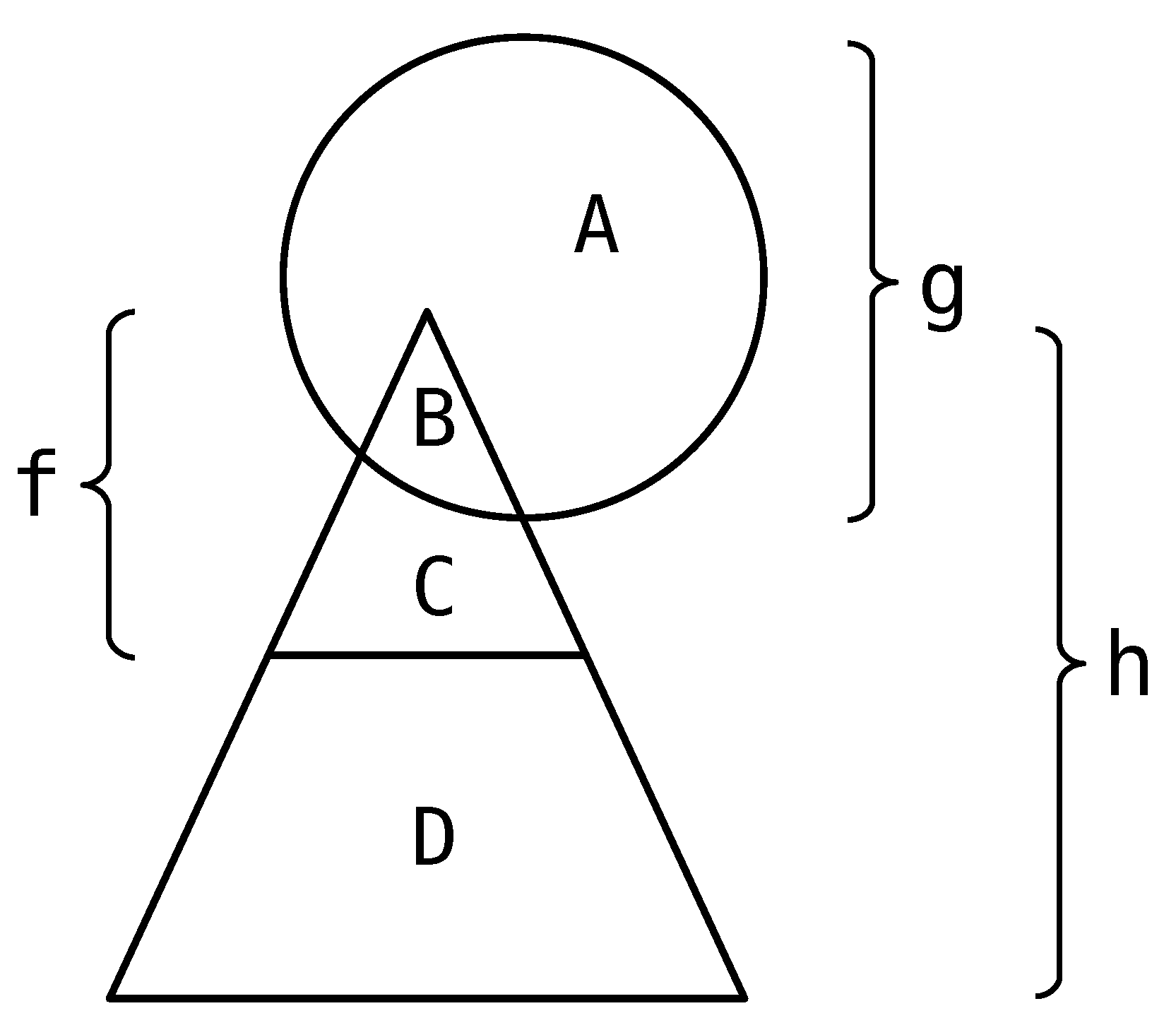
- Constraint System Tree Decomposition
- Nodes are sets of Boolean variables of the constraint system such that, for each constraint f of the system, its support is included in at least one node in B;
- The set of edges forms an undirected spanning tree on B and is such that, for every Boolean variable x, the set of nodes containing x is connected.
- Projection operators
- Forward Reduction
- Assuming and , then
- If , then
- -
- -
- Back-Selection
| Algorithm 1: Back-Selection |
|
- Correctness of the CoSTreD method
- h denotes the constraint obtained by combining all constraints in the sub-tree rooted in s;
- f denotes the constraint to be processed by the Forward Reduction step;
- g denotes the constraint obtained by combining every other constraint.
- ;
- ;
- ;
- h is a Boolean constraint such that .
- 1.
- ;
- 2.
- is forward reduced in ;
- 3.
- , the sub-CSTD of rooted in s, is forward reduced.
5.7. Multimode Decompositional Approach
6. Structural Analysis of Long Modes in the IsamDAE Tool
6.1. Structural Analysis Chain
- Model parsing is performed in order to extract the structural data of the model, as detailed in Table 1, Section 4.1.
- The multimode -method, introduced in Section 4.3, is applied. In particular, the primal problem is solved by means of the CoSTreD method presented in Section 5.
- If the primal problem cannot be solved for all modes, then the set of modes in which no perfect matching exists is extracted; the multimode Dulmage–Mendelsohn decomposition detailed in Section 4.2, and made more efficient with the help of the CoSTreD method (Section 5), is used for computing the under- and over-determined subsystems in these modes. This information is partially returned to the model designer as diagnostics to help them correct their model.
- The Conditional Dependency Graph of system (as defined in Section 4.3) is finally computed and returned to the user. This step is described further in (Section 6 of [6]); at its core, it relies on multimode adaptations of standard graph algorithms, such as Tarjan’s algorithm for computing the Strongly Connected Components of a graph [33], implemented with adapted data structures for efficiency purposes.
6.2. Assessment of Results
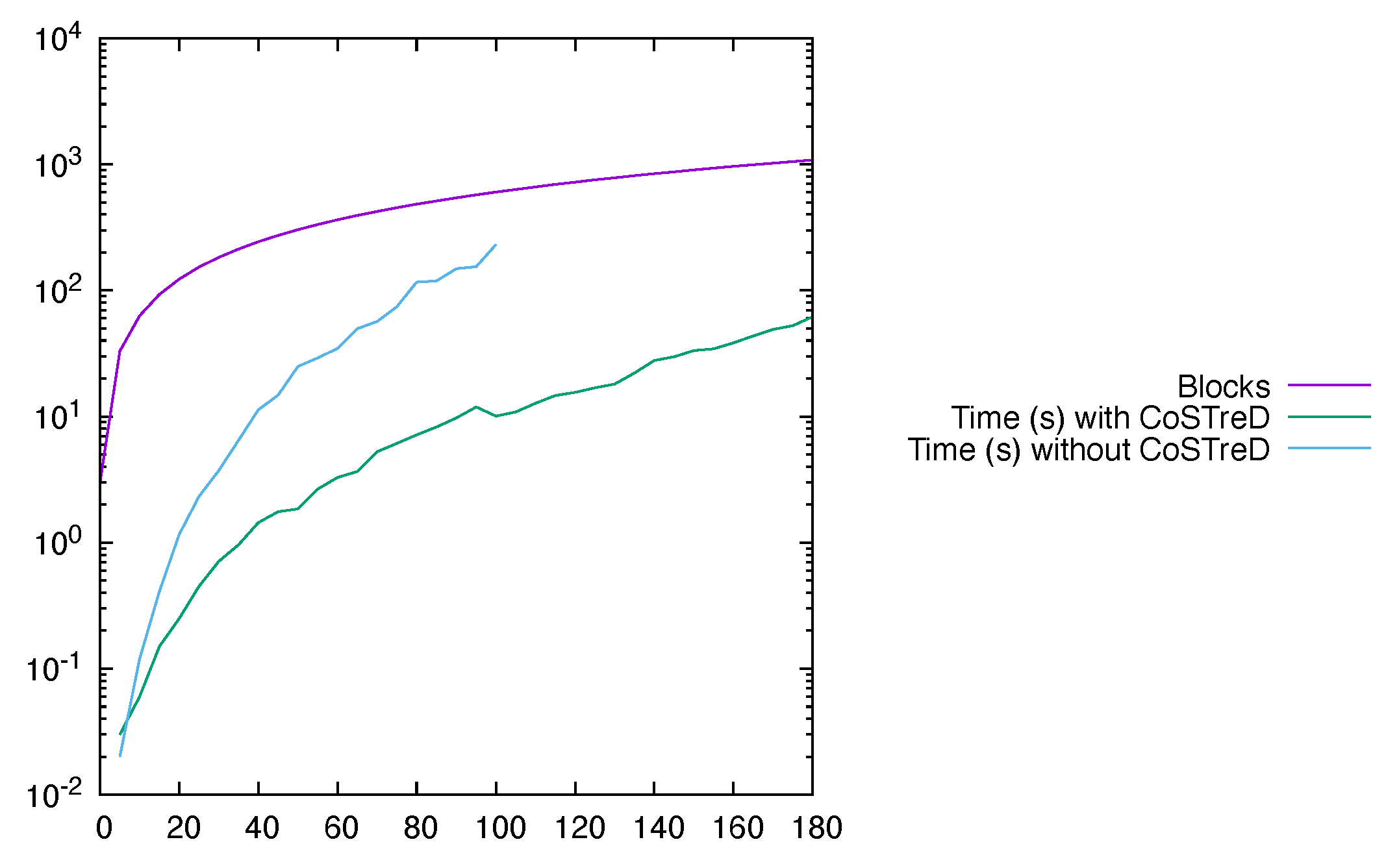
6.3. Scalability
7. Consistent Initialization of Multimode Systems
7.1. Consistent Initialization of DAE Systems
7.2. Extension to Multimode Systems
- The invariant involves both modes and initialization scenarios, returning if and only if is a possible initialization scenario and is a possible initial mode in this scenario;
- Edges are unweighted, as the system of equations for consistent initialization is regarded as a purely algebraic system.
- Select one matching of maximal cardinality for each scenario and each mode, that is, for each pair such that holds; this information is represented by functions for , each of which indicates for which initialization scenarios and in which modes the edge is part of the chosen matching.
- Compute the multimode Dulmage–Mendelsohn decomposition of the system for each initialization scenario and each corresponding initial mode.
- If the over- and underdetermined subsets are empty, the consistent initialization problem is well-posed; otherwise, return diagnostics to the user.
8. Structural Analysis of Mode Changes and Generation of Restart Conditions
- A diagnosis of the mode change model, from the perspective of mode changes: they can be structurally regular, or over/under-specified;
- A first step in generating effective restart conditions to be evaluated at runtime (for a structurally regular mode change model).
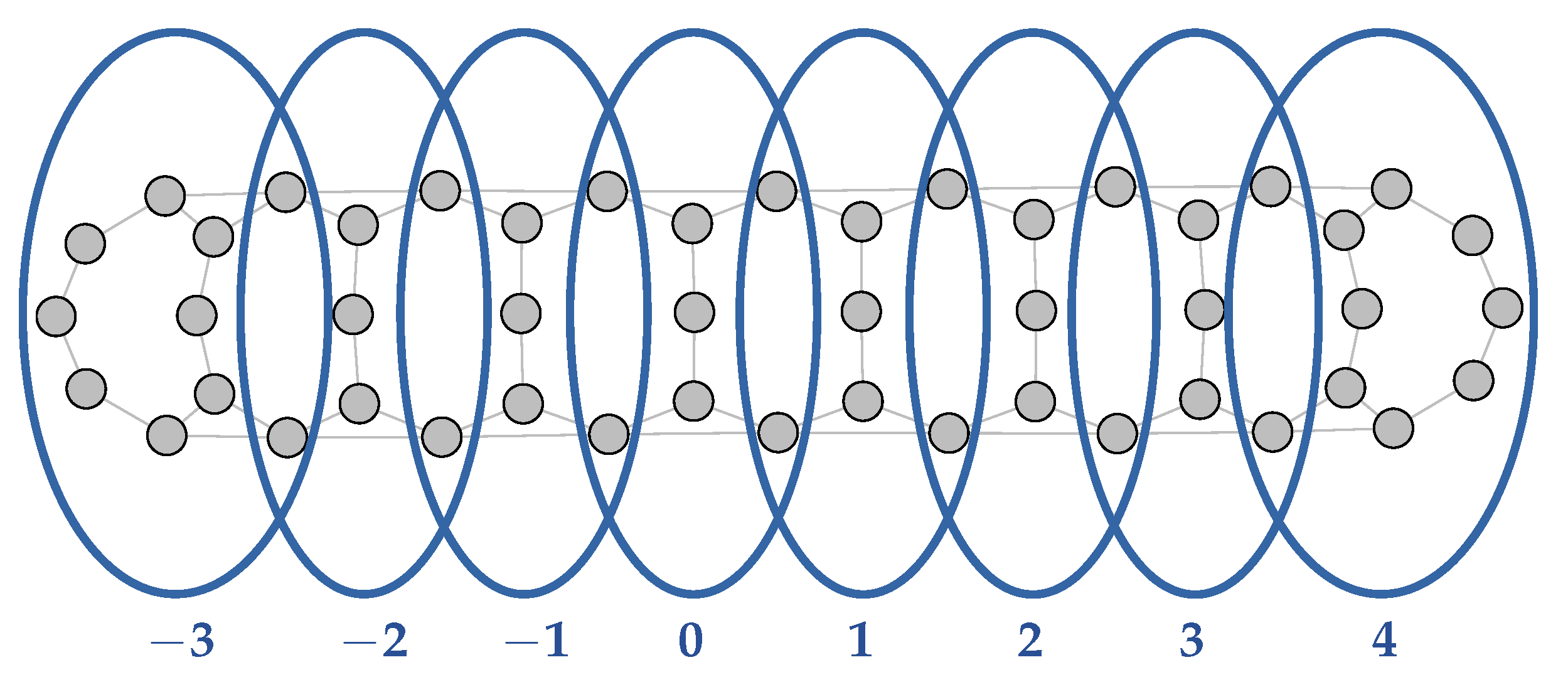
8.1. Infinitesimal Time Discretization
- There exist infinitesimals, defined as hyperreals that are smaller in absolute value than any real number. The arithmetic operations +, ×, etc., and usual relations, are lifted to .
- For every finite hyperreal , there is a unique standard real number such that is infinitesimal, and is called the standard part (or standardization) of x. Standardizing functions or systems of equations, however, raises difficulties.
- For an -valued (standard) signal (), denote the nonstandard internalization of x (see [17], Section I.2).
- Any finite real time is infinitesimally close to some element of (hence, covers and can be used to index continuous-time dynamics); and
- is “discrete”: every instant has a predecessor (except for ) and a successor .
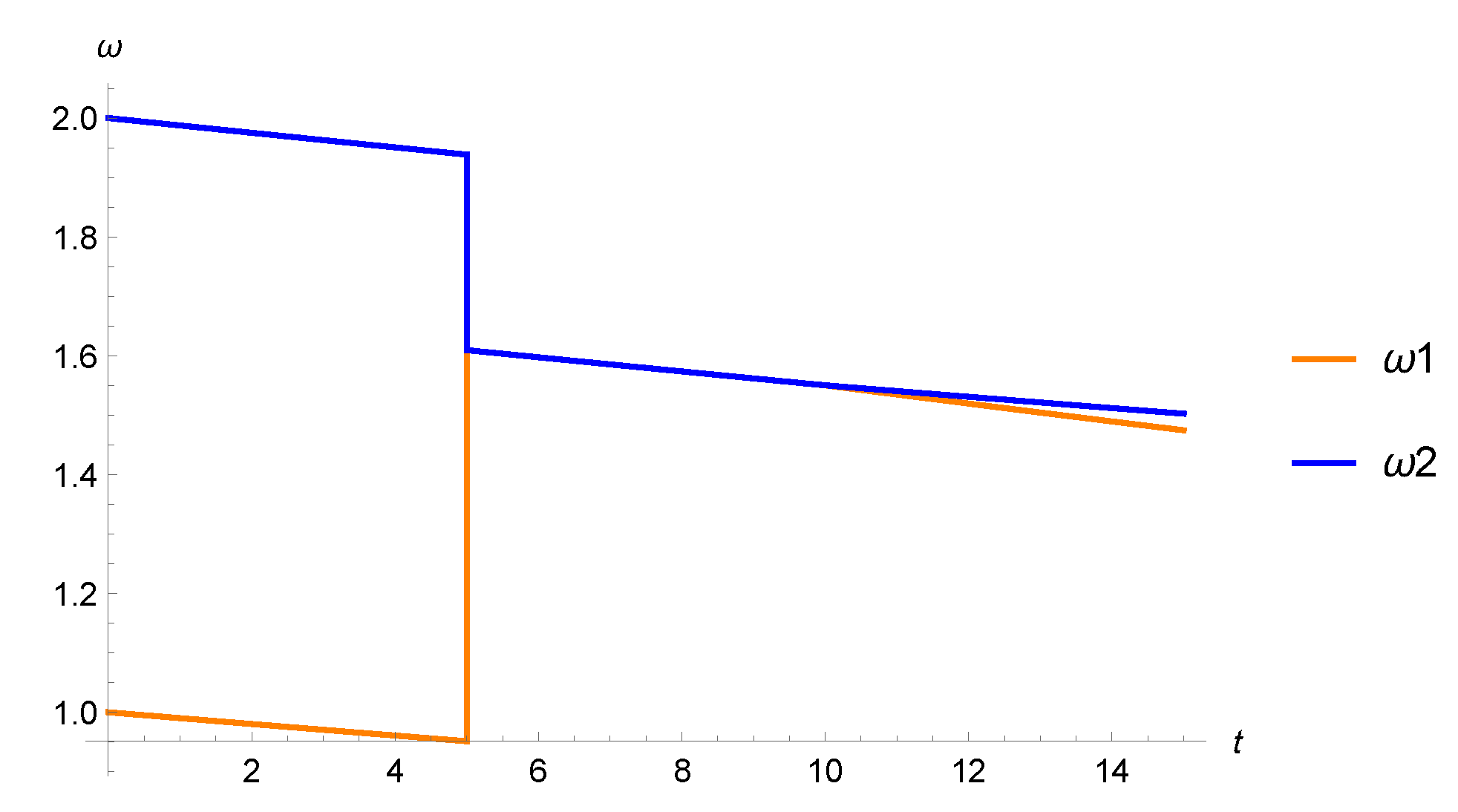
8.2. The Clutch Example
- Structural analysis of mode changes
- Generating effective code for restart
8.3. The Cup-and-Ball Example
- The Cup-and-Ball in Modelica
- Structural analysis of mode changes
- Generating effective code for restart
8.4. Handling Transient Modes
- Declaring transient modes
8.5. Multimode Structural Analysis in General
- We consider only systems possessing long modes (having DAE-based dynamics for a positive duration) alternating with finite cascades of transient modes (having a zero duration, such as the straight rope mode in the Cup-and-Ball model with elastic impact).
- We assume that the information regarding the type of a mode (long vs. transient) is known by the compiler—the two different Modelica primitives if and when should be used to declare long and transient modes, respectively.
- In addition, we require that the current mode is defined by the left-limits of some predicates, see the reasoning leading to the corrected model (48) for the Cup-and-Ball.
- Apply Dulmage–Mendelsohn decomposition with respect to the dependent variables of the array, which partitions the array into its over-determined, regular, and under-determined parts.
- Remove conflicts by considering the subarray , and apply again Dulmage–Mendelsohn decomposition with respect to the same set of dependent variables—we know that the over-determined part of this decomposition will be empty. Then,
- If is non-empty, we return to the user the set of undetermined variables and warn that the model is insufficiently specified.
- Alternatively, if is empty, the structural analysis of the array succeeds and we can move to generating restart conditions for the long exit mode, using .
| Algorithm 2 Structural analysis of mode changes |
|
- Important remark: The algorithm presented in Definition 2 involves two successive calls to the Dulmage–Mendelsohn decomposition, without any explicit reference to a particular mode. Note, however, that the difference array itself is attached to a cascade of (transient) modes, i.e., it depends on a mode trajectory. Therefore, an efficient implementation of this algorithm must use our dual representation of mode-dependent dynamics, presented in Section 4.1, and extensively used in the presentation of algorithmic building blocks in Section 4. The implementation of the two successive calls to Dulmage–Mendelsohn decomposition in the algorithm of Definition 2 must rely on the multimode extension of this method, as presented in Section 4.2. The software implementation of the algorithm presented in Definition 2 is in progress.
- Identification of impulsive variables. We present in Section 9 a calculus for this, which is ready for automatization (this is under development in our IsamDAE tool).
- Elimination of impulsive variables. This is easy if impulsive variables enter linearly in the model—this was the case for the Clutch and Cup-and-Ball examples. It is highly costly but still doable if impulsive variables enter polynomially in the model, but cannot be performed practically in all other cases. As a result, the elimination of such variables only seems adapted in practice to a subclass of multimode models in which these variables occur in a linear fashion. Alternative approaches for the handling of impulsive variables are proposed in Section 9.
- Clever choice of how to map nonstandard variables to restart conditions. This was straightforward for the Clutch, but definitely not for the Cup-and-Ball (Section 8.3), where expansion (46) for the derivatives was used for resetting positions, whereas expansion (47) was used for resetting velocities. Works are in progress for automating this choice.
9. Impulse Analysis
- 1.
- A dependent variable x has impulse order in Eif and only if the solution of system E is such that is provably a finite non-zero (standard) real number. The impulse order of x, when exists, is denoted .
- 2.
- x is impulsive if . By convention .
- 3.
- The impulse analysis of a system of equations S is the system of constraints satisfied by the impulse orders of the dependent variables of S.
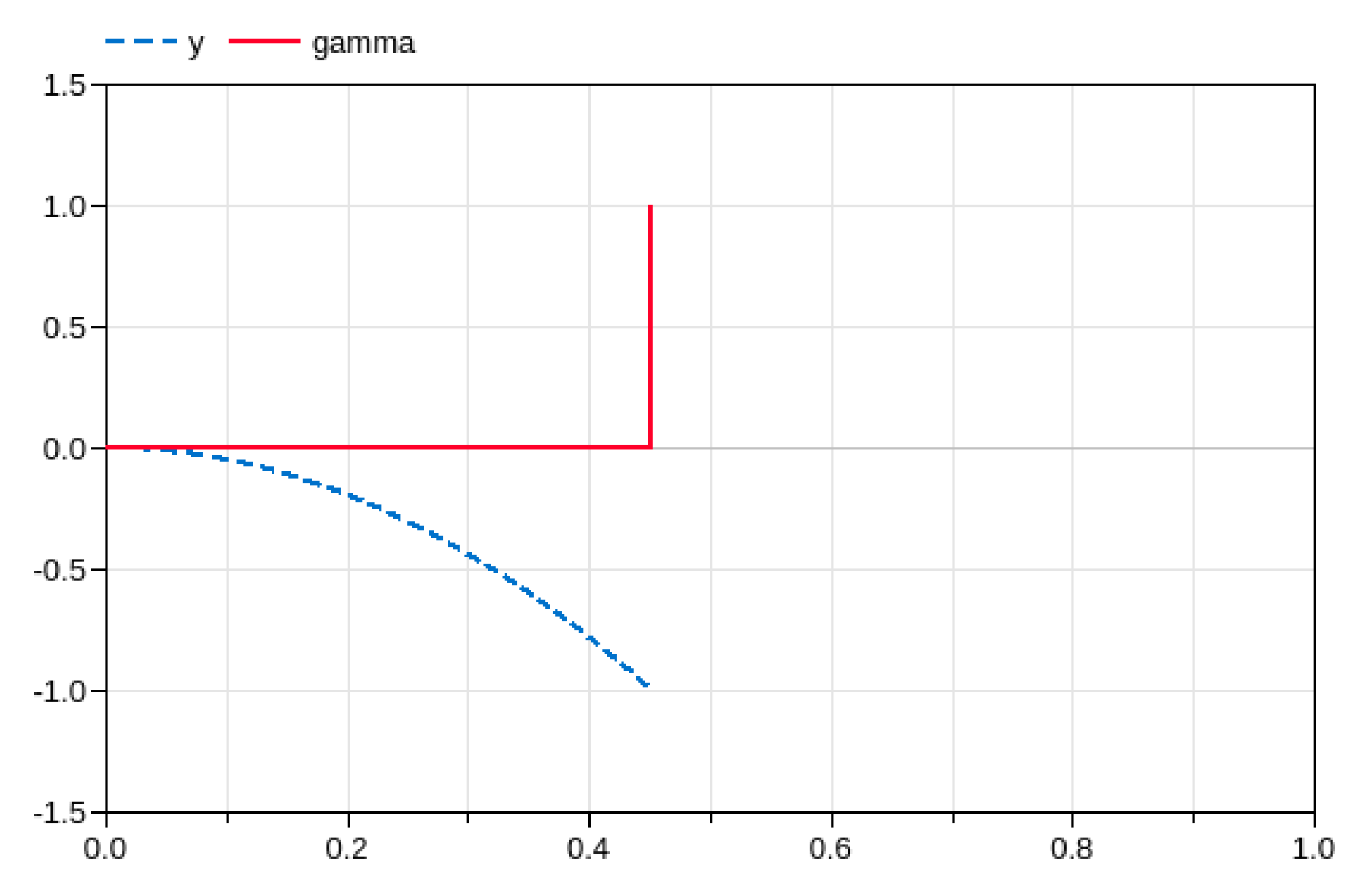
9.1. The Cup-and-Ball Example
9.2. General Impulse Analysis
- Problem setting
- Since is involved, the infinitesimal ∂ occurs in time; and
- Since is involved, the infinitesimal ∂ occurs both in time and space, due to the expansion .
- The rules of impulse analysis
9.3. Computing Restart Conditions
- Eliminating impulsive variables
- Rescaling impulsive variables
- Bruteforce solving of the restart system
10. A Model Transformation for Multimode Modelica Models
10.1. A Reduced Index Mode-Independent Structure (RIMIS) Form
- Conditional Dependency Graph: The CDG of the source model is computed by the multimode structural analysis method. This graph defines a block-triangular decomposition of the reduced-index system, for each mode of the system. It will be used throughout the transformation.
- Source Model Variable Declarations: Variable declarations from the source model are copied unchanged, with the exception of real variables, whose initialization parts are removed.
- Replicate and Dummy Derivative Variables: For each block of the CDG, replicates of written variables (unknowns) are declared. Whenever an unknown appears differentiated, a dummy derivative variable [2] is declared. Initialization statements for state variables are copied from the source model. As an optional optimization, non-leading replicate variables can be shared among a disjunction of modes, in order to decrease the number of variables in the resulting model.
- Mode Equations: Equations defining mode variables are copied unchanged. For the sake of simplicity, these equations are assumed to be of the form b = (expr > = 0), where is a real expression.
- Replicate and Dummy Equations: Equations are replaced with replicates, according to the following principle:For each block in the CDG, equations appearing in this block are replicated, substituting (i) every written variable (unknown of the block) by the replicate declared in step 3, and (ii) every read variable (parameter of the block) by the corresponding replicate, if it is a leading variable. Both mode variables and read state variables are left unchanged.As a result, the single-mode structural analysis of the resulting equation system yields a block-triangular decomposition that contains all the blocks of the CDG obtained by the multimode structural analysis of the original model.For each equation in the fresh model, the propositional formula conditioning the block in which this equation appears can be taken into account: a partial evaluation of the equation is performed [39]. This has the effect of simplifying the equation, by eliminating some of the conditionals (if … then … else … operators).Note that the resulting equations may still be multimode: in general, not all conditionals can be eliminated by partial evaluation. However, the fact that the structure of the resulting equations is independent of the mode is still guaranteed: the multimode structural analysis ensures that each equation block has the same structure (in particular, the same read and written variables) in all the modes in which it is defined, even if one or several of its equations contain conditional statements.First-order differential equations are also added in accordance with the dummy derivatives method.
- Multiplexing Equations: In order to retrieve the values of the source model variables from the replicates in the fresh model, multiplexing equations have to be added. These are multimode equations, containing conditional operators, but these equations contain no dynamics: each multiplexing equation focuses on a source model variable that corresponds to several replicates in the transformed model, specifying which of the latter currently holds the value of the former.
- Reinitializations: Reinitialization statements finally have to be inserted, in order to reset replicate variables that are state variables to a correct value upon the occurrence of a mode switching. Therefore, these statements are triggered by mode changes.
10.2. Transformation of a Simple Model
- when p is true, x is a leading variable, meaning that it is the unknown that needs to be solved;
- when p is false, the leading variable is x′, the first-order time derivative of x, while x itself is a state variable.
- The CDG graph of the source model is shown in Figure 2a.
- Declarations of variables x and p are copied.
Real x;
Boolean p(start=false,fixed=true);Remark that the declaration of x has been stripped of its initialization part. - Replicate variables are created according to the two blocks of the CDG. Two leading replicate variables x_2 (holding the value of x if p holds) and x_p_3 (holding the value of x′ if not p holds), and one state replicate variable x_3 that is meaningful only if not p holds, are declared.
Real x_2;
Real x_p_3;
Real x_3(start=0,fixed=true);Note that the initialization of variable x in the source model is copied here, to initialize the replicate state variable x_3. - One mode equation is copied from the source model.
p = (x >= 1); - Replicate equations are generated from the CDG, which has two blocks of one equation each.From the block p : e → x, one replicate equation is generated by replacing variable x with its replicate x_2, then performing the partial evaluation [39] under the assumption that the Boolean condition p holds.
// Block e_2 -> x_2
/* e2 : */ 1 = x_2;From the second block not p: e → x′, one replicate equation is generated in a similar way.// Block e_3 -> x_p_3
/* e3 : */ 1 = x_p_3;A differential equation is also generated, linking replicate variable x_3 with its dummy derivative x_p_3.der(x_3) = x_p_3; - One multiplexing equation is generated, to be solved for variable x.
x = if p then x_2 else x_3; - Finally, the only case in which a state variable has to be reinitialized is when entering the mode not p. The value of replicate variable x_3 is then set to be the left limit of x.
when not p then
reinit(x_3,pre(x));
end when;
10.3. Successful Simulations of the Water Tank System in RIMIS Form
10.4. Formalizing the RIMIS Form Transformation
- Partial evaluation of expressions and equations
- Variable renaming
- Formal definition of the RIMIS form transformation
- MD is the set of mode (Boolean) variable declarations and initializations;
- RD is the set of real variable declarations, stripped of their initializations;
- RI is the set of real variable initializations;
- ME is the set of mode variable equations;
- RE is the set of real equations.
- , a Boolean expression;
- , a set of equations, possibly differentiated;
- , a set of read variables (parameters of the block of equations);
- , a set of written variables (unknowns of the block of equations).
- , a Boolean expression;
- , two blocks.
- decides whether variable u is a leading variable in some mode satisfying the Boolean formula p;
- decides whether u is an algebraic variable in some mode satisfying p;
- decides whether u is a state variable in some mode satisfying p.
- MD is the set of mode (Boolean) variable declarations and initializations, taken from M;
- RD is the set of real variable declarations, taken from M;
- DECL is the set of replicate variable declarations, defined below;
- INIT is the set of replicate variable initializations, defined below;
- ME is the set of mode variable equations, taken from M;
- REPL is the set of replicate equations, defined below;
- MULTI is the set of multiplexing equations, defined below;
- DIFF is the set of differential equations, defined below;
- REINIT is the set of reinitialization equations, defined below.
- Optimization
11. Conclusions and Perspectives
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Casella, F. Simulation of Large-Scale Models in Modelica: State of the Art and Future Perspectives. In Proceedings of the 11th International Modelica Conference, Versailles, France, 21–23 September 2015; Elmqvist, H., Fritzson, P., Eds.; Linköping University Electronic Press: Linköping, Sweden, 2015. [Google Scholar]
- Mattsson, S.E.; Söderlind, G. Index Reduction in Differential-Algebraic Equations Using Dummy Derivatives. SIAM J. Sci. Comput. 1993, 14, 677–692. [Google Scholar] [CrossRef]
- Pantelides, C.C. The Consistent Initialization of Differential-Algebraic Systems. SIAM J. Sci. Stat. Comput. 1988, 9, 213–231. [Google Scholar] [CrossRef]
- Pryce, J.D. A Simple Structural Analysis Method for DAEs. BIT Numer. Math. 2001, 41, 364–394. [Google Scholar] [CrossRef]
- Elmqvist, H.; Gaucher, F.; Mattsson, S.E.; Dupont, F. State Machines in Modelica. In Proceedings of the 9th International Modelica Conference, Munich, Germany, 3–5 September 2012; Otter, M., Zimmer, D., Eds.; Linköping University Electronic Press: Linköping, Sweden, 2012; pp. 37–46. [Google Scholar]
- Caillaud, B.; Malandain, M.; Thibault, J. Implicit structural analysis of multimode DAE systems. In Proceedings of the HSCC ’20: 23rd ACM International Conference on Hybrid Systems: Computation and Control, Sydney, NSW, Australia, 22–24 April 2020; Ames, A.D., Seshia, S.A., Deshmukh, J., Eds.; ACM: New York, NY, USA, 2020; pp. 20:1–20:11. [Google Scholar] [CrossRef]
- Benveniste, A.; Caillaud, B.; Malandain, M. The mathematical foundations of physical systems modeling languages. Annu. Rev. Control 2020, 50, 72–118. [Google Scholar] [CrossRef]
- Benveniste, A.; Caillaud, B.; Malandain, M. Handling Multimode Models and Mode Changes in Modelica. In Proceedings of the 14th International Modelica Conference, Hamburg, Germany, 7–8 March 2005; Number 181 in Linköping Electronic Conference Proceedings. Sjölund, M., Buffoni, L., Pop, A., Ochel, L., Eds.; Linköping University Electronic Press: Linköping, Sweden, 2021; pp. 507–517. [Google Scholar] [CrossRef]
- Benveniste, A.; Caillaud, B.; Malandain, M. Compile-Time Impulse Analysis in Modelica. In Proceedings of the 14th International Modelica Conference, Linköping, Sweden, 20–24 September 2021; Number 181 in Linköping Electronic Conference Proceedings. Sjölund, M., Buffoni, L., Pop, A., Ochel, L., Eds.; Linköping University Electronic Press: Linköping, Sweden, 2021; pp. 549–559. [Google Scholar] [CrossRef]
- Caillaud, B.; Malandain, M.; Benveniste, A. A Reduced Index Mode-Independent Structure Model Transformation for Multimode Modelica Models. In Proceedings of the 14th International Modelica Conference, Linköping, Sweden, 20–24 September 2021; Number 181 in Linköping Electronic Conference Proceedings. Sjölund, M., Buffoni, L., Pop, A., Ochel, L., Eds.; Linköping University Electronic Press: Linköping, Sweden, 2021; pp. 519–528. [Google Scholar] [CrossRef]
- Utkin, V.I. Sliding Modes in Control and Optimization; Communications and Control Engineering Series; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar] [CrossRef]
- Unger, J.; Kröner, A.; Marquardt, W. Structural analysis of differential-algebraic equation systems—Theory and applications. Comput. Chem. Eng. 1995, 19, 867–882. [Google Scholar] [CrossRef]
- Chowdhry, S.; Krendl, H.; Linninger, A.A. Symbolic Numeric Index Analysis Algorithm for Differential Algebraic Equations. Ind. Eng. Chem. Res. 2004, 43, 3886–3894. [Google Scholar] [CrossRef]
- Tan, G.; Nedialkov, N.S.; Pryce, J.D. Symbolic-numeric methods for improving structural analysis of differential-algebraic equation systems. In Mathematical and Computational Approaches in Advancing Modern Science and Engineering; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Pothen, A.; Fan, C. Computing the block triangular form of a sparse matrix. ACM Trans. Math. Softw. 1990, 16, 303–324. [Google Scholar] [CrossRef]
- Robinson, A. Nonstandard Analysis. In Princeton Landmarks in Mathematics; Princeton University Press: Princeton, UK, 1996; ISBN 0-691-04490-2. [Google Scholar]
- Lindstrøm, T. An Invitation to Nonstandard Analysis. In Nonstandard Analysis and Its Applications; Cutland, N., Ed.; Cambridge Univ. Press: Cambridge, UK, 1988; pp. 1–105. [Google Scholar]
- The Modelica Association. Modelica, A Unified Object-Oriented Language for Systems Modeling. Language Specification, Version 3.5. 2021. Available online: https://specification.modelica.org/maint/3.5/MLS.pdf (accessed on 29 July 2022).
- Fritzson, P.; Pop, A.; Abdelhak, K.; Ashgar, A.; Bachmann, B.; Braun, W.; Bouskela, D.; Braun, R.; Buffoni, L.; Casella, F.; et al. The OpenModelica Integrated Environment for Modeling, Simulation, and Model-Based Development. Model. Identif. Control 2020, 41, 241–295. [Google Scholar] [CrossRef]
- Dassault Systèmes. Dymola Official Webpage. 2022. Available online: https://www.3ds.com/products-services/catia/products/dymola/ (accessed on 29 July 2022).
- Van Der Schaft, A.; Schumacher, J. Complementarity modeling of hybrid systems. IEEE Trans. Autom. Control 1998, 43, 483–490. [Google Scholar] [CrossRef]
- Lee, C.Y. Representation of Switching Circuits by Binary-Decision Programs. Bell Syst. Tech. J. 1959, 38, 985–999. [Google Scholar] [CrossRef]
- Akers, S.B. Binary Decision Diagrams. IEEE Trans. Comput. 1978, C-27, 509–516. [Google Scholar] [CrossRef]
- Bryant, R.E. Graph-Based Algorithms for Boolean Function Manipulation. IEEE Trans. Comput. 1986, C-35, 677–691. [Google Scholar] [CrossRef]
- Dulmage, A.L.; Mendelsohn, N.S. Coverings of Bipartite Graphs. Can. J. Math. 1958, 10, 517–534. [Google Scholar] [CrossRef]
- Schiex, T.; Fargier, H.; Verfaillie, G. Weighted Constraint Satisfaction Problems: Hard and Easy Problems. In Proceedings of the IJCAI, Montreal, QC, Canada, 20–25 August 1995. [Google Scholar]
- Thibault, J. Constraint System Decomposition; Research Report RR-9478; INRIA Rennes—Bretagne Atlantique and University of Rennes: Rennes, France, 2022. [Google Scholar]
- Robertson, N.; Seymour, P.D. Graph Minors. II. Algorithmic Aspects of Tree-Width. J. Algorithms 1986, 7, 309–322. [Google Scholar] [CrossRef]
- Dechter, R. Constraint Processing; Morgan Kaufmann: Burlington, MA, USA, 2003. [Google Scholar]
- Lange, J.H.; Swoboda, P. Efficient Message Passing for 0-1 ILPs with Binary Decision Diagrams. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2020. [Google Scholar] [CrossRef]
- Cox, A. GitHub Page of the MLBDD Package. Available online: https://github.com/arlencox/mlbdd (accessed on 29 July 2022).
- Thibault, J. GitLab page of the Snowflake Package. Available online: https://gitlab.com/boreal-ldd/snowflake (accessed on 29 July 2022).
- Tarjan, R. Depth-first search and linear graph algorithms. In Proceedings of the 12th Annual Symposium on Switching and Automata Theory, East Lansing, MI, USA, 13–15 October 1971; IEEE: Piscataway, NJ, USA, 1971. [Google Scholar] [CrossRef]
- Benveniste, A.; Caillaud, B.; Elmqvist, H.; Ghorbal, K.; Otter, M.; Pouzet, M. Structural Analysis of Multi-Mode DAE Systems. In Proceedings of the 20th International Conference on Hybrid Systems: Computation and Control, Pittsburgh, PA, USA, 18–20 April 2017; ACM: New York, NY, USA, 2017; pp. 253–263. [Google Scholar]
- Benveniste, A.; Caillaud, B.; Elmqvist, H.; Ghorbal, K.; Otter, M.; Pouzet, M. Multi-Mode DAE Models—Challenges, Theory and Implementation. In Computing and Software Science—State of the Art and Perspectives; Springer: Berlin/Heidelberg, Germany, 2019; pp. 283–310. [Google Scholar] [CrossRef]
- Mattsson, S.E.; Otter, M.; Elmqvist, H. Modelica Hybrid Modeling and Efficient Simulation. In Proceedings of the 38th IEEE Conference on Decision and Control, Phoenix, AZ, USA, 7–10 December 1999; IEEE: Piscataway, NJ, USA, 1999; pp. 3502–3507. [Google Scholar]
- Campbell, S.L.; Gear, C.W. The index of general nonlinear DAEs. Numer. Math. 1995, 72, 173–196. [Google Scholar] [CrossRef]
- Bourke, T.; Pouzet, M. Zélus: A Synchronous Language with ODEs. In Proceedings of the 16th International Conference on Hybrid Systems: Computation and Control (HSCC 2013), Philadelphia, PA, USA, 8–11 April 2013; Belta, C., Ivancic, F., Eds.; ACM: New York, NY, USA, 2013; pp. 113–118. [Google Scholar]
- Jones, N.D.; Gomard, C.K.; Sestoft, P. Partial Evaluation and Automatic Program Generation; Prentice Hall International Series in Computer Science; Prentice Hall: Hoboken, NJ, USA, 1993. [Google Scholar]
- Danvy, O.; Glück, R.; Thiemann, P. (Eds.) Partial Evaluation, International Seminar, Dagstuhl Castle, Germany, 12–16 February 1996, Selected Papers; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1996; Volume 1110. [Google Scholar] [CrossRef]
- Jeannet, B. Bddapron. Available online: http://pop-art.inrialpes.fr/~bjeannet/bjeannet-forge/bddapron/ (accessed on 23 May 2022).
- Schrijver, A. Theory of Linear and Integer Programming; Wiley: Hoboken, NJ, USA, 1998. [Google Scholar]
- Schrammel, P.; Jeannet, B. Logico-Numerical Abstract Acceleration and Application to the Verification of Data-Flow Programs. In Proceedings of the Static Analysis—18th International Symposium, SAS 2011, Venice, Italy, 14–16 September 2011; pp. 233–248. [Google Scholar] [CrossRef] [Green Version]
- Miné, A.A. A New Numerical Abstract Domain Based on Difference-Bound Matrices. In Symposium on Program as Data Objects; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Rocca, A.; Acary, V.; Brogliato, B. Index-2 hybrid DAE: A case study with well-posedness and numerical analysis. In Proceedings of the IFAC World Congress 2020, Berlin, Germany, 12–17 July 2020. [Google Scholar]
- Bunus, P.; Fritzson, P. Methods for Structural Analysis and Debugging of Modelica Models. In Proceedings of the 2nd International Modelica Conference, Oberpfaffenhofen, Germany, 18–19 March 2002. [Google Scholar]











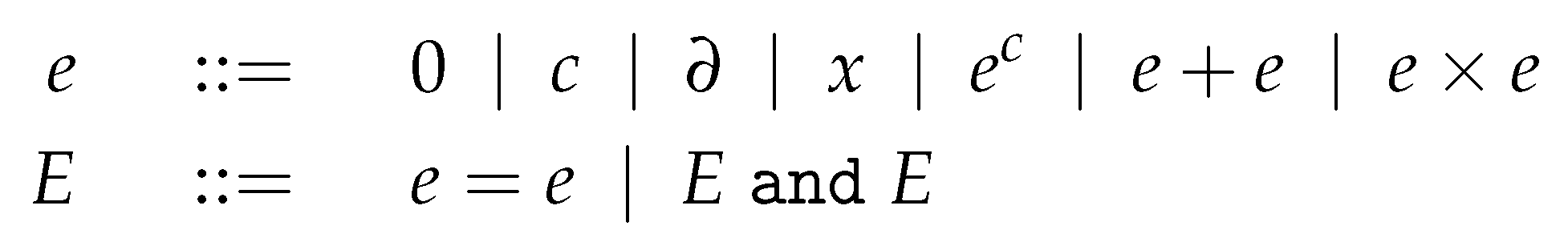
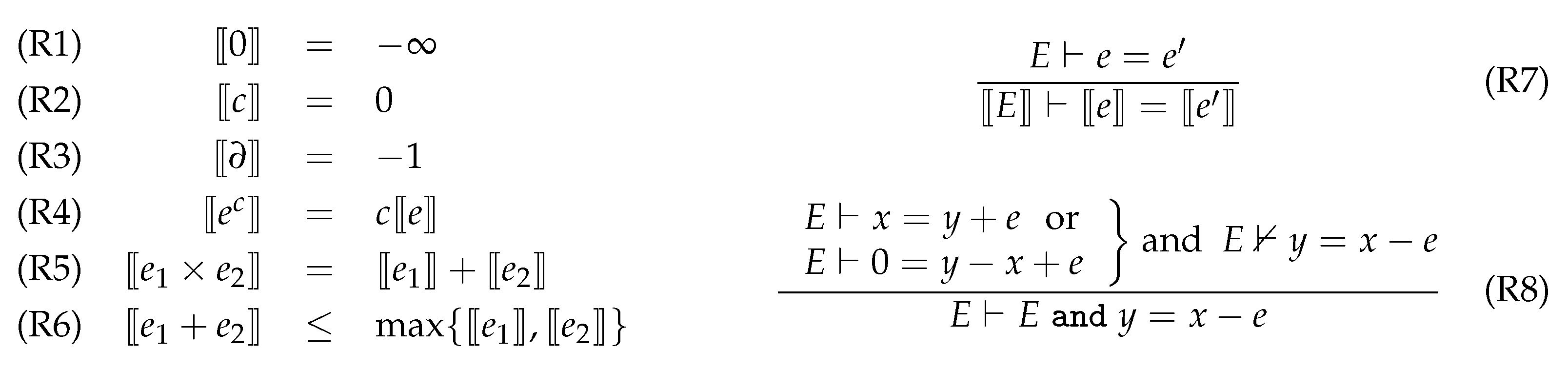




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Type | Meaning |
|---|---|---|
| Invariant | ||
| Mode dependency of equations | ||
| Mode dependency of variables | ||
| Mode dependency of edges | ||
| Mode-dependent values of the ’s |
| Name | Type | Meaning |
|---|---|---|
| Invariant | ||
| Mode dependency of equations | ||
| Mode dependency of variables | ||
| Mode dependency of edges |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benveniste, A.; Caillaud, B.; Malandain, M.; Thibault, J. Algorithms for the Structural Analysis of Multimode Modelica Models. Electronics 2022, 11, 2755. https://doi.org/10.3390/electronics11172755
Benveniste A, Caillaud B, Malandain M, Thibault J. Algorithms for the Structural Analysis of Multimode Modelica Models. Electronics. 2022; 11(17):2755. https://doi.org/10.3390/electronics11172755
Chicago/Turabian StyleBenveniste, Albert, Benoît Caillaud, Mathias Malandain, and Joan Thibault. 2022. "Algorithms for the Structural Analysis of Multimode Modelica Models" Electronics 11, no. 17: 2755. https://doi.org/10.3390/electronics11172755
APA StyleBenveniste, A., Caillaud, B., Malandain, M., & Thibault, J. (2022). Algorithms for the Structural Analysis of Multimode Modelica Models. Electronics, 11(17), 2755. https://doi.org/10.3390/electronics11172755