
Trajectory Prediction with Correction Mechanism for Connected and Autonomous Vehicles


Abstract
:1. Introduction
- A trajectory correction module is introduced into the interactive network model. Probability forcing is applied in the trajectory correction module to predict the trajectories of surrounding vehicles. In each step, the prediction result of the previous step or the ground truth is fed into the model with a certain probability for trajectory prediction.
- Extensive experiments are conducted based on real datasets. The prediction accuracy produced by our proposed model outperforms other recent authoritative methods in both short-term and long-term predictions, which demonstrates the effectiveness of the probability forcing scheme.
2. Related Work
2.1. Trajectory Prediction
2.2. Teacher Forcing and Scheduled Sampling
- Linear decay: where is the minimum amount of truth to be given to the model, and k and c provide the offset and slope of the decay, which depend on the expected speed of convergence, i represents the number of the i-th mini-batch.
- Exponential decay: where is a constant that depends on the expected speed of convergence.
- Inverse sigmoid decay: where depends on the expected speed of convergence.
3. Problem Description
3.1. Inputs and Outputs
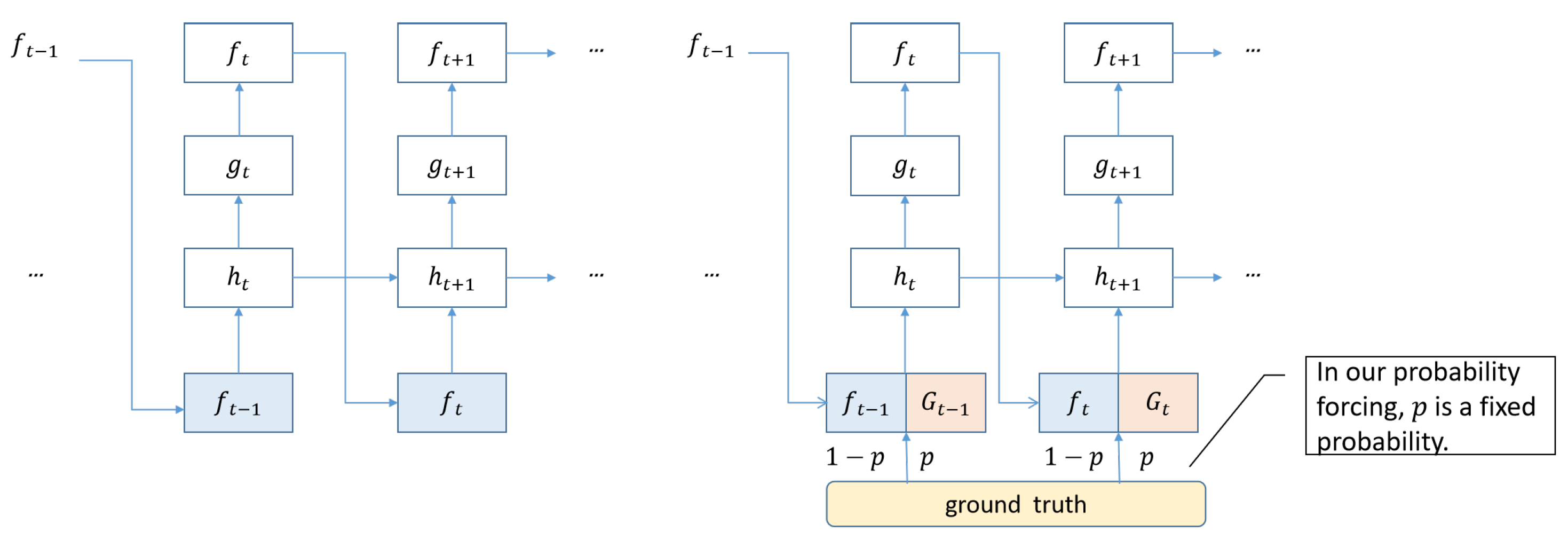
3.2. Probability Forcing
4. System Model
4.1. Encoding Layer
4.2. Convolutional Interaction Layer
4.3. Trajectory Correction Module
4.4. Decoding Layer
5. Experimental Evaluation
5.1. Experimental Settings
5.2. Datasets
5.3. Evaluation Metric
5.4. Comparison Models
- CS-LSTM(M) [15]: This convolutional social pooling approach with a maneuver class LSTM decoder generates multimodal trajectory predictions based on two longitudinal and three lateral behaviors;
- MATF [16]: This model encodes the scene context and past vehicle trajectories, and deploys convolutional layers to capture interactions. The decoder generates predicted trajectories using adversarial loss;
- NLS-LSTM [40]: Local and non-local operations are combined to generate an adapted context vector for social pooling. The non-local multi-head attention mechanism captures the relative importance of each vehicle and the local blocks represent nearby interactions between vehicles;
- JSTM [41]: This joint time-series model is based on the shared LSTM layer and further FC regression networks for different driving styles. A common LSTM temporal pattern network is trained, and concatenate networks are fine-tuned for each driving style;
- PiP [42]: a planning-coupled module extracts interaction features with a special channel for injecting future planning, and a target fusion module encodes and decodes tightly coupled future interactions among agents;
- MTP [29]: a spatiotemporal convolutional network model captures interactions between vehicles to predict trajectories considering multiple possible maneuvering intentions and movements of vehicles.
6. Results and Discussion
6.1. Results
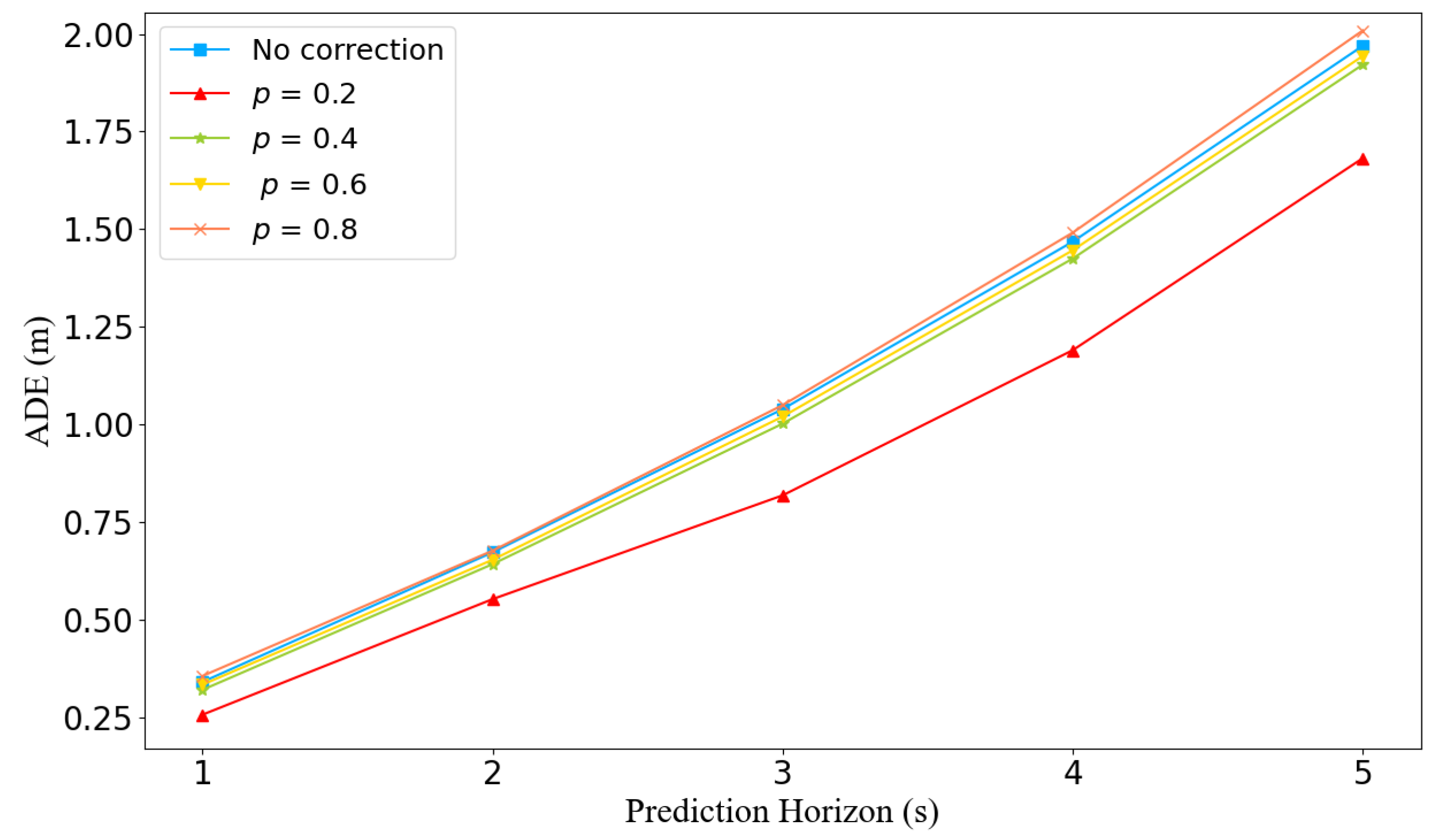
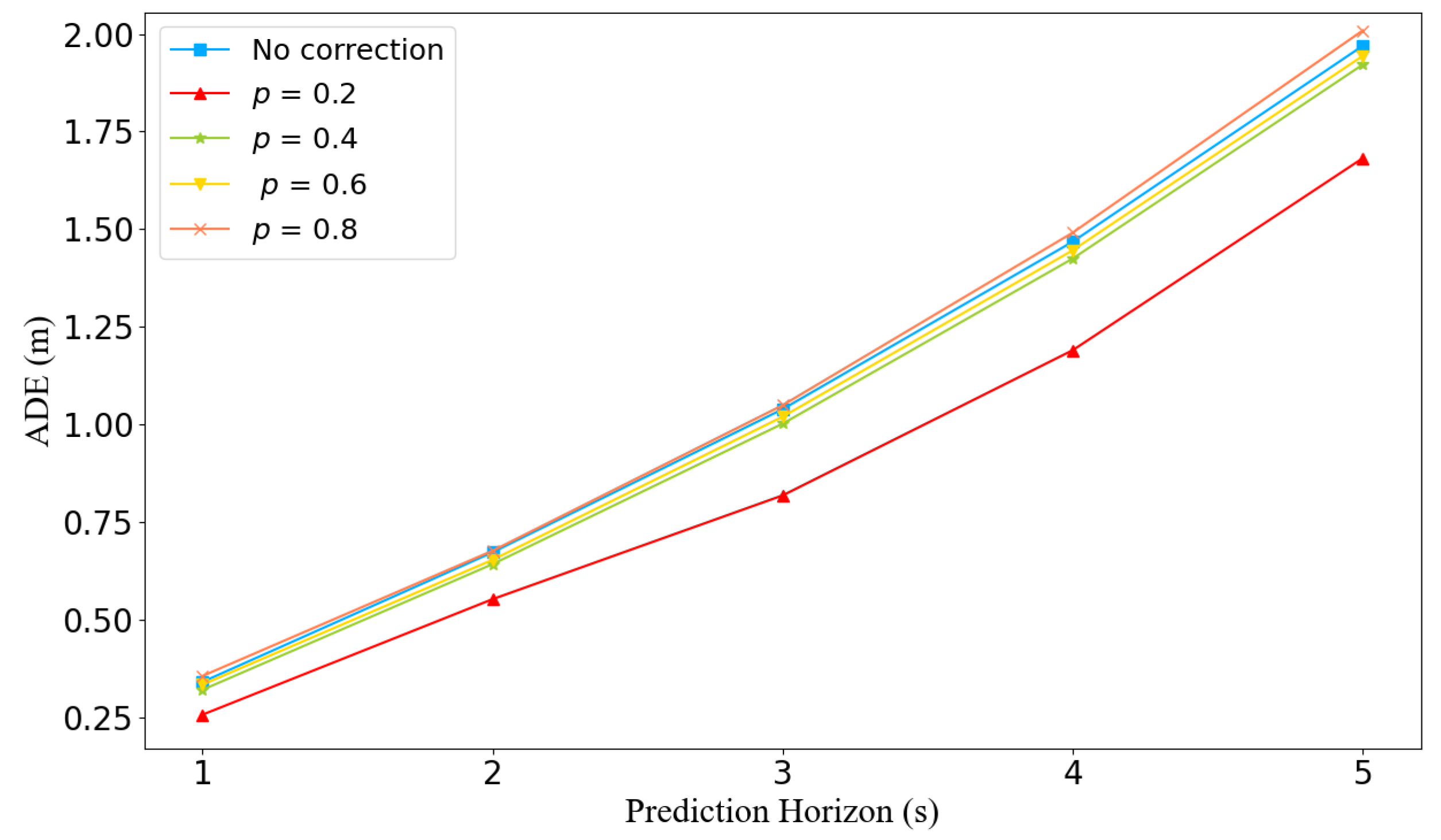
6.2. Analyzing the Correction Module in Trajectory Prediction
6.3. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Tight, M.; Sun, Q.; Kang, R. A systematic review: Road infrastructure requirement for connected and autonomous vehicles (CAVs). In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2019; Volume 1187, p. 042073. [Google Scholar]
- Guanetti, J.; Kim, Y.; Borrelli, F. Control of connected and automated vehicles: State of the art and future challenges. Annu. Rev. Control 2018, 45, 18–40. [Google Scholar] [CrossRef] [Green Version]
- Shiwakoti, N.; Stasinopoulos, P.; Fedele, F. Investigating the state of connected and autonomous vehicles: A literature review. Transp. Res. Procedia 2020, 48, 870–882. [Google Scholar] [CrossRef]
- Bila, C.; Sivrikaya, F.; Khan, M.A.; Albayrak, S. Vehicles of the future: A survey of research on safety issues. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1046–1065. [Google Scholar] [CrossRef]
- Giuliari, F.; Hasan, I.; Cristani, M.; Galasso, F. Transformer networks for trajectory forecasting. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 10335–10342. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, J.; Fang, L.; Jiang, Q.; Zhou, B. Multimodal motion prediction with stacked transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7573–7582. [Google Scholar] [CrossRef]
- Schlechtriemen, J.; Wirthmueller, F.; Wedel, A.; Breuel, G.; Kuhnert, K.D. When will it change the lane? A probabilistic regression approach for rarely occurring events. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; pp. 1373–1379. [Google Scholar] [CrossRef]
- Deo, N.; Trivedi, M.M. Multi-modal trajectory prediction of surrounding vehicles with maneuver based LSTMs. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018; pp. 1179–1184. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Yang, Y.; Zhang, T.; Qu, X.; Cao, D.; Cheng, B.; Li, K. Risk assessment based collision avoidance decision-making for autonomous vehicles in multi-scenarios. Transp. Res. Part C Emerg. Technol. 2021, 122, 102820. [Google Scholar] [CrossRef]
- Li, A.; Sun, L.; Zhan, W.; Tomizuka, M.; Chen, M. Prediction-based reachability for collision avoidance in autonomous driving. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 7908–7914. [Google Scholar] [CrossRef]
- Huang, C.; Huang, H.; Hang, P.; Gao, H.; Wu, J.; Huang, Z.; Lv, C. Personalized trajectory planning and control of lane-change maneuvers for autonomous driving. IEEE Trans. Veh. Technol. 2021, 70, 5511–5523. [Google Scholar] [CrossRef]
- Zhao, W.; Liu, R.; Ngoduy, D. A bilevel programming model for autonomous intersection control and trajectory planning. Transp. A Transp. Sci. 2019, 17, 34–58. [Google Scholar] [CrossRef]
- Toledo-Moreo, R.; Zamora-Izquierdo, M.A. IMM-based lane-change prediction in highways With low-cost GPS/INS. IEEE Trans. Intell. Transp. Syst. 2009, 10, 180–185. [Google Scholar] [CrossRef] [Green Version]
- Barth, A.; Franke, U. Where will the oncoming vehicle be the next second? In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 1068–1073. [Google Scholar] [CrossRef]
- Deo, N.; Trivedi, M.M. Convolutional social pooling for vehicle trajectory prediction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1468–1476. [Google Scholar] [CrossRef] [Green Version]
- Zhao, T.; Xu, Y.; Monfort, M.; Choi, W.; Baker, C.; Zhao, Y.; Wang, Y.; Wu, Y.N. Multi-agent tensor fusion for contextual trajectory prediction. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12118–12126. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Colyar, J.; Halkia, J. US Highway 101 Dataset; Federal Highway Administration, US Department of Transportation: Washington, DC, USA, 2007. Available online: https://rosap.ntl.bts.gov/view/dot/38724 (accessed on 20 April 2022).
- Halkia, J.; Colyar, J. Interstate 80 Freeway Dataset; Federal Highway Administration, US Department of Transportation: Washington, DC, USA, 2006. Available online: https://rosap.ntl.bts.gov/view/dot/38708 (accessed on 20 April 2022).
- Lefèvre, S.; Vasquez, D.; Laugier, C. A survey on motion prediction and risk assessment for intelligent vehicles. ROBOMECH J. 2014, 1, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Xie, G.; Gao, H.; Qian, L.; Huang, B.; Li, K.; Wang, J. Vehicle trajectory prediction by integrating physics- and maneuver-based approaches using interactive multiple models. IEEE Trans. Ind. Electron. 2018, 65, 5999–6008. [Google Scholar] [CrossRef]
- Batz, T.; Watson, K.; Beyerer, J. Recognition of dangerous situations within a cooperative group of vehicles. In Proceedings of the 2009 IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; pp. 907–912. [Google Scholar] [CrossRef]
- Tomar, R.S.; Verma, S. Safety of lane change maneuver through a priori prediction of trajectory using neural networks. Netw. Protoc. Algorithms 2012, 4, 4–21. [Google Scholar] [CrossRef]
- Schreier, M.; Willert, V.; Adamy, J. An integrated approach to maneuver-based trajectory prediction and criticality assessment in arbitrary road environments. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2751–2766. [Google Scholar] [CrossRef]
- Xing, Y.; Lv, C.; Wang, H.; Cao, D.; Velenis, E.; Wang, F.Y. Driver activity recognition for intelligent vehicles: A deep learning approach. IEEE Trans. Veh. Technol. 2019, 68, 5379–5390. [Google Scholar] [CrossRef] [Green Version]
- Mukherjee, S.; Wang, S.; Wallace, A. Interacting vehicle trajectory prediction with convolutional recurrent neural networks. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–4 June 2020; pp. 4336–4342. [Google Scholar] [CrossRef]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social LSTM: Human trajectory prediction in crowded spaces. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar] [CrossRef] [Green Version]
- Mersch, B.; Höllen, T.; Zhao, K.; Stachniss, C.; Roscher, R. Maneuver-based trajectory prediction for self-driving cars using spatio-temporal convolutional networks. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4888–4895. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Drossos, K.; Gharib, S.; Magron, P.; Virtanen, T. Language modelling for sound event detection with teacher forcing and scheduled sampling. In Proceedings of the International Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE), New York, NY, USA, 25–26 October 2019; pp. 59–63. [Google Scholar] [CrossRef] [Green Version]
- Williams, R.J.; Zipser, D. A learning algorithm for continually running fully recurrent neural networks. Neural Comput. 1989, 1, 270–280. [Google Scholar] [CrossRef]
- Bengio, S.; Vinyals, O.; Jaitly, N.; Shazeer, N. Scheduled sampling for sequence prediction with recurrent neural networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 1171–1179. [Google Scholar]
- Mihaylova, T.; Martins, A.F. Scheduled sampling for transformers. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, Florence, Italy, 28 July–2 August 2019; pp. 351–356. [Google Scholar]
- Messaoud, K.; Yahiaoui, I.; Verroust-Blondet, A.; Nashashibi, F. Attention based vehicle trajectory prediction. IEEE Trans. Intell. Veh. 2021, 6, 175–185. [Google Scholar] [CrossRef]
- Lee, N.; Choi, W.; Vernaza, P.; Choy, C.B.; Torr, P.H.; Chandraker, M. Desire: Distant future prediction in dynamic scenes with interacting agents. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 336–345. [Google Scholar]
- Willmott, C.J. Some comments on the evaluation of model performance. Bull. Am. Meteorol. Soc. 1982, 63, 1309–1313. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Messaoud, K.; Yahiaoui, I.; Verroust-Blondet, A.; Nashashibi, F. Non-local social pooling for vehicle trajectory prediction. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 975–980. [Google Scholar]
- Xing, Y.; Lv, C.; Cao, D. Personalized vehicle trajectory prediction based on joint time-series modeling for connected vehicles. IEEE Trans. Veh. Technol. 2020, 69, 1341–1352. [Google Scholar] [CrossRef]
- Song, H.; Ding, W.; Chen, Y.; Shen, S.; Wang, M.Y.; Chen, Q. Pip: Planning-informed trajectory prediction for autonomous driving. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 598–614. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Lin, L.; Li, W.; Bi, H.; Qin, L. Vehicle trajectory prediction using LSTMs with spatial-temporal attention mechanisms. IEEE Intell. Transp. Syst. Mag. 2022, 14, 197–208. [Google Scholar] [CrossRef]
- Ivanovic, B.; Pavone, M. The trajectron: Probabilistic multi-agent trajectory modeling with dynamic spatiotemporal graphs. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2375–2384. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameter | Value |
|---|---|
| learning rate | 0.001 |
| 0.9 | |
| 0.98 | |
| batch_size | 128 |
| encoder_size | 64 |
| conv1_depth | 64 |
| conv2_depth | 16 |
| decoder_size | 128 |
| activation function | leaky-ReLU ( = 0.1) |
| Datasets | Prediction Horizon(s) | CS-LSTM(M) | MATF | NLS-LSTM | JSTM | PiP | MTP | Ours |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.62 | 0.66 | 0.56 | 0.57 | 0.55 | 0.53 | 0.45 | |
| 2 | 1.29 | 1.34 | 1.22 | 1.38 | 1.18 | 1.17 | 0.98 | |
| NGSIM | 3 | 2.13 | 2.08 | 2.02 | 2.21 | 1.94 | 1.93 | 1.72 |
| 4 | 3.20 | 2.97 | 3.03 | 3.03 | 2.88 | 2.88 | 2.78 | |
| 5 | 4.52 | 4.13 | 4.31 | 3.77 | 4.04 | 4.05 | 4.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, P.; Liu, H.; Xu, J.; Li, T. Trajectory Prediction with Correction Mechanism for Connected and Autonomous Vehicles. Electronics 2022, 11, 2149. https://doi.org/10.3390/electronics11142149
Lv P, Liu H, Xu J, Li T. Trajectory Prediction with Correction Mechanism for Connected and Autonomous Vehicles. Electronics. 2022; 11(14):2149. https://doi.org/10.3390/electronics11142149
Chicago/Turabian StyleLv, Pin, Hongbiao Liu, Jia Xu, and Taoshen Li. 2022. "Trajectory Prediction with Correction Mechanism for Connected and Autonomous Vehicles" Electronics 11, no. 14: 2149. https://doi.org/10.3390/electronics11142149
APA StyleLv, P., Liu, H., Xu, J., & Li, T. (2022). Trajectory Prediction with Correction Mechanism for Connected and Autonomous Vehicles. Electronics, 11(14), 2149. https://doi.org/10.3390/electronics11142149