
Defect Detection for Metal Base of TO-Can Packaged Laser Diode Based on Improved YOLO Algorithm


Abstract
:1. Introduction
- Building image dataset. On the basis of obtaining metal TO-base appearance defect images, we used Labelme open-source tool to label the appearance defects in the image and built a dataset for metal TO-base appearance defects.
- Proposing a metal TO-base defect detection model called YOLO-SO based on the YOLO-V5 framework. According to the characteristics of the metal TO-base dataset, the model’s structure was developed from three aspects, including convolutional block attention mechanism (CBAM), random-paste-mosaic (RPM) small-target data augmentation, and optimization of anchor box clustering algorithm.
- Training and testing the YOLO-SO model. The training of the YOLO-SO model was implemented based on Pytorch and the high-performance GPU computing platform, and the performance of the YOLO-SO model was tested and evaluated on the test dataset. This study also compared the improved YOLO-V5 model with the already existing state-of-the-art object detection algorithms and demonstrated the effectiveness of the modified model.
2. Related Work
3. Materials and Methods
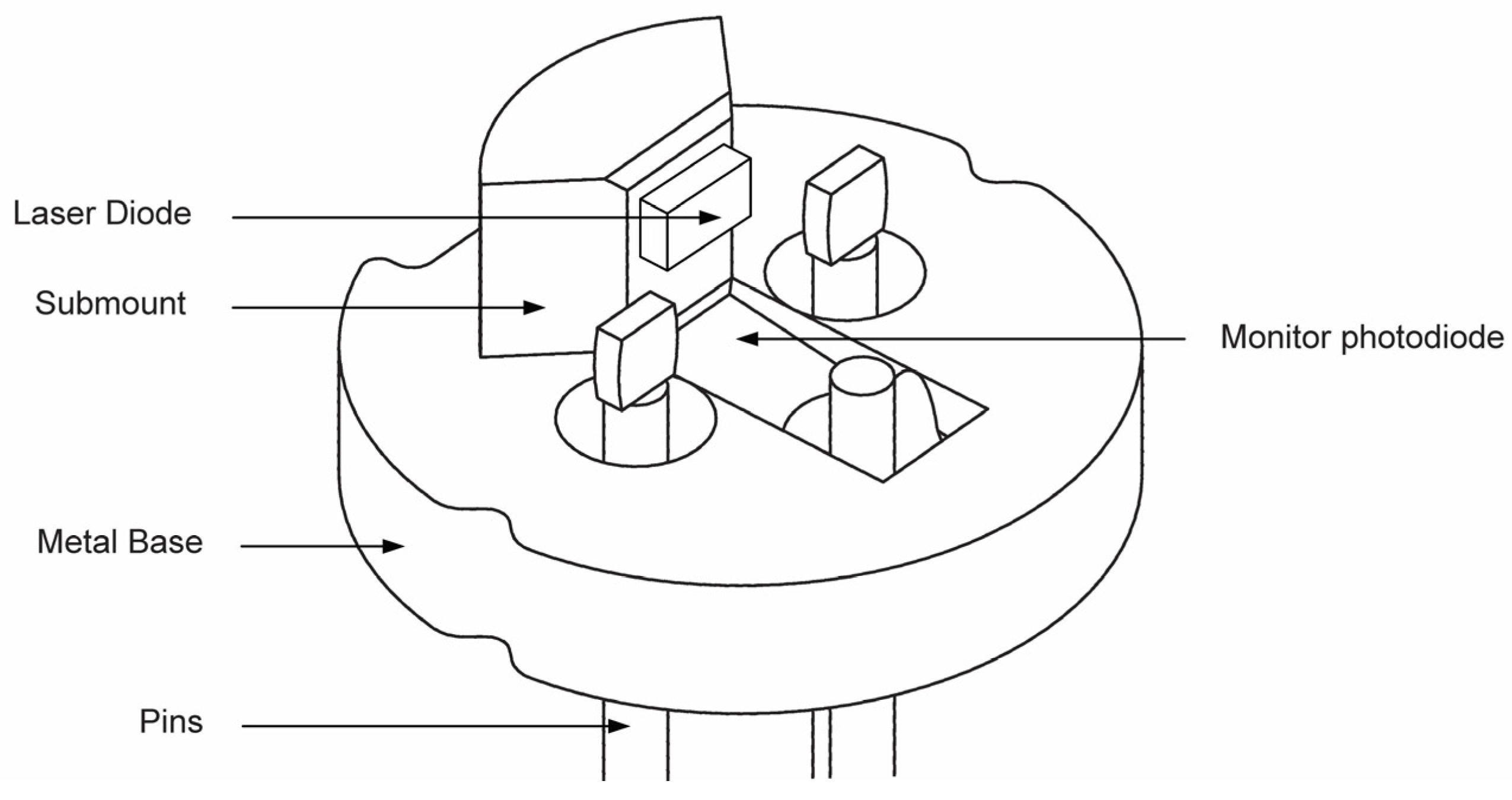
3.1. Metal TO-Base Defect Dataset
3.2. Method
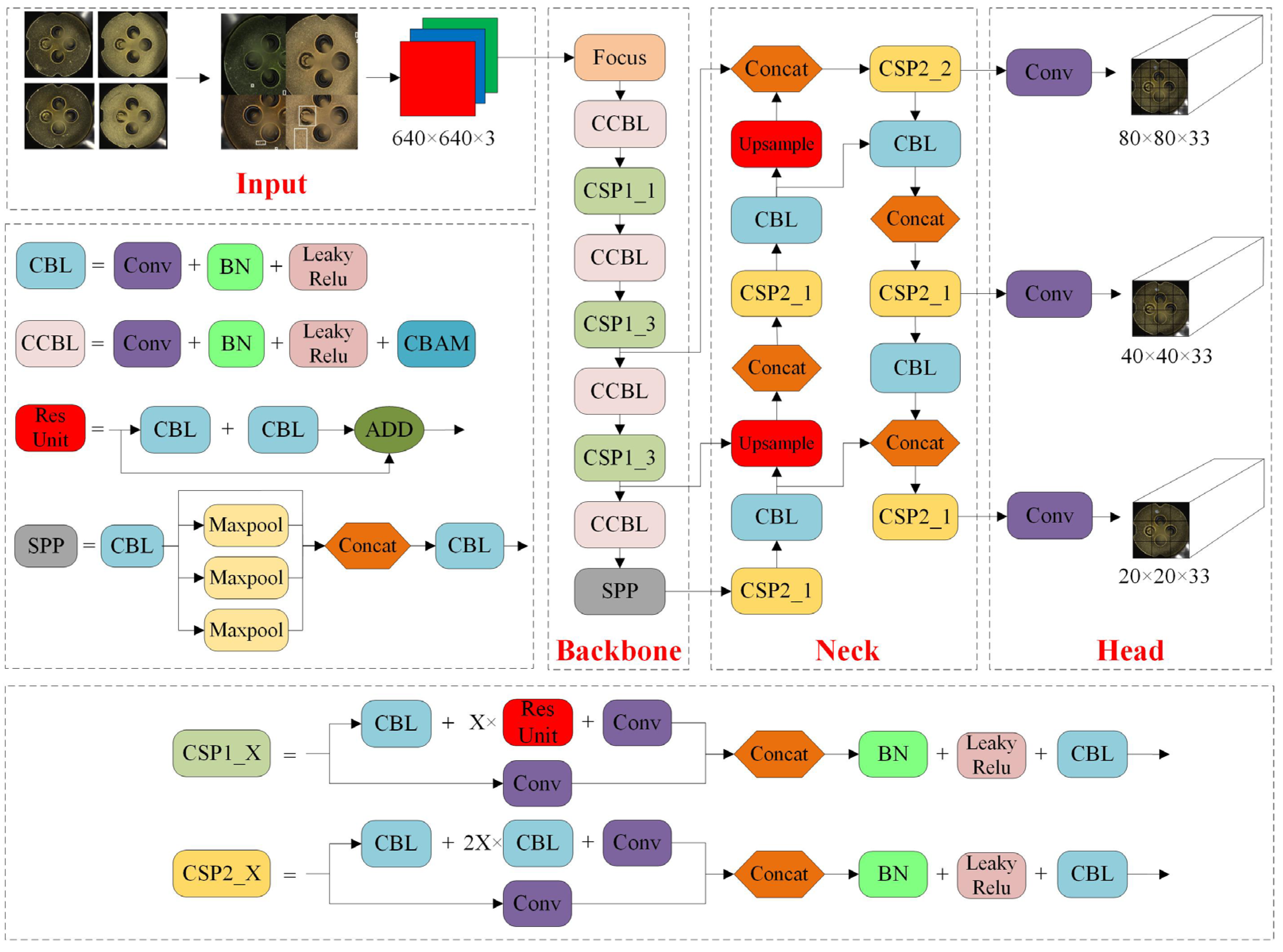
3.2.1. Structure of YOLO-SO Network
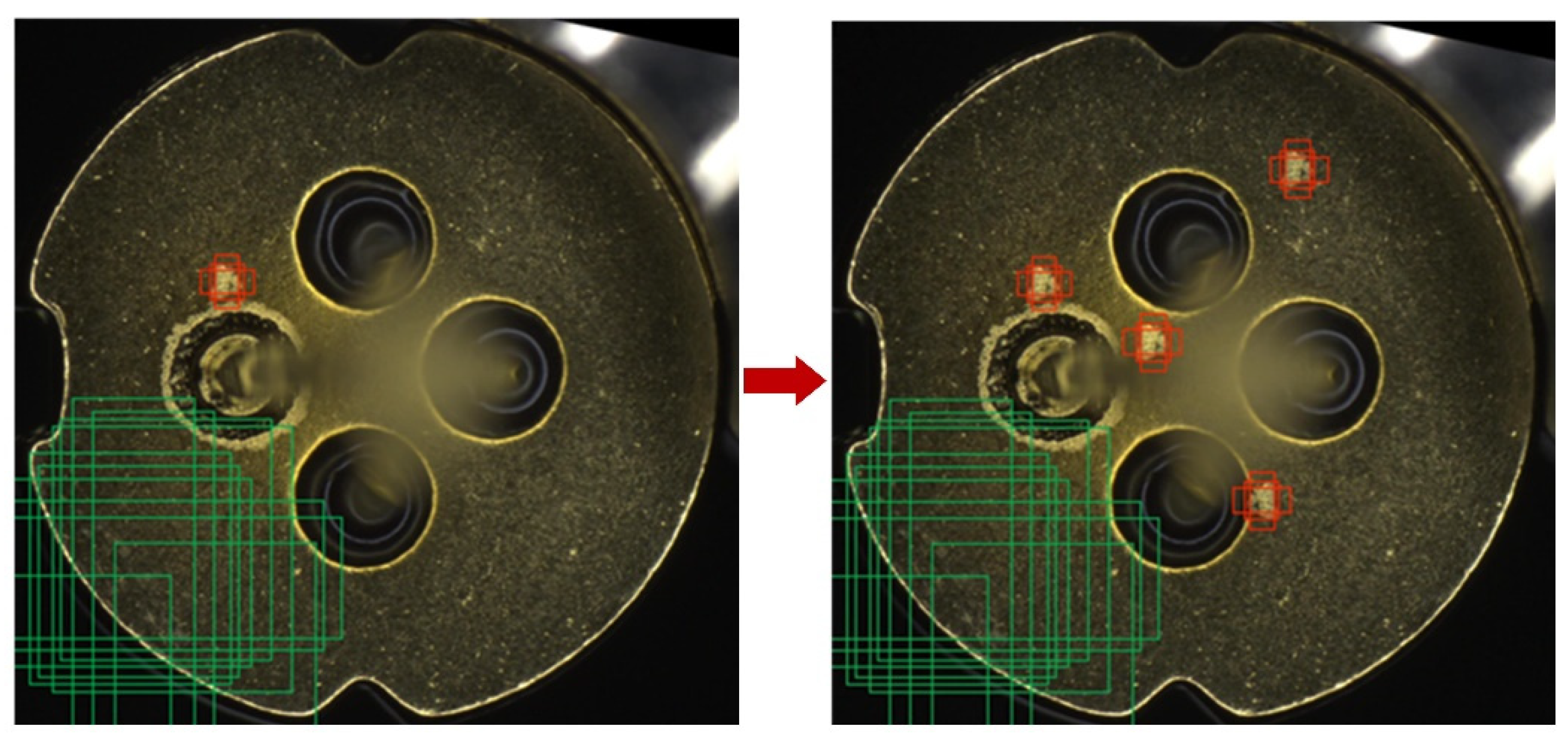
3.2.2. RPM Data Augmentation
| Algorithm 1: Random-Paste-Mosaic (RPM) Small-Target Data Augmentation Algorithm |
| Input: Images in the training dataset Output: Batch Size Enter the picture size (1) Input the dataset into the neural network to obtain the labels in each image, ensuring that each image has corresponding labels for the defects and no damaged files; (2) Filter the labels and extract small-target labels according to Equation (2); (3) Crop and save the filtered small targets in image format to the small-target database; (4) Select n small-target images randomly from the small-target database for random transformations, including ±20% scaling, ±15° rotation, flipping, and brightness change; (5) Paste the transformed small-target images c times at random positions of the image in the training dataset while avoiding the overlap with the original defect labels; (6) Generate the new defect image and label and replace the original one; (7) Repeat steps (4) to Step (6) until all images in the training dataset complete the random-paste small-target data augmentation operation; (8) Select four images randomly from the training dataset for mosaic data augmentation. |
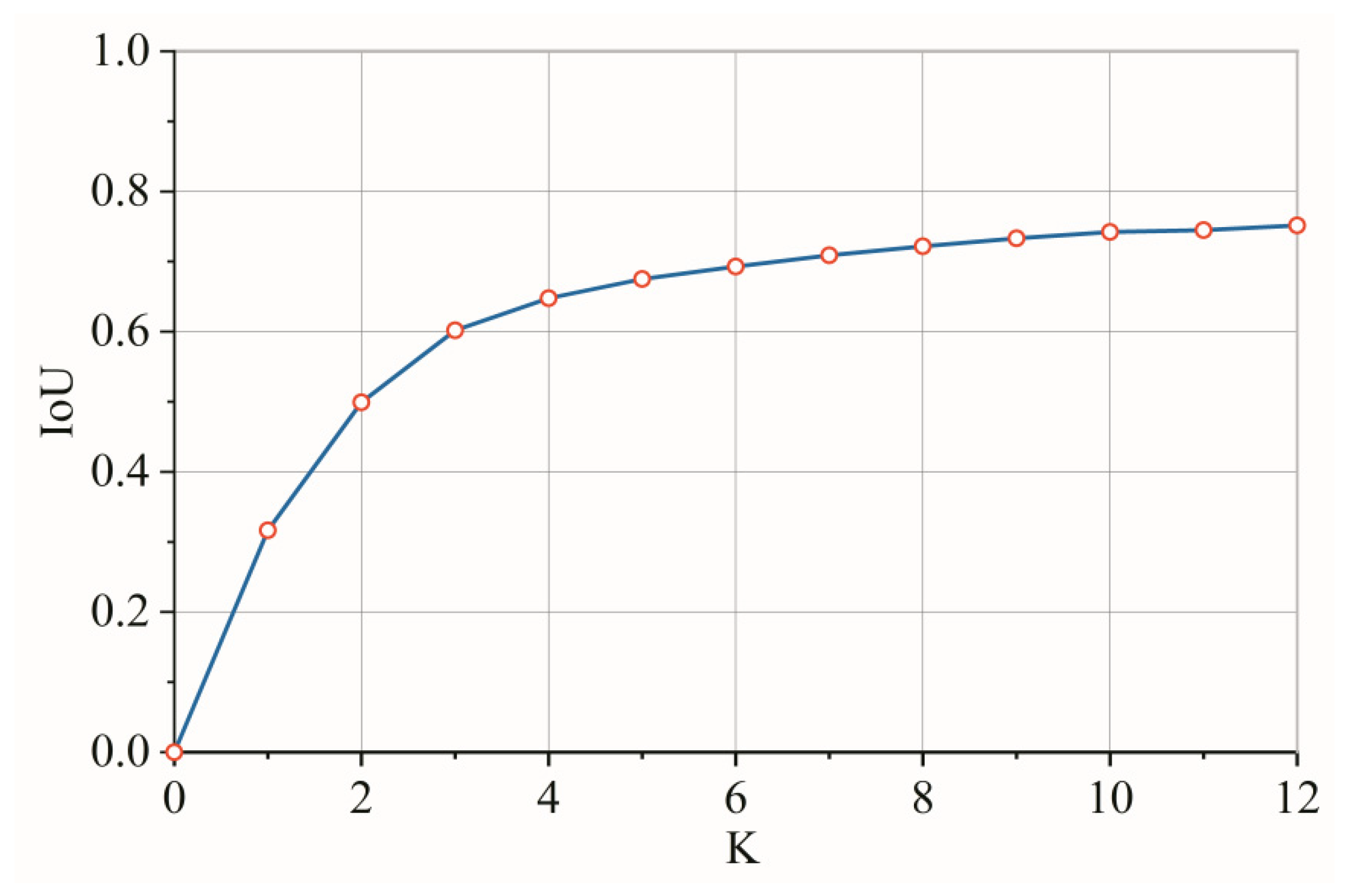
3.2.3. K-Means++ Clustering Algorithm
| Algorithm 2: K-Means++ Clustering Algorithm | |
| Input: Labels in the training dataset Output: K anchor boxes (1) Randomly select a sample from the training data set as the initial clustering center; (2) Calculate the shortest distance between each sample in the training dataset and the existing clustering center and the probability of being selected as the next clustering center. Select the sample with the highest probability as the next clustering center. Distance (D) and probability (P) are calculated as: | |
| (3) | |
| (4) | |
| where box refers to the size of the rectangular box; cen refers to the center of the rectangular box; IoU is the intersection over union of two rectangular boxes. (3) Repeat step (2) until the K clustering centers are selected; (4) Calculate the distance to the K cluster centers for each sample in the training set and divide it into the class corresponding to the clustering center with the smallest distance; (5) Recalculate the clustering centers according to the division results according to Equation (5); | |
| (5) | |
| (6) Repeat steps (4) and (5) until the clustering center position is no longer changed and the final cluster center is output. | |
4. Experimental Results and Analysis
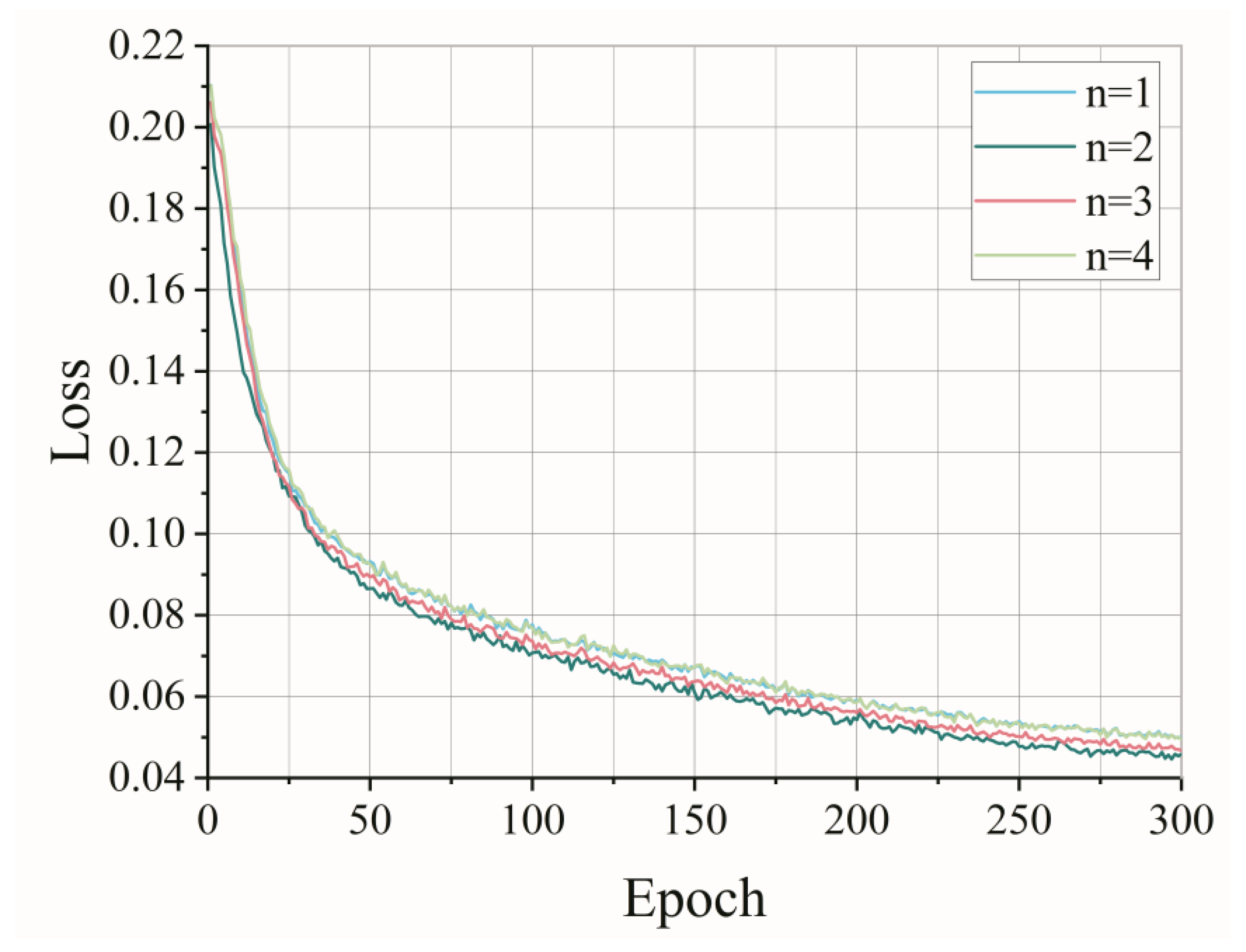
4.1. Experiments and Parameter Determination
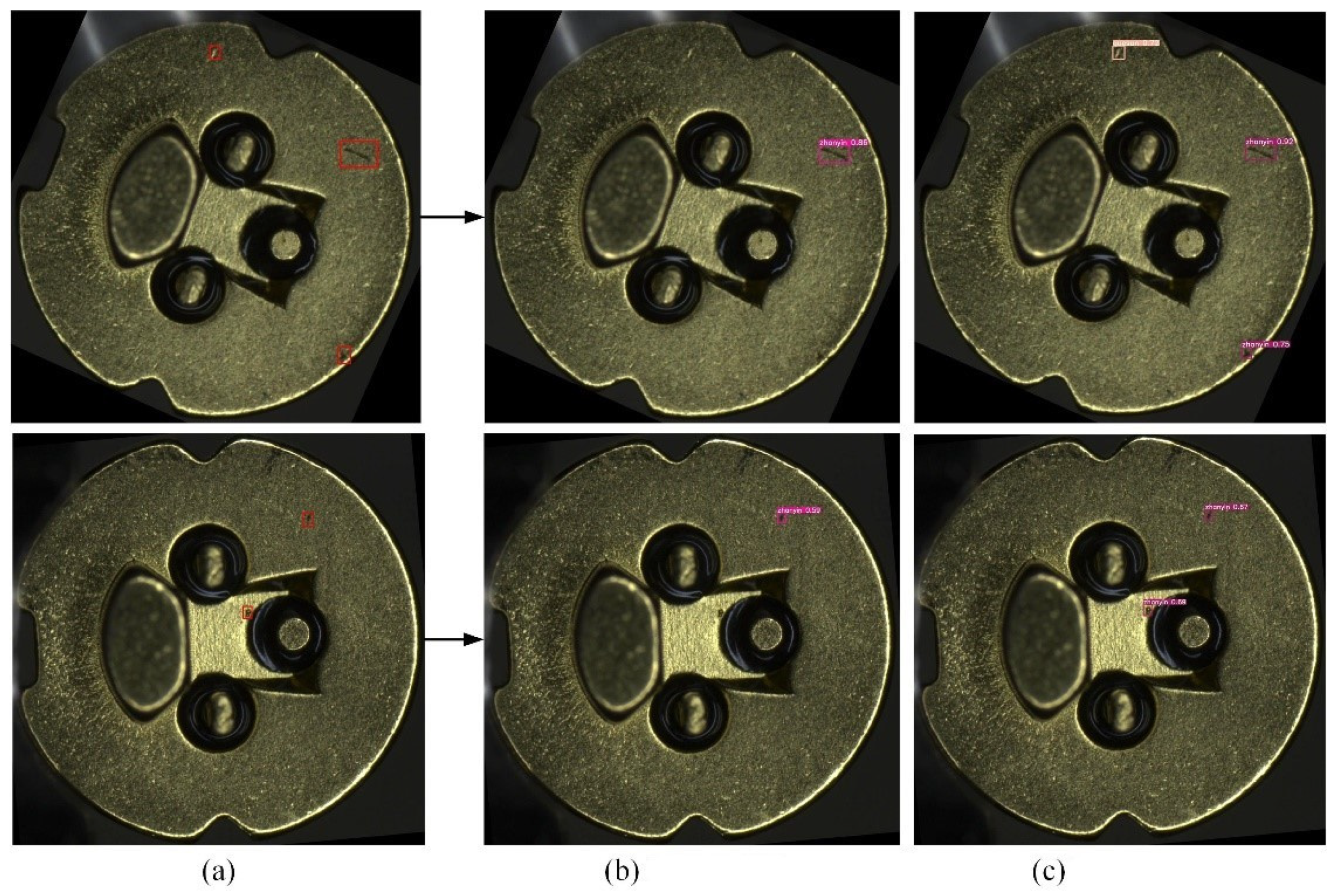
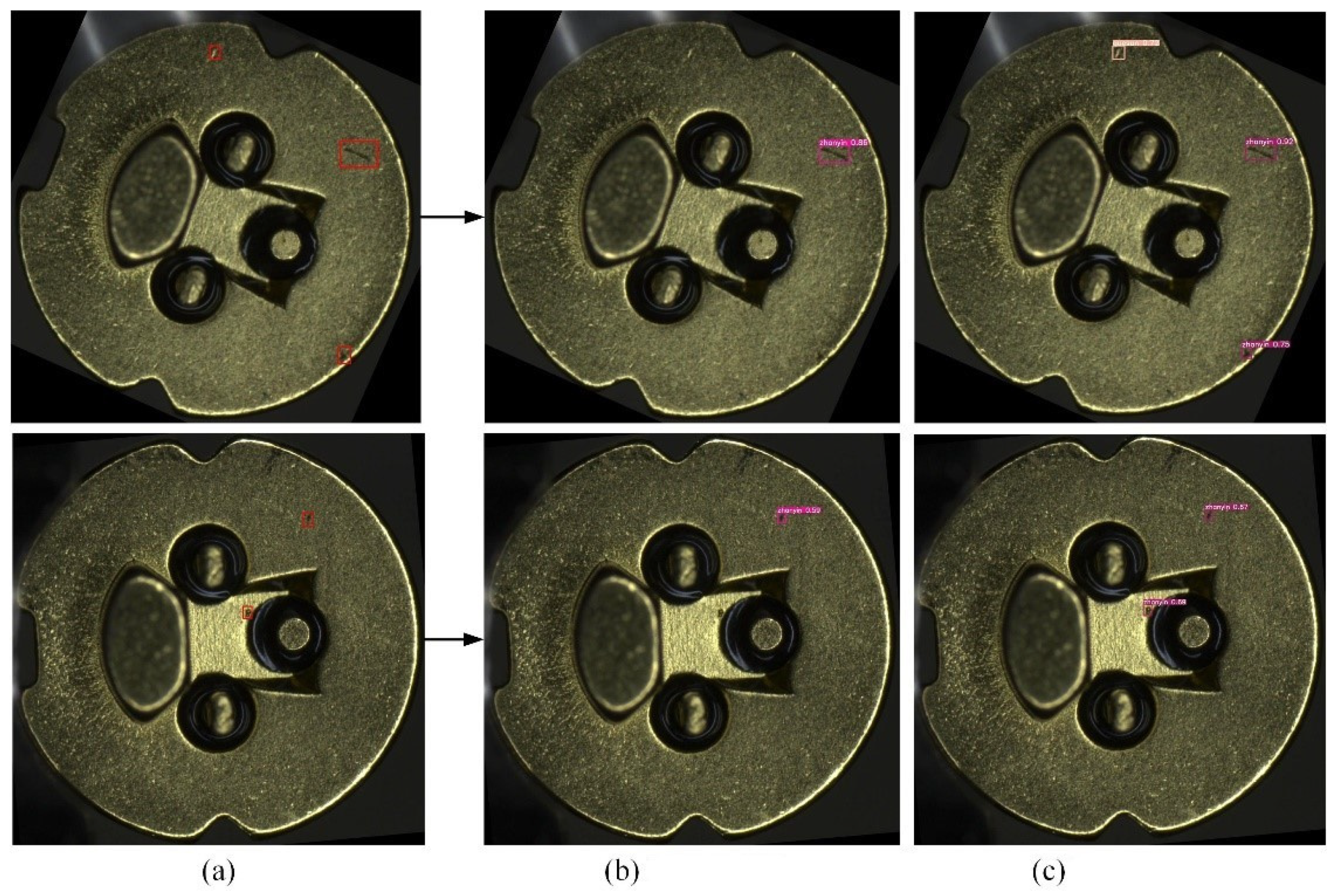
4.2. Evaluation and Analysis of Model Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chien, H.T.; Lee, D.S.; Ding, P.P.; Chiu, S.L.; Chen, P.H. Disk-shaped miniature heat pipe (DMHP) with radiating micro grooves for a to can laser diode package. IEEE Trans. Compon. Packag. Technol. 2003, 26, 569–574. [Google Scholar] [CrossRef]
- Wu, Y.L.; Zhang, A.C.; Chun, J.; Li, S.Y. Simulation and experimental study of laser hammering for laser diode packaging. IEEE Trans. Compon. Packag. Technol. 2007, 30, 163–169. [Google Scholar] [CrossRef]
- Shih, T.T.; Lin, M.C.; Cheng, W.H. High-Performance Low-Cost 10-Gb/s Coaxial DFB Laser Module Packaging by Conventional TO-Can Materials and Processes. IEEE J. Sel. Top. Quantum Electron. 2006, 12, 1009–1016. [Google Scholar] [CrossRef]
- Shih, T.T.; Tseng, P.H.; Chen, H.W.; Tien, C.C.; Wu, S.M.; Cheng, W.H. Low-Cost TO-Can Header for Coaxial Laser Modules in 25-Gbit/s Transmission Applications. IEEE Trans. Compon. Packag. Manuf. Technol. 2011, 1, 557–565. [Google Scholar] [CrossRef]
- Tandon, N.; Choudhury, A. A review of vibration and acoustic measurement methods for the detection of defects in rolling element bearings. Tribol. Int. 1999, 32, 469–480. [Google Scholar] [CrossRef]
- Li, M.; Jia, J.; Lu, X.; Zhang, Y. A Method of Surface Defect Detection of Irregular Industrial Products Based on Machine Vision. Wirel. Commun. Mob. Comput. 2021, 2021, 6630802. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999. [Google Scholar]
- Papageorgiou, C.P.; Oren, M.; Poggio, T. General framework for object detection. In Proceedings of the Sixth International Conference on Computer Vision, Mumbai, India, 7 January 1998. [Google Scholar]
- Yang, J.; Li, S.; Wang, Z.; Dong, H.; Wang, J.; Tang, S. Using Deep Learning to Detect Defects in Manufacturing: A Comprehensive Survey and Current Challenges. Materials 2020, 13, 5755. [Google Scholar] [CrossRef]
- Lv, X.; Duan, F.; Jiang, J.J.; Fu, X.; Gan, L. Deep Metallic Surface Defect Detection: The New Benchmark and Detection Network. Sensors 2020, 20, 1562. [Google Scholar] [CrossRef] [Green Version]
- Sultana, F.; Sufian, A.; Dutta, P. Advancements in Image Classification using Convolutional Neural Network. In Proceedings of the 2018 Fourth International Conference on Research in Computational Intelligence and Communication Networks (ICRCICN), Kolkata, India, 22–23 November 2018. [Google Scholar]
- Zhou, X.; Wei, G.; Fu, W.L.; Du, F. Application of deep learning in object detection. In Proceedings of the 2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Processing Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Wang, C.; Wu, Y.; Wang, Q.C.; Huang, D.S. Attention Deep Model with Multi-Scale Deep Supervision for Person Re-Identification. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 70–78. [Google Scholar] [CrossRef]
- Mery, D. Aluminum Casting Inspection using Deep Object Detection Methods and Simulated Ellipsoidal Defects. Mach. Vis. Appl. 2021, 32, 72. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xu, Z.H.; Lan, S.W.; Yang, Z.J.; Cao, J.Z.; Wu, Z.Z.; Cheng, Y.Q. MSB R-CNN: A Multi-Stage Balanced Defect Detection Network. Electronics 2021, 10, 1924. [Google Scholar] [CrossRef]
- Zhang, K.H.; Shen, H.K. Solder Joint Defect Detection in the Connectors Using Improved Faster-RCNN Algorithm. Appl. Sci. 2021, 11, 576. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhao, B.; Dai, M.; Li, P.; Xue, R.; Ma, X. Defect Detection Method for Electric Multiple Units Key Components Based on Deep Learning. IEEE Access 2020, 8, 136808–136818. [Google Scholar] [CrossRef]
- Duan, L.; Yang, K.; Ruan, L. Research on Automatic Recognition of Casting Defects Based on Deep Learning. IEEE Access 2021, 9, 12209–12216. [Google Scholar] [CrossRef]
- Liu, C.; Wu, Y.; Liu, J.; Han, J. MTI-YOLO: A Light-Weight and Real-Time Deep Neural Network for Insulator Detection in Complex Aerial Images. Energies 2021, 14, 1426. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Yeh, I.-H.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W. CSPNet: A New Backbone that Can Enhance Learning Capability of CNN. arXiv 2019, arXiv:1911.11929. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Weight | Yolov5s.pt |
| Batch size | 8 |
| Origin learning rate | 0.01 |
| Epochs | 300 |
| Momentum | 0.937 |
| Non-maximum suppression (NMS) | 0.6 |
| Feature Map Size (Pixels × Pixels) | Detection Object | Anchor Box Size (Pixels × Pixels) | |
|---|---|---|---|
| Original YOLO-V5 | Original YOLO-V5 | ||
| 20 × 20 | Large target | 10 × 13, 16 × 30, 33 × 23 | 11 × 12, 17 × 15, 15 × 23 |
| 40 × 40 | Medium target | 30 × 61, 62 × 45, 59 × 119 | 24 × 28, 28 × 53, 40 × 21 |
| 80 × 80 | Small target | 116 × 90, 156 × 98, 373 × 326 | 41 × 35, 65 × 74, 128 × 134 |
| Model | Pr (%) | Re (%) | mAP (%) |
|---|---|---|---|
| Baseline | 88.6 | 75.0 | 78.5 |
| Baseline + K-means++ | 87.5 | 75.4 | 80.1 |
| Baseline + CBAM | 87.4 | 75.7 | 79.8 |
| Baseline + RPM | 89.2 | 80.2 | 82.8 |
| Baseline + RPM + CBAM + K-means++ | 91.9 | 77.8 | 84.0 |
| Model | AP (%) | mAP (%) | FPS | Weight Size (MB) | |||||
|---|---|---|---|---|---|---|---|---|---|
| Baiban | Quesun | Yinbujun | Zhanyin | Xiuji | Huahen | ||||
| Faster R-CNN | 62.9 | 75.8 | 100 | 61.1 | 65.0 | 56.3 | 70.2 | 6 | 315.2 |
| SSD | 45.0 | 50.8 | 93.3 | 42.5 | 57.6 | 15.3 | 50.8 | 19 | 105.0 |
| YOLO-V3 | 51.3 | 76.6 | 94.7 | 75.1 | 64.9 | 43.3 | 67.6 | 11 | 235.2 |
| YOLO-V4 | 59.8 | 78.1 | 96.0 | 76.6 | 82.5 | 47.6 | 73.4 | 9 | 244.5 |
| YOLO-V5 | 67.0 | 80.5 | 99.5 | 80.1 | 87.4 | 56.5 | 78.5 | 24 | 13.7 |
| YOLO-SO | 74.4 | 83.9 | 99.5 | 82.2 | 92.7 | 71.6 | 84.0 | 25 | 13.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Zhu, X.; Zhou, X.; Qian, S.; Yu, J. Defect Detection for Metal Base of TO-Can Packaged Laser Diode Based on Improved YOLO Algorithm. Electronics 2022, 11, 1561. https://doi.org/10.3390/electronics11101561
Liu J, Zhu X, Zhou X, Qian S, Yu J. Defect Detection for Metal Base of TO-Can Packaged Laser Diode Based on Improved YOLO Algorithm. Electronics. 2022; 11(10):1561. https://doi.org/10.3390/electronics11101561
Chicago/Turabian StyleLiu, Jiayi, Xingfei Zhu, Xingyu Zhou, Shanhua Qian, and Jinghu Yu. 2022. "Defect Detection for Metal Base of TO-Can Packaged Laser Diode Based on Improved YOLO Algorithm" Electronics 11, no. 10: 1561. https://doi.org/10.3390/electronics11101561
APA StyleLiu, J., Zhu, X., Zhou, X., Qian, S., & Yu, J. (2022). Defect Detection for Metal Base of TO-Can Packaged Laser Diode Based on Improved YOLO Algorithm. Electronics, 11(10), 1561. https://doi.org/10.3390/electronics11101561