
Reconfigurable Binary Neural Network Accelerator with Adaptive Parallelism Scheme




Abstract
1. Introduction
2. Background
2.1. Binary Neural Network
2.2. BNN Acceleration Hardware
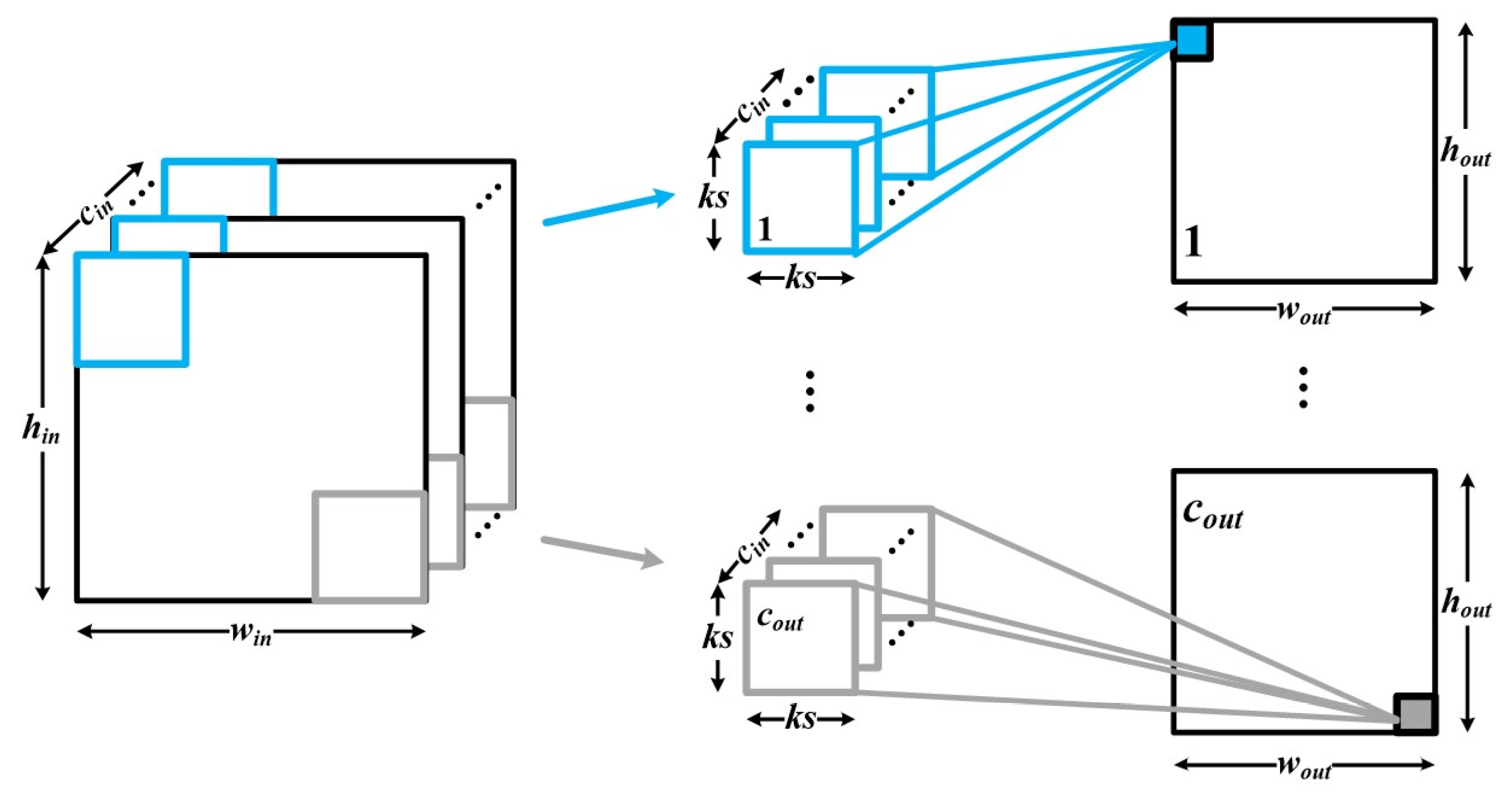
3. Proposed Parallelism Scheme
3.1. Proposed Parallelism Scheme of the BNN Accelerator
3.2. Simulation Results
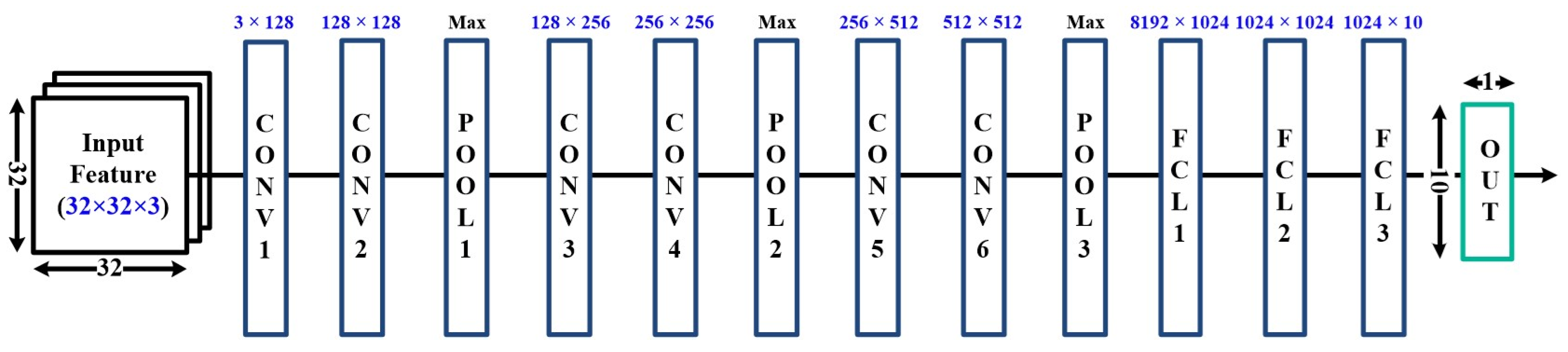
3.2.1. Target Network Topologies
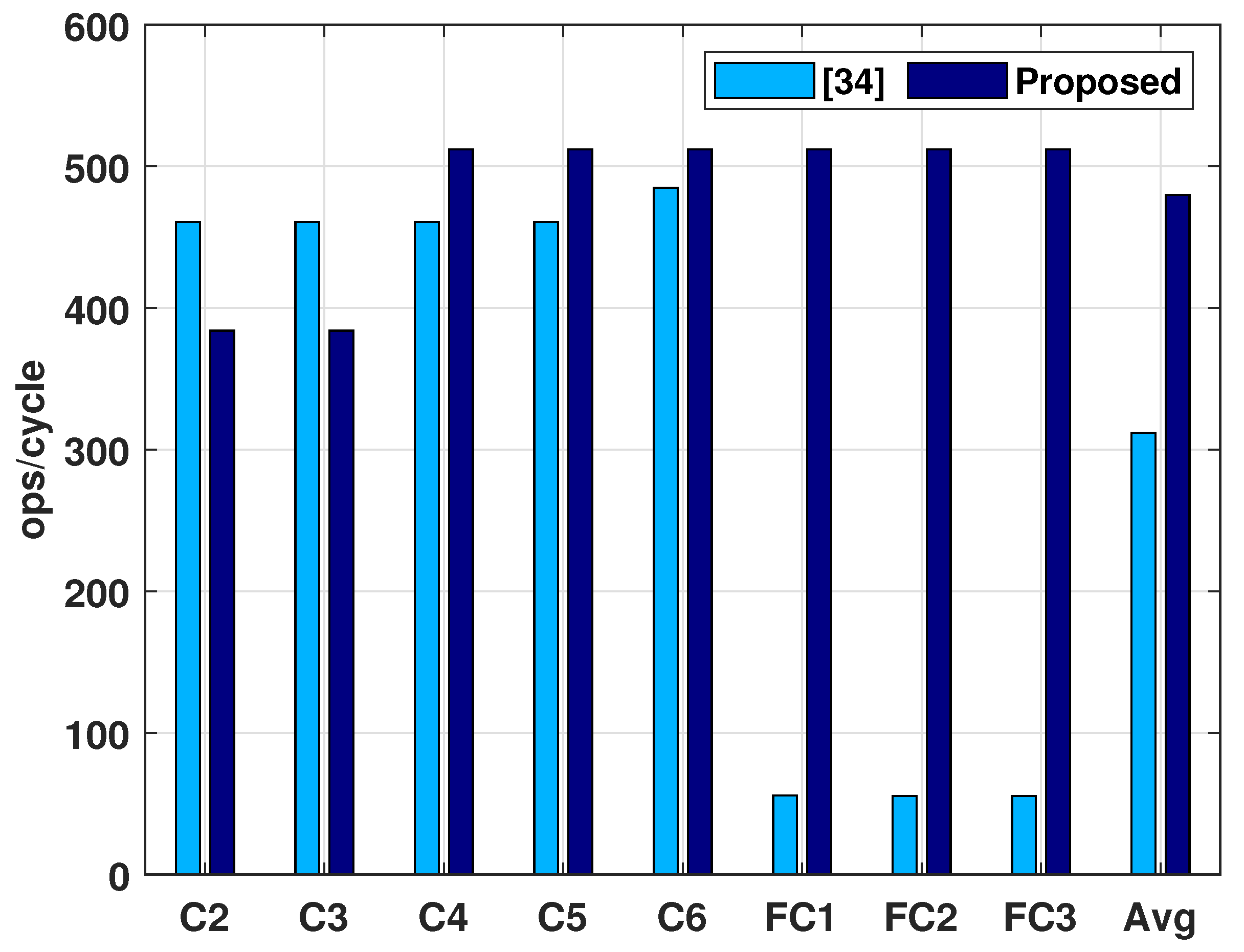
3.2.2. Performance Evaluation Results
4. Design and Implementation Results
4.1. Hardware Architecture
4.2. Implementation Results
4.2.1. FPGA Implementation Results
4.2.2. VLSI Implementation Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jiao, L.; Zhao, J. A Survey on the New Generation of Deep Learning in Image Processing. IEEE Access 2019, 7, 172231–172263. [Google Scholar] [CrossRef]
- Alom, M.; Tha, T.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.; Hasan, M.; Essen, B.; Awwal, A.; Asari, V. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- Hu, R.; Peng, Z.; Ma, J.; Li, W. CNN-Based Vehicle Target Recognition with Residual Compensation for Circular SAR Imaging. Electronics 2020, 9, 555. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sze, V.; Chen, Y.; Yang, T.; Ember, J. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Cho, J.; Jung, Y.C.; Lee, S.; Jung, Y.H. VLSI Implementation of Restricted Coulomb Energy Neural Network with Improved Learning Scheme. Electronics 2019, 8, 563. [Google Scholar] [CrossRef]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights. arXiv 2017, arXiv:1702.03044. [Google Scholar]
- Lee, E.H.; Miyashita, D.; Chai, E.; Murmann, B.; Wong, S. LogNet: Energy-efficient neural networks using logarithmic computation. In Proceedings of the IEEE ICASSP, New Orleans, LA, USA, 5–9 March 2017; pp. 5900–5904. [Google Scholar]
- Li, F.; Zhang, B.; Liu, B. Ternary Weight Networks. In Proceedings of the NIPS Workshop Efficient Methods Deep Neural Networks, Barcelona, Spain, 8 December 2016. [Google Scholar]
- Jiao, L.; Luo, C.; Cao, W.; Zhou, X.; Wang, L. Accelerating Low bit-width Convolutional Neural Networks with Embedded FPGA. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017. [Google Scholar]
- Vita, A.D.; Pau, D.; Benedetto, L.D.; Rubino, A.; Petro, F.; Licciardo, G.D. Low Power Tiny Binary Neural Network with improved accuracy in Human Recognition Systems. In Proceedings of the 2020 23rd Euromicro Conference on Digital System Design (DSD), Kranj, Slovenia, 26–28 August 2020. [Google Scholar]
- Vita, A.D.; Russo, A.; Pau, D.; Benedetto, L.D.; Rubino, A.; Licciardo, G.D. A Partially Binarized Hybrid Neural Network System for Low-Power and Resource Constrained Human Activity Recognition. IEEE Trans. CAS 1 2020, 67, 3893–3904. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J. BinaryConnect: Training Deep Neural Networks with Binary Weights during propagations. In Proceedings of the NIPS, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; EI-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Rastegary, M.; Ordonez, V.; Redon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. arXiv 2016, arXiv:1603.05279. [Google Scholar]
- Lin, X.; Zhao, C.; Pan, W. Towards Accurate Binary Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Darabi, S.; Belbahri, M.; Courbariaux, M.; Nia, V.P. BNN+: Improved Binary Network Training. In Proceedings of the Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–10. [Google Scholar]
- Simons, T.; Lee, D. A Review of Binarized Networks. Electronics 2019, 8, 661. [Google Scholar] [CrossRef]
- Bethge, J.; Bartz, C.; Yang, H.; Chen, Y.; Meinel, C. MeliusNet: Can Binary Neural Networks Achieve MobileNet-level Accuracy? arXiv 2020, arXiv:2001.05936. [Google Scholar]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. FINN. In Proceedings of the ACM/SIGDA International Symposium on FPGA, Monterey, CA, USA, 22–24 February 2017; ACM Press: New York, NY, USA, 2017; pp. 65–74. [Google Scholar]
- BloTT, M.; Preuber, T.B.; Frased, N.J.; Gambardella, G.; O’brien, K.; Umuroglu, Y.; Leeser, M.; Vissers, K. FINN-R: An End-to-End Deep-Learning Framework for Fast Exploration of Quantized Neural Networks. ACM Trans. Reconfigurable Technol. Syst. 2018, 11, 1–23. [Google Scholar] [CrossRef]
- Fiscaletti, G.; Speziali, M.; Stornaiuolo, L.; Santambrogio, M.D.; Sciuto, D. BNNsplit: Binarized Neural Networks for Embedded Distributed FPGA-based Computing Systems. In Proceedings of the 2020 DATE, Grenoble, France, 9–13 March 2020; pp. 975–978. [Google Scholar]
- Nurvitadhi, E.; Sheffield, D.; Sim, J.; Mishra, A.; Venkatesh, G.; Marr, D. Accelerating Binarized Neural Networks: Comparison of FPGA, CPU, GPU, and ASIC. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016; pp. 77–84. [Google Scholar]
- Liang, S.; Yin, S.; Liu, L.; Luk, W.; Wei, S. FP-BNN: Binarized Neural Network on FPGA. Neurocomputing 2012, 275, 1072–1086. [Google Scholar] [CrossRef]
- Fu, C.; Zhu, S.; Chen, H.; Koushanfar, F.; Su, H.; Zhao, J. SimBNN: A Similarity-Aware Binarized Neural Network Acceleration Framework. In Proceedings of the IEEE FCCM, San Diego, CA, USA, 28 April–1 May 2019; p. 319. [Google Scholar]
- Ghasemzadeh, M.; Samragh, M.; Koushanfar, F. ReBNet: Residual Binarized Neural Network. In Proceedings of the IEEE FCCM, Boulder, CO, USA, 29 April–1 May 2018; pp. 57–64. [Google Scholar]
- Geng, T.; Wang, T.; Wu, C.; Yang, C.; Song, S.; Li, A.; Herbordt, M. LP-BNN: Ultra-low-latency BNN Inference with Layer Parallelism. In Proceedings of the 2019 IEEE 30th International Conference on Application-specific Systems, Architectures and Processors (ASAP), New York, NY, USA, 15–17 July 2019; pp. 9–16. [Google Scholar]
- Bahou, A.A.; Karunaratne, G.; Andri, R.; Cavigelli, L.; Benini, L. XNORBIN: A 95 TOp/s/W Hardware Accelerator for Binary Convolutional Neural Networks. In Proceedings of the IEEE Symp. COOL CHIPS, Yokohama, Japan, 18–20 April 2018; pp. 1–3. [Google Scholar]
- Lin, J.; Xing, T.; Zhao, R.; Zhang, Z.; Srivastava, M.; Tu, Z.; Gupta, R.K. Binarized Convolutional Neural Networks with Separable Filters for Efficient Hardware Acceleration. In Proceedings of the IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 27–35. [Google Scholar]
- Wang, E.; Davis, J.J.; Cheung, P.Y.K.; Constantinides, G.A. LUTNet: Learning FPGA Configurations for Highly Efficient Neural Network Inference. IEEE Trans. Comput. 2020, 69, 1795–1808. [Google Scholar] [CrossRef]
- Lammie, C.; Xiang, W.; Azghadi, M.R. Training Progressively Binarizing Deep Networks using FPGAs. In Proceedings of the IEEE ISCAS, Sevilla, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar]
- Yonekawa, H.; Nakahara, H. On-Chip Memory Based Binarized Convolutional Deep Neural Network Applying Batch Normalization Free Technique on an FPGA. In Proceedings of the IEEE IPDPSW, Orlando, FL, USA, 29 May–2 June 2017; pp. 98–105. [Google Scholar]
- Gu, P.; Ma, H.; Chen, R.; Li, P.; Xie, S.; Wang, D. FBNA: A Fully Binarized Neural Network Accelerator. In Proceedings of the 2018 28th International Conference on Field Programmable Logic and Applications (FPL), Dublin, Ireland, 27–31 August 2018; pp. 51–54. [Google Scholar]
- Zhou, Y.; Redkar, S.; Huang, X. Deep Learning Binary Neural Network on an FPGA. In Proceedings of the IEEE MWSCAS, Boston, MA, USA, 6–9 August 2017; pp. 281–284. [Google Scholar]
- Conti, F.; Schiavone, D.; Benini, L. XNOR Neural Engine: A Hardware Accelerator IP for 21.6fj/op Binary Neural Network Inference. IEEE Trans. CAD 2018, 37, 2940–2951. [Google Scholar] [CrossRef]
- Rusci, M.; Cavigelli, L.; Benini, L. Design Automation for Binarized Neural Networks: A Quantum Leap Opportunity? In Proceedings of the IEEE ISCAS, Florence, Italy, 27–30 May 2018. [Google Scholar]
- Jung, Y.C.; Cho, J.; Lee, S.; Jung, Y.H. Area-Efficient Pipelined FFT Processor for Zero-Padded Signals. Electronics 2019, 8, 1397. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mode | Parallelism Scheme |
|---|---|
| = 0 | First scheme introduced in Figure 2 |
| = 1 | Second scheme shown in Figure 4 |
| Network | Architecture | Dataset | Accuracy |
|---|---|---|---|
| BNN-Cifar10 | 2C128-MP-2C256-MP-2C512-MP-2FC1024-FC10 | CIFAR-10 | 89.95% |
| VGG-16 | 2C64-MP-2C128-MP-3C256-MP-3C512-MP-3C512-MP-2FC4096-FC1000 | ImageNet | 75.5% |
| [34] | [35] | Proposed ( = 256) | ||
|---|---|---|---|---|
| FPGA | XCZU9EG | XC7Z020 | XCZU7EV | |
| Target Network | VGG-16 | BNN-Cifar10 | VGG-16 | |
| Parallelism | Filter-level | Proposed | ||
| Operating Frequency | 150 MHz | 143 MHz | 371 MHz | |
| CLB (Slice) | 47,946 | N.A. | 1050 | |
| LUT | N.A. | 34.9 K | 4.8 K | |
| DSP | 4 | 0 | 2 | |
| BRAM | 1367 | 103 | 89 | |
| Peak Performance | 460.8 Gops/s | 722.8 Gops/s | 177.68 Gops/s | |
| Area Efficiency | Gops/s/KLUT | N.A. | 21 | 37.02 |
| Gops/s/KCLB | 9.61 | N.A. | 169.22 | |
| Power Efficiency (Gops/s/W) | 20.94 | 219 | 250 | |
| [30] | [37] | Proposed ( = 128) | ||
|---|---|---|---|---|
| Technology | 65 nm | 65 nm | 22 nm | 40 nm |
| Area (10 m) | 540 | 41.2 | 7.6 | 16.49 |
| Normalized Area | 204.49 | 15.60 | 25.12 | 16.49 |
| Operating Frequency | 156 MHz | 300 MHz | 300 MHz | |
| Peak Performance | 244 Gops/s | 66 Gops/s | 74 Gops/s | |
| Area Efficiency (Gops/s/) | 1.19 | 4.23 | 2.63 | 4.49 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, J.; Jung, Y.; Lee, S.; Jung, Y. Reconfigurable Binary Neural Network Accelerator with Adaptive Parallelism Scheme. Electronics 2021, 10, 230. https://doi.org/10.3390/electronics10030230
Cho J, Jung Y, Lee S, Jung Y. Reconfigurable Binary Neural Network Accelerator with Adaptive Parallelism Scheme. Electronics. 2021; 10(3):230. https://doi.org/10.3390/electronics10030230
Chicago/Turabian StyleCho, Jaechan, Yongchul Jung, Seongjoo Lee, and Yunho Jung. 2021. "Reconfigurable Binary Neural Network Accelerator with Adaptive Parallelism Scheme" Electronics 10, no. 3: 230. https://doi.org/10.3390/electronics10030230
APA StyleCho, J., Jung, Y., Lee, S., & Jung, Y. (2021). Reconfigurable Binary Neural Network Accelerator with Adaptive Parallelism Scheme. Electronics, 10(3), 230. https://doi.org/10.3390/electronics10030230