Design and Implementation of a Farrow-Interpolator-Based Digital Front-End in LTE Receivers for Carrier Aggregation


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
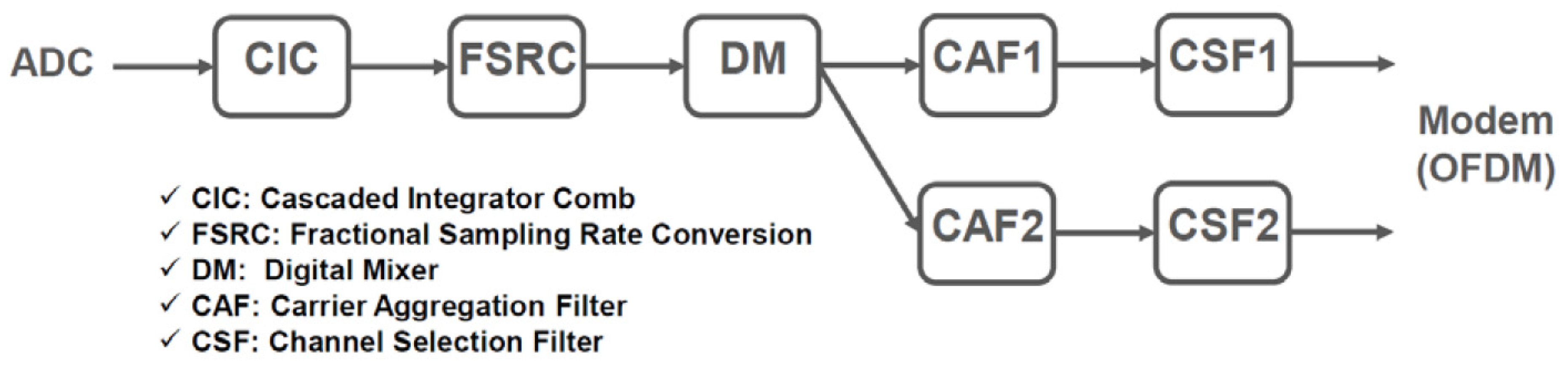
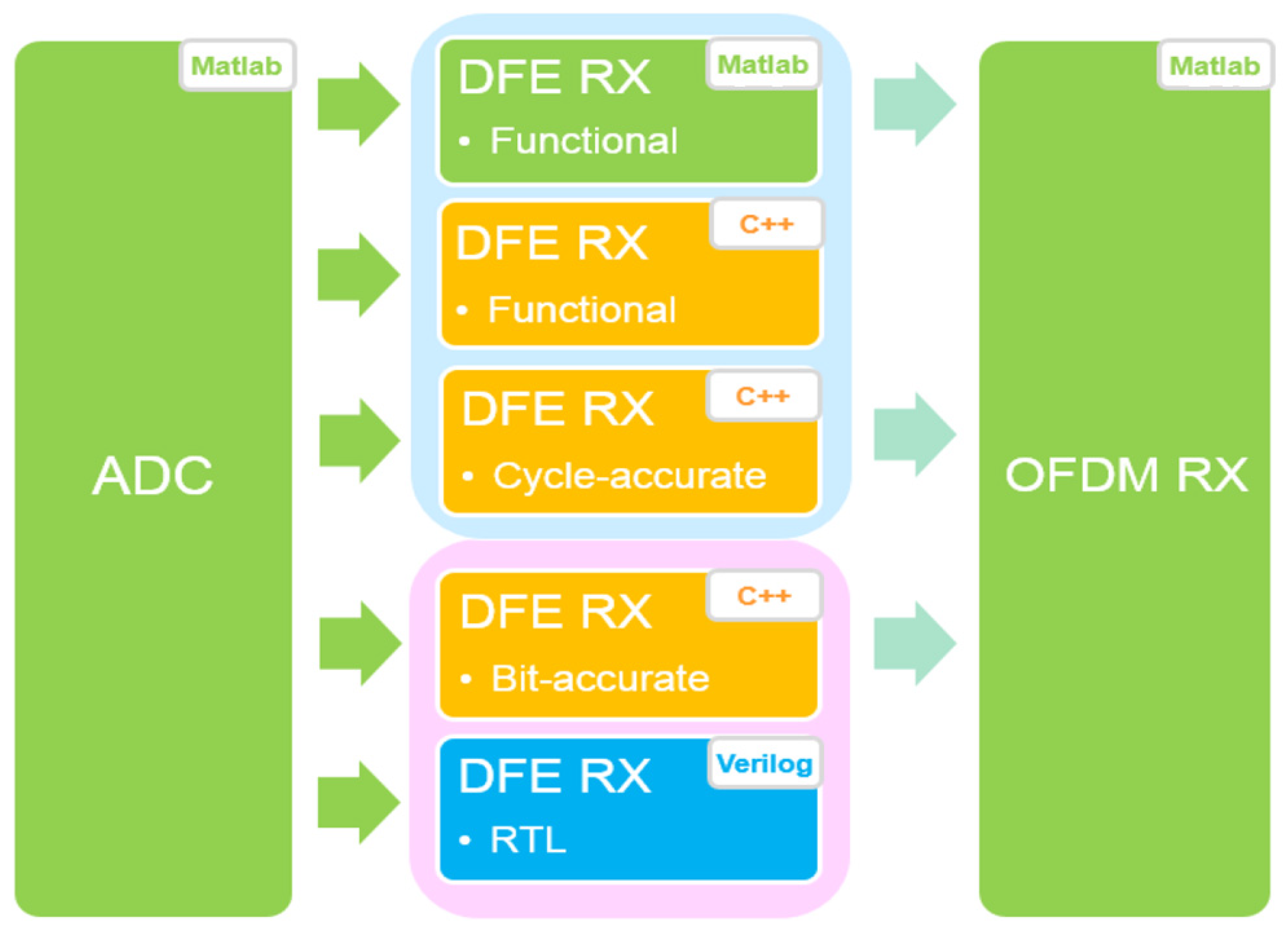
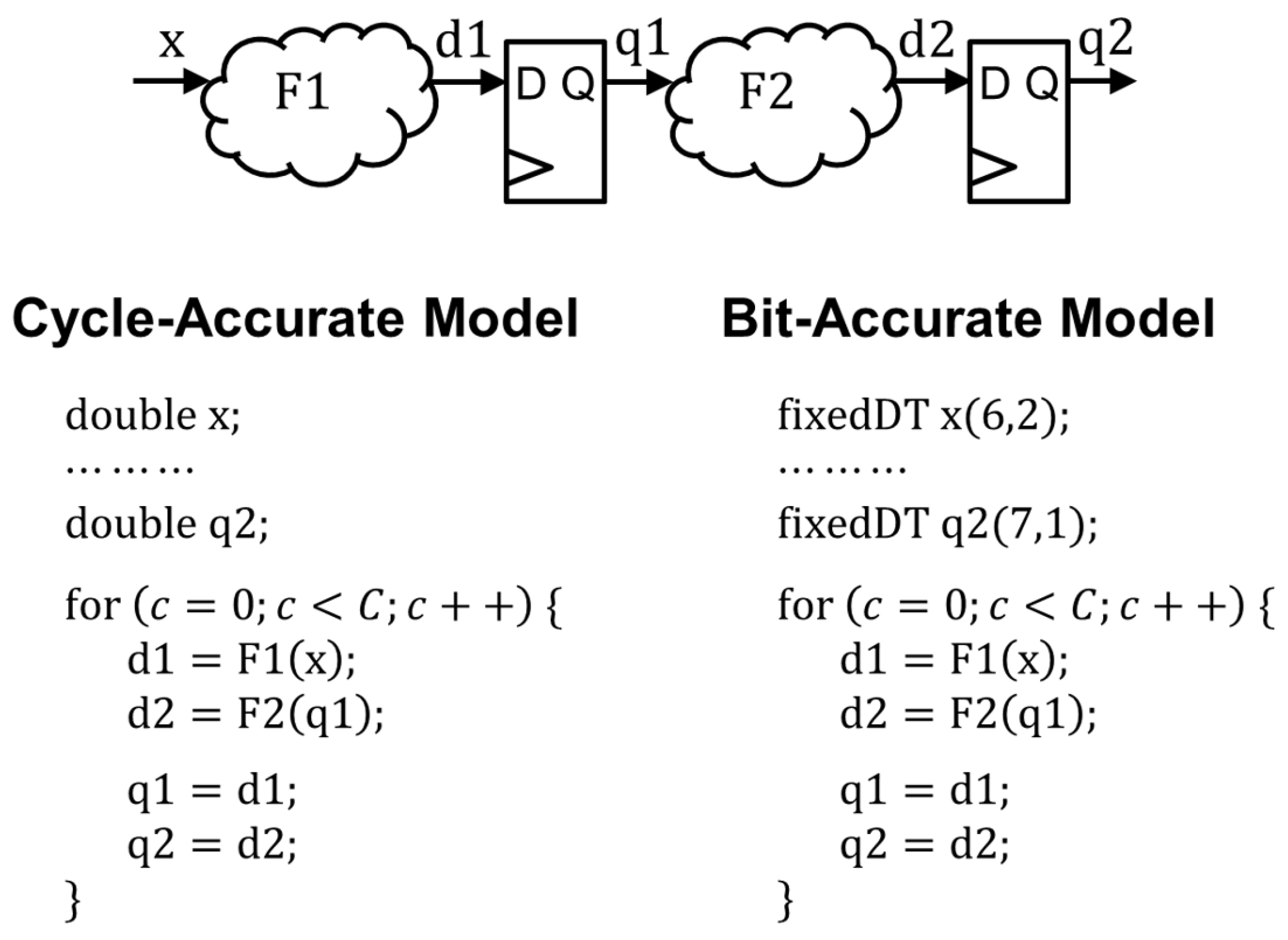
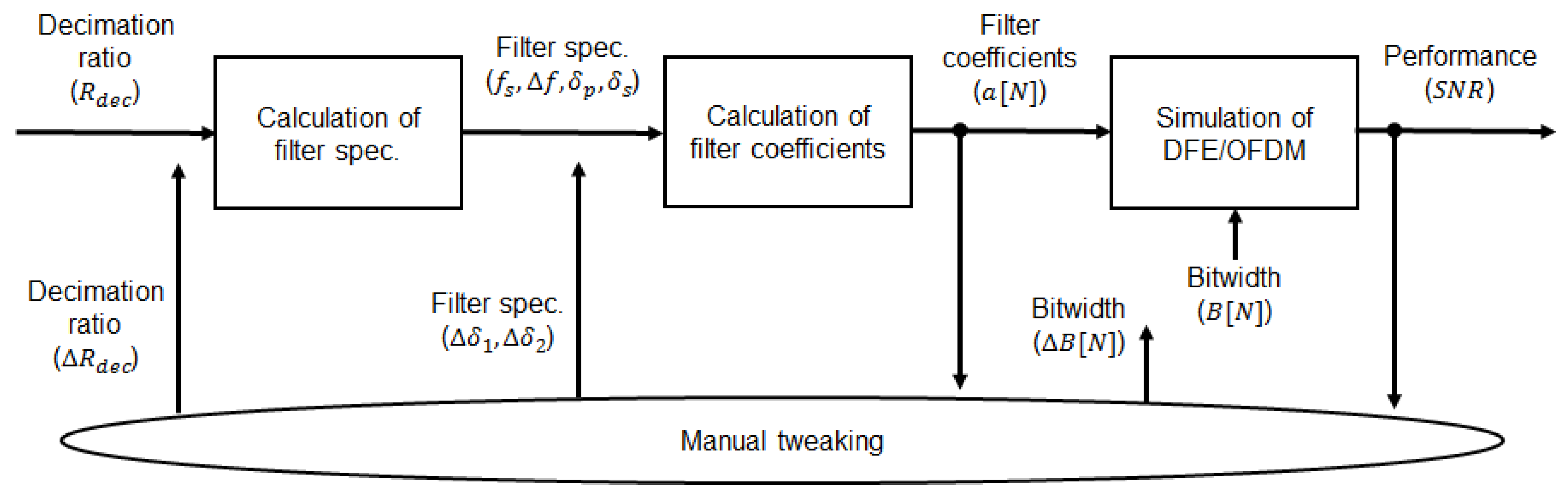
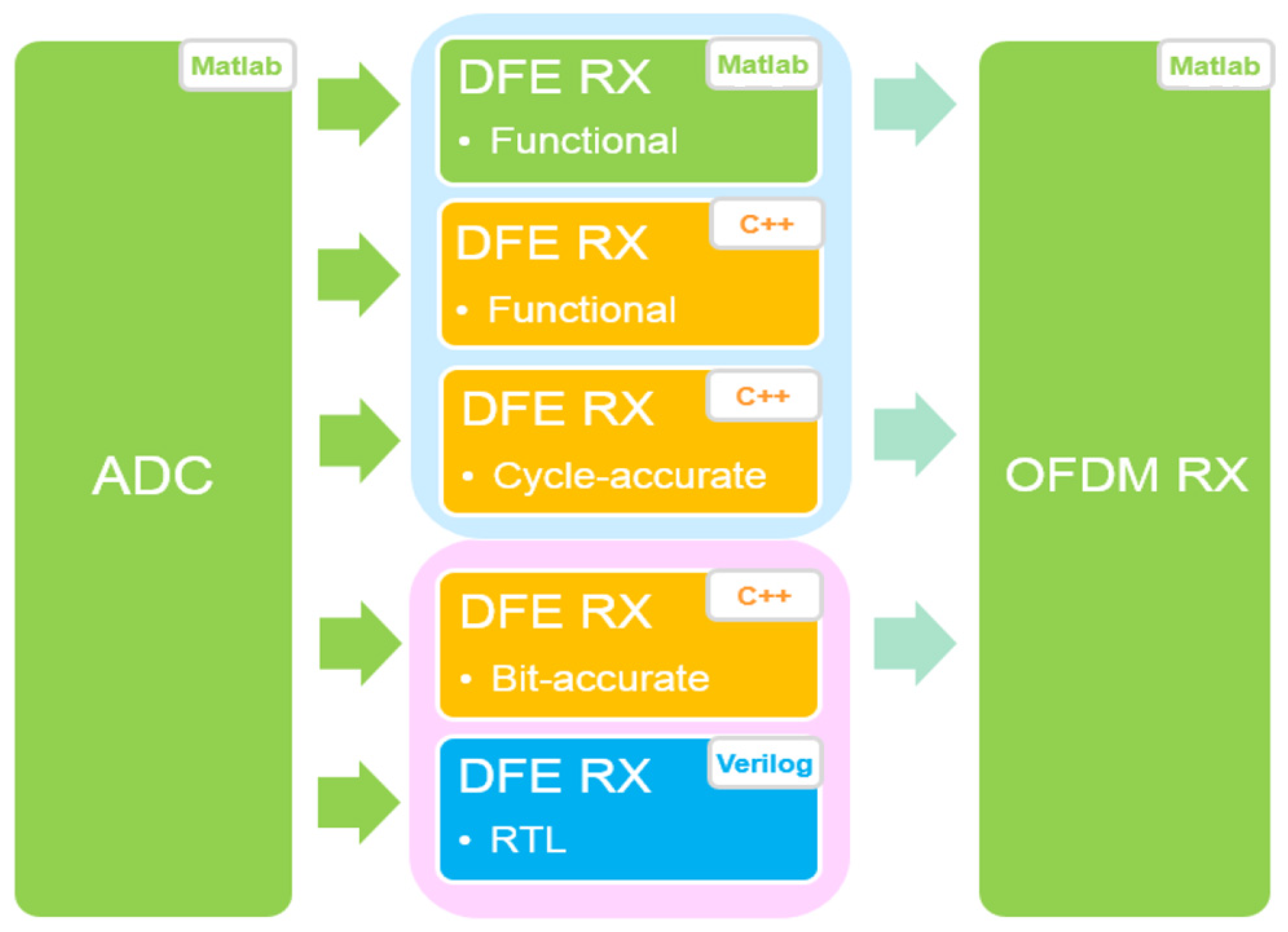
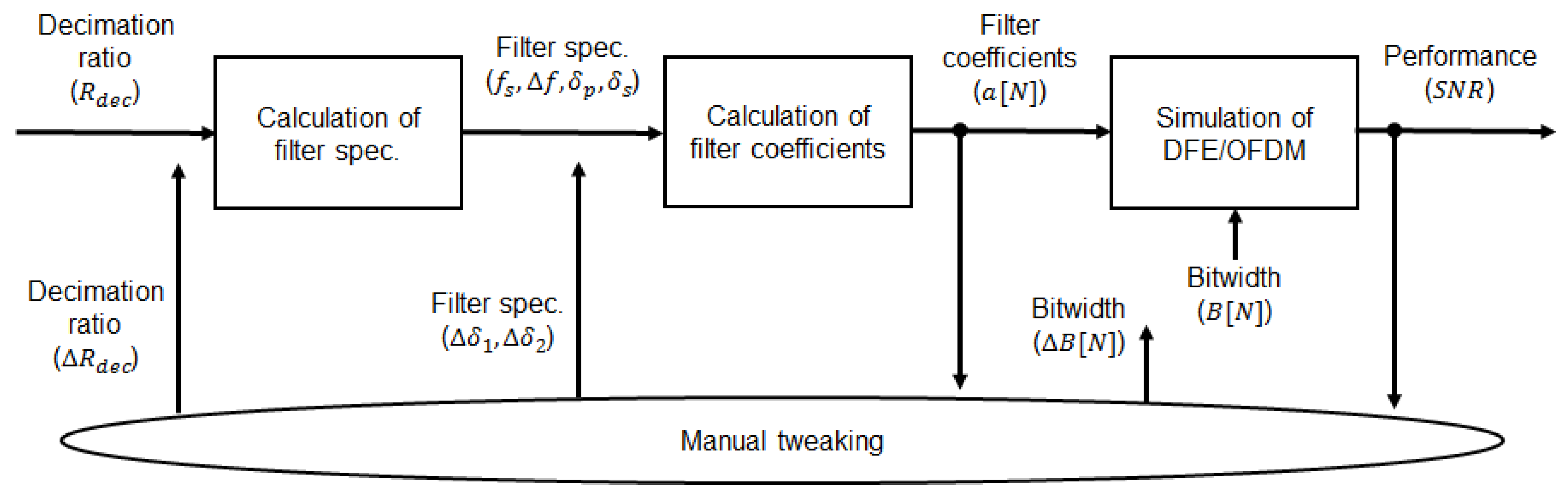
2. Design Flow and the Overall DFE Architecture
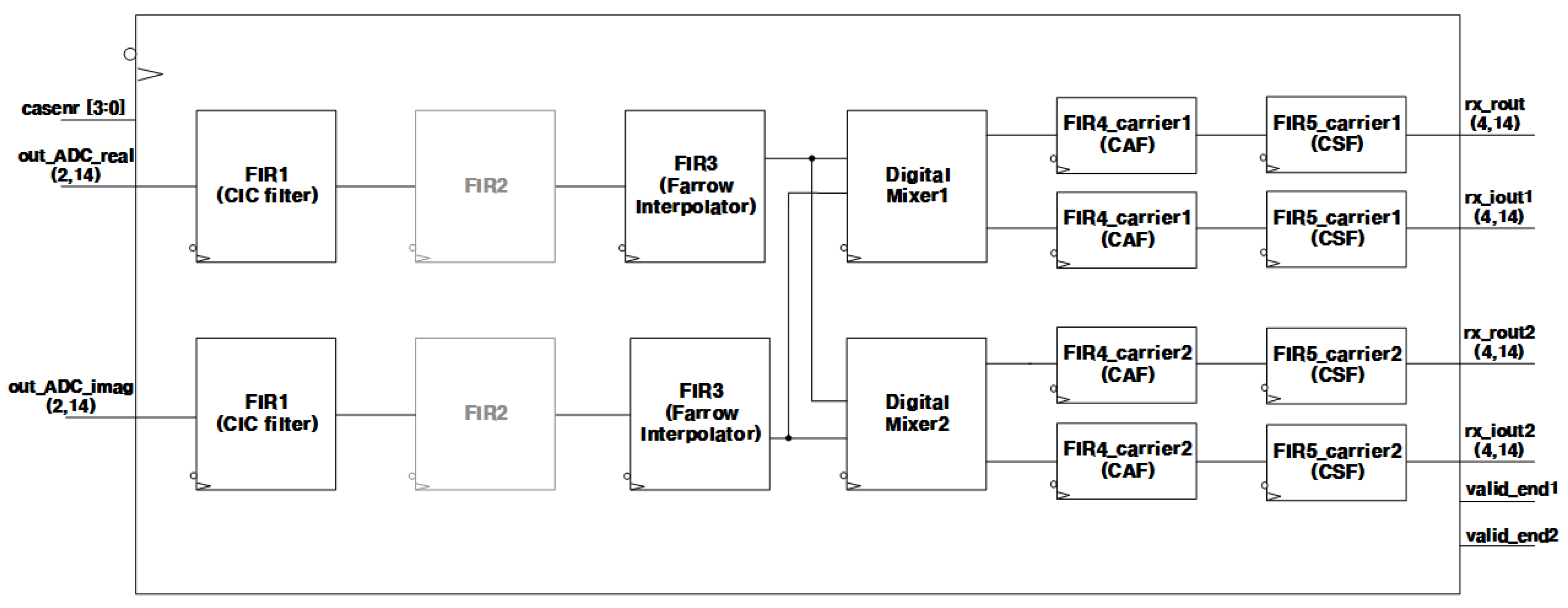
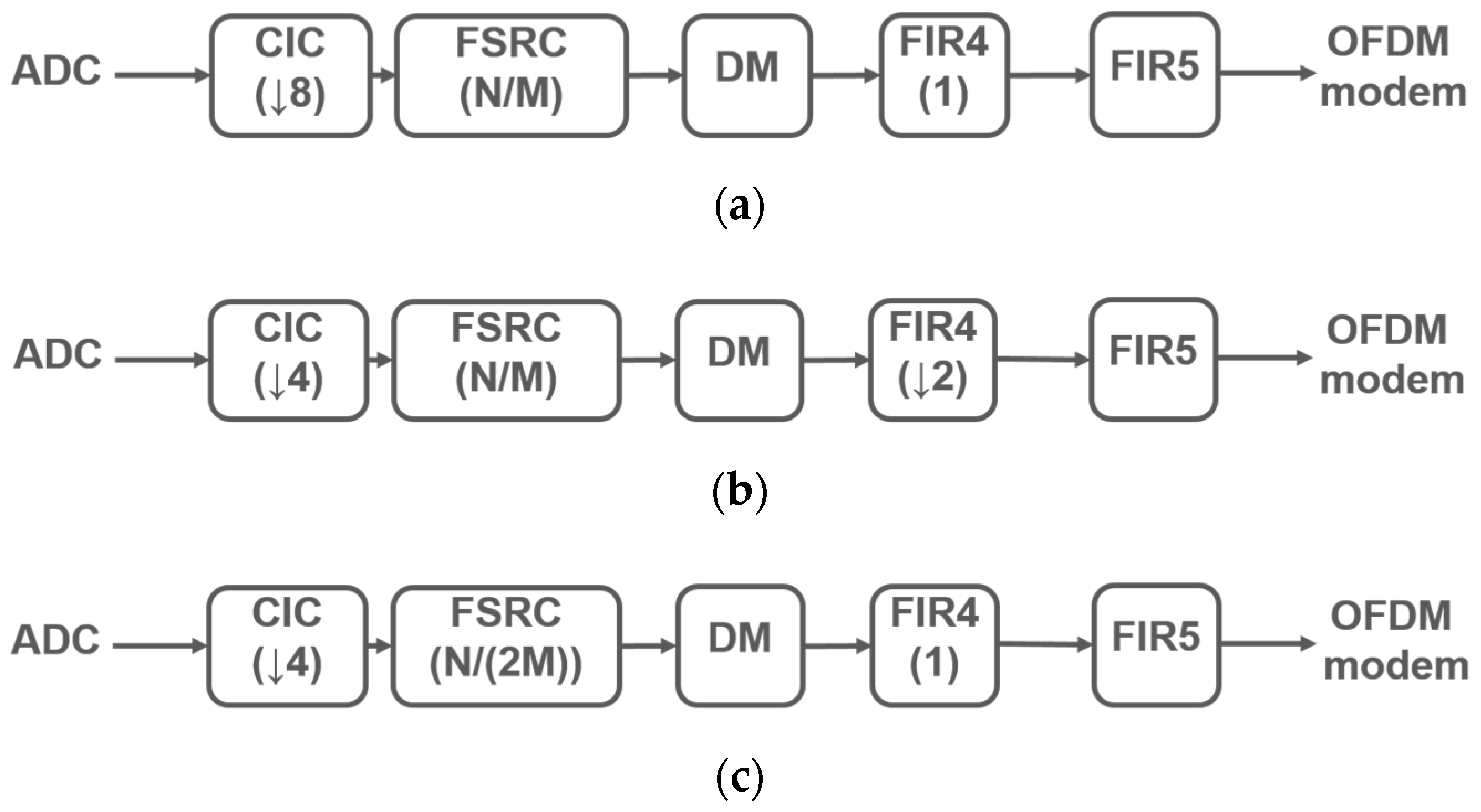
3. Building Blocks of the Overall DFE Architecture
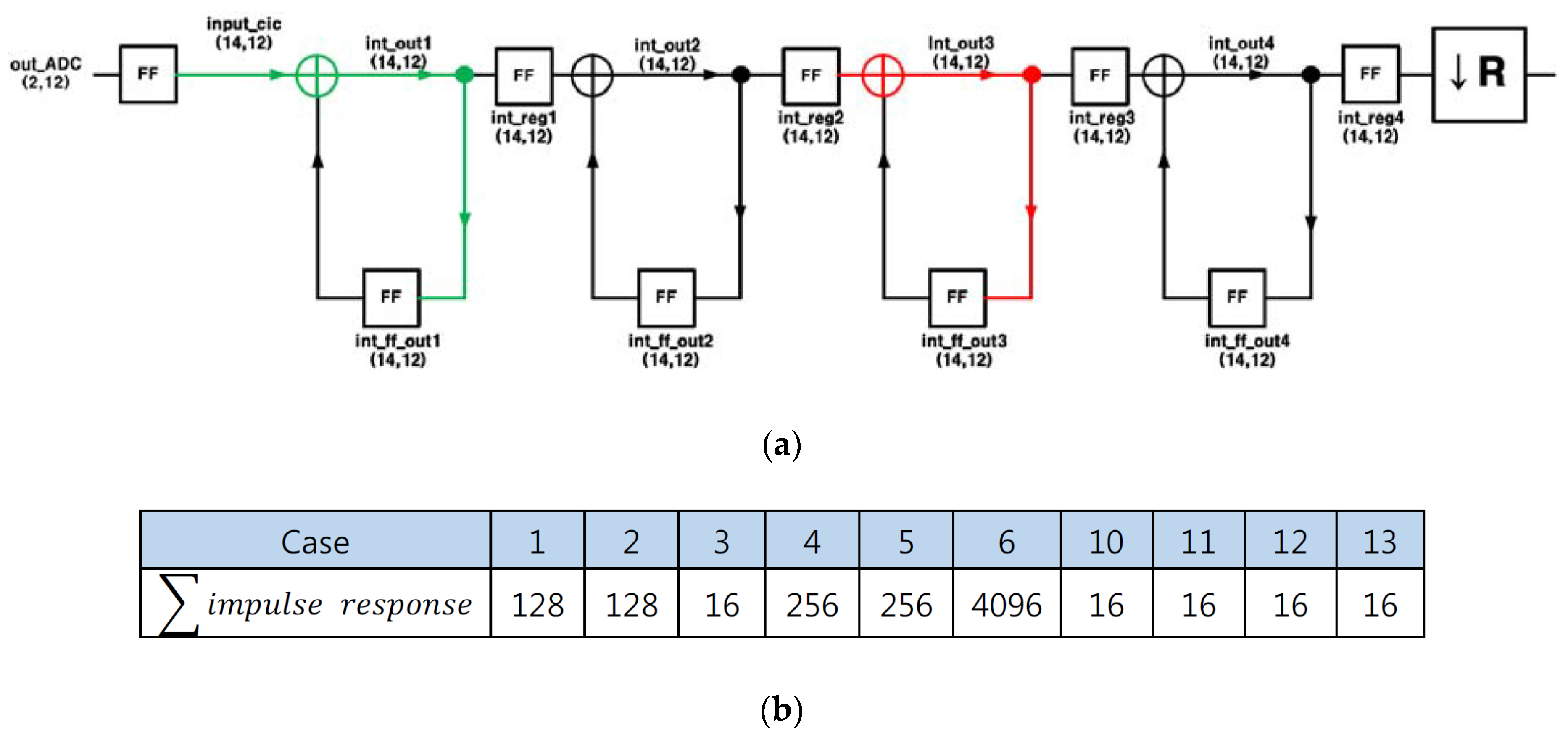
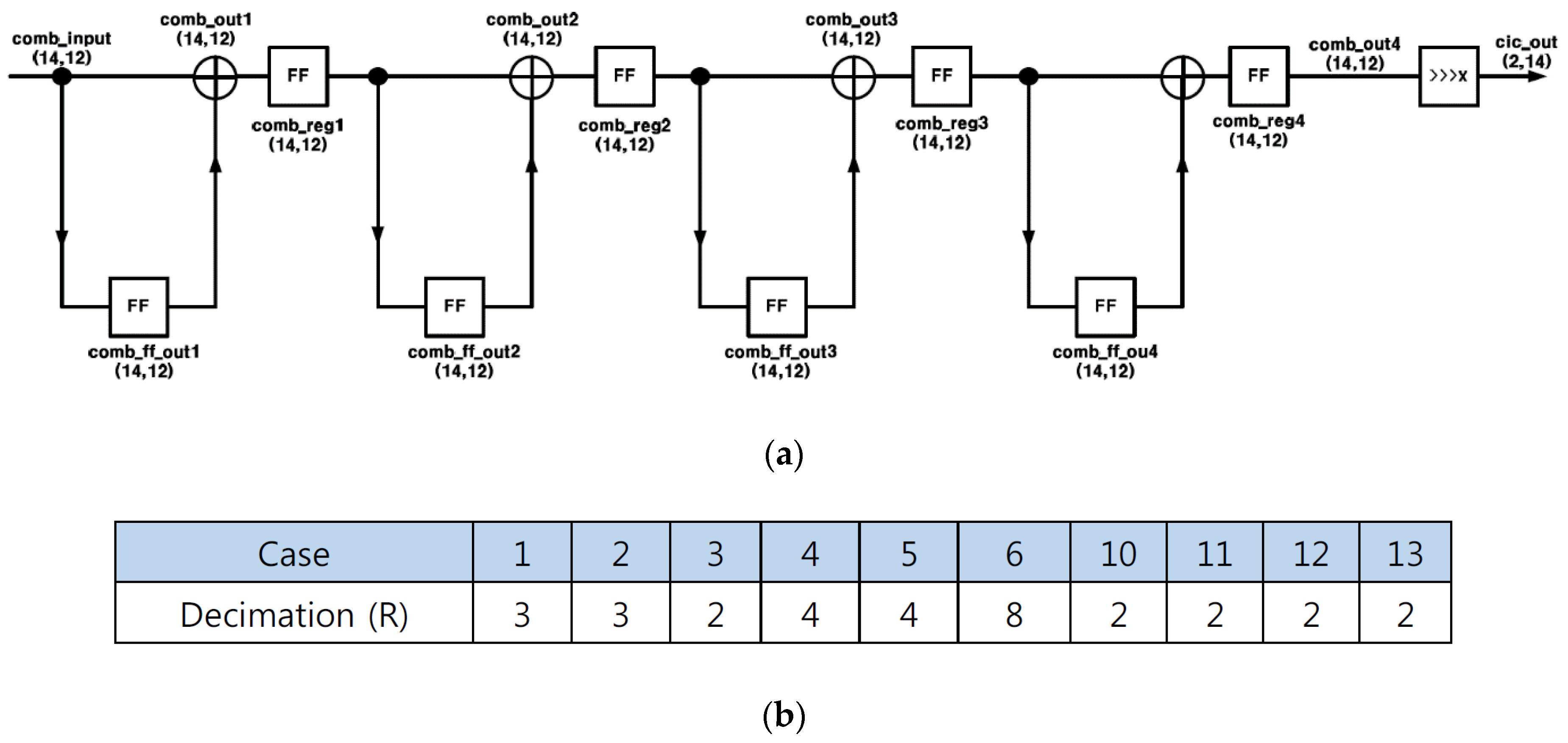
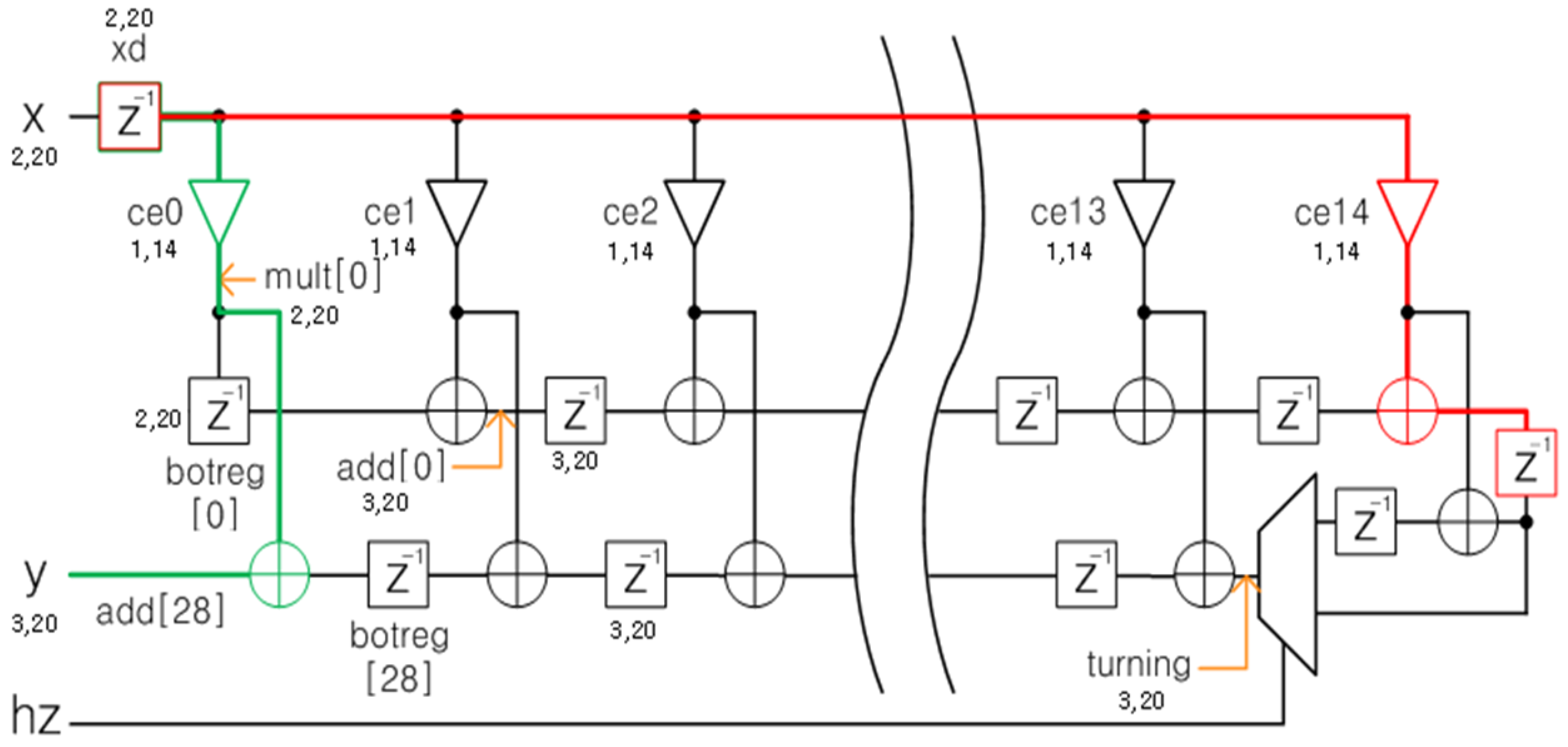
3.1. FIR1 (CIC Filter)
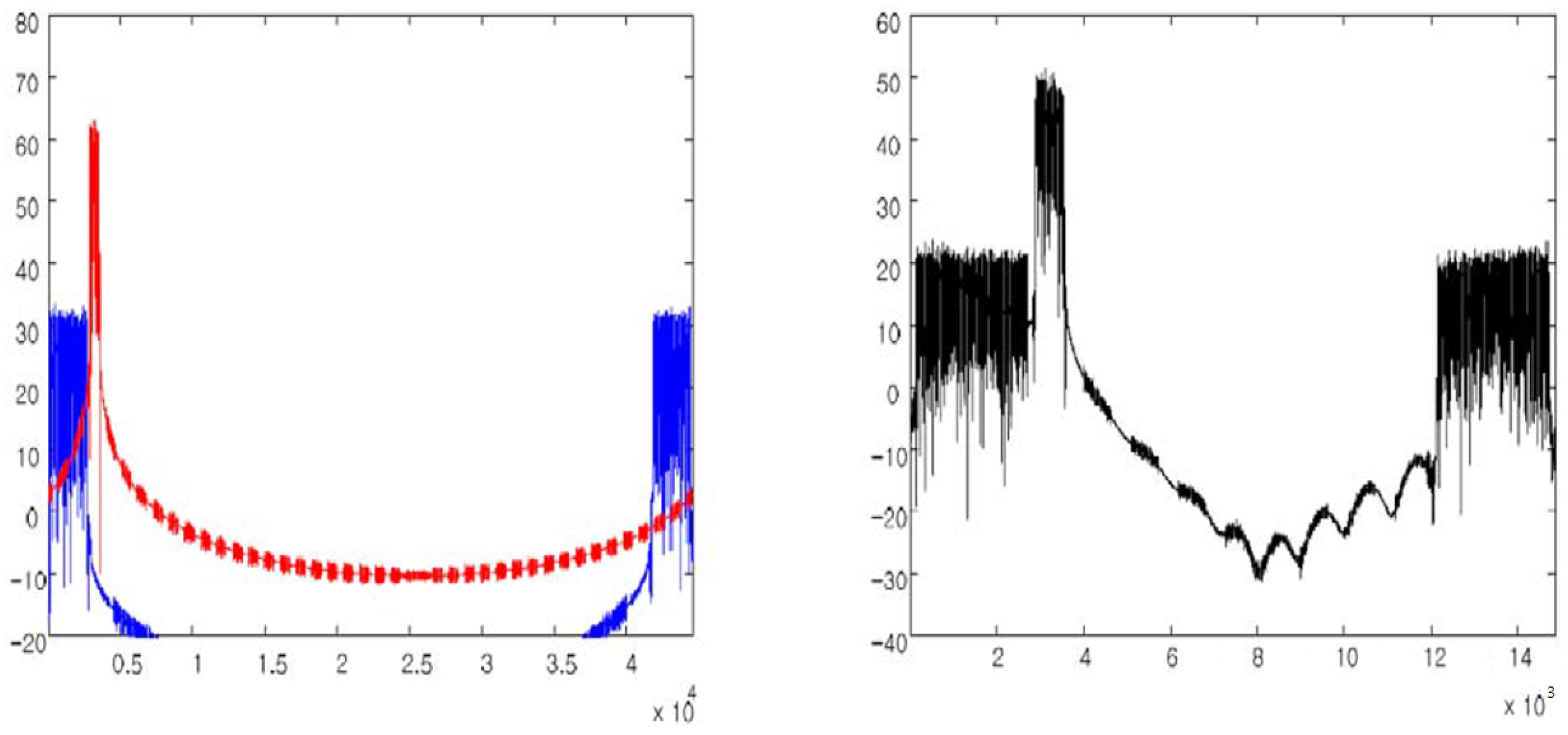
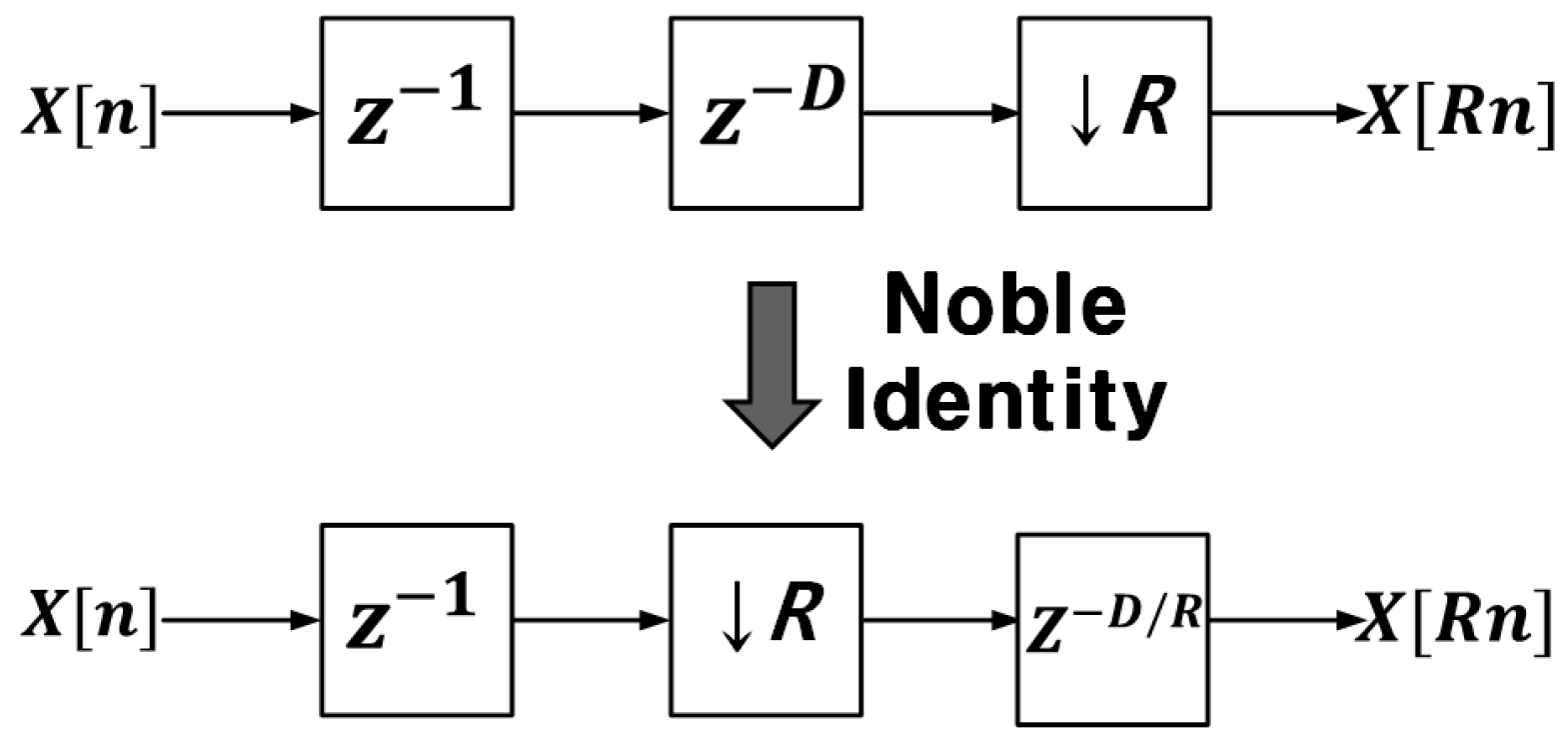
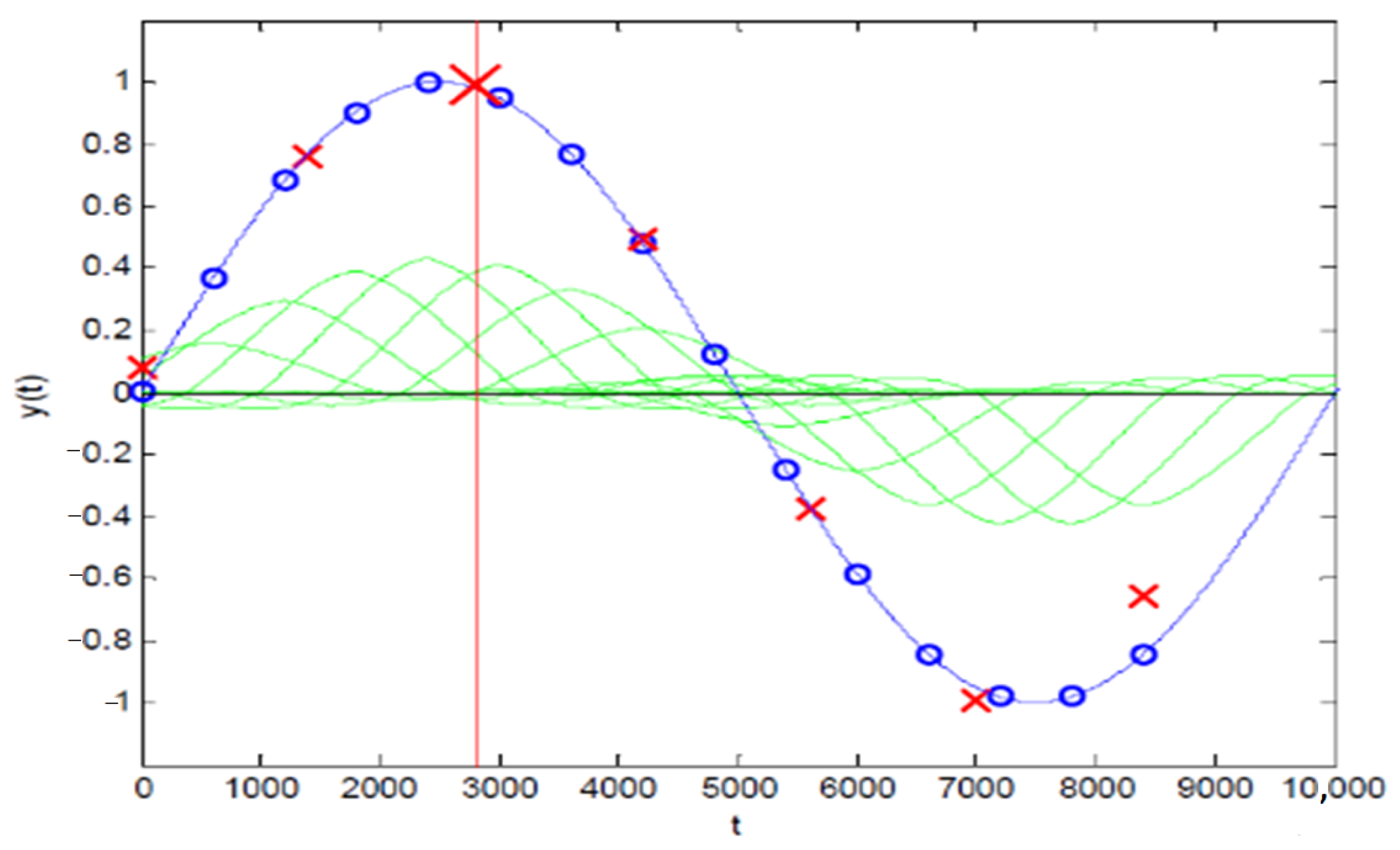
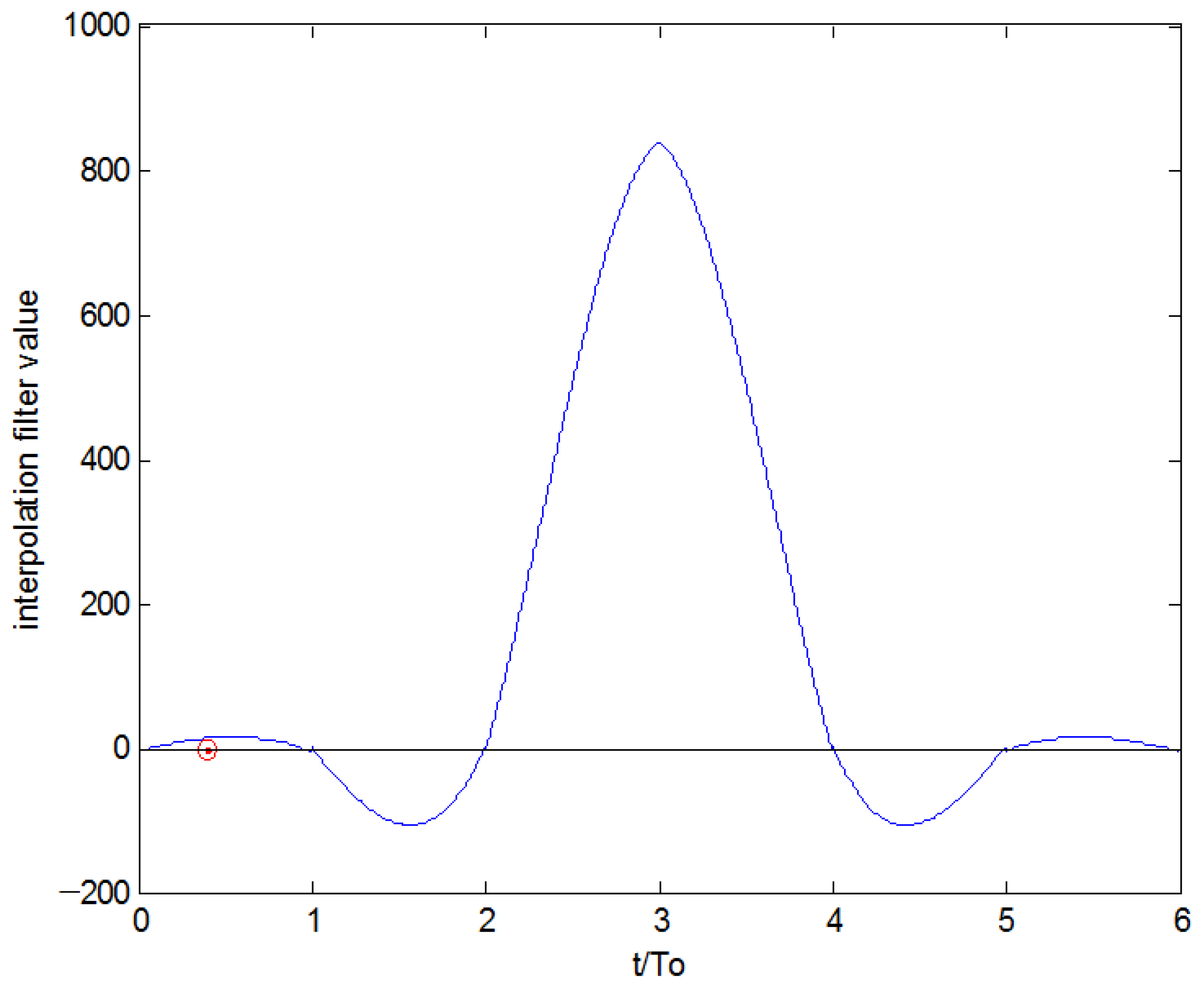
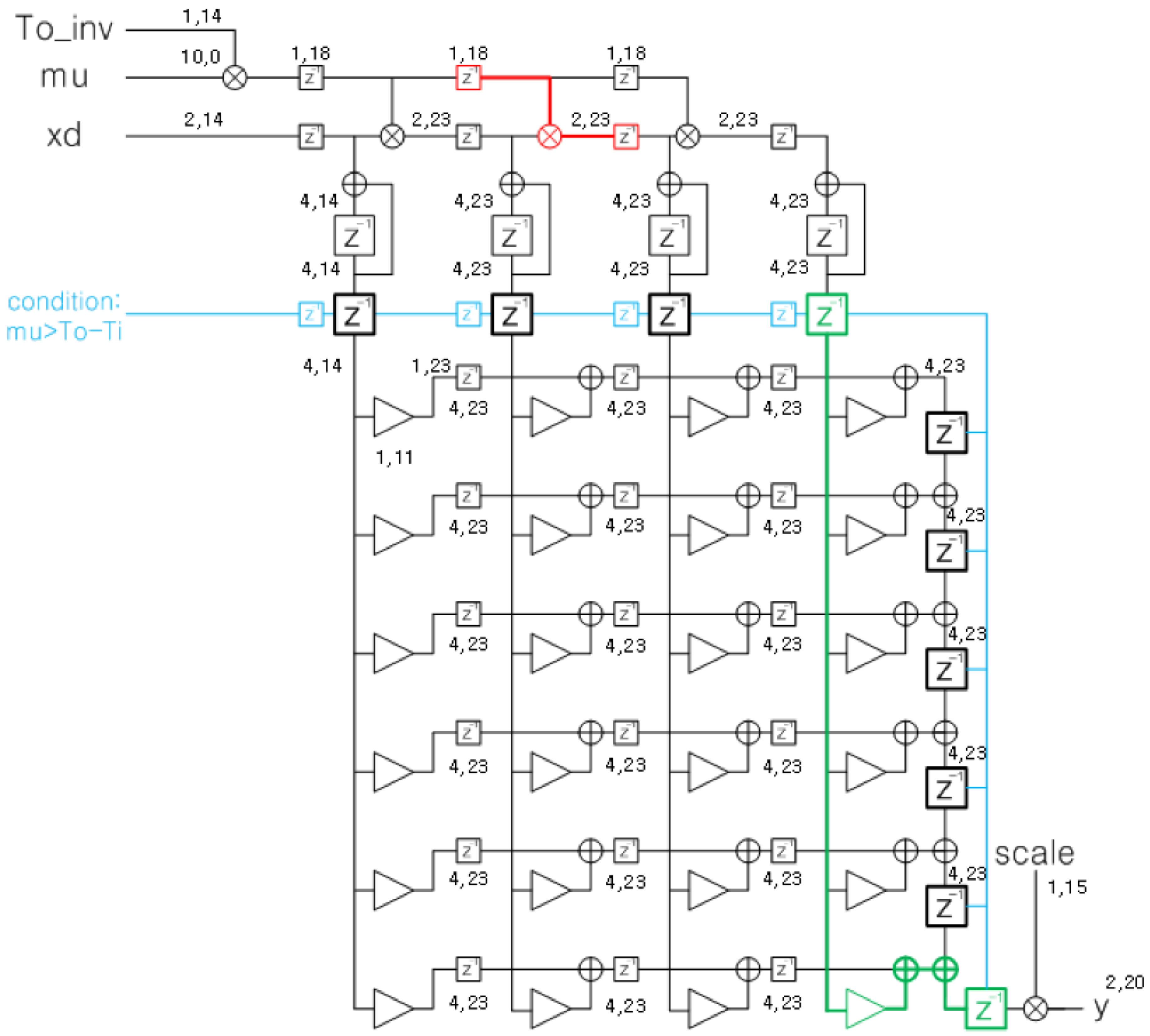
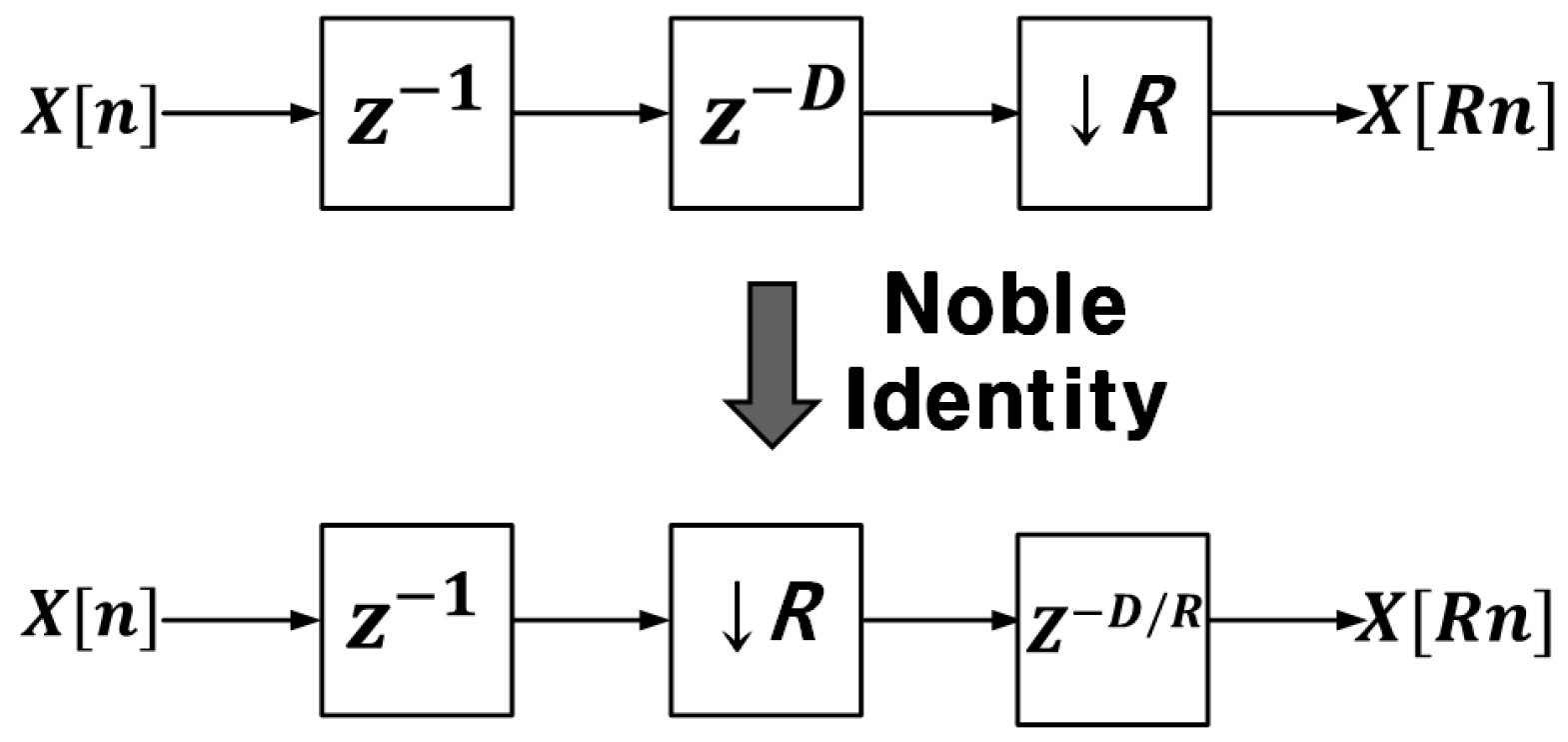
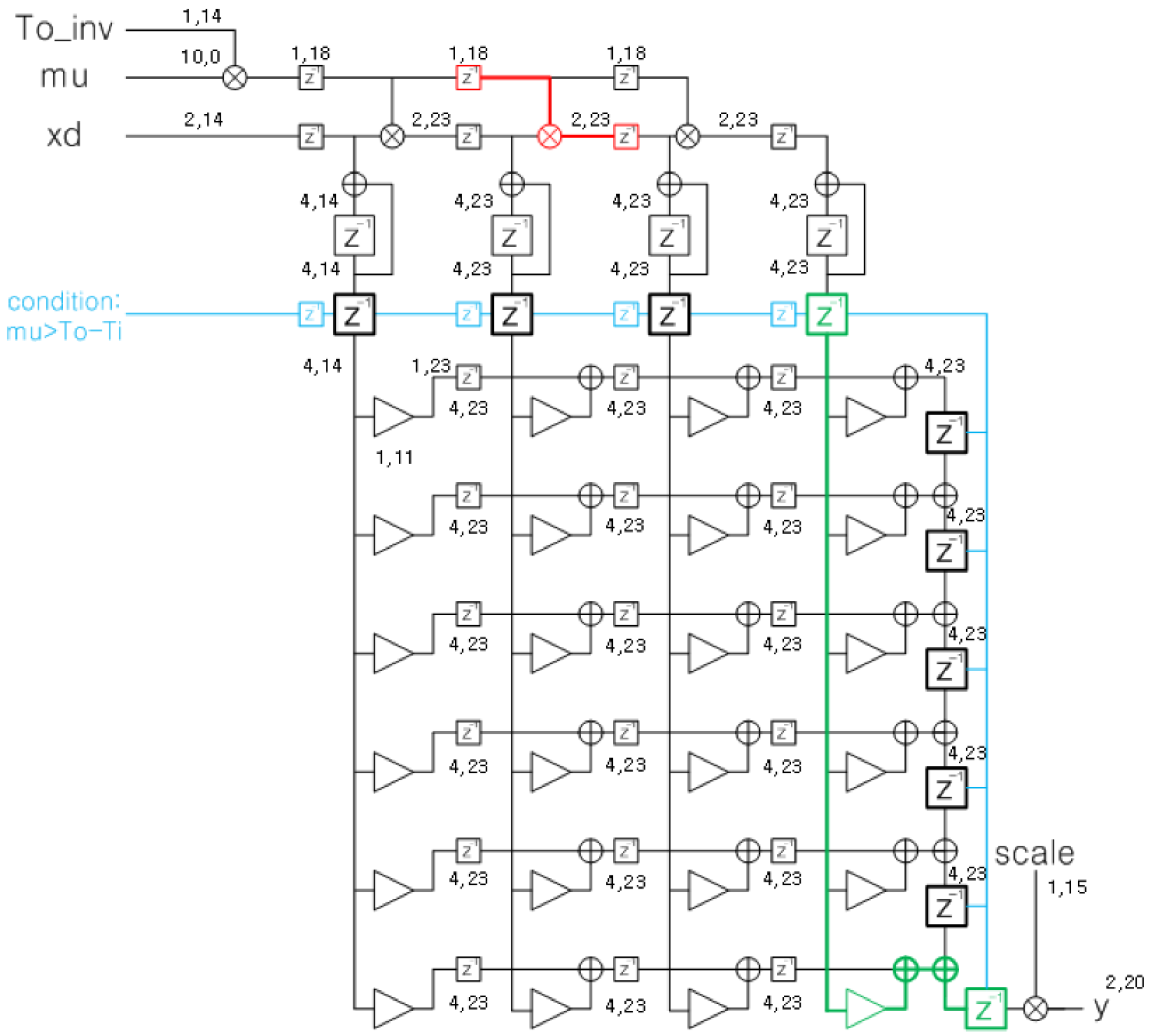
3.2. FIR3 (Farrow Interpolator)
- frac_delay = 1/325:1/325:1;
- for i = 1:length(frac_delay),
- farrow_matrix = [−4 96 −128 32;
- 3 −558 820 −264;
- 839 −166 −1340 664;
- −3 854 652 −664;
- 1 −290 28 264;
- −4 64 −32 −32];
- mu=frac_delay(i);
- interp_coefs(i,:) = flipud(farrow_matrix) * [mu.^(0:3)]’;
- end;
- hinterp=reshape(interp_coefs,[],1);
- plot(0:1/325:6 − 1/325,hinterp);
- hold on,plot(128/325,hinterp(129),‘or’);
- xlabel(‘t/To’);
- ylabel(‘interpolation filter value’).
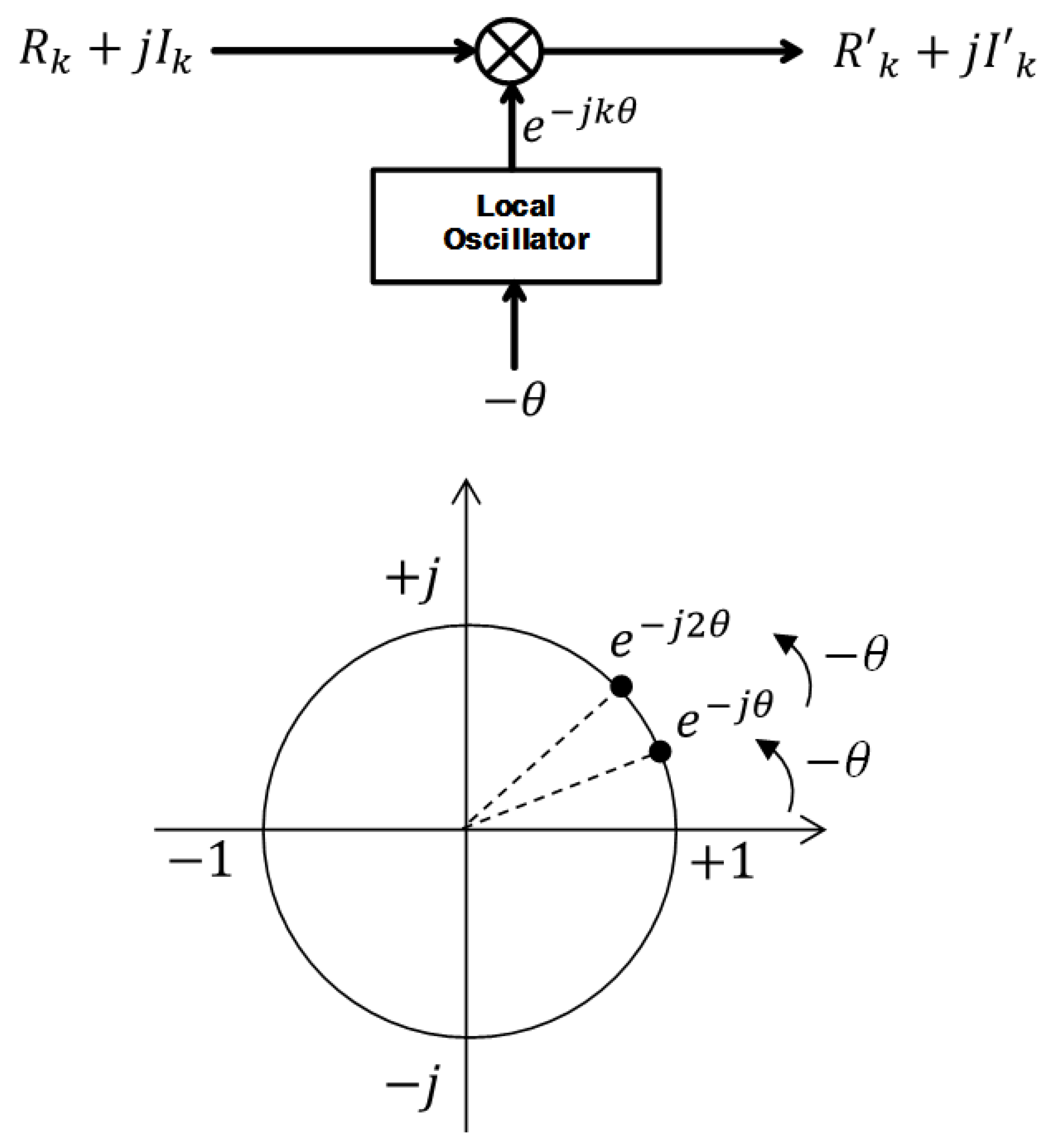
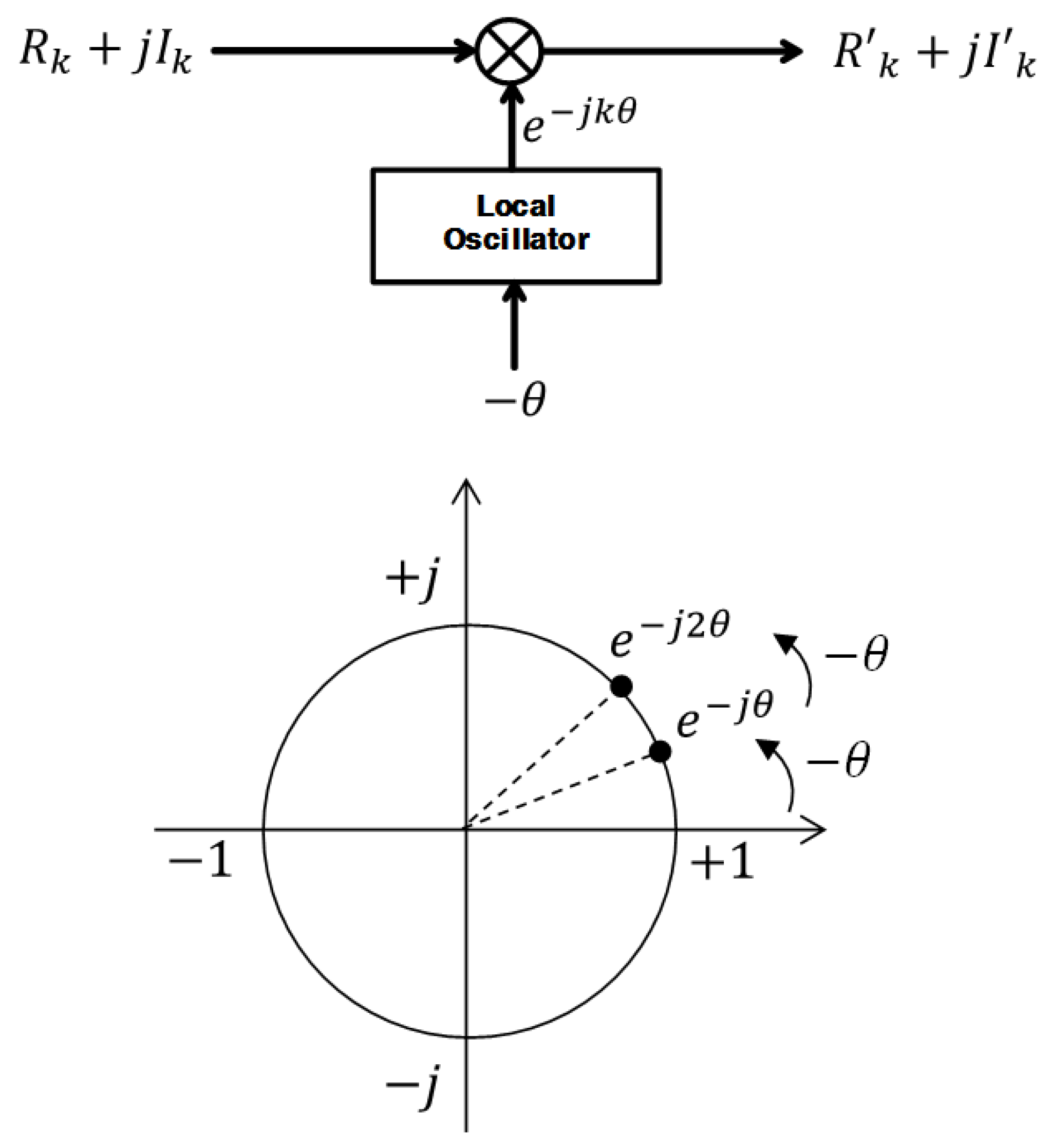
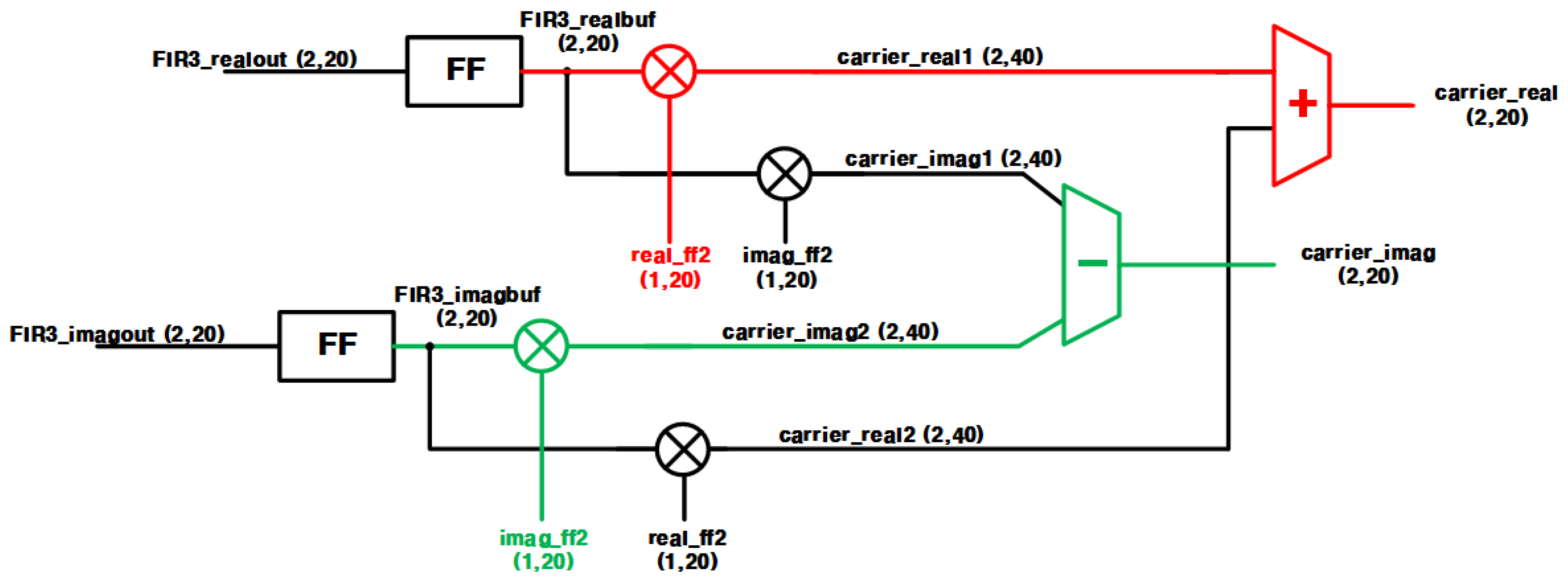
3.3. Digital Mixer
3.4. FIR4 (Carrier Aggregation Filter)
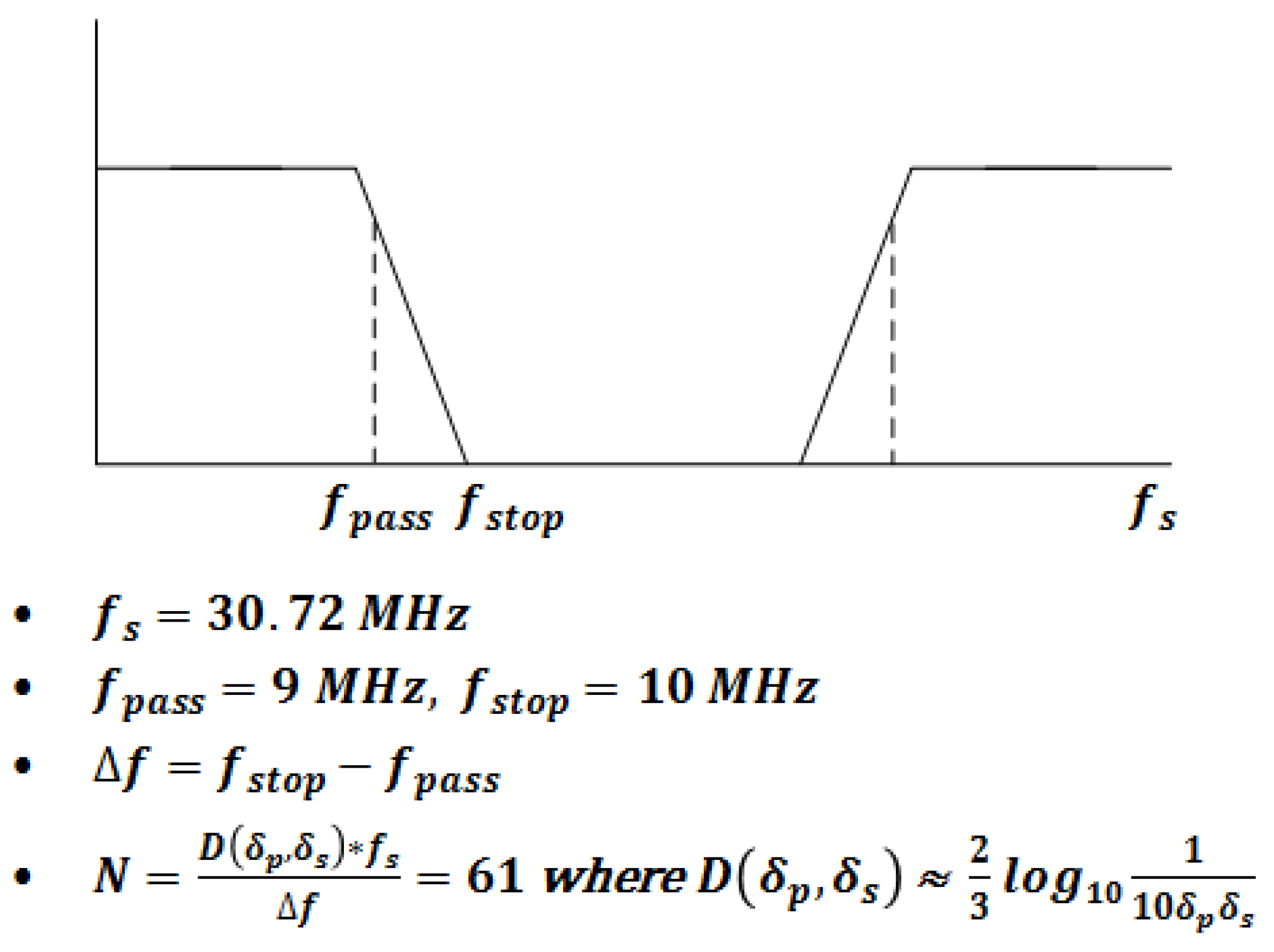
3.5. FIR5 (Channel Selection Filter)
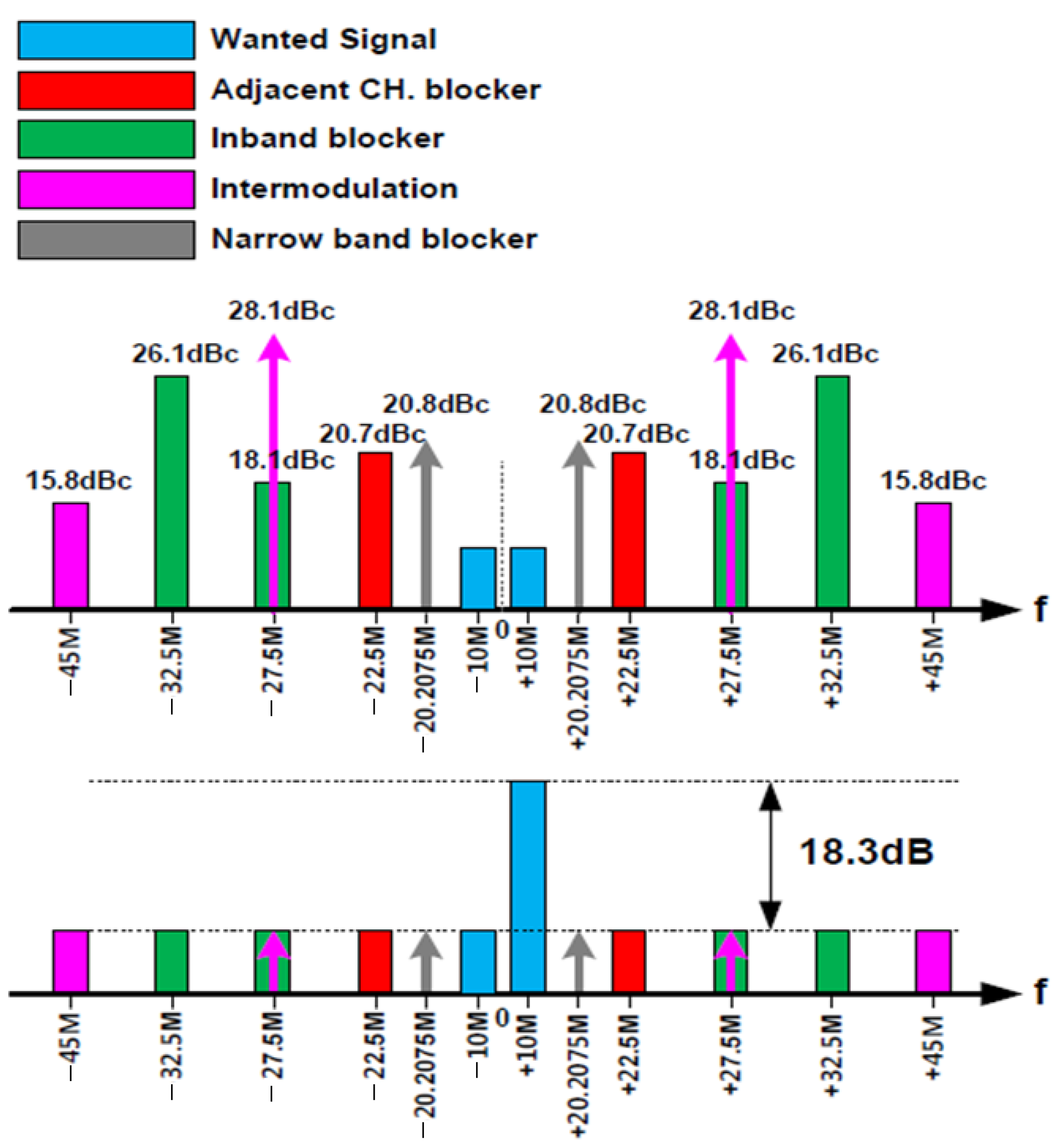
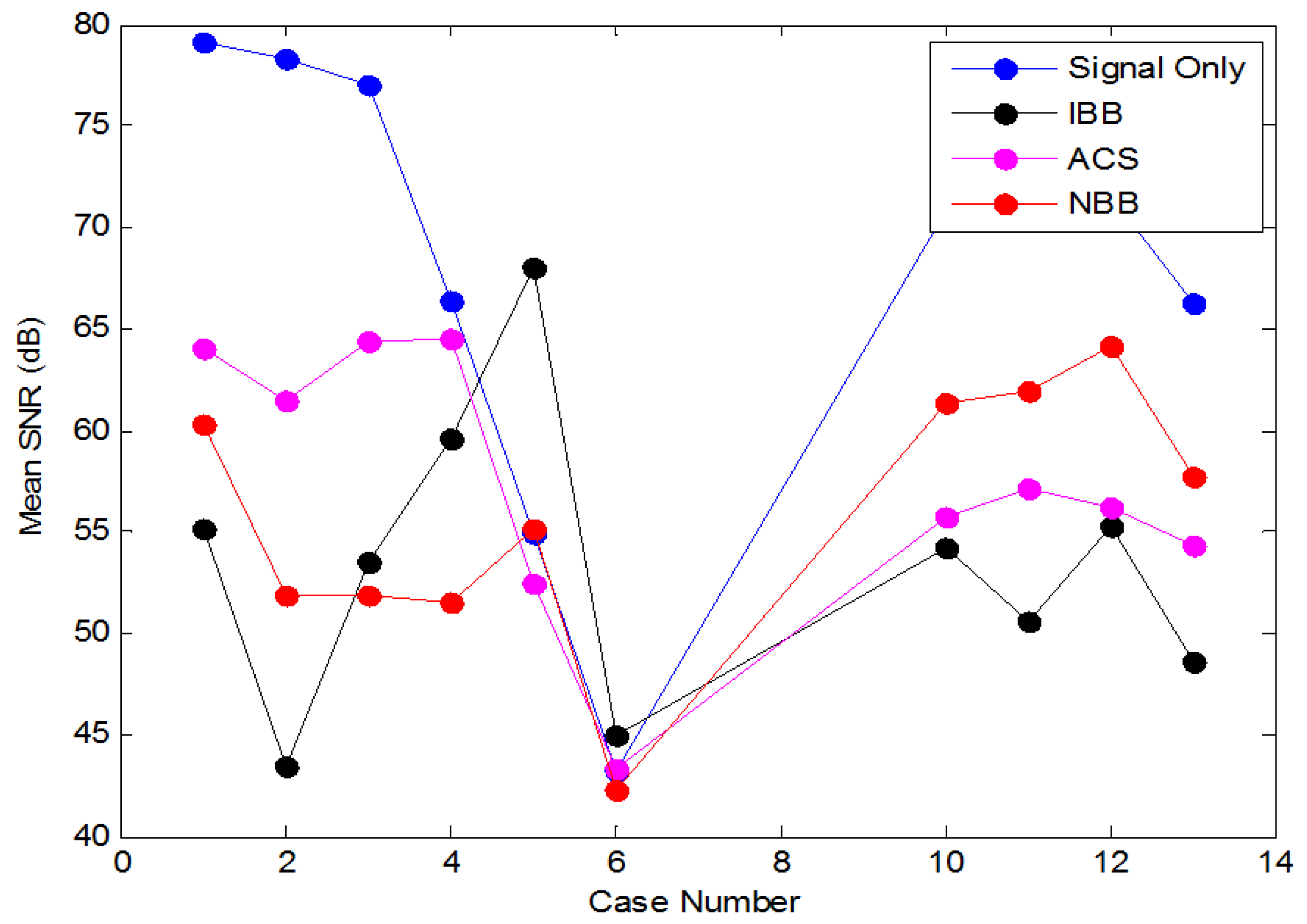
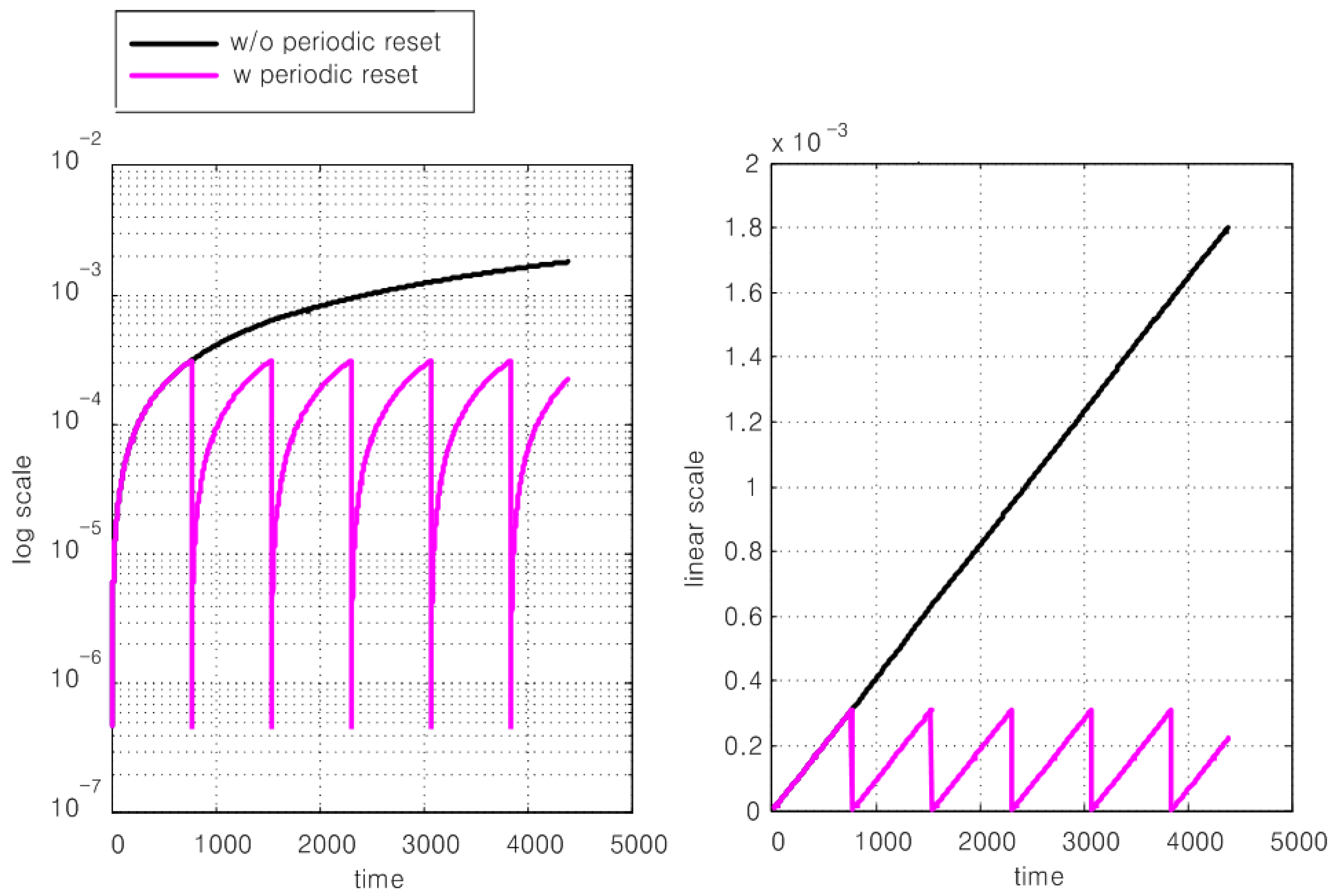
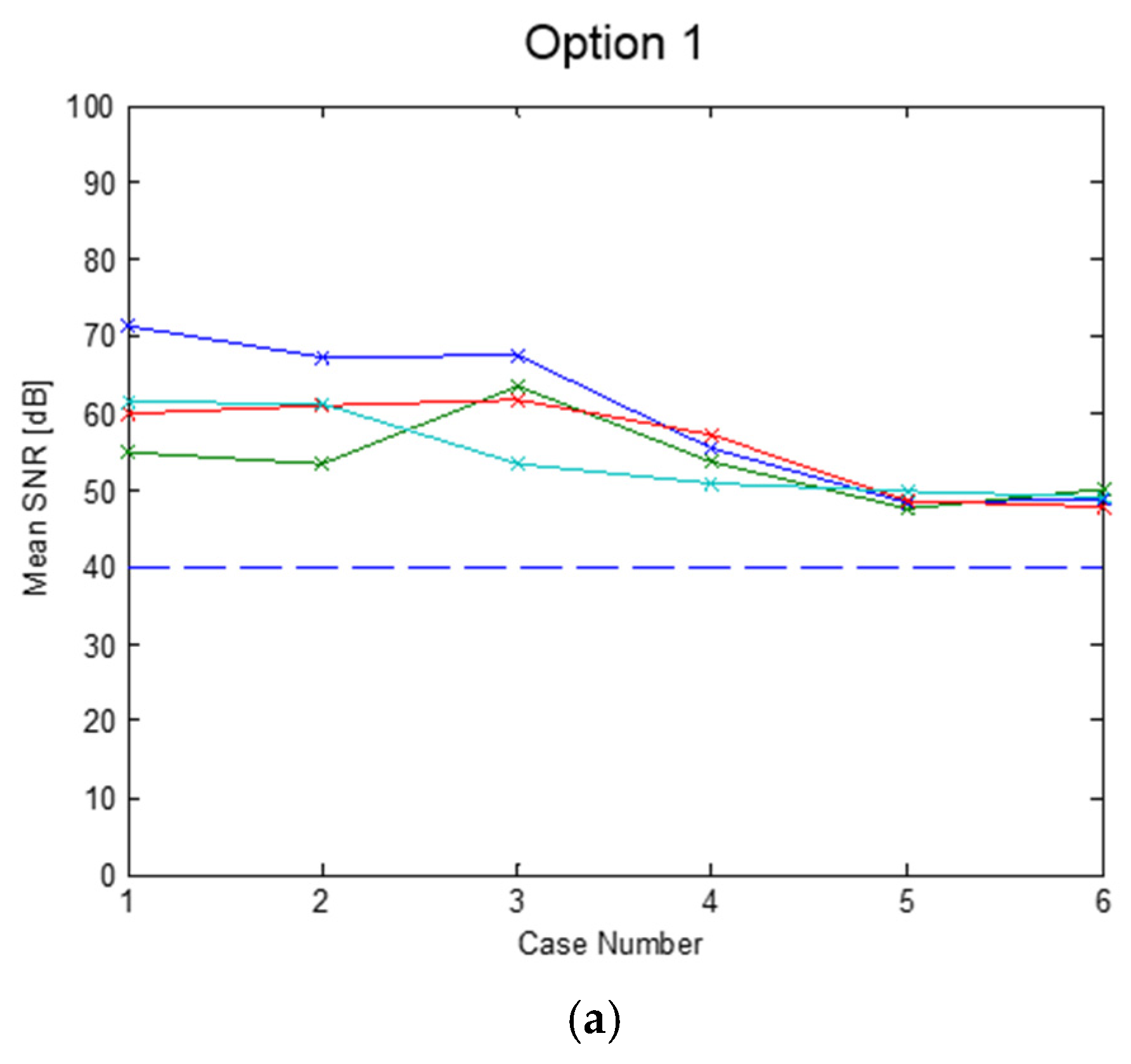
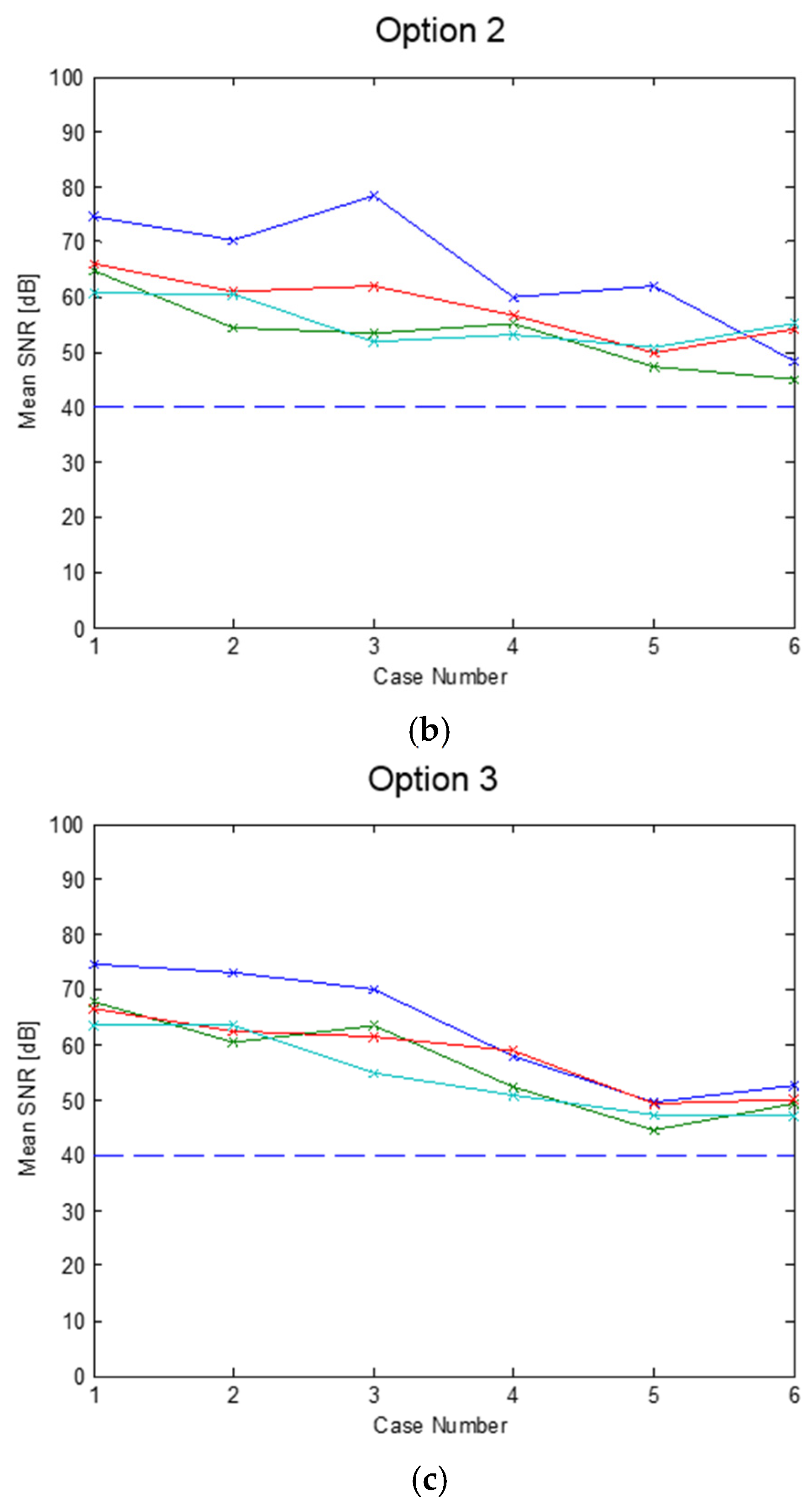
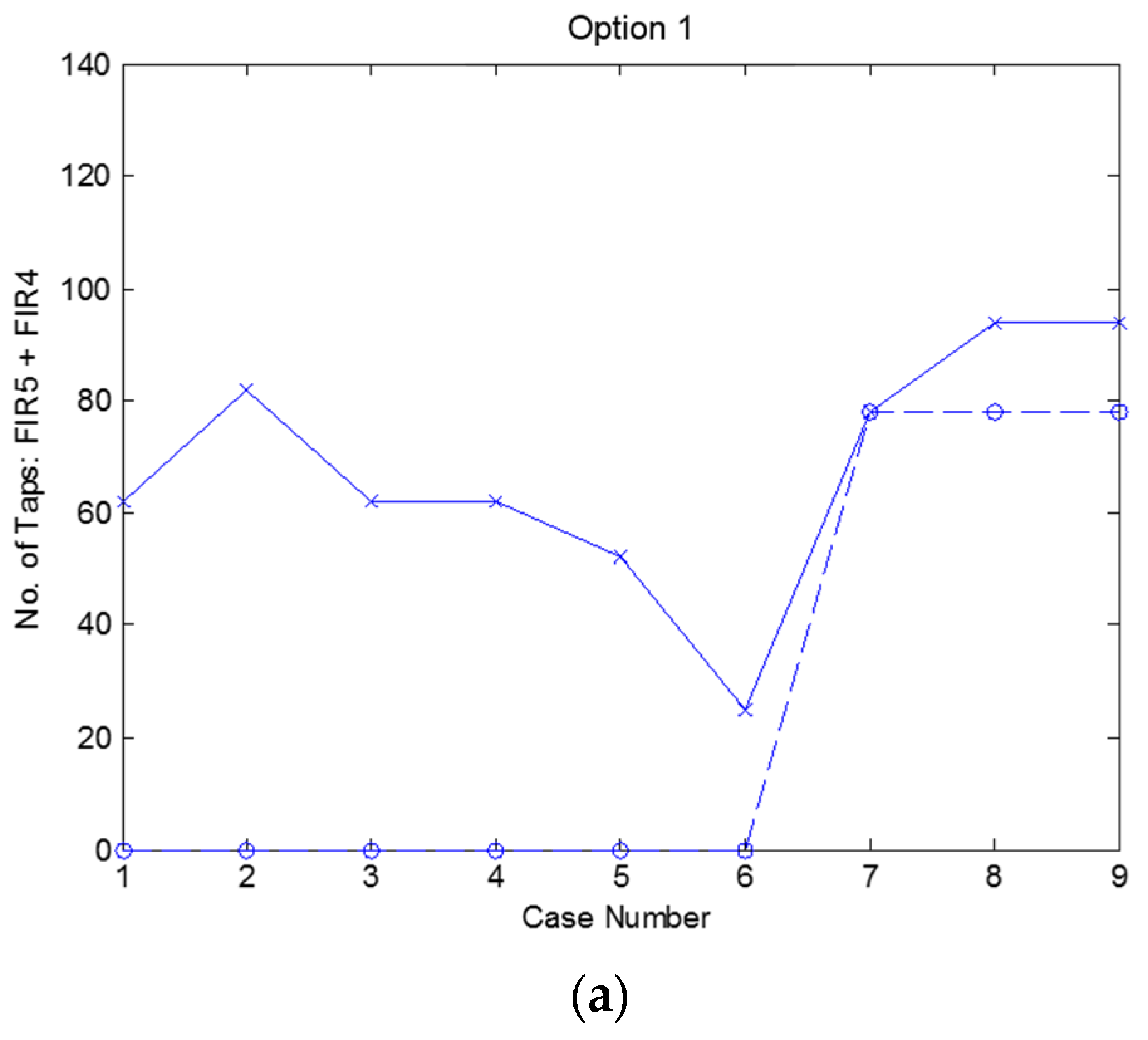
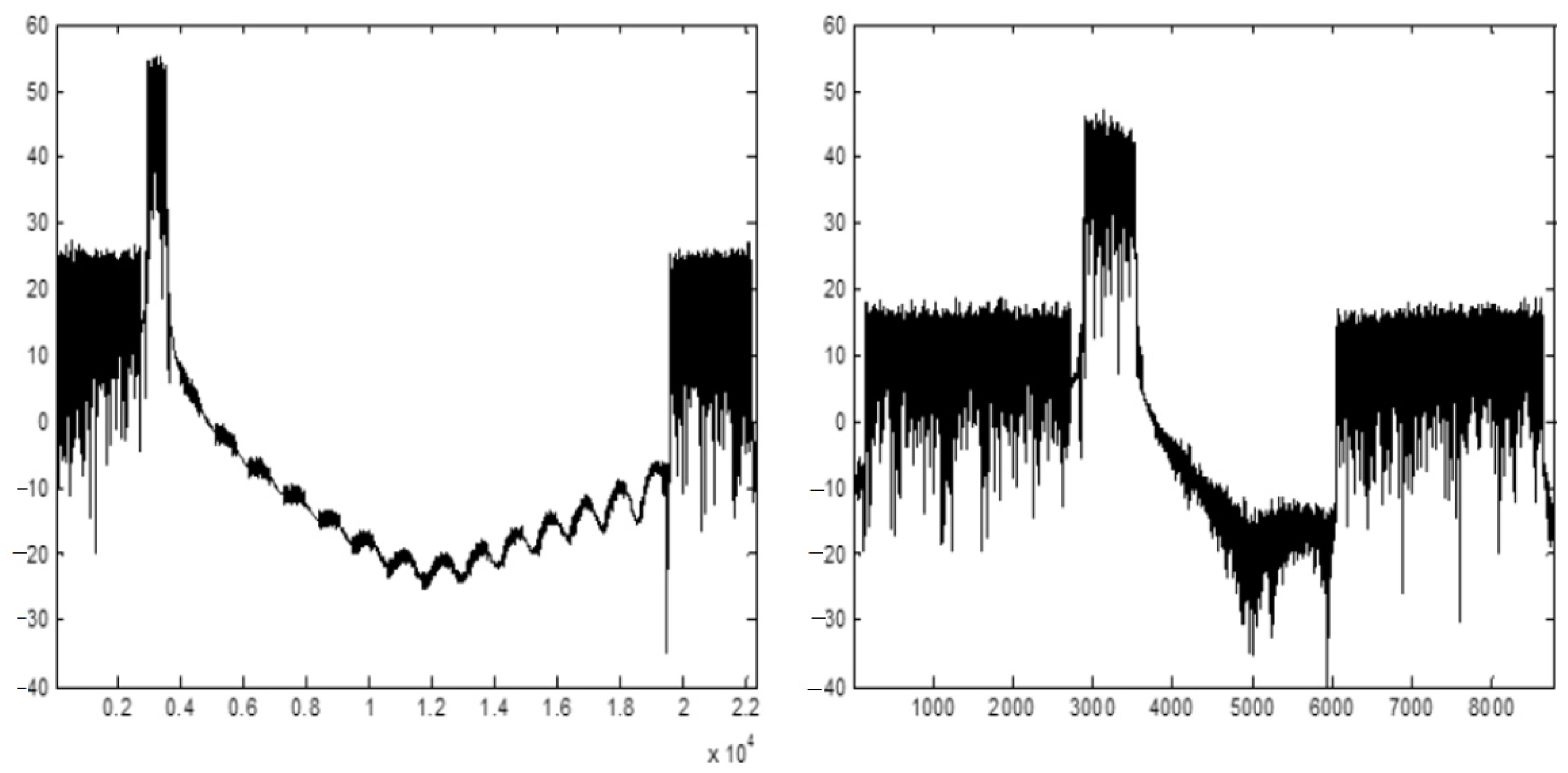
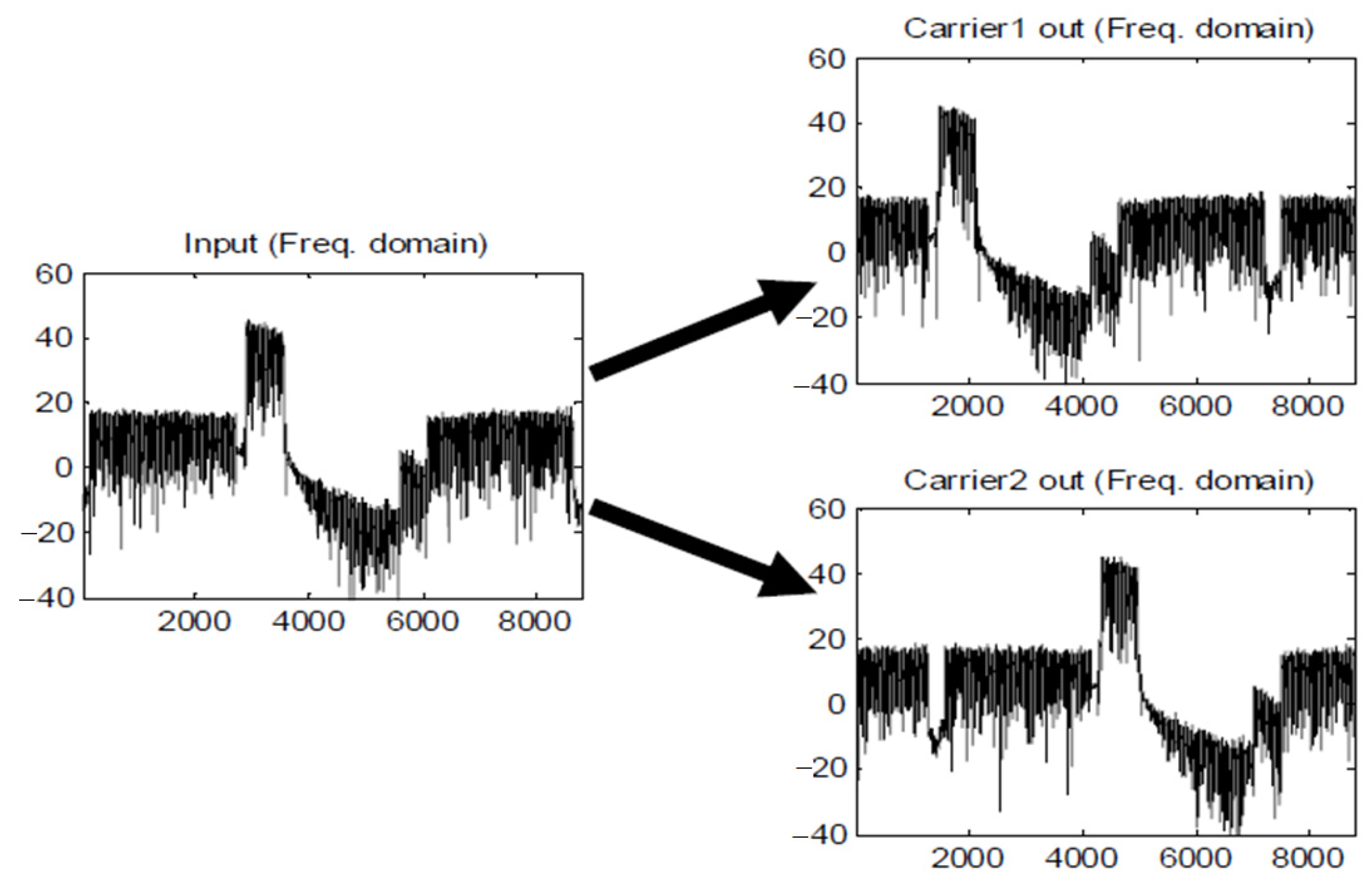
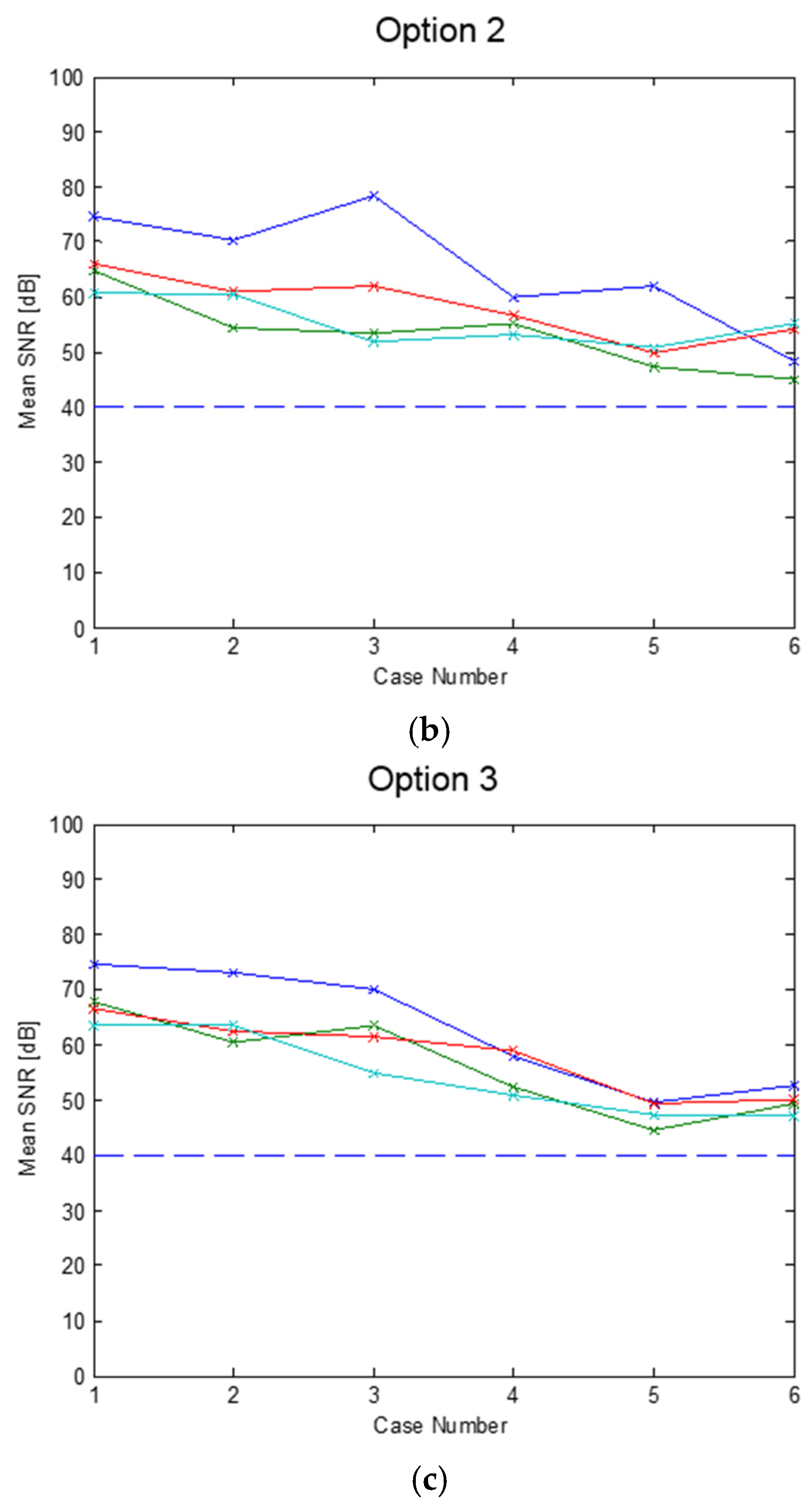
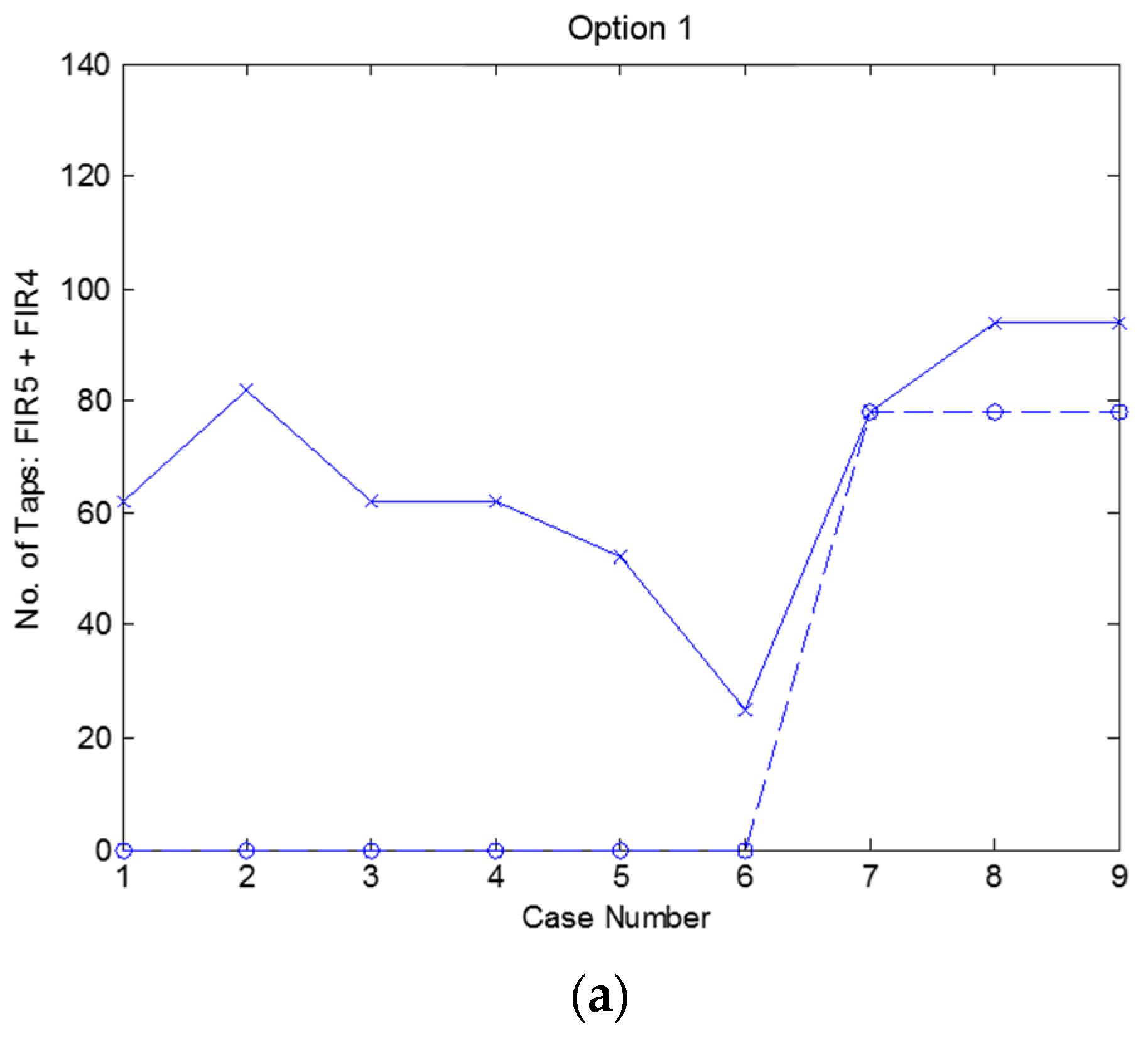
4. Simulated Results of the Overall DFE Architecture
5. Hardware Implementation and Experimental Results
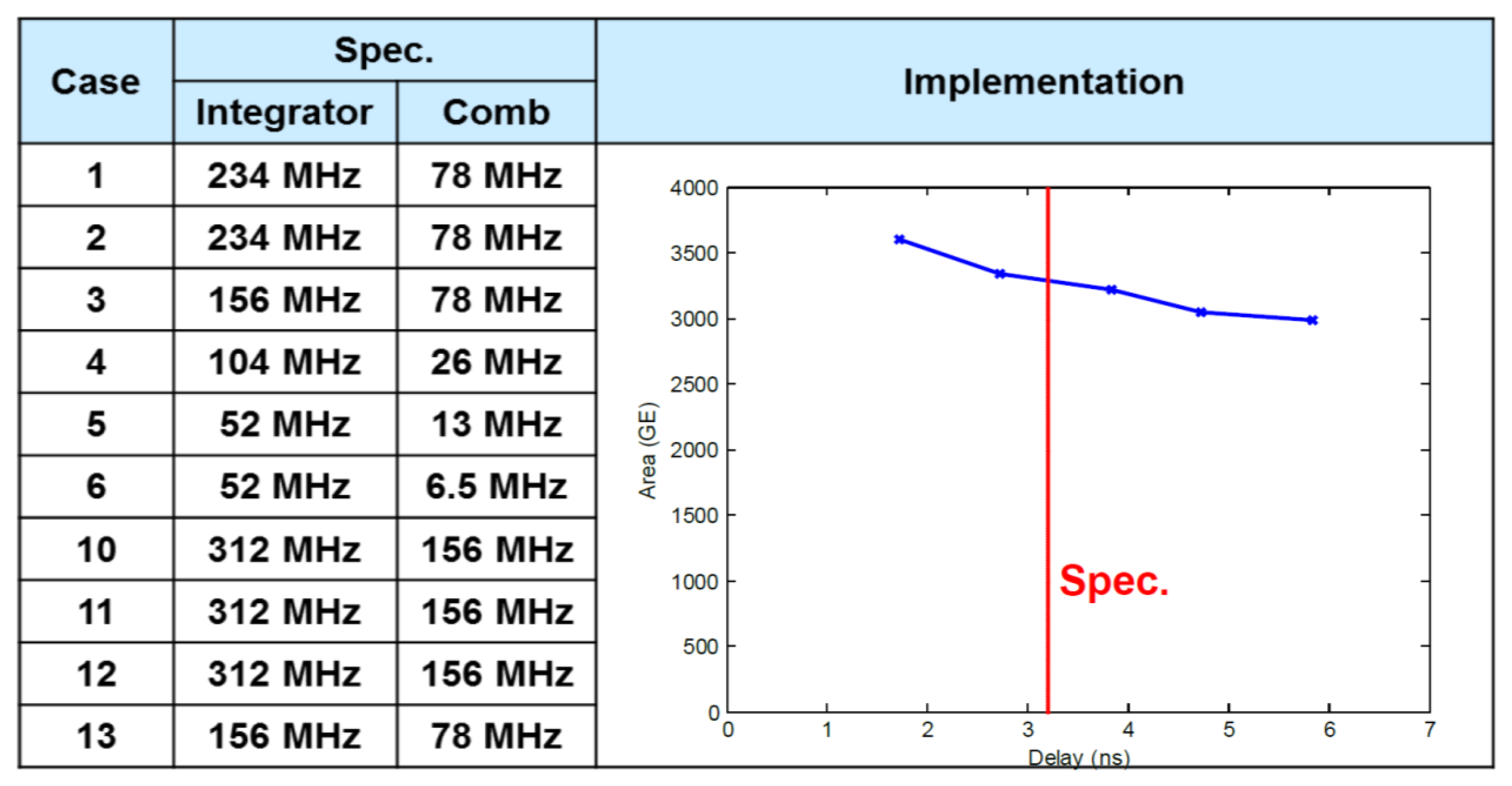
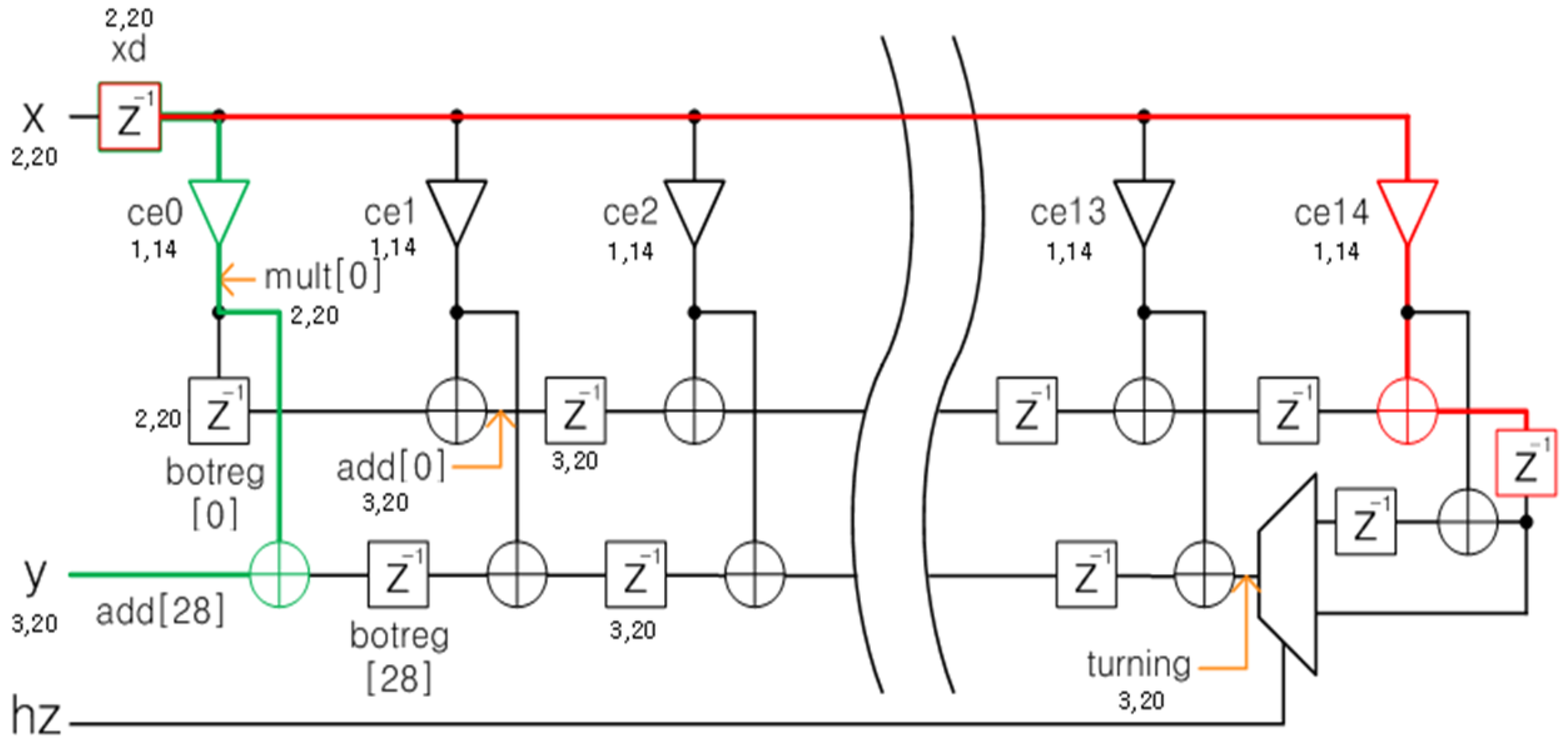
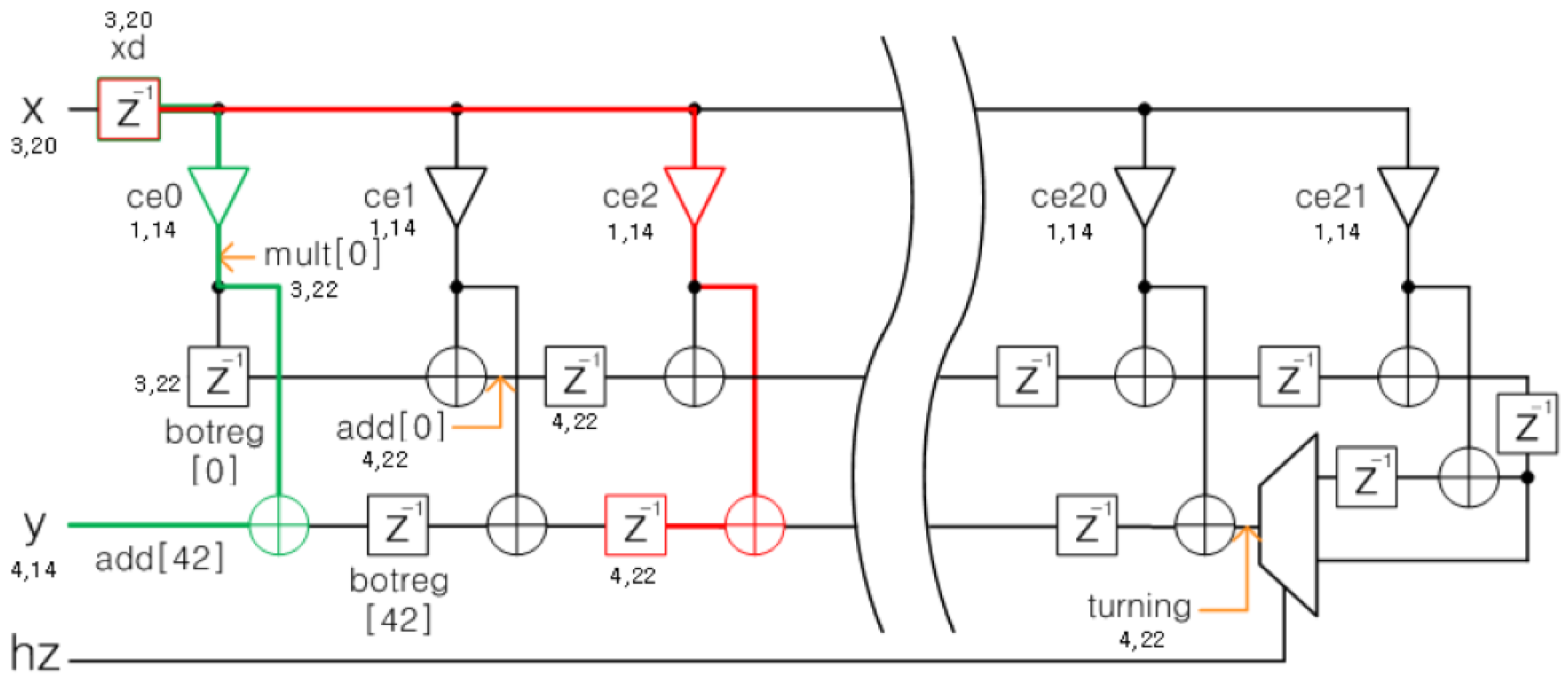
5.1. FIR1 (CIC Filter)
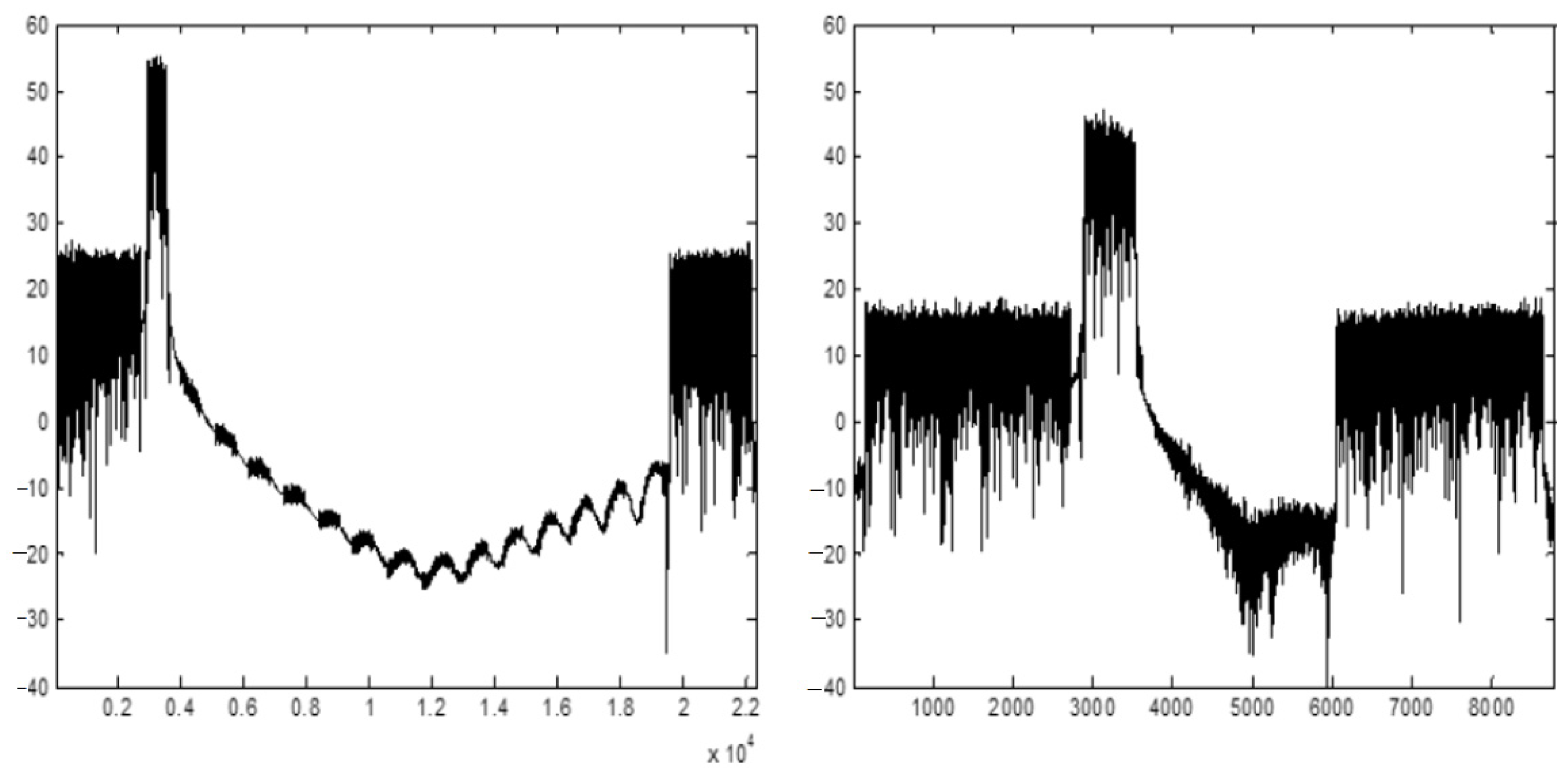
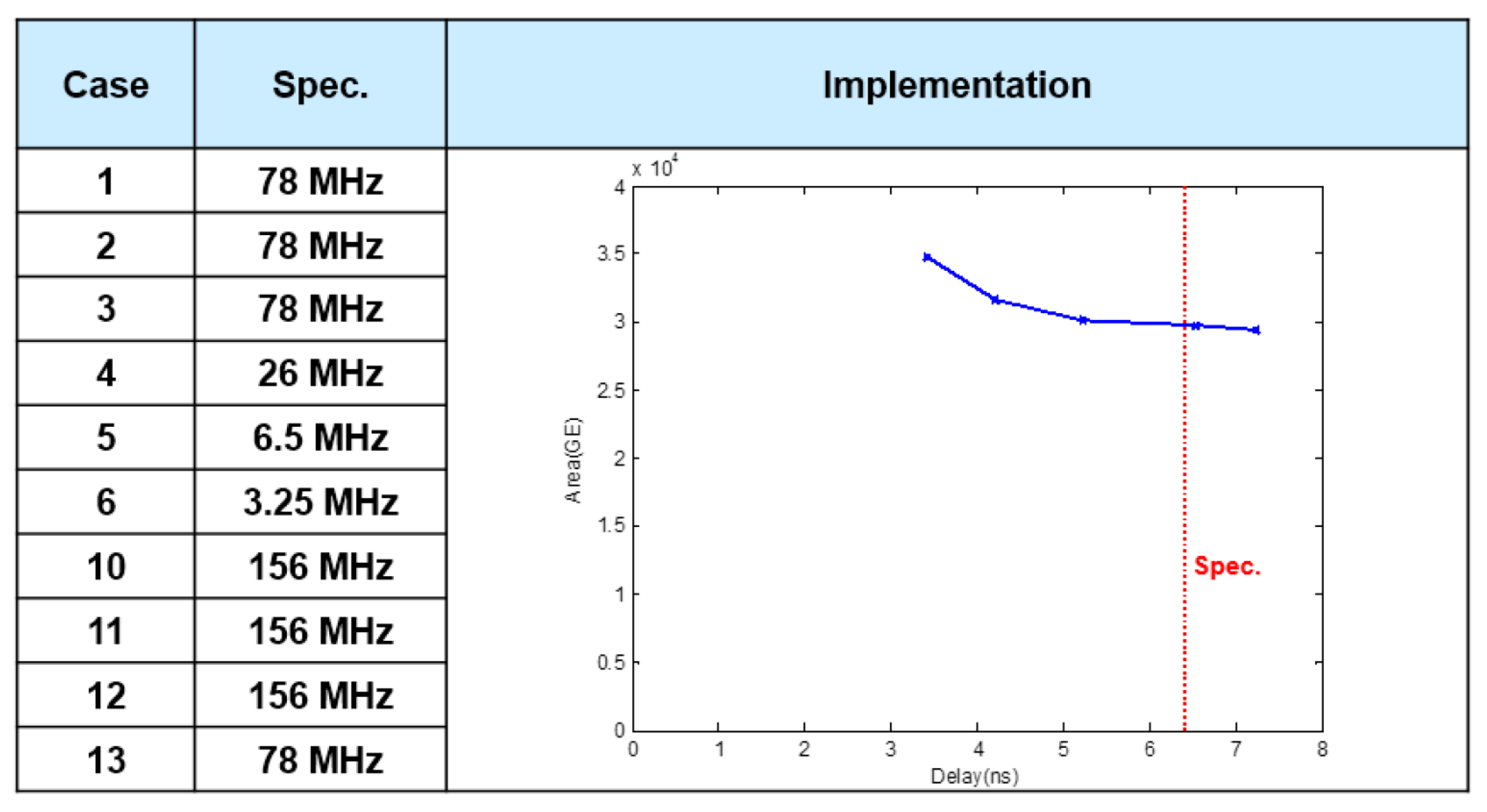
5.2. FIR3 (Farrow Interpolator)
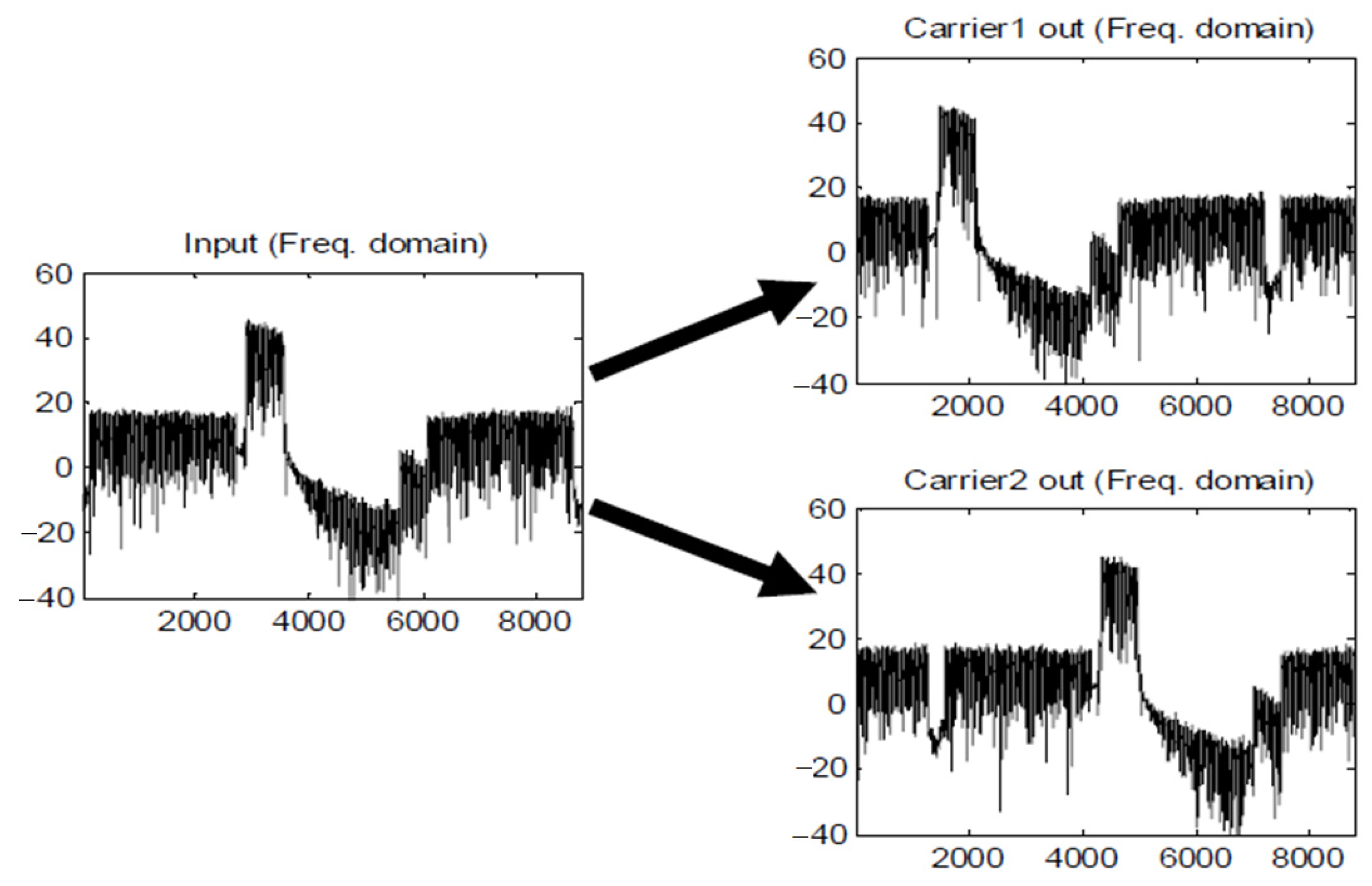
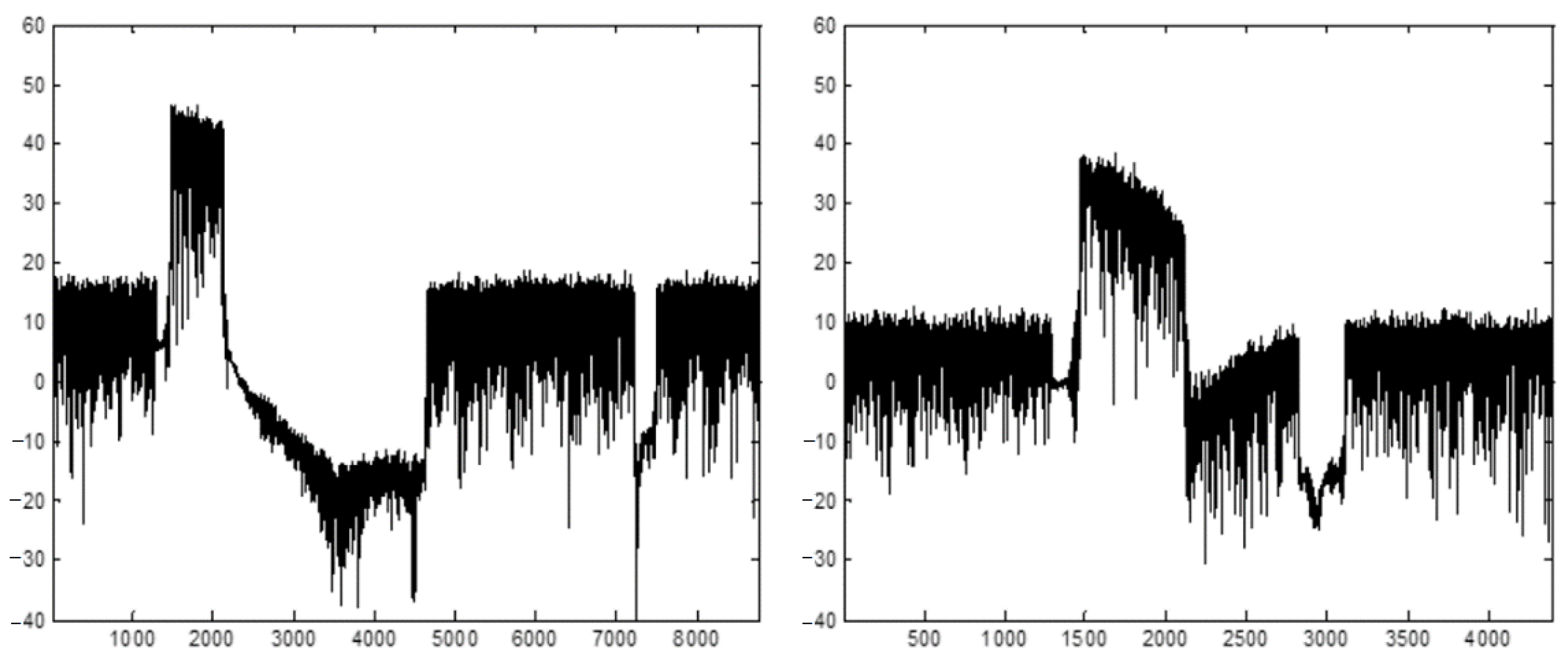
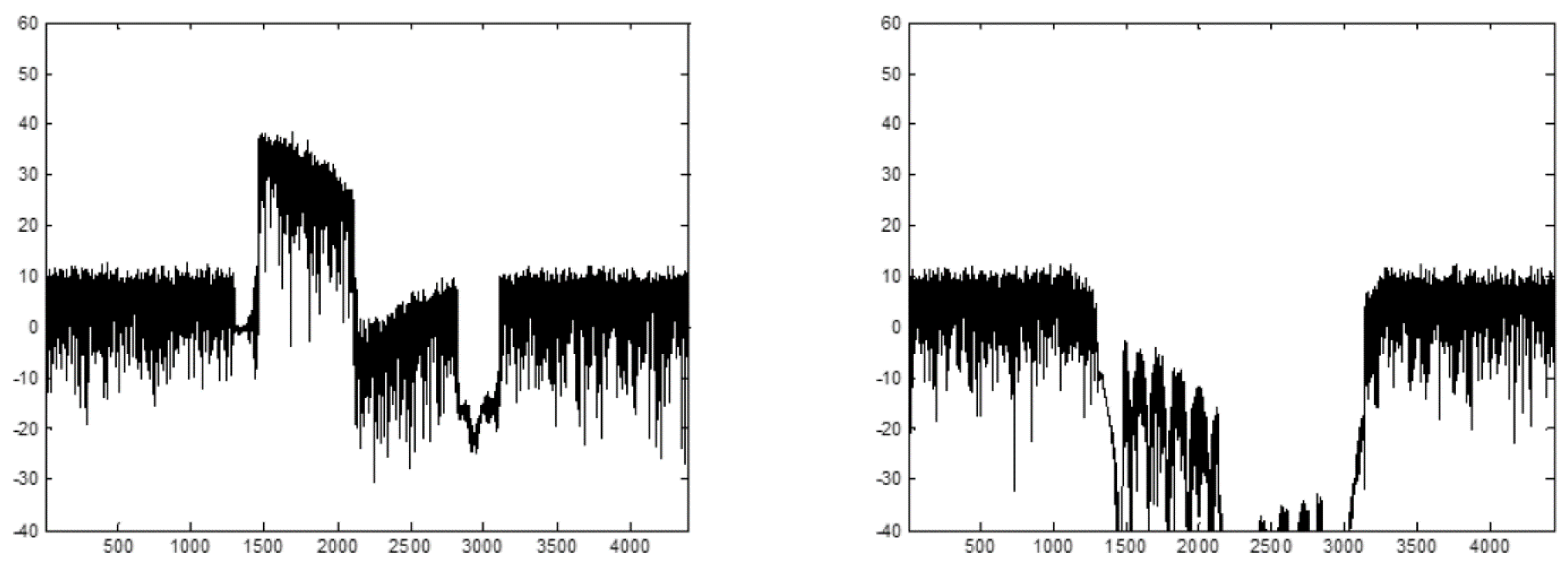
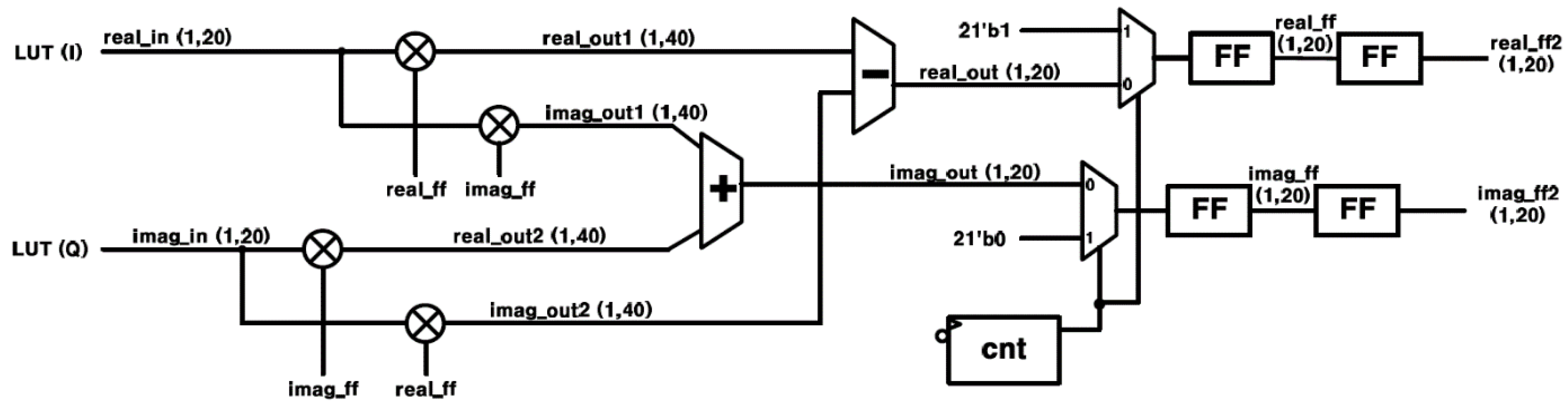
5.3. Digital Mixer
5.4. FIR4 (Carrier Aggregation Filter)
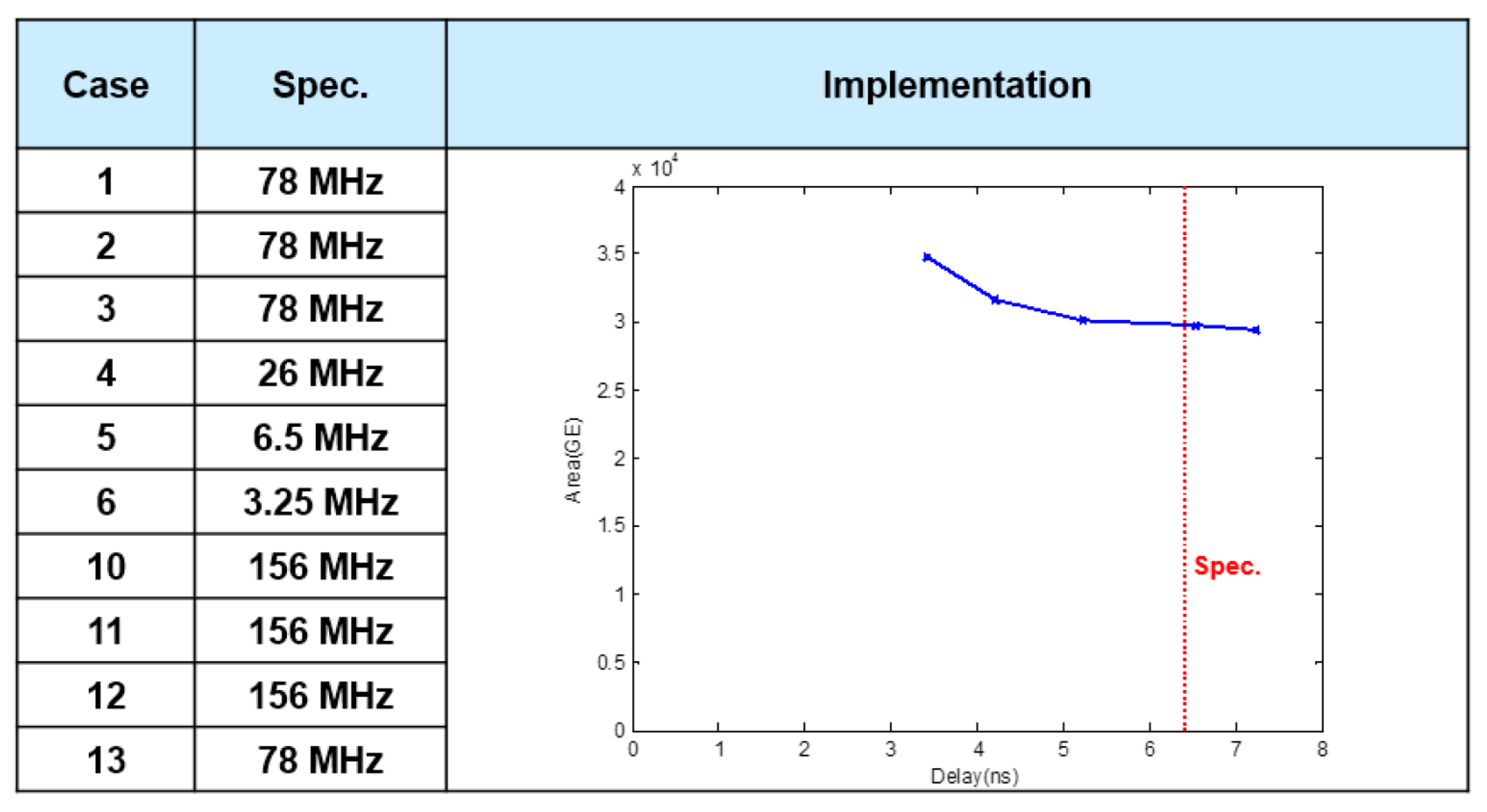
5.5. FIR5 (Channel Selection Filter)
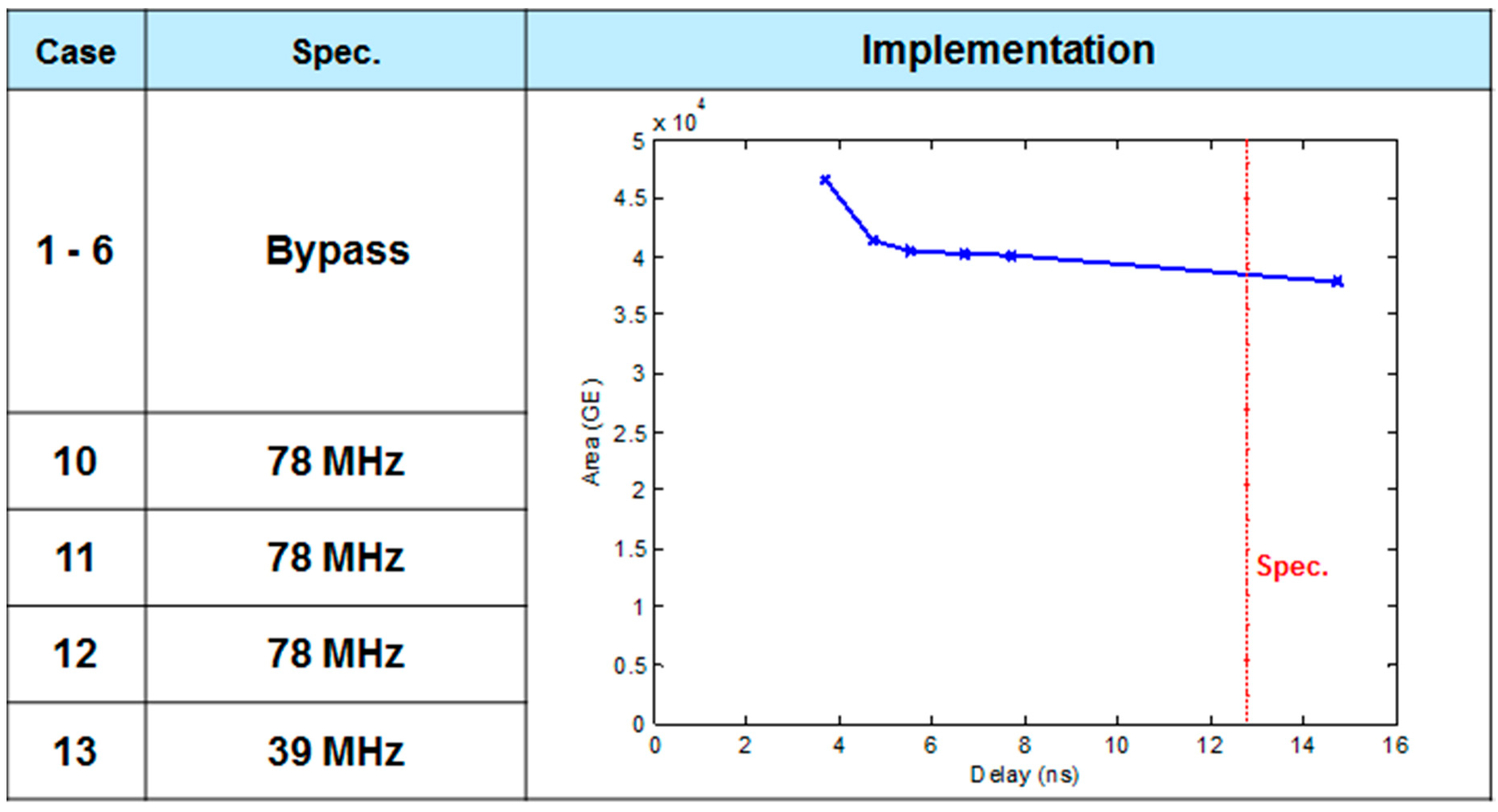
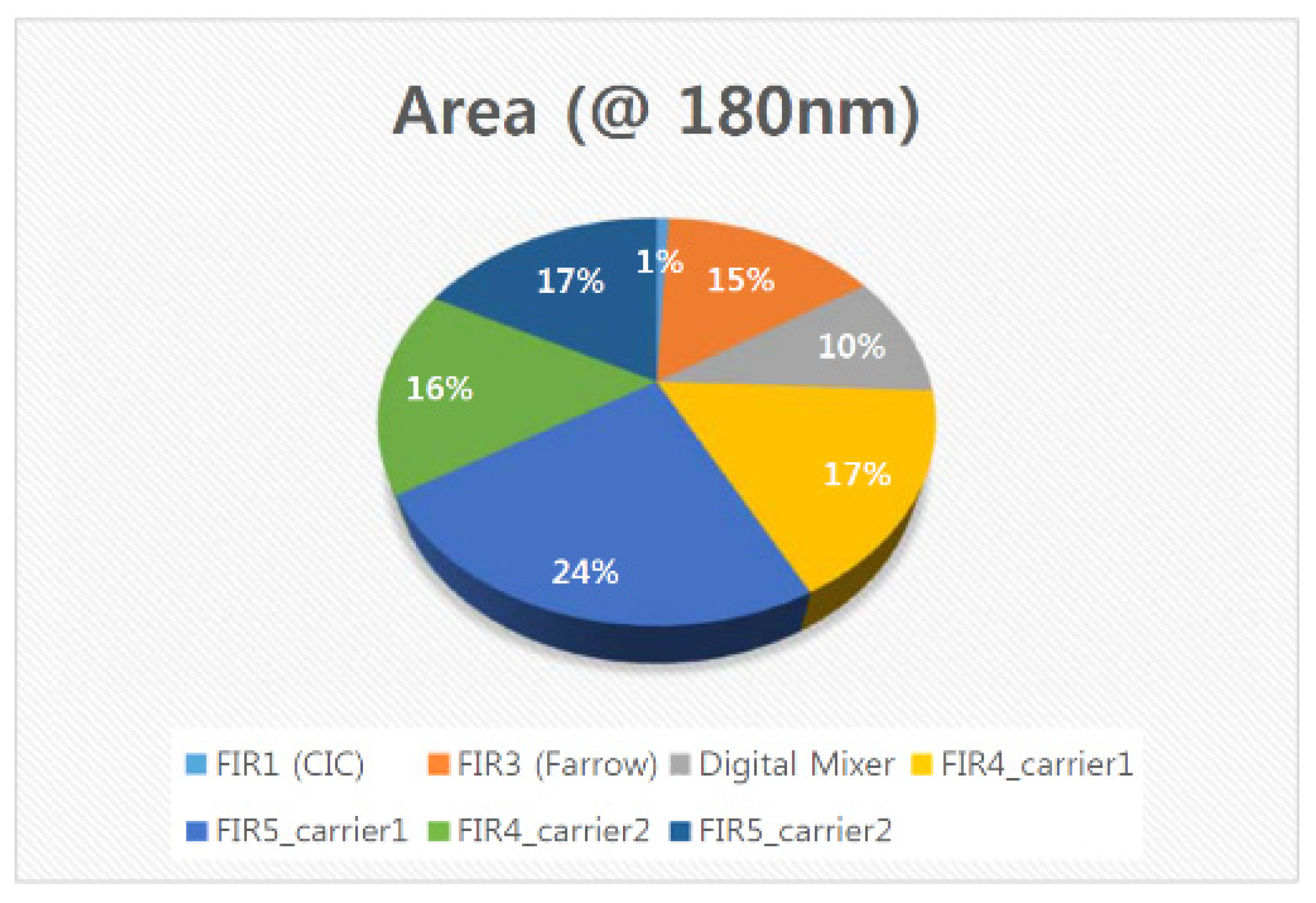
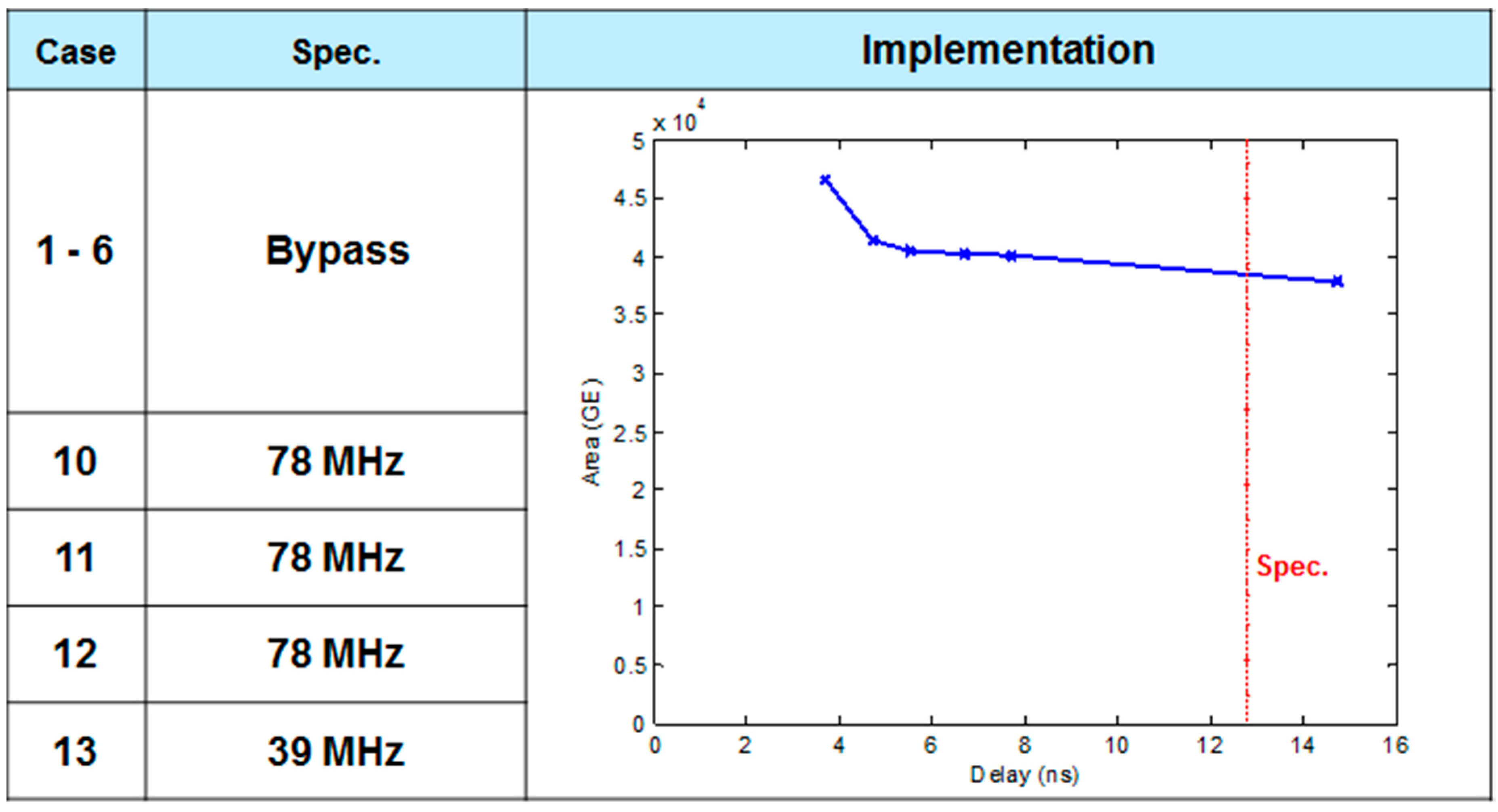
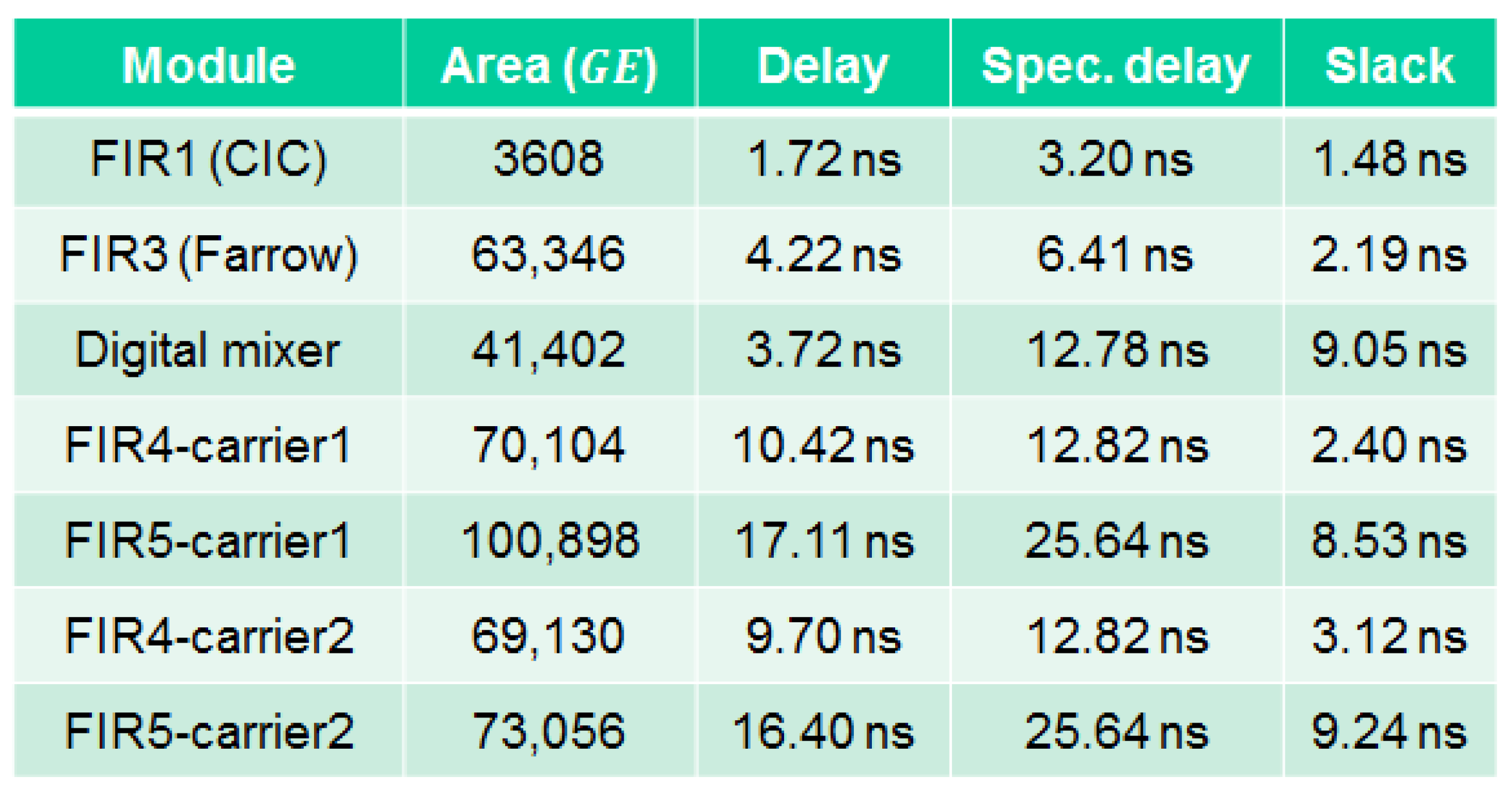
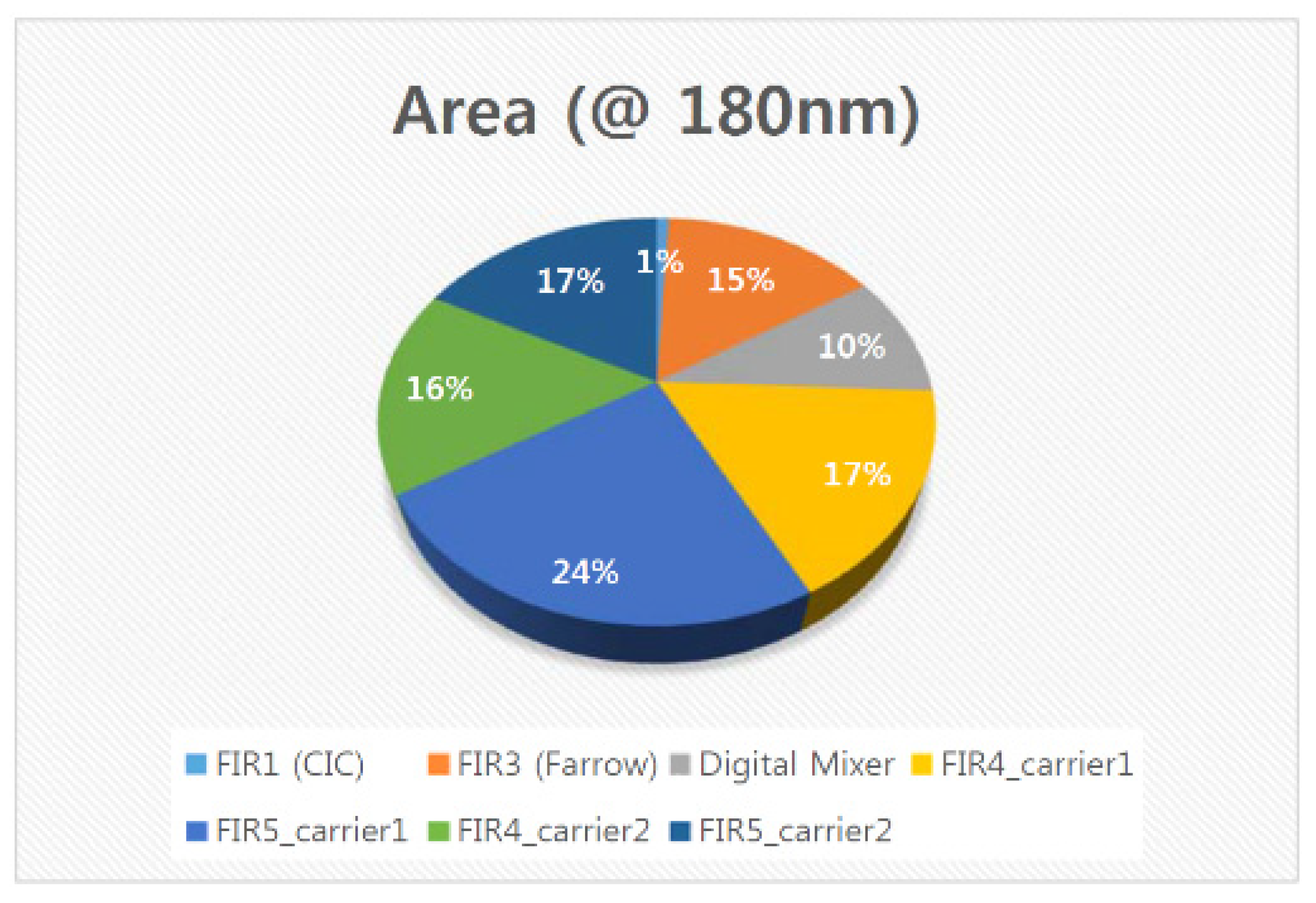
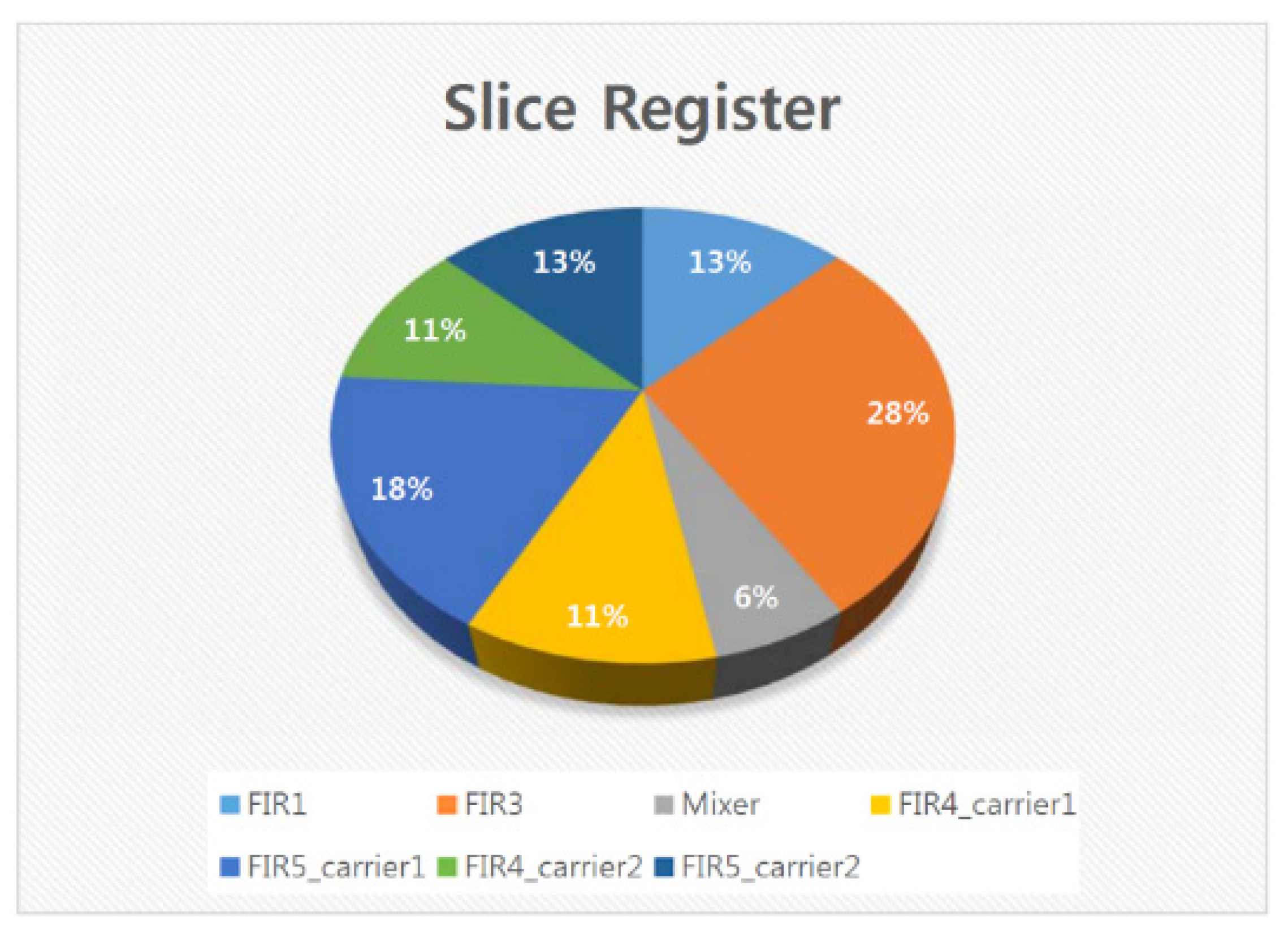
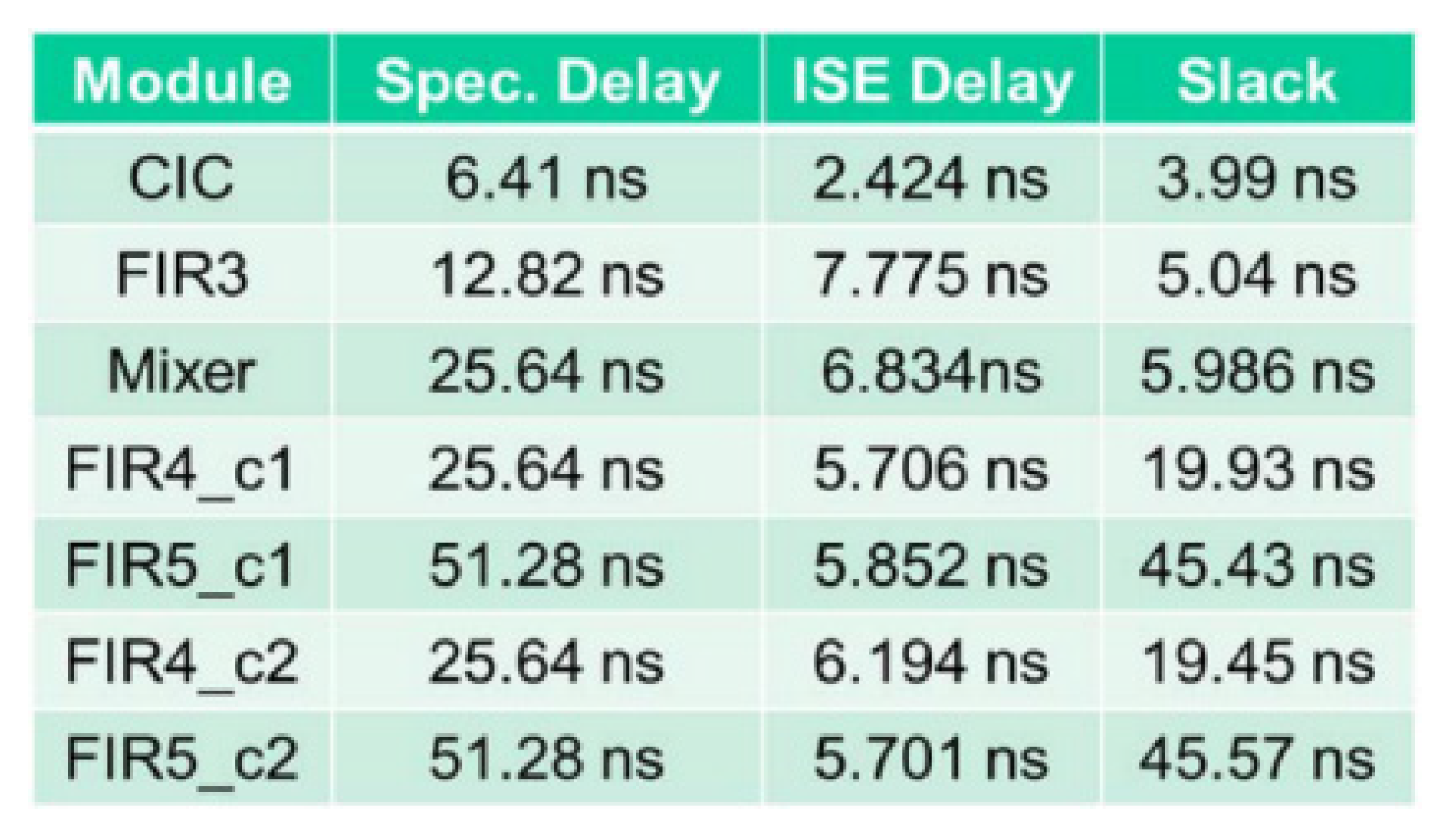
5.6. ASIC Synthesis of the Overall DFE Architecture
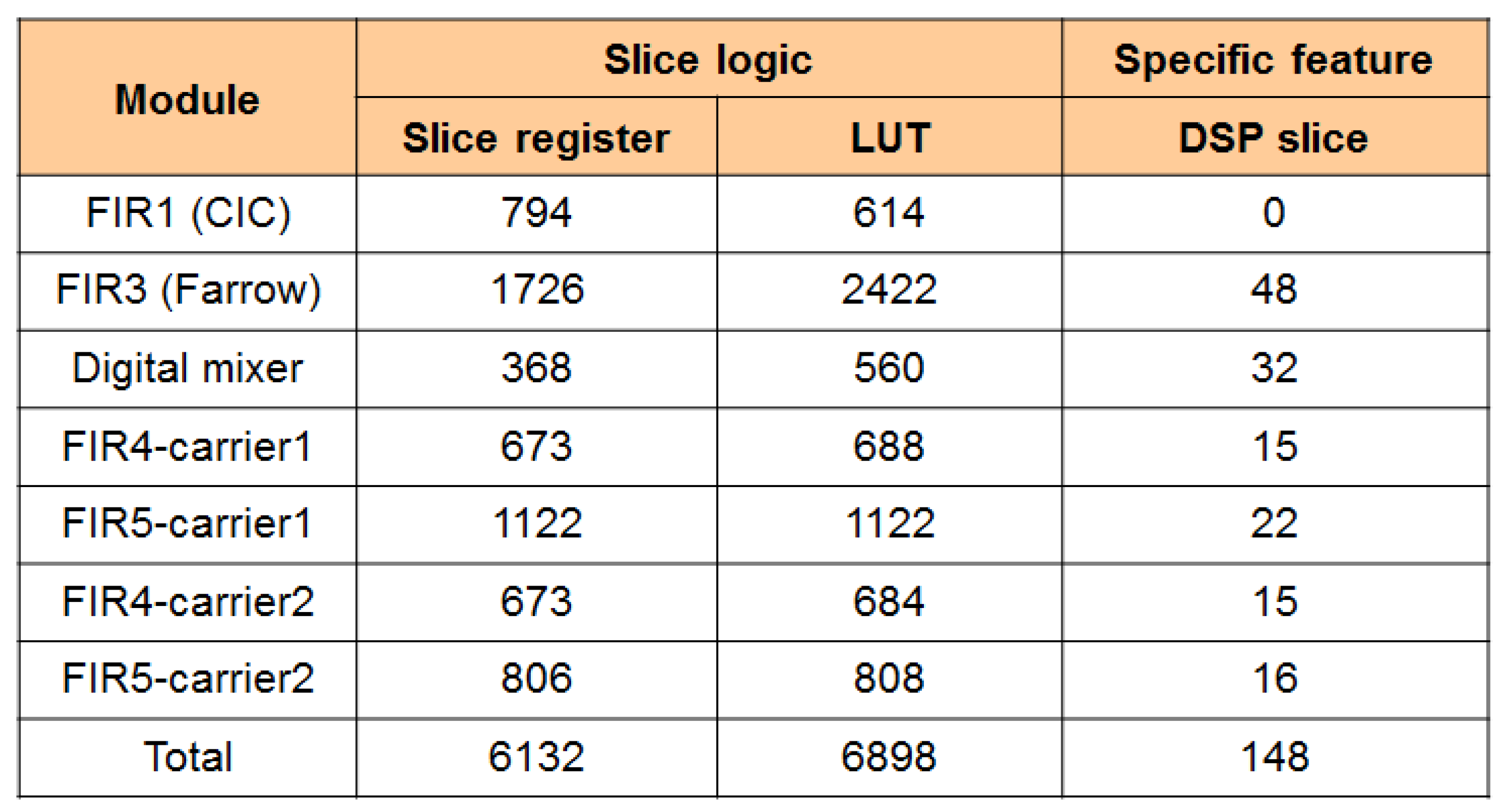
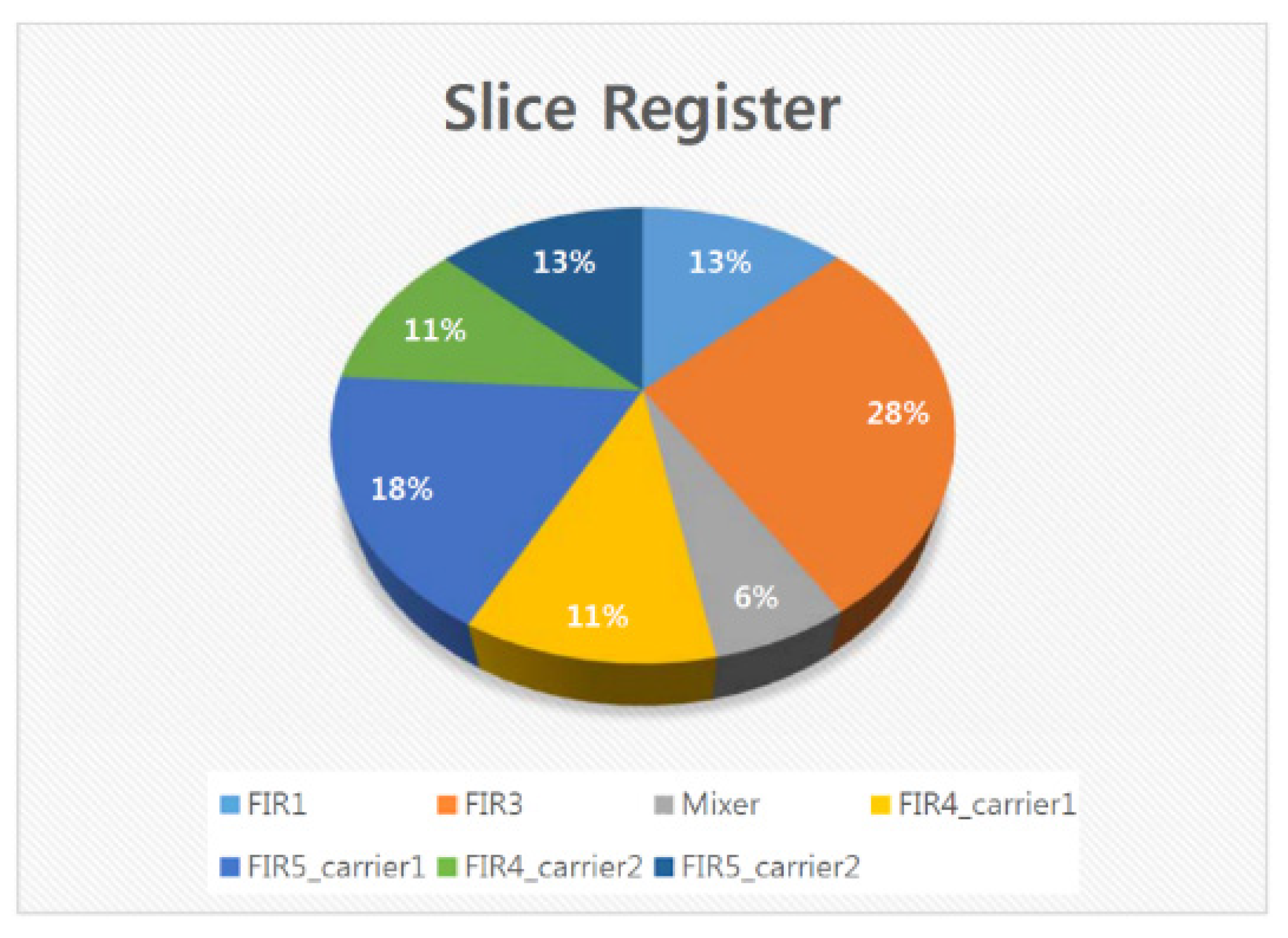
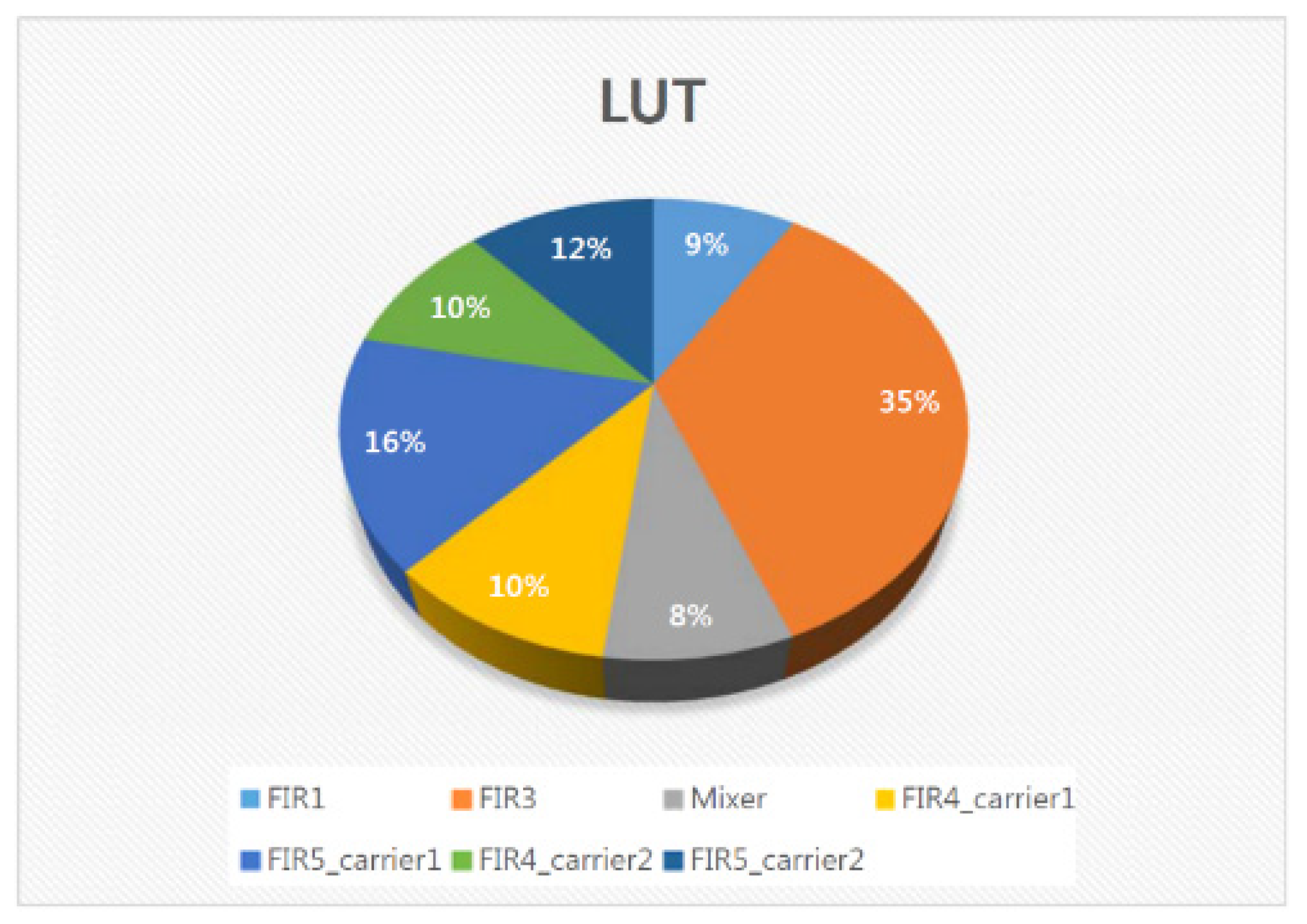
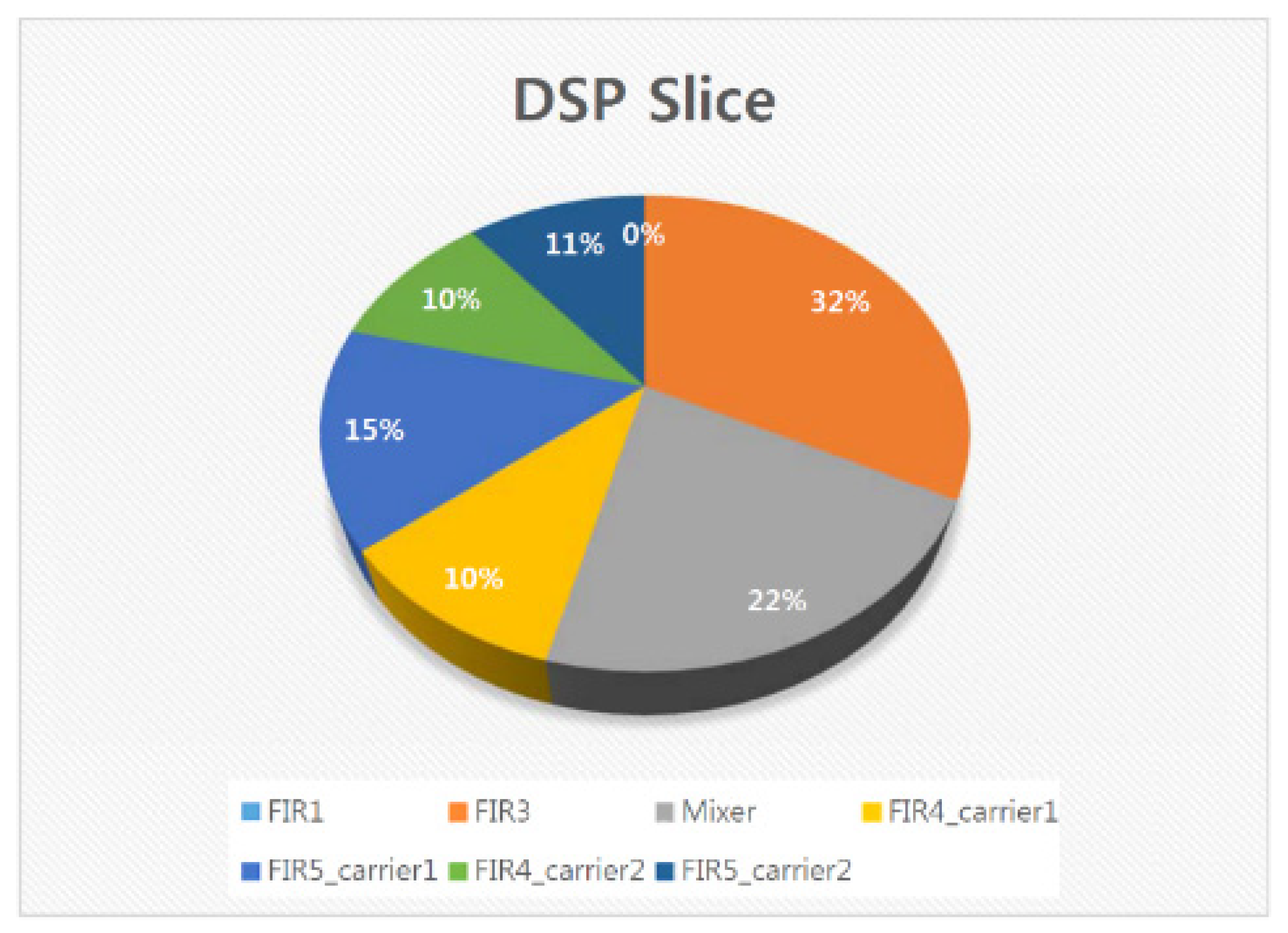
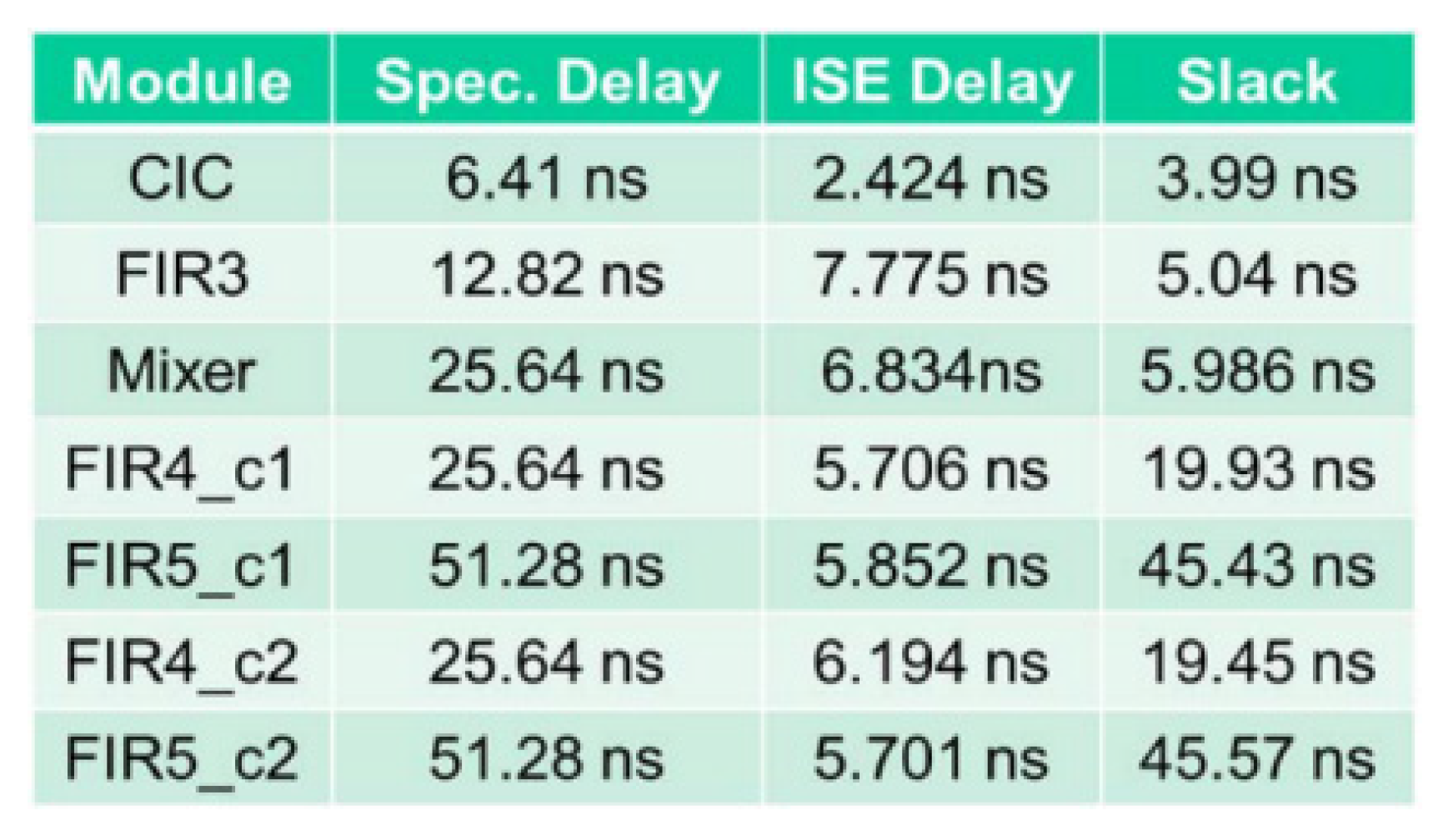
5.7. FPGA Placement and Routing Results of the Overall DFE Architecture
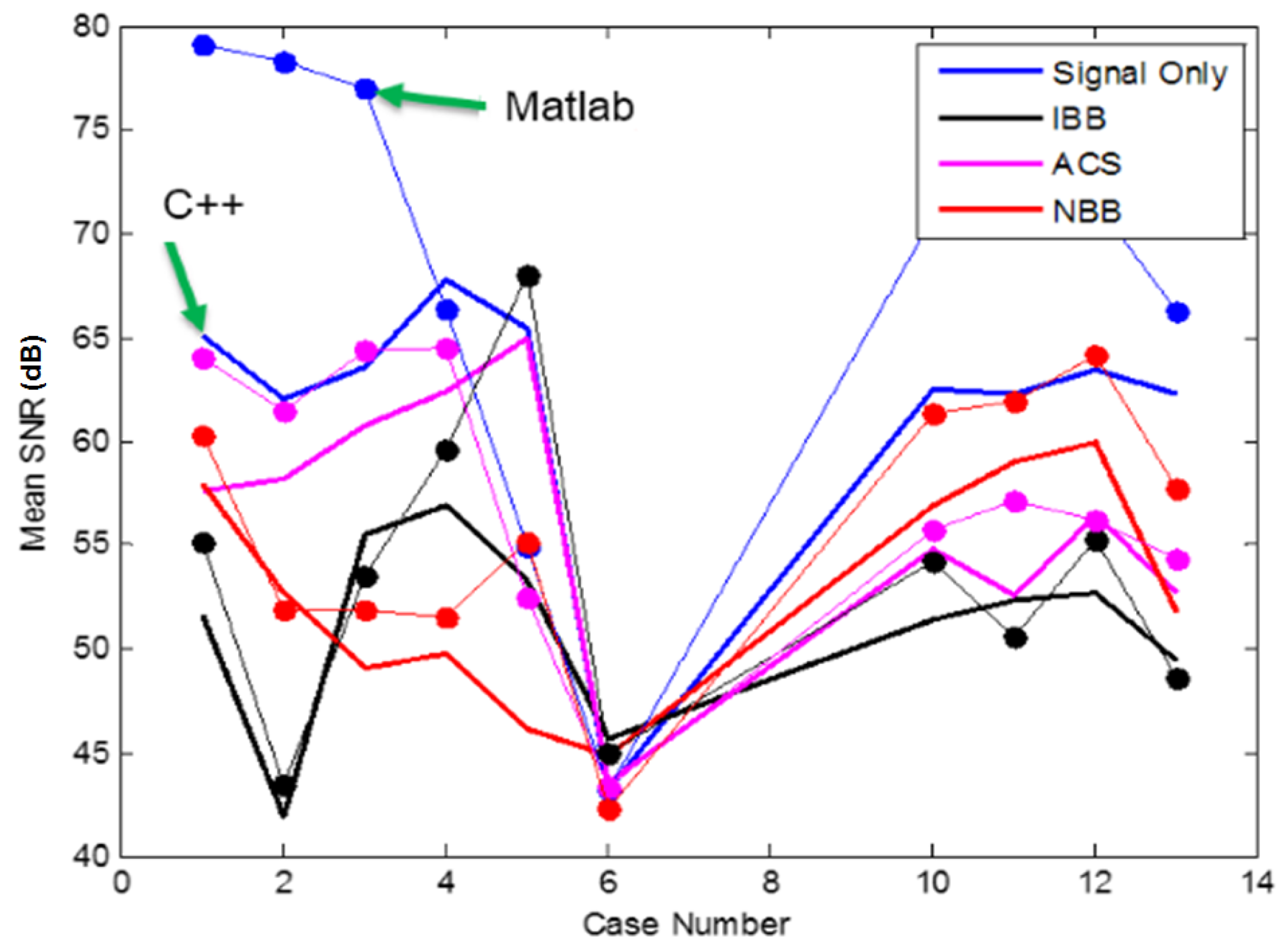
5.8. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- White, B.; Elmasry, M. Low-power design of decimation filters for a digital IF receiver. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2000, 8, 339–345. [Google Scholar] [CrossRef]
- Yuce, M.; Liu, W. Design and implementation of a multirate sub-sampling front-end in software radio systems. In Proceedings of the 2004 IEEE Radio and Wireless Conference (IEEE Cat. No.04TH8746), Atlanta, GA, USA, 22 September 2004; pp. 529–532. [Google Scholar]
- Wang, T.; Li, C. Sample Rate Conversion Technology in Software Defined Radio. In Proceedings of the 2006 Canadian Conference on Electrical and Computer Engineering, Ottawa, ON, Canada, 7–10 May 2006; pp. 1355–1358. [Google Scholar] [CrossRef]
- Fettweis, G.P.; Hentschel, T. The Digital Front End: Bridge between RF and Baseband Processing. In Software Defined Radio: Enabling Technologies; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2003; Chapter 6; pp. 151–198. [Google Scholar]
- Yeary, M.; Zhang, W.; Trelewicz, J.; Zhai, Y.; McGuire, B. Theory and Implementation of a Computationally Efficient Decimation Filter for Power-Aware Embedded Systems. IEEE Trans. Instrum. Meas. 2006, 55, 1839–1849. [Google Scholar] [CrossRef]
- Abidi, A.A. The Path to the Software-Defined Radio Receiver. IEEE J. Solid-State Circuits 2007, 42, 954–966. [Google Scholar] [CrossRef]
- Lin, F.-Y.; Qiao, W.-M.; Zhang, J.-C.; Nan, G.-Y.; Li, W.-B.; Mao, W.-Y. Programmable Digital Front-End Design for Software Defined Radio. In Proceedings of the 2010 Second International Conference on Networks Security, Wireless Communications and Trusted Computing, Wuhan, China, 24–25 April 2010; Volume 1, pp. 321–324. [Google Scholar]
- Agarwal, A.; Boppana, L.; Kodali, R.K.; Agarwal, A. A fractional sample rate conversion filter for a software radio receiver on FPGA. In Proceedings of the TENCON 2014—2014 IEEE Region 10 Conference, Bangkok, Thailand, 22–25 October 2014; pp. 1–6. [Google Scholar]
- Mocanu, V.; Anghel, C.; Enescu, A. FPGA implementation of a Digital Front End block for a Multi-Carrier Multi-Antenna system. In Proceedings of the 2009 International Semiconductor Conference, Sinaia, Romania, 12–14 October 2009; pp. 431–434. [Google Scholar] [CrossRef]
- Darak, S.J.; Vinod, A.P.; Mahesh, R.; Lai, E.M.-K. A reconfigurable filter bank for uniform and non-uniform channelization in multi-standard wireless communication receivers. In Proceedings of the 2010 17th International Conference on Telecommunications, Doha, Qatar, 4–7 April 2010; pp. 951–956. [Google Scholar]
- Shahein, A.; Afifi, M.; Becker, M.; Lotze, N.; Manoli, Y. A Power-Efficient Tunable Narrow-Band Digital Front End for Bandpass Sigma–Delta ADCs in Digital FM Receivers. IEEE Trans. Circuits Syst. II Express Briefs 2010, 57, 883–887. [Google Scholar] [CrossRef]
- Nanda, R.; Chen, H.; Markovic, D. A low-power digital front-end direct-sampling receiver for flexible radios. In Proceedings of the IEEE Asian Solid-State Circuits Conference, Jeju, Korea, 14–16 November 2011; pp. 377–380. [Google Scholar]
- Kim, G.; Capoccia, R.; Leblebici, Y. Design optimization of polyphase digital down converters for extremely high frequency wireless communications. In Proceedings of the 2015 IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC), Daejeon, Korea, 5–7 October 2015; pp. 207–212. [Google Scholar] [CrossRef]
- Tafreshi, M.A.; Yli-Kaakinen, J.; Levanen, T.; Korhonen, V.; Jaaskelainen, P.; Renfors, M.; Valkama, M.; Takala, J. Parallel pro-cessing intensive digital front-end for IEEE 802.11ac receiver. In Proceedings of the IEEE 49th Asilomar Conference Signals, Systems and Computers, Pacific Grove, CA, USA, 8–11 November 2015; pp. 1619–1626. [Google Scholar]
- Li, H.; Torfs, G.; Kazaz, T.; Bauwelinck, J.; Demeester, P. Farrow structured variable fractional delay Lagrange filters with im-proved midpoint response. In Proceedings of the IEEE 40th International Conference on Telecommunications and Signal Processing, Barcelona, Spain, 5–7 July 2017; pp. 506–509. [Google Scholar]
- Meyr, H.; Moeneclaey, M.; Fechtel, S.A. Digital Communication Receivers; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1998; Chapter 9; pp. 505–532. [Google Scholar]
- Sheikh, F.; Masud, S. Sample rate conversion filter design for multi-standard software radios. Digit. Signal Process. 2010, 20, 3–12. [Google Scholar] [CrossRef]
- Xilinx. Cascaded Integrator-Comb (CIC) Filter V3.0, Product Specification; Xilinx: San Jose, CA, USA, 2002. [Google Scholar]
- Hogenauer, E. An economical class of digital filters for decimation and interpolation. IEEE Trans. Acoust. Speech Signal Process. 1981, 29, 155–162. [Google Scholar] [CrossRef]
- Vesma, J.; Renfors, M.K.; Rinne, J. Comparison of efficient interpolation techniques for symbol timing recovery. In Proceedings of the IEEE Global Telecommunications Conference, London, UK, 18–22 November 1996; pp. 953–957. [Google Scholar]
- Gardner, F.M. Interpolation in digital modems-Part I: Fundamentals. IEEE Trans. Commun. 1993, 41, 501–507. [Google Scholar] [CrossRef]
- Erup, L.; Gardner, F.M.; Harris, R.A. Interpolation in digital modems-Part II: Implementation and Performance. IEEE Trans. Commun. 1993, 41, 998–1008. [Google Scholar] [CrossRef]
- Bi, G.; Mitra, S.K. Sampling Rate Conversion in the Frequency Domain. IEEE Signal Process. Mag. 2011, 28, 140–144. [Google Scholar] [CrossRef]
- Menon, S.; Cho, G.; Soderstrand, M. An improved numerically controlled digital oscillator. In Proceedings of the 2003 IEEE Pacific Rim Conference on Communications Computers and Signal Processing, Victoria, BC, Canada, 28–30 August 2003; pp. 1040–1044. [Google Scholar]
- Bellanger, M. Digital Processing of Signals: Theory and Practice, 3rd ed.; John Wiley and Sons: Hoboken, NJ, USA, 2000; Chapter 5. [Google Scholar]
- Rabiner, L.; Herrmann, O. The predictability of certain optimum finite-impulse-response digital filters. IEEE Trans. Circuit Theory 1973, 20, 401–408. [Google Scholar] [CrossRef]
- Hueber, G.; Maurer, L.; Strasser, G.; Stuhlberger, R.; Chabrak, K.; Hagelauer, R. On the design of a multi-mode receive digi-tal-front-end for cellular terminal RFICs. In Proceedings of the IEEE European Microwave Conference, Paris, France, 4–6 October 2005. [Google Scholar]
- Hueber, G.; Maurer, L.; Strasser, G.; Stuhlberger, R.; Hagelauer, R. On the concept of a multi-mode agile receive digi-tal-front-end for cellular terminals. In Proceedings of the IEEE International Symposium on Personal, Indoor and Mobile Radio Communications, Berlin, Germany, 11–14 September 2005; pp. 690–694. [Google Scholar]
- Hueber, G.; Maurer, L.; Strasser, G.; Stuhlberger, R.; Chabrak, K.; Hagelauer, R. The design of a multi-mode/multi-system ca-pable software radio receiver. In Proceedings of the IEEE International Symposium on Circuits and Systems, Island of Kos, Greece, 21–24 May 2006; pp. 3958–3961. [Google Scholar]
- Hueber, G.; Stuhlberger, R.; Springer, A. An adaptive digital front-end for multimode wireless receivers. IEEE Trans. Circuits Syst. Part II Express Briefs 2008, 55, 349–353. [Google Scholar] [CrossRef]























Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, C.S.; Kim, S.; Wang, J.; Park, S. Design and Implementation of a Farrow-Interpolator-Based Digital Front-End in LTE Receivers for Carrier Aggregation. Electronics 2021, 10, 231. https://doi.org/10.3390/electronics10030231
Park CS, Kim S, Wang J, Park S. Design and Implementation of a Farrow-Interpolator-Based Digital Front-End in LTE Receivers for Carrier Aggregation. Electronics. 2021; 10(3):231. https://doi.org/10.3390/electronics10030231
Chicago/Turabian StylePark, Chester Sungchung, Sunwoo Kim, Jooho Wang, and Sungkyung Park. 2021. "Design and Implementation of a Farrow-Interpolator-Based Digital Front-End in LTE Receivers for Carrier Aggregation" Electronics 10, no. 3: 231. https://doi.org/10.3390/electronics10030231
APA StylePark, C. S., Kim, S., Wang, J., & Park, S. (2021). Design and Implementation of a Farrow-Interpolator-Based Digital Front-End in LTE Receivers for Carrier Aggregation. Electronics, 10(3), 231. https://doi.org/10.3390/electronics10030231