
Deep Learning Control for Digital Feedback Systems: Improved Performance with Robustness against Parameter Change



Abstract
1. Introduction
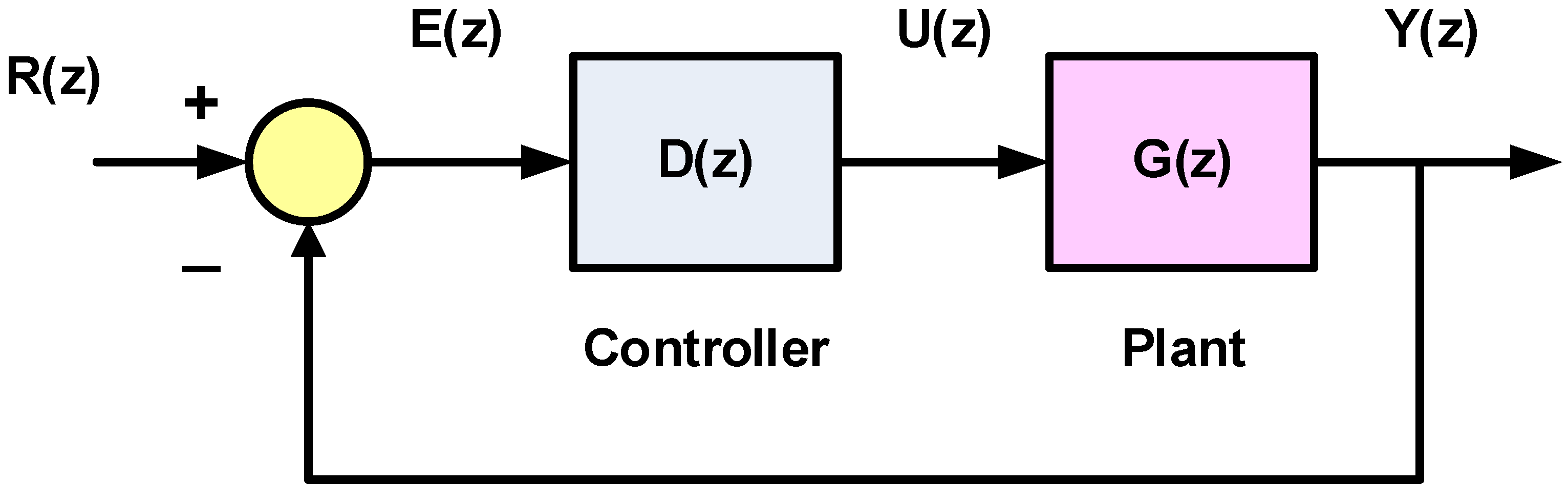
2. Conventional Controller Design for Digital Feedback Control System
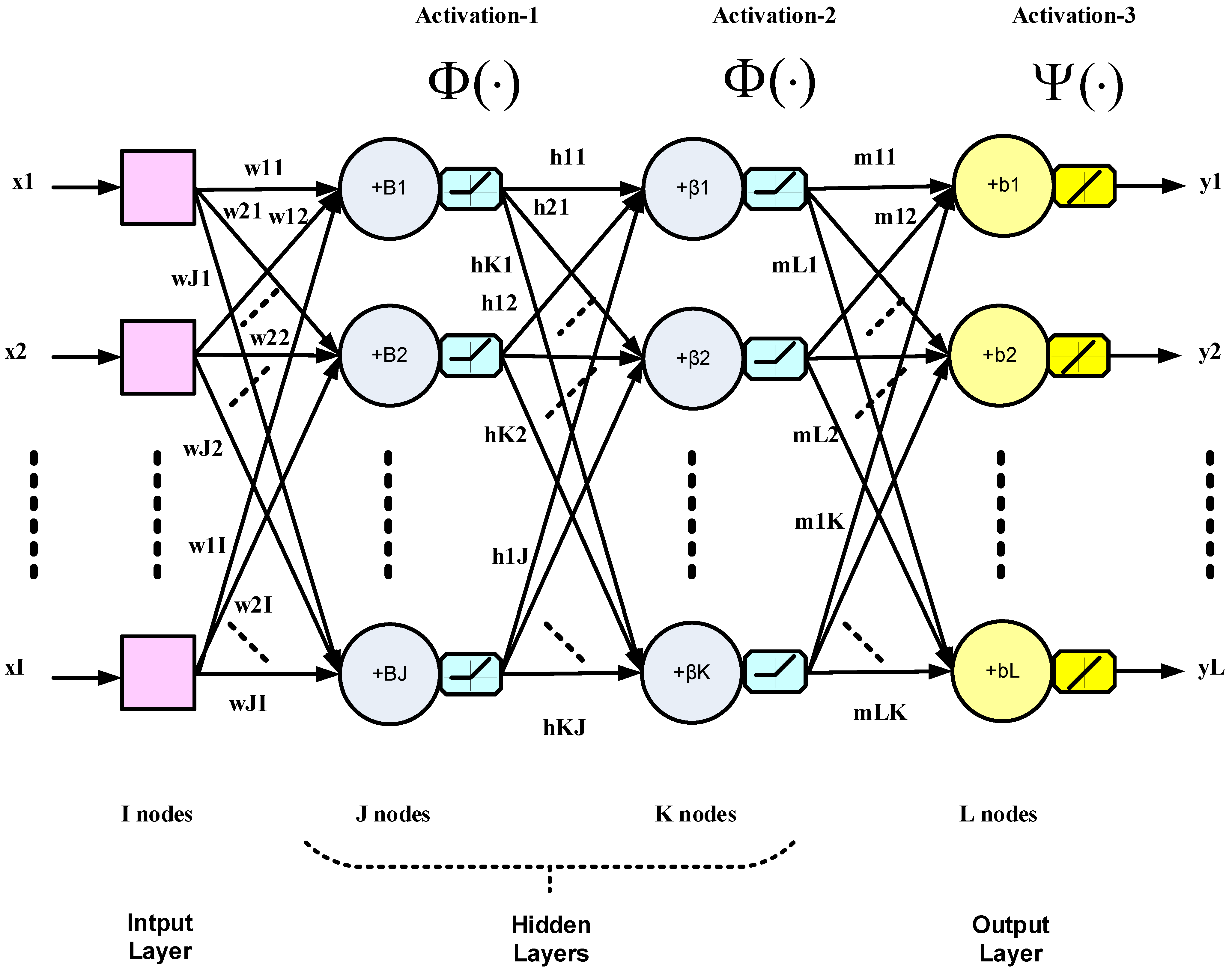
3. The DL Controller
4. Simulation Results and Discussion
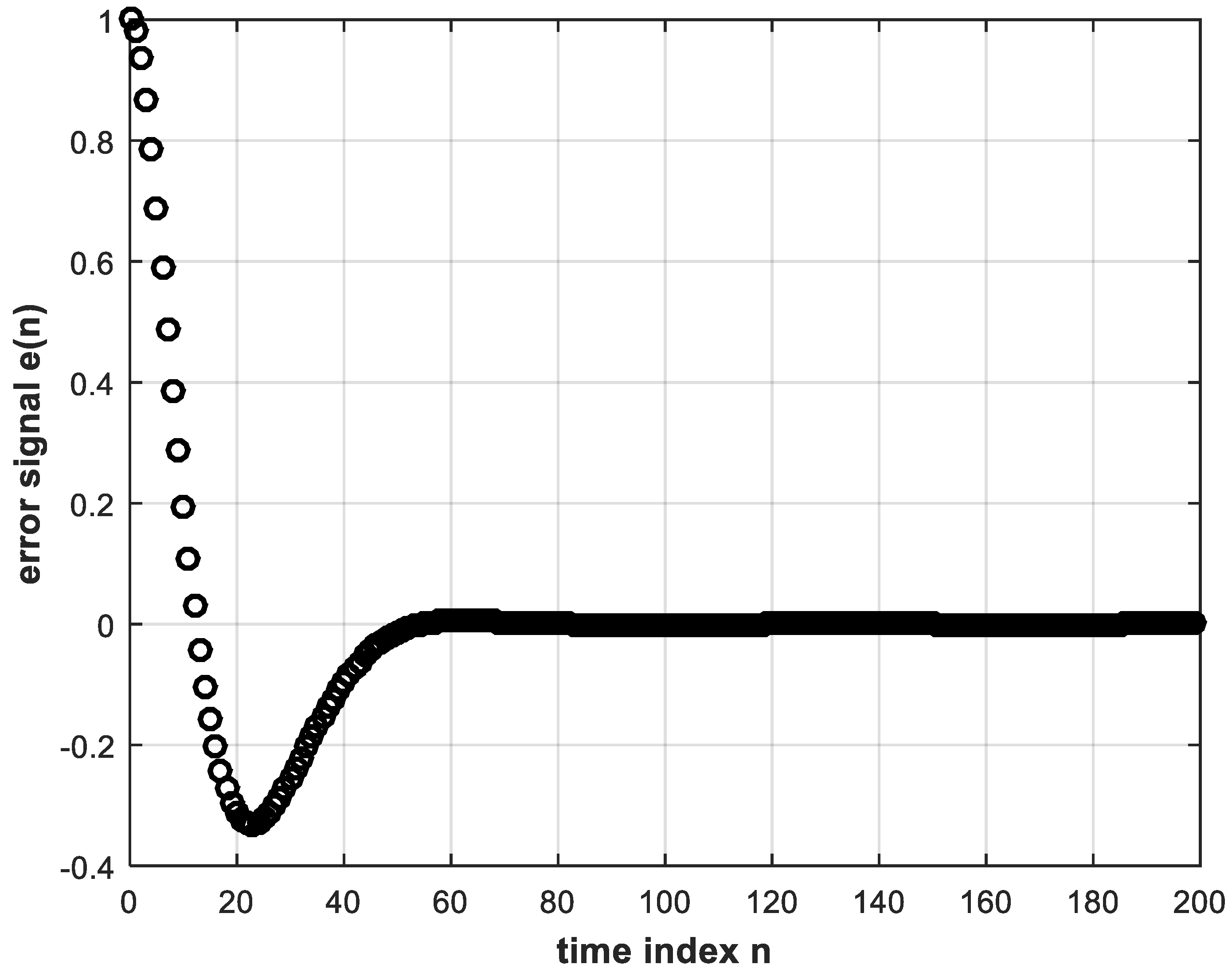
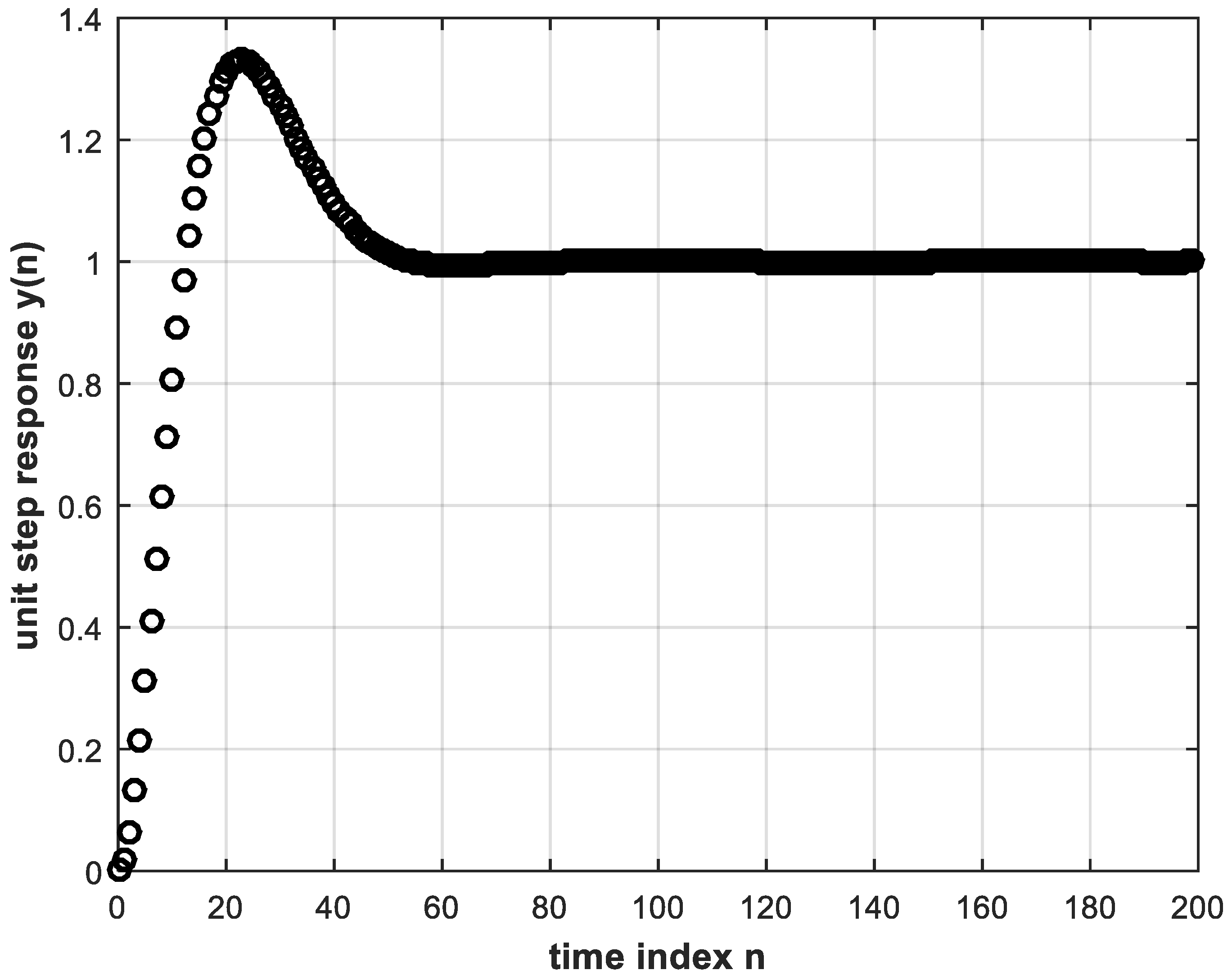
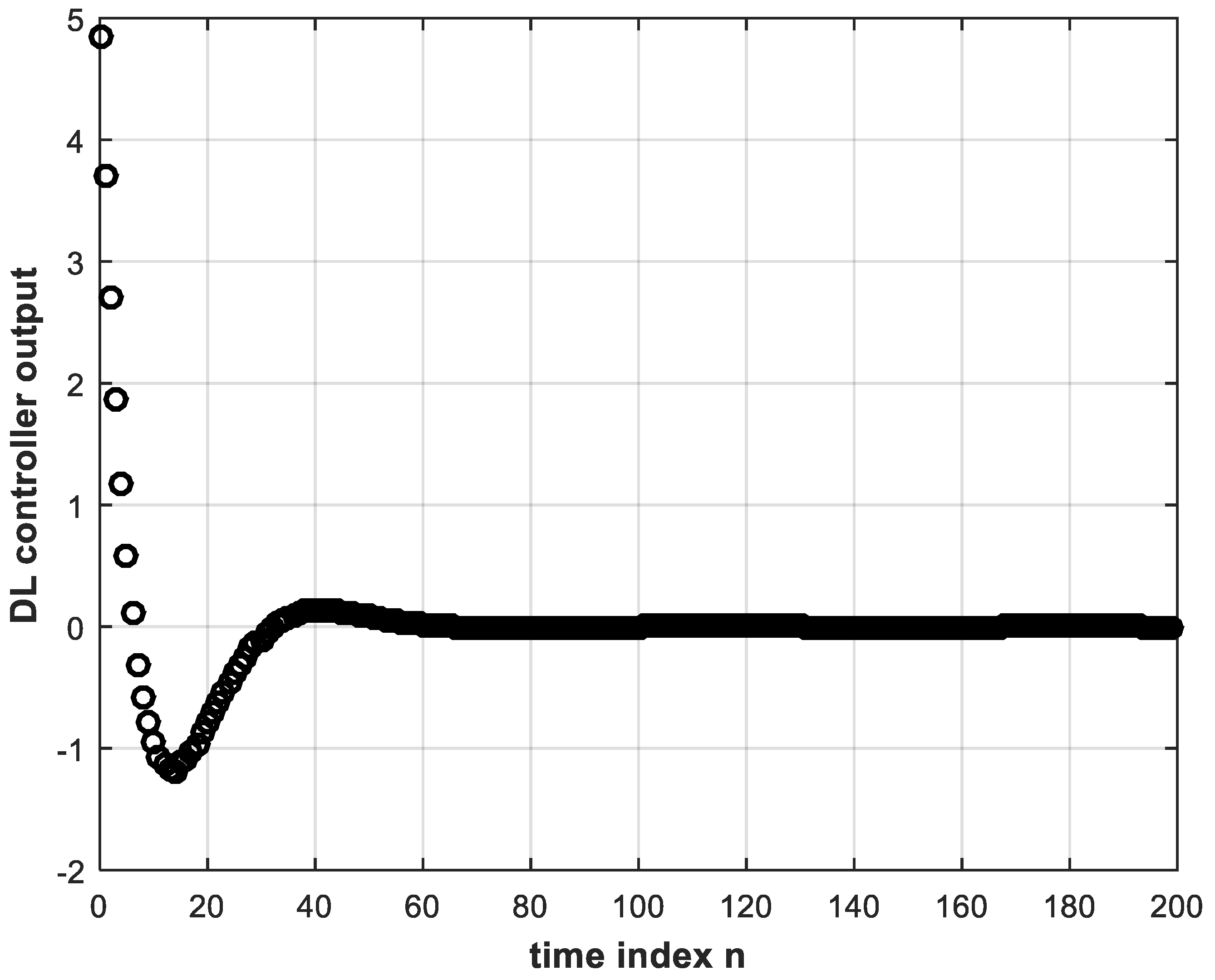
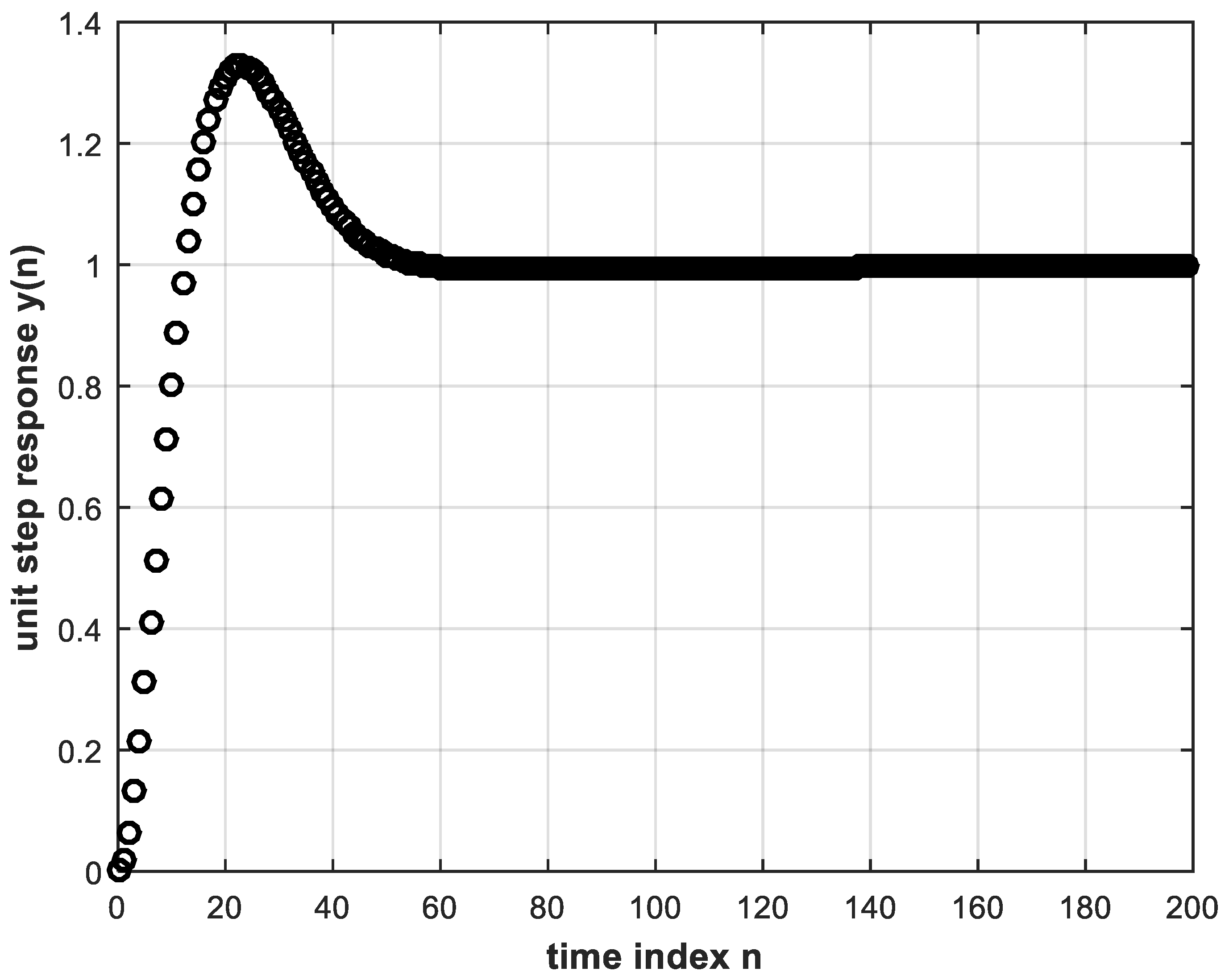
4.1. DL Training Process
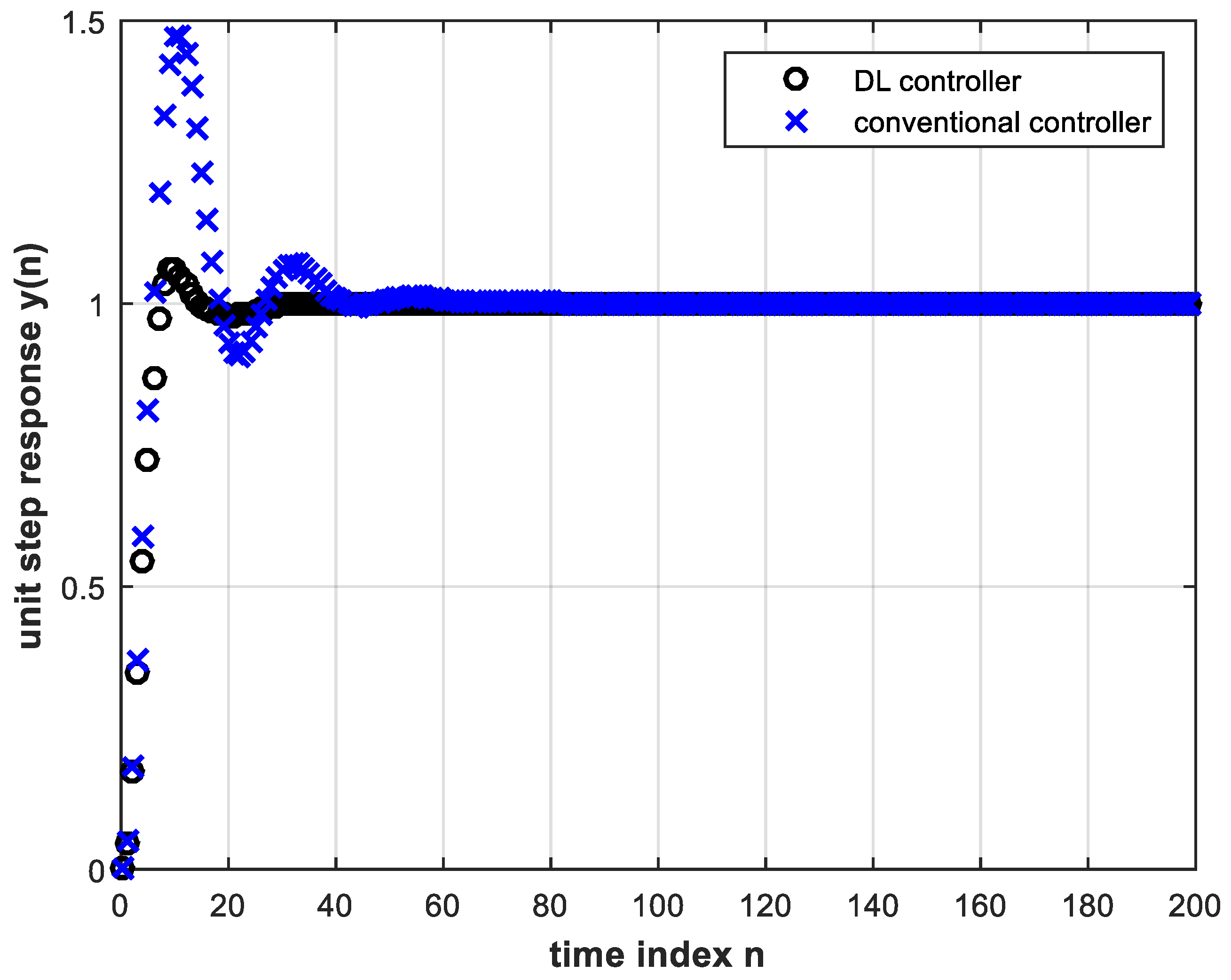
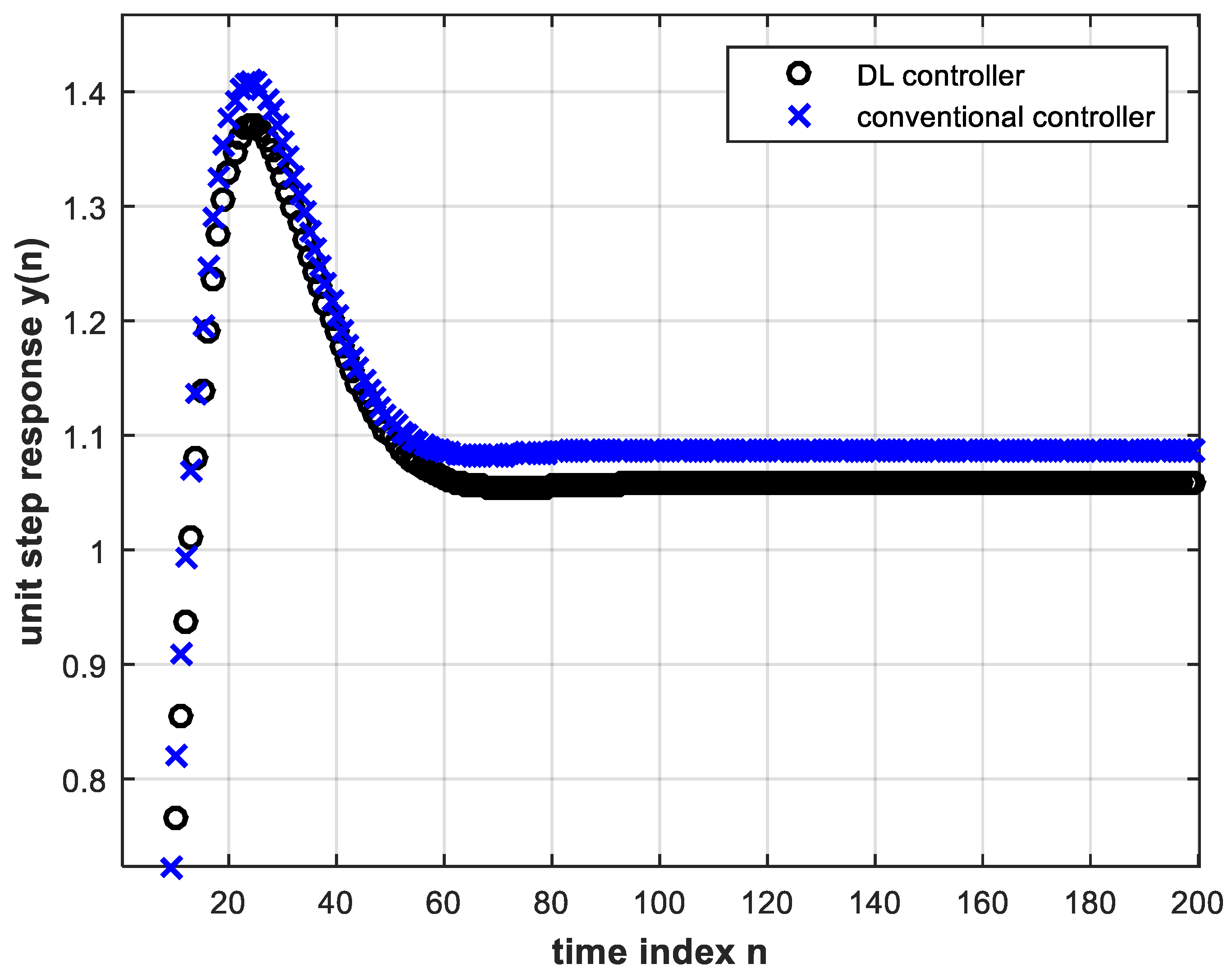
4.2. Performance of the DL Controller versus Electronic Controller
4.3. Robustness against System Parameter Change
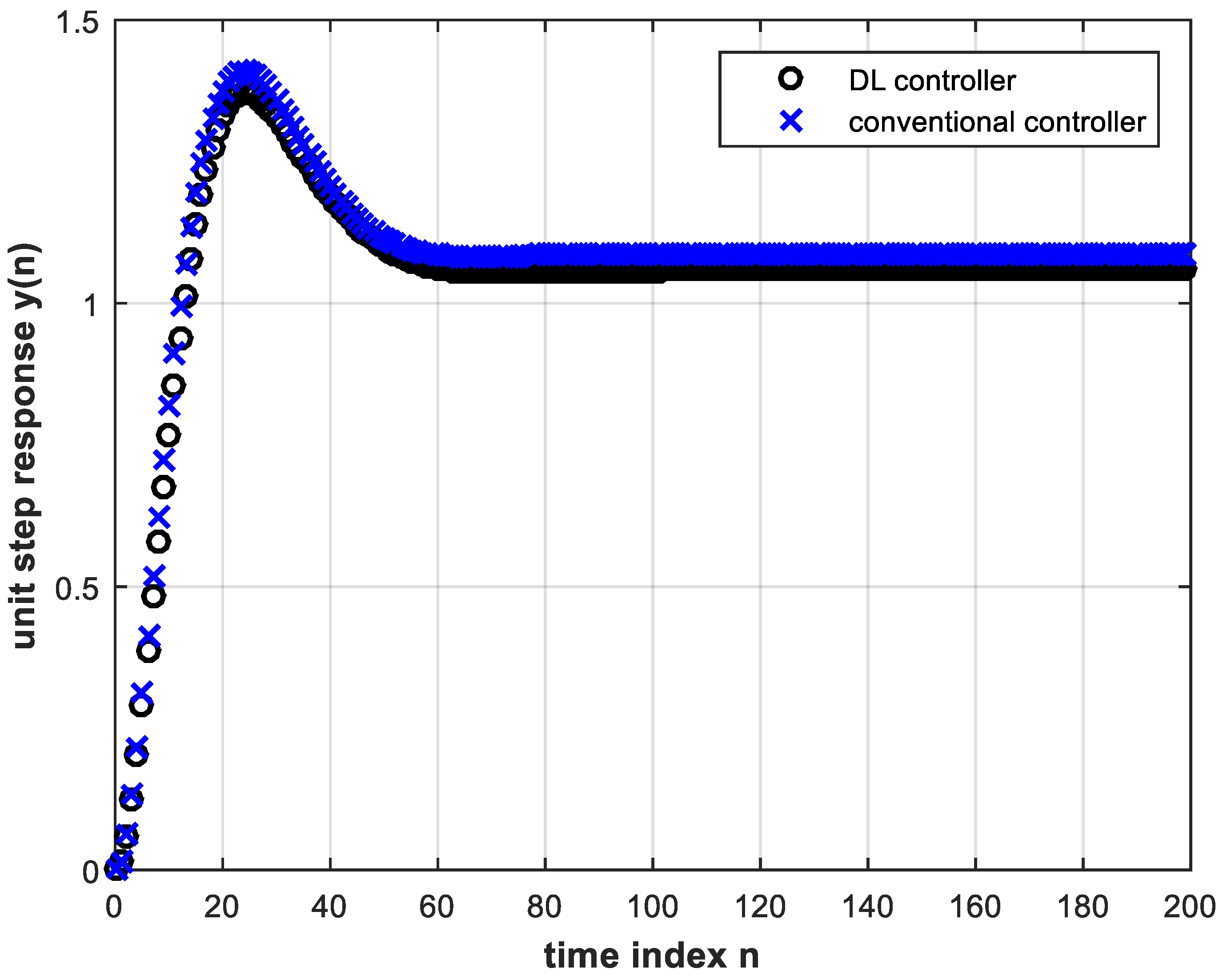
4.3.1. Performance under Plant Gain Change
4.3.2. Performance under Pole Location Change
4.4. Effect of Activation Functions
4.5. Final Remarks and Future Directions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Louis, F.L.; Ge, S.S. Neural networks in feedback control systems. In Mechanical Engineers’ Handbook; Kutz, M., Ed.; John Wiley: Hoboken, NJ, USA, 2005. [Google Scholar]
- Werbos, P.J. Neural network for control and system identification. In Proceedings of the 28th IEEE Conference Decision and Control, Tampa, FL, USA, 13–15 December 1989; pp. 260–265. [Google Scholar]
- Kawato, M. Computational schemes and neural network models for formation and control of multi-joint arm trajectory. In Neural Networks and Control; Miller, W.T., Sutton, R.S., Werbos, P.J., Eds.; MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Igelnik, B.; Pao, Y.H. Stochastic choice of basis functions in adaptive function approximation and functional-link net. IEEE Trans. Neural Netw. 1995, 6, 1320–1329. [Google Scholar] [CrossRef] [PubMed]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kim, P. MATLAB Deep Learning; Apress: Basingstoke, UK, 2016. [Google Scholar]
- Liu, Y.; Xu, S.; Hashimoto, S.; Kawaguchi, T. A reference-model-based neural network control method for multi-input multi-output temperature control system. Processes 2020, 8, 1365. [Google Scholar] [CrossRef]
- Cheon, K.; Kim, J.H.; Hamadache, M.; Lee, D. On replacing PID controller with deep learning controller for DC motor system. J. Autom. Control Eng. 2015, 3, 452–456. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Neural Networks and Deep Learning; Springer: Berlin, Germany, 2018. [Google Scholar]
- Zaki, A.M.; El-Nagar, A.M.; El-Bardini, M.; Soliman, F.A.S. Deep learning controller for nonlinear system based on Lyapunov stability criterion. Neural Comput. Appl. 2021, 33, 1515–1531. [Google Scholar] [CrossRef]
- Lapan, M. Deep Reinforcement Learning Hands-on; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Liu, R.; Nageotte, F.; Zanne, P.; de Mathelin, M.; Dresp-Langley, B. Deep reinforcement learning for the control of robotic manipulation: A focused mini-review. Robotics 2021, 10, 22. [Google Scholar] [CrossRef]
- Manrique-Escobar, C.A.; Pappalardo, C.M.; Guida, D. A parametric study of a deep reinforcement learning control system applied to the swing-up problem of the cart-pole. Appl. Sci. 2020, 10, 9013. [Google Scholar] [CrossRef]
- Erenturk, K. Design of deep learning controller. Int. J. Eng. Appl. Sci. 2018, 5, 122–124. [Google Scholar] [CrossRef]
- Kumar, S.S.P.; Tulsyan, A.; Gopaluni, B.; Loewen, P. A deep learning architecture for predictive control. IFAC Papers Online 2018, 51, 512–517. [Google Scholar] [CrossRef]
- Adhau, S.; Patil, S.; Ingole, D.; Sonawane, D. Embedded implementation of deep learning-based linear model predictive control. In Proceedings of the 2019 Sixth Indian Control Conference (ICC), IIT Hyderabad, India, 18–20 December 2019; pp. 200–205. [Google Scholar]
- Orosz, T.; Rassolkin, A.; Kallaste, A.; Arsenio, P.; Panek, D.; Kaska, J.; Karban, P. Robust design optimization and emerging technologies for electrical machines: Challenges and open problems. Appl. Sci. 2020, 10, 6653. [Google Scholar] [CrossRef]
- Dorf, R.C.; Bishop, R.H. Modern Control Systems, 11th ed.; Pearson Prentice Hall: Hoboken, NJ, USA, 2008. [Google Scholar]
- Baptista, F.D.; Rodrigues, S.; Morgado-Dias, F. Performance comparison of ANN training algorithms for classification. In Proceedings of the 2013 IEEE 8th International Symposium on Intelligent Signal Processing, Funchal, Portugal, 16–18 September 2013; pp. 115–120. [Google Scholar]
- Heaton, J. Introduction to Neural Networks with Java; Heaton Research Inc.: St. Louis, MO, USA, 2008. [Google Scholar]
- Vujicic, T.; Matijevic, T.; Ljucovic, J.; Balota, A.; Sevarac, Z. Comparative analysis of methods for determining number of hidden neurons in artificial neural network. In Proceedings of the Central European Conference on Information and Intelligent Systems, Varazdin, Croatia, 21–23 September 2016. [Google Scholar]
- Hunter, D.; Yu, H.; Pukish, M.S.; Kolbusz, J.; Wilamowski, B.M. Selection of proper neural network sizes and architectures. IEEE Trans. Ind. Inform. 2012, 8, 228–240. [Google Scholar] [CrossRef]
- Thomas, A.J.; Walters, S.D.; Gheytassi, S.M.; Morgan, R.E.; Petridis, M. On the optimal node ratio between hidden layers: A probabilistic study. Int. J. Mach. Learn. Comput. 2016, 6, 241–247. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Tan, Y.; Dang, X.; Cauwenberghi, A.V. Generalized nonlinear PID controller based on neural networks. In Proceedings of the IEEE Decision and Control Symposium, Crowne Plaza Hotel and Resort Phoenix, Phoenix, AZ, USA, 7–10 December 1999; pp. 519–524. [Google Scholar]
- Deutscher, J. Input-output linearization of nonlinear systems using multivariable Legendre polynomials. Automatica 2005, 2, 299–304. [Google Scholar] [CrossRef]
- Cheng, D.; Hu, X.; Shen, T. Linearization of Nonlinear Systems. In Analysis and Design of Nonlinear Control Systems; Springer: Berlin, Germany, 2010. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Controller Type | Settling Times (Milliseconds) within r % of Final Value | ||
|---|---|---|---|
| r = 2 | r = 0.2 | r = 0.02 | |
| Conventional | 48 | 74 | 104 |
| DL with 2 hidden layers | 49 | >200 | >200 |
| DL with 3 hidden layers | 49 | 85 | 120 |
| DL with 4 hidden layers | 47 | 55 | 92 |
| Controller Type | Settling Times (Milliseconds) within r % of Final Value | ||
|---|---|---|---|
| r = 2 | r = 0.2 | r = 0.02 | |
| Conventional | 40 | 80 | 114 |
| DL with 4 hidden layers | 14 | 30 | 43 |
| Relative Percentage Pole Change () | Steady State Error | |
|---|---|---|
| (DL Controller) | (Conventional Controller) | |
| −75 | 0 | 0 |
| −77.5 | +0.01 | +0.02 |
| −87.5 | −0.05 | −0.09 |
| −90 | −0.045 | −0.07 |
| −92.5 | −0.03 | −0.05 |
| −95 | −0.02 | −0.035 |
| −97.5 | −0.011 | −0.017 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alwan, N.A.S.; Hussain, Z.M. Deep Learning Control for Digital Feedback Systems: Improved Performance with Robustness against Parameter Change. Electronics 2021, 10, 1245. https://doi.org/10.3390/electronics10111245
Alwan NAS, Hussain ZM. Deep Learning Control for Digital Feedback Systems: Improved Performance with Robustness against Parameter Change. Electronics. 2021; 10(11):1245. https://doi.org/10.3390/electronics10111245
Chicago/Turabian StyleAlwan, Nuha A. S., and Zahir M. Hussain. 2021. "Deep Learning Control for Digital Feedback Systems: Improved Performance with Robustness against Parameter Change" Electronics 10, no. 11: 1245. https://doi.org/10.3390/electronics10111245
APA StyleAlwan, N. A. S., & Hussain, Z. M. (2021). Deep Learning Control for Digital Feedback Systems: Improved Performance with Robustness against Parameter Change. Electronics, 10(11), 1245. https://doi.org/10.3390/electronics10111245