
Context-Based Inter Mode Decision Method for Fast Affine Prediction in Versatile Video Coding


Abstract
1. Introduction
2. Related Work
3. Proposed Method
4. Experiment Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bross, B.; Chen, J.; Liu, S.; Wang, Y. Versatile Video Coding (Draft 10). In Proceedings of the 19th Meeting Joint Video Experts Team (JVET), Teleconference (Online), 6–10 July 2020. [Google Scholar]
- Sze, V.; Budagavi, M.; Sullivan, G.J. High efficiency video coding (HEVC). In Integrated Circuit and Systems, Algorithms and Architectures; Springer: Berlin, Germany, 2014; pp. 1–375. [Google Scholar]
- Bross, F.; Li, X.; Suehring, K. AHG Report: Test Model Software Development (AHG3). In Proceedings of the 19th Meeting Joint Video Experts Team (JVET), Teleconference (Online), 6–10 July 2020. [Google Scholar]
- Versatile Video Coding (VVC) Test Model (VTM). Available online: https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM (accessed on 21 March 2021).
- Sullivan, G.; Ohm, J.; Han, W.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Bossen, F.; Boyce, J.; Suehring, K.; Li, X.; Seregin, V. JVET Common Test Conditions and Software Reference Configurations for SDR Video. In Proceedings of the 12th Meeting Joint Video Experts Team (JVET), Macao, China, 3–12 October 2018. [Google Scholar]
- Yang, H.; Chen, H.; Zhao, Y.; Chen, J. Draft Text for Affine Motion Compensation. In Proceedings of the 11th Meeting Joint Video Experts Team (JVET), Ljubljana, Slovenia, 11–18 July 2018. Document JVET-K0565. [Google Scholar]
- Su, Y.-C.; Chen, C.; Huang, Y.; Lei, S.; He, Y.; Luo, J.; Xiu, X.; Ye, Y. CE4-Related: Generalized Bi-Prediction Improvements Combined. In Proceedings of the 12th Meeting Joint Video Experts Team (JVET), Macao, China, 3–12 October 2018. Document JVET-L0197, JVET-L0296, and JVET-L0646. [Google Scholar]
- Zhang, Y.; Han, Y.; Chen, C.; Hung, C.; Chien, W.; Karczewicz, M. CE4.3.3: Locally Adaptive Motion Vector Resolution and MVD Coding. In Proceedings of the 11th Meeting Joint Video Experts Team (JVET), Ljubljana, Slovenia, 10–18 July 2018. Document JVET-K0357. [Google Scholar]
- Luo, J.; He, Y. CE4-Related: Simplified Symmetric MVD Based on CE4.4.3. In Proceedings of the 13th Meeting Joint Video Experts Team (JVET), Marrakech, Morocco, 9–18 January 2019. Document JVET-M0444. [Google Scholar]
- Gao, H.; Esenlik, S.; Alshina, E.; Kotra, A.; Wang, B.; Liao, R.; Chen, J.; Ye, Y.; Luo, J.; Reuzé, K.; et al. Integrated Text for GEO. In Proceedings of the 17th Meeting Joint Video Experts Team (JVET), Brussels, Belgien, 7–17 January 2020. Document JVET-Q0806. [Google Scholar]
- Jeong, S.; Park, M.; Piao, Y.; Park, M.; Choi, K. CE4 Ultimate Motion Vector Expression. In Proceedings of the 12th Meeting Joint Video Experts Team (JVET), Macao, China, 3–12 October 2018. Document JVET-L0054. [Google Scholar]
- Sethuraman, S. CE9: Results of DMVR Related Tests CE9.2.1 and CE9.2.2. In Proceedings of the 13th Meeting Joint Video Experts Team (JVET), Marrakech, Morocco, 9–18 January 2019. Document JVET-M0147. [Google Scholar]
- Chiang, M.; Hsu, C.; Huang, Y.; Lei, S. CE10.1.1: Multi-Hypothesis Prediction for Improving AMVP Mode, Skip or Merge Mode, and Intra Mode. In Proceedings of the 12th Meeting Joint Video Experts Team (JVET), Macao, China, 3–12 October 2018. Document JVET-L0100. [Google Scholar]
- Chien, W.; Boyce, J. JVET AHG report: Tool Reporting Procedure (AHG13). In Proceedings of the 19th Meeting Joint Video Experts Team (JVET), Teleconference, 22 June–1 July 2020. Document JVET-S0013. [Google Scholar]
- Rahaman, D.; Paul, M. Virtual view synthesis for free viewpoint video and multiview video compression using gaussian mixture modelling. IEEE Trans. Image Process 2018, 27, 1190–1201. [Google Scholar] [CrossRef]
- Paul, M. Efficient multiview video coding using 3-D coding and saliency-based bit allocation. IEEE Trans. Broadcast. 2018, 64, 235–246. [Google Scholar] [CrossRef]
- Pan, Z.; Jin, P.; Lei, J.; Zhang, Y.; Sun, X.; Kwong, S. Fast reference frame selection based on content similarity for low complexity HEVC encoder. J. Vis. Commun. Represent. 2016, 40, 516–524. [Google Scholar] [CrossRef]
- Yang, S.-H.; Jiang, J.-Z.; Yang, H. Fast motion estimation for HEVC with directional search. Electron. Lett. 2014, 50, 673–675. [Google Scholar] [CrossRef]
- Nalluri, P.; Alves, L.; Navarro, A. Complexity reduction methods for fast motion estimation in HEVC. Signal Process. Image Commun. 2015, 39, 280–292. [Google Scholar] [CrossRef]
- Chien, W.; Liao, K.; Yang, J. Enhanced AMVP mechanism based adaptive motion search range decision algorithm for fast HEVC coding. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 3696–3699. [Google Scholar]
- Rosewarne, C.; Bross, B.; Naccari, M.; Sharman, K.; Sullivan, G. High Efficiency Video Coding (HEVC) Test Model 16 (HM 16) Improved Encoder Description Update 9. In Proceedings of the 28th Meeting Joint Collaborative Team on Video Coding (JCT-VC), Torino, Italy, 13–21 July 2017. Document JCTVC-AB1002. [Google Scholar]
- Park, S.; Lee, S.; Jang, E.; Jun, D.; Kang, J. Efficient biprediction decision scheme for fast high efficiency video coding encoding. J. Electron. Imaging 2016, 25, 063007. [Google Scholar] [CrossRef]
- Rhee, C.; Lee, H. Early decision of prediction direction with hierarchical correlation for HEVC compression. IEICE Trans. Inf. Syst. 2013, 96, 972–975. [Google Scholar] [CrossRef]
- Shen, L.; Zhang, Z.; An, P. Fast CU size decision and mode decision algorithm for HEVC intra coding. IEEE Trans. Consum. Electron. 2013, 59, 207–213. [Google Scholar] [CrossRef]
- Shen, L.; Zhang, Z.; Liu, Z. Adaptive inter-mode decision for HEVC jointly utilizing inter-level and spatiotemporal correlations. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1709–1722. [Google Scholar] [CrossRef]
- Tan, H.; Liu, F.; Tan, Y.; Yeo, C. On fast coding tree block and mode decision for high-Efficiency Video Coding (HEVC). In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 825–828. [Google Scholar]
- Xiong, J.; Li, H.; Wu, Q.; Meng, F. A fast HEVC inter CU selection method based on pyramid motion divergence. IEEE Trans. Multimed. 2014, 16, 559–564. [Google Scholar] [CrossRef]
- Lee, J.; Kim, S.; Lim, K.; Lee, S. A fast CU size decision algorithm for HEVC. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 411–421. [Google Scholar]
- Zhou, M. CE4: Test Results of CE4.1.11 on Line Buffer Reduction for Affine Mode. In Proceedings of the 12th Meeting Joint Video Experts Team (JVET), Macao, China, 3–12 October 2018. Document JVET-L0045. [Google Scholar]
- Zhang, K.; Zhang, L.; Liu, H.; Wang, Y.; Zhao, P.; Hong, D. CE4: Affine Prediction with 4×4 Sub-blocks for Chroma Components (Test 4.1.16). In Proceedings of the 12th Meeting Joint Video Experts Team (JVET), Macao, China, 3–12 October 2018. Document JVET-L0265. [Google Scholar]
- Park, S.; Kang, J. Fast Affine Motion Estimation for Versatile Video Coding (VVC) Encoding. IEEE Access 2019, 7, 158075–158084. [Google Scholar] [CrossRef]
- Martínez-Rach, M.O.; Migallón, H.; López-Granado, O.; Galiano, V.; Malumbres, M.P. Imaging performance overview of the latest video coding proposals: HEVC, JEM and VVC. J. Imaging 2021, 7, 39. [Google Scholar] [CrossRef]
- Bjontegaard, G. Calculation of Average PSNR Differences between RD Curves. In Proceedings of the 13th Meeting Video Coding Experts Group (VCEG), Austin, TX, USA, 2–4 April 2001. Document VCEG-M33. [Google Scholar]








{kind=link}
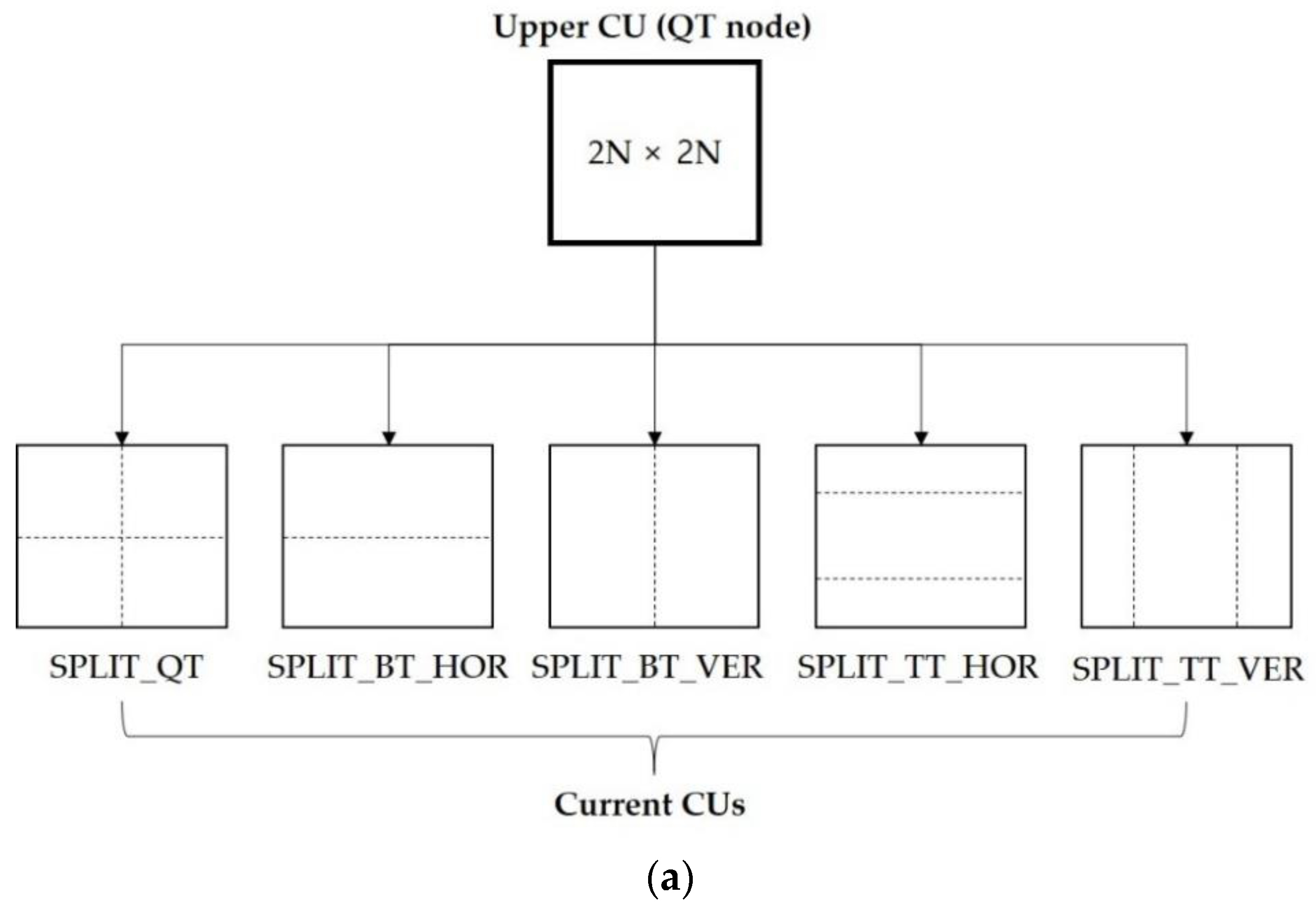{kind=link}
{kind=link}
{kind=link}
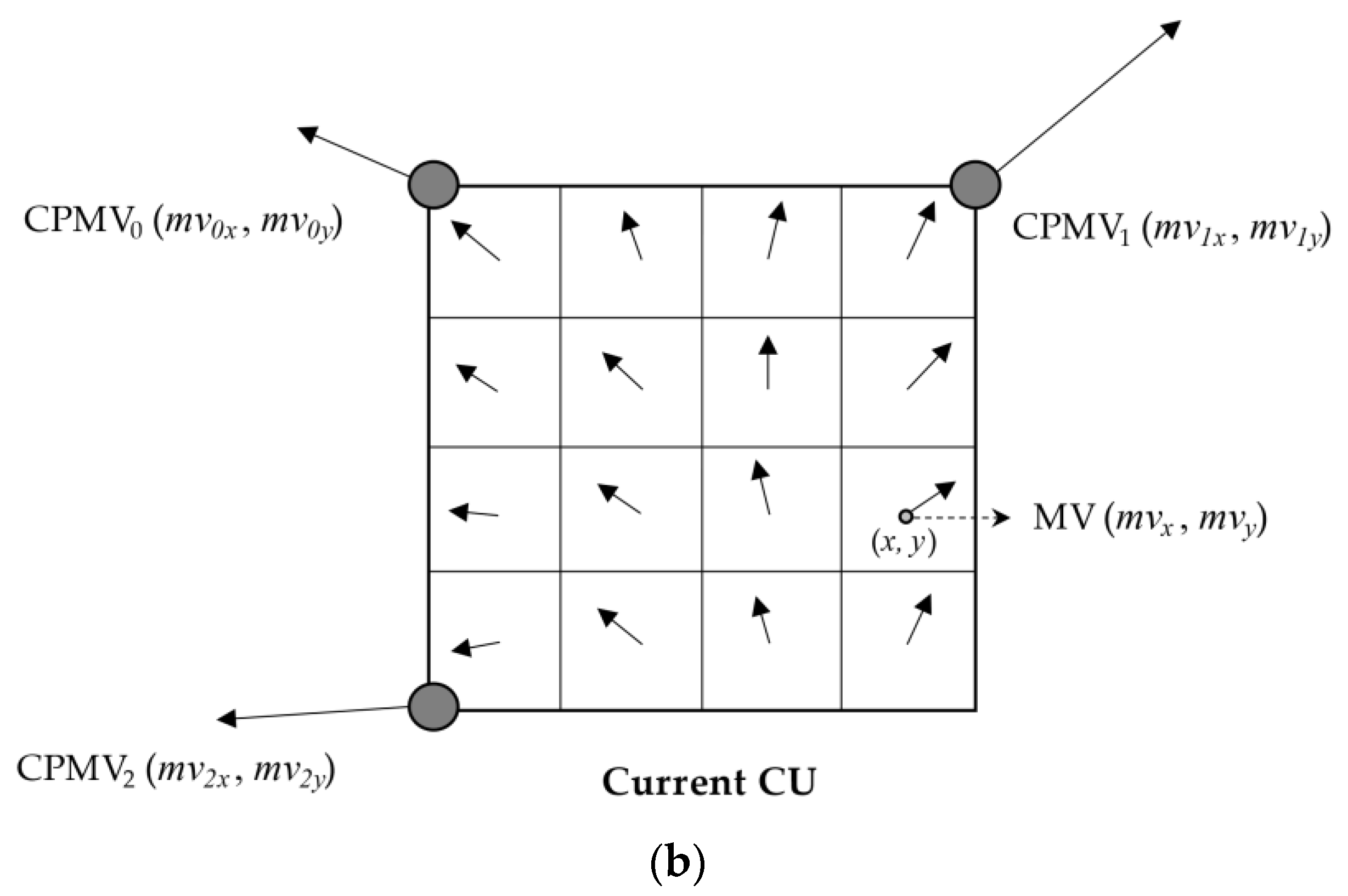{kind=link}
{kind=link}
{kind=link}
| Sequence | QP | Prior Probability | Posterior Probability |
|---|---|---|---|
| RitualDance | 25 | 27.17% | 9.01% |
| 30 | 24.84% | 9.45% | |
| 35 | 22.34% | 9.93% | |
| BQTerrace | 25 | 13.83% | 6.92% |
| 30 | 11.69% | 6.11% | |
| 35 | 9.52% | 5.86% | |
| Total | - | 15.80% | 5.54% |
| Sequences/ resolution/ frame rate | Tango2 | UHD (3840 × 2160) | 60 Hz |
| FoodMarket4 | 60 Hz | ||
| CatRobot | 60 Hz | ||
| DaylightRoad2 | 60 Hz | ||
| ParkRunning3 | 50 Hz | ||
| MarketPlace | FHD (1920 × 1080) | 60 Hz | |
| RitualDance | 60 Hz | ||
| Cactus | 50 Hz | ||
| BasketballDrive | 50 Hz | ||
| BQTerrace | 60 Hz | ||
| Encoding parameters | QP | 22, 27, 32, 37 | |
| Num. of reference frames | 2 | ||
| Num. of encoding frames | 33 | ||
| Search range | 384 | ||
| RD optimization | Enable | ||
| Use hadamard | Enable | ||
| GOP size | 16 | ||
| Coding configuration | Random access | ||
| Experimental Environment | Options |
|---|---|
| Processor | Inter(R) Xeon(R) Gold 6138 |
| RAM | 256 GB |
| Operating system | 64-bit Windows 10 |
| C++ compiler | Microsoft Visual C++ 2019 |
| Class | Sequence Name | Park [32] | Proposed | ||
|---|---|---|---|---|---|
| TSAMT | TSTET | TSAMT | TSTET | ||
| UHD | Tango2 | 18% | 1% | 31% | 4% |
| FoodMarket4 | 14% | 2% | 32% | 6% | |
| CatRobot | 23% | 5% | 29% | 6% | |
| DaylightRoad2 | 17% | 1% | 31% | 3% | |
| ParkRunning3 | 12% | 1% | 28% | 4% | |
| Average | 17% | 2% | 30% | 5% | |
| FHD | MarketPlace | 19% | 4% | 28% | 5% |
| RitualDance | 7% | 0% | 38% | 8% | |
| Cactus | 20% | 2% | 27% | 2% | |
| BasketballDrive | 15% | 1% | 33% | 5% | |
| BQTerrace | 36% | 5% | 54% | 3% | |
| Average | 19% | 2% | 36% | 5% | |
| Overall Average | 18% | 2% | 33% | 5% | |
| Class | Sequence Name | VTM 10.0 | Park [32] | Proposed | |||
|---|---|---|---|---|---|---|---|
| AMT | TET | AMT | TET | AMT | TET | ||
| UHD | Tango2 | 22,085 | 161,006 | 18,168 | 159,777 | 15,264 | 155,151 |
| FoodMarket4 | 17,135 | 102,896 | 14,668 | 101,114 | 11,621 | 96,835 | |
| CatRobot | 22,865 | 134,108 | 17,618 | 127,569 | 16,210 | 125,670 | |
| DaylightRoad2 | 30,100 | 188,027 | 24,895 | 185,325 | 20,772 | 181,654 | |
| ParkRunning3 | 36,030 | 257,759 | 31,795 | 255,167 | 26,053 | 247,644 | |
| FHD | MarketPlace | 7706 | 40,471 | 6255 | 38,985 | 5541 | 38,510 |
| RitualDance | 7404 | 38,528 | 6873 | 38,366 | 4555 | 35,370 | |
| Cactus | 5144 | 39,340 | 4105 | 38,580 | 3778 | 38,579 | |
| BasketballDrive | 7043 | 51,514 | 5998 | 50,858 | 4689 | 48,899 | |
| BQTerrace | 3299 | 37,509 | 2098 | 35,605 | 1513 | 36,279 | |
| Class | Sequence Name | Park [32] | Proposed | ||||
|---|---|---|---|---|---|---|---|
| BDBR-Y | BDBR-U | BDBR-V | BDBR-Y | BDBR-U | BDBR-V | ||
| UHD | Tango2 | −0.16% | 0.02% | 0.02% | −0.11% | −0.92% | 0.12% |
| FoodMarket4 | −0.02% | 0.36% | 0.33% | −0.08% | 0.35% | 0.21% | |
| CatRobot | 0.06% | 0.29% | −0.11% | 0.07% | −0.60% | −0.11% | |
| DaylightRoad2 | 0.05% | −1.55% | −0.21% | 0.06% | −1.14% | −0.06% | |
| ParkRunning3 | −0.02% | 0.02% | 0.21% | 0.05% | 0.03% | 0.15% | |
| Average | −0.02% | −0.17% | 0.05% | 0.00% | −0.46% | 0.06% | |
| FHD | MarketPlace | 0.00% | −0.08% | −0.31% | −0.04% | 0.13% | −0.76% |
| RitualDance | 0.19% | 0.41% | −0.15% | 0.23% | 0.18% | −0.38% | |
| Cactus | 0.10% | −0.08% | 0.55% | 0.04% | 0.54% | 0.17% | |
| BasketballDrive | 0.22% | 0.00% | 0.37% | 0.16% | −1.70% | 0.40% | |
| BQTerrace | 0.06% | 0.06% | −0.04% | 0.02% | −0.37% | 0.51% | |
| Average | 0.11% | 0.06% | 0.08% | 0.08% | −0.24% | −0.01% | |
| Overall Average | 0.05% | −0.05% | 0.07% | 0.04% | −0.35% | 0.03% | |
| Class | Sequence Name | affine_inter_off | affine_inter_4P |
|---|---|---|---|
| UHD | Tango2 | 32% | 1% |
| FoodMarket4 | 30% | 1% | |
| CatRobot | 31% | 2% | |
| DaylightRoad2 | 36% | 5% | |
| ParkRunning3 | 35% | 2% | |
| Average | 33% | 2% | |
| FHD | MarketPlace | 31% | 4% |
| RitualDance | 37% | 4% | |
| Cactus | 30% | 7% | |
| BasketballDrive | 33% | 4% | |
| BQTerrace | 55% | 1% | |
| Average | 37% | 4% | |
| Overall Average | 35% | 3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, S.; Jun, D. Context-Based Inter Mode Decision Method for Fast Affine Prediction in Versatile Video Coding. Electronics 2021, 10, 1243. https://doi.org/10.3390/electronics10111243
Jung S, Jun D. Context-Based Inter Mode Decision Method for Fast Affine Prediction in Versatile Video Coding. Electronics. 2021; 10(11):1243. https://doi.org/10.3390/electronics10111243
Chicago/Turabian StyleJung, Seongwon, and Dongsan Jun. 2021. "Context-Based Inter Mode Decision Method for Fast Affine Prediction in Versatile Video Coding" Electronics 10, no. 11: 1243. https://doi.org/10.3390/electronics10111243
APA StyleJung, S., & Jun, D. (2021). Context-Based Inter Mode Decision Method for Fast Affine Prediction in Versatile Video Coding. Electronics, 10(11), 1243. https://doi.org/10.3390/electronics10111243