A Fresh View on the Microarchitectural Design of FPGA-Based RISC CPUs in the IoT Era


Abstract
1. Introduction
- Communication and memory-centric design evaluation. We explored the intricate relationship between the cache, the on-chip interconnect and the branch prediction schemes to optimally design the SoC microarchitecture of IoT platforms. The analysis considers timing, area and performance design metrics to offer a complete set of pros and cons for different microarchitectural solutions still ensuring their implementation feasibility.
- Set of design guidelines for IoT RISC CPU on FPGA. Such guidelines are drawn from the results obtained after the complete evaluation of all the proposed microarchitectural variations on a newly designed RISC CPU implementing the RISC-V ISA. The newly proposed RISC CPU represents a common substrate that enables the focused evaluation of pros and cons for each microarchitectural variation.
2. Related Works and Background
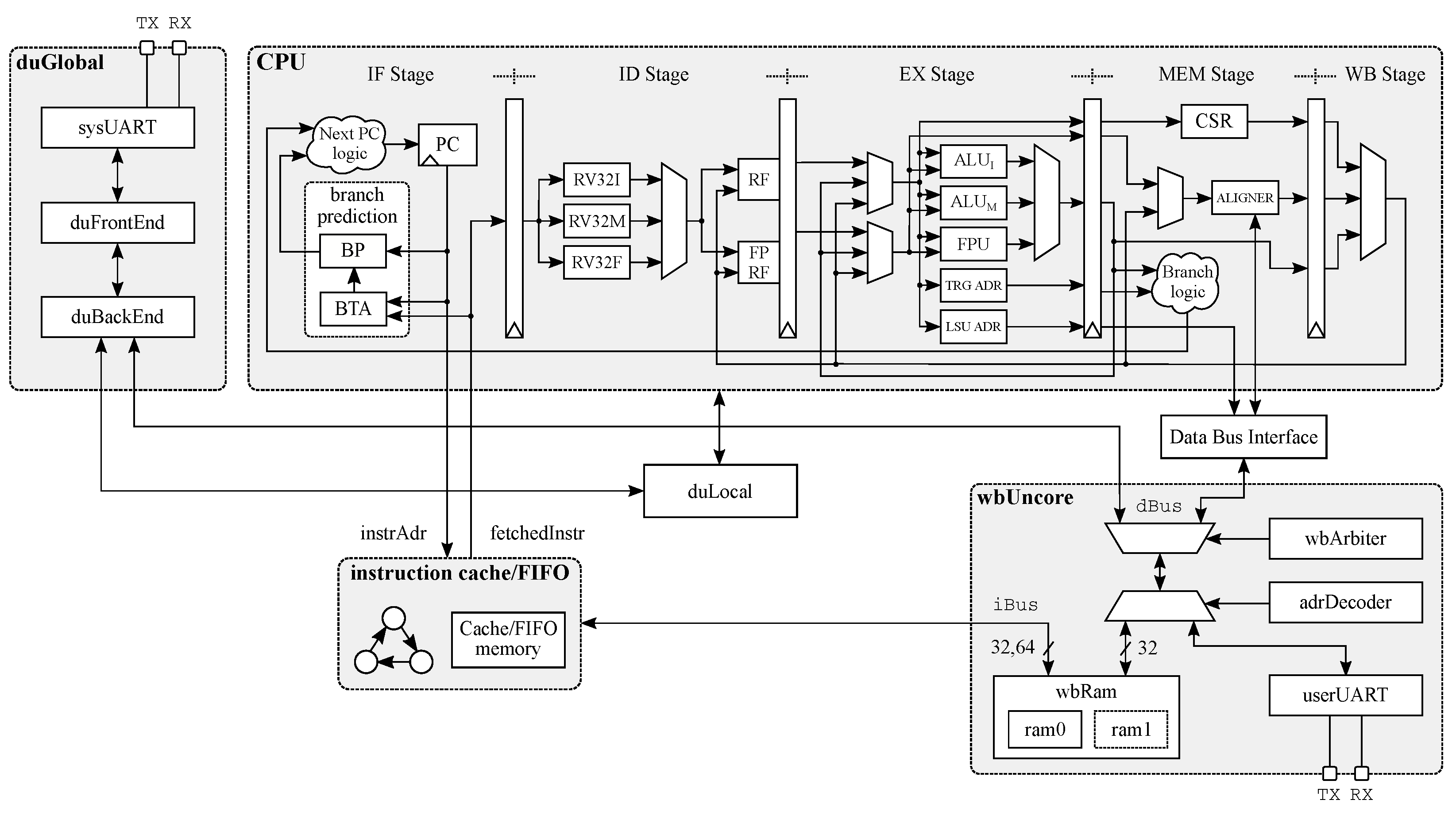
3. Architectural View of the Proposed IoT Processor
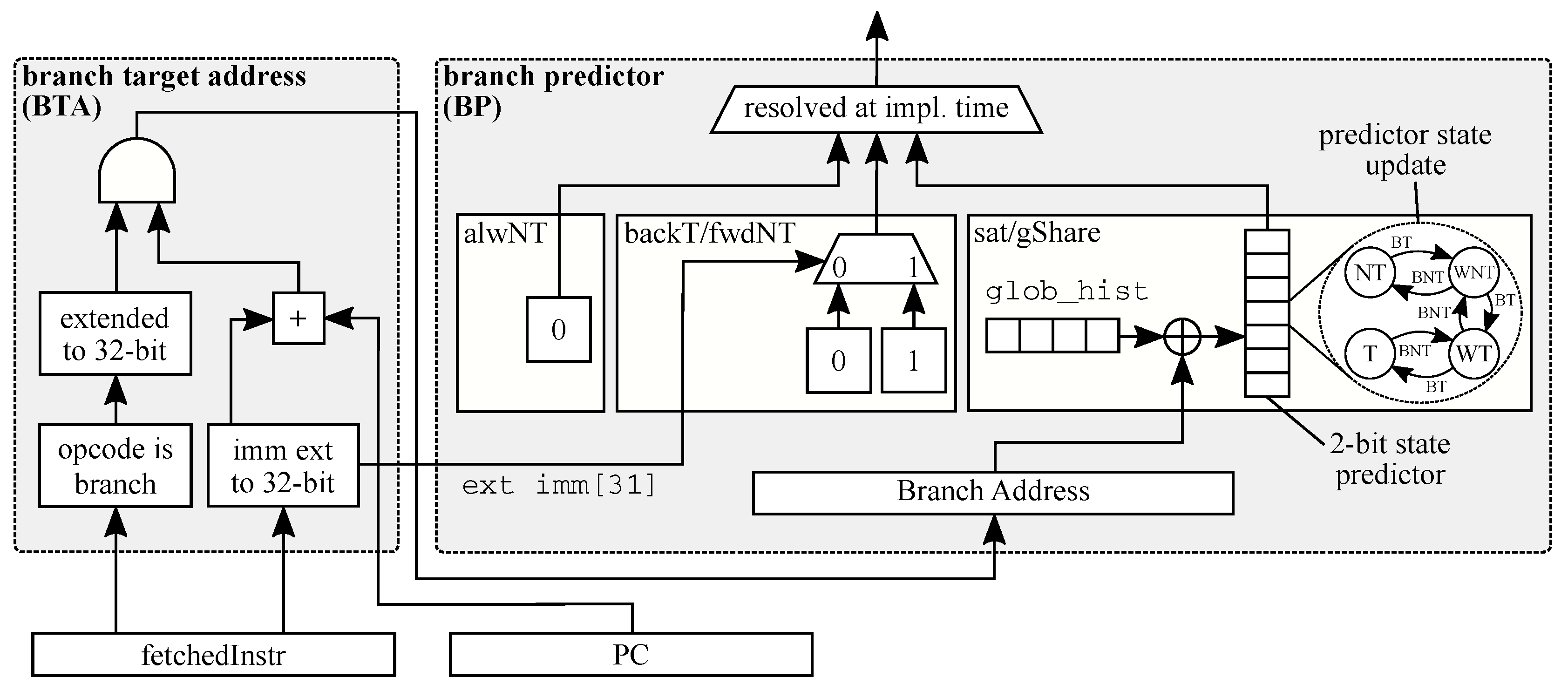
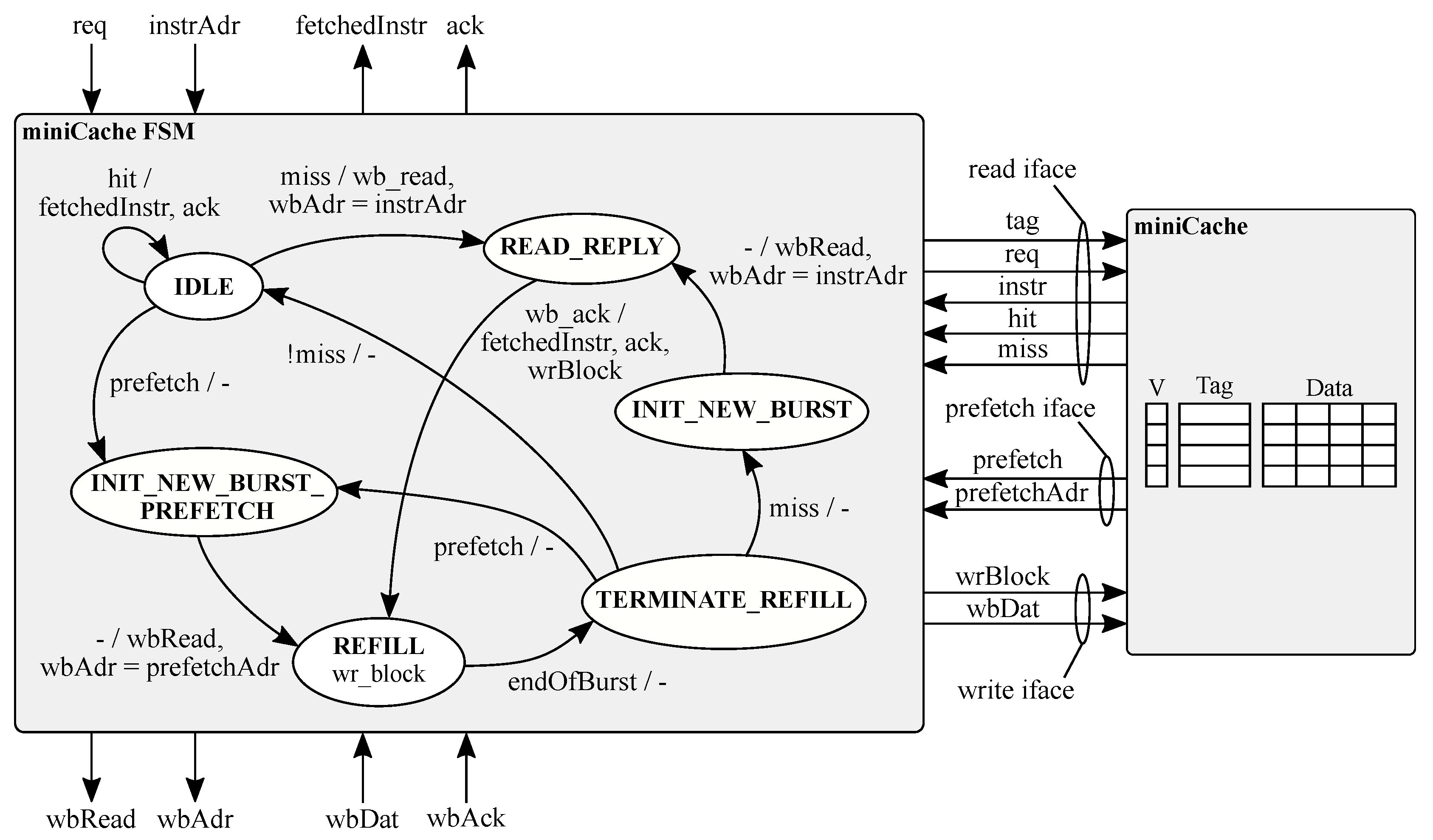
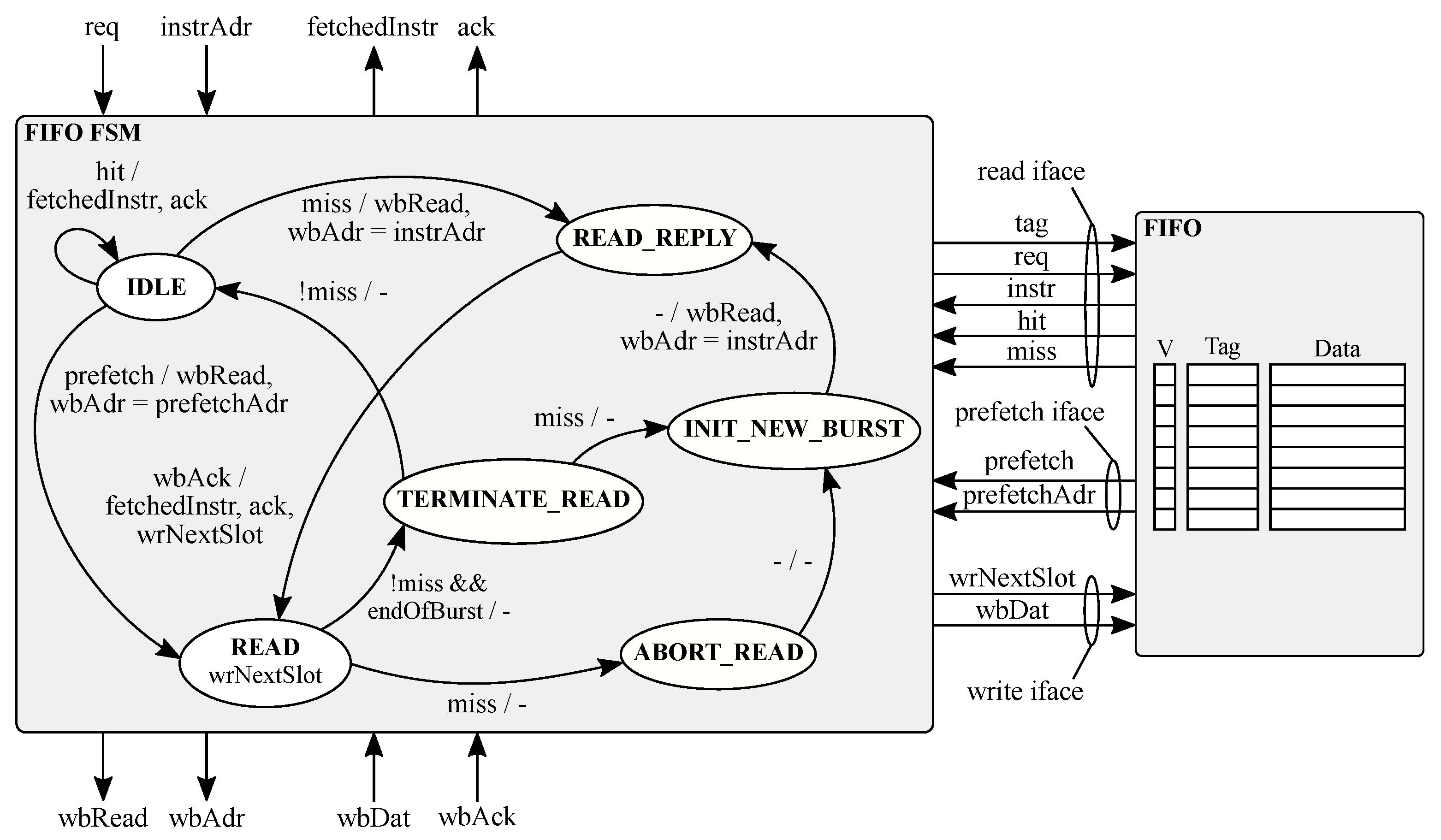
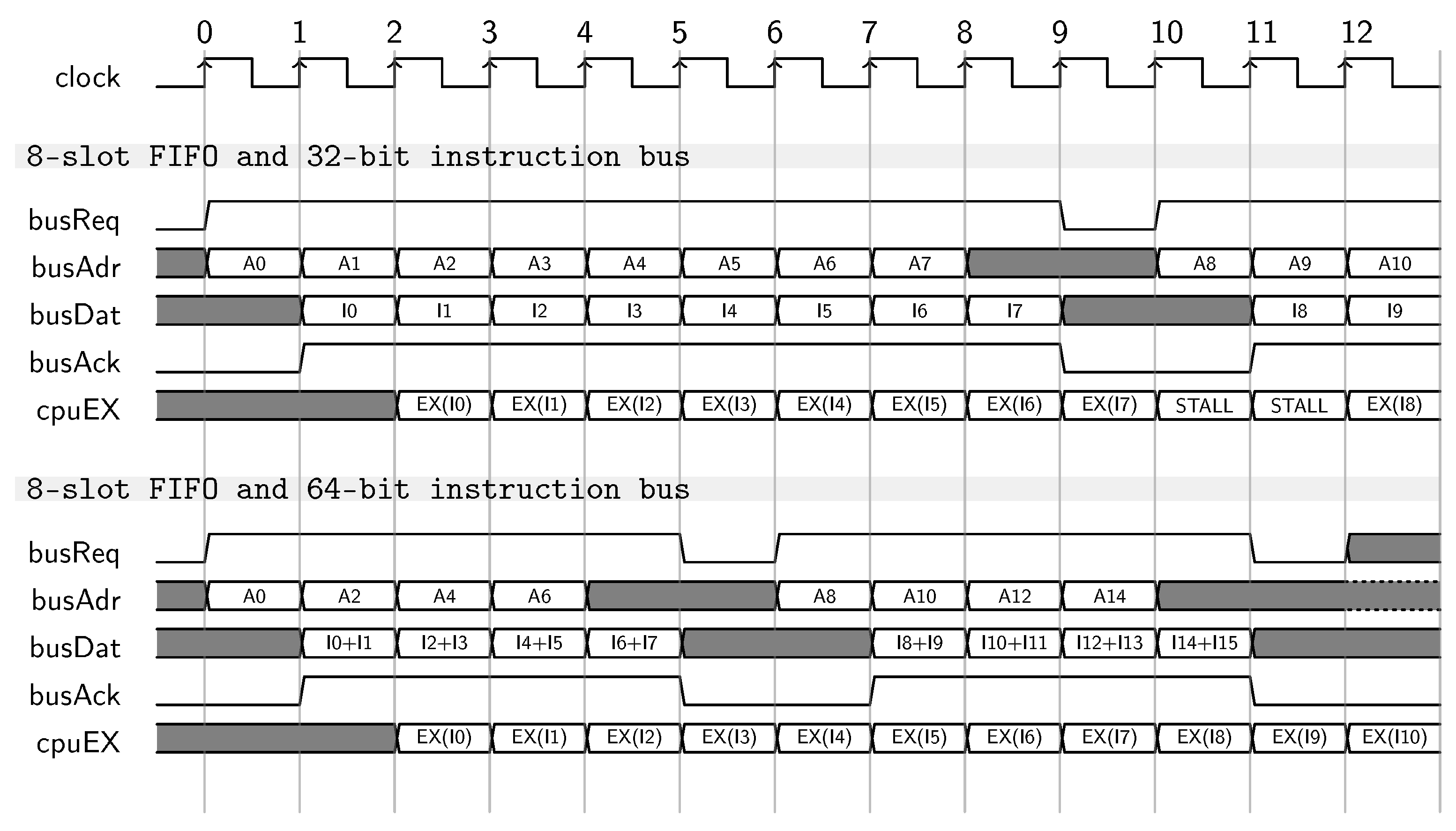
Microarchitectural Optimization of the Instruction Fetch Stage
4. Experimental Results
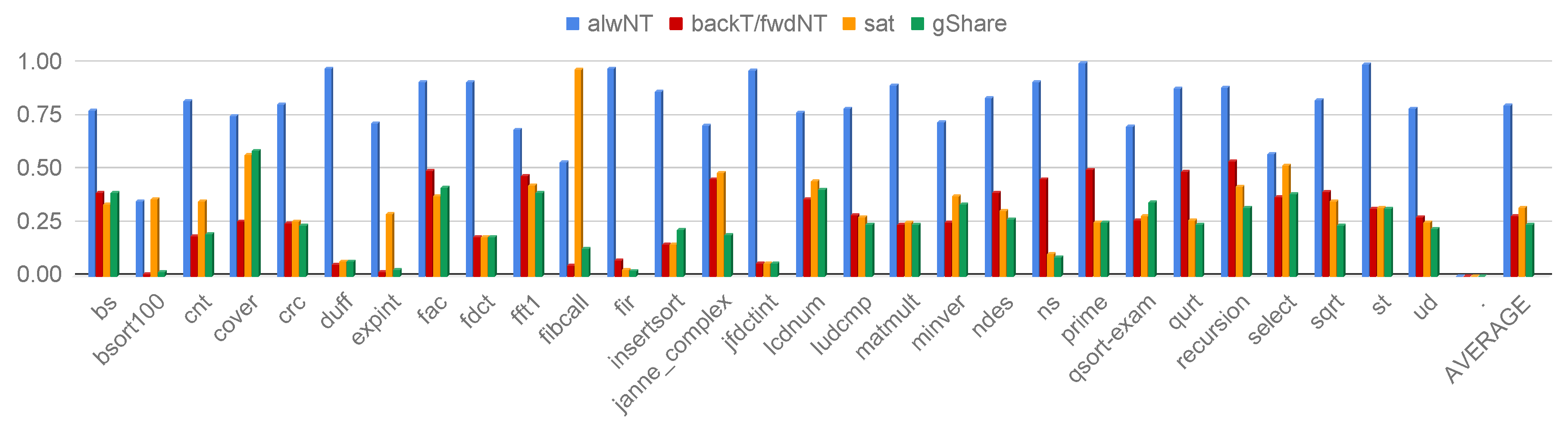
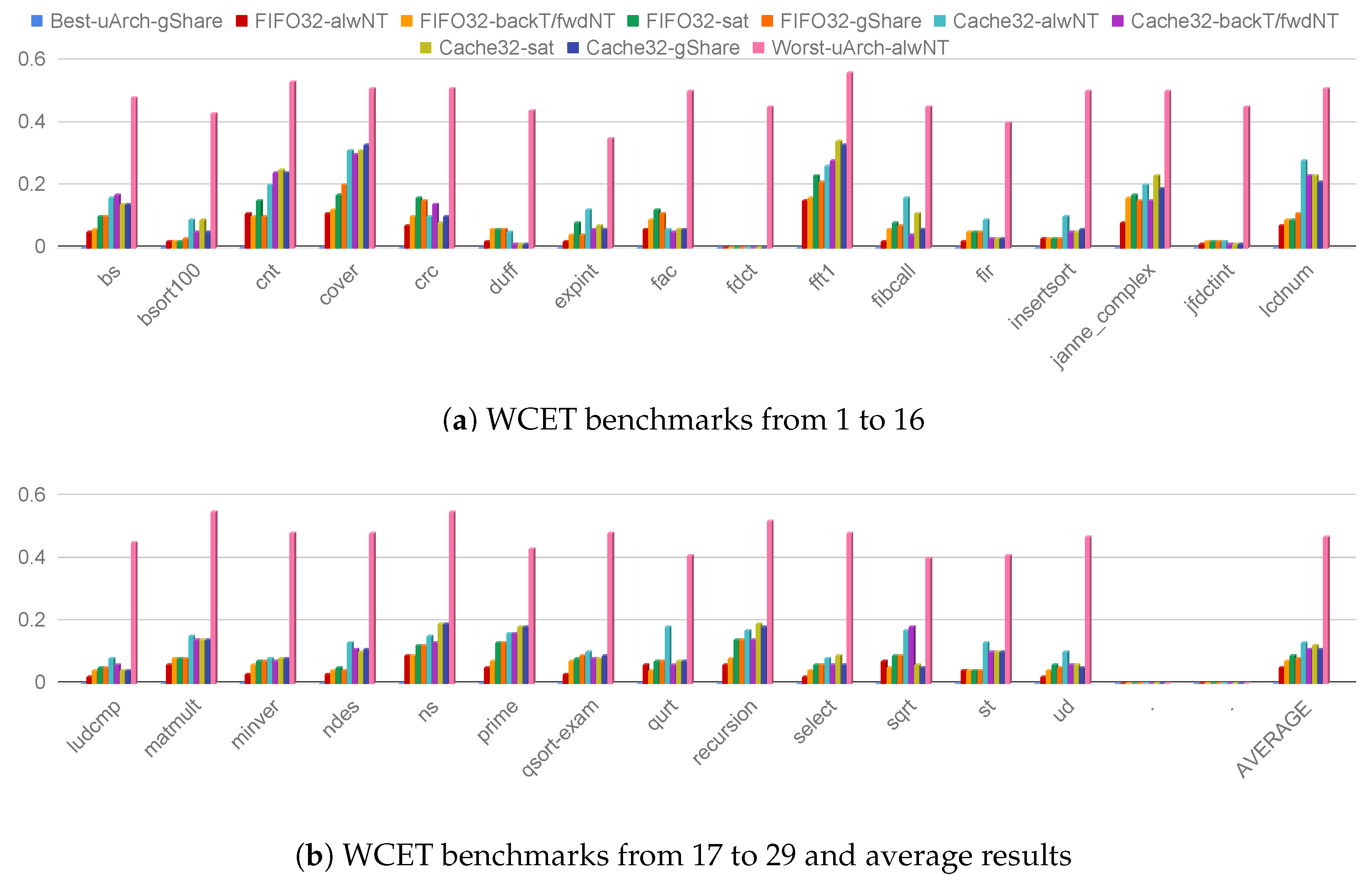
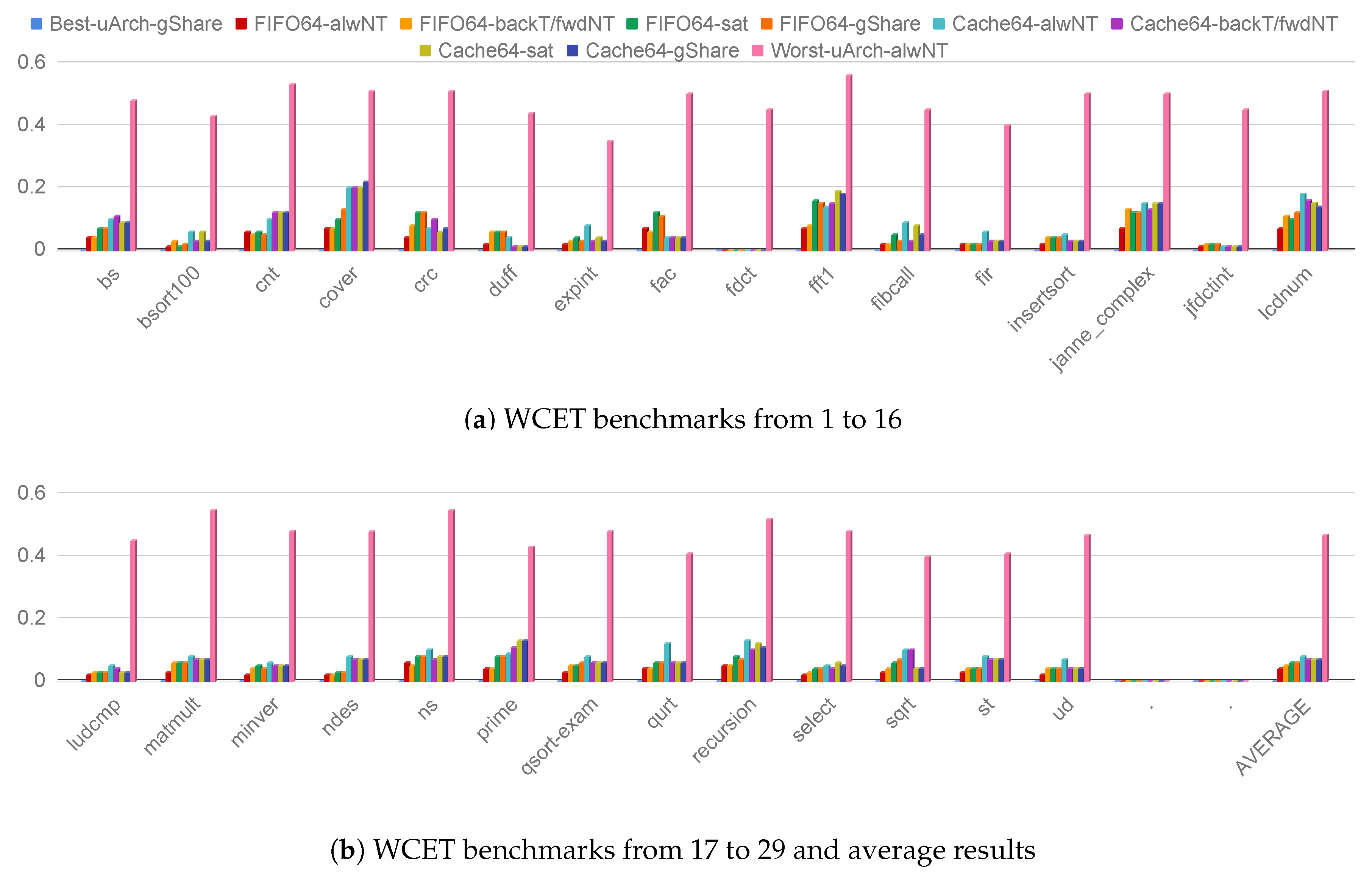
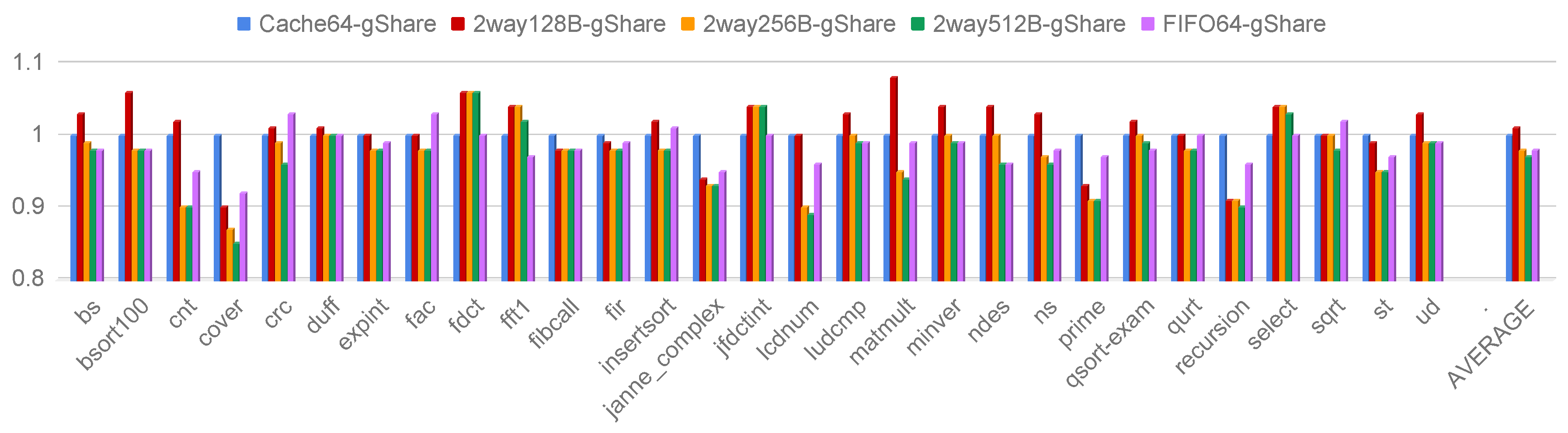
4.1. Performance evaluation
4.2. Area and Timing Evaluation
5. FPGA-Based Design Suggestions for IoT CPUs
- Guidelines 1: FIFO for area constrained designs. The instruction FIFO represents the best design choice when the area overhead is critical. It offers good performance due to its high flexibility that permits to abort a burst transaction and start serving an instruction miss. Moreover, the simple prefetch scheme offers a full-throughput pipeline if the instructions are executed in program order. In particular, it always offers superior performance compared to a miniCache. By contrast, the use of a bigger standard cache coupled with a 64-bit instruction bus can offer better performance in a multi-master platform.
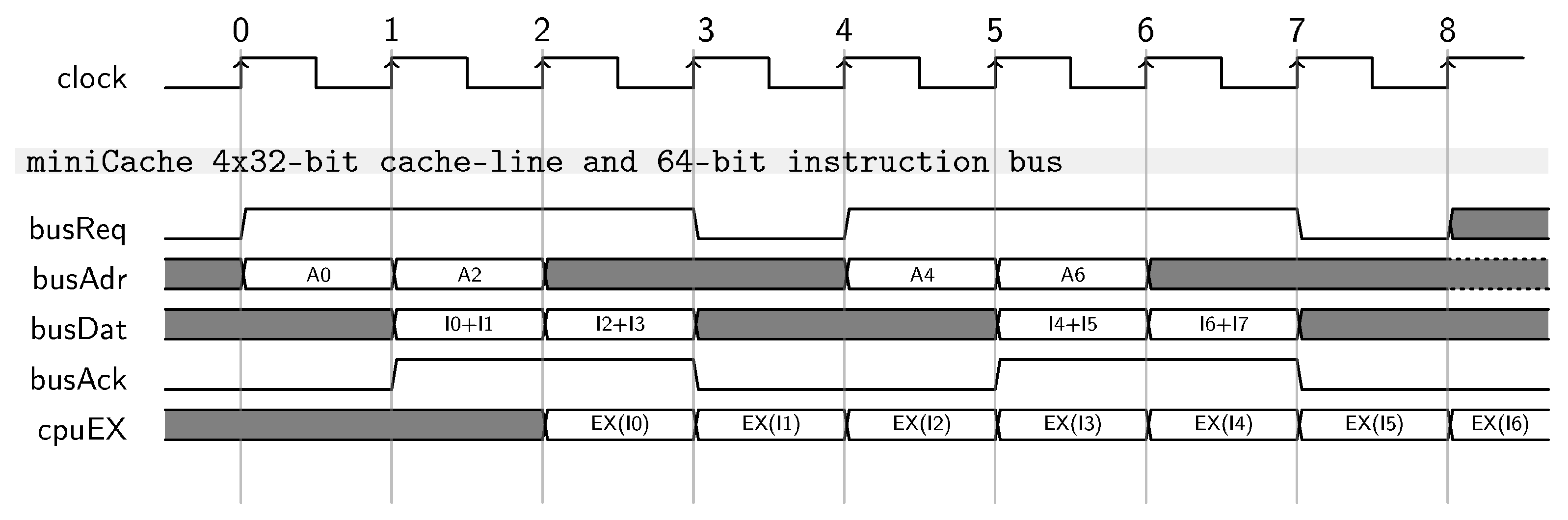
- Guidelines 2: use 64-bit instruction bus on 32-bit architectures. The use of a 64-bit instruction bus offers superior performance by dramatically reducing the latency of any on-chip burst transaction. Moreover, the implementation results demonstrated a negligible impact on both timing and area design metrics. Last, a wider bus reduces the contention in multi-master platforms.
- Guidelines 3: Branch prediction scheme. We note that the branch prediction scheme greatly improves the overall performance even if the scheme is as simple as the backT/FwdNT one. In particular, the selected branch predictor scheme can marginally affect the area while the reported timing slack is not dominated by a specific scheme. To this extent, we suggest the use of a backT/FwdNT scheme for area constrained designs or a more capable gShare with a small number of saturation predictors. We also note that it is always important to check the percentage of actually used saturation predictors implemented in the gShare scheme to avoid wasting resources.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Piazza, E.; Romanoni, A.; Matteucci, M. Real-Time CPU-Based Large-Scale Three-Dimensional Mesh Reconstruction. IEEE Rob. Autom. Lett. 2018, 3, 1584–1591. [Google Scholar] [CrossRef]
- Romanoni, A.; Ciccone, M.; Visin, F.; Matteucci, M. Multi-view Stereo with Single-View Semantic Mesh Refinement. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 706–715. [Google Scholar]
- Romanoni, A.; Fiorenti, D.; Matteucci, M. Mesh-based 3D textured urban mapping. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3460–3466. [Google Scholar]
- Hennessy, J.; Patterson, D. A new golden age for computer architecture: Domain-specific hardware/software co-design, enhanced security, open instruction sets, and agile chip development. In Proceedings of the 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 1–6 June 2018; pp. 27–29. [Google Scholar]
- Foundation, R.V. RISC-V Instruction Set Architecture (ISA). Available online: https://riscv.org/ (accessed on 19 Feburary 2019).
- Zoni, D.; Colombo, L.; Fornaciari, W. DarkCache: Energy-Performance Optimization of Tiled Multi-Cores by Adaptively Power-Gating LLC Banks. ACM Trans. Archit. Code Optim. 2018, 15, 21:1–21:26. [Google Scholar] [CrossRef]
- Zoni, D.; Flich, J.; Fornaciari, W. CUTBUF: Buffer Management and Router Design for Traffic Mixing in VNET-Based NoCs. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1603–1616. [Google Scholar] [CrossRef]
- Zoni, D.; Canidio, A.; Fornaciari, W.; Englezakis, P.; Nicopoulos, C.; Sazeides, Y. BlackOut: Enabling fine-grained power gating of buffers in Network-on-Chip routers. J. Parallel Distrib. Comput. 2017, 104, 130–145. [Google Scholar] [CrossRef]
- arm Ltd. Designstart FPGA. Available online: https://www.arm.com/resources/designstart/designstart-fpga (accessed on 19 Feburary 2019).
- Patsidis, K.; Konstantinou, D.; Nicopoulos, C.; Dimitrakopoulos, G. A low-cost synthesizable RISC-V dual-issue processor core leveraging the compressed Instruction Set Extension. Microprocess. Microsyst. 2018, 61, 1–10. [Google Scholar] [CrossRef]
- Conti, F.; Rossi, D.; Pullini, A.; Loi, I.; Benini, L. PULP: A Ultra-Low Power Parallel Accelerator for Energy-Efficient and Flexible Embedded Vision. J. Signal Process. Syst. 2016, 84, 339–354. [Google Scholar] [CrossRef]
- openrisc. Mor1kx Project. 2016. Available online: https://github.com/openrisc/mor1kx (accessed on 19 February 2019).
- Project, O. OpenRISC Reference Platform SoC Version 3. 2016. Available online: https://github.com/fusiled/ORPSocv3 (accessed on 19 February 2019).
- Asanović, K.; Avizienis, R.; Bachrach, J.; Beamer, S.; Biancolin, D.; Celio, C.; Cook, H.; Dabbelt, D.; Hauser, J.; Izraelevitz, A.; et al. The Rocket Chip Generator; Technical Report UCB/EECS-2016-17; EECS Department, University of California: Berkeley, CA, USA, 2016. [Google Scholar]
- VectorBlox. Orca Core. Available online: https://github.com/vectorblox/orca (accessed on 19 February 2019).
- Celio, C.; Patterson, D.A.; Asanović, K. The Berkeley Out-of-Order Machine (BOOM): An Industry-Competitive, Synthesizable, Parameterized RISC-V Processor; Technical Report UCB/EECS-2015-167; EECS Department, University of California: Berkeley, CA, USA, 2015. [Google Scholar]
- Celio, C.; Chiu, P.F.; Nikolic, B.; Patterson, D.A.; Asanović, K. BOOM v2: An Open-Source Out-of-Order RISC-V Core; Technical Report UCB/EECS-2017-157; EECS Department, University of California: Berkeley, CA, USA, 2017. [Google Scholar]
- VexRiscv Core. SpinalHDL. 2017. Available online: https://github.com/SpinalHDL/VexRiscv (accessed on 19 February 2019).
- Gray, J. GRVI Phalanx: A Massively Parallel RISC-V FPGA Accelerator. In Proceedings of the 2016 IEEE 24th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Washington, DC, USA, 1–3 May 2016; pp. 17–20. [Google Scholar]
- OpenRISC 1000 Architectural Manual. Available online: https://openrisc.io/or1k.html (accessed on 19 Feburary 2019).
- Kristiansson, S. Bare-Metal Introspection Application for the AR100 Controller of Allwinner A31 SoCs. Available online: https://github.com/skristiansson/ar100-info (accessed on 19 Feburary 2019).
- Linux Kernel OpenRISC Subtree. Available online: https://github.com/kdgwill/OR1K/wiki/Build-Linux-Kernel-For-OpenRisc-1000 (accessed on 19 Feburary 2019).
- Kurth, A.; Vogel, P.; Capotondi, A.; Marongiu, A.; Benini, L. HERO: Heterogeneous Embedded Research Platform for Exploring RISC-V Manycore Accelerators on FPGA. arXiv, 2017; arXiv:1712.06497. [Google Scholar]
- Davidson, S.; Xie, S.; Torng, C.; Al-Hawai, K.; Rovinski, A.; Ajayi, T.; Vega, L.; Zhao, C.; Zhao, R.; Dai, S.; et al. The Celerity Open-Source 511-Core RISC-V Tiered Accelerator Fabric: Fast Architectures and Design Methodologies for Fast Chips. IEEE Micro 2018, 38, 30–41. [Google Scholar] [CrossRef]
- Eldridge, S.; Swaminathan, K.; Verma, V.; Joshi, R. A Low Voltage RISC-V Heterogeneous System Boosted SRAMs, Machine Learning, and Fault Injection on VELOUR. 2017. Available online: https://pdfs.semanticscholar.org/608e/831e8ab14c0e5700eb5f3a01cc054b0d663e.pdf (accessed on 19 February 2019).
- onchipuis. mriscv. Available online: https://github.com/onchipuis/mriscv (accessed on 19 February 2019).
- Matthews, E.; Shannon, L. Taiga: A configurable RISC-V soft-processor framework for heterogeneous computing systems research. In Proceedings of the First Workshop on Computer Architecture Research with RISC-V (CARRV 2017), Boston, MA, USA, 14 October 2017. [Google Scholar]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The Gem5 Simulator. SIGARCH Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Zoni, D.; Fornaciari, W. Modeling DVFS and Power Gating Actuators for Cycle Accurate NoC-based Simulators. J. Emerg. Technol. Comput. Syst. 2015, 12, 1–15. [Google Scholar] [CrossRef]
- Zoni, D.; Terraneo, F.; Fornaciari, W. A DVFS Cycle Accurate Simulation Framework with Asynchronous NoC Design for Power-Performance Optimizations. J. Signal Process. Syst. 2016, 83, 357–371. [Google Scholar] [CrossRef]
- OpenCores. Wishbone System-on-Chip (SoC) Interconnection Architecture for Portable IP Cores. Available online: http://docplayer.net/6521799-Wishbone-system-on-chip-soc-interconnection-architecture-for-portable-ip-cores.html (accessed on 2 Feburary 2019).
- Patterson, D.A.; Hennessy, J.L. Computer Organization and Design—The Hardware/Software Interface, 4th ed.; The Morgan Kaufmann Series in Computer Architecture and Design; Academic Press: New York, NY, USA, 2012. [Google Scholar]
- Martin, T. The Designer’s Guide to the Cortex-M Processor Family, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Gustafsson, J.; Betts, A.; Ermedahl, A.; Lisper, B. The Malardalen WCET Benchmarks: Past, Present and Future. In Proceedings of the 10th International Workshop on Worst-Case Execution Time Analysis, Brussels, Belgium, 6 July 2010. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Core | ISA | Pipeline Stages | Out-of-Order | Issue Width | Caches | Branch Prediction |
|---|---|---|---|---|---|---|
| Mor1kx Cappuccino [12] | OpenRISC | 5 | in-order | 1 | yes | no |
| Mor1kx Espresso [12] | OpenRISC | 3 | in-order | 1 | no | no |
| Mor1kx ProntoEspresso [12] | OpenRISC | 3 | in-order | 1 | no | yes |
| ORPSoC v3 [13] | OpenRISC | 5 | in-order | 1 | yes | yes |
| Rocket [14] | RV32/64/IMAFD | 5 | in-order | 1 | yes | yes |
| ORCA [15] | RV32/IM | 4,5 | in-order | 1 | no | no |
| BOOM v1 [16] | RV64/IMAFD | 6 | out-of-order | up to 3 | yes | yes |
| BOOM v2 [17] | RV64/IMAFD | 6 | out-of-order | up to 4 | yes | yes |
| PULP Ariane [11] | RV32/IMF | 6 | in-order | 1 | yes | yes |
| PULPino [18] | RV32/IMCF | 4 | in-order | 1 | yes (+FIFO) | no |
| VexRiscv [19] | RV32IM | 5 | in-order | 1 | yes | no |
| mriscv [11] | RV32/I | 3 | in-order | 1 | no | no |
| dualIssueRiscv [10] | RV32/IMCF | 6 | in-order | up to 2 | yes | yes |
| Instruction Bus 32 bit | Instruction Bus 64 bit | |||
|---|---|---|---|---|
| Instruction FIFO | Instruction Cache | Instruction FIFO | Instruction Cache | |
| always not taken | FIFO32-alwNT | Cache32-alwNT | FIFO64-alwNT | Cache64-alwNT |
| backward taken forward not taken | FIFO32-BackT/FwdNT | Cache32-BackT/FwdNT | FIFO64-BackT/FwdNT | Cache64-BackT/FwdNT |
| saturation | FIFO32-sat | Cache32-sat | FIFO64-sat | Cache64-sat |
| gShare | FIFO32-gShare | Cache32-gShare | FIFO64-gShare | Cache64-gShare |
| Benchmark | Total # of | # of Taken | Number of Instructions Per Type (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Instructions | Branch | Branch | Jump | ALU | NOP | MUL/DIV | FPU | LD/ST | |
| bs | 158 | 8 | 7.5 | 3.8 | 32.2 | 9.4 | 0.0 | 0.0 | 46.8 |
| bsort100 | 251,516 | 5452 | 6.2 | 0.0 | 38.5 | 2.2 | 0.0 | 0.0 | 52.8 |
| cnt | 7575 | 220 | 4.5 | 4.3 | 62.1 | 7.2 | 1.3 | 0.0 | 20.3 |
| cover | 4222 | 180 | 8.6 | 8.7 | 34.8 | 13.0 | 0.0 | 0.0 | 34.7 |
| crc | 56,028 | 3493 | 8.5 | 3.2 | 41.1 | 9.4 | 0.0 | 0.0 | 37.6 |
| duff | 2149 | 105 | 5.0 | 0.2 | 33.5 | 5.5 | 0.0 | 0.0 | 55.6 |
| expint | 3714 | 151 | 6.8 | 2.8 | 20.8 | 6.9 | 8.1 | 0.0 | 54.4 |
| fac | 527 | 21 | 5.3 | 9.3 | 29.9 | 13.2 | 2.8 | 0.0 | 39.2 |
| fdct | 5305 | 16 | 0.3 | 0.0 | 44.5 | 0.4 | 3.6 | 0.0 | 50.9 |
| fft1 | 55,939 | 3065 | 9.8 | 4.1 | 58.8 | 10.6 | 3.2 | 1.3 | 12.0 |
| fibcall | 562 | 30 | 10.5 | 0.5 | 17.9 | 5.8 | 0.0 | 0.0 | 65.1 |
| fir | 478,682 | 25,541 | 5.4 | 0.1 | 20.5 | 5.4 | 5.2 | 0.0 | 63.1 |
| insertsort | 2052 | 54 | 3.1 | 0.4 | 53.5 | 3.1 | 0.0 | 0.0 | 39.7 |
| janne_complex | 398 | 40 | 15.0 | 2.0 | 26.1 | 12.0 | 0.0 | 0.0 | 44.7 |
| jfdctint | 5548 | 80 | 1.5 | 0.0 | 44.3 | 1.5 | 4.6 | 0.0 | 47.8 |
| lcdnum | 302 | 15 | 8.6 | 6.9 | 31.7 | 11.9 | 0.0 | 0.0 | 40.7 |
| ludcmp | 6113 | 213 | 4.7 | 1.1 | 39.4 | 4.6 | 5.0 | 4.9 | 39.9 |
| matmult | 9133 | 215 | 2.8 | 1.6 | 70.3 | 4.1 | 1.9 | 0.0 | 19.1 |
| minver | 4880 | 145 | 4.6 | 1.4 | 48.5 | 4.5 | 0.3 | 3.2 | 37.1 |
| ndes | 106,484 | 3437 | 4.4 | 3.0 | 41.6 | 6.2 | 0..0 | 0.0 | 44.6 |
| ns | 23,321 | 1404 | 6.6 | 0.6 | 58.4 | 6.7 | 0.0 | 0.0 | 27.4 |
| prime | 13,508 | 863 | 6.4 | 6.4 | 25.9 | 12.8 | 6.4 | 0.0 | 41.8 |
| qsort-exam | 2078 | 80 | 6.5 | 2.3 | 38.4 | 6.8 | 0.0 | 3.4 | 42.4 |
| qurt | 1205 | 93 | 9.2 | 3.7 | 14.6 | 11.4 | 0.0 | 16.6 | 44.2 |
| recursion | 4960 | 241 | 6.6 | 9.4 | 33.0 | 14.2 | 0.0 | 0.0 | 36.6 |
| select | 1033 | 31 | 6.0 | 1.0 | 44.0 | 4.1 | 0.0 | 2.6 | 42.1 |
| sqrt | 451 | 38 | 11.1 | 3.9 | 13.7 | 12.6 | 0.0 | 15.7 | 42.7 |
| st | 254,551 | 7156 | 2.8 | 4.7 | 31.5 | 7.6 | 1.5 | 12.8 | 38.7 |
| ud | 5855 | 207 | 4.7 | 0.9 | 42.0 | 4.5 | 7.0 | 0.0 | 40.6 |
| Instruction Bus Width 32 bit | |||||||
|---|---|---|---|---|---|---|---|
| Instruction FIFO | Instruction Cache | ||||||
| Always Not Taken | Backward Taken Forward Not Taken | Saturation | gShare | Always Not Taken | Backward Taken Forward Not Taken | Saturation | gShare |
| 1.00/1.00 | 1.01/1.00 | 1.01/1.00 | 1.02/1.01 | 1.05 /1.02 | 1.08/1.02 | 1.06/1.02 | 1.09/1.02 |
| Instruction Bus Width 64 bit | |||||||
| Instruction FIFO | Instruction Cache | ||||||
| Always Not Taken | Backward Taken Forward Not Taken | Saturation | gShare | Always Not Taken | Backward Taken | Saturation Forward Not Taken | gShare |
| 1.01/0.99 | 1.01/0.99 | 1.01/0.99 | 1.03/1.00 | 1.06/1.02 | 1.07/1.02 | 1.07/1.02 | 1.08/1.03 |
| Instruction Bus Width 32 bit | |||||||
|---|---|---|---|---|---|---|---|
| Instruction FIFO | Instruction Cache | ||||||
| Always Not Taken | Backward Taken Forward Not Taken | Saturation | gShare | Always Not Taken | Backward Taken Forward Not Taken | Saturation | gShare |
| 1.81 (1.00) | 0.27 (0.15) | 0.74 (0.41) | 0.22 (0.12) | 2.10 (1.16) | 0.90 (0.49) | 0.47 (0.26) | 0.88 (0.49) |
| Instruction Bus Width 64 bit | |||||||
| Instruction FIFO | Instruction Cache | ||||||
| Always Not Taken | Backward Taken Forward Not Taken | Saturation | gShare | Always Not Taken | Backward Taken Forward Not Taken | Saturation | gShare |
| 1.91 (1.05) | 0.23 (0.12) | 0.78 (0.43) | 0.62 (0.34) | 2.11 (1.17) | 0.84 (0.46) | 0.80 (0.44) | 0.50 (0.27) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Scotti, G.; Zoni, D. A Fresh View on the Microarchitectural Design of FPGA-Based RISC CPUs in the IoT Era. J. Low Power Electron. Appl. 2019, 9, 9. https://doi.org/10.3390/jlpea9010009
Scotti G, Zoni D. A Fresh View on the Microarchitectural Design of FPGA-Based RISC CPUs in the IoT Era. Journal of Low Power Electronics and Applications. 2019; 9(1):9. https://doi.org/10.3390/jlpea9010009
Chicago/Turabian StyleScotti, Giovanni, and Davide Zoni. 2019. "A Fresh View on the Microarchitectural Design of FPGA-Based RISC CPUs in the IoT Era" Journal of Low Power Electronics and Applications 9, no. 1: 9. https://doi.org/10.3390/jlpea9010009
APA StyleScotti, G., & Zoni, D. (2019). A Fresh View on the Microarchitectural Design of FPGA-Based RISC CPUs in the IoT Era. Journal of Low Power Electronics and Applications, 9(1), 9. https://doi.org/10.3390/jlpea9010009